
Prediction of Severity of COVID-19-Infected Patients Using Machine Learning Techniques



Abstract
1. Introduction
2. Results
2.1. Multilayer Perceptron
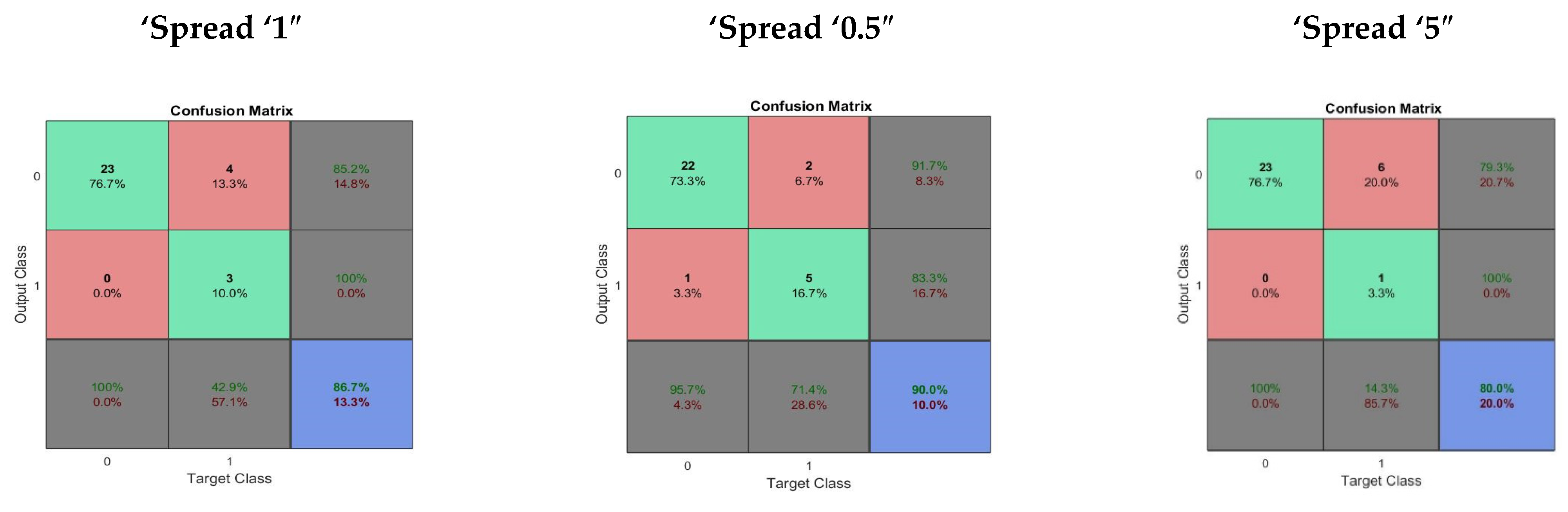
2.2. Radial Basis Neural Network
2.3. General Regression Neural Network
2.4. Support Vector Machine
2.5. Random Forest
3. Discussion
4. Materials and Methods
4.1. Dataset
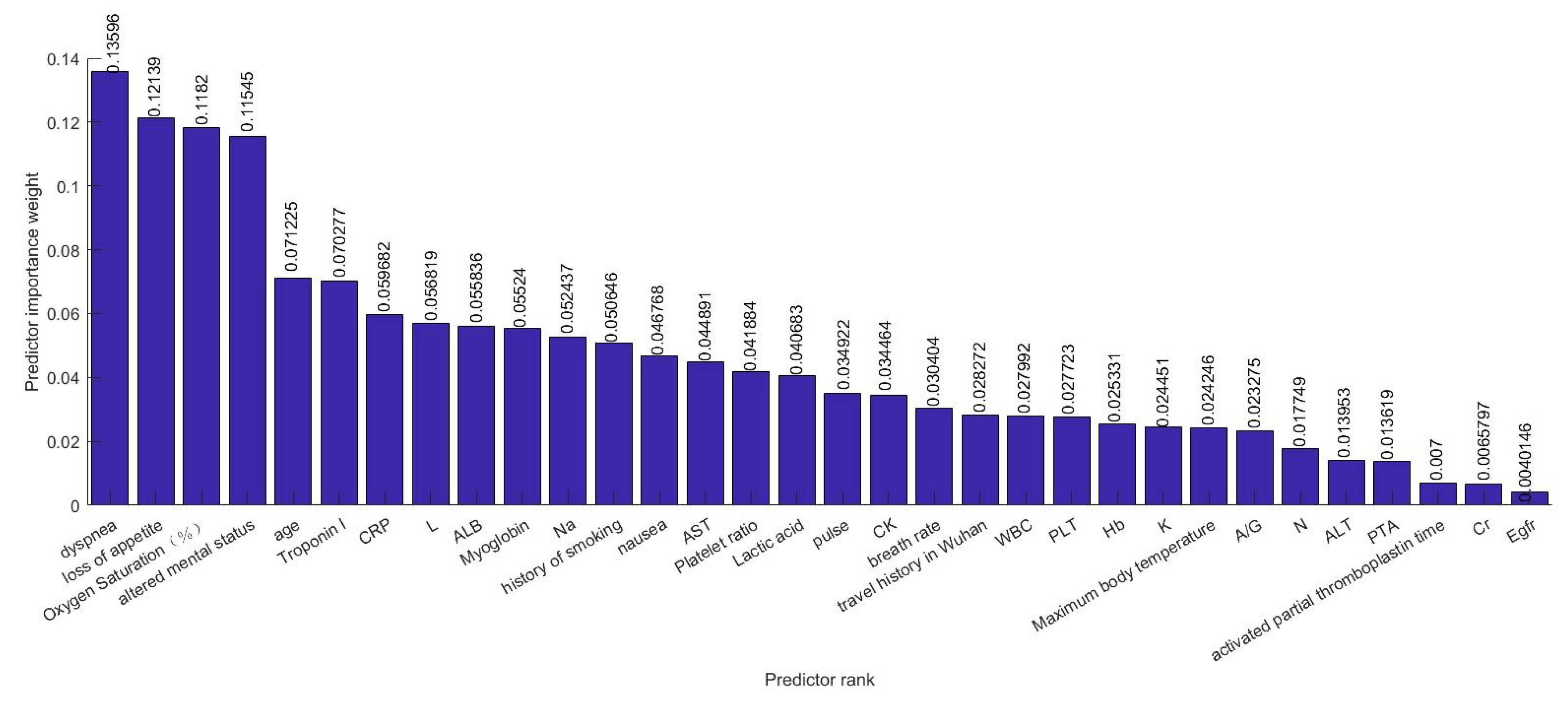
4.2. Feature Selection
4.3. Machine Learning Methodologies
4.3.1. Multilayer Perceptron
4.3.2. Radial Basis Function Network
4.3.3. General Regression Neural Network
4.3.4. Support Vector Machine
4.3.5. Random Forest Regression
- A coordinate of is selected at each tree node, with the feature which has the selection probability of .
- After obtaining the selected coordinate, the split is at the midpoint of the chosen side of every node.
