
Simulating an Integrated Photonic Image Classifier for Diffractive Neural Networks



Abstract
:1. Introduction
2. Design Framework of Integrated Diffractive Deep Neural Network
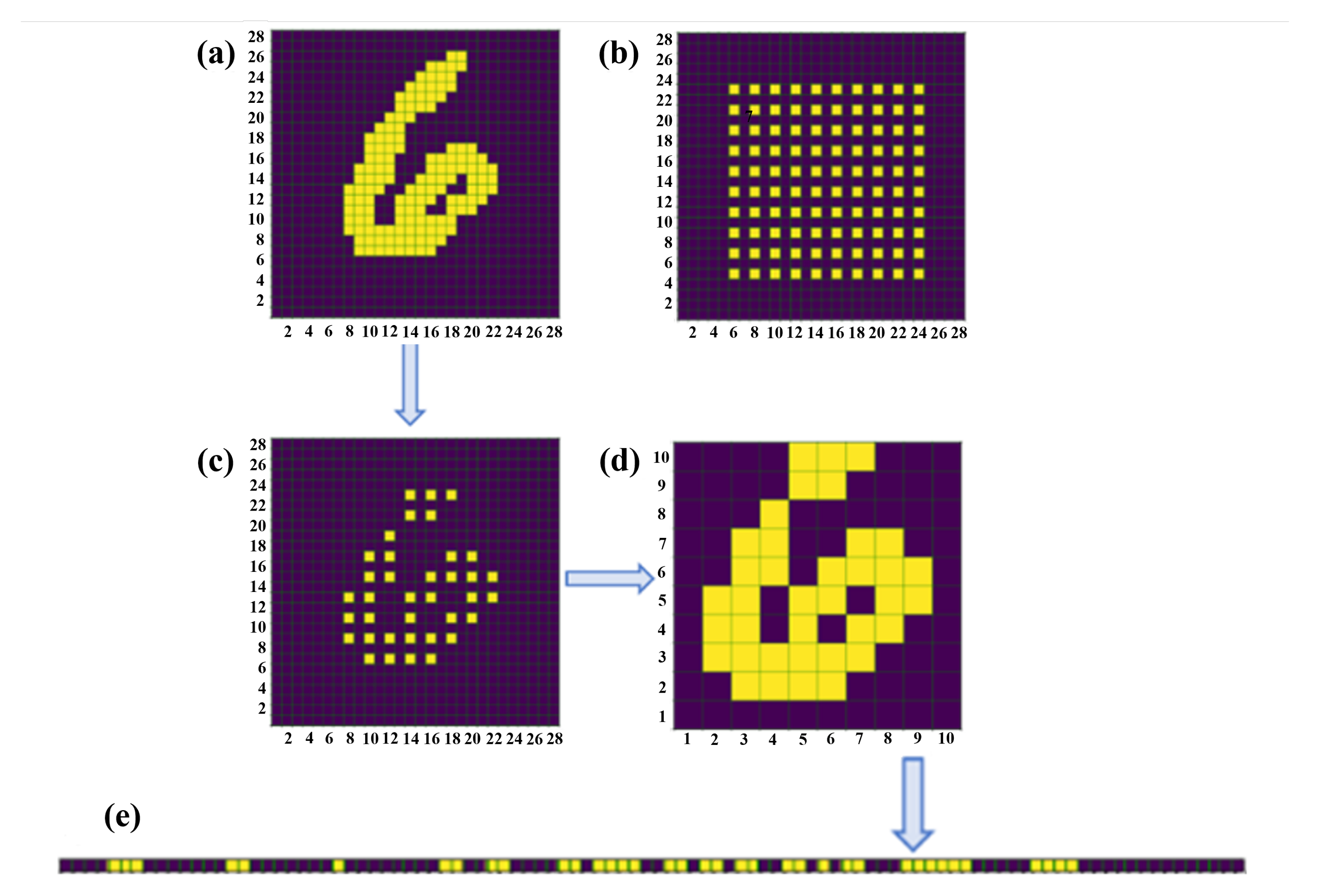
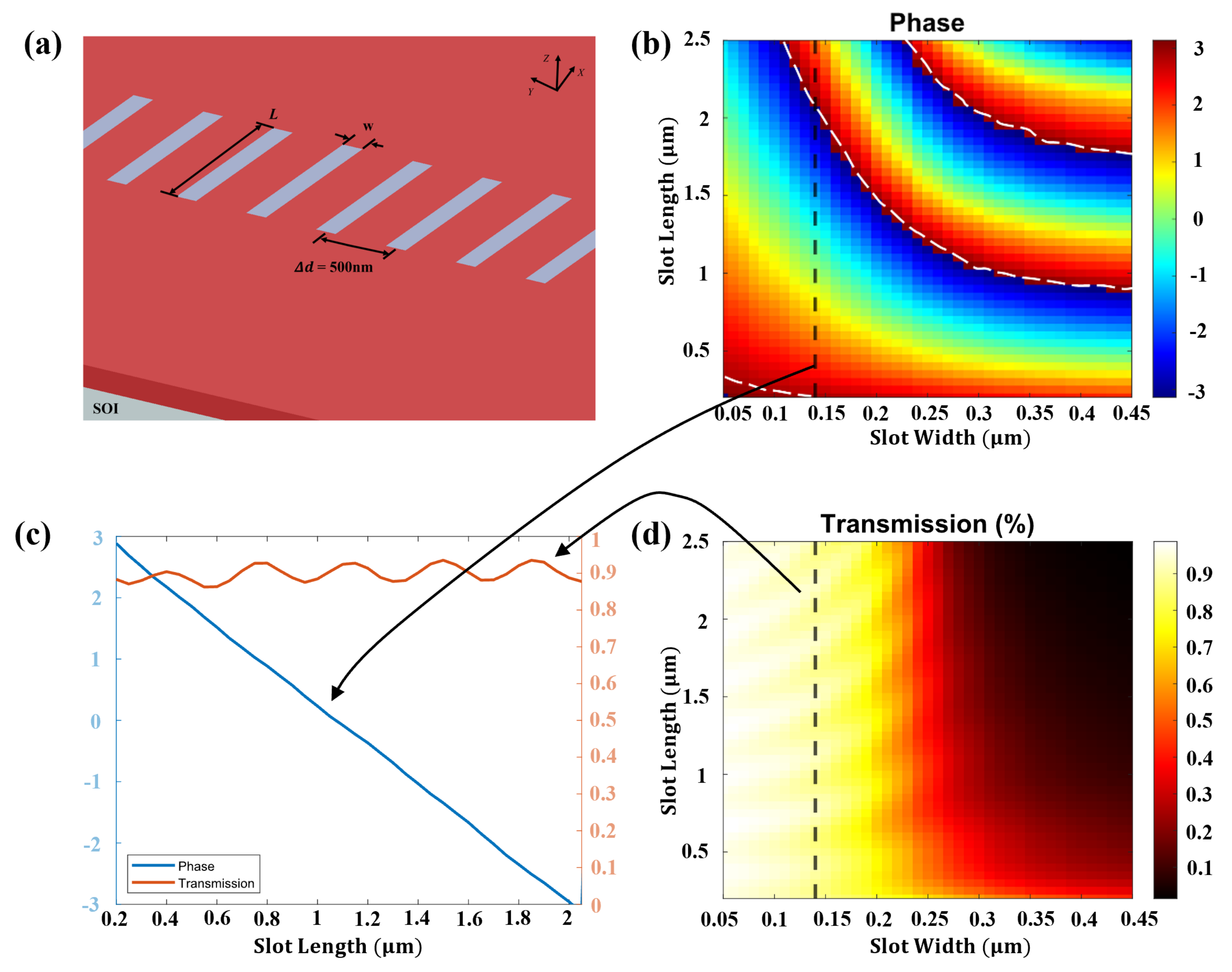
2.1. Physical Input to the Integrated Diffractive Deep Neural Network
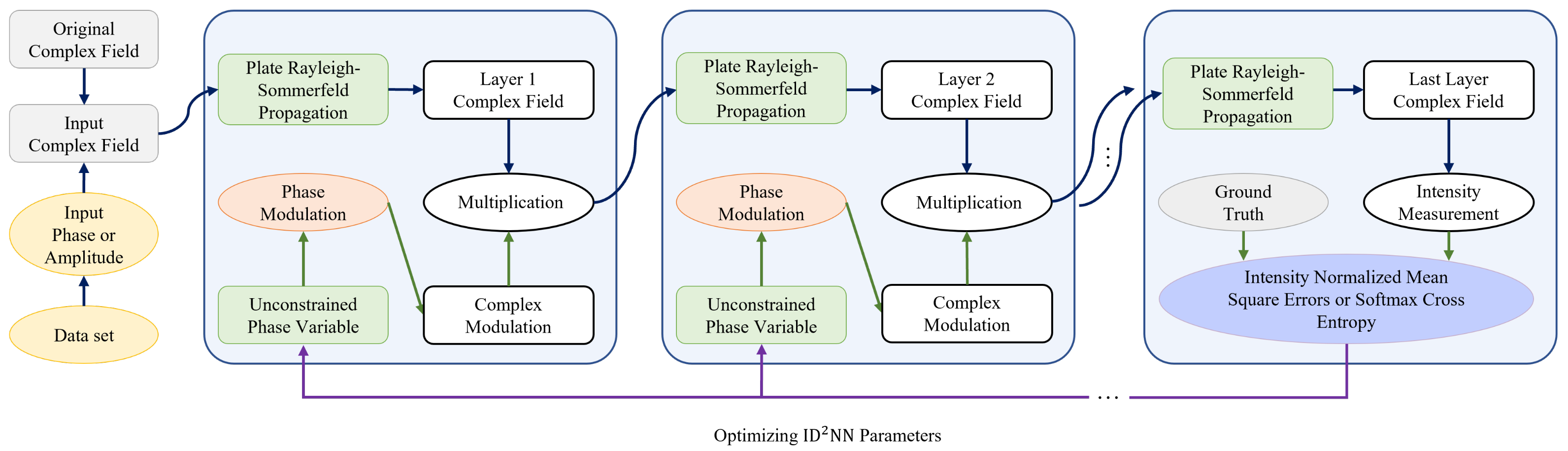
2.2. Forward Propagation and Error Back-Propagation Model
2.3. Neural Value Mapping and Verification of the Designed IDNN
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Umar, A.M.; Linus, O.U.; Arshad, H.; Kazaure, A.A.; Gana, U.; Kiru, M.U. Comprehensive review of artificial neural network applications to pattern recognition. IEEE Access 2019, 7, 158820–158846. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech recognition using deep neural networks: A systematic review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Tripathi, M. Analysis of convolutional neural network based image classification techniques. J. Innov. Image Process. 2021, 3, 100–117. [Google Scholar] [CrossRef]
- Lin, Z.; Wang, H.; Li, S. Pavement anomaly detection based on transformer and self-supervised learning. Autom. Constr. 2022, 143, 104544. [Google Scholar] [CrossRef]
- Tao, Y.; Shi, J.; Guo, W.; Zheng, J. Convolutional Neural Network Based Defect Recognition Model for Phased Array Ultrasonic Testing Images of Electrofusion Joints. J. Press. Vessel. Technol. 2023, 145, 024502. [Google Scholar] [CrossRef]
- Goldberg, Y. Neural Network Methods for Natural Language Processing; Springer Nature: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Li, J.; Cheng, J.H.; Shi, J.Y.; Huang, F. Brief Introduction of Back Propagation (BP) Neural Network Algorithm and Its Improvement. In Advances in Computer Science and Information Engineering; Jin, D., Lin, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 553–558. [Google Scholar]
