
Scalable Traffic Signal Controls Using Fog-Cloud Based Multiagent Reinforcement Learning




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
2.1. Reinforcement Learning
2.2. Graph Neural Networks
3. Methodology
DRL Model Architecture
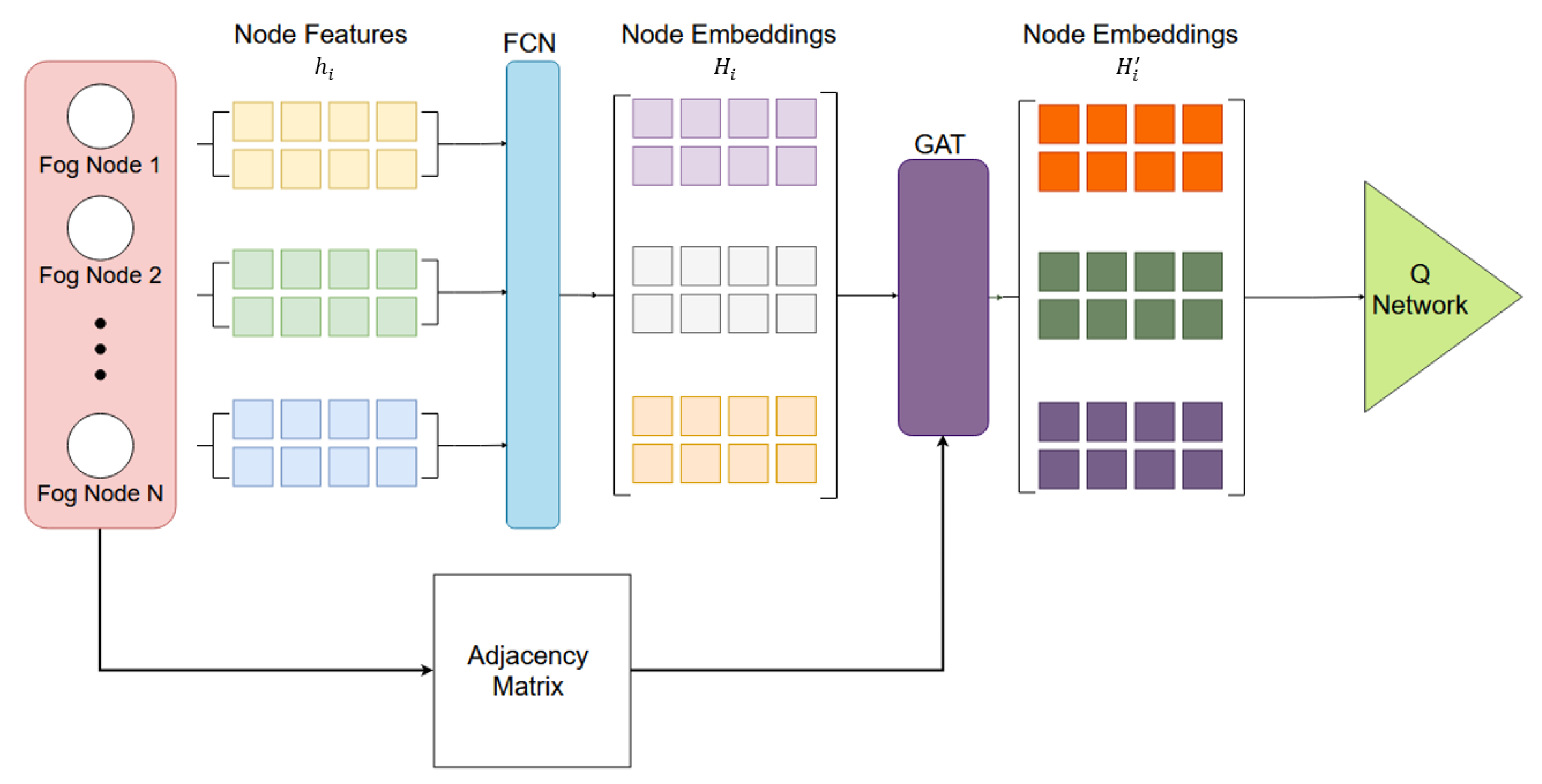
