
Use Cases Requiring Privacy-Preserving Record Linkage in Paediatric Oncology
 , , , ,
, , , ,  ,
,
Abstract
Simple Summary
Abstract

1. Introduction
- Personalised data, containing personal unique identifiers (IDs) or quasi-identifiers (QIDs), such as name, data of birth, and others, as defined by [2].
- Pseudonymised data, containing patient codes (“pseudonyms”) that can be associated with related QIDs, if necessary.
- Anonymised data, which cannot be associated with related QIDs anymore.
- Aggregated data, e.g., statistical results as published in journals.
2. Materials and Methods
((((“record” OR “dataset” OR “registr*”) AND (“link*” OR “merg*” OR “combin*”)) AND (“privacy” OR “GDPR” OR “data protection” OR “pseudonym*” OR “anonym*” OR “de-identif*” OR “deidentif*” OR “leak*”)) OR “PPRL”) AND ((“paediatr*” OR “pediatr*” OR “child*” OR “infant”) AND (“cancer” OR “oncolog*” OR “tumor” OR “tumour”)).
3. Results
3.1. Overview of Dimensions in Privacy-Preserving Record Linkage
3.2. Single-Dimensional Use Cases
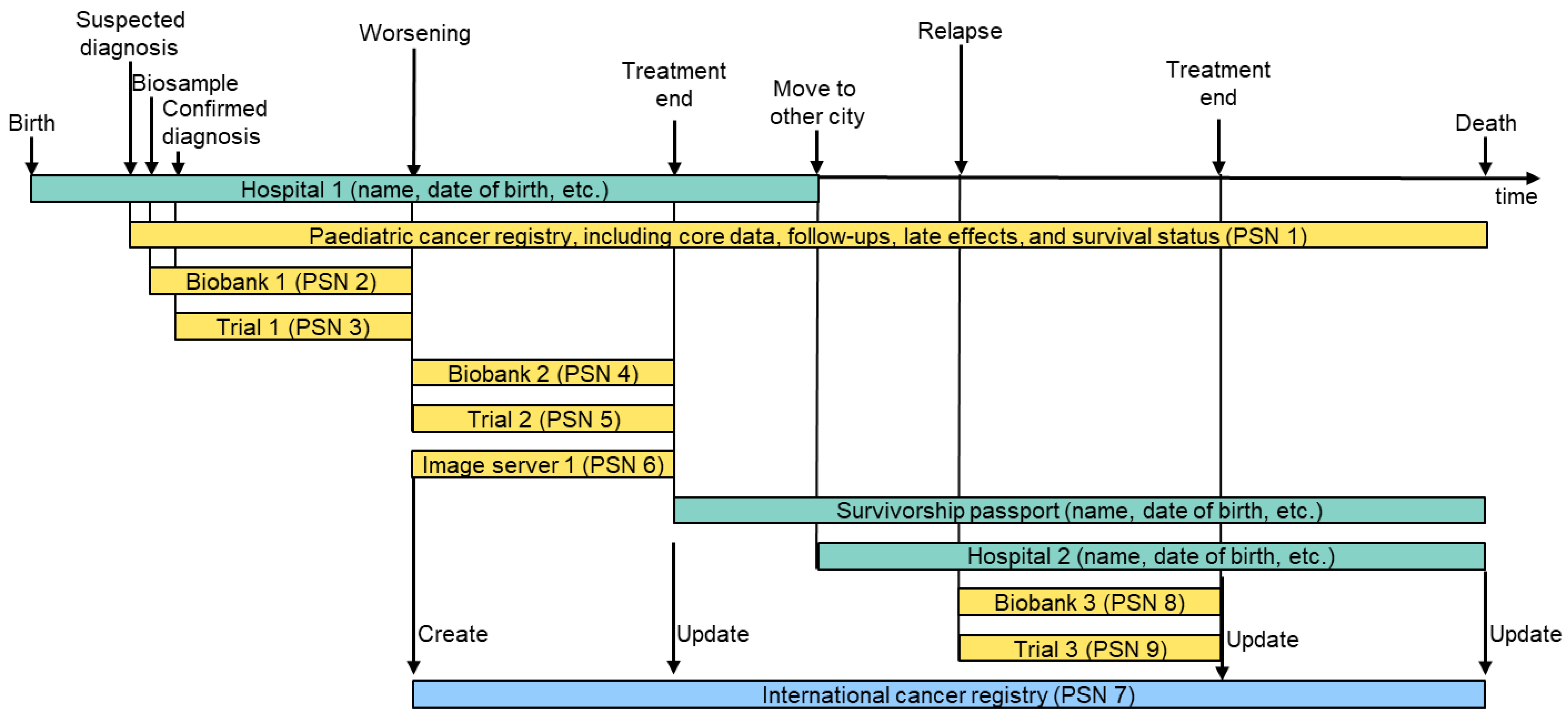
3.2.1. Distributed Personalised/Pseudonymised Data Sources
Multiple Hospitals
Different Types of Data
Suspected Diagnosis
Multiple Subsequent Trials
Multiple Concurrent Trials
Transition from a Trial to Long-Term Follow-Up
Transition from Routine Care to Research (and Back)
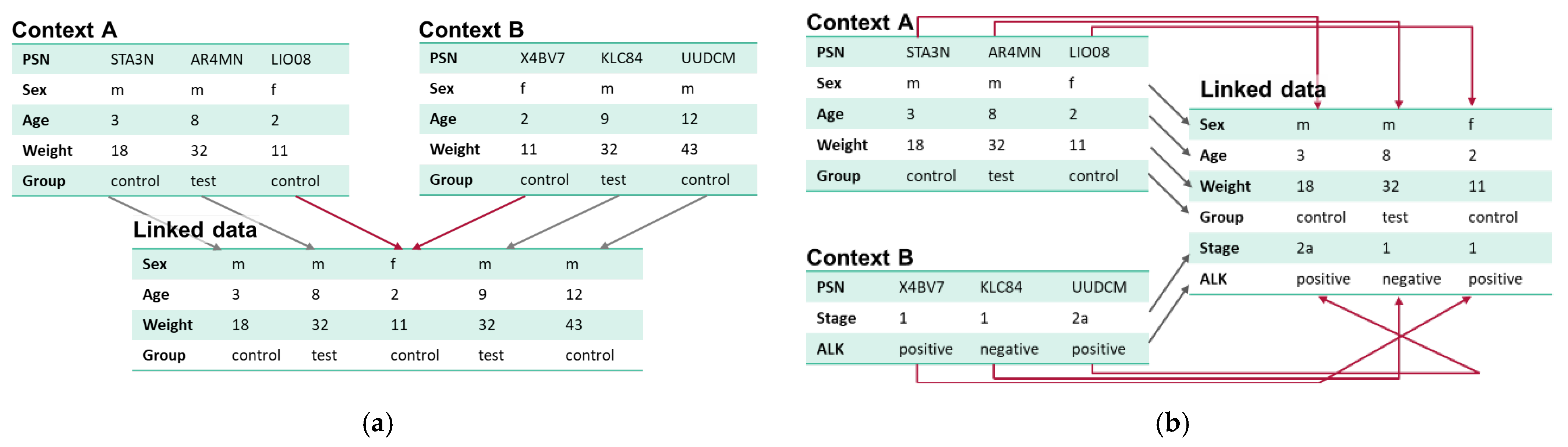
3.2.2. Record Linkage/Linked Data
Temporarily Linked Data
Linked Data Stores and Registries
