
Deep Convolutional Framelets for Dose Reconstruction in Boron Neutron Capture Therapy with Compton Camera Detector

 , ,
, ,  , and
, and 
Simple Summary
Abstract
1. Introduction
1.1. Boron Neutron Capture Therapy
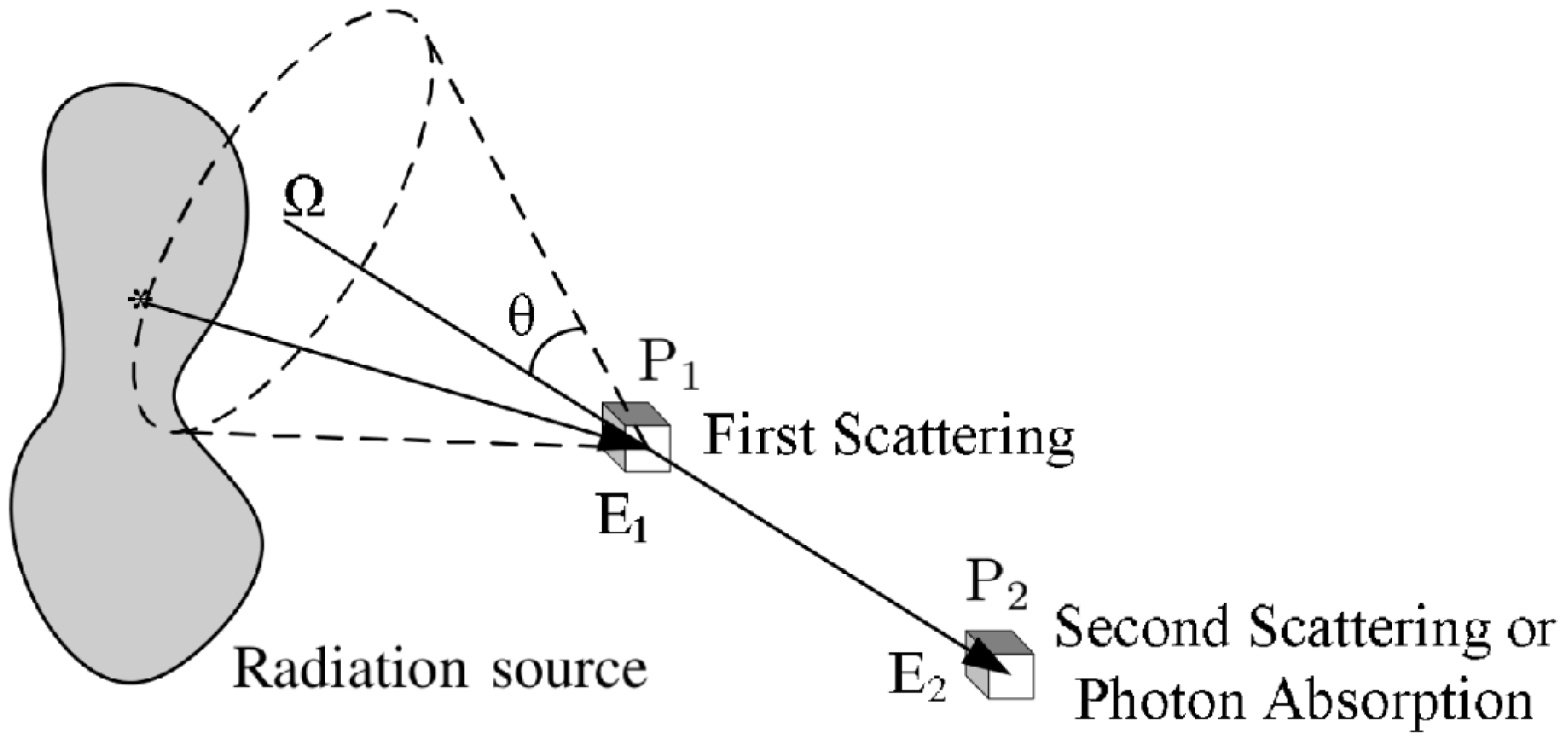
1.2. Compton Imaging
1.3. Compton Image Reconstruction
1.4. Research Outline and Discussion
2. Deep Learning Models
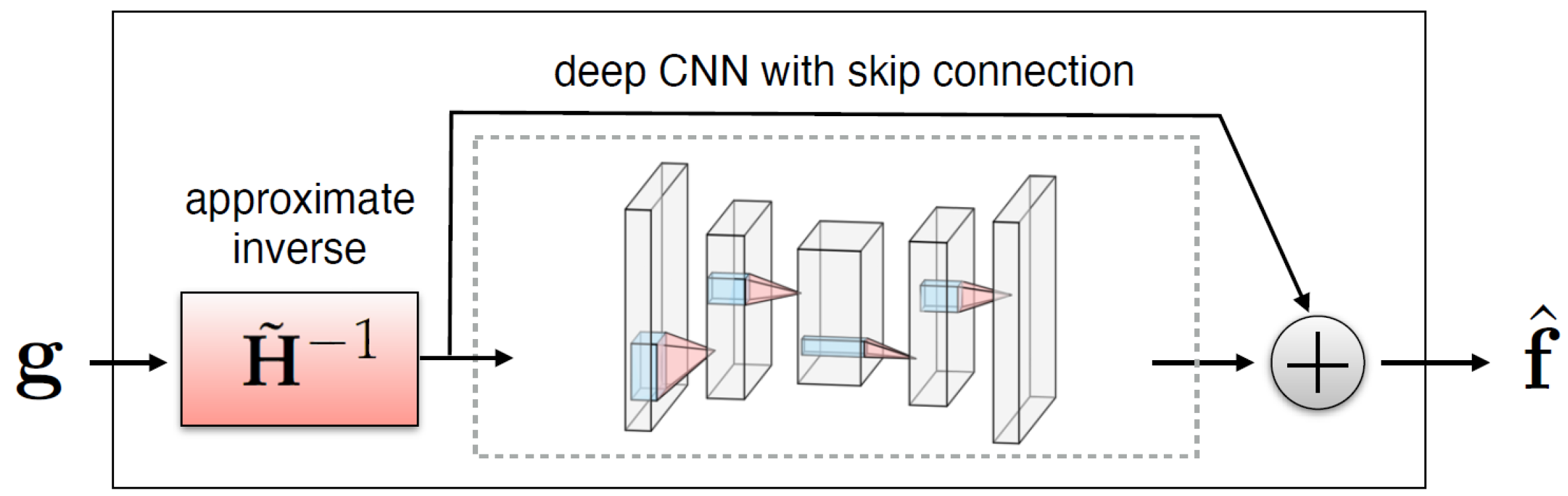
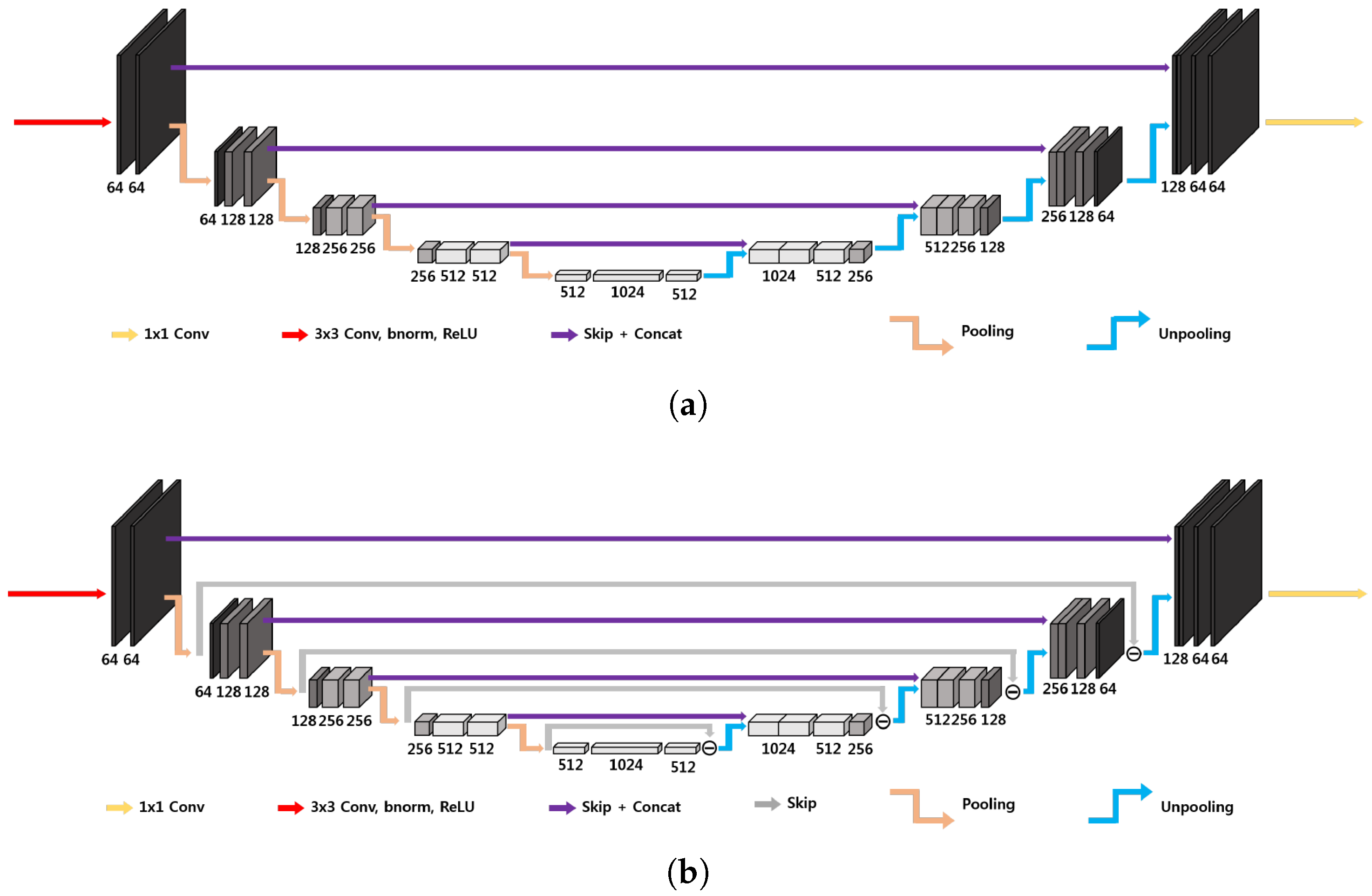
Image Degradation Reduction: U-Nets and Deep Convolutional Framelets
3. Methods
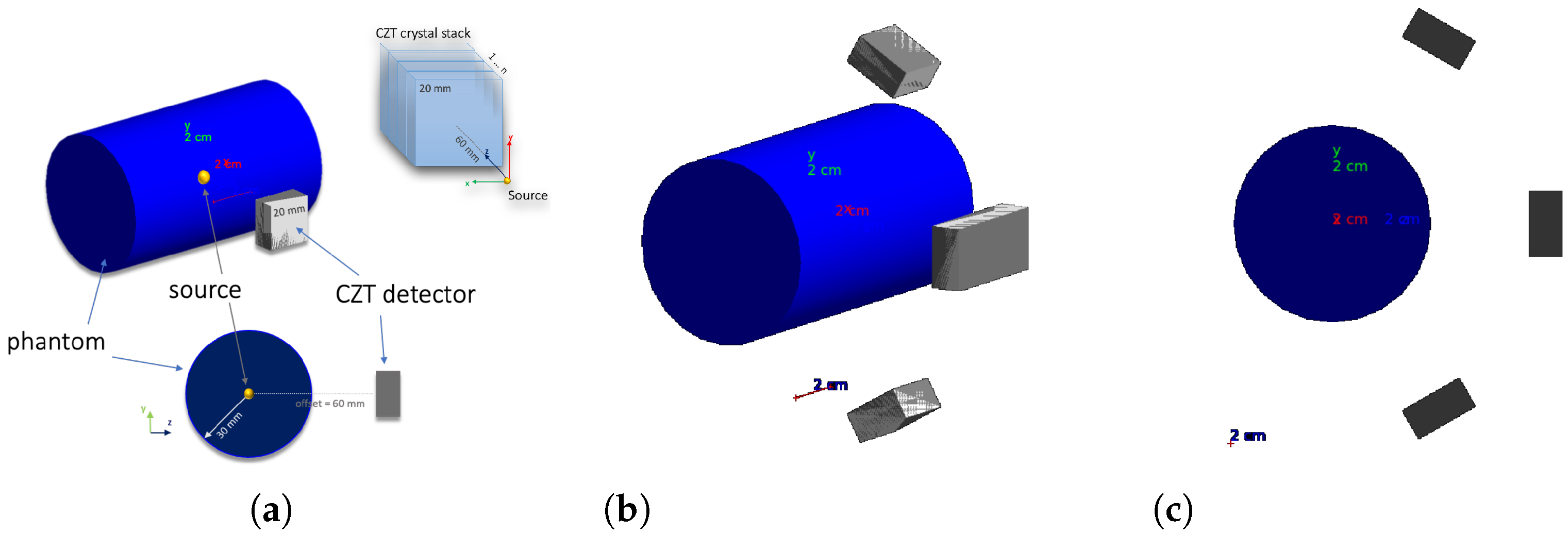
3.1. Monte Carlo Simulation
3.2. U-Nets: Dataset, Network Architectures, Training, and Evaluation
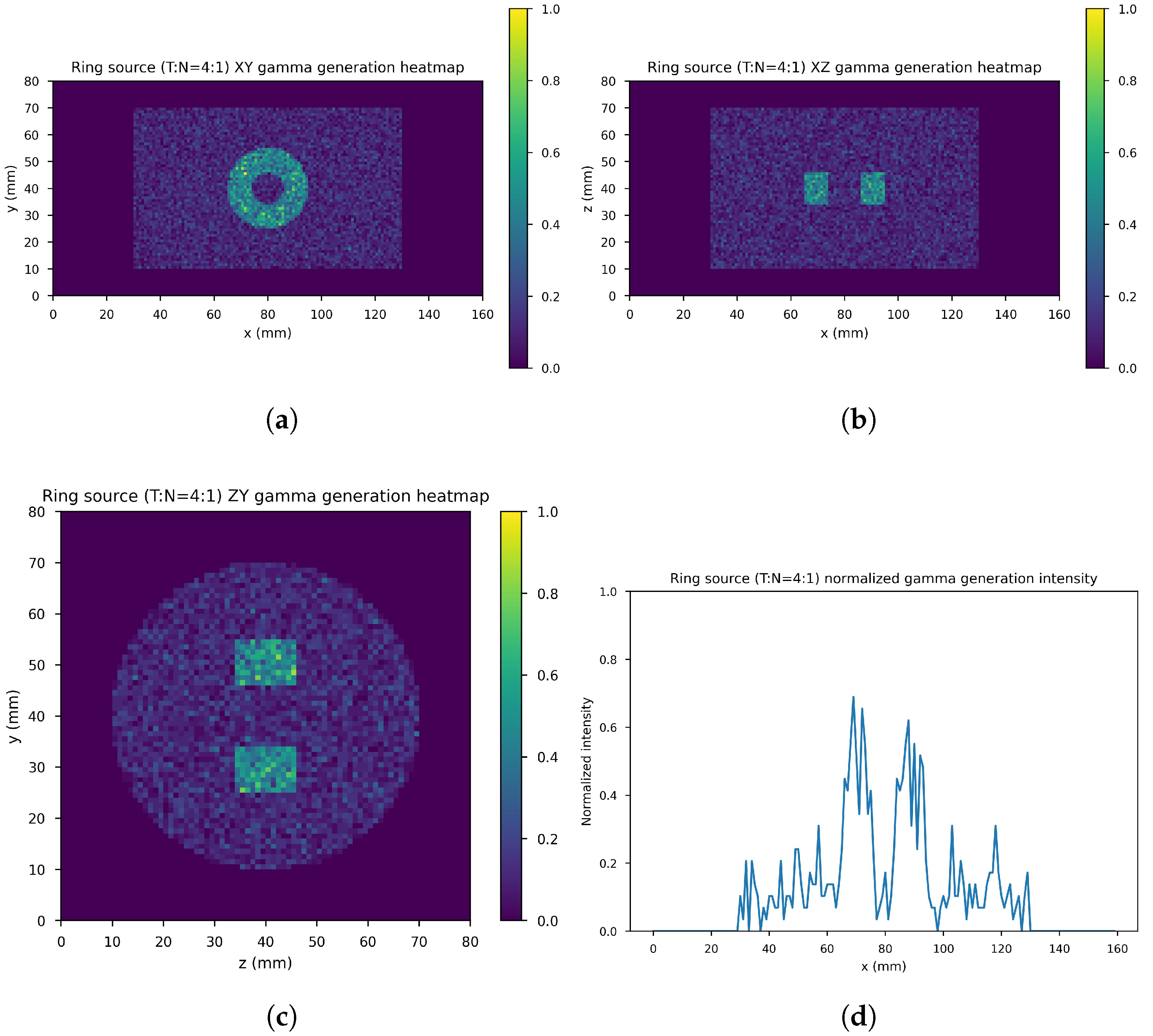
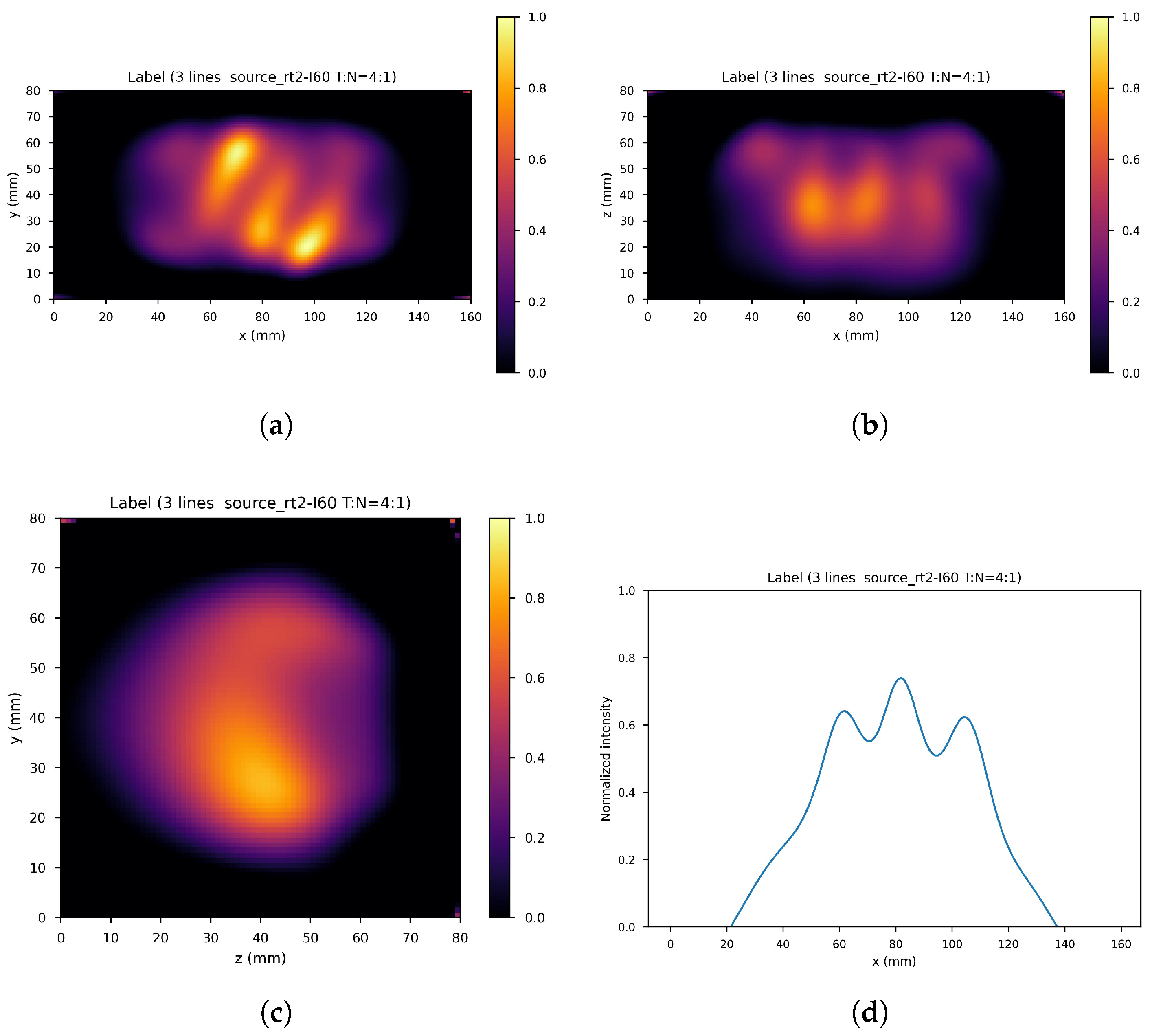
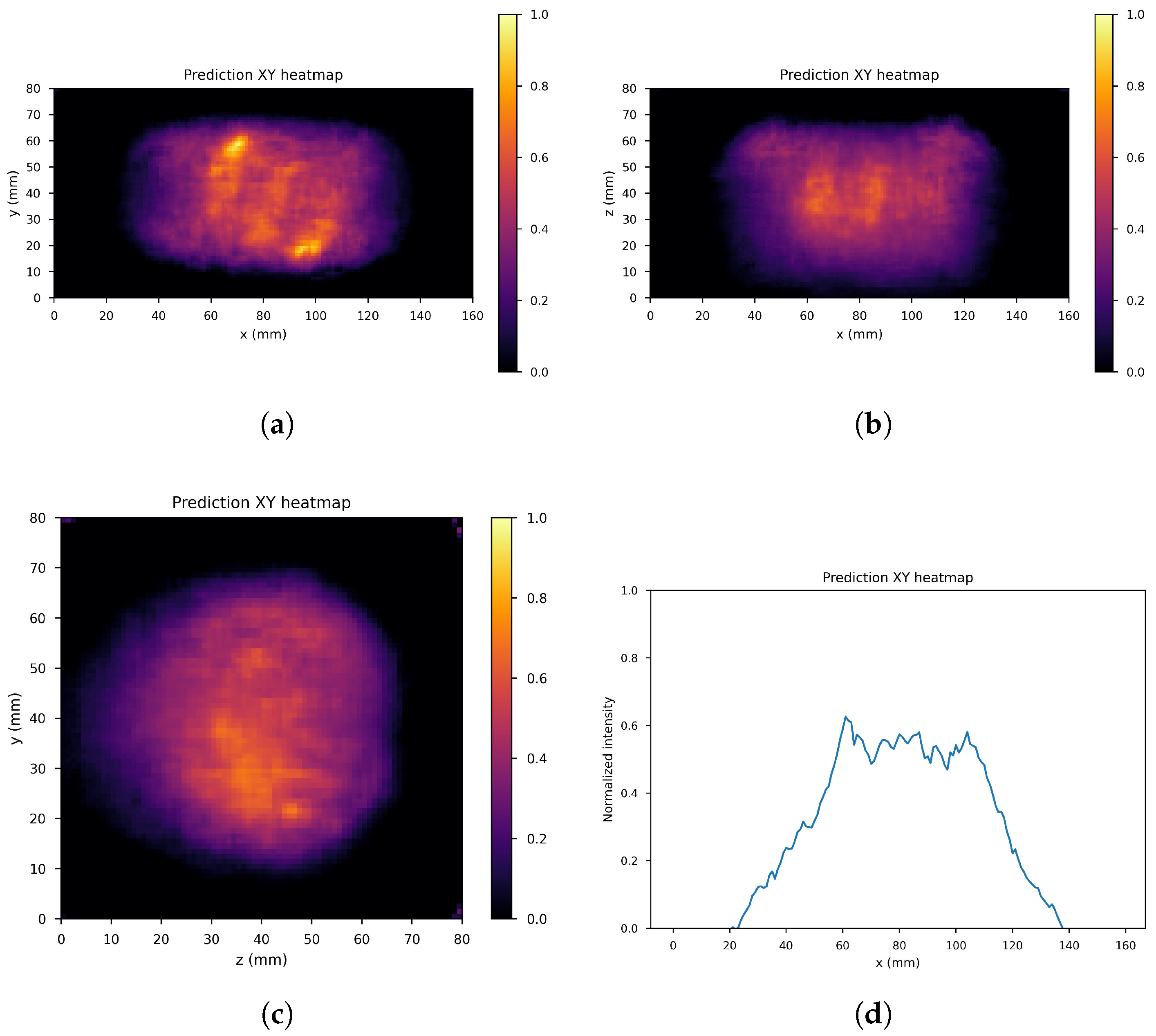
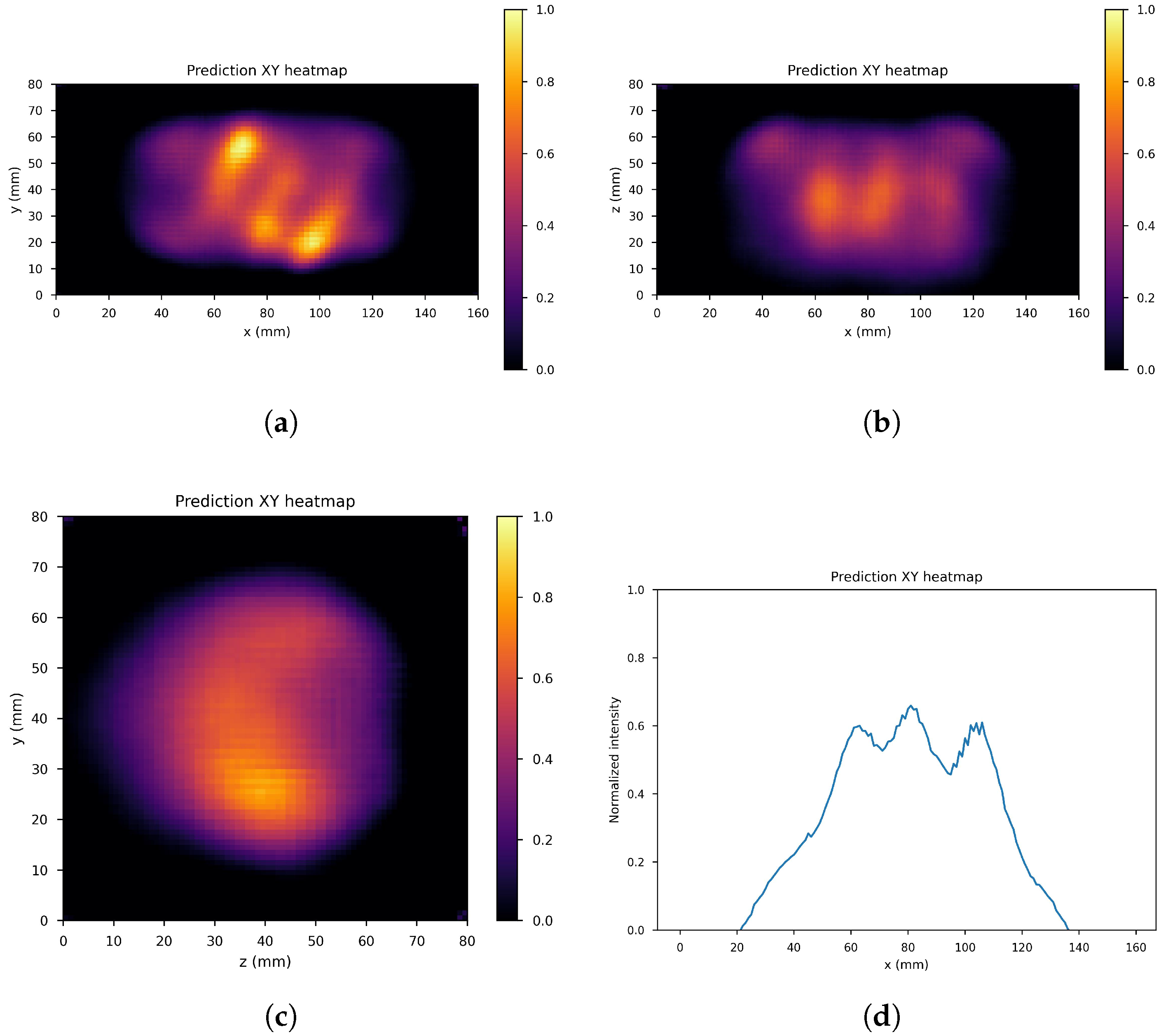
4. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- IAEA. Current Status of Neutron Capture Therapy; International Atomic Energy Agency: Vienna, Austria, 2001. [Google Scholar]
- Obertelli, A.; Sagawa, H. (Eds.) Modern Nuclear Physics: From Fundamentals to Frontiers; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Isao, T.; Hiroshi, T.; Toshitaka, K. (Eds.) Handbook of Nuclear Physics; Springer: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Podgorsak, E.B. (Ed.) Radiation