1. Introduction
Rice is a fundamental staple, nourishing roughly half the global population. It is crucial for ensuring food security and promoting community well-being, contributing over 21% to the caloric intake of humans worldwide [
1,
2,
3]. Therefore, rice production forecasting is key in supporting strategic planning and decision-making in the agricultural sector. This process is vital for optimizing resource allocation, stabilizing prices, and ensuring food availability [
4,
5,
6]. With precise forecasting, policymakers and stakeholders can proactively anticipate production needs and market demand dynamics, as well as be effective in storage management and responding to fluctuations or crises that may occur. Various factors such as rainfall, temperature, pesticide use, and climate change affect rice production and are crucial features in the forecasting process [
7]. In addition, genetic factors play a significant role in determining rice traits, as highlighted by studies identifying quantitative trait loci (QTL) related to germination and seedling growth [
8]. The integration of these diverse datasets enhances the forecasting model’s accuracy and reliability [
9,
10]. However, the reality is that many developing countries often show limitations in dataset features, mainly due to the lack of adoption of advanced agricultural technologies. These limitations demand innovative approaches in feature processing to produce reliable predictions.
Various methods have been applied in forecasting research efforts, adapting to the type and quality of available data. Traditional time series analysis methods such as Autoregressive Integrated Moving Average (ARIMA) or improved ARIMA, namely SARIMAX, are useful for extracting trends, cycles, and seasonal patterns from historical data [
11,
12,
13]. These methods have proven effective in certain scenarios but often fall short when dealing with highly non-linear and complex data. Regression approaches, whether linear, multiple, or multivariate, utilize relationships between variables to predict crop yields [
14]. While these methods can provide insights, they often lack the capability to capture intricate non-linear inherent interactions.
Machine learning techniques have shown great promise in overcoming these limitations. Techniques such as Random Forest, Support Vector Machines (SVM), and neural networks offer the ability to uncover non-linear relationships and more complex interactions between influential features [
12,
15,
16,
17,
18,
19,
20]. Apart from that, ensemble methods, such as Extreme Gradient Boosting (XGBoost), have gained popularity due to their ability to provide accurate and efficient predictions. XGBoost integrates machine learning models in an ensemble format that improves prediction performance by sequentially strengthening weak to strong models. The main advantage of XGBoost is its speed in data processing, which is useful in dealing with large datasets, and its flexibility in handling various types of data [
21,
22,
23,
24,
25]. This technique is also known for its superior performance in many Kaggle competitions, often outperforming other machine learning models.
Furthermore, deep learning methods such as Long Short-Term Memory (LSTM) and Bidirectional LSTM (BiLSTM) stand out in their ability to learn hidden relations, interaction complexity, and deep temporal and non-linear patterns [
12,
26,
27,
28,
29,
30,
31,
32]. Additionally, the ability of deep learning models to double as feature extractors provides significant advantages. These models analyze data for prediction or classification and automatically extract important features from structured and even raw data. This process reduces the need for manual intervention or complex feature engineering techniques because the model can automatically identify important patterns or characteristics in the data.
While deep learning models can effectively function as regressors or classifiers, often in practice, they are more commonly used as feature extraction tools, where the resulting features are then further processed using other machine learning methods. For example, features extracted by LSTM or BiLSTM can be utilized as input for more traditional regression models such as Support Vector Machines (SVM) [
33] or ensemble methods such as XGBoost, which is known for its robust prediction capabilities [
34,
35]. Research [
14] also uses transfer learning methods such as EfficientNet and MobileNet for feature extraction, then classification is carried out using multivariate regression. This hybrid approach makes it possible to combine the power of deep learning in capturing data complexity with the efficiency and accuracy of more conventional machine learning algorithms, thereby providing optimal prediction results.
New approaches that utilize the principles of quantum mechanics—such as superposition and entanglement—open new insights into data processing. Known as quantum feature processing, this technique explores broader and more complex data representations, enriching features with new dimensions inaccessible to classical technologies [
36,
37,
38,
39,
40]. The benefits of this approach are not only limited to improving the accuracy and speed of machine learning algorithms but also in their ability to identify hidden patterns that can significantly improve forecasting results.
Several recent studies propose combining quantum–classical hybrid methods in various fields, especially forecasting, for example, in research [
41,
42,
43,
44,
45]. A study [
41] combined classical layers and quantum layers in a feedforward neural network (FFN). The use of quantum layers enables data processing in higher dimensions, which is effective for complex and chaotic data. This results in richer features that increase the accuracy of solar radiation predictions. Quantum layers can perform operations that encode and entangle input data into quantum states, allowing the model to explore more complex data representations than classical layers alone.