3.2.3. Data Analysis
Counts, Statistical Measures, and Statistical Plots
Tables with Subsets of Linked Data
Single Case Visualisation
Patient Apps and Digital Companions
Artificial Intelligence (AI)
3.3. Multi-Dimensional Use Cases
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| COG | US Children’s Oncology Group |
| EHDS | European Health Data Space |
| EJP-RD | European Joint Programme on Rare Diseases |
| ENISA | European Union Agency for Cybersecurity |
| EUPID | European Patient Identity |
| FAIR | Findable, Accessible, Interoperable, and Re-usable |
| GDPR | General Data Protection Regulation |
| GPAP | RD-Connect Genome Phenome Analysis Platform |
| INRG | International Neuroblastoma Risk Group |
| ITCC | Innovative Therapies for Children with Cancer |
| OMS | Opsoclonus Myoclonus Syndrome |
| PACS | Picture Archiving and Communication System |
| PO | Paediatric Oncology |
| PPRL | Privacy-Preserving Record Linkage |
| PSN | Pseudonym |
| QID | Quasi-Identifier |
| SIOPE | European Society for Paediatric Oncology |
| SIOPEN | SIOPE Neuroblastoma |
References
- World Health Organization. International Agency for Research on Cancer Cancer Today; World Health Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Office for Civil Rights. Guidance Regarding Methods for De-identification of Protected Health Information in Accordance with the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule; Office for Civil Rights: Washington, DC, USA, 2012.
