1. Introduction
Rural Networks enable the flow of information between devices, sensors, actuators, and data centers, allowing farmers to monitor their agricultural operations remotely. This connectivity is essential for deploying various smart agricultural technologies (precision farming, sensor monitoring, and data analytics) that leverage the power of the Internet of Things (IoT) and artificial intelligence (AI). The success of Smart Agriculture Services is related to an adequate design of the Rural Network Connectivity, ensuring that even remote and traditionally unserved agricultural areas are covered. In this scenario, Software-Defined Wide Area Networking (SD-WAN) emerges as a key player in optimizing network performance, ensuring a secure, scalable, and flexible infrastructure for seamless communication across vast agricultural landscapes.
In the past, connecting enterprise sites over long distances relied on dedicated leased lines provided by network operators. However, these lines were associated with high costs and limited speeds, prompting the exploration of alternative technologies for the creation of inter-site connections over public Wide Area Networks (WANs) [
1]. Based on packet-switching technology, public WANs matured in the early 1980s and saw continuous development. Technologies like Asynchronous Transfer Mode (ATM) [
2], Frame Relay (FR) [
3], and Multi-protocol Label Switching (MPLS) [
4] were gradually adopted to establish overlaid tunnels for interconnecting enterprise networks (ENs) across sites. MPLS, in particular, has gained popularity due to its ability to ensure QoS through Service Level Agreements (SLAs), which is achieved by establishing dedicated paths within the IP (Internet Protocol) network, leveraging DiffServ (Differentiated Services) technology. However, MPLS has drawbacks such as high bandwidth costs, configuration complexity, and the time required to scale or upgrade paths dynamically.
SD-WAN has emerged as a novel solution in the global enterprise networking landscape, with the aim of offering a low-cost solution that is at least close to the performance of MPLS-based WANs. It leverages the advantages of Software-Defined Networking (SDN) to enhance WANs by separating control and data planes. This approach enables the programming of network devices from a centralized controller, as introduced in [
5]. SDN centralizes control plane functions, extracting control logic from underlying routers and switches. This approach simplifies network management and enables innovation through network programmability. While SDN was initially designed to meet the demands of modern computing in data center networks, SD-WAN applies SDN technology to facilitate end-to-end connections between users and networks across the WAN. SD-WAN effectively combines the low cost of Internet access and guarantees a level of availability by introducing a centralized software controller. The SD-WAN overlay architecture is more adaptable to dynamic configurations in response to network conditions than MPLS. This adaptability is facilitated by a controller connected exclusively to edge devices, eliminating the need for direct access to internal WAN equipment, such as providers’ routers and switches, to operate an SD-WAN system. This feature is particularly relevant in rural scenarios, in which the simplicity and flexibility of SD-WAN can address the challenges posed by limited resources and infrastructure. Its centralized overlay architecture simplifies network management, minimizing operational complexity, which is particularly advantageous in contexts with limited resources. SD-WAN is the leading technology for many of today’s WAN architectures because it guarantees secure, agile, and flexible connectivity among the edge nodes [
6]. This is particularly relevant in rural areas where cellular coverage is limited and satellites, Wi-Fi mesh, and fixed xDSL may be present. Furthermore, SD-WAN’s ability to adapt dynamically to network conditions is precious in rural areas where connectivity may be unstable or subject to variations. Using a centralized software controller enables dynamic configuration of the SD-WAN architecture to quickly respond to changes in network availability. Its implementation can significantly enhance connectivity and network management in rural environments, facilitating digital transformation even in settings with limited resources.
Tunnel selection is pivotal in SD-WANs, influencing latency, bandwidth, and reliability. Traditional methods often need help to dynamically adapt to changing network-connectivity conditions, making them less effective in highly dynamic environments. The tunnel represents an overlay link, with the CPE (Customer Premises Equipment) possessing a number of outputs corresponding to the technology employed. The CPE is envisioned as an experimental Virtual Network Function (VNF) deployable on generic hardware [
7]. It facilitates the automated setup of encrypted tunnels, including IPSec tunnels, across diverse network access technologies like satellite connectivity, mesh WiFi, 4G/5G, xDSL, and fiber optics. In our scenario, a farmer has only one outgoing router, which can serve as the CPE. However, the CPE might also be a more sophisticated device, such as a firewall or a tool for implementing SD-WAN functionalities like connection to the provider, Traffic Engineering (TE), security, and monitoring capabilities.
Reinforcement Learning (RL) [
8] has emerged as a powerful paradigm for training agents to make intelligent decisions in dynamic and uncertain environments. In this work, we apply RL techniques to the challenging problem of SD-WAN tunnel selection, aiming to improve the network performance and reliability in rural areas. We introduce a custom SD-WAN environment, implemented using the Mininet and OpenFlow [
5] frameworks, to simulate network conditions and evaluate the performance of the RL-based link selection algorithm. The proposed algorithm utilizes a Deep Q-Network (DQN) agent to learn an optimal link selection policy through interactions with the SD-WAN environment.
