Abstract
Continuous-flow microfluidic biochips (CFMBs) automatically execute various bioassays by precisely controlling the transport of fluid samples, which is driven by pressure delivered through fluidic ports. High-level synthesis, as an important stage in the design flow of CFMBs, generates binding and scheduling solutions whose quality directly affects the efficiency of the execution of bioassays. Existing high-level synthesis methods perform numerous transport tasks concurrently to increase efficiency. However, fluidic ports cannot be shared between concurrently executing transport tasks, resulting in a large number of fluidic ports introduced by existing methods. Increasing the number of fluidic ports undermines the integration, reduces the reliability, and increases the manufacturing cost. In this paper, we propose a port-driven high-level synthesis method based on integer linear programming (ILP) called SlimPort, integrating the optimization of fluidic port number into high-level synthesis, which has never been considered in prior work. Meanwhile, to ensure bioassay correctness, volume management between devices with a non-fixed input/output ratio is realized. Additionally, two acceleration strategies for ILP, scheduling constraint reduction and upper boundary estimation of fluidic port number, are proposed to improve the efficiency of SlimPort. Experimental results from multiple benchmarks demonstrate that SlimPort leads to high assay execution efficiency and a low number of fluidic ports.
1. Introduction
Continuous-flow microfluidic biochips (CFMBs), also known as lab-on-a-chip systems, have attracted considerable research interest in both academia and industry over the past decade, owing to their high precision, high throughput, and low cost [1,2]. CFMBs have been developed for use in various bioassays, such as point-of-care diagnosis [3], cancer diagnostic [4,5], immunoassays [6,7], and air quality monitoring [8].
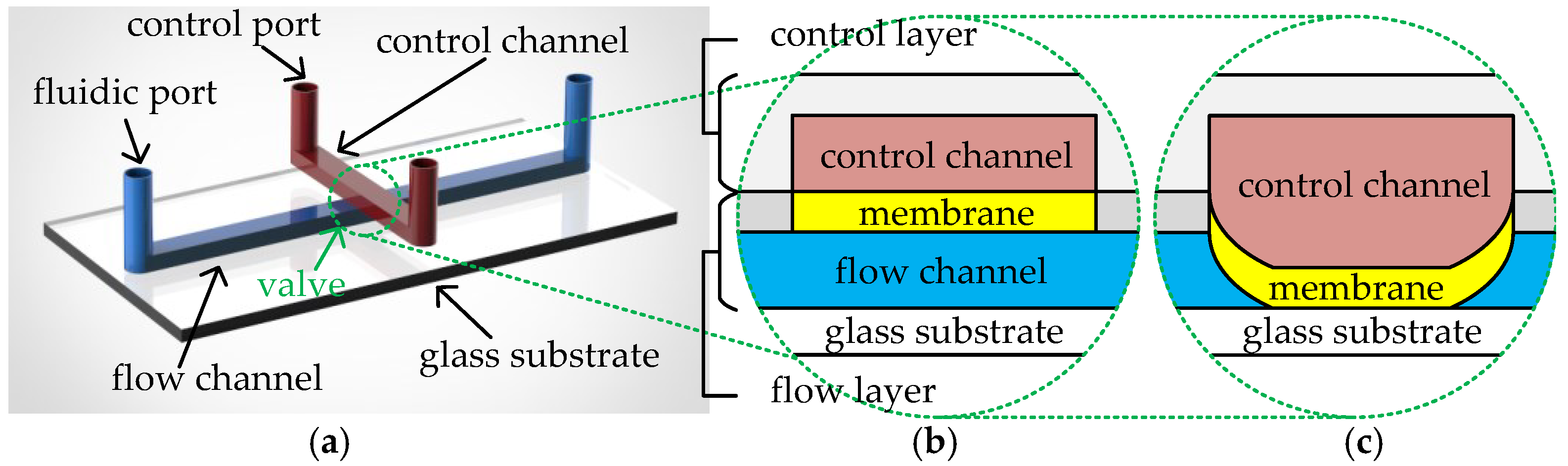
A CFMB typically consists of two layers of polydimethylsiloxane (PDMS) material on a glass substrate [9], referred to as the control layer and the flow layer, respectively. Each of the two layers has its own channel network and is connected to the environment through its own ports, as shown in Figure 1a. Channels in the flow layer, also called flow channels, are connected to the external environment of the biochip through fluidic ports. Fluidic ports are divided into flow ports and waste ports. Flow ports are used for the input of samples/reagents and the injection of air pressure from external pressure sources. Waste ports collect the output fluid and release the air pressure. Channels in the control layer, also called control channels, are connected to the external pressure source through control ports. The overlapping region between a flow channel and a control channel forms an elastic PDMS membrane. The structure is capable of controlling fluid transport in the corresponding flow channel according to the air pressure in the control channel; hence, it is called a valve. Figure 1b,c illustrate the cross-section of the valve in the open and closed states, respectively. To close the valve, the high pressure, generated by an external pressure source injected through the control port, is conducted to the valve via the control channel. This causes the valve’s elastic membrane to be pushed downwards, sealing the corresponding flow channel, as shown in Figure 1c. When the high pressure is released, the valve’s elastic membrane returns to its original state and the flow channel reopens for fluid transfer.
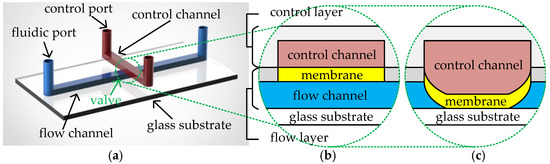
Figure 1.
(a) Structure of a CFMB. Cross-section of (b) an open valve and (c) a closed valve.
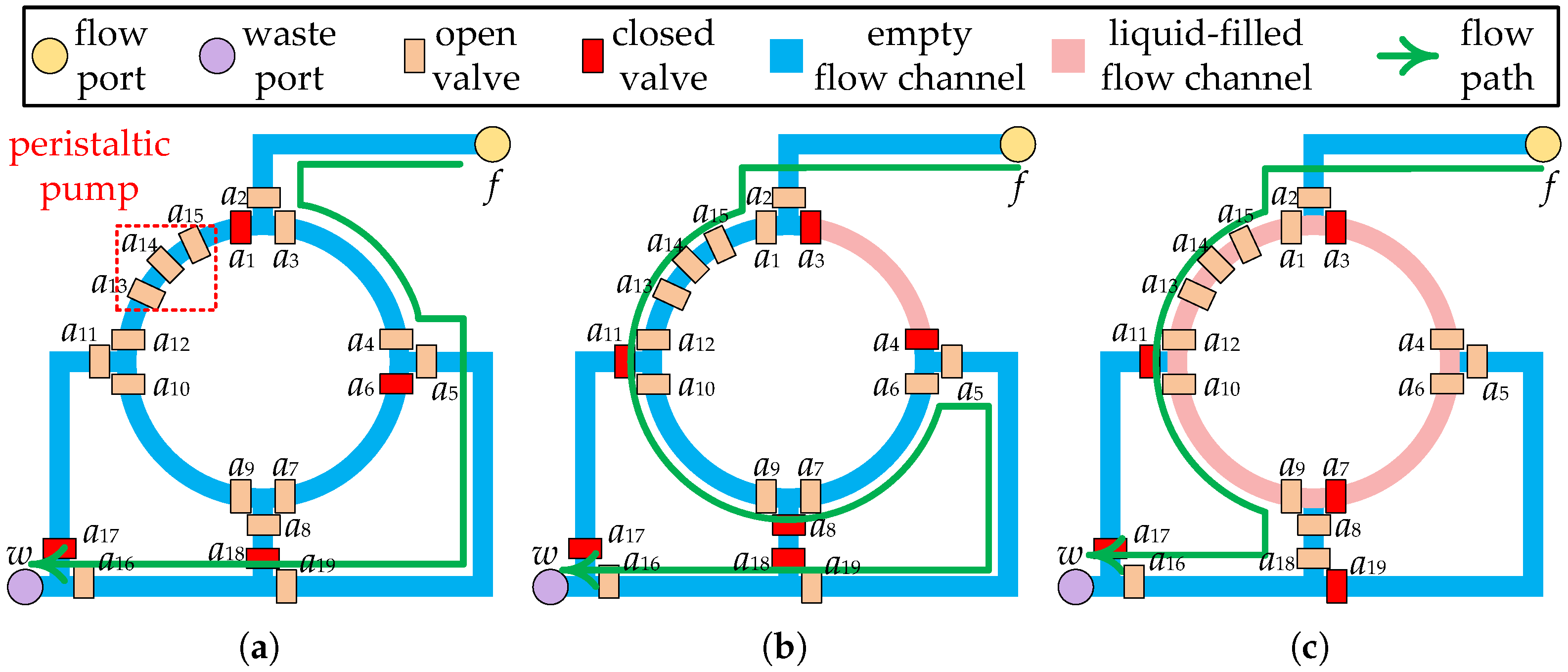
Complex microfluidic devices can be constructed with various combinations of valves, flow channels, and functional components (e.g., peristaltic pump, heating component, etc.) to perform a variety of biochemical operations [10]. For example, a four-segment rotary mixer, as shown in Figure 2a, consists of valves (), ring channels, and a peristaltic pump (), which has been widely used on CFMBs [11]. By orderly transport of samples/reagents between different devices, CFMBs are able to accomplish complex bioassays automatically. The transport of samples/reagents is driven by the pressure injected through the flow port, so flow channels are employed to construct a complete pressure propagation path, called a flow path. A flow path starts at a flow port, passes through the fluid start location and the fluid target location, and ends at a waste port. For example, the flow path for the transport task shown in Figure 2a is flow port waste port . The fluid start location is the flow port, and the fluid target location is the channel between and .
