
Printed Circuit Board Sample Expansion and Automatic Defect Detection Based on Diffusion Models and ConvNeXt


Abstract
1. Introduction
- Different from previous inspection methods that can only detect a single PCB soldered component, the proposed inspection method can detect defects in multiple soldered components within a single picture, which improves inspection efficiency.
- Using the diffusion model to expand the PCB solder defect detection dataset with samples, the validity of the approach has been verified for the target detection results.
- ConvNext is utilised as a backbone network to modify the Cascade Mask-RCNN detection algorithm to enhance the accuracy of classification and examination of the PCB soldering defect dataset.
2. Related Work
3. Proposed Method
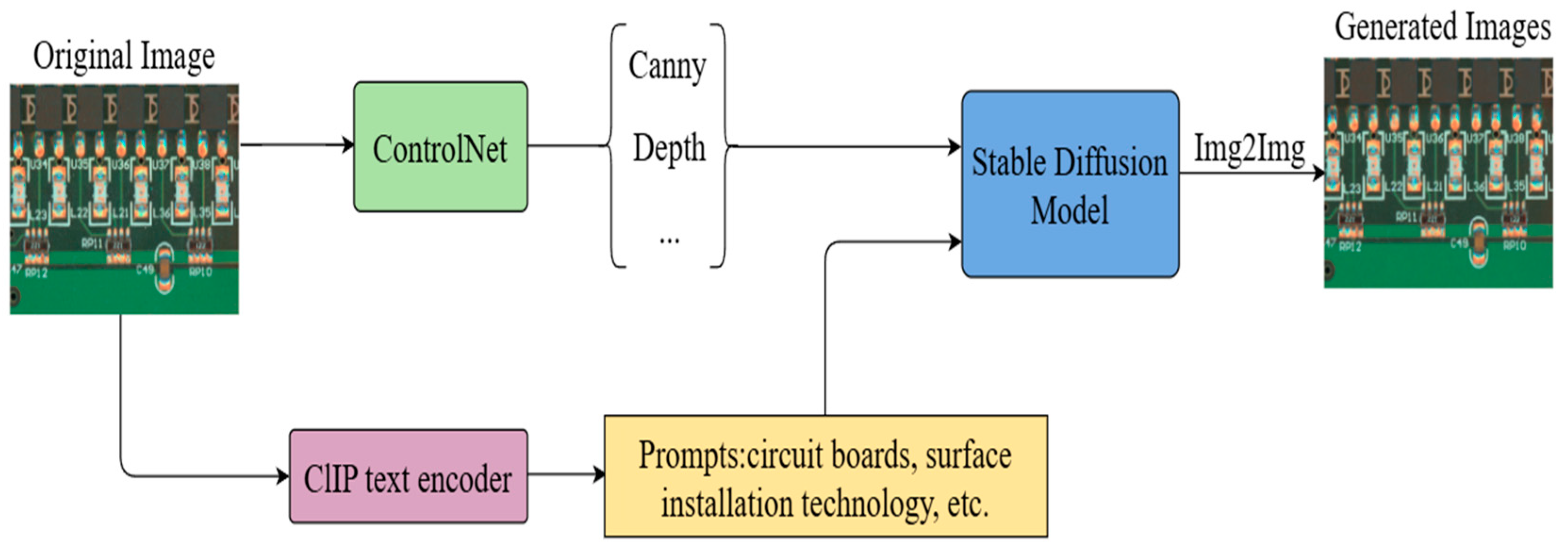
3.1. Expansion of Data Samples Based on Diffusion Model
3.2. Target Detection Based on R-CNN Series of Models
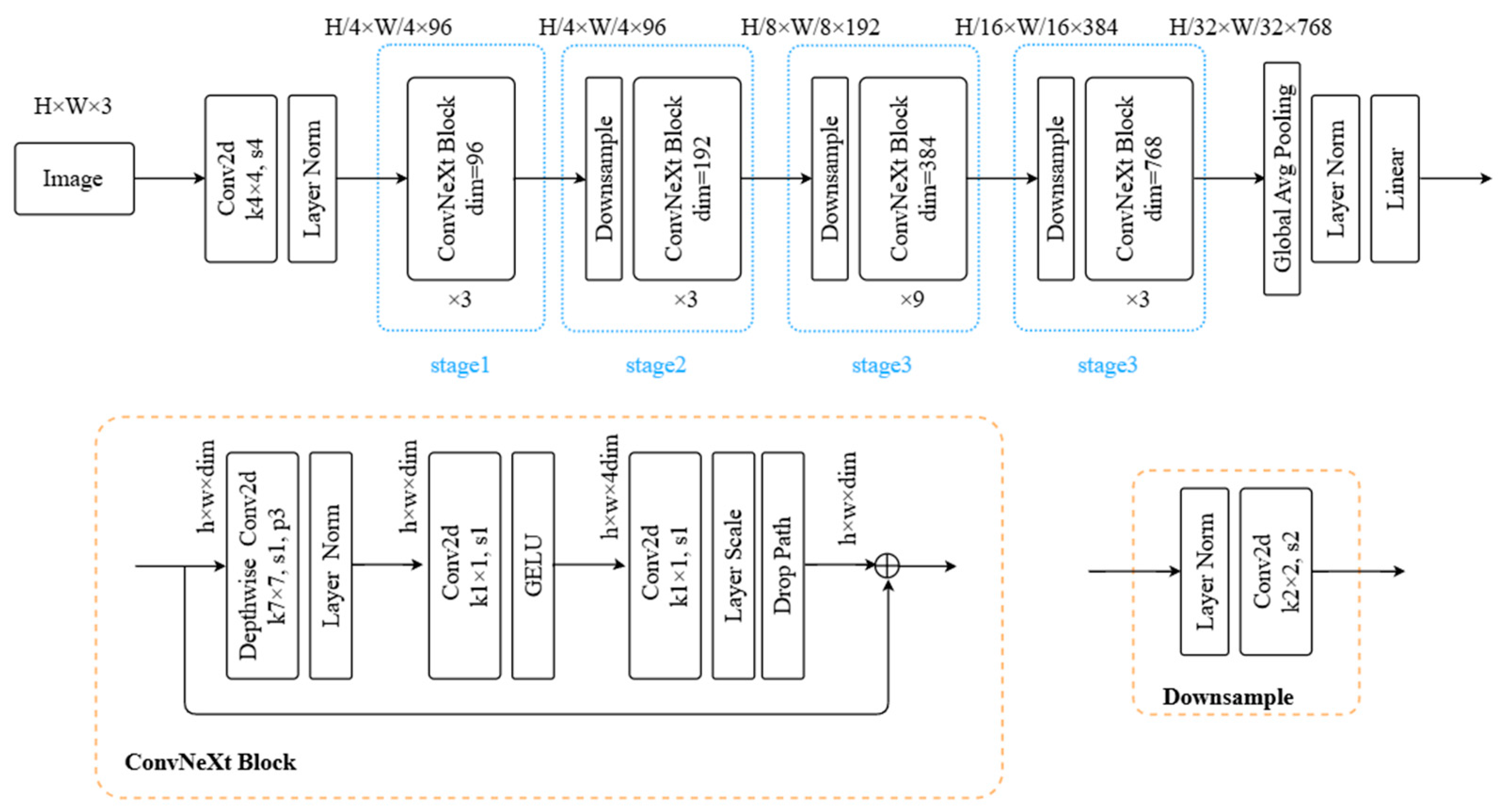
3.3. ConvNeXt Backbone
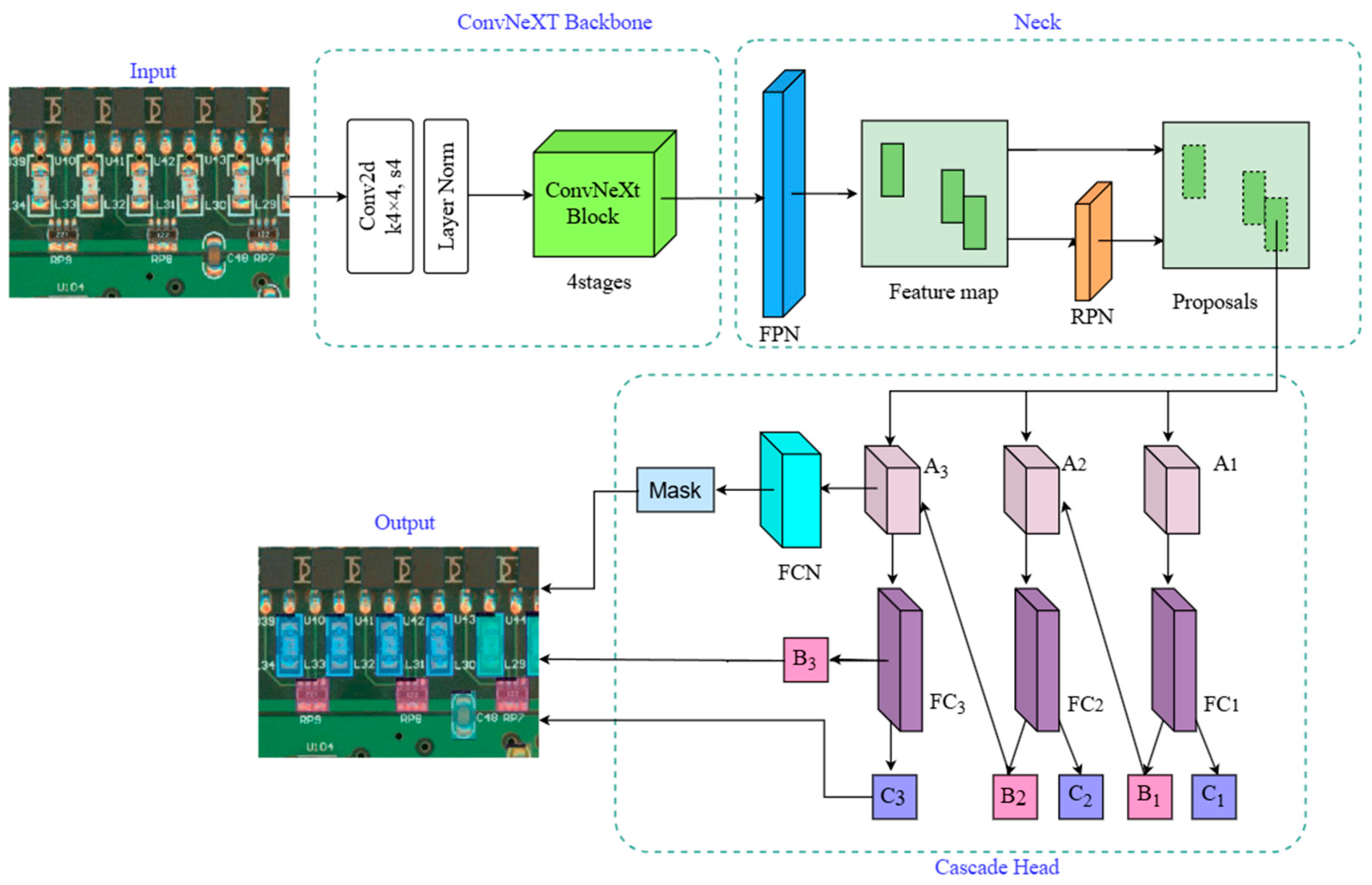
3.4. Defect Detection Method Based on ConvNext Cascade Mask R-CNN
4. Experimental Results
4.1. Experimental Results of Data Sample Expansion on the Basis of Diffusion Model
4.2. ConvNext Cascade Mask R-CNN-Based Defect Detection Experiments
4.2.1. Experimental Dataset and Parameter Settings
4.2.2. Comparison of Experimental Results of Defect Detection
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Da Silva, H.G.; Amaral, T.G. Automatic Optical Inspection for Detecting Defective Solders on Printed Circuit Boards. In Proceedings of the 36th Annual Conference of IEEE Industrial Electronics Society, Glendale, AZ, USA, 7–10 November 2010; pp. 1087–1091. [Google Scholar]
- Cai, N.; Lin, J.; Ye, Q.; Wang, H.; Weng, S.; Ling, B.W. A New IC Solder Joint Inspection Method for an Automatic Optical Inspection System Based on an Improved Visual Background Extraction Algorithm. IEEE Trans. Compon. Packag. Manuf. Technol. 2016, 6, 161–172. [Google Scholar]
