
Patchless Multi-Stage Transfer Learning for Improved Mammographic Breast Mass Classification




Abstract
:Simple Summary
Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Datasets
3.1.1. Cancer Cell Line Dataset
3.1.2. Mammography Dataset
- Digital Database for Screening Mammography (DDSM): DDSM is a dataset used in many studies involving deep learning for mammographic breast cancer diagnosis. It is publicly available for researchers (accessible at http://www.eng.usf.edu/cvprg/mammography/database.html (accessed on 8 September 2021)). It is the largest publicly available database and has 2620 cases of mediolateral oblique (MLO) and craniocaudal (CC) views of both breasts, for a total of 10,480 images. The images include all types of findings, from normal images to images with benign and malignant lesions. It includes patient information, such as age, and has breast imaging reporting and data system (BI-RADS) annotations and breast-density annotations based on the American College of Radiology (ACR). The images are annotated as a pixel-level boundary of the findings.
- INbreast: The INbreast dataset is composed of full-field mammography images acquired between April 2008 and July 2010 from the Breast Center in CHSJ, Porto. INbreast is another popular publicly available dataset (accessible at https://biokeanos.com/source/INBreast (accessed on 8 September 2021)). with 410 images, including 115 cases, of which 90 cases are with MLO and CC views of each breast and 25 cases are from only one breast collected from women who underwent mastectomy. The dataset involves all types of findings. Information about the age of patients and family history as well as BI-RADS classification and ACR breast density annotations are provided. Biopsy results for BI-RADS 3, 4, 5, and 6 cases are also included. This dataset has strong annotation, including the labels of individual findings.
- The Mammographic Image Analysis Society’s digital mammogram database (MIAS): MIAS is the oldest mammographic image dataset that has been used to develop many deep-learning algorithms for breast cancer diagnosis (accessible at http://peipa.essex.ac.uk/info/mias.html (accessed on 8 September 2021)). MIAS is a dataset with 161 cases with MLO views only, constituting 322 digitized images. It involves all types of findings, including benign and malignant lesions as well as normal images. It possesses breast-density information that is not classified according to ACR standards. The annotation was performed in such a way that the center and radius of a circle around the area of interest are provided.
