
Traffic Request Generation through a Variational Auto Encoder Approach


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Variational Autoencoders as Generative Models
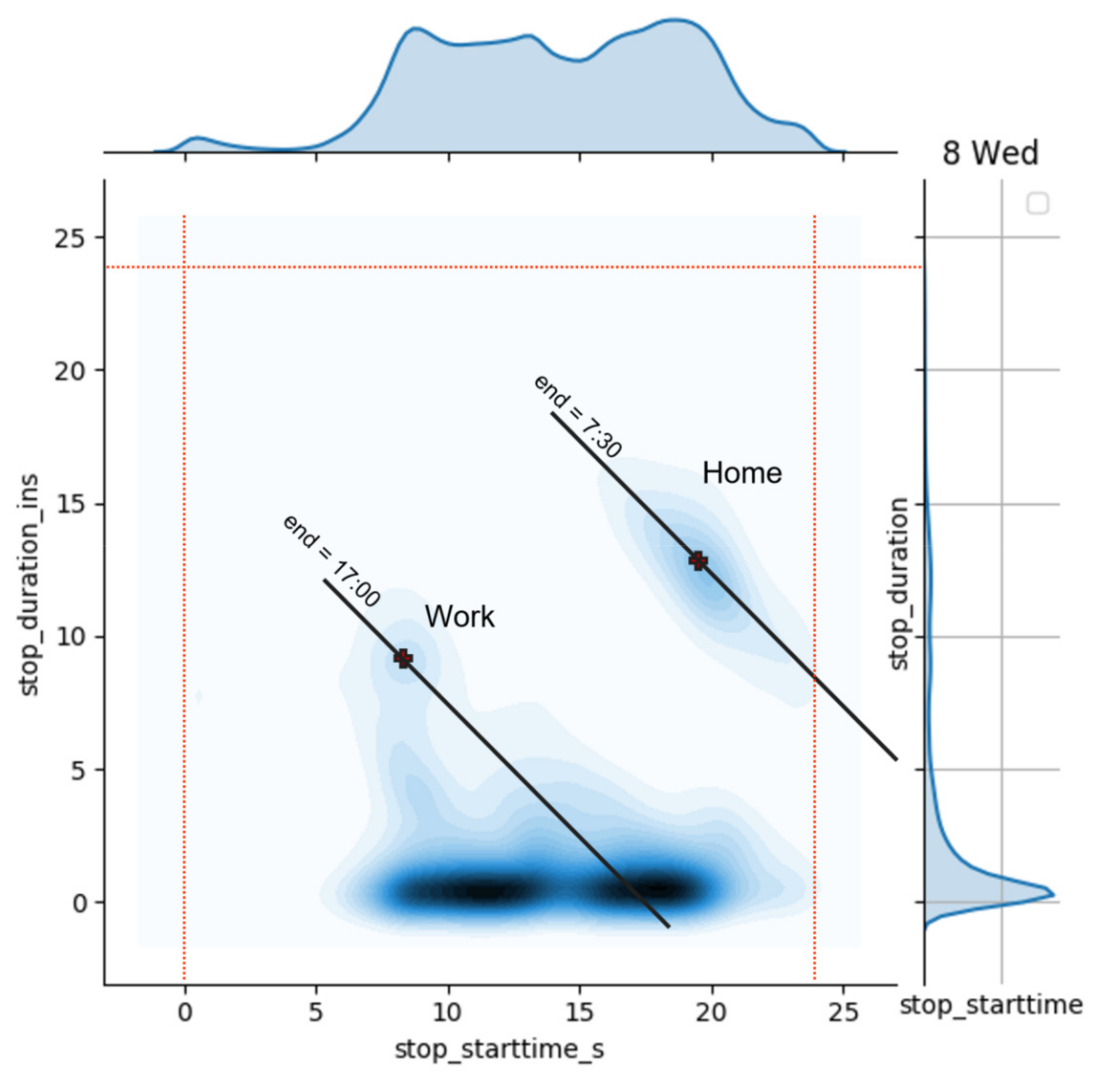
3.2. The Dataset
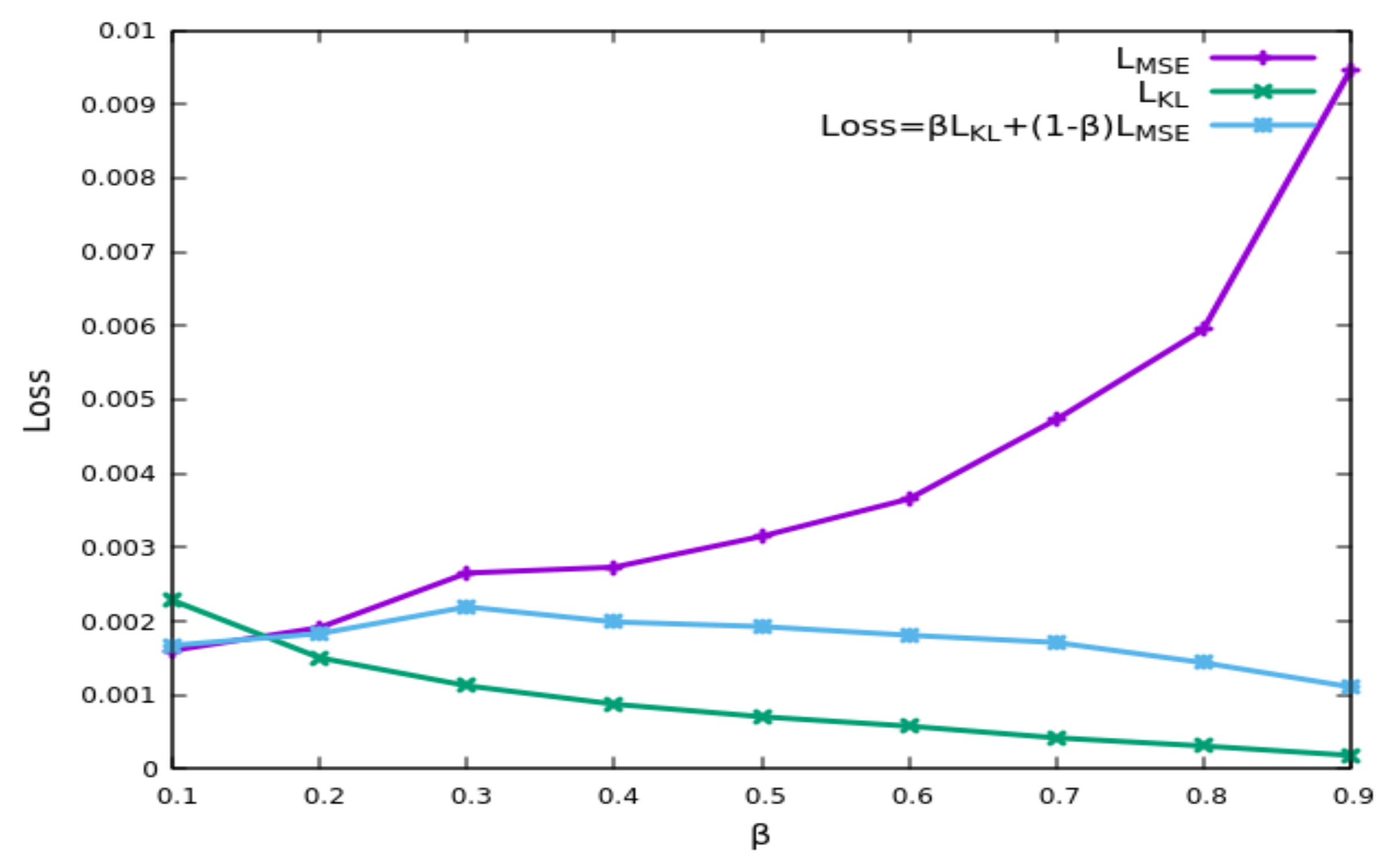
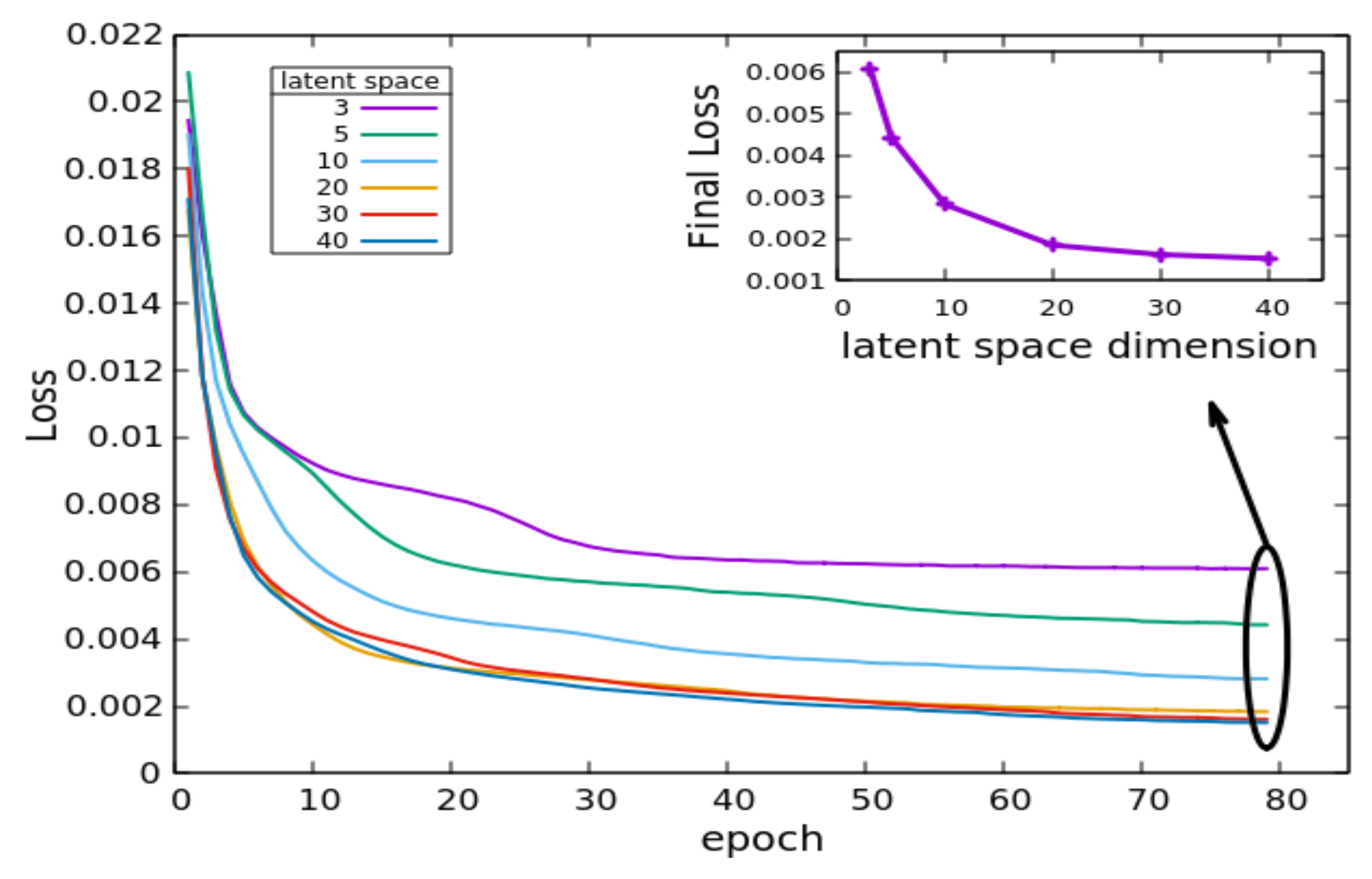
3.3. Training
4. Results
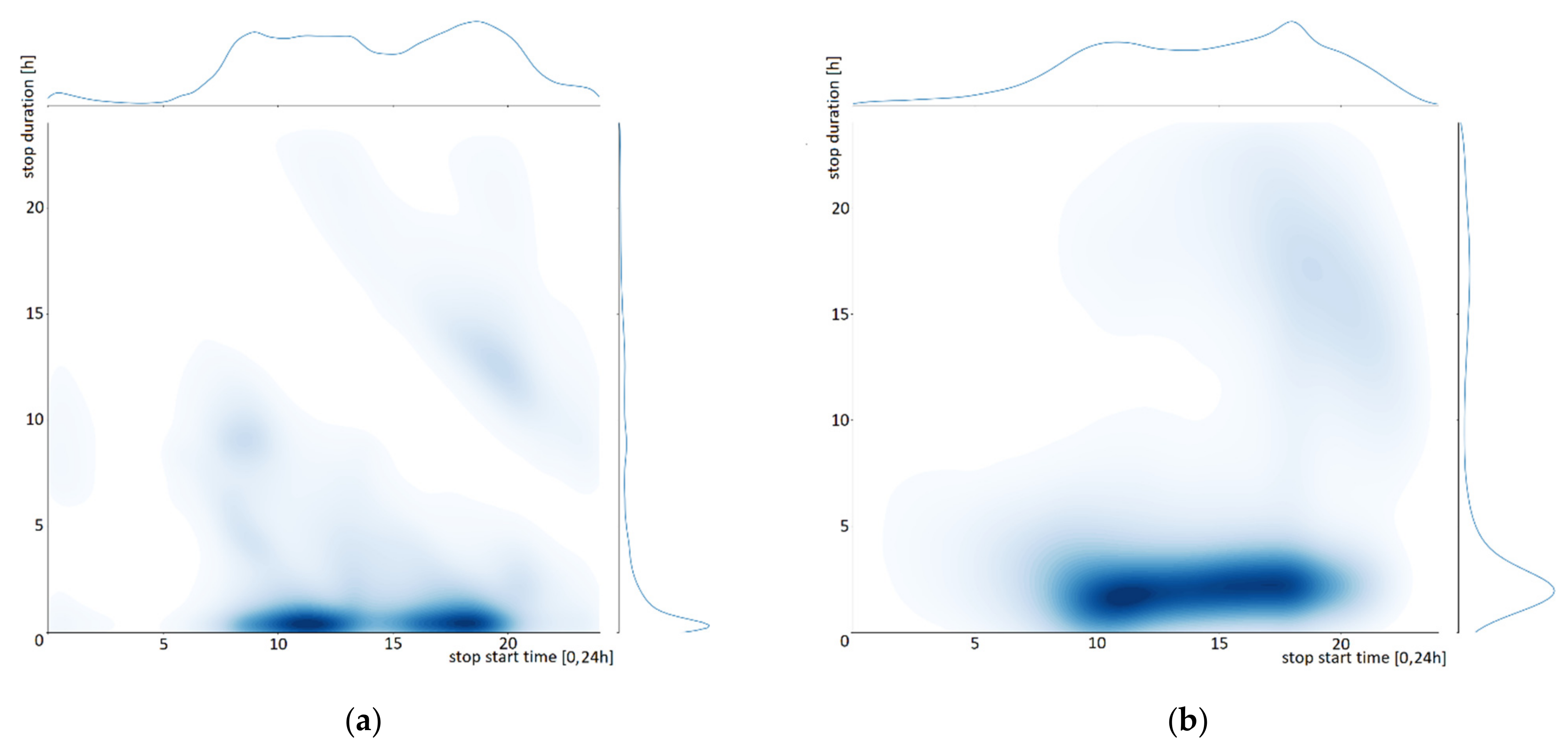
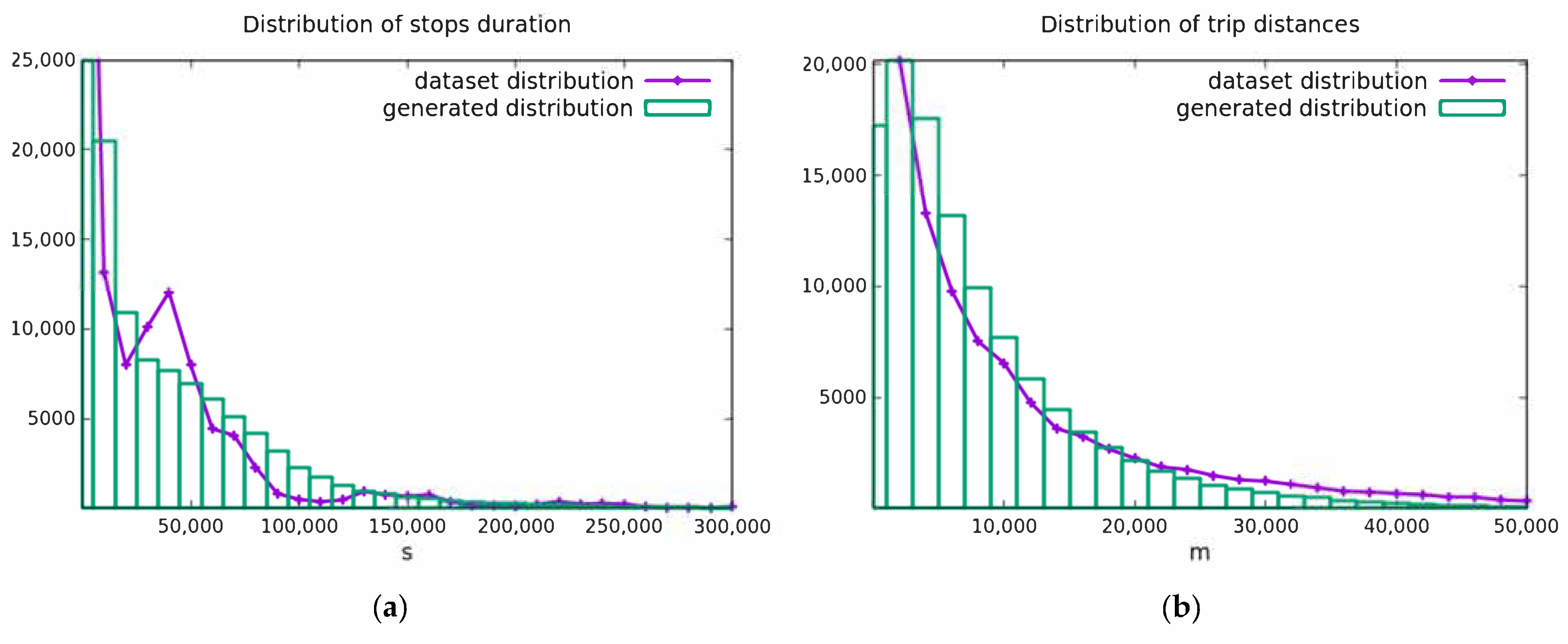
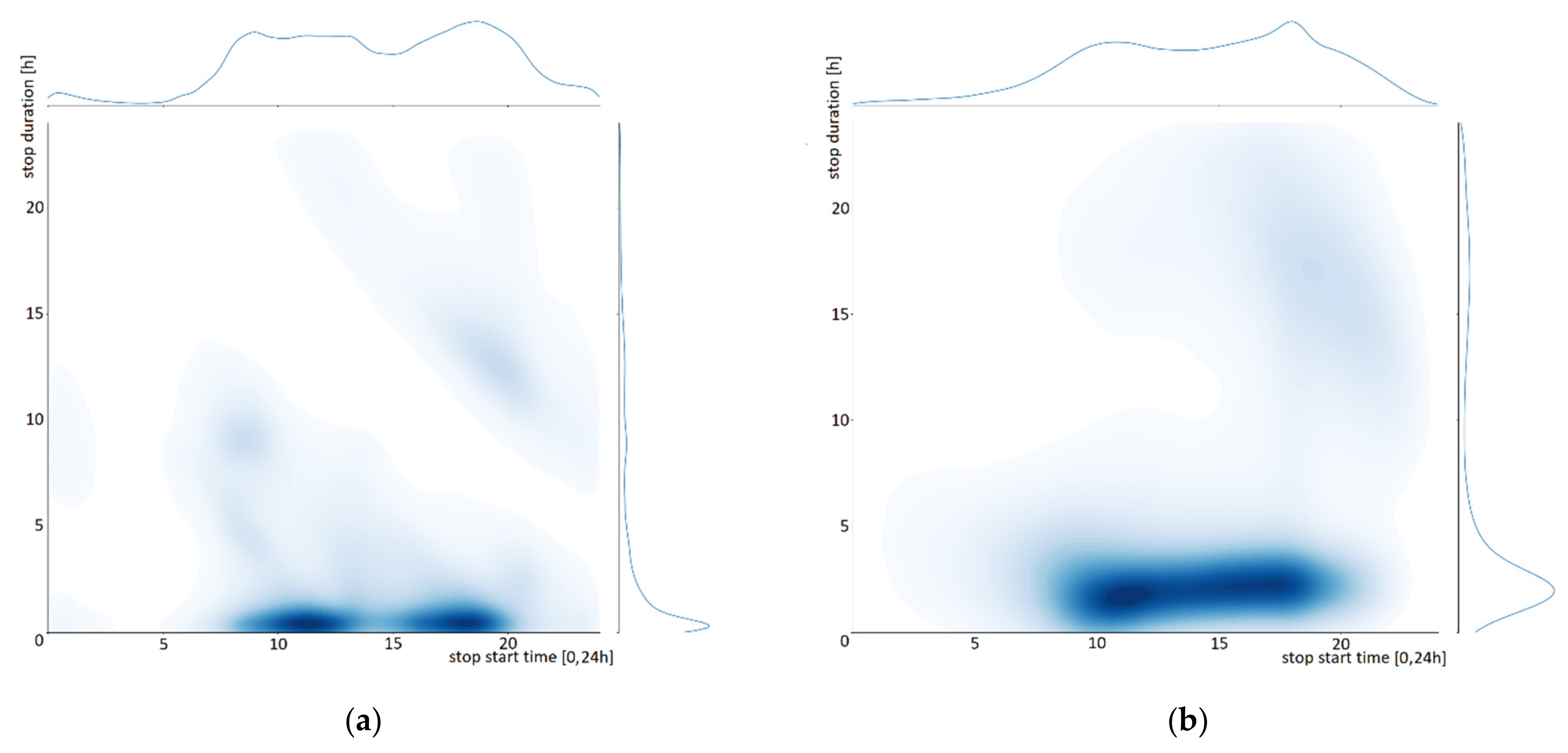
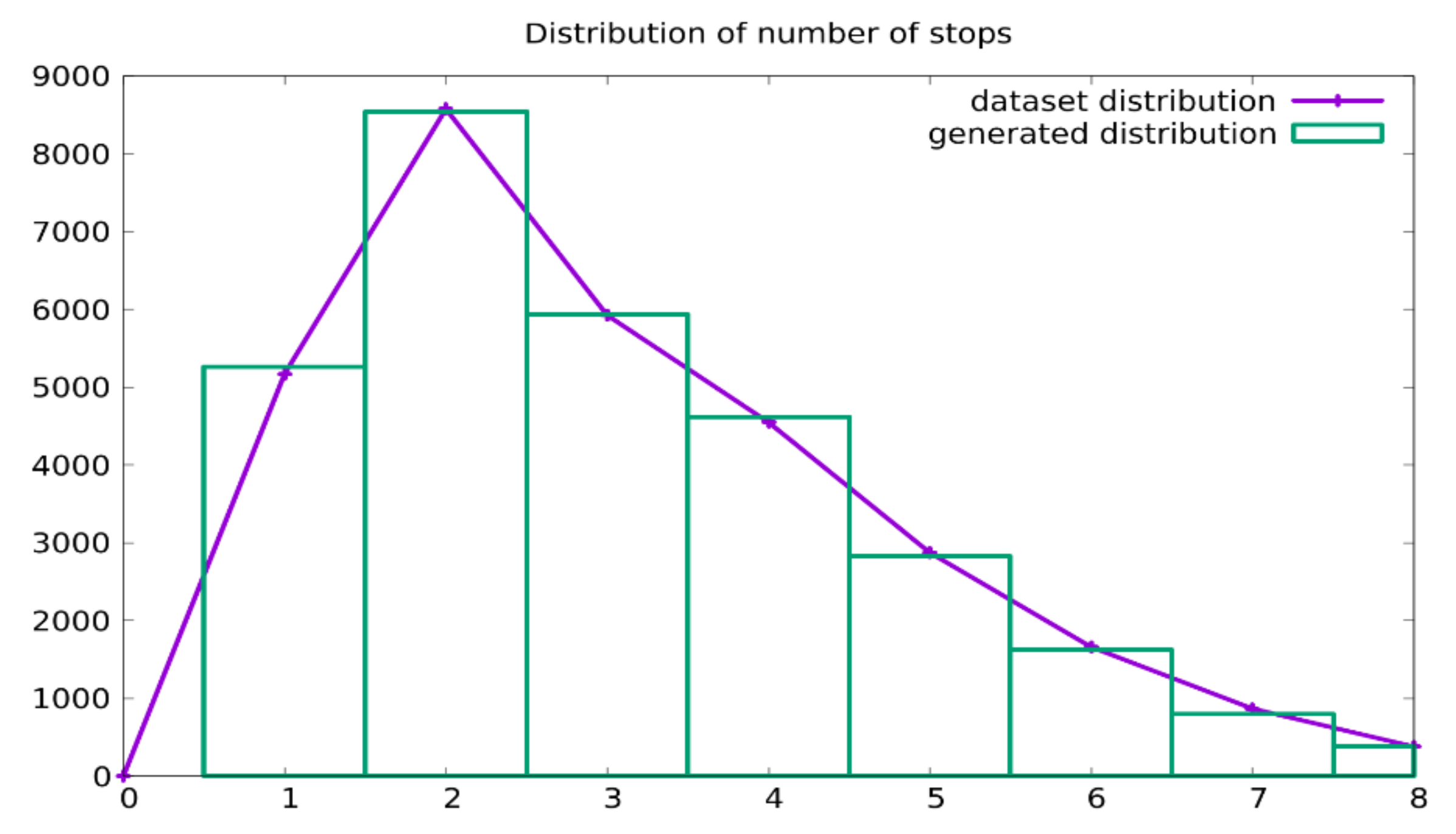
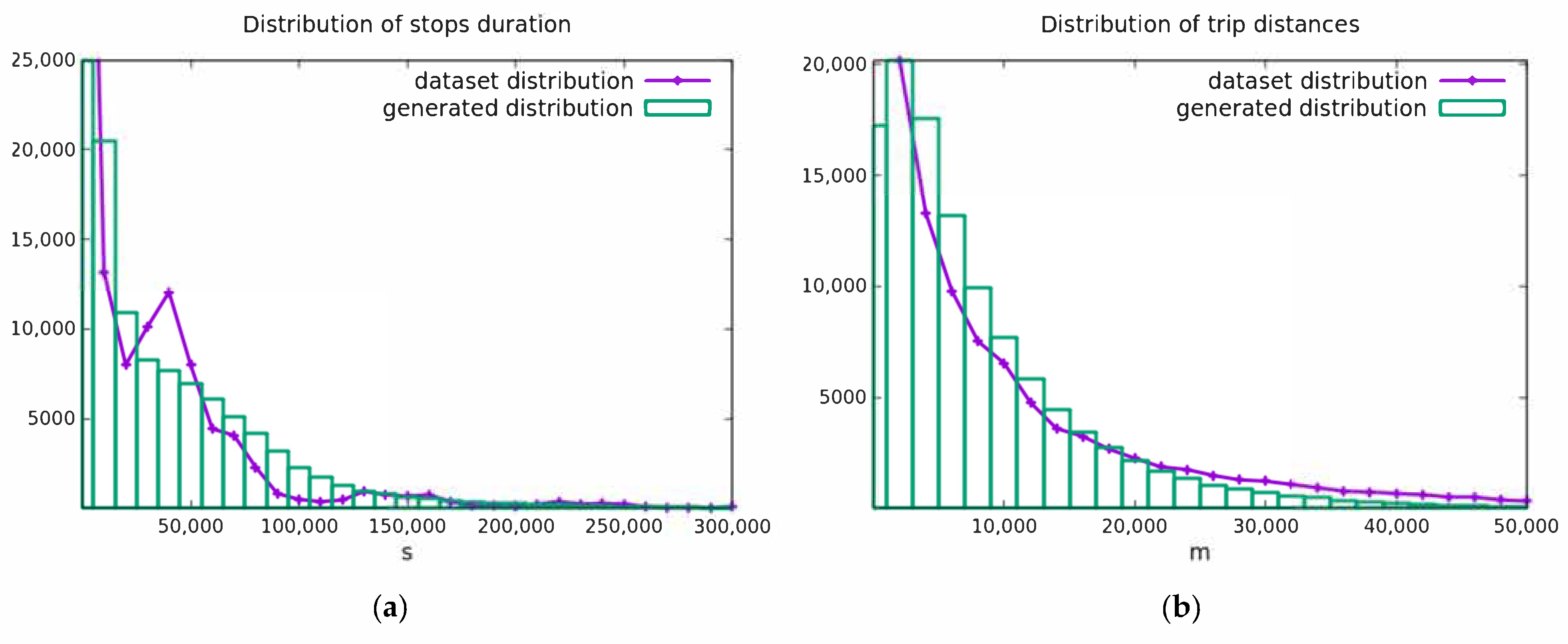
4.1. Generation
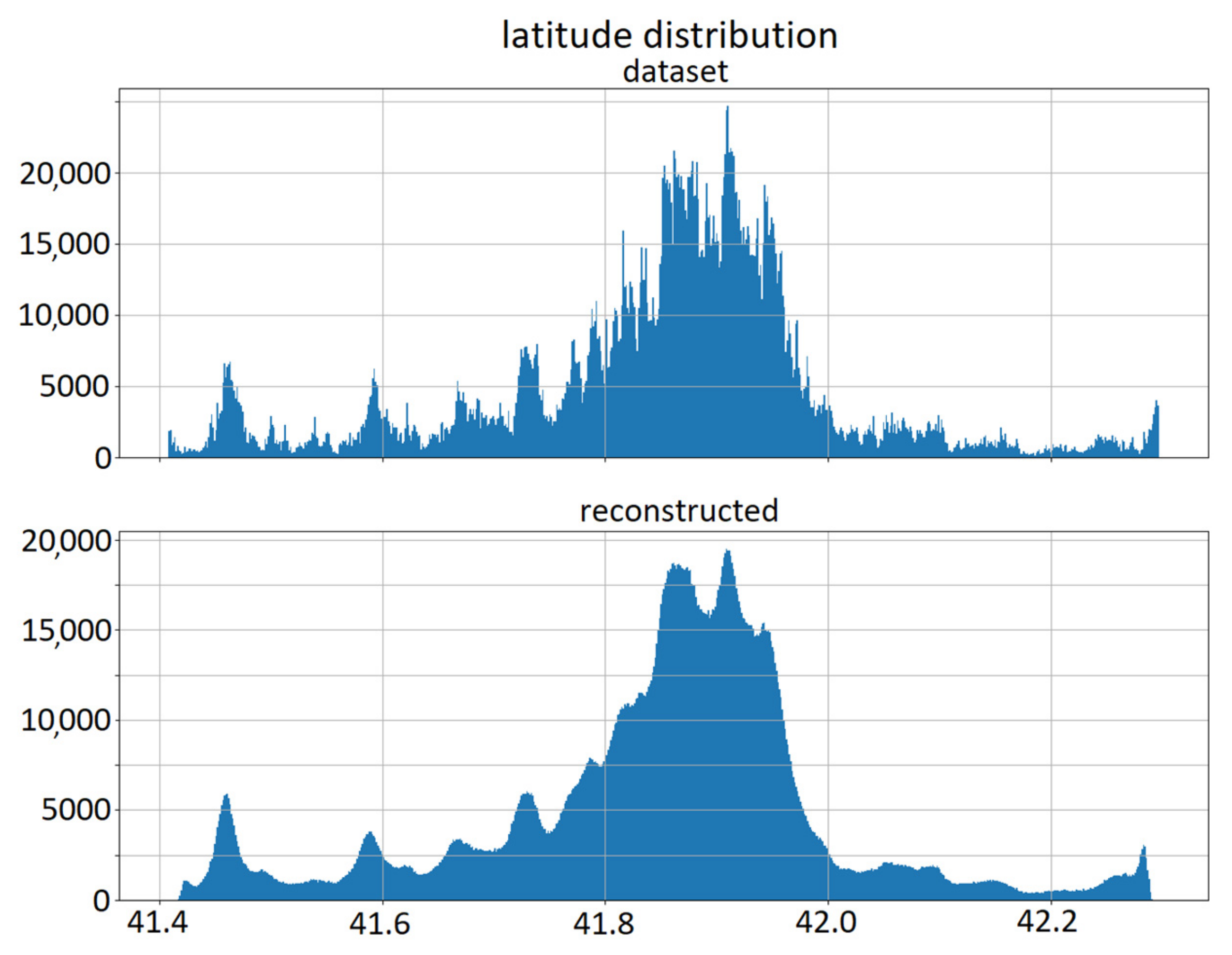
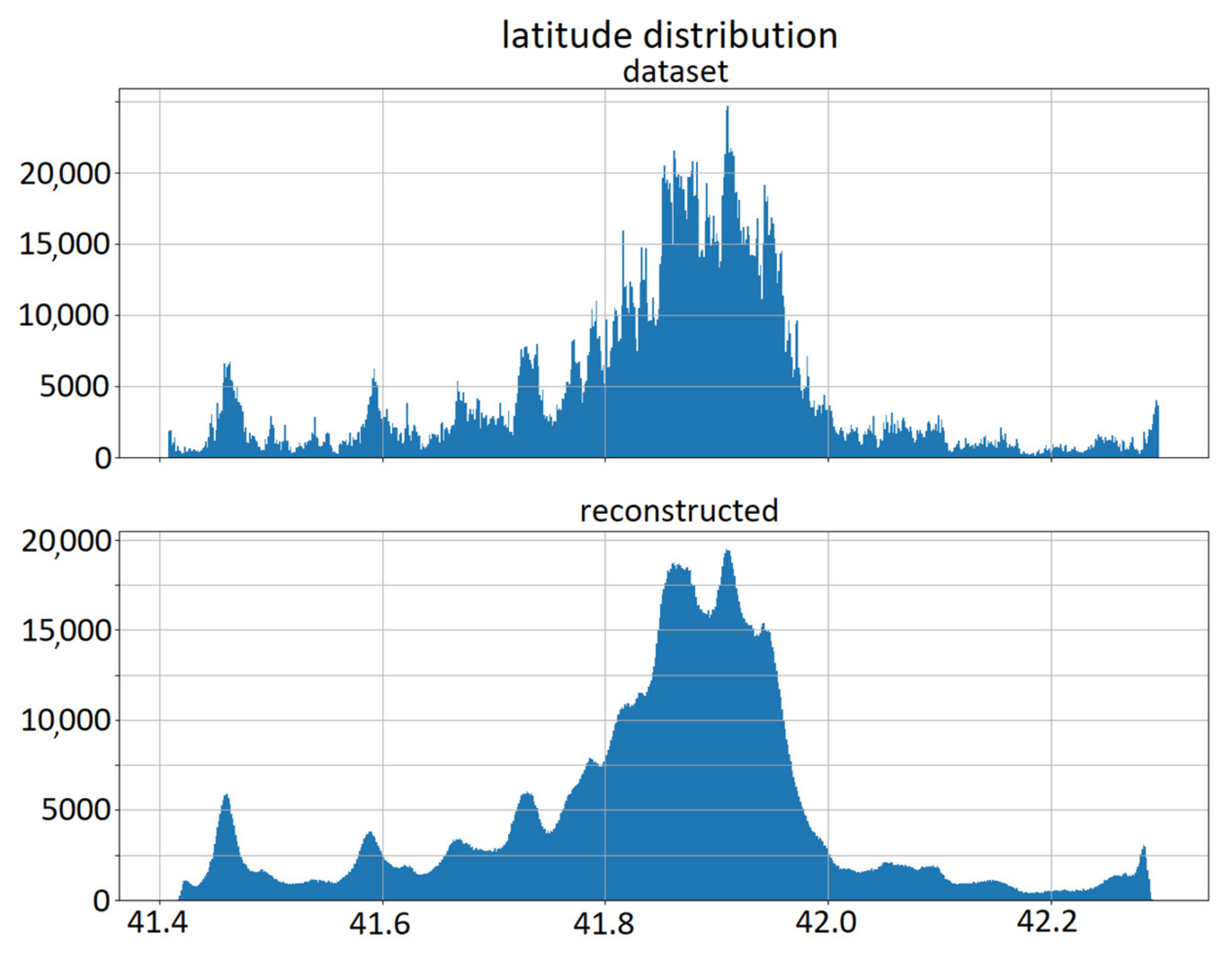
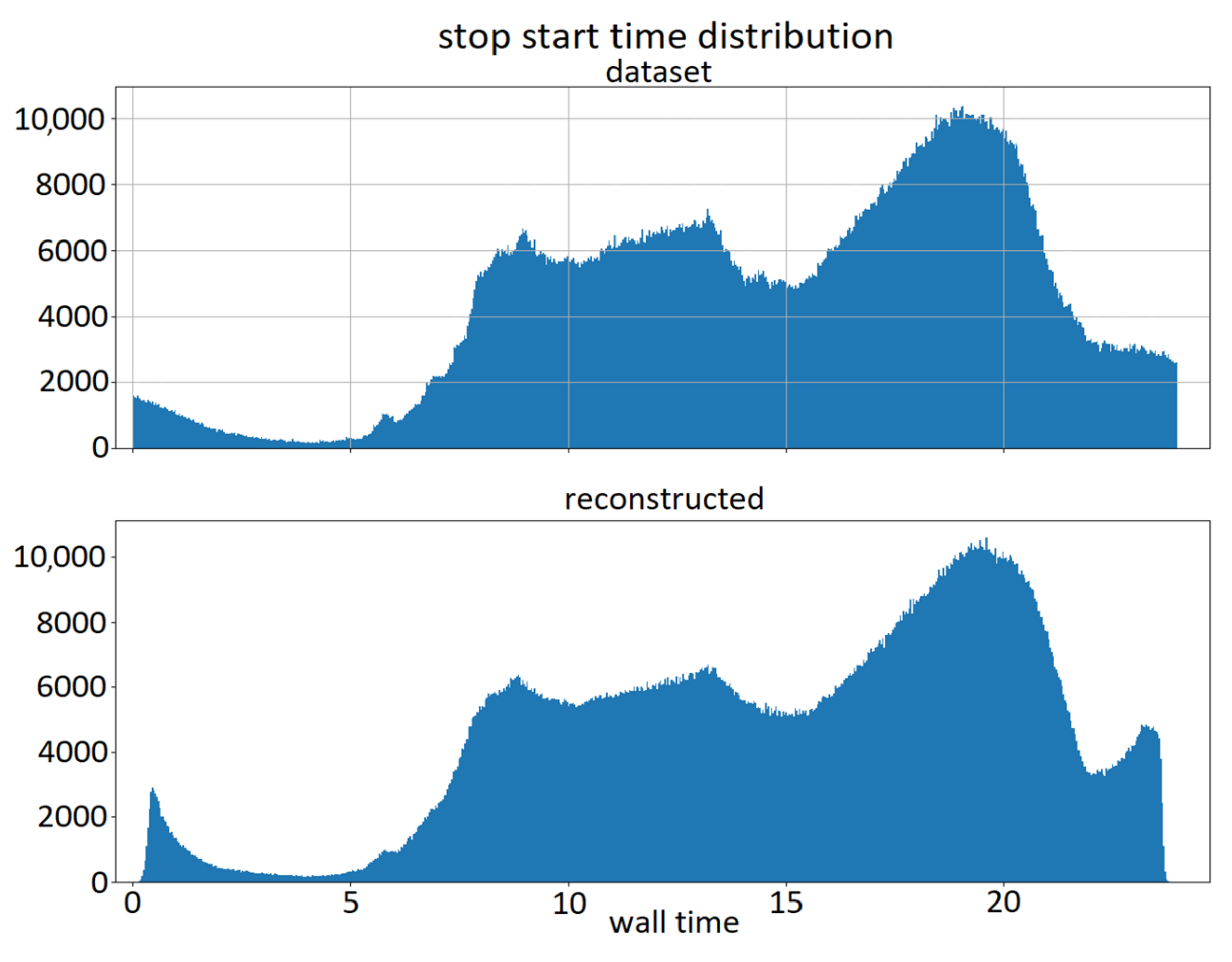
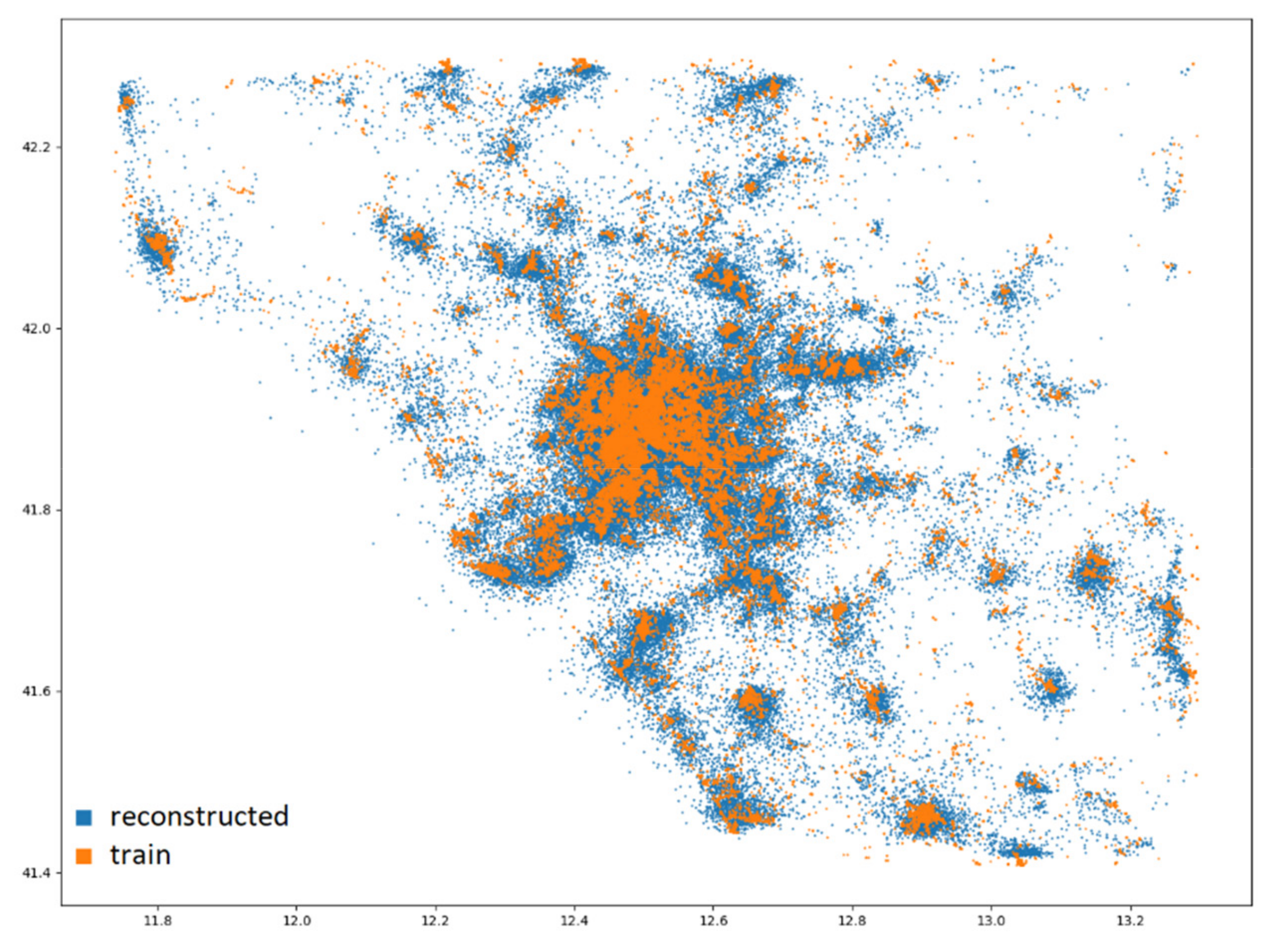
4.2. Reconstruction
