
Machine Learning Models Integrating Dietary Indicators Improve the Prediction of Progression from Prediabetes to Type 2 Diabetes Mellitus

 ,
,  , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
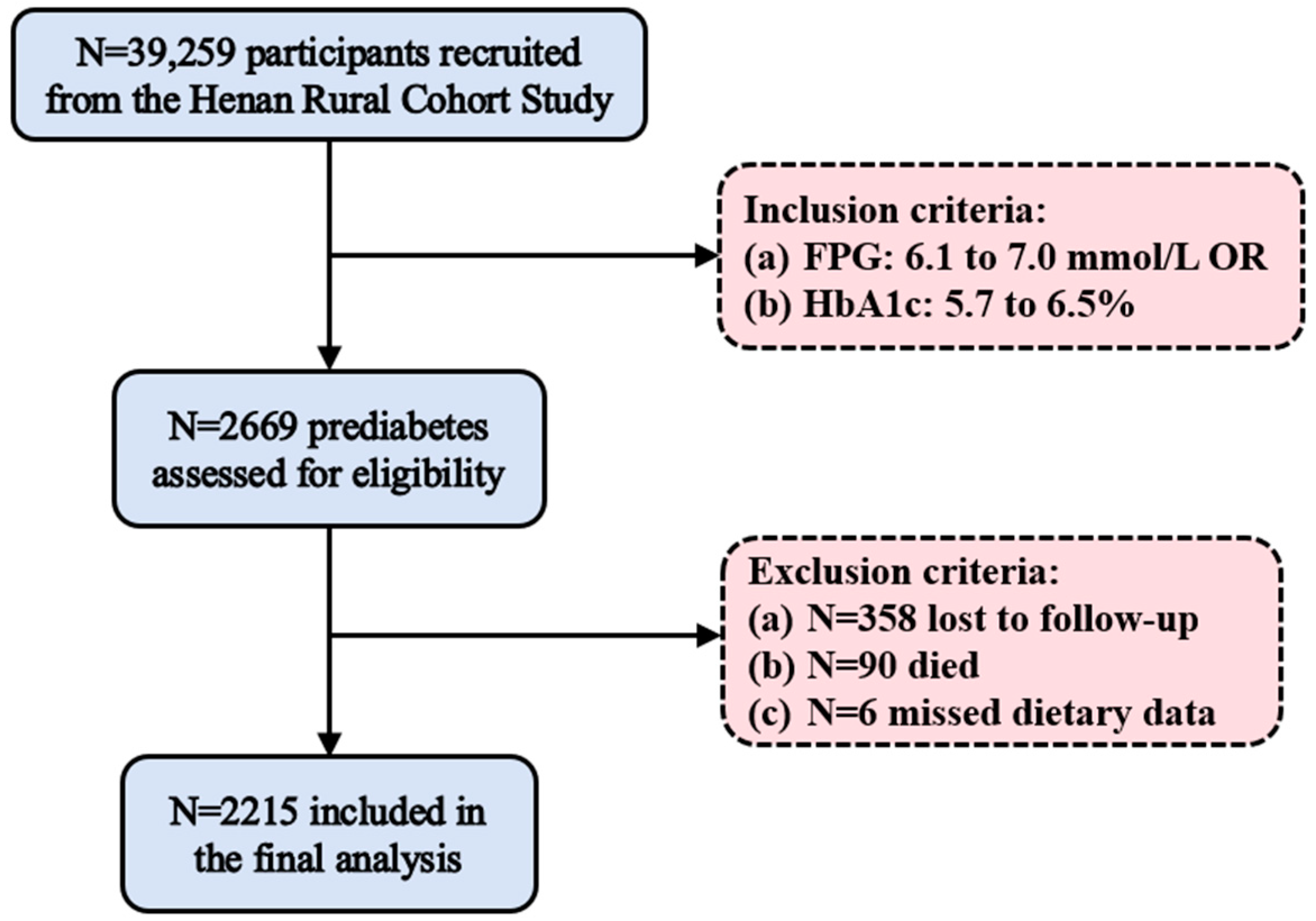
2.1. Study Design
2.2. Definitions of Prediabetes and T2DM
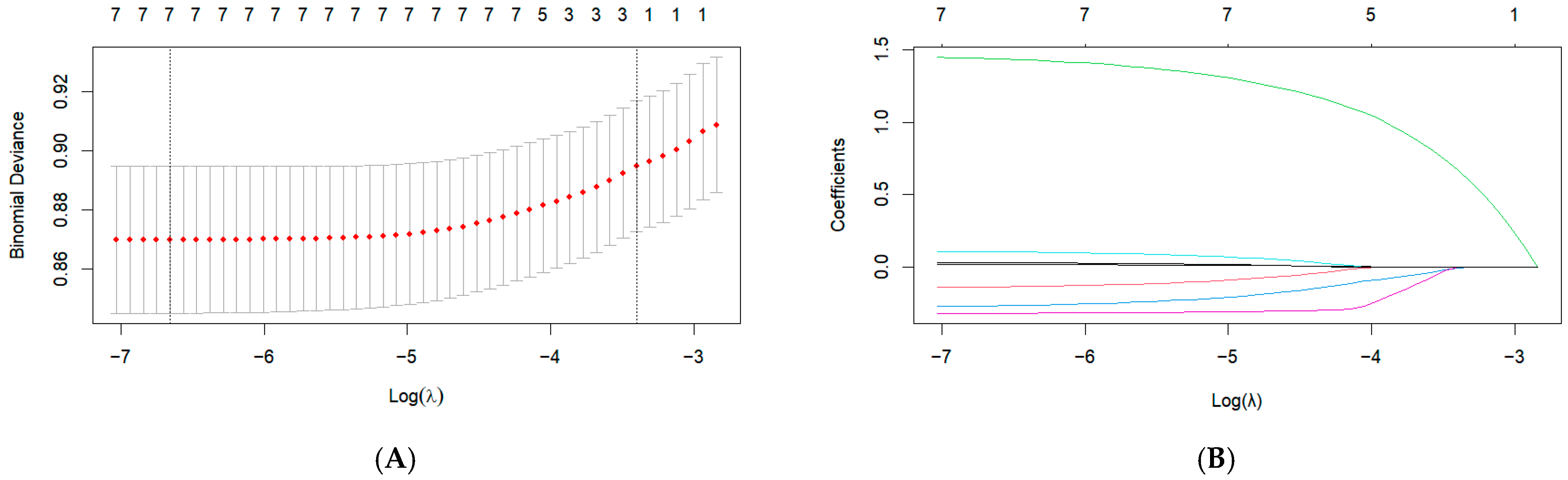
2.3. Data Preprocessing
2.4. Model Training
2.5. Model Evaluation
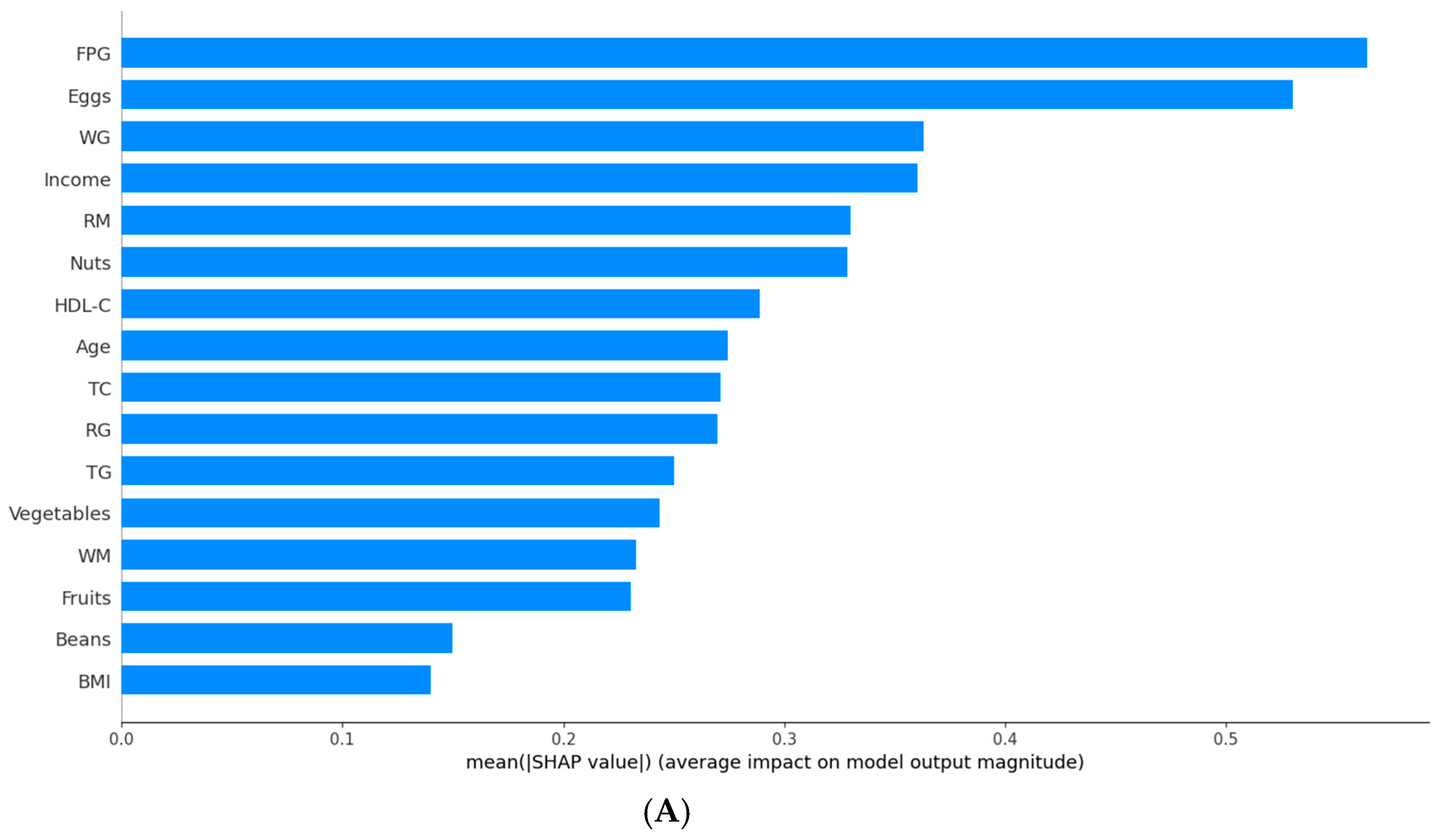
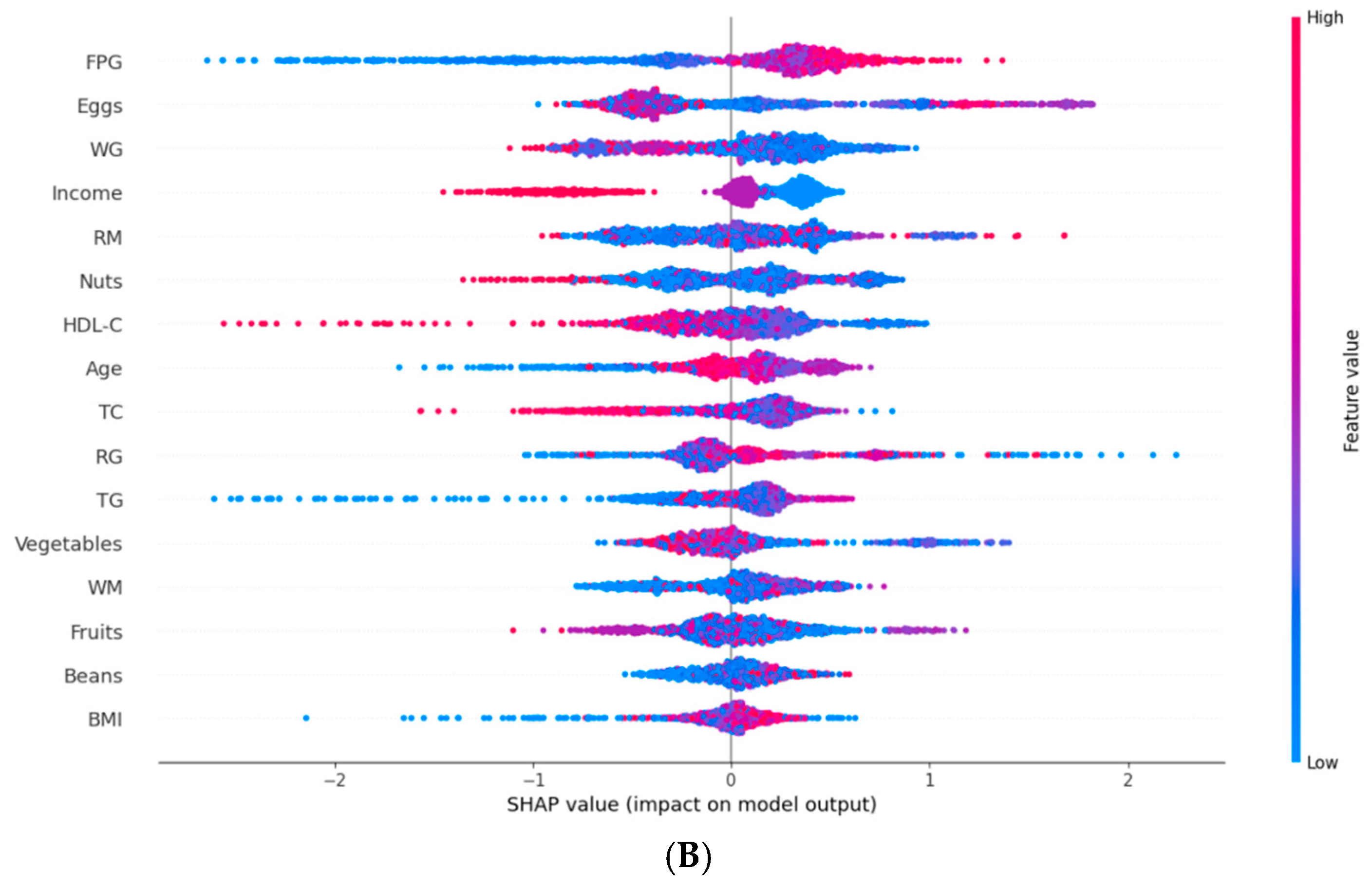
2.6. Model Interpretation
3. Results
3.1. T2DM Prediction Model Based on Traditional Indicators
3.2. T2DM Prediction Model Based on Traditional Indicators and Dietary Indicators
3.3. Sensitivity Analysis
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADA | American Diabetes Association |
| AI | artificial intelligence |
| ASTRAL | Acute Stroke Registry and Analysis of Lausanne |
| AUC | area under the curve |
| BMI | body mass index |
| DCA | decision curve analysis |
| EWH | egg white hydrolysate |
| FPG | fasting plasma glucose |
| HDL-C | high-density lipoprotein cholesterol |
| IGT | impaired glucose tolerance |
| LASSO | least absolute shrinkage and selection operator |
| LR | logistic regression |
| ML | machine learning |
| NGT | normal glucose tolerance |
| RF | random forest |
| ROC | receiver operating characteristic |
| SHAP | SHapley Additive exPlanations |
| SMOTE | Synthetic Minority Over-sampling Technique |
| SVM | support vector machine |
| T2DM | type 2 diabetes mellitus |
| TC | total cholesterol |
