
WPD-Enhanced Deep Graph Contrastive Learning Data Fusion for Fault Diagnosis of Rolling Bearing


Abstract
:1. Introduction
- (1)
- We explored the distribution of wavelet energy in different frequency bands at the last level of wavelet packet decomposition for the original signal. Based on this, the Pearson correlation coefficient was introduced to calculate the correlation between wavelet energy in different frequency bands. Subsequently, a node graph construction method was proposed, where each frequency band served as a node, and the wavelet energy in the frequency band served as the node feature. The Pearson correlation coefficient was used as the edge weight between nodes, resulting in the construction of an undirected node graph to represent the information of the original signal.
- (2)
- In consideration of the graph structure attributes of the node graph, the impact of node and edge deletion or addition on the graph structure and information was analyzed. Eventually, a method was proposed to use node and edge addition during the data augmentation phase. In the two augmentation steps, one involved computing the mean of the existing node features as the feature of the newly added node, while the other involved calculating the variance as the feature of the newly added node. The Pearson correlation coefficient was used to determine the relationship between the newly added node and the existing nodes, serving as the weight for the newly added edges.
- (3)
- During the encoding process with graph convolutional neural networks, the weights of edges were utilized as the adjacency matrix, providing a more accurate representation of the relationships between the central node and its neighboring nodes.
- (4)
- We analyzed the comprehensive performance of the proposed method using the vibration signal dataset from the bearing driving end of Western Reserve University. Experimental results demonstrate that WPDPCC-DGCL exhibits superior data processing capability and achieves better fault diagnosis of rolling bearings compared to contrastive learning (CL).
