Active Expression of Genes for Protein Modification Enzymes in Habu Venom Glands

 , , , ,
, , , ,  and
and
Abstract
:1. Introduction
2. Results
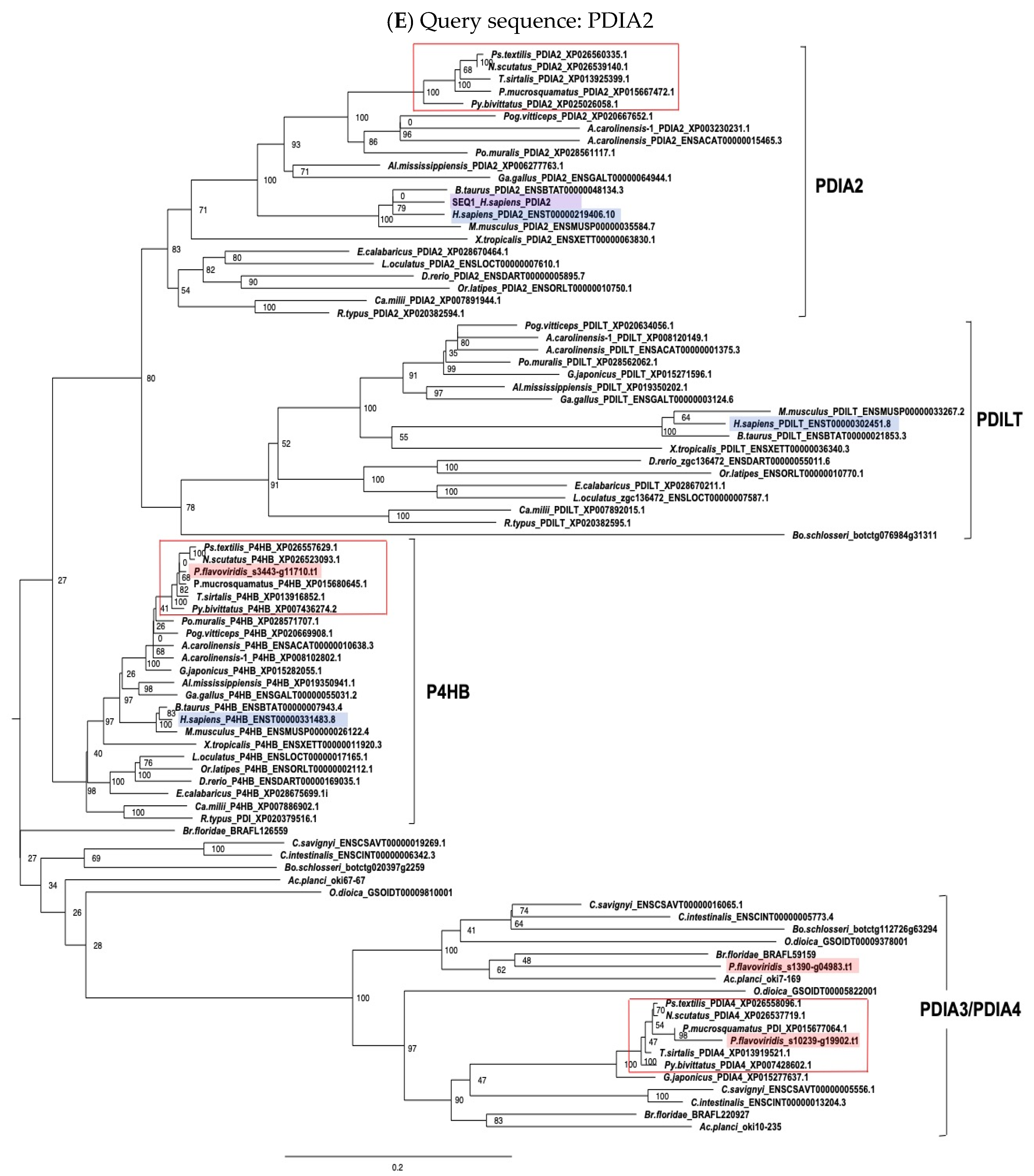
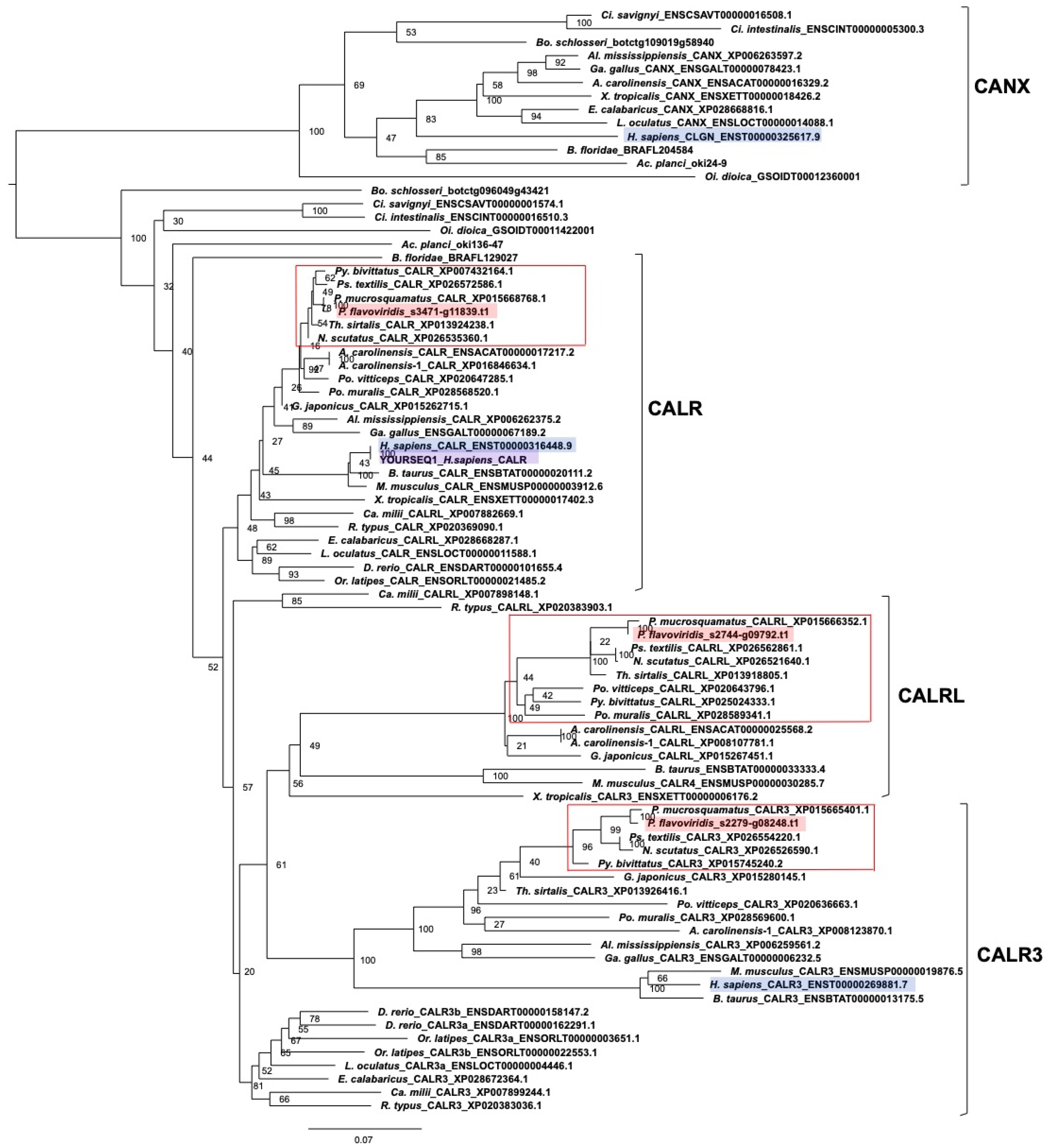
2.1. Identification of Candidate Genes for Modification, Folding, and Quality Control of Venom Proteins
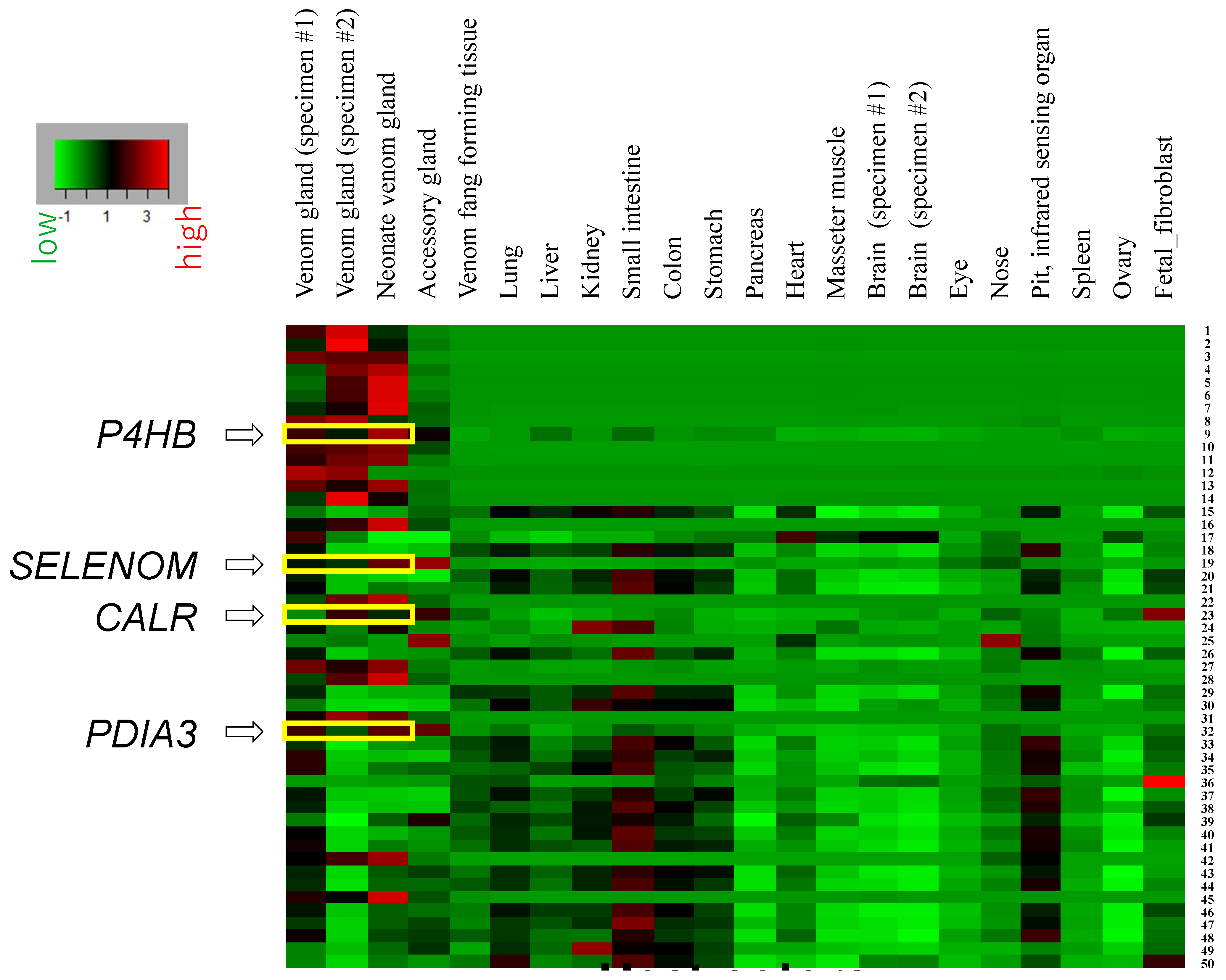
2.2. Expression Profiles of Highly Active Genes, P4HB, SELENOM, CALR, and PDIA3, Are Specific to Venom Glands
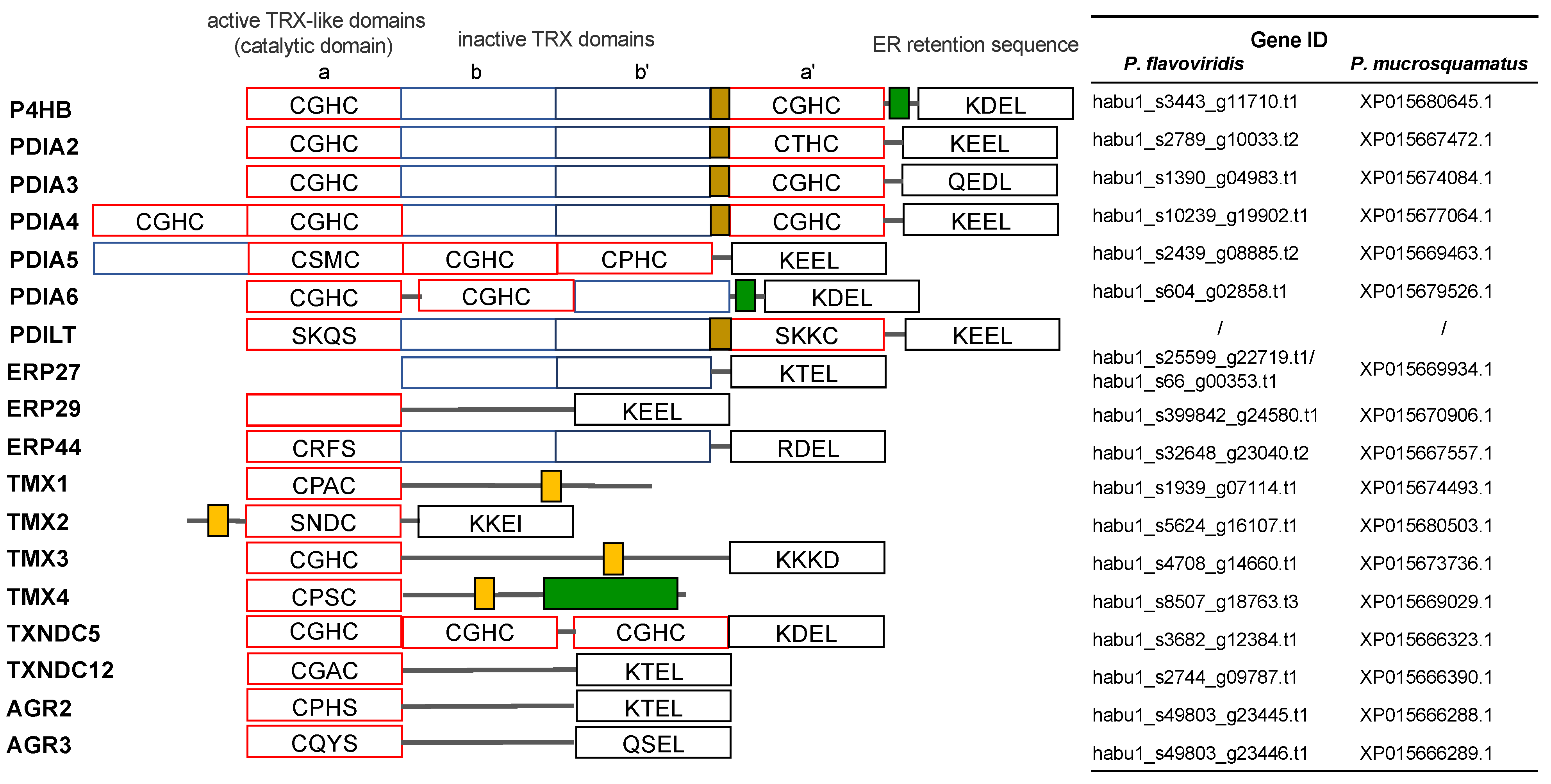
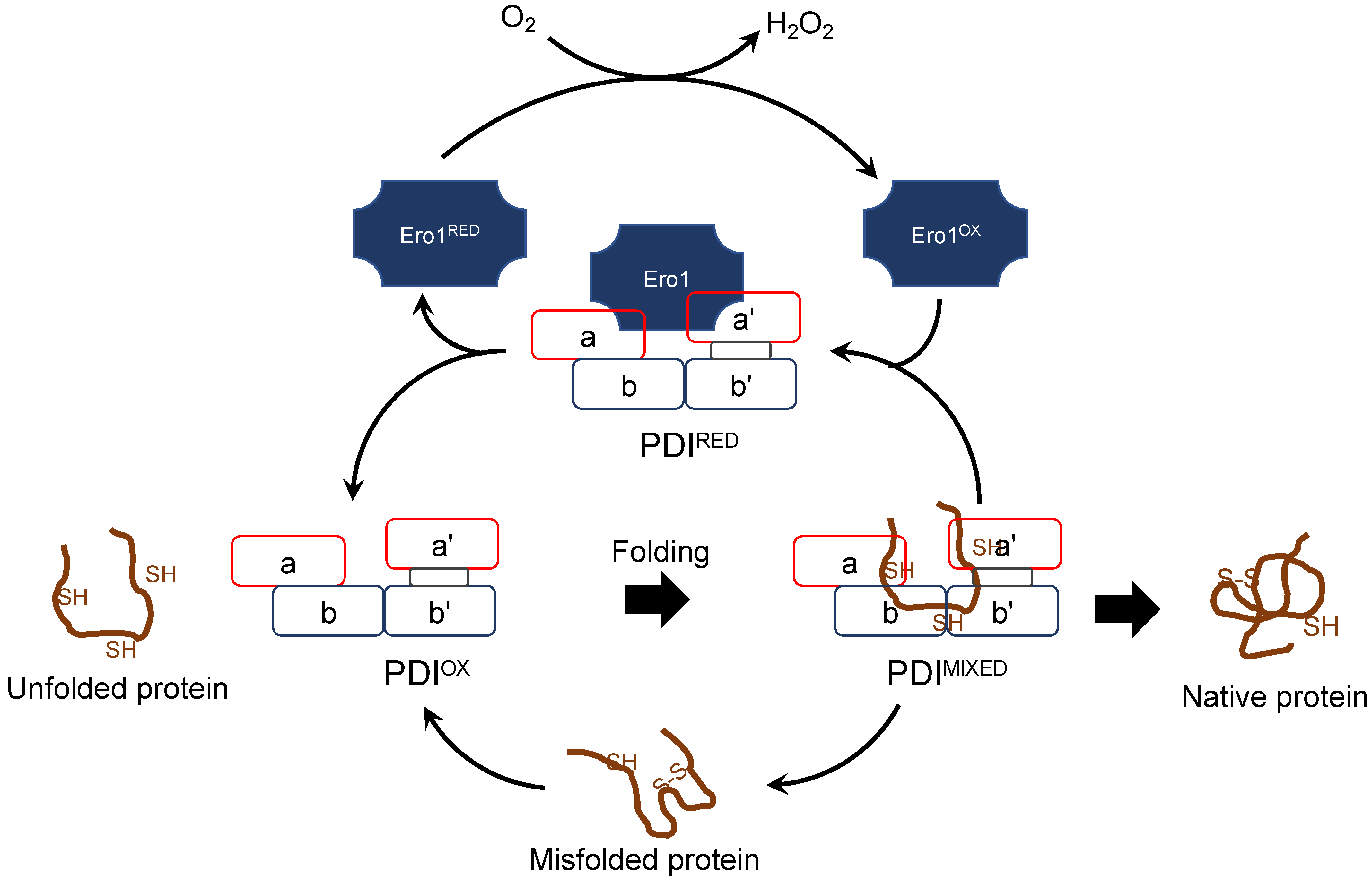
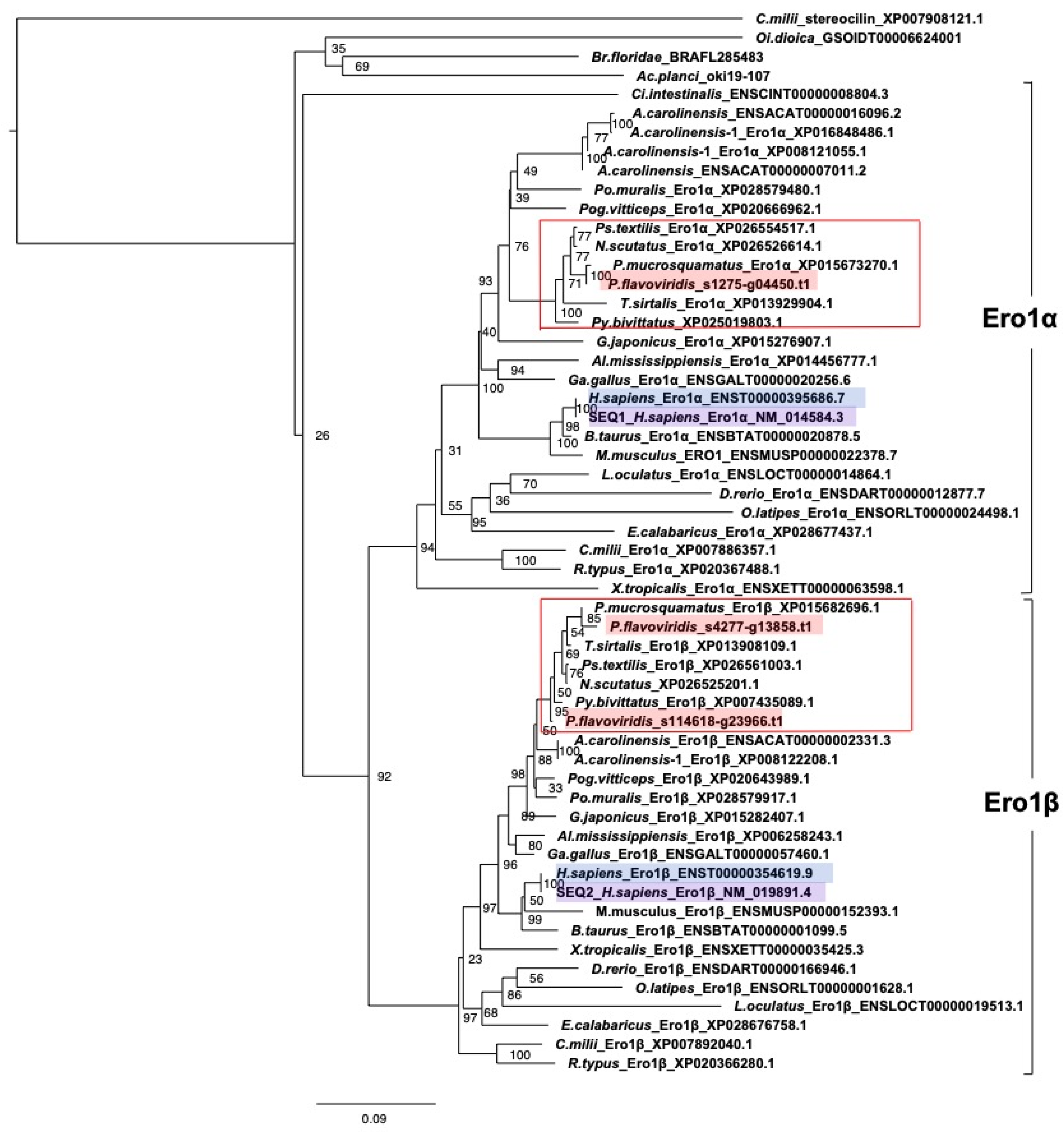
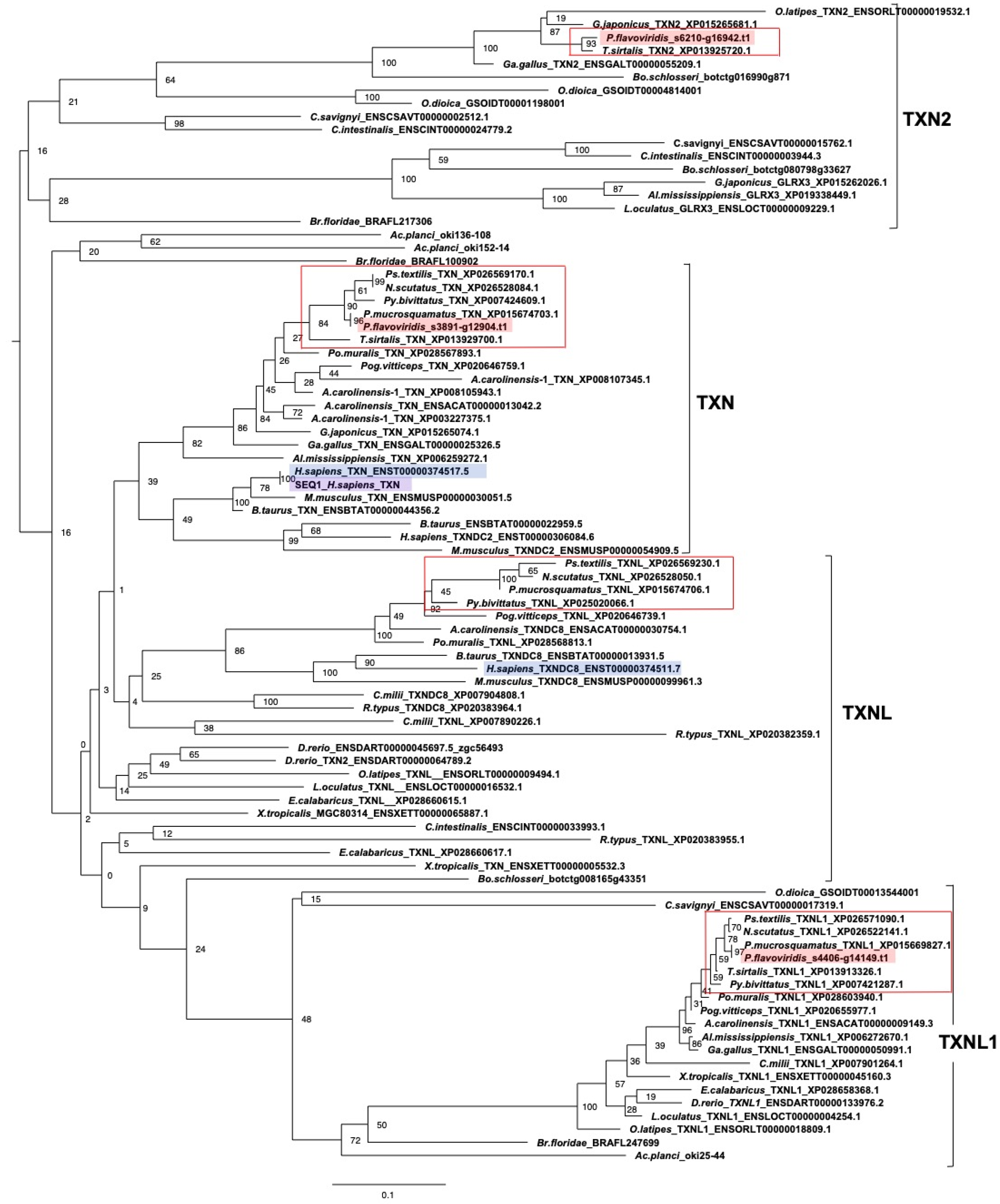
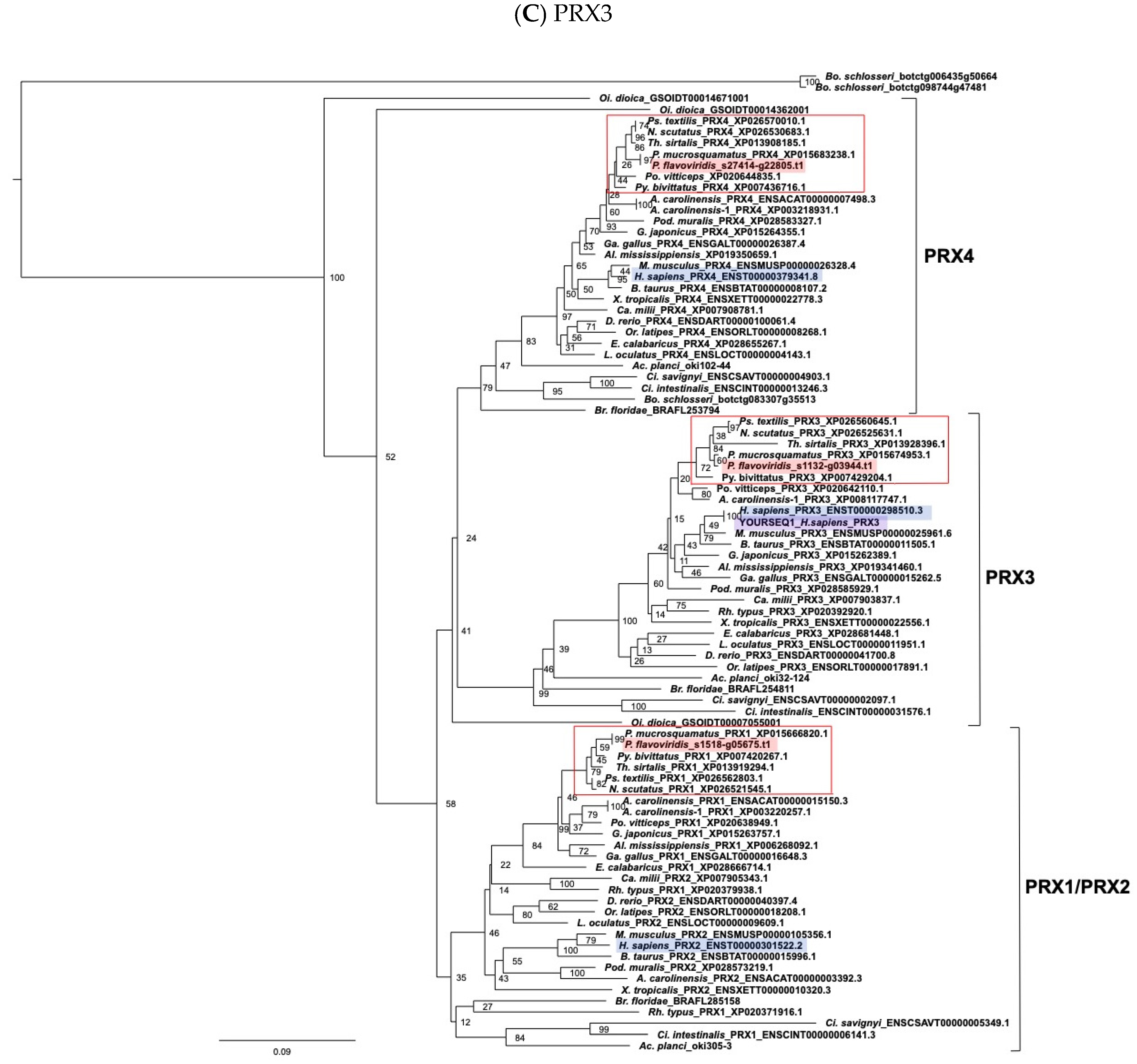
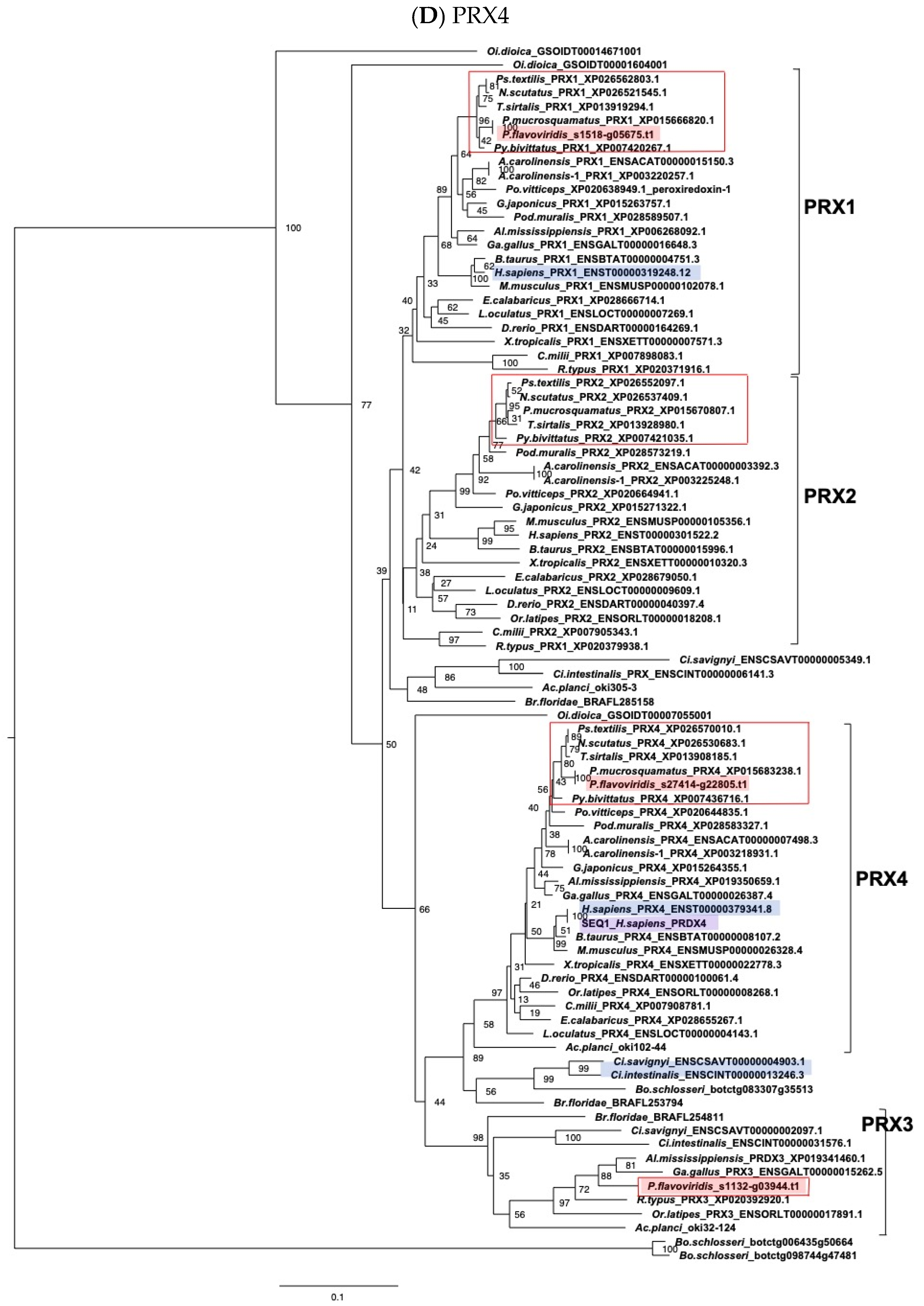
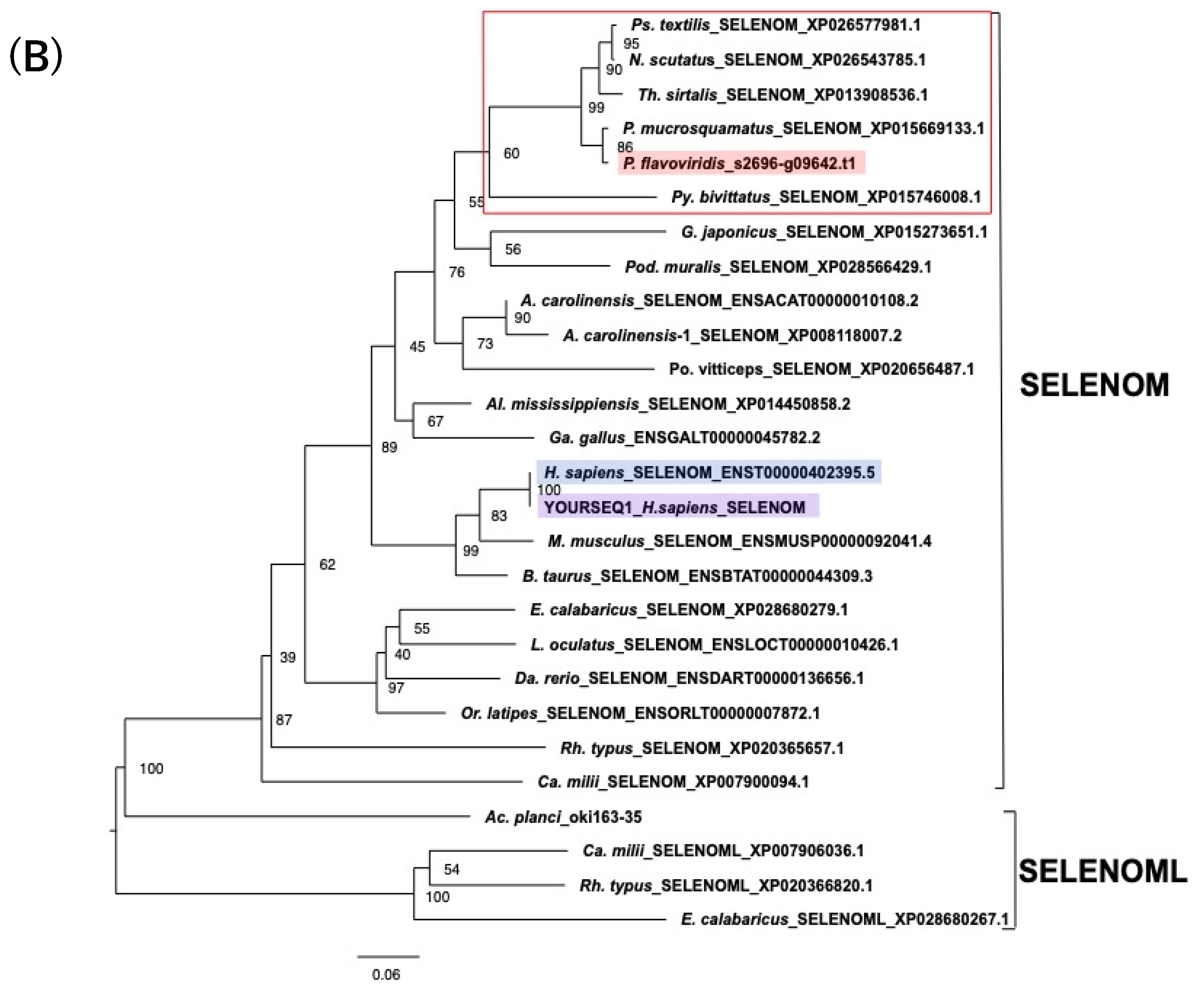
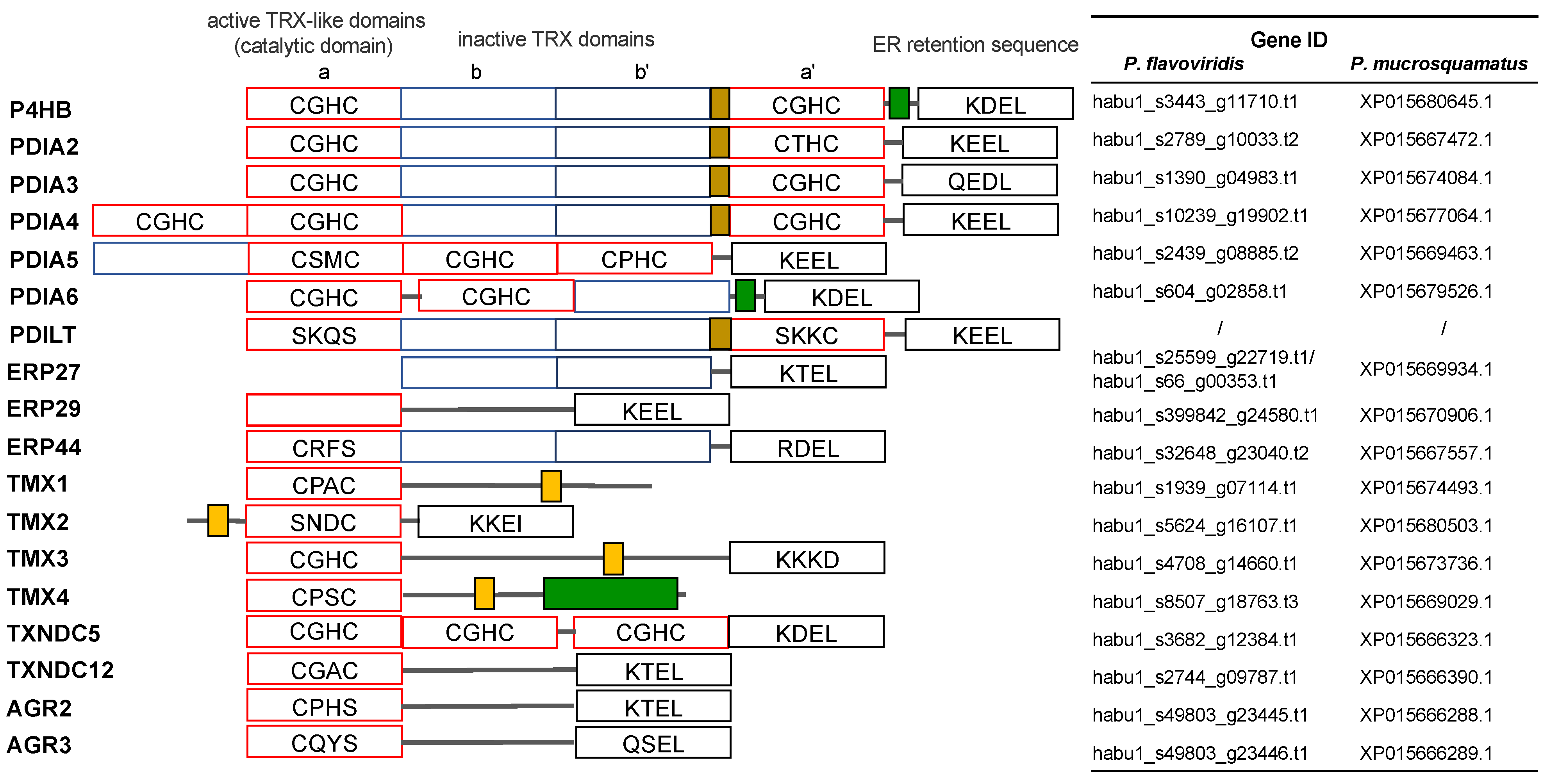
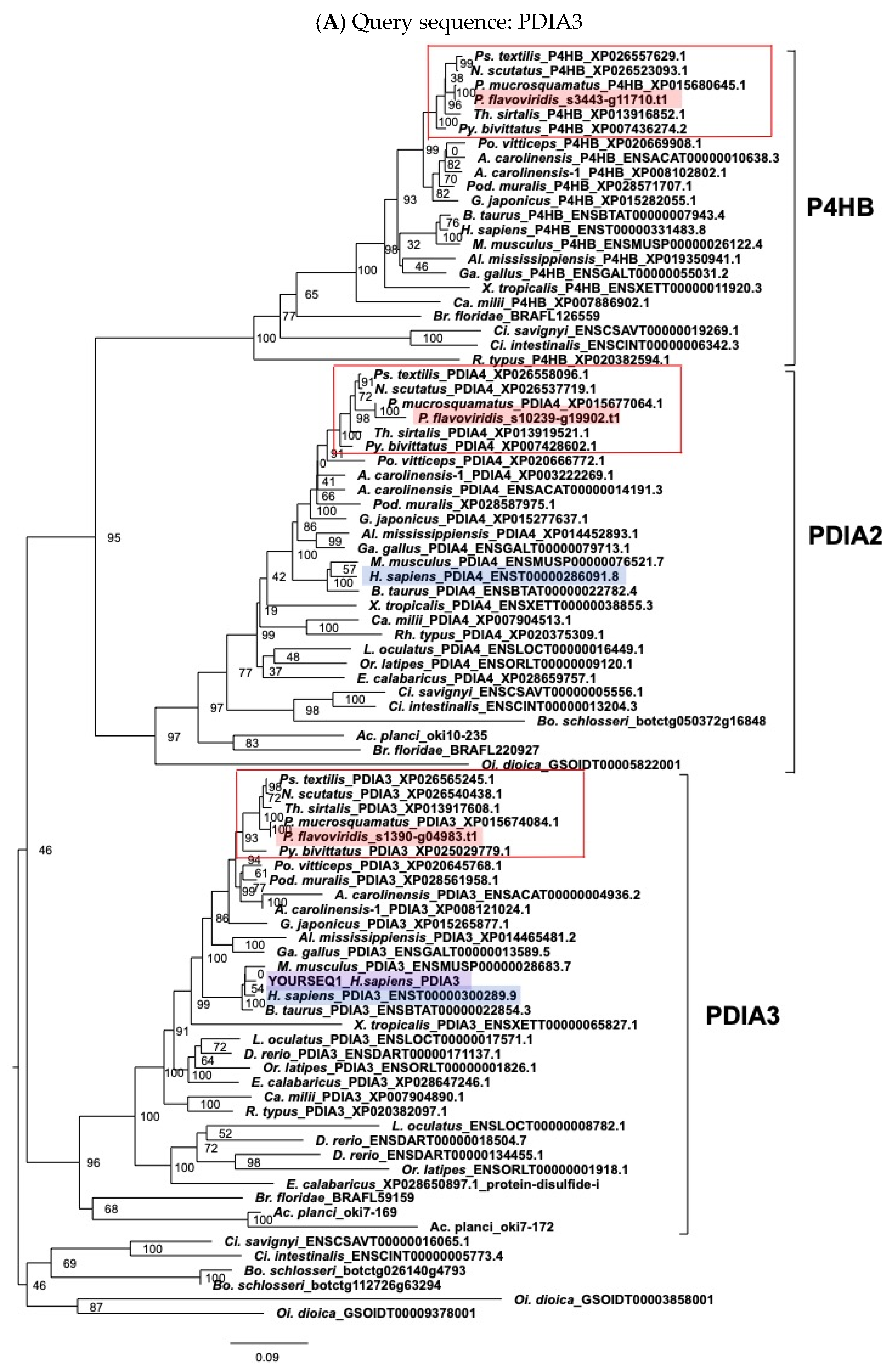
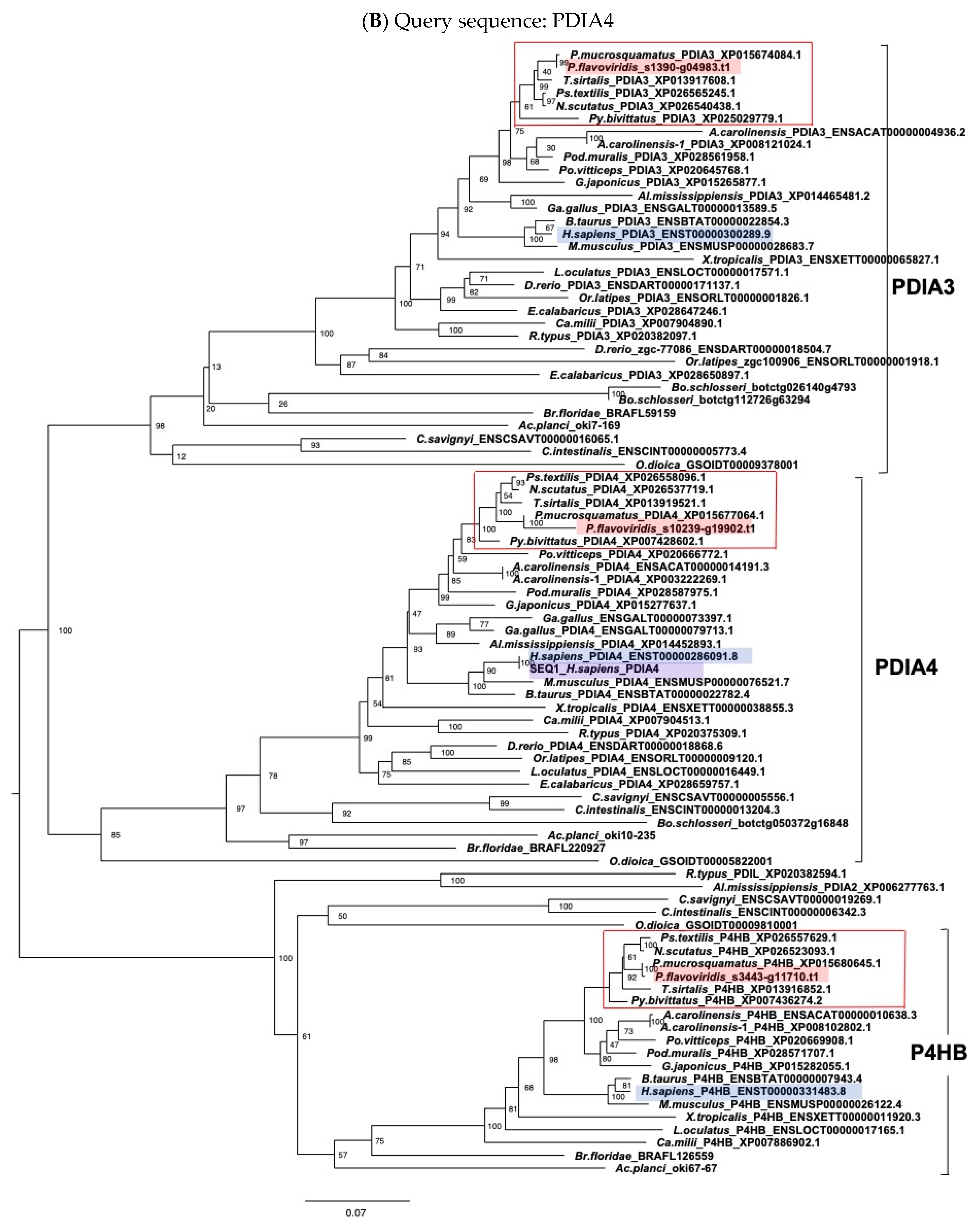
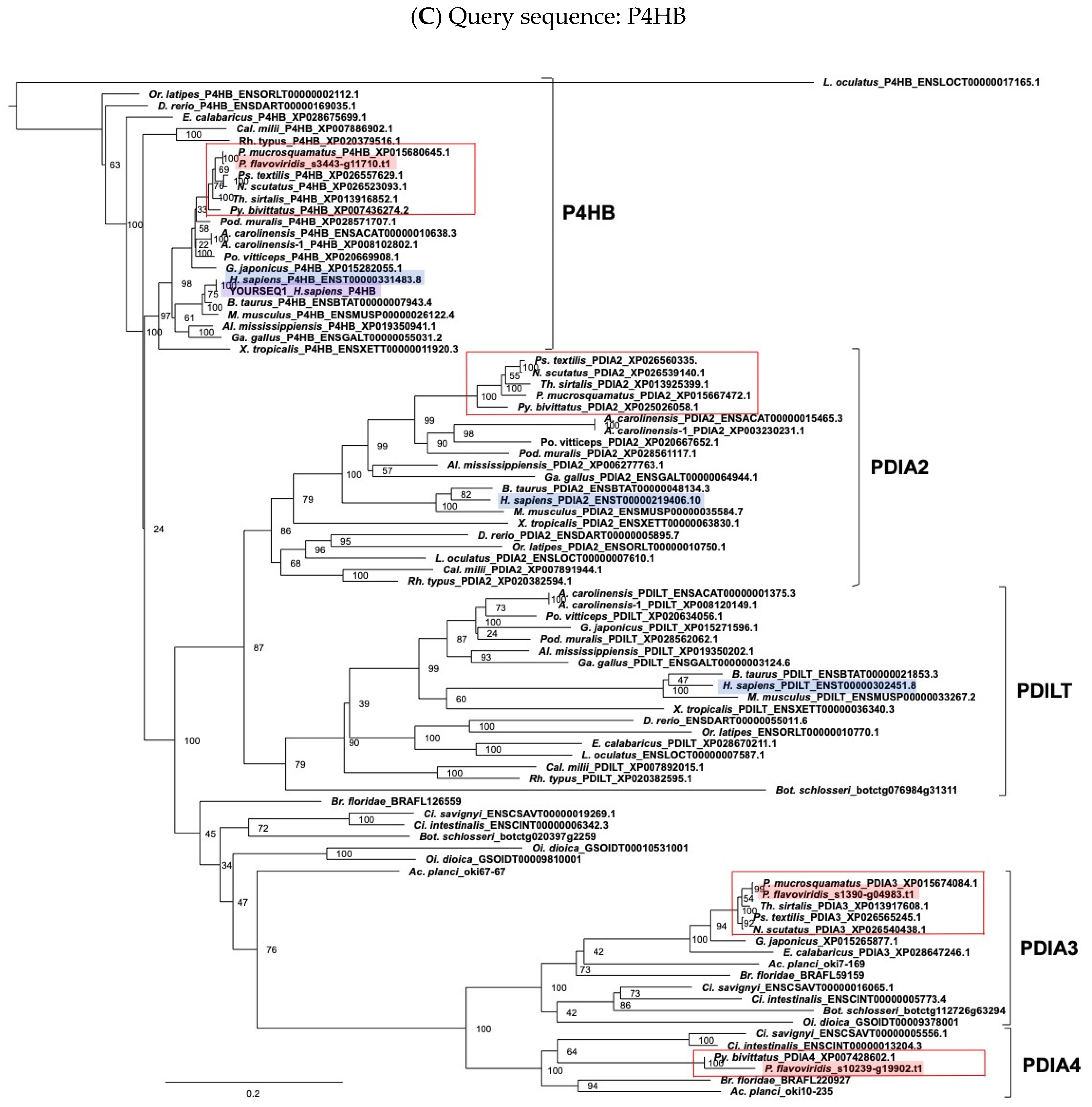
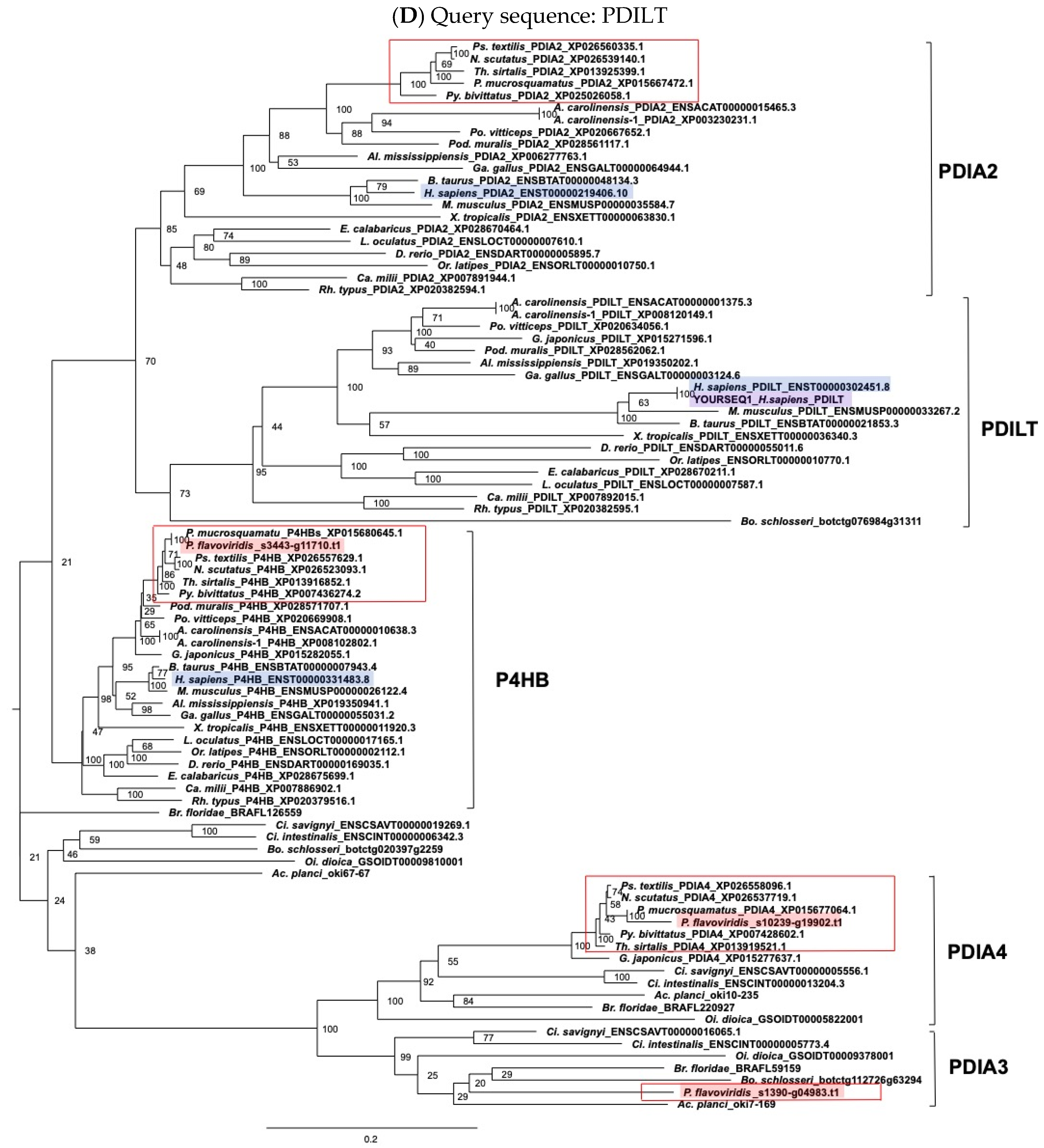
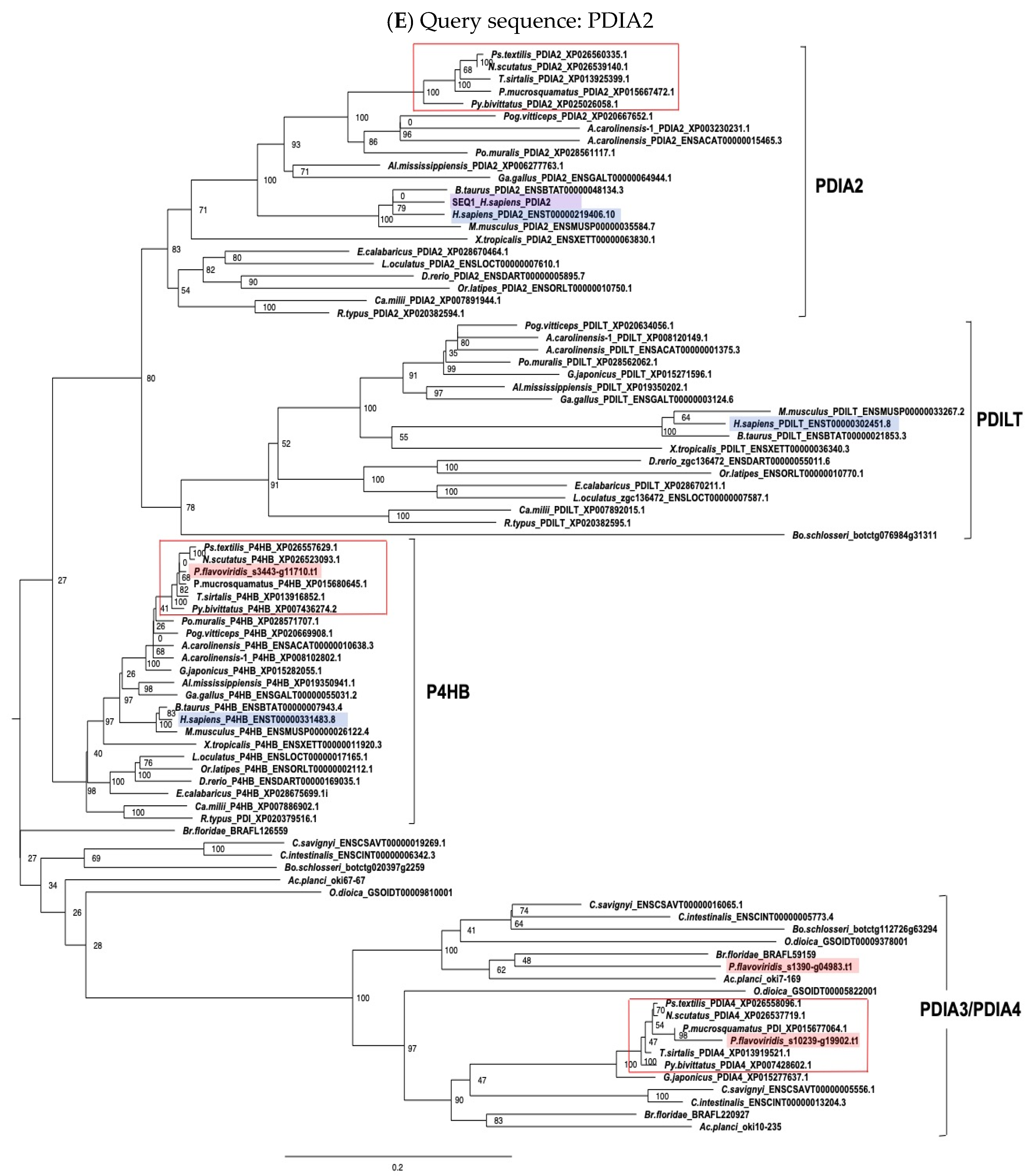
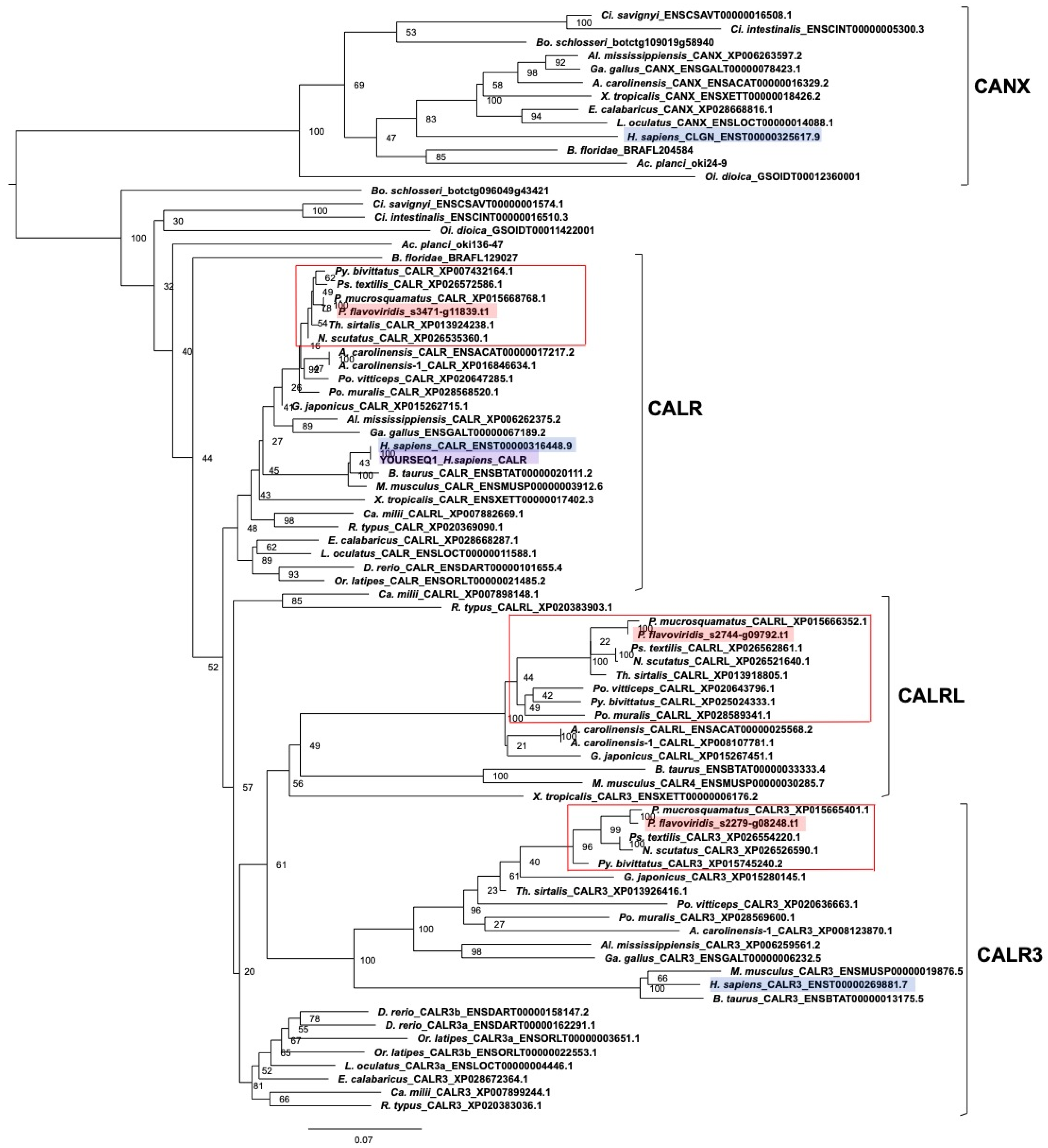
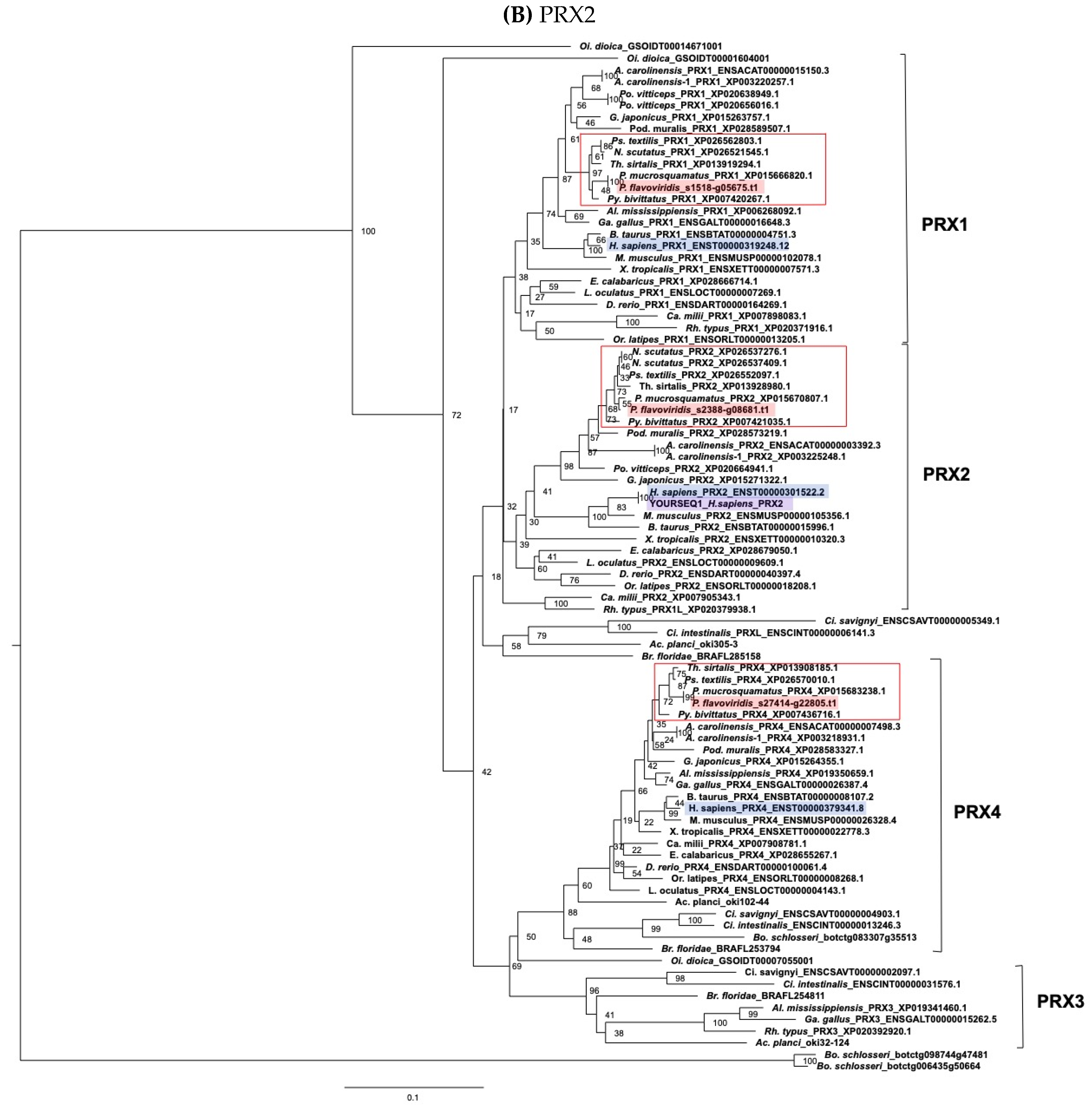
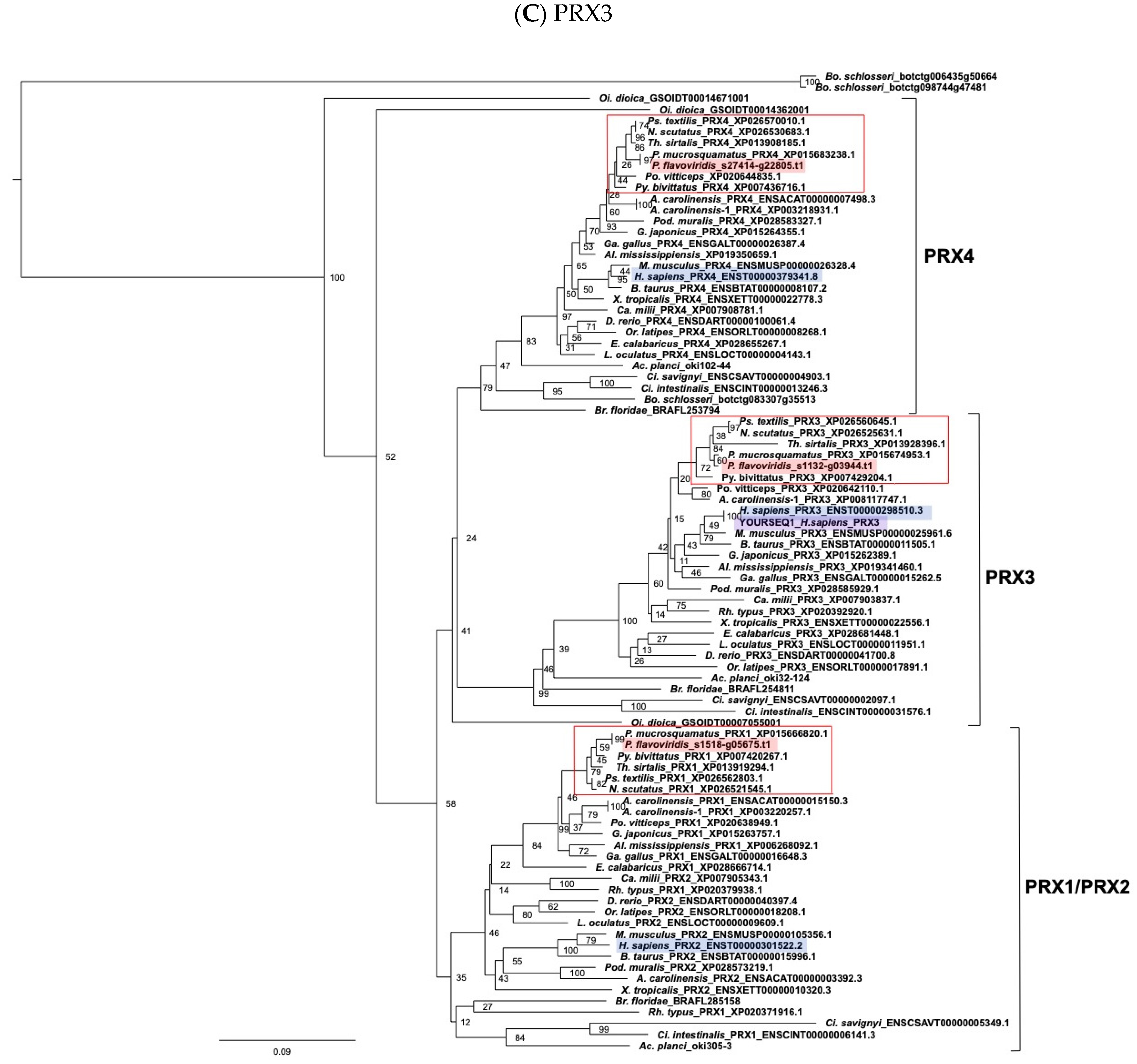
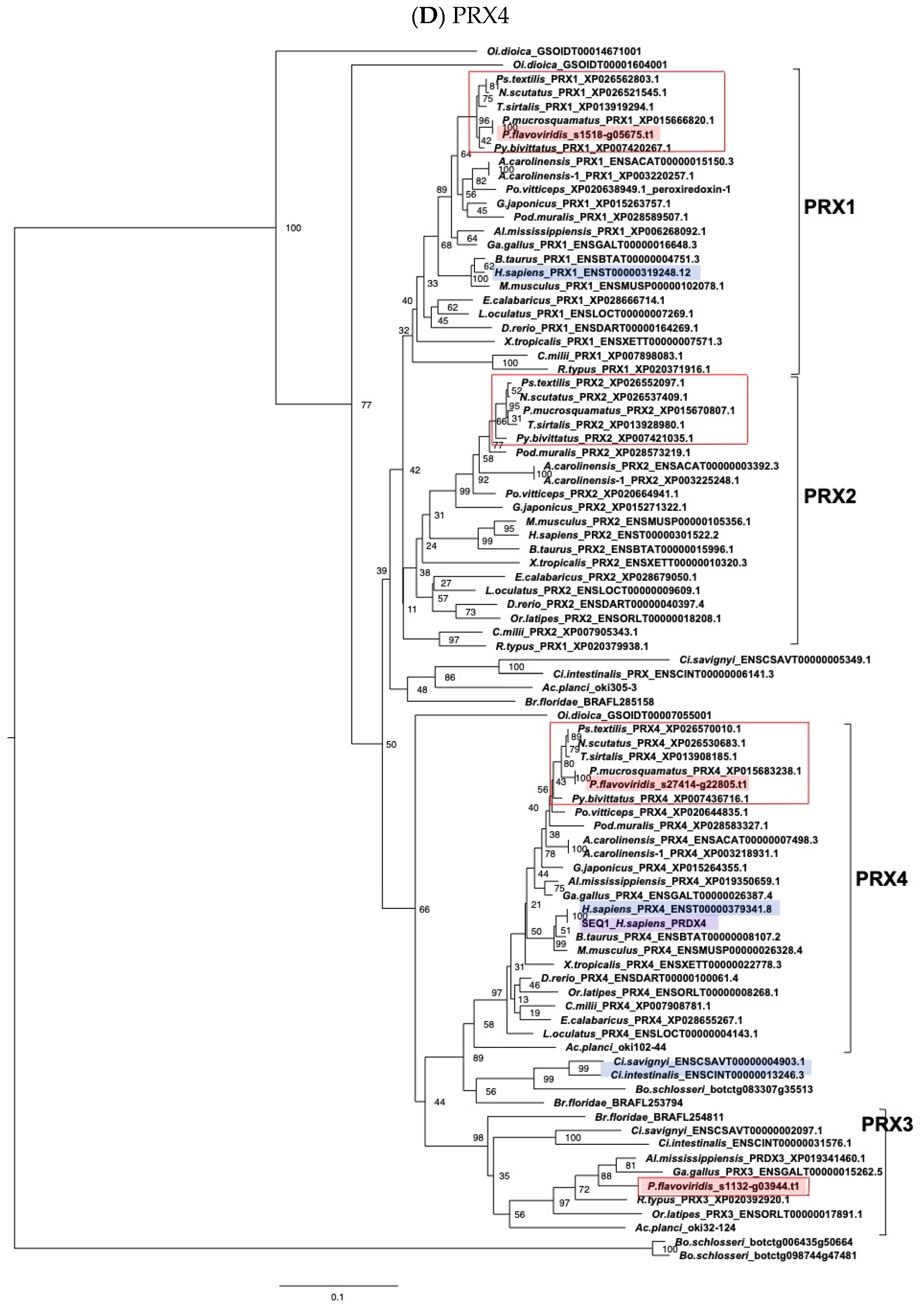
2.3. Characterization of Genes for PDI Family Proteins and PDI-Related Proteins in Habu Venom Glands
- (a)
- PDI family
- (b) Other PDI family-related members
- (c) Calreticulin members
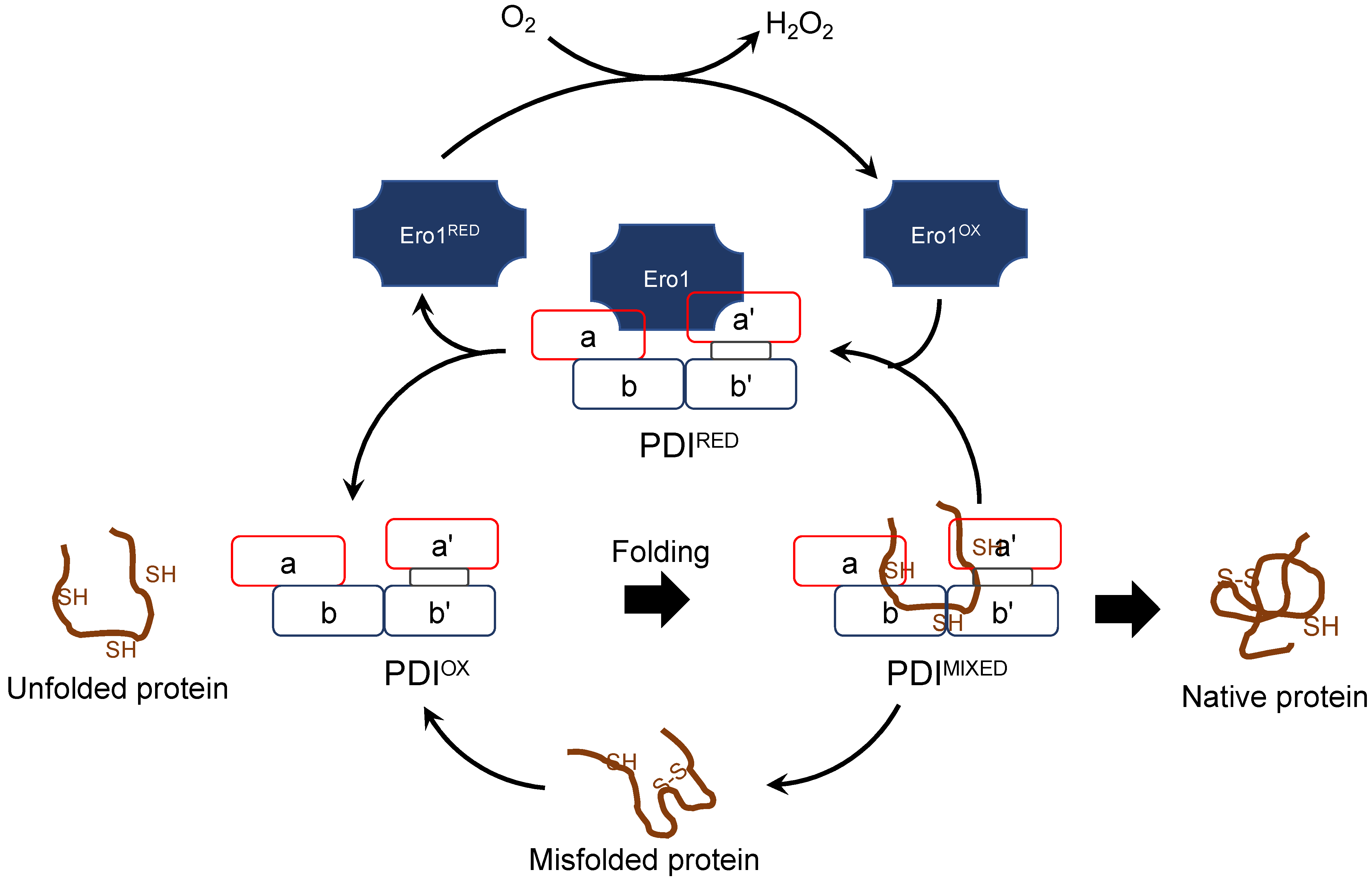
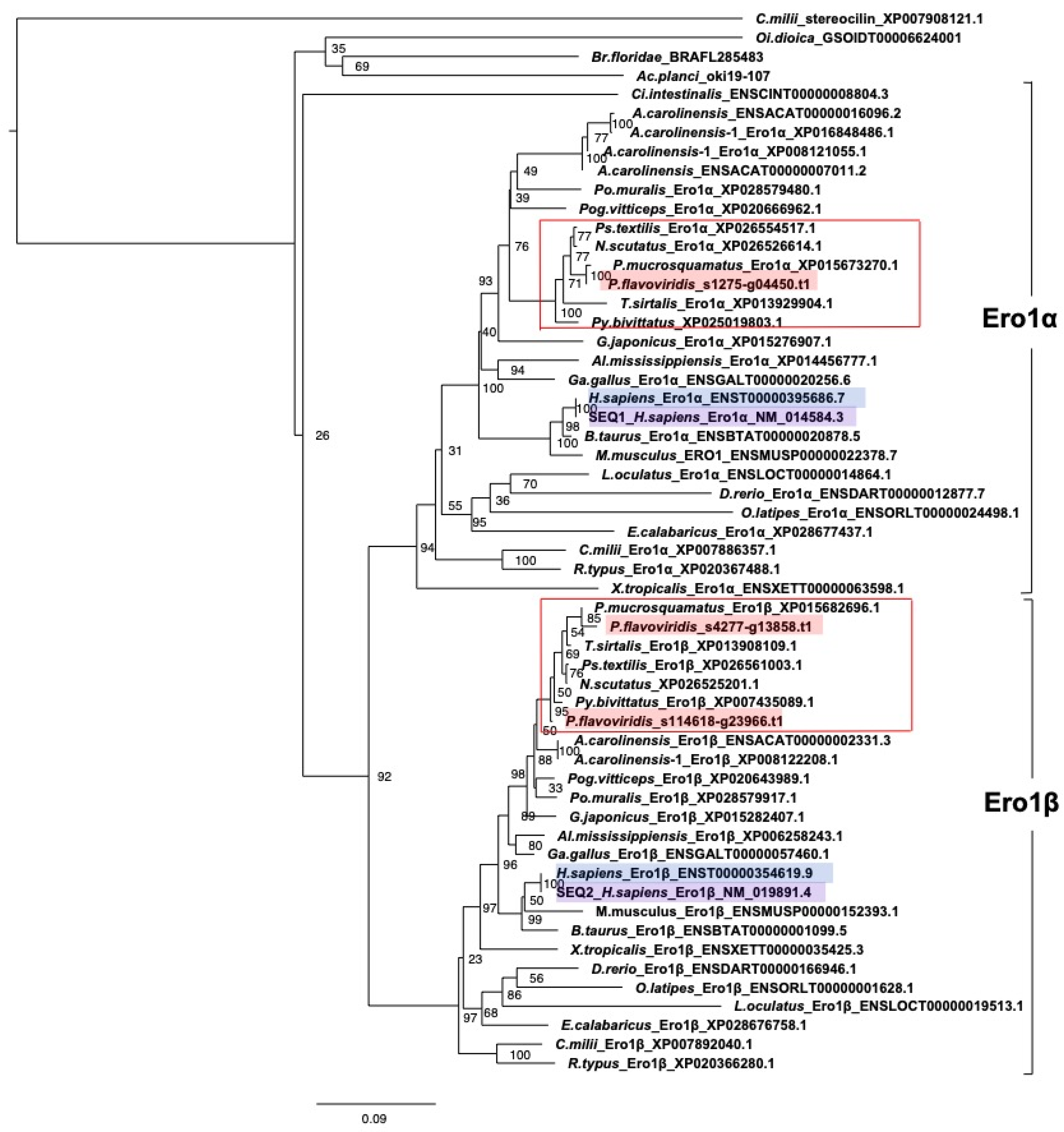
- (d) Redox partner proteins of PDI family proteins, Ero1α and Ero1β
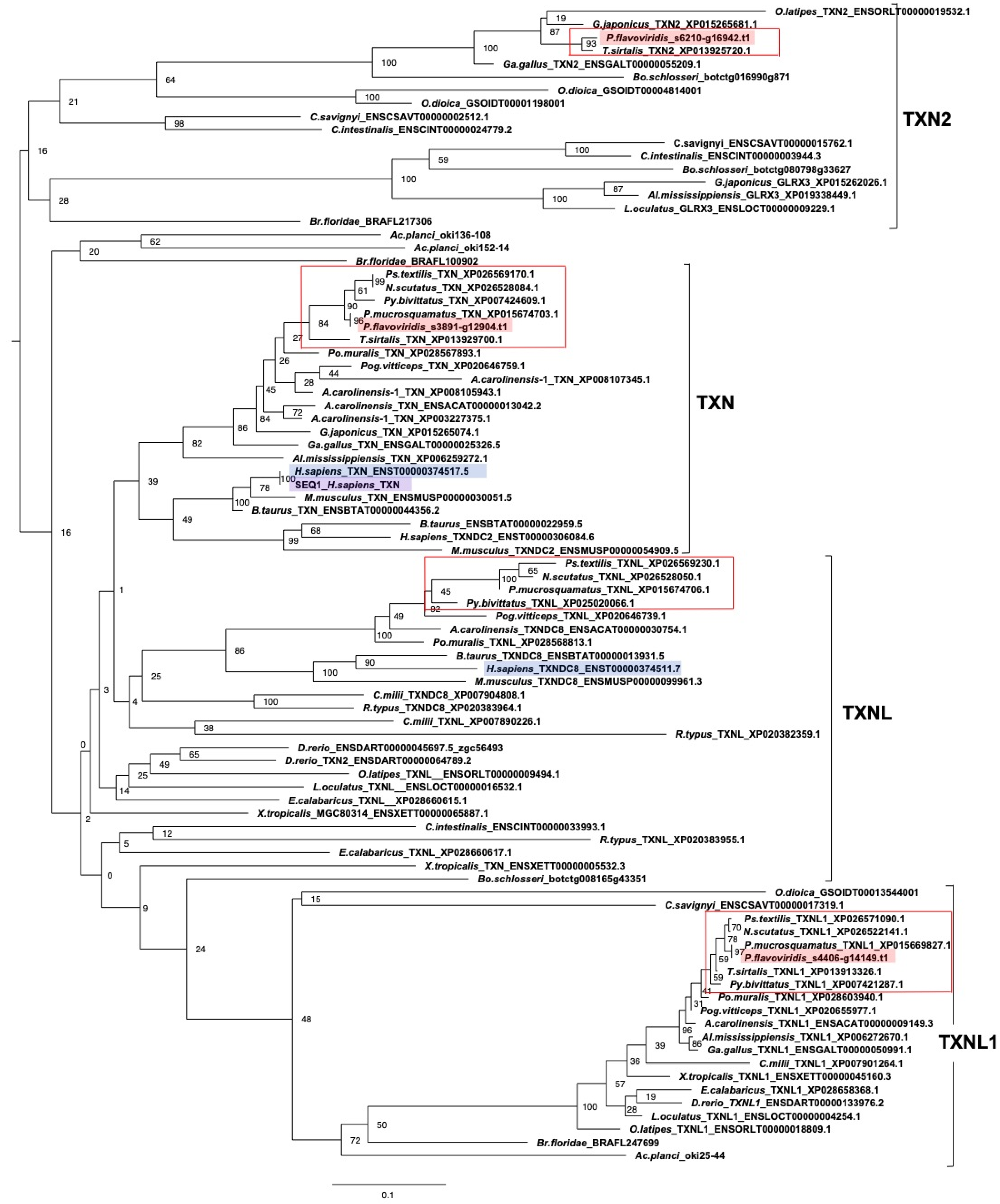
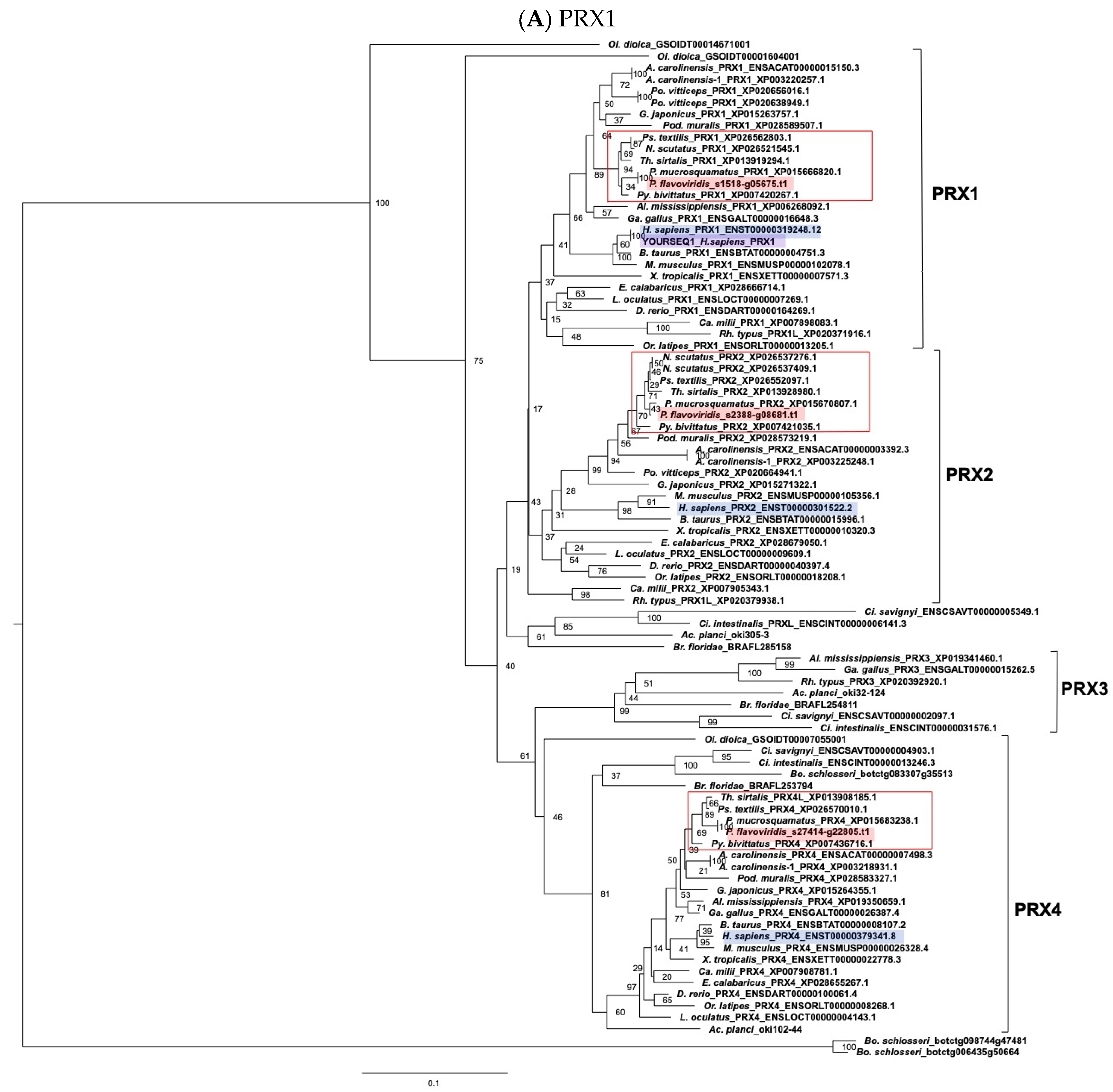
- (e) TXN and PRX members
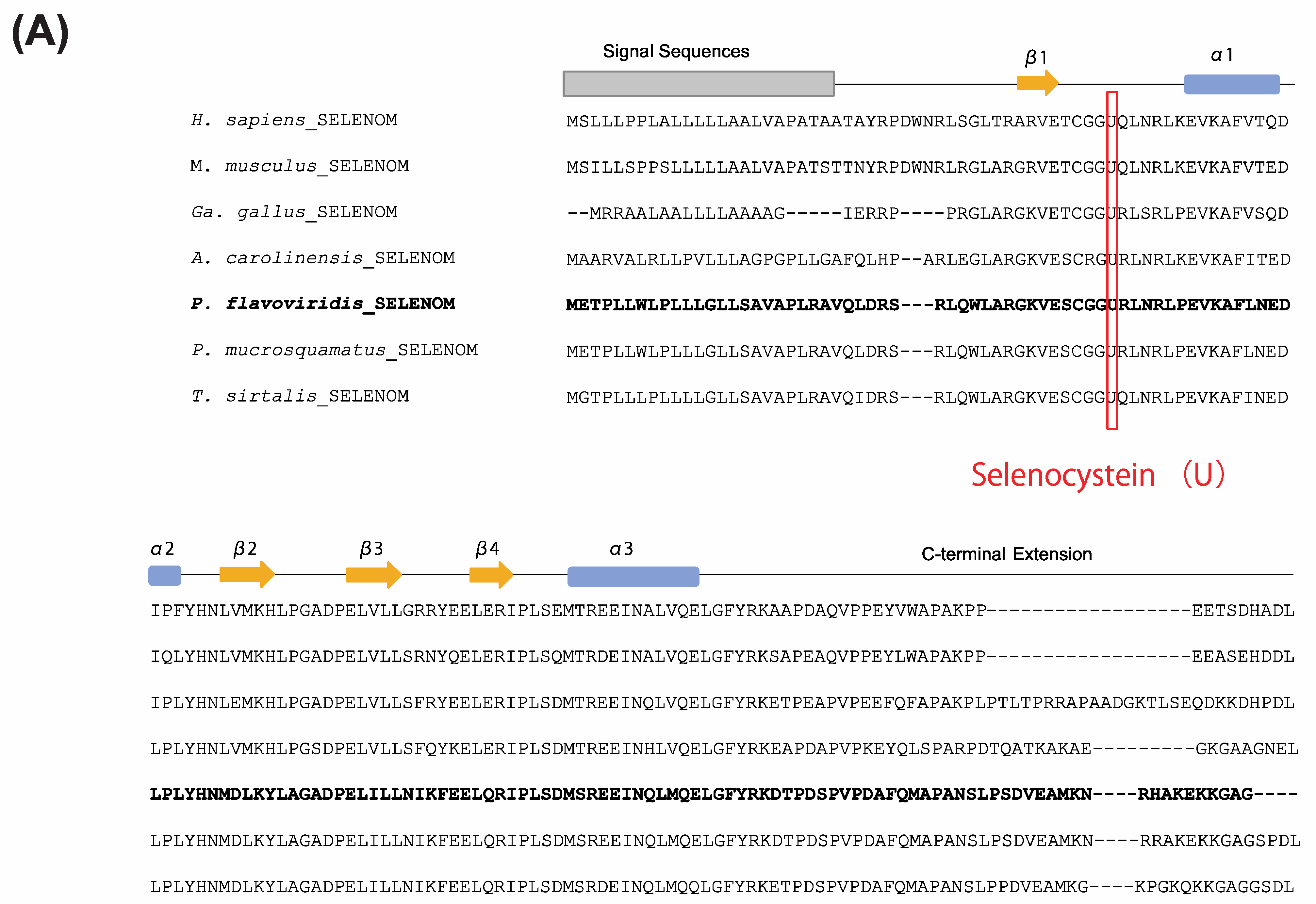
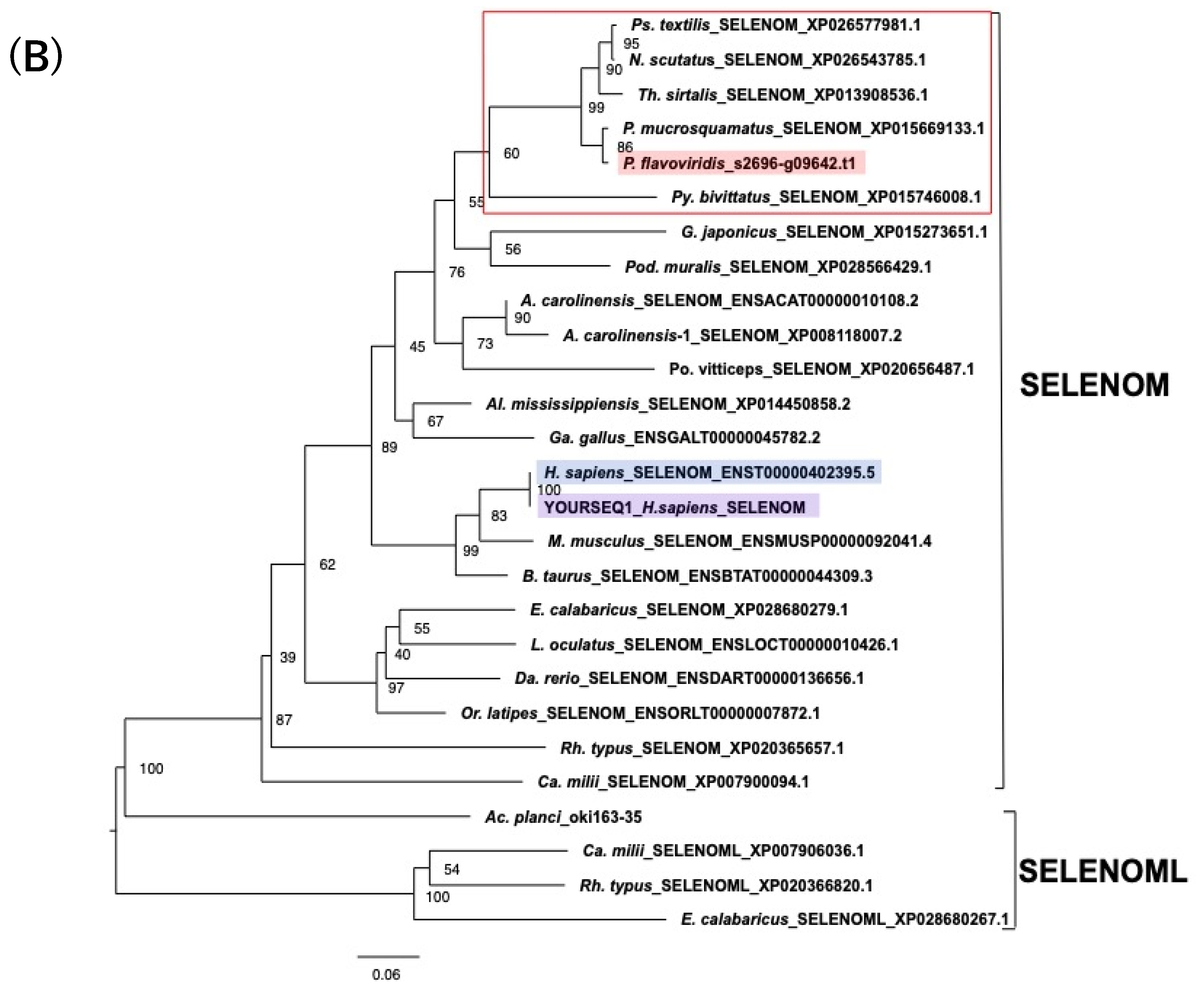
2.4. Characterization of the Habu SELENOM Gene
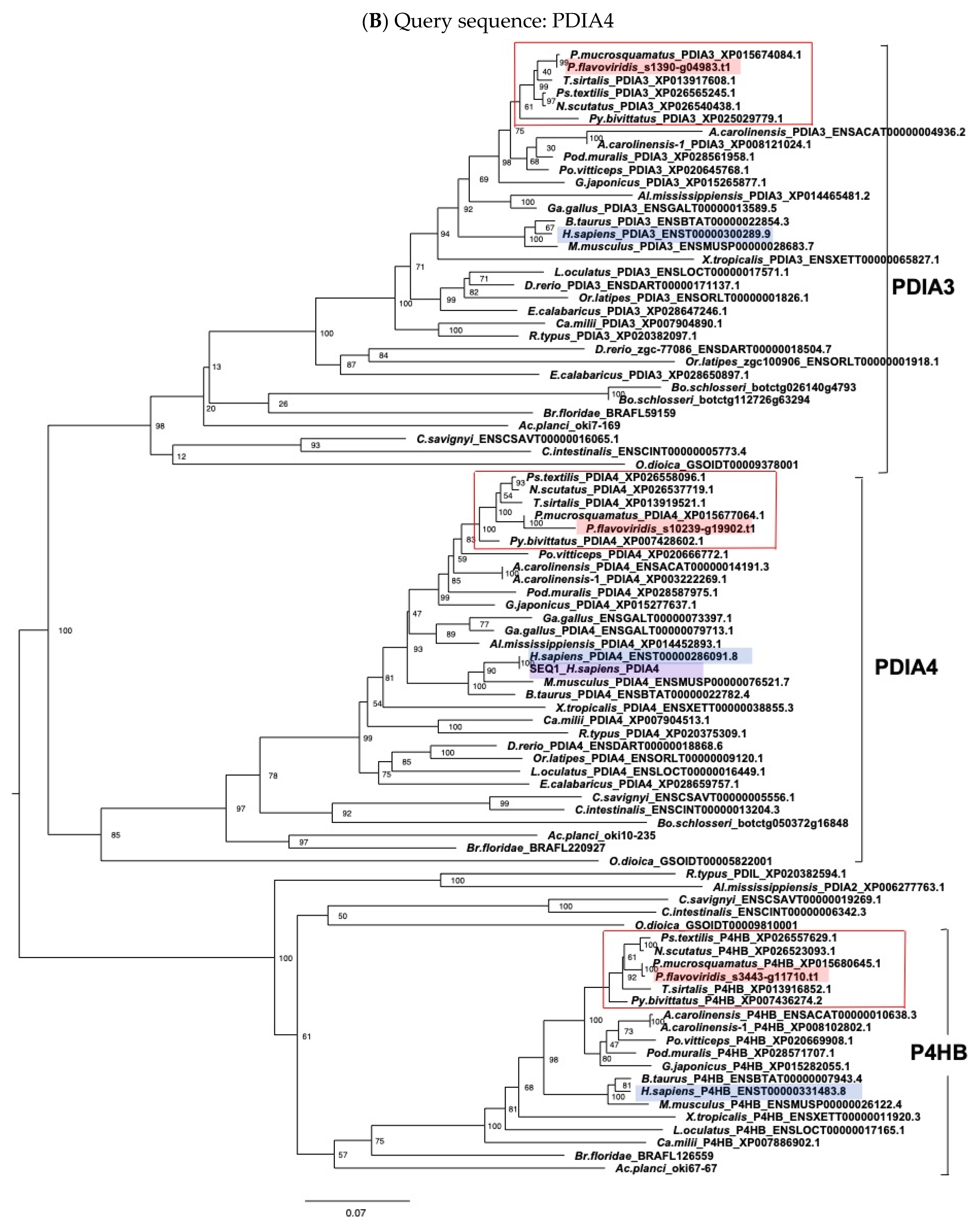
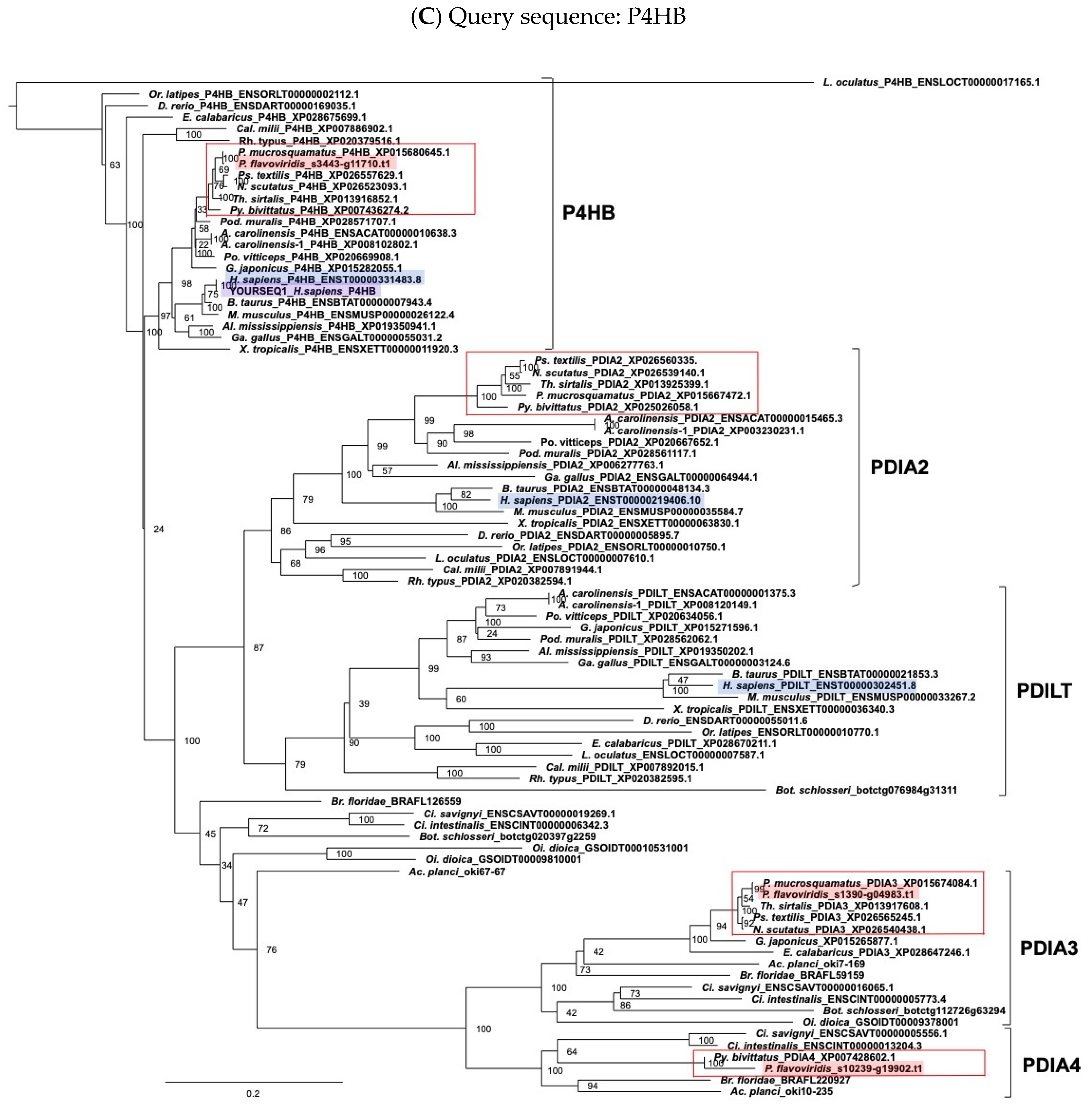
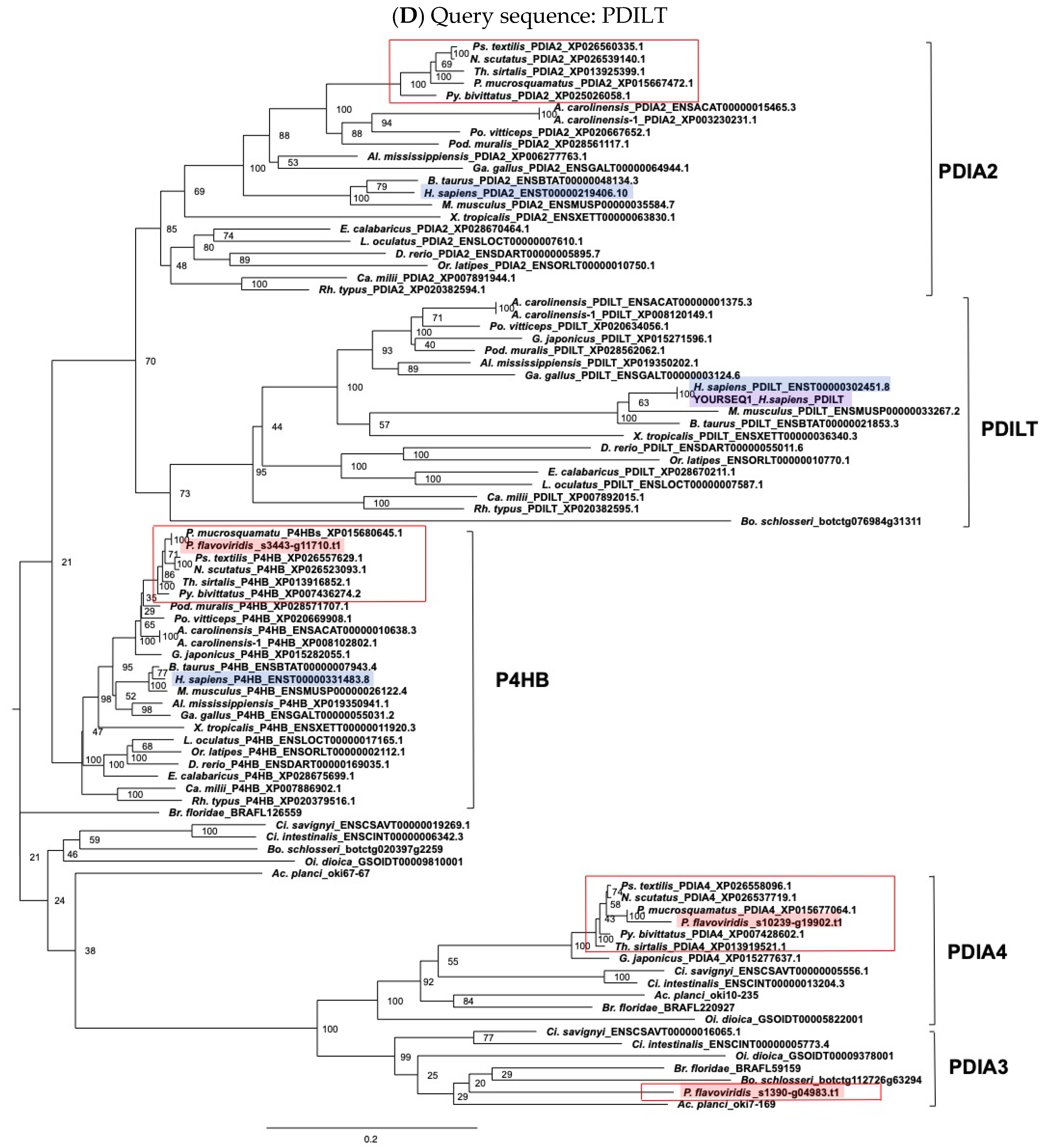
2.5. Expression Profiles of Genes Encoding PDI and PDI-Related Proteins in the Habu
2.6. No Accelerated Evolution of Genes for Candidate Venom Protein Modification Enzymes or Chaperones
3. Discussion
4. Conclusions
5. Materials and Methods
5.1. Transcriptomic Data and Comparative Analyses
5.2. Molecular Phylogenetic Analysis
5.3. Alignment and Molecular Evolutionary Analysis
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shibata, H.; Chijiwa, T.; Hattori, S.; Terada, K.; Ohno, M.; Fukumaki, Y. The taxonomic position and the unexpected divergence of the Habu viper, Protobothrops among Japanese subtropical islands. Mol. Phylogenet. Evol. 2016, 101, 91–100. [Google Scholar] [CrossRef] [PubMed]
- Miyagi, Y. Dokujyakousyoh. Clin. All-Round 2004, 53, 1245–1249. [Google Scholar]