Research [
42] combines quantum-inspired neural networks with classical deep learning consisting of Convolutional Neural Networks (CNNs) and LSTM networks. The study used CNN to extract spatiotemporal features from wind speed data, thereby effectively capturing spatial patterns. The LSTM network then processes these features to understand the temporal relationships in the data. This hybrid approach leverages the strengths of both models to capture complex relationships in wind speed data, thereby improving prediction accuracy. Similarly, the study in [
43] integrated a classical neural network based on the Keras framework with quantum-inspired optimization techniques to predict supply chain backorders. By incorporating quantum algorithms for optimization, these models benefit from the superior search capabilities of quantum computing, which can navigate large solution spaces more efficiently than classical methods.
In [
44], a classical convolutional autoencoder is used for feature extraction, followed by a quantum regression algorithm to predict the atomization energy. Autoencoders compress input data into a lower dimensional representation, which is then processed by a quantum regression algorithm to achieve high prediction accuracy. Study [
45] also uses a hybrid quantum–classic method in the Hybrid Quantized Elman Neural Network (HQENN) model. Quantum neurons in the quantum map layer convert the input into quantum format by phase shift and quantum reversal operations. The results are processed by classical neurons in the hidden layer and output using the classical sigmoid activation function. The extended quantum learning algorithm updates the weights of the context and hidden layers simultaneously, thereby improving forecasting accuracy.
Other research also uses hybrid methods with quantum applications for feature selection [
46,
47], feature extraction [
48], as well as feature optimization and selection [
49]. Quantum algorithms can identify the most relevant features in a data set or create new features that capture important patterns. Quantum feature optimization involves fine-tuning these features to improve model performance. Thus, the hybrid method positively influences prediction accuracy, especially for reading features with complex patterns.
A hybrid quantum–classical approach can improve the model. Quantum computing excels at handling complex, high-dimensional data through quantum feature processing, which can reveal complex patterns that classical methods might miss. This capability is especially useful in dealing with chaotic, non-linear, and multivariate data. So, we develop a hybrid quantum–classical machine learning model. This model combines features extracted using Bi-LSTM with quantum computing technology to enrich feature information. Then, it uses XGBoost as a regressor algorithm to improve prediction accuracy. So, significant advantages are obtained in forecasting rice production. This proposed research aims to develop and validate such a hybrid model, hoping to produce a more sophisticated forecasting tool to support critical decisions in the global agricultural sector.
The main contributions of this paper are as follows:
Introduction of a novel Hybrid Quantum Deep Learning model for rice yield forecasting.
Demonstrate how quantum feature processing can enhance data representation and improve prediction accuracy.
A combination of Bi-LSTM and XGBoost in a hybrid model is needed to leverage the strengths of both deep learning and ensemble methods.
To provide a clear structure for this paper, we present the organization:
Section 2 discusses the dataset analysis, the hybrid quantum–classical deep learning model framework, and the preprocessing steps.
Section 3 presents the proposed model’s implementation and the results of the experiments.
Section 4 discusses the results, comparing them with other models and literature, and performs ablation studies. Finally,
Section 5 concludes the paper and outlines future work.
2. Materials and Methods
2.1. Dataset Analysis
This research uses a compilation of Food and Agriculture Organization (FAO) and World Bank datasets taken from research [
1]. Some important features used in this research from this dataset are area/country, year, production value/crop yield, average rainfall mm per year (annual rainfall), pesticides, and average temperature. In the first step, dataset analysis was carried out to ensure that the method selection proposed in this research was appropriate. First, the relationship between crop yields and factors such as rainfall, pesticide use, and average temperature was analyzed, as presented in
Figure 1.
The dataset used in this research consists of 3270 records from 67 countries. While this dataset provides significant information, it may not be sufficient to capture all the variations and complexities present in global rice production. The dataset may have limitations in terms of feature variety and geographical representation. Some countries might be underrepresented, affecting the model’s ability to make accurate predictions in diverse environmental and climatic conditions. Additionally, the dataset may lack certain features that could further enhance the model’s predictive capabilities, such as soil quality, irrigation practices, and socio-economic factors influencing agricultural output.
Figure 1a shows the relationship between crop yield and annual rainfall, but it appears that there is no clear linear pattern. This indicates the relationship may be non-linear or influenced by other variables. The plot of the relationship between crop yield and pesticide use in
Figure 1b also does not show a strong linear pattern. Likewise, the plot between crop yield and average temperature (
Figure 1c) also does not show a clear linear relationship, indicating that temperature may influence crop yield in a more complex way. The complex interactions between these features require sophisticated models for better understanding. We also performed temporal feature analysis, as shown in
Figure 2.
Temporal feature analysis reveals that rice yields significantly vary over time between countries and from year to year. In addition, there appear to be non-smooth fluctuations and trends based on moving averages in several countries, especially Mauritius, Albania, Romania, Azerbaijan, Rwanda, and Kenya. This variation could indicate that deep learning models are more appropriate because they are more sophisticated for understanding and predicting crop yields more accurately, especially if we want to make accurate predictions [
26].