- Koppula, S.; Orosa, L.; Yağlıkçı, A.G.; Azizi, R.; Shahroodi, T.; Kanellopoulos, K.; Mutlu, O. EDEN: Enabling Energy-Efficient, High-Performance Deep Neural Network Inference Using Approximate DRAM. In MICRO ’52, Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture; Association for Computing Machinery: New York, NY, USA, 2019; pp. 166–181. [Google Scholar] [CrossRef]
- Xu, X.; Tan, M.; Corcoran, B.; Wu, J.; Nguyen, T.G.; Boes, A.; Chu, S.T.; Little, B.E.; Morandotti, R.; Mitchell, A.; et al. Photonic perceptron based on a Kerr Microcomb for high-speed, scalable, optical neural networks. Laser Photonics Rev. 2020, 14, 2000070. [Google Scholar] [CrossRef]
- Wetzstein, G.; Ozcan, A.; Gigan, S.; Fan, S.; Englund, D.; Soljačić, M.; Denz, C.; Miller, D.A.; Psaltis, D. Inference in artificial intelligence with deep optics and photonics. Nature 2020, 588, 39–47. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Yoo, H.J. An Overview of Energy-Efficient Hardware Accelerators for On-Device Deep-Neural-Network Training. IEEE Open J. Solid-State Circuits Soc. 2021, 1, 115–128. [Google Scholar] [CrossRef]
- Chen, Y.; Yang, T.J.; Emer, J.; Sze, V. Understanding the limitations of existing energy-efficient design approaches for deep neural networks. Energy 2018, 2, L3. [Google Scholar]
- Habib, G.; Qureshi, S. Optimization and acceleration of convolutional neural networks: A survey. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 4244–4268. [Google Scholar] [CrossRef]
- Patterson, D.; Gonzalez, J.; Le, Q.; Liang, C.; Munguia, L.M.; Rothchild, D.; So, D.; Texier, M.; Dean, J. Carbon Emissions and Large Neural Network Training. arXiv 2021, arXiv:2104.10350. [Google Scholar]
- Lin, X.; Rivenson, Y.; Yardimci, N.T.; Veli, M.; Luo, Y.; Jarrahi, M.; Ozcan, A. All-optical machine learning using diffractive deep neural networks. Science 2018, 361, 1004–1008. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Li, T.; Soman, A.; Mao, D.; Kananen, T.; Gu, T. On-chip wavefront shaping with dielectric metasurface. Nat. Commun. 2019, 10, 3547. [Google Scholar] [CrossRef] [PubMed]