- The European Parliament and of the Council. Regulation (eu) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the Protection of Natural Persons with Regard to the Processing of Personal Data and on the Free Movement of Such Data, and Repealing Directive 95/46/EC (General Data Protection Regulation); The European Parliament and of the Council: Brussels, Belgium, 2016. [Google Scholar]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed]
- SIOP Europe; CCI Europe; PANCARE. A Europe for Children & Adolescents with Cancer: Don’t Leave Them Behind—Position Paper of the European Paediatric Cancer Community; SIOP Europe: Woluwe-Saint-Lambert, Ethiopia, 2022. [Google Scholar]
- SIOP Europe; CCI Europe; PANCARE. International Childhood Cancer Awareness Day (ICCD2020): Artificial Intelligence and Big Data: Towards the Next Frontier in Paediatric Cancer Research & Innovation in Europe; SIOP Europe: Woluwe-Saint-Lambert, Ethiopia, 2020. [Google Scholar]
- Vassal, G.; Lazarov, D.; Rizzari, C.; Szczepański, T.; Ladenstein, R.; Kearns, P.R. The impact of the EU General Data Protection Regulation on childhood cancer research in Europe. Lancet Oncol. 2022, 23, 974–975. [Google Scholar] [CrossRef] [PubMed]
- Karakasidis, A.; Verykios, V. Secure Blocking + Secure Matching = Secure Record Linkage. J. Comput. Sci. Eng. 2011, 5, 223–235. [Google Scholar] [CrossRef]
- Etienne, B.; Cheatham, M.; Grzebala, P. An Analysis of Blocking Methods for Private Record Linkage. In Proceedings of the AAAI Fall Symposia Symposium Series, Arlington, VA, USA, 17–19 November 2016; pp. 244–248. [Google Scholar]
- Dusserre, L.; Quantin, C.; Bouzelat, H. A one way public key cryptosystem for the linkage of nominal files in epidemiological studies. Medinfo 1995, 8 Pt 1, 644–647. [Google Scholar] [PubMed]
- Quantin, C.; Bouzelat, H.; Allaert, F.A.; Benhamiche, A.M.; Faivre, J.; Dusserre, L. How to ensure data security of an epidemiological follow-up: Quality assessment of an anonymous record linkage procedure. Int. J. Med. Inform. 1998, 49, 117–122. [Google Scholar] [CrossRef]
- Pang, C.; Gu, L.; Hansen, D.; Maeder, A. Privacy-Preserving Fuzzy Matching Using a Public Reference Table. In Intelligent Patient Management; McClean, S., Millard, P., El-Darzi, E., Nugent, C., Eds.; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 2009; pp. 71–89. [Google Scholar]
- Vatsalan, D. Scalable and Approximate Privacy-Preserving Record Linkage; Australian National University: Canberra, Australia, 2014. [Google Scholar]
- Scannapieco, M.; Figotin, I.; Bertino, E.; Elmagarmid, A.K. Privacy preserving schema and data matching. In Proceedings of the ACM SIGMOD Conference, Beijing, China, 11–14 June 2007. [Google Scholar]
- Yakout, M.; Atallah, M.J.; Elmagarmid, A. Efficient Private Record Linkage. In Proceedings of the 2009 IEEE 25th International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; pp. 1283–1286. [Google Scholar]
- Bonomi, L.; Xiong, L.; Chen, R.; Fung, B.C.M. Frequent grams based embedding for privacy preserving record linkage. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 1597–1601. [Google Scholar]
- He, X.; Machanavajjhala, A.; Flynn, C.; Srivastava, D. Composing Differential Privacy and Secure Computation: A Case Study on Scaling Private Record Linkage. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1389–1406. [Google Scholar]
- Inan, A.; Kantarcioglu, M.; Bertino, E.; Scannapieco, M. A Hybrid Approach to Private Record Linkage. In Proceedings of the 2008 IEEE 24th International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008; pp. 496–505. [Google Scholar]