In this paper, we delve into using SD-WAN technology to ensure comprehensive reliability in areas where a single Long-Term Evolution (LTE) connection may fall short of providing continuous connectivity. By integrating a Low Earth Orbit (LEO) satellite tunnel and employing deep RL for tunnel selection, we propose a solution for rural zones.
To the best of our knowledge, this work is the first to present SD-WAN technology within a rural environment. Let us resume the main contribution of the paper. Firstly, we have developed a simulator for SD-WAN, allowing for the exploration of various scenarios involving multiple tunnels and traffic requests. Our focus lies in the rural scenario, where both LTE and LEO tunnels are available for utilization. We also conduct simulations employing three distinct algorithms to address the tunnel selection problem: random selection, deterministic approaches, and RL-based strategies. The simulation confirms that our proposed methodology shows a promising solution for guaranteeing a reliable connection, underscoring our solution’s viability in rural settings.
The rest of the paper is organized as follows.
Section 2 presents some of the most relevant works about SD-WAN in remote areas, Traffic Engineering in SD-WAN, and Satellite Internet in remote areas.
Section 3 gives an overview of Deep-Reinforcement Learning, focusing on the Deep-Q learning algorithm.
Section 4 provides the description of the reference scenario, and
Section 5 details the three algorithms.
Section 6 describes the implementation and analyzes the results of the experiments. Finally,
Section 7 concludes the work.
3. Reinforcement Learning in SD-WAN
RL [
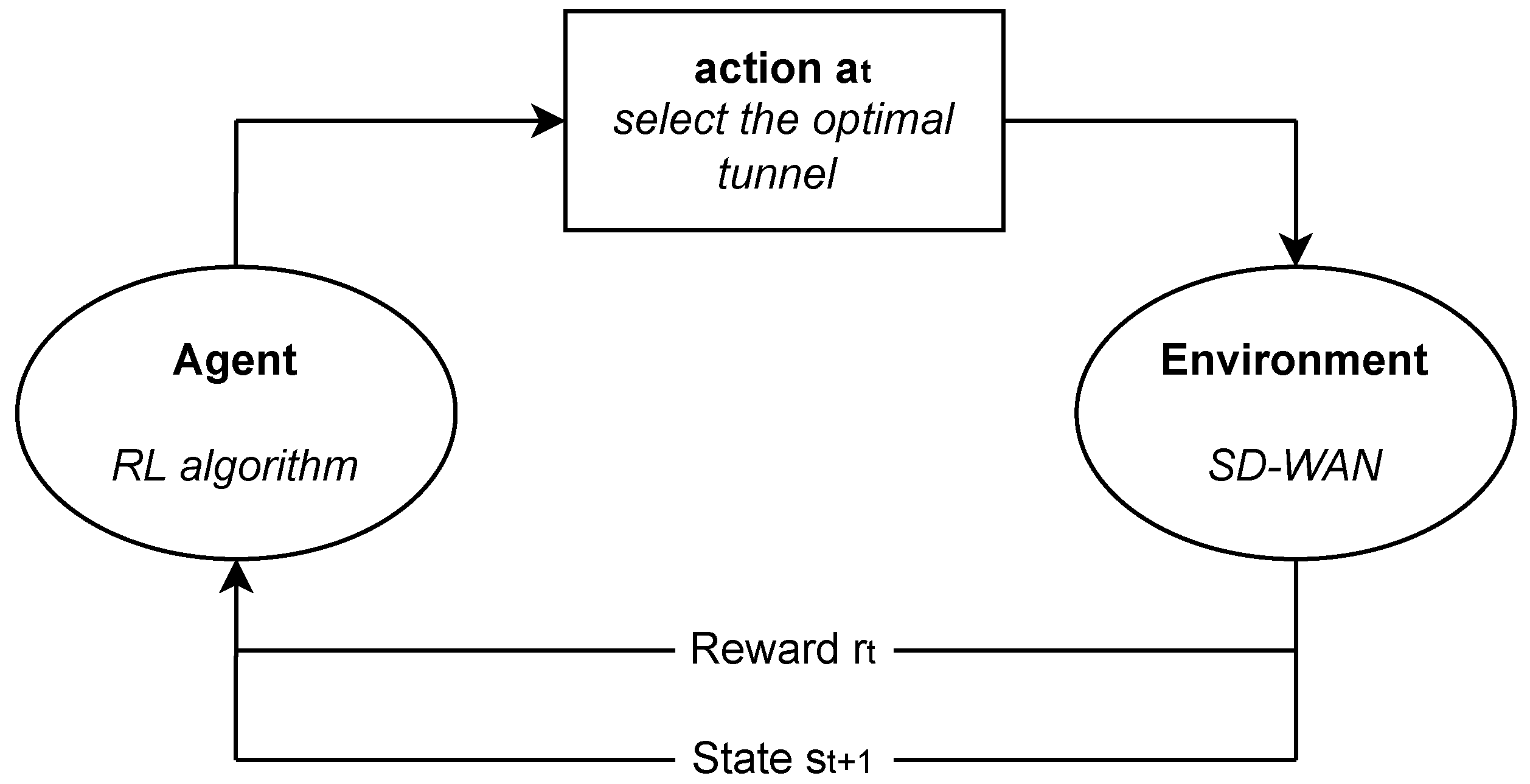
8] is a machine learning paradigm in which an agent learns to make decisions by interacting with an environment in order to maximize a cumulative reward. RL aims to identify optimal actions within a specified environment. This process entails the environment assigning positive or negative rewards based on the actions taken by the agent. The agent plays a key role in decision-making and interaction with the environment, learning from its experiences through iterative interactions with the environment.