2. Proposed Method
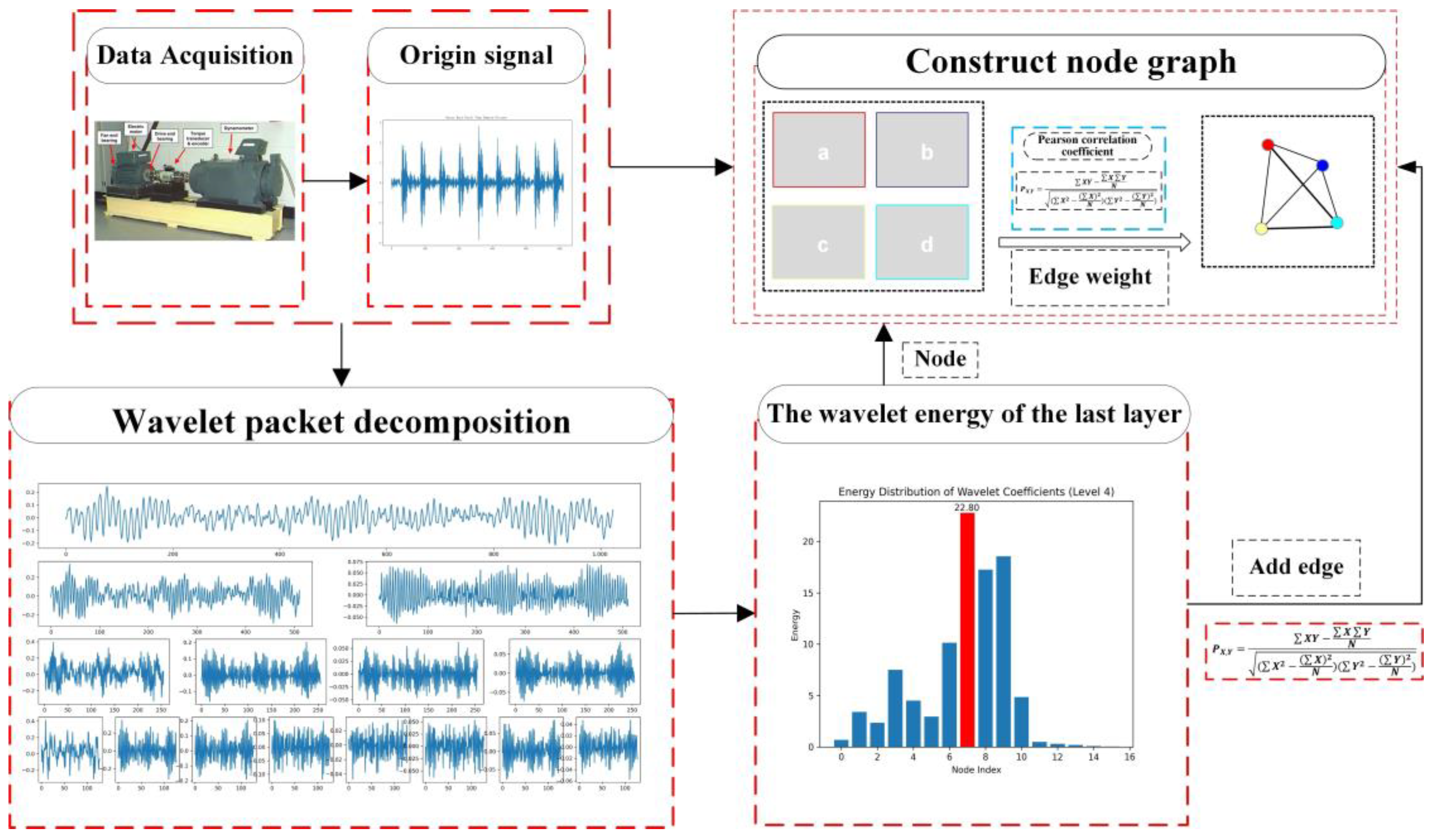
2.1. WPDPCC Construct Node Graphs
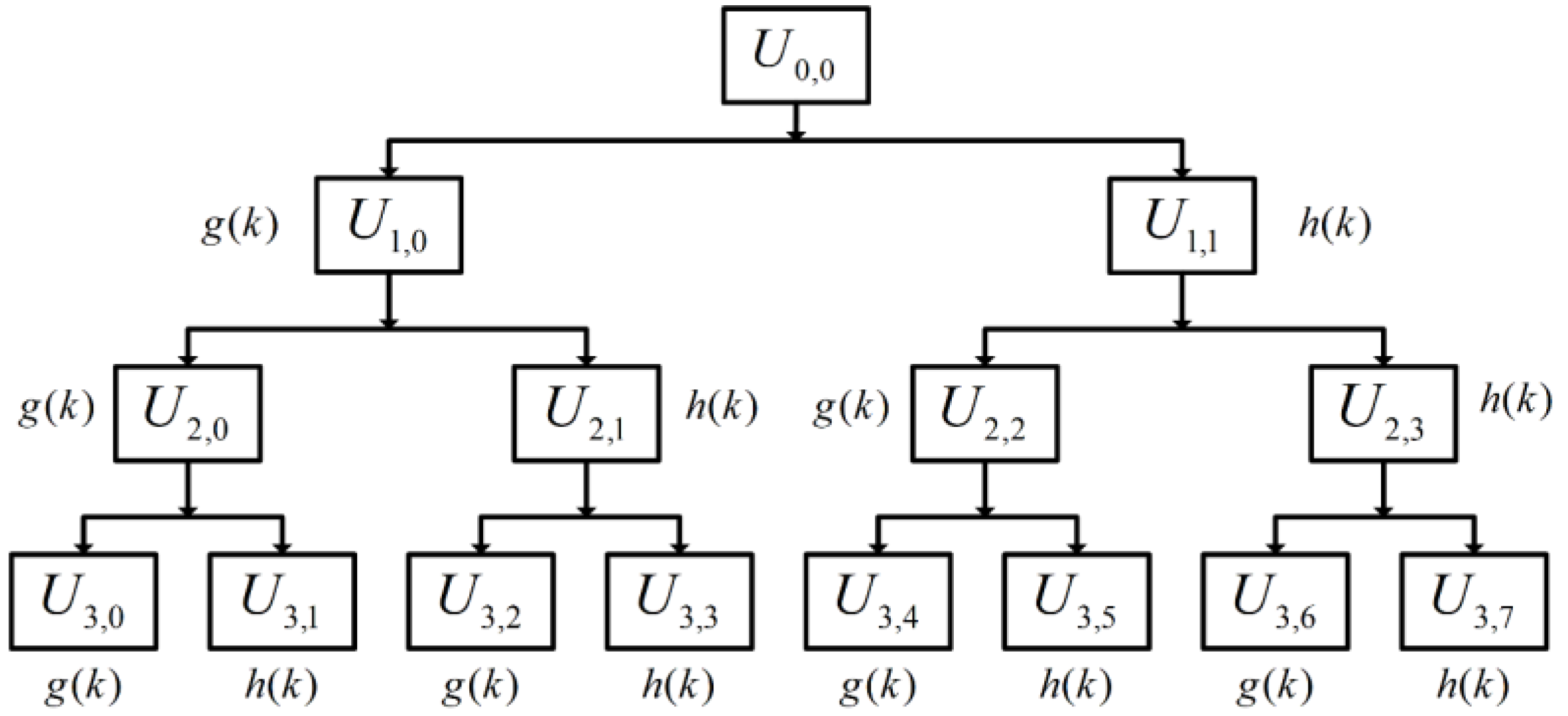
2.1.1. Vibration Signal WPD Stage
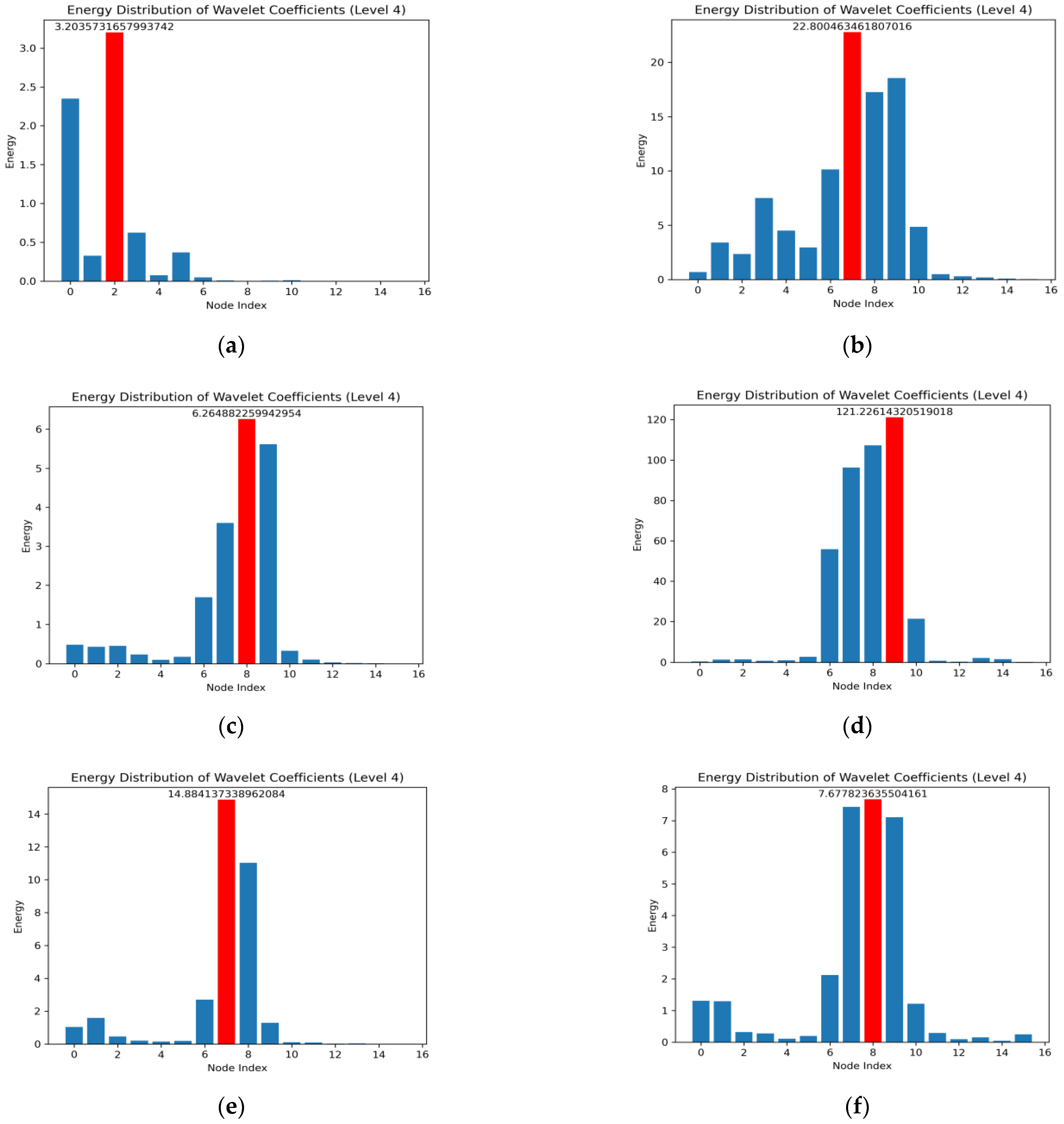
2.1.2. Constructing Node Graph Stage
- Considering the feature vector of each frequency band as a vertex of a nodal graph;
- Calculating the PCC between two vertices and using the value of PCC as the weight of the edge between the two nodes;
- Constructing the adjacency matrix of the sample graph , which represents the relationship of the edges between each vertex, where is a symmetric matrix, and take the lower triangle for convenience of subsequent calculations.
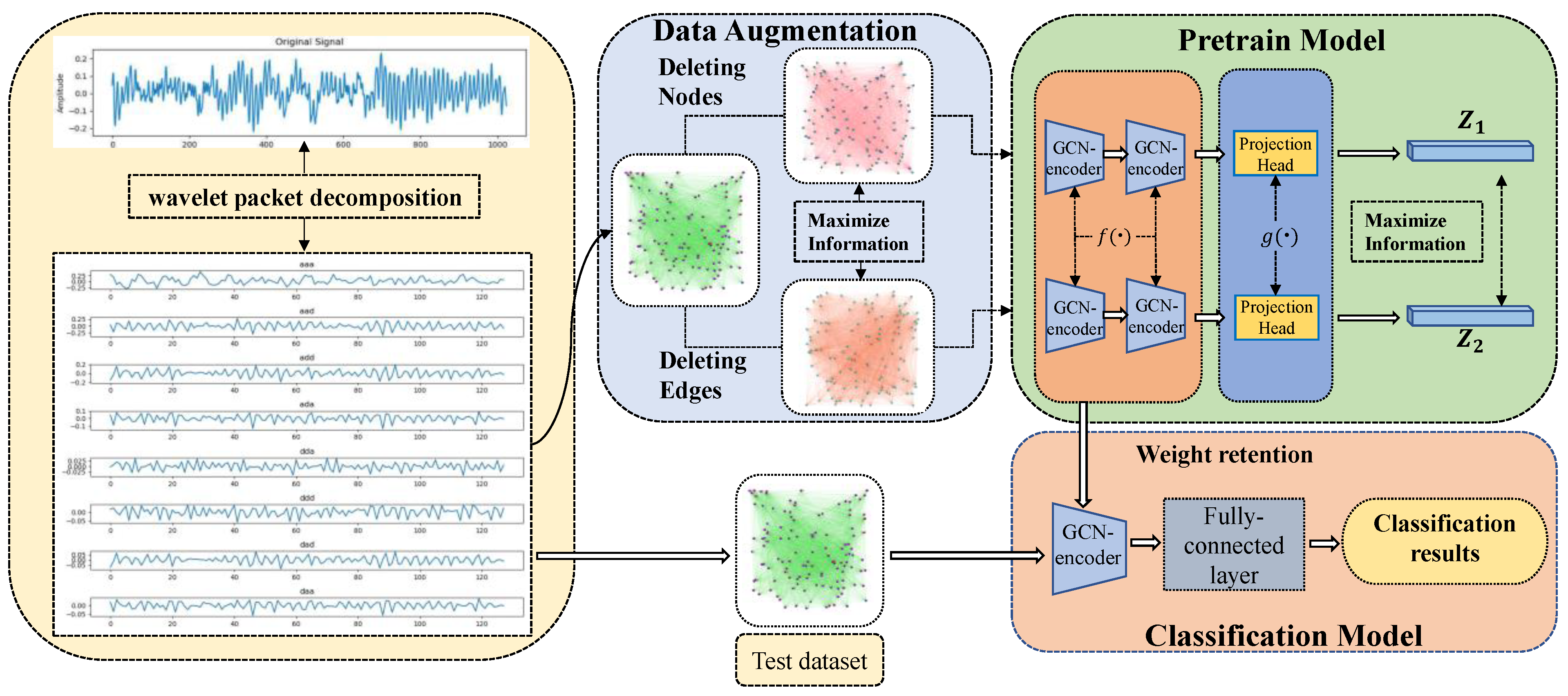
2.2. DGCL Pre-Training Model
2.2.1. Data Augmentation Stage
2.2.2. Node Graph Feature Learning Stage
2.2.3. Projection Head Stage
2.2.4. Contrast Loss Function
2.2.5. Fault Diagnosis Procedure
3. Case Study
3.1. The Performance on the CWRU Dataset
3.1.1. Data Sources
3.1.2. Parameter Setting
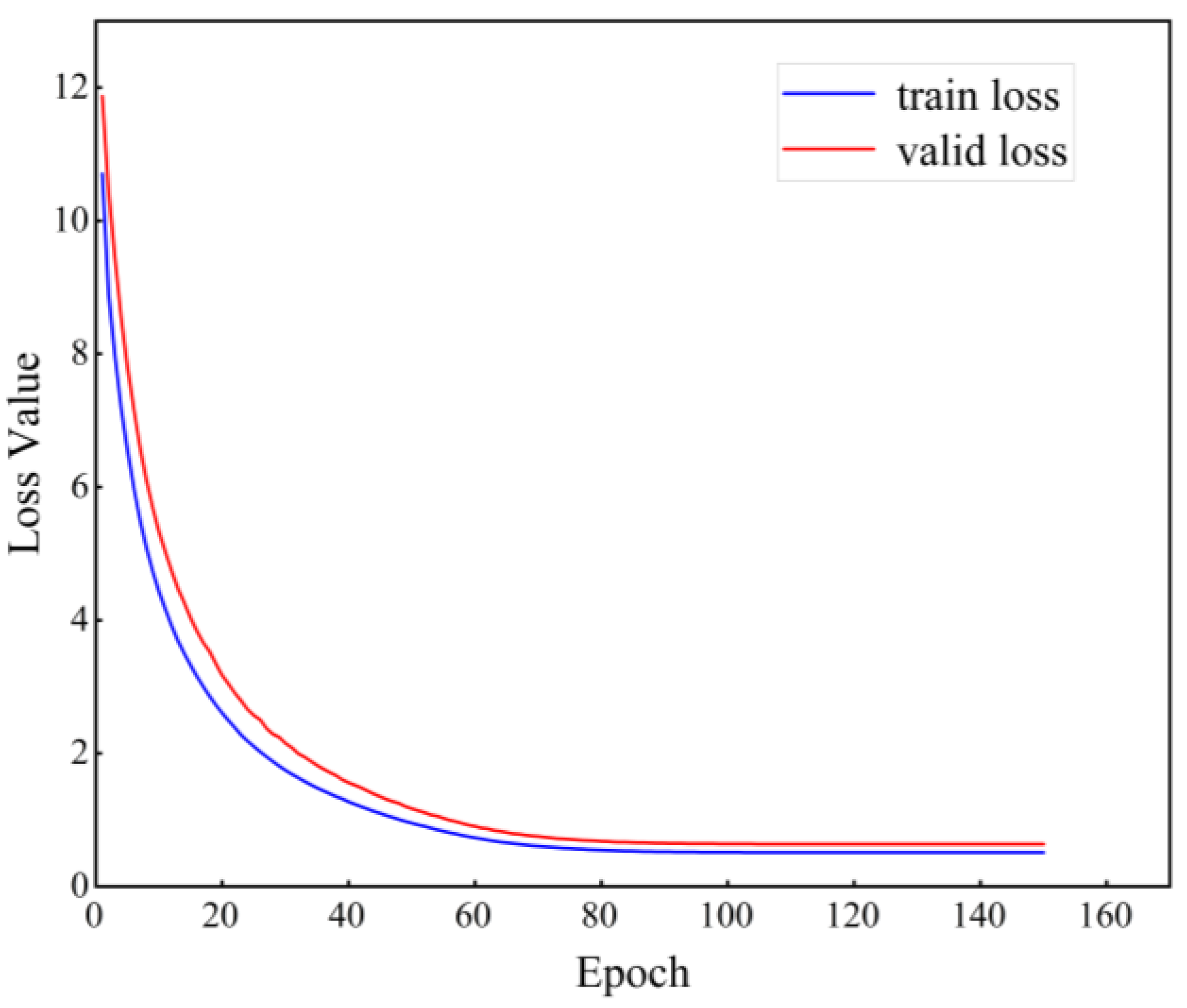
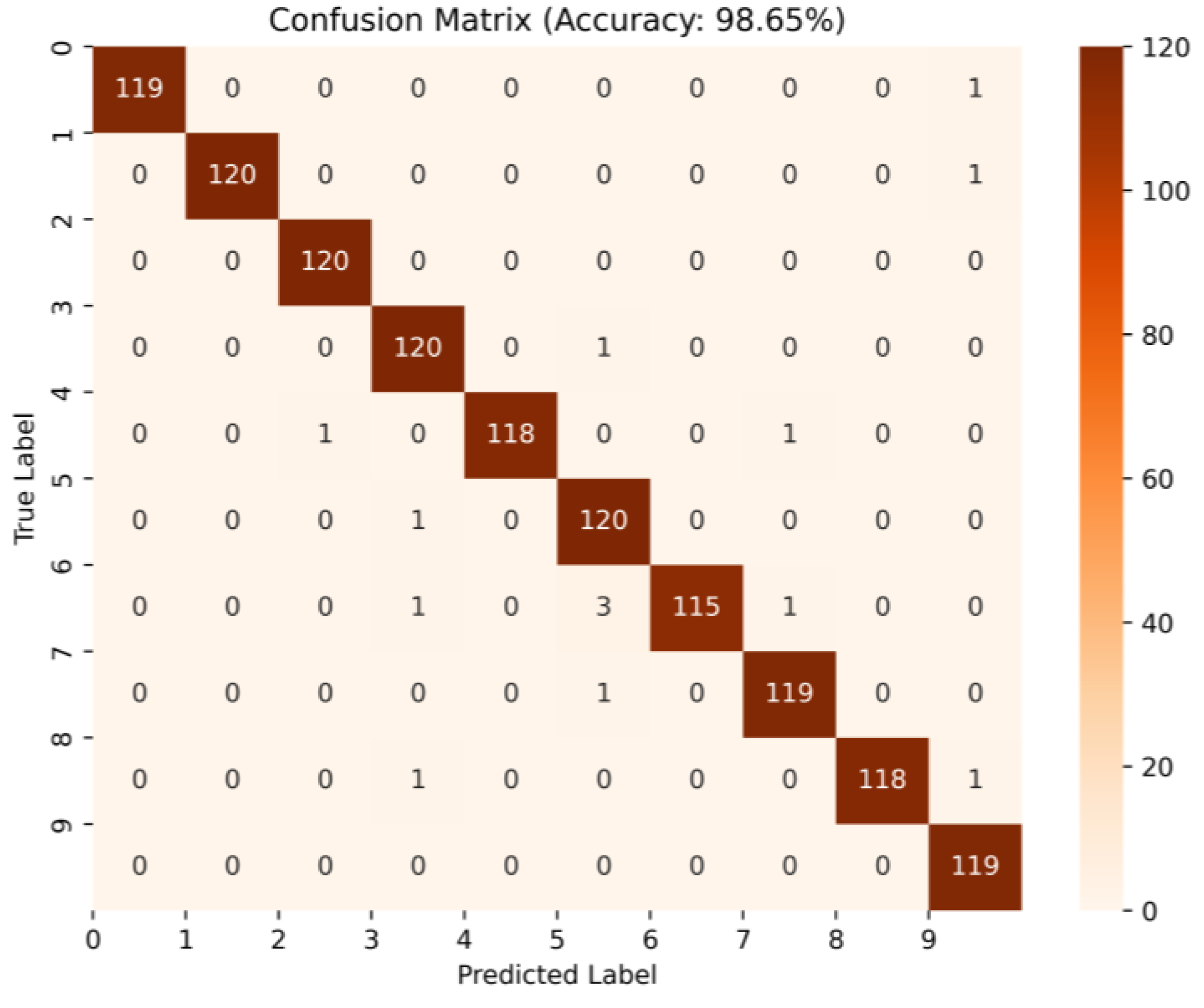
3.1.3. Results and Analysis
3.2. The Performance on the Paderborn University Dataset
3.2.1. Data Sources
3.2.2. Data Preparation
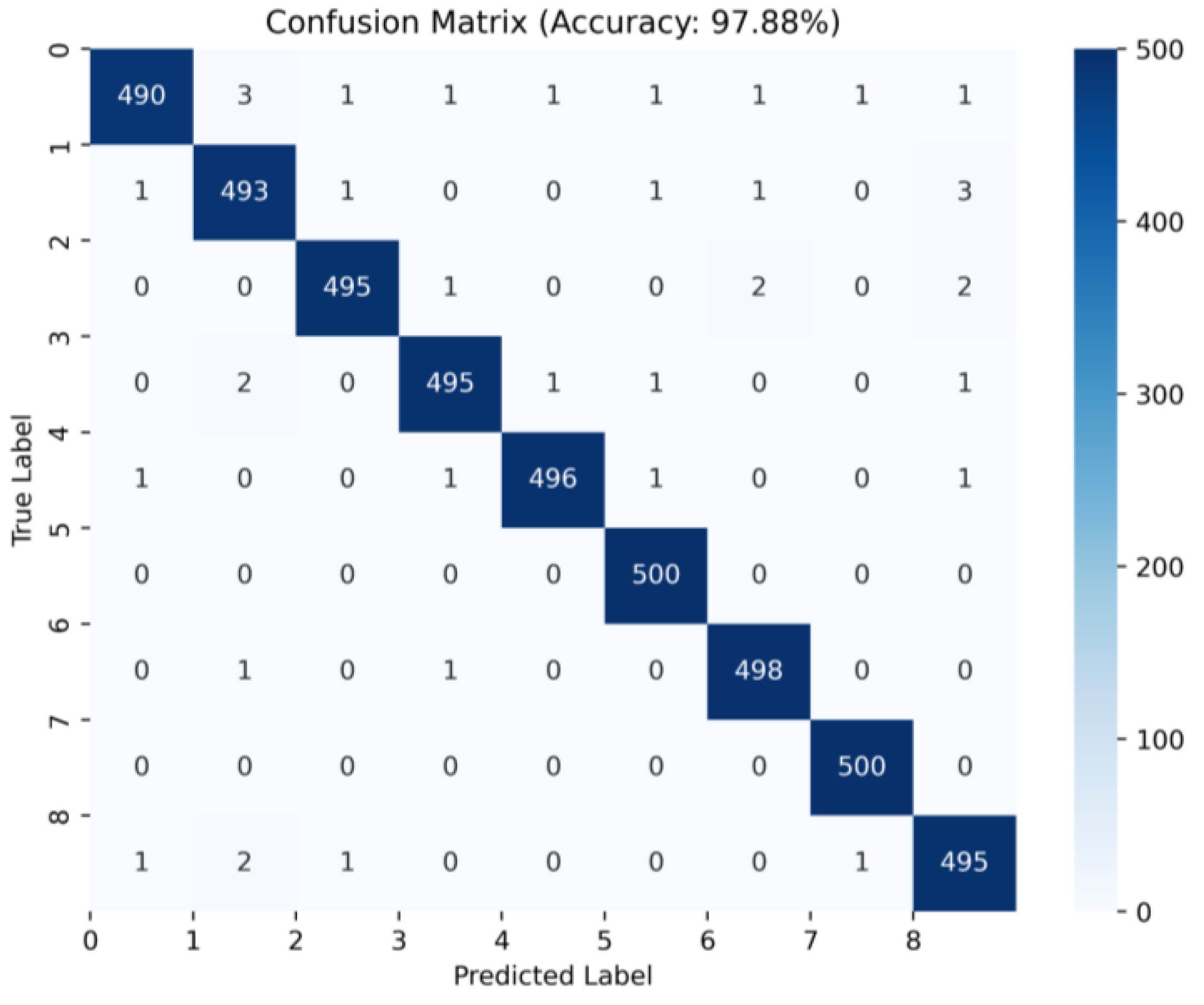
3.2.3. Classification Results
4. Conclusions
- (1)
- High requirements for pre-processing of the original signal and the need for comprehensive analysis in conjunction with the characteristics of the original signal in the construction of a high-quality node graph;
- (2)
- The long training time of the DCCL method due to the large amount of data and the repetition of positive and negative samples during the training process;
- (3)
- The generalization capability of the model needs to be improved, and the mode of data set processing needs to be modified in the future.
