Elderly Care Based on Hand Gestures Using Kinect Sensor




Abstract
1. Introduction
2. Related Works
3. Materials and Methods
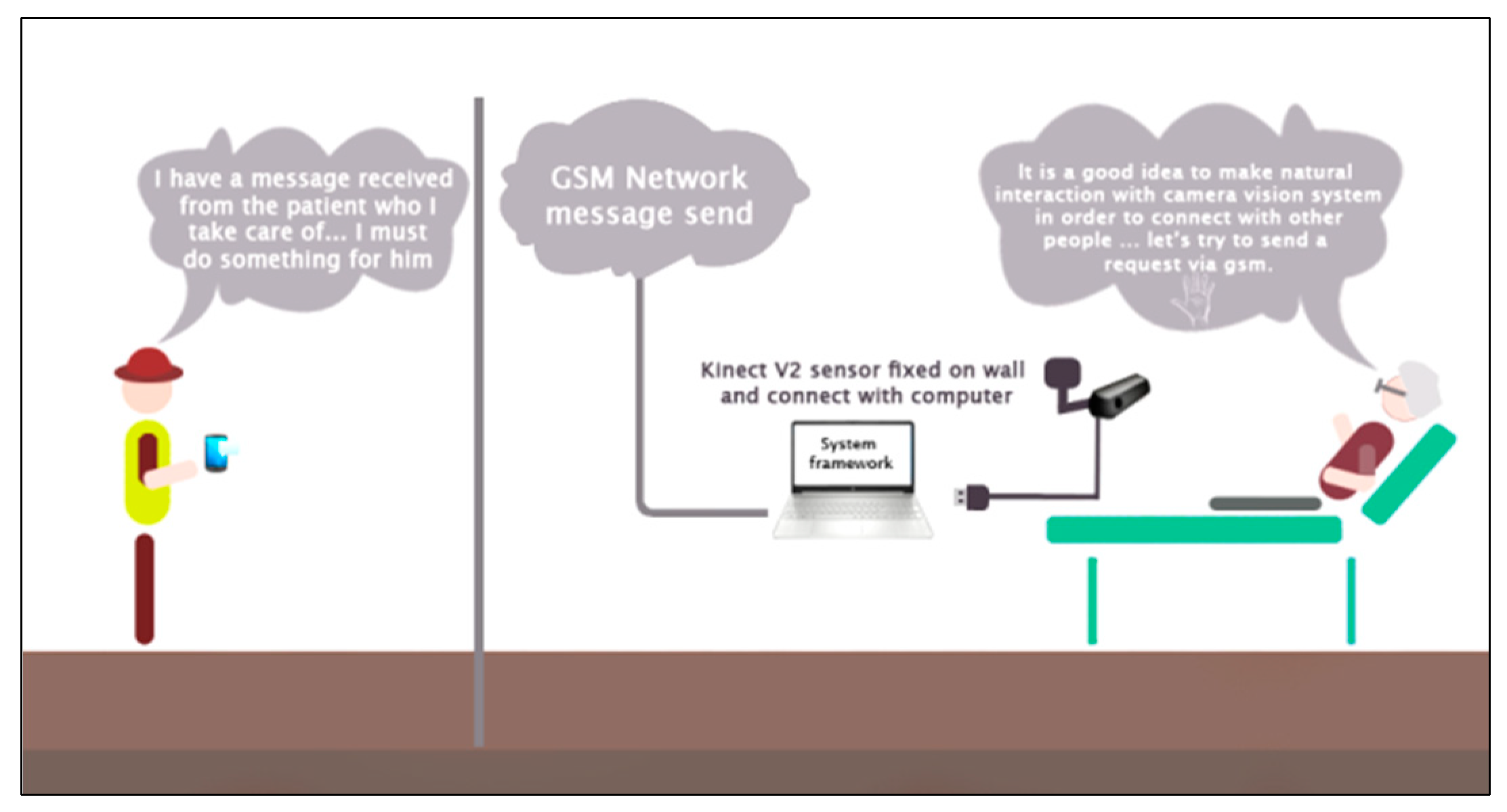
3.1. Participants and Experimental Setup
3.2. Hardware
3.2.1. Microsoft Kinect Sensor
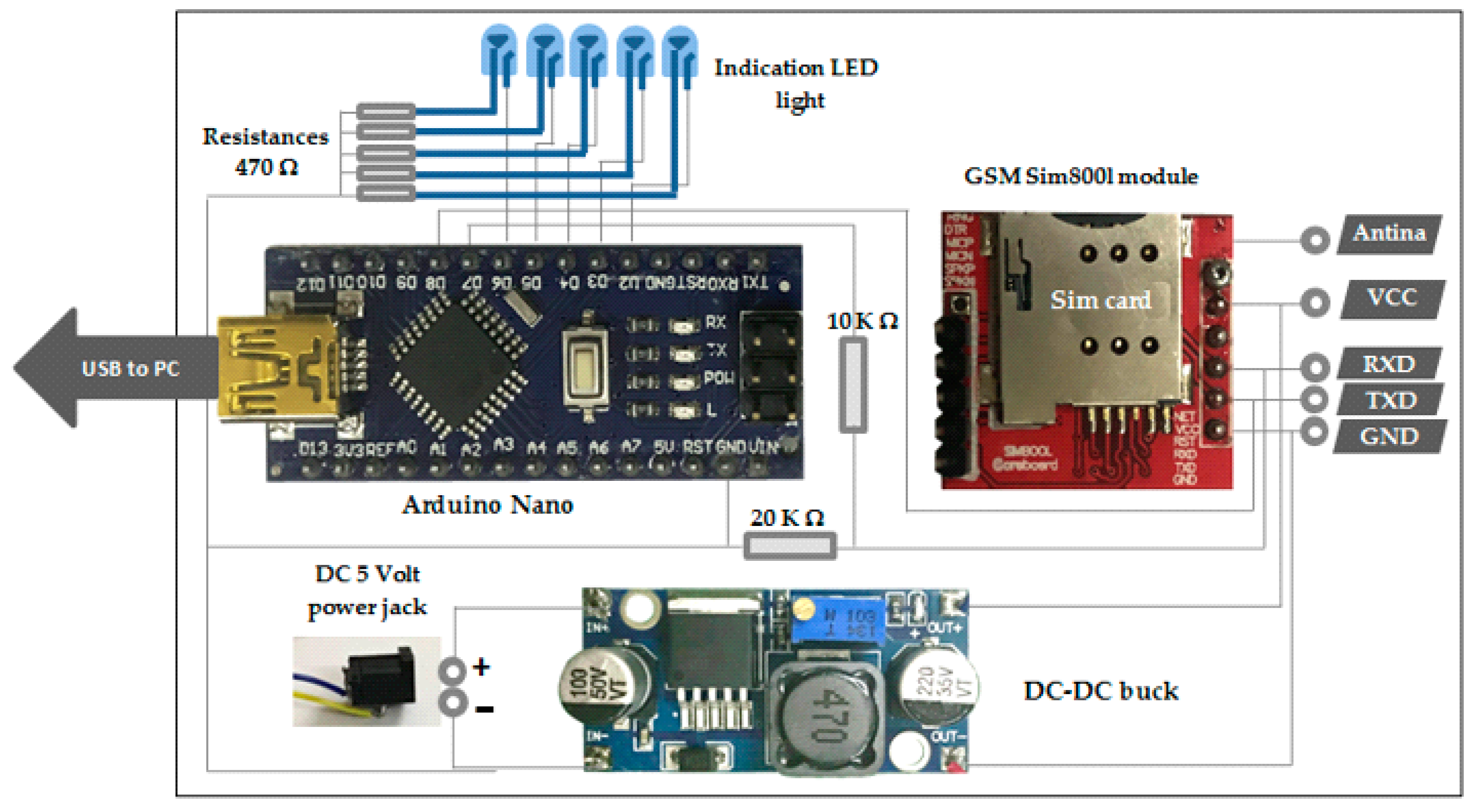
3.2.2. Arduino Nano Microcontroller
3.2.3. GSM Module Sim800L
3.2.4. DC-DC Chopper (Buck)
3.3. Software
- MATLAB R2019a (Image processing toolbox, Computer vision toolbox, Deep learning toolbox).
- Microsoft standard development kit (SDK) for Kinect V2.
- Kinect for Windows Runtime V2.
- Arduino program (IDE).