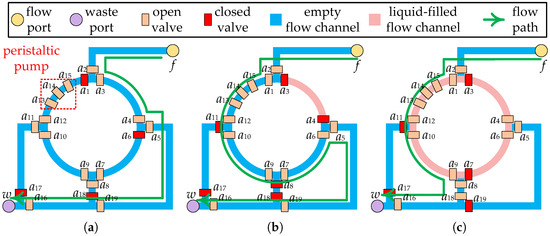
Figure 2.
Part of the layout of the CFMB with a 4-segment rotary mixer. (a) Input fluid at 1/4 mixer capacity. (b) Input fluid at 3/4 mixer capacity. (c) Output fluid at 1/2 mixer capacity after mixing.
The feature size of the CFMB has been continuously reduced with the advancement of microfluidic manufacturing technology [12,13,14]. This allows CFMBs to perform more complex bioassays. Fluidigm’s 96.96 Dynamic Array, for instance, can run 9216 parallel polymerase chain reactions [15]. However, complex bioassays also mean that a large number of transport tasks need to be performed in parallel. To avoid pressure mutual interference and sample/reagent cross-contamination, separate flow paths need to be constructed for these parallel transport tasks. Each flow path requires a pair of fluidic ports, i.e., a flow port and a waste port. This leads to a rapid increase in fluidic ports. Previous work [16] has discussed the damage to the CFMB caused by integrating too many control ports. Analogous to the control ports, the fluidic ports are actually holes punched on the CFMB [17]. Too many holes punched on the CFMB not only take up chip area but also weaken the structural strength of the CFMB, making it more susceptible to physical failure [16]. In addition, fluidic ports also need to be connected to peripheral equipments (e.g., air pressure sources, etc.) for sample/reagent input and collection and to provide power for transport tasks. These peripheral pieces of equipment are still made for mechanical devices and are large in size [16]. These limit the potential of large-scale integration of CFMBs.
Over the past decade, considerable effort has been devoted to the design automation of CFMBs due to the high complexity of the CFMB architecture and bioassay protocol [18,19,20,21,22,23]. The architectural synthesis of CFMBs is usually divided into three major stages, high-level synthesis, physical design of the flow layer, and physical design of the control layer. High-level synthesis is an important step in the architectural synthesis of CFMBs. The goal of the high-level synthesis is to obtain binding and scheduling schemes that can be used as inputs for subsequent design steps, such as placement for devices, routing for flow path, etc. It is worth noting that the final chip layout is not determined during the high-level synthesis of biochips. As such, the binding and scheduling scheme generated in the high-level synthesis phase functions merely as an initial scheme that may be adapted in subsequent phases, but its quality directly affects the optimization of the subsequent phases. For example, the binding and scheduling scheme determines the devices to be placed and the connection relationships between them. A number of methods for high-level synthesis of CFMBs have been proposed. In [24], a list scheduling-based heuristic method is proposed to reduce the total application completion time. In [25], a graph-based approach, which formulates the high-level synthesis as a maximum clique finding problem, is proposed to accurately obtain an optimal binding and scheduling scheme. In [10], a component-oriented high-level synthesis method is proposed to improve the utilization of chip resources and to accommodate multiple types of microfluidic devices. In [26], a path-driven synthesis methodology is presented to integrate the actual fluid manipulations into both high-level synthesis and physical design. Volume management between devices and the removal of excess/waste fluids are introduced into the high-level synthesis to ensure the correctness of assay outcomes. In [16], a synthesis flow called MiniControl is proposed to generate chip architectures under strict constraints of control ports, where control-port minimization is considered systematically during the complete flow-layer design, including high-level synthesis. In [27], a high-level synthesis method considering fluid volume and channel storage is proposed to reduce the requirement of cache, thus ensuring the reliability of fluid caching under the distributed channel-storage architecture. In [28], the time constraints are introduced into the high-level synthesis to satisfy the real-time requirements of timing-sensitive bioassays. However, these methods do not take the fluidic port into account and perform numerous transportation tasks concurrently to increase efficiency. This results in a large demand for fluidic ports. The enormous potential for reducing the number of fluidic ports in high-level synthesis is neglected.
Due to the limitations of existing methods and the importance of reducing the number of ports, in this paper, we propose SlimPort, a high-level synthesis method for CFMBs. The major contributions are listed below.
- A reduction in the fluidic port number is incorporated into high-level synthesis for the first time, thereby reducing the fabrication cost and improving the reliability of CFMBs.
- We propose extended volume management to achieve volume constraints for devices with a non-fixed input/output ratio, ensuring the correctness of bioassay outcomes.
- We propose two acceleration strategies for integer linear programming (ILP), scheduling constraint reduction and upper boundary estimation of the port number, to reduce the complexity of the ILP model and speed up the time required to solve it.
- The effectiveness of SlimPort is demonstrated by experimental results on five real-world bioassays and five synthetic benchmarks.