- (1)
- Considering the spatial layout of sensors in the initial stage, data preprocessing is used to decompose the 1D time series data at different spatial locations, and the results of 1D signal decomposition are concatenated on the spatial layout according to the location of sensors to achieve the multi-dimensional representation of the signal;
- (2)
- Keeping up exploring the signal decomposition methods, such as wavelet packet decomposition, empirical mode decomposition, and other methods in the application of 1D signal decomposition, extracting more accurate and complete feature vectors as node features, and determining the weight relationship between nodes by measuring the distribution similarity and distance of node features in space to provide a feasible theoretical method for constructing high-quality node graphs;
- (3)
- The experimental verification of data enhancement methods of deleting nodes or adding nodes is improved to ensure the interpretability and feasibility of data enhancement.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tang, X.N.; Yuan, S.Q.; Zhu, Y. Deep Learning-Based Intelligent Fault Diagnosis Methods Toward Rotating Machinery. IEEE Access 2021, 8, 9335–9346. [Google Scholar] [CrossRef]
- Zhou, Y.Q.; Kumar, A.; Parkash, C.; Vashishtha, G.; Tang, H.; Xiang, J. A novel entropy-based sparsity measure for prognosis of bearing defects and development of a sparsogram to select sensitive filtering band of an axial piston pump. Measurement 2022, 203, 111997. [Google Scholar] [CrossRef]
- Duy, T.H.; Hee, J.K. A Survey on Deep Learning Based Bearing Fault Diagnosis. Neurocomputing 2018, 335, 327–335. [Google Scholar]
- Prajoy, P.; Sanchita, R.D.; Mondal, M.R.H.; Subrato, B.; Azra, M.; Hasan, M.J.; Farzin, P. LDDNet: A Deep Learning Framework for the Diagnosis of Infectious Lung Diseases. Sensors 2023, 23, 480. [Google Scholar]