| TG | triglycerides |
| VIF | variance inflation factor |
| WC | waist circumference |
| XGBoost | extreme gradient boosting |
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | directory of open access journals |
| TLA | three letter acronym |
| LD | linear dichroism |
References
- Saeedi, P.; Petersohn, I.; Salpea, P.; Malanda, B.; Karuranga, S.; Unwin, N.; Colagiuri, S.; Guariguata, L.; Motala, A.A.; Ogurtsova, K.; et al. Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: Results from the International Diabetes Federation Diabetes Atlas, 9th edition. Diabetes Res. Clin. Pract. 2019, 157, 107843. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Saeedi, P.; Karuranga, S.; Pinkepank, M.; Ogurtsova, K.; Duncan, B.B.; Stein, C.; Basit, A.; Chan, J.C.N.; Mbanya, J.C.; et al. IDF Diabetes Atlas: Global, regional and country-level diabetes prevalence estimates for 2021 and projections for 2045. Diabetes Res. Clin. Pract. 2022, 183, 109119. [Google Scholar] [CrossRef]
- American Diabetes Association. (2) Classification and diagnosis of diabetes. Diabetes Care 2015, 38, S8–S16. [Google Scholar] [CrossRef] [PubMed]
- American Diabetes Association. Diagnosis and classification of diabetes mellitus. Diabetes Care 2011, 34 (Suppl. S1), S62–S69. [Google Scholar] [CrossRef]
- Wang, H.; Shara, N.M.; Calhoun, D.; Umans, J.G.; Lee, E.T.; Howard, B.V. Incidence rates and predictors of diabetes in those with prediabetes: The Strong Heart Study. Diabetes/Metab. Res. Rev. 2010, 26, 378–385. [Google Scholar] [CrossRef]