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, Y.; Capra, L.; Wolfson, O.; Yang, H. Urban computing: Concepts, methodologies, and applications. ACM Trans. Intell. Sys. Technol. 2014, 5, 38. [Google Scholar] [CrossRef]
- Qiao, F.; Liu, T.; Sun, H.; Guo, L.; Chen, Y. Modelling and simulation of urban traffic systems: Present and future. Int. J. Cybern. Cyber Phys. Sys. 2021, 1, 1–32. [Google Scholar] [CrossRef]
- Chu, Z.; Cheng, L.; Chen, H. A Review of Activity-Based Travel Demand Modeling. In Proceedings of the Twelfth COTA International Conference of Transportation Professionals, Beijing, China, 3–6 August 2012; pp. 48–59. [Google Scholar] [CrossRef]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Qu, Z.; Blumm, N.; Barabasi, A.L. Limits of predictability in human mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alessandretti, L.; Sapiezynski, P.; Lehmann, S.; Baronchelli, A. Evidence for a Conserved Quantity in Human Mobility. Nat. Hum. Behav. 2018, 2, 485–491. [Google Scholar] [CrossRef] [PubMed]
- Keβler, C.; McKenzie, G. A geoprivacy manifesto. Trans. GIS 2018, 22, 3–19. [Google Scholar] [CrossRef] [Green Version]
- Harshvardhan, G.M.; Gourisaria, M.K.; Pandey, M.; Rautaray, S.S. A comprehensive survey and analysis of generative models in machine learning. Comput. Sci. Rev. 2020, 38, 100285. [Google Scholar] [CrossRef]
- Yin, M.; Sheehan, M.; Feygin, S.; Paiement, J.; Pozdnoukhov, A. A Generative Model of Urban Activities from Cellular Data. IEEE Trans. Intel. Transp. Sys. 2018, 19, 1682–1696. [Google Scholar] [CrossRef]