At each time step t, the scenario unfolds as follows:
The environment is characterized by its state .
The agent executes the action .
The environment transitions to the state and conveys the reward to the agent.
These observations, actions, and rewards collectively form the history, defined as
. This cyclic process represents the core of RL, where the agent continuously refines its decision-making based on the feedback received from the environment. RL has also found applications in trading and finance, healthcare, and gaming, such as in the development of AlphaGo Zero [
27], which learned the game of Go from scratch using RL.
Unlike supervised learning, which uses labeled training data, or unsupervised learning, which discovers patterns without guidance, RL requires the agent to actively gather experience about system states, actions, transitions, and rewards to take action in order to maximize a cumulative reward function. In the context of SD-WAN, RL can offer significant advantages in managing and optimizing network performance in dynamic environments. The dynamic nature of network traffic and changing conditions make SD-WAN an ideal candidate for reinforcement learning applications.
Figure 1 presents a scheme of RL for the tunnel selection problem in SD-WAN that will be analyzed in the following sections.
There are several RL algorithms, but analyzing the comparison carried out in [
18], we focus on Deep Q-learning because of computational time and performance.
Deep Q-Learning (DQN)
The agent’s objective is to perform the propel actions, maximizing future rewards. We adopt the common assumption that future rewards are discounted by a factor
per time step. The future discounted return at time
t is defined as
, where
T is the time-step when the simulation terminates. The optimal action-value function
in (
1) represents the maximum expected return that can be achieved by following any strategy after observing a sequence
s and taking action
a:
where
is a policy that maps sequences to actions.
The optimal action-value function in (
2) is based on the Bellman equation, which is grounded in the intuition that if the optimal values
for the sequence
at the next time-step were known for all possible actions
, then the optimal strategy would be to select the action
that will maximize the expected value of
in the environment
E:
Many RL algorithms adhere to the basic idea of estimating the action-value function using the Bellman equation as an iterative update:
. However, this approach becomes impractical in practice, as the action-value function is estimated separately for each sequence without generalization. Instead, a function approximator, typically a Q-network, is commonly employed to estimate the action-value function
, where
represents the network weights [
28].
Training a Q-network involves minimizing a sequence of loss functions , where is the target for iteration i, and represents a probability distribution over sequences s and actions a referred to as the behavior distribution. The parameters from the previous iteration are fixed when optimizing the loss function . Note that the targets depend on the network weights; this contrasts with the targets used for supervised learning, which are fixed before learning begins.
Differentiating the loss function concerning the weights, we arrive at the gradient in (
3):
Rather than computing the full expectations in the above gradient, it is often computationally reasonable to optimize the loss function by stochastic gradient descent. If the weights are updated after every time step, and expectations are replaced by single samples from the behavior distribution
and the environment
E, respectively, then we arrive at the familiar Q-learning algorithm [
29].
It is crucial to note that this algorithm is model-free, meaning it directly solves the RL task using samples from the environment E without explicitly constructing an estimate of E. Furthermore, it is off-policy, as it learns about the greedy strategy while following a behavior distribution that ensures sufficient state space exploration. In practical applications, the behavior distribution is often selected using an -greedy strategy, where the agent follows the greedy strategy with a high probability of and selects a random action with a probability of .
4. Reference Architecture
We introduce the reference scenario (see
Figure 2), providing a high-level, generalized system description. The system operates within a rural environment, with
N peripherals connected with
K tunnels to a central site. Each peripheral could connect
M different users with different types of traffic requests. This architecture aims to enhance efficient data exchange and reliable communication in rural landscapes where conventional infrastructure might be limited. The system leverages SDN as an enabler in the SD-WAN framework. SDN offers a centralized control mechanism, enhancing the management and orchestration of network resources. The central controller is the focal point for decision-making, allowing for dynamic adjustments in response to varying network conditions. A crucial element in this system is the utilization of Tunnel Selection Algorithms (TSAs). These algorithms are pivotal in efficiently forwarding traffic through the network tunnels. Their primary function is to assess and select the most optimal tunnel based on specific criteria, bandwidth availability, overall network load, tunnel availability, and traffic type. In this work, we will consider three different algorithms, and the description of each algorithm will be presented in
Section 5.