- Andes, L.J.; Cheng, Y.J.; Rolka, D.B.; Gregg, E.W.; Imperatore, G. Prevalence of Prediabetes Among Adolescents and Young Adults in the United States, 2005–2016. JAMA Pediatr. 2020, 174, e194498. [Google Scholar] [CrossRef] [PubMed]
- Liang, K.; Guo, X.; Wang, C.; Yan, F.; Wang, L.; Liu, J.; Hou, X.; Li, W.; Chen, L. Nomogram Predicting the Risk of Progression from Prediabetes to Diabetes After a 3-Year Follow-Up in Chinese Adults. Diabetes Metab. Syndr. Obes. 2021, 14, 2641–2649. [Google Scholar] [CrossRef]
- Li, N.; Lu, C.; Ma, Y.; Wang, X.; Ling, Y.; Yin, Y.; Li, S.; Huang, J.; Yu, L.; Dong, W. Factors associated with progression of different prediabetic status to Diabetes: A Community-based cohort study. Diabetes Res. Clin. Pract. 2022, 184, 109193. [Google Scholar] [CrossRef]
- Yang, H.; Kuang, M.; Qiu, J.; He, S.; Yu, C.; Sheng, G.; Zou, Y. Relative importance of triglyceride glucose index combined with body mass index in predicting recovery from prediabetic state to normal fasting glucose: A cohort analysis based on a Chinese physical examination population. Lipids Health Dis. 2024, 23, 71. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, Q.; He, Y.; Zou, J.; Guo, Y.; Yan, Y. Predicting the 2-Year Risk of Progression from Prediabetes to Diabetes Using Machine Learning among Chinese Elderly Adults. J. Pers. Med. 2022, 12, 1055. [Google Scholar] [CrossRef]