- Aird, S.D.; Watanabe, Y.; Villar-Briones, A.; Roy, M.C.; Terada, K.; Mikheyev, A.S. Quantitative high-throughput profiling of snake venom gland transcriptomes and proteomes (Ovophis okinavensis and Protobothrops flavoviridis). BMC Genom. 2013, 14, 790. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aird, S.D.; Aggarwal, S.; Villar-Briones, A.; Tin, M.M.; Terada, K.; Mikheyev, A.S. Snake venoms are integrated systems, but abundant venom proteins evolve more rapidly. BMC Genom. 2015, 16, 647. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Castoe, T.A.; Hall, K.T.; Guibotsy Mboulas, M.L.; Gu, W.; de Koning, A.P.; Fox, S.E.; Poole, A.W.; Vemulapalli, V.; Daza, J.M.; Mockler, T.; et al. Discovery of highly divergent repeat landscapes in snake genomes using high-throughput sequencing. Genome Biol. Evol. 2011, 3, 641–653. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ohno, M.; Ménez, R.; Ogawa, T.; Danse, J.M.; Shimohigashi, Y.; Fromen, C.; Ducancel, F.; Zinn-Justin, S.; Le Du, M.H.; Boulain, J.C.; et al. Molecular evolution of snake toxins: Is the functional diversity of snake toxins associated with a mechanism of accelerated evolution? Prog. Nucleic Acid Res. Mol. Biol. 1998, 59, 307–364. [Google Scholar]
- Ohno, M.; Ogawa, T.; Oda-Ueda, N.; Chijiwa, T.; Hattori, S. Accelerated and Regional Evolution of Snake Venom Gland Isozymes; Ménez, A., Ed.; Perspectives in Molecular Toxinology; John Wiley & Sons: New York, NY, USA, 2002; pp. 387–400. [Google Scholar]
- Ohno, M.; Chijiwa, T.; Oda-Ueda, N.; Ogawa, T.; Hattori, S. Molecular evolution of myotoxic phospholipases A2 from snake venom. Toxicon 2003, 42, 841–854. [Google Scholar] [CrossRef] [PubMed]
- Shibata, H.; Chijiwa, T.; Oda-Ueda, N.; Nakamura, H.; Yamaguchi, K.; Hattori, S.; Matsubara, K.; Matsuda, Y.; Yamashita, A.; Isomoto, A.; et al. The habu genome reveals accelerated evolution of venom protein genes. Sci. Rep. 2018, 8, 11300. [Google Scholar] [CrossRef]
- Ogawa, T.; Oda-Ueda, N.; Hisata, K.; Nakamura, H.; Chijiwa, T.; Hattori, S.; Isomoto, A.; Yugeta, H.; Yamasaki, S.; Fukumaki, Y.; et al. Alternative mRNA Splicing in Three Venom Families Underlying a Possible Production of Divergent Venom Proteins of the Habu Snake. Toxins 2019, 11, 581. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reeks, T.A.; Fry, B.G.; Alewood, P.F. Privileged frameworks from snake venom. Cell Mol. Life Sci. 2015, 72, 1939–1958. [Google Scholar] [CrossRef] [PubMed]
- Mobli, M.; King, G.F. NMR methods for determining disulfide-bond connectivities. Toxicon 2010, 56, 849–854. [Google Scholar] [CrossRef] [PubMed]
- Takeda, S.; Takeya, H.; Iwanaga, S. Snake venom metalloproteinases: Structure, function and relevance to the mammalian ADAM/ADAMTS family proteins. Biochim. Biophys. Acta 2012, 1824, 164–176. [Google Scholar] [CrossRef]
- Rokyta, D.R.; Lemmon, A.R.; Margres, M.J.; Aronow, K. The venom-gland transcriptome of the eastern diamondback rattlesnake (Crotalus adamanteus). BMC Genom. 2012, 13, 312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luna, M.S.; Valente RHe Perales, J.; Vieira, M.L.; Yamanouyea, N. Activation of Bothrops jararaca snake venom gland and venom production: A proteomic approach. J. Proteom. 2013, 94, 460–472. [Google Scholar] [CrossRef]