To contextualize, let us present a specific scenario (see
Figure 3) where we considered four rural sites (
) connected to a central data center; this is based on the general SD-WAN architecture. Each rural area is connected through an SD-WAN CPE and two tunnels (
), and may generate two types of traffic requests (
) that we define as type A and type B. The first tunnel is an LTE tunnel, while the other represents a LEO tunnel. It is worth noting that when we talk about SD-WAN, the management will be at the end-to-end level, and the underlay routing within each tunnel will not be controllable.
The LTE tunnel and LEO tunnel diverge significantly in terms of reliability and QoS. LTE offers a terrestrial wireless communication standard known for its reliability. However, its performance may vary, especially with intermittent connectivity and fluctuating QoS. On the other hand, the LEO tunnel provides constant connectivity, ensuring a stable connection, but it still exhibits variable QoS based on factors such as weather conditions, equipment quality, the satellite technology used, and the geographical location. While generally reliable, the LTE tunnel experiences intermittent connectivity in the rural scenario we considered. This means that the connection may not be consistently available, introducing variability in its QoS, making it crucial to assess these factors when considering the suitability of this tunnel for specific types of traffic. In contrast, the LEO tunnel offers constant connectivity, ensuring a reliable and stable connection. However, its QoS remains variable, influenced by the factors listed above. The choice between LTE and LEO tunnels depends on the nature of the traffic and the specific QoS requirements.
5. Tunnel Selection Algorithms
We present three different algorithms to evaluate the efficacy of the proposed solution with a particular focus on rural areas: random, deterministic, and Deep Q-learning-based. For all algorithms, the selection of the tunnel is exclusive, and no forms of multipath or redundancy are allowed. In our analysis, we examined the collective traffic generated by all CPEs, and the algorithms presented herein are intended to be applied individually to each CPE.
5.1. Random
The first Algorithm 1 adopts a random approach to tunnel selection, reflecting the unpredictability inherent in network conditions. A simple function that can be allocated in the controller randomly selects an action that corresponds to the selection of a tunnel. Traffic will be forwarded over one of the K tunnels with the same probability independently of the tunnels’ statues and bandwidth.
| Algorithm 1 Random |
- 1:
Initialize system parameters: user_traffic, available_bw, traffic_type - 2:
for traffic event do - 3:
Randomly select action ▹ Among K Tunnels - 4:
end for
|
5.2. Deterministic
As regards the deterministic algorithm, we introduce specific rules for tunnel selection based on the user traffic and available bandwidth for each tunnel. In particular, we compare the user traffic bandwidth with the available bandwidth in the first tunnel that corresponds to the default tunnel. As shown in the pseudo-code of the Algorithm 2, if the default tunnel does not have enough bandwidth to satisfy the user traffic request, the algorithm will select the tunnel with the highest available bandwidth.
| Algorithm 2 Deterministic with K Tunnels |
- 1:
Initialize system parameters: user_traffic, available_bw, traffic_type - 2:
for traffic event do - 3:
if then - 4:
▹ Default tunnel - 5:
else - 6:
- 7:
for to K do - 8:
if then - 9:
- 10:
▹ Select tunnel i - 11:
end if - 12:
end for - 13:
end if - 14:
end for
|
5.3. DQN-Based
The third Algorithm 3 introduces the RL-based approach that leverages DQN with the aim of selecting the propel tunnel in real-time. The most important advantage of using RL is that the algorithm will learn in real-time, as described in Section Deep Q-Learning (DQN). In other words, it is possible to forecast the overcoming of the QoS threshold, and it will change the tunnel not only when the instant SLA threshold is not satisfied but also before that situation occurs. The primary objective of DQN is to learn and adapt the tunnel selection, particularly in scenarios in which the presence or absence of a primary connectivity becomes a critical determinant. When the existing tunnel bandwidth is insufficient to meet traffic requirements, DQN strategically anticipates the impending challenge and proactively recommends a tunnel change. This proactive approach enhances the overall network performance and contributes to resource efficiency.
DQN combines Q-learning (which updates Q-values using the Bellman equation, ensuring the model learns from historical experiences) with deep neural networks to approximate the Q-value function, representing the expected return for a given action in a specific state. The following parameters characterize the neural network:
Input Layer: The input layer is designed to match the environment’s state space size, capturing the relevant features required for decision-making. In particular, the implemented input layer has as many input nodes corresponding to the dimension of the state with a dimension of where K is the number of tunnels (we see this in our simulation scenario , and so the input layer will have four nodes).
Hidden Layers: There are two hidden layers, each comprising 24 neurons and activated by the Rectified Linear Units (ReLU) function. Each neuron in this layer receives inputs from the three features previously listed. The hidden layer transforms the input information into a higher-dimensional space through the weighted connections and activation function, facilitating the neural network’s ability to learn and generalize from the observed states.