Lastly, we also analyzed the correlation between features using the heatmap presented in
Figure 3. The values in the heatmap represent the Pearson correlation coefficient between pairs of variables. This value ranges from −1 to 1, where a value close to 1 indicates a strong positive correlation, a value close to −1 indicates a strong negative correlation and a value close to 0 indicates no correlation. From this heatmap, several important things can be concluded, such as (1) a negative correlation between pesticide use and crop yields, which may indicate that higher pesticide use does not always correlate with increased yields. Pesticides are important in controlling pests and diseases in plants [
50]. (2) Average temperature has a relatively strong negative correlation with crop yield, indicating that higher temperatures may not be favorable for rice production. (3) There is no strong correlation between rainfall and crop yield according to these data, indicating that factors other than rainfall may be more significant in determining crop yield because there is no strong correlation between observed variables and crop yields, as well as indications of non-linearity and the importance of temporal factors, a deep learning model approach with a combination of quantum feature analysis is undoubtedly appropriate to capture more complex dynamics.
2.2. Framework of Hybrid Quantum–Classical Deep Learning Model
2.3. Preprocessing, Normalization, and One Hot Encoding
After carrying out an analysis to ensure that the method chosen is appropriate. Some preprocessing was completed on the dataset used, such as checking and removing missing values and duplicate data, then normalizing and one-hot encoding. In this case, the normalization technique used is minimax to scale numerical features from 0 to 1. The goal is to ensure that the features are on the same scale so that no feature dominates the others during the model training process. This is important because machine learning algorithms can often converge more quickly when features are at the same scale. Equation (1) is used to perform MinMax normalization.
where
MinMax normalized value of feature value
;
is the minimum value of that feature in the entire dataset, while
is the maximum value of that feature in the entire dataset.
One-hot encoding is a technique used to convert categorical variables into a format that machine learning algorithms can understand [
51]. This is important because many machine learning algorithms cannot handle category labels directly because they can only work with numeric values. One-hot encoding helps overcome this problem by creating a binary numeric representation. In this case, one-hot encoding converts the area as a categorical variable.
2.4. Deep Learning Feature Extractor Model Design
This model uses an effective Bidirectional Long Short-Term Memory (BiLSTM) architecture to learn long-term dependencies in data. BiLSTM utilizes information from both time directions in sequential data. It has four layers consisting of three BiLSTM layers and one dense layer. The BiLSTM layer with return_sequences = True allows information to flow to the next LSTM layer. In contrast, the final layer with return_sequences = False consolidates the information into a single output vector that is then processed by the Dense layer to produce the final prediction. The Adam optimizer was chosen for efficiency in training, and evaluation was performed using standard metrics for regression problems. Training is carried out using cross-validation to ensure a robust model and avoid overfitting. More detailed designs are presented in
Table 1.
A more detailed explanation of the specifications of the model. Multiple BiLSTM layers allow the model to learn more complex and abstract data representations. Each BiLSTM layer can extract and reconstruct information from sequential features at different levels, allowing the model to learn deeper time dependencies and more complex patterns. Choosing the number of layers has several impacts. If the number of layers is less, it can lead to underfitting, poor generalization, and limited performance on complex data. Conversely, if there are too many, it can also cause overfitting and high computational requirements, and problems with back-propagated gradients can disappear or even explode. The selection of the number of layers was determined based on several experiments and observations, as well as the selection of the number of units in each layer.
A dense layer, also known as a fully connected layer, is one in which every unit is connected to every unit in the previous layer. This layer is usually used as an output layer in a neural network to combine the features extracted by previous layers and produce a final prediction. In the context of regression, the dense layer typically has one unit (neuron) to produce one continuous value representing the prediction.
The Leaky ReLU activation function is a variation of ReLU designed to overcome the vanishing gradient problem that can occur on inactive ReLU units. In contrast to ReLU, whose output is 0 for all negative inputs, Leaky ReLU allows small values for negative inputs, thereby reducing the risk of the ReLU unit becoming permanently inactive. Leaky ReLU can be calculated with Equation (2).
where
is a small leakage constant, generally in the range of 0.01. This ensures that even when the unit is inactive, a small gradient still passes through, which helps in the learning process during backpropagation.
The optimization algorithm chosen is Adaptive Moment Estimation (Adam). This is useful for updating network weights iteratively based on training data. Adam combines the advantages of the Adaptive Gradient Algorithm (AdaGrad) and Root Mean Square Propagation (RMSProp). Adam calculates adaptive learning rates for each parameter. Adam also stores estimates of the gradient’s first (mean) and second gradients (variance); This helps set the learning rate and makes it suitable for problems with many parameters or large data.
The cost function measures how well the model makes predictions compared to reality. Mean squared error (MSE) is one of the most commonly used cost functions for regression problems. The MSE measures the average of the squares of the errors between the predicted values and the actual values. The MSE formula can be calculated with Equation (3).
where
is actual value,
is the predicted value, and
is the number of samples.