- Lee, S. A continuous-time optical neural network. In Proceedings of the IEEE 1988 International Conference on Neural Networks, San Diego, CA, USA, 24–27 July 1988; Volume 2, pp. 373–384. [Google Scholar] [CrossRef]
- Abu-Mostafa, Y.S.; Psaltis, D. Optical Neural Computers. Sci. Am. 1987, 256, 88–95. [Google Scholar] [CrossRef]
- Vandoorne, K.; Dierckx, W.; Schrauwen, B.; Verstraeten, D.; Baets, R.; Bienstman, P.; Campenhout, J.V. Toward optical signal processing using Photonic Reservoir Computing. Opt. Express 2008, 16, 11182–11192. [Google Scholar] [CrossRef] [PubMed]
- Fiers, M.A.A.; Van Vaerenbergh, T.; Wyffels, F.; Verstraeten, D.; Schrauwen, B.; Dambre, J.; Bienstman, P. Nanophotonic Reservoir Computing With Photonic Crystal Cavities to Generate Periodic Patterns. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 344–355. [Google Scholar] [CrossRef]
- Toole, R.; Tait, A.N.; Ferreira de Lima, T.; Nahmias, M.A.; Shastri, B.J.; Prucnal, P.R.; Fok, M.P. Photonic Implementation of Spike-Timing-Dependent Plasticity and Learning Algorithms of Biological Neural Systems. J. Light. Technol. 2016, 34, 470–476. [Google Scholar] [CrossRef]
- Tait, A.N.; Nahmias, M.A.; Tian, Y.; Shastri, B.J.; Prucnal, P.R. Photonic Neuromorphic Signal Processing and Computing. In Nanophotonic Information Physics: Nanointelligence and Nanophotonic Computing; Naruse, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 183–222. [Google Scholar] [CrossRef]
- Wang, Z.; Chang, L.; Wang, F.; Li, T.; Gu, T. Integrated photonic metasystem for image classifications at telecommunication wavelength. Nat. Commun. 2022, 13, 2131. [Google Scholar] [CrossRef]
- Zarei, S.; Marzban, M.r.; Khavasi, A. Integrated photonic neural network based on silicon metalines. Opt. Express 2020, 28, 36668–36684. [Google Scholar] [CrossRef]