Output Layer: The output layer of the neural network is designed to reflect the two possible actions that the agent can take. This layer comprises two neurons, aligning with the count of available actions, and serves as the neural network’s interface to provide Q-value estimates for the available actions. Furthermore, it uses a linear activation function for the output layer to directly obtain the expected Q-values for each action without any nonlinear transformation.
Loss Function and Optimizer: The Mean Squared Error (MSE) loss function quantifies the difference between predicted and actual Q-values. With a learning rate of 0.001, the Adam optimizer [
30] orchestrates the iterative refinement of model parameters during the training process.
| Algorithm 3 Deep Q-Learning with experience replay |
- 1:
Parameters: , , , , , - 2:
- 3:
for episode to do - 4:
Reset environment to initial state s - 5:
for step to do - 6:
Select action a using -greedy policy based on current Q-values - 7:
Execute action a in the environment, observe next state and get reward r - 8:
Store in replay memory D - 9:
if then - 10:
Sample a random batch from D - 11:
for in batch do - 12:
Predict Q-values for state s - 13:
Update Q-value for action a in Q-values - 14:
Train the model with state s and updated Q-values - 15:
end for - 16:
▹ Update exploration rate - 17:
- 18:
end if - 19:
end for - 20:
end for
|
This RL model uses experience replay, in which experiences are stored and randomly sampled, enhancing their learning efficiency. The Q-network’s weights are updated to minimize the disparity between predicted and target Q-values. A target network stabilizes learning, and a mean squared error loss function quantifies the difference between predicted and target Q-values. The DQN implementation incorporates a discount factor (
) to balance immediate and future rewards, emphasizing long-term gains. The general state
s has a dimension of
, where
K is the number of tunnels. The first element is 0 when the default tunnel is not available; from 1 to
K are 0 when the k-th tunnel does not have enough available bandwidth with respect to the user traffic; and the last element represents the traffic type. In
Section 6, we will describe in detail the state for a specific simulated scenario. As described previously, the agent’s objective is to maximize the cumulative sum of reward-based learning from past experience. In this study, the reward function is designed to let the agent learn about the tunnel’s availability and the bandwidth’s availability. The chosen parameters play a key role in defining the behavior of the DQN agent (see
Table 2).
Discount Factor (): The discount factor, set to 0.95, emphasizes future rewards. A high value (close to one) indicates a strategic focus on long-term gains.
Replay Memory Size: With a replay memory size of 1000, the agent leverages past experiences to enhance learning. This memory enables the agent to draw from diverse historical scenarios, mitigating potential biases associated with learning from consecutive experiences and contributing to the stability of the training process.
Batch Size for Training: Training occurs in batches of 32 experiences randomly sampled from the replay memory. This batching strategy prevents overfitting to specific experiences and promotes smoother learning, enhancing the agent’s ability to generalize across different situations.
Exploration Rate: The exploration–exploitation trade-off is managed through an
-greedy strategy [
31]. Exploration is gradually reduced over time, transitioning from random exploration to exploitation of learned policies. During the action selection phase, the agent considers two scenarios:
Exploration (with probability ): The agent randomly explores new actions instead of following the current policy, generating a random number from a uniform distribution between 0 and 1. If the random number is less than (the exploration rate), a random action is chosen from all possible actions.
Exploitation (with probability ): The agent exploits the knowledge gained by selecting the action with the maximum Q-value for the current state.
Starting with an exploration rate of 1.0, the rate gradually decays exponentially over time with a decay value of 0.995, reaching a minimum value of 0.01.
6. Implementation and Simulation Results
In this section, we present the implementation of the SD-WAN architecture in a simulated environment. Moreover, we implement and evaluate the algorithms presented in
Section 5 in a specific rural scenario. In particular, we consider a rural site where the single LTE connection is not able to guarantee complete spatial and temporal coverage and provide adequate reliability. An additional LEO satellite tunnel is considered. We considered two types of traffic (Type A and B) generated as in the
Section 6.1. In both cases, ensuring reliable data transmission is critical in remote and rural areas. Losing packets can have significant consequences, especially for critical applications like file transfers, web browsing, and emails.
In this results section, we will show that by adding an LEO tunnel with a proper tunnel selection allowed by SD-WAN, we can guarantee continuous coverage in space and time, allowing uninterrupted communication compared to if we had only LTE for our type of traffic requests. We will make a comparison with the scenario in which LTE is the only connection solution, and we will also compare the various algorithms to see which one performs better.
6.1. Simulated Bandwidth Generation
We consider Background Traffic (BT) and User Traffic (UT) in our simulation. Available Bandwidth is derived by subtracting the BT from the total Tunnel Bandwidth, which is constant. We considered BT=0 for the LEO tunnel in our simulated scenario. BT represents the persistent flow of data over the network, which is typically attributed to long-term connections like long-lived TCP sessions originating from peripheral sites or other users who share the tunnel links. This traffic has been generated according to a model inspired by [
32].
Figure 4 shows the BT of one simulation.