2.5. Quantum Circuit Design and Quantum Feature Processing
Integration with quantum circuits in this research is needed to overcome the limitations of classical feature selection techniques, which are often trapped in local optima and have difficulty handling combinatorial optimization problems in large feature spaces. Quantum circuits, with their ability to exploit superposition and entanglement, can simultaneously explore a broader and more complex solution space. This allows data processing in higher dimensions and can capture more complex and non-linear data patterns, which are difficult to achieve with classical techniques. Using quantum simulators such as PennyLane allows us to test and optimize quantum algorithms on classical hardware before implementing them on real quantum devices, ensuring the feasibility and efficiency of the proposed method.
However, it is important to note that designing the architecture of quantum circuits requires deep hypotheses and multiple trials and errors. An inappropriate quantum architecture may not provide a positive impact; on the contrary, it may increase excessive complexity, reduce the richness of feature representation, and thereby decrease prediction performance. For example, while quantum entanglement can enhance feature interactions, poorly designed entanglement patterns can introduce noise and irrelevant correlations that confuse the model. Similarly, the depth of the quantum circuit must be carefully balanced; too shallow a circuit might fail to capture necessary feature interactions, while too deep a circuit might suffer from issues like decoherence and increased computational burden [
52,
53,
54].
Quantum circuits are invoked for each piece of data to process each sample. These circuits take classical parameters and features as input, encode the classical features into quantum states (qubits), and then apply a series of quantum operations (rotation and entanglement) before performing measurements (converting back to the classical state). Rotation and entanglement in quantum computing play a key role in manipulating qubit states to extract patterns or information that are not easily obtained through classical computing. Rotation enables exploration of the entire Bloch state space, encoding richer information into qubit states. By exploiting rotation, classical features can be encoded into the amplitude and phase of quantum states, which allows us to exploit quantum superposition to capture simultaneous combinations of features [
55]. Circuits are also built with parameter tuning to find classical data’s most effective quantum representation.
Meanwhile, entanglement is a quantum phenomenon in which the state of one quantum particle cannot be explained independently of the state of another particle, even if a large distance separates the particles. In quantum machine learning, this allows us to capture correlations between features that classical models cannot [
37]. Through entanglement, we can create new “quantum features” that combine information from several original features in a non-linear and highly complex manner [
56]. When measuring a qubit after rotation and entanglement have been applied, information is obtained that represents the combined influence of all classical features and the non-linear correlations between them that have been “mapped” to quantum space.
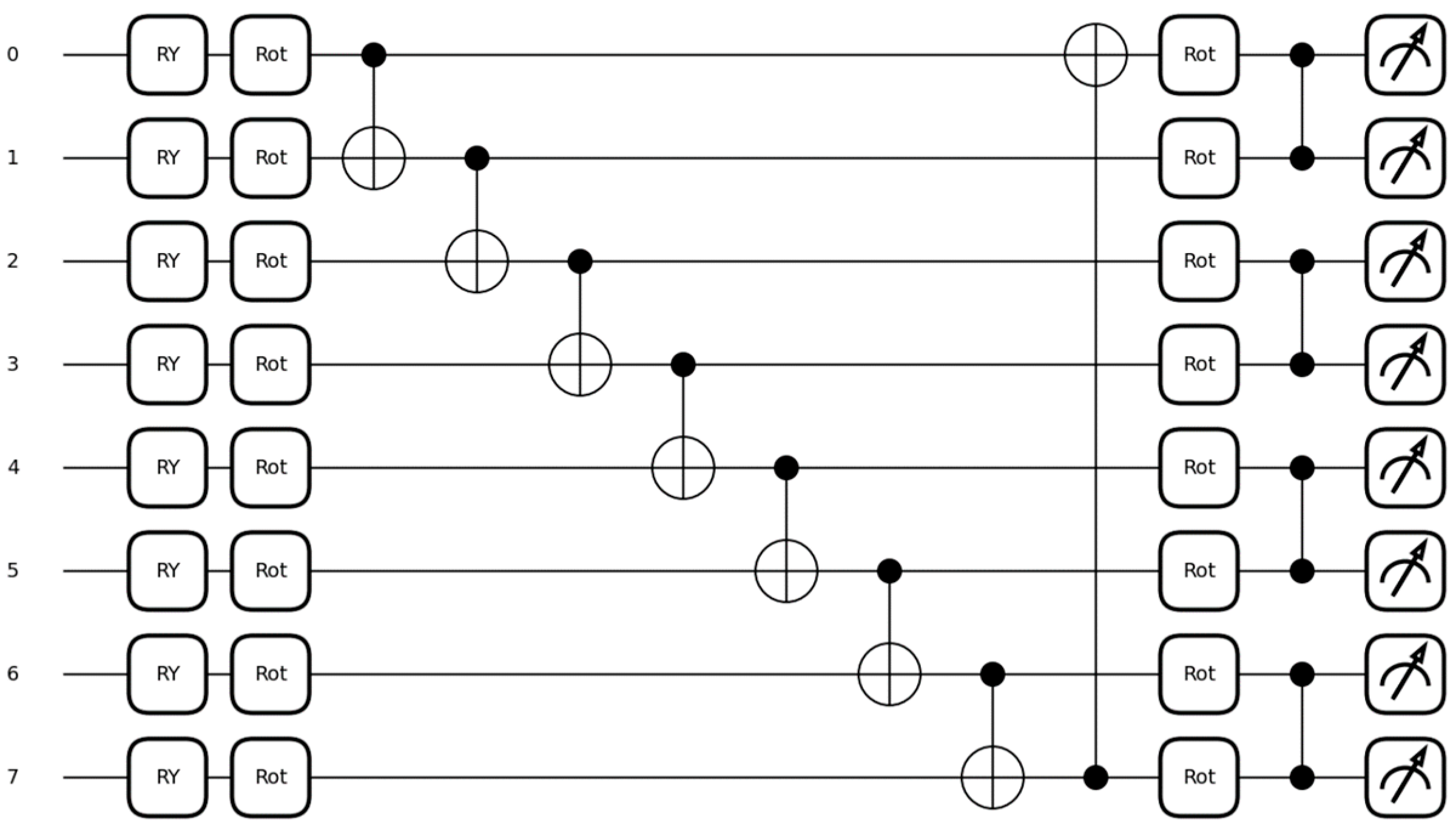
The quantum circuit is built with the PennyLane simulator, where the general design of the quantum circuit used is presented in
Figure 5. Based on
Figure 5, you can see the details of the process in the designed quantum circuit, namely:
State Preparation: Start by encoding classical features into quantum states (qubits) using gates. is a gate for rotation around the y-axis on the Bloch sphere. The gate has a parameter , which rotates the state by an angle about the y-axis.