2. High-Level Synthesis, Motivation, and Problem Formulation
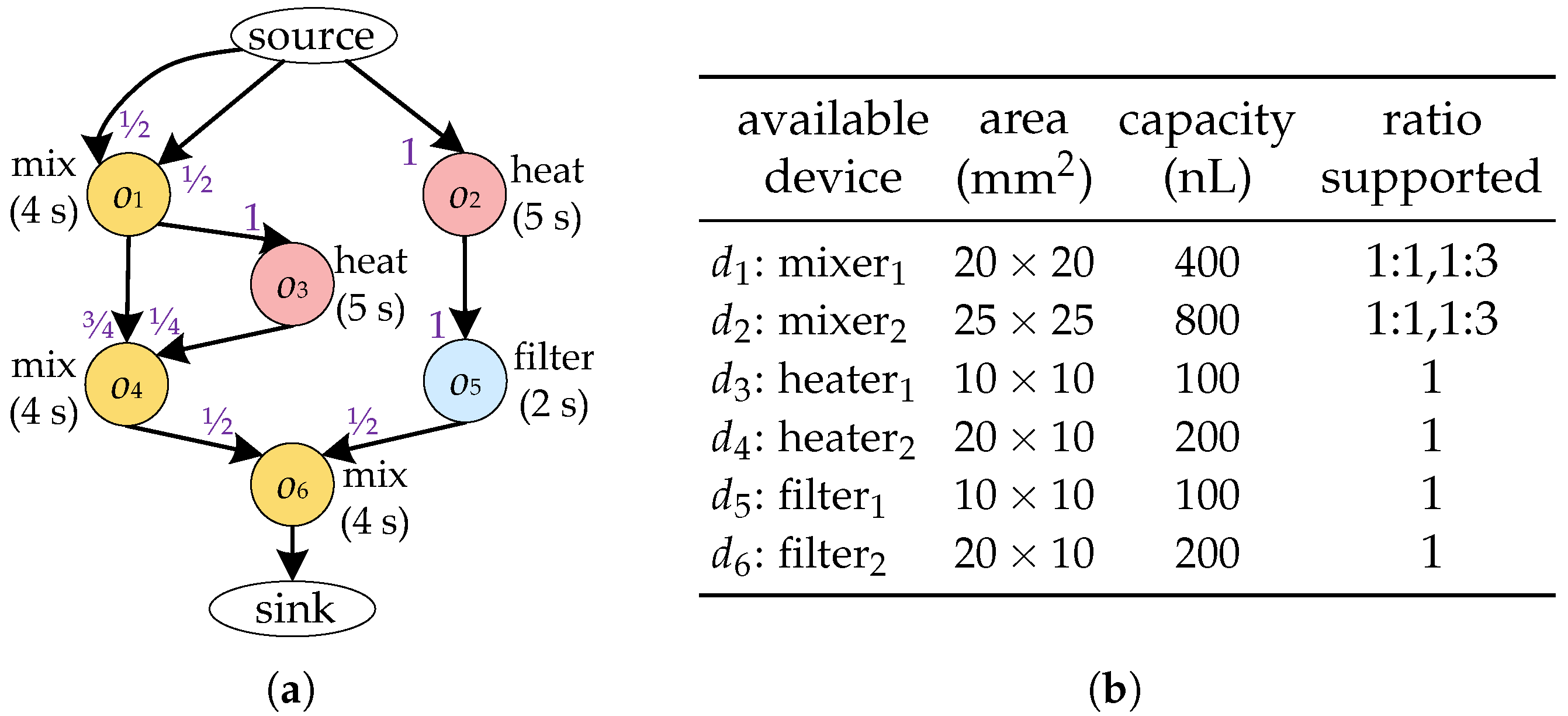
High-level synthesis inputs include the bioassay protocol to be implemented and a device library to automatically generate an optimized binding and scheduling scheme for a given bioassay. As shown in Figure 3a, the bioassay protocol is modelled as a directed graph , also known as a sequencing graph. Each node represents a biochemical operation, such as heating and mixing, and is associated with a weight indicating its duration. Each edge specifies the dependency between operations—i.e., operation is a parent node of in G. For the sake of simplicity, hereinafter we denote the device bound to operation by . We use to represent the fluid from that needs to be transported to . An edge specifies the dependency between operations—i.e., operation is a parent node of in G. Each edge is associated with weights , which denotes the ratio of the volume to the capacity after inputting into . A device library D used for realizing the execution of operations in G. Each device is associated with its area and capacity, as shown in Figure 3b. The device library also provides the input/output ratios supported by each device. Given the sequencing graph of a bioassay and the corresponding device library, the high-level synthesis of CFMBs is usually divided into two major tasks: binding and scheduling.
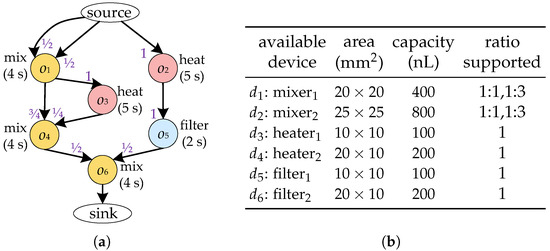
Figure 3.
(a) Sequencing graph. (b) Device library.
2.1. Volume Management Between Devices with Non-Fixed Input/Output Ratio and Binding
The goal of binding is to select a specific device for the execution of each operation and to satisfy the volume constraint between devices [26]. The reaction chamber of the microfluidic device consists of one or more flow channel segments that are divided by valves [10]. For example, the reaction chamber of a four-segment rotary mixer consists of a ring flow channel divided into four flow channel segments by valves (), as shown in Figure 2a. The flow channel section of the device is filled with air rather than a vacuum in the initial state. All air should be removed from the device before the operation is carried out so that it does not affect the operation. At the start of the operation, it is also important to avoid leaving the air that drives the samples/reagents in the device. To prevent operations from failing, a minimum volume should be set for each input of a device to allow air to be expelled from the device while preventing outside air from entering.
Prior work has set a fixed minimum input volume limit for each device [26]. However, such setups cannot be applied on devices with non-fixed input/output ratios. Each device supports one or more input/output ratios, depending on the device architecture. For example, the four-segment rotary mixer can mix fluid in 1:1, 1:3, 1:1:2, or 1:1:1:1. As shown in Figure 2a,b, using the flow path as indicated by the green arrows, the mixer was successively input fluid with one-quarter and three-quarter mixer capacity, respectively. After performing a 1:3 ratio mixing operation, the fluid with one-half capacity of mixer can be removed using the flow path as shown by the green arrow in Figure 2c. It is possible to perform a 1:1 ratio mixing operation in the same mixer following the input of a fluid with one-half mixer capacity using the same flow path.
Due to the structural limitations of the device, the device cannot output/input fluid at any ratio. For example, the four-segment rotary mixer shown in Figure 2c is unable to remove all of the fluid from the ring channel with a single output procedure. Therefore, to ensure that the fluid volume input to the device satisfies the requirements of the operation , should be bound to a device that supports the required input ratio. Moreover, the fluid volume output by should be determined based on the output ratio supported by to satisfy the volume constraint between devices. Consider the bioassay described in Figure 3a as an example. When and are bound to , if is output at 1:1, the volume of is 200 nL, which is less than the volume of fluid required for (300 nL), violating the volume constraint between devices. In contrast, if is output at 1:3, has a volume of 300 nL and has a volume of 100 nL, satisfying the volume constraint.
2.2. Optimization of Fluidic Port Number and Scheduling
The goal of scheduling is to determine the start and end time for each operation and each transport task and to minimize bioassay completion time while satisfying given dependencies. Transport tasks in CFMBs can be divided into three categories: fluid transportation, excess fluid removal, and waste fluid removal [26]. The fluid transportation is the task of transporting samples/reagents between devices or between a port and a device. The excess fluid is cached in both ends of the device when the volume of input fluid is greater than the minimum input volume limit. To prevent excess fluid from interfering with other fluids in the CFMB, excess fluid removal should be performed before the next input to that device. Additionally, when the parent–child operations and are bound to the same device, if there are other inputs to the child operation and the volume of in is greater than the minimum input volume limit, then waste fluid removal should be performed to remove the fluid that is not needed anymore out of .