- Shuai, M.; Zhang, G.; Zeng, F.F.; Fu, Y.; Liang, X.; Yuan, L.; Xu, F.; Gou, W.; Miao, Z.; Jiang, Z. Human Gut Antibiotic Resistome and Progression of Diabetes. Adv. Sci. 2022, 9, e2104965. [Google Scholar] [CrossRef]
- Bennasar-Veny, M.; Fresneda, S.; López-González, A.; Busquets-Cortés, C.; Aguiló, A.; Yañez, A.M. Lifestyle and Progression to Type 2 Diabetes in a Cohort of Workers with Prediabetes. Nutrients 2020, 12, 1538. [Google Scholar] [CrossRef] [PubMed]
- Hu, H.; Kawasaki, Y.; Kuwahara, K.; Nakagawa, T.; Honda, T.; Yamamoto, S.; Eguchi, M.; Kochi, T.; Nishihara, A.; Imai, T. Trajectories of body mass index and waist circumference before the onset of diabetes among people with prediabetes. Clin. Nutr. 2020, 39, 2881–2888. [Google Scholar] [CrossRef]
- Wong, B.W.X.; Tan, D.Y.Z.; Li, L.J.; Yong, E.L. Individual and combined effects of muscle strength and visceral adiposity on incident prediabetes and type 2 diabetes in a longitudinal cohort of midlife Asian women. Diabetes Obes. Metab. 2025, 27, 155–164. [Google Scholar] [CrossRef] [PubMed]
- Deschênes, S.S.; McInerney, A.; Nearchou, F.; Byrne, B.; Nouwen, A.; Schmitz, N. Prediabetes and the risk of type 2 diabetes: Investigating the roles of depressive and anxiety symptoms in the Lifelines cohort study. Diabet. Med. 2023, 40, e15061. [Google Scholar] [CrossRef] [PubMed]
- Jiang, L.; Atasoy, S.; Johar, H.; Herder, C.; Peters, A.; Kruse, J.; Ladwig, K.H. Anxiety boosts progression of prediabetes to type 2 diabetes: Findings from the prospective Cooperative Health Research in the Region of Augsburg F4 and FF4 studies. Diabet. Med. 2020, 37, 1737–1741. [Google Scholar] [CrossRef]