- Lin, Z.; Yin, M.; Feygin, S.; Sheehan, M.; Paiement, J.F.; Pozdnoukhov, A. Deep Generative Models of Urban Mobility. In Proceedings of the KDD’17, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Anda, C.; Ordonez Medina, S.A. Privacy-by-design generative models of urban mobility. Arb. Verk. Raumplan. 2019, 1454. [Google Scholar] [CrossRef]
- Pappalardo, L.; Simini, F. Data-driven generation of spatio-temporal routines in human mobility. Data Min. Knowl. Discov. 2018, 32, 787–829. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Huang, D.; Song, X.; Fan, Z.; Jiang, R.; Shibasaki, R.; Zhang, Y.; Wang, H.; Kato, Y. A Variational Autoencoder Based Generative Model of Urban Human Mobility. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 425–430. [Google Scholar] [CrossRef]
- Berke, A.; Doorley, R.; Larson, K.; Moro, E. Generating synthetic mobility data for a realistic population with RNNs to improve utility and privacy. arXiv 2022, arXiv:2201.01139. [Google Scholar] [CrossRef]
- Rao, J.; Gao, S.; Kang, Y.; Huang, Q. LSTM-TrajGAN: A Deep Learning Approach to Trajectory Privacy Protection. In Proceedings of the 11th International Conference on Geographic Information Science, GIScience (2021), Poznań, Poland, 27–30 September 2021. [CrossRef]
- Ouyang, K.; Shokri, R.; Rosenblum, D.S.; Yang, W. A Non-Parametric Generative Model for Human Trajectories. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, Stockholm, Sweden, 9–19 July 2018; pp. 3812–3817. [Google Scholar] [CrossRef] [Green Version]
