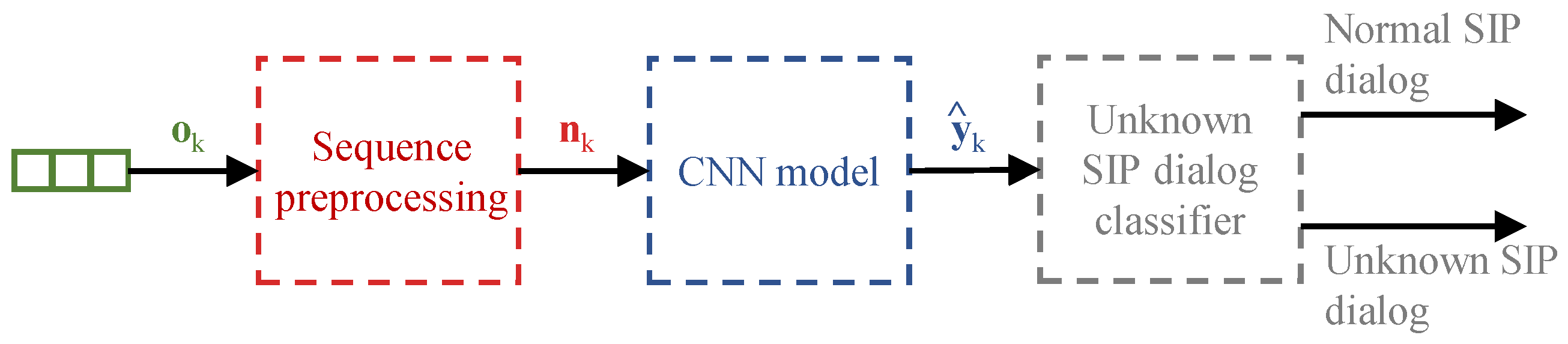
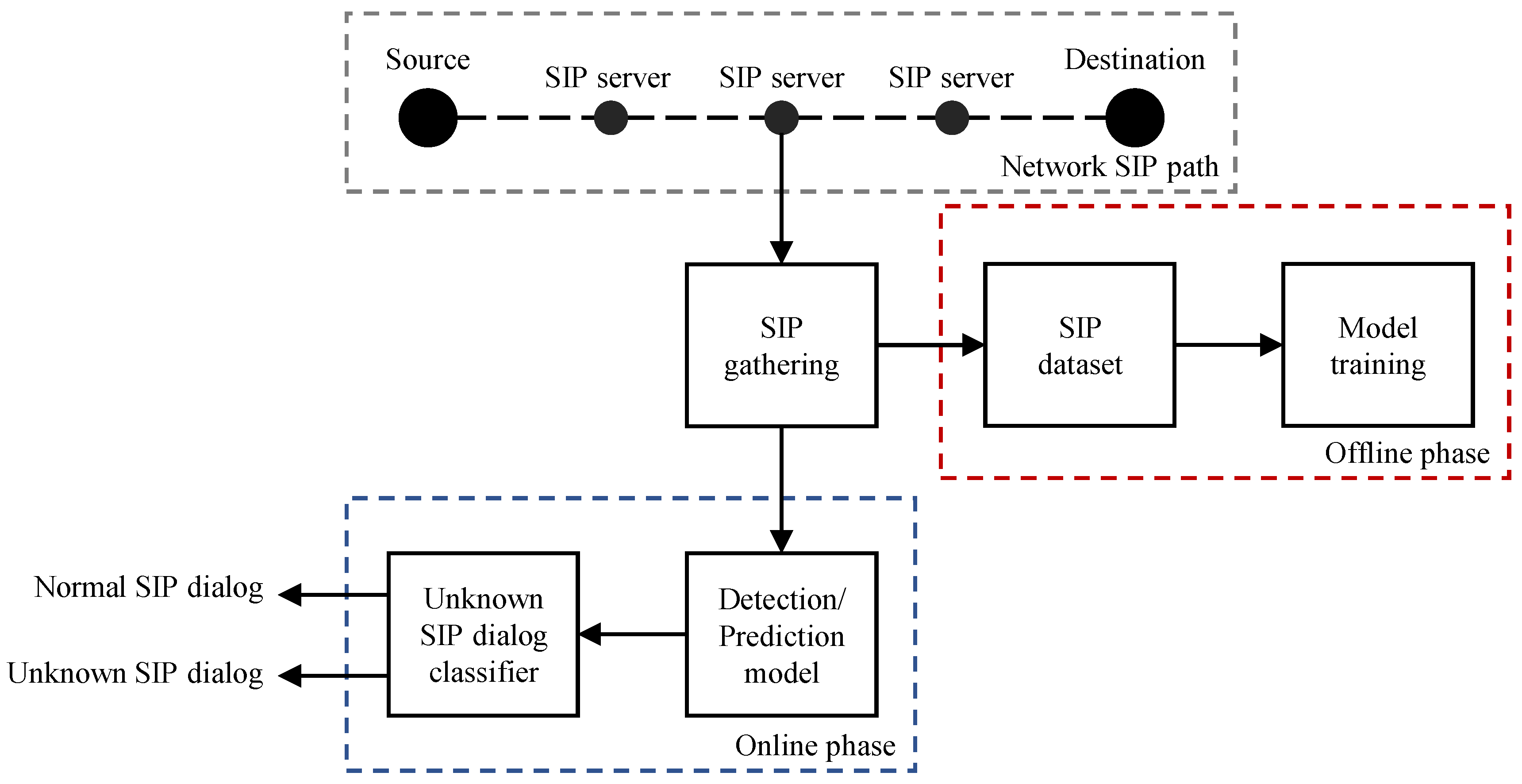
The methodology to detect abnormal SIP dialogs can be implemented locally at each SIP server or SIP peer. Additionally, the SIP peers or servers can also send the SIP messages to cloud services running the proposed methodology. The methodology is fed by the information collected in the consecutive SIP messages exchanged between the SIP Source and SIP Destination nodes, represented in the figure by the “SIP gathering” block. Specifically, the “SIP gathering” block is responsible to organize the multiple SIP messages into a SIP dataset that is used for training purposes in an offline manner. The block model “Model training” implements the training of the neural networks and the computation of the abnormal classifiers’ thresholds. Additionally, the “SIP gathering” block also feeds the SIP messages processed in the SIP path to the “Detection/Prediction model” block. The “Detection/Prediction model” block implements the neural network models trained offline and provides the input to the abnormal SIP dialogs classifiers represented in the figure by the block “Unknown SIP dialog classifier”.