- Mixed dataset: The mixed dataset was formulated by mixing the three datasets (DDSM, INbreast, and MIAS) to investigate the robustness of the proposed method for datasets from different sources. The mixed dataset was formed in such a way that all the breast mass images from DDSM, INbreast, and MIAS datasets are added together to form a larger, diversified dataset. The benign images from the three datasets formed a benign mixed dataset whereas the malignant images from the three datasets formed a malignant mixed dataset.
3.1.3. Dataset Size and Categories
3.2. Pre-Processing
3.3. The Deep-Learning Method
3.4. Implementation Details
3.5. Experimental Settings
3.5.1. Patchless Multi-Stage Transfer Learning Evaluation Experimental Settings
3.5.2. The Dataset and Algorithm Wise Robustness Analysis Settings
3.5.3. Comparison of the Proposed Multi-Stage Transfer Learning (MSTL) Method against the Conventional Transfer Learning (CTL) Method Settings
3.5.4. Comparison against Patch and Whole Image Classifier Settings
3.5.5. Evaluation and Statistical Analysis
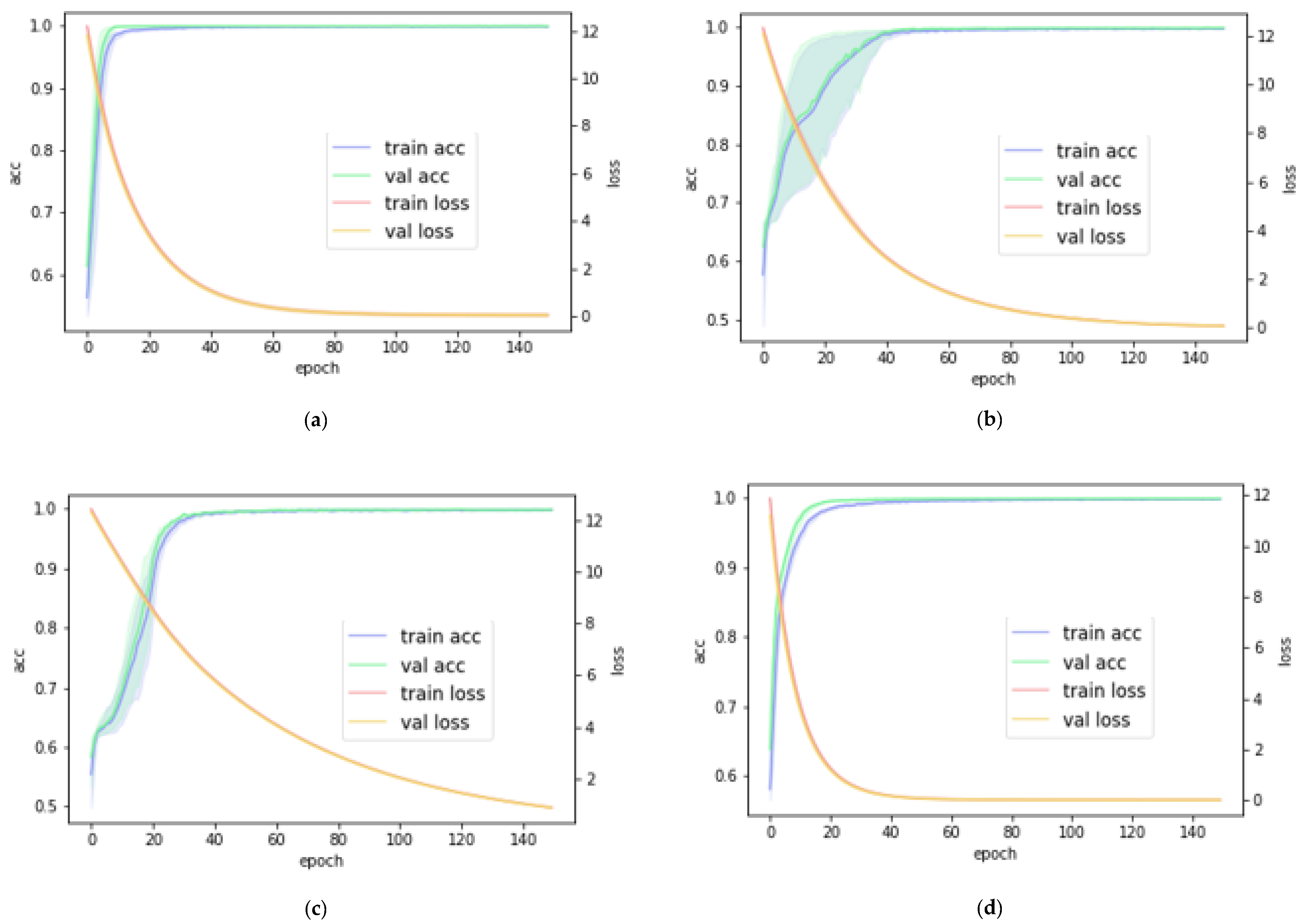
4. Results
4.1. Results on DDSM
4.2. Results on INbreast
4.3. Results on MIAS
4.4. Robustness Analysis Using Mixed Dataset
4.5. Robustness Analysis Using Other CNN Architectures and Optimizers
4.6. Comparison of the Proposed Multi-Stage Transfer Learning (MSTL) Method with Conventional Transfer Learning (CTL)
4.7. Comparison of the Proposed Method with Patch and Whole Image Classifier
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Weedon-Fekjaer, H.; Romundstad, P.R.; Vatten, L.J. Modern mammography screening and breast cancer mortality: Population study. BMJ 2014, 348, g3701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seely, J.M.; Alhassan, T. Screening for breast cancer in 2018—What should we be doing today? Curr. Oncol. 2018, 25, S115–S124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lehman, C.D.; Arao, R.F.; Sprague, B.L.; Lee, J.M.; Buist, D.S.M.; Kerlikowske, K.; Henderson, L.M.; Onega, T.; Tosteson, A.N.A.; Rauscher, G.H.; et al. National Performance Benchmarks for Modern Screening Digital Mammography: Update from the Breast Cancer Surveillance Consortium. Radiology 2017, 283, 49–58. [Google Scholar] [CrossRef] [PubMed]
- Rothschild, J.; Lourenco, A.P.; Mainiero, M.B. Screening Mammography Recall Rate: Does Practice Site Matter? Radiology 2013, 269, 348–353. [Google Scholar] [CrossRef]
- Woods, R.W.; Sisney, G.S.; Salkowski, L.R.; Shinki, K.; Lin, Y.; Burnside, E.S. The Mammographic Density of a Mass Is a Significant Predictor of Breast Cancer. Radiology 2011, 258, 417–425. [Google Scholar] [CrossRef] [Green Version]
- The American Cancer Society. Available online: https://www.cancer.org/cancer/breast-cancer/screening-tests-and-early-detection.html (accessed on 2 December 2021).