- Kuzu, M.; Kantarcioglu, M.; Inan, A.; Bertino, E.; Durham, E.; Malin, B. Efficient Privacy-Aware Record Integration. In Proceedings of the 16th International Conference on Extending Database Technology, Genoa, Italy, 18–22 March 2013; pp. 167–178. [Google Scholar]
- Stammler, S.; Kussel, T.; Schoppmann, P.; Stampe, F.; Tremper, G.; Katzenbeisser, S.; Hamacher, K.; Lablans, M. Mainzelliste SecureEpiLinker (MainSEL): Privacy-preserving record linkage using secure multi-party computation. Bioinformatics 2022, 38, 1657–1668. [Google Scholar] [CrossRef]
- Kussel, T.; Brenner, T.; Tremper, G.; Schepers, J.; Lablans, M.; Hamacher, K. Record linkage based patient intersection cardinality for rare disease studies using Mainzelliste and secure multi-party computation. J. Transl. Med. 2022, 20, 458. [Google Scholar] [CrossRef]
- Dalal, H.M.; Doherty, P.; McDonagh, S.T.; Paul, K.; Taylor, R.S. Virtual and in-person cardiac rehabilitation. BMJ 2021, 373, n1270. [Google Scholar] [CrossRef]
- Vatsalan, D.; Christen, P.; Verykios, V. A taxonomy of privacy-preserving record linkage techniques. Inf. Syst. 2013, 38, 946–969. [Google Scholar] [CrossRef]
- Gkoulalas-Divanis, A.; Vatsalan, D.; Karapiperis, D.; Kantarcioglu, M. Modern Privacy-Preserving Record Linkage Techniques: An Overview. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4966–4987. [Google Scholar] [CrossRef]
- Christen, P.; Ranbaduge, T.; Schnell, R. Linking Sensitive Data; Springer: New York, NY, USA, 2020. [Google Scholar]
- European Union Agency for Cybersecurity. Data Pseudonymisation: Advanced Techniques & Use Cases—Technical Analysis of Cybersecurity Measures in Data Protection and Privacy; European Union Agency for Cybersecurity: Attiki, Greece, 2021. [Google Scholar]
- European Union Agency for Cybersecurity. Deploying Pseudonymisation Techniques—The case of the Health Sector; European Union Agency for Cybersecurity: Attiki, Greece, 2022. [Google Scholar]
- European Union Agency for Cybersecurity. Pseudonymisation Techniques and Best Practices—Recommendations on Shaping Technology According to Data Protection and Privacy Provisions; European Union Agency for Cybersecurity: Attiki, Greece, 2019. [Google Scholar]
- Gatta, G.; Botta, L.; Rossi, S.; Aareleid, T.; Bielska-Lasota, M.; Clavel, J.; Dimitrova, N.; Jakab, Z.; Kaatsch, P.; Lacour, B.; et al. Childhood cancer survival in Europe 1999–2007: Results of EUROCARE-5—A population-based study. Lancet Oncol. 2014, 15, 35–47. [Google Scholar] [CrossRef] [PubMed]
- Nitzlnader, M.; Schreier, G. Patient identity management for secondary use of biomedical research data in a distributed computing environment. Stud. Health Technol. Inform. 2014, 198, 211–218. [Google Scholar] [PubMed]
- Ly, S.; Runacres, F.; Poon, P. Journey mapping as a novel approach to healthcare: A qualitative mixed methods study in palliative care. BMC Health Serv. Res. 2021, 21, 915. [Google Scholar] [CrossRef] [PubMed]
- Reihs, R.; Proynova, R.; Maqsood, S.; Ataian, M.; Lablans, M.; Quinlan, P.R.; Lawrence, E.; Bowman, E.; van Enckevort, E.; Bučík, D.F.; et al. BBMRI-ERIC Negotiator: Implementing Efficient Access to Biobanks. Biopreserv. Biobank. 2021, 19, 414–421. [Google Scholar] [CrossRef] [PubMed]
- Laurie, S.; Piscia, D.; Matalonga, L.; Corvó, A.; Fernández-Callejo, M.; Garcia-Linares, C.; Hernandez-Ferrer, C.; Luengo, C.; Martínez, I.; Papakonstantinou, A.; et al. The RD-Connect Genome-Phenome Analysis Platform: Accelerating diagnosis, research, and gene discovery for rare diseases. Hum. Mutat. 2022, 43, 717–733. [Google Scholar] [CrossRef] [PubMed]