- Inoue, J.; Satoh, N. ORTHOSCOPE: An Automatic Web Tool for Phylogenetically Inferring Bilaterian Orthogroups with User-Selected Taxa. Mol. Biol. Evol. 2019, 36, 621–631. [Google Scholar] [CrossRef] [PubMed]
- Galligan, J.J.; Petersen, D.R. The human protein disulfide isomerase gene family. Hum. Genom. 2012, 6, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Inaba, K.; Masui, S.; Iida, H.; Vavassori, S.; Sitia, R.; Suzuki, M. Crystal structures of human Ero1α reveal the mechanisms of regulated and targeted oxidation of PDI. EMBO J. 2010, 29, 3330–3343. [Google Scholar] [CrossRef] [Green Version]
- Sato, Y.; Kojima, R.; Okumura, M.; Hagiwara, M.; Masui, S.; Maegawa, K.; Saiki, M.; Horibe, T.; Suzuki, M.; Inaba, K. Synergistic cooperation of PDI family members in peroxiredoxin 4-driven oxidative protein folding. Sci. Rep. 2013, 3, 2456. [Google Scholar] [CrossRef] [PubMed]
- Okumura, M.; Kadokura, H.; Inaba, K. Structures and functions of protein disulfide isomerase family members involved in proteostasis in the endoplasmic reticulum. Free Radic. Biol. Med. 2015, 83, 314–322. [Google Scholar] [CrossRef]
- Araki, K.; Inaba, K. Structure, mechanism, and evolution of Ero1 family enzymes. Antioxid. Redox Signal. 2012, 16, 790–799. [Google Scholar] [CrossRef]
- Andreu, C.I.; Woehlbier, U.; Torres, M.; Hetz, C. Protein disulfide isomerases in neurodegeneration: From disease mechanisms to biomedical applications. FEBS Lett. 2012, 586, 2826–2834. [Google Scholar] [CrossRef] [Green Version]
- Zito, E.; Melo, E.P.; Yang, Y.; Wahlander, Å.; Neubert, T.A.; Ron, D. Oxidative protein folding by an endoplasmic reticulum-localized peroxiredoxin. Mol. Cell 2010, 40, 787–797. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tavender, T.J.; Springate, J.J.; Bulleid, N.J. Recycling of peroxiredoxin IV provides a novel pathway for disulphide formation in the endoplasmic reticulum. EMBO J. 2010, 29, 4185–4197. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sato, Y.; Inaba, K. Disulfide bond formation network in the three biological kingdoms, bacteria, fungi and mammals. FEBS J. 2012, 279, 2262–2271. [Google Scholar] [CrossRef] [PubMed]
- Kojima, R.; Okumura, M.; Masui, S.; Kanemura, S.; Inoue, M.; Saiki, M.; Yamaguchi, H.; Hikima, T.; Suzuki, M.; Akiyama, S.; et al. Radically different thioredoxin domain arrangement of ERp46, an efficient disulfide bond introducer of the mammalian PDI family. Structure 2014, 22, 431–443. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dias-Gunasekara, S.; Gubbens, J.; van Lith, M.; Dunne, C.; Williams, J.A.G.; Kataky, R.; Scoones, D.; Lapthorn, A.; Bulleid, N.J.; Benham, A.M. Tissue-specific expression and dimerization of the endoplasmic reticulum oxidoreductase Ero1 beta. J. Biol. Chem. 2005, 280, 33066–33075. [Google Scholar] [CrossRef] [Green Version]
- Suryamohan, K.; Krishnankutty, S.P.; Guillory, J.; Jevit, M.; Schröder, M.S.; Wu, M.; Kuriakose, B.; Mathew, O.K.; Perumal, R.C.; Koludarov, I.; et al. The Indian cobra reference genome and transcriptome enables comprehensive identification of venom toxins. Nat. Genet. 2020, 52, 106–117. [Google Scholar] [CrossRef] [Green Version]