3.4. Methods
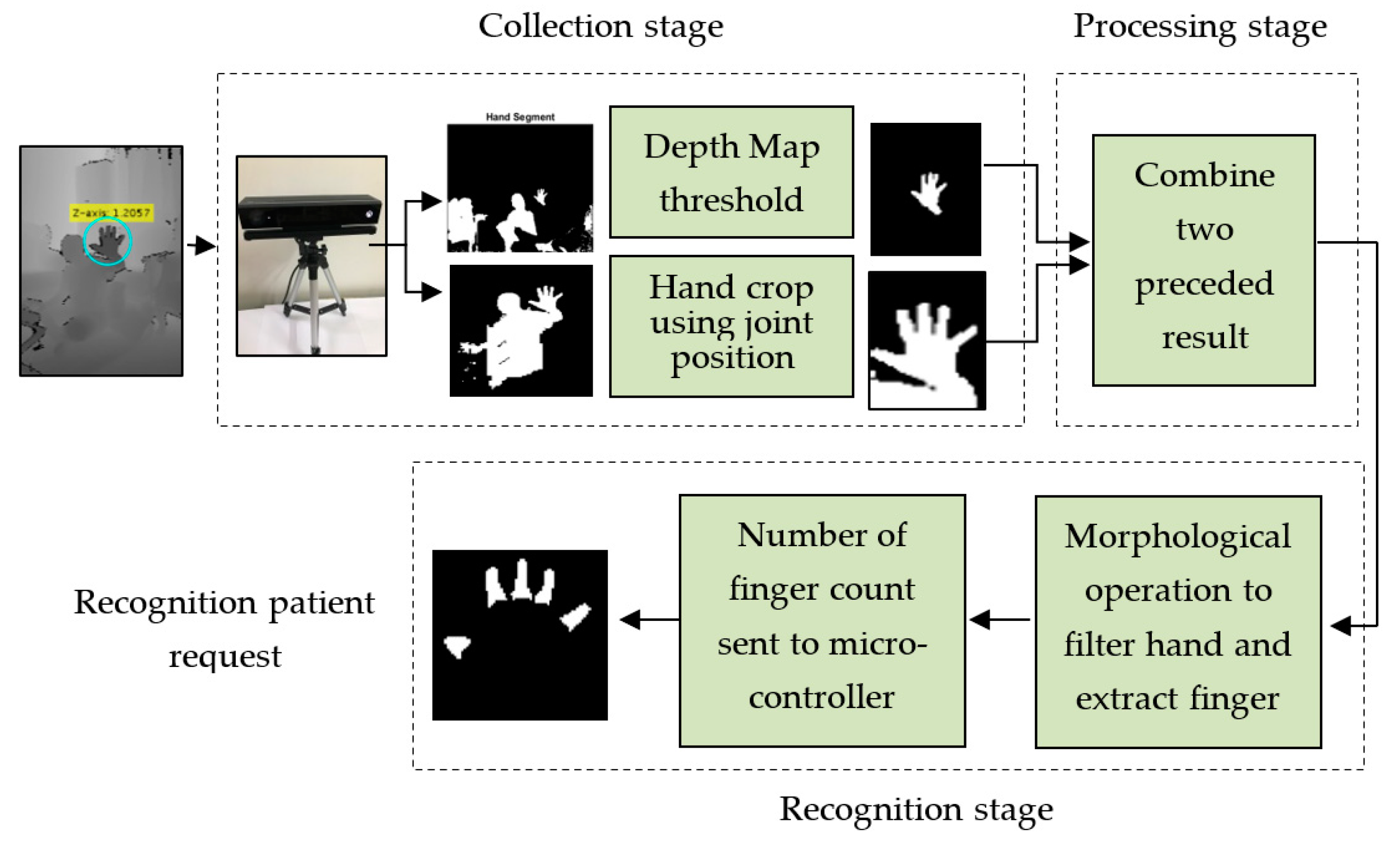
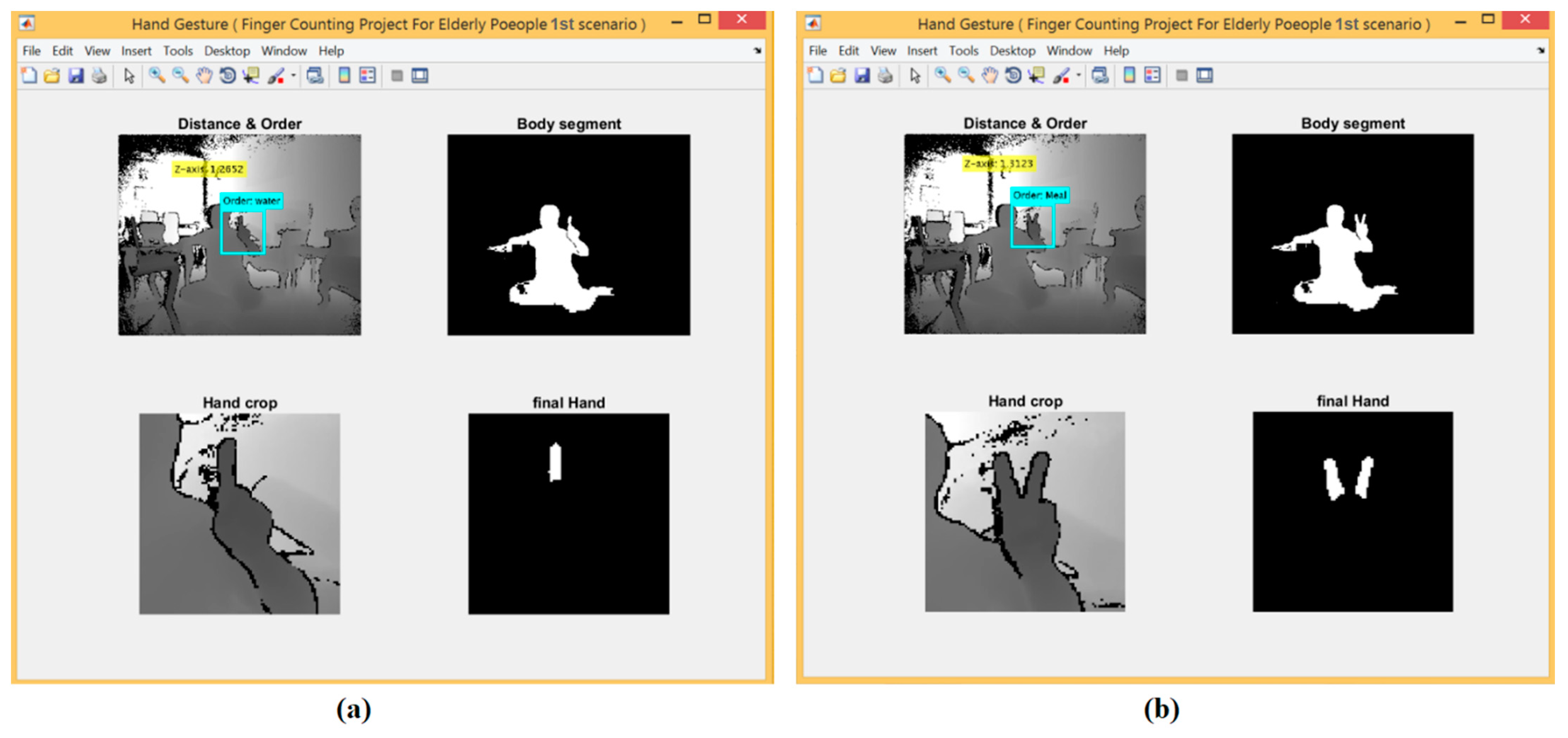
3.4.1. The First Scenario: Hand Detection Using Depth Threshold and Depth Metadata
- After acquiring the depth frame from the Kinect depth sensor, it can be easy to locate the centre of the palm of the hand from depth metadata using the joint position property. This point is mapped onto the depth map, and their depth values are saved for the next step.
- As every skeleton point in 3D space is associated with a position and an orientation, we can obtain the position of the central palm in real-time.
- The depth metadata returned by the depth sensor gave body tracking data so that the body index frame property enabled segmentation of the full human body into six bodies.
- After segmenting the body, a rectangular region was selected (for example, with size 200 × 200) around the central point of the hand/palm in the depth images. Initial segmentation was conducted based on the hand crop using the tracking point of the central palm. Because the right hand conforms more to the habit of human-computer interaction, we chose the right hand as the identification target.