- Chiesa, S.; Taraglio, S. Traffic modelling through a LSTM variational auto encoder approach: Preliminary results. In Computational Science and Its Applications—ICCSA 2021. Lecture Notes in Computer Science LNCS 12950, Proceedings of the ICSSA 2021, Cagliari, 13–16 September 2021; Gervasi, O., Murgante, B., Misra, S., Garau, C., Blečić, I., Taniar, D., Apduhan, B.O., Rocha, A.M.A.C., Tarantino, E., Torre, C.M., Eds.; Springer: Cham, Switzerland, 2021; pp. 598–606. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F. Deep Learning with Python; Manning Pub Co.: Shelter Island, NY, USA, 2018; Chapter 6. [Google Scholar]
- OCTO Telematics Italia s.r.l. Available online: https://www.octotelematics.com/it/home-it/ (accessed on 30 March 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Latitude | Longitude | Duration (s) | Start Time (h) | Day of Week | Trip Distance (m) | |
|---|---|---|---|---|---|---|
| 1 | 41.854031 | 12.497663 | 43,406.00 | 20.266 | 3 | 6035.0 |
| 2 | 41.844841 | 12.490471 | 16,362.00 | 8.433 | 4 | 1580.0 |
| 3 | 41.829877 | 12.510948 | 411.00 | 13.149 | 4 | 3606.0 |
| 4 | 41.853169 | 12.497894 | 4363.00 | 13.516 | 4 | 5553.0 |
| 5 | 41.852843 | 12.498169 | 57,320.99 | 14.933 | 4 | 4348.0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 |
| Variable | Generated Data | Reconstructed Data |
|---|---|---|
| Latitude | 4.44 × 10−4 | 2.03 × 10−4 |
| Longitude | 1.56 × 10−4 | 9.21 × 10−5 |
| Duration | 8.30 × 10−5 | 7.79 × 10−5 |
| Trip Distance | 3.46 × 10−3 | 2.68 × 10−3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chiesa, S.; Taraglio, S. Traffic Request Generation through a Variational Auto Encoder Approach. Computers 2022, 11, 71. https://doi.org/10.3390/computers11050071
Chiesa S, Taraglio S. Traffic Request Generation through a Variational Auto Encoder Approach. Computers. 2022; 11(5):71. https://doi.org/10.3390/computers11050071
Chicago/Turabian StyleChiesa, Stefano, and Sergio Taraglio. 2022. "Traffic Request Generation through a Variational Auto Encoder Approach" Computers 11, no. 5: 71. https://doi.org/10.3390/computers11050071
APA StyleChiesa, S., & Taraglio, S. (2022). Traffic Request Generation through a Variational Auto Encoder Approach. Computers, 11(5), 71. https://doi.org/10.3390/computers11050071