An Order-Sensitive Hierarchical Neural Model for Early Lung Cancer Detection Using Dutch Primary Care Notes and Structured Data

 , , , and
, , , and
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Patient and Data
2.2. Data and Predictor Extraction
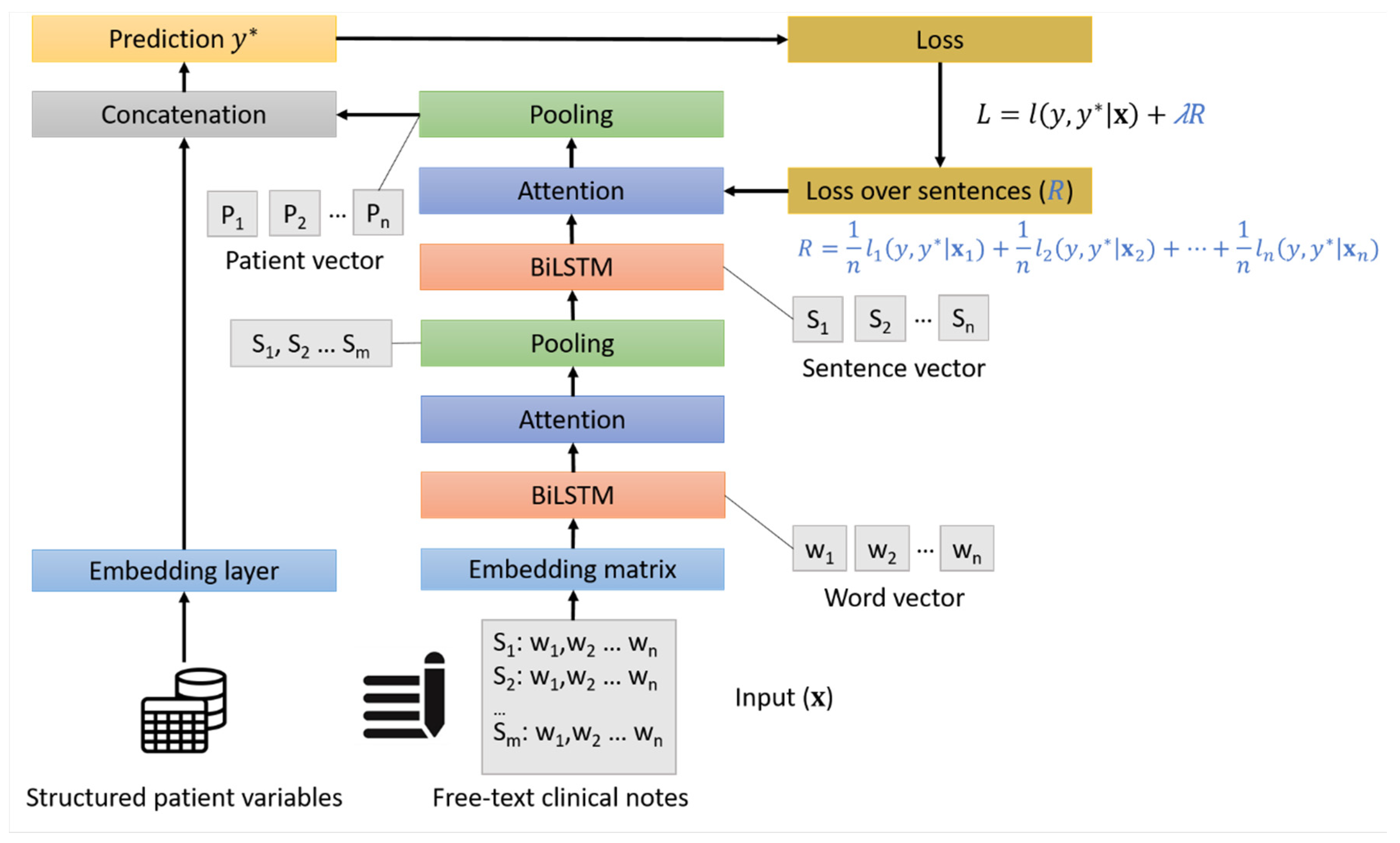
2.3. Model Development
2.4. Model Evaluation
3. Results
3.1. Patient Characteristics
3.2. Predictive Performance of the HAN Models
3.3. Ablation Study and Comparison with Other Models
- Hierarchical network (HN). It is a variation of the HAN-Text model where the attention layers have been removed.