- Zhu, H.; Zou, J.; Zhang, H.; Shi, Y.; Luo, S.; Wang, N.; Cai, H.; Wan, L.; Wang, B.; Jiang, X.; et al. Space-efficient optical computing with an integrated chip diffractive neural network. Nat. Commun. 2022, 13, 1044. [Google Scholar] [CrossRef]
- Zhuge, X.; Wang, J.; Zhuge, F. Photonic synapses for ultrahigh-speed neuromorphic computing. Physica Status Solidi (RRL)—Rapid Res. Lett. 2019, 13, 1900082. [Google Scholar] [CrossRef]
- Xiang, S.; Han, Y.; Song, Z.; Guo, X.; Zhang, Y.; Ren, Z.; Wang, S.; Ma, Y.; Zou, W.; Ma, B.; et al. A review: Photonics devices, architectures, and algorithms for optical neural computing. J. Semicond. 2021, 42, 023105. [Google Scholar] [CrossRef]
- Sui, X.; Wu, Q.; Liu, J.; Chen, Q.; Gu, G. A review of optical neural networks. IEEE Access 2020, 8, 70773–70783. [Google Scholar] [CrossRef]
- Hulea, M.; Ghassemlooy, Z.; Rajbhandari, S.; Younus, O.I.; Barleanu, A. Optical axons for electro-optical neural networks. Sensors 2020, 20, 6119. [Google Scholar] [CrossRef] [PubMed]
- Xiao, X.; On, M.B.; Van Vaerenbergh, T.; Liang, D.; Beausoleil, R.G.; Yoo, S. Large-scale and energy-efficient tensorized optical neural networks on III–V-on-silicon MOSCAP platform. Apl Photonics 2021, 6, 126107. [Google Scholar] [CrossRef]
- Chen, H.; Feng, J.; Jiang, M.; Wang, Y.; Lin, J.; Tan, J.; Jin, P. Diffractive deep neural networks at visible wavelengths. Engineering 2021, 7, 1483–1491. [Google Scholar] [CrossRef]
- Pang, H.; Yin, S.; Deng, Q.; Qiu, Q.; Du, C. A novel method for the design of diffractive optical elements based on the Rayleigh–Sommerfeld integral. Opt. Lasers Eng. 2015, 70, 38–44. [Google Scholar] [CrossRef]
- Nisar, M.S.; Lu, L. Polarization-insensitive 1D unidirectional compact grating coupler for the C-band using a 500 nm SOI. Appl. Opt. 2022, 61, 7373–7379. [Google Scholar] [CrossRef]