3.1. CNN Model
Before introducing the proposed model, we summarize the notation used in the paper in
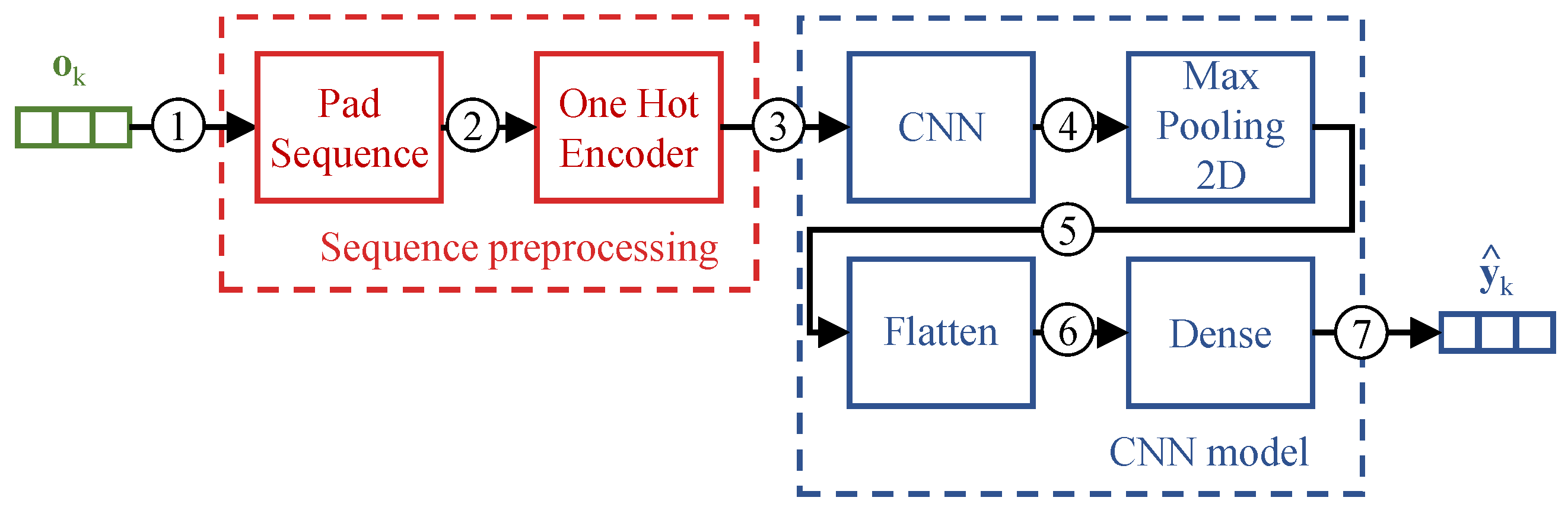
Table 2. To perform the detection and prediction of a SIP dialog identifier we adopted the CNN model illustrated in
Figure 3, comprising the CNN, Max Pooling, Flatten, and Dense layers.
Although the CNNs were not originally designed to process temporal sequences as opposed to the Long Short-Term Memory (LSTM) Recurrent Neural Networks (RNNs) adopted in [
7], the CNNs can also be trained to recognize a specific SIP dialog.
Before introducing the model we assume that it can be adopted by the SIP user agents or by the SIP servers traversed by the SIP messages. The first concept to be introduced is the SIP message . SIP messages are the atomic unit exchanged by the SIP peers to establish, maintain, update, and terminate a signaling session.
Definition 1. A SIP message carried in a SIP packet and denoted by , , is a SIP request or SIP response of a specific type. The variable M denotes the total number of unique SIP requests and responses.
The SIP protocol relies on Request and Response SIP messages. A SIP message can be formed by either a numerical code representing the type of the SIP response or a text field indicating the type of the SIP request. However, to use the SIP message as an input we need to encode each SIP message, since the CNN model can only process numerical values. The encoding process is performed using the One Hot Encoder algorithm [
21] to transform each SIP message
into a unique Boolean vector orthogonal to the others.
Definition 2. An encoded SIP message is represented by a Boolean vector with length that univocally identifies the type of the SIP message , i.e., .
All interactions of a SIP session are implemented through SIP messages, which create different transactions. A SIP session for a specific purpose (e.g., a voice call) is composed of multiple SIP messages. The set of all messages exchanged during the session forms the SIP dialog. A SIP dialog is completed when the multimedia session formed by the multiple transactions is terminated.
Definition 3. A SIP dialogdenoted by is formed by a sequence of consecutive SIP messages , where j represents the position of the SIP message in the dialog sequence. The length of the SIP dialog is represented by . The SIP messages forming the SIP dialog contain the same Call ID string as well as the sender and receiver addresses in the packet’s header.