First Layer Rotation and Entanglement: Perform rotation on each qubit using the Rot gate. The Rot gate has three parameters, namely (). This gate is a general rotation and can be described as rotation around the z (), y (), and again z () on the Bloch sphere. Next, entanglement is applied between neighboring qubits using a CNOT gate and another CNOT to create an entanglement loop from the last qubit to the first qubit.
Second Layer Rotation and Entanglement: Performs another series of rotations on each qubit with the Rot gate. Then, different entanglement patterns will be created using CZ gates on paired qubits. The CZ gate is similar to CNOT, but the CZ gate will add a π phase at the 〉 state. In simpler terms, if both qubits are in the 〉 state, and then the target qubit’s state will be multiplied by −1.
Measurements: Pauli-Z value expectation-based measurements were performed, which is one of the standard basis sets for quantum measurements. The measurement results are usually expressed as +1 and −1, which correlate with the 〉 or 〉 state of each qubit. The results at this stage are that quantum information is converted again into classical information that classical machine learning models can use to make predictions.
The use of quantum circuits provides significant advantages by exploiting quantum phenomena to process data in ways that classical methods cannot. This can be called a feature engineering process on the BiLSTM extracted features, which enriches the representation [
57]. This has the positive impact of improved prediction accuracy, demonstrating the potential of quantum-enhanced machine learning models in handling complex high-dimensional data sets.
2.6. Concatenate Features and Reshaping
The resulting quantum features are then combined with classical features. This means that the representation of each sample now includes both classical and quantum information. The combined feature data are transformed to match the input expected by the LSTM model. LSTM expects data in the format [samples, time steps, features], so changes are made to conform to this structure.
The combined feature data are transformed to match the input expected by the LSTM model. LSTM expects data in the format [samples, time steps, features], so changes are made to conform to this structure. Combining quantum and classical features leverages the strengths of both approaches. Quantum features capture intricate, non-linear relationships that are difficult for classical models to detect, while BiLSTM excels at understanding temporal dependencies. The enriched feature set is then used to train the XGBoost model, which benefits from the enhanced representation of the data, leading to improved prediction accuracy.
2.7. Train and Validation Using XGBoost Regressor
The data are divided into training and testing sets in the loop using 5-fold cross-validation. This is important for validating the model and ensuring that the model can generalize well to data that has never been seen before. In this phase, the XGBoost model is defined and configured by optimizing a number of critical hyperparameters and selected n_estimators = 150 to build the ensemble model, which collectively contributes to the predictive power. The choice of the number of trees considers the balance between model capacity and the potential for overfitting, considering the volume and complexity of the data being processed. Meanwhile, the learning_rate was set at 0.05 to facilitate gradual and stable convergence to the minimum loss function. These hyperparameters are critical in moderating the rate of model adaptation to prediction errors during the training phase, allowing for increased precision without compromising on model generalization. This implementation assumes an iterative process in which model weights are systematically adjusted, absorbing information from features extracted via BiLSTM and quantum processing, to obtain an optimal regression model in the context of the dataset under consideration.