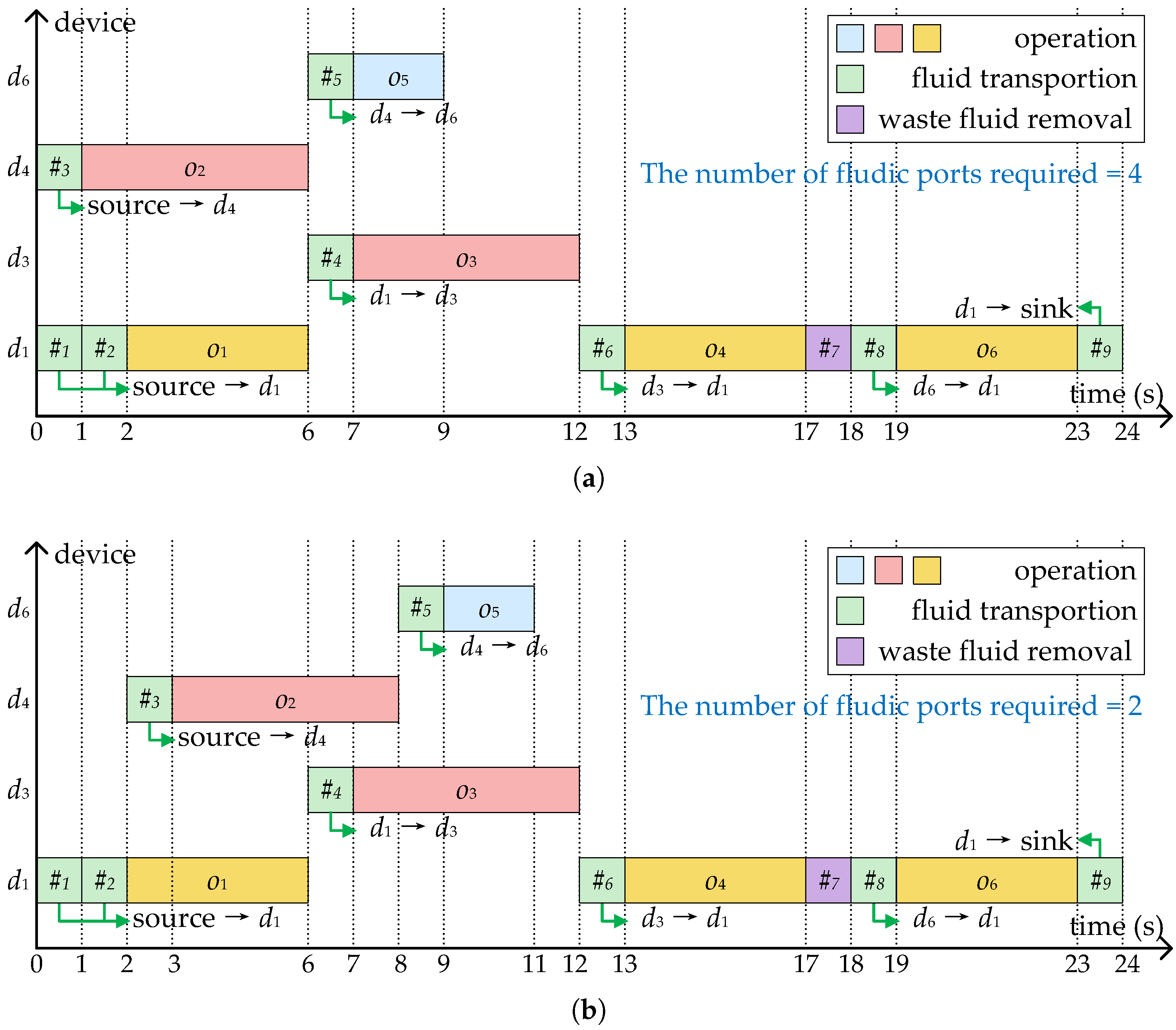
Figure 4a shows the scheduling results of the bioassay described in Figure 3a, where four devices are allocated to execute operations , and the bioassay completed in 24 s with nine transport tasks. As mentioned before, each transport task needs to construct a flow path and associate it with a pair of flow ports. To avoid pressure mutual interference and sample/reagent cross-contamination, the same pair of flow ports cannot be shared between parallel transport tasks. In the scheduling scheme shown in Figure 4a, since and , , and are executed in parallel, at least two pairs of flow ports are required.

Figure 4.
Two binding and scheduling schemes corresponding to Figure 3. (a) The scheme without considering the optimization of fluidic ports. (b) The scheme generated by SlimPort.
Correspondingly, Figure 4b shows a scheduling scheme considering the optimization of fluidic ports. By delaying the start of and , there are no transport tasks that need to be performed in parallel throughout the bioassay. All transport tasks are allowed to share the same pair of fluidic ports—in other words, only two flow ports are required.
2.3. Problem Formulation
The high-level synthesis problem for CFMBs considered in this paper can be formulated as follows, based on the above analysis:
Inputs:
- A bioassay modeled as a sequencing graph with the type and duration of each operation, as well as the volume ratio of each input.
- A device library D with the area and capacity of each device and the input/output ratios supported by each device.
Outputs:
- A binding scheme satisfying the volume constraints between devices.
- The volume of fluid output from each operations.
- A scheduling scheme indicating the start and end time for each operation and each transport task.
Objectives: Minimizing the following indicators.
- The completion time of the bioassay.
- The number of fluidic ports required.
- The total area of devices employed.
- The volume of excess fluid and waste fluid.
3. Details of the Proposed Port-Driven High-Level Synthesis
In this section, we discuss the proposed SlimPort in detail. In the following, the high-level synthesis is formulated and solved as an integer linear programming (ILP) model to obtain an optimal binding and scheduling scheme. Moreover, we present the two acceleration strategies, constraint reduction and boundary estimation, both of which reduce the computational overhead of our approach. Table 1 lists symbols that are frequently used in SlimPort.

Table 1.
Symbols frequently used in SlimPort.
3.1. ILP Model Constructed by SlimPort
3.1.1. Binding with Extended Volume Management
To ensure that each operation performs its function, each operation should be bound to a device. Thus, we have the following constraint:
where and are binary variables representing whether operation is bound to a device and whether can support the functions and input ratios required by , respectively.
Each device supports one or more output ratios. When the device outputs at a specific ratio, we refer to the ratio between output fluid volume and device capacity as an output mode. We note all output modes supported by devices in the device library D as . When the device outputs in one output mode , we use to represent the h-th ratio between the output fluid volume and the device capacity. For example, the associated with the equipment library shown in Figure 3b is . Furthermore, the output modes supported by device are and . The operation can be output in only one output mode, which can be formulated as follows:
where and are binary variables representing whether outputs in the output mode and whether can support the output mode .
should be transported from to for every . To determine the volume of , we use a binary variable to represent whether the ratio between the volume of and the capacity of is . can be further constrained as follows:
Then, the volume constraint between devices with a non-fixed input/output ratio can be formulated as follows:
where is the capacity of device , is the ratio of the volume to the capacity after is input to , and is the volume of the excess fluid or the waste fluid generated by .
3.1.2. Scheduling with Optimization of Fluidic Ports
When transporting to , we can optionally cache in storage and later transport it to . We use and to represent the fluid transportation from to the storage and the fluid transportation to . When is transported directly from to , only the fluid transportation is performed. After completing the input of to , if , the excess liquids cached at both ends of should be removed. This results in excess fluid removal, denoted by . When and are bound to the same device and does not need to be cached in storage, it is unnecessary to perform . If in this case, there is waste fluid in that needs to be removed. This results in waste fluid removal, denoted by . Thus, we have the following constraint:
where and are the end time and the start time of , respectively. represents the duration of a transport task. is a binary variable representing whether should be performed. can be further constrained as follows:
where and are binary variables representing whether is greater than 0 and whether and are bound to , respectively. can be further constrained as follows:
The fluid transportation should not be started until the fluid transportation has been completed. Moreover, the excess fluid removal should be performed after transportation has finished. Then, the waste fluid removal is performed. Thus, we have the following constraint:
The inputs of should be loaded separately, which can be constrained as follows:
where is a binary variable representing the order of the inputs from and to and M is a very large constant for transforming two situations indicated by into linear constraints.
The operation can only be performed after all inputs have been completed. The operation should then last for the specified time to implement the corresponding functionality. Thus, we have the following constraint:
where and are the end time and the start time of , respectively, and is the execution time of .
Outputs of should only be executed after the operation has been completed and the outputs of should be removed separately. Thus, we have the following constraint:
where is a binary variable representing the order of the outputs from to and .