- Pagani, M.; Fabbri, M.; Benedetti, C.; Fassio, A.; Pilati, S.; Bulleid, N.J.; Cabibbo, A.; Sitia, R. Endoplasmic reticulum oxidoreductin 1-lbeta (ERO1-Lbeta), a human gene induced in the course of the unfolded protein response. J. Biol. Chem. 2000, 275, 23685–23692. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Zhu, L.; Wang, C.C. The endoplasmic reticulum sulfhydryl oxidase Ero1β drives efficient oxidative protein folding with loose regulation. Biochem. J. 2011, 434, 113–121. [Google Scholar] [CrossRef] [Green Version]
- Safavi-Hemami, H.; Siero, W.A.; Gorasia, D.G.; Young, N.D.; Macmillan, D.; Williamson, N.A.; Purcell, A.W. Specialisation of the venom gland proteome in predatory cone snails reveals functional diversification of the conotoxin biosynthetic pathway. J. Proteome Res. 2011, 10, 3904–3919. [Google Scholar] [CrossRef]
- Grabherr, M.G.; Haas, B.J.; Yassour, M.; Levin, J.Z.; Thompson, D.A.; Amit, I.; Adiconis, X.; Fan, L.; Raychowdhury, R.; Zeng, Q.; et al. Full-length transcriptome assembly from RNA-Seq data without a reference genome. Nat. Biotechnol. 2011, 29, 644–652. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haas, B.J.; Papanicolaou, A.; Yassour, M.; Grabherr, M.; Blood, P.D.; Bowden, J.; Couger, M.B.; Eccles, D.; Li, B.; Lieber, M.; et al. De novo transcript sequence reconstruction from RNA-seq using the Trinity platform for reference generation and analysis. Nat. Protoc. 2013, 8, 1494–1512. [Google Scholar] [CrossRef] [PubMed]
- Bolger, A.M.; Lohse, M.; Usadel, B. Trimmomatic: A flexible trimmer for Illumina sequence data. Bioinformatics 2014, 30, 2114–2120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bray, N.L.; Pimentel, H.; Melsted, P.; Pachter, L. Near-optimal probabilistic RNA-seq quantification. Nat. Biotechnol. 2016, 34, 525–527. [Google Scholar] [CrossRef] [PubMed]
- Katoh, K.; Misawa, K.; Kuma, K.; Miyata, T. MAFFT: A novel method for rapid multiple sequence alignment based on fast Fourier transform. Nucleic Acids Res. 2002, 30, 3059–3066. [Google Scholar] [CrossRef] [Green Version]
- Capella-Gutiérrez, S.; Silla-Martínez, J.M.; Gabaldón, T. trimAl: A tool for automated alignment trimming in large-scale phylogenetic analyses. Bioinformatics 2009, 25, 1972–1973. [Google Scholar] [CrossRef]
- Suyama, M.; Torrents, D.; Bork, P. PAL2NAL: Robust conversion of protein sequence alignments into the corresponding codon alignments. Nucleic Acids Res. 2006, 34, W609–W612. [Google Scholar] [CrossRef] [Green Version]
- Saitou, N.; Nei, M. The neighbor-joining method: A new method for reconstructing phylogenetic trees. Mol. Biol. Evol. 1987, 4, 406–425. [Google Scholar] [CrossRef]
- Popescu, A.A.; Huber, K.T.; Paradis, E. ape 3.0: New tools for distance-based phylogenetics and evolutionary analysis in R. Bioinformatics 2012, 28, 1536–1537. [Google Scholar] [CrossRef]
