
Cost-Efficient Approaches for Fulfillment of Functional Coverage during Verification of Digital Designs



Abstract
1. Introduction
- To provide readers with a straightforward but efficient automated mechanism for DUT input stimuli generation sequences; the implementation of this mechanism should be performed in a common high-level language that can interact with Electronic Design Automation (EDA) tools;
- To compare the currently developed approaches with two well-known evolutionary algorithms: NSGA-II and SPEA2;
- To highlight an original way of configuring genetic algorithms to achieve a better performance in terms of coverage fulfillment;
- To reduce the time needed for the functional verification process;
- To describe how a freely available tool (some limitations occur) can be successfully used in the functional verification process.
2. Literature Review
3. Materials and Methods
3.1. Use of Genetic Algorithm Approaches
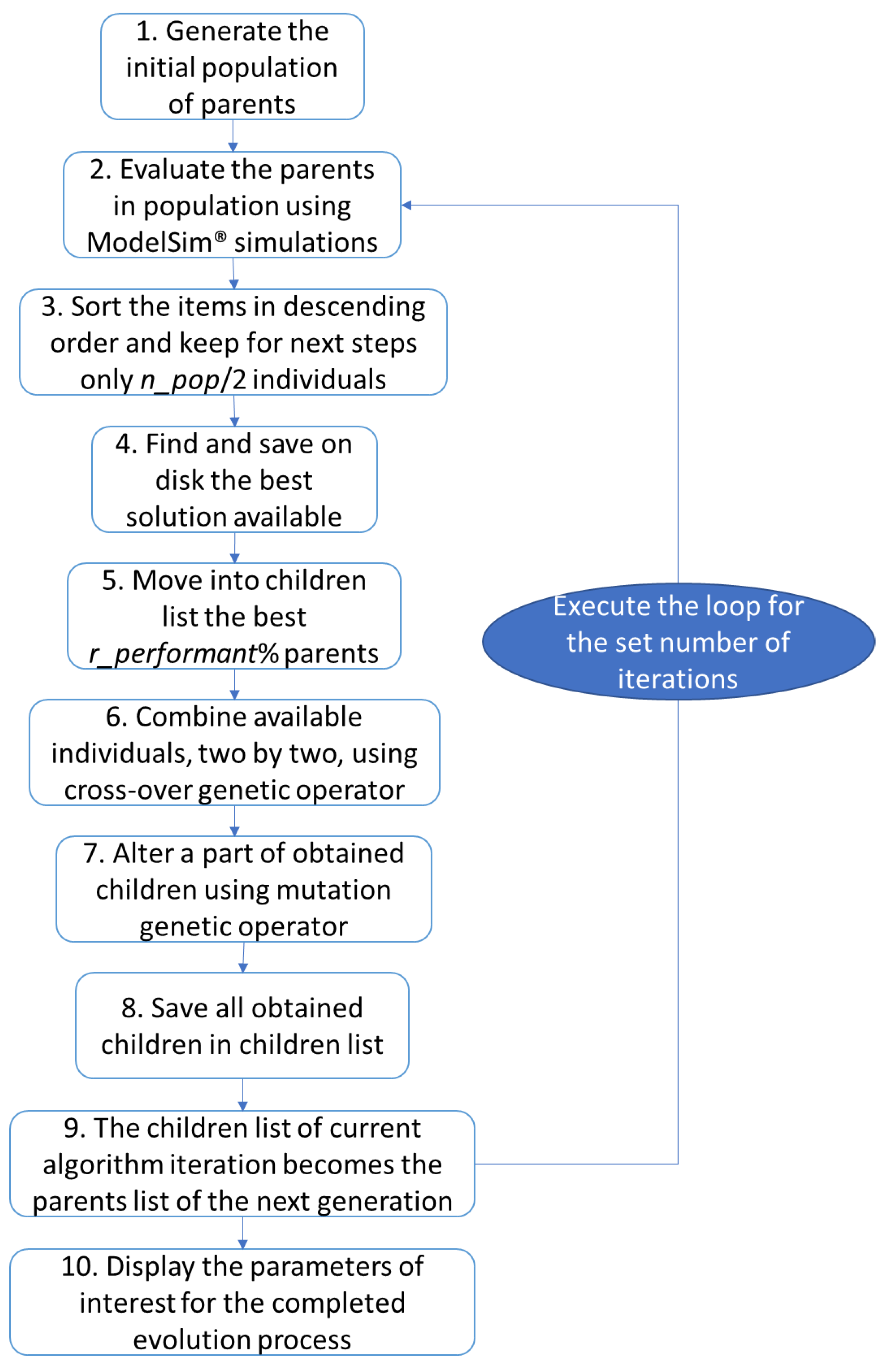
3.1.1. Genetic Algorithms
- Fitness calculation: this is how to calculate how close an individual’s representation is to the solution being sought.
- Selection: this stage is inspired by nature’s “survival of the fittest” paradigm, meaning that individuals whose representations are furthest from the optimal solution are simply discarded, keeping only those who might converge to the solution, as represented in Equation (1).where selected_population represents the group of individuals which will play the parents’ role in the next population, CS (children_set) represents the individuals generated in the current population and no_of_parents represents the number of parents which must be selected from the children group at each new generation; in the current approach, this number is equal with the size of the initial population.
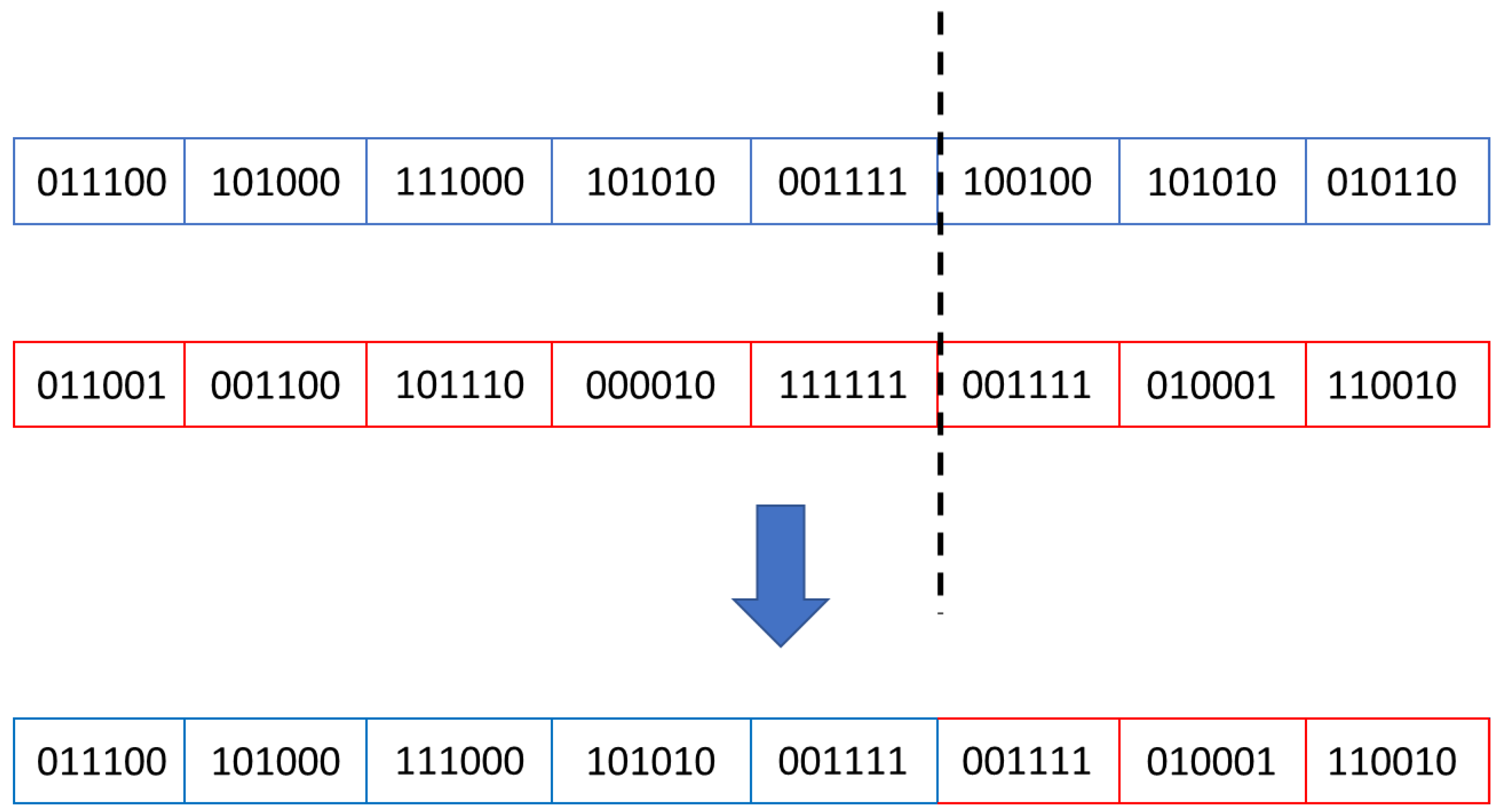
- Crossover: in this stage, an individual’s properties are shared and combined with other parts obtained from another individual of the same generation. The aim is to create new individuals whose fitness might be closer to the desired result. In the current study, the crossover process, in which two parents generated two children, followed the Equation (2).where the crossover_point variable is a randomly generated number in range [1…no_of_genes−1].
