1. Introduction
Network intrusion detection is used to discover any unauthorized attempts to a network by analyzing network traffic coming in and out of the network and looking for any signs of malicious activity. This is often regarded as one of the most critical network security mechanisms to block or stop cyberattacks [
1].
Traditional machine learning (ML) approaches, such as supervised network intrusion detection, have shown reasonable performance for detecting malicious payloads included in network traffic-based data sets labeled with ground truth [
2]. However, with the mass increase in the size of data, it has become either too expensive or no longer possible to label a huge number of data sets (i.e., big data) [
3]. Unsupervised intrusion detection methods have been proposed as it no longer demands the requirement for labeled data. In addition, these unsupervised methods can utilize only the samples from one class (e.g., normal samples) for training to recognize any patterns that deviate from the training observations. However, the detection accuracy of these unsupervised learning methods tends to suffer as soon as an imbalanced class appears (e.g., the number of samples in a class is significantly more or less compared to the number of samples in other classes).
A number of generative models have been proposed including Autoencoders [
4] and generative adversarial networks (GANs) [
5] with the ability to generate realistic synthetic data sets to improve detection accuracy based on anomaly detection techniques.
Autoencoder (AE) is composed of an encoder and decoder. The encoder can compress high-dimensional input data into low-dimensional latent space. The decoder generates the output that resembles the input by reassembling the (reduced) data representation from the latent space. Typically, a reconstruction loss is computed between the output and the input and used as a mechanism to identify anomalies. The encoder in AE captures the semantic attributes of the input data into the latent space, as a form of vector representation, to represent the corresponding input sample from the real data space.
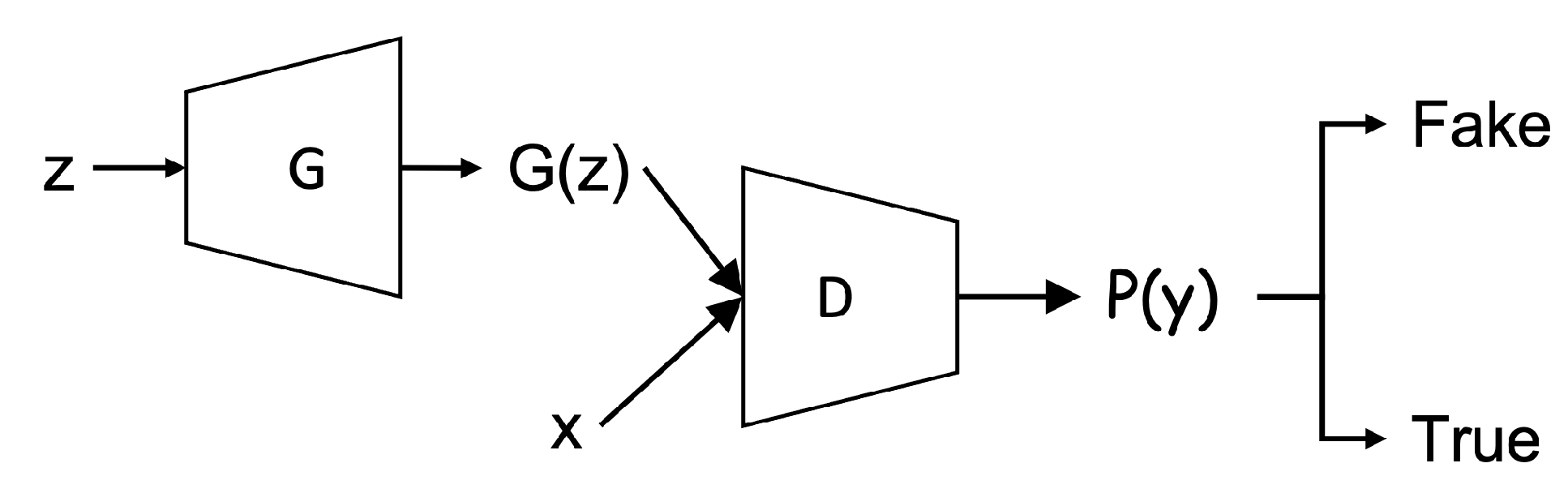
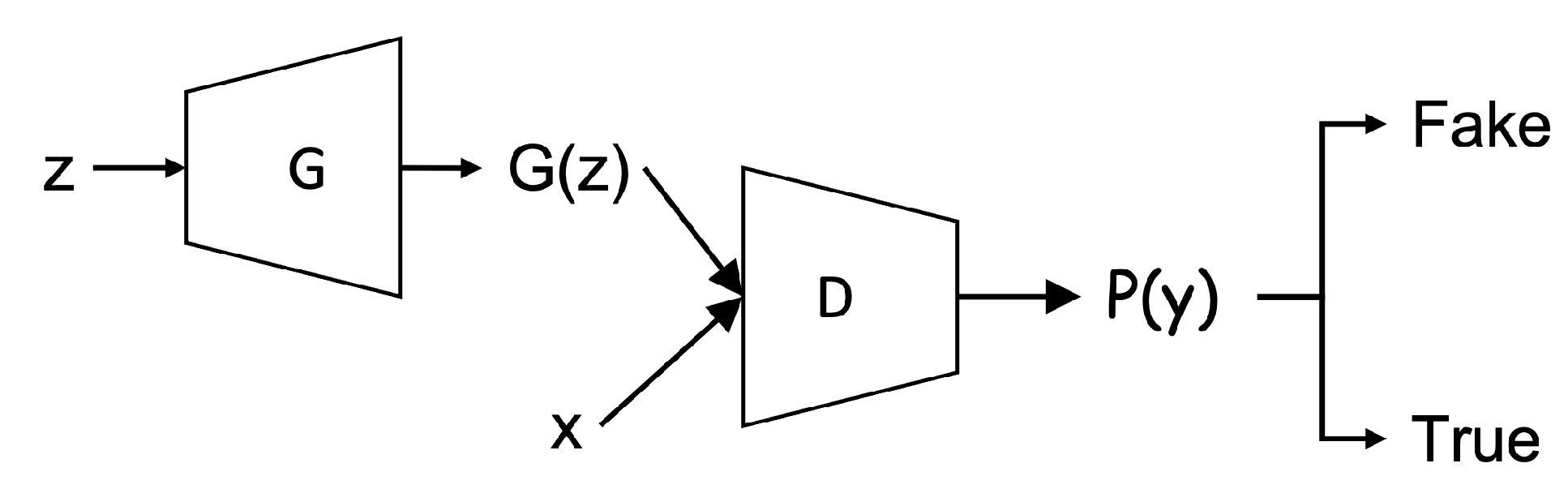
In particular, GANs have emerged as a leading yet very powerful technique for generating realistic data sets, especially in the image identification and processing involved in the natural images despite arbitrarily complex data distributions that exist in the real data sets. In GANs, two deep neural networks, the generator and the discriminator, respectively, are involved in the main GANs’ structure. The generator and the discriminator are trained in turn by playing an adversarial game. That is, the generator produces the output (i.e., somewhat based on the distribution of real data) while the discriminator takes the fake data (i.e., the output of the generator) and real data as input and aims to distinguish them. The goal of the generator is to generate the fake data that resembles as much as the real data to “fool” the discriminator (i.e., it can’t distinguish the fake data from real data). The generator and the discriminator are highly dependent on each other to reach the optima.
Rather than only generating synthetic images that resemble the original input, anomaly detection-based GAN approaches have been proposed to classify abnormal images whose feature deviates significantly from the original images [
6,
7,
8]. Moving from applying anomaly detection-based GAN on images, several works such as [
9,
10] attempted to apply the same principle for network intrusion detection tasks.
