Simple Summary
The survival of patients diagnosed with ovarian cancer depends largely on the extent of the disease upon diagnosis. When confined to the ovaries, patients’ 10-year survival is more than 70%. This drastically drops to less than 5% when patients are diagnosed with far-advanced disease. Unfortunately, more than 80% of patients are diagnosed at advanced stage due to the lack of test for early detection. We report the development of a blood test measuring four proteins (macrophage migration inhibitory factor, osteopontin, prolactin and cancer antigen 125), which can distinguish ovarian cancer samples, even early-stage disease, from healthy samples in the population tested. This study is another step towards the application of a useful test for early detection of ovarian cancer that is both highly accurate and specific.
Abstract
Background: Mortality from ovarian cancer remains high due to the lack of methods for early detection. The difficulty lies in the low prevalence of the disease necessitating a significantly high specificity and positive-predictive value (PPV) to avoid unneeded and invasive intervention. Currently, cancer antigen- 125 (CA-125) is the most commonly used biomarker for the early detection of ovarian cancer. In this study we determine the value of combining macrophage migration inhibitory factor (MIF), osteopontin (OPN), and prolactin (PROL) with CA-125 in the detection of ovarian cancer serum samples from healthy controls. Materials and Methods: A total of 432 serum samples were included in this study. 153 samples were from ovarian cancer patients and 279 samples were from age-matched healthy controls. The four proteins were quantified using a fully automated, multi-analyte immunoassay. The serum samples were divided into training and testing datasets and analyzed using four classification models to calculate accuracy, sensitivity, specificity, PPV, negative predictive value (NPV), and area under the receiver operating characteristic curve (AUC). Results: The four-protein biomarker panel yielded an average accuracy of 91% compared to 85% using CA-125 alone across four classification models (p = 3.224 × 10−9). Further, in our cohort, the four-protein biomarker panel demonstrated a higher sensitivity (median of 76%), specificity (median of 98%), PPV (median of 91.5%), and NPV (median of 92%), compared to CA-125 alone. The performance of the four-protein biomarker remained better than CA-125 alone even in experiments comparing early stage (Stage I and Stage II) ovarian cancer to healthy controls. Conclusions: Combining MIF, OPN, PROL, and CA-125 can better differentiate ovarian cancer from healthy controls compared to CA-125 alone.
1. Introduction
Ovarian cancer remains the leading cause of death from gynecologic cancers [1]. Although the 5-year survival rate of ovarian cancer can be as high as 90%, this is observed in only 20% of patients – those who are diagnosed at an early stage (Stage I or Stage II) [1,2]. Unfortunately, most patients are diagnosed at advanced stage (Stage III and Stage IV), with a 5-year survival rate of approximately 30% [2]. Early symptoms of ovarian cancer are nonspecific and the lack of a cost-effective method to detect early stage disease results in 80% of diagnoses at an advanced stage [2,3]. Ovarian cancer screening continues to be a challenging and elusive undertaking.
The difficulty in achieving a good screening test for ovarian cancer lies in the need for both a high sensitivity and specificity due to the low prevalence of the disease [4]. A screening test should be able to identify those who require further investigation and diagnostic intervention. Treatment of ovarian cancer universally involves invasive surgery and chemotherapy. Thus, an ovarian cancer screening test should have a low number of false positives to reduce unnecessary surgery and associated morbidity. For a disease such as ovarian cancer, with an inicudence of 40 per 100,000 per year, the recommended cut offs for an acceptable screening test is sensitivity of greater than 75% and a high specificity, preferably greater than 99.6%, in order to obtain a high positive predictive value (PPV) of 10% [4,5].
Multiple screening and detection methods have been evaluated [6]. The most historically recognized test is cancer antigen-125 (CA-125), discovered by Bast and colleagues in 1981 [7]. Although a clinically useful biomarker, serum CA-125 is a poor screening test due to its relatively low sensitivity, specificity and positive predictive value [8]. Other screening strategies currently being investigated use the combination of CA-125, transvaginal ultrasound and multi-step algorithms, which demonstrate higher sensitivities and specificities compared to CA-125 alone. These methods however require appropriate facilities and experienced ultrasonographers. Thus, although utilizing multi-step algorithms are showing improved statistical success, biomarker investigations should not be abandoned due to the efficiency, convenience, cost-effectiveness and increased compliance to a blood test [8,9,10].
We have previously described and investigated a panel of six serologic protein biomarkers (leptin, prolactin (PROL), osteopontin (OPN), insulin-like growth factor II (IGF-II), macrophage migration inhibitory factor (MIF), and CA-125) for the detection of ovarian cancer with a sensitivity of 95.3% and specificity of 99.4% [11,12]. Individual analysis of all six biomarkers however, showed that leptin and IGF-II had the lowest sensitivity and specificity. Thus, the objective of this study is to assess the performance of the four top-performing markers, MIF, OPN, PROL and CA-125 in detecting ovarian cancer patients from healthy controls in a retrospective study comprised of patients with both early and late-stage ovarian cancer. More recently, Guo et al. validated two of these biomarkers and demonstrated that the combination OPN, MIF, CA-125 and anti-IL-8 autoantibodies was able to increase detection of ovarian cancer compared to CA125 alone [13].
To quantify MIF, OPN, PROL and CA-125, we used the SimplePlexTM platform, a fully automated microfluidic immunoassay, which uses an automated analyzer, Ella, and a multi-analyte specific cartridge. The benefits of SimplePlexTM include the fact that it is fully automated, validated, rapid and reproducible with high sensitivity, when compared to conventional ELISAs [14].
This protein biomarker panel was used for each type of classifier, in two patient cohorts, one used for training and the other used for validation. We used four different classification models: KNN, logistic regression, random forest and support vector machines (SVM). Our results show that MIF, OPN and PROL, in combination with CA-125 provide statistically significant higher sensitivity, specificity and accuracy when compared to CA-125 alone.
2. Results
2.1. Development of the Test Model
Our objective is to determine the combined utility of CA-125, MIF, OPN and PROL in distinguishing ovarian cancer serum samples from healthy controls and compare its usefulness to CA-125 alone as a single biomarker. We used serum samples from a total of 153 patients diagnosed with ovarian cancer and 279 serum samples from age-matched healthy controls. We first divided the samples into two cohorts, cohort 1 and cohort 2 (Table 1) for the purpose of using them as training and testing sets. Within each cohort, samples were subdivided into cancer (C) and healthy (H) datasets. The cancer samples were further subdivided into early stage (E) and late stage datasets (L) (Table 1). Each data set (e.g., E1 or early-stage cancer cohort 1) was interchangeably assigned to training and testing groups (Table 2) to produce the most representative, reproducible and unbiased data. At all times, we trained our models on one data set and test on a completely different set. First, we used E1 dataset (serum samples from early-stage ovarian cancer patients from cohort 1 versus H1 dataset (serum samples from healthy controls from cohort 1 to both train and test the model (Experiment ID#1 in Table 2, Table 3, Table 4, Table 5 and Table 6). This was followed by testing 17 other experiments using different dataset combinations as shown in Table 2, Table 3, Table 4, Table 5 and Table 6. We used KNN, logistic regression, random forest, and SVM, which are four commonly used classification models, to analyze the statistical success of using combination CA-125, MIF, OPN, and PROL versus using CA-125 alone. The complete reports of all statistical measures, namely accuracy, sensitivity, specificity, PPV, NPV and AUC are shown in Table 2, Table 3, Table 4, Table 5, Table 6 and Table 7 respectively. The PPV and NPV were calculated on the indicated cohorts and do not represent the PPV and NPV expected of this panel in the general population. This is because the OVCA will have a much lower prevalence in the general population compared with these cohorts.

Table 1.
Breakdown of each sample population in each cohort.
Table 2.
Comparison of accuracy between CA-125 alone and all four proteins (CA-125, MIF, OPN, and PROL) when using the four classification methods, K-Nearest Neighbor (KNN), Logistic Regression (LR), Random Forest (RF), and Support Vector Machine (SVM), in various experiments. In each experiment, “training” column and “testing” column list the subsets used for training and testing the classification models. In these columns, the letters “C”, “E”, “L”, and “H” denote serum samples from ovarian patients, from patients in early stage, in late stage of ovarian cancer, and healthy samples, respectively. The suffix, e.g., 1 or 2, indicates that samples are from cohort set 1 and cohort set 2. The accuracy measures the ability to correctly label the testing samples and is defined as the ratio of the number of samples correctly classified to the total number of samples. We highlighted the cell(s) with best accuracy in each experiment. In general, using logistic regression and all four proteins yield the best results on most occasions.
Table 3.
The comparison of sensitivity between CA-125 alone and all four proteins (CA-125, MIF, OPN, and PROL) when using the four classification techniques. The sensitivity measures the ability to correctly identify condition samples and is defined as the ratio of the number of condition samples correctly classified to the total number of condition samples. We highlighted the cell(s) with best sensitivity in each experiment. Using random forest and all four proteins yield the best results on most occasions.
Table 4.
The comparison of specificity between CA-125 alone and all four proteins (CA-125, MIF, OPN, and PROL) when using the four classification techniques, namely K-Nearest Neighbor (KNN), Logistic Regression (LR), Random Forest (RF), and Support Vector Machine (SVM). The specificity measures the ability to correctly identify control samples and is defined as the ratio of the number of control samples correctly classified to the total number of control samples. We highlighted the cell(s) with best specificity in each experiment. Using logistic regression and all four proteins yield the best results on most occasions.
Table 5.
The comparison of positive predicted value (PPV) between CA-125 alone and all four proteins (CA-125, MIF, OPN, and PROL) when using the four classification techniques, namely K-Nearest Neighbor (KNN), Logistic Regression (LR), Random Forest (RF), and Support Vector Machine (SVM). The PPV measures the liability of a positive test result and is defined as the ratio of the number of condition samples correctly identified to the total number of positive test results. We highlighted the cell(s) with best PPV in each experiment. In general, using logistic regression and all four proteins yield the best results on most occasions.
Table 6.
The comparison of negative predicted value (NPV) between CA-125 alone and all four proteins (CA-125, MIF, OPN, and PROL) when using four classification techniques, namely K-Nearest Neighbor (KNN), Logistic Regression (LR), Random Forest (RF), and Support Vector Machine (SVM), in various experiments. The NPV measures the liability of a negative test result and is defined as the ratio of the number of control samples correctly identified to the total number of negative test results. We highlighted the cell(s) with best NPV in each experiment. In general, using random forest and all four proteins yield the best results on most occasions.
Table 7.
The comparison of the area under the ROC (AUC) between CA-125 alone and all four proteins (CA-125, MIF, OPN, and PROL) when using three classification techniques, namely K-Nearest Neighbor (KNN), Logistic Regression (LR), and Random Forest (RF) (the AUC is not available for Support Vector Machine), in various experiments. The AUC measures the performance of the model across all possible classification thresholds. Since SVM has a fixed classification threshold, the AUC is not useful and hence removed from the comparison. We highlighted the cell(s) with best in each experiment. In general, using random forest and all four proteins yield the best results on most occasions.
Table 2 shows the individual and average accuracies obtained from the four classification models. The average accuracy is shown for each of the 18 experiments and compares the average accuracy when the four-protein panel was used compared to CA-125 alone. The combined usage of CA-125, MIF, PROL, and OPN provides better average accuracies than the use of CA-125 alone in all experiments regardless of the dataset used to train and test the model. The only exception is experiment 16 (Table 2). Despite the lower accuracy however, the four-protein panel yields much higher sensitivities, demonstrating better ability to detect ovarian cancer from healthy controls compared to CA-125 alone (Table 3).
2.2. Accuracies of the Models
We then evaluated the accuracies obtained from all 18 experiments for each of the four classification models (left panel) as well as average accuracies for all the models. When the four-protein panel was used, we observed a median accuracy of 91% compared to 85% median accuracy when CA-125 was used alone (Figure 1A). This demonstrates that the four-protein panel performed better than CA-125 alone in distinguishing cancer (irrespective of stage) from healthy controls and in distinguishing late-stage cancer from healthy controls. More importantly, the use of the four-protein panel also performed better than CA-125 alone in distinguishing early-stage ovarian cancer from healthy control. The Wilcoxon p-value = 3.224 × 10−9 indicates that this is superior and statistically significant. The four-protein panel also demonstrated better sensitivity (median of 76%), specificity (median of 98%), PPV (median of 91.5%), NPV (median of 92%) and AUC (median of 93.5%) compared to CA-125 alone in distinguishing ovarian cancer from healthy controls (Wilcoxon p-values: 2.22 × 10−7, 0.02, 1.27 × 10−2, and 3.629× 10−7and and 2.34 × 10−7, respectively; Figure 1B–F).
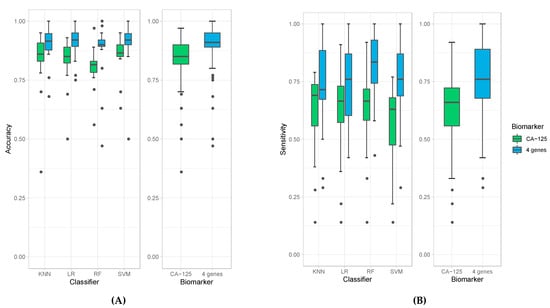
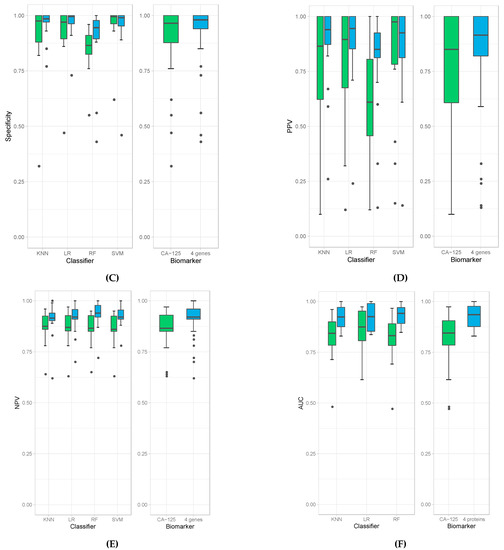
Figure 1.
Box plots of accuracies (A), sensitivities (B), specificity (C), PPV (D), NPV (E), and AUC (F) obtained by individual classifiers (left panel), namely K-Nearest Neighbor (KNN), Logistic Regression (LR), Random Forest (RF), and Support Vector Machine (SVM), and average accuracies of all models (right panel) when using CA-125 alone (green bars) and using all four genes (blue bars).
The results obtained from the four classification models used in these experiments are comparable but with some differences. All of them derive high accuracies in all experiments, especially when using the four-protein panel (e.g., all median accuracies are over 0.9). Among all classification models, random forest produced the highest sensitivity; however, it resulted in the lowest specificity (Figure 1B,C). Random forest models also produced the highest median value of NPV (Figure 1E) and AUC (Figure 1F). The highest specificity and PPV are achieved with logistic regression (Figure 1D). Due to these variations amongst classification models, we report the average calculations of the classification models to obtain the most unbiased, representative and reliable data in terms of comparing the four-protein panel versus CA-125 alone.
In the experiments that used samples from patients with early stage (Stage I/II) ovarian cancer for training, the sensitivities to detect cancer are notably lower than in experiments that used samples from late-stage patients (Stage III/IV) (Wilcoxon p-value = 7.78 × 10−8). This result is likely due to the lower quantity of samples of patients with early stage (n = 37) compared to late stage ovarian cancer (n = 116).
3. Discussion
In the current study, we investigated the ability of four serologic protein biomarkers to distinguish ovarian cancer serum samples from healthy control serum samples using an automated, multi-analyte, microfluidic cartridge-based immunoassay. Compared to conventional ELISA and other multiplex methods, the Simple Plex assay allows for more automated, reproducible, and rapid assays in triplicates using small volume samples [14]. The four-protein biomarker panel yielded an accuracy of 91% compared to 85% using CA-125 alone across all the classification models, which was statistically significant (p = 3.224 × 10−9). Further, the four-protein model produced a higher sensitivity (median of 76%), specificity (median of 98%), PPV (median of 91.5%), NPV (median of 92%) and and AUC (median of 93.5%) compared to CA-125. These PPV and NPV are those for the test samples used in this study. We do recognize that the high PPV values (> 90%) are due to the high prevalence of ovarian cancer in our cohort, compared to the general, or even a high-risk population.
Ovarian cancer is the leading cause of mortality amongst gynecologic cancers and the fifth most common cause of death in women [1]. The problem lies with the inability to diagnose ovarian cancer at an early stage, when the prognosis is favorable. An effective method for early detection would most certainly help mitigate this burden. Thus, an ongoing goal amongst gynecologic oncology investigators is to develop methods that are both accurate in detecting early stage disease, but also one that limits false positives. The other advantage of this biomarker panel may be its use to detect early recurrence or persistence after treatment.
There is a general consensus that a serologic screening test for the general population is essentially futile, unless extremely high specificity is attained, due to the very low prevalence of ovarian cancer in the population [6]. However, in patients who are at high risk of ovarian cancer, such as patients with BRCA1/2 mutations, there may be some utility and benefit [15]. Serologic tests have the benefit of cost effectiveness, availability and are least invasive. The candidate protein biomarkers included in this study are CA-125, MIF, OPN, and PROL. Individually, they have demonstrated to be elevated in patients with ovarian cancer when compared to healthy individuals [7,16,17,18]; however, this exact combination was yet to be studied for the purpose of early detection.
CA-125 is a high-molecular-weight membrane glycoprotein recognized by the monoclonal antibody OC 125 [7]. It was originally described to be increased in the serum of at least 80% of patients with epithelial ovarian cancer [19]. Since its inception, CA-125 continues to play a large role in the diagnosis and surveillance of ovarian cancer. In regards to screening, although CA-125 is not adequate by itself, it continues to be studied and integrated into screening algorithms [5,20,21,22,23] resulting in higher sensitivities and specificities.
MIF is an inflammatory cytokine originally described to be a product of activated T lymphocytes and played a primary role in inhibiting macrophage migration [16,24]. However, monocytes and macrophages were later implicated as the primary site for the production of MIF, typically following exposure to various toxins, bacteria or cytokines [25,26,27]. MIF is a key regulator in various immune and inflammatory pathways and a by-product of many cells and tissues [24]. More importantly, MIF has been found to have high circulating levels in various malignancies, including epithelial ovarian cancer [28,29]. The mechanism likely involves its role in the inflammatory process, angiogenesis, p53 expression and apoptosis associated with malignant neoplasia [16,29].
Osteopontin (OPN) is a secreted calcium-binding glycophosphoprotein that is involved in a number of biological processes, including inflammation, angiogenesis, immunity and tumor development [30,31]. Osteopontin is known to be overly expressed in several malignant tissues, including ovarian cancer cells [17]. Furthermore, it has been associated with late disease progression and tumor metastasis [17,32]. The phenotypic effects of OPN are likely due to activation of the MAPK, NF-kB, and PI3-K/Akt pathways [33,34]. These discoveries led way for OPN as a biomarker candidate for the detection of ovarian cancer [35,36].
Prolactin is a hormone secreted predominantly by lactrotroph cells of the anterior pituitary gland. It is involved in numerous biological processes, most notably, lactation and reproduction [37]. Prolactin is also produced in many other tissues, including the ovaries [38]. Previous studies have revealed that prolactin leads to growth and migration of ovarian epithelial cells, as well as inhibition of apoptosis [39,40]. Prolactin has been demonstrated to be elevated in serum samples of patients with ovarian cancer compared to healthy individuals and thus a biomarker of interest for the early detection of ovarian cancer [18].
We sought to analyze these proteins to characterize their sensitivity, specificity, PPV, NPV and overall accuracy in patients with early and late stage ovarian cancer versus healthy. Since CA-125 has been a longstanding historical serum protein biomarker for monitoring patients’ cancer progression, we used this as a reference marker when comparing our four-protein model. We analyzed them using two separate cohort sets, which were performed in different laboratories, with different serum samples and different experimenters to prove reproducibility. Classification models used were k-nearest neighbors algorithm (KNN), logistic regression, random forest, and support vector machine (SVM).
Averaging all results of the four classification models, we determined that the sensitivity, specificity, PPV, NPV, AUC and overall accuracy with our 4-protein model faired better than CA-125 alone. In the clinical setting, CA-125 values considered abnormal are typically above 35 U/mL in the postmenopausal patient [41]. One of the major issues with CA-125 is that it is nonspecific to ovarian cancer leading to high false positives, which results in healthy patients undergoing unnecessary surgical intervention [42]. Adding protein biomarkers to CA125 could improve detection of cancers otherwise not identified by CA125 alone.
It should be acknowledged that the PPV and NPV reported are those for the tested samples in our relatively small cohort and not for the general population. Given that the incidence of ovarian cancer in the general population is low at 40 per 10,000 a year, the value of such diagnostic test will best fit the screening of high-risk population. The high-risk population in ovarian cancer are those with known genetic mutation such as BRCA1 and BRCA2 and those with known history of early-onset ovarian cancer in first degree relatives. Our group has an on-going longitudinal study to determine the value of the described four-biomarker panel in detecting ovarian cancer in the high-risk population. It should also be acknowledged that limitations of this study are the limited number of samples and the lack of serial samples from the same patient.
This study is another step forward towards developing a useful serologic biomarker panel for early detection of ovarian cancer that is both highly accurate and specific. The value of these markers and its potential application is not based on a single test, but monitoring their changes through multiple tests. We would like to apply our models and the novel SimplePlex assay to a larger cohort of high-risk patients prospectively, including serial samples from the same patient to determine the fluctuations between normal ranges and the modifications associated with the presence of the disease.
4. Materials and Methods
4.1. Patient Population
The ovarian cancer group (n = 153, average age = 57.1 year) was composed of women with newly diagnosed ovarian cancer following discovery of pelvic mass. Serum samples were collected in the clinic prior to surgery. The diagnosis was made following histopathologic evaluation of the surgical specimen by a pathologist. Of the 153 ovarian cancer patients, 37 were diagnosed with stage I/II and 116 were diagnosed with stage III/IV. Table 8 shows the breakdown of stages and histological diagnosis. The healthy control group (n = 279) was composed of age-matched healthy individuals who presented for routine gynecologic examination and had no evidence of ovarian or other cancer. These women also had no known personal risk factors for development of ovarian cancer and were disease free at least 6 months after sample collection.
Table 8.
Stage and histopathologic diagnosis of patient population.
4.2. Sample Collection
Serum samples were obtained with informed consent and collected under the approval of Yale University School of Medicine Human Investigations Committee. Collection, preparation, and storage of the blood samples were done as previously described [11,12] using guidelines set by the National Cancer Institute Inter-group Specimen Banking Committee.
4.3. Simple PlexTM Immunoassay
Levels of CA-125, MIF, OPN and PROL were quantified using the fully automated immunoassay platform, Ella (Protein Simple/Biotechne, San Jose, CA, USA) as previously described [43]. All four proteins were quantified using a single disposable microfluidic SimplePlexTM cartridge, which holds up to 32 serum samples per assay. The serum samples were thawed on ice and diluted 1:10 with manufacturer’s provided diluent. 50 uL of diluted serum were added to each well of the SimplePlexTM cartridge and the cartridge was placed in Ella for automated analysis and quantitation. Within the cartridge, each serum sample gets further divided into four unique microfluidic parallel channels that are specific for each of the four proteins being analyzed. Each protein channel contains three analyte-specific glass nanoreactors, which allows for each serum samples to be run in triplicates for each of the four protein samples. The following raw data were obtained: mean relative fluorescence units (RFUs), relative fluorescence units as percentage of coefficient of variance (RFU% CV), mean concentration and concentration as percentage of coefficient of variance. The mean concentration was used to perform the statistical analysis.
4.4. Statistical Analysis
A total of 432 serum samples (153 serum samples from ovarian cancer patients and 279 serum samples from healthy controls) were evaluated in this study. From these serum samples, we created several different cohorts for the purpose of training and testing (Table 8). A first cohort included a total of 153 serum samples, with 80 samples from healthy controls and 73 samples from ovarian cancer patients. In this set, 18 samples were from patients diagnosed with Stage I/II ovarian cancer and 55 samples were from patients diagnose with Stage III/IV. A second cohort included a total of 279 serum samples, with 199 samples from healthy controls and 80 samples from ovarian cancer patients. In this set, 19 samples were from patients diagnosed with Stage I/II ovarian cancer and 61 samples were from patients diagnose with Stage III/IV. Four classification models KNN, logistic regression, Random forest, and SVM were first trained and then used to predict whether a sample was ovarian cancer or healthy. Subsequently, we calculated the panel’s accuracy, sensitivity, specificity, PPV, NPV and area under the receiver operating characteristic curve (AUC) in differentiating ovarian cancer serums from healthy controls. Notice since SVM does not derive a continuous class probability/score but a fixed classification threshold instead, the ROC is not useful in this case and hence we did not include AUC of SVM in our comparison. For each classifier, the performance indicators above were calculated using only test samples, not used during the training of that particular classifier.
5. Conclusions
Combining MIF, OPN, PROL, and CA-125 can better differentiate ovarian cancer from healthy controls compared to CA-125 alone. This study is another step towards developing a useful serologic biomarker panel for early detection of ovarian cancer that is both highly accurate and specific.
Supplementary Materials
The following are available online at https://www.mdpi.com/2072-6694/13/2/325/s1, Table S1: Confusion matrices when applying KNN to identify the samples of patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. Note that in this experiment the cohort of early stage cancer samples and healthy samples in data set 1 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 1 in Table 3, Table S2: Confusion matrices when applying logistic regression to identify the samples of patients in ear-ly stage and healthy patients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. Note that in this experiment the cohort of early stage cancer samples and healthy samples in data set 1 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 1 in Table 3, Table S3: Confusion matrices when applying random forest to identify the samples of patients in early stage and healthy patients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. Note that in this experiment the cohort of early stage cancer samples and healthy samples in data set 1 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 1 in Table 3, Table S4: Confusion matrices when applying SVM to identify the samples of patients in early stage and healthy patients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. Note that in this experiment the cohort of early stage cancer samples and healthy samples in data set 1 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 1 in Table 3, Table S5: Confusion matrices when applying KNN to identify the samples of patients in early stage and healthy pa-tients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 2 in Table 3, Table S6: Confusion matrices when applying logistic regression to identify the samples of pa-tients in early stage and healthy patients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 2 in Table 3, Table S7: Confusion matrices when applying random forest to identify the samples of patients in early stage and healthy patients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. This ex-periment is corresponding to experiment ID 2 in Table 3, Table S8: Confusion matrices when ap-plying SVM to identify the samples of patients in early stage and healthy patients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 2 in Table 3, Table S9: Confusion ma-trices when applying KNN to identify the samples of ovarian cancer patients and healthy pa-tients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 3 in Table 3, Table S10: Confusion matrices when applying logistic regression to identify the samples of ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. This experiment is corre-sponding to experiment ID 3 in Table 3, Table S11: Confusion matrices when applying random forest to identify the samples of ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 3 in Table 3, Table S12: Confusion matrices when applying SVM to identify the samples of ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 1 (E1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 3 in Table 3, Table S13: Confusion matrices when applying KNN to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 1 (L1 vs. H1) were used to train the model. Note that in this experiment the cohort of late stage cancer samples and healthy samples in data set 1 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 4 in Table 3, Table S14: Confusion matrices when applying logistic regression to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), using only CA-125 (left panel) and all four proteins (right pan-el). The samples from patients in late stage cancer and healthy patients in data set 1 (L1 vs. H1) were used to train the model. Note that in this experiment the cohort of late stage cancer sam-ples and healthy samples in data set 1 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 4 in Table 3, Table S15: Confusion matrices when applying random forest to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The sam-ples from patients in late stage cancer and healthy patients in data set 1 (L1 vs. H1) were used to train the model. Note that in this experiment the cohort of late stage cancer samples and healthy samples in data set 1 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 4 in Table 3, Table S16: Confusion matrices when applying SVM to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), us-ing only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 1 (L1 vs. H1) were used to train the model. Note that in this experiment the cohort of late stage cancer samples and healthy samples in data set 1 was divided into 60% for training and 40% for testing. This experiment is corresponding to experi-ment ID 4 in Table 3, Table S17: Confusion matrices when applying KNN to identify the samples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 1 (L1 vs. H1) were used to train the model. This experiment is corre-sponding to experiment ID 5 in Table 3, Table S18: Confusion matrices when applying logistic regression to identify the samples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from pa-tients in late stage cancer and healthy patients in data set 1 (L1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 5 in Table 3, Table S19: Confusion matrices when applying random forest to identify the samples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 1 (L1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 5 in Table 3, Table S20: Confusion matrices when applying SVM to identify the samples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 1 (L1 vs. H1) were used to train the model. This experiment is corresponding to experi-ment ID 5 in Table 3, Table S21: Confusion matrices when applying KNN to identify the samples of ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 1 (L1 vs. H1) were used to train the model. This experiment is corre-sponding to experiment ID 6 in Table 3, Table S22: Confusion matrices when applying logistic regression to identify the samples of ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 1 (L1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 6 in Table 3, Table S23: Confusion matrices when applying random forest to identify the samples of ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 1 (L1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 6 in Table 3, Table S24: Confusion matrices when applying SVM to identify the samples of ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy pa-tients in data set 1 (L1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 6 in Table 3, Table S25: Confusion matrices when applying KNN to identify the samples of patients in early stage and healthy patients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 7 in Table 3, Table S26: Confusion matrices when applying lo-gistic regression to identify the samples of patients in early stage and healthy patients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1) were used to train the mod-el. This experiment is corresponding to experiment ID 7 in Table 3, Table S27: Confusion matri-ces when applying random forest to identify the samples of patients in early stage and healthy patients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right pan-el). The samples from ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 7 in Table 3, Table S28: Confusion matrices when applying SVM to identify the samples of patients in early stage and healthy patients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 7 in Table 3, Table S29: Confusion matrices when applying KNN to identify the samples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 8 in Table 3, Table S30: Confusion matrices when applying logistic regression to identify the sam-ples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 8 in Table 3, Table S31: Confusion matrices when applying random forest to identify the samples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer pa-tients and healthy patients in data set 1 (C1 vs. H1) were used to train the model. This experi-ment is corresponding to experiment ID 8 in Table 3, Table S32: Confusion matrices when ap-plying SVM to identify the samples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1) were used to train the mod-el. This experiment is corresponding to experiment ID 8 in Table 3, Table S33: Confusion matri-ces when applying KNN to identify the samples of ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 9 in Table 3, Table S34: Confusion matrices when applying logistic regression to identify the samples of ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 9 in Table 3, Table S35: Confusion matrices when applying random forest to identify the samples of ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 9 in Table 3, Table S36: Confusion matrices when applying SVM to identify the samples of ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1) were used to train the model. This experiment is corresponding to experiment ID 9 in Table 3, Table S37: Confusion matrices when applying KNN to identify the samples of patients in early stage and healthy patients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 2 (E2 vs. E2) were used to train the model. Note that in this experiment the cohort of early stage cancer samples and healthy samples in da-ta set 2 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 9 in Table 3. This experiment is corresponding to experiment ID 10 in Table 3, Table S38: Confusion matrices when applying logistic regression to identify the samples of pa-tients in early stage and healthy patients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 2 (E2 vs. E2) were used to train the model. Note that in this experiment the cohort of early stage cancer samples and healthy samples in data set 2 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 10 in Table 3, Table S39: Confusion matrices when applying random forest to identify the samples of patients in early stage and healthy patients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 2 (E2 vs. E2) were used to train the model. Note that in this experiment the cohort of early stage cancer samples and healthy samples in data set 2 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 10 in Table 3, Table S40: Confusion matrices when applying SVM to identify the samples of patients in early stage and healthy patients in data set 2 (E2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 2 (E2 vs. E2) were used to train the model. Note that in this experiment the cohort of early stage cancer samples and healthy samples in data set 2 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 10 in Table 3, Table S41: Confusion matrices when applying KNN to identify the samples of patients in early stage and healthy pa-tients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 2 (E2 vs. E2) were used to train the model. This experiment is corresponding to experiment ID 11 in Table 3, Table S42: Confusion matrices when applying logistic regression to identify the samples of patients in early stage and healthy patients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 2 (E2 vs. E2) were used to train the model. This experiment is corresponding to ex-periment ID 11 in Table 3, Table S43: Confusion matrices when applying random forest to iden-tify the samples of patients in early stage and healthy patients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 2 (E2 vs. E2) were used to train the model. This ex-periment is corresponding to experiment ID 11 in Table 3, Table S44: Confusion matrices when applying SVM to identify the samples of patients in early stage and healthy patients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 2 (E2 vs. E2) were used to train the model. This experiment is corresponding to experiment ID 11 in Table 3, Table S45: Confusion matrices when applying KNN to identify the samples of ovarian cancer patients and healthy pa-tients in data set 1 (C1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 2 (E2 vs. E2) were used to train the model. This experiment is corresponding to experiment ID 12 in Table 3, Table S46: Confusion matrices when applying logistic regression to identify the samples of ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy pa-tients in data set 2 (E2 vs. E2) were used to train the model. This experiment is corresponding to experiment ID 12 in Table 3, Table S47: Confusion matrices when applying random forest to identify the samples of ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1), us-ing only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 2 (E2 vs. E2) were used to train the model. This experiment is corresponding to experiment ID 12 in Table 3, Table S48: Confusion matrices when applying SVM to identify the samples of ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in early stage cancer and healthy patients in data set 2 (E2 vs. E2) were used to train the model. This experiment is corresponding to experiment ID 12 in Table 3, Table S49: Confusion matrices when applying KNN to identify the samples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 2 (L2 vs. L2) were used to train the model. Note that in this experiment the cohort of late stage cancer samples and healthy samples in data set 2 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 13 in Table 3. Table S50: Confusion matrices when applying logistic regression to identify the samples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right pan-el). The samples from patients in late stage cancer and healthy patients in data set 2 (L2 vs. L2) were used to train the model. Note that in this experiment the cohort of late stage cancer sam-ples and healthy samples in data set 2 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 13 in Table 3. Table S51: Confusion matrices when applying random forest to identify the samples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The sam-ples from patients in late stage cancer and healthy patients in data set 2 (L2 vs. L2) were used to train the model. Note that in this experiment the cohort of late stage cancer samples and healthy samples in data set 2 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 13 in Table 3, Table S52: Confusion matrices when applying SVM to identify the samples of patients in late stage and healthy patients in data set 2 (L2 vs. H2), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 2 (L2 vs. L2) were used to train the model. Note that in this experiment the cohort of late stage cancer samples and healthy samples in data set 2 was divided into 60% for training and 40% for testing. This experiment is corresponding to experiment ID 13 in Table 3, Table S53: Confusion matrices when applying KNN to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 2 (L2 vs. L2) were used to train the model. This experiment is corre-sponding to experiment ID 14 in Table 3, Table S54: Confusion matrices when applying logistic regression to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from pa-tients in late stage cancer and healthy patients in data set 2 (L2 vs. L2) were used to train the model. This experiment is corresponding to experiment ID 14 in Table 3, Table S55: Confusion matrices when applying random forest to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 2 (L2 vs. L2) were used to train the model. This experiment is corresponding to experiment ID 14 in Table 3, Table S56: Confusion matrices when applying SVM to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 2 (L2 vs. L2) were used to train the model. This experiment is corresponding to experi-ment ID 14 in Table 3, Table S57: Confusion matrices when applying KNN to identify the sam-ples of ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 2 (L2 vs. L2) were used to train the model. This experiment is corre-sponding to experiment ID 15 in Table 3, Table S58: Confusion matrices when applying logistic regression to identify the samples of ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 2 (L2 vs. L2) were used to train the model. This experiment is corresponding to experiment ID 15 in Table 3, Table S59: Confusion matrices when applying random forest to identify the samples of ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy patients in data set 2 (L2 vs. L2) were used to train the model. This experiment is corresponding to experiment ID 15 in Table 3, Table S60: Confusion matrices when applying SVM to identify the samples of ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from patients in late stage cancer and healthy pa-tients in data set 2 (L2 vs. L2) were used to train the model. This experiment is corresponding to experiment ID 15 in Table 3, Table S61: Confusion matrices when applying KNN to identify the samples of patients in early stage and healthy patients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the model. This experiment is corresponding to experiment ID 16 in Table 3, Table S62: Confusion matrices when applying lo-gistic regression to identify the samples of patients in early stage and healthy patients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the mod-el. This experiment is corresponding to experiment ID 16 in Table 3, Table S63: Confusion ma-trices when applying random forest to identify the samples of patients in early stage and healthy patients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right pan-el). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the model. This experiment is corresponding to experiment ID 16 in Table 3, Table S64: Confusion matrices when applying SVM to identify the samples of patients in early stage and healthy patients in data set 1 (E1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the model. This experiment is corresponding to experiment ID 16 in Table 3, Table S65: Confusion matrices when applying KNN to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the model. This experiment is corresponding to experiment ID 17 in Table 3, Table S66: Confusion matrices when applying logistic regression to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the model. This experiment is corre-sponding to experiment ID 17 in Table 3, Table S67: Confusion matrices when applying random forest to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the model. This experiment is corresponding to experiment ID 17 in Table 3, Table S68: Confusion matrices when applying SVM to identify the samples of patients in late stage and healthy patients in data set 1 (L1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the mod-el. This experiment is corresponding to experiment ID 17 in Table 3, Table S69: Confusion ma-trices when applying KNN to identify the samples of ovarian cancer patients and healthy pa-tients in data set 1 (C1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the model. This experiment is corresponding to experiment ID 18 in Table 3, Table S70: Confusion matrices when applying logistic regression to identify the samples of ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the model. This experiment is corresponding to experi-ment ID 18 in Table 3, Table S71: Confusion matrices when applying random forest to identify the samples of ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the model. This experiment is corresponding to experiment ID 18 in Table 3, Table S72: Confusion matrices when applying SVM to identify the samples of ovarian cancer patients and healthy patients in data set 1 (C1 vs. H1), using only CA-125 (left panel) and all four proteins (right panel). The samples from ovarian cancer patients and healthy patients in data set 2 (C2 vs. H2) were used to train the model. This experiment is corresponding to experiment ID 18 in Table 3, Figure S1: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 1 in Table 8, using only CA-125 and all four proteins. Figure S2: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 2 in Table 8, using only CA-125 and all four proteins. Figure S3: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 3 in Table 8, using only CA-125 and all four proteins. Figure S4: The AUC and Youden index when applying KNN, lo-gistic regression, and random forest to identify control and healthy samples in experiment 4 in Table 8, using only CA-125 and all four proteins. Figure S5: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 5 in Table 8, using only CA-125 and all four proteins, Figure S6: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 6 in Table 8, using only CA-125 and all four proteins, Figure S7: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 7 in Table 8, using only CA-125 and all four proteins, Figure S8: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 8 in Table 8, using only CA-125 and all four proteins, Figure S9: The AUC and Youden index when applying KNN, lo-gistic regression, and random forest to identify control and healthy samples in experiment 9 in Table 8, using only CA-125 and all four proteins, Figure S10: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 10 in Table 8, using only CA-125 and all four proteins, Figure S11: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 11 in Table 8, using only CA-125 and all four proteins, Figure S12: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 12 in Table 8, using only CA-125 and all four proteins, Figure S13: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 13 in Table 8, using only CA-125 and all four proteins, Figure S14: The AUC and Youden index when applying KNN, lo-gistic regression, and random forest to identify control and healthy samples in experiment 14 in Table 8, using only CA-125 and all four proteins, Figure S15: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 15 in Table 8, using only CA-125 and all four proteins, Figure S16: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 16 in Table 8, using only CA-125 and all four proteins, Figure S17: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 17 in Table 8, using only CA-125 and all four proteins, Figure S18: The AUC and Youden index when applying KNN, logistic regression, and random forest to identify control and healthy samples in experiment 17 in Table 8, using only CA-125 and all four proteins.
Author Contributions
Conceptualization: T.R., G.M.; Data Curation: C.W., T.-M.N., S.J.; Formal Analysis: C.W., T.-M.N., A.B.A., S.D., G.M.; Methodology, D.-A.S., T.R., S.D., G.M.; Resources, D.-A.S., T.R.; Writing Original Draft Preparation: C.W., T.-M.N., A.B.A.; Writing—Review & Editing: T.R., S.D., G.M.; Supervision: A.B.A., S.D., G.M. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by Teasley Foundation.
Institutional Review Board Statement
The Yale University Human Investigations Committee (HIC# 9903010425) approved this study.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cress, R.D.; Chen, Y.S.; Morris, C.R.; Petersen, M.; Leiserowitz, G.S. Characteristics of Long-Term Survivors of Epithelial Ovarian Cancer. Obstet. Gynecol. 2015, 126, 491–497. [Google Scholar] [CrossRef]
- Siegel, R.L.; Miller, K.D.M.; Jemal, A. Cancer statistics, 2018. CA A Cancer J. Clin. 2018, 68, 7–30. [Google Scholar] [CrossRef]
- Torre, L.A.; Trabert, B.; DeSantis, C.E.; Mph, K.D.M.; Samimi, G.; Runowicz, C.D.; Gaudet, M.M.; Jemal, A.; Siegel, R.L. Ovarian cancer statistics, 2018. CA A Cancer J. Clin. 2018, 68, 284–296. [Google Scholar] [CrossRef]
- Skates, S.J.; Xu, F.-J.; Yu, Y.-H.; Sjövall, K.; Einhorn, N.; Chang, Y.; Bast, R.C.; Knapp, R.C. Toward an optimal algorithm for ovarian cancer screening with longitudinal tumor markers. Cancer 1995, 76, 2004–2010. [Google Scholar] [CrossRef]
- Lu, K.H.; Skates, S.; Hernandez, M.A.; Bedi, D.; Bevers, T.; Leeds, L.; Moore, R.; Granai, C.; Harris, S.; Newland, W.; et al. A 2-stage ovarian cancer screening strategy using the Risk of Ovarian Cancer Algorithm (ROCA) identifies early-stage incident cancers and demonstrates high positive predictive value. Cancer 2013, 119, 3454–3461. [Google Scholar] [CrossRef]
- Menon, U.; Griffin, M.; Gentry-Maharaj, A. Ovarian cancer screening—Current status, future directions. Gynecol. Oncol. 2014, 132, 490–495. [Google Scholar] [CrossRef]
- Bast, R.C.; Feeney, M.; Lazarus, H.; Nadler, L.M.; Colvin, R.B.; Knapp, R.C. Reactivity of a monoclonal antibody with human ovarian carcinoma. J. Clin. Investig. 1981, 68, 1331–1337. [Google Scholar] [CrossRef]
- Buys, S.S.; Partridge, E.; Black, A.; Johnson, C.C.; Lamerato, L.; Isaacs, C.; Reding, D.J.; Greenlee, R.T.; Yokochi, L.A.; Kessel, B.; et al. Effect of screening on ovarian cancer mortality: The Prostate, Lung, Colorectal and Ovarian (PLCO) Cancer Screening Randomized Controlled Trial. JAMA 2011, 305, 2295–2303. [Google Scholar] [CrossRef]
- Grossman, D.C.; Curry, S.J.; Owens, D.K.; Michael, J.; Barry, M.J.; Davidson, K.W.; Doubeni, C.A.; Epling, J.W., Jr.; Kemper, A.R.; Krist, A.H.; et al. Screening for Ovarian Cancer: US Preventive Services Task Force Recommendation Statement. JAMA 2018, 319, 588–594. [Google Scholar] [CrossRef]
- Haque, R.; Skates, S.J.; Armstrong, M.A.; Lentz, S.E.; Anderson, M.; Jiang, W.; Alvarado, M.M.; Chillemi, G.; Shaw, S.F.; Kushi, L.H.; et al. Feasibility, patient compliance and acceptability of ovarian cancer surveillance using two serum biomarkers and Risk of Ovarian Cancer Algorithm compared to standard ultrasound and CA 125 among women with BRCA mutations. Gynecol. Oncol. 2020, 157, 521–528. [Google Scholar] [CrossRef]
- Visintin, I.; Feng, Z.; Longton, G.; Ward, D.C.; Alvero, A.B.; Lai, Y.; Tenthorey, J.; Leiser, A.; Flores-Saaib, R.; Yu, H.; et al. Diagnostic Markers for Early Detection of Ovarian Cancer. Clin. Cancer Res. 2008, 14, 1065–1072. [Google Scholar] [CrossRef]
- Mor, G.; Visintin, I.; Lai, Y.; Zhao, H.; Schwartz, P.; Rutherford, T.; Yue, L.; Bray-Ward, P.; Ward, D.C. Serum protein markers for early detection of ovarian cancer. Proc. Natl. Acad. Sci. USA 2005, 102, 7677–7682. [Google Scholar] [CrossRef]
- Guo, J.; Yang, W.-L.; Pak, D.; Celestino, J.; Lu, K.H.; Ning, J.; Lokshin, A.E.; Cheng, Z.; Lu, Z.; Bast Jr, R.C. Osteopontin, Macrophage Migration Inhibitory Factor and Anti-Interleukin-8 Autoantibodies Complement CA125 for Detection of Early Stage Ovarian Cancer. Cancers 2019, 11, 596. [Google Scholar] [CrossRef]
- Dysinger, M.; Marusov, G.; Fraser, S. Quantitative analysis of four protein biomarkers: An automated microfluidic cartridge-based method and its comparison to colorimetric ELISA. J. Immunol. Methods 2017, 451, 1–10. [Google Scholar] [CrossRef]
- Skates, S.J.; Greene, M.H.; Buys, S.S.; Mai, P.L.; Brown, P.; Piedmonte, M.; Rodriguez, G.; Schorge, J.O.; Sherman, M.; Daly, M.B.; et al. Early Detection of Ovarian Cancer using the Risk of Ovarian Cancer Algorithm with Frequent CA125 Testing in Women at Increased Familial Risk - Combined Results from Two Screening Trials. Clin. Cancer Res. 2017, 23, 3628–3637. [Google Scholar] [CrossRef]
- Hagemann, T.; Robinson, S.C.; Thompson, R.G.; Charles, K.; Kulbe, H.; Balkwill, F.R. Ovarian cancer cell–derived migration inhibitory factor enhances tumor growth, progression, and angiogenesis. Mol. Cancer Ther. 2007, 6, 1993–2002. [Google Scholar] [CrossRef]
- Song, G.; Cai, Q.-F.; Mao, Y.-B.; Ming, Y.-L.; Bao, S.-D.; Ouyang, G. Osteopontin promotes ovarian cancer progression and cell survival and increases HIF-1α expression through the PI3-K/Akt pathway. Cancer Sci. 2008, 99, 1901–1907. [Google Scholar] [CrossRef]
- Karthikeyan, S.; Russo, A.; Dean, M.; Lantvit, D.D.; Endsley, M.; Burdette, J.E. Prolactin signaling drives tumorigenesis in human high grade serous ovarian cancer cells and in a spontaneous fallopian tube derived model. Cancer Lett. 2018, 433, 221–231. [Google Scholar] [CrossRef]
- Einhorn, N.; Sjövall, K.; Knapp, R.C.; Hall, P.; E Scully, R.; Bast, R.C.; Zurawski, V.R. Prospective evaluation of serum CA 125 levels for early detection of ovarian cancer. Obstet. Gynecol. 1992, 80, 14–18. [Google Scholar] [CrossRef]
- Baker, S.G.; Kramer, B.S.; McIntosh, M.; Patterson, B.H.; Shyr, Y.; Skates, S. Evaluating markers for the early detection of cancer: Overview of study designs and methods. Clin. Trials 2006, 3, 43–56. [Google Scholar] [CrossRef]