- LSTM. A flat LSTM model, which does not exploit the hierarchy of words and sentences. Here, a BiLSTM layer represents a patient note (visit) and the final patient representation averages the representation of each note of the same patient.
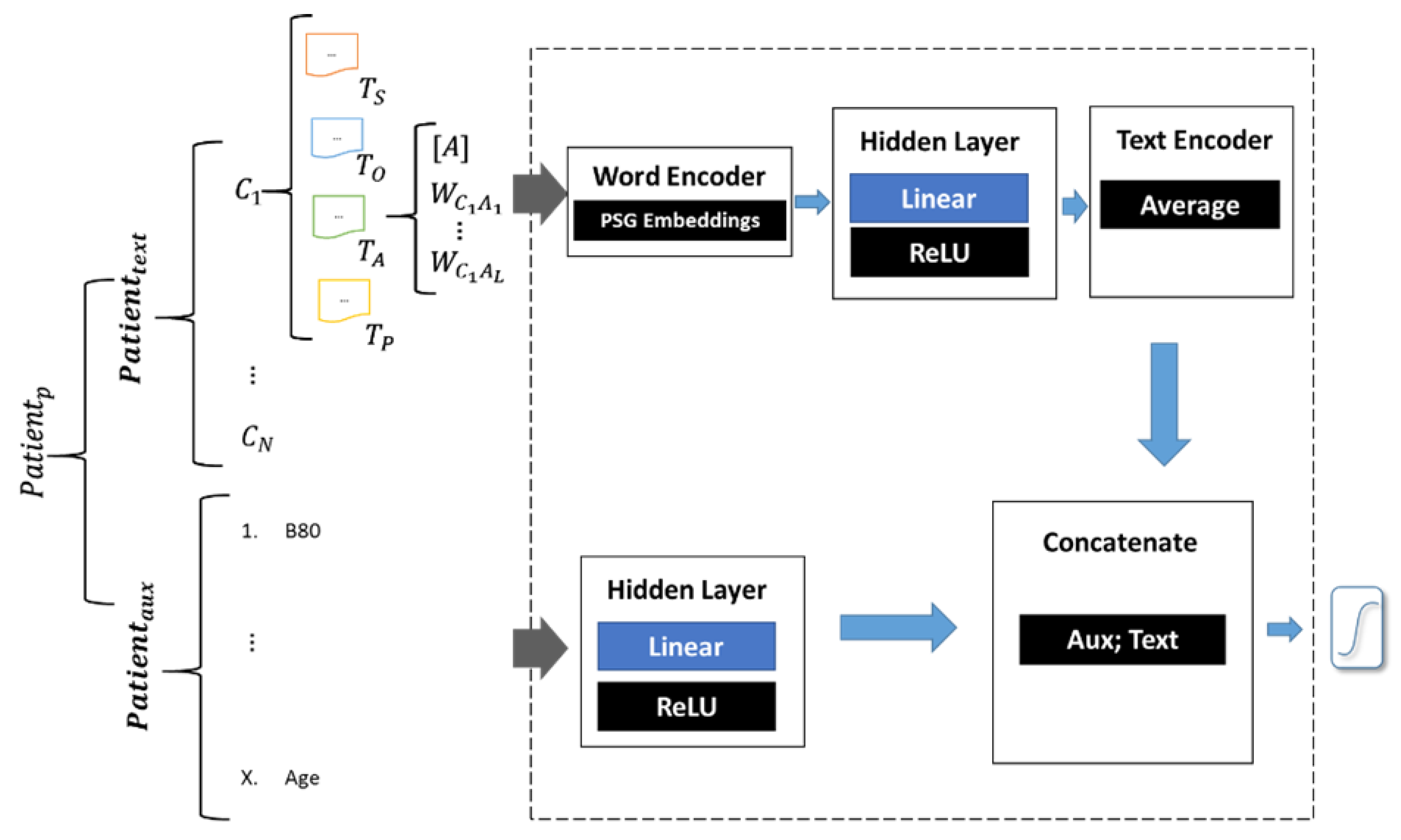
- Phrase Skip-Gram Neural Network (PSGNN). This model uses representation of 3-word phrases obtained with the Phrase Skip-Gram (PSG) algorithm [4]. These representations (embeddings) were then fed to a neural network prediction model through a hidden layer. The output of this layer was averaged to produce a single embedding that represents all the patient text. A logistic regression model was used to predict the probability of lung cancer. The architecture of the PGSNN model is shown in Figure A1 and described more in detail in Appendix A.