- Hasan, M.J.; Islam, M.M.M.; Kim, J.-M. Bearing Fault Diagnosis Using Multidomain Fusion-Based Vibration Imaging and Multitask Learning. Sensors 2022, 22, 56. [Google Scholar] [CrossRef]
- Li, X.; Shao, H.D.; Jiang, H.K.; Xiang, J.W. Modified Gaussian Convolutional Deep Belief Network and Infrared Thermal Imaging for Intelligent Fault Diagnosis of Rotor-Bearing System under Time-Varying Speeds. Struct Health Monit. 2022, 21, 339–353. [Google Scholar]
- Xue, Y.; Cai, C.; Chi, Y. Frame Structure Fault Diagnosis Based on a High-Precision Convolution Neural Network. Sensors 2022, 22, 9427. [Google Scholar] [CrossRef]
- Liu, Z.-H.; Lu, B.-L.; Wei, H.-L.; Chen, L.; Li, X.-H.; Wang, C.-T. A Stacked Auto-Encoder Based Partial Adversarial Domain Adaptation Model for Intelligent Fault Diagnosis of Rotating Machines. IEEE Trans. Ind. Inform. 2021, 17, 6798–6809. [Google Scholar] [CrossRef]
- Tong, Q.; Lu, F.; Feng, Z.; Wan, Q.; An, G.; Cao, J.; Guo, T. A Novel Method for Fault Diagnosis of Bearings with Small and Imbalanced Data Based on Generative Adversarial Networks. Appl. Sci. 2022, 12, 7346. [Google Scholar] [CrossRef]
- Huang, D.J.; Zhang, W.A.; Guo, F.H.; Liu, W.J.; Shi, X.M. Wavelet Packet Decomposition-Based Multi scale CNN for Fault Diagnosis of Wind Turbine Gearbox. IEEE Trans. Cybern. 2023, 53, 443–453. [Google Scholar] [CrossRef]
- Zhou, Y.; Kumar, A.; Parkash, C.; Vashishtha, G.; Tang, H.; Glowacz, A.; Dong, A.; Xiang, J. Development of entropy measure for selecting highly sensitive WPT band to identify defective components of an axial piston pump. Appl. Acoust. 2023, 203, 109225. [Google Scholar] [CrossRef]
- Vashishtha, G.; Kumar, R. Pelton Wheel Bucket Fault Diagnosis Using Improved Shannon Entropy and Expectation Maxi-mization Principal Component Analysis. J. Vib. Eng. Technol. 2022, 10, 335–349. [Google Scholar] [CrossRef]