- Mutation: this stage is inspired by the modifications that appear at individuals without being inherited from their parents. In biology, these mutations can be caused by environmental factors (e.g., UV or nuclear radiations), by internal reactions in the body which lead to DNA damage of some cells [19], etc. The aim of this step is to avoid the algorithm getting stuck at local optima. If the mutation will result in the creation of an individual with a low chance of survival, then the offspring produced will be discarded, but if the mutation creates a highly fit individual, it will improve the genetic characteristics of the population. Usually, mutation operator affects only a few genes (even only one gene as seen in Equation (3)) of an individual.where gene [0…n − 1] represent the components of the individual to be mutated, the index k (which is randomly chosen in range [0…n − 1]), represents the position of the gene to be changed, and the random_number represents the value (randomly chosen) used to updates the gene with index k, and the curly brackets represent the concatenation operator.
3.1.2. The Custom Algorithms Developed Taking into Account the Principles of Genetic Algorithms
3.1.3. Established Genetic Algorithms Used for Comparison Purposes
- A classical NGSA-II implementation, available in [29], in which the cross-over process consists of splitting the parent information using a single cross-over point; the children contain one section of data from the first parent and the other section of data from the second parent; the mutation operator modifies up to 5 randomly chosen bits in a data individual, according to Equation (5) (the result of this equation, which is 6 bits wide, is then rounded to the nearest integer; the mutation_stength is a parameter of the evolution process; the function random returns a real number between 0 and 1);
- Compared to the classical implementation, the mutation operator has been changed to Polynomial Mutation and cross-over operator was changed to Simulated Binary Crossover [32], according to the implementations presented in [31]; this version of the algorithm is hereafter referred to as “modified NGSA-II”.
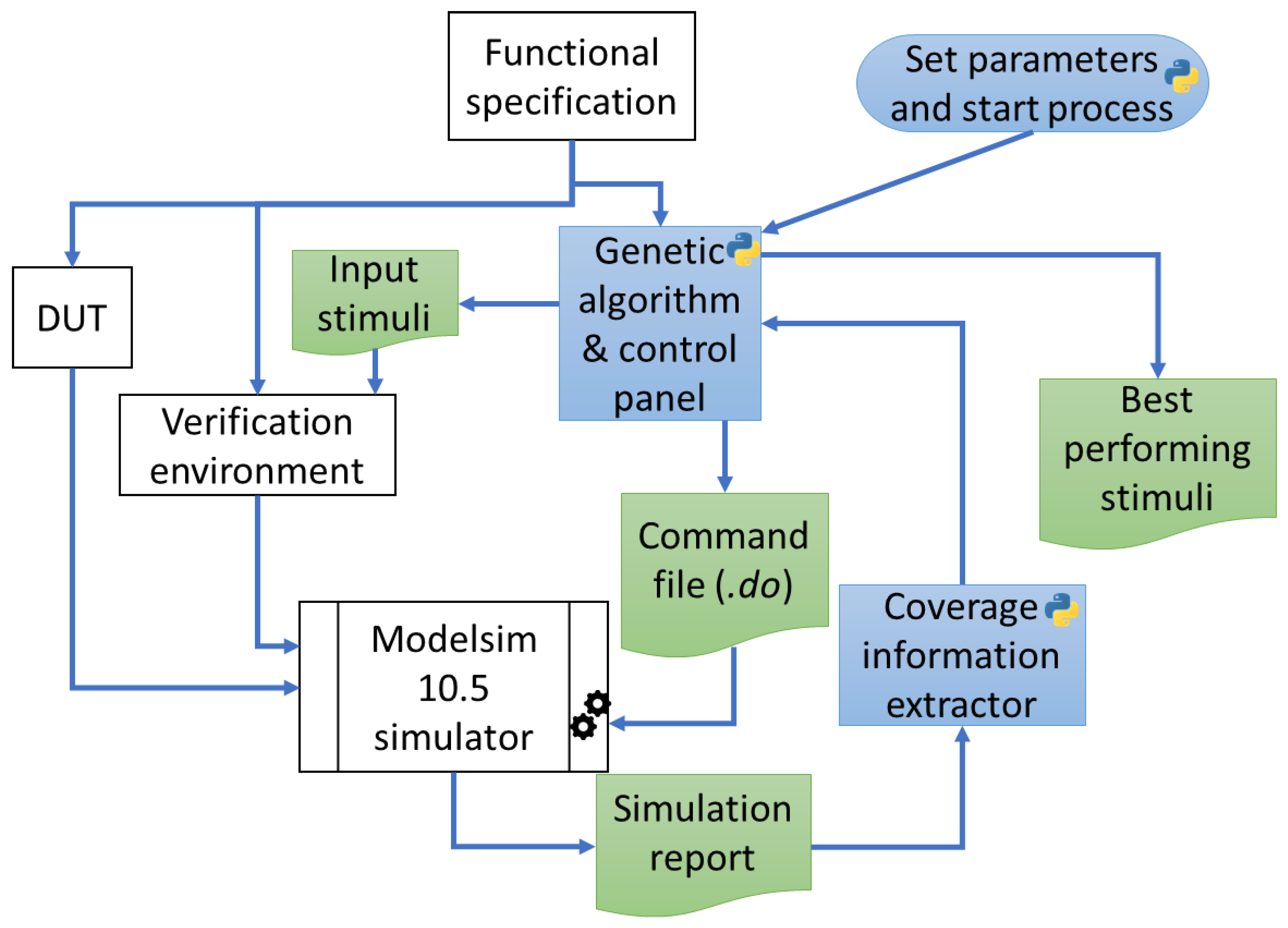
3.2. Running UVM in Modelsim
- After the ModelSim simulator is started, the directory must be set to the location of the Verilog/SystemVerilog sources;
- The library work is created;
- The following commands are issued: File -> Import -> Library-> Browse -> (go to ../ModelSim_ase/verilog_src/ and select the folder uvm-1.2)->ok->Next->Next->(Choose the destination folder containing the sources) ->Next->Next;
- The +define+UVM_NO_DPI flag is added to each compilation directive, as can be seen in following commands used to compile the sources;#compile uvm libraryvlog +define+UVM_NO_DPI uvm-1.2/src/uvm_pkg.sv# compile the designvlog +define+UVM_NO_DPI-reportprogress 300-work work design.svvlog +define+UVM_NO_DPI-reportprogress 300-work work actuator_interface.svvlog +define+UVM_NO_DPI-reportprogress 300-work work button_interface.svvlog +define+UVM_NO_DPI-reportprogress 300-work work sensor_interface.svvlog +define+UVM_NO_DPI-reportprogress 300 +define+WIDTH=8 +define+MAX_LIGHT_VALUE=900 +define+NO_OF_INTERVALS=20 -work work testbench.sv
- The uvm_macros.svh file must be included in the testbench (the top file of the project) and in the base test that is inherited in all verification tests;
- In many files in the imported uvm-1.2 library, paths to other files may need to be changed. An example of change is: from ‘include “uvm_hdl.svh” to ‘include “dpi/uvm_hdl.svh”.