- Yuan, W.H.; Hsu, H.C.; Chen, Y.Y.; Wu, C.H. Supplemental breast cancer-screening ultrasonography in women with dense breasts: A systematic review and meta-analysis. Br. J. Cancer 2020, 123, 673–688. [Google Scholar] [CrossRef]
- Drukteinis, J.S.; Mooney, B.P.; Flowers, C.I.; Gatenby, R.A. Beyond Mammography: New Frontiers in Breast Cancer Screening. Am. J. Med. 2013, 126, 472–479. [Google Scholar] [CrossRef] [Green Version]
- Hovda, T.; Tsuruda, K.; Hoff, S.R.; Sahlberg, K.K.; Hofvind, S. Radiological review of prior screening mammograms of screen-detected breast cancer. Eur. Radiol. 2021, 31, 2568–2579. [Google Scholar] [CrossRef]
- Fulton, L.; McLeod, A.; Dolezel, D.; Bastian, N.; Fulton, C.P. Deep Vision for Breast Cancer Classification and Segmentation. Cancers 2021, 13, 5384. [Google Scholar] [CrossRef]
- Yala, A.; Lehman, C.; Schuster, T.; Portnoi, T.; Barzilay, R. A deep learning mammography-based model for improved breast cancer risk prediction. Radiology 2019, 292, 60–66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yala, A.; Schuster, T.; Miles, R.; Barzilay, R.; Lehman, C. A deep learning model to triage screening mammograms: A simulation study. Radiology 2019, 293, 38–46. [Google Scholar] [CrossRef] [PubMed]
- Lotter, W.; Sorensen, G.; Cox, D. A multi-scale CNN and curriculum learning strategy for mammogram classification. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2017; pp. 169–177. [Google Scholar] [CrossRef] [Green Version]
- McKinney, S.M.; Sieniek, M.; Godbole, V.; Godwin, J.; Antropova, N.; Ashrafian, H.; Back, T.; Chesus, M.; Corrado, G.C.; Darzi, A.; et al. International evaluation of an AI system for breast cancer screening. Nature 2020, 577, 89–94. [Google Scholar] [CrossRef]
- Salim, M.; Wåhlin, E.; Dembrower, K.; Azavedo, E.; Foukakis, T.; Liu, Y.; Smith, K.; Eklund, M.; Strand, F. External Evaluation of 3 Commercial Artificial Intelligence Algorithms for Independent Assessment of Screening Mammograms. JAMA Oncol. 2020, 6, 1581–1588. [Google Scholar] [CrossRef] [PubMed]
- Frazer, H.M.L.; Qin, A.K.; Pan, H.; Brotchie, P. Evaluation of deep learning-based artificial intelligence techniques for breast cancer detection on mammograms: Results from a retrospective study using a BreastScreen Victoria dataset. J. Med. Imaging Radiat. Oncol. 2021, 65, 529–537. [Google Scholar] [CrossRef] [PubMed]
- Samala, R.K.; Chan, H.P.; Hadjiiski, L.M.; Helvie, M.A.; Richter, C.D. Generalization error analysis for deep convolutional neural network with transfer learning in breast cancer diagnosis. Phys. Med. Biol. 2020, 65, 105002. [Google Scholar] [CrossRef] [PubMed]
- Lotter, W.; Diab, A.R.; Haslam, B.; Kim, J.G.; Grisot, G.; Wu, E.; Wu, K.; Onieva, J.O.; Boyer, Y.; Boxerman, J.L.; et al. Robust breast cancer detection in mammography and digital breast tomosynthesis using an annotation-efficient deep learning approach. Nat. Med. 2021, 27, 244–249. [Google Scholar] [CrossRef] [PubMed]
- Aboutalib, S.S.; Mohamed, A.A.; Berg, W.A.; Zuley, M.L.; Sumkin, J.H.; Wu, S. Deep learning to distinguish recalled but benign mammography images in breast cancer screening. Clin. Cancer Res. 2018, 24, 5902–5909. [Google Scholar] [CrossRef] [Green Version]
- Al-antari, M.A.; Han, S.M.; Kim, T.S. Evaluation of deep learning detection and classification towards computer-aided diagnosis of breast lesions in digital X-ray mammograms. Comput. Methods Programs Biomed. 2020, 196, 105584. [Google Scholar] [CrossRef]
- Al-masni, M.A.; Al-antari, M.A.; Park, J.M.; Gi, G.; Kim, T.Y.; Rivera, P.; Valarezo, E.; Choi, M.T.; Han, S.M.; Kim, T.S. Simultaneous detection and classification of breast masses in digital mammograms via a deep learning YOLO-based CAD system. Comput. Methods Programs Biomed. 2018, 157, 85–94. [Google Scholar] [CrossRef]