- Hayn, D.; Falgenhauer, M.; Kropf, M.; Nitzlnader, M.; Welte, S.; Ebner, H.; Ladenstein, R.; Schleiermacher, G.; Hero, B.; Schreier, G. IT Infrastructure for Merging Data from Different Clinical Trials and Across Independent Research Networks. Stud. Health Technol. Inform. 2016, 228, 287–291. [Google Scholar] [PubMed]
- Mulder, R.L.; van der Pal, H.J.H.; Levitt, G.A.; Skinner, R.; Kremer, L.C.M.; Brown, M.C.; Bárdi, E.; Windsor, R.; Michel, G.; Frey, E. Transition guidelines: An important step in the future care for childhood cancer survivors. A comprehensive definition as groundwork. Eur. J. Cancer 2016, 54, 64–68. [Google Scholar] [CrossRef] [PubMed]
- Hjorth, L.; Haupt, R.; Skinner, R.; Grabow, D.; Byrne, J.; Karner, S.; Levitt, G.; Michel, G.; van der Pal, H.; Bárdi, E.; et al. Survivorship after childhood cancer: PanCare: A European Network to promote optimal long-term care. Eur. J. Cancer 2015, 51, 1203–1211. [Google Scholar] [CrossRef] [PubMed]
- Henson, K.E.; Brock, R.; Shand, B.; Coupland, V.H.; Elliss-Brookes, L.; Lyratzopoulos, G.; Godfrey, P.; Haigh, A.; Hunter, K.; McCabe, M.G.; et al. Cohort profile: Prescriptions dispensed in the community linked to the national cancer registry in England. BMJ Open 2018, 8, e020980. [Google Scholar] [CrossRef]
- Liang, W.H.; Federico, S.M.; London, W.B.; Naranjo, A.; Irwin, M.S.; Volchenboum, S.L.; Cohn, S.L. Tailoring Therapy for Children With Neuroblastoma on the Basis of Risk Group Classification: Past, Present, and Future. JCO Clin. Cancer Inform. 2020, 4, 895–905. [Google Scholar] [CrossRef]
- Ladenstein, R.; Pötschger, U.; Valteau-Couanet, D.; Luksch, R.; Castel, V.; Ash, S.; Laureys, G.; Brock, P.; Michon, J.M.; Owens, C.; et al. Investigation of the Role of Dinutuximab Beta-Based Immunotherapy in the SIOPEN High-Risk Neuroblastoma 1 Trial (HR-NBL1). Cancers 2020, 12, 309. [Google Scholar] [CrossRef] [PubMed]
- Baugh, J.; Bartels, U.; Leach, J.; Jones, B.; Chaney, B.; Warren, K.E.; Kirkendall, J.; Doughman, R.; Hawkins, C.; Miles, L.; et al. The international diffuse intrinsic pontine glioma registry: An infrastructure to accelerate collaborative research for an orphan disease. J. Neurooncol. 2017, 132, 323–331. [Google Scholar] [CrossRef] [PubMed]
- Kitlinski, M.; Giwercman, A.; Elenkov, A. Paternity through use of assisted reproduction technology in male adult and childhood cancer survivors: A nationwide register study. Hum. Reprod. 2023, 38, 973–981. [Google Scholar] [CrossRef] [PubMed]
- Youlden, D.R.; Baade, P.D.; Hallahan, A.R.; Valery, P.C.; Green, A.C.; Aitken, J.F. Conditional survival estimates for childhood cancer in Australia, 2002–2011: A population-based study. Cancer Epidemiol. 2015, 39, 394–400. [Google Scholar] [CrossRef] [PubMed]
- Oberaigner, W.; Siebert, U. Are survival rates for Tyrol published in the Eurocare studies biased? Acta Oncol. 2009, 48, 984–991. [Google Scholar] [CrossRef] [PubMed]
- Botta, L.; Gatta, G.; Didonè, F.; Lopez Cortes, A.; Pritchard-Jones, K.; Group, B.P.W. International benchmarking of childhood cancer survival by stage at diagnosis: The BENCHISTA project protocol. PLoS ONE 2022, 17, e0276997. [Google Scholar] [CrossRef]
