



A New Method of Disabling Face Detection by Drawing Lines between Eyes and Mouth


Abstract
:1. Introduction
2. Related Works
2.1. Face Detection
2.1.1. Multi-Task Convolutional Neural Network
2.1.2. Single Shot Multi-Box Detector
2.1.3. Single Shot Scale-Invariant Face Detector
2.1.4. Convolutional Neural Networks
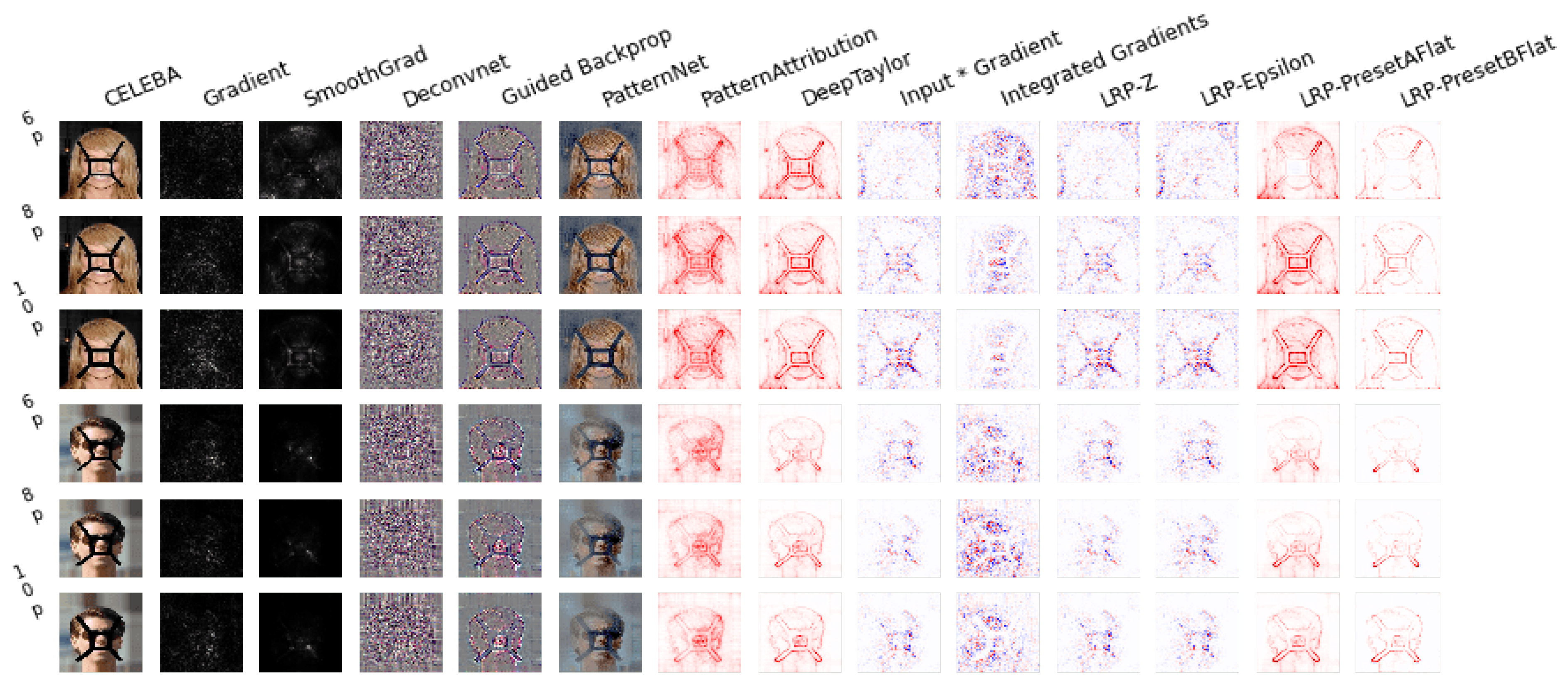
2.2. Interpretability of Neural Networks
2.3. Neural Style Transfer
3. Experiment and Discussion
3.1. Correlation of Background and Face (Experiment 1)
3.1.1. Method and Results
3.1.2. Discussion
3.2. Adding Black Line Structure (Experiment 2)
3.2.1. Datasets
3.2.2. Method
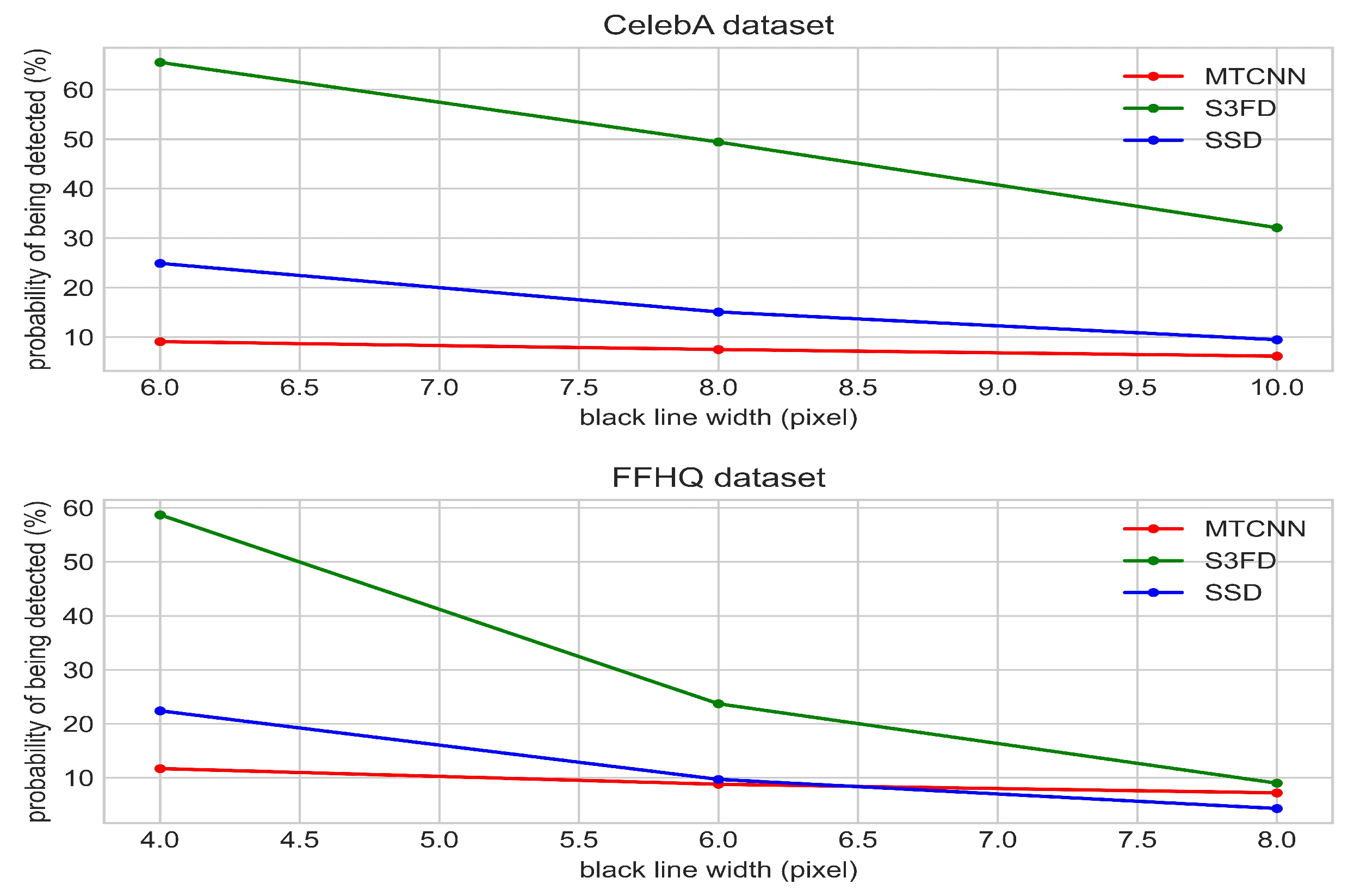
3.2.3. Result
3.2.4. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rao, Y.; Ni, J. A deep learning approach to detection of splicing and copy-move forgeries in images. In Proceedings of the 2016 IEEE International Workshop on Information Forensics and Security (WIFS), Abu Dhabi, United Arab Emirates, 4–7 December 2016; pp. 1–6. [Google Scholar]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. S3fd: Single shot scale-invariant face detector. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 192–201. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- OpenCV. 2022. Available online: https://opencv.org/ (accessed on 1 July 2022).
