
Progressive Two-Stage Network for Low-Light Image Enhancement




Abstract
:1. Introduction
- A two-stage image enhancement network was proposed, which grades the deep learning enhancement problem into two stages of coarsening and refinement for step by step processing and obtains preliminary enhancement results before refinement of specific scenes.
- With the introduction of a two-stage lightweight network structure, enhancing complex scenes at night is more readily resolved, and the recovered images are richer in color, higher in sharpness and contrast, and with generally better visual quality.
- The residual dense attention module is introduced into the network, which enhances feature extraction and recovers clear background images.
2. Proposed Method
2.1. Overall Network Architecture
2.2. RDAM
2.2.1. RDB
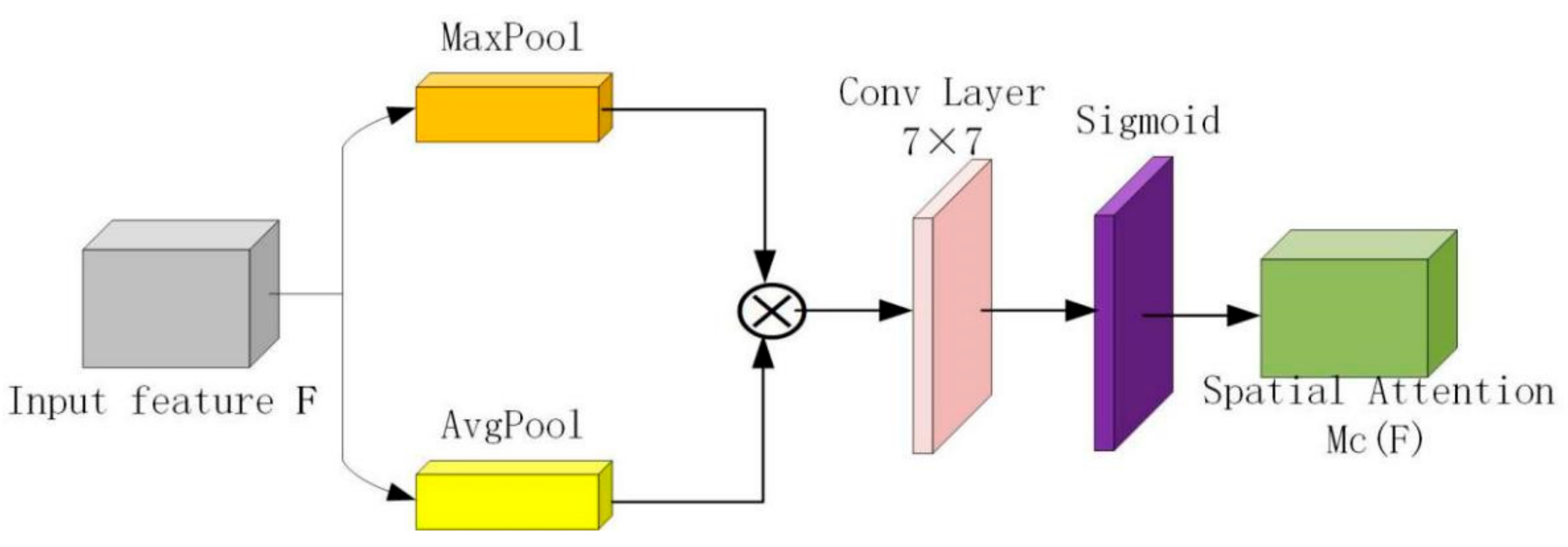
2.2.2. Attention Mechanism
2.3. Two-Stage Network
2.3.1. Phase I Network
2.3.2. Phase II Network
2.4. Loss Function
3. Experimental Results and Analysis
3.1. Data Sets
3.2. Parameters Setting for the Experimental Environment
3.3. Objective Indicators
3.4. LOL Results Analysis of Open Data Sets
3.5. Natural Real Image Test Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, Y.; Lu, Y.; Liu, R.W.; Yang, M.; Chui, K.T. Low-Light Image Enhancement with Regularized Illumination Optimization and Deep Noise Suppression. IEEE Access 2020, 8, 145297–145315. [Google Scholar] [CrossRef]
- Luo, J.; Yang, Y.; Shi, B. Multithreshold image segmentation of 2D Otsu based on improved adaptive differential evolution algorithm. J. Electron. Inf. Technol. 2019, 41, 2017–2024. [Google Scholar] [CrossRef]
- Banik, P.P.; Saha, R.; Kim, K.D. Contrast enhancement of low-light image using histogram equalization and illumination adjustment. In Proceedings of the 2018 International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018. [Google Scholar]
- Kong, T.L.; Isa, N. Histogram based image enhancement for non-uniformly illuminated and low contrast images. In Proceedings of the 2015 IEEE 10th Conference on Industrial Electronics and Applications (ICIEA), Auckland, New Zealand, 15–17 June 2015; pp. 586–591. [Google Scholar]
- Sujee, R.; Padmavathi, S. Image enhancement through pyramid histogram matching. In Proceedings of the International Conference on Computer Communication & Informatics, Coimbatore, India, 5–7 January 2017; pp. 1–5. [Google Scholar]