However, there are two issues with these existing methods. The first issue is the strong dependence between the generator and the discriminator. That is, the number of training iterations both the generator and the discriminator go through are typically in sync. However, this dependence can be relaxed for the network intrusion tasks because of the difference in the input structure that is fed to GAN models. For network intrusion inputs, the dimensionality of features is significantly lower compared to images, the majority of features in the network intrusion datasets are discrete, as well as the size of inputs relatively smaller. Due to these reasons, the training of the discriminator does not require as many iterations to assess the difference between the synthetic data and the real input [
10]. The second issue is the complexity of producing anomaly scores that are used to decide which input samples are normal or not. The existing methods used on images typically use at least two or more loss functions to accurately produce anomaly scores. However, text-based network intrusion inputs whose structure is a lot simpler than images, a simpler loss function can be used.
To address these two issues, we propose a new Bidirectional GAN (Bi-GAN) model that can effectively detect network intrusions without unnecessary training steps and with a simpler loss function.
The contributions of our proposed approach are following:
We relax the requirement for the generator and the discriminator to train them in sync. The generator (along with the encoder) in our proposed model goes through more rigorous training iterations in order to produce more reliable synthetic data set that highly resembles the real traffic samples. This can effectively remove any overheads associated with the discriminator trained overly. Our proposed model shows that the generator’s performance is greatly improved by offering the generator (and encoder) to train more than the discriminator, which in turn, also actually improves the discriminator’s performance better.
In our promised model, a cross-entropy is used to keep track of the overall balance in terms of the number of relative training iterations required for the generator and the discriminator. In addition, we employ a -log (D) trick to train the generator to obtain sufficient gradient in the early training stage by inverting the label.
We offer new construction of a one-class classifier using the trained encoder-discriminator for detecting anomalous traffic from normal traffic instead of having to calculate either anomaly scores or thresholds which are computationally expensive and complex.
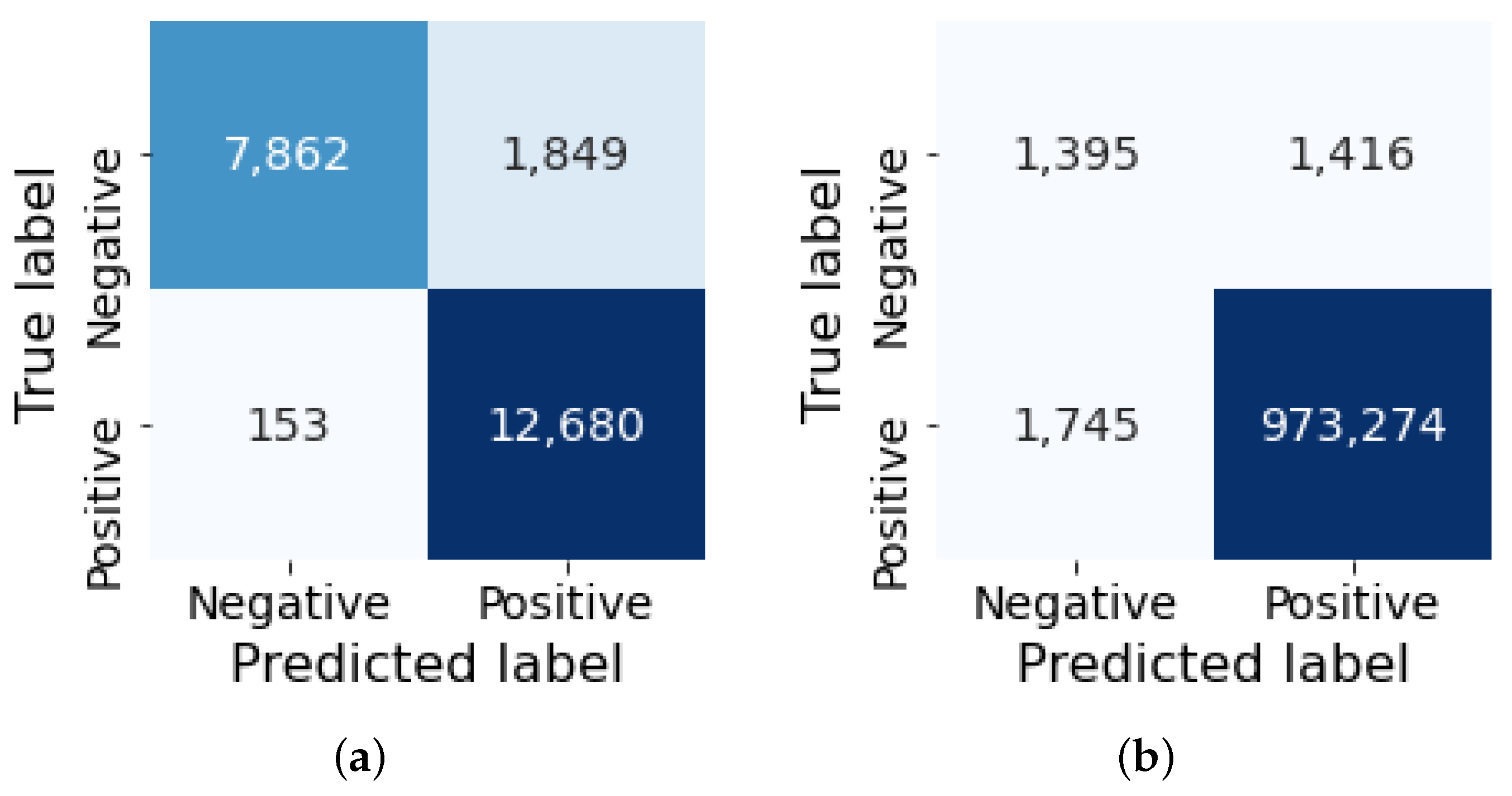
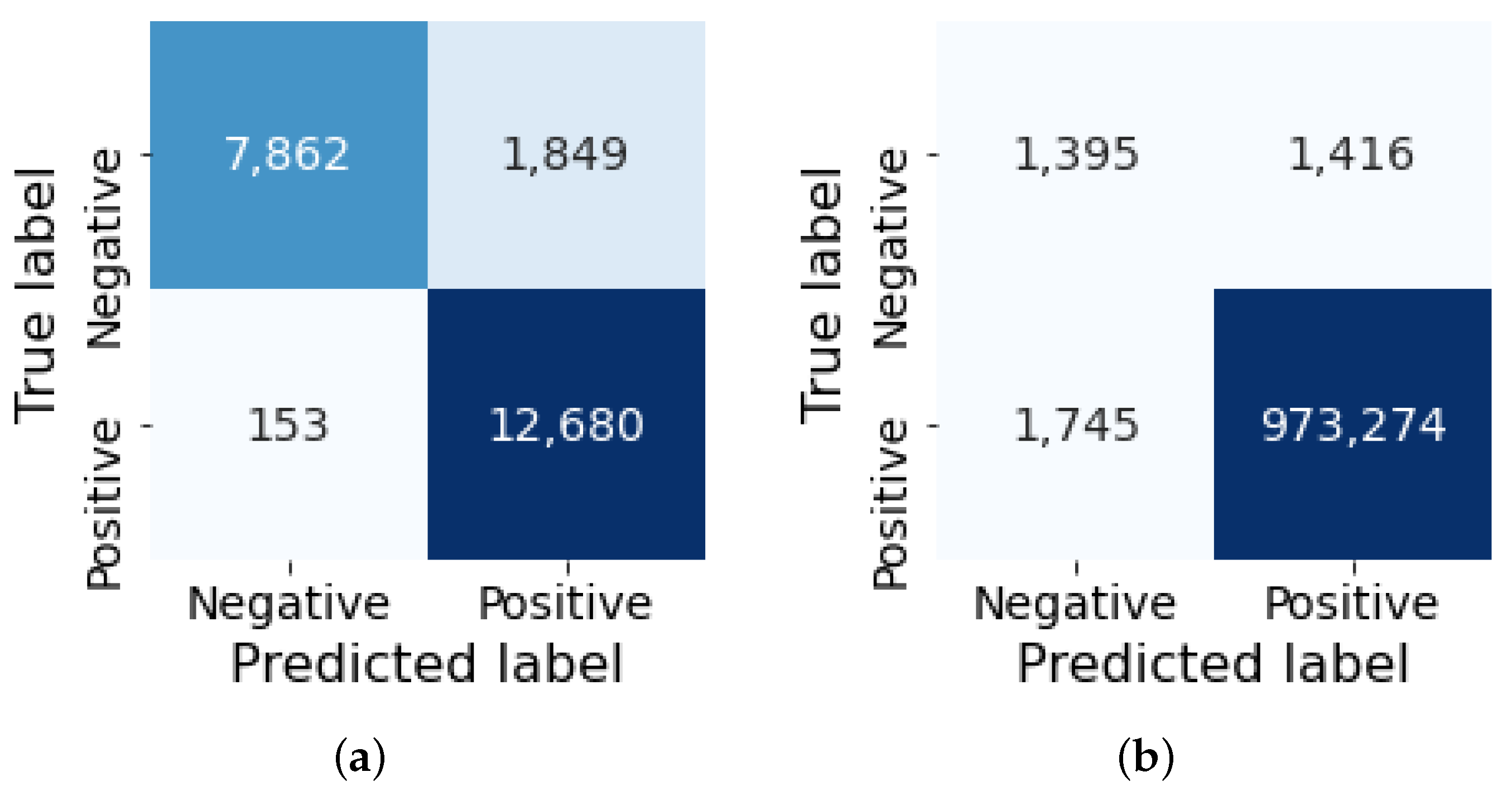
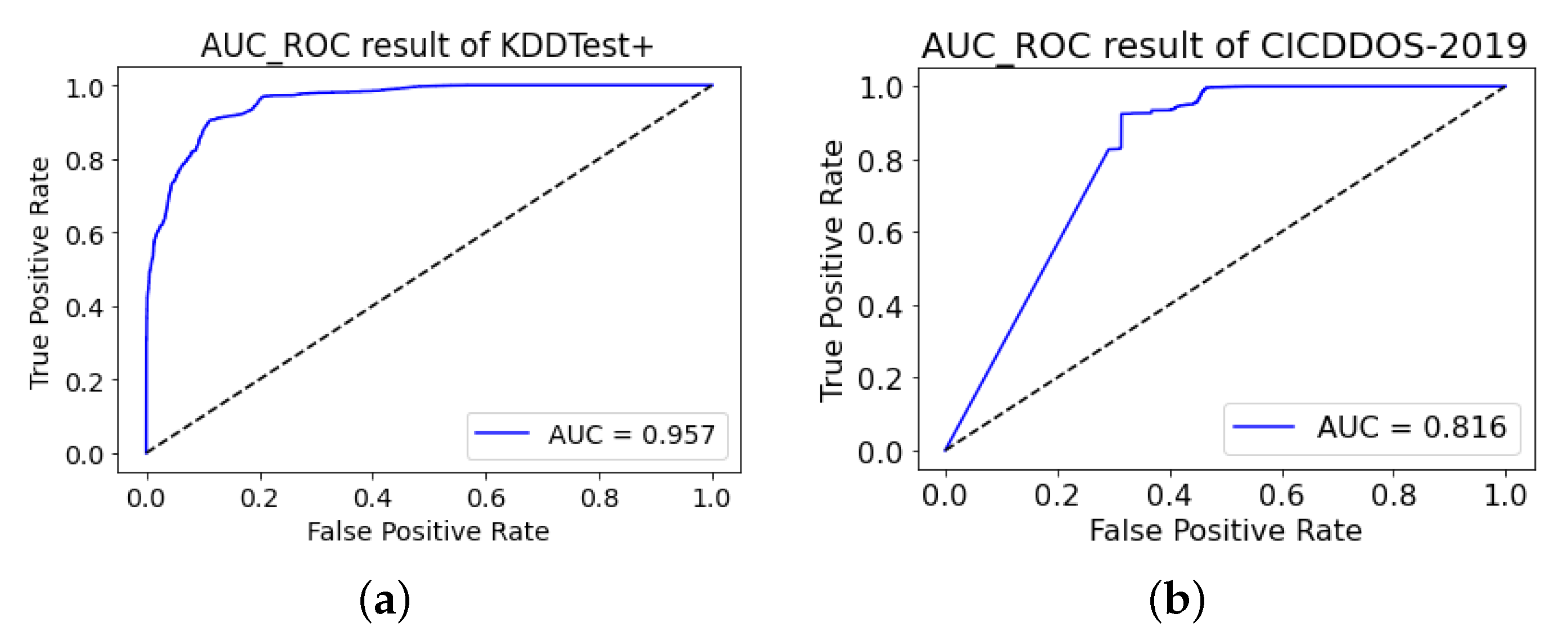