- Sun, W.; Zhou, J.; Sun, B.; Zhou, Y.; Jiang, Y. Markov Transition Field Enhanced Deep Domain Adaptation Network for Milling Tool Condition Monitoring. Micromachines 2022, 13, 873. [Google Scholar] [CrossRef]
- Zhou, Y.; Xue, W. Review of tool condition monitoring methods in milling processes. Int. J. Adv. Manuf. Technol. 2018, 96, 2509–2523. [Google Scholar] [CrossRef]
- Wang, W.; Li, C.; Li, A.; Li, F.; Chen, J.; Zhang, T. One-stage self-supervised momentum contrastive learning network for open-set cross-domain fault diagnosis. Knowl.-Based Syst. 2023, 275, 110692. [Google Scholar] [CrossRef]
- An, Y.; Zhang, K.; Chai, Y.; Liu, Q.; Huang, X. Domain adaptation network base on contrastive learning for bearings fault diagnosis under variable working conditions. Expert Syst. Appl. 2023, 212, 118802. [Google Scholar] [CrossRef]
- Wang, R.; Chen, H.; Guan, H. A self-supervised contrastive learning framework with the nearest neighbors matching for the fault diagnosis of marine machinery. Ocean Eng. 2023, 270, 113437. [Google Scholar] [CrossRef]
- Zhang, J.; Zou, J.; Su, Z.; Tang, J.; Kang, Y.; Xu, H.; Liu, Z.; Fan, S. A class-aware supervised contrastive learning framework for imbalanced fault diagnosis. Knowl.-Based Syst. 2022, 252, 109437. [Google Scholar] [CrossRef]
- Shao, H.D.; Xia, M.; Han, G.J.; Zhang, Y.; Wan, J.F. Intelligent Fault Diagnosis of Rotor-Bearing System under Varying Working Conditions with Modified Transfer CNN and Thermal Images. IEEE Trans. Ind. Inform. 2020, 14, 3488–3496. [Google Scholar]
- Miao, R.; Yang, Y.T.; Juan, X.; Xue, H.T.; Wang, Y.; Wang, X. Negative samples selecting strategy for graph contrastive learning. Inf. Sci. 2022, 613, 667–681. [Google Scholar] [CrossRef]
- Peng, M.; Juan, X.; Li, Z. Graph prototypical contrastive learning. Inf. Sci. 2022, 612, 816–834. [Google Scholar] [CrossRef]
- Wang, H.; Sun, W.; Sun, W.; Ren, Y.; Zhou, Y.; Qian, Q.; Kumar, A. A novel tool condition monitoring based on Gramian angular field and comparative learning. Int. J. Hydromechatron. 2023, 6, 93. [Google Scholar] [CrossRef]