- Aggarwal, R.; Sounderajah, V.; Martin, G.; Ting, D.S.W.; Karthikesalingam, A.; King, D.; Ashrafian, H.; Darzi, A. Diagnostic accuracy of deep learning in medical imaging: A systematic review and meta-analysis. NPJ Digit. Med. 2021, 4, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Gardezi, S.J.S.; Elazab, A.; Lei, B.; Wang, T. Breast cancer detection and diagnosis using mammographic data: Systematic review. J. Med. Internet Res. 2019, 21, 1–22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geras, K.J.; Mann, R.M.; Moy, L. Artificial intelligence for mammography and digital breast tomosynthesis: Current concepts and future perspectives. Radiology 2019, 293, 246–259. [Google Scholar] [CrossRef]
- Hamidinekoo, A.; Denton, E.; Rampun, A.; Honnor, K.; Zwiggelaar, R. Deep learning in mammography and breast histology, an overview and future trends. Med. Image Anal. 2018, 47, 45–67. [Google Scholar] [CrossRef] [Green Version]
- Burt, J.R.; Torosdagli, N.; Khosravan, N.; Raviprakash, H.; Mortazi, A.; Tissavirasingham, F.; Hussein, S.; Bagci, U. Deep learning beyond cats and dogs: Recent advances in diagnosing breast cancer with deep neural networks. Br. J. Radiol. 2018, 91, 20170545. [Google Scholar] [CrossRef]
- Ayana, G.; Dese, K.; Choe, S. Transfer Learning in Breast Cancer Diagnoses via Ultrasound Imaging. Cancers 2021, 13, 738. [Google Scholar] [CrossRef]
- Xie, X.; Niu, J.; Liu, X.; Chen, Z.; Tang, S.; Yu, S. A survey on incorporating domain knowledge into deep learning for medical image analysis. Med. Image Anal. 2021, 69, 101985. [Google Scholar] [CrossRef] [PubMed]
- Murtaza, G.; Shuib, L.; Abdul Wahab, A.W.; Mujtaba, G.; Mujtaba, G.; Nweke, H.F.; Al-garadi, M.A.; Zulfiqar, F.; Raza, G.; Azmi, N.A. Deep learning-based breast cancer classification through medical imaging modalities: State of the art and research challenges. Artif. Intell. Rev. 2020, 53, 1655–1720. [Google Scholar] [CrossRef]
- Shen, L.; Margolies, L.R.; Rothstein, J.H.; Fluder, E.; McBride, R.; Sieh, W. Deep Learning to Improve Breast Cancer Detection on Screening Mammography. Sci. Rep. 2019, 9, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Mridha, M.F.; Hamid, M.A.; Monowar, M.M.; Keya, A.J.; Ohi, A.Q.; Islam, M.R.; Kim, J.-M. A Comprehensive Survey on Deep-Learning-Based Breast Cancer Diagnosis. Cancers 2021, 13, 6116. [Google Scholar] [CrossRef]
- Agnes, S.A.; Anitha, J.; Pandian, S.I.A.; Peter, J.D. Classification of Mammogram Images Using Multiscale all Convolutional Neural Network (MA-CNN). J. Med. Syst. 2020, 44, 30. [Google Scholar] [CrossRef] [PubMed]
- Xie, L.; Zhang, L.; Hu, T.; Huang, H.; Yi, Z. Neural networks model based on an automated multi-scale method for mammogram classification. Knowl.-Based Syst. 2020, 208, 106465. [Google Scholar] [CrossRef]
- Chougrad, H.; Zouaki, H.; Alheyane, O. Deep Convolutional Neural Networks for breast cancer screening. Comput. Methods Programs Biomed. 2018, 157, 19–30. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Niu, J.; Li, D.; Zhang, C. Classification of breast mass in two-view mammograms via deep learning. IET Image Process. 2021, 15, 454–467. [Google Scholar] [CrossRef]
- Carneiro, G.; Nascimento, J.; Bradley, A.P. Automated Analysis of Unregistered Multi-View Mammograms with Deep Learning. IEEE Trans. Med. Imaging 2017, 36, 2355–2365. [Google Scholar] [CrossRef]
- Dhungel, N.; Carneiro, G.; Bradley, A.P. A deep learning approach for the analysis of masses in mammograms with minimal user intervention. Med. Image Anal. 2017, 37, 114–128. [Google Scholar] [CrossRef] [Green Version]
