
Arbitrarily Parallelizable Code: A Model of Computation Evaluated on a Message-Passing Many-Core System



Abstract
1. Introduction
- Introduces Asynchronous Graph Programming (AGP), a programming paradigm based on dynamic asynchronous graphs. A graph represents the potential execution of a program, expressing it as a set of data dependencies, merges between branches, and graph-expansion rules. In order-theoretic mathematics, AGP is a series-parallel partial order. We show this by expressing programs in such a manner that it is possible to partition graphs (parallelize the program) efficiently using knowledge of the target architecture and graph structure to minimize dependencies. These properties hold at runtime, allowing for seamless re-application.
- Formally describes its model of computation for programs expressed as they are in the paradigm. AGP provides a mechanism for evaluating programs across N processing elements in parallel, guaranteeing semantic correctness; e.g., the MoC guarantees that sequential events are processed in the correct order, regardless of the parallel allocation, while performing a best-effort first come, first served evaluation across events of arbitrary order.
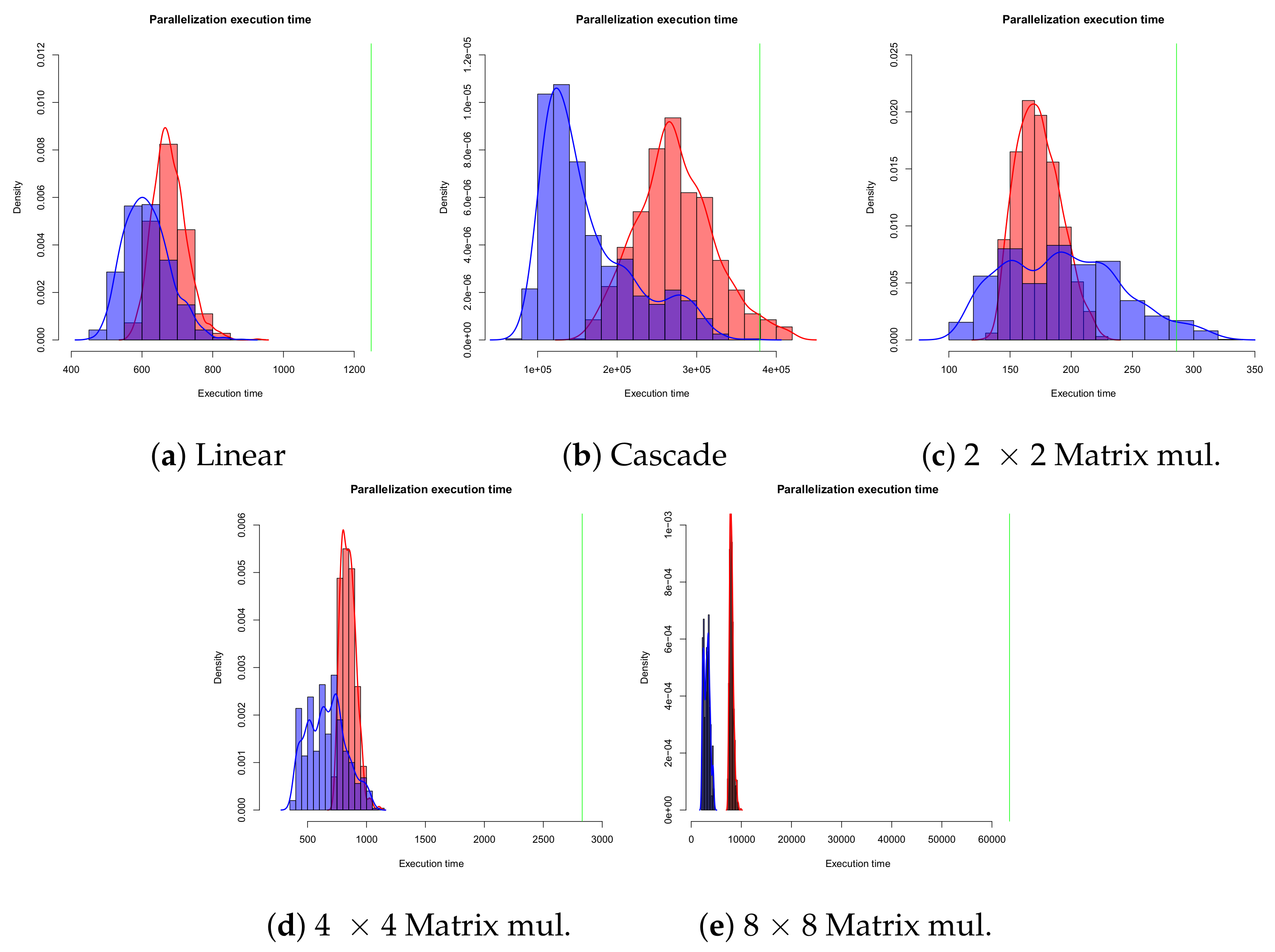
- We describe an implementation to empirically support this claim and evaluate the benefits of parallelization using a prototype open-source compiler, targeting a message-passing many-core simulation. We empirically verify the correctness of arbitrary parallelization, supporting the validity of our formal semantics, analyze the distribution of operations within cores to understand the implementation impact of the paradigm, and measure performance improvement of random parallelization across five micro-benchmarks with increasing levels of parallelization opportunities, showing that, on average, it is possible to reduce execution time between 28% and 87%, when moving from single-core to a 2 × 2 multi-core configuration and between 33% and 95%, when moving from single-core to a 4 × 4 multi-core configuration.