- Yin, J.; Xie, J.; Ma, Z.; Guo, J. MPCCL: Multiview predictive coding with contrastive learning for person re-identification. Pattern Recognit. 2022, 129, 108710. [Google Scholar] [CrossRef]
- Sun, S.; Tian, H.; Wang, R.; Zhang, Z. Biomedical Interaction Prediction with Adaptive Line Graph Contrastive Learning. Mathematics 2023, 11, 732. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 18 July 2020. [Google Scholar]
- Dong, X.W.; Thanou, D.; Toni, L.; Bronstein, M. Graph Signal Processing for Machine Learning: A Review and New Perspec-tives. IEEE Signal Proc. Mag. 2020, 37, 117–127. [Google Scholar] [CrossRef]
- Rahim, A.; Abdullah, S.; Singh, S.; Nuawi, M. Fatigue strain signal reconstruction technique based on selected wavelet decomposition levels of an automobile coil spring. Eng. Fail. Anal. 2021, 125, 105434. [Google Scholar] [CrossRef]
- Sun, T.; Wang, X.; Zhang, K.; Jiang, D.; Lin, D.; Jv, X.; Ding, B.; Zhu, W. Medical Image Authentication Method Based on the Wavelet Packet and Energy Entropy. Entropy 2022, 24, 798. [Google Scholar] [CrossRef] [PubMed]
- Tao, H.; Qiu, J.; Chen, Y.; Stojanovic, V.; Cheng, L. Unsupervised cross-domain rolling bearing fault diagnosis based on time-frequency information fusion. J. Frankl. Inst. 2023, 360, 1454–1477. [Google Scholar] [CrossRef]
- Li, S.L.; Li, Z.; Li, H.S. A Rolling Bearing Fault Monitoring Method Based on Wavelet Packet Energy Features. J. Syst. Simul. 2003, 1, 76–80+83. [Google Scholar]
- Zhou, Z.; Shi, J.; Zhang, S.; Huang, Z.; Li, Q. Effective stabilized self-training on few-labeled graph data. Inf. Sci. 2023, 631, 369–384. [Google Scholar] [CrossRef]
- Qin, L.; Yang, G.; Sun, Q. Maximum correlation Pearson correlation coefficient deconvolution and its application in fault diagnosis of rolling bearings. Measurement 2022, 205, 112162. [Google Scholar] [CrossRef]