4.4. Training Functions
4.4.1. Levenberg–Marquard (“Trainlm”)
4.4.2. Bayesian Regularization (“Trainbr”)
4.4.3. Scale Conjugate Gradient (“Trainscg”)
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, N.; Zhang, D.; Wang, W.; Li, X.; Yang, B.; Song, J.; Zhao, X.; Huang, B.; Shi, W.; Lu, R.; et al. A novel coronavirus from patients with pneumonia in China, 2019. N. Engl. J. Med. 2020. [Google Scholar] [CrossRef] [PubMed]
- Su, S.; Wong, G.; Shi, W.; Liu, J.; Lai, A.C.K.; Zhou, J.; Liu, W.; Bi, Y.; Gao, G.F. Epidemiology, Genetic Recombination, and Pathogenesis of Coronaviruses. Trends Microbiol. 2016, 24, 490–502. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Wang, Y.; Li, X.; Ren, L.; Zhao, J.; Hu, Y.; Zhang, L.; Fan, G.; Xu, J.; Gu, X.; et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 2020. [Google Scholar] [CrossRef]
- Wu, Z.; McGoogan, J.M. Characteristics of and Important Lessons from the Coronavirus Disease 2019 (COVID-19) Outbreak in China: Summary of a Report of 72314 Cases from the Chinese Center for Disease Control and Prevention. JAMA-J. Am. Med. Assoc. 2020, 323, 1239–1242. [Google Scholar] [CrossRef] [PubMed]
- Dai, M.; Liu, D.; Liu, M.; Zhou, F.; Li, G.; Chen, Z.; Zhang, Z.; You, H.; Wu, M.; Zheng, Q.; et al. Patients with cancer appear more vulnerable to SARS-CoV-2: A multicenter study during the COVID-19 outbreak. Cancer Discov. 2020. [Google Scholar] [CrossRef] [PubMed]
- Asadollahi-Amin, A.; Hasibi, M.; Ghadimi, F.; Rezaei, H.; SeyedAlinaghi, S.A. Lung involvement found on chest CT scan in a pre-symptomatic person with SARS-CoV-2 infection: A case report. Trop. Med. Infect. Dis. 2020, 5, 56. [Google Scholar] [CrossRef] [PubMed]
- Yan, L.; Zhang, H.-T.; Xiao, Y.Y.; Wang, M.; Sun, C.; Liang, J.; Li, S.; Zhang, M.; Guo, Y.; Xiao, Y.Y.; et al. Prediction of criticality in patients with severe COVID-19 infection using three clinical features: A machine learning-based prognostic model with clinical data in Wuhan. medRxiv 2020. 2020.02.27.20028027. [Google Scholar]
- Kira, K.; Rendell, L.A. Feature selection problem: Traditional methods and a new algorithm. In Proceedings of the Proceedings Tenth National Conference on Artificial Intelligence, San Jose, CA, USA, 12–16 July 1992; pp. 129–134. [Google Scholar]
- Rida, I.; Al-Maadeed, N.; Al-Maadeed, S.; Bakshi, S. A comprehensive overview of feature representation for biometric recognition. Multimed. Tools Appl. 2020. [Google Scholar] [CrossRef]
- Rida, I.; Al Maadeed, S.; Jiang, X.; Lunke, F.; Bensrhair, A. An Ensemble Learning Method Based on Random Subspace Sampling for Palmprint Identification. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing - Proceedings, Calgary, AB, Canada, 15–20 April 2018; pp. 2047–2051. [Google Scholar]
- Shamim, M.Z.; Syed, S.; Shiblee, M.; Usman, M.; Zaidi, M.; Ahmad, Z.; Muqeet, M.; Habeeb, M. Detecting benign and pre-cancerous tongue lesions using deep convolutional neural networks for early signs of oral cancer. Basic Clin. Pharmacol. Toxicol. 2019, 125, 184–185. [Google Scholar]
- Indola, R.P.; Ebecken, N.F.F. On extending F-measure and G-mean metrics to multi-class problems. WIT Trans. Inf. Commun. Technol. 2005, 35, 10. [Google Scholar]
- Cao, Z.; Li, T.; Liang, L.; Wang, H.; Wei, F.; Meng, S.; Cai, M.; Zhang, Y.; Xu, H.; Zhang, J.; et al. Clinical characteristics of Coronavirus Disease 2019 patients in Beijing, China. PLoS ONE 2020, 15, e0234764. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014. [Google Scholar] [CrossRef]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning Internal Representations By Error Propagation (original). Explor. Micro-Struct. Cogn. 1986, 1. [Google Scholar]