- Convolutional Neural Network (CNN). A two-layers CNN with max-pooling and target replication as performed by Grnarova et al. for mortality prediction [9]. The model is described more in detail in Appendix A.
4. Discussion
4.1. Main Findings
4.2. Related Work
4.3. Strengths and Limitations
4.4. Implications
4.5. Future Research
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Actual | |||
|---|---|---|---|
| Non Lung Cancer | Lung Cancer | ||
| Predicted | Non lung cancer | 30,992 | 31 |
| Lung cancer | 5402 | 109 | |
| Actual | |||
|---|---|---|---|
| Non Lung Cancer | Lung Cancer | ||
| Predicted | Non lung cancer | 33,766 | 48 |
| Lung cancer | 2628 | 92 | |
References
- Helsper, C.C.W.; van Erp, N.N.F.; Peeters, P.; de Wit, N.N. Time to diagnosis and treatment for cancer patients in the Netherlands: Room for improvement? Eur. J. Cancer 2017, 87, 113–121. [Google Scholar] [CrossRef] [PubMed]
- Hippisley-Cox, J.; Coupland, C. Identifying patients with suspected lung cancer in primary care: Derivation and validation of an algorithm. Br. J. Gen. Pract. J. R. Coll. Gen. Pract. 2011, 61, e715–e723. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, W.; Peters, T.J.; Round, A.; Sharp, D. What are the clinical features of lung cancer before the diagnosis is made? A population based case-control study. Thorax 2005, 60, 1059–1065. [Google Scholar] [CrossRef] [PubMed]
- Schut, M.C.; Luik, T.T.; Vagliano, I.; Rios, M.; Helsper, C.; van Asselt, K.; de Wit, N.; Abu-Hanna, A.; van Weert, H. Artificial Intelligence for early detection of lung cancer in General Practitioners’ clinical notes. Br. J. Gen. Pract. 2025, BJGP.2023.0489. [Google Scholar] [CrossRef]
- Luik, T.T.; Rios, M.; Abu-Hanna, A.; van Weert, H.C.P.M.; Schut, M.C. The Effectiveness of Phrase Skip-Gram in Primary Care NLP for the Prediction of Lung Cancer. In Proceedings of the Artificial Intelligence in Medicine. AIME 2021, Virtual, 15–18 June 2021; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2021; Volume 12721. [Google Scholar] [CrossRef]
- Vagliano, I.; Dormosh, N.; Rios, M.; Luik, T.; Buonocore, T.; Elbers, P.; Dongelmans, D.; Schut, M.; Abu-Hanna, A. Prognostic models of in-hospital mortality of intensive care patients using neural representation of unstructured text: A systematic review and critical appraisal. J. Biomed. Inform. 2023, 146, 104504. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Z.; Razavian, N. Deep EHR: Chronic Disease Prediction Using Medical Notes. In Proceedings of the 3rd Machine Learning for Healthcare Conference, Palo Alto, CA, USA, 17–18 August 2018; Volume 85, pp. 440–464. [Google Scholar]
- Wang, G.; Liu, X.; Xie, K.; Chen, N.; Chen, T. DeepTriager: A Neural Attention Model for Emergency Triage with Electronic Health Records. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 978–982. [Google Scholar] [CrossRef]
- Grnarova, P.; Schmidt, F.; Hyland, S.L.; Eickhoff, C. Neural document embeddings for intensive care patient mortality prediction. In Proceedings of the Machine learning for Health, Barcelona, Spain, 2016. [Google Scholar]