Additionally, without loss of correctness, we make equal to the time at which all fluids generated by leave via the following constraints:
When two operations are bound to the same component, all fluids generated by one operation should be removed before the other operation can start executing the inputs, constrained as follows:
where is a binary variable representing the order of and .
We assume that there is at most one storage on the CFMBs. Due to the bandwidth limitations of the storage, all cache inputs and cache outputs should be separated.
where is a binary variable representing the order of and .
As previously mentioned, each transport task should be associated with a pair of fluidic ports to provide pressure. We use a binary variable to represent whether the is bound to fluidic port pair . We have
where P is the set of fluidic port pairs.
Transport tasks bound to the same pair of fluid ports cannot be executed in parallel, constrained as follows:
where is a binary variable representing the order of and .
3.1.3. Optimization Objective
Once all operations and transport tasks have been completed, the bioassay is complete, constrained as follows:
where is the completion time of the bioassay.
We use binary variables and to represent whether and are allocated, respectively, constrained as follows:
where represents the storage in the device library.
Finally, an efficient high-level scheme can be generated by solving the following problem:
where , , , and are three weighting factors and is the area of .
3.2. Acceleration Strategies
To ensure the efficiency of SlimPort, two acceleration strategies, scheduling constraint reduction and upper boundary estimation of the port number, are proposed in this paper. The complexity of an ILP model is related to the number of its constraints and variables. The main idea of our proposed acceleration strategies is to reduce the number of constraints and variables that need to be constructed using the a priori knowledge provided by the inputs to achieve the acceleration.
3.2.1. Scheduling Constraint Reduction
The constraint given in (27) restricts the order between two-by-two operations. For the sake of simplicity, we define the upstream operations of as all operations on the path from the source to . Similarly, the downstream operations of are all operations on the path from to the source. Based on the dependencies in the sequencing graph, it is known that the upstream operations of should be completed before is executed and the downstream operations of should be executed after is completed. For operations of known order, we remove them from Constraint (27), thus achieving the reduction of Constraint (27).
Constraints (28) and (30) restrict the order between two-by-two transport tasks. For the sake of simplicity, we define the upstream edges of as all edges on the path from the source to . Similarly, the downstream edges of are all operations on the path from to the source. Based on the dependencies in the sequencing graph, it is known that if is the upstream edge of , should be completed before is executed. And if is the downstream edge of , should be executed after is completed. For transport tasks of known order, we remove them from Constraints (28) and (30), thus achieving the reduction of Constraints (28) and (30).
3.2.2. Upper Boundary Estimation of Fluidic Port Number
The number of variables and the number of Constraints (29) and (30) are related to the number of ports in P. To ensure the correctness while reducing the complexity of the ILP model, we estimate the upper bound on the number of fluid ports using Algorithm 1. For the sake of simplicity, we define and such that they are compatible when (1) is not the upstream/downstream edge of and (2) . Given the sequencing graph and the component library D, we first construct an edge-compatible graph. A node of the edge-compatible graph is represented as . The edge between and represents that and are compatible. We then obtain all maximal cliques in the edge-compatible graph via the Bron–Kerbosch algorithm [29]. Finally, we traverse all maximal clusters and obtain the upper bound on the number of fluid ports.