Our experimental result shows that our proposed method is highly effective in using a GAN-based model for network anomaly detection tasks by achieving more than 92% F1-score on the NSL-KDD dataset and more than 99% F1-score on the CIC-DDoS2019 dataset.
The rest of this paper is organized as follows.
Section 2 summarizes the review of the literature relevant to our study. Background knowledge in the generic GAN and BiGAN that is required to understand our study is presented in
Section 3.
Section 4 describes the details of our proposed model.
Section 5 describes the data and the data preprocessing methodologies we used while
Section 6 demonstrates our experimental results and provides analysis.
Section 7 provides the concluding remarks along with the future work that is planned.
2. Related Work
In this section, we review the existing state-of-arts that use two generative deep learning models, Autoencoder and GAN, to detect anomalies (i.e., including intrusions) using anomaly-based detection approaches.
The autoencoder-based approaches typically use reconstruction methods where computing a reconstruction error and use it as a threshold to detect anomalies [
11,
12,
13,
14]. In this approach, an autoencoder is trained only with the normal samples to learn the distribution in their latent representation and use the distribution to reconstruct the input. The difference in the input and output termed reconstruction error is used to detect anomalies that typically generate high reconstruction loss compared to the normal samples. The work suggested by [
15] confirmed the efficiency of such an anomaly-based autoencoder approach to be useful by showing a higher accuracy in network intrusion detection compared to existing (shallow) machine learning techniques. Other improved versions of the autoencoder approach were suggested to improve network intrusion detection. In [
16], the authors used a Denoising Autoencoder (DAE) to remove the features that potentially degrade the overall performance, termed as noises, using stochastic analysis. An and Cho (2015) [
12] proposed a Variational Autoencoder (VAE) based approach which used Gaussian distribution of input samples and use them as a part of reconstruction loss to identify anomalies.
GAN-based models for anomaly detection tasks came later than Autoencoders mostly from the field of computer vision. Schlegl et al. proposed AnoGAN [
6], which was the first anomaly detection-based model. They further proposed f-AnoGAN [
7], which improved the computational efficiency by adding an encoder before the generator to enable the mapping from data to the latent space directly thus avoiding expensive extra backpropagation. GANomaly [
8] further improves the performance which adds two encoders. In their approach, one encoder is used before the generator to learn the latent space of the original data while the other encoder is used after the generator to learn the latent space of the reconstructed data.