- Jacobs, I.; Menon, U.; Ryan, A.; Gentry-Maharaj, A.; Burnell, M.; Kalsi, J.K.; Amso, N.N.; Apostolidou, S.; Benjamin, E.; Cruickshank, D.; et al. Ovarian cancer screening and mortality in the UK Collaborative Trial of Ovarian Cancer Screening (UKCTOCS): A randomised controlled trial. Lancet 2016, 387, 945–956. [Google Scholar] [CrossRef]
- Malkasian, G.D.; Knapp, R.C.; Lavin, P.T.; Zurawski, V.R.; Podratz, K.C.; Stanhope, C.R.; Mortel, R.; Berek, J.S.; Bast, R.C.; E Ritts, R. Preoperative evaluation of serum CA 125 levels in premenopausal and postmenopausal patients with pelvic masses: Discrimination of benign from malignant disease. Am. J. Obstet. Gynecol. 1988, 159, 341–346. [Google Scholar] [CrossRef]
- Moore, R.G.; Brown, A.K.; Miller, M.C.; Skates, S.; Allard, W.J.; Verch, T.; Steinhoff, M.; Messerlian, G.; DiSilvestro, P.; Granai, C.; et al. The use of multiple novel tumor biomarkers for the detection of ovarian carcinoma in patients with a pelvic mass. Gynecol. Oncol. 2008, 108, 402–408. [Google Scholar] [CrossRef]
- Calandra, T.; Roger, T. Macrophage migration inhibitory factor: A regulator of innate immunity. Nat. Rev. Immunol. 2003, 3, 791–800. [Google Scholar] [CrossRef]
- Calandra, T.; Bernhagen, J.; Mitchell, R.A.; Bucala, R. The macrophage is an important and previously unrecognized source of macrophage migration inhibitory factor. J. Exp. Med. 1994, 179, 1895–1902. [Google Scholar] [CrossRef]
- Calandra, T.; Spiegel, L.A.; Metz, C.N.; Bucala, R. Macrophage migration inhibitory factor is a critical mediator of the activation of immune cells by exotoxins of Gram-positive bacteria. Proc. Natl. Acad. Sci. USA 1998, 95, 11383–11388. [Google Scholar] [CrossRef]
- Martiney, J.A.; Sherry, B.; Metz, C.N.; Espinoza, M.; Ferrer, A.S.; Calandra, T.; Broxmeyer, H.E.; Bucala, R. Macrophage migration inhibitory factor release by macrophages after ingestion of Plasmodium chabaudi-infected erythrocytes: Possible role in the pathogenesis of malarial anemia. Infect Immun. 2000, 68, 2259–5567. [Google Scholar] [CrossRef]
- Agarwal, R.; Whang, D.H.; Alvero, A.B.; Visintin, I.; Lai, Y.; Segal, E.A.; Schwartz, P.; Ward, D.; Rutherford, T.; Mor, G. Macrophage migration inhibitory factor expression in ovarian cancer. Am. J. Obstet. Gynecol. 2007, 196, 348.e1–348.e5. [Google Scholar] [CrossRef]
- Mitchell, R.A. Mechanisms and effectors of MIF-dependent promotion of tumourigenesis. Cell. Signal. 2004, 16, 13–19. [Google Scholar] [CrossRef]
- Rangaswami, H.; Bulbule, A.; Kundu, G.C. Osteopontin: Role in cell signaling and cancer progression. Trends Cell Biol. 2006, 16, 79–87. [Google Scholar] [CrossRef]
- Wai, P.Y.; Kuo, P.C. Osteopontin: Regulation in tumor metastasis. Cancer Metastasis Rev. 2007, 27, 103–118. [Google Scholar] [CrossRef]
- Rittling, S.R.; Chambers, A.F. Role of osteopontin in tumour progression. Br. J. Cancer 2004, 90, 1877–1881. [Google Scholar] [CrossRef]
- Hur, E.M.; Youssef, S.; Haws, M.E.; Zhang, S.Y.; A Sobel, R.; Steinman, L. Osteopontin-induced relapse and progression of autoimmune brain disease through enhanced survival of activated T cells. Nat. Immunol. 2006, 8, 74–83. [Google Scholar] [CrossRef]
- Lin, Y.-H.; Yang-Yen, H.-F. The Osteopontin-CD44 Survival Signal Involves Activation of the Phosphatidylinositol 3-Kinase/Akt Signaling Pathway. J. Biol. Chem. 2001, 276, 46024–46030. [Google Scholar] [CrossRef]
- Brakora, K.; Lee, H.; Yusuf, R.; Sullivan, L.; Harris, A.L.; Colella, T.; Seiden, M.V. Utility of osteopontin as a biomarker in recurrent epithelial ovarian cancer. Gynecol. Oncol. 2004, 93, 361–365. [Google Scholar] [CrossRef]
- Kim, J.-H.; Skates, S.J.; Uede, T.; Wong, K.; Schorge, J.O.; Feltmate, C.M.; Berkowitz, R.S.; Cramer, D.W.; Mok, S.C. Osteopontin as a potential diagnostic biomarker for ovarian cancer. JAMA 2002, 287, 1671–1679. [Google Scholar] [CrossRef]
- Bernard, V.; Young, J.; Chanson, P.; Binart, N. New insights in prolactin: Pathological implications. Nat. Rev. Endocrinol. 2015, 11, 265–275. [Google Scholar] [CrossRef]
- Freeman, M.E.; Kanyicska, B.; Lerant, A.; Nagy, G. Prolactin: Structure, Function, and Regulation of Secretion. Physiol. Rev. 2000, 80, 1523–1631. [Google Scholar] [CrossRef]
- Levina, V.V.; Nolen, B.; Su, Y.; Godwin, A.K.; Fishman, D.; Liu, J.; Mor, G.; Maxwell, L.G.; Herberman, R.B.; Szczepanski, M.J.; et al. Biological Significance of Prolactin in Gynecologic Cancers. Cancer Res. 2009, 69, 5226–5233. [Google Scholar] [CrossRef]
- Tan, D.; Chen, K.E.; Khoo, T.; Walker, A.M. Prolactin increases survival and migration of ovarian cancer cells: Importance of prolactin receptor type and therapeutic potential of S179D and G129R receptor antagonists. Cancer Lett. 2011, 310, 101–108. [Google Scholar] [CrossRef]
- Bon, G.G.; Kenemans, P.; Verstraeten, R.; Van Kamp, G.J.; Hilgers, J. Serum tumor marker immunoassays in gynecologic oncology: Establishment of reference values. Am. J. Obstet. Gynecol. 1996, 174, 107–114. [Google Scholar] [CrossRef]
- Jacobs, I.J.; Skates, S.; Davies, A.P.; Woolas, R.P.; Jeyerajah, A.; Weidemann, P.; Sibley, K.; Oram, D.H. Risk of diagnosis of ovarian cancer after raised serum CA 125 concentration: A prospective cohort study. BMJ 1996, 313, 1355–1358. [Google Scholar] [CrossRef]
- Aldo, P.; Marusov, G.; Svancara, D.; David, J.; Mor, G. Simple Plex ™: A Novel Multi-Analyte, Automated Microfluidic Immunoassay Platform for the Detection of Human and Mouse Cytokines and Chemokines. Am. J. Reprod. Immunol. 2016, 75, 678–693. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).