- Land, E.H.; McCann, J.J. Lightness and Retinex Theory. J. Opt. Soc. Am. 1971, 61, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. Properties and Performance of a Center/Surround Retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef] [PubMed]
- Jobson, D.J.; Rahman, Z.; Woodel, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, X.; Yu, L.; Ling, H. LIME: Low-light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Zeng, D.; Yue, H.; Zhang, W.P.; Ding, X.A. Weighted Variational Model for Simultaneous Reflectance and Illumination Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A Deep Autoencoder Approach to Natural Low-light Image Enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. LightenNet: A Convolutional Neural Network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Wang, W.; Chen, W.; Yang, W.; Liu, J. GLADNet: Low-Light Enhancement Network with Global Awareness. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–18 May 2018. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In British Machine Vision Conference; 2018; p. 220. [Google Scholar]
- Wang, R.; Zhang, Q.; Fu, C.W.; Shen, X.; Zheng, W.-S.; Jia, J. Underexposed Photo Enhancement Using Deep Illumination Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Lim, S.; Kim, W. DSLR: Deep Stacked Laplacian Restorer for Low-light Image Enhancement. IEEE Trans. Multimed. 2020, 23, 4272–4284. [Google Scholar] [CrossRef]
- Li, Y.; Chen, X. A Coarse-to-Fine Two-Stage Attentive Network for Haze Removal of Remote Sensing Images. IEEE Geosci. Remote. Sens. Lett. 2020, 18, 1751–1755. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | LightenNet | MBLLEN | Retinex-Net | RRDNet | DSLR | Ours |
|---|---|---|---|---|---|---|
| PSNR/dB | 11.85 | 20.23 | 19.27 | 13.00 | 17.16 | 22.14 |
| SSIM | 0.6023 | 0.8233 | 0.5792 | 0.6646 | 0.7562 | 0.8352 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Chang, Z.; Zhao, Y.; Hua, Z.; Li, S. Progressive Two-Stage Network for Low-Light Image Enhancement. Micromachines 2021, 12, 1458. https://doi.org/10.3390/mi12121458
Sun Y, Chang Z, Zhao Y, Hua Z, Li S. Progressive Two-Stage Network for Low-Light Image Enhancement. Micromachines. 2021; 12(12):1458. https://doi.org/10.3390/mi12121458
Chicago/Turabian StyleSun, Yanpeng, Zhanyou Chang, Yong Zhao, Zhengxu Hua, and Sirui Li. 2021. "Progressive Two-Stage Network for Low-Light Image Enhancement" Micromachines 12, no. 12: 1458. https://doi.org/10.3390/mi12121458
APA StyleSun, Y., Chang, Z., Zhao, Y., Hua, Z., & Li, S. (2021). Progressive Two-Stage Network for Low-Light Image Enhancement. Micromachines, 12(12), 1458. https://doi.org/10.3390/mi12121458