- Goodfellow, J.I.; Pouget-Abadie, J.; Mirza, M. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision: ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 2232–2969. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion Models Beat GANs on Image Synthesis. Adv. Neural Inf. Process. Syst. 2021, 8780–8794. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding Conditional Control to Text-to-Image Diffusion Models. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision: ICCV 2023, Paris, France, 1–6 October 2023; pp. 3813–3824. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10674–10685. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV 2015), Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision: ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 2970–3705. [Google Scholar]
- Song, H.C.; Knag, M.S.; Kimg, T.E. Object Detection based on Mask R-CNN from Infrared Camera. J. Digit. Contents Soc. 2018, 19, 1213–1218. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition: CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1–731. [Google Scholar]
- Lee, S.H.; Gao, G. A Study on Pine Larva Detection System Using Swin Transformer and Cascade R-CNN Hybrid Model. Appl. Sci. 2023, 13, 1330. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition: CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 752–1502. [Google Scholar]
- Jiang, J.; Cheng, J. Color Biological Features-Based Solder Paste Defects Detection and Classification on Printed Circuit Boards. IEEE Trans. Compon. Packag. Manuf. Technol. 2012, 2, 1536–1544. [Google Scholar] [CrossRef]
- Xue, B.; Sun, C.; Chu, H.; Meng, Q.; Jiao, S. Method of electronic component location, grasping and inserting based on machine vision-based on machine vision. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1968–1971. [Google Scholar]
- Wu, H. Solder joint defect classification based on ensemble learning. Solder. Surf. Mt. Technol. 2017, 29, 164–170. [Google Scholar] [CrossRef]
- Zheng, Z.; Zheng, L. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3754–3762. [Google Scholar]