- Zhu, Y.Q.; Xu, Y.C.; Yu, F.; Liu, Q.; Wang, L. Graph Contrastive Learning with Adaptive Augmentation. In Proceedings of the Web Conference 2021 (WWW ’21), Ljubljana, Slovenia, 23 April 2021; ACM: New York, NY, USA, 2021. [Google Scholar]
- Fu, S.C.; Wang, S.L.; Liu, W.F.; Liu, B.D.; Peng, Q.M.; Jing, X.Y. Adaptive graph convolutional collaboration networks for semi-supervised classification. Inf. Sci. 2022, 611, 262–276. [Google Scholar] [CrossRef]
- Wu, F.; Jing, X.Y.; Wei, P.F.; Jiang, G.P. Semi-supervised multi-view graph convolutional networks with application to webpage classification. Inf. Sci. 2022, 591, 142–154. [Google Scholar] [CrossRef]
- Sohn, K. Improved Deep Metric Learning with Multi-Class N-Pair Loss Objective. In Proceedings of the 30th Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Wade, A.S.; Robert, B.R. Rolling Element Bearing Diagnostics Using the Case Western Reserve University Data: A Benchmark Study. Mech. Syst. Signal Pract. 2015, 64–65, 100–131. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | File Name | Failure Location | Size (Inch) |
|---|---|---|---|
| 0 | 97.mat | normal | 0 |
| 1 | 106.mat | inner race | 0.007 |
| 2 | 131.mat | out race | 0.007 |
| 3 | 119.mat | ball | 0.014 |
| 4 | 170.mat | inner race | 0.014 |
| 5 | 198.mat | out race | 0.014 |
| 6 | 186.mat | ball | 0.021 |
| 7 | 210.mat | inner race | 0.021 |
| 8 | 235.mat | out race | 0.021 |
| 9 | 223.mat | ball | 0.021 |
| Epoch | In Channels | Hidden Channels | Out Channels | Batch Size |
|---|---|---|---|---|
| 150 | 1 | 32 | 10 | 32 |
| Method | BR-30 | BR-50 | BR-70 | BR-90 |
|---|---|---|---|---|
| WPDPCC-GCN | 62.30% | 65.23% | 71.51% | 79.65% |
| WPDPCC-CL | 71.35% | 74.50% | 79.68% | 89.36% |
| WPDPCC-DGCL | 80.69% | 84.72% | 92.31% | 98.65% |
| Bearing Code | Run-in Period [h] | Radial Load [N] | Speed [min−1 ] |
|---|---|---|---|
| K001 | >50 | 1000–3000 | 1500–2000 |
| K002 | 19 | 3000 | 2900 |