- Lipton, Z.C.; Kale, D.C.; Elkan, C.; Wetzel, R.C. Learning to Diagnose with LSTM Recurrent Neural Networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Elfrink, A.; Vagliano, I.; Abu-Hanna, A.; Calixto, I. Soft-Prompt Tuning to Predict Lung Cancer Using Primary Care Free-Text Dutch Medical Notes. In Proceedings of the Artificial Intelligence in Medicine. AIME 2023, Portoroz, Slovenia, 12–15 June 2023; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2023; Volume 13897. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (2016), San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Mikolov, I.; Sutskever, K.; Chen, K.; Corrado, G.; Jeffrey, D. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems—Volume 2 (NIPS’13), Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Hamilton, W. The CAPER studies: Five case-control studies aimed at identifying and quantifying the risk of cancer in symptomatic primary care patients. Br. J. Cancer 2009, 101 (Suppl. S2), S80–S86. [Google Scholar] [CrossRef]
- Coupland, C.; Hippisley-Cox, J. Predicting risk of bladder cancer in the UK. Br. J. Gen. Pract. J. R. Coll. Gen. Pract. 2012, 62, 570–571. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Stahlschmidt, S.R.; Ulfenborg, B.; Synnergren, J. Multimodal deep learning for biomedical data fusion: A review. Brief Bioinform. 2022, 23, bbab569. [Google Scholar] [CrossRef]
- Steyerberg, E. Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating, Statistics for Biology and Health; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Hanna, T.P.; King, W.D.; Thibodeau, S.; Jalink, M.; Paulin, G.A.; Harvey-Jones, E.; O’Sullivan, D.E.; Booth, C.M.; Sullivan, R.; Aggarwal, A. Mortality due to cancer treatment delay: Systematic review and meta-analysis. BMJ 2020, 371, m4087. [Google Scholar] [CrossRef]
- McDermott, M.; Zhang, H.; Hansen, L.; Angelotti, G.; Gallifant, J. A Closer Look at AUROC and AUPRC under Class Imbalance. Adv. Neural Inf. Process. Syst. 2024, 37, 44102–44163. [Google Scholar]
- Seinen, T.M.; A Fridgeirsson, E.; Ioannou, S.; Jeannetot, D.; John, L.H.; A Kors, J.; Markus, A.F.; Pera, V.; Rekkas, A.; Williams, R.D.; et al. Use of unstructured text in prognostic clinical prediction models: A systematic review. J. Am. Med. Inform. Assoc. 2022, 29, 1292–1302. [Google Scholar]
- Gao, Y.; Dligach, D.; Christensen, L.; Tesch, S.; Laffin, R.; Xu, D.; Miller, T.; Uzuner, O.; Churpek, M.M.; Afshar, M. A scoping review of publicly available language tasks in clinical natural language processing. J. Am. Med. Inform. Assoc. 2022, 29, 1797–1806. [Google Scholar] [PubMed]
- Kalyan, K.S.; Sangeetha, S. SECNLP: A survey of embeddings in clinical natural language processing. J. Biomed. Inform. 2020, 101, 103323. [Google Scholar]
- Kop, R.; Hoogendoorn, M.; Teije, A.T.; Büchner, F.L.; Slottje, P.; Moons, L.M.; Numans, M.E. Predictive modeling of colorectal cancer using a dedicated pre-processing pipeline on routine electronic medical records. Comput. Biol. Med. 2016, 76, 30–38. [Google Scholar] [PubMed]
- Hoogendoorn, M.; Szolovits, P.; Moons, L.M.; Numans, M.E. Utilizing uncoded consultation notes from electronic medical records for predictive modeling of colorectal cancer. Artif. Intell. Med. 2016, 69, 53–61. [Google Scholar]
- Amirkhan, R.; Hoogendoorn, M.; Numans, M.E.; Moons, L. Using recurrent neural networks to predict colorectal cancer among patients. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017. [Google Scholar]