- FCN Encoder : Dense (32) + Dense (32)
- GAT Layer : GATConv (32)
- Q Network: Dense (32) + Dense (32) + Dense (64) + Dense (32)
- Output Layer: Dense (5)
4. Case Study
4.1. Network Descriptions

4.2. Markov Decision Process Settings
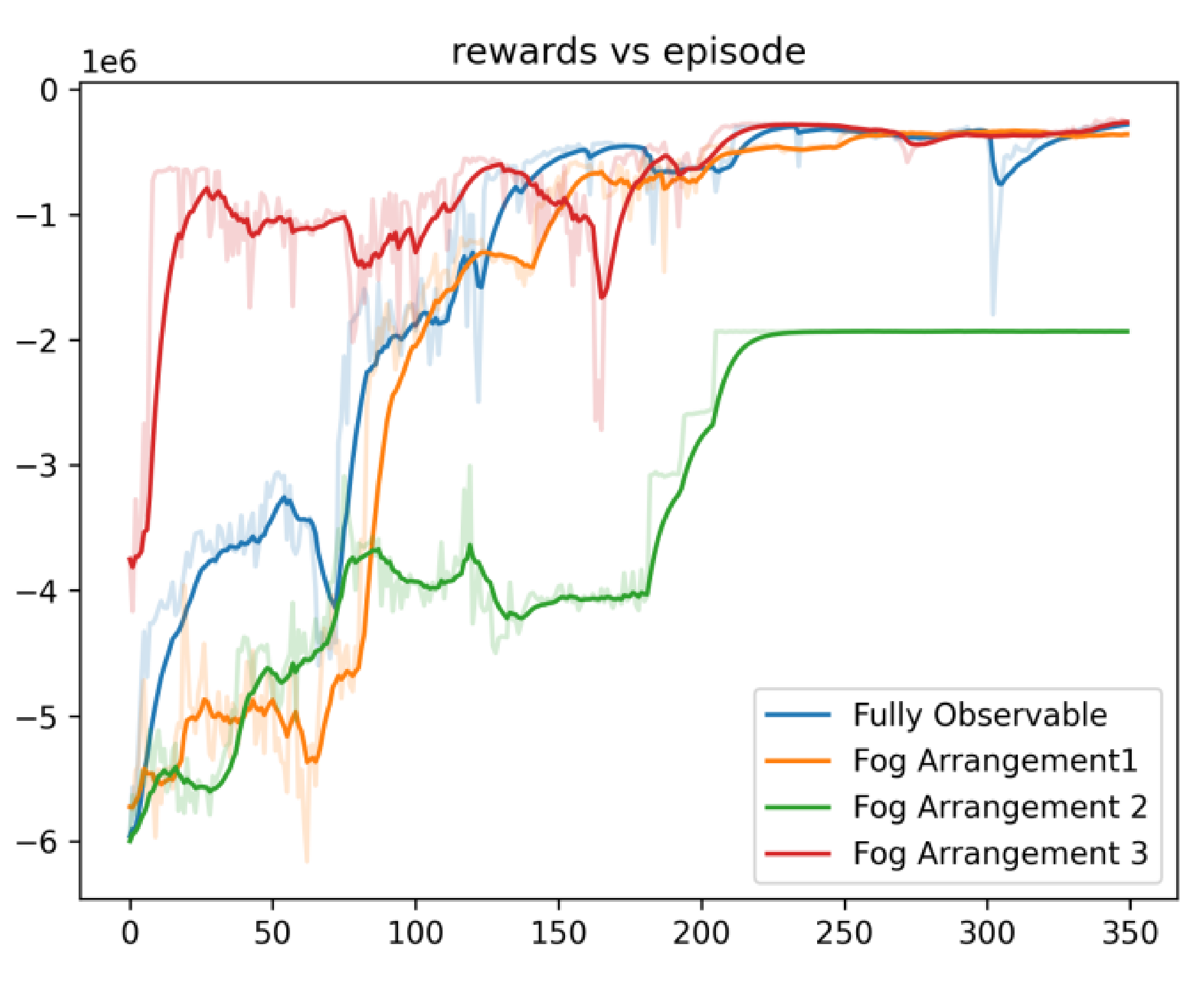
5. Results