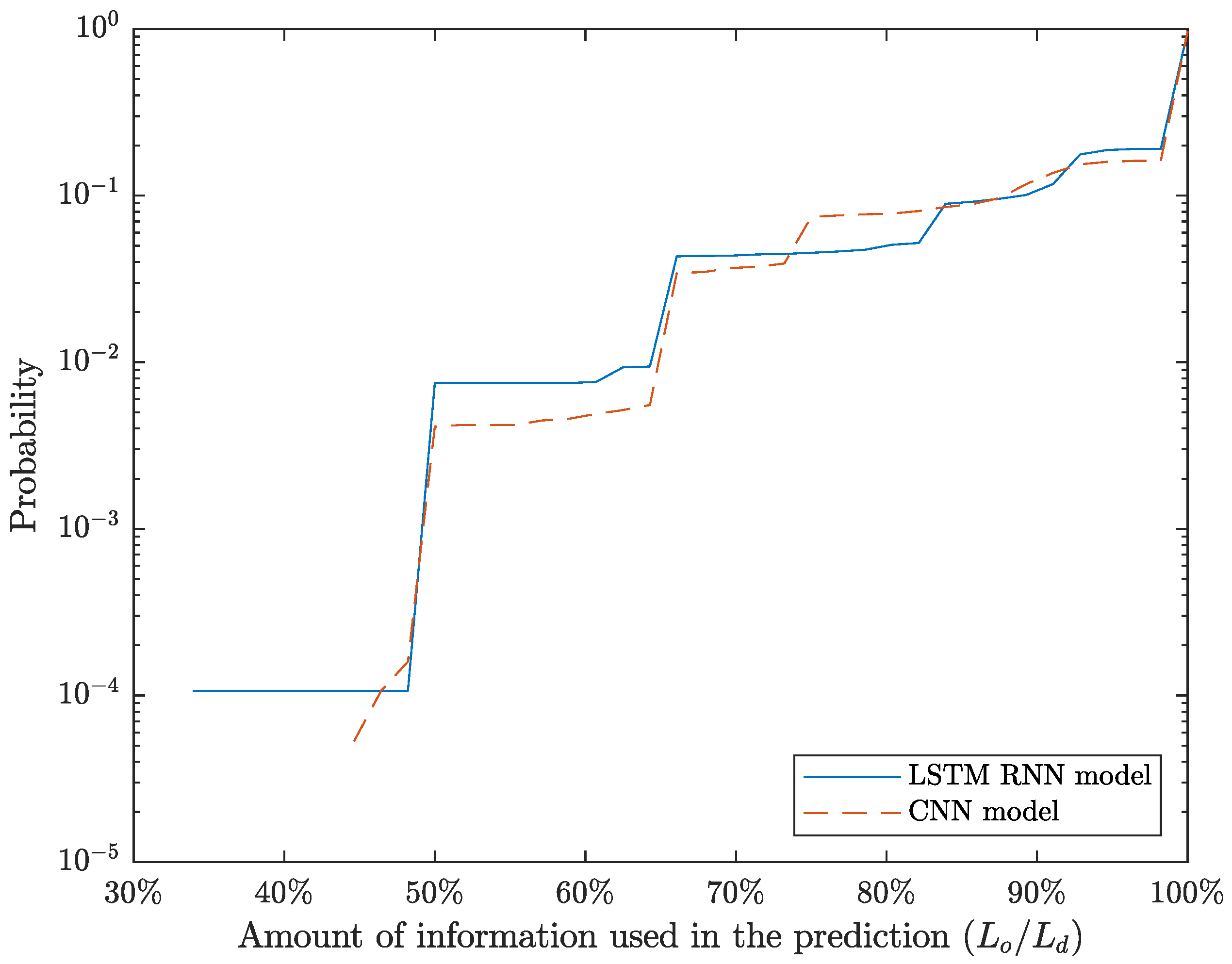
Although a SIP dialog is only defined when all SIP messages are exchanged, we assume that the model can estimate the dialog when only part of the SIP dialogs’ messages has been exchanged. Therefore, instead of considering only sequences with length , the model can process their subsequences, i.e., . Thus, depending on the length of the observation, the CNN model is either predicting () or detecting () a SIP dialog identifier.
Definition 4. An observationk is a sequence of consecutive encoded SIP messages denoted as , where represents the observation length. To describe the consecutive relation of the messages, each encoded SIP message is represented by , . The SIP messages in the observation constitute either a sub or complete dialog and, consequently, they share the same SIP Call ID.
The observations can have different lengths (), being transformed into a fixed-length stuffed sequence defined as follows.
Definition 5. A pad sequence is formed for each observation , by adding n zeros at the end of the observation , i.e., . The length of the pad sequences is denoted by , where ,.
So far, we have considered that a padding symbol is added to each . Besides the encoding of each SIP message, the padding symbols are also encoded according to Definition 2. Consequently, the encoded SIP message has length , considering all types of SIP messages (M) and the zero-padding symbol.
Next, we describe the input and output state spaces, which are created during the training stage of the CNN model. The state spaces are then used in the prediction/detection stages to map the SIP dialogs with their correspondent identifier.
Definition 6. The input state space of the supervised learning implemented through the CNN is the set of padded sequences , with learnt in the model’s training stage.
Definition 7. The set represents the output state spaceof the neural network, where N denotes the number of unique SIP dialogs in the training dataset and, the identifier of SIP dialog .
In the detection stage, the CNN model can compute the most likely SIP dialog identifier for a given observed sequence, which can be viewed as a regression problem
. The estimated SIP dialog identifier
is obtained through the estimate function
which is defined by interactively computing the weights of the CNN model (
) during the training period, so that the input and output state spaces are correctly mapped. The steps followed by the CNN model during the prediction/detection of a SIP dialog identifier are identified in
Table 3.
Knowing that the field of deep learning is focused on different techniques and model architectures that are hard to compare in a formal way (e.g., regularization, latent space representation, efficient loss functions, gradient-based optimization, etc.), we highlight that the deep learning models used in our work are not a novelty per see and the focus of our work is not on innovative learning models but on their use to derive the classifiers proposed in
Section 3.2. In this way, the proposed CNN topology is compared against an LSTM topology proposed in [
7].