- Loong, L.; Huntley, C.; McRonald, F.; Santaniello, F.; Pethick, J.; Torr, B.; Allen, S.; Tulloch, O.; Goel, S.; Shand, B.; et al. Germline mismatch repair (MMR) gene analyses from English NHS regional molecular genomics laboratories 1996–2020: Development of a national resource of patient-level genomics laboratory records. J. Med. Genet. 2023, 60, 669–678. [Google Scholar] [CrossRef] [PubMed]
- Walker, J.L.; Grint, D.J.; Strongman, H.; Eggo, R.M.; Peppa, M.; Minassian, C.; Mansfield, K.E.; Rentsch, C.T.; Douglas, I.J.; Mathur, R.; et al. UK prevalence of underlying conditions which increase the risk of severe COVID-19 disease: A point prevalence study using electronic health records. BMC Public Health 2021, 21, 484. [Google Scholar] [CrossRef]
- Paulson, K.G.; Gupta, D.; Kim, T.S.; Veatch, J.R.; Byrd, D.R.; Bhatia, S.; Wojcik, K.; Chapuis, A.G.; Thompson, J.A.; Madeleine, M.M.; et al. Age-Specific Incidence of Melanoma in the United States. JAMA Dermatol. 2020, 156, 57–64. [Google Scholar] [CrossRef]
- Sayeed, S.; Barnes, I.; Ali, R. Childhood cancer incidence by ethnic group in England, 2001–2007: A descriptive epidemiological study. BMC Cancer 2017, 17, 570. [Google Scholar] [CrossRef]
- Hammer, G.P.; Seidenbusch, M.C.; Schneider, K.; Regulla, D.; Zeeb, H.; Spix, C.; Blettner, M. Cancer incidence rate after diagnostic X-ray exposure in 1976–2003 among patients of a university children’s hospital. Rofo 2010, 182, 404–414. [Google Scholar] [CrossRef] [PubMed]
- Hargreave, M.; Mørch, L.S.; Andersen, K.K.; Winther, J.F.; Schmiegelow, K.; Kjaer, S.K. Maternal use of hormonal contraception and risk of childhood leukaemia: A nationwide, population-based cohort study. Lancet Oncol. 2018, 19, 1307–1314. [Google Scholar] [CrossRef] [PubMed]
- Waitman, L.R.; Song, X.; Walpitage, D.L.; Connolly, D.C.; Patel, L.P.; Liu, M.; Schroeder, M.C.; VanWormer, J.J.; Mosa, A.S.; Anye, E.T.; et al. Enhancing PCORnet Clinical Research Network data completeness by integrating multistate insurance claims with electronic health records in a cloud environment aligned with CMS security and privacy requirements. J. Am. Med. Inform. Assoc 2022, 29, 660–670. [Google Scholar] [CrossRef]
- Smoll, N.R.; Brady, Z.; Scurrah, K.J.; Lee, C.; Berrington de González, A.; Mathews, J.D. Computed tomography scan radiation and brain cancer incidence. Neuro Oncol. 2023, 25, 1368–1376. [Google Scholar] [CrossRef] [PubMed]
- Specht, I.O.; Huybrechts, I.; Frederiksen, P.; Steliarova-Foucher, E.; Chajes, V.; Heitmann, B.L. The influence of prenatal exposure to trans-fatty acids for development of childhood haematopoietic neoplasms (EnTrance): A natural societal experiment and a case-control study. Nutr. J. 2018, 17, 13. [Google Scholar] [CrossRef] [PubMed]
- Duke, J.; Wood, F.; Semmens, J.; Edgar, D.W.; Rea, S. Trends in hospital admissions for sunburn in Western Australia, 1988 to 2008. Asia Pac. J. Public Health 2013, 25, 102–109. [Google Scholar] [CrossRef] [PubMed]
- Hylin, H.; Thrane, H.; Pedersen, K.; Kristiansen, I.S.; Burger, E.A. The healthcare costs of treating human papillomavirus-related cancers in Norway. BMC Cancer 2019, 19, 426. [Google Scholar] [CrossRef] [PubMed]
- Mathoulin-Pélissier, S.; Pritchard-Jones, K. Evidence-based data and rare cancers: The need for a new methodological approach in research and investigation. Eur. J. Surg. Oncol. 2019, 45, 22–30. [Google Scholar] [CrossRef] [PubMed]
- Mushtaq, N.; Qureshi, B.M.; Javed, G.; Sheikh, N.A.; Bakhshi, S.K.; Laghari, A.A.; Enam, S.A.; Anwar, S.S.M.; Hilal, K.; Kabir, A.; et al. Capacity building for pediatric neuro-oncology in Pakistan- a project by my child matters program of Foundation S. Front. Oncol. 2024, 14, 1325167. [Google Scholar] [CrossRef]