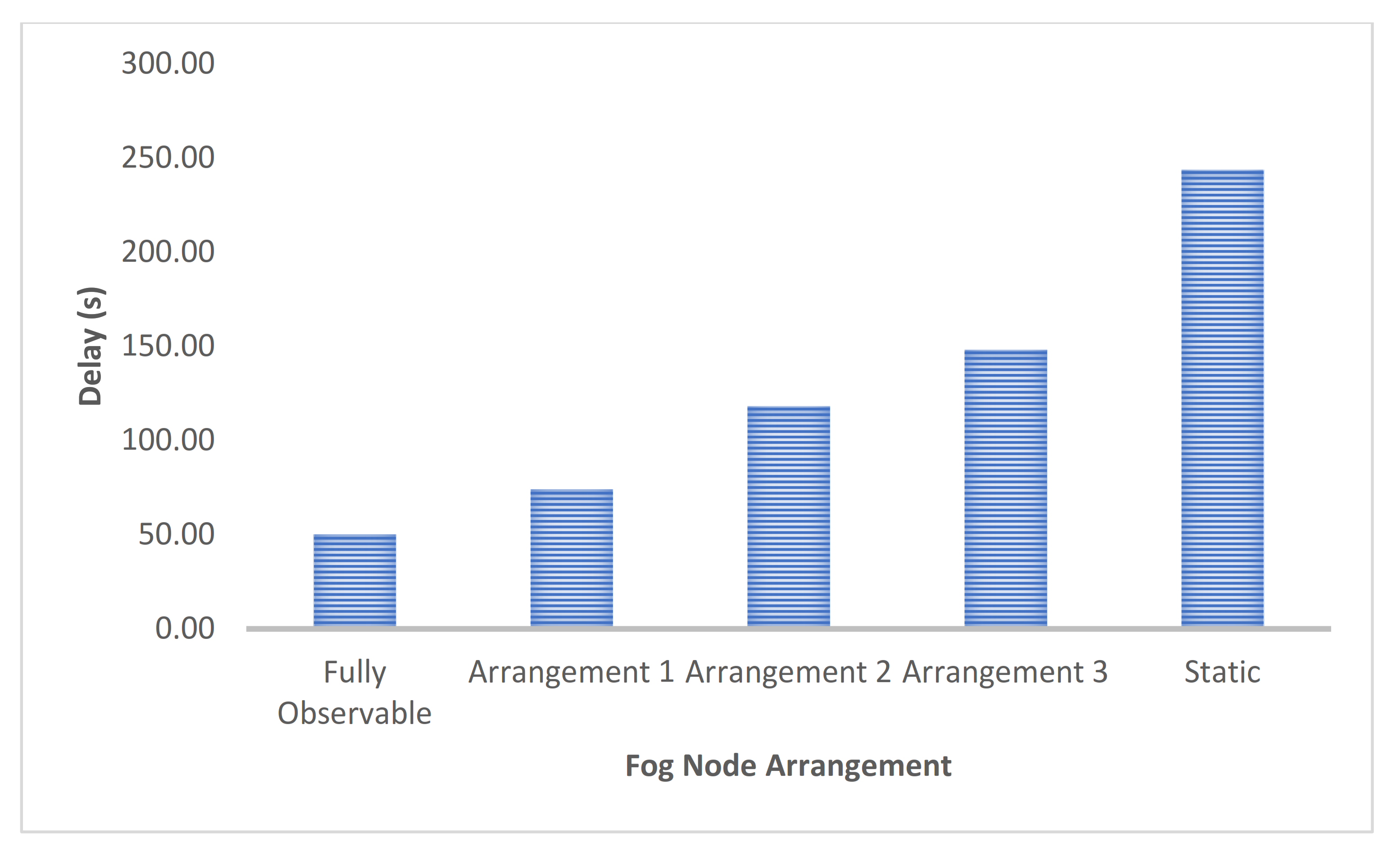
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- FHWA. Traffic Congestion and Reliability: Trends and Advanced Strategies for Congestion Mitigation. 2020. Available online: https://ops.fhwa.dot.gov/congestion_report/executive_summary.htm (accessed on 3 July 2021).