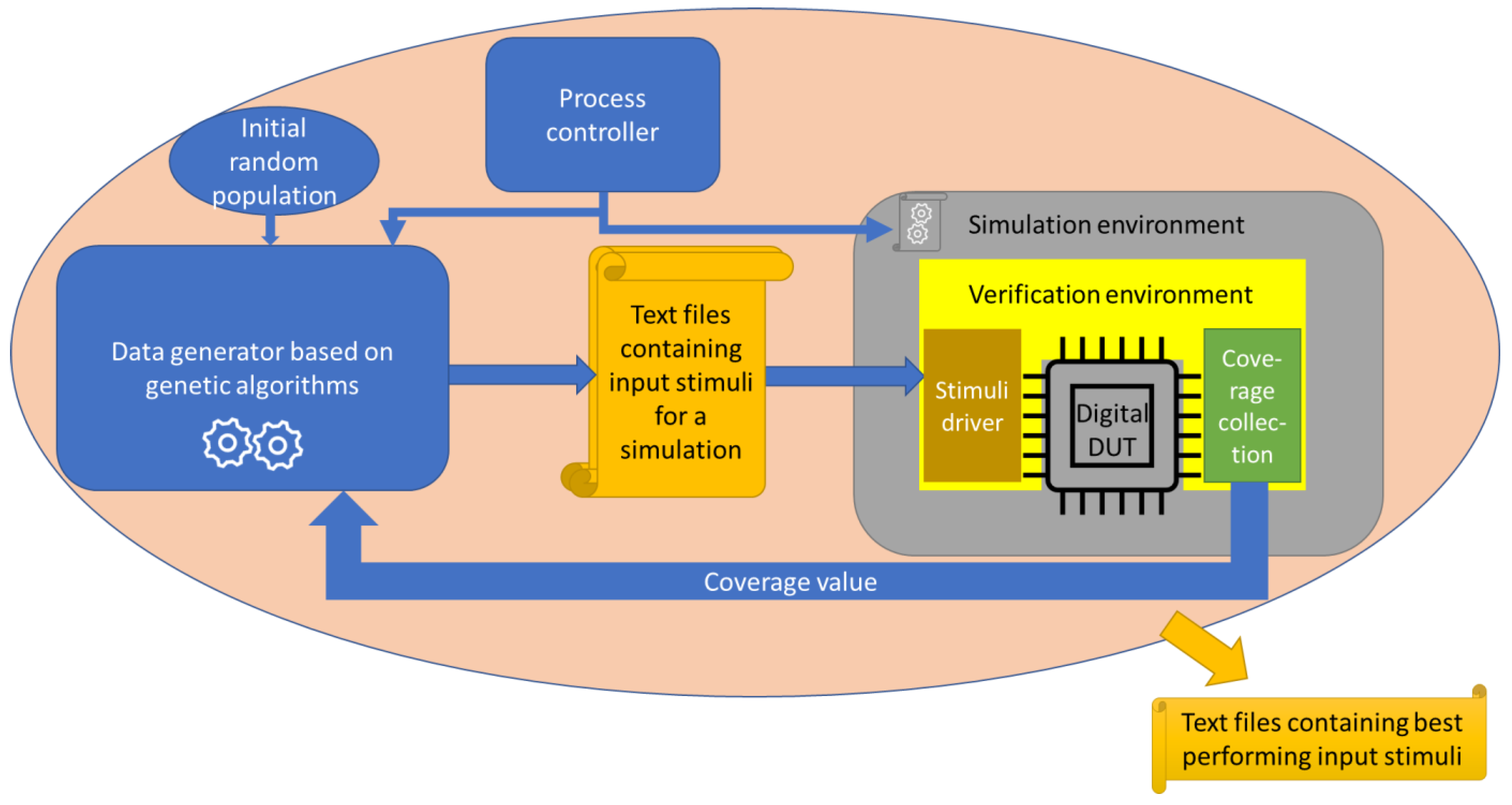
3.3. Using Genetic Algorithms-Based Approaches in Functional Verification
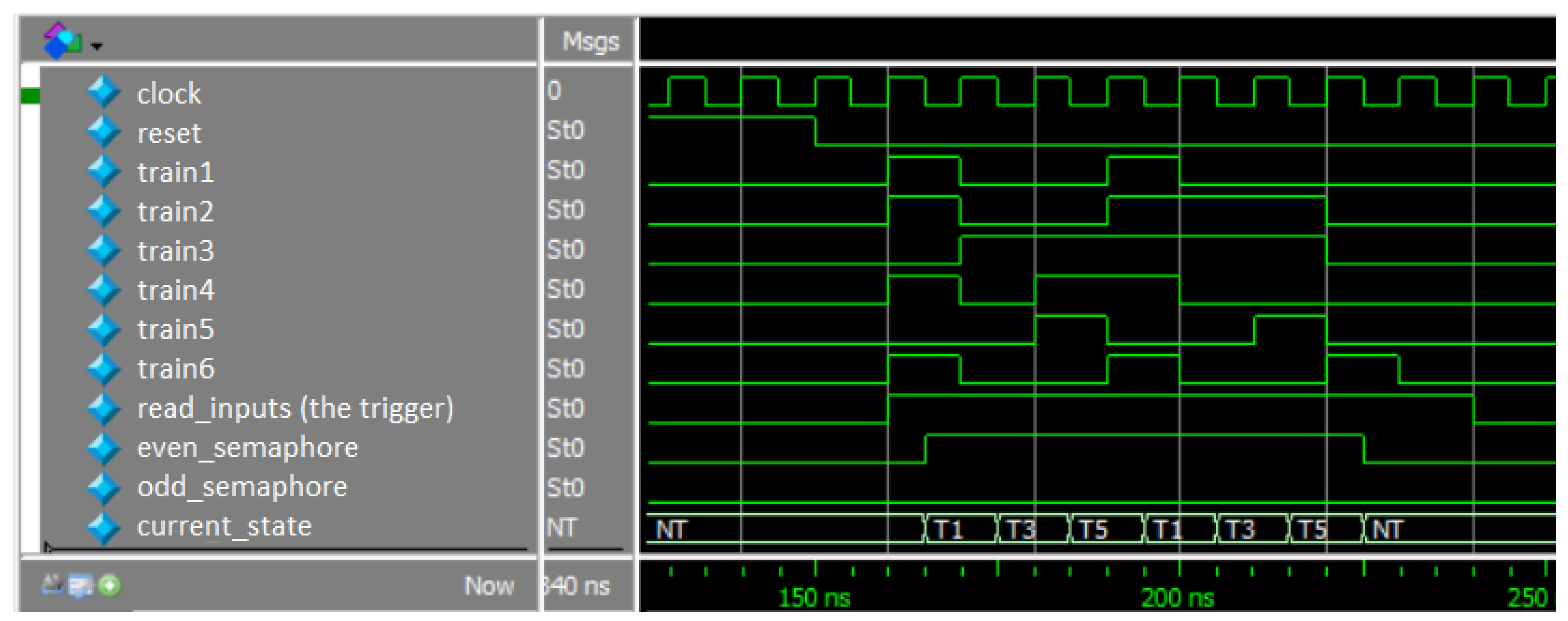
3.4. Automation of the Verification Process
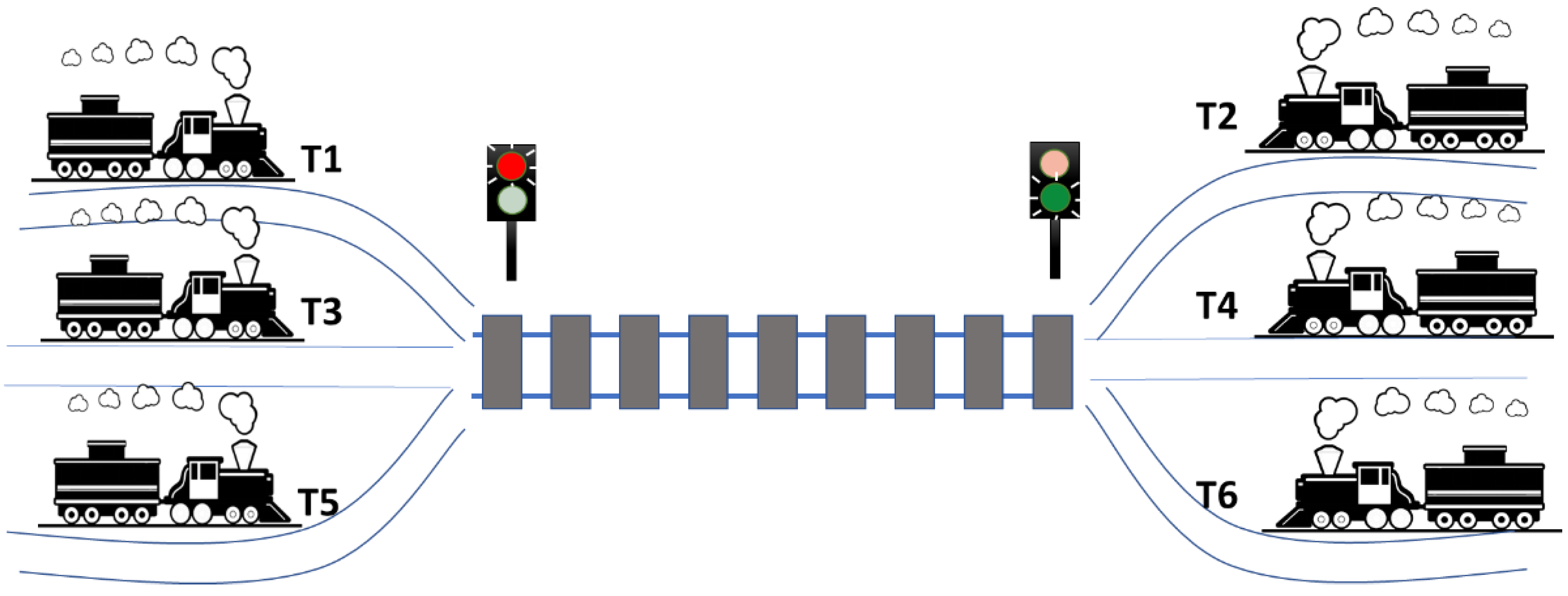
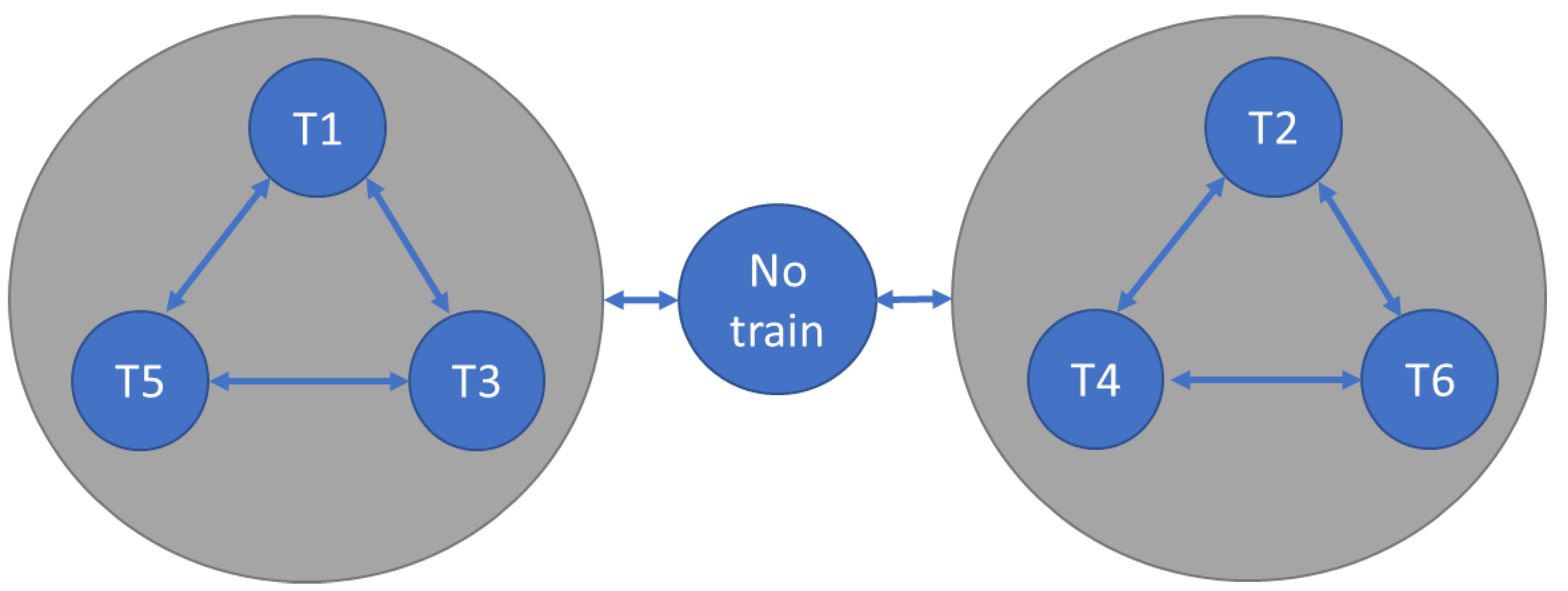
3.5. DUT Description and Coverage Target
- Traffic is controlled by two semaphores: if an odd-numbered train entered the HIRS, the semaphore for T1, T2, and T3 is green, and the semaphore for T2, T4, and T6 is red. If an even-numbered train arrives on the line, the reverse is true. If the section of track is empty, both traffic lights are green.