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Li, Y.; Yang, X.; Wu, B.; Lyu, S. Hiding faces in plain sight: Disrupting ai face synthesis with adversarial perturbations. arXiv 2019, arXiv:1906.09288. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Lu, J.; Sibai, H.; Fabry, E. Adversarial examples that fool detectors. arXiv 2017, arXiv:1712.02494. [Google Scholar]
- Chang, K.T. Introduction to Geographic Information Systems; McGraw-Hill: Boston, MA, USA, 2008; Volume 4. [Google Scholar]
- Zhang, C.; Qi, Y.; Kameda, H. Multi-scale perturbation fusion adversarial attack on MTCNN face detection system. In Proceedings of the 2022 4th International Conference on Communications, Information System and Computer Engineering (CISCE), Shenzhen, China, 27–29 May 2022; pp. 142–146. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Fukushima, K.; Miyake, S. Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition. In Competition and Cooperation in Neural Nets; Springer: Berlin/Heidelberg, Germany, 1982; pp. 267–285. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef]
- Iwana, B.K.; Kuroki, R.; Uchida, S. Explaining convolutional neural networks using softmax gradient layer-wise relevance propagation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 4176–4185. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2018–2025. [Google Scholar]
- Alber, M.; Lapuschkin, S.; Seegerer, P.; Hägele, M.; Schütt, K.T.; Montavon, G.; Samek, W.; Müller, K.R.; Dähne, S.; Kindermans, P.J. iNNvestigate neural networks! J. Mach. Learn. Res. 2019, 20, 1–8. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CelebA | Original | 6 Pixels | 8 Pixels | 10 Pixels |
|---|---|---|---|---|
| S3FD | 99.67% | 65.5% | 49.4% | 32.1% |
| SSD | 99.71% | 24.9% | 15.08% | 9.47% |
| MTCNN | 99.79% | 9.08% | 7.49% | 6.15% |
| FFHQ | Original | 4 Pixels | 6 Pixels | 8 Pixels |
|---|---|---|---|---|
| S3FD | 99.7% | 58.7% | 23.7% | 9% |
| SSD | 99.93% | 22.4% | 9.7% | 4.3% |
| MTCNN | 99.96% | 11.7% | 8.8% | 7.2% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Kameda, H. A New Method of Disabling Face Detection by Drawing Lines between Eyes and Mouth. Computers 2022, 11, 134. https://doi.org/10.3390/computers11090134
Zhang C, Kameda H. A New Method of Disabling Face Detection by Drawing Lines between Eyes and Mouth. Computers. 2022; 11(9):134. https://doi.org/10.3390/computers11090134
Chicago/Turabian StyleZhang, Chongyang, and Hiroyuki Kameda. 2022. "A New Method of Disabling Face Detection by Drawing Lines between Eyes and Mouth" Computers 11, no. 9: 134. https://doi.org/10.3390/computers11090134
APA StyleZhang, C., & Kameda, H. (2022). A New Method of Disabling Face Detection by Drawing Lines between Eyes and Mouth. Computers, 11(9), 134. https://doi.org/10.3390/computers11090134