- van Herpt, T.T.W.; Ligthart, S.; Leening, M.J.G.; van Hoek, M.; Lieverse, A.G.; Ikram, M.A.; Sijbrands, E.J.G.; Dehghan, A.; Kavousi, M. Lifetime risk to progress from pre-diabetes to type 2 diabetes among women and men: Comparison between American Diabetes Association and World Health Organization diagnostic criteria. BMJ Open Diabetes Res. Care 2020, 8, e001529. [Google Scholar] [CrossRef]
- Dekamin, A.; Wahab, M.I.M.; Keshavjee, K.; Guergachi, A. High cardiovascular disease risk-associated with the incidence of Type 2 diabetes among prediabetics. Eur. J. Intern. Med. 2022, 106, 56–62. [Google Scholar] [CrossRef]
- Crosby, L.; Rembert, E.; Levin, S.; Green, A.; Ali, Z.; Jardine, M.; Nguyen, M.; Elliott, P.; Goldstein, D.; Freeman, A.; et al. Changes in Food and Nutrient Intake and Diet Quality on a Low-Fat Vegan Diet Are Associated with Changes in Body Weight, Body Composition, and Insulin Sensitivity in Overweight Adults: A Randomized Clinical Trial. J. Acad. Nutr. Diet. 2022, 122, 1922–1939.e0. [Google Scholar] [CrossRef]
- Pestoni, G.; Riedl, A.; Breuninger, T.A.; Wawro, N.; Krieger, J.P.; Meisinger, C.; Rathmann, W.; Thorand, B.; Harris, C.; Peters, A.; et al. Association between dietary patterns and prediabetes, undetected diabetes or clinically diagnosed diabetes: Results from the KORA FF4 study. Eur. J. Nutr. 2021, 60, 2331–2341. [Google Scholar] [CrossRef]