- Miotto, R.; Li, L.; Kidd, B.A.; Dudley, J.T. Deep Patient: An Unsupervised Representation to Predict the Future of Patients from the Electronic Health Records. Sci. Rep. 2016, 6, 26094. [Google Scholar]
- Boag, W.; Doss, D.; Naumann, T.; Szolovits, P. What’s in a Note? Unpacking Predictive Value in Clinical Note Representations. AMIA Jt Summits Transl Sci Proc. 2018, 2017, 26–34. [Google Scholar]
- Luik, T.T.; Abu-Hanna, A.; van Weert, H.C.P.M.; Schut, M.C. Early detection of colorectal cancer by leveraging Dutch primary care consultation notes with free text embeddings. Sci. Rep. 2023, 13, 10760. [Google Scholar] [CrossRef]
- Benedum, C.M.; Sondhi, A.; Fidyk, E.; Cohen, A.B.; Nemeth, S.; Adamson, B.; Estévez, M.; Bozkurt, S. Replication of Real-World Evidence in Oncology Using Electronic Health Record Data Extracted by Machine Learning. Cancers 2023, 15, 1853. [Google Scholar] [CrossRef]
- Khadanga, S.; Aggarwal, K.; Joty, S.; Srivastava, J. Using Clinical Notes with Time Series Data for ICU Management. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Seattle, WA, USA; pp. 6432–6437. [Google Scholar]
- Lovelace, J.; Hurley, N.; Haimovich, A.; Mortazavi, B. Dynamically Extracting Outcome-Specific Problem Lists from Clinical Notes with Guided Multi-Headed Attention. In Proceedings of the 5th Machine Learning for Healthcare Conference 2020, Virtual, 7–8 August 2020; pp. 245–270. [Google Scholar]
- Hashir, M.; Sawhney, R. Towards unstructured mortality prediction with free-text clinical notes. J. Biomed. Inform. 2020, 108, 103489. [Google Scholar]
- Zhang, D.; Yin, C.; Zeng, J.; Yuan, X.; Zhang, P. Combining structured and unstructured data for predictive models: A deep learning approach. BMC Med. Inform. Decis. Mak. 2020, 20, 280. [Google Scholar]
- Lin, M.; Wang, S.; Ding, Y.; Zhao, L.; Wang, F.; Peng, Y. An empirical study of using radiology reports and images to improve ICU-mortality prediction. IEEE Int. Conf. Healthc. Inform. 2021, 2021, 497–498. [Google Scholar]
- Naik, A.; Parasa, S.; Feldman, S.; Wang, L.; Hope, T. Literature-Augmented Clinical Outcome Prediction. In Findings of the Association for Computational Linguistics: NAACL 2022; Association for Computational Linguistics: Seattle, WA, USA, 2022; pp. 438–453. [Google Scholar]
- van Aken, B.; Papaioannou, J.-M.; Mayrdorfer, M.; Budde, K.; Gers, F.; Loeser, A. Clinical Outcome Prediction from Admission Notes using Self-Supervised Knowledge Integration. In Proceedings of the EACL 2021, Virtual, 16 April 2021; pp. 881–893. [Google Scholar]
- Kehl, K.L.; Xu, W.; Lepisto, E.; Elmarakeby, H.; Hassett, M.J.; Van Allen, E.M.; Johnson, B.E.; Schrag, D. Natural Language Processing to Ascertain Cancer Outcomes from Medical Oncologist Notes. JCO Clin. Cancer Inform. 2020, 4, 680–690. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]

| Sentence 1 | S word1, word2, word3 … O word1, word2, word3…E… P … |
| Sentence 2 | S word1 word2, … O word1, … E word1, … P word1, …. |
| Non-Lung Cancer | Lung Cancer | Total | |
|---|---|---|---|
| N (%) | 182,300 (99.61) | 712 (0.39) | 183,012 (100.00) |
| Age—Median (IQR) | 52 (40–64) | 68 (61–76) | 52 (40–64) |