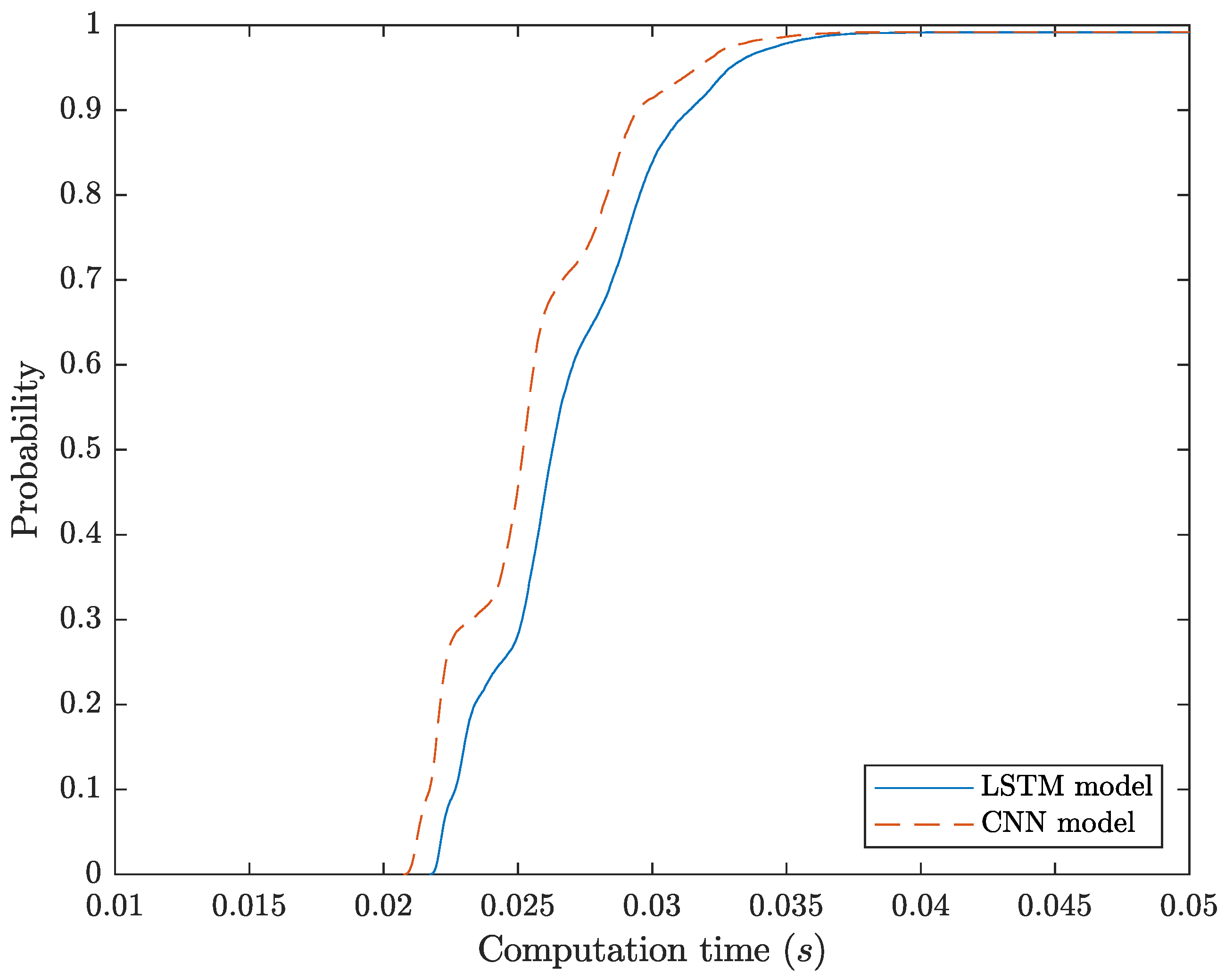
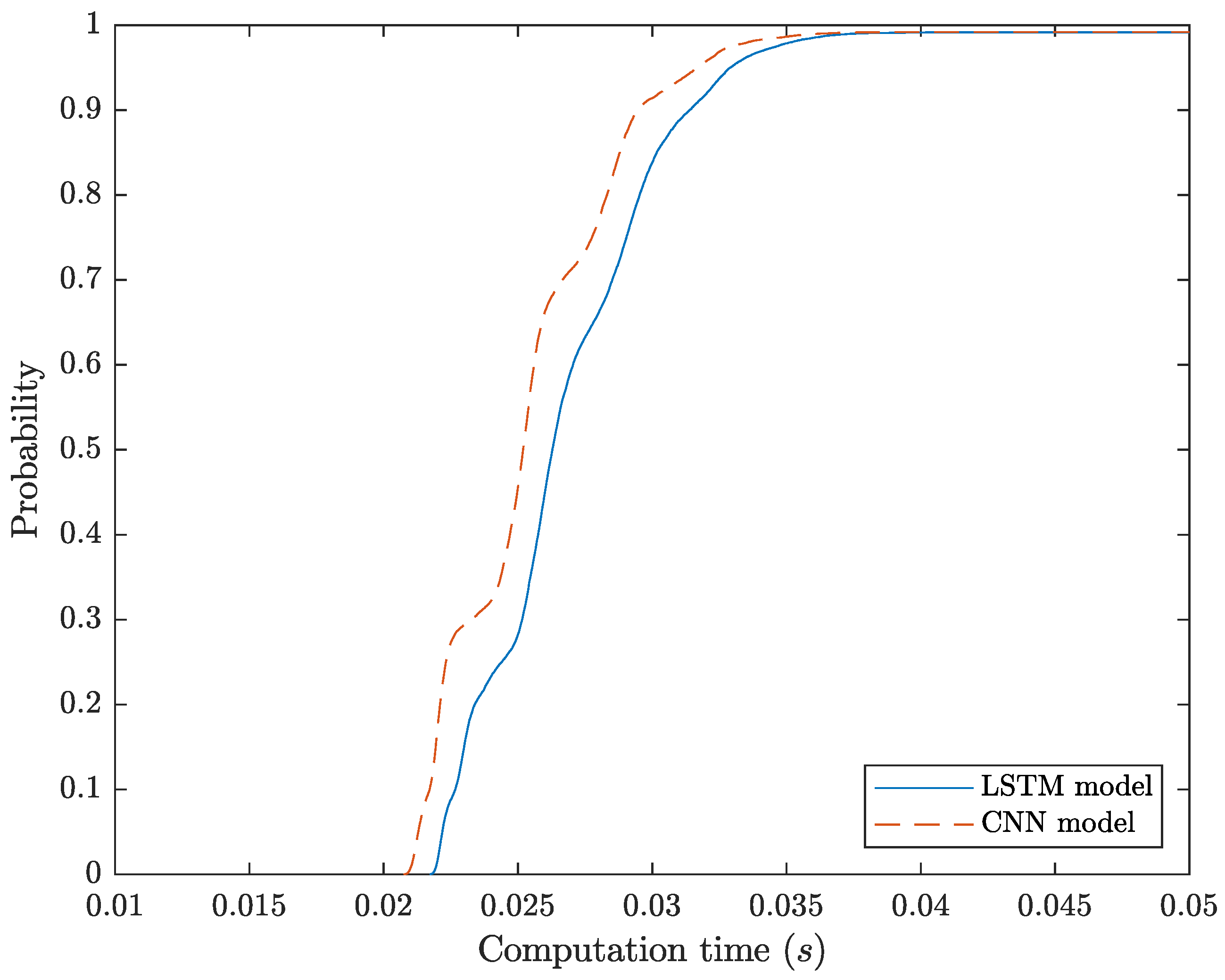
Table 4 and
Table 5 describe the parameters adopted in the CNN and LSTM models, respectively. We highlight that more complex models were also evaluated in our work; however, we did not consider them as a solution because they achieved similar classification performance results but have higher computation times.