- McAtee, J.R.; Tao, M.H.; King, C.; Chai, W. Association of Home Food Availability with Prediabetes and Diabetes among Adults in the United States. Nutrients 2020, 12, 1209. [Google Scholar] [CrossRef] [PubMed]
- Xue, Y.; Liu, C.; Wang, B.; Mao, Z.; Yu, S.; Wang, Y.; Zhang, D.; Wang, C.; Li, W.; Li, X. The association between dietary patterns with type 2 diabetes mellitus and pre-diabetes in the Henan rural cohort study. Public Health Nutr. 2021, 24, 5443–5452. [Google Scholar] [CrossRef]
- Han, Y.; Hu, H.; Liu, Y.; Wang, Z.; Liu, D. Nomogram model and risk score to predict 5-year risk of progression from prediabetes to diabetes in Chinese adults: Development and validation of a novel model. Diabetes Obes. Metab. 2023, 25, 675–687. [Google Scholar] [CrossRef] [PubMed]
- Nicolaisen, S.K.; Thomsen, R.W.; Lau, C.J.; Sørensen, H.T.; Pedersen, L. Development of a 5-year risk prediction model for type 2 diabetes in individuals with incident HbA1c-defined pre-diabetes in Denmark. BMJ Open Diabetes Res. Care 2022, 10, e002946. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Liu, D.; Du, Q.; Zhu, J.; Lu, L.; Wu, Z.; Zhang, D.; Ji, X.; Zheng, X. Construction of a 3-year risk prediction model for developing diabetes in patients with pre-diabetes. Front. Endocrinol. 2024, 15, 1410502. [Google Scholar] [CrossRef]
- Yokota, N.; Miyakoshi, T.; Sato, Y.; Nakasone, Y.; Yamashita, K.; Imai, T.; Hirabayashi, K.; Koike, H.; Yamauchi, K.; Aizawa, T. Predictive models for conversion of prediabetes to diabetes. J. Diabetes Complicat. 2017, 31, 1266–1271. [Google Scholar] [CrossRef]