- If a train of one parity entered the HIRS, and in the next time slot priority is given to a train of a different parity, the rail section must remain empty for a time slot. Afterwards, the priority scheme is evaluated again.
- Odd numbered trains have priority over even numbered trains.
- Lower numbered trains have priority over higher numbered trains of the same parity.
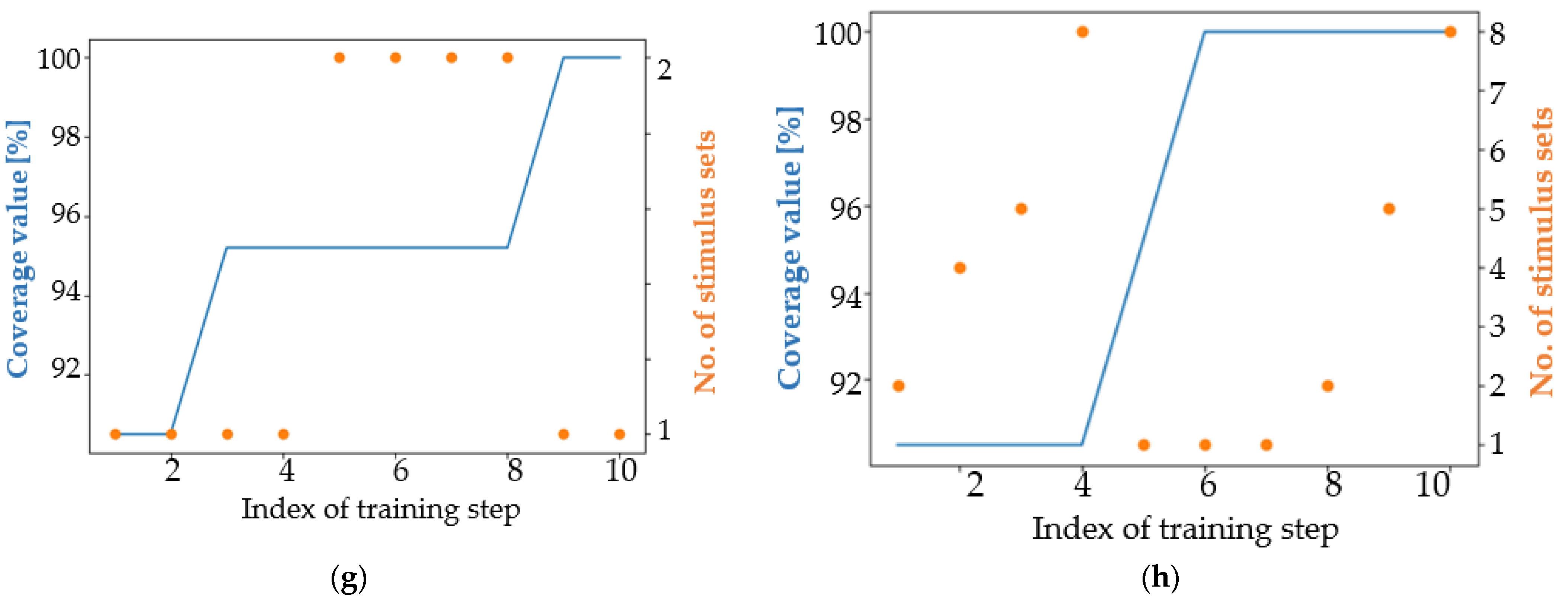
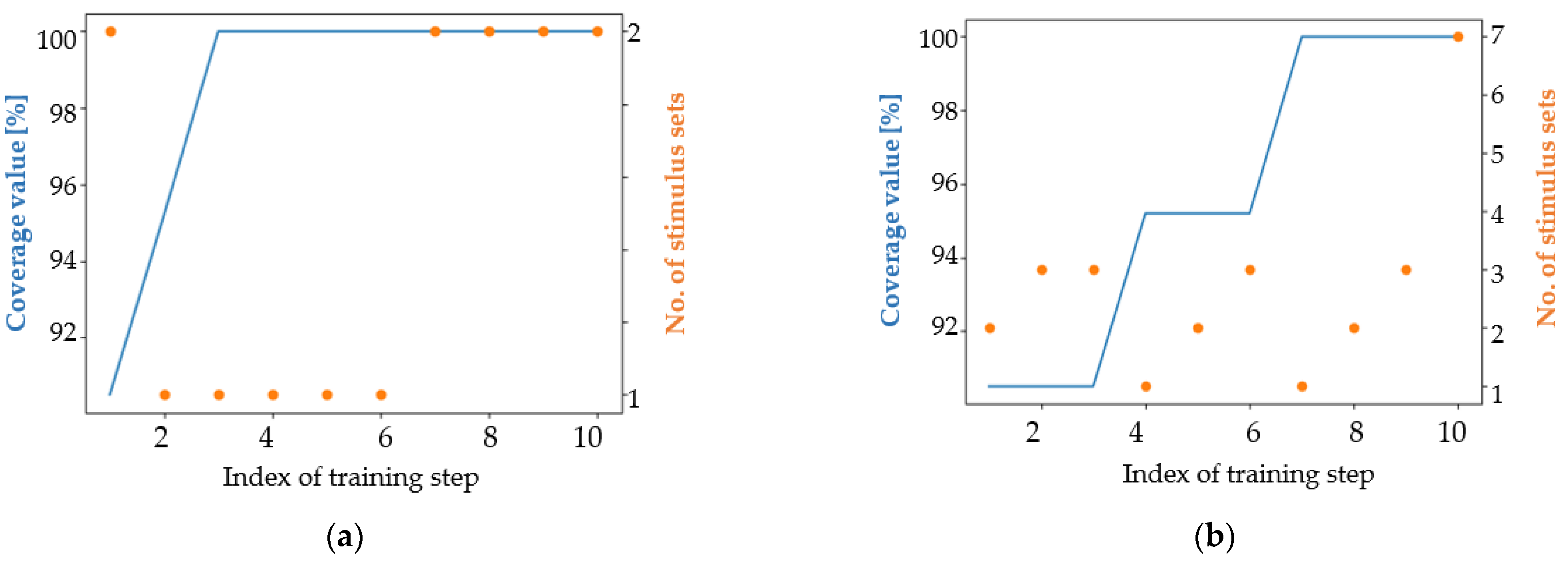
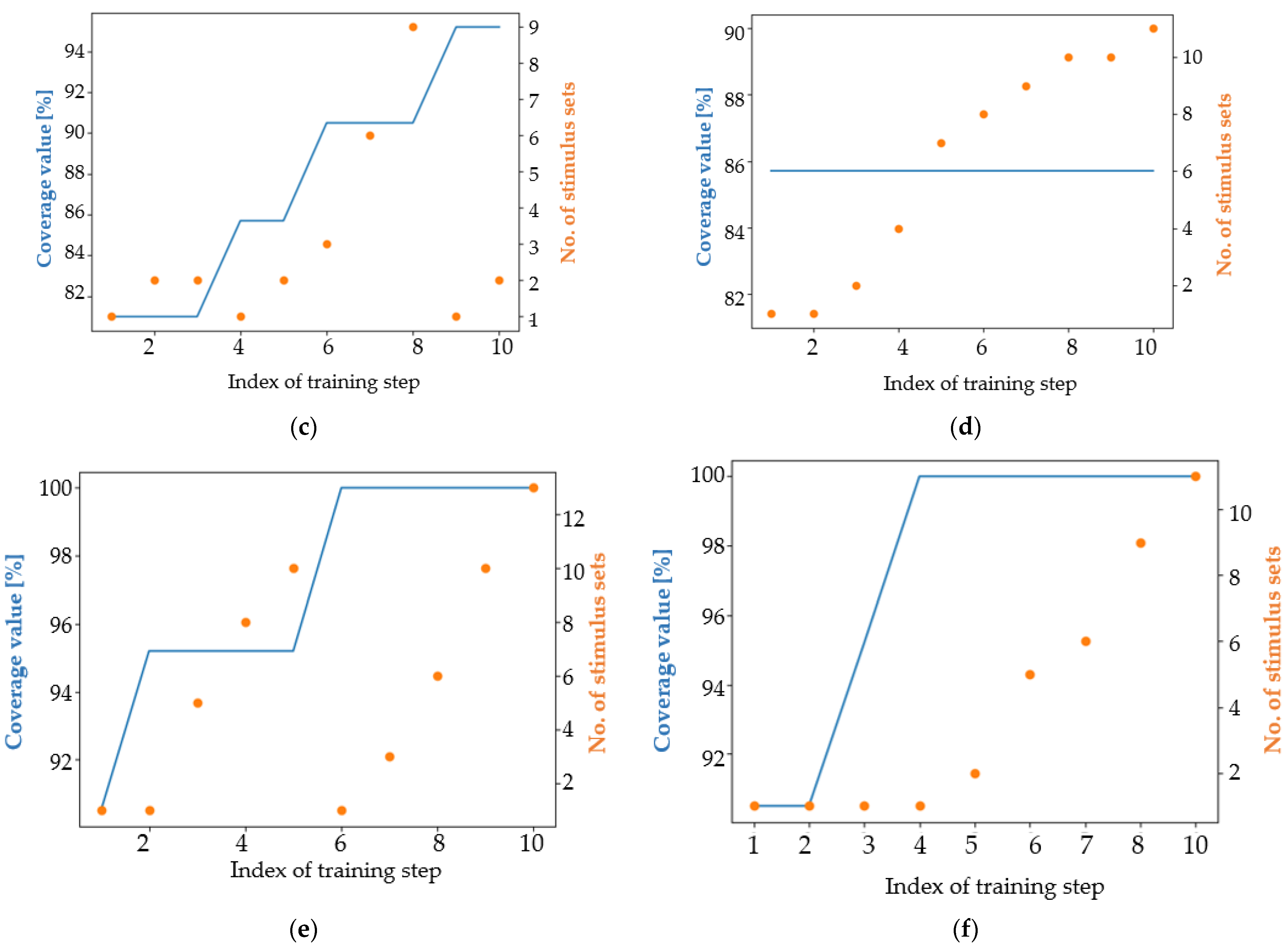
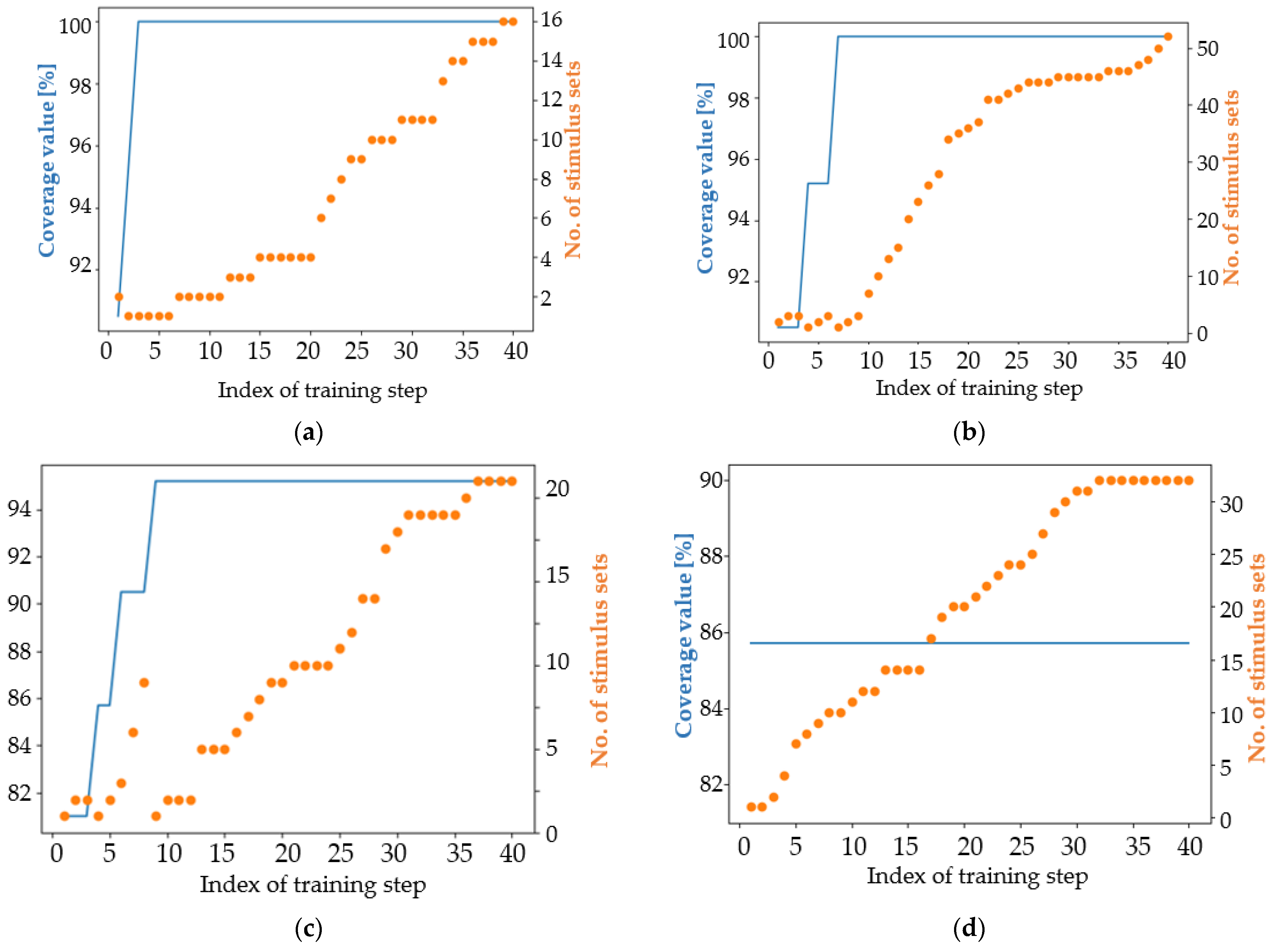
4. Results
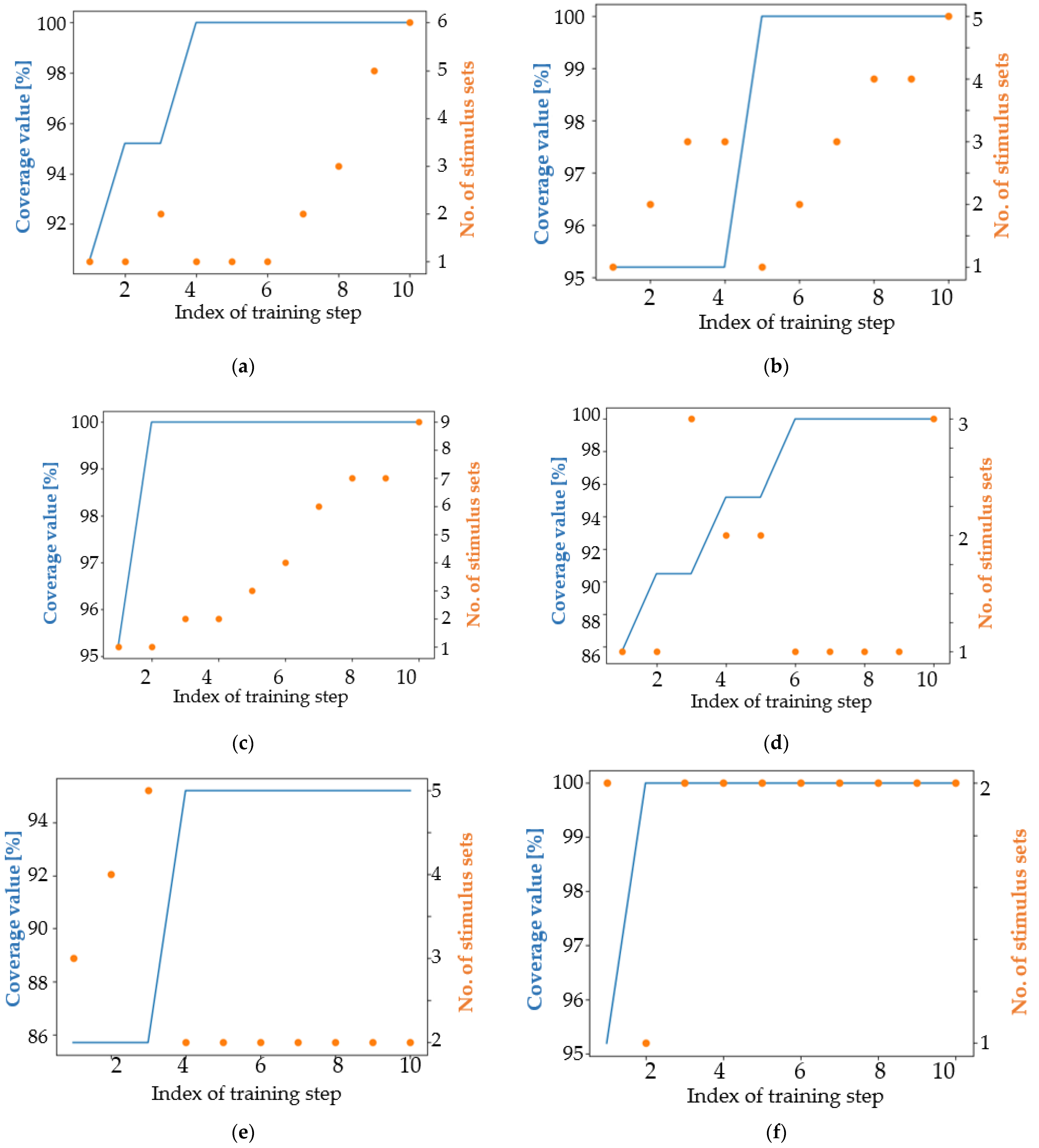
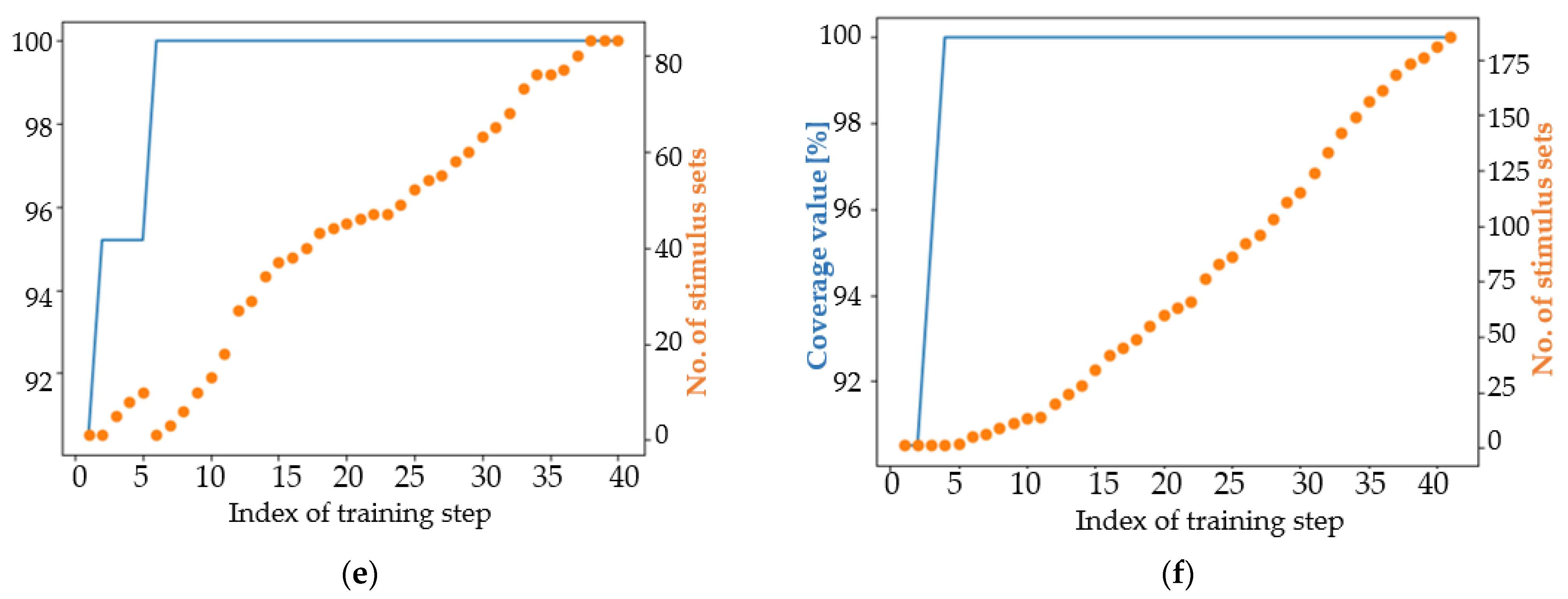
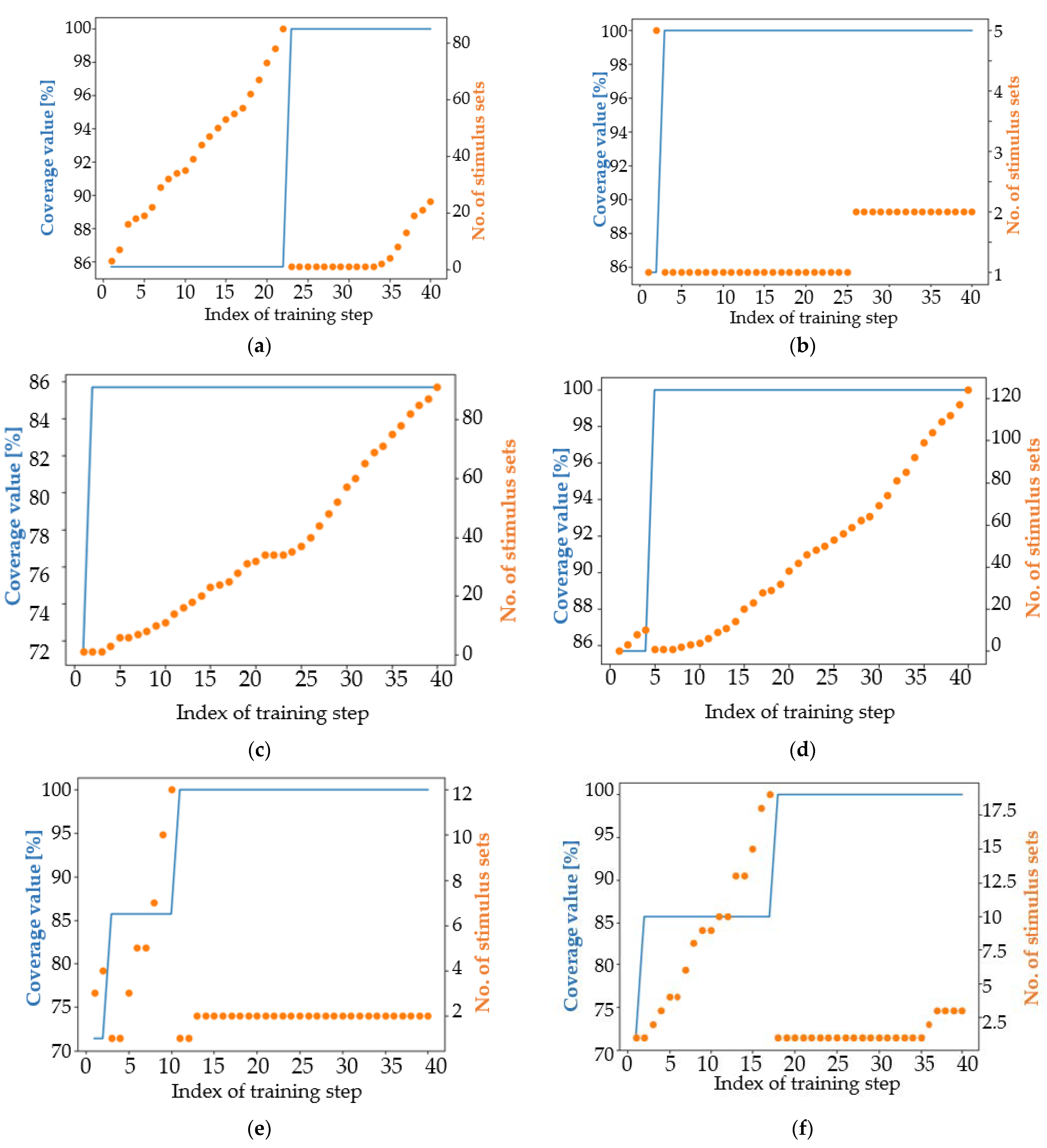
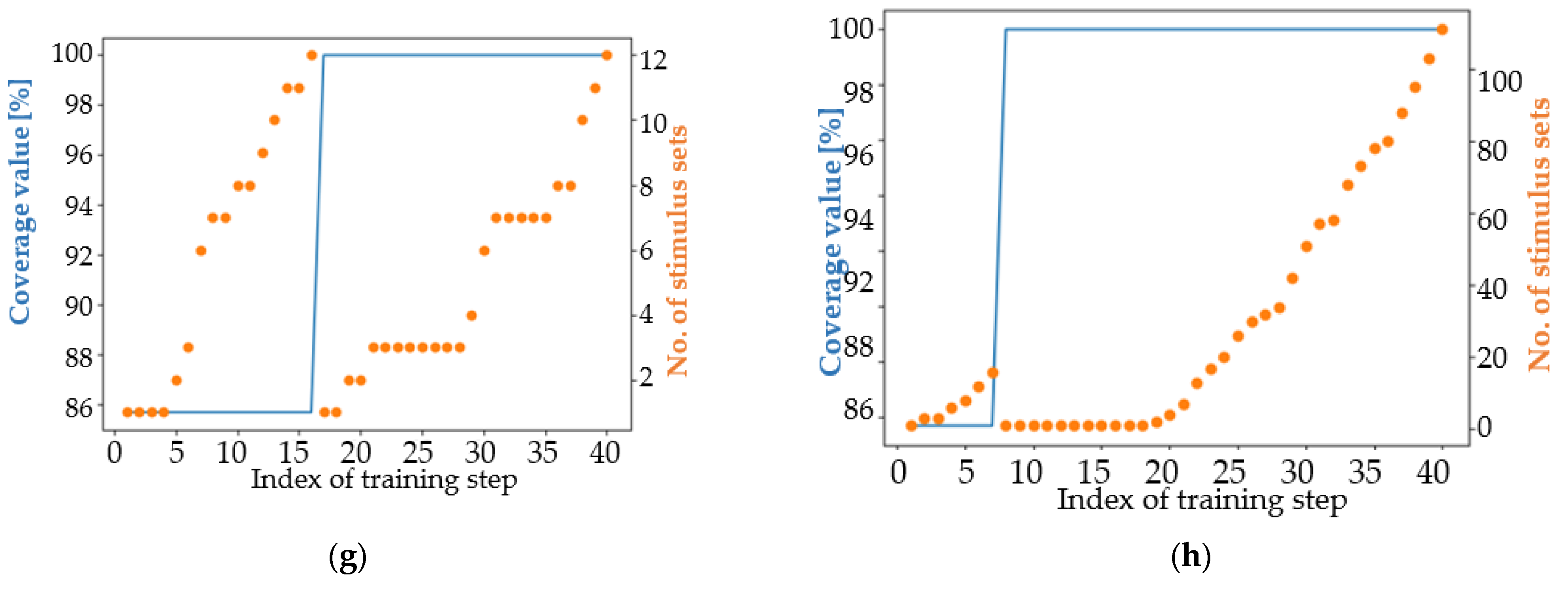
4.1. Analysis of the Results in Terms of the Main Coverage Target
4.2. Analysis of the Results in Terms of an Easier Coverage Target
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cho, K.; Kim, J.; Choi, D.Y.; Yoon, Y.H.; Oh, J.H.; Lee, S.E. An FPGA-Based ECU for Remote Reconfiguration in Automotive Systems. Micromachines 2021, 12, 1309. [Google Scholar] [CrossRef]
- Bouderbala, M.; Bossoufi, B.; Deblecker, O.; Alami Aroussi, H.; Taoussi, M.; Lagrioui, A.; Motahhir, S.; Masud, M.; Alraddady, F.A. Experimental Validation of Predictive Current Control for DFIG: FPGA Implementation. Electronics 2021, 10, 2670. [Google Scholar]
- Jammigumpula, M.; Shah, P.K. A new mechanism in functional coverage to ensure end to end scenarios. In Proceedings of the IEEE International Conference for Innovation in Technology (INOCON), Singapore, 6 November 2020; pp. 1–8. [Google Scholar]
- Cristescu, M.-C. Machine Learning Techniques for Improving the Performance Metrics of Functional Verification. Sci. Technol. 2021, 24, 99–116. [Google Scholar]
- Dranga, D.; Bolcaș, R.D. Artificial Intelligence Enhancements in the field of Functional Verification. Electroteh. Electron. Autom. 2021, 69, 95–102. [Google Scholar] [CrossRef]
