
Detection of DoH Traffic Tunnels Using Deep Learning for Encrypted Traffic Classification

Abstract
1. Introduction
- We introduce fewer features, which improves the training efficiency and classification performance.
- It employs time-series-based preprocessing, which ultimately minimizes the possibility of inconsistencies in the experimental results.
- It presents the leveraging of ML models to detect malicious activities designed to be deployed in the internal network of an enterprise.
- The proposed method combines the benefits of machine learning and deep neural networks in terms of learning the potential correlation between features.
- The proposed stacking model combines the SMOTE method and the stacking model to detect tunneling in DNS traffic in the imbalanced CIC-DoHBrw2020 dataset with high Accuracy.
2. Related Work
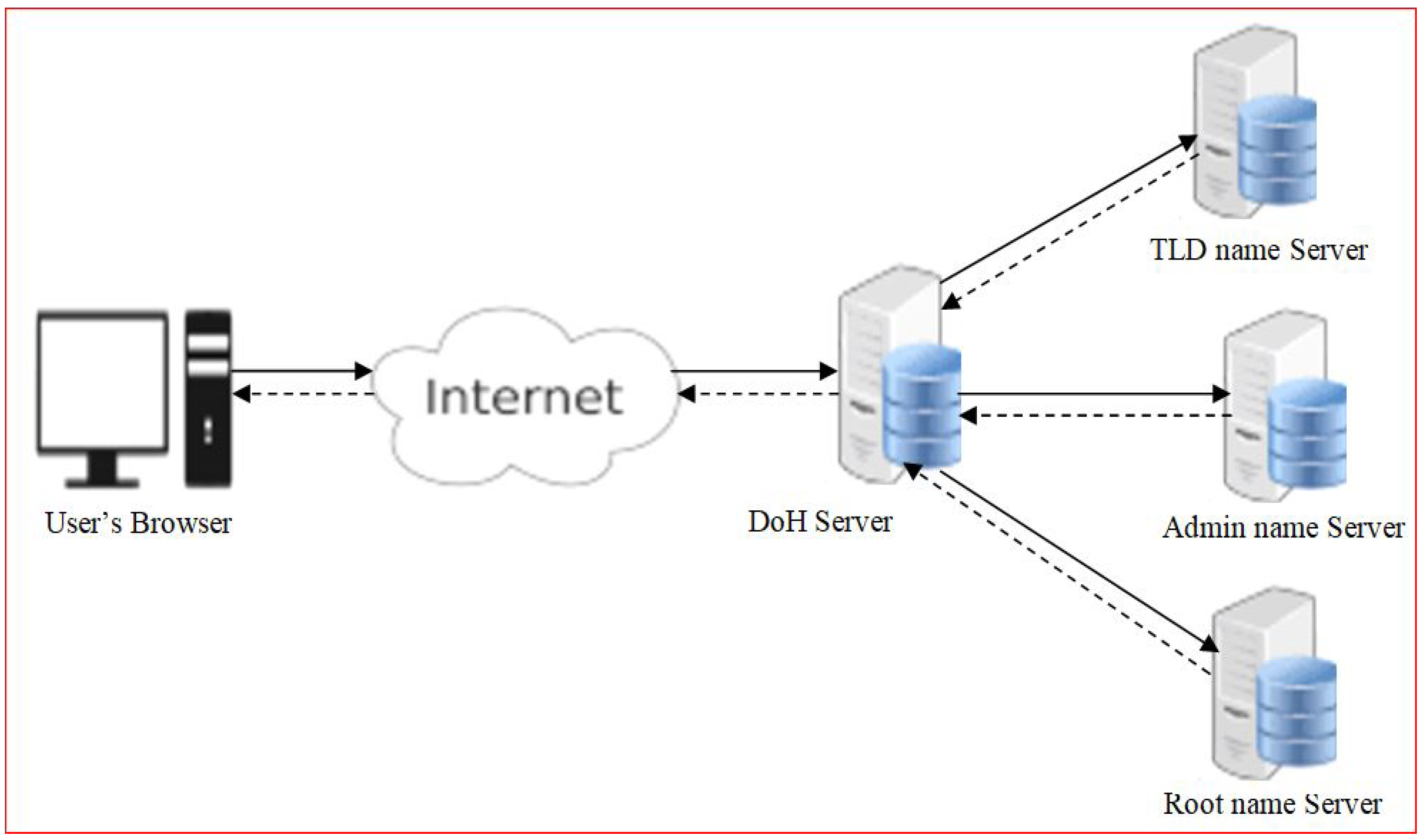
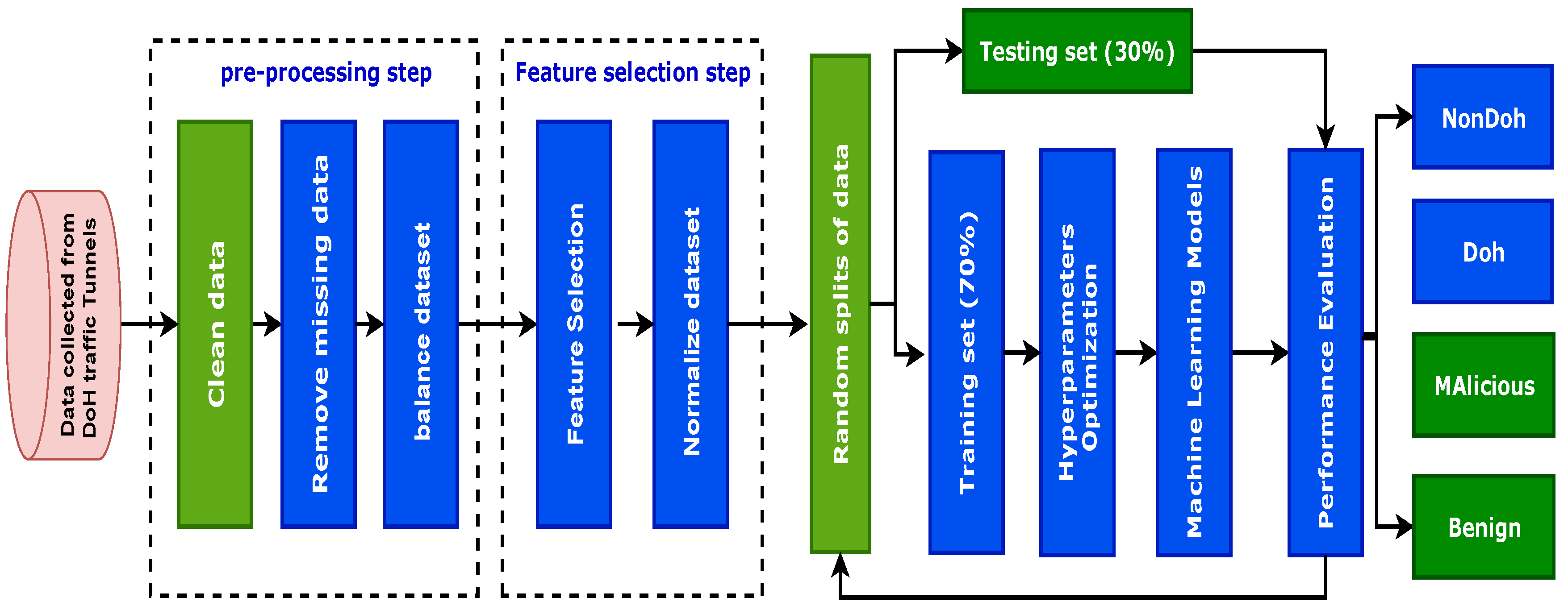
3. The Proposed Method
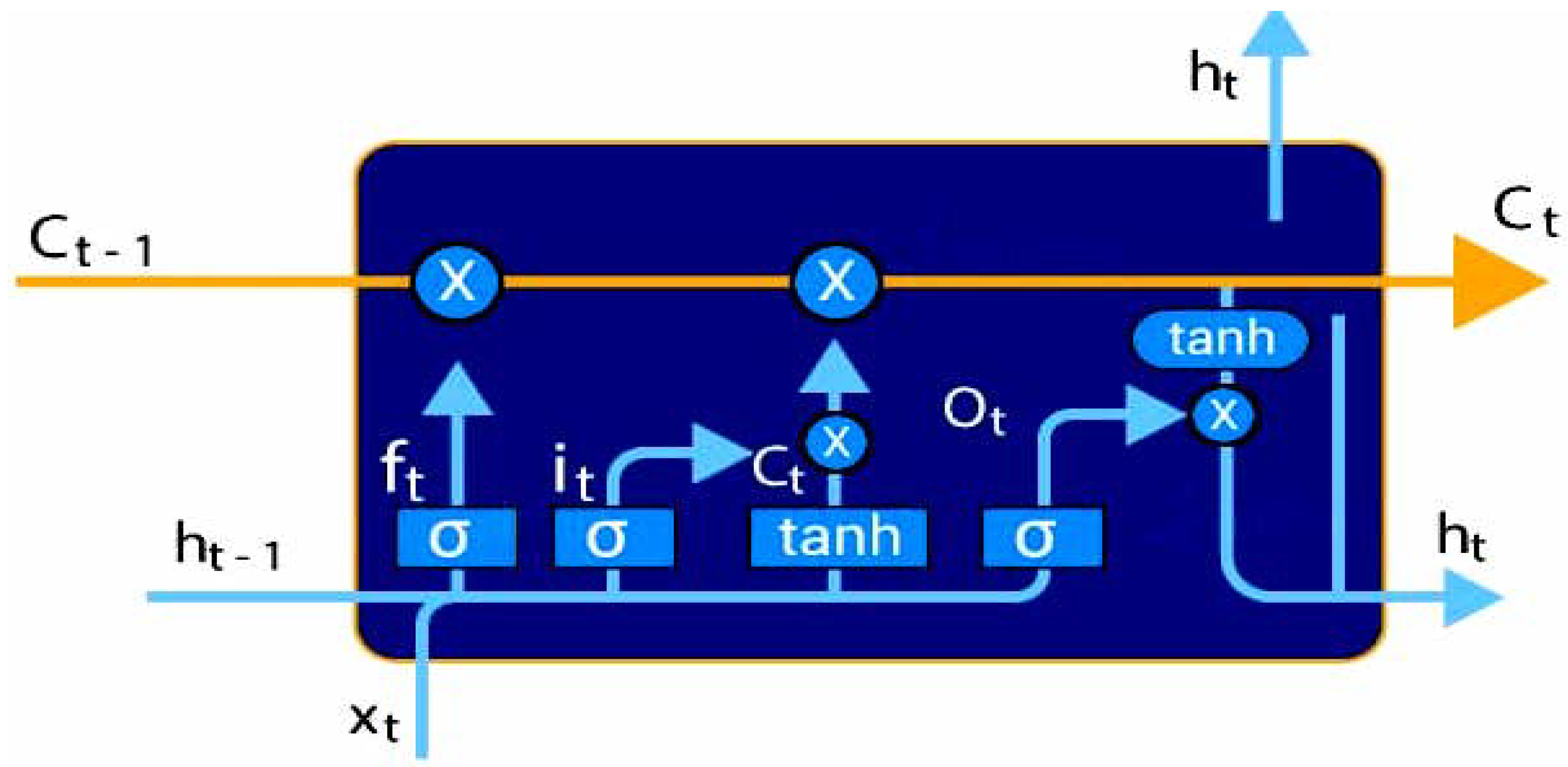
3.1. Deep Learning
3.2. Machine Learning Approach
4. Dataset Description
5. Experimental Results and Discussions
5.1. Performance Evaluations
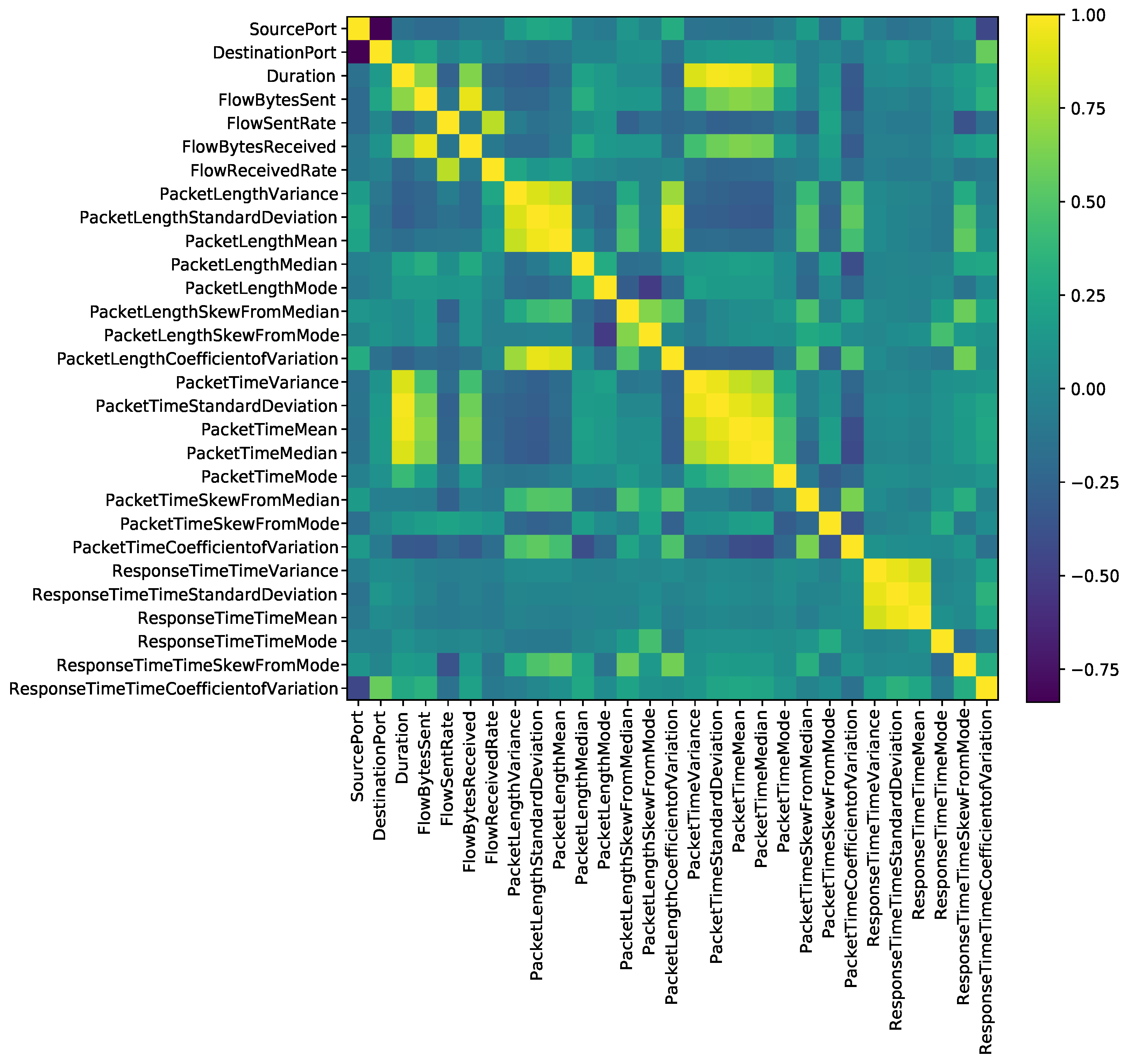
5.2. Feature Selection
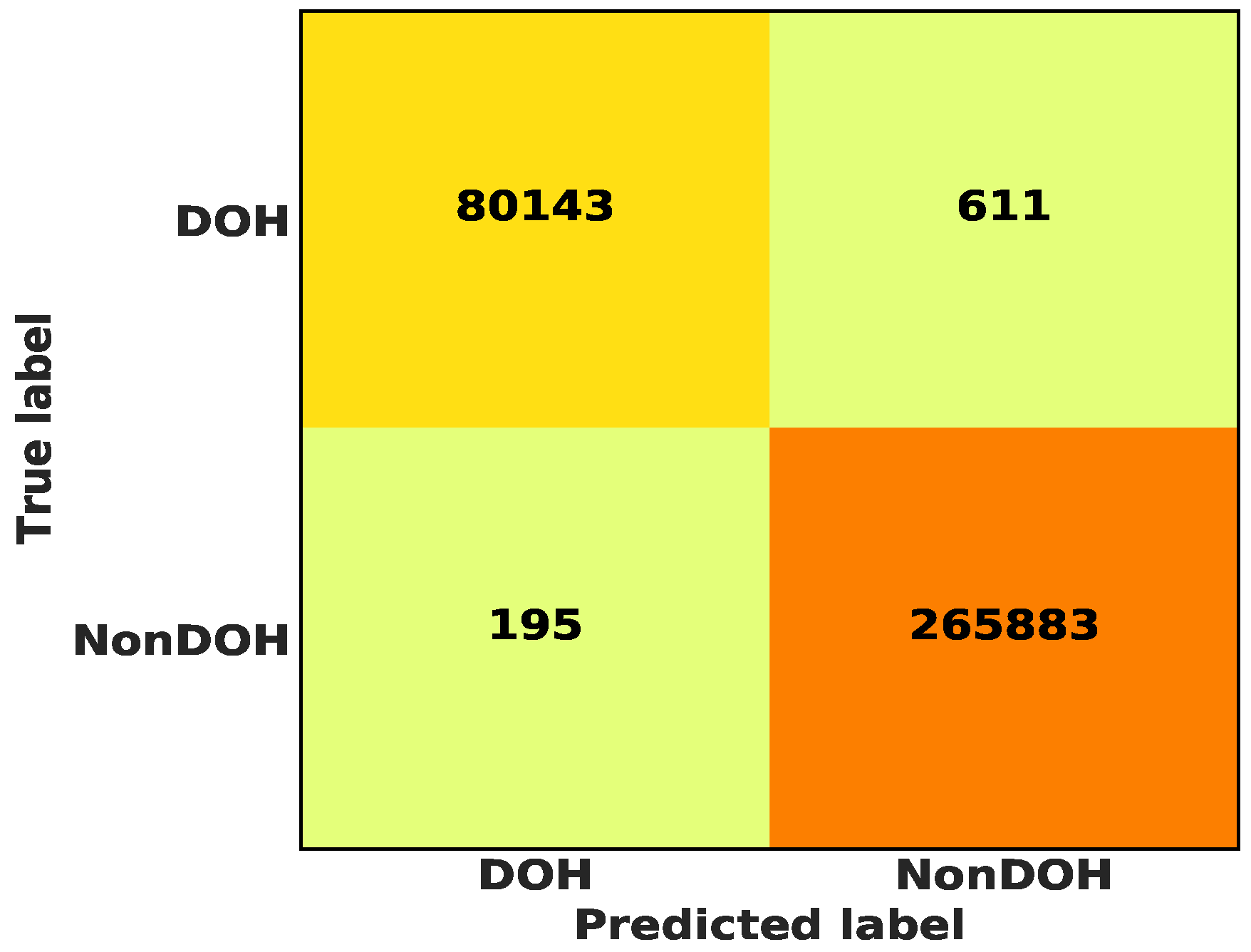
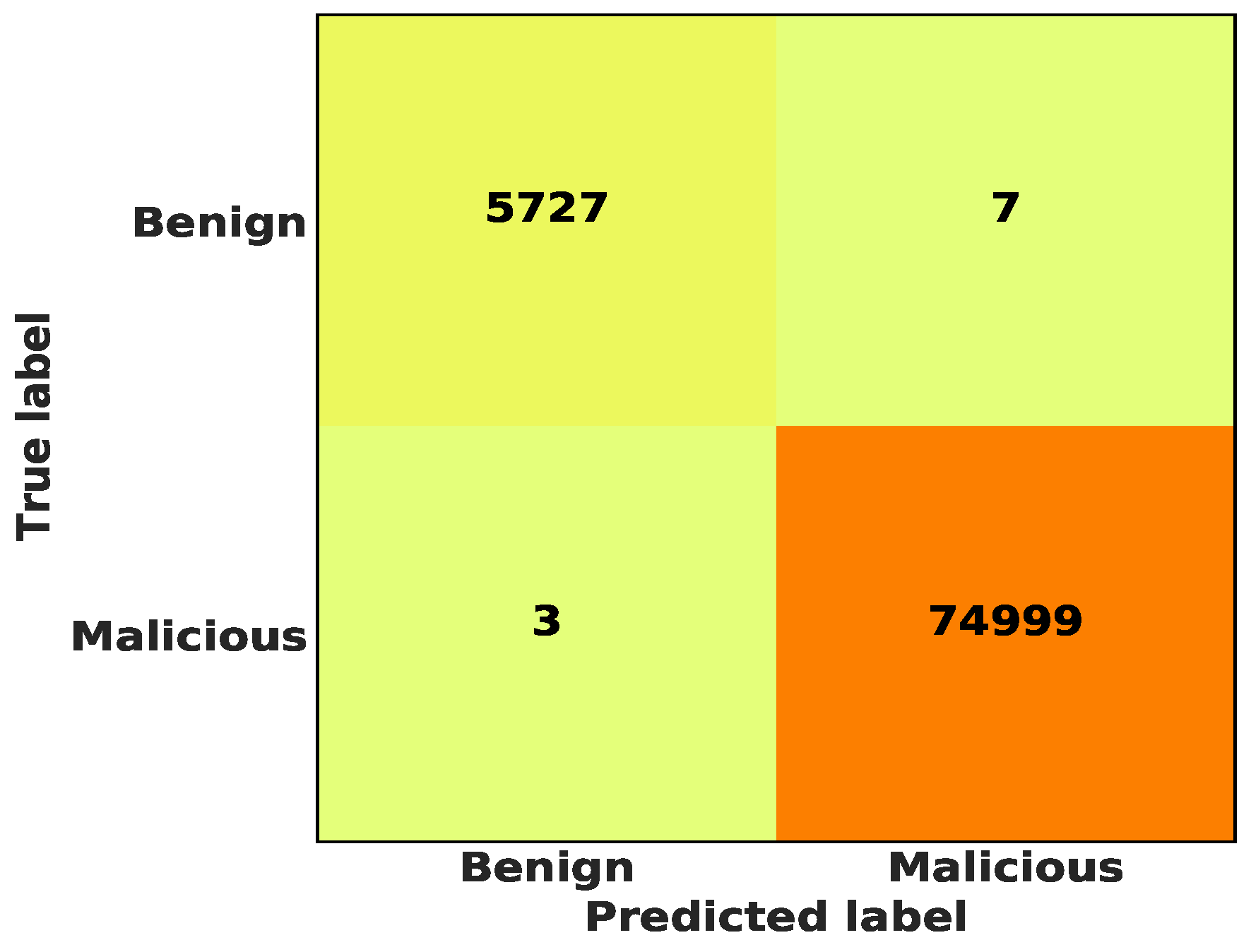
5.3. Binary Class Classification
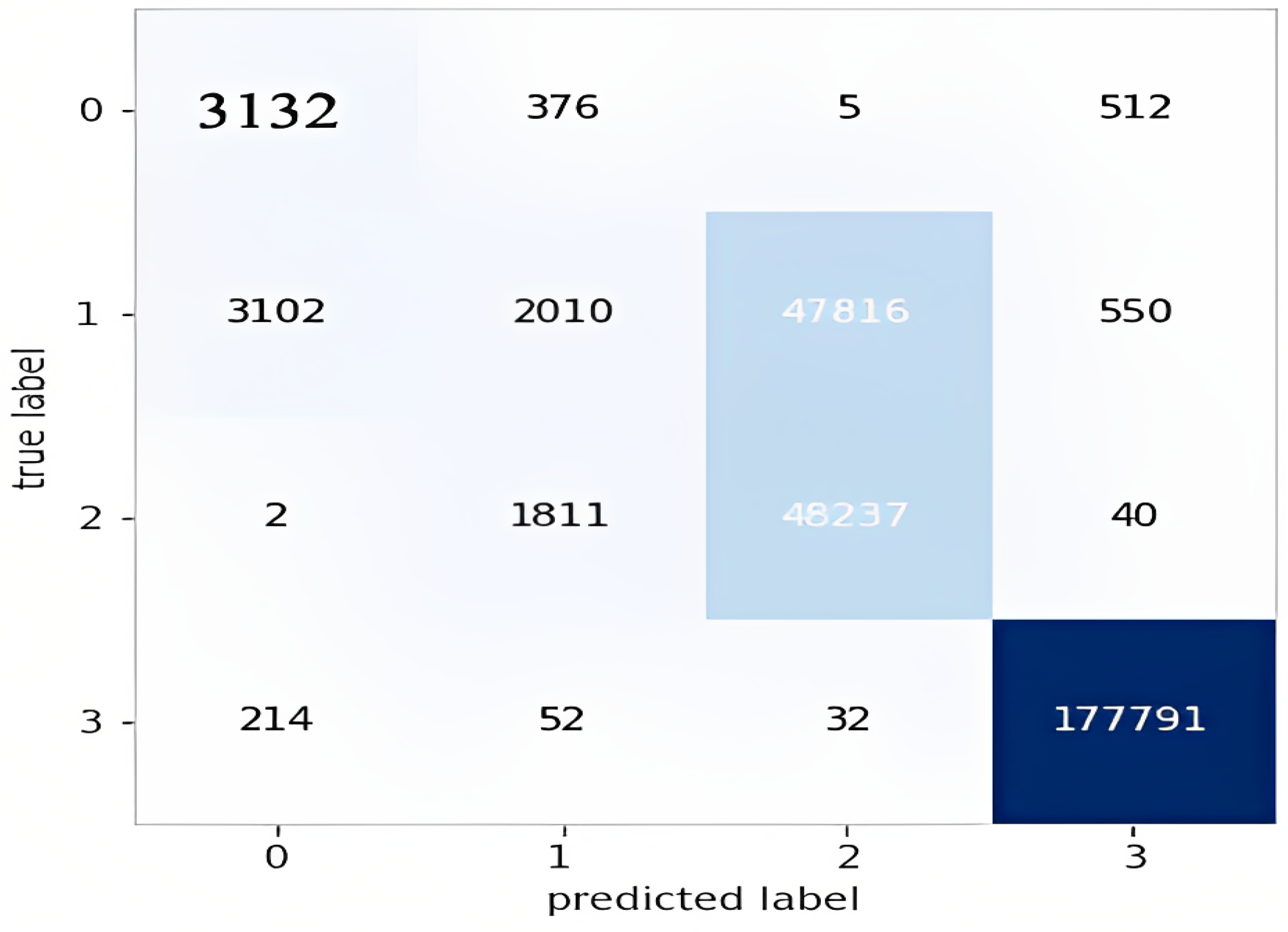
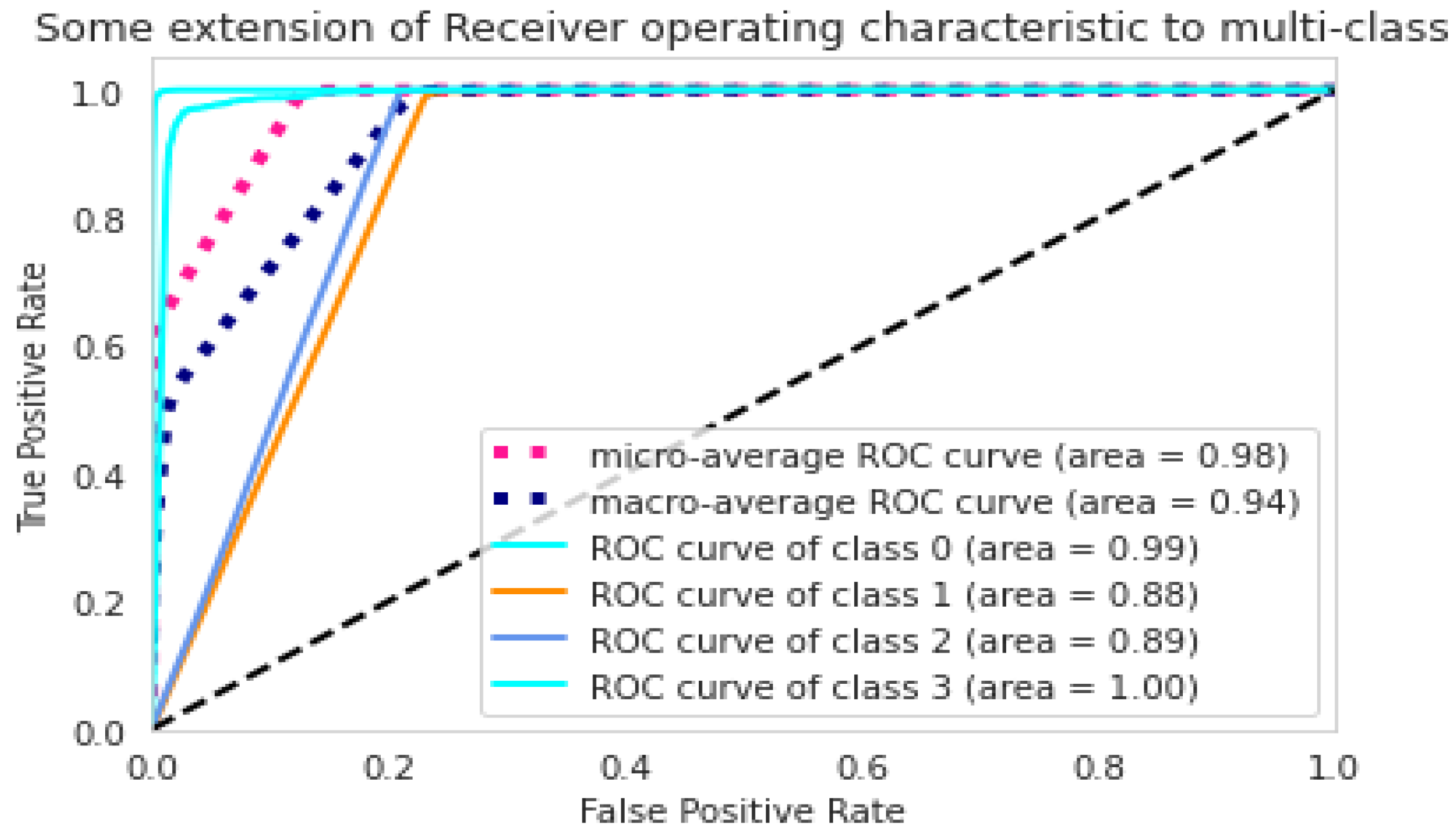
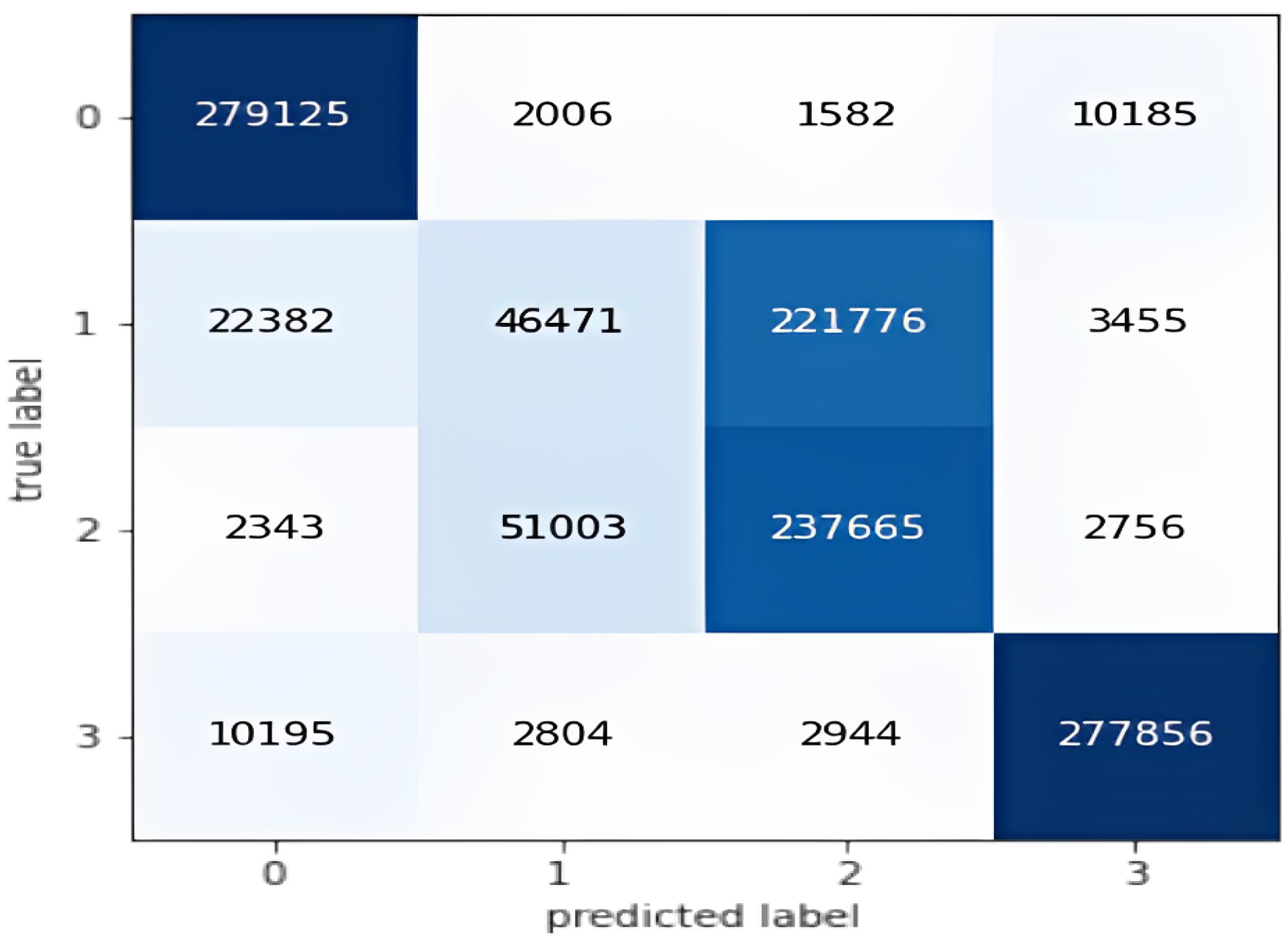
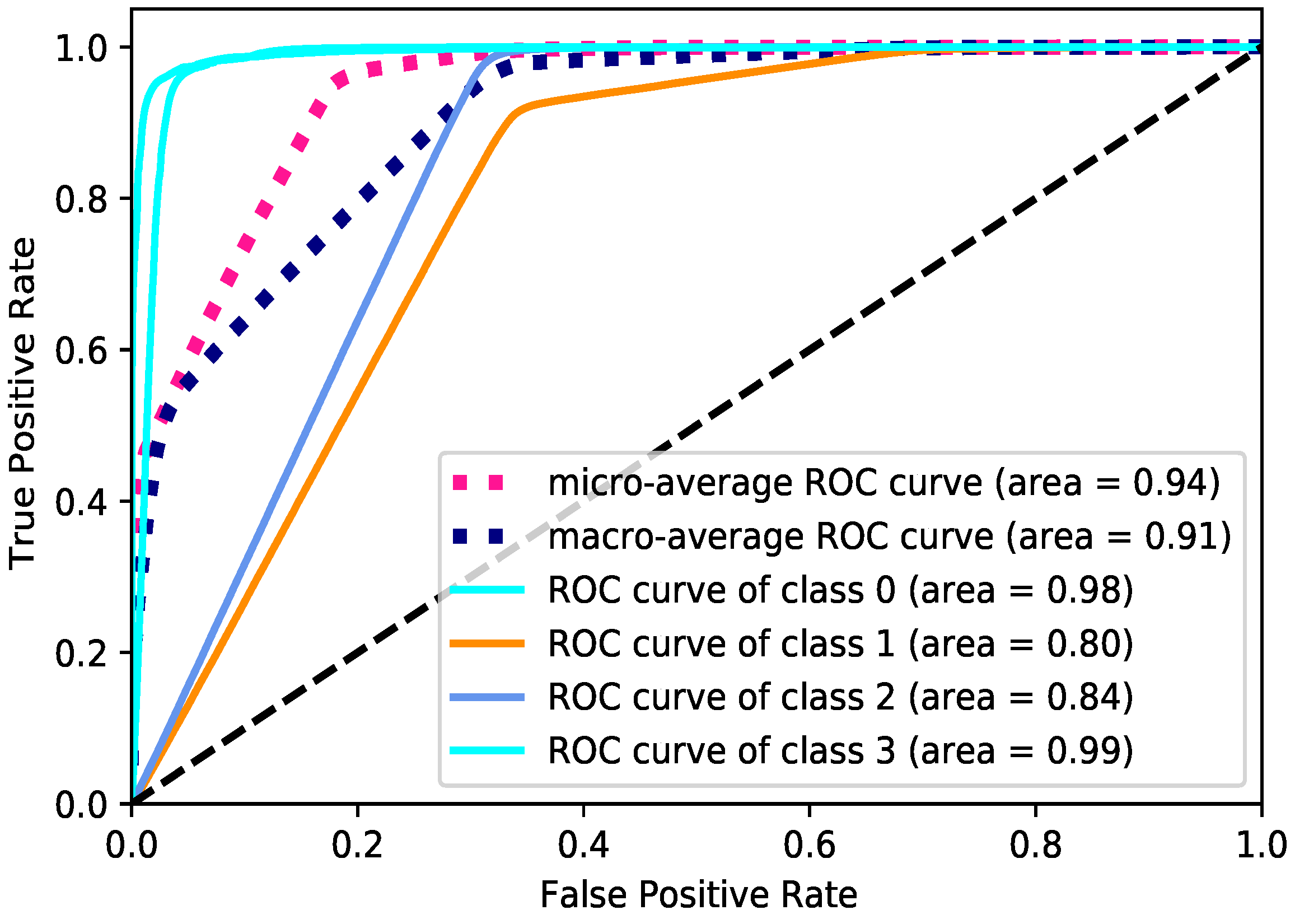
5.4. Multi-Class Classification
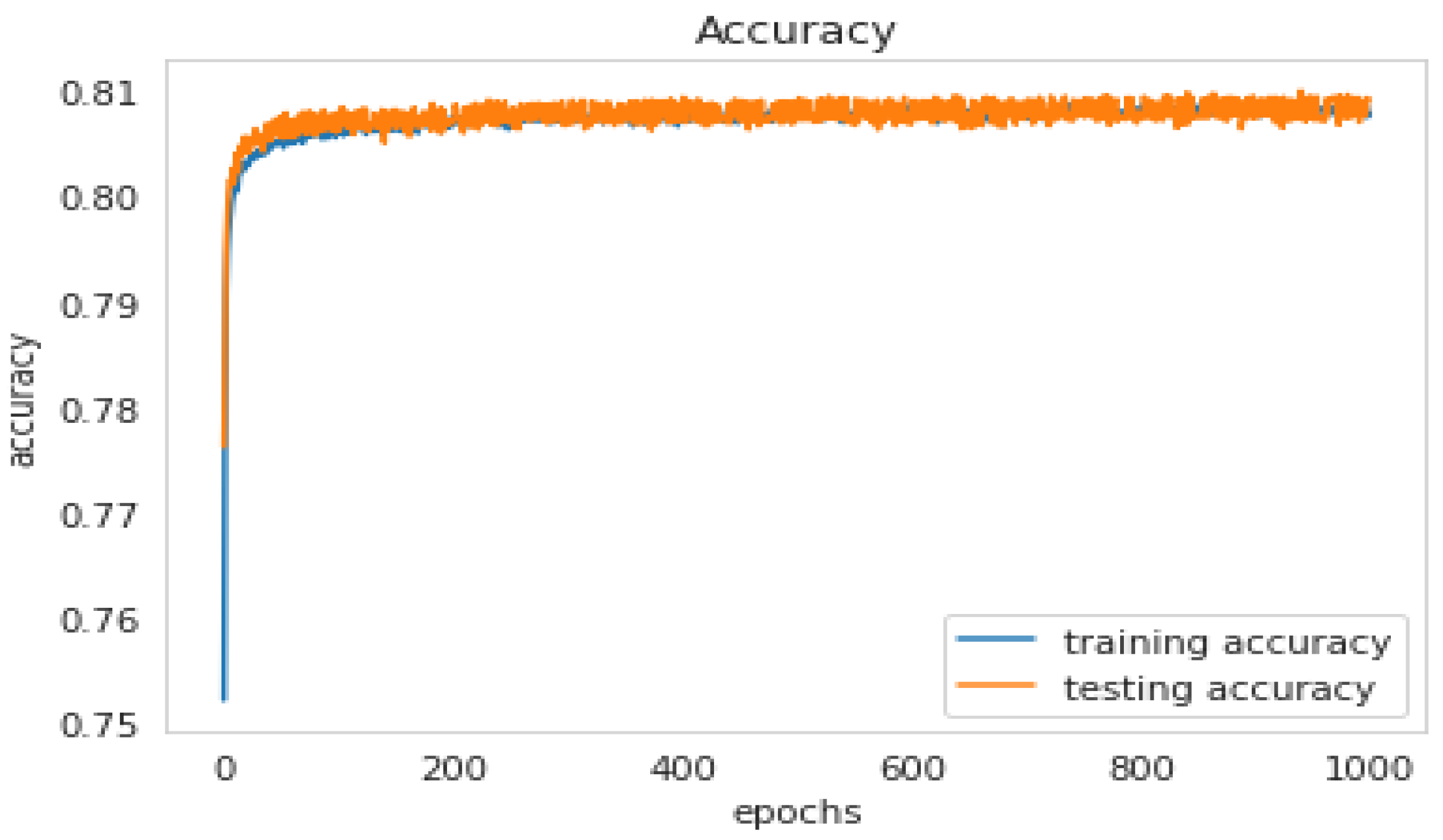
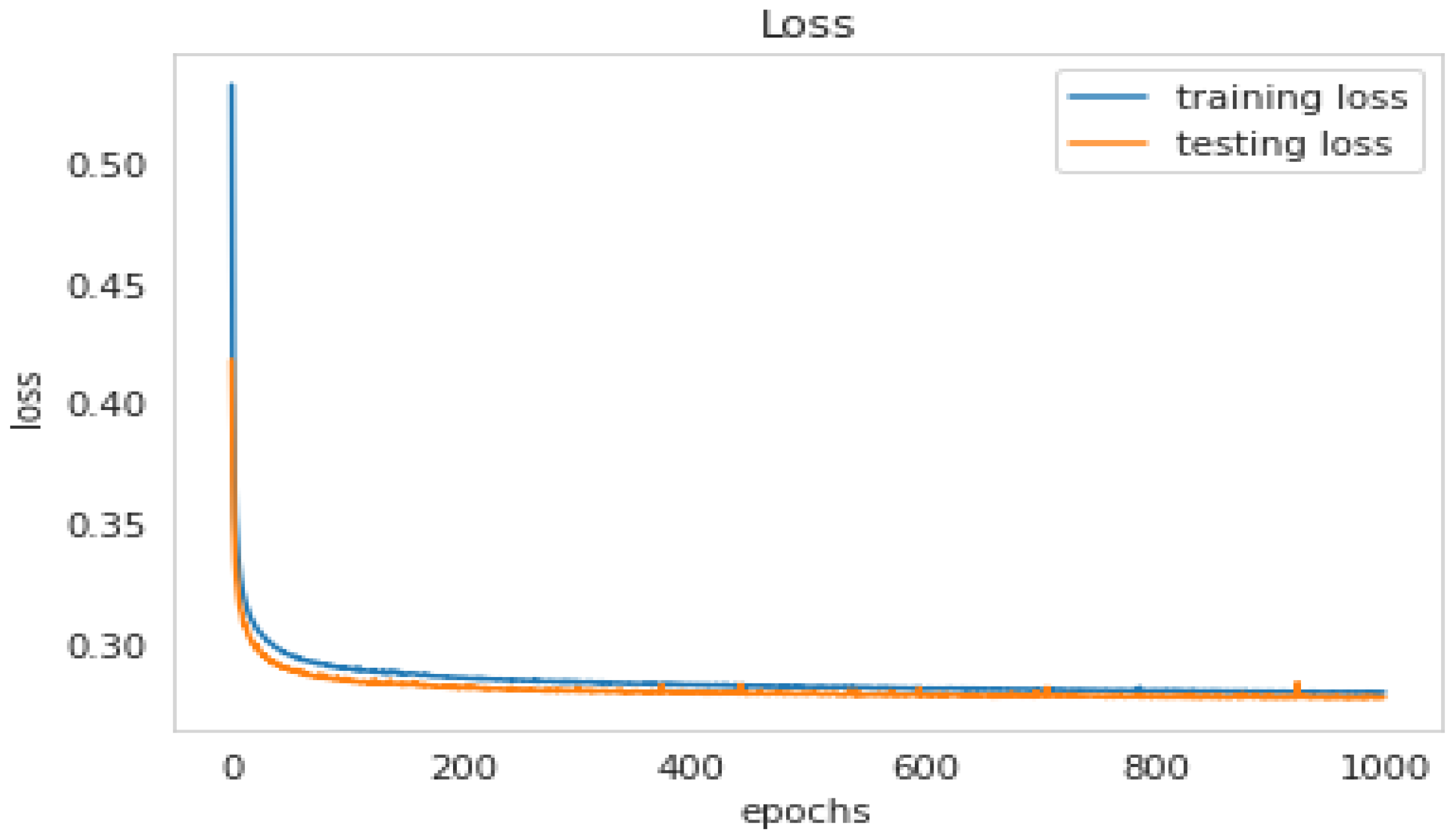
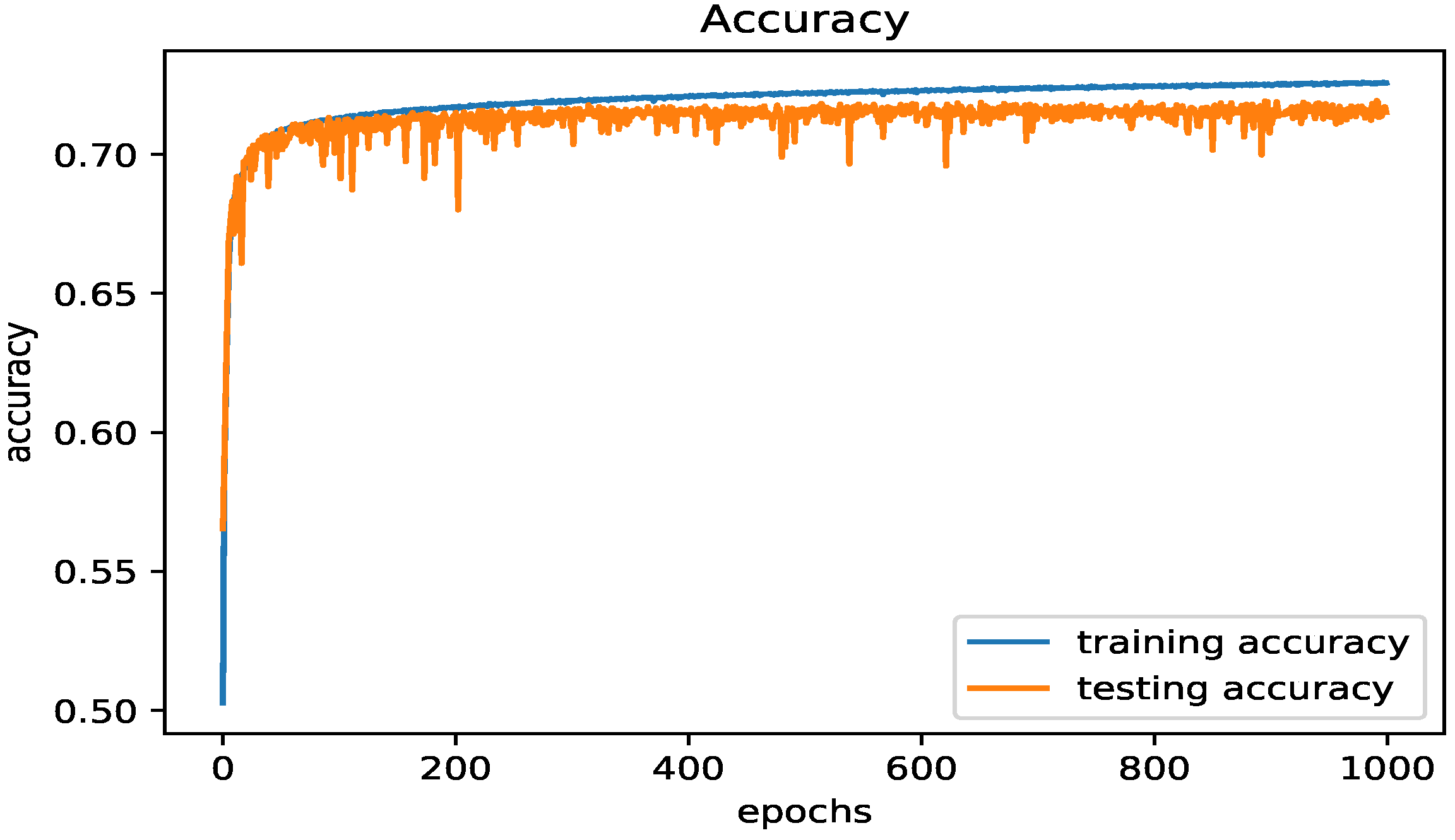
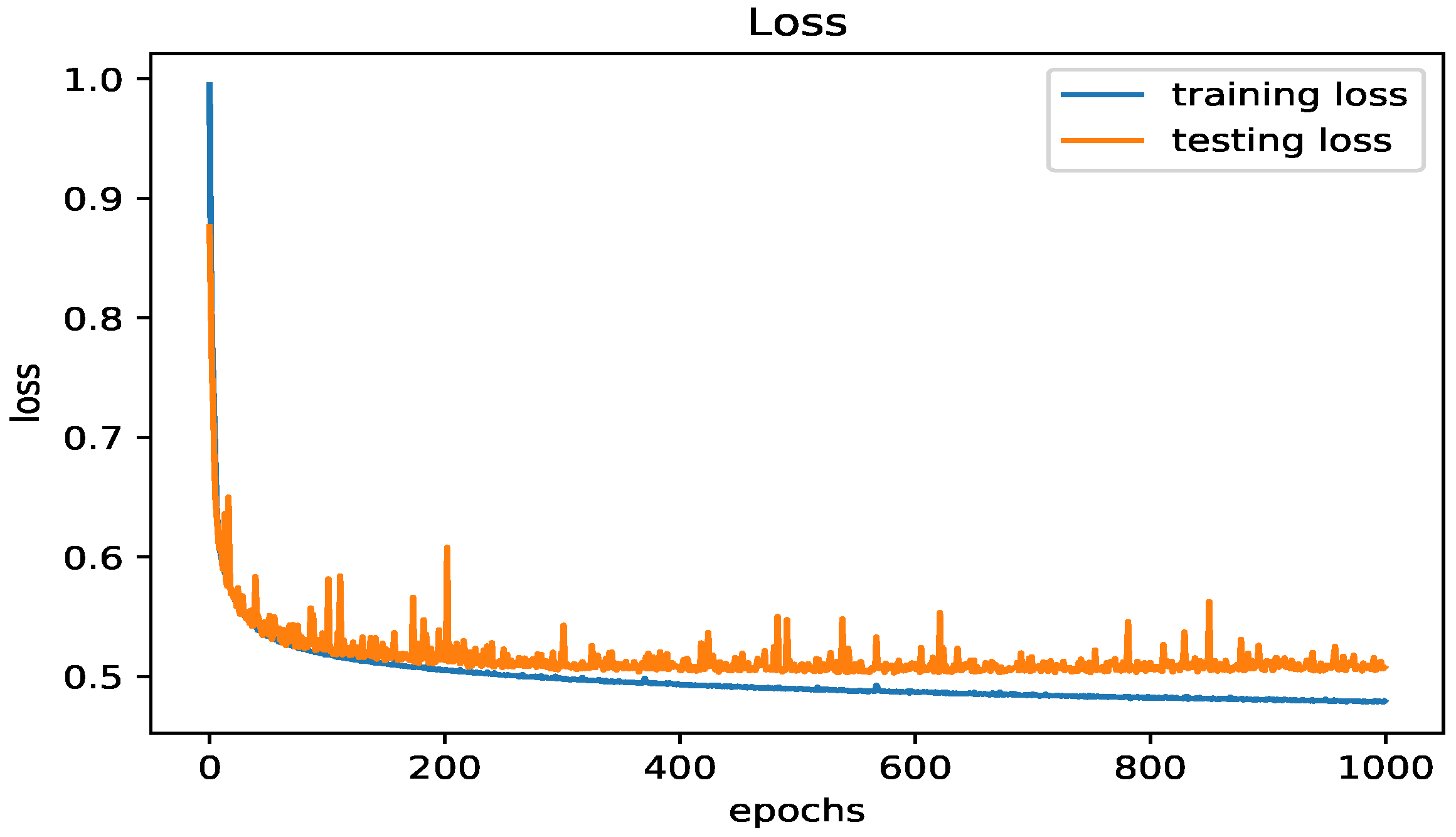
5.4.1. The LSTM Model
5.4.2. Data Balancing and SMOTE
6. Conclusions and Future Work
Funding
Data Availability Statement
Conflicts of Interest
References
- Böttger, T.; Cuadrado, F.; Antichi, G.; Fernandes, E.L.; Tyson, G.; Castro, I.; Uhlig, S. An Empirical Study of the Cost of DNS-over-HTTPS. In Proceedings of the Internet Measurement Conference, Amsterdam, The Netherlands, 21–23 October 2019; pp. 15–21. [Google Scholar]