- Chen, X.; Zhou, S.; Yang, L.; Zhong, Q.; Liu, H.; Zhang, Y.; Yu, H.; Cai, Y. Risk Prediction of Diabetes Progression Using Big Data Mining with Multifarious Physical Examination Indicators. Diabetes Metab. Syndr. Obes. 2024, 17, 1249–1265. [Google Scholar] [CrossRef] [PubMed]
- Zou, X.; Luo, Y.; Huang, Q.; Zhu, Z.; Li, Y.; Zhang, X.; Zhou, X.; Ji, L. Differential effect of interventions in patients with prediabetes stratified by a machine learning-based diabetes progression prediction model. Diabetes Obes. Metab. 2024, 26, 97–107. [Google Scholar] [CrossRef]
- Li, J.; Yu, Y.; Sun, Y.; Fu, Y.; Shen, W.; Cai, L.; Tan, X.; Cai, Y.; Wang, N.; Lu, Y.; et al. Nuclear magnetic resonance-based metabolomics with machine learning for predicting progression from prediabetes to diabetes. Elife 2024, 13, RP98709. [Google Scholar] [CrossRef]
- Liu, X.; Mao, Z.; Li, Y.; Wu, W.; Zhang, X.; Huo, W.; Yu, S.; Shen, L.; Li, L.; Tu, R.; et al. Cohort Profile: The Henan Rural Cohort: A prospective study of chronic non-communicable diseases. Int. J. Epidemiol. 2019, 48, 1756–1756j. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Griauzde, D.H.; O’Brien, A.; Yancy, W.S., Jr.; Richardson, C.R.; Krinock, J.; DeJonckheere, M.; Isaman, D.J.M.; Vanias, K.; Shopinski, S.; Saslow, L.R. Testing a very low-carbohydrate adaption of the Diabetes Prevention Program among adults with prediabetes: Study protocol for the Lifestyle Education about prediabetes (LEAP) trial. Trials 2022, 23, 827. [Google Scholar] [CrossRef] [PubMed]
- Nakanga, W.P.; Crampin, