

Depth-Aware Neural Style Transfer for Videos

Abstract
1. Introduction
- We develop a depth-aware neural network for artistic stylization that considers depth information infused by a depth encoder network.
- We implement a loss function that combines depth and optical flow to encourage temporal stability.
- We present qualitative and quantitative results that demonstrate that our algorithm’s performance is superior when compared to state-of-the-art approaches.

2. Related Work
2.1. Video Style Transfer
2.2. Depth-Aware Style Transfer
2.3. Style Transfer in Games
3. Method
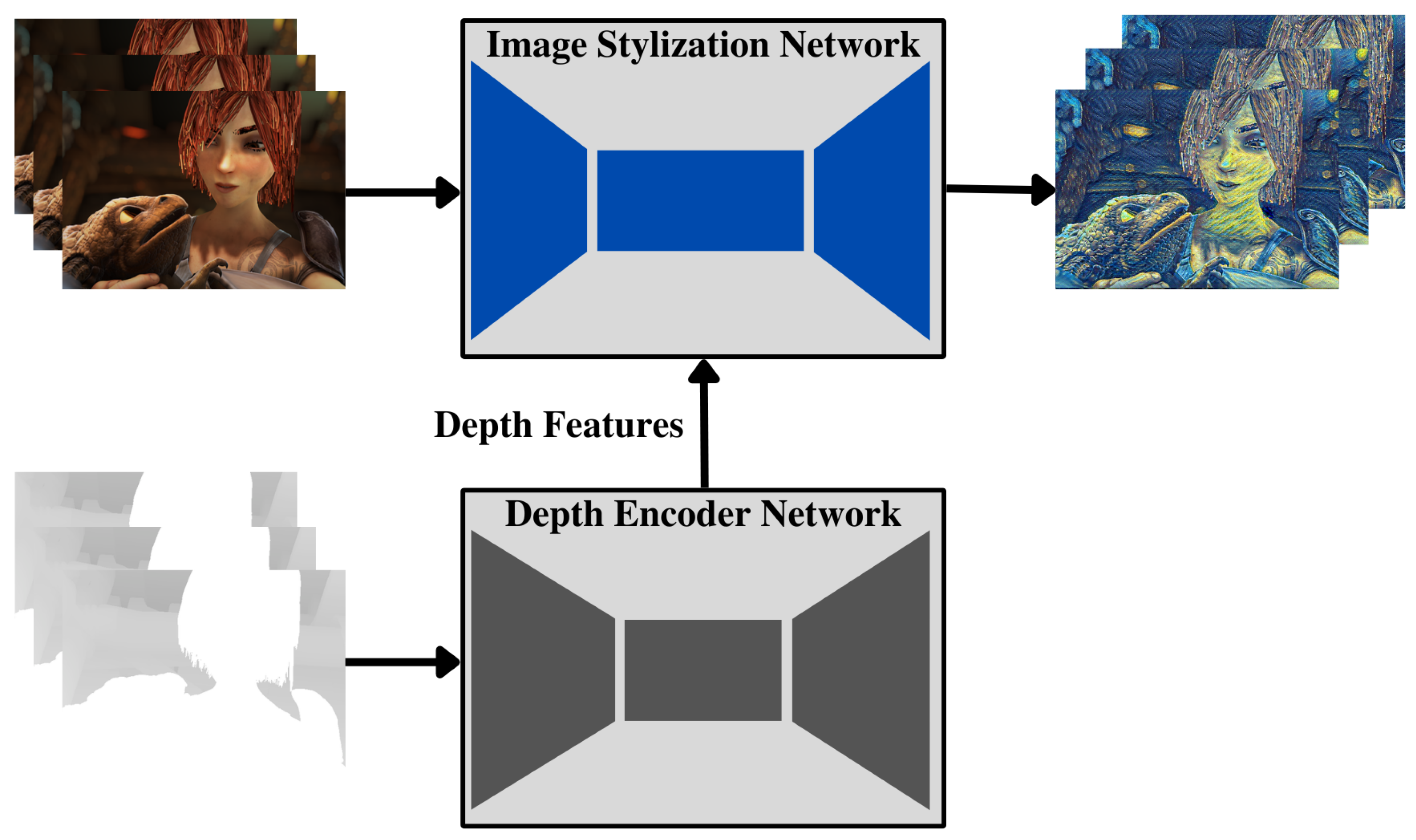
3.1. Overview
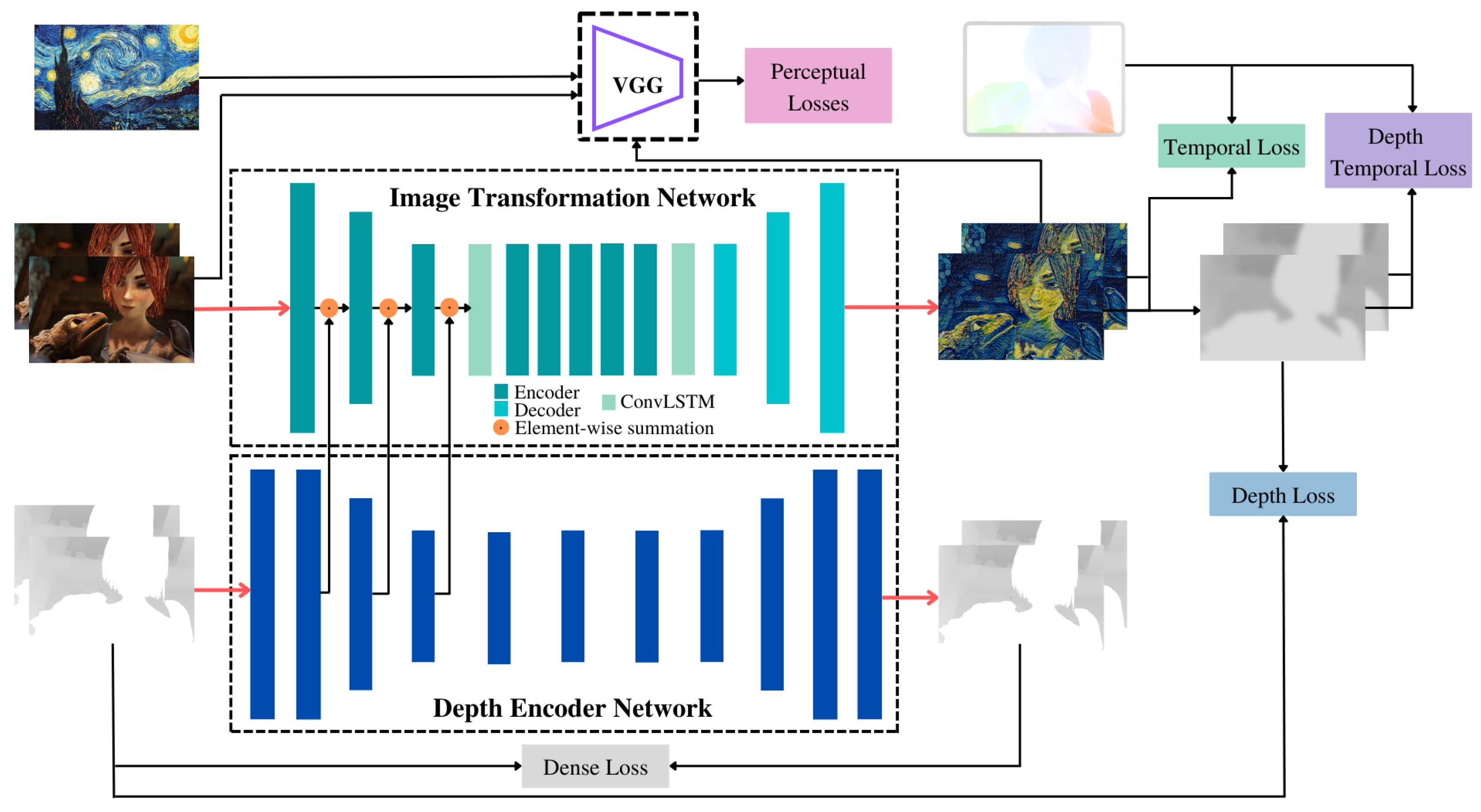
3.2. Network Architecture
3.3. Loss Functions
3.3.1. Perceptual losses
3.3.2. Depth Loss
3.3.3. Temporal Losses
3.4. Dataset
3.5. Training Details
4. Results and Discussion
4.1. Qualitative Results
4.2. Quantitative Results
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A Neural Algorithm of Artistic Style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Huang, H.; Wang, H.; Luo, W.; Ma, L.; Jiang, W.; Zhu, X.; Li, Z.; Liu, W. Real-time neural style transfer for videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 783–791. [Google Scholar]
- Ruder, M.; Dosovitskiy, A.; Brox, T. Artistic style transfer for videos and spherical images. Int. J. Comput. Vis. 2018, 126, 1199–1219. [Google Scholar] [CrossRef]
- Gao, C.; Gu, D.; Zhang, F.; Yu, Y. Reconet: Real-time coherent video style transfer network. In Proceedings of the Computer Vision—ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part VI 14. Springer: Berlin/Heidelberg, Germany, 2019; pp. 637–653. [Google Scholar]
- Gao, W.; Li, Y.; Yin, Y.; Yang, M.H. Fast video multi-style transfer. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 3222–3230. [Google Scholar]
- Liu, X.C.; Cheng, M.M.; Lai, Y.K.; Rosin, P.L. Depth-aware neural style transfer. In Proceedings of the Symposium on Non-Photorealistic Animation and Rendering, Los Angeles, CA, USA, 29–30 July 2017; pp. 1–10. [Google Scholar]
- Liu, S.; Zhu, T. Structure-Guided Arbitrary Style Transfer for Artistic Image and Video. IEEE Trans. Multimed. 2022, 24, 1299–1312. [Google Scholar] [CrossRef]
- Zabaleta, I.; Bertalmío, M. Photorealistic style transfer for cinema shoots. In Proceedings of the 2018 Colour and Visual Computing Symposium (CVCS), Gjovik, Norway, 19–20 September 2018; pp. 1–6. [Google Scholar]
- Luan, F.; Paris, S.; Shechtman, E.; Bala, K. Deep photo style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4990–4998. [Google Scholar]
- Ioannou, E.; Maddock, S. Depth-aware neural style transfer using instance normalization. In Proceedings of the Computer Graphics & Visual Computing (CGVC), Cardiff, UK, 15–16 September 2022. [Google Scholar]
- Microsoft. 2022. Available online: https://www.microsoft.com/en-au/windows-server (accessed on 14 March 2023).
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Baraldi, P.; De Micheli, E.; Uras, S. Motion and Depth from Optical Flow. In Proceedings of the Alvey Vision Conference, Reading, UK, 25–28 September 1989; pp. 1–4. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A Learned Representation For Artistic Style. arXiv 2016, arXiv:1610.07629. [Google Scholar]
- Deng, Y.; Tang, F.; Dong, W.; Huang, H.; Ma, C.; Xu, C. Arbitrary video style transfer via multi-channel correlation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 1210–1217. [Google Scholar]
- Lu, H.; Wang, Z. Universal video style transfer via crystallization, separation, and blending. In Proceedings of the International Joint Conferences on Artificial Intelligence Organization (IJCAI), Vienna, Austria, 23–29 July 2022; Volume 36, pp. 4957–4965. [Google Scholar]
- Liu, S.; Lin, T.; He, D.; Li, F.; Wang, M.; Li, X.; Sun, Z.; Li, Q.; Ding, E. Adaattn: Revisit attention mechanism in arbitrary neural style transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6649–6658. [Google Scholar]
- Jamriška, O.; Sochorová, Š.; Texler, O.; Lukáč, M.; Fišer, J.; Lu, J.; Shechtman, E.; Sỳkora, D. Stylizing video by example. ACM Trans. Graph. 2019, 38, 107. [Google Scholar] [CrossRef]
- Gupta, A.; Johnson, J.; Alahi, A.; Fei-Fei, L. Characterizing and improving stability in neural style transfer. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4067–4076. [Google Scholar]
- Chen, T.Q.; Schmidt, M. Fast patch-based style transfer of arbitrary style. arXiv 2016, arXiv:1612.04337. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Wang, O.; Shechtman, E.; Yumer, E.; Yang, M.H. Learning blind video temporal consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 170–185. [Google Scholar]
- Dong, X.; Bonev, B.; Zhu, Y.; Yuille, A.L. Region-based temporally consistent video post-processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 714–722. [Google Scholar]
- Chen, W.; Fu, Z.; Yang, D.; Deng, J. Single-Image Depth Perception in the Wild. In Proceedings of the Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Cheng, M.M.; Liu, X.C.; Wang, J.; Lu, S.P.; Lai, Y.K.; Rosin, P.L. Structure-Preserving Neural Style Transfer. IEEE Trans. Image Process. 2020, 29, 909–920. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Deliot, T.; Guinier, F.; Vanhoey, K. Real-Time Style Transfer in Unity Using Deep Neural Networks. 2020. Available online: https://blog.unity.com/engine-platform/real-time-style-transfer-in-unity-using-deep-neural-networks (accessed on 14 March 2023).
- Poplin, R.; Prins, A. Behind the Scenes with Stadia’s Style Transfer ML. 2019. Available online: https://stadia.google.com/gg/ (accessed on 14 March 2023).
- Ghiasi, G.; Lee, H.; Kudlur, M.; Dumoulin, V.; Shlens, J. Exploring the structure of a real-time, arbitrary neural artistic stylization network. arXiv 2017, arXiv:1705.06830. [Google Scholar]