- Borgolte, K.; Chattopadhyay, T.; Feamster, N.; Kshirsagar, M.; Holland, J.; Hounsel, A.; Schmitt, P. How DNS over HTTPS is reshaping privacy, performance, and policy in the internet ecosystem. In Proceedings of the TPRC47: The 47th Research Conference on Communication, Information and Internet Policy, Washington, DC, USA, 20–21 September 2019. [Google Scholar]
- Jafar, M.T.; Al-Fawa’reh, M.; Al-Hrahsheh, Z.; Jafar, S.T. Analysis and Investigation of Malicious DNS Queries Using CIRA-CIC-DoHBrw-2020 Dataset. Manch. J. Artif. Intell. Appl. Sci. (MJAIAS) 2021, 2, 65–70. [Google Scholar]
- Bumanglag, K.; Kettani, H. On the Impact of DNS Over HTTPS Paradigm on Cyber Systems. In Proceedings of the 2020 3rd International Conference on Information and Computer Technologies (ICICT), San Jose, CA, USA, 9–12 March 2020; pp. 494–499. [Google Scholar]
- Siby, S.; Juarez, M.; Vallina-Rodriguez, N.; Troncoso, C. DNS Privacy not so private: The traffic analysis perspective. In Proceedings of the 11th Workshop on Hot Topics in Privacy Enhancing Technologies (HotPETs 2018), Barcelona, Spain, 27 July 2018. [Google Scholar]
- Montazeri Shatoori, M.; Davidson, L.; Kaur, G.; Lashkari, A.H. Detection of DoH Tunnels using Time-series Classification of Encrypted Traffic. In Proceedings of the 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 17–22 August 2020; pp. 63–70. [Google Scholar]
- Munteanu, D.; Bejan, C.; Munteanu, N.; Zamfir, C.; Vasić, M.; Petrea, S.M.; Cristea, D. Deep-Learning-Based System for Assisting People with Alzheimer’s Disease. Electronics 2022, 11, 3229. [Google Scholar] [CrossRef]
- Amaratunga, T. Building Your First Deep Learning Model. In Deep Learning on Windows; Apress: Berkeley, CA, USA, 2020; pp. 67–100. [Google Scholar]
- Gad, I.; Hosahalli, D.; Manjunatha, B.R.; Ghoneim, O.A. A robust Deep Learning model for missing value imputation in big NCDC dataset. Iran J. Comput. Sci. 2020, 4, 67–84. [Google Scholar] [CrossRef]