- Dinu, A.; Ogrutan, P.L. Coverage fulfillment methods as key points in functional verification of integrated circuits. In Proceedings of the 42nd International Semiconductor Conference (CAS), Sinaia, Romania, 8–11 October 2019; pp. 199–202. [Google Scholar]
- Chiriac, R.-L.; Chiru, A.; Boboc, R.G.; Kurella, U. Advanced Engine Technologies for Turbochargers Solutions. Appl. Sci. 2021, 11, 10075. [Google Scholar] [CrossRef]
- Serrestou, Y.; Beroulle, V.; Robach, C. How to Improve a set of design validation data by using mutation-based test. In Proceedings of the IEEE Design and Diagnostics of Electronic Circuits and systems, Prague, Czech Republic, 18–21 April 2006; pp. 75–76. [Google Scholar]
- Cristescu, M.-C.; Bob, C. Flexible Framework for Stimuli Redundancy Reduction in Functional Verification Using Artificial Neural Networks. In Proceedings of the 2021 International Symposium on Signals, Circuits and Systems (ISSCS), Iasi, Romania, 15–16 July 2021; pp. 1–4. [Google Scholar]
- Cristescu, M.C.; Ciupitu, D. Stimuli Redundancy Reduction for Nonlinear Functional Verification Coverage Models Using Artificial Neural Networks. In Proceedings of the 2021 International Semiconductor Conference (CAS), Sinaia, Romania, 6–8 October 2022; pp. 217–220. [Google Scholar]
- Ferreira, A.; Franco, R.; da Silva, K.R.G. Using genetic algorithm in functional verification to reach high level functional coverage. In Proceedings of the 28th Southern Microelectronics Symposium, Porto Alegre, Brazil, 29 April–3 May 2013; pp. 1–4. [Google Scholar]
- Gad, M.; Aboelmaged, M.; Mashaly, M.; Ghany, M.A.A.e. Efficient Sequence Generation for Hardware Verification Using Machine Learning. In Proceedings of the 28th IEEE International Conference on Electronics, Circuits, and Systems (ICECS), Dubai, United Arab Emirates, 28 November–1 December 2021; pp. 1–5. [Google Scholar]