Physics for Medical Physicists; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Sauerwein, W.; Wittig, A.; Moss, R.; Nakagawa, Y. (Eds.) Neutron Capture Therapy: Principles and Applications; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- IAEA. Advances in Boron Neutron Capture Therapy; International Atomic Energy Agency: Vienna, Austria, 2023. [Google Scholar]
- Nillius, P.; Danielsson, M. Theoretical bounds and optimal configurations for multi-pinhole spect. In Proceedings of the 2008 IEEE Nuclear Science Symposium Conference Record, Dresden, Germany, 19–25 October 2008; IEEE: Piscataway, NJ, USA, 2008. [Google Scholar]
- Bertero, M.; Boccacci, P.; Mol, C.D. Introduction to Inverse Problems in Imaging, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Chen, G.; Wei, Y.; Xue, Y. The generalized condition numbers of bounded linear operators in banach spaces. J. Aust. Math. Soc. 2004, 76, 281–290. [Google Scholar] [CrossRef]
- van Neerven, J. Functional Analysis; corrected edition; Cambridge University Press: Cambridge, UK, 2024. [Google Scholar]
- Wernick, M.N.; Aarsvold, J.N. (Eds.) Emission Tomography: The Fundamentals of PET and SPECT; Elsevier Academic Press: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Jain, A.K. Fundamentals of Digital Image Processing; Pearson: London, UK, 1988. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Pearson: London, UK, 2017. [Google Scholar]
- Kobayashi, H.; Mark, B.L.; Turin, W. Probability, Random Processes, and Statistical Analysis: Applications to Communications, Signal Processing, Queueing Theory and Mathematical Finance; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Lozano, I.V.; Dedes, G.; Peterson, S.; Mackin, D.; Zoglauer, A.; Beddar, S.; Avery, S.; Polf, J.; Parodi, K. Comparison of reconstructed prompt gamma emissions using maximum likelihood estimation and origin ensemble algorithms for a compton camera system tailored to proton range monitoring. Z. Für Med. Phys. 2023, 33, 124–134. [Google Scholar] [CrossRef] [PubMed]
- Maxim, V.; Lojacono, X.; Hilaire, E.; Krimmer, J.; Testa, E.; Dauvergne, D.; Magnin, I.; Prost, R. Probabilistic models and numerical calculation of system matrix and sensitivity in list-mode mlem 3d reconstruction of compton camera images. Phys. Med. Biol. 2015, 61, 243. [Google Scholar] [CrossRef] [PubMed]