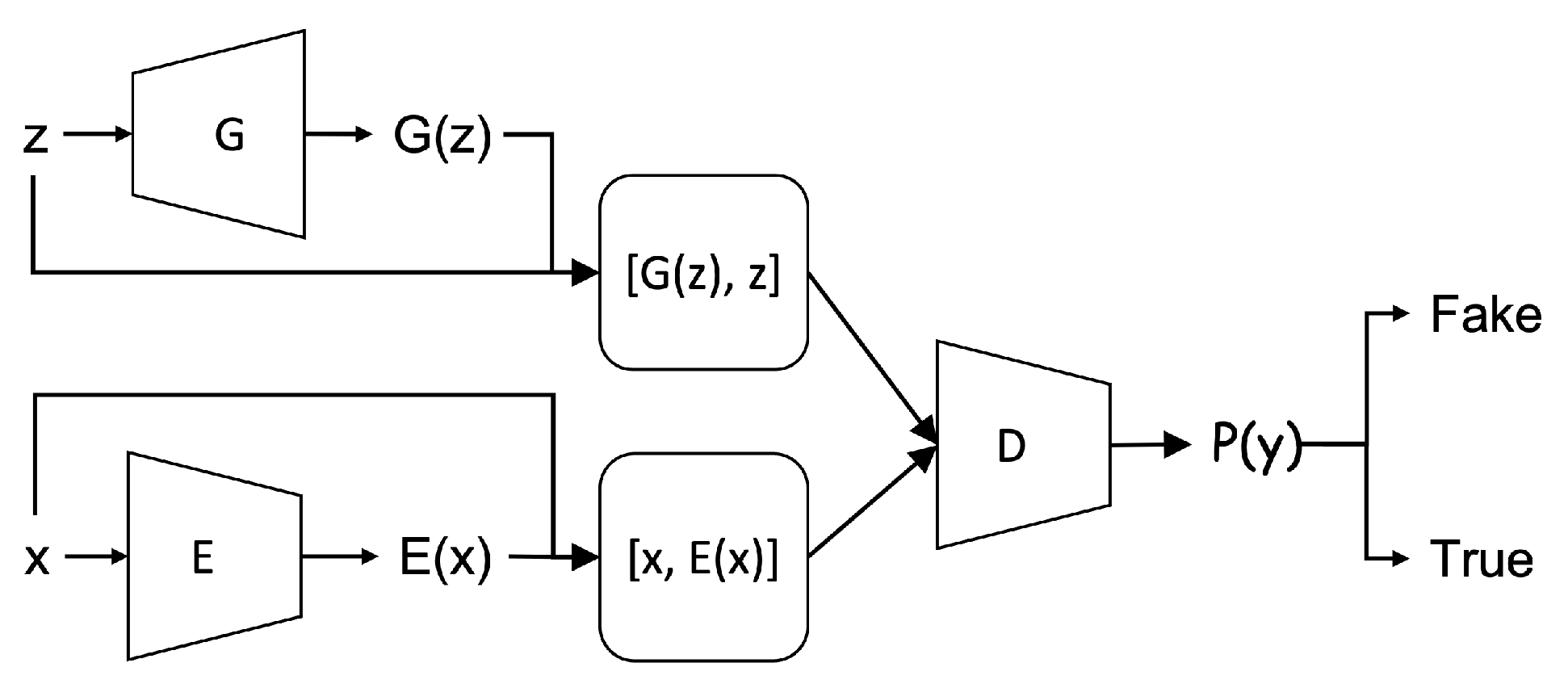
BiGAN further improved its ability to detect anomalies in a simpler way with the ability of mapping data to latent space more efficiently. The BiGAN also comprises three components similar to many previous GAN variants used in anomaly-based detection. These include the generator, the discriminator, and an encoder, but have a different structure. In BiGAN, the encoder is independent of the generator as another input source for the discriminator. In this way, the BiGAN can learn to map the latent space to data (by the generator) and vice versa (by the encoder) simultaneously.
Efficient GAN [
17] utilized BiGAN’s ability of inverse learning and demonstrated that it can be effectively used to detect anomalies not only on images but also on network intrusion datasets such as using the KDD99 dataset. In their approach, they introduced two similar losses as f-AnoGAN to form the anomaly score function. Since the encoder and the generator can compose an auto-encoder structure, ref. [
10] suggests adding an Autoencoder style training step to the original BiGAN architecture to stabilize the model.
In the existing GAN approaches, there is a strong dependence between the generator and the discriminator. That is, the training strategy for the generator and the discriminator needs to be in sync to produce synthetic data that resembles the original images. This is necessary for images where the inputs have high dimensions, feature values are complex, and input size is large. However, network intrusion inputs are simpler, with fewer dimensions, the majority of features are discrete features, and the input size is relatively small. In this case, the dependence of training between the generator and the discriminator can be relaxed [
10].
In addition, many existing methods require at least two or even more loss metrics to compute anomaly scores which have proven to be very expensive [
7,
8,
17]. However, it has been shown in [
10,
18], that a more straightforward resolution could be used such as using the discriminator as a one-class classifier to detect anomalies instead of computing anomaly scores.
4. Our Proposed Model
Extending from the BiGAN approach, our proposed model offers a new training strategy for the generator and encoder. By further relaxing the dependence with the discriminator, our proposed model allows the generator and encoder to train until they produce a set of new data samples that resembles the real distribution of the original data while maintaining strong semantic relationships that exist in the text-based features of the original network traffic samples. Our proposed model also offers a new construct for the trained encoder–discriminator to use as a one-class binary classifier.
4.1. Main Components
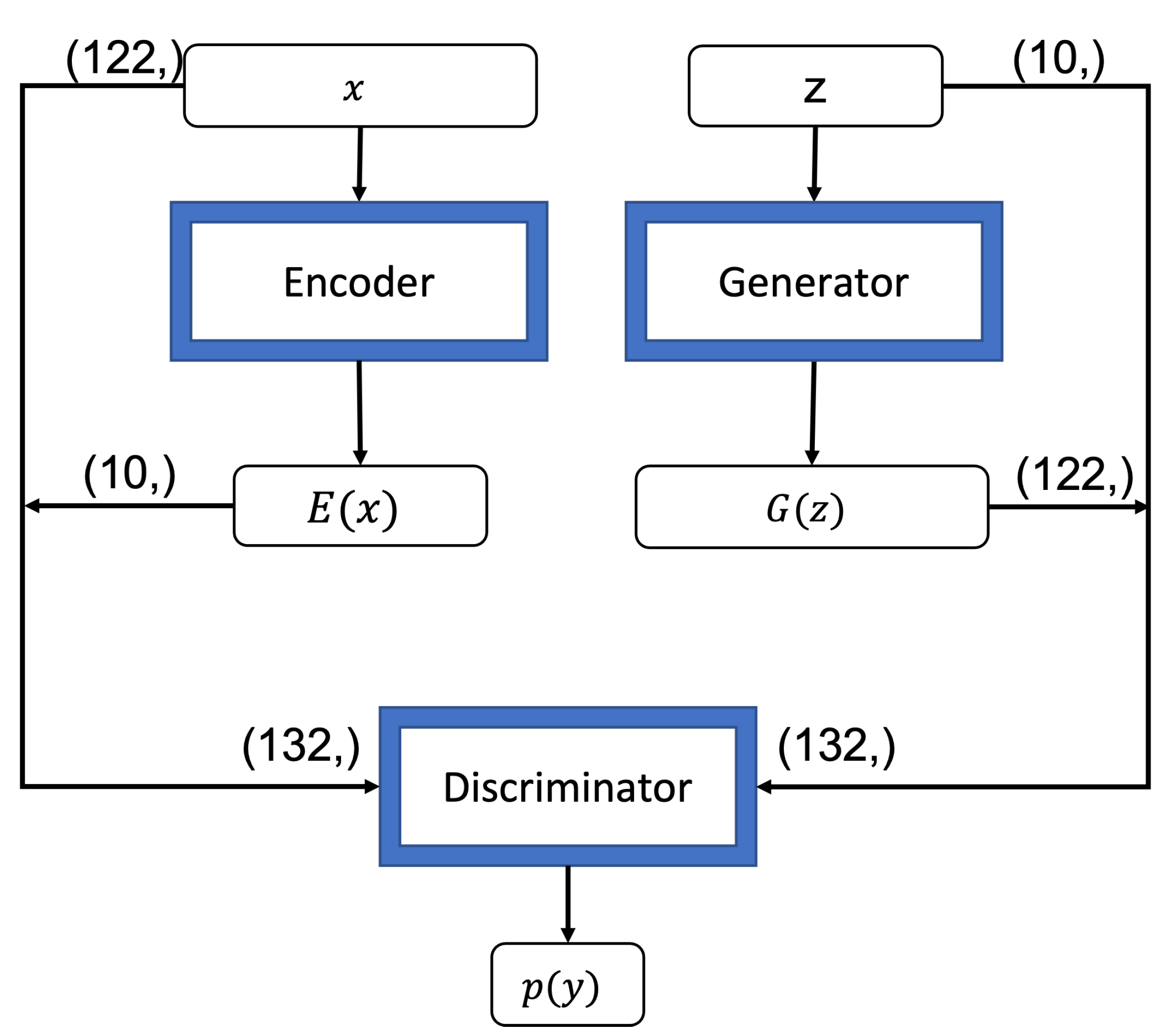
4.1.1. Encoder
The encoder in our proposed model is used for learning feature representation [
20] which takes the real samples as inputs and maps them to a low dimensional vector in a latent space. In our approach, the encoder is a neural network with three dense layers and has ReLU as the activation function for the hidden layer and the output layer. As this typically works as an inverse mapping of the generator, the size of the latent space is typically set at the same dimension size of the input data used for the generator.