- Wang, F.; Zhu, H.; Popli, P.; Xiao, Y.; Bodgan, P.; Nazarian, S. Accelerating coverage directed test generation for functional verification: A neural network-based framework. In Proceedings of the Great Lakes Symposium on VLSI, Chicago, IL, USA, 23–25 May 2018; pp. 207–212. [Google Scholar]
- Dinu, A.; Ogrutan, P.L. Opportunities of using artificial intelligence in hardware verification. In Proceedings of the IEEE 25th International Symposium for Design and Technology in Electronic Packaging, Cluj, Romania, 23–26 October 2019; pp. 224–227. [Google Scholar]
- Roy, R.; Duvedi, C.; Godil, S.; Williams, M. Deep Predictive Coverage Collection. In Proceedings of the design and verification conference and exhibition US (DVCon), San Jose, CA, USA, 2–5 March 2018. [Google Scholar]
- El Mandouh, E.; Wassal, A.G. Automatic generation of functional coverage models. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Montréal, QC, Canada, 22–25 May 2016; pp. 754–757. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T.A.M.T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the strength Pareto evolutionary algorithm. TIK-Report 2001, 103, 742–751. [Google Scholar]
- Nguyen, T.; Brunson, D.; Crespi, C.L.; Penman, B.W.; Wishnok, J.S.; Tannenbaum, S.R. DNA damage and mutation in human cells exposed to nitric oxide in vitro. Proc. Natl. Acad. Sci. USA 1992, 89, 3030–3034. [Google Scholar] [CrossRef]
- Danciu, G.M.; Dinu, A. Coverage Fulfillment Automation in Hardware Functional Verification Using Genetic Algorithms. Appl. Sci. 2022, 12, 1559. [Google Scholar] [CrossRef]
- David, E. Goldberg. In Genetic Algorithms in Search, Optimization and Machine Learning, 1st ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1989. [Google Scholar]
- Yusoff, Y.; Ngadiman, M.S.; Zain, A.M. Overview of NSGA-II for optimizing machining process parameters. Procedia Eng. 2011, 15, 3978–3983. [Google Scholar]