- Wilderman, S.J.; Clinthorne, N.H.; Fessler, J.A.; Rogers, W.L. List-mode maximum likelihood reconstruction of compton scatter camera images in nuclear medicine. In Proceedings of the 1998 IEEE Nuclear Science Symposium Conference Record. 1998 IEEE Nuclear Science Symposium and Medical Imaging Conference (Cat. No.98CH36255), Toronto, ON, Canada, 8–14 November 1998; IEEE: Piscataway, NJ, USA, 1998; Volume 3, pp. 1716–1720. [Google Scholar]
- Parra, L.C. Reconstruction of cone-beam projections from compton scattered data. IEEE Trans. Nucl. Sci. 2000, 47, 1543–1550. [Google Scholar] [CrossRef]
- Han, Y.; Ye, J.C. Framing u-net via deep convolutional framelets: Application to sparse-view ct. IEEE Trans. Med Imaging 2018, 37, 1418–1429. [Google Scholar] [CrossRef] [PubMed]
- Kang, E.; Chang, W.; Jaejun, Y.; Ye, J.C. Deep Convolutional Framelet Denosing for Low-Dose CT via Wavelet Residual Network. IEEE Trans. Med Imaging 2018, 37, 1358–1369. [Google Scholar] [CrossRef] [PubMed]
- Sherwani, M.K.; Gopalakrishnan, S. A systematic literature review: Deep learning techniques for synthetic medical image generation and their applications in radiotherapy. Front. Radiol. 2024, 4, 1385742. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.M.; Lee, J.S. A comprehensive review on Compton camera image reconstruction: From principles to AI innovations. Biomed. Eng. Lett. 2024, 14, 1175–1193. [Google Scholar] [CrossRef] [PubMed]