3.2. Unknown SIP Dialogs’ Classifiers
Although the CNN model identifies the most likely SIP dialog identifier given an observed sequence of SIP messages, , we cannot assume that the SIP dialog identifier is always correctly detected. An example of a misdetection can be observed whenever the CNN model detects/predicts the identifier of an unknown observed sequence, i.e., a sequence not considered in the input and output state spaces during the CNN training stage. Thus, two classifiers were developed to distinguish between unknown and trained/known SIP dialogs. The classification is performed considering the output vector from the CNN model .
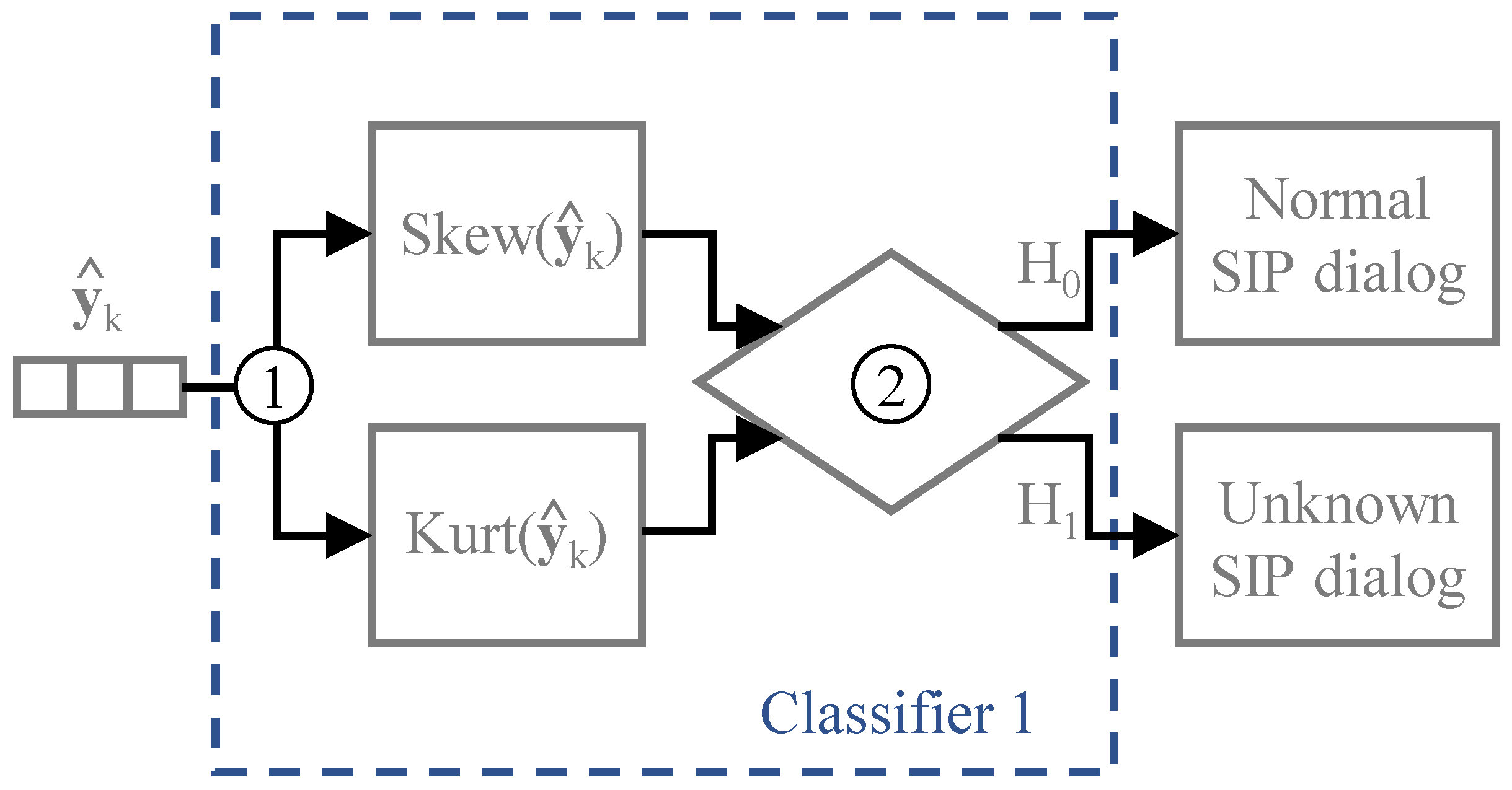
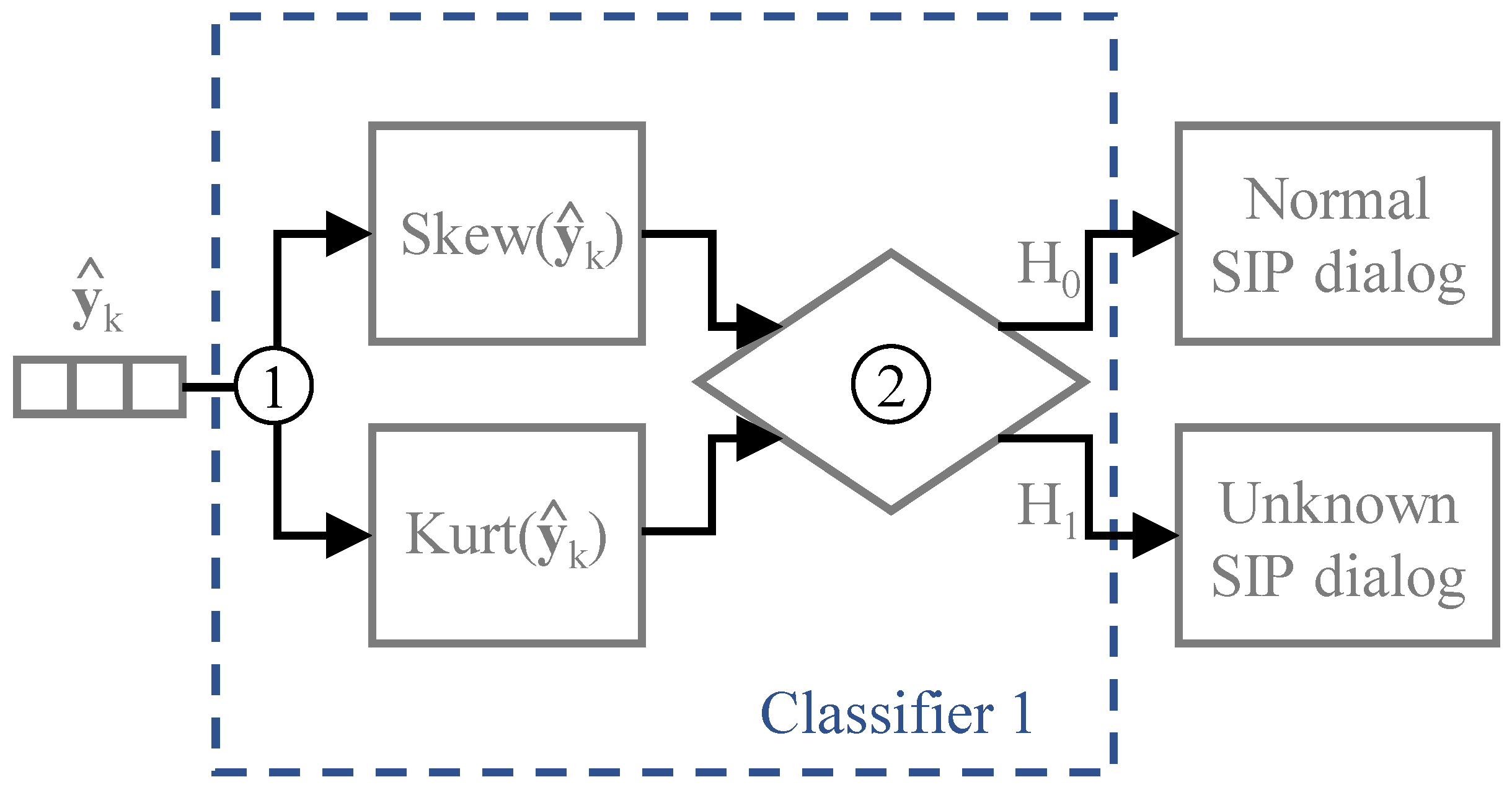
In the first classifier, proposed in [
7], the detection of unknown SIP dialogs is based on statistical information computed from the output vectors
of the neural network, particularly the skewness and kurtosis standardized moments. Therefore, the first step to be taken is to compute the skewness and kurtosis standardized moments, i.e.,
and
. Then, in the second step the classifier evaluates the statistical information collected from
and classifies the SIP dialog as already trained/known dialog (hypothesis
) or unknown dialog (hypothesis
). The abnormal SIP dialogs are included in the unknown dialogs, and only a further analysis of all unknown SIP dialogs allows the evaluation of its vulnerability level.
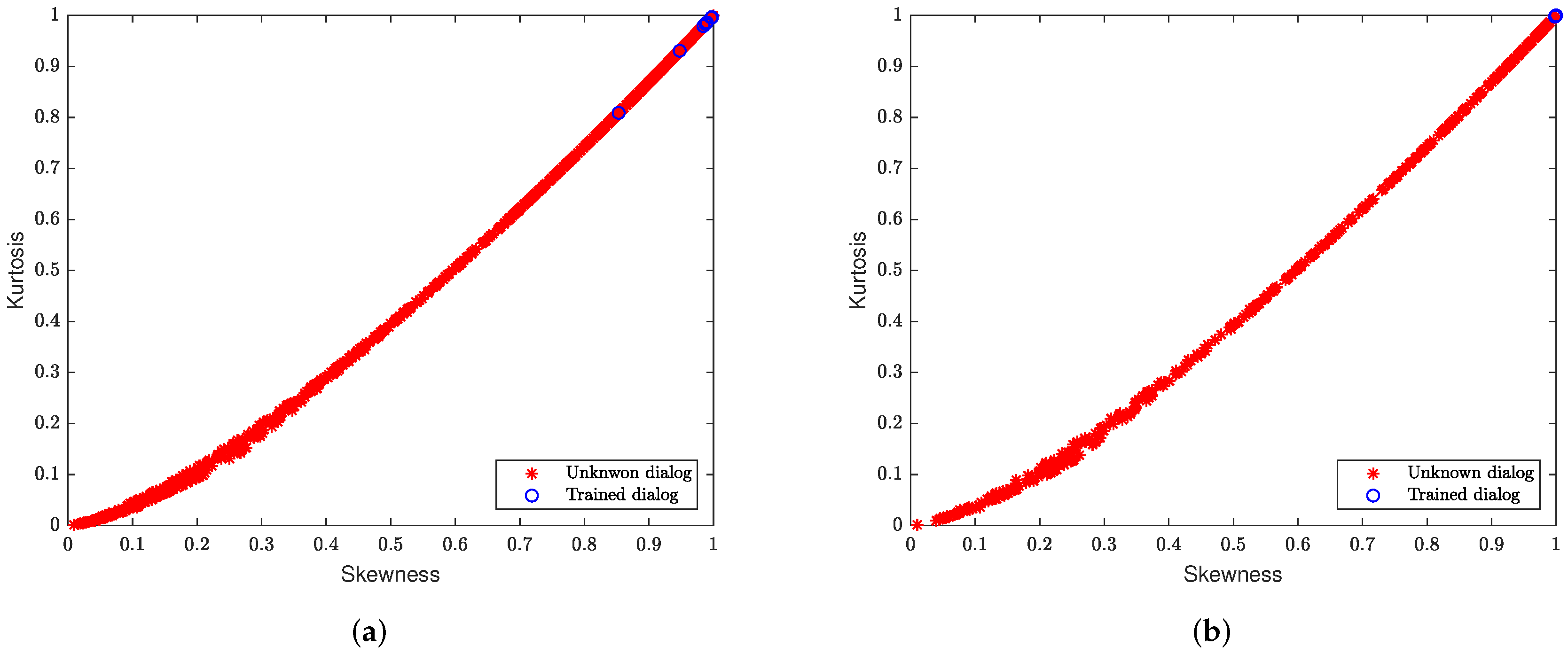
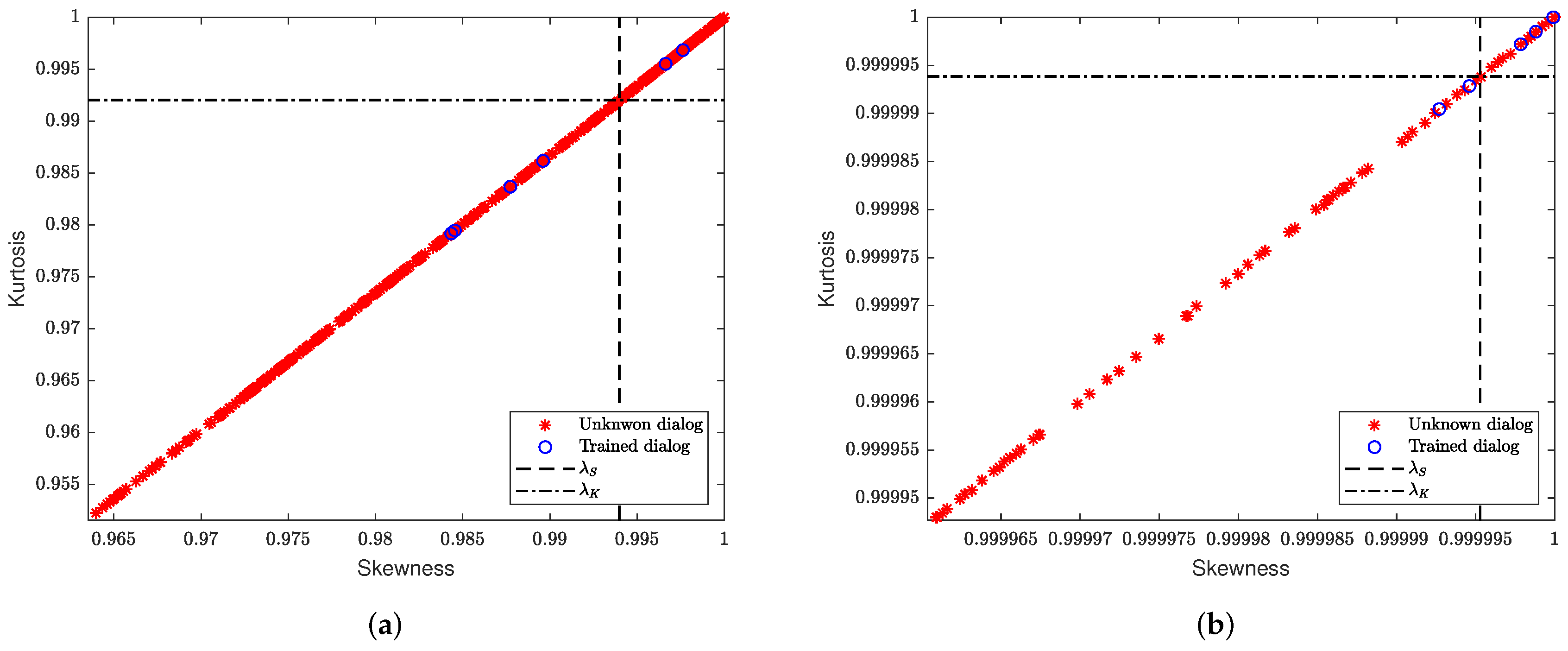
The statistical information of the trained dialogs is used to classify the SIP dialogs observed in real-time. The conceptual model of the first classifier and the steps needed to classify each dialog are illustrated in
Figure 4. The classifier evaluates if the skewness and kurtosis of neural network outputs of the trained dialogs are above certain threshold values, given by
and
, respectively. The variables
,
,
, and
denote the average
and variance
of the skewness or kurtosis central standardized of the trained dialogs. The hypotheses tested in the second step are written as
where
represents the case when an observed SIP dialog is classified as normal and
represents the condition to classify it as unknown. Note that the classification is computed through the comparison of the skewness and kurtosis computed from the outputs of the trained neural model for the observed SIP dialog,
and
with the statistics of the trained SIP dialogs,
and
.