2. Background: Code Parallelization Strategies
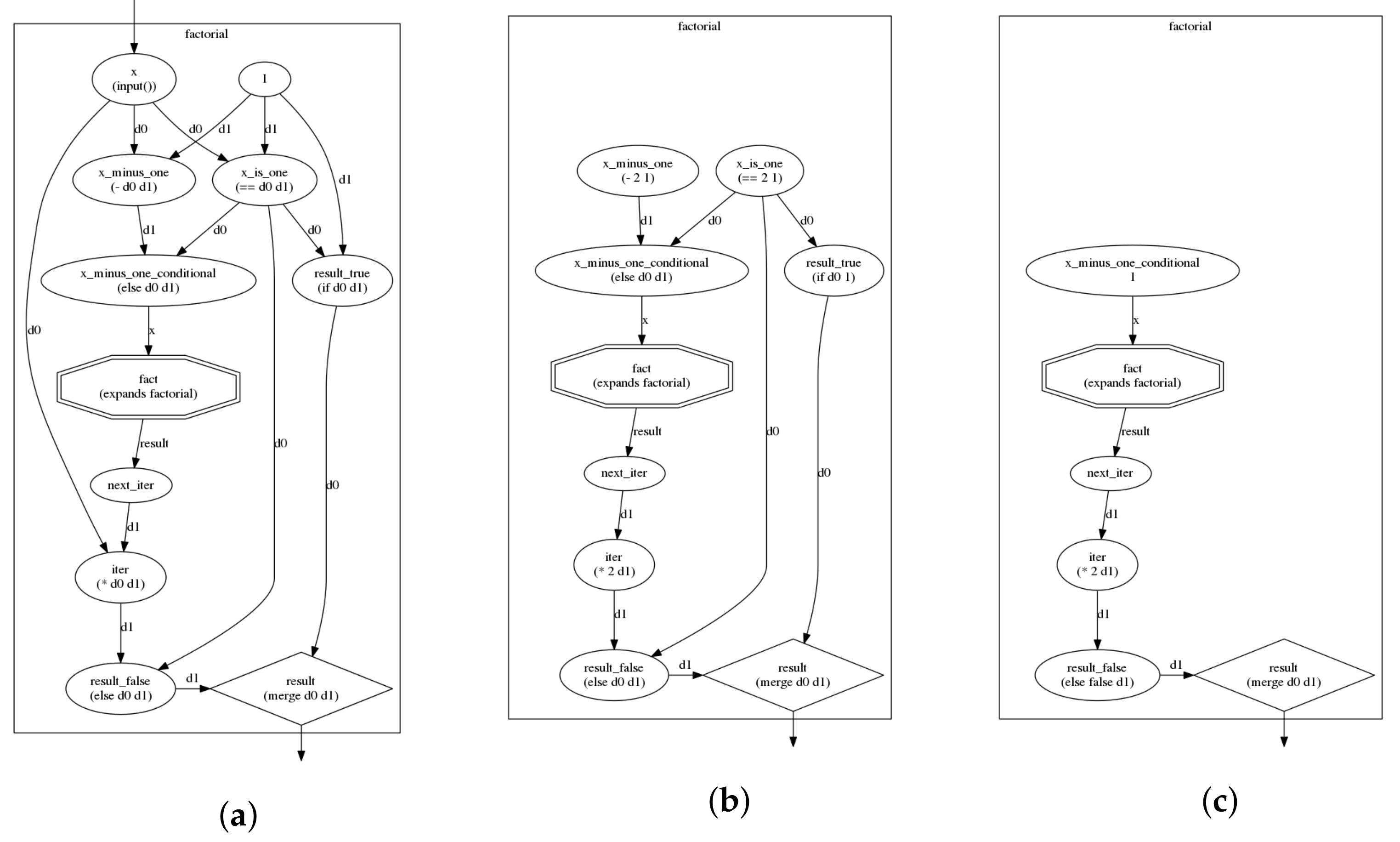
3. Programming Model
| Listing 1: BNF grammar describing an AGP implementation. <op> (operations), <identifier> and <const> (constants) not defined for brevity. |
|
| Listing 2: “Factorial” function highlighting all aspects of AGP. Pseudo-syntax for legibility. |
|
3.1. Rationale
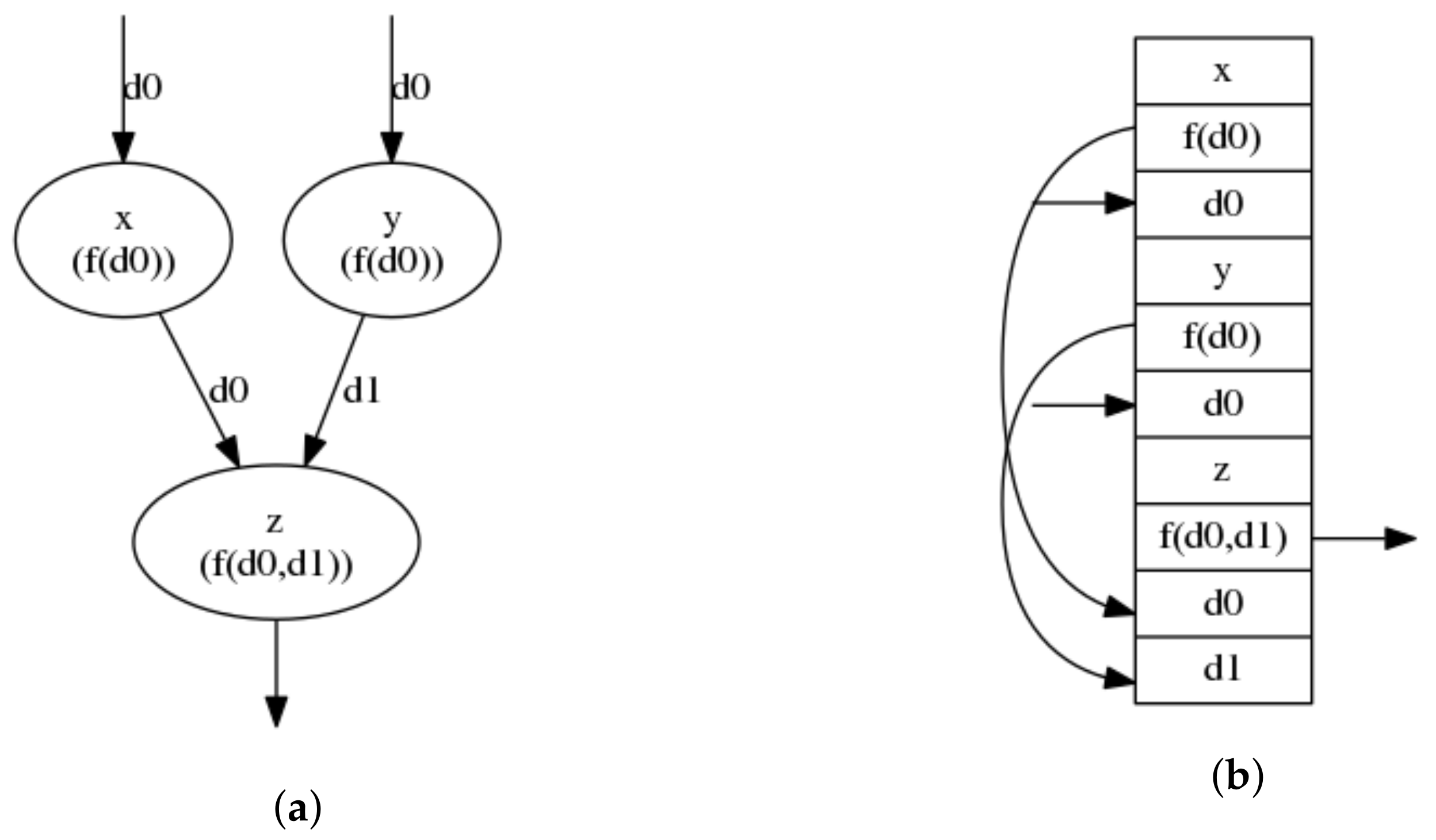
4. Model of Computation
4.1. AGP Semantics
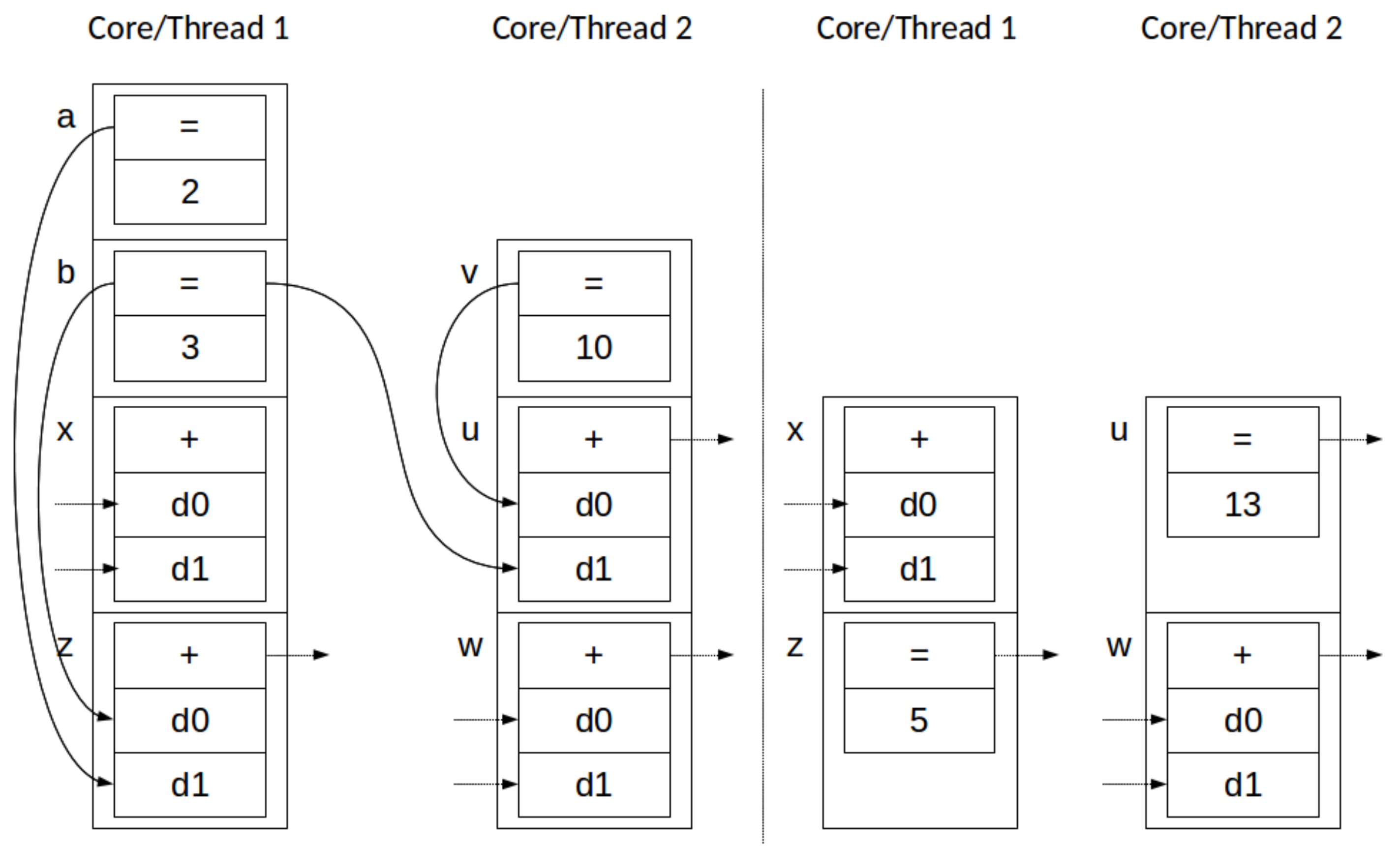
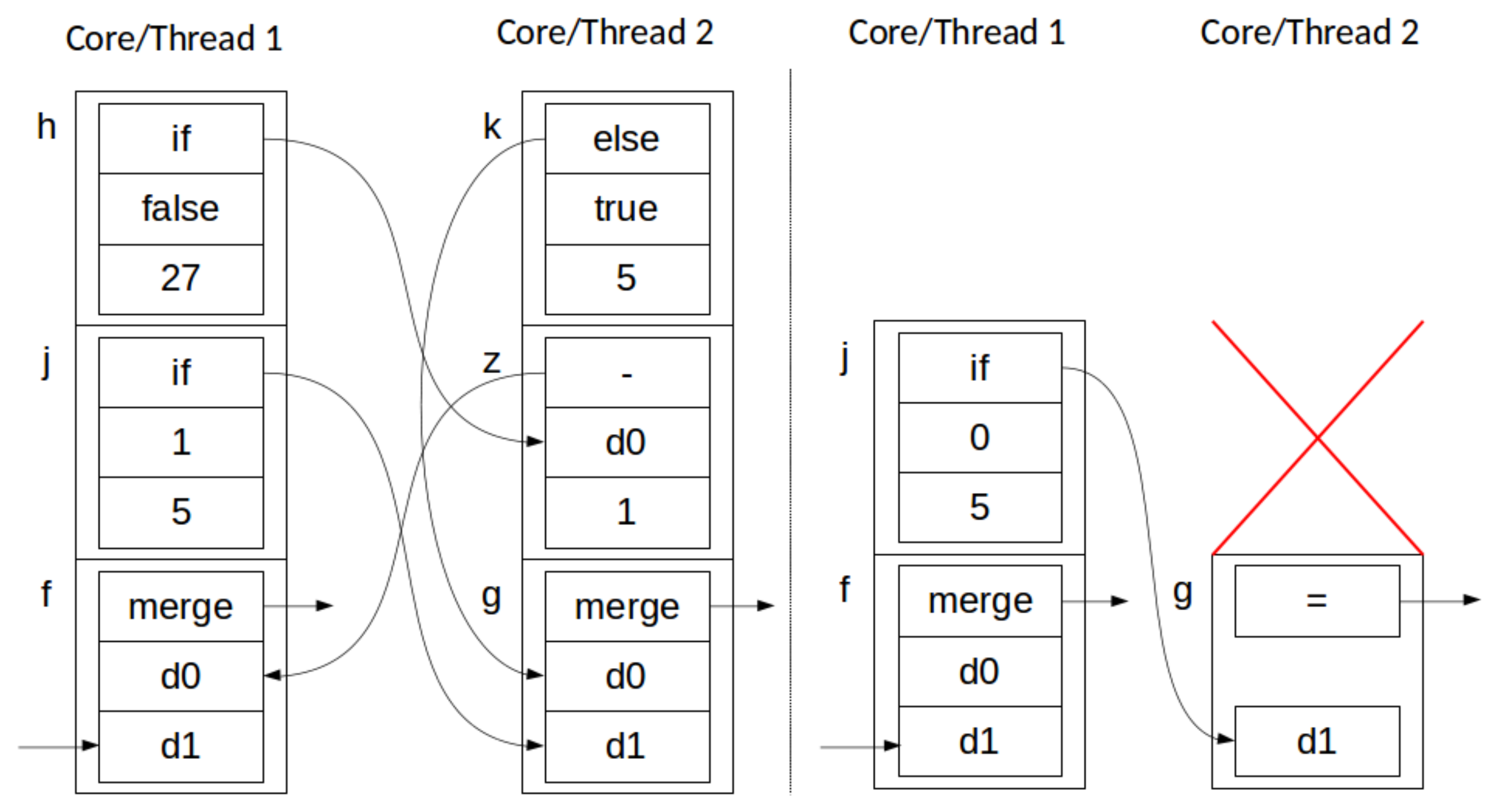
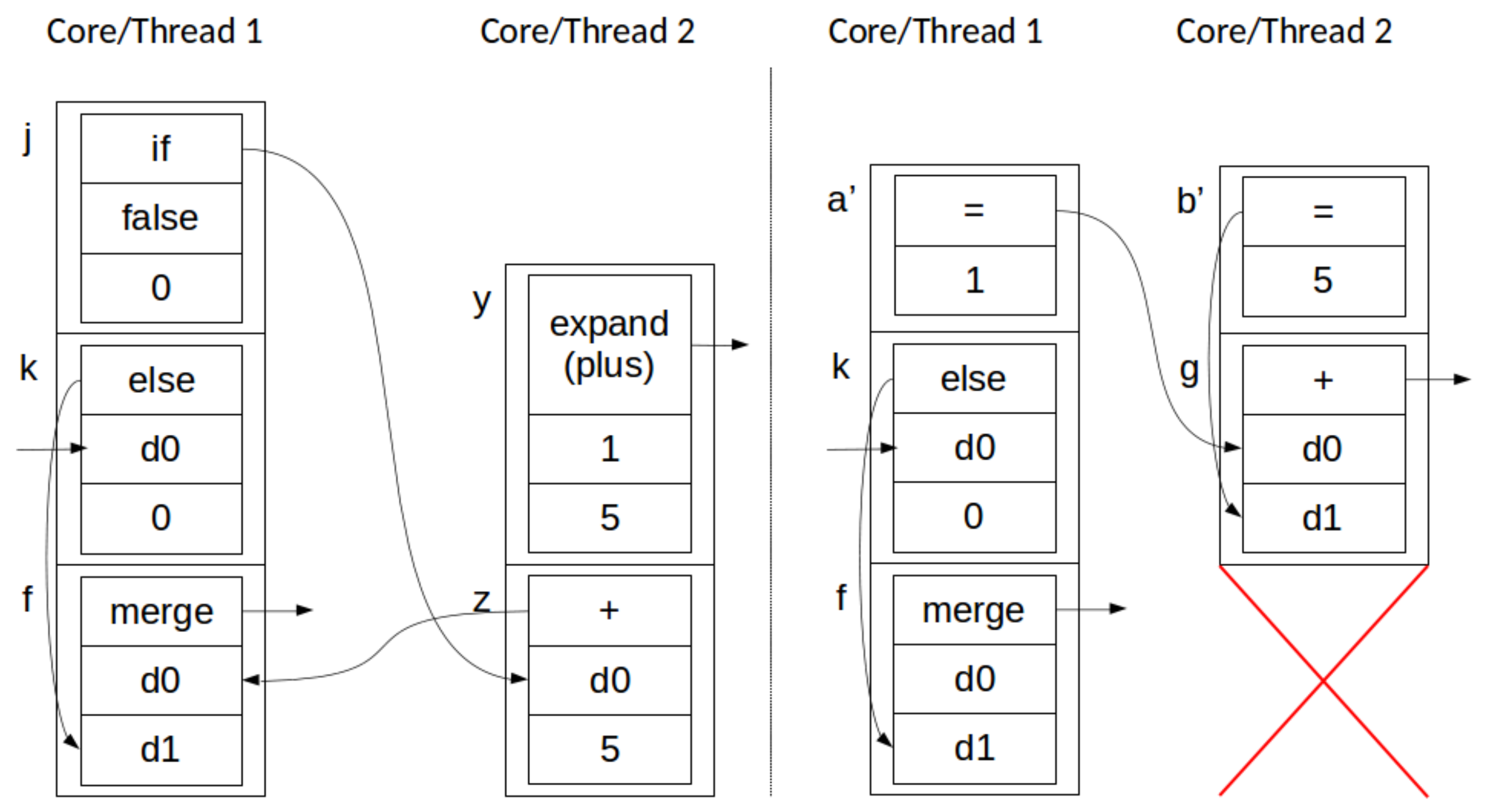
4.2. Parallelizing AGP
5. Experimental Evaluation
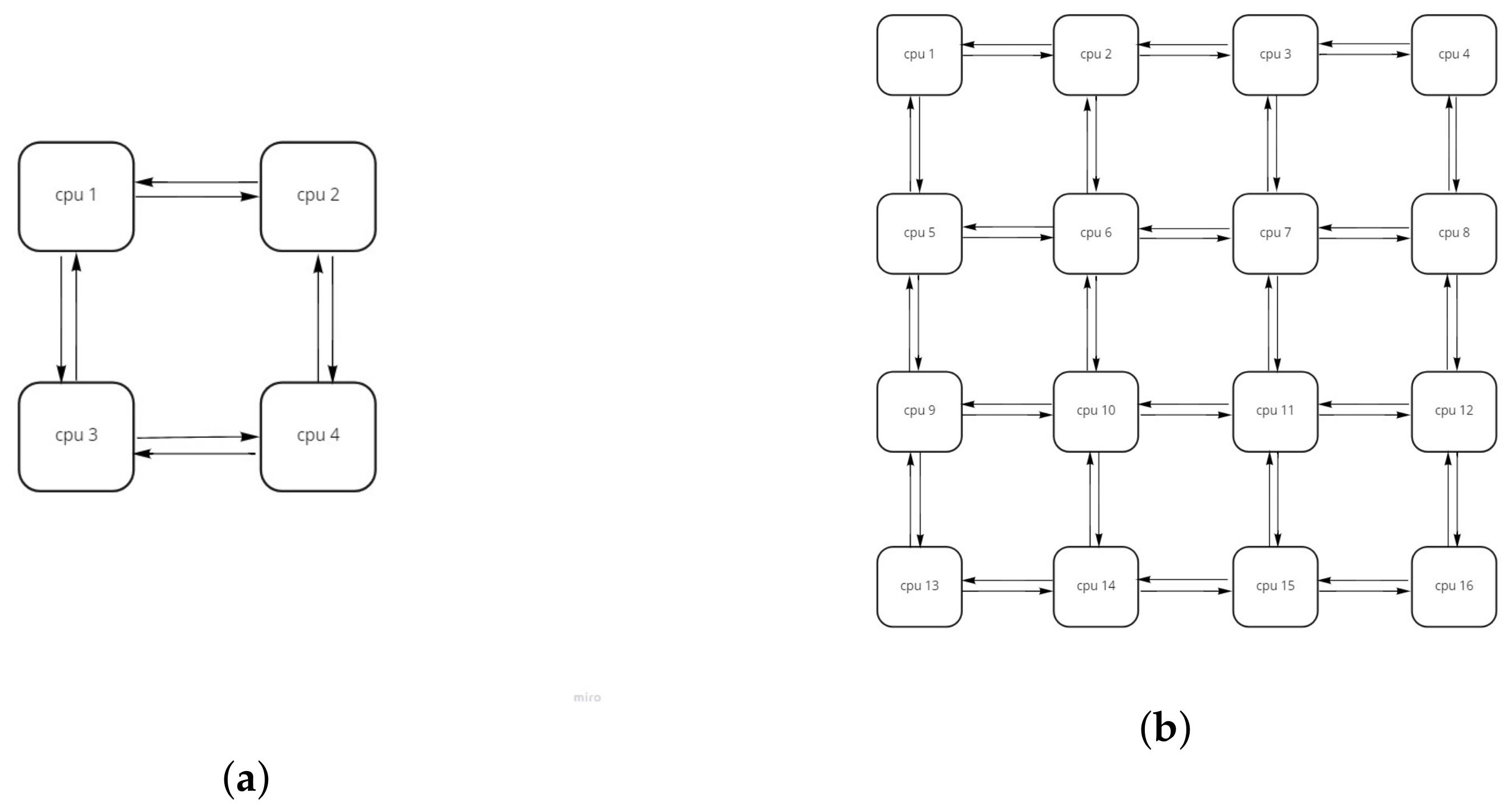
5.1. Evaluation Framework
| Algorithm 1: Core evaluation loop. | |
| allocated nodes | |
| ifthen | ▹ Communication block |
| if N should be forwarded then | |
| else | |
| ▹ Update local stack with N | |
| end if | |
| end if | |
| whiledo | |
| while do | |
| ▹ Garbage Collect top of stack | |
| end while | |
| if = expansion() then | ▹ Should expand graph |
| ▹ Propagate nodes allocated elsewhere | |
| else | |
| results ← process(S) | |
| ▹ Update local stack and forward results to other cores | |
| end if | |
| end while |
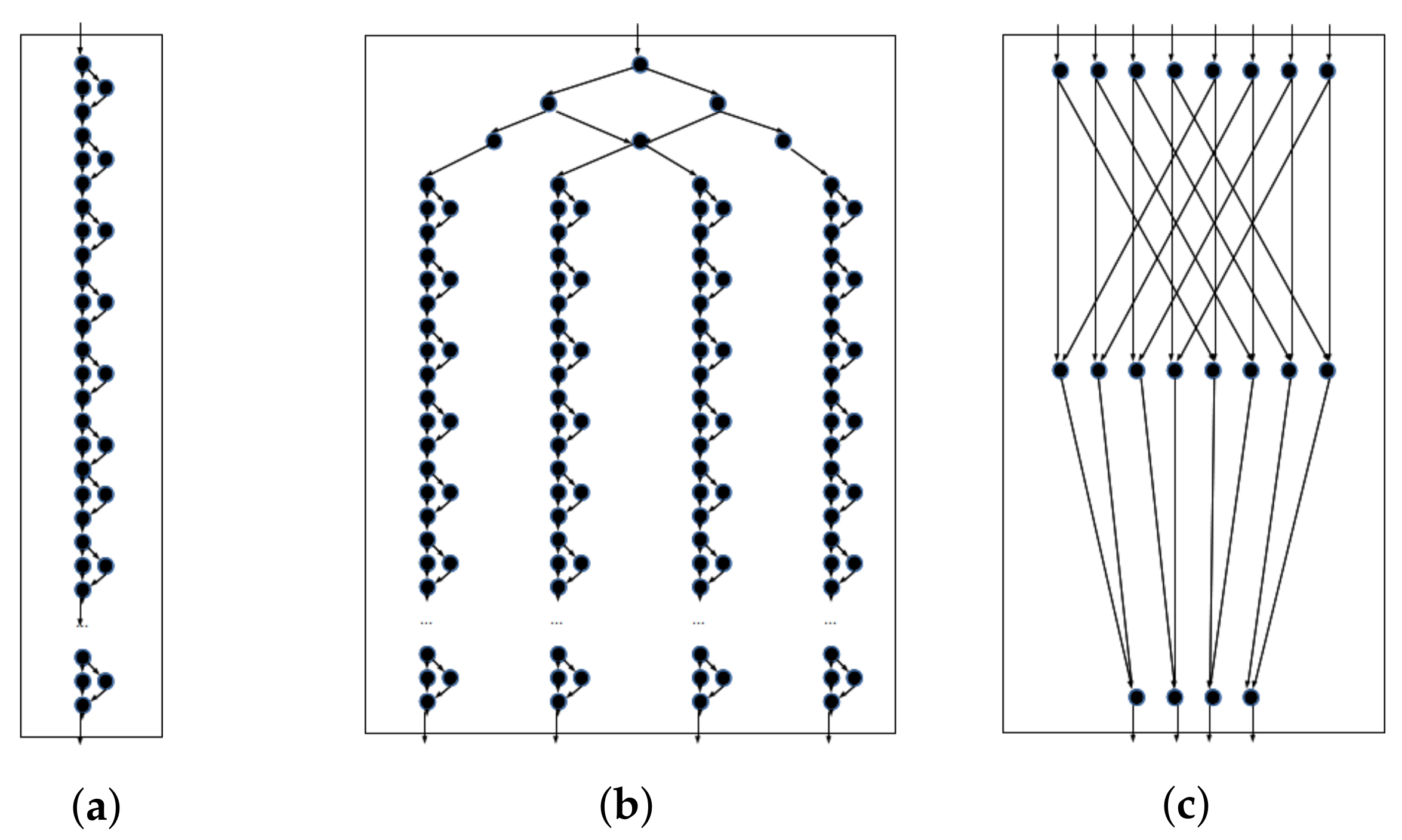
5.2. Experiments and Results
- Empirically verifying the correctness of arbitrary parallelization, supporting the validity of our formal semantics.
- Analyzing the distribution of operations within cores to understand the implementation impact of the paradigm (i.e., identify optimization opportunities for compilers).
- Measuring speedup compared to single-core execution, for various different node allocations.
5.3. Discussion of Results
5.4. Deployment Considerations
6. Related Work
6.1. Source Code Parallelization
6.2. Compile-Time Parallelization
6.3. Parallel Models of Computation
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rau, B.R.; Fisher, J.A. Instruction-level parallel processing: History, overview, and perspective. In Instruction-Level Parallelism; Springer: Berlin/Heidelberg, Germany, 1993; pp. 9–50. [Google Scholar]