4.1.2. Generator
The generator in our approach maps a low-dimensional vector (i.e., random input values) to a higher-dimensional vector in the latent space. The generator acts exactly opposite to the encoder. It accepts a n-dimensional noise as the input source and the n is identical to the dimension size of latent space in the encoder. Our generator draws the n-dimensional noise from the standard normal distribution. The generator has a neural network structure of three dense layers. ReLU is used as the activation function for the hidden layer while the sigmoid function is used as the activation function for the output layer to restrain the distribution of output within the range of [0, 1]. The output layer of the generator has the same number of neurons as the input layer of the encoder and the sigmoid function ensures that the generator’s output has the same data distribution range as the encoder’s input.
4.1.3. Discriminator
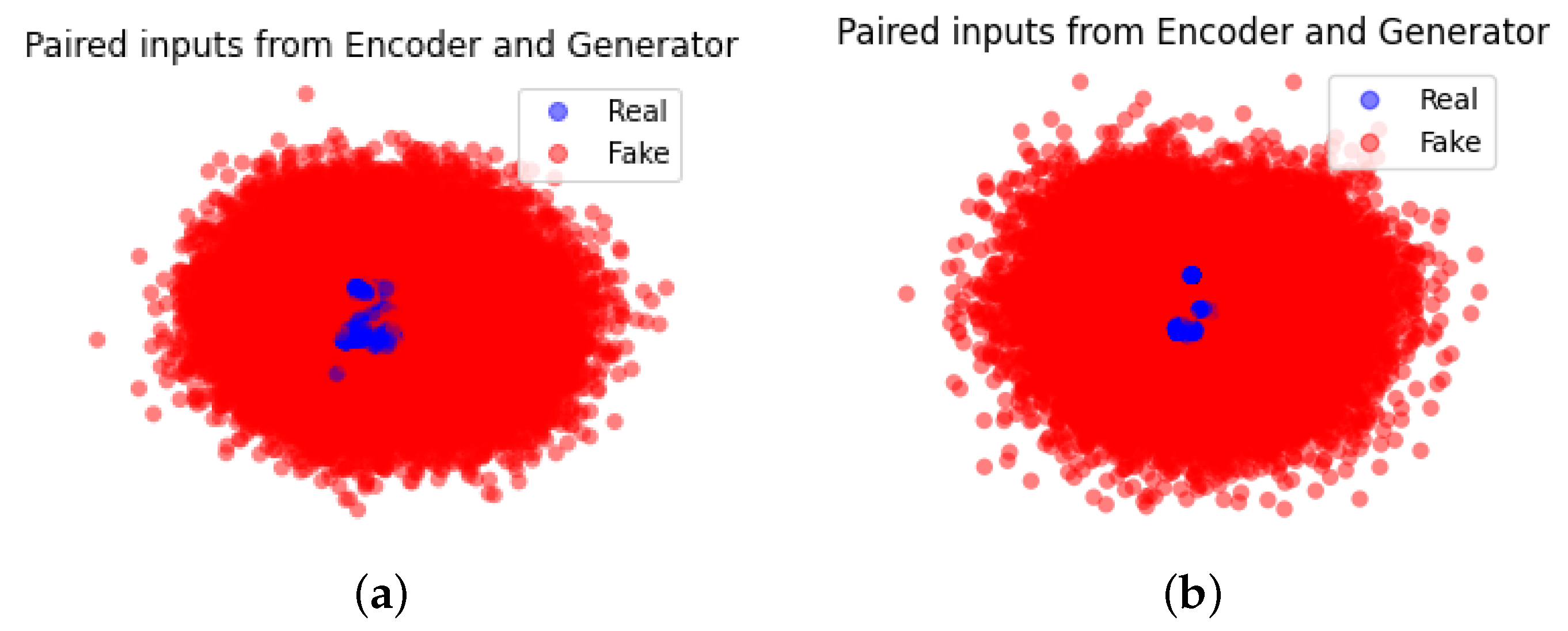
The discriminator in our approach is to distinguish whether the input data is derived from the encoder or forged by the generator in the training phase. It comprises a concatenate layer which receives (i.e., the paired input from the encoder) and (i.e., the paired input from the generator), a hidden dense layer with ReLU as the activation function, and an output layer with only one neuron. The sigmoid activation function is used for the output layer to produce the binary classification result.
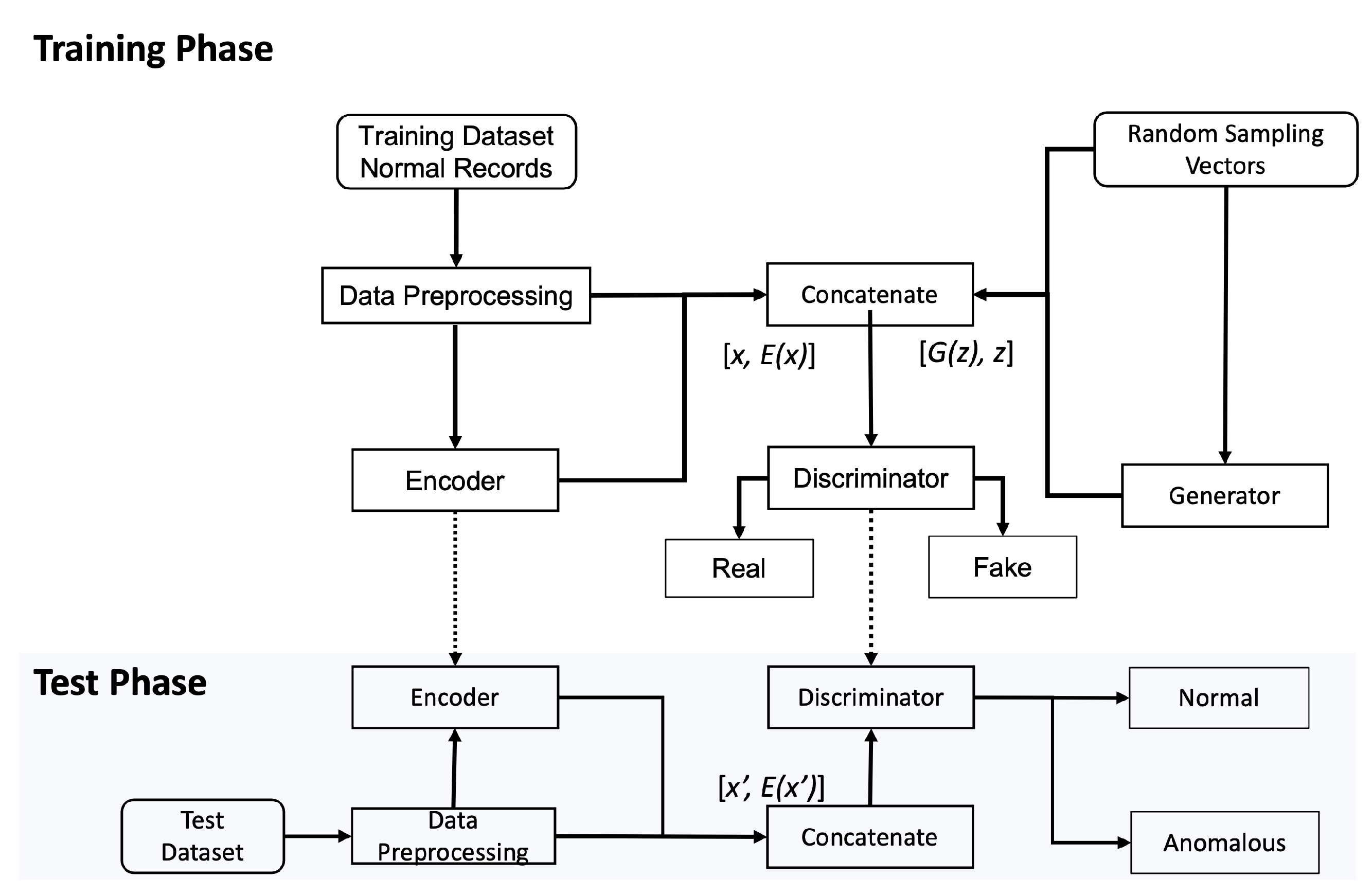
4.2. Training Phase
The ultimate goal of the training strategy involved in a GAN approach is for the generator and the discriminator to reach Nash equilibrium where their chosen training strategies maximize the payoffs (i.e., the generator produces the fake data as resembles as the real data while the discriminator has built up enough knowledge to distinguish the real from fake samples). In the existing GAN approaches dealing with natural images, this often requires both the generator and the discriminator to improve their capabilities at a relatively equivalent speed.
However, this training strategy often does not work in many application scenarios, because often the semantic relationships of the feature sets require to be maintained in the data set produced by the generator, and the data set being operated on in the discriminator differ from each other, which often leaves the training of the generator unstable (i.e., the loss of the generator fluctuates widely) [
21].
In many cases, discriminator converges easily at the beginning of training [
22], making the generator never reach its optimum. To address this issue for network intrusion detection tasks, we train the generator (and the encoder accordingly) more iterations than the discriminator. This new training strategy can prevent an optimum discriminator from appearing too early in the training stage thus keeping the training to be more balanced between the generator and discriminator.
Our training strategy is depicted in Algorithm 3 where the training is processed in mini-batch. In the first stage, the discriminator is trained and updated with a batch of real samples (input from the encoder) and a batch of fake samples (input from the generator) in sequence. In the next stage, the discriminator is fixed and the encoder and the generator are trained
k times. Like it was used in [
20], we also adopt the “—log(D) trick” [
5] to train the generator and the encoder more efficiently by flipping the target label between the generator and the encoder. For example, the input from the encoder is labeled as 1 (fake) while the input from the generator is labeled as 0 (real). Now the result of
is reversed which generates large gradients. This reflects the second part of an iteration in Algorithm 3 (i.e., the inner for-loop).
Training Loss Function
In many cases, Kullback–Leibler (KL) divergence or Jensen–Shannon (JS) divergence are used to measure the distance between the joint distribution of
and
in many image-based BiGAN variants which produces the optimum,
and the divergence of 0. This does not work for text-based BiGAN as the divergence of the two joint distributions of
and
cannot be computed directly but can only be approximated indirectly using the discriminator. With this understanding, we use the cross-entropy to approximate the divergence. Equation (
3) depicts the cross-entropy of two distribution
and
and where
is the actual target (0 or 1) and the
is the joint distribution of
or
.
where
is the actual target (0 or 1) and the
is the predict. Now we can unify the updating of the encoder, generator, and discriminator to minimize the result of this loss.
| Algorithm 3: Training Phase of our proposed method |
![Computers 11 00085 i003]() |
In the first stage of training, the discriminator is updated in iteration: if the input comes from the encoder, the second part of the objective function (
2) becomes 0. maximizing the first part of the objective function equals to minimize the cross-entropy values between
and
as seen in the following Equation:
If the input comes from the generator, the first part of the objective function (
2) becomes 0. The second part of the objective function is equivalent to minimizing the cross-entropy values between
and
, as seen in the following Equation:
When training the generator and the encoder, the parameters of the discriminator is fixed. In fact, the two modules are trained separately: the encoder is trained in the encoder-discriminator joint structure while the generator is trained in the generator-discriminator joint network. Since the labels of input are swapped, the target label will set to be 0 when the input is a real sample
x∼
. Updating the encoder is to minimize the cross-entropy between
and
:
On the other hand, updating the generator is to minimize the cross-entropy between
and
:
4.3. Testing Phase
After the training is completed, the discriminator has full knowledge of the joint distribution of normal samples. The output probability is close to 0 when the input of the encoder is normal samples, and far from 0 if the input is anomalous samples.
This knowledge at the discriminator is used in the testing phase. If the probability value is greater than a given
, the discriminator has high confidence to label the test sample anomalous. We follow the convention to set
to use it as a marker to decide whether a network traffic record in the testing set is normal or anomalous. In another words, if
, the discriminator in our proposed model mark the inputted test data point as an anomaly. This evaluation process is depicted in Algorithm 4.
| Algorithm 4: Testing Phase of our proposed method |
![Computers 11 00085 i004]() |
The intuition behind this one-class classifier is whether a network traffic sample in the test data set is normal or anomalous is following. In the training phase, the encoder only operates on normal data samples with its data distribution represented by and learns the distribution in the latent representation (). Now at the test phase where the encoder receives not only normal data samples but also anomalous data samples (), the encoder still compresses the anomalous inputs to the same latent distribution (). Since the anomalous input samples falls outside the “normal distribution” (), their latent representations () are most likely outliers, that is . This enables the discriminator to produce a high probability value close to 1, which now the discriminator can mark them as anomalies.