- Popa, L.; Popa, V. Software instrument used as interface in the design of technical installations. IOP Conf. Ser. Mater. Sci. Eng. 2019, 564, 012059. [Google Scholar] [CrossRef]
- Nica, A.; Balan, A.; Zaharia, C.; Balan, T. Automated Testing of GUI Based Communication Elements. In Online Engineering and Society 4.0: Proceedings of the 18th International Conference on Remote Engineering and Virtual Instrumentation; Auer, M.E., Bhimavaram, K.R., Yue, X.-G., Eds.; Springer Nature: Cham, Switzerland, 2021; Volume 298, pp. 380–390. [Google Scholar]
- Qamar, N.; Akhtar, N.; Younas, I. Comparative analysis of evolutionary algorithms for multi-objective travelling salesman problem. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 371–379. [Google Scholar] [CrossRef]
- Kannan, S.; Baskar, S.; McCalley, J.D.; Murugan, P. Application of NSGA-II algorithm to generation expansion planning. IEEE Trans. Power Syst. 2008, 24, 454–461. [Google Scholar] [CrossRef]
- Zangooei, M.H.; Habibi, J.; Alizadehsani, R. Disease Diagnosis with a hybrid method SVR using NSGA-II. Neurocomputing 2014, 136, 14–29. [Google Scholar] [CrossRef]
- Liangsong, F.A.N. Manufacturing job shop scheduling problems based on improved meta-heuristic algorithm and bottleneck identification. Acad. J. Manuf. Eng. 2020, 18, 98–103. [Google Scholar]
- Implementation of NSGA-II Algorithm as a Python Library. Available online: https://github.com/wreszelewski/nsga2 (accessed on 26 March 2022).
- Liagkouras, K.; Metaxiotis, K. An elitist polynomial mutation operator for improved performance of MOEAs in computer networks. In Proceedings of the 22nd International Conference on Computer Communication and Networks (ICCCN), Nassau, Bahamas, 30 July–2 August 2013; pp. 1–5. [Google Scholar]
- Implementation of NSGA-II Algorithm in form of a Python Library. Available online: https://github.com/baopng/NSGA-II (accessed on 19 March 2022).