- Daniel, G.; Gutierrez, Y.; Limousin, O. Application of a deep learning algorithm to Compton imaging of radioactive point sources with a single planar CdTe pixelated detector. Nucl. Eng. Technol. 2022, 54, 1747–1753. [Google Scholar] [CrossRef]
- Yao, Z.; Shi, C.; Tian, F.; Xiao, Y.; Geng, C.; Tang, X. Technical note: Rapid and high-resolution deep learning–based radiopharmaceutical imaging with 3D-CZT Compton camera and sparse projection data. Med. Phys. 2022, 49, 7336–7346. [Google Scholar] [CrossRef] [PubMed]
- Hou, Z.; Geng, C.; Shi, X.T.C.; Tian, F.; Zhao, S.; Qi, J.; Shu, D.; Gong, C. Boron concentration prediction from Compton camera image for boron neutron capture therapy based on generative adversarial network. Appl. Radiat. Isot. 2022, 186, 110302. [Google Scholar] [CrossRef] [PubMed]
- Yedder, H.B.; Cardoen, B.; Hamarneh, G. Deep learning for biomedical image reconstruction: A survey. Artif. Intell. Rev. 2020, 54, 215–251. [Google Scholar] [CrossRef]
- Ongie, G.; Jalal, A.; Metzler, C.A.; Baraniuk, R.G.; Dimakis, A.G.; Willett, R. Deep learning techniques for inverse problems in imaging. IEEE J. Sel. Areas Inf. Theory 2020, 1, 39–56. [Google Scholar] [CrossRef]
- Ye, J.C.; Eldar, Y.C.; Unser, M. (Eds.) Deep Learning for Biomedical Image Reconstruction; Cambridge University Press: Cambridge, UK, 2023. [Google Scholar]