- Lefort, V.; Desper, R.; Gascuel, O. FastME 2.0: A Comprehensive, Accurate and Fast Distance-Based Phylogeny Inference Program. Mol. Biol. Evol. 2015, 32, 2798–2800. [Google Scholar] [CrossRef] [Green Version]
- Tamura, K.; Nei, M. Estimation of the number of nucleotide substitutions in the control region of mitochondrial DNA in humans and chimpanzees. Mol. Biol. Evol. 1993, 10, 512–526. [Google Scholar] [CrossRef]
- Yang, Z. Maximum likelihood phylogenetic estimation from DNA sequences with variable rates over sites: Approximate methods. J. Mol. Evol. 1994, 39, 306–314. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Whelan, S.; Goldman, N. A general empirical model of protein evolution derived from multiple protein families using a maximum-likelihood approach. Mol. Biol. Evol. 2001, 18, 691–699. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Edgar, R.C. MUSCLE: Multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res. 2004, 32, 1792–1797. [Google Scholar] [CrossRef] [Green Version]
- Larkin, M.A.; Blackshields, G.; Brown, N.P.; Chenna, R.; McGettigan, P.A.; McWilliam, H.; Valentin, F.; Wallace, I.M.; Wilm, A.; Lopez, R.; et al. Clustal W and Clustal X version 2.0. Bioinformatics 2007, 23, 2947–2948. [Google Scholar] [CrossRef] [Green Version]
- Nei, M.; Gojobori, T. Simple methods for estimating the numbers of synonymous and nonsynonymous nucleotide substitutions. Mol. Biol. Evol. 1986, 3, 418–426. [Google Scholar] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gene Model ID | Gene Name | Annotation by Blast2GO | TPM | |
|---|---|---|---|---|
| habu1_s258676_g24318.t1 | CNP01 | Bradykinin-potentiating and C-type natriuretic peptides | 438,781.0 | Venom protein |
| habu1_s47459_g23397.t1 | svPLA2-02, svPLA2-03 | phospholipase a2 | 88,799.1 | Venom protein |
| habu1_s14911_g21429.t1 | svMP06 | p-ii partial | 76,130.9 | Venom protein |
| habu1_s9571_g19434.t1 | svPLA2-01 | phospholipase a2 | 44,208.4 | Venom protein |
| habu1_s9570_g19432.t1 | svPLA2-07 | phospholipase a2 | 34,366.9 | Venom protein |
| habu1_s9571_g19433.t1 | svPLA2-08 | phospholipase a2 | 31,067.9 | Venom protein |
| habu1_s14911_g21430.t1 | svMP07, svMP08 | snake venom metalloproteinase | 30,773.7 | Venom protein |
| habu1_s10061_g19809.t1 | svCTLP06 | flavocetin-A beta | 15,201.6 | Venom protein |
| habu1_s3443_g11710.t1 | P4HB | protein disulfide-isomerase | 8572.4 | Modification enzyme for proteins analyzed in this study |
| habu1_s10061_g19810.t1 | svCTLP03, svCTLP04, svCTLP07 | snaclec stejaggregin-a subunit alpha | 6786.0 | Venom protein |
| habu1_s3258_g11210.t1 | svMP04 | metalloprotease piia | 4821.0 | Venom protein |
| habu1_s3168_g10977.t1 | svCTLP08 | venom c-type lectin mannose binding isoform 1 | 3305.5 | Venom protein |
| habu1_s3258_g11211.t1 | svMP05 | snake venom metalloproteinase | 2659.2 | Venom protein |
| habu1_s6789_g17480.t1 | svSP04 | snake venom serine protease 2a homolog | 2416.4 | Venom protein |
| habu1_s2955_g10552.t1 | elongation factor 1-alpha 1 | 2283.4 | ||
| habu1_s402940_g24950.t1 | LAAO01 | l-amino acid oxidase | 2124.7 | Venom protein |