- Krishnaiyer, R.; Kultursay, E.; Chawla, P.; Preis, S.; Zvezdin, A.; Saito, H. Compiler-based data prefetching and streaming non-temporal store generation for the intel (r) xeon phi (tm) coprocessor. In Proceedings of the 2013 IEEE International Symposium on Parallel & Distributed Processing, Workshops and Phd Forum, Cambridge, MA, USA, 20–24 May 2013; pp. 1575–1586. [Google Scholar]
- Cho, S.; Melhem, R.G. On the interplay of parallelization, program performance, and energy consumption. IEEE Trans. Parallel Distrib. Syst. 2009, 21, 342–353. [Google Scholar] [CrossRef]
- Diaz, J.; Munoz-Caro, C.; Nino, A. A survey of parallel programming models and tools in the multi and many-core era. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 1369–1386. [Google Scholar] [CrossRef]
- Lukefahr, A.; Padmanabha, S.; Das, R.; Dreslinski, R., Jr.; Wenisch, T.F.; Mahlke, S. Heterogeneous microarchitectures trump voltage scaling for low-power cores. In Proceedings of the Proceedings of the 23rd International Conference on Parallel Architectures and Compilation, Edmonton, AB, Canada, 24–27 August 2014; pp. 237–250. [Google Scholar]
- El-Araby, E.; Gonzalez, I.; El-Ghazawi, T. Exploiting partial runtime reconfiguration for high-performance reconfigurable computing. ACM Trans. Reconfigurable Technol. Syst. (TRETS) 2009, 1, 21. [Google Scholar] [CrossRef]
- Liu, S.; Pittman, R.N.; Forin, A.; Gaudiot, J.L. Achieving energy efficiency through runtime partial reconfiguration on reconfigurable systems. ACM Trans. Embed. Comput. Syst. (TECS) 2013, 12, 72. [Google Scholar] [CrossRef]
- Leung, S.T.; Zahorjan, J. Improving the performance of runtime parallelization. In Proceedings of the Fourth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, New York, NY, USA, 19–23 May 1993; pp. 83–91. [Google Scholar]
- Dogan, H.; Ahmad, M.; Kahne, B.; Khan, O. Accelerating Synchronization Using Moving Compute to Data Model at 1,000-Core Multicore Scale. ACM Trans. Archit. Code Optim. 2019, 16, 1–27. [Google Scholar] [CrossRef]