- Ye, J.C.; Han, Y.; Cha, E. Deep convolutional framelets: A general deep learning framework for inverse problems. SIAM J. Imaging Sci. 2018, 11, 991–1048. [Google Scholar] [CrossRef]
- Casazza, P.G.; Kutyniok, G. (Eds.) Finite Frames: Theory and Applications; Birkhäuser: Boston, MA, USA, 2013. [Google Scholar]
- Grohs, P.; Kutyniok, G. (Eds.) Mathematical Aspects of Deep Learning; Cambridge University Press: Cambridge, UK, 2022. [Google Scholar]
- Ye, J.C. Geometry of Deep Learning: A Signal Processing Perspective; Springer: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Jin, K.; Mccann, M.; Froustey, E.; Unser, M. Deep convolutional neural network for inverse problems in imaging. IEEE Trans. Image Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef] [PubMed]
- Mallat, S. A Wavelet Tour of Signal Processing: The Sparse Way, 3rd ed.; Elsevier Academic Press: Amsterdam, The Netherlands, 2009. [Google Scholar]
- Damelin, S.B.; Miller, W., Jr. The Mathematics of Signal Processing; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Tashima, H.; Yamaya, T. Compton imaging for medical applications. Radiol. Phys. Technol. 2022, 15, 187–205. [Google Scholar] [CrossRef] [PubMed]