- Zhao, D.; Dai, Y.; Zhang, Z. Computational intelligence in urban traffic signal control: A survey. IEEE Trans. Syst. Man Cybern. Part C 2011, 42, 485–494. [Google Scholar] [CrossRef]
- Webster, F.V. Traffic Signal Settings; Road Research Technical Paper no. 39; H.M.S.O: London, UK, 1958. [Google Scholar]
- Koonce, P.; Rodegerdts, L. Traffic Signal Timing Manual; No. FHWA-HOP-08-024; Federal Highway Administration: Washigton, DC, USA, 2008. [Google Scholar]
- Ceylan, H.; Bell, M.G.H. Traffic signal timing optimisation based on genetic algorithm approach, including drivers’ routing. Transp. Res. Part B Methodol. 2004, 38, 329–342. [Google Scholar] [CrossRef]
- Guo, Q.; Li, L.; Ban, X.J. Urban traffic signal control with connected and automated vehicles: A survey. Transp. Res. Part C Emerg. Technol. 2019, 101, 313–334. [Google Scholar] [CrossRef]
- Wang, X.; Ke, L.; Qiao, Z.; Chai, X. Large-Scale Traffic Signal Control Using a Novel Multiagent Reinforcement Learning. IEEE Trans. Cybern. 2021, 51, 174–187. [Google Scholar] [CrossRef] [PubMed]
- Tesauro, G. Temporal difference learning and TD-Gammon. Commun. ACM 1995, 38, 58–68. [Google Scholar] [CrossRef]
- Lin, L.-J. Reinforcement Learning for Robots Using Neural Networks; Carnegie Mellon University: Pittsburgh PA, USA, 1992. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Wiering, M.A. Multi-agent reinforcement learning for traffic light control. In Machine Learning: Proceedings of the Seventeenth International Conference (ICML’2000); Morgan Kaufmann Publishers Inc: Stanford, CA, USA, 2000; pp. 1151–1158. [Google Scholar]
- Prashanth, L.A.; Bhatnagar, S. Reinforcement learning with function approximation for traffic signal control. IEEE Trans. Intell. Transp. Syst. 2010, 12, 412–421. [Google Scholar]
- Chu, T.; Wang, J.; Codeca, L.; Li, Z. Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1086–1095. [Google Scholar] [CrossRef] [Green Version]
- Vinitsky, E.; Parvate, K.; Kreidieh, A.; Wu, C.; Bayen, A. Lagrangian Control through Deep-RL: Applications to Bottleneck Decongestion. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, Proceedings, ITSC, 2018, Maui, HI, USA, 4–7 November 2018; Volume 2018, pp. 759–765. [Google Scholar]
- Ha, P.Y.J.; Chen, S.; Dong, J.; Du, R.; Li, Y.; Labi, S. Leveraging the capabilities of connected and autonomous vehicles and multi-agent reinforcement learning to mitigate highway bottleneck congestion. arXiv 2020, arXiv:2010.05436. [Google Scholar]
- Liu, D.; Yang, C. A deep reinforcement learning approach to proactive content pushing and recommendation for mobile users. IEEE Access 2019, 7, 83120–83136. [Google Scholar] [CrossRef]
- Dong, J.; Chen, S.; Li, Y.; Du, R.; Steinfeld, A.; Labi, S. Space-weighted information fusion using deep reinforcement learning: The context of tactical control of lane-changing autonomous vehicles and connectivity range assessment. Transp. Res. Part C Emerg. Technol. 2021, 128, 103192. [Google Scholar] [CrossRef]
- Du, R.; Chen, S.; Dong, J.; Ha PY, J.; Labi, S. GAQ-EBkSP: A DRL-based Urban Traffic Dynamic Rerouting Framework using Fog-Cloud Architecture. In Proceedings of the 2021 IEEE International Smart Cities Conference (ISC2), Manchester, UK, 7–10 September 2021; pp. 1–7. [Google Scholar]