| habu1_s158_g00895.t1 | forkhead box protein j1 | 2102.3 | ||
| habu1_s5309_g15576.t1 | 40S ribosomal protein S25 | 1678.5 | Ribosomal protein | |
| habu1_s2696_g09642.t1 | SELENOM | Selenoprotein M | 1514.7 | Modification enzyme for proteins analyzed in this study |
| habu1_s68614_g23647.t1 | 60s ribosomal protein l7 | 1508.8 | Ribosomal protein | |
| habu1_s1917_g07050.t1 | 60s ribosomal protein l7a | 1458.7 | Ribosomal protein | |
| habu1_s4106_g13431.t1 | serine partial | 1457.8 | Venom protein | |
| habu1_s3471_g11839.t1 | CALR | Calreticulin | 1422.0 | Modification enzyme for proteins analyzed in this study |
| habu1_s4158_g13542.t1 | 55 kda erythrocyte membrane protein | 1406.7 | ||
| habu1_s4037_g13262.t1 | low quality protein: glutathione peroxidase 3 | 1337.9 | ||
| habu1_s3765_g12603.t1 | 40s ribosomal protein s3a | 1259.4 | Ribosomal protein | |
| habu1_s22025_g22470.t1 | CRISP01, CRISP02 | cysteine-rich venom partial | 1201.7 | Venom protein |
| habu1_s22023_g22469.t1 | svSP11 | snake venom serine protease 2 | 1194.1 | Venom protein |
| habu1_s6274_g17028.t1 | ubiquitin-40s ribosomal protein s27a | 1159.9 | Ribosomal protein | |
| habu1_s1466_g05403.t1 | peptidyl-prolyl cis-trans isomerase a-like | 1149.4 | ||
| habu1_s399953_g24864.t1 | svMP09, svMP10 | metalloproteinase precursor | 1138.2 | Venom protein |
| habu1_s1390_g04983.t1 | PDIA3 | protein disulfide-isomerase a3 | 1085.9 | Modification enzyme for proteins analyzed in this study |
| habu1_s2087_g07635.t1 | ribosomal protein | 1075.8 | Ribosomal protein | |
| habu1_s7284_g17906.t1 | 40s ribosomal protein s13 | 1019.6 | Ribosomal protein | |
| habu1_s9530_g19385.t1 | Elongation factor 1-beta | 999.5 | ||
| habu1_s4833_g14854.t1 | tmsb4x partial | 971.8 | ||
| habu1_s2449_g08987.t1 | 60s ribosomal protein l31 | 965.9 | Ribosomal protein | |
| habu1_s7991_g18513.t1 | 40s ribosomal protein partial | 934.3 | Ribosomal protein | |
| habu1_s37466_g23178.t1 | growth-related translationally controlled tumor protein | 928.1 | ||
| habu1_s16120_g21649.t1 | 60s ribosomal protein l18a | 906.8 | Ribosomal protein | |
| habu1_s7978_g18472.t1 | 60s acidic ribosomal protein p2 | 902.7 | Ribosomal protein | |
| habu1_s2862_g10314.t1 | svMP01, svMP02, svMP03, svMP11, nvMP57 | disintegrin and metalloproteinase domain-containing protein 28 | 902.6 | Venom protein |
| habu1_s1408_g05043.t1 | 60s ribosomal protein l5 | 892.3 | Ribosomal protein | |
| habu1_s74_g00428.t1 | 60s ribosomal protein l11 | 872.1 | Ribosomal protein | |
| habu1_s6028_g16570.t1 | sv5Nase | ecto-5 -nucleotidase | 852.8 | Venom protein |
| habu1_s399842_g24584.t1 | 60s ribosomal protein l6 | 852.5 | Ribosomal protein | |
| habu1_s188_g01057.t1 | 60s ribosomal protein partial | 852.1 | Ribosomal protein | |
| habu1_s1608_g06024.t1 | 40s ribosomal protein s4 | 837.9 | Ribosomal protein | |
| habu1_s1167_g04045.t1 | polyadenylate-binding protein 1 isoform x1 | 834.0 | ||
| habu1_s2592_g09366.t1 | cytoplasmic 2 | 819.2 |