- Abbene, L.; Gerardi, G.; Principato, F.; Buttacavoli, A.; Altieri, S.; Protti, N.; Tomarchio, E.; Sordo, S.D.; Auricchio, N.; Bettelli, M.; et al. Recent advances in the development of high-resolution 3D cadmium–zinc–telluride drift strip detectors. J. Synchrotron. Radiat. 2020, 27, 1564–1576. [Google Scholar] [CrossRef] [PubMed]
- Abbene, L.; Principato, F.; Buttacavoli, A.; Gerardi, G.; Bettelli, M.; Zappettini, A.; Altieri, S.; Auricchio, N.; Caroli, E.; Zanettini, S.; et al. Potentialities of high-resolution 3-d czt drift strip detectors for prompt gamma-ray measurements in bnct. Sensors 2022, 22, 1502. [Google Scholar] [CrossRef] [PubMed]
- Sayed, A.H. Inference and Learning From Data, Vol.I-III; Cambridge University Press: Cambridge, UK, 2022. [Google Scholar]
- Baydin, A.; Pearlmutter, B.; A, R.; Siskind, J. Automatic differentiation in machine learning: A survey. J. Mach. Learn. Res. 2018, 18, 1–43. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Murphy, K.P. Probabilistic Machine Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2022. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Best Epoch | Tr. NMSE | Val. NMSE | |
|---|---|---|---|---|
| U-Net | 56 | 39 | 0.03396 | 0.02865 |
| Dual frame U-Net | 53 | 50 | 0.03280 | 0.02571 |
| Tight frame U-Net | 52 | 48 | 0.01102 | 0.01113 |
| NMSE | PSNR | SSIM | |
|---|---|---|---|
| Standard U-Net | |||
| Dual-frame U-Net | |||
| Tight-frame U-Net |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Didonna, A.; Ramos Lopez, D.; Iaselli, G.; Amoroso, N.; Ferrara, N.; Pugliese, G.M.I. Deep Convolutional Framelets for Dose Reconstruction in Boron Neutron Capture Therapy with Compton Camera Detector. Cancers 2025, 17, 130. https://doi.org/10.3390/cancers17010130
Didonna A, Ramos Lopez D, Iaselli G, Amoroso N, Ferrara N, Pugliese GMI. Deep Convolutional Framelets for Dose Reconstruction in Boron Neutron Capture Therapy with Compton Camera Detector. Cancers. 2025; 17(1):130. https://doi.org/10.3390/cancers17010130
Chicago/Turabian StyleDidonna, Angelo, Dayron Ramos Lopez, Giuseppe Iaselli, Nicola Amoroso, Nicola Ferrara, and Gabriella Maria Incoronata Pugliese. 2025. "Deep Convolutional Framelets for Dose Reconstruction in Boron Neutron Capture Therapy with Compton Camera Detector" Cancers 17, no. 1: 130. https://doi.org/10.3390/cancers17010130
APA StyleDidonna, A., Ramos Lopez, D., Iaselli, G., Amoroso, N., Ferrara, N., & Pugliese, G. M. I. (2025). Deep Convolutional Framelets for Dose Reconstruction in Boron Neutron Capture Therapy with Compton Camera Detector. Cancers, 17(1), 130. https://doi.org/10.3390/cancers17010130