- Hosahalli, D.; Gad, I. A Generic Approach of Filling Missing Values in NCDC Weather Stations Data. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018. [Google Scholar]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep learning for IoT big data and streaming analytics: A survey. IEEE Commun. Surv. Tutor. 2018, 20, 2923–2960. [Google Scholar] [CrossRef]
- Vekshin, D.; Hynek, K.; Cejka, T. DoH insight: Detecting dns over https by machine learning. In Proceedings of the 15th International Conference on Availability, Reliability, and Security, Virtual, 25–28 August 2020; pp. 1–8. [Google Scholar]
- Hounsel, A.; Borgolte, K.; Schmitt, P.; Holland, J.; Feamster, N. Analyzing the costs (and benefits) of DNS, DoT, and DoH for the modern web. In Proceedings of the Applied Networking Research Workshop, Montreal, QC, Canada, 22 July 2019; pp. 20–22. [Google Scholar]
- Bushart, J.; Rossow, C. Padding Ain’t Enough: Assessing the Privacy Guarantees of Encrypted {DNS}. In Proceedings of the 10th USENIX Workshop on Free and Open Communications on the Internet (FOCI 20), Online, 11 August 2020. [Google Scholar]
- Lu, C.; Liu, B.; Li, Z.; Hao, S.; Duan, H.; Zhang, M.; Leng, C.; Liu, Y.; Zhang, Z.; Wu, J. An end-to-end, large-scale measurement of dns-over-encryption: How far have we come? In Proceedings of the Internet Measurement Conference, Amsterdam, The Netherlands, 21–23 October 2019; pp. 22–35. [Google Scholar]
- Singanamalla, S.; Chunhapanya, S.; Vavruša, M.; Verma, T.; Wu, P.; Fayed, M.; Heimerl, K.; Sullivan, N.; Wood, C. Oblivious DNS over HTTPS (ODoH): A Practical Privacy Enhancement to DNS. arXiv 2020, arXiv:2011.10121. [Google Scholar] [CrossRef]
- Deccio, C.; Davis, J. DNS privacy in practice and preparation. In Proceedings of the 15th International Conference on Emerging Networking Experiments And Technologies, Orlando, FL, USA, 9–12 December 2019; pp. 138–143. [Google Scholar]