- Huynh, B.Q.; Li, H.; Giger, M.L. Digital mammographic tumor classification using transfer learning from deep convolutional neural networks. J. Med. Imaging 2016, 3, 034501. [Google Scholar] [CrossRef]
- Kooi, T.; Gubern-Merida, A.; Mordang, J.-J.; Mann, R.; Pijnappel, R.; Schuur, K.; den Heeten, A.; Karssemeijer, N. A Comparison Between a Deep Convolutional Neural Network and Radiologists for Classifying Regions of Interest in Mammography. In International Workshop on Breast Imaging; Springer: Cham, Switzerland, 2016; Volume 9699, pp. 51–56. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Tseng, T.-L.; Zhang, J.; Qian, W. Enhancing deep convolutional neural network scheme for breast cancer diagnosis with unlabeled data. Comput. Med. Imaging Graph. 2017, 57, 4–9. [Google Scholar] [CrossRef] [Green Version]
- Mendes, A.; Togelius, J.; dos Coelho, L.S. Multi-Stage Transfer Learning with an Application to Selection Process. Front. Artif. Intell. Appl. 2020, 325, 1770–1777. [Google Scholar] [CrossRef]
- Zhou, J.; Zheng, L.-Y.; Wang, Y.; Gogu, C. A Multistage Deep Transfer Learning Method for Machinery Fault Diagnostics Across Diverse Working Conditions and Devices. IEEE Access 2020, 8, 80879–80898. [Google Scholar] [CrossRef]
- Samala, R.K.; Chan, H.-P.; Hadjiiski, L.; Helvie, M.A.; Richter, C.D.; Cha, K.H. Breast Cancer Diagnosis in Digital Breast Tomosynthesis: Effects of Training Sample Size on Multi-Stage Transfer Learning Using Deep Neural Nets. IEEE Trans. Med. Imaging 2019, 38, 686–696. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Li, H.; Wang, J.; Chen, M.; Gozdas, E.; Dillman, J.R.; Parikh, N.A. A multi-task, multi-stage deep transfer learning model for early prediction of neurodevelopment in very preterm infants. Sci. Rep. 2020, 10, 15072. [Google Scholar] [CrossRef]
- Vidal, P.L.; de Moura, J.; Novo, J.; Ortega, M. Multi-stage transfer learning for lung segmentation using portable X-ray devices for patients with COVID-19. Expert Syst. Appl. 2021, 173, 114677. [Google Scholar] [CrossRef] [PubMed]
- Hernández Santa Cruz, J.F. An ensemble approach for multi-stage transfer learning models for COVID-19 detection from chest CT scans. Intell. Med. 2021, 5, 100027. [Google Scholar] [CrossRef] [PubMed]
- Heath, M.; Bowyer, K.; Kopans, D.; Kegelmeyer, P.; Moore, R.; Chang, K.; Munishkumaran, S. Current Status of the Digital Database for Screening Mammography. In Computational Imaging and Vision; Springer: Dordrecht, The Netherlands, 1998; pp. 457–460. [Google Scholar]
- Heath, M.; Bowyer, K.; Kopans, D.; Moore, R.; Philip, K.W. The Digital Database for Screening Mammography. In Proceedings of the Fifth International Workshop on Digital Mammography, Toronto, ON, Canada, 11–14 June 2000; pp. 212–218. [Google Scholar]
- Moreira, I.C.; Amaral, I.; Domingues, I.; Cardoso, A.; Cardoso, M.J.; Cardoso, J.S. INbreast: Toward a Full-field Digital Mammographic Database. Acad. Radiol. 2012, 19, 236–248. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Suckling, J.; Parker, J.; Dance, D.; Astley, S.; Hutt, I.; Boggis, C.; Ricketts, I. Mammographic Image Analysis Society (MIAS) Dataset. Available online: http://peipa.essex.ac.uk/info/mias.html (accessed on 8 September 2021).
- Roy, P.; Dutta, S.; Dey, N.; Dey, G.; Chakraborty, S.; Ray, R. Adaptive thresholding: A comparative study. In Proceedings of the 2014 International Conference on Control, Instrumentation, Communication and Computational Technologies (ICCICCT), Kanyakumari, India, 10–11 July 2014; pp. 1182–1186. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 10691–10700. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Taqi, A.M.; Awad, A.; Al-Azzo, F.; Milanova, M. The Impact of Multi-Optimizers and Data Augmentation on TensorFlow Convolutional Neural Network Performance. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 140–145. [Google Scholar]