| Algorithm 1: Upper Boundary Estimation of Fluidic Port Number |
| Input: The sequencing graph and the device library D Output: The upper boundary of fluidic port number 1 for each do 2 ; 3 Add all into ; 4 Add all into ; 5 Initialize a stack and push all into ; 6 while do 7 ; 8 Push all into ; 9 Add all into ; 10 end while 11 end for 12 Construct an edge-compatible graph with each node representing any edge in E, and if , then connect the nodes corresponding to these and with a single edge; 13 Get all maximal cliques in the edge-compatible graph; 14 for each do 15 Get the parent operations corresponding to the edge nodes in and count the number of operations of each type, denoted as , where is the type number of all device in D; 16 Get the child operations corresponding to the edge nodes in and count the number of operations of each type, denoted as ; 17 , where is the number of devices with type i; 18 end for 19 |
4. Experimental Results
The proposed SlimPort was implemented in Python 3.11.11 and tested on a PC with 2.50 GHz CPU and 8 GB memory. The solver Gurobi was employed to solve the ILP model proposed in Section 3. As shown in Table 2, there are ten benchmarks to verify the performance of SlimPort. Five are synthetic benchmarks and the rest are real-world biochemical applications [26]. Parameters ,, and in Table 2 are the operation number and the edge number of the sequencing graph and the number of corresponding devices provided, respectively. The experimental parameters are set as follows: , , , and .
Table 2.
Details of benchmarks used in experiments.
4.1. Validation of the Proposed SlimPort
Since there is no existing work considering the volume management between devices with a non-fixed input/output ratio, we implemented another method, called PD, by modifying the high-level synthesis method in [26], to verify the performance of the proposed SlimPort.
We ran both algorithms on the aforementioned benchmarks. Table 3 shows comparison results between SlimPort and PD, where columns , , and are the completion time of the bioassay, the volume of excess/waste fluid, and the number of fluidic ports required, respectively. Moreover, the column “Imp (%)” provides the relative improvements of SlimPort over PD.
Table 3.
Comparison results between SlimPort and PD in terms of the completion time of the bioassay, the volume of excess/waste fluid, and the number of fluidic ports required.
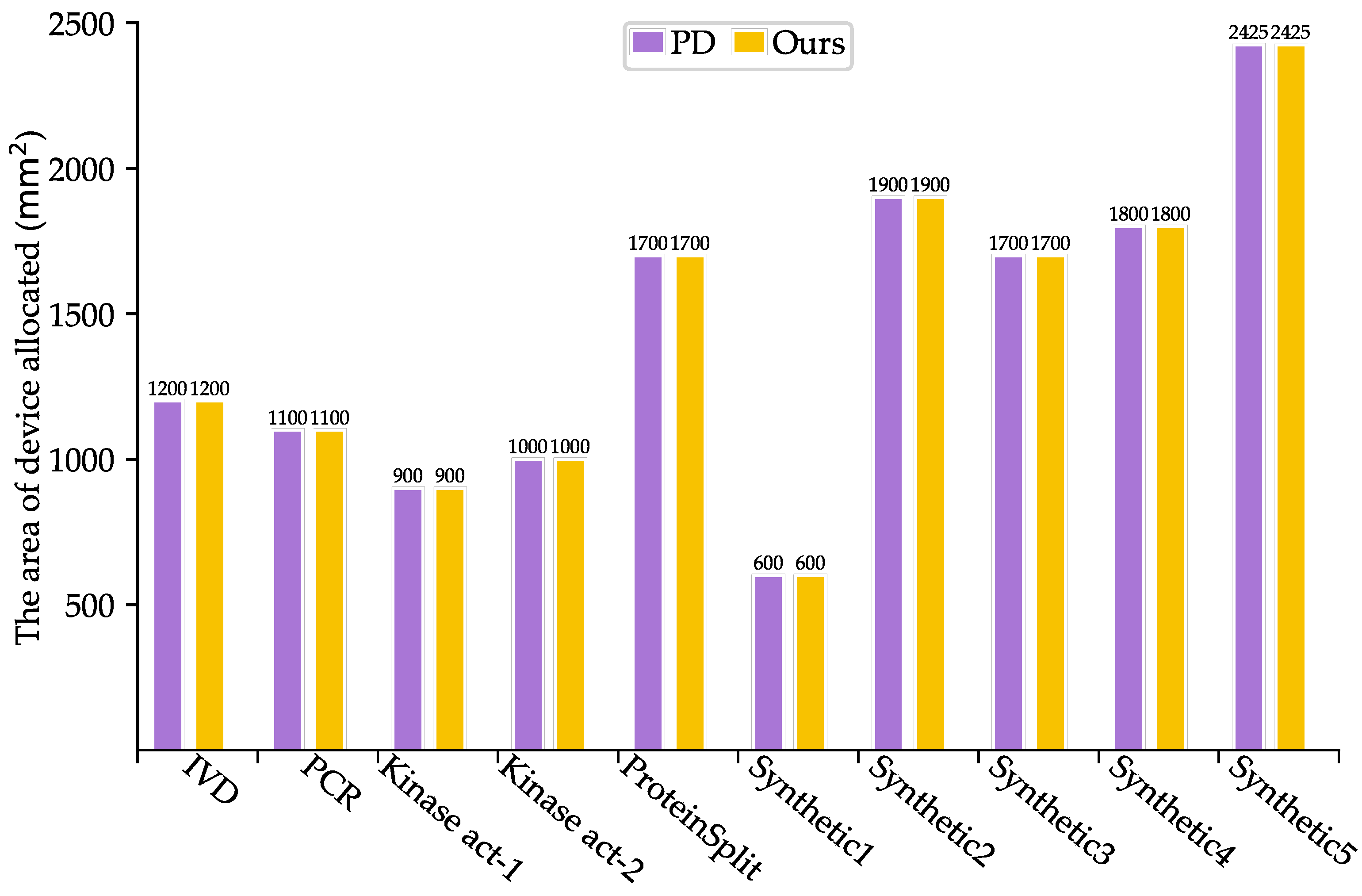
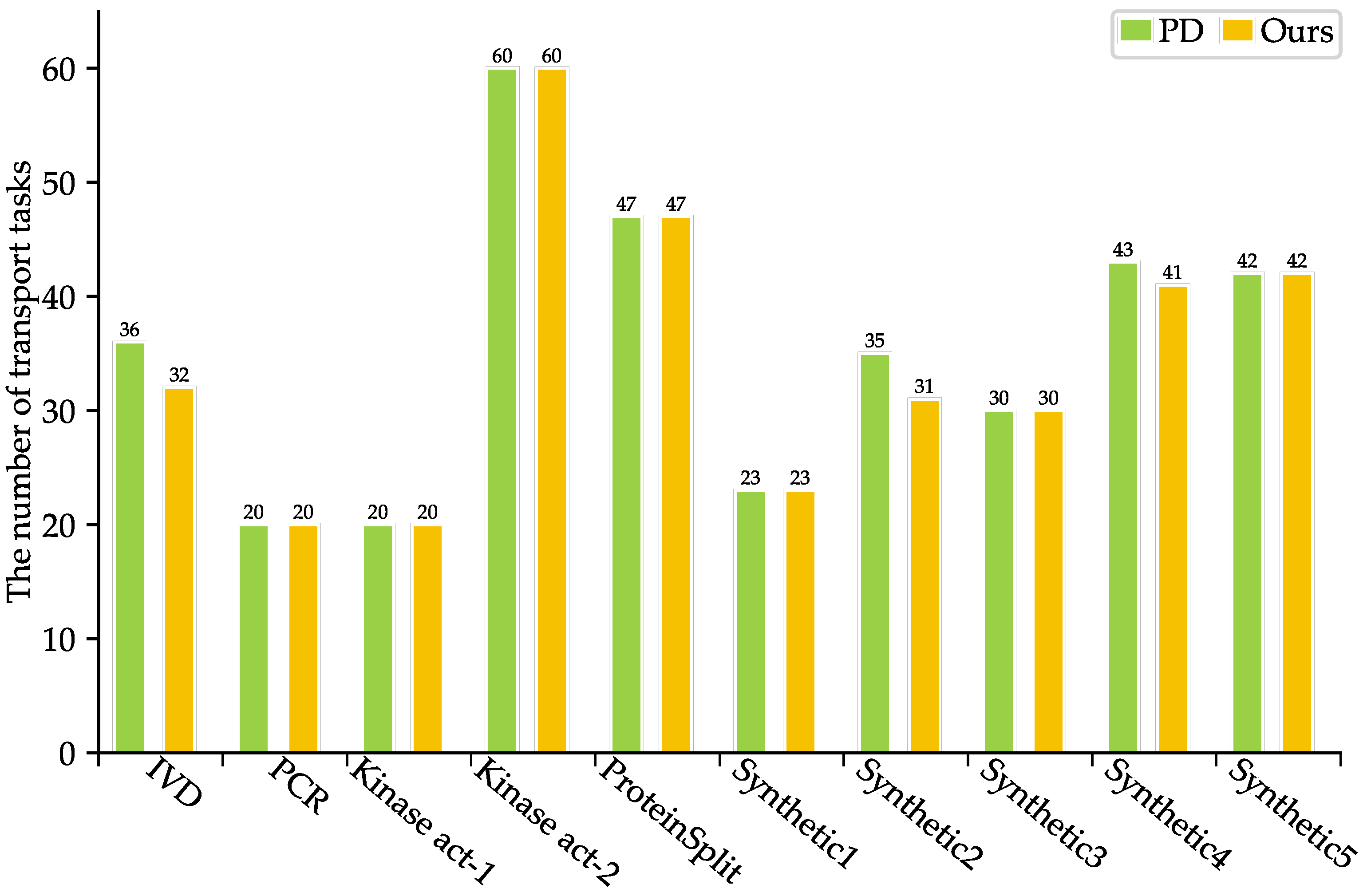
As shown in Table 3, SlimPort achieves a 33.3–66.7% reduction in terms of the number of fluidic ports required, with an average reduction of 51.67%, while maintaining the optimal solution in terms of bioassay completion time. Moreover, the volume of excess/waste fluid is reduced by 12.54%, thus reducing reagent consumption. As shown in Figure 5 and Figure 6, SlimPort maintains the optimal solution in terms of the area of devices allocated and improves the number of transport tasks by 2.72% on average compared with PD. PD takes the bioassay completion time and the area of devices allocated as the optimization objective and achieves the optimal solution. SlimPort is able to optimize the number of fluidic ports required, the volume of excess/waste fluid, and the number of transport tasks and maintain the optimal bioassay completion time and the area of devices allocated.
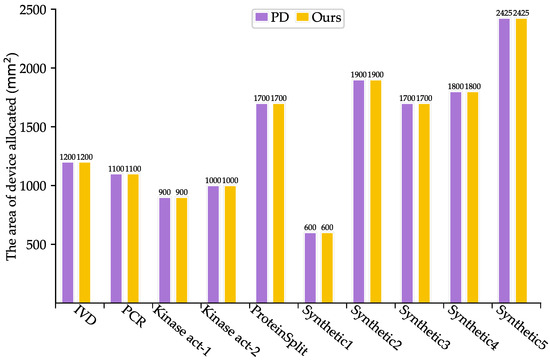
Figure 5.
Comparison results between PD and SlimPort in terms of the area of devices allocated.
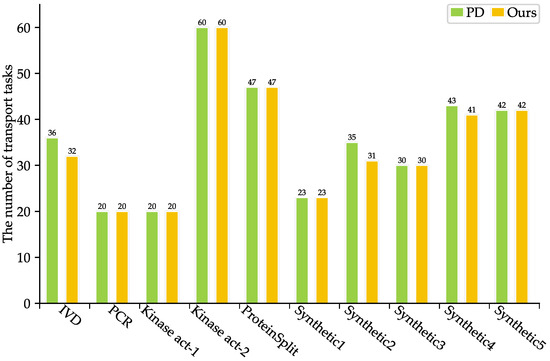
Figure 6.
Comparison results between PD and SlimPort in terms of the number of transport tasks.