- Singh, S.K.; Roy, P.K. Detecting Malicious DNS over HTTPS Traffic Using Machine Learning. In Proceedings of the 2020 International Conference on Innovation and Intelligence for Informatics, Computing and Technologies (3ICT), Virtual, 20–21 December 2020; pp. 1–6. [Google Scholar]
- Hounsel, A.; Borgolte, K.; Schmitt, P.; Holland, J.; Feamster, N. Comparing the effects of dns, dot, and doh on web performance. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 562–572. [Google Scholar]
- López Romera, C. DNS Over HTTPS Traffic Analysis and Detection. Master’s Thesis, Universitat Oberta de Catalunya, Barcelona, Spain, 2020. [Google Scholar]
- Palau, F.; Catania, C.; Guerra, J.; Garcia, S.; Rigaki, M. DNS tunneling: A Deep Learning based lexicographical detection approach. arXiv 2020, arXiv:2006.06122. [Google Scholar]
- Houser, R.; Li, Z.; Cotton, C.; Wang, H. An investigation on information leakage of DNS over TLS. In Proceedings of the 15th International Conference on Emerging Networking Experiments and Technologies, Orlando, FL, USA, 9–12 December 2019; pp. 123–137. [Google Scholar]
- Huang, Q.; Chang, D.; Li, Z. A Comprehensive Study of DNS-over-HTTPS Downgrade Attack. In Proceedings of the 10th USENIX Workshop on Free and Open Communications on the Internet (FOCI 20), Online, 11 August 2020. [Google Scholar]
- Banadaki, Y.M. Detecting Malicious DNS over HTTPS Traffic in Domain Name System using Machine Learning Classifiers. J. Comput. Sci. Appl. 2020, 8, 46–55. [Google Scholar] [CrossRef]
- de Vries, L. Detection of DoH Tunnelling: Comparing Supervised with Unsupervised Learning. Master Thesis, University of Twente, Enschede, The Netherlands, 2021. [Google Scholar]
- Hayashi, Y. Emerging Trends in Deep Learning for Credit Scoring: A Review. Electronics 2022, 11, 3181. [Google Scholar] [CrossRef]
- Doreswamy; Gad, I.; Manjunatha, B.R. Multi-label Classification of Big NCDC Weather Data Using Deep Learning Model. In Soft Computing Systems; Springer: Singapore, 2018; pp. 232–241. [Google Scholar]