- Li, L.; Lv, Y.; Wang, F.Y. Traffic signal timing via deep reinforcement learning. IEEE/CAA J. Autom. Sin. 2016, 3, 247–254. [Google Scholar]
- Songsang, K.; Zhou, B.; Fang, H.; Yang, P.; Yang, Z.; Yang, Q.; Guan, L.; Ji, Z. Real-time deep reinforcement learning based vehicle navigation. Appl. Soft Comput. 2020, 96, 106694. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Shapley, L.S. Stochastic games. Proc. Natl. Acad. Sci. USA 1953, 39, 1095–1100. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Xu, T.; Niu, X.; Tan, C.; Chen, E.; Xiong, H. STMARL: A Spatio-Temporal Multi-Agent Reinforcement Learning Approach for Cooperative Traffic Light Control. IEEE Trans. Mob. Comput. 2020. Available online: https://ieeexplore.ieee.org/document/9240060 (accessed on 3 July 2021).
- Wei, H.; Xu, N.; Zhang, H.; Zheng, G.; Zang, X.; Chen, C.; Zhang, W.; Zhu, Y.; Xu, K.; Li, Z. Colight: Learning network-level cooperation for traffic signal control. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1913–1922. [Google Scholar]
- Devailly, F.X.; Larocque, D.; Charlin, L. IG-RL: Inductive Graph Reinforcement Learning for Massive-Scale Traffic Signal Control. IEEE Trans Intell. Transp. Syst. 2021. Available online: https://ieeexplore.ieee.org/document/9405489 (accessed on 3 July 2021).
- Sikai, C.; Dong, J.; Ha, P.; Li, Y.; Labi, S. Graph neural network and reinforcement learning for multi-agent cooperative control of connected autonomous vehicles. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 838–857. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press Cambridge: Boston, MA, USA, 2016; Volume 1. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017—Conference Track Proceedings, Toulon, France, 24–26 April 2017. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; van den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the European Semantic Web Conference, Crete, Greece, 3–7 June 2018; pp. 593–607. [Google Scholar]
- Velicković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Krajzewicz, D.; Erdmann, J.; Behrisch, M.; Bieker, L. Recent Development and Applications of SUMO—Simulation of Urban MObility. Int. J. Adv. Syst. Meas. 2012, 5, 128–138. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ha, P.; Chen, S.; Du, R.; Labi, S. Scalable Traffic Signal Controls Using Fog-Cloud Based Multiagent Reinforcement Learning. Computers 2022, 11, 38. https://doi.org/10.3390/computers11030038
Ha P, Chen S, Du R, Labi S. Scalable Traffic Signal Controls Using Fog-Cloud Based Multiagent Reinforcement Learning. Computers. 2022; 11(3):38. https://doi.org/10.3390/computers11030038
Chicago/Turabian StyleHa, Paul (Young Joun), Sikai Chen, Runjia Du, and Samuel Labi. 2022. "Scalable Traffic Signal Controls Using Fog-Cloud Based Multiagent Reinforcement Learning" Computers 11, no. 3: 38. https://doi.org/10.3390/computers11030038
APA StyleHa, P., Chen, S., Du, R., & Labi, S. (2022). Scalable Traffic Signal Controls Using Fog-Cloud Based Multiagent Reinforcement Learning. Computers, 11(3), 38. https://doi.org/10.3390/computers11030038