| Gene Model ID | Gene Name | Venom Gland (Specimen #1) | Venom Gland (Specimen #2) | Venom Fang Forming Tissue | Lung | Liver | Kidney | Small Intestine | Colon | Stomach | Pancreas | Heart | Masseter Muscle | Brain (Specimen #1) | Brain (Specimen #2) | Eye | Nose | Pit, Infrared Sensing Organ | Spleen | Ovary | Fetal Fibroblast |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| habu1_s2696_g09642 | SELENOM | 1928.2 | 1514.7 | 273.2 | 104.5 | 3.9 | 12.1 | 38.7 | 179.5 | 31.5 | 311.1 | 53.2 | 15.0 | 178.8 | 72.2 | 675.8 | 1184.5 | 407.1 | 213.1 | 4.1 | 261.9 |
| habu1_s3471_g11839 | CALR | 361.1 | 1422.0 | 531.0 | 258.3 | 71.7 | 172.5 | 295.9 | 375.4 | 167.4 | 78.4 | 139.7 | 141.8 | 281.4 | 319.0 | 184.1 | 569.8 | 413.7 | 159.2 | 464.0 | 1859.1 |
| habu1_s3443_g11710 | P4HB | 13,303.9 | 8572.4 | 955.2 | 1564.9 | 3765.2 | 1874.4 | 4083.9 | 1789.5 | 2381.0 | 2265.3 | 349.7 | 601.7 | 249.8 | 213.4 | 771.6 | 1268.3 | 1256.5 | 1916.5 | 645.9 | 917.0 |
| habu1_s2789_g10033 | PDIA2 | 0.1 | 0.2 | 0.4 | 0.7 | 0.1 | 0.0 | 0.4 | 0.3 | 59.1 | 0.1 | 0.2 | 0.6 | 0.6 | 0.5 | 0.3 | 1.1 | 0.5 | 0.1 | 0.5 | 0.2 |
| habu1_s1390_g04983 | PDIA3 | 2266.3 | 1085.9 | 601.2 | 856.4 | 420.2 | 614.1 | 1074.1 | 857.4 | 675.8 | 425.2 | 272.4 | 214.7 | 270.0 | 276.4 | 434.1 | 892.6 | 728.6 | 455.6 | 427.0 | 872.6 |
| habu1_s10239_g19902 | PDIA4 | 95.7 | 172.3 | 159.4 | 164.9 | 68.8 | 83.5 | 61.6 | 121.6 | 164.6 | 129.3 | 63.4 | 29.2 | 47.0 | 50.3 | 82.5 | 141.3 | 182.9 | 122.6 | 134.7 | 252.0 |
| habu1_s2439_g08885 | PDIA5 | 15.8 | 27.7 | 35.9 | 14.1 | 9.9 | 7.1 | 26.8 | 44.1 | 24.9 | 3.0 | 5.6 | 1.5 | 17.4 | 13.8 | 14.4 | 38.1 | 34.2 | 6.5 | 72.8 | 79.6 |
| habu1_s604_g02858 | PDIA6 | 181.2 | 388.5 | 146.1 | 71.4 | 18.6 | 33.8 | 35.9 | 146.4 | 40.3 | 29.6 | 34.4 | 30.5 | 68.4 | 66.3 | 62.9 | 195.6 | 149.5 | 83.5 | 135.3 | 541.2 |
| habu1_s25599_g22719 | ERp27 | 0.1 | 0.7 | 1.5 | 2.9 | 0.0 | 1.2 | 0.2 | 2.4 | 0.7 | 402.7 | 0.5 | 1.6 | 1.1 | 0.8 | 1.6 | 0.6 | 4.9 | 240.8 | 0.3 | 2.0 |
| habu1_s66_g00353 | ERp27 | 15.7 | 5.9 | 119.4 | 203.5 | 20.6 | 32.1 | 41.4 | 170.0 | 50.9 | 885.9 | 49.8 | 12.0 | 275.5 | 312.6 | 39.9 | 86.8 | 134.5 | 791.5 | 6.4 | 262.6 |
| habu1_s399842_g24580 | ERp29 | 53.1 | 38.4 | 112.9 | 84.2 | 19.5 | 22.6 | 100.1 | 109.9 | 43.6 | 10.1 | 36.5 | 15.4 | 44.9 | 48.3 | 40.5 | 180.2 | 102.4 | 32.8 | 52.0 | 239.2 |
| habu1_s32648_g23040 | ERp44 | 15.2 | 15.5 | 45.5 | 17.9 | 5.8 | 13.1 | 19.6 | 22.8 | 15.6 | 4.3 | 12.3 | 4.5 | 24.3 | 22.9 | 14.8 | 32.1 | 27.2 | 10.4 | 42.5 | 25.7 |
| habu1_s1939_g07114 | TMX1 | 6.9 | 5.0 | 23.1 | 25.4 | 17.1 | 22.9 | 20.3 | 23.8 | 11.2 | 4.7 | 21.4 | 11.9 | 30.5 | 38.9 | 12.9 | 21.1 | 21.6 | 17.8 | 46.5 | 26.3 |
| habu1_s5624_g16107 | TMX2 | 18.9 | 9.5 | 36.8 | 43.6 | 25.9 | 45.5 | 30.2 | 35.9 | 42.8 | 9.1 | 93.2 | 29.3 | 122.0 | 142.7 | 35.3 | 43.4 | 42.5 | 14.8 | 101.2 | 26.9 |
| habu1_s4708_g14660 | TMX3 | 8.0 | 3.8 | 43.3 | 23.1 | 5.4 | 19.7 | 13.0 | 19.3 | 13.6 | 2.2 | 20.5 | 4.5 | 42.7 | 43.6 | 15.3 | 54.6 | 33.7 | 12.5 | 25.6 | 56.0 |