- Tang, J.; Yang, R.; Yuan, G.; Mao, Y. Time-Series Deep Learning Models for Reservoir Scheduling Problems Based on LSTM and Wavelet Transformation. Electronics 2022, 11, 3222. [Google Scholar] [CrossRef]
- Mantas, C.J.; Castellano, J.G.; Moral-García, S.; Abellán, J. A comparison of random forest based algorithms: Random credal random forest versus oblique random forest. Soft Comput. 2018, 23, 10739–10754. [Google Scholar] [CrossRef]
- Bhukya, D.P.; Ramachandram, S. Decision Tree Induction: An Approach for Data Classification Using AVL-Tree. Int. J. Comput. Electr. Eng. 2010, 2, 660–665. [Google Scholar] [CrossRef]
- Doreswamy; Hooshmand, M.K.; Gad, I. Feature selection approach using ensemble learning for network anomaly detection. CAAI Trans. Intell. Technol. 2020, 5, 283–293. [Google Scholar] [CrossRef]
- Gładyszewska-Fiedoruk, K.; Sulewska, M.J. Thermal Comfort Evaluation Using Linear Discriminant Analysis (LDA) and Artificial Neural Networks (ANNs). Energies 2020, 13, 538. [Google Scholar] [CrossRef]
- Sa, S. Comparative Study of Naive Bayes, Gaussian Naive Bayes Classifier and Decision Tree Algorithms for Prediction of Heart Diseases. Int. J. Res. Appl. Sci. Eng. Technol. 2021, 9, 475–486. [Google Scholar] [CrossRef]
- Shahraki, A.; Abbasi, M.; Haugen, Ø. Boosting algorithms for network intrusion detection: A comparative evaluation of Real AdaBoost, Gentle AdaBoost and Modest AdaBoost. Eng. Appl. Artif. Intell. 2020, 94, 103770. [Google Scholar] [CrossRef]
- Pingalkar, A.S. Prediction of Solar Eclipses using Extreme Gradient Boost Algorithm. Int. J. Res. Appl. Sci. Eng. Technol. 2020, 8, 1353–1357. [Google Scholar] [CrossRef]
- Nayebi, H. Logistic Regression Analysis. In Advanced Statistics for Testing Assumed Casual Relationships; Springer International Publishing: Zurich, Switwerland, 2020; pp. 79–109. [Google Scholar]
- Schulze, J.P.; Sperl, P.; Böttinger, K. Double-Adversarial Activation Anomaly Detection: Adversarial Autoencoders are Anomaly Generators. arXiv 2021, arXiv:2101.04645. [Google Scholar]