- The depth threshold was provided for the depth map and the hand segment using a z-axis threshold.
- The hand cropped result was combined with the depth threshold result to improve the outcome.
- The binary image was smoothed using a median filter, and we set 5 as the linear aperture size.
- Using some morphological operations, such as erosion and dilation and image subtraction to extract the palm by drawing a circle covering the whole area of the palm using a tracked joint of the central palm. The fingers were then segmented, where the number of fingers counted appear as a white area and were then connected with a specific request.
- Finally, five fingers carried out five requests according to finger count that was sent by the microcontroller as a numeric value via the serial port to control the GSM module.
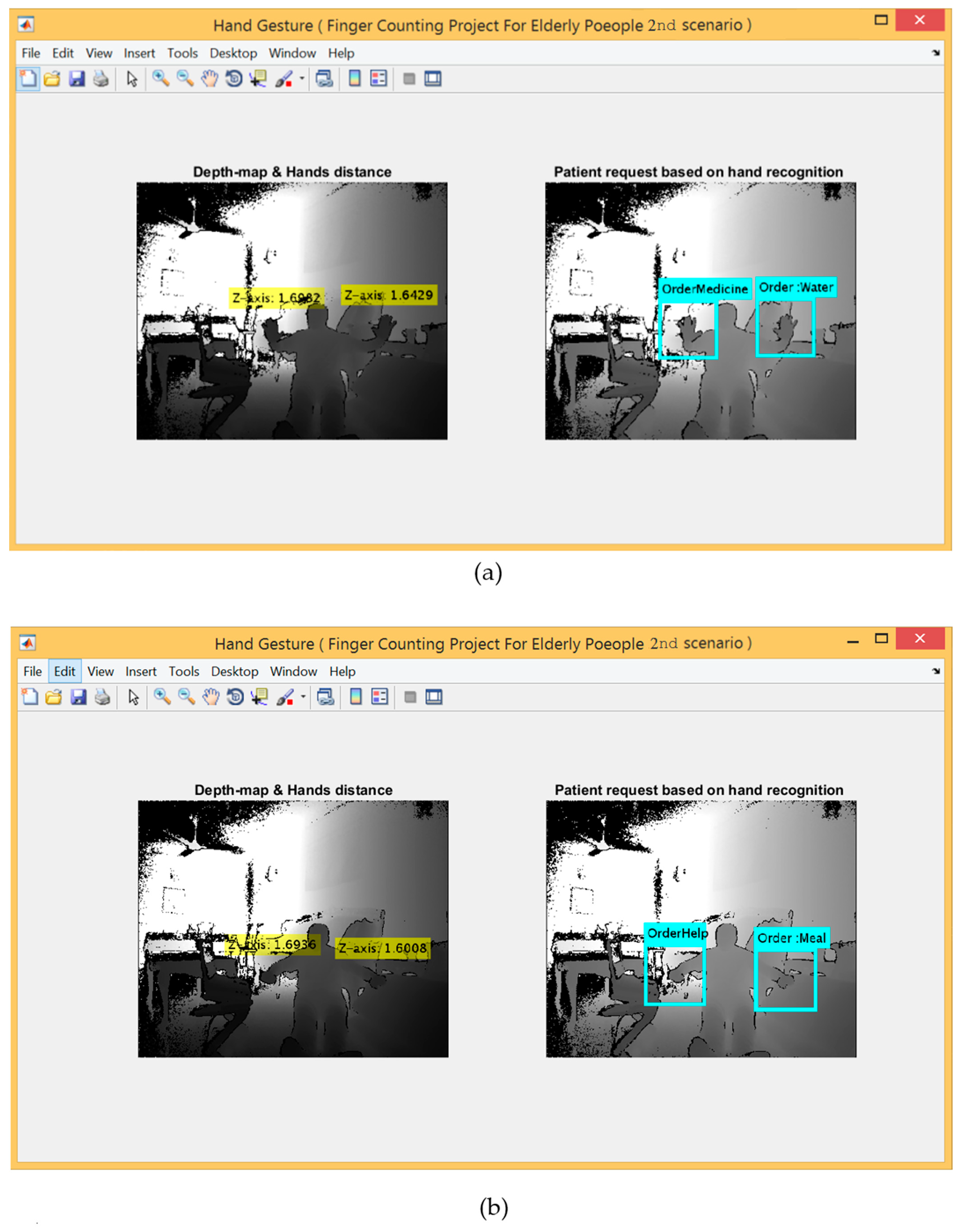
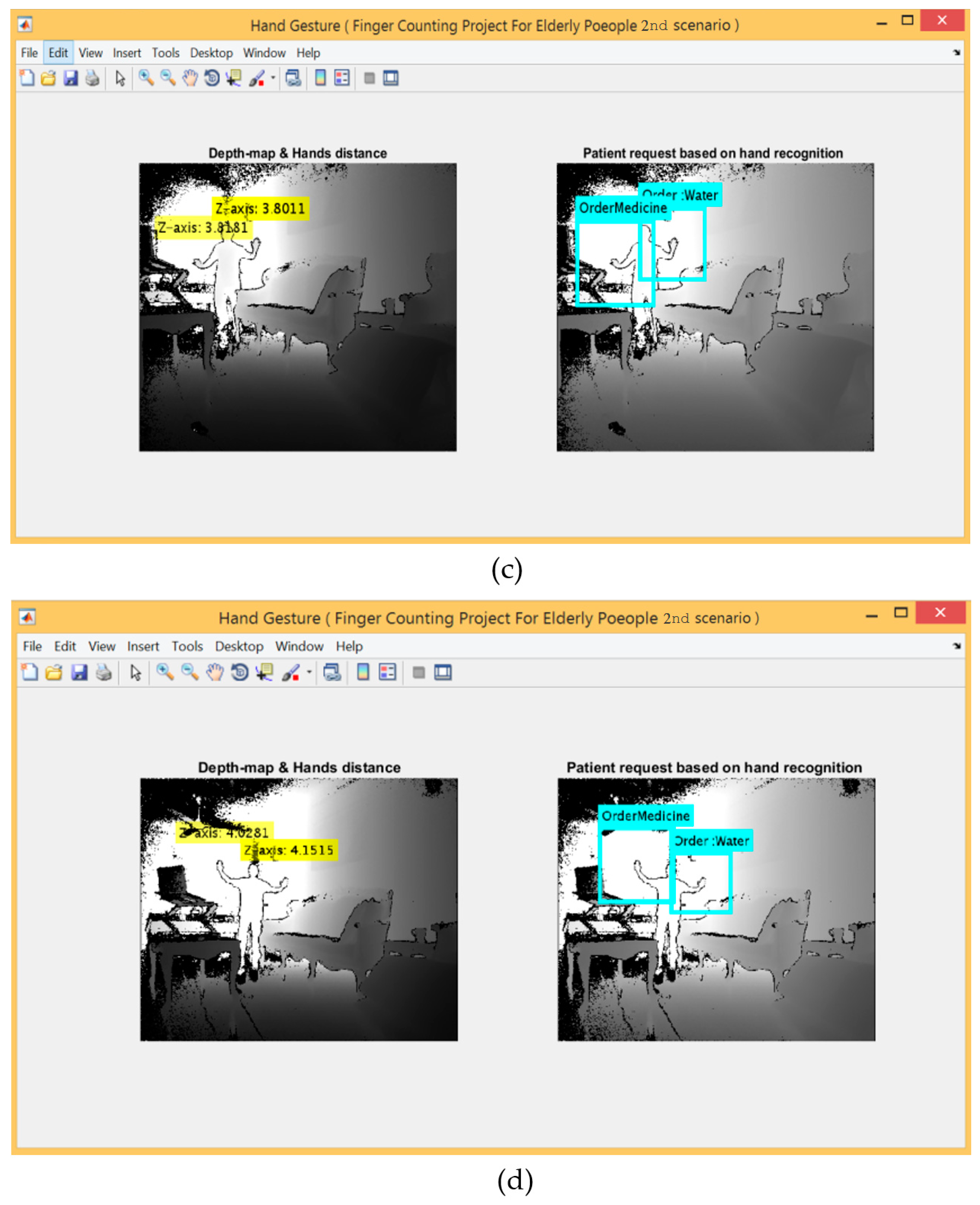
3.4.2. The Second Scenario: Hand Detection and Tracking Using Kinect V2 Embedded System