- Hajian-Tilaki, K. Receiver operating characteristic (ROC) curve analysis for medical diagnostic test evaluation. Casp. J. Intern. Med. 2013, 4, 627–635. [Google Scholar]
- Hossin, M.; Sulaiman, M.N. A Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar] [CrossRef]
- Bey, R.; Goussault, R.; Grolleau, F.; Benchoufi, M.; Porcher, R. Fold-stratified cross-validation for unbiased and privacy-preserving federated learning. J. Am. Med. Inform. Assoc. 2020, 27, 1244–1251. [Google Scholar] [CrossRef]
- Agresti, A.; Coull, B.A. Approximate Is Better than “Exact” for Interval Estimation of Binomial Proportions. Am. Stat. 1998, 52, 119. [Google Scholar] [CrossRef]
- Ribli, D.; Horváth, A.; Unger, Z.; Pollner, P.; Csabai, I. Detecting and classifying lesions in mammograms with Deep Learning. Sci. Rep. 2018, 8, 1–7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saraswathi, D.; Srinivasan, E. A high-sensitivity computer-aided system for detecting microcalcifications in digital mammograms using curvelet fractal texture features. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2017, 5, 263–273. [Google Scholar] [CrossRef]
- Ayana, G.; Park, J.; Jeong, J.W.; Choe, S.W. A Novel Multistage Transfer Learning for Ultrasound Breast Cancer Image Classification. Diagnostics 2022, 12, 135. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | DDSM | INbreast | MIAS |
|---|---|---|---|
| Origin | USA | Portugal | UK |
| Age | Yes | Yes | No |
| Number of cases | 2620 | 115 | 161 |
| Views | MLO and CC | MLO and CC | MLO |
| Number of images | 10,480 | 410 | 322 |
| Resolution | 8 and 16 bits/pixel | 14 bits/pixel | 8 bits/pixel |
| Benign: malignant ratio | 0.65:0.35 | 0.72:0.28 | 0.84:0.16 |
| Lesion type | All types of lesions | All types of lesions | All types of lesions |
| Annotation | Pixel level annotation | Annotation including label of individual finding | Center and ROI |
| Breast density information | Yes | Yes | Yes |
| Dataset | Category | Sub-Category | Dataset Size | Validation | Test |
|---|---|---|---|---|---|
| DDSM | Benign | - | 3582 | 1194 | 1194 |
| Malignant | - | 4293 | 1431 | 1431 | |
| INbreast | Benign | - | 1512 | 504 | 504 |
| Malignant | - | 3066 | 1022 | 1022 | |
| MIAS | Benign | - | 1422 | 474 | 474 |
| Malignant | - | 864 | 288 | 288 | |
| Mixed | Benign | DDSM | 3582 | 1194 | 1194 |
| INbreast | 1512 | 504 | 504 | ||
| MIAS | 1422 | 474 | 474 | ||
| Total | 6516 | 2172 | 2172 | ||
| Malignant | DDSM | 4293 | 1431 | 1431 | |
| INbreast | 3066 | 1022 | 1022 | ||
| MIAS | 864 | 288 | 288 | ||
| Total | 8233 | 2741 | 2741 |
| Layer Type | Input | Output |
|---|---|---|
| Input Layer | 16 × 227 × 227 × 3 | 16 × 227 × 227 × 3 |
| EfficientNetB2 | Load EfficientNetB2 from Keras and remove classifier & input Layer | |
| Global Average Pooling | 16 × 7 × 7 × 1408 | 16 × 1408 |
| Fully Connected Layer1 with L2 | 16 × 1408 | 16 × 1024 |
| Fully Connected Layer2 | 16 × 1024 | 16 × 8 |
| Fully Connected Layer3 | 16 × 8 | 16 × 8 |
| Softmax | 16 × 8 | 16 × 2 |
| Dataset | Training Condition | Validation Accuracy | Loss | Stopping Epoch |
|---|---|---|---|---|
| DDSM | Early stop with patience = 5 | 100 | 0.65 | 150 |
| Early stop with patience = 5 | 99.97 | 0.64 | 150 | |
| Fixed epoch of 150 | 100 | 0.05 | 150 | |
| INbreast | Early stop with patience = 5 | 99.93 | 0.078 | 150 |
| Early stop with patience = 5 | 99.93 | 0.08 | 150 | |
| Fixed epoch of 150 | 99.93 | 0.078 | 150 | |
| MIAS | Early stop with patience = 5 | 99.92 | 0.87 | 150 |