4.2. Validation of the Acceleration Strategies
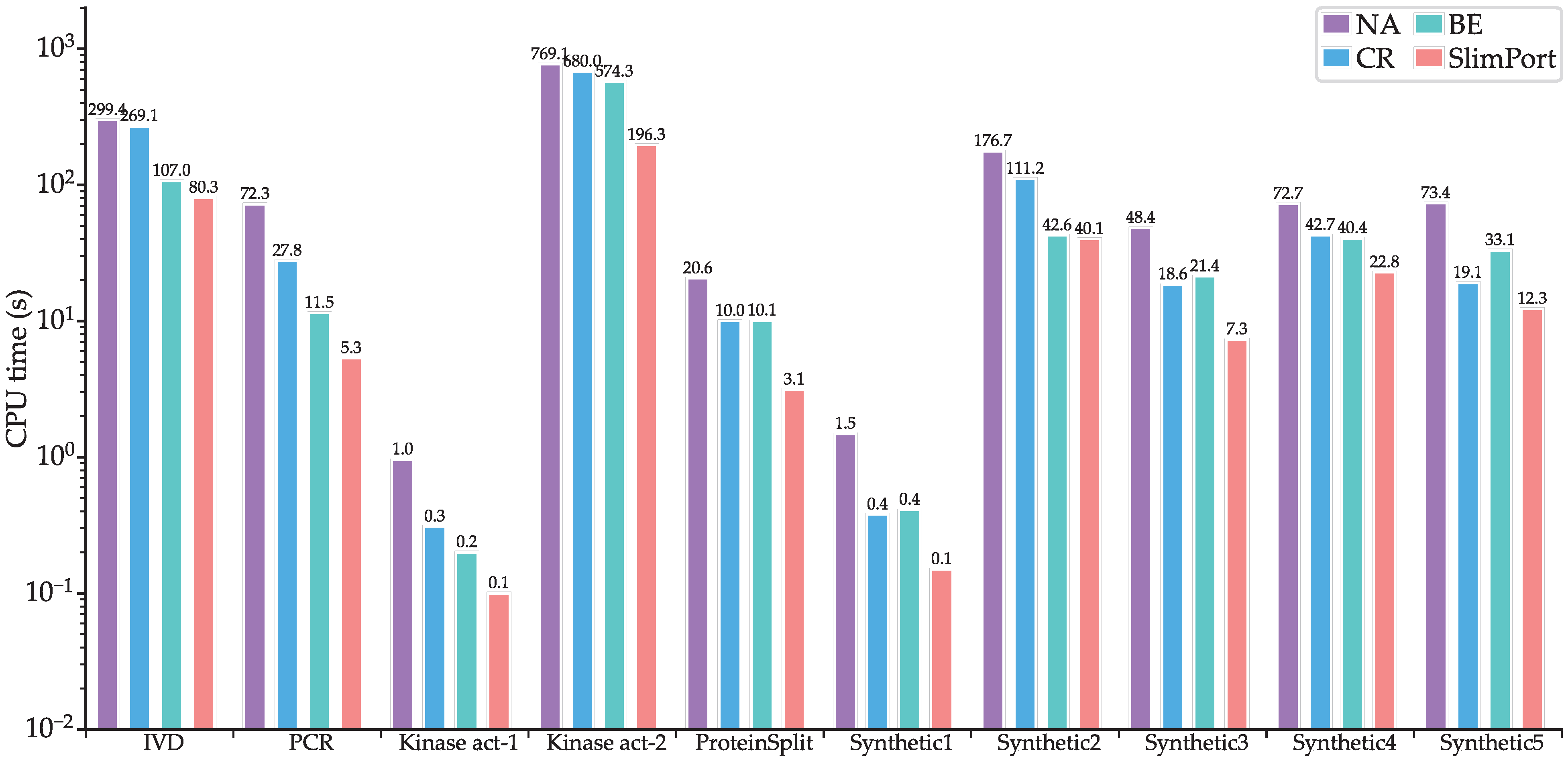
To verify the effectiveness of the proposed acceleration strategies, we implemented three other methods, NA, CR, and BE, where NA is based on the ILP model without acceleration, CR is based on the ILP model with scheduling constraint reduction, and BE is based on the ILP model with upper boundary estimation of the fluidic port number. Figure 7 shows CPU times of NA, CR, BE, and SlimPort. It can be seen that the computational efficiency improved for SlimPort across all the benchmarks compared with NA, CR, and BE. Compared with NA, CR achieves a maximum speedup of 3.8× with an average speedup of 2.3×, BE achieves a maximum speedup of 6.2× with an average speedup of 3.1×, and SlimPort achieves a maximum speedup of 13.5× with an average speedup of 6.7×. The acceleration capability of the acceleration strategies is demonstrated by the results above.
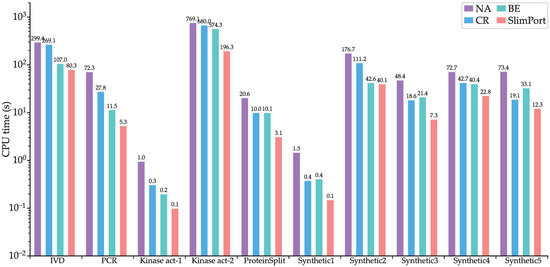
Figure 7.
CPU times of NA, CR, BE, and SlimPort.
5. Conclusions
In this paper, we proposed a port-driven high-level synthesis method, called SlimPort, for CFMBs. Compared with the previous methods, SlimPort for the first time integrates the optimization of fluidic port number into the high-level synthesis. Volume management between devices with a non-fixed input/output ratio is also taken into account by SlimPort. Furthermore, two acceleration strategies were proposed to improve the overall performance of SlimPort: reducing scheduling constraints and estimating the upper bound of the fluidic port number. Experimental results on both real-life chip applications and synthetic benchmarks confirm the effectiveness of SlimPort.
Furthermore, in the future, we intend to implement a physical design method, which will be based on the results of the proposed SlimPort, for the co-design of the flow and control layers and flow path planning. The objective of this method is to generate an efficient chip architecture and optimize the number of fluidic and control ports together.