- Sideris, C.; Khachaturian, A.; White, A.D.; Bruno, O.P.; Hajimiri, A. Foundry-fabricated grating coupler demultiplexer inverse-designed via fast integral methods. Commun. Phys. 2022, 5, 68. [Google Scholar] [CrossRef]
- Nisar, M.S.; Iqbal, S.; Wong, S.W. On-chip beam steering through reprogrammable integrated coding metasurfaces. Results Phys. 2023, 48, 106440. [Google Scholar] [CrossRef]
- Zhu, H.; Lu, Y.; Cai, L. Wavelength-shift-free racetrack resonator hybrided with phase change material for photonic in-memory computing. Opt. Express 2023, 31, 18840–18850. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Stegmaier, M.; Nukala, P.; Giambra, M.A.; Ferrari, S.; Busacca, A.; Pernice, W.H.P.; Agarwal, R. Mixed-Mode Operation of Hybrid Phase-Change Nanophotonic Circuits. Nano Lett. 2017, 17, 150–155. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System Design Parameter | Parameter Value |
|---|---|
| Wavelength in free space | m |
| Number of neurons per layer | 300 |
| Neuron feature size | m |
| Distance between diffraction layers | m |
| Number of hidden layers | 5 |
| Refractive index of diffraction layer | 1.0 |
| Refractive index of propagation medium | 3.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheng, H.; Nisar, M.S. Simulating an Integrated Photonic Image Classifier for Diffractive Neural Networks. Micromachines 2024, 15, 50. https://doi.org/10.3390/mi15010050
Sheng H, Nisar MS. Simulating an Integrated Photonic Image Classifier for Diffractive Neural Networks. Micromachines. 2024; 15(1):50. https://doi.org/10.3390/mi15010050
Chicago/Turabian StyleSheng, Huayi, and Muhammad Shemyal Nisar. 2024. "Simulating an Integrated Photonic Image Classifier for Diffractive Neural Networks" Micromachines 15, no. 1: 50. https://doi.org/10.3390/mi15010050
APA StyleSheng, H., & Nisar, M. S. (2024). Simulating an Integrated Photonic Image Classifier for Diffractive Neural Networks. Micromachines, 15(1), 50. https://doi.org/10.3390/mi15010050