4.4. Putting It Together
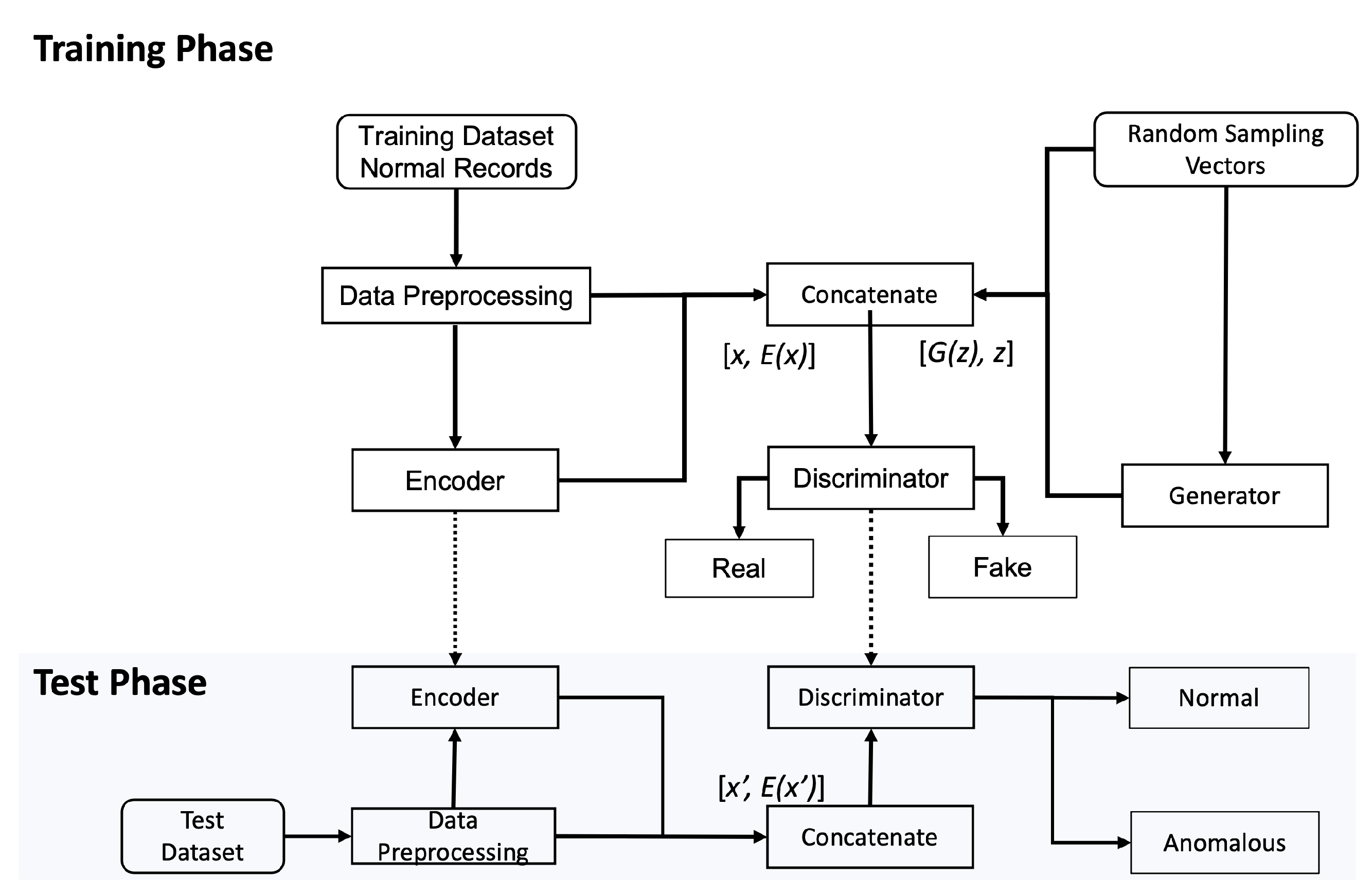
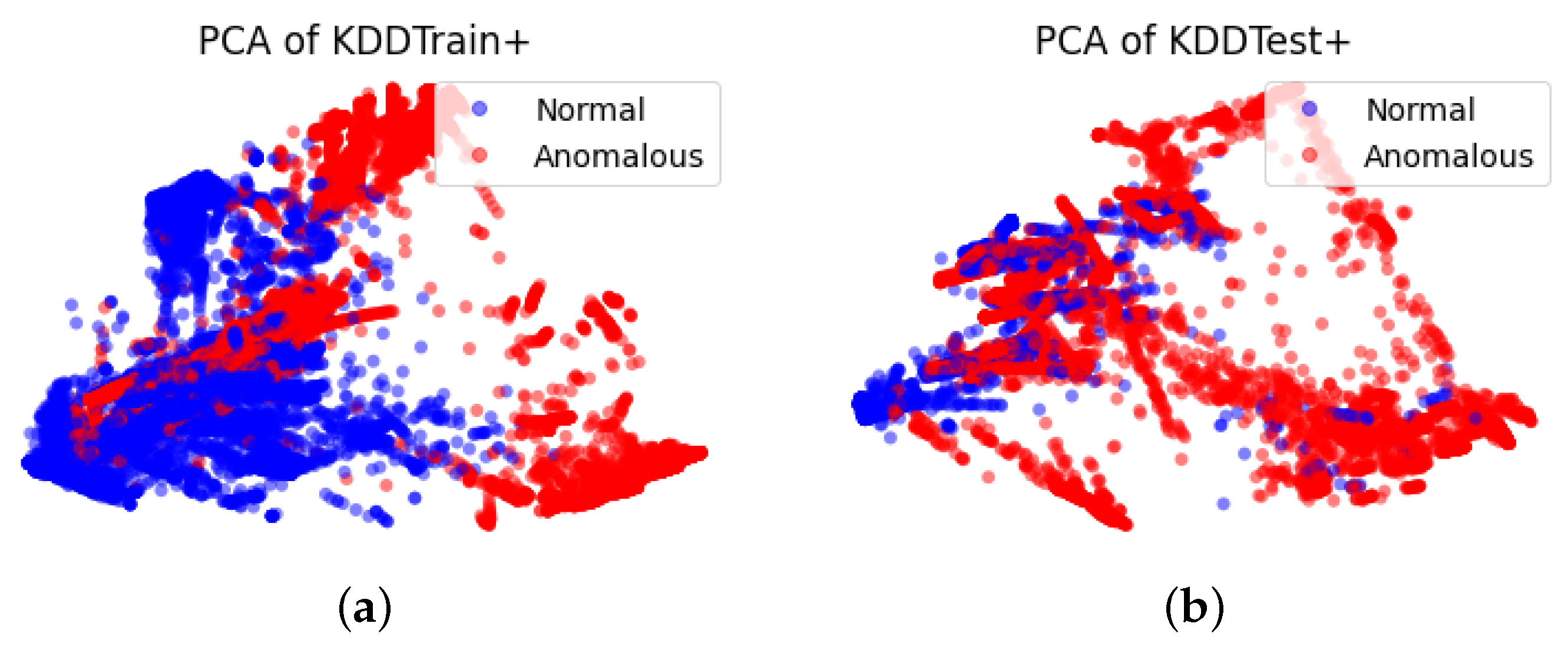
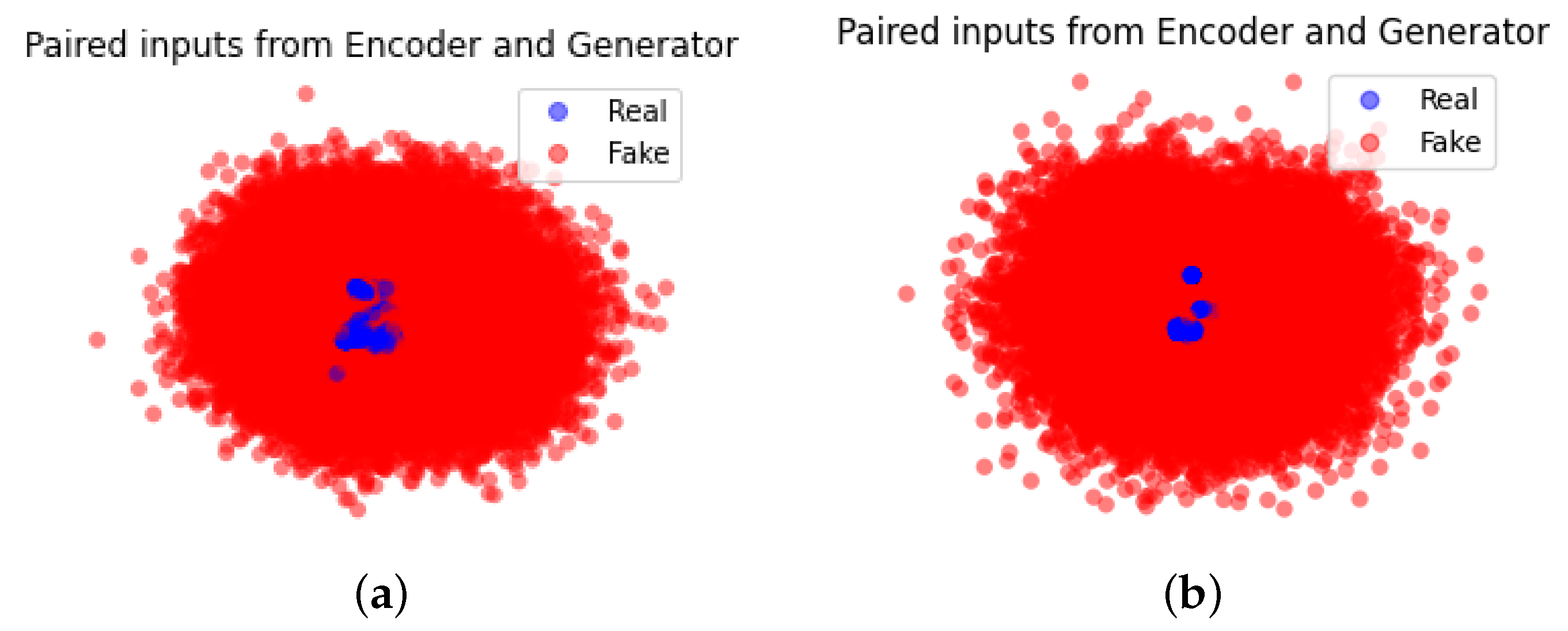
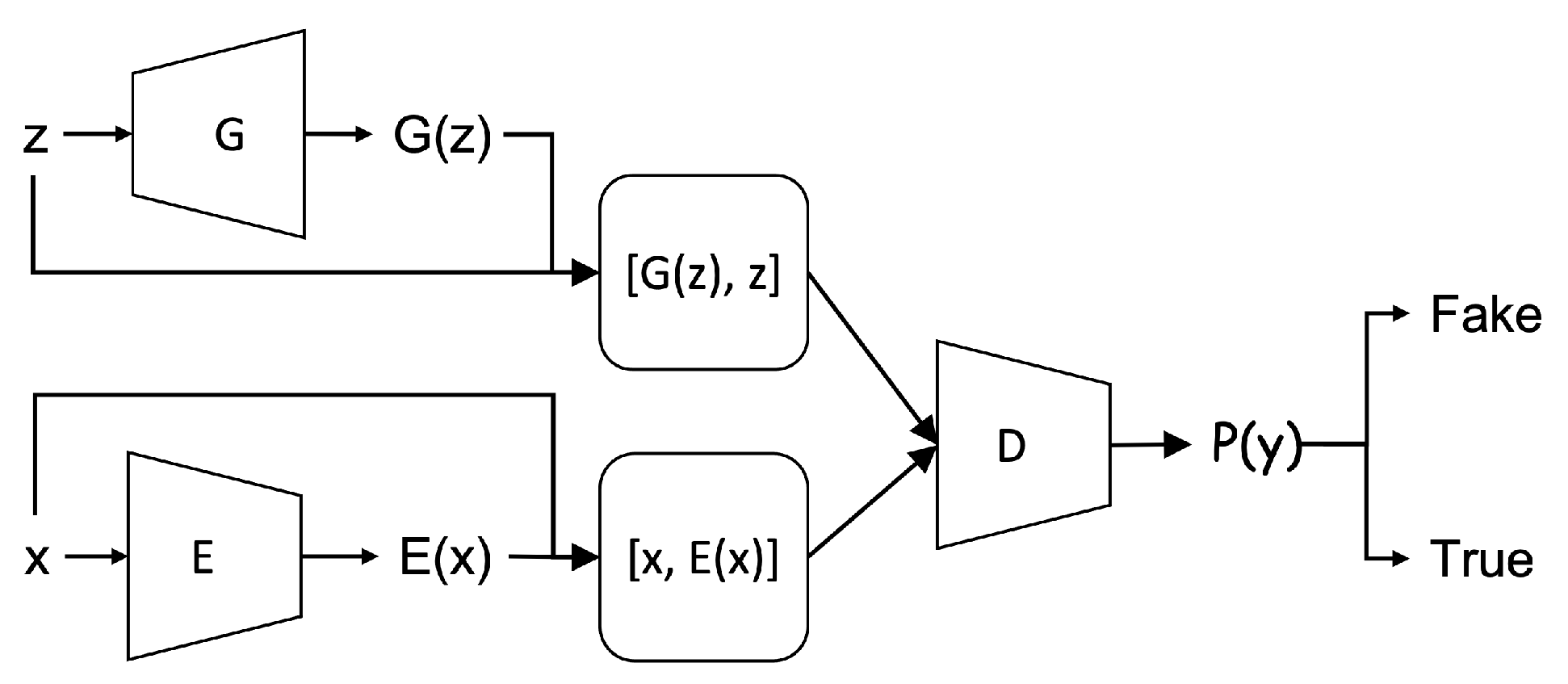
Figure 3 illustrates our proposed approach.
During the training phase, a normal traffic sample x is processed to feed into the encoder as the input. The encoder maps x to latent representations as the output. Their concatenation becomes an input to the discriminator representing real data, labeled with the value 0.
The generator draws a low dimensional vector z and fills it with random values derived from a standard distribution to generate synthetic samples . Their concatenation becomes another input to the discriminator representing fake data, labeled with the value 1.
The discriminator outputs a probability to estimate whether the input is a “real” sample or a “fake” sample. For example, if , the discriminator predicts that the input is the real sample from the encoder, otherwise, the input is the fake sample from the generator. The cross-entropy is used as the unified loss function to update all the three modules in our proposed model while flipping labels provide a strong gradients signal for updating the encoder and the generator.
During the testing phase, the testing samples () containing both normal and abnormal traffic samples are inputted to the encoder which outputs a low dimensional feature representation of these inputs . The paired vector becomes the input to the discriminator. The discriminator, by now well trained to see which probability values to associate with the real or fake samples, produces a probability value of each input sample, and predicts whether the input is normal or anomalous since the anomalous input produces considerably dissimilar probabilistic values observed during the training on normal samples.
7. Conclusions
In this study, we proposed a new Bidirectional GAN model more suited to detect network intrusion attacks with less training overheads and a less expensive one-class classifier. Unlike existing GANs used in natural image processing which demand a strong dependence between the generator and the discriminator to produce realistic fake images, our proposed model allows the generator and the discriminator to be trained without needing to be in sync in their training iterations. By relaxing the dependence between these