- Yang, L.; Tse, Y.C.; Sander, P.V.; Lawrence, J.; Nehab, D.; Hoppe, H.; Wilkins, C.L. Image-based bidirectional scene reprojection. In Proceedings of the 2011 SIGGRAPH Asia Conference, Hong Kong, China, 12–15 December 2011; pp. 1–10. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. Fusenet: Incorporating depth into semantic segmentation via fusion-based cnn architecture. In Proceedings of the Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 213–228. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. 2015. Available online: http://xxx.lanl.gov/abs/1409.1556 (accessed on 14 March 2023).
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1623–1637. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Mayer, N.; Ilg, E.; Häusser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Videvo. 2019. Available online: https://www.videvo.net/ (accessed on 14 March 2023).
- Butler, D.J.; Wulff, J.; Stanley, G.B.; Black, M.J. A naturalistic open source movie for optical flow evaluation. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 611–625, Part IV, LNCS 7577. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Warping Error | Depth Loss | LPIPS |
|---|---|---|---|
| FVMST [5] | 0.2589 | 69.6017 | 0.5289 |
| ReCoNet [4] | 0.2686 | 52.3109 | 0.5156 |
| CSBNet [16] | 0.2335 | 46.422 | 0.5004 |
| MCCNet [15] | 0.2516 | 52.6037 | 0.4160 |
| Ours | 0.2472 | 38.7580 | 0.5038 |
| Configuration | Warping Error | Depth Loss |
|---|---|---|
| Ours | 0.2472 | 38.7580 |
| W/O Depth fusion | 0.2335 | 43.4186 |
| W/O Depth temp loss | 0.2537 | 30.4074 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ioannou, E.; Maddock, S. Depth-Aware Neural Style Transfer for Videos. Computers 2023, 12, 69. https://doi.org/10.3390/computers12040069
Ioannou E, Maddock S. Depth-Aware Neural Style Transfer for Videos. Computers. 2023; 12(4):69. https://doi.org/10.3390/computers12040069
Chicago/Turabian StyleIoannou, Eleftherios, and Steve Maddock. 2023. "Depth-Aware Neural Style Transfer for Videos" Computers 12, no. 4: 69. https://doi.org/10.3390/computers12040069
APA StyleIoannou, E., & Maddock, S. (2023). Depth-Aware Neural Style Transfer for Videos. Computers, 12(4), 69. https://doi.org/10.3390/computers12040069