- Gamatié, A.; Devic, G.; Sassatelli, G.; Bernabovi, S.; Naudin, P.; Chapman, M. Towards energy-efficient heterogeneous multicore architectures for edge computing. IEEE Access 2019, 7, 49474–49491. [Google Scholar] [CrossRef]
- Tampouratzis, N.; Papaefstathiou, I.; Nikitakis, A.; Brokalakis, A.; Andrianakis, S.; Dollas, A.; Marcon, M.; Plebani, E. A Novel, Highly Integrated Simulator for Parallel and Distributed Systems. ACM Trans. Archit. Code Optim. 2020, 17, 1–28. [Google Scholar] [CrossRef]
- Scaife, N.; Horiguchi, S.; Michaelson, G.; Bristow, P. A parallel SML compiler based on algorithmic skeletons. J. Funct. Program. 2005, 15, 615. [Google Scholar] [CrossRef]
- Butko, A.; Bruguier, F.; Gamatié, A.; Sassatelli, G. Efficient programming for multicore processor heterogeneity: Openmp versus ompss. In Proceedings of the OpenSuCo, Frankfurt, Germany, 20 June 2017. [Google Scholar]
- Thoman, P.; Dichev, K.; Heller, T.; Iakymchuk, R.; Aguilar, X.; Hasanov, K.; Gschwandtner, P.; Lemarinier, P.; Markidis, S.; Jordan, H.; et al. A taxonomy of task-based parallel programming technologies for high-performance computing. J. Supercomput. 2018, 74, 1422–1434. [Google Scholar] [CrossRef]
- Ying, V.A.; Jeffrey, M.C.; Sanchez, D. T4: Compiling sequential code for effective speculative parallelization in hardware. In Proceedings of the 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 30 May–3 June 2020; pp. 159–172. [Google Scholar]
- France-Pillois, M.; Martin, J.; Rousseau, F. A Non-Intrusive Tool Chain to Optimize MPSoC End-to-End Systems. ACM Trans. Archit. Code Optim. (TACO) 2021, 18, 21. [Google Scholar] [CrossRef]
- Rasch, A.; Schulze, R.; Steuwer, M.; Gorlatch, S. Efficient Auto-Tuning of Parallel Programs with Interdependent Tuning Parameters via Auto-Tuning Framework (ATF). ACM Trans. Archit. Code Optim. 2021, 18, 1. [Google Scholar] [CrossRef]
- Muller, S.K.; Singer, K.; Goldstein, N.; Acar, U.A.; Agrawal, K.; Lee, I.T.A. Responsive parallelism with futures and state. In Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation, London, UK, 15–20 June 2020; pp. 577–591. [Google Scholar]