| Early stop with patience = 5 | 99.92 | 0.87 | 150 | |
| Fixed epoch of 150 | 99.92 | 0.86 | 150 | |
| Mixed dataset | Early stop with patience = 5 | 99.95 | 0.05 | 133 |
| Early stop with patience = 5 | 99.98 | 0.07 | 150 | |
| Fixed epoch of 150 | 99.98 | 0.07 | 150 |
| Dataset | F1 | AUC | Test Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|---|
| DDSM | 1 | 1 | 1 | 1 | 1 |
| INbreast | 0.9995 | 0.9994 | 0.9993 | 0.9996 | 0.9992 |
| MIAS | 0.9989 | 0.9993 | 0.9992 | 0.9987 | 1 |
| Mixed | 0.9998 | 0.9998 | 0.9998 | 1 | 0.9997 |
| Dataset | CNN-Optimizer Combination | F1-Score | AUC | Test Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|---|---|
| DDSM | EfficientNetB2-Adagrad | 1.0 | 1 | 1.0 | 1.0 | 1.0 |
| EfficientNetB2-Adam | 0.99993 | 0.99993 | 0.99992 | 1.0 | 0.99986 | |
| EfficientNetB2-SGD | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | |
| ResNet50-Adagrad | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | |
| ResNet50-Adam | 0.94108 | 0.89991 | 0.90898 | 0.79983 | 1.0 | |
| ResNet50-SGD | 0.99986 | 0.99986 | 0.99984 | 1.0 | 0.99972 | |
| InceptionV3-Adagrad | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | |
| InceptionV3-Adam | 0.88227 | 0.8 | 0.81809 | 0.6 | 1.0 | |
| InceptionV3-SGD | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | |
| INbreast | EfficientNetB2-Adagrad | 0.99951 | 0.99941 | 0.99934 | 0.99960 | 0.99921 |
| EfficientNetB2-Adam | 0.99872 | 0.99802 | 0.99829 | 0.99722 | 0.99882 | |
| EfficientNetB2-SGD | 0.99664 | 0.99637 | 0.99554 | 0.99880 | 0.99393 | |
| ResNet50-Adagrad | 0.99892 | 0.99821 | 0.99855 | 0.99722 | 0.99921 | |
| ResNet50-Adam | 0.97055 | 0.96968 | 0.96371 | 0.98730 | 0.95209 | |
| ResNet50-SGD | 0.99647 | 0.99486 | 0.99528 | 0.99365 | 0.99608 | |
| InceptionV3-Adagrad | 0.99793 | 0.99764 | 0.99724 | 0.99880 | 0.99647 | |
| InceptionV3-Adam | 0.99786 | 0.99603 | 0.99711 | 0.99285 | 0.99921 | |
| InceptionV3-SGD | 0.99892 | 0.99852 | 0.99855 | 0.99841 | 0.99863 | |
| MIAS | EfficientNetB2-Adagrad | 0.99896 | 0.99936 | 0.99921 | 0.99873 | 1.0 |
| EfficientNetB2-Adam | 0.99860 | 0.99874 | 0.99895 | 0.99957 | 0.99791 | |
| EfficientNetB2-SGD | 0.99310 | 0.99564 | 0.99475 | 0.99199 | 0.99930 | |
| ResNet50-Adagrad | 0.99193 | 0.99242 | 0.99396 | 0.99873 | 0.98611 | |
| ResNet50-Adam | 0.95908 | 0.96780 | 0.96825 | 0.96962 | 0.96597 | |
| ResNet50-SGD | 0.99235 | 0.99365 | 0.99422 | 0.99536 | 0.99236 | |
| InceptionV3-Adagrad | 0.99614 | 0.99645 | 0.99711 | 0.99915 | 0.99375 | |
| InceptionV3-Adam | 0.99450 | 0.99608 | 0.99580 | 0.99494 | 0.99722 | |
| InceptionV3-SGD | 0.99476 | 0.99554 | 0.99606 | 0.99831 | 0.99236 | |
| Mixed | EfficientNetB2-Adagrad | 0.99985 | 0.99985 | 0.99983 | 1.0 | 0.99970 |
| EfficientNetB2-Adam | 0.99919 | 0.99913 | 0.99910 | 0.99935 | 0.99890 | |
| EfficientNetB2-SGD | 0.99926 | 0.99926 | 0.99918 | 0.99990 | 0.99861 | |
| ResNet50-Adagrad | 0.99905 | 0.99893 | 0.99894 | 0.99889 | 0.99897 | |
| ResNet50-Adam | 0.93016 | 0.88472 | 0.89688 | 0.77956 | 0.98986 | |
| ResNet50-SGD | 0.99766 | 0.99737 | 0.99739 | 0.99714 | 0.99759 | |
| InceptionV3-Adagrad | 0.99828 | 0.99806 | 0.99808 | 0.99788 | 0.99824 | |
| InceptionV3-Adam | 0.88094 | 0.79390 | 0.81700 | 0.59410 | 0.99365 | |
| InceptionV3-SGD | 0.99821 | 0.99797 | 0.99800 | 0.99769 | 0.99824 |
| Model | Dataset Type | CNN Architecture | Optimizer | Time (h) | Five-Fold Cross Validation Test Accuracy (%) |
|---|---|---|---|---|---|
| Best practice Conventional TL | DDSM | ResNet50 | Adam | 1.846567529 | 85.723 |
| INbreast | ResNet50 | Adam | 1.824081421 | 83.566 | |
| MIAS | ResNet50 | Adam | 1.805489539 | 90.670 | |
| Mixed | ResNet50 | Adam | 1.858144065 | 86.335 | |