- Deb, K.; Agrawal, R.B. Simulated binary crossover for continuous search space. Complex Syst. 1995, 9, 115–148. [Google Scholar]
- Amuso, V.J.; Enslin, J. The Strength Pareto Evolutionary Algorithm 2 (SPEA2) applied to simultaneous multi-mission waveform design. In Proceedings of the IEEE International Waveform Diversity and Design Conference, Pisa, Italy, 4–8 June 2007; pp. 407–417. [Google Scholar]
- Liu, X.; Zhang, D. An improved SPEA2 algorithm with local search for multi-objective investment decision-making. Appl. Sci. 2019, 9, 1675. [Google Scholar] [CrossRef]
- Dariane, A.B.; Sabokdast, M.M.; Karami, F.; Asadi, R.; Ponnambalam, K.; Mousavi, S.J. Integrated Operation of MultiReservoir and Many-Objective System Using Fuzzified Hedging Rule and Strength Pareto Evolutionary Optimization Algorithm (SPEA2). Water 2021, 13, 1995. [Google Scholar] [CrossRef]
- Liu, L.; Chen, H.; Xu, Z. SPMOO: A Multi-Objective Offloading Algorithm for Dependent Tasks in IoT Cloud-Edge-End Collaboration. Information 2022, 13, 75. [Google Scholar] [CrossRef]
- Dinu, A.; Gheorghe, S.; Danciu, G.M.; Ogrutan, P.L. Debugging FPGA projects using artificial intelligence. Sci. Technol. 2021, 24, 299–320. [Google Scholar]
- Reyes Fernández de Bulnes, D.; Dibene Simental, J.C.; Maldonado, Y.; Trujillo, L. High-level synthesis through metaheuristics and LUTs optimization in FPGA devices. AI Commun. 2017, 30, 151–168. [Google Scholar] [CrossRef]
- Lopez-Ibanez, M.; Prasad, T.D.; Paechter, B. Multi-objective optimisation of the pump scheduling problem using SPEA2. In Proceedings of the IEEE Congress on Evolutionary Computation, Edinburgh, UK, 2–5 September 2005; pp. 435–442. [Google Scholar]
- Pereira, V. Project: Metaheuristic-SPEA-2. Available online: https://github.com/Valdecy/Metaheuristic-SPEA-2 (accessed on 22 March 2022).
- Accellera Systems Initiative. Universal Verification Methodology (UVM) 1.2 User’s Guide. 2015. Available online: https://www.accellera.org/images/downloads/standards/uvm/uvm_users_guide_1.2.pdf (accessed on 12 January 2022).
- Bergeron, J. Writing Testbenches Using SystemVerilog; Springer Science & Business Media: New York, NY, USA, 2007. [Google Scholar]
- Dinu, A.; Danciu, G.M.; Gheorghe, Ș. Level up in verification: Learning from functional snapshots. In Proceedings of the 16th International Conference on Engineering of Modern Electric Systems (EMES), Oradea, Romania, 10–11 June 2021; pp. 1–4. [Google Scholar]
- Ștefan, G.; Alexandru, D. Controlling hardware design behavior using Python based machine learning algorithms. In Proceedings of the 16th International Conference on Engineering of Modern Electric Systems (EMES), Oradea, Romania, 10–11 June 2021; pp. 1–4. [Google Scholar]
- Lee, J. Design and Simulation of ARM Processor using VHDL. J. Inst. Internet Broadcasting Commun. 2018, 18, 229–235. [Google Scholar]
- Digalakis, J.G.; Margaritis, K.G. On benchmarking functions for genetic algorithms. Int. J. Comput. Math. 2001, 77, 481–506. [Google Scholar] [CrossRef]
- Thierens, D. Adaptive mutation rate control schemes in genetic algorithms. In Proceedings of the Congress on Evolutionary Computation (CEC), Honolulu, Hawaii, 12–17 May 2002; pp. 980–985. [Google Scholar]
- Patil, S.; Bhende, M. Comparison and analysis of different mutation strategies to improve the performance of genetic algorithm. Int. J. Comput. Sci. Inf. Technol. (IJCSIT) 2014, 5, 4669–4673. [Google Scholar]
- Zheng, Z.; Guo, J.; Gill, E. Swarm satellite mission scheduling & planning using hybrid dynamic mutation genetic algorithm. Acta Astronaut. 2017, 137, 243–253. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm Version | The Best Performing Parents Are Copied in the Next Generation | Offspring Identical to Their Parents Are Discarded |
|---|---|---|
| V3.2 | twice | yes |
| V3.21 | once | yes |
| V3.3 | twice | no |
| V3.6 | once | no |
| Criterion | Proposed Approaches | Classical Approach | Established Genetic Algorithms | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| V3.2 | V3.21 | V3.3 | V3.6 | Random Stimuli | Classical NSGA-II (Adapted after [29]) | Classical-Modified NSGA-II (Adapted after [31]) | Modified NSGA-II (Adapted after [31]) | SPEA2 2 (Adapted after [40]) | ||
| Trial I | Trial II | |||||||||
| maximum coverage reached | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| parents/generation | 20 | 20 | 20 | 20 | 800 | 20 | 20 | 20 | 20 | 20 |
| the first iteration containing a dataset which leads to maximum coverage | 4 | 5 | 2 | 5 | 1 | 15 | 2 | 9 | 6 | 3 |
| time passed until first high-performing dataset is reached [minutes] | 6 m | 6 m | 4 m | 11 m | 38 m | 24 m | 3 m | 12 m | 21 m | 11 m |
| first generation when at least n_pop 1/2 elements having maximum coverage were obtained | 12 | 12 | 11 | 13 | n/a | 27 | n/a | n/a | 11 | 15 |
| time passed until n_pop/2 elements having maximum coverage were obtained [minutes] | 19 m | 17 m | 24 m | 26 m | n/a | 44 m | n/a | n/a | 38 m | 53 m |
| the number of sets of stimuli that achieve maximum coverage | 49 (1) | 176 (1) | 146 (1) | 205 (1) | 1 | 45 (1) | 3 (3) | 2 (2) | 285 (2) | 212 (3) |
| Criterion | Proposed Approaches | Established Alg. | ||||
|---|---|---|---|---|---|---|
| V3.2 | V3.21 | V3.3 | V3.6 | SPEA2 2 [40] | ||
| Trial I | Trial II | |||||
| maximum coverage reached | 100 | 100 | 95.2 | 85.7 | 100 | 100 |
| parents/generation | 20 | 20 | 20 | 20 | 20 | 20 |
| the first iteration containing a dataset that leads to maximum coverage | 3 | 7 | 9 | 1 | 6 | 4 |
| time passed until first dataset with 100% coverage is reached [minutes] | 6 m | 10 m | n/a | n/a | 22 m | 12 m |
| first generation when at least n_pop 1/2 elements having maximum coverage were obtained | 26 | 11 | 21 | 8 | 9 | 9 |
| time passed until n_pop/2 elements having 100% coverage were obtained [minutes] | 48 m | 16 m | n/a | n/a | 31 m | 26 m |
| the number of stimulus sets that achieve maximum coverage | 16 (3) | 52 (2) | 21 (1) | 32 (1) | 84 (1) | 175 (1) |
| Criterion | Proposed Approaches | Classical Approach | Established Genetic Algorithms | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| V3.2 | V3.21 | V3.3 | V3.6 | Random Stimuli | Classical NSGA-II (Adapted after [29]) | Classical-Modified NSGA-II (Adapted after [31]) | Modified NSGA-II (Adapted after [31]) | SPEA2 (Adapted after [40]) | ||
| maximum coverage reached | 100 | 100 | 85.7 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| parents/generation | 20 | 20 | 20 | 20 | 800 | 200 | 20 | 20 | 20 | 20 |
| the first iteration containing a dataset that leads to maximum coverage | 22 | 3 | 2 | 5 | 1 | 1 | 11 | 18 | 17 | 8 |
| first generation when at least n_pop 1/2 elements having maximum coverage were obtained | 36 | n/a | 9 | 13 | n/a | n/a | n/a | n/a | 34 | 22 |
| the number of stimulus sets that achieve maximum coverage | 24 (1) | 2 (2) | 172 (2) | 125 (1) | 3 (3) | 1 (1) | 2 (1) | 3 (3) | 12 (12) | 111 (1) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dinu, A.; Danciu, G.M.; Ogrutan, P.L. Cost-Efficient Approaches for Fulfillment of Functional Coverage during Verification of Digital Designs. Micromachines 2022, 13, 691. https://doi.org/10.3390/mi13050691
Dinu A, Danciu GM, Ogrutan PL. Cost-Efficient Approaches for Fulfillment of Functional Coverage during Verification of Digital Designs. Micromachines. 2022; 13(5):691. https://doi.org/10.3390/mi13050691
Chicago/Turabian StyleDinu, Alexandru, Gabriel Mihail Danciu, and Petre Lucian Ogrutan. 2022. "Cost-Efficient Approaches for Fulfillment of Functional Coverage during Verification of Digital Designs" Micromachines 13, no. 5: 691. https://doi.org/10.3390/mi13050691
APA StyleDinu, A., Danciu, G. M., & Ogrutan, P. L. (2022). Cost-Efficient Approaches for Fulfillment of Functional Coverage during Verification of Digital Designs. Micromachines, 13(5), 691. https://doi.org/10.3390/mi13050691