- Wang, Y.E.; Wu, C.J.; Wang, X.; Hazelwood, K.; Brooks, D. Exploiting Parallelism Opportunities with Deep Learning Frameworks. ACM Trans. Archit. Code Optim. 2021, 18, 9. [Google Scholar] [CrossRef]
- Röger, H.; Mayer, R. A comprehensive survey on parallelization and elasticity in stream processing. ACM Comput. Surv. (CSUR) 2019, 52, 36. [Google Scholar] [CrossRef]
- Hou, N.; Yan, X.; He, F. A survey on partitioning models, solution algorithms and algorithm parallelization for hardware/software co-design. Des. Autom. Embed. Syst. 2019, 23, 57–77. [Google Scholar] [CrossRef]
- Hanxleden, R.V.; Mendler, M.; Aguado, J.; Duderstadt, B.; Fuhrmann, I.; Motika, C.; Mercer, S.; O’brien, O.; Roop, P. Sequentially Constructive Concurrency—A Conservative Extension of the Synchronous Model of Computation. ACM Trans. Embed. Comput. Syst. 2014, 13, 144. [Google Scholar] [CrossRef]
- Hokkanen, J.; Kraus, J.; Herten, A.; Pleiter, D.; Kollet, S. Accelerated hydrologic modeling: ParFlow GPU implementation. In Proceedings of the EGU General Assembly Conference Abstracts, Online, 4–8 May 2020; p. 12904. [Google Scholar]
- Forster, Y.; Smolka, G. Weak call-by-value lambda calculus as a model of computation in Coq. In Proceedings of the International Conference on Interactive Theorem Proving, Brasília, Brazil, 26–29 September 2017; Springer: Cham, Switzerland, 2017; pp. 189–206. [Google Scholar]
- Cristescu, I.D.; Krivine, J.; Varacca, D. Rigid Families for CCS and the Pi-calculus. In Proceedings of the International Colloquium on Theoretical Aspects of Computing, Cali, Colombia, 29–31 October 2015; Springer: Cham, Switzerland, 2015; pp. 223–240. [Google Scholar]
- Burckhardt, S.; Leijen, D.; Sadowski, C.; Yi, J.; Ball, T. Two for the price of one: A model for parallel and incremental computation. ACM SIGPLAN Not. 2011, 46, 427–444. [Google Scholar] [CrossRef]
- Gao, G.R.; Sterling, T.; Stevens, R.; Hereld, M.; Zhu, W. ParalleX: A Study of A New Parallel Computation Model. In Proceedings of the 2007 IEEE International Parallel and Distributed Processing Symposium, Long Beach, CA, USA, 26–30 March 2007; pp. 1–6. [Google Scholar] [CrossRef]