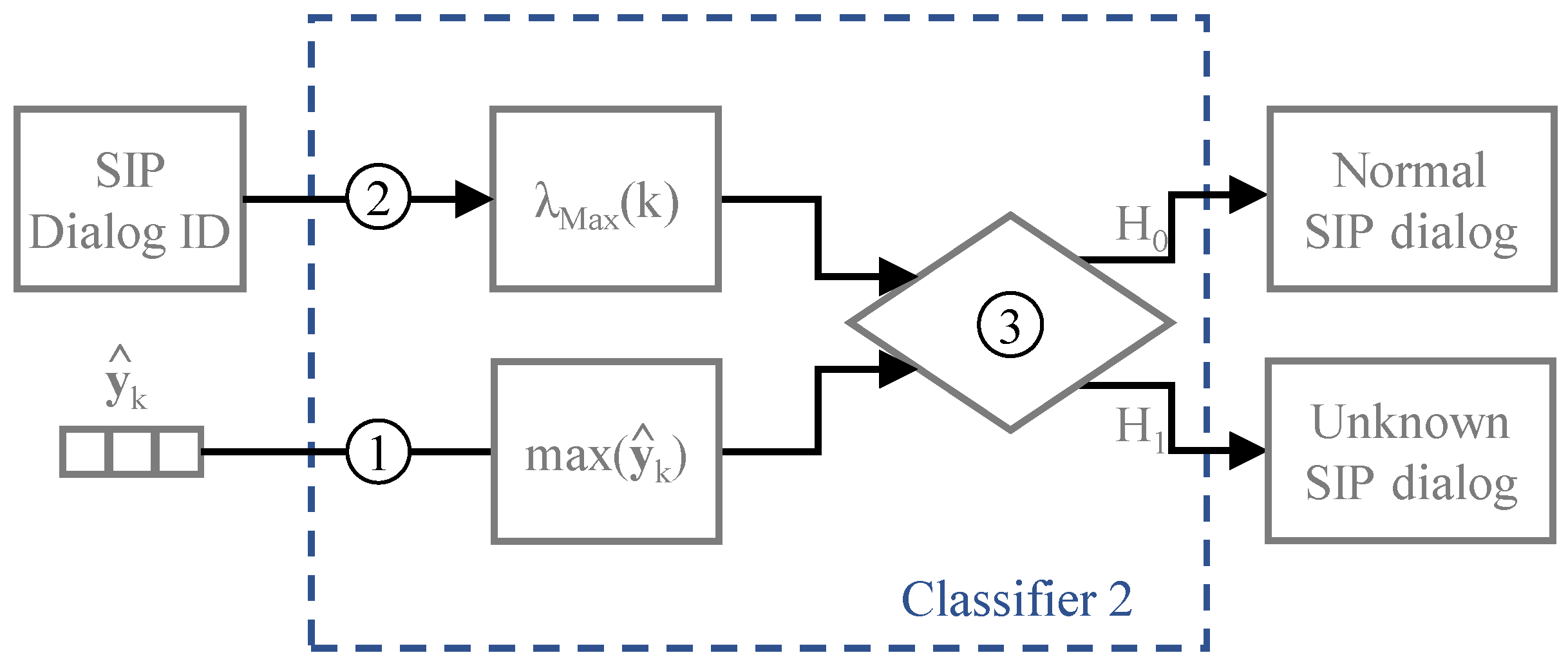
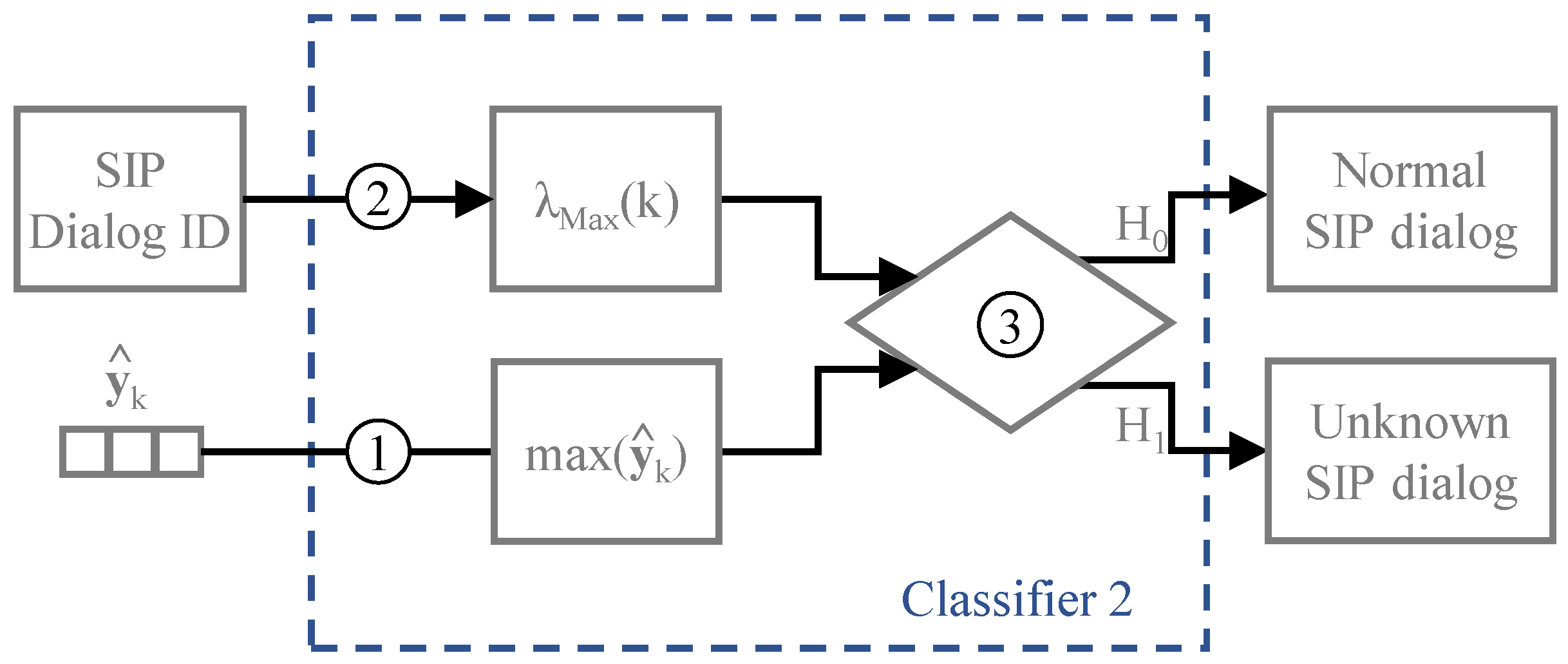
Rather than computing the standardized moments of the set of features, the second classifier detects possible unknown dialogs by comparing the output inferred by the CNN model
with the outputs from the SIP dialogs previously trained. Specifically, whenever an observed SIP dialog is detected, the maximum output-based classifier compares the maximum value of the CNN output vector
with an average threshold value
computed with the trained SIP dialogs. The threshold value
represents the average of the maximum output value from each SIP dialog labelled as trained dialog. However, the classifier’s threshold is not computed based on the average of the maximum output of all trained dialogs. Instead, we compute
N average thresholds, once per unique SIP dialog as represented in the vector of thresholds
, where
denotes the number of occurrences of dialog
in the training subdataset. Therefore, the classifier compares the maximum value of the predicted SIP dialog identifier
with the corresponding threshold value
. The decision between a trained dialog (hypothesis
) or an unknown dialog (hypothesis
) is written as
The conceptual model for the maximum output-based classifier is described in
Figure 5. Regarding the steps represented in the conceptual model, in the first step, the classifier computes the maximum value of the neural network output. Then, in the second step, the threshold value corresponding to the detected SIP dialog identifier is returned from
. Finally, with the coefficients assigned, the classifier evaluates which of the hypotheses holds true.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}