- Coebergh, J.W.; van den Hurk, C.; Louwman, M.; Comber, H.; Rosso, S.; Zanetti, R.; Sacchetto, L.; Storm, H.; van Veen, E.B.; Siesling, S.; et al. EUROCOURSE recipe for cancer surveillance by visible population-based cancer RegisTrees in Europe: From roots to fruits. Eur. J. Cancer 2015, 51, 1050–1063. [Google Scholar] [CrossRef]
- Haupt, R.; Essiaf, S.; Dellacasa, C.; Ronckers, C.M.; Caruso, S.; Sugden, E.; Zadravec Zaletel, L.; Muraca, M.; Morsellino, V.; Kienesberger, A.; et al. The ‘Survivorship Passport’ for childhood cancer survivors. Eur. J. Cancer 2018, 102, 69–81. [Google Scholar] [CrossRef] [PubMed]
- Chronaki, C.; Charalambous, E.; Cangioli, G.; Schreier, G.; van den Oever, S.; van der Pal, H.; Kremer, L.; Uyttebroeck, A.; Van den Bosch, B.; Trinkunas, J.; et al. Factors Influencing Implementation of the Survivorship Passport: The IT Perspective. Stud. Health Technol. Inform. 2022, 293, 161–168. [Google Scholar] [PubMed]
- Martí-Bonmatí, L.; Alberich-Bayarri, Á.; Ladenstein, R.; Blanquer, I.; Segrelles, J.D.; Cerdá-Alberich, L.; Gkontra, P.; Hero, B.; García-Aznar, J.M.; Keim, D.; et al. PRIMAGE project: Predictive in silico multiscale analytics to support childhood cancer personalised evaluation empowered by imaging biomarkers. Eur. Radiol. Exp. 2020, 4, 22. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
Stakeholder
“As a...” |
Research Focus
“...I Would Like to...” |
Objective
“...so That I Can...” |
Output Format
“...and Visualise the Results as...” |
|---|---|---|---|
| clinician (corresponds to PO patient OR parent of a PO patient) | know if there have been patients in the past in any source who were similar to my patient, and their outcome | choose the optimal therapy for my patient | a table with key patient characteristics, data sources, and outcomes |
| discuss my patient’s case in a tumour board based on all the distributed data of my patient | comprehensive overview of my patient’s case including tables, images, etc. | ||
| compare the predicted survival rate of my patient, depending on the selection of treatment A or treatment B | two survival probabilities as derived from an AI algorithm (preferably including explanations) | ||
| paediatric cancer survivor | know which sources hold any data or samples of mine | have an overview of my data and samples | a table of data sources and types of data/samples they hold of mine |
| receive life-long suggestions concerning screenings, etc., based on all my own data and recent study results | improve my life expectancy, health status, and quality of life | suggestions and summaries provided by a survivorship app | |
| make sure that my data are used for further research in the most valuable way | contribute to the improvement of paediatric cancer treatment | – | |
| researcher in the field of PO | compare the outcome of treatment A with that of treatment B (taken from source A) in patients fulfilling a certain eligibility criterion (taken from source B) | see if the type of treatment is correlated with the outcome | a Kaplan–Meier-curve with two groups, for treatments A and B |
| compare the outcome of study A with that of study B in patients fulfilling certain criteria | see if one of the studies’ outcomes is superior | a Kaplan–Meier curve with two groups, for studies A and B | |
| know all follow-up results of one of the patients in my study, no matter within which context the follow-up was performed | use the most recent follow-up data for the analysis of my study | a table of all follow-ups including dates, sources, and results | |