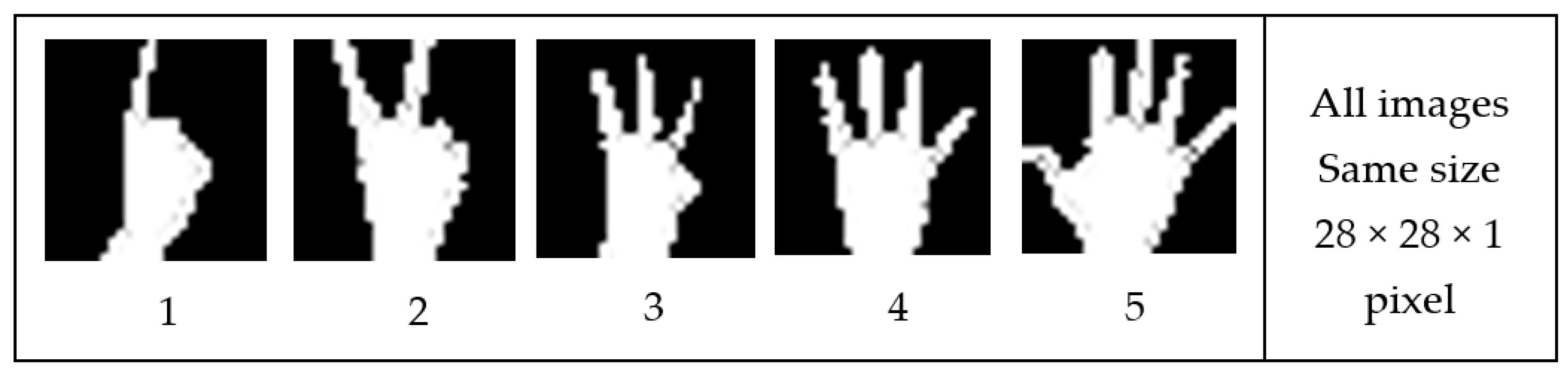
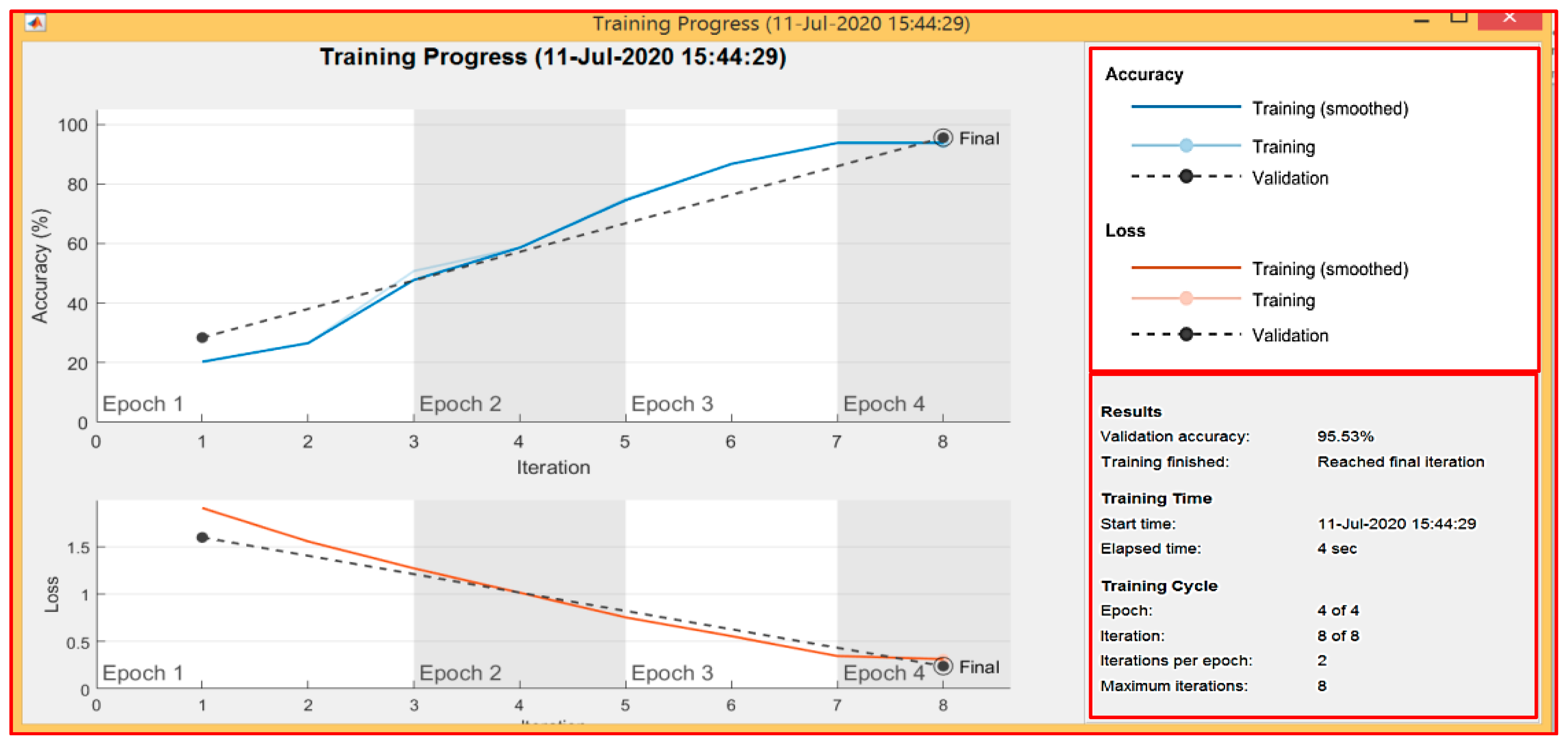
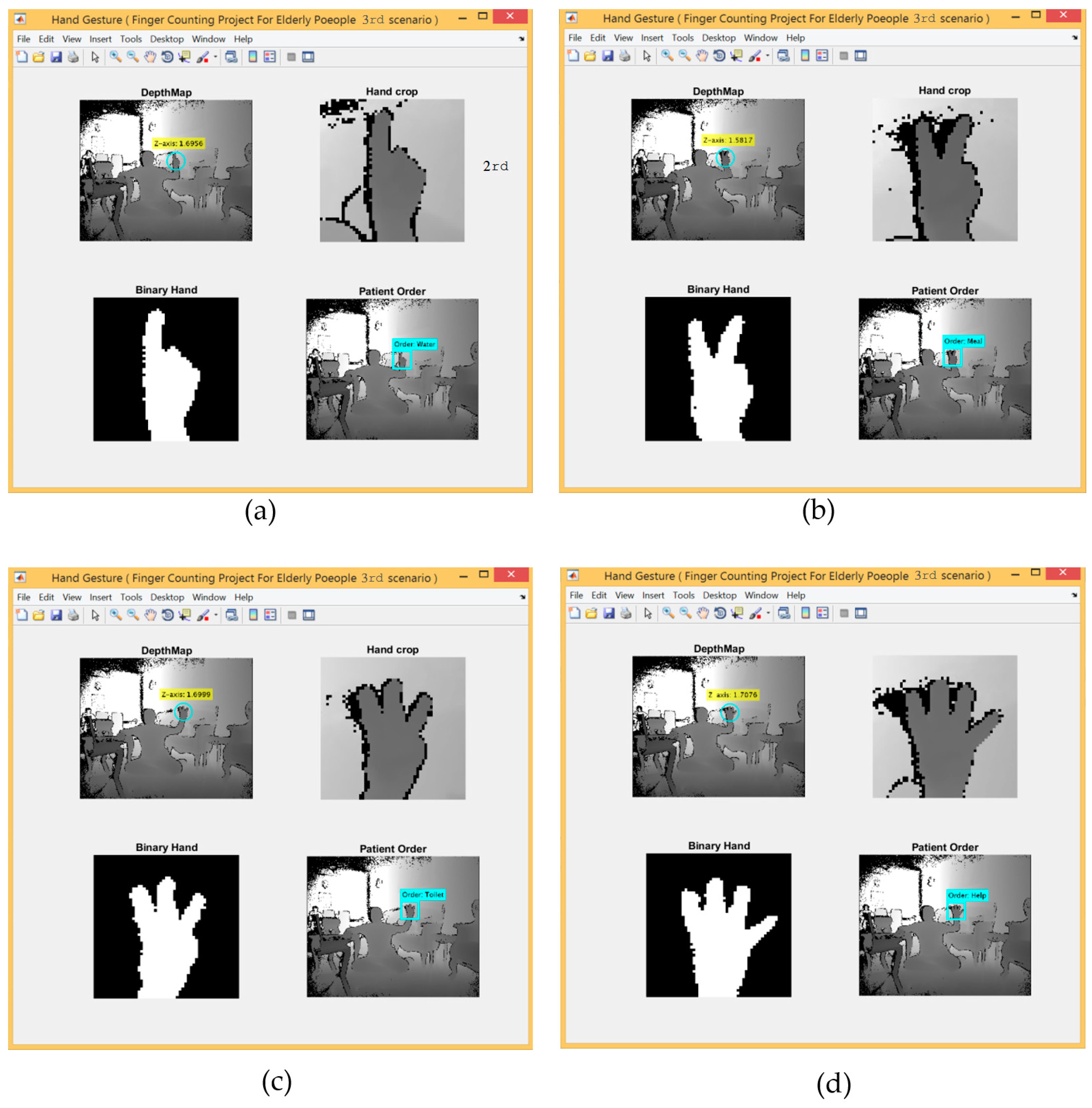
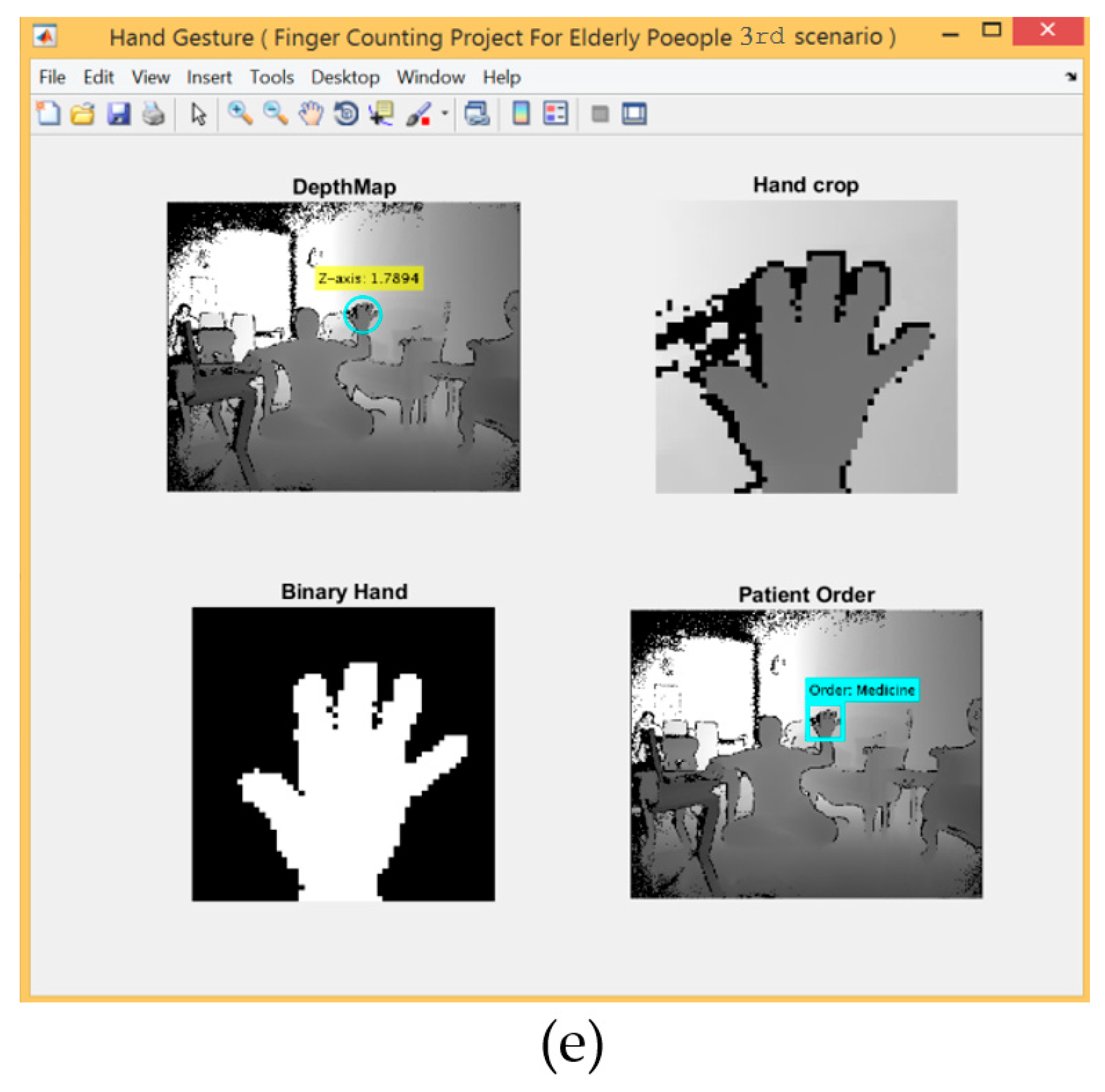
3.4.3. The Third Scenario: Hand Gestures Based on SCNN and Depth Metadata
- Specify Training and Validation Sets
- Define Network Architecture
- Input Layer Image
- 2.
- Convolutional Layer
- 3.
- Batch Normalisation Layer
- 4.
- ReLU Layer
- 5.
- Max Pooling Layer
- 6.
- Fully Connected Layer
- 7.
- Softmax Layer
- 8.
- Classification Layer
- Specify Training Options
- Train Network Using Training Data
4. Experimental Results and Discussion
4.1. Experimental Results
4.2. Discussion
- The first scenario offers acceptable results, but has limitations in regard to classification, where the number of fingers recognised is based on the apparent white area and results are affected by any white speckle.
- The second scenario provides a high recognition rate because it offers better flexibility in regard to distance during capturing the gestures in real-time if compared with other categories. However, the only type of gestures that can be read are three active gestures for every hand (from the default of the embedded system provided by the Kinect) and five hand gestures must be performed by both hands using three gestures for each hand, respectively.
- The third scenario provides a good recognition rate but suffered due to the distance limitation related to the range sensor used when the dataset was created.
4.3. Comparison Result with Related Work
- The two proposed methods presented in the first and second row by [112, 88] cannot use a dim environment because they use RGB and mobile cameras and effected by lightning conditions while this paper proposed three methods that can be used in a dim environment.
- The two proposed methods presented in the first and second row by [112, 88] can be used only at the short distance while this paper proposed three different methods with flexible distance.
- The two proposed methods presented in the first and second row by [112, 88] carried out only hand gesture recognition while this thesis proposed three hand gestures recognition methods with a practical circuit that send text message according to these gestures.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Truelsen, T.; Bonita, R.; Jamrozik, K. Surveillance of stroke: A global perspective. Int. J. Epidemiol. 2001, 30, S11–S16. [Google Scholar] [CrossRef] [PubMed]
- Pansare, J.R.; Gawande, S.H.; Ingle, M. Real-Time Static Hand Gesture Recognition for American Sign Language (ASL) in Complex Background. J. Signal Inf. Process. 2012, 3, 364–367. [Google Scholar] [CrossRef]
- Li, Y. Hand gesture recognition using Kinect. In Proceedings of the 2012 IEEE International Conference on Computer Science and Automation Engineering, Beijing, China, 22–24 June 2012; pp. 196–199. [Google Scholar]
- Poupyrev, I. Occluded Gesture Recognition. US Patent 9,778,749B2, 3 October 2017. [Google Scholar]
- Ma, X.; Peng, J. Kinect Sensor-Based Long-Distance Hand Gesture Recognition and Fingertip Detection with Depth Information. J. Sens. 2018, 2018, 1–9. [Google Scholar] [CrossRef]
- Ren, Z.; Meng, J.; Yuan, J. Depth camera based hand gesture recognition and its applications in Human-Computer-Interaction. In Proceedings of the 2011 8th International Conference on Information, Communications & Signal Processing, Singapore, 13–16 December 2011; pp. 1–5. [Google Scholar]
- Wen, Y.; Hu, C.; Yu, G.; Wang, C. A robust method of detecting hand gestures using depth sensors. In Proceedings of the 2012 IEEE International Workshop on Haptic Audio Visual Environments and Games (HAVE 2012) Proceedings, Munich, Germany, 8–9 October 2012; pp. 72–77. [Google Scholar]
- Lee, U.; Tanaka, J. Finger identification and hand gesture recognition techniques for natural user interface. In Proceedings of the 11th Asia Pacific Conference on Computer Human Interaction, Bangalore, India, 24–27 September 2013; pp. 274–279. [Google Scholar]
- Ma, B.; Xu, W.; Wang, S. A Robot Control System Based on Gesture Recognition Using Kinect. TELKOMNIKA Indones. J. Electr. Eng. 2013, 11, 2605–2611. [Google Scholar] [CrossRef]
- Marin, G.; Dominio, F.; Zanuttigh, P. Hand gesture recognition with leap motion and kinect devices. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 1565–1569. [Google Scholar]
- Abu Bakar, M.Z.; Samad, R.; Pebrianti, D.; Aan, N.L.Y. Real-time rotation invariant hand tracking using 3D data. In Proceedings of the 2014 IEEE International Conference on Control System, Computing and Engineering (ICCSCE 2014), Ferringhi, Malaysia, 28–30 November 2014; pp. 490–495. [Google Scholar]
- Abu Bakar, M.Z.; Samad, R.; Pebrianti, D.; Mustafa, M.; Abdullah, N.R.H. Finger application using K-Curvature method and Kinect sensor in real-time. In Proceedings of the 2015 International Symposium on Technology Management and Emerging Technologies (ISTMET), Langkawai Island, Malaysia, 25–27 August 2015; pp. 218–222. [Google Scholar]
- Karbasi, M.; Bhatti, Z.; Nooralishahi, P.; Shah, A.; Mazloomnezhad, S.M.R. Real-time hands detection in depth image by using distance with Kinect camera. Int. J. Internet Things 2015, 4, 1–6. [Google Scholar]
- Kim, M.-S.; Lee, C.H. Hand Gesture Recognition for Kinect v2 Sensor in the Near Distance Where Depth Data Are Not Provided. Int. J. Softw. Eng. Its Appl. 2016, 10, 407–418. [Google Scholar] [CrossRef][Green Version]
- Pal, D.H.; Kakade, S.M. Dynamic hand gesture recognition using kinect sensor. In Proceedings of the 2016 International Conference on Global Trends in Signal Processing, Information Computing and Communication (ICGTSPICC), Jalgaon, India, 22–24 December 2016; pp. 448–453. [Google Scholar]
- Desai, S.; Desai, A.A. Human Computer Interaction Through Hand Gestures for Home Automation Using Microsoft Kinect. In Proceedings of International Conference on Communication and Networks. Advances in Intelligent Systems and Computing; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2017; Volume 508, pp. 19–29. [Google Scholar]
- Desai, S. Segmentation and Recognition of Fingers Using Microsoft Kinect. In Proceedings of International Conference on Communication and Networks. Advances in Intelligent Systems and Computing; Springer: Singapore; Berlin/Heidelberg, Germany, 2017; Volume 508, pp. 45–53. [Google Scholar]
- Xi, C.; Chen, J.; Zhao, C.; Pei, Q.; Liu, L. Real-time Hand Tracking Using Kinect. In Proceedings of the 2nd International Conference on Digital Signal Processing ICDSP, Tokyo Japan, 25–27 February 2018; pp. 37–42. [Google Scholar] [CrossRef]
- Li, J.; Wang, J.; Ju, Z. A Novel Hand Gesture Recognition Based on High-Level Features. Int. J. Humanoid Robot. 2018, 15, 1750022. [Google Scholar] [CrossRef]
- Özerdem, M.S.; Bamwenda, J. Recognition of static hand gesture with using ANN and SVM. DÜMF Mühendislik Dergisi 2019, 10, 561–568. [Google Scholar] [CrossRef][Green Version]
- Oudah, M.; Al-Naji, A.; Chahl, J.S. Hand Gesture Recognition Based on Computer Vision: A Review of Techniques. J. Imaging 2020, 6, 73. [Google Scholar] [CrossRef]
- Samir, M.; Golkar, E.; Rahni, A.A.A. Comparison between the KinectTM V1 and KinectTM V2 for respiratory motion tracking. In Proceedings of the 2015 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 19–21 October 2015; pp. 150–155. [Google Scholar]
- Kim, C.; Yun, S.; Jung, S.-W.; Won, C.S. Color and Depth Image Correspondence for Kinect v2. In Lecture Notes in Electrical Engineering; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2015; pp. 111–116. [Google Scholar]
- Yang, L.; Zhang, L.; Dong, H.; Alelaiwi, A.; El Saddik, A. Evaluating and Improving the Depth Accuracy of Kinect for Windows v2. IEEE Sensors J. 2015, 15, 4275–4285. [Google Scholar] [CrossRef]
- Sarbolandi, H.; Lefloch, D.; Kolb, A. Kinect range sensing: Structured-light versus Time-of-Flight Kinect. Comput. Vis. Image Underst. 2015, 139, 1–20. [Google Scholar] [CrossRef]
- Mutto, C.D.; Zanuttigh, P.; Cortelazzo, G.M. Time-Of-Flight Cameras and Microsoft Kinect (TM); Springer Publishing Company Incorporated: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Al-Naji, A.; Gibson, K.; Lee, S.-H.; Chahl, J.S. Real Time Apnoea Monitoring of Children Using the Microsoft Kinect Sensor: A Pilot Study. Sensors 2017, 17, 286. [Google Scholar] [CrossRef] [PubMed]
- Al-Naji, A.; Chahl, J.S. Detection of Cardiopulmonary Activity and Related Abnormal Events Using Microsoft Kinect Sensor. Sensors 2018, 18, 920. [Google Scholar] [CrossRef] [PubMed]
- Sudhan, R.; Kumar, M.; Prakash, A.; Devi, S.R.; Sathiya, P. Arduino ATMEGA-328 microcontroller. IJIREEICE 2015, 3, 27–29. [Google Scholar] [CrossRef]
- Mluyati, S.; Sadi, S. Internet of Things (IoT) Pada Prototipe Pendeteksi Kebocoran Gas Berbasis MQ-2 Dan SIM800L. J. Tek. 2019, 7, 2. [Google Scholar]
- Oudah, M.; Al-Naji, A.; Chahl, J. Hand Gestures for Elderly Care Using a Microsoft Kinect. Nano Biomed. Eng. 2020, 12, 3. [Google Scholar]
- Ganokratanaa, T.; Pumrin, S. The vision-based hand gesture recognition using blob analysis. In Proceedings of the 2017 International Conference on Digital Arts, Media and Technology (ICDAMT), Chiang Mai, Thailand, 1–4 March 2017; pp. 336–341. [Google Scholar]
- Alnaim, N.; Abbod, M.; Albar, A. Hand Gesture Recognition Using Convolutional Neural Network for People Who Have Experienced A Stroke. In Proceedings of the 2019 3rd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 10–11 December 2019; pp. 1–6. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Type of Camera | Resolution | Techniques/Methods for Segmentation | Feature Extract Type | Classify Algorithm | Recognition Rate | No. of Gestures | Application Area | Invariant Factor | Distance from Camera |
|---|---|---|---|---|---|---|---|---|---|---|
| Ren et al. [6] 2011 | Kinect V1 | 640 × 480 320 × 240 | depth map & colour image | finger | Near-convex Decomposition & Finger-Earth Mover’s Distance (FEMD) | 93.9% | 10-gesture | HCI applications | No | No |
| Wen et al. [7] 2012 | Kinect V1 | Depth– 640 × 480 | skin colour segmentation and depth joint | fingertip | K-means clustering & convex hull | No | fingertip gesture | human-computer interaction (HCI) | No | No |
| Li et al. [3] 2012 | Kinect V1 | 640 × 480 320 × 240 | Depth thresholds | fingertip | K-means clustering algorithm convex hulls | 90% | 9-gesture | real-time communication such as chatting with speech | the difficulty of recognising one of the nine gesture | 0.5 to 0.8 m |
| Lee et al. [8] 2013 | Kinect V1 | 640 × 480 320 × 240 | 3D depth sensor | fingertips | shape bases matching | 91% | 6-gesture | finger painting and mouse controlling | low accuracy in rough conditions | 0.5 to 0.8 m |
| Ma et al. [9] 2013 | Kinect V1 | 640 × 480 320 × 240 | depth threshold | fingertip | k-curvature algorithm | No | 5-gesture | human-robot interactions | No | No |
| Marin et al. [10] 2014 | Kinect V1 | depth– 640 × 480 | depth and colour data & leap motion | Position of the fingertips | multi-class SVM classifier | 91:3% | 10-gesture | a subset of the American Manual Alphabet | Leap motion is limit while Kinect provides the full depth map. | No |
| Bakar et al. [11] 2014 | Kinect V1 | depth– 640 × 480 | threshold range | hand gesture | No | No | hand gesture | hand rehabilitation system | No | 0.4–1.5 m |
| Bakar et al. [12] 2015 | Kinect V1 | depth– 640 × 480 | depth threshold and K-curvature | finger counting | depth threshold and K-curvature | 73.7% | 5 gestures | picture selection application | detection fingertips should though the hand was moving or rotating | No |
| Karbasi et al. [13] 2015 | Kinect V1 | depth– 640 × 480 | distance method | hand gesture | No | No | hand gesture | human-computer interaction (HCI) | No | No |
| Kim et al. [14] 2016 | Kinect V2 | depth– 512 × 424 | operation of depth and infrared images | finger counting & hand gesture | number of separate areas | No | finger count & two hand gestures | mouse-movement controlling | No | <0.5 m |
| Pal et al. [15] 2016 | Kinect V1 | 640 × 480 320 × 240 | skin and motion detection & hu moments | dynamic hand gesture | Discrete Hidden Markov Model | Table | single handed postures combination of position, orientation & 10-gesture | controlling DC servo motor action | backward movement gesture effect recognition rate | No |
| Desai et al. [16] 2017 | Kinect V1 | depth– 640 × 480 | range of depth image | hand gestures 1–5 | kNN classifier & Euclidian distance | 88% | 5 gestures | electronic home appliances | No | 0.25–0.65 m |
| Desai et al. [17] 2017 | Kinect V2 | RGB– 1920 × 1080 depth– 512 × 424 | Otsu’s global threshold | finger gesture | kNN classifier & Euclidian distance | 90% | finger count | Human computer interaction (HCI) | hand not identified if it’s not connected with boundary | 0.25–0.65 m |
| Xi et al. [18] 2018 | Kinect V2 | 1920 × 1080 512 × 424 | threshold and recursive connected component analysis | hand skeleton & fingertip | Euclidean distance and geodesic distance | No | hand motion | controlling actions and interactions. | occlusions may have side effects on the depth data. | No |