| K004 | 5 | 3000 | 3000 |
| Bearing Code | Bearing Name | Damage | Class | Combination | Arrangement | Damage Extent | Characteristic of Damage |
|---|---|---|---|---|---|---|---|
| KA04 | OR1 | fatigue: pitting | OR | S | no repetition | 1 | single point |
| KA16 | OR3 | fatigue: pitting | OR | R | random | 2 | single point |
| KA22 | OR4 | fatigue: pitting | OR | S | no repetition | 1 | single point |
| KI04 | IR1 | fatigue: pitting | IR | M | no repetition | 1 | single point |
| KI14 | IR2 | fatigue: pitting | IR | M | no repetition | 1 | single point |
| KI16 | IR3 | fatigue: pitting | IR | S | no repetition | 3 | single point |
| Epoch | In Channels | Hidden Channels | Out Channels | Batch Size |
|---|---|---|---|---|
| 150 | 1 | 64 | 32 | 64 |
| Method | BR-100 | BR-250 | BR-400 | BR-500 |
|---|---|---|---|---|
| WPDPCC-GCN | 61.25% | 65.19% | 70.96% | 78.75% |
| WPDPCC-CL | 70.29% | 75.32% | 80.58% | 89.43% |
| WPDPCC-DGCL | 75.63% | 83.49% | 91.84% | 97.88% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, R.; Wang, X.; Kumar, A.; Sun, B.; Zhou, Y. WPD-Enhanced Deep Graph Contrastive Learning Data Fusion for Fault Diagnosis of Rolling Bearing. Micromachines 2023, 14, 1467. https://doi.org/10.3390/mi14071467
Liu R, Wang X, Kumar A, Sun B, Zhou Y. WPD-Enhanced Deep Graph Contrastive Learning Data Fusion for Fault Diagnosis of Rolling Bearing. Micromachines. 2023; 14(7):1467. https://doi.org/10.3390/mi14071467
Chicago/Turabian StyleLiu, Ruozhu, Xingbing Wang, Anil Kumar, Bintao Sun, and Yuqing Zhou. 2023. "WPD-Enhanced Deep Graph Contrastive Learning Data Fusion for Fault Diagnosis of Rolling Bearing" Micromachines 14, no. 7: 1467. https://doi.org/10.3390/mi14071467
APA StyleLiu, R., Wang, X., Kumar, A., Sun, B., & Zhou, Y. (2023). WPD-Enhanced Deep Graph Contrastive Learning Data Fusion for Fault Diagnosis of Rolling Bearing. Micromachines, 14(7), 1467. https://doi.org/10.3390/mi14071467