- Bramer, M. Estimating the Predictive Accuracy of a Classifier. In Principles of Data Mining; Springer: London, UK, 2020; pp. 79–92. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wei, G.; Zhao, J.; Feng, Y.; He, A.; Yu, J. A novel hybrid feature selection method based on dynamic feature importance. Appl. Soft Comput. 2020, 93, 106337. [Google Scholar] [CrossRef]
- Majzoub, H.A.; Elgedawy, I. AB-SMOTE: An Affinitive Borderline SMOTE Approach for Imbalanced Data Binary Classification. Int. J. Mach. Learn. Comput. 2020, 10, 31–37. [Google Scholar] [CrossRef]
- Silveira, M.R.; Cansian, A.M.; Kobayashi, H.K. Detection of Malicious Domains Using Passive DNS with XGBoost. In Proceedings of the 2020 IEEE International Conference on Intelligence and Security Informatics (ISI), Arlington, VA, USA, 9–11 November 2020. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Output Shape | Param # |
|---|---|---|
| Lstm (LSTM) | (None, 1, 40) | 11,200 |
| Dropout_3 (Dropout) | (None, 1, 40) | 0 |
| Lstm_1 (LSTM) | (None, 1, 40) | 12,960 |
| Dropout_4 (Dropout) | (None, 1, 40) | 0 |
| Lstm_2 (LSTM) | (None, 40) | 12,960 |
| Dropout_5 (Dropout) | (None, 40) | 0 |
| Dense_1 (Dense) | (None, 4) | 164 |
| Total params: | 37,284 | |
| Trainable params: | 37,284 | |
| Non-trainable params: | 0 |
| Source IP | Destination IP | Source Port | Destination Port | ... | Response Time Skew from Mode | Response Time Coefficient of Variation | Label | |
|---|---|---|---|---|---|---|---|---|
| 0 | 192.168.20.191 | 176.103.130.131 | 50,749 | 443 | ... | 0.024715 | 1.174948 | DoH |
| 1 | 192.168.20.191 | 176.103.130.131 | 50,749 | 443 | ... | −0.075845 | 1.402382 | DoH |
| Layer 1 | Count | Layer 2 | Count |
|---|---|---|---|
| Non-DoH | 897,493 | Malicious | 249,836 |
| DoH | 269,643 | Benign | 19,807 |
| Layer 2 | p-Value | Layer 1 | p-Value |
|---|---|---|---|
| PacketLengthStandardDeviation | 0.0 | Duration | 0.0 |
| PacketLengthCoefficientofVariation | 0.0 | ResponseTimeTimeSkewFromMedian | 0.0 |