| researcher in the field of biology | know which biobanks have further samples on which I need to perform an additional experiment | contact these biobanks and ask for additional material | a table with the sample type and biobank including contact information |
| know specific results, as stored in genome–phenome analysis platforms, which were achieved with the probes from my biobank | gain further insights into the properties of my samples | a table with platforms and results per probe in my biobank | |
| know which sources contain patients with a specific biomarker | contact these sources to perform further research on that biomarker | a table with the number of patients per source | |
| future principal investigator of a specific research activity | know how many cases fulfilling specific eligibility criteria are present in at least two data sources | estimate the number of cases for my study | a number of overall cases |
| know which data sources contain cases fulfilling specific eligibility criteria (age, diagnosis, biomarker, treatment, etc.) | get in contact with these sources to consider them in my study | a table with cases per source | |
| correlate variables in patients from various sources, fulfilling my eligibility criteria, with one another | optimise stratification in my study | correlation between the variables | |
| member of the SIOPE board | compare the survival rate of all neuroblastoma patients in all sources in 2001–2010 to the rate in 2011–2020 | evaluate the improvements in neuroblastoma research in Europe | a boxplot |
| compare the rate of severe adverse events per member state during immunotherapy with a certain biological in all sources | identify differences across Europe and improve potential shortfalls | a landscape, color-coded with the rate of severe adverse events | |
| healthcare politician | know whether a specific type of PO treatment is cost-effective | optimise PO treatment based on outcomes and costs | table listing costs and outcomes of two different PO treatment options |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hayn, D.; Kreiner, K.; Sandner, E.; Baumgartner, M.; Jammerbund, B.; Falgenhauer, M.; Düster, V.; Devi-Marulkar, P.; Schleiermacher, G.; Ladenstein, R.; et al. Use Cases Requiring Privacy-Preserving Record Linkage in Paediatric Oncology. Cancers 2024, 16, 2696. https://doi.org/10.3390/cancers16152696
Hayn D, Kreiner K, Sandner E, Baumgartner M, Jammerbund B, Falgenhauer M, Düster V, Devi-Marulkar P, Schleiermacher G, Ladenstein R, et al. Use Cases Requiring Privacy-Preserving Record Linkage in Paediatric Oncology. Cancers. 2024; 16(15):2696. https://doi.org/10.3390/cancers16152696
Chicago/Turabian StyleHayn, Dieter, Karl Kreiner, Emanuel Sandner, Martin Baumgartner, Bernhard Jammerbund, Markus Falgenhauer, Vanessa Düster, Priyanka Devi-Marulkar, Gudrun Schleiermacher, Ruth Ladenstein, and et al. 2024. "Use Cases Requiring Privacy-Preserving Record Linkage in Paediatric Oncology" Cancers 16, no. 15: 2696. https://doi.org/10.3390/cancers16152696
APA StyleHayn, D., Kreiner, K., Sandner, E., Baumgartner, M., Jammerbund, B., Falgenhauer, M., Düster, V., Devi-Marulkar, P., Schleiermacher, G., Ladenstein, R., & Schreier, G. (2024). Use Cases Requiring Privacy-Preserving Record Linkage in Paediatric Oncology. Cancers, 16(15), 2696. https://doi.org/10.3390/cancers16152696