2.8. Model Evaluation
After training, the model is evaluated using metrics such as MSE,
, and mean absolute error (MAE) to measure model performance on test data. MSE can be used to measure cost functions and performance measurement tools. The MSE formula for model evaluation is also the same as the cost function shown in Equation (3). MSE measures model performance by calculating the average squared error between model predictions and actual values. This provides a measure of the model’s effectiveness in predicting new data. Meanwhile,
is helpful for comparing how effective a predictive model is in explaining variations in data compared to a straightforward model that only uses the average of the data as a prediction. A higher
value (closer to 1) indicates that the model performs better.
can be calculated with Equation (4).
where
is a mean value of
.
MAE is often used to obtain an illustration of the average “error” created by a model, where all errors are calculated on the same scale, and no error is dominant over another. MAE gives an idea of the magnitude of error in predictions without considering its direction (positive or negative). The MAE value is calculated using Equation (5).
The combination of these three measuring instruments is important to use because it provides a detailed explanation. Low MAE and MSE indicate low prediction error, which usually means more accurate predictions. A high indicates that your model can explain variations in the data better, often meaning more precise predictions. MAE is more robust against outliers than MSE because it does not square the different results. So, a model with a low MAE may not always have a low MSE if there are outliers in the data, while is useful for assessing the overall model fit to the targeted data.
3. Results
This research was implemented using Python, Pennylane Quantum Simulator, and Google Collab Pro, while the local hardware used was a personal computer with an Intel Core i7-1165G7 11th Gen CPU with 16GB memory. Regarding dataset collection and initial analysis are explained in
Section 2.1, and the implementation results of the proposed framework are presented in more detail in the following section. In the first stage of data set reading and preprocessing,
Figure 6 shows the sample data set used.
Based on
Figure 6, it appears that the records in the dataset are not all unique and complete. There are 297 records of duplicate data or missing values, which were calculated from initial data of 3270 (see
Table 2) and reduced to 2973 (see
Table 3). Removing duplicate and missing values in data preprocessing aims to improve the dataset’s quality. Duplicate values can cause bias in the model by repeating the same information while missing values can hinder algorithms that require a complete dataset to operate effectively. By eliminating both, we can reduce the risk of overfitting, ensure the integrity of the analysis, and simplify the training process, resulting in more accurate and reliable models [
58]. Next, the normalization stage is carried out on all numerical values. The normalization process is carried out before the one-hot encoding process (see
Table 4). Normalization before one-hot encoding is preferred because it ensures that only numerical features that scale differently are adjusted, while categorical features transformed via one-hot encoding remain in the desired binary format. Encoded categorical features should not be normalized because they inherently contain values 0 or 1, reflecting the absence or presence of categories. Additional normalization could distort the meaning of this binary and reduce the clarity of model interpretation. Separating the normalization and one-hot encoding processes can ensure that the data are processed appropriately and improve the scale of numerical features without disturbing the correct representation of categorical features [
59,
60,
61]. The results of the one-hot encoding process are presented in
Figure 6.
One-hot encoding is used to change the “Area” column of the sample dataset shown in
Figure 6, which becomes a series of binary columns, each representing one country. This process removes categorical values and replaces them with numeric values, where each new column added will have a value of 1 for the row corresponding to that country and 0 for all other countries. As a result, each entry in the dataset that previously represented a country by name is now represented by a unique binary pattern, allowing machine learning algorithms to process the data without ordinal bias and increasing the total number of features according to the number of unique countries present in the data.
After the preprocessing stage is complete, the training and validation process is carried out in k-fold cross-validation, where k = 5. In 5-fold cross-validation, the dataset is divided into five folds. At each iteration, one-fold is used as the validation set, and the other four are used as the training set. The model is trained on the training set and evaluated on the test set. This process is repeated five times so that each fold has one chance to become a test set. The training and validation results are then measured using MSE,
, and MAE, where the average values of these three measuring instruments are presented in
Table 2. Apart from that, a plot of the regression results is also presented, which is presented in
Figure 7.