- Schwenker, F.; Kestler, H.A.; Palm, G. Three learning phases for radial-basis-function networks. Neural Netw. 2001. [Google Scholar] [CrossRef]
- Specht, D.F. A General Regression Neural Network. IEEE Trans. Neural Netw. 1991. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001. [Google Scholar] [CrossRef]
- Suk, H.I. An Introduction to Neural Networks and Deep Learning. In Deep Learning for Medical Image Analysis; Academic Press: Cambridge, MA, USA, 2017; ISBN 9780128104095. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Algorithm | Performance Measures | |||||
|---|---|---|---|---|---|---|
| Accuracy | Sensitivity | Specificity | Precision | F_Score | G-Mean | |
| “trainlcg” | 0.8499 | 0.6220 | 0.9643 | 0.8889 | 0.7285 | 0.7740 |
| “trainslm” | 0.8750 | 0.7341 | 0.9296 | 0.8090 | 0.7691 | 0.8257 |
| “trainbr” | 0.9083 | 0.7976 | 0.9781 | 0.9330 | 0.8476 | 0.8791 |
| Spread | Performance Measures | |||||
|---|---|---|---|---|---|---|
| Accuracy | Sensitivity | Specificity | Precision | F_Score | G-Mean | |
| Spread “Normal” | 0.7666 | 0.4047 | 0.9565 | 0.6667 | 0.4000 | 0.5228 |
| Spread “Small” | 0.7667 | 0.4761 | 0.8592 | 0.6061 | 0.5210 | 0.6177 |
| Spread “Large” | 0.8166 | 0.8333 | 0.8157 | 0.6227 | 0.7117 | 0.8225 |
| Spread | Performance Measures | |||||
|---|---|---|---|---|---|---|
| Accuracy | Sensitivity | Specificity | Precision | F_Score | G-Mean | |
| Spread “Normal” | 0.8167 | 0.5476 | 0.8809 | 0.9444 | 0.4881 | 0.5630 |
| Spread “Small” | 0.8333 | 0.4682 | 0.9782 | 0.9166 | 0.5664 | 0.6489 |
| Spread “Large” | 0.7833 | 0.4047 | 0.8809 | 0.9722 | 0.3068 | 0.4247 |
| Kernels | Performance Measures | |||||
|---|---|---|---|---|---|---|
| Accuracy | Sensitivity | Specificity | Precision | F_Score | G-Mean | |
| “linear” | 0.8400 | 0.5607 | 0.9375 | 0.7714 | 0.6321 | 0.7177 |
| “polynomial” | 0.8667 | 0.6964 | 0.9275 | 0.8047 | 0.6945 | 0.7841 |
| “rbf” | 0.8000 | 0.4017 | 0.9328 | 0. 6750 | 0.5035 | 0.6120 |
| Ensemble Methods | Performance Measures | |||||
|---|---|---|---|---|---|---|
| Accuracy | Sensitivity | Specificity | Precision | F_Score | G-Mean | |
| “LPBoost” | 0.9033 | 0.7857 | 0.9456 | 0.8303 | 0.8012 | 0.8607 |
| “GentleBoost” | 0.9083 | 0.6785 | 0.9782 | 0.9083 | 0.7756 | 0.8140 |
| “AdaBoostM1” | 0.9000 | 0.6785 | 0.9673 | 0.8786 | 0.7619 | 0.8093 |
| “RobustBoost” | 0.8750 | 0.6785 | 0.9347 | 0.7812 | 0.7211 | 0.7956 |
| “TotalBoost” | 0.8666 | 0.6428 | 0.9345 | 0.7535 | 0.6913 | 0.7740 |
| “RUSBoost” | 0.8667 | 0.7500 | 0.9021 | 0.6979 | 0.7205 | 0.8199 |
| “Bag” | 0.8666 | 0.5238 | 0.9710 | 0.8500 | 0.6464 | 0.7118 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, A.; Shiblee, M.; Alshahrani, A. Prediction of Severity of COVID-19-Infected Patients Using Machine Learning Techniques. Computers 2021, 10, 31. https://doi.org/10.3390/computers10030031
Alotaibi A, Shiblee M, Alshahrani A. Prediction of Severity of COVID-19-Infected Patients Using Machine Learning Techniques. Computers. 2021; 10(3):31. https://doi.org/10.3390/computers10030031
Chicago/Turabian StyleAlotaibi, Aziz, Mohammad Shiblee, and Adel Alshahrani. 2021. "Prediction of Severity of COVID-19-Infected Patients Using Machine Learning Techniques" Computers 10, no. 3: 31. https://doi.org/10.3390/computers10030031
APA StyleAlotaibi, A., Shiblee, M., & Alshahrani, A. (2021). Prediction of Severity of COVID-19-Infected Patients Using Machine Learning Techniques. Computers, 10(3), 31. https://doi.org/10.3390/computers10030031