| Multistage TL with the same set up as CTL | DDSM | ResNet50 | Adam | 1.711060605 | 90.898 |
| INbreast | ResNet50 | Adam | 1.708678728 | 96.371 | |
| MIAS | ResNet50 | Adam | 1.694282732 | 96.825 | |
| Mixed | ResNet50 | Adam | 1.724357648 | 89.688 | |
| Multistage TL with our best model | DDSM | EfficientNetB2 | Adagrad | 1.60336038 | 100 |
| INbreast | EfficientNetB2 | Adagrad | 1.51702123 | 99.934 | |
| MIAS | EfficientNetB2 | Adagrad | 1.50130263 | 99.921 | |
| Mixed | EfficientNetB2 | Adagrad | 1.62434423 | 99.983 |
| Fold Number | Patch and Whole Image Classifier | Proposed Patchless Multistage Transfer Learning Method | ||
|---|---|---|---|---|
| Accuracy (%) | Time (h) | Accuracy (%) | Time (h) | |
| Fold 1 | 98.165 | 2.1730723 | 99.213 | 1.714756812 |
| Fold 2 | 77.129 | 2.12583438 | 99.737 | 1.757123122 |
| Fold 3 | 87.614 | 2.10610313 | 99.344 | 1.736005956 |
| Fold 4 | 94.695 | 2.09312669 | 99.279 | 1.730858592 |
| Fold 5 | 99.476 | 1.71885766 | 99.017 | 1.733659677 |
| Average | 91.416 | 2.043398834 | 99.344 | 1.734480832 |
| Paper | Application | Image Dataset | Dataset Size | Model Validation | CNN Model | AUC | Accuracy (%) |
|---|---|---|---|---|---|---|---|
| Al-masni et al. [22] | Classification | DDSM | 600 with augmentation | 5-fold CV | CNN, F-CNN | 0.9645 | 96.33 |
| Al-antari et al. [21] | Classification | DDSM, INbreast | 9240 DDSM and 2266 INbreast with augmentation | 5-fold CV | CNN, ResNet50, InceptionResNet-V2 | CNN = 0.945, ResNet-50 = 0.9583, and InceptionResNet-V2 = 0.975 on DDSM and CNN = 0.8767, ResNet50 = 0.9233, and InceptionResNet-V2 = 0.9391 on INbreast | CNN = 94.5, ResNet-50 = 95.83, and InceptionResNet-V2 = 97.5 on DDSM and CNN = 88.74, ResNet50 = 92.55, and InceptionResNet-V2 = 95.32 on INbreast |
| Ribli et al. [63] | Classification | DDSM, SUD, INbreast | 2949 with augmentation | NA | Faster RCNN | 0.95 | NA |
| Chougrad et al. [35] | Classification | DDSM, BCDR, INbreast, mixed, MIAS | 6116 with augmentation | 5-fold CV | Deep CNN | 0.98 on DDSM, on 0.96 BCDR, 0.97 on INbreast, and 0.99 on MIAS | 97.35 on DDSM, on 96.67 BCDR, 95.50 on INbreast, and 98.23 on MIAS |
| Lotter et al. [14] | Classification | DDSM | 10,480 with augmentation | CV by patient | Wide ResNet | 0.92 | NA |
| Dhungel et al. [38] | Classification | INbreast | 410 without augmentation | 5-fold CV | CNN, RF, BO | 0.69–0.76 MUI, 0.8–0.91 MS | Maximum of 95% |
| Saraswathi & Srinivasan [64] | Classification | MIAS | 322 without augmentation | 10-fold CV | FCRN | NA | 94.7 |
| The proposed method | Classification | DDSM, INbreast, MIAS, mixed | 13,128 DDSM, 7632 INbreast, and 3816 MIAS. 24,576 mixed | 5-fold CV | EfficientNetB2 | 1 on DDSM, 0.9995 on INbreast, 0.9989 on MIAS, and 0.9998 on mixed dataset | 100 on DDSM, 99.93 on INbreast, 99.92 on MIAS, and 99.98 on mixed dataset |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayana, G.; Park, J.; Choe, S.-w. Patchless Multi-Stage Transfer Learning for Improved Mammographic Breast Mass Classification. Cancers 2022, 14, 1280. https://doi.org/10.3390/cancers14051280
Ayana G, Park J, Choe S-w. Patchless Multi-Stage Transfer Learning for Improved Mammographic Breast Mass Classification. Cancers. 2022; 14(5):1280. https://doi.org/10.3390/cancers14051280
Chicago/Turabian StyleAyana, Gelan, Jinhyung Park, and Se-woon Choe. 2022. "Patchless Multi-Stage Transfer Learning for Improved Mammographic Breast Mass Classification" Cancers 14, no. 5: 1280. https://doi.org/10.3390/cancers14051280
APA StyleAyana, G., Park, J., & Choe, S.-w. (2022). Patchless Multi-Stage Transfer Learning for Improved Mammographic Breast Mass Classification. Cancers, 14(5), 1280. https://doi.org/10.3390/cancers14051280