| habu1_s8507_g18763 | TMX4 | 1.7 | 1.4 | 9.9 | 8.6 | 25.7 | 14.9 | 6.0 | 6.6 | 3.1 | 0.5 | 3.4 | 1.0 | 19.5 | 16.5 | 6.5 | 5.5 | 9.5 | 4.5 | 51.4 | 10.8 |
| habu1_s3682_g12384 | TXNDC5 | 53.1 | 38.4 | 112.9 | 84.2 | 19.5 | 22.6 | 100.1 | 109.9 | 43.6 | 10.1 | 36.5 | 15.4 | 44.9 | 48.3 | 40.5 | 180.2 | 102.4 | 32.8 | 52.0 | 239.2 |
| habu1_s2744_g09787 | TXNDC12 | 99.8 | 160.0 | 134.1 | 101.1 | 28.8 | 51.5 | 72.6 | 75.0 | 58.3 | 21.8 | 54.4 | 24.5 | 99.7 | 70.7 | 60.8 | 127.3 | 127.1 | 50.3 | 49.0 | 224.3 |
| habu1_s49803_g23445 | AGR2 | 22.4 | 3.0 | 406.3 | 183.2 | 0.3 | 77.9 | 199.0 | 777.2 | 649.1 | 1.8 | 0.5 | 12.3 | 6.8 | 1.4 | 33.8 | 884.0 | 356.9 | 0.7 | 0.7 | 0.2 |
| habu1_s49803_g23446 | AGR3 | 0.0 | 0.0 | 0.3 | 0.0 | 0.6 | 0.1 | 0.0 | 0.0 | 0.1 | 0.5 | 0.2 | 0.1 | 0.0 | 0.1 | 0.4 | 11.4 | 0.6 | 0.1 | 0.3 | 0.0 |
| habu1_s2168_g07811 | DNAJC10 | 2.2 | 5.7 | 10.8 | 3.3 | 0.6 | 4.8 | 4.5 | 6.8 | 9.6 | 0.4 | 11.0 | 5.2 | 18.1 | 16.3 | 3.8 | 10.0 | 10.7 | 2.9 | 102.0 | 58.3 |
| habu1_s2370_g08604 | CASQ1 | 3732.7 | 97.1 | 485.9 | 6.5 | 4.7 | 12.9 | 118.6 | 5.1 | 16.0 | 1.2 | 19.3 | 42,708.5 | 61.8 | 59.8 | 142.0 | 114.3 | 1277.6 | 4.3 | 39.8 | 9.4 |
| habu1_s8721_g18867 | CASQ2 | 1.3 | 0.1 | 0.5 | 2.6 | 0.0 | 0.5 | 0.2 | 1.9 | 0.8 | 0.1 | 662.8 | 11.7 | 22.2 | 20.0 | 22.2 | 0.9 | 26.3 | 1.3 | 1.7 | 0.6 |
| habu1_s1275_g04450 | Ero1α | 1.8 | 3.3 | 21.0 | 9.2 | 1.2 | 3.2 | 7.4 | 13.3 | 16.7 | 0.3 | 2.0 | 0.4 | 25.2 | 18.9 | 4.6 | 12.0 | 5.9 | 3.3 | 7.7 | 29.3 |
| habu1_s114618_g23966 habu1_s4277_g13858 | Ero1β | 75.1 | 247.6 | 91.8 | 44.0 | 50.4 | 24.2 | 20.7 | 37.1 | 45.1 | 182.8 | 21.5 | 8.5 | 49.6 | 59.8 | 60.1 | 498.9 | 125.2 | 200.8 | 255.9 | 117.9 |
| habu1_s27414_g22805 | PRX4 | 211.6 | 229.4 | 118.4 | 280.8 | 342.2 | 98.1 | 245.3 | 154.7 | 157.9 | 229.6 | 71.1 | 28.8 | 52.8 | 53.5 | 68.6 | 121.5 | 144.5 | 187.7 | 104.7 | 215.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Isomoto, A.; Shoguchi, E.; Hisata, K.; Inoue, J.; Sun, Y.; Inaba, K.; Satoh, N.; Ogawa, T.; Shibata, H. Active Expression of Genes for Protein Modification Enzymes in Habu Venom Glands. Toxins 2022, 14, 300. https://doi.org/10.3390/toxins14050300
Isomoto A, Shoguchi E, Hisata K, Inoue J, Sun Y, Inaba K, Satoh N, Ogawa T, Shibata H. Active Expression of Genes for Protein Modification Enzymes in Habu Venom Glands. Toxins. 2022; 14(5):300. https://doi.org/10.3390/toxins14050300
Chicago/Turabian StyleIsomoto, Akiko, Eiichi Shoguchi, Kanako Hisata, Jun Inoue, Yinrui Sun, Kenji Inaba, Noriyuki Satoh, Tomohisa Ogawa, and Hiroki Shibata. 2022. "Active Expression of Genes for Protein Modification Enzymes in Habu Venom Glands" Toxins 14, no. 5: 300. https://doi.org/10.3390/toxins14050300
APA StyleIsomoto, A., Shoguchi, E., Hisata, K., Inoue, J., Sun, Y., Inaba, K., Satoh, N., Ogawa, T., & Shibata, H. (2022). Active Expression of Genes for Protein Modification Enzymes in Habu Venom Glands. Toxins, 14(5), 300. https://doi.org/10.3390/toxins14050300