| Number of consultations per patient—Mean (SD) | 140 (170) | 160 (170) | 140 (170) |
| Number of unique ICPC codes per patient—Mean (SD) | 12 (32) | 11 (28) | 12 (32) |
| Model | AUROC | AUPRC | Brier Score (×100) |
|---|---|---|---|
| HAN-Text | 0.908 (0.886, 0.932) | 0.0773 (0.030, 0.103) | 0.37 (0.31, 0.43) |
| HAN-Combined | 0.913 (0.892, 0.935) | 0.048 (0.028, 0.062) | 0.38 (0.32, 0.44) |
| Model | Sensitivity | Specificity | PPV | NPV |
|---|---|---|---|---|
| HAN-Text | 0.852 (0.839, 0.866) | 0.779 (0.694, 0.855) | 0.0200 (0.015, 0.024) | 0.999 (0.999, 0.999) |
| HAN-Combined | 0.928 (0.919, 0.939) | 0.657 (0.585, 0.740) | 0.034 (0.024, 0.043) | 0.999 (0.998, 0.999) |
| Model | Hierarchical | Attention | Target Replication |
|---|---|---|---|
| HAN-Text | ● | ● | ● |
| HN | ● | ● | |
| LSTM | ● | ||
| PSGNN | |||
| CNN | ● | ● |
| Model | AUROC | AUPRC | Brier Score (×100) |
|---|---|---|---|
| HAN-Text | 0.908 (0.886, 0.932) | 0.0773 (0.030, 0.103) | 0.37 (0.31, 0.43) |
| HN | 0.876 (0.847, 0.910) | 0.060 (0.027, 0.083) | 0.37 (0.32, 0.43) |
| LSTM | 0.872 (0.841, 0.905) | 0.042 (0.015, 0.054) | 0.39 (0.32, 0.44) |
| PSGNN | 0.870 (0.776, 0.847) | 0.017 (−0.003, 0.023) | 2.10 (1.97, 2.22) |
| CNN | 0.813 (0.782, 0.844) | 0.029 (−0.001, 0.043) | 0.38 (0.31, 0.44) |
| Model | Sensitivity | Specificity | PPV | NPV |
|---|---|---|---|---|
| HAN-Text | 0.852 (0.839, 0.866) | 0.779 (0.694, 0.855) | 0.0200 (0.015, 0.024) | 0.999 (0.999, 0.999) |
| HN | 0.963 (0.958, 0.969) | 0.500 (0.403, 0.586) | 0.049 (0.034, 0.061) | 0.998 (0.997, 0.999) |
| LSTM | 0.830 (0.809, 0.856) | 0.786 (0.714, 0.861) | 0.018 (0.013, 0.022) | 0.999 (0.998, 0.999) |
| PSGNN | 0.898 (0.889, 0.907) | 0.500 (0.415, 0.583) | 0.019 (0.013, 0.023) | 0.998 (0.997, 0.999) |
| CNN | 0.816 (0.798, 0.836) | 0.614 (0.526, 0.708) | 0.013 (0.010, 0.016) | 0.998 (0.998, 0.999) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vagliano, I.; Rios, M.; Abukmeil, M.; Schut, M.C.; Luik, T.T.; van Asselt, K.M.; van Weert, H.C.P.M.; Abu-Hanna, A. An Order-Sensitive Hierarchical Neural Model for Early Lung Cancer Detection Using Dutch Primary Care Notes and Structured Data. Cancers 2025, 17, 1151. https://doi.org/10.3390/cancers17071151
Vagliano I, Rios M, Abukmeil M, Schut MC, Luik TT, van Asselt KM, van Weert HCPM, Abu-Hanna A. An Order-Sensitive Hierarchical Neural Model for Early Lung Cancer Detection Using Dutch Primary Care Notes and Structured Data. Cancers. 2025; 17(7):1151. https://doi.org/10.3390/cancers17071151
Chicago/Turabian StyleVagliano, Iacopo, Miguel Rios, Mohanad Abukmeil, Martijn C. Schut, Torec T. Luik, Kristel M. van Asselt, Henk C. P. M. van Weert, and Ameen Abu-Hanna. 2025. "An Order-Sensitive Hierarchical Neural Model for Early Lung Cancer Detection Using Dutch Primary Care Notes and Structured Data" Cancers 17, no. 7: 1151. https://doi.org/10.3390/cancers17071151
APA StyleVagliano, I., Rios, M., Abukmeil, M., Schut, M. C., Luik, T. T., van Asselt, K. M., van Weert, H. C. P. M., & Abu-Hanna, A. (2025). An Order-Sensitive Hierarchical Neural Model for Early Lung Cancer Detection Using Dutch Primary Care Notes and Structured Data. Cancers, 17(7), 1151. https://doi.org/10.3390/cancers17071151