Author Contributions
Conceptualization, Y.P., X.H. and G.L.; methodology, Y.P., Y.X. and Z.C.; software, Y.P., Y.X. and Z.C.; validation, Y.P., X.H. and G.L.; formal analysis, Y.P., X.H. and G.L.; investigation, Y.P., X.H. and G.L.; resources, Y.P., Y.X. and Z.C.; data curation, Y.P., Y.X. and Z.C.; writing—original draft preparation, Y.P.; writing—review and editing, Y.P.; visualization, Y.P.; supervision, Y.P., X.H. and G.L.; project administration, Y.P., X.H. and G.L.; funding acquisition, X.H. and G.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China under grant number 62372109, and the Natural Science Foundation of Fujian Province under grant numbers 2023J06017 and 2024J01984.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Dataset available on request from the authors.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| PDMS | Polydimethylsiloxane |
| CFMB | Continuous-flow microfluidic biochip |
| ILP | Integer linear programming |
References
- Huang, X.; Ho, T.Y.; Guo, W.; Li, B.; Chakrabarty, K.; Schlichtmann, U. Computer-Aided Design Techniques for Flow-Based Microfluidic Lab-on-a-Chip Systems. ACM Comput. Surv. 2021, 54, 97. [Google Scholar] [CrossRef]
- Liu, G.; Huang, H.; Chen, Z.; Lin, H.; Liu, H.; Huang, X.; Guo, W. Design Automation for Continuous-Flow Microfluidic Biochips: A Comprehensive Review. Integration 2022, 82, 48–66. [Google Scholar] [CrossRef]
- Chin, C.D.; Laksanasopin, T.; Cheung, Y.K.; Steinmiller, D.; Linder, V.; Parsa, H.; Wang, J.; Moore, H.; Rouse, R.; Umviligihozo, G.; et al. Microfluidics-Based Diagnostics of Infectious Diseases in the Developing World. Nat. Med. 2011, 17, 1015–1019. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.P.; Chuang, Y.J.; Lee, W.B.; Tsai, Y.C.; Lin, C.N.; Hsu, K.F.; Lee, G.B. An Integrated Microfluidic System for Rapid, Automatic and High-Throughput Staining of Clinical Tissue Samples for Diagnosis of Ovarian Cancer. Lab Chip 2020, 20, 1103–1109. [Google Scholar] [CrossRef] [PubMed]
- Chu, Y.; Gao, Y.; Tang, W.; Qiang, L.; Han, Y.; Gao, J.; Zhang, Y.; Liu, H.; Han, L. Attomolar-Level Ultrasensitive and Multiplex microRNA Detection Enabled by a Nanomaterial Locally Assembled Microfluidic Biochip for Cancer Diagnosis. Anal. Chem. 2021, 93, 5129–5136. [Google Scholar] [CrossRef] [PubMed]
- Kartalov, E.P.; Zhong, J.F.; Scherer, A.; Quake, S.R.; Taylor, C.R.; Anderson, W.F. High-Throughput Multi-Antigen Microfluidic Fluorescence Immunoassays. BioTechniques 2006, 40, 85–90. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.; Li, X.; Zhang, Y.; Wang, Y.; Wang, B.; Zheng, L.; Zhang, D.; Zhuang, S. Rapid Quantitative Detection of Chloramphenicol in Milk by Microfluidic Immunoassay. Food Chem. 2021, 339, 127857. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Zhao, M.; Dai, B.; Xue, Z.; Kang, Y.; Liu, S.; Hou, L.; Zhuang, S.; Zhang, D. Integrated System for Rapid Enrichment and Detection of Airborne Polycyclic Aromatic Hydrocarbons. Sci. Total Environ. 2023, 864, 161057. [Google Scholar] [CrossRef] [PubMed]
- Unger, M.A.; Chou, H.P.; Thorsen, T.; Scherer, A.; Quake, S.R. Monolithic Microfabricated Valves and Pumps by Multilayer Soft Lithography. Science 2000, 288, 113–116. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Tseng, T.M.; Li, B.; Ho, T.Y.; Schlichtmann, U. Component-Oriented High-Level Synthesis for Continuous-Flow Microfluidics Considering Hybrid-Scheduling. In Proceedings of the 2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Huang, C.M.; Liu, C.H.; Huang, J.D. Volume-Oriented Sample Preparation for Reactant Minimization on Flow-Based Microfluidic Biochips with Multi-Segment Mixers. In Proceedings of the 2015 Design, Automation & Test in Europe Conference & Exhibition (DATE), EDA Consortium, Grenoble, France, 9–13 March 2015; pp. 1114–1119. [Google Scholar]
- Thorsen, T.; Maerkl, S.J.; Quake, S.R. Microfluidic Large-Scale Integration. Science 2002, 298, 580–584. [Google Scholar] [CrossRef] [PubMed]
- Melin, J.; Quake, S.R. Microfluidic Large-Scale Integration: The Evolution of Design Rules for Biological Automation. Annu. Rev. Biophys. 2007, 36, 213–231. [Google Scholar] [CrossRef] [PubMed]
- Hu, K.; Chakrabarty, K.; Ho, T.Y. Computer-Aided Design of Microfluidic Very Large Scale Integration (mVLSI) Biochips; Springer: Cham, Switzerland, 2017; pp. 26–27. [Google Scholar] [CrossRef]
- Perkel, J.M. Life Science Technologies: Microfluidics—Bringing New Things to Life Science. Science 2008, 322, 975–977. [Google Scholar] [CrossRef]
- Huang, X.; Ho, T.Y.; Li, Z.; Liu, G.; Wang, L.; Li, Q.; Guo, W.; Li, B.; Schlichtmann, U. MiniControl 2.0: Co-Synthesis of Flow and Control Layers for Microfluidic Biochips with Strictly Constrained Control Ports. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2022, 41, 5449–5463. [Google Scholar] [CrossRef]
- Stanford Microfluidics Foundry Basic Design Tips. Available online: https://www.stanfordmicrofluidics.com/design-basics (accessed on 2 April 2025).
- Tseng, T.M.; Li, M.; Freitas, D.N.; McAuley, T.; Li, B.; Ho, T.Y.; Araci, I.E.; Schlichtmann, U. Columba 2.0: A Co-Layout Synthesis Tool for Continuous-Flow Microfluidic Biochips. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 1588–1601. [Google Scholar] [CrossRef]
- Liu, C.; Huang, X.; Li, B.; Yao, H.; Pop, P.; Ho, T.Y.; Schlichtmann, U. DCSA: Distributed Channel-Storage Architecture for Flow-Based Microfluidic Biochips. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2021, 40, 115–128. [Google Scholar] [CrossRef]
- Huang, X.; Pan, Y.; Chen, Z.; Guo, W.; Wang, L.; Li, Q.; Wille, R.; Ho, T.Y.; Schlichtmann, U. Design Automation for Continuous-Flow Lab-on-a-Chip Systems: A One-Pass Paradigm. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2023, 42, 327–331. [Google Scholar] [CrossRef]
- Zhu, Y.; Liu, G.; Guo, W.; Huang, X. FTCD: Fault-Tolerant Co-Design of Flow and Control Layers for Fully Programmable Valve Array Biochips. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2025, 1–14. [Google Scholar] [CrossRef]
- Huang, X.; Cai, H.; Guo, W.; Liu, G.; Ho, T.Y.; Chakrabarty, K.; Schlichtmann, U. Control-Logic Synthesis of Fully Programmable Valve Array Using Reinforcement Learning. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2024, 43, 277–290. [Google Scholar] [CrossRef]
- Liu, G.; Zeng, Y.; Zhu, Y.; Cai, H.; Guo, W.; Li, Z.; Ho, T.Y.; Huang, X. Towards Automated Testing of Multiplexers in Fully Programmable Valve Array Biochips. In Proceedings of the 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC), Incheon, Republic of Korea, 22–25 January 2024; pp. 570–575. [Google Scholar] [CrossRef]
- Minhass, W.H.; Pop, P.; Madsen, J. System-Level Modeling and Synthesis of Flow-Based Microfluidic Biochips. In Proceedings of the 2011 14th International Conference on Compilers, Architectures and Synthesis for Embedded Systems (CASES), Taipei, Taiwan, 9–14 October 2011; pp. 225–233. [Google Scholar] [CrossRef]
- Dinh, T.A.; Yamashita, S.; Ho, T.Y.; Hara-Azumi, Y. A Clique-Based Approach to Find Binding and Scheduling Result in Flow-Based Microfluidic Biochips. In Proceedings of the 2013 18th Asia and South Pacific Design Automation Conference (ASP-DAC), Yokohama, Japan, 22–25 January 2013; pp. 199–204. [Google Scholar] [CrossRef]
- Huang, X.; Pan, Y.; Zhang, G.L.; Li, B.; Guo, W.; Ho, T.Y.; Schlichtmann, U. PathDriver+: Enhanced Path-Driven Architecture Design for Flow-Based Microfluidic Biochips. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2022, 41, 2185–2198. [Google Scholar] [CrossRef]
- Chen, Z.; Zhu, Y.; Chen, Z.; Chen, Z.; Liu, G. High-Level Synthesis for Microfluidic Biochips Considering Actual Volume Management and Channel Storage. In Proceedings of the 2024 25th International Symposium on Quality Electronic Design (ISQED), San Francisco, CA, USA, 3–5 April 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Ye, Z.; Chen, Z.; Pan, Y.; Liu, G.; Guo, W.; Ho, T.Y.; Huang, X. Timing-Driven High-Level Synthesis for Continuous-Flow Microfluidic Biochips. In Proceedings of the 2024 25th International Symposium on Quality Electronic Design (ISQED), San Francisco, CA, USA, 3–5 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Bron, C.; Kerbosch, J. Algorithm 457: Finding All Cliques of an Undirected Graph. Commun. ACM 1973, 16, 575–577. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).