| Li et al. [19] 2018 | Kinect V2 | RGB– 1920 × 1080 depth– 512 × 424 | double-threshold segmentation and skeletal data | fingertip | fingertip angle characteristics & SIFT key points | No | 10-gesture | (HCI) | some constraints are set in hand segmentation | No |
| Ma et al. [5] 2018 | Kinect V2 | 1920 × 1080 512 × 424 | threshold segmentation & local neighbour method | fingertip | convex hull detection algorithm | 96 % | 6-gesture | natural human-robot interaction. | Some small noise spots around the hands will reduce the detection performance of fingertips | 0.5 to 2.0 m |
| Bamwenda et al. [20] 2019 | Kinect V2 | depth– 512 × 424 | skeletal data stream & depth & colour data streams | hand gesture | support vector machine (SVM) & artificial neural networks (ANN) | 93.4% for SVM 98.2% for ANN | 24 alphabets hand gesture | American Sign Language | No | 0.5–0.8 m |
| Feature | Description |
|---|---|
| Body tracking | Up to 6 persons |
| Joint detection | Up to 25 joint per person |
| Depth sensing | 512 × 424 resolution 30 Hz |
| Active infrared | 3 IR emitter |
| Colour camera | 1920 × 1080 resolution 30 Hz |
| Depth range | 0.5 m to 4.5 m |
| Field of view | 70-horizontal and 60-vertical |
| Microphone array | Four microphone sensors linearly aligned |
| No. | Parameters of the Body Data Obtained by the Depth Sensor | Struct Array |
|---|---|---|
| 1 | IsBodyTracked | [1 × 6 logical] |
| 2 | BodyTrackingID | [1 × 6 double] |
| 3 | BodyIndexFrame | [424 × 512 double] |
| 4 | ColorJointIndices | [25 × 2 × 6 double] |
| 5 | DepthJointIndices | [25 × 2 × 6 double] |
| 6 | HandLeftState | [1 × 6 double] |
| 7 | HandRightState | [1 × 6 double] |
| 8 | HandLeftConfidence | [1 × 6 double] |
| 9 | HandRightConfidence | [1 × 6 double] |
| 10 | JointTrackingStates | [25 × 6 double] |
| 11 | JointPositions | [25 × 3 × 6 double] |
| Hand Gesture Type | Total Number of the Sample per Tested Gesture | Number of Recognised Gestures | Number of Unrecognised Gestures | Percentage of Correct Recognition for Total Number of Sample Gesture % | Percentage of Fault Recognition for Total Number of Sample Gesture % |
|---|---|---|---|---|---|
| 0 | 65 | 65 | 0 | 100.00 | 0 |
| 1 | 65 | 55 | 10 | 84.62 | 15.38 |
| 2 | 65 | 52 | 13 | 80.00 | 20.00 |
| 3 | 65 | 50 | 15 | 76.92 | 23.08 |
| 4 | 65 | 49 | 16 | 75.38 | 24.62 |
| 5 | 65 | 53 | 12 | 81.54 | 18.6 |
| Total | 390 | 324 | 66 | 83.07% | 16.94% |
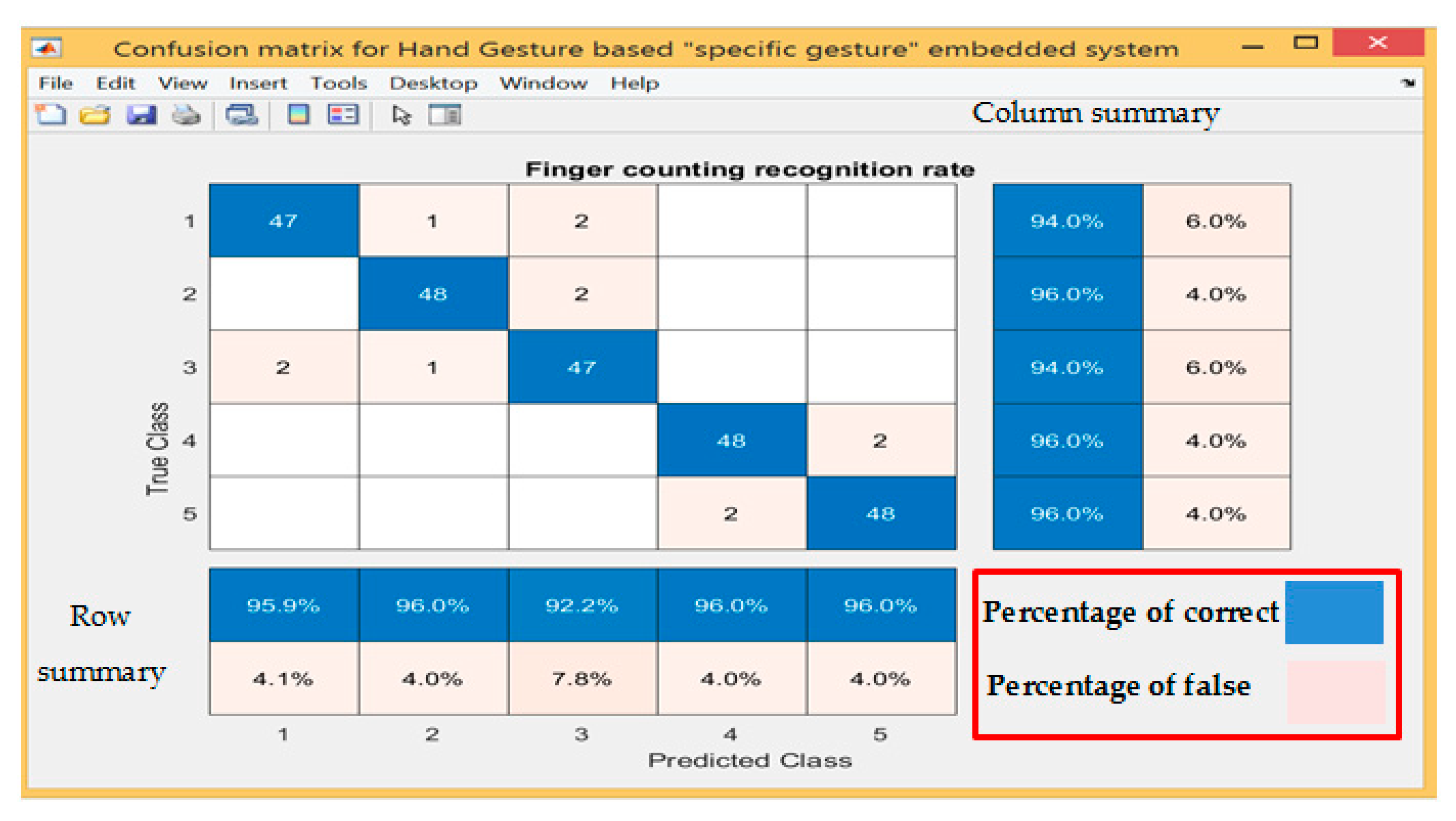
| Hand Gesture Type | Total Number of Sample per Tested Gesture | Number of Recognised Gestures | Number of Unrecognised Gestures | Percentage of Correct Recognition for Total Number of Sample Gesture % | Percentage of Fault Recognition for Total Number of Sample Gesture % |
|---|---|---|---|---|---|
| 1 | 50 | 47 | 3 | 94.00 | 6.00 |
| 2 | 50 | 48 | 2 | 96.00 | 4.00 |
| 3 | 50 | 47 | 3 | 94.00 | 6.00 |
| 4 | 50 | 48 | 2 | 96.00 | 4.00 |
| 5 | 50 | 48 | 2 | 96.00 | 4.00 |
| Total | 250 | 238 | 12 | 95.2% | 4.8% |
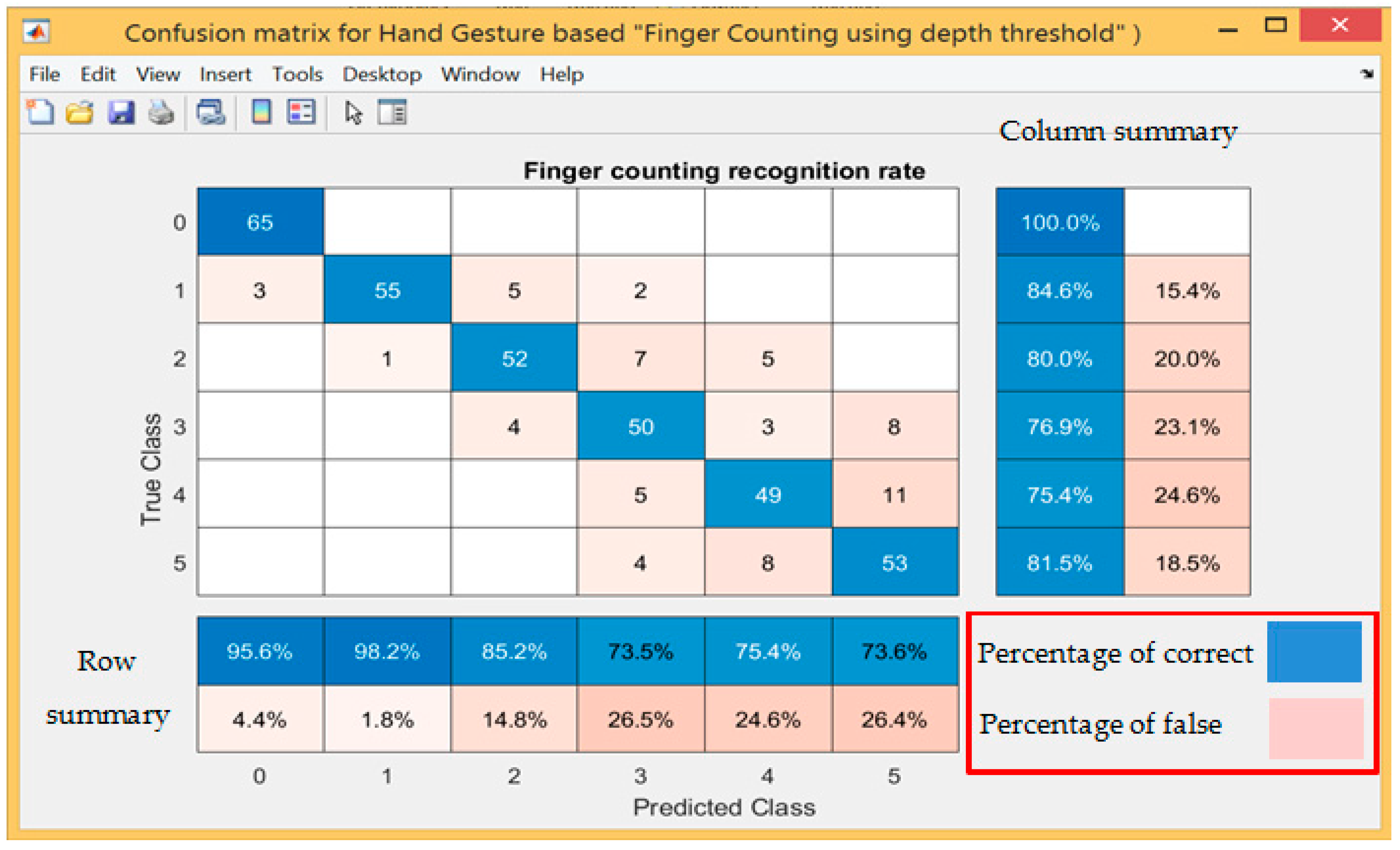
| Hand Gesture Type | Total Number of Sample per Tested Gesture | Number of Recognised Gestures | Number of Unrecognised Gestures | Percentage of Correct Recognition for Total Number of Sample Gesture % | Percentage of Fault Recognition for Total Number of Sample Gesture % |
|---|---|---|---|---|---|
| 1 | 65 | 64 | 1 | 98.46 | 1.54 |
| 2 | 73 | 73 | 0 | 100.00 | 0.00 |
| 3 | 49 | 49 | 0 | 100.00 | 0.00 |
| 4 | 65 | 53 | 12 | 81.54 | 18.46 |
| 5 | 61 | 60 | 1 | 98.36 | 1.6 |
| Total | 313 | 299 | 14 | 95.53% | 4.47% |
| Method | Type of Gesture | Principle | Classification | Image Pixel | Recognition Rate | Distance from the Camera |
|---|---|---|---|---|---|---|
| Scenario 1 | Finger count (0–5) Single hand | Depth threshold and skeleton joint tracking using metadata information | Appearance of white area | 512 × 424 | 83.07% | 1.2~1.5 m |
| Scenario 2 | Specific gesture both hand | Metadata parameter | Hand left state, hand right state parameter by Kinect depth | 512 × 424 | 95.2% | 0.5~4.5 m |
| Scenario 3 | Finger count image features (1–5) Single hand | SCNN Depth metadata | CNN | Dataset 28 × 28 × 1 | 95.53% | 1.5~1.7 m |
| Ref | Camera | Number of Gesture | Principle | Classification Algorithm | Issues | Recognition Rate | Distance from the Camera |
|---|---|---|---|---|---|---|---|
| Ganokr-atanaa et al. [32] 2017 | RGB camera | 6 gestures | optical flow and blob analysis | blob analysis technique | error pre-processing stage because shadow under the hand | good results | Not mentioned |
| Norah et al. [33] 2019 | Mobile Camera | 7 gestures | CNN | CNN | backgrounds, illumination | accuracy is 99% | short distances |
| This paper | Depth camera | 5 gestures | Depth threshold | Connected component | White speckle | 83.07% | 1.2~1.5 m |
| embedded | - - | Depth range | 95.2% | 0.5~4.5 m | |||
| CNN | CNN | Depth range | 95.53% | 1.5~1.7 m |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oudah, M.; Al-Naji, A.; Chahl, J. Elderly Care Based on Hand Gestures Using Kinect Sensor. Computers 2021, 10, 5. https://doi.org/10.3390/computers10010005
Oudah M, Al-Naji A, Chahl J. Elderly Care Based on Hand Gestures Using Kinect Sensor. Computers. 2021; 10(1):5. https://doi.org/10.3390/computers10010005
Chicago/Turabian StyleOudah, Munir, Ali Al-Naji, and Javaan Chahl. 2021. "Elderly Care Based on Hand Gestures Using Kinect Sensor" Computers 10, no. 1: 5. https://doi.org/10.3390/computers10010005
APA StyleOudah, M., Al-Naji, A., & Chahl, J. (2021). Elderly Care Based on Hand Gestures Using Kinect Sensor. Computers, 10(1), 5. https://doi.org/10.3390/computers10010005