
Breast Cancer Detection Using Convoluted Features and Ensemble Machine Learning Algorithm

 , , , ,
, , , , 
Abstract
Simple Summary
Abstract
1. Introduction
- This study analyzes the impact of hand-crafted and deep convoluted features in breast cancer prediction. For convoluted features, this study uses the convolutional neural network (CNN).
- An ensemble model is proposed, which offers high breast cancer prediction accuracy. The model employs a logistic regression (LR) and stochastic gradient descent (SGD) classifier, and a voting mechanism is used to make the final prediction.
- Performance analysis is carried out by employing several machine learning models, including stochastic gradient descent (SGD), random forest (RF), extra tree classifier (ETC), gradient boosting machine (GBM), gaussian Naive Bayes (GNB), K-nearest neighbor (KNN), support vector machine (SVM), logistic regression (LR), and decision tree (DT). In addition, the performance of the proposed ensemble model is compared with the recent state-of-the-art models to show the significance of the proposed approach.
2. Literature Review
- Several of these works used smaller datasets and the performance evaluation of the proposed approach is not evaluated properly,
- Some of the previous works did not use breast area segmentation before the classification,
- Many works include the manual region of interest extraction regarding the breast area,
- Similarly, several works used the accuracy metric only. However, the good value of accuracy does not mean that the system can recognize different classes equally when an imbalanced dataset is used.
3. Materials and Methods
3.1. Dataset
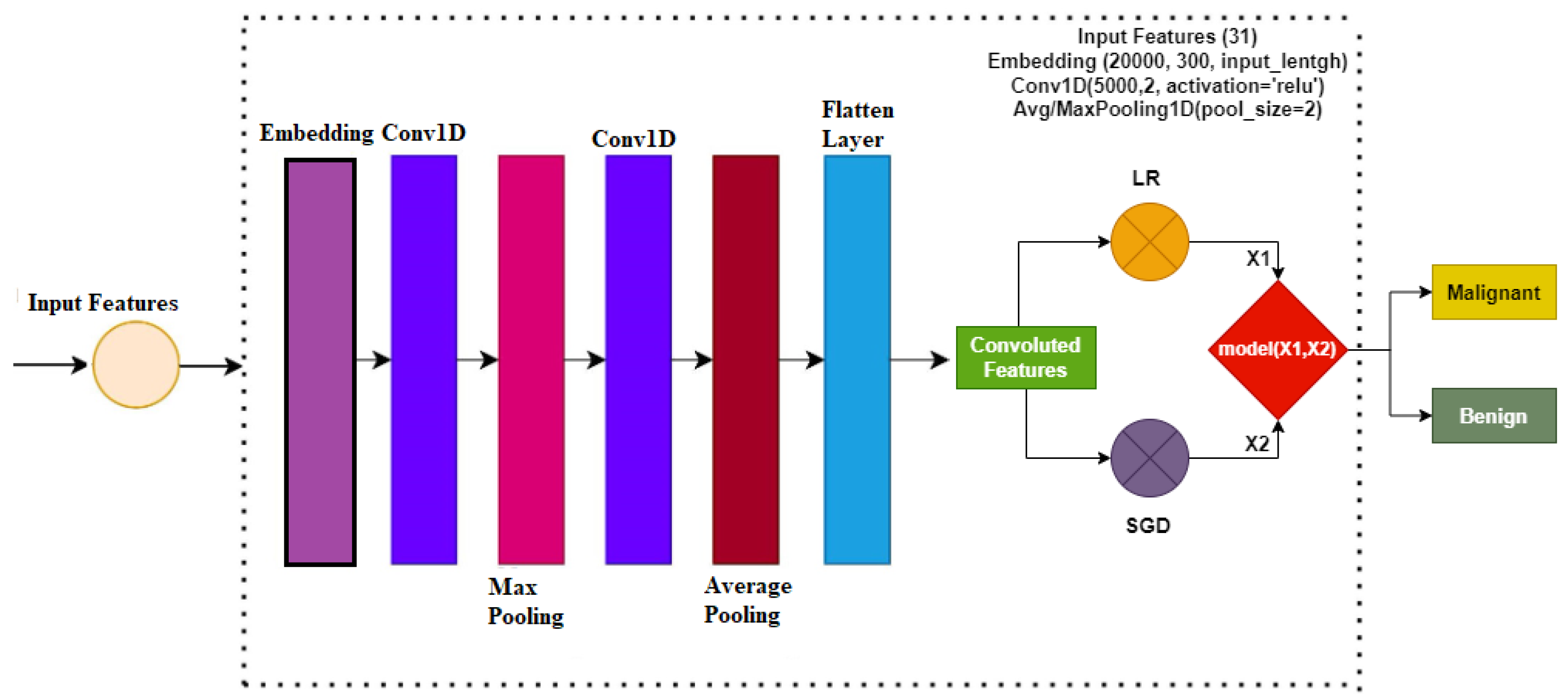
3.2. Convolutional Neural Networks
3.3. Classifiers
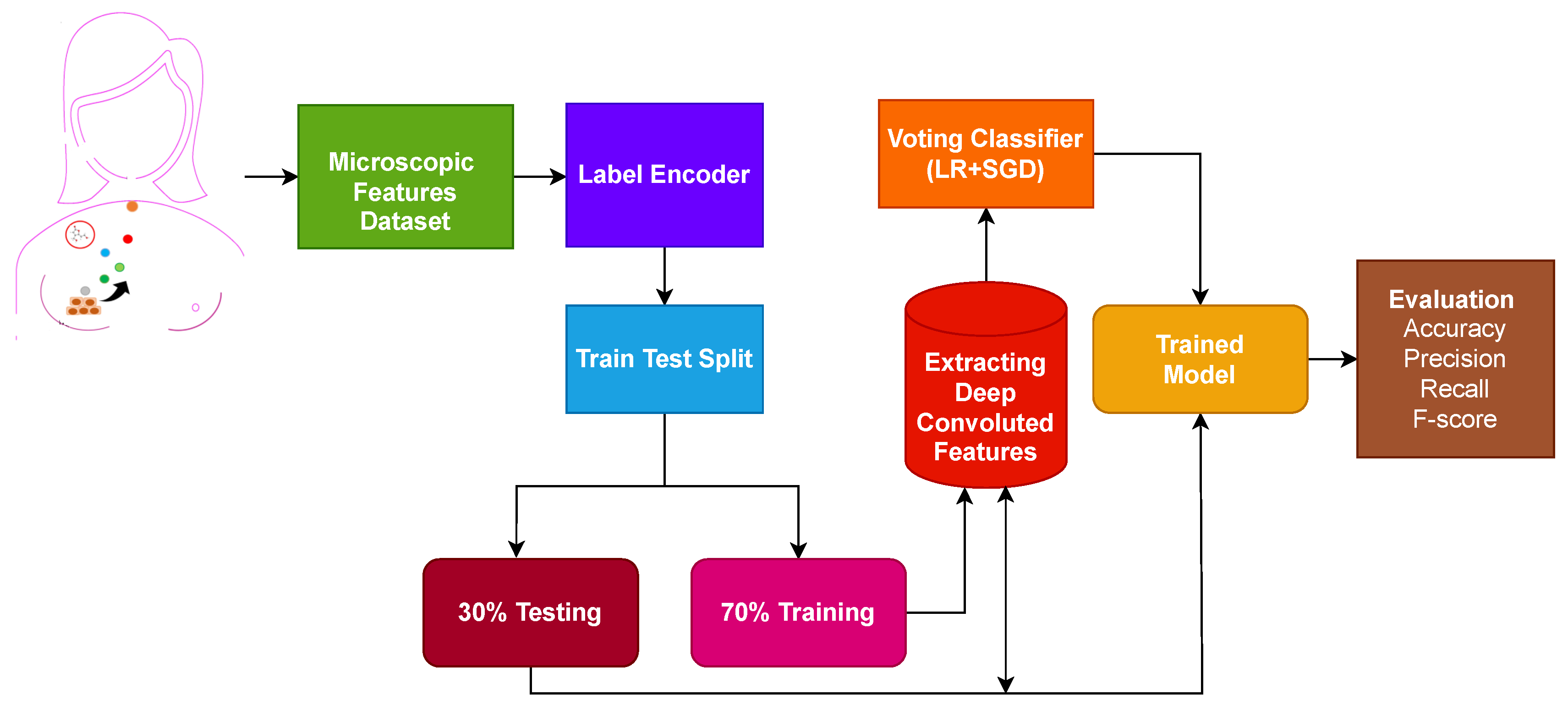
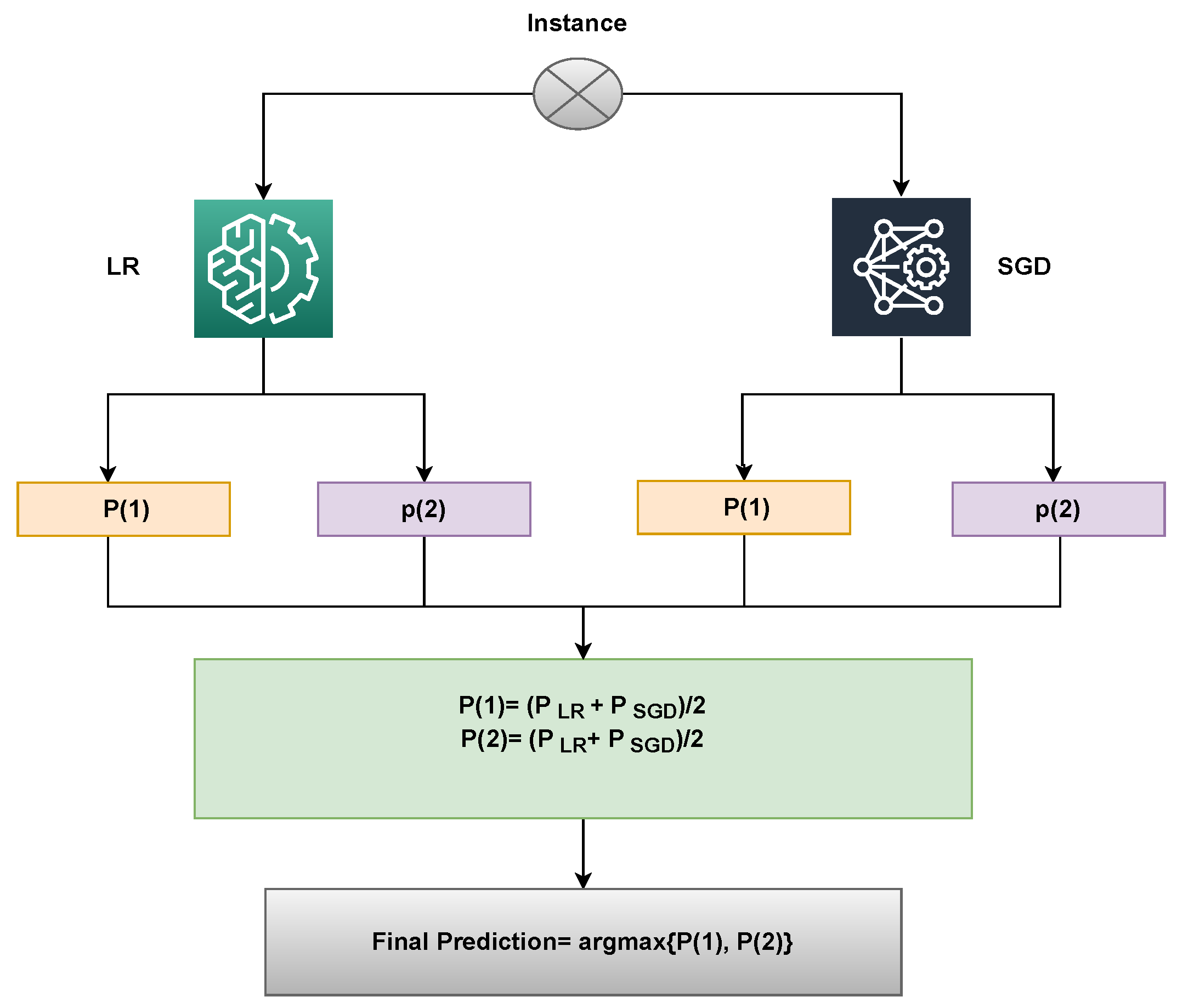
3.4. Proposed Methodology
| Algorithm 1 Ensembling of LR and SGD. |
Input: input data = Trained_ LR = Trained_ SGD
|
3.5. Evaluation Metrics
4. Experiments and Results
4.1. Performance of Models Using Original Features
4.2. Performance of Models Using CNN Features
4.3. Results of K-Fold Cross-Validation
4.4. Performance Comparison with Existing Studies
4.5. Statistical t-Test
4.6. Limitations of Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Cancer: Key Facts. 2022. Available online: https://www.who.int/news-room/fact-sheets/detail/cancer (accessed on 1 October 2022).
- World Health Organization. Breast Cancer. 2022. Available online: https://www.who.int/news-room/fact-sheets/detail/breast-cancer (accessed on 1 October 2022).
- Cancer Research, U.K. Breast Cancer Statistics. 2022. Available online: https://www.cancerresearchuk.org/health-professional/cancer-statistics/statistics-by-cancer-type/breast-cancer#heading-Two (accessed on 1 October 2022).
- Sun, Y.S.; Zhao, Z.; Yang, Z.N.; Xu, F.; Lu, H.J.; Zhu, Z.Y.; Shi, W.; Jiang, J.; Yao, P.P.; Zhu, H.P. Risk factors and preventions of breast cancer. Int. J. Biol. Sci. 2017, 13, 1387. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, F.K.; Yusoff, N. Classifying breast cancer types based on fine needle aspiration biopsy data using random forest classifier. In Proceedings of the 2013 13th International Conference on Intellient Systems Design and Applications, Salangor, Malaysia, 8–10 December 2013; pp. 121–125. [Google Scholar]
- Robertson, F.M.; Bondy, M.; Yang, W.; Yamauchi, H.; Wiggins, S.; Kamrudin, S.; Krishnamurthy, S.; Le-Petross, H.; Bidaut, L.; Player, A.N.; et al. Inflammatory breast cancer: The disease, the biology, the treatment. CA A Cancer J. Clin. 2010, 60, 351–375. [Google Scholar] [CrossRef] [PubMed]
- Masciari, S.; Larsson, N.; Senz, J.; Boyd, N.; Kaurah, P.; Kandel, M.J.; Harris, L.N.; Pinheiro, H.C.; Troussard, A.; Miron, P.; et al. Germline E-cadherin mutations in familial lobular breast cancer. J. Med. Genet. 2007, 44, 726–731. [Google Scholar] [CrossRef] [PubMed]
- Chaudhury, A.R.; Iyer, R.; Iychettira, K.K.; Sreedevi, A. Diagnosis of invasive ductal carcinoma using image processing techniques. In Proceedings of the 2011 International Conference on Image Information Processing, Shimla, India, 3–5 November 2011; pp. 1–6. [Google Scholar]
- Pervez, S.; Khan, H. Infiltrating ductal carcinoma breast with central necrosis closely mimicking ductal carcinoma in situ (comedo type): A case series. J. Med. Case Rep. 2007, 1, 83. [Google Scholar] [CrossRef]
- Memis, A.; Ozdemir, N.; Parildar, M.; Ustun, E.E.; Erhan, Y. Mucinous (colloid) breast cancer: Mammographic and US features with histologic correlation. Eur. J. Radiol. 2000, 35, 39–43. [Google Scholar] [CrossRef]
- Gradilone, A.; Naso, G.; Raimondi, C.; Cortesi, E.; Gandini, O.; Vincenzi, B.; Saltarelli, R.; Chiapparino, E.; Spremberg, F.; Cristofanilli, M.; et al. Circulating tumor cells (CTCs) in metastatic breast cancer (MBC): Prognosis, drug resistance and phenotypic characterization. Ann. Oncol. 2011, 22, 86–92. [Google Scholar] [CrossRef]
- Hou, R.; Mazurowski, M.A.; Grimm, L.J.; Marks, J.R.; King, L.M.; Maley, C.C.; Hwang, E.S.S.; Lo, J.Y. Prediction of upstaged ductal carcinoma in situ using forced labeling and domain adaptation. IEEE Trans. Biomed. Eng. 2019, 67, 1565–1572. [Google Scholar] [CrossRef]
- Dongola, N. Mammography in breast cancer. MedScape 2018, 4, 102–110. [Google Scholar]
- Løberg, M.; Lousdal, M.L.; Bretthauer, M.; Kalager, M. Benefits and harms of mammography screening. Breast Cancer Res. 2015, 17, 63. [Google Scholar] [CrossRef]
- Ishaq, A.; Sadiq, S.; Umer, M.; Ullah, S.; Mirjalili, S.; Rupapara, V.; Nappi, M. Improving the prediction of heart failure patients’ survival using SMOTE and effective data mining techniques. IEEE Access 2021, 9, 39707–39716. [Google Scholar] [CrossRef]
- Amrane, M.; Oukid, S.; Gagaoua, I.; Ensari, T. Breast cancer classification using machine learning. In Proceedings of the 2018 Electric Electronics, Computer Science, Biomedical Engineerings’ Meeting (EBBT), Istanbul, Turkey, 18–19 April 2018; pp. 1–4. [Google Scholar]
- Obaid, O.I.; Mohammed, M.A.; Ghani, M.K.A.; Mostafa, A.; Taha, F. Evaluating the performance of machine learning techniques in the classification of Wisconsin Breast Cancer. Int. J. Eng. Technol. 2018, 7, 160–166. [Google Scholar]
- Nawaz, M.; Sewissy, A.A.; Soliman, T.H.A. Multi-class breast cancer classification using deep learning convolutional neural network. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 316–332. [Google Scholar] [CrossRef]
- Singh, S.J.; Rajaraman, R.; Verlekar, T.T. Breast Cancer Prediction Using Auto-Encoders. In International Conference on Data Management, Analytics & Innovation; Springer: Singapore, 2023; pp. 121–132. [Google Scholar]
- Murphy, A. Breast Cancer Wisconsin (Diagnostic) Data Analysis Using GFS-TSK. In North American Fuzzy Information Processing Society Annual Conference; Springer: Cham, Switzerland, 2021; pp. 302–308. [Google Scholar]
- Ghosh, P. Breast Cancer Wisconsin (Diagnostic) Prediction. Available online: https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic) (accessed on 1 October 2022).
- Akbulut, S.; Cicek, I.B.; Colak, C. Classification of Breast Cancer on the Strength of Potential Risk Factors with Boosting Models: A Public Health Informatics Application. Med Bull. Haseki/Haseki Tip Bul. 2022, 60, 196–203. [Google Scholar] [CrossRef]
- Ak, M.F. A Comparative Analysis of Breast Cancer Detection and Diagnosis Using Data Visualization and Machine Learning Applications. Healthcare 2020, 8, 111. [Google Scholar] [CrossRef] [PubMed]
- Kashif, M.; Malik, K.R.; Jabbar, S.; Chaudhry, J. Application of machine learning and image processing for detection of breast cancer. In Innovation in Health Informatics; Elsevier: Hoboken, NJ, USA, 2020; pp. 145–162. [Google Scholar]
- Dey, N.; Rajinikanth, V.; Hassanien, A.E. An examination system to classify the breast thermal images into early/acute DCIS class. In Proceedings of the International Conference on Data Science and Applications; Springer: Singapore, 2021; pp. 209–220. [Google Scholar]
- Rajinikanth, V.; Kadry, S.; Taniar, D.; Damaševičius, R.; Rauf, H.T. Breast-cancer detection using thermal images with marine-predators-algorithm selected features. In Proceedings of the 2021 Seventh International Conference on Bio Signals, Images, and Instrumentation (ICBSII), Chennai, India, 25–27 March 2021; pp. 1–6. [Google Scholar]
- Hamed, G.; Marey, M.A.E.R.; Amin, S.E.S.; Tolba, M.F. Deep learning in breast cancer detection and classification. In The International Conference on Artificial Intelligence and Computer Vision; Springer: Cham, Switzerland, 2020; pp. 322–333. [Google Scholar]
- Abdar, M.; Zomorodi-Moghadam, M.; Zhou, X.; Gururajan, R.; Tao, X.; Barua, P.D.; Gururajan, R. A new nested ensemble technique for automated diagnosis of breast cancer. Pattern Recognit. Lett. 2020, 132, 123–131. [Google Scholar] [CrossRef]
- Cabıoğlu, Ç.; Oğul, H. Computer-aided breast cancer diagnosis from thermal images using transfer learning. In Proceedings of the International Work-Conference on Bioinformatics and Biomedical Engineering, Granada, Spain, 6–8 May 2020; Springer: Cham, Switzerland, 2020; pp. 716–726. [Google Scholar]
- Khan, S.; Islam, N.; Jan, Z.; Din, I.U.; Rodrigues, J.J.C. A novel deep learning based framework for the detection and classification of breast cancer using transfer learning. Pattern Recognit. Lett. 2019, 125, 1–6. [Google Scholar] [CrossRef]
- McKinney, S.M.; Sieniek, M.; Godbole, V.; Godwin, J.; Antropova, N.; Ashrafian, H.; Back, T.; Chesus, M.; Corrado, G.S.; Darzi, A.; et al. International evaluation of an AI system for breast cancer screening. Nature 2020, 577, 89–94. [Google Scholar] [CrossRef]
- Ting, F.F.; Tan, Y.J.; Sim, K.S. Convolutional neural network improvement for breast cancer classification. Expert Syst. Appl. 2019, 120, 103–115. [Google Scholar] [CrossRef]
- de Freitas Barbosa, V.A.; de Santana, M.A.; Andrade, M.K.S.; de Lima, R.d.C.F.; dos Santos, W.P. Deep-wavelet neural networks for breast cancer early diagnosis using mammary termographies. In Deep Learning for Data Analytics; Elsevier: Hoboken, NJ, USA, 2020; pp. 99–124. [Google Scholar]
- Repository, U. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic) (accessed on 1 October 2022).
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Saranya, N.; Samyuktha, M.S.; Isaac, S.; Subhanki, B. Diagnosing chronic kidney disease using KNN algorithm. In Proceedings of the 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 19–20 March 2021; Volume 1, pp. 2038–2041. [Google Scholar]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Chandra, B.; Varghese, P.P. Fuzzy SLIQ decision tree algorithm. IEEE Trans. Syst. Man, Cybern. Part (Cybern.) 2008, 38, 1294–1301. [Google Scholar] [CrossRef] [PubMed]
- Wien, M.; Schwarz, H.; Oelbaum, T. Performance analysis of SVC. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 1194–1203. [Google Scholar] [CrossRef]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 398. [Google Scholar]
- CHEN, T.; GUESTRIN, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Lavanya, D.; Rani, D.K.U. Analysis of feature selection with classification: Breast cancer datasets. Indian J. Comput. Sci. Eng. (IJCSE) 2011, 2, 756–763. [Google Scholar]
- Sachdeva, R.K.; Bathla, P. A Machine Learning-Based Framework for Diagnosis of Breast Cancer. Int. J. Softw. Innov. (IJSI) 2022, 10, 1–11. [Google Scholar] [CrossRef]
- Dubey, A.K.; Gupta, U.; Jain, S. Analysis of k-means clustering approach on the breast cancer Wisconsin dataset. Int. J. Comput. Assist. Radiol. Surg. 2016, 11, 2033–2047. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Ref. | Methods | Dataset | Findings |
|---|---|---|---|
| [16] | KNN and NB | Breast cancer dataset | KNN achieved 97.5% accuracy. |
| [17] | SVM, KNN and DT | Breast cancer dataset | High performance by SVM with 98.1% accuracy. |
| [18] | CNN | BreakHis dataset | CNN achievd 95.4% accuracy. |
| [19] | Auto encoder | Breast Cancer Wisconsin dataset | The proposed approach surpassed other models. |
| [20] | Fuzzy Logic Systems | Breast Cancer Wisconsin dataset | Genetic algorithm outperforms in combination with fuzzy logic. |
| [21] | XGBoost | Breast Cancer Wisconsin dataset | The proposed approach achieved 977% accuracy using 13 features. |
| [22] | GBM, XGBoost, LightGBM | Breast Cancer Wisconsin dataset | LightGBM has shown robust results in breast tumor classification. |
| [23] | LR, DT, KNN and NB | Breast Cancer Wisconsin dataset | LR achieved highest results. |
| [24] | ML algorithms | Mammogram | Hybrid models have shown robust results |
| [25] | KNN, SVM and DT | Breast thermal images | firefly algorithm in applied to improve the quality of images. |
| [26] | SVM-cubic and SVM-coarse Gaussian | Breast thermal images | The proposed apptoach achieved 93.5% accuracy. |
| [27] | RetinaNet, YOLO | Mammogram | The study is limited in way that it uses only five images in experiments. |
| [28] | NE Model | Breast Cancer Wisconsin dataset | The proposed layered ensemble approach outperformed other individual models. |
| [29] | Transfer learning with CNN | Thermal images | The proposed approach has achieved 94.3% accuracy. |
| [30] | GoogleNet, VGGNet, ResNet | breast microscopic image data sets | The proposed transfer learning approach surpassed the individual models. |
| [31] | AI-based system | Mammogram | The proposed approach have shown promising results. |
| [32] | CNNI-BCC | Mammogram | The proposed approach used CNN to improve breast cancer classification. |
| [33] | Deep-wavelet neural network (DWNN) | Thermographic images | The proposed model detected breast lesion with 95% sensitivity. |
| Feature | Description |
|---|---|
| id | It represents the ID number of the. |
| fractal_dimension_worst | It is the “worst” or largest mean value for “coastline approximation” −1 |
| radius_mean | It is the mean of the distance from the center to its perimeter. |
| concave points_worst | It is the "worst" or largest mean value for the number of concave portions of the contour. |
| perimeter_mean | It is the mean of core tumor size. |
| compactness_worst | It is the “worst” or largest mean value for perimeter⌃2 / area −1.0 |
| smoothness_mean | It is the mean of local variation in radius lengths |
| fractal_dimension_mean | It is the mean for “coastline approximation” −1 |
| concavity_mean | It is the mean of the severity of concave portions of the contour |
| texture_se | It is the standard error for standard deviation of gray-scale values |
| symmetry_mean | |
| concave points_mean | It is the mean for the number of concave portions of the contour |
| radius_se | It is the standard error for the mean of distances from the center to points on the perimeter |
| texture_worst | It is the "worst" or largest mean value for standard deviation of gray-scale values |
| perimeter_se | |
| perimeter_worst | |
| smoothness_se | It is standard error for local variation in radius lengths |
| radius_worst | It is the “worst” or largest mean value for the mean of distances from the center to points on the perimeter |
| concavity_se | It is the standard error for the severity of concave portions of the contour |
| symmetry_se | |
| fractal_dimension_se | It is the standard error for “coastline approximation” −1 |
| concave points_se | It is the standard error for the number of concave portions of the contour |
| area_se | |
| smoothness_worst | It is the “worst” or largest mean value for local variation in radius lengths |
| area_worst | |
| compactness_se | It is the standard error for perimeter⌃2 / area −1.0 |
| compactness_mean | It is the mean of perimeter⌃2 / area −1.0 |
| concavity_worst | It is the “worst” or largest mean value for the severity of concave portions of the contour |
| area_mean | |
| symmetry_worst | |
| texture_mean | It is the standard deviation of gray-scale values |
| Diagnosis (Target Class) | The diagnosis of breast tissues (M = malignant, B = benign) |
| MLA | Description | Advantages | Limitations |
|---|---|---|---|
| RF [35] | For the development of the decision trees. It performed a random selection of features with controlled variance. | Decreased in overfitting. | Very slow in real-time prediction. Complex classifier |
| KNN [36,37] | It is a straightforward instance-based classifier widely used in medical data mining. | The optimal value is easily achieved through it. | Classification is very slow. |
| DT [38] | From the set of class labels, it constructs the decision trees. It is a structural method represented as a flow chart similar to a tree. | It combines numeric and categorical data. Very fast and simple. | Problems with the high dimensionalities and unbalanced data. A longer training time is needed. Not a good choice for larger datasets. |
| SVM [39] | It is a linear classification algorithm that works well on low-dimensional and uncomplicated data. However, it also gives good results on complex and high-dimensional data. | Easily separate the data space. One of the most robust and accurate algorithms. Has a strong basis in statistical learning theory. | Classification is very slow. Required longer training time. |
| LR [40] | It is a linear model for classification rather than regression. It uses the regression model to estimate the probability of the class members. | More robust and handles nonlinear data. Good for numeric and categorical classification. | Boolean values only. Not a good choice for predicting the value of a binary value. |
| GBM [41] | In conjunction, it enhances the classifier performance. Very sensitive to handling noisy data. | Less suspectable to overfitting problems. | Very sensitive to outliers. Pre-adjustment is needed to achieve optimal performance. |
| Model | Accuracy | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Voting (LR + SGD) | 0.772 | B | 0.75 | 0.79 | 0.77 |
| M | 0.78 | 0.80 | 0.79 | ||
| M Avg. | 0.76 | 0.79 | 0.78 | ||
| W Avg. | 0.76 | 0.79 | 0.78 | ||
| GBM | 0.745 | B | 0.77 | 0.81 | 0.79 |
| M | 0.80 | 0.81 | 0.80 | ||
| M Avg. | 0.79 | 0.81 | 0.79 | ||
| W Avg. | 0.78 | 0.81 | 0.79 | ||
| GNB | 0.756 | B | 0.78 | 0.82 | 0.80 |
| M | 0.80 | 0.80 | 0.80 | ||
| M Avg. | 0.79 | 0.81 | 0.80 | ||
| W Avg. | 0.79 | 0.80 | 0.80 | ||
| ETC | 0.759 | B | 0.78 | 0.83 | 0.80 |
| M | 0.82 | 0.85 | 0.83 | ||
| M Avg. | 0.80 | 0.84 | 0.81 | ||
| W Avg. | 0.80 | 0.85 | 0.82 | ||
| LR | 0.769 | B | 0.79 | 0.79 | 0.79 |
| M | 0.82 | 0.83 | 0.82 | ||
| M Avg. | 0.81 | 0.81 | 0.80 | ||
| W Avg. | 0.80 | 0.81 | 0.80 | ||
| SGD | 0.761 | B | 0.80 | 0.80 | 0.80 |
| M | 0.83 | 0.81 | 0.82 | ||
| M Avg. | 0.81 | 0.80 | 0.81 | ||
| W Avg. | 0.81 | 0.80 | 0.81 | ||
| RF | 0.743 | B | 0.72 | 0.73 | 0.72 |
| M | 0.77 | 0.85 | 0.81 | ||
| M Avg. | 0.75 | 0.79 | 0.77 | ||
| W Avg. | 0.75 | 0.80 | 0.77 | ||
| KNN | 0.751 | B | 0.78 | 0.82 | 0.80 |
| M | 0.81 | 0.83 | 0.82 | ||
| M Avg. | 0.79 | 0.82 | 0.81 | ||
| W Avg. | 0.79 | 0.81 | 0.81 | ||
| SVM | 0.767 | B | 0.77 | 0.79 | 0.78 |
| M | 0.80 | 0.81 | 0.80 | ||
| M Avg. | 0.78 | 0.80 | 0.79 | ||
| W Avg. | 0.78 | 0.80 | 0.79 | ||
| DT | 0.739 | B | 0.70 | 0.71 | 0.70 |
| M | 0.74 | 0.78 | 0.76 | ||
| M Avg. | 0.72 | 0.74 | 0.73 | ||
| W Avg. | 0.72 | 0.74 | 0.73 |
| Model | Accuracy | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Voting (LR + SGD) | 1.000 | B | 1.00 | 1.00 | 1.00 |
| M | 1.00 | 1.00 | 1.00 | ||
| M Avg. | 1.00 | 1.00 | 1.00 | ||
| W Avg. | 1.00 | 1.00 | 1.00 | ||
| GBM | 0.951 | B | 0.94 | 0.98 | 0.96 |
| M | 0.96 | 0.91 | 0.94 | ||
| M Avg. | 0.95 | 0.95 | 0.95 | ||
| W Avg. | 0.95 | 0.95 | 0.95 | ||
| GNB | 0.965 | B | 0.98 | 0.96 | 0.97 |
| M | 0.95 | 0.97 | 0.96 | ||
| M Avg. | 0.96 | 0.97 | 0.96 | ||
| W Avg. | 0.97 | 0.97 | 0.97 | ||
| ETC | 0.965 | B | 0.95 | 0.99 | 0.97 |
| M | 0.98 | 0.93 | 0.96 | ||
| M Avg. | 0.97 | 0.96 | 0.96 | ||
| W Avg. | 0.97 | 0.97 | 0.96 | ||
| LR | 0.991 | B | 0.99 | 1.00 | 0.99 |
| M | 1.00 | 0.98 | 0.99 | ||
| M Avg. | 0.99 | 0.99 | 0.99 | ||
| W Avg. | 0.99 | 0.99 | 0.99 | ||
| SGD | 0.986 | B | 0.98 | 1.00 | 0.99 |
| M | 1.00 | 0.97 | 0.98 | ||
| M Avg. | 0.99 | 0.98 | 0.99 | ||
| W Avg. | 1.00 | 0.97 | 0.98 | ||
| RF | 0.951 | B | 0.94 | 0.98 | 0.96 |
| M | 0.96 | 0.91 | 0.94 | ||
| M Avg. | 0.95 | 0.95 | 0.95 | ||
| W Avg. | 0.95 | 0.95 | 0.95 | ||
| KNN | 0.972 | B | 0.98 | 0.95 | 0.96 |
| M | 0.95 | 0.92 | 0.94 | ||
| M Avg. | 0.96 | 0.94 | 0.95 | ||
| W Avg. | 0.96 | 0.93 | 0.95 | ||
| SVM | 0.979 | B | 0.97 | 0.93 | 0.95 |
| M | 0.95 | 0.92 | 0.93 | ||
| M Avg. | 0.96 | 0.92 | 0.94 | ||
| W Avg. | 0.96 | 0.92 | 0.94 | ||
| DT | 0.943 | B | 0.92 | 0.90 | 0.91 |
| M | 0.93 | 0.91 | 0.92 | ||
| M Avg. | 0.92 | 0.90 | 0.91 | ||
| W Avg. | 0.92 | 0.90 | 0.91 |
| Fold Number | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| Fold-1 | 0.999 | 0.999 | 0.999 | 0.999 |
| Fold-2 | 0.996 | 0.997 | 0.998 | 0.997 |
| Fold-3 | 0.999 | 0.999 | 0.999 | 0.999 |
| Fold-4 | 1.000 | 1.000 | 1.000 | 1.000 |
| Fold-5 | 1.000 | 1.000 | 1.000 | 1.000 |
| Fold-6 | 1.000 | 1.000 | 1.000 | 1.000 |
| Fold-7 | 0.997 | 0.996 | 0.998 | 0.997 |
| Fold-8 | 0.999 | 0.999 | 0.999 | 0.999 |
| Fold-9 | 0.999 | 0.999 | 0.999 | 0.999 |
| Fold-10 | 1.000 | 1.000 | 1.000 | 1.000 |
| Average | 0.9989 | 0.9989 | 0.9992 | 0.9990 |
| Reference | Approach | Accuracy |
|---|---|---|
| [44] | K-means clustering | 92.01% |
| [42] | PCA features with SVM | 96.99% |
| [17] | Quadratic SVM | 98.11% |
| [19] | Auto-encoder | 98.40% |
| [20] | GF-TSK | 94.11% |
| [21] | XgBoost | 97.11% |
| [22] | Five most significant features with LightGBM | 95.03% |
| [43] | Chi-square features | 98.21% |
| [23] | LR with all features | 98.10% |
| Proposed | Deep convoluted features with voting classifier (LR + SGD) | 100% |
| Acronyms | Definition |
|---|---|
| AI | Artificial Intelligence |
| AUC | Area under the curve |
| CAD | Computer-aided diagnostic |
| CNN | Convolutional Neural Network |
| DCIS | Ductal carcinoma in situ |
| DWNN | deep wavelet Neural network |
| DT | Decision Tree |
| ETC | Extra Tree classifier |
| GBM | Gradient boosting machine |
| GNB | Gausssian Naive Bayes |
| IBC | Inflammatory breast cancer |
| IDC | Invasive ductal carcinoma |
| LBC | Lobular breast cancer |
| KNN | K nearest neighbor |
| LR | Logistic Regression |
| MBC | Mucinous breast cancer |
| MTBC | Mixed tumors breast cancer |
| PCA | Principal component analysis |
| ReLU | Rectified Linear Unit |
| SGD | Stochastic gradient descent |
| SVM | Support vector machine |
| VC | Voting classifier |
| WHO | World health organization |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Umer, M.; Naveed, M.; Alrowais, F.; Ishaq, A.; Hejaili, A.A.; Alsubai, S.; Eshmawi, A.A.; Mohamed, A.; Ashraf, I. Breast Cancer Detection Using Convoluted Features and Ensemble Machine Learning Algorithm. Cancers 2022, 14, 6015. https://doi.org/10.3390/cancers14236015
Umer M, Naveed M, Alrowais F, Ishaq A, Hejaili AA, Alsubai S, Eshmawi AA, Mohamed A, Ashraf I. Breast Cancer Detection Using Convoluted Features and Ensemble Machine Learning Algorithm. Cancers. 2022; 14(23):6015. https://doi.org/10.3390/cancers14236015
Chicago/Turabian StyleUmer, Muhammad, Mahum Naveed, Fadwa Alrowais, Abid Ishaq, Abdullah Al Hejaili, Shtwai Alsubai, Ala’ Abdulmajid Eshmawi, Abdullah Mohamed, and Imran Ashraf. 2022. "Breast Cancer Detection Using Convoluted Features and Ensemble Machine Learning Algorithm" Cancers 14, no. 23: 6015. https://doi.org/10.3390/cancers14236015
APA StyleUmer, M., Naveed, M., Alrowais, F., Ishaq, A., Hejaili, A. A., Alsubai, S., Eshmawi, A. A., Mohamed, A., & Ashraf, I. (2022). Breast Cancer Detection Using Convoluted Features and Ensemble Machine Learning Algorithm. Cancers, 14(23), 6015. https://doi.org/10.3390/cancers14236015