- Wu, H.; Liu, Y.; Xu, Y. An LCD Detection Method Based on the Simultaneous Automatic Generation of Samples and Masks Using Generative Adversarial Networks. Electronics 2023, 12, 5037. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Peebles, W.; Xie, S. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4195–4205. [Google Scholar]
- Zunair, H.; Hamza, A.B. Sharp U-Net: Depthwise convolutional network for biomedical image segmentation. Comput. Biol. Med. 2021, 136, 104699. [Google Scholar] [CrossRef]
- Li, P.; Yuan, X.; Wang, J.; Wang, Y. EMPViT: Efficient multi-path vision transformer for security risks detection in power distribution network. Neurocomputing 2025, 617, 128967. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, M.; Zheng, P.; Yang, H.; Zou, J. A smart surface inspection system using faster R-CNN in cloud-edge computing environment. Adv. Eng. Inform. 2020, 43, 101037. [Google Scholar] [CrossRef]
- Wu, H.; Gao, W.; Xu, X. Solder Joint Recognition Using Mask R-CNN Method. IEEE Trans. Compon. Packag. Manuf. Technol. 2020, 10, 525–530. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes; Cornell University Library: Ithaca, NY, USA, 2013. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning: ICML 2021, Online, 18–24 July 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Cheng, Z.; Yu, X.; Jian, Y. Automatic modulation classification based on Alex Net with data augmentation. J. China Univ. Posts Telecommun. 2022, 29, 51–61. [Google Scholar]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition: CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 2792–3715. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, H. Automatic Solder Defect Detection in Electronic Components Using Transformer Architecture. IEEE Trans. Compon. Packag. Manuf. Technol. 2024, 14, 166–175. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Type | Name | Advantage | Disadvantage |
|---|---|---|---|