| FlowReceivedRate | 0.0 | ResponseTimeTimeMode | 0.0 |
| PacketLengthMean | 0.0 | ResponseTimeTimeMedian | 0.0 |
| Duration | 0.0 | ResponseTimeTimeMean | 0.0 |
| PacketTimeSkewFromMedian | 0.0 | PacketTimeSkewFromMedian | 0.0 |
| FlowSentRate | 0.0 | PacketTimeMode | 0.0 |
| PacketLengthVariance | 0.0 | PacketTimeMedian | 0.0 |
| PacketTimeMean | 0.0 | PacketTimeMean | 0.0 |
| PacketTimeStandardDeviation | 0.0 | ResponseTimeTimeSkewFromMode | 0.0 |
| ResponseTimeTimeMedian | 0.0 | PacketTimeVariance | 0.0 |
| PacketTimeMedian | 0.0 | PacketLengthCoefficientofVariation | 0.0 |
| ResponseTimeTimeSkewFromMode | 0.0 | PacketTimeStandardDeviation | 0.0 |
| ResponseTimeTimeMean | 0.0 | PacketLengthMode | 0.0 |
| ResponseTimeTimeMode | 0.0 | PacketLengthMedian | 0.0 |
| PacketTimeCoefficientofVariation | 0.0 | PacketLengthMean | 0.0 |
| ResponseTimeTimeSkewFromMedian | 0.0 | FlowBytesSent | 0.0 |
| PacketTimeMode | 0.0 | ResponseTimeTimeCoefficientofVariation | 0.0 |
| FlowBytesSent | 0.0 | PacketLengthStandardDeviation | 0.0 |
| FlowBytesReceived | 0.0 | PacketLengthVariance | 0.0 |
| PacketLengthMode | 0.0 | PacketTimeCoefficientofVariation | 0.0 |
| ResponseTimeTimeCoefficientofVariation | 0.0 | FlowReceivedRate | 0.0 |
| PacketLengthSkewFromMedian | 0.0 | ResponseTimeTimeStandardDeviation | 0.0 |
| PacketTimeVariance | 0.000008364485 | PacketLengthSkewFromMode | 0.0 |
| PacketLengthMedian | 0.00005997378 | FlowBytesReceived | 0.0 |
| PacketTimeSkewFromMode | 0.00006506026 | PacketLengthSkewFromMedian | 0.001868 |
| ResponseTimeTimeStandardDeviation | 0.01694301 | FlowSentRate | 0.505078 |
| ResponseTimeTimeVariance | 0.03453484 | ResponseTimeTimeVariance | 0.552312 |
| PacketLengthSkewFromMode | 0.9945070 | PacketTimeSkewFromMode | 0.642348 |
| DoH | Non-DoH | Benign | Malicious | |
|---|---|---|---|---|
| Before | 269,299 | 889,809 | 19,746 | 249,553 |
| Classifier | Accuracy | Recall | Precision | AUC |
|---|---|---|---|---|