- Fryer, J.; Garcia, P. Towards a Programming Paradigm for Reconfigurable Computing: Asynchronous Graph Programming. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020; Volume 1, pp. 1721–1728. [Google Scholar]
- Engler, D.; Ashcraft, K. RacerX: Effective, static detection of race conditions and deadlocks. ACM SIGOPS Oper. Syst. Rev. 2003, 37, 237–252. [Google Scholar] [CrossRef]
- Coelho, R.; Tanus, F.; Moreira, A.; Nazar, G. ACQuA: A Parallel Accelerator Architecture for Pure Functional Programs. In Proceedings of the 2020 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Limassol, Cyprus, 6–8 July 2020; pp. 346–351. [Google Scholar] [CrossRef]
- Lifflander, J.; Krishnamoorthy, S. Cache locality optimization for recursive programs. In Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation, Barcelona, Spain, 18–23 June 2017; pp. 1–16. [Google Scholar]
- Molka, D.; Hackenberg, D.; Schone, R.; Muller, M.S. Memory performance and cache coherency effects on an intel nehalem multiprocessor system. In Proceedings of the 2009 18th International Conference on Parallel Architectures and Compilation Techniques, Raleigh, NC, USA, 12–16 September 2009; pp. 261–270. [Google Scholar]
- Cyphers, S.; Bansal, A.K.; Bhiwandiwalla, A.; Bobba, J.; Brookhart, M.; Chakraborty, A.; Constable, W.; Convey, C.; Cook, L.; Kanawi, O.; et al. Intel ngraph: An intermediate representation, compiler, and executor for deep learning. arXiv 2018, arXiv:1801.08058. [Google Scholar]
- Tiganourias, E.; Mavropoulos, M.; Keramidas, G.; Kelefouras, V.; Antonopoulos, C.P.; Voros, N. A Hierarchical Profiler of Intermediate Representation Code based on LLVM. In Proceedings of the 2021 10th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 7–10 June 2021; pp. 1–5. [Google Scholar]
- Wang, P.; McAllister, J. Streaming elements for FPGA signal and image processing accelerators. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2016, 24, 2262–2274. [Google Scholar] [CrossRef]
- Marino, D.; Singh, A.; Millstein, T.; Musuvathi, M.; Narayanasamy, S. DRFx: An Understandable, High Performance, and Flexible Memory Model for Concurrent Languages. ACM Trans. Program. Lang. Syst. 2016, 38, 16. [Google Scholar] [CrossRef]
- Puthoor, S.; Lipasti, M.H. Systems-on-Chip with Strong Ordering. ACM Trans. Archit. Code Optim. 2021, 18, 15. [Google Scholar] [CrossRef]
- Bora, U.; Das, S.; Kukreja, P.; Joshi, S.; Upadrasta, R.; Rajopadhye, S. LLOV: A Fast Static Data-Race Checker for OpenMP Programs. ACM Trans. Archit. Code Optim. 2020, 17, 35. [Google Scholar] [CrossRef]
- Dodds, M.; Jagannathan, S.; Parkinson, M.J.; Svendsen, K.; Birkedal, L. Verifying Custom Synchronization Constructs Using Higher-Order Separation Logic. ACM Trans. Program. Lang. Syst. 2016, 38, 4. [Google Scholar] [CrossRef]
- Liu, Y.A.; Stoller, S.D.; Lin, B. From Clarity to Efficiency for Distributed Algorithms. ACM Trans. Program. Lang. Syst. 2017, 39, 12. [Google Scholar] [CrossRef]
- Bondhugula, U.; Acharya, A.; Cohen, A. The Pluto+ Algorithm: A Practical Approach for Parallelization and Locality Optimization of Affine Loop Nests. ACM Trans. Program. Lang. Syst. 2016, 38, 12. [Google Scholar] [CrossRef]
- Acharya, A.; Bondhugula, U.; Cohen, A. Effective Loop Fusion in Polyhedral Compilation Using Fusion Conflict Graphs. ACM Trans. Archit. Code Optim. 2020, 17, 26. [Google Scholar] [CrossRef]
- Rajendran, A.; Nandivada, V.K. DisGCo: A Compiler for Distributed Graph Analytics. ACM Trans. Archit. Code Optim. 2020, 17, 28. [Google Scholar] [CrossRef]
- Zhang, Y.; Liao, X.; Gu, L.; Jin, H.; Hu, K.; Liu, H.; He, B. AsynGraph: Maximizing Data Parallelism for Efficient Iterative Graph Processing on GPUs. ACM Trans. Archit. Code Optim. 2020, 17, 29. [Google Scholar] [CrossRef]
- Schardl, T.B.; Moses, W.S.; Leiserson, C.E. Tapir: Embedding Fork-Join Parallelism into LLVM’s Intermediate Representation. SIGPLAN Not. 2017, 52, 249–265. [Google Scholar] [CrossRef]
- Yiapanis, P.; Brown, G.; Luján, M. Compiler-Driven Software Speculation for Thread-Level Parallelism. ACM Trans. Program. Lang. Syst. 2015, 38, 5. [Google Scholar] [CrossRef]
- Sanan, D.; Zhao, Y.; Lin, S.W.; Yang, L. CSim2: Compositional Top-down Verification of Concurrent Systems Using Rely-Guarantee. ACM Trans. Program. Lang. Syst. 2021, 43, 2. [Google Scholar] [CrossRef]
- Swalens, J.; Koster, J.D.; Meuter, W.D. Chocola: Composable Concurrency Language. ACM Trans. Program. Lang. Syst. 2021, 42, 17. [Google Scholar] [CrossRef]
- Hirzel, M.; Schneider, S.; Gedik, B. SPL: An Extensible Language for Distributed Stream Processing. ACM Trans. Program. Lang. Syst. 2017, 39, 5. [Google Scholar] [CrossRef]
- de Supinski, B.R.; Scogland, T.R.; Duran, A.; Klemm, M.; Bellido, S.M.; Olivier, S.L.; Terboven, C.; Mattson, T.G. The ongoing evolution of openmp. Proc. IEEE 2018, 106, 2004–2019. [Google Scholar] [CrossRef]
- Gerbessiotis, A.; Valiant, L. Direct Bulk-Synchronous Parallel Algorithms. J. Parallel Distrib. Comput. 1994, 22, 251–267. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | |||
|---|---|---|---|
| Benchmark | 1 × 1 | 2 × 2 | 4 × 4 |
| Ticks | Ticks | Ticks | |
| Linear | |||
| Cascade | |||
| 2 × 2 Matrix mul. | |||
| 4 × 4 Matrix mul. | |||
| 8 × 8 Matrix mul. | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cook, S.; Garcia, P. Arbitrarily Parallelizable Code: A Model of Computation Evaluated on a Message-Passing Many-Core System. Computers 2022, 11, 164. https://doi.org/10.3390/computers11110164
Cook S, Garcia P. Arbitrarily Parallelizable Code: A Model of Computation Evaluated on a Message-Passing Many-Core System. Computers. 2022; 11(11):164. https://doi.org/10.3390/computers11110164
Chicago/Turabian StyleCook, Sebastien, and Paulo Garcia. 2022. "Arbitrarily Parallelizable Code: A Model of Computation Evaluated on a Message-Passing Many-Core System" Computers 11, no. 11: 164. https://doi.org/10.3390/computers11110164
APA StyleCook, S., & Garcia, P. (2022). Arbitrarily Parallelizable Code: A Model of Computation Evaluated on a Message-Passing Many-Core System. Computers, 11(11), 164. https://doi.org/10.3390/computers11110164