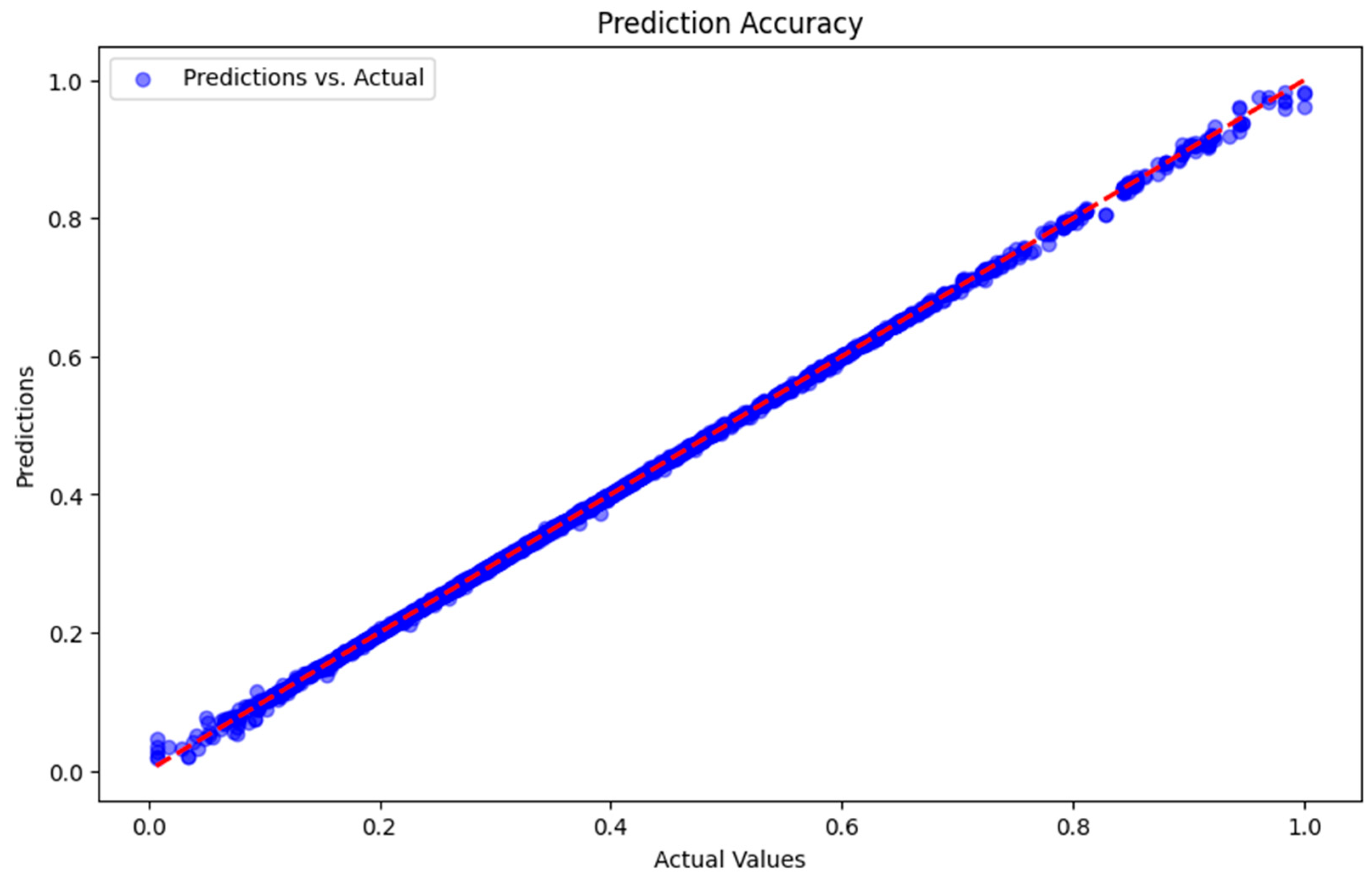
The plot presented in
Figure 7 displays all predictions of each fold against the actual value. At each cross-validation iteration, the model makes a series of predictions for the fold being tested, and these predictions are collected together in the “predictions variable”. In contrast, the actual value of the fold is collected in the “actuals variable”. The blue dots in the scatter plot show the relationship between predicted and actual values for all folds. Each point represents the model prediction for one sample in the test set. The dashed red line shows the identity line, where the perfect predicted value would lie. If all predictions are perfect, all points will lie on that line, and it seems that the plot results show that the blue points are around that line, indicating something very positive about the prediction results. The results of this plot are also supported by the MSE and MAE, and
results are shown in
Table 5.
4. Discussion
Based on the data displayed in the results section, it appears that the proposed model can perform sophisticated work and predict the expected results. The results are also relatively stable, as seen by looking at the very low MSE and MAE figures in each validation fold. The
value is also very high, approaching 1, meaning that this result can tell how well the model can “explain” the variations that occur in the data used. This is very important because perfect data are rarely obtained in the real world. In this way, this model can produce the expected predictions and not be far from reality. However, the results above also need further analysis. In this section, the results are compared with other popular models, while several ablation studies are carried out to determine the effects of using hybrid quantum–classical features. The comparison results are presented in
Table 6.
The data in
Table 3 contains several important findings. Firstly, the use of hybrid features has succeeded in increasing the performance of all methods. Quantum circuits have the potential to explore complex and high-dimensional feature spaces more efficiently than classical methods. This can lead to the discovery of novel feature interactions and patterns that might be overlooked by classical models. The use of several layers of rotation and entanglement enriches the viewpoint from which to study the recognition of hidden relations, interaction complexity, and deep temporal and non-linear patterns in features that have been extracted with BiLSTM. Secondly, XGBoost methods, which are ensemble methods, are still more robust than the deep learning regressor implementation.