| Random Forest | 0.8665 ± 0.0269 | 0.8665 ± 0.0269 | 0.8647 ± 0.0344 | 0.8637 ± 0.0683 |
| Decision Tree | 0.8598 ± 0.0264 | 0.8598 ± 0.0264 | 0.8596 ± 0.0344 | 0.7993 ± 0.0636 |
| K-Nearest Neighbors | 0.9021 ± 0.0309 | 0.9021 ± 0.0309 | 0.9001 ± 0.0313 | 0.8711 ± 0.0686 |
| Linear Discriminant Analysis | 0.8069 ± 0.0234 | 0.8069 ± 0.0234 | 0.7952 ± 0.0301 | 0.8463 ± 0.0473 |
| Gaussian Naive Bayes | 0.8059 ± 0.0240 | 0.8059 ± 0.0240 | 0.7940 ± 0.0304 | 0.8463 ± 0.0473 |
| Adaboost | 0.9004 ± 0.0307 | 0.9004 ± 0.0307 | 0.9035 ± 0.0250 | 0.9006 ± 0.0655 |
| Gradient Boost | 0.9071 ± 0.0318 | 0.9071 ± 0.0318 | 0.9087 ± 0.0277 | 0.9118 ± 0.0592 |
| Logistic Regression | 0.8074 ± 0.0227 | 0.8074 ± 0.0227 | 0.7969 ± 0.0303 | 0.8463 ± 0.0473 |
| Stacking Model | 0.8485 ± 0.0207 | 0.8485 ± 0.0207 | 0.8485 ± 0.0207 | - |
| Loss | Accuracy | Val Loss | Val Accuracy |
|---|---|---|---|
| 0.2797 | 0.8082 | 0.2783 | 0.8092 |
| DoH | Non-DoH | Benign | Malicious | |
|---|---|---|---|---|
| Before | 269,299 | 889,809 | 19,746 | 249,553 |
| After | 889,809 | 889,809 | 889,809 | 889,809 |
| Accuracy | Precision | Recall | F1 | F_b |
|---|---|---|---|---|
| 0.71612 | 0.699716 | 0.71612 | 0.681352 | 0.714445 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzighaibi, A.R. Detection of DoH Traffic Tunnels Using Deep Learning for Encrypted Traffic Classification. Computers 2023, 12, 47. https://doi.org/10.3390/computers12030047
Alzighaibi AR. Detection of DoH Traffic Tunnels Using Deep Learning for Encrypted Traffic Classification. Computers. 2023; 12(3):47. https://doi.org/10.3390/computers12030047
Chicago/Turabian StyleAlzighaibi, Ahmad Reda. 2023. "Detection of DoH Traffic Tunnels Using Deep Learning for Encrypted Traffic Classification" Computers 12, no. 3: 47. https://doi.org/10.3390/computers12030047
APA StyleAlzighaibi, A. R. (2023). Detection of DoH Traffic Tunnels Using Deep Learning for Encrypted Traffic Classification. Computers, 12(3), 47. https://doi.org/10.3390/computers12030047