two, the generator and encoder working together, we can produce more accurate synthetic text-based network traffic samples without excess training overheads of the discriminator. This approach is more suited to the network intrusion inputs that exhibit less complex feature structures with a few feature dimensions, mostly discrete feature values, and the size of input relatively smaller compared to the existing GAN variants used for anomaly detection tasks on images.
Our model is also equipped with a one-class binary classifier for the trained encoder and discriminator to use for detecting anomalous traffic from normal traffic. By offering a one-class (binary) classifier, a complex calculation involved in finding a threshold or anomaly score can be avoided.
Our proposed model, evaluated on extensive experimental results on two separate datasets, demonstrates that it is highly effective for the generator to produce a synthetic network traffic dataset that can contribute to detecting anomalous network traffic. Our benchmarking result shows that our proposed model outperformed other similar generative models by achieving more than 92% F1-score on the NSL-KDD dataset and more than 99% F1-score on the CIC-DDoS2019 dataset.
Many existing network intrusion datasets currently used to develop many deep learning models suffer from high false positives due to the presence of minority classes. To address this issue, we plan to extend our work as a general data argumentation technique to produce more synthetic data samples that resemble actual samples. We may consider employing a similarity function such as Pearson Correlation or flocking methods proposed by [
25,
26], or other statistical analysis methods to evaluate the similarity between the synthetic data and actual samples from many different aspects of data distribution. Eventually, we plan to test such GAN-based data augmentation technique for our previous works on DDoS attack classification [
27], Android-based malware detection [
28,
29], or ransomware detection and classification tasks [
30,
31,
32] by improving the quality of rare minority classes. We also plan to apply our technique for other application areas, such as finding defects in X-ray images [
33] to evaluate the feasibility, extensionability, and generalizability of our approach.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}