Apart from that there are several main justifications that need to be considered. The first is future scalability, where the computing power of quantum processors is expected to far exceed classical processors. Investing in quantum-based methods today can provide a foundation for taking advantage of future advances. Secondly, integrating quantum computing with machine learning represents a cutting-edge approach that pushes the boundaries of traditional computing methods into an interdisciplinary innovation.
Next, we also compared several models in the literature related to rice production prediction, which are presented in
Table 7.
Based on the results presented in
Table 4, the proposed method shows the best performance in predicting rice production. This method uses quantum features that provide significant advantages in increasing prediction accuracy, which is reflected in very low MSE and MAE values and is almost perfect
. Compared with other methods, such as those used in research in Ref. [
19] and Ref. [
1], which also show good results but are still inferior in terms of accuracy and prediction error. Ref. [
5] uses data from three districts in India and shows quite good R², but with higher MSE, indicating lower accuracy. Meanwhile, Ref. [
20] shows much lower performance with high MSE and MAE values.
The MSE measures the mean squared difference between predicted values and actual values. In the context of forecasting, a lower MSE indicates that the model predictions are closer to the actual values, thereby giving more weight to larger errors. The proposed method’s MSE of 1.2 × 10
−5 is significantly lower than the MSE values reported in Ref. [
5] and Ref. [
20], indicating that our model makes more precise predictions with smaller deviations from the actual values. MAE measures the average absolute difference between predicted values and actual values. In contrast to MSE, MAE provides a direct average error in the same units as the data, making it easier to interpret. The MAE of the proposed method is 0.00139, which is much lower than the MAE values in related studies, such as Ref. [
19] and Ref. [
20], indicating that our model consistently produces predictions that are very close to the true values.
shows how well the model explains the variance of the data. An
value close to 1 indicates that the model can account for almost all of the variability in the data. The proposed method obtains
R2 of 0.99993, which is higher than the values reported in Ref. [
19] and Ref. [
5], indicating that our model fits the data better.
The combination of these three metrics, MSE, MAE, and is very important for the comprehensive evaluation of model performance. MSE and MAE assess the accuracy of predictions by measuring the magnitude of the error while evaluates the explanatory power of the model. Optimal values on all these metrics indicate that the model is not only accurate in its predictions but also robust in capturing underlying patterns in the data. This comprehensive performance analysis underscores the superiority of the proposed hybrid quantum–classical model in providing accurate and reliable rice production estimates compared to traditional methods and other related efforts. Overall, the hybrid quantum–classical method proposed in this research is proven superior in providing more accurate and reliable rice production predictions. This is very important for practical applications where accurate forecasting is essential for agricultural planning and management decision-making.
5. Conclusions
This research succeeded in developing a hybrid quantum deep learning model for rice production forecasting, which shows great potential for increasing prediction accuracy compared to traditional methods. This model integrates the advantages of quantum feature processing with advanced deep learning techniques such as BiLSTM and XGBoost regressors, providing a robust solution that can handle the large, non-linear, and multivariate data complexities often encountered in agricultural data.
The results of this study show that: (1) the use of quantum features helps in revealing hidden patterns and improves the quality of data representation, which significantly enriches the information available for prediction; (2) the integration of features from BiLSTM and quantum computing in the hybrid model provides significant improvements in all evaluation metrics—mean squared error (MSE), coefficient of determination (), and mean absolute error (MAE), demonstrating the effectiveness of this combination in predicting rice yields; (3) hybrid quantum deep learning models offer superior flexibility and adaptability in dealing with variations in agricultural data, which is promising for applications in real-world scenarios.
However, there are several cons related to the current state of quantum technology and deep learning: (1) Quantum computing hardware is still in its infancy. This restricts the practical implementation of quantum algorithms and necessitates using quantum simulators, which may not fully capture the potential of real quantum processors. (2) Both quantum simulations and deep learning models require significant computational resources. (3) Scaling quantum algorithms to handle larger datasets and more complex problems is still a major challenge. Despite these challenges, the future of quantum computing holds immense promise. As quantum hardware advances and becomes more accessible, it is expected to surpass classical processors, enabling the exploration of complex feature spaces and the discovery of novel patterns.
By leveraging quantum technology and deep learning, this research opens new avenues in agronomic forecasting and can be considered a step forward in AI applications in the agricultural sector. Therefore, we recommend wider adoption of this hybrid approach in future similar studies, as well as further exploration of the potential of quantum technology in various aspects of machine learning. We hope these findings can inspire other researchers to explore and develop this technology further so that globally, decisions in the agricultural sector can be further optimized, helping to increase food production and environmental sustainability.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}