| Traditional Machine Learning Detection Methods | Classifier detection method based on image features | The method is simple and uncomplicated | Time-consuming and not very accurate |
| Deep Learning-Based Detection Algorithms | Faster R-CNN, Mask R-CNN, etc. | Target defects can be detected automatically | Poor classification and detection accuracy for multiple-target defective items |
| Our proposed methodology | High accuracy of classification and detection of defective items with multiple targets | Larger model, longer computation time |
| mAPbbox | mAPbbox_50 | mAPbbox_75 | AR | |
|---|---|---|---|---|
| Original dataset | 0.838 | 0.925 | 0.925 | 0.870 |
| Expanded dataset | 0.876 | 0.954 | 0.954 | 0.897 |
| Model | mAPbbox | mAPbbox_50 | mAPbbox_75 | AR | Params | Flops |
|---|---|---|---|---|---|---|
| Faster R-CNN [9] | 0.759 | 0.921 | 0.905 | 0.790 | 41.44M | 0.178T |
| Mask R-CNN [11] | 0.746 | 0.926 | 0.919 | 0.792 | 43.75M | 0.258T |
| Cascade Mask R-CNN [12] | 0.793 | 0.914 | 0.910 | 0.819 | 77.09M | 0.390T |
| ST–Mask R-CNN [33] | 0.853 | 0.937 | 0.934 | 0.872 | 47.37M | 0.262T |
| Our proposed method | 0.876 | 0.954 | 0.954 | 0.897 | 85.84M | 0.472T |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Wu, H.; Liu, Y.; Liu, X. Printed Circuit Board Sample Expansion and Automatic Defect Detection Based on Diffusion Models and ConvNeXt. Micromachines 2025, 16, 261. https://doi.org/10.3390/mi16030261
Xu Y, Wu H, Liu Y, Liu X. Printed Circuit Board Sample Expansion and Automatic Defect Detection Based on Diffusion Models and ConvNeXt. Micromachines. 2025; 16(3):261. https://doi.org/10.3390/mi16030261
Chicago/Turabian StyleXu, Youzhi, Hao Wu, Yulong Liu, and Xiaoming Liu. 2025. "Printed Circuit Board Sample Expansion and Automatic Defect Detection Based on Diffusion Models and ConvNeXt" Micromachines 16, no. 3: 261. https://doi.org/10.3390/mi16030261
APA StyleXu, Y., Wu, H., Liu, Y., & Liu, X. (2025). Printed Circuit Board Sample Expansion and Automatic Defect Detection Based on Diffusion Models and ConvNeXt. Micromachines, 16(3), 261. https://doi.org/10.3390/mi16030261