UT is a short-term traffic component that takes into account new traffic demands coming from the end-users at the peripheral site: this traffic has been generated according to a truncated normal distribution [
33]. For traffic type ‘Type A’, the request of traffic is generated using a normal distribution with a mean of 15 Mbps (
) and a standard deviation of 2 Mbps (
). On the other hand, for traffic type ‘Type B’, the generation uses a mean of 5 Mbps (
) and a standard deviation of 2 Mbps (
), reflecting common bandwidth values and variations encountered in real-world SD-WAN environments [
34]. We consider 2/3 of the traffic Type A and 1/3 Type B. The truncation is introduced so that negative values are not considered even if the probability is very small. With a mean of 5, we have
probability of having negative values and
when the mean is 15.
6.2. Simulation Scheme
The SD-WAN simulator was fully developed in Python, allowing us to integrate some RL libraries, which will be specified later. The implementation allows the creation of a scenario with multiple types of traffic requests and multiple user sites that communicate with a data center with multiple tunnels. In this paper, we considered a specific scenario and three TSAs, but the simulation scenario can be easily changed and adapted to other situations.
According to the scenario previously described and the algorithms in
Section 5, we performed some tests to evaluate how the three algorithms behave in the simulated scenario.
We implemented a DQN agent to learn the optimal tunnel selection policy. The agent’s neural network model uses the Keras library [
35] with a TensorFlow [
36] backend. For the RL algorithm, we employed OpenAI Gym [
37], a Python library designed for developing and comparing RL algorithms. It provides a standardized API (Application Programming Interface) for communication between learning algorithms and environments and a set of environments that comply with the established API. The random algorithm will select, with a probability of 0.5, one of the two available tunnels. In
Figure 5, we present the general scheme of the simulation. Let us summarize the simulation steps:
Select the type of traffic (Type A and Type B) and generate BT according to
Section 6.1.
The three TSAs (
Section 5) select the tunnel (LTE or Satellite LEO).
Generate the LTE status (present or not). In order to simulate a rural scenario, we considered the LEO tunnel as always being present, while the LTE tunnel is present with a probability of 0.8.
We update the QoS statistics, taking into account the selected tunnel and the LTE status.
Repeat starting from (1) until the SD-WAN simulation stops.
In the following sections, we present some results based on the scenario implemented and the three different algorithms.
6.3. Tunnel Selection
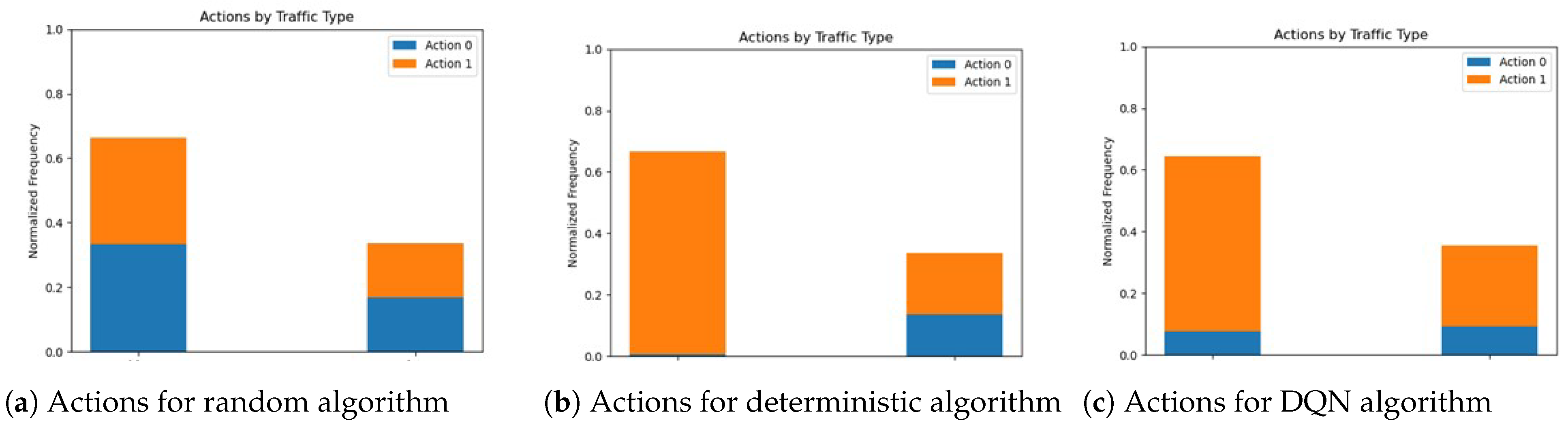
Figure 6 illustrates the normalized frequency of occurrences for action 0 (LEO tunnel selection) and action 1 (LTE tunnel selection), considering the two different traffic types and the three algorithms.
Figure 6a confirms that the random algorithm does not consider any criteria as contributing toward best performance. We can see that the deterministic (
Figure 6b) and DQN approach (
Figure 6c) present different behaviors of the selected tunnel, in accordance with the goal of selecting the best tunnel according to the available bandwidth.
6.4. Reward Function
The design of the reward function is a crucial element of RL. By providing positive or negative values with different absolute values, we present different situations that the algorithm should reward or penalize. The general rule is to force the algorithm to learn the forwarding of the traffic in order to ensure minimal loss, avoiding the LTE tunnel when it is down and considering the bandwidth availability for both tunnels. The difference in the values is justified by performing an action with 100% loss (LTE not present), <100% loss, or 0% loss. For example, negative values are justified by the fact that we penalize the case in which the chosen tunnel does not have enough bandwidth and thus is unnecessarily occupied by taking up bandwidth for another traffic request. In
Table 3, we present the instantaneous value for the specific scenario simulated in accordance with the action taken and the state
, where
a is 0 when the LTE tunnel is not available,
b and
c are 0 when the LTE and LEO tunnel, respectively, do have not enough bandwidth available with respect to the user traffic, and
d is 0 when the traffic type is Type B. We excluded the inconsistent states
in which the LTE tunnel is not present but has sufficient bandwidth in accordance with the proposed simulation model.
As shown in
Table 3, let us explain three examples according to the action selected in a particular state:
State with action 0: In this case, the reward is highly negative (−4) because the algorithm has selected the LTE tunnel that is not present with a consequent loss of 100%.
State: In the case of action 0, the reward is slightly negative (−2) because the algorithm has selected the LTE tunnel that does not have enough bandwidth (loss < 100%). But on the other hand, action 1 will also have a loss. In this last case, we assign a positive reward (+2) because, as a general strategy, the algorithm should learn to forward to the LEO tunnel when neither of them has sufficient bandwidth.
State with action 0: The type of traffic is considered only when both tunnels guarantee sufficient bandwidth. In this case, we force the algorithm to forward type A to the LEO tunnel. In this case, we assign a very high positive because not only is the loss 0%, but the type of traffic has been forwarded to a preferential tunnel.
6.5. Learning Trend
In order to show the learning trend of the DQN-based algorithm,
Figure 7 presents the behavior of the reward for one simulation. Analyzing reward trends offers an understanding of the adaptive learning dynamics of the network. The reward in the DQN approach shows an upward trend over time. This phenomenon is the direct consequence of the inherent nature of DQN, wherein the algorithm learns from its own actions with the goal of maximizing the reward. These results underscore the effectiveness of DQN in dynamic learning in accordance with network conditions, emphasizing the importance of learning-based approaches in our tunnel selection scenario in SD-WAN.
6.6. Comparison with LTE-Only Scenario
As previously described, our work aims to showcase that our proposed and implemented SD-WAN architecture can be effective in a rural area where an LTE connection exhibits intermittent coverage. In
Table 4, we conducted a comparison between the SD-WAN scenario, where three algorithms (DQN, Deterministic, and Random) dynamically select one tunnel, as outlined in the preceding sections, and a scenario featuring only LTE connectivity. In terms of how this is implemented in our system, SD-WAN inherently guarantees 100% coverage, since at least one tunnel is always available. In contrast, we considered the same scenario while excluding diversion to the LEO tunnel, resulting in a coverage of 72%.
Table 4 also introduces the Traffic Excess Factor (TEF) metric, representing the difference (in %) between the UT and the available bandwidth normalized with the total UT only at the steps with losses (i.e., when the difference is positive). In other words, it serves as a kind of “pseudo-packet loss”. In this context, we compared the performance of the three algorithms within the SD-WAN framework. The results confirm that DQN exhibited the best values, leveraging its ability to learn the evolving tunnel availability over time and predict traffic forwarding to tunnels that may soon become bandwidth-insufficient. The lower values of TEF for DQN (8%) and deterministic (10%) show that it is possible to control the tunnel selection in order to avoid the tunnel with limited capabilities. The point that we would like to highlight is that the DQN algorithm is able to learn a policy in order to achieve an improvement in terms of the metric presented, and it can reach or overcome the performance of a ruled-based algorithm as the deterministic one.
It is important to note that all three algorithms outperformed the LTE-only case, where the TEF metric considers bandwidth unavailability even when the tunnel itself is not accessible.
6.7. Ratio of Steps with Sufficient Bandwidth
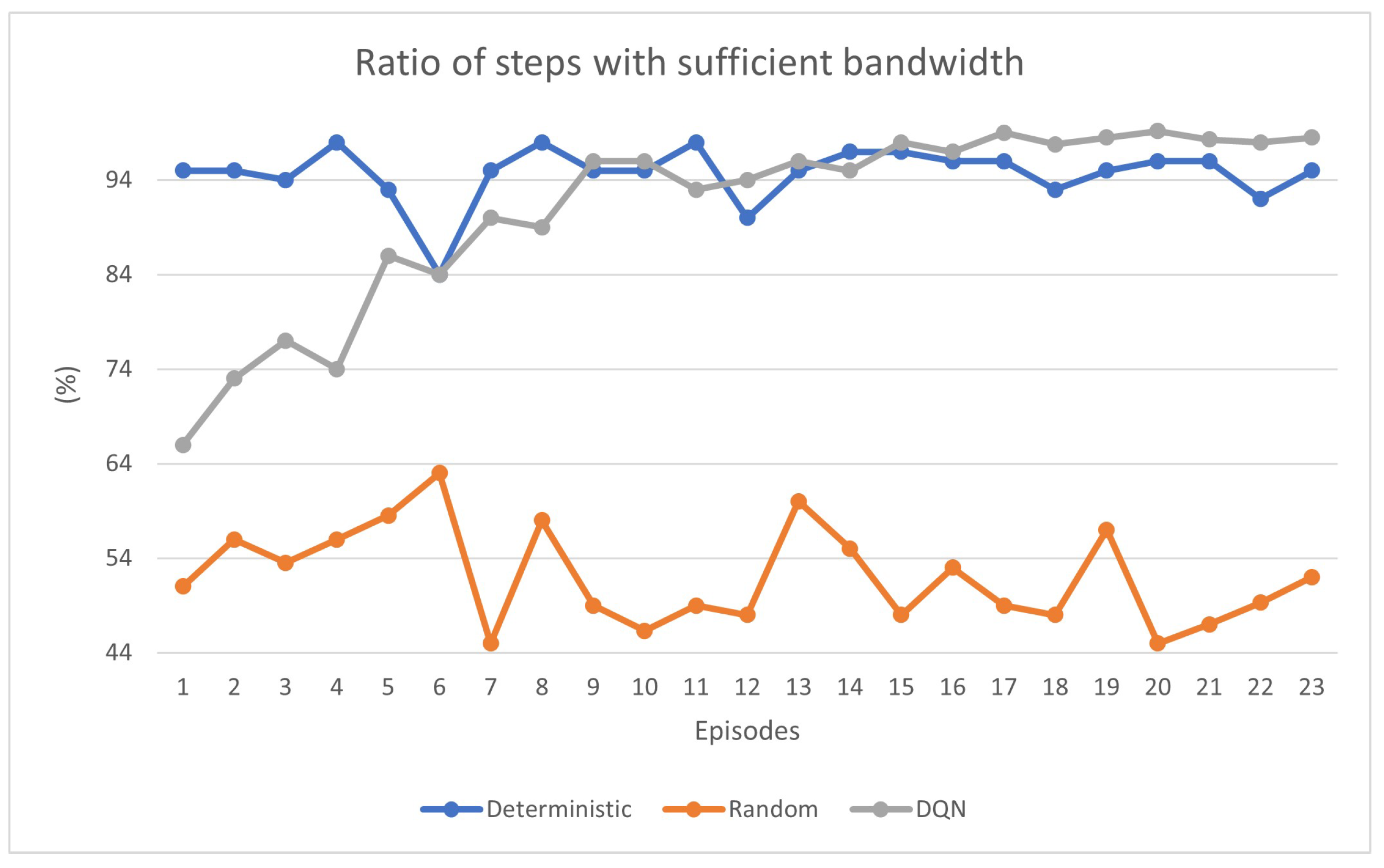
We define the “ratio of steps with sufficient bandwidth” as the ratio between the number of steps with the tunnel bandwidth that does not exceed the residual bandwidth and the total number of steps in each episode. In other words, it quantifies the percentage of times wherein the chosen tunnel provides adequate bandwidth. Starting from the random algorithm, we can notice from
Figure 8 (orange line) that this ratio has lower values with respect to the other two algorithms, and this behavior reflects its random nature as the tunnel selection is performed without following any criteria and we cannot observe any particular advantage in using a backup tunnel. On the other hand, the deterministic algorithm (blue line) presents higher values, with the lowest peaks always greater than the random. As regards the DQN (gray line), it is noteworthy to observe the system’s capability to learn and dynamically opt for the most suitable tunnel based on the previous network conditions. This adaptive behavior highlights the effectiveness of DQN in autonomously adjusting tunnel selection in response to varying network conditions, thereby mitigating instances where the bandwidth requirements exceed the capabilities of the chosen tunnel with a consequence of increasing the trend over time. Both the deterministic and DQN algorithms reach a stable value of over 95% of the metric considered, indicating their effectiveness. In contrast, the random approach shows a peak of 64%, which differs significantly from the DQN and deterministic results.
Finally,
Table 5 compares the throughput of the algorithms that we are considering in this work. The throughput achieved with the DQN algorithm has been considered in two specific episodes: the first and the last after training. As a reference, the random algorithm achieves a throughput of 9.3 Mbps, while the deterministic algorithm achieves a value of 13.2 Mbps. In the first episode of DQN, the throughput is 8.7 Mbps, indicating that the initial performance of the algorithm is comparable to a random selection (exploration phase of RL). However, after only 15 episodes of training, the throughput significantly improves to 13.7 Mbps, demonstrating the effectiveness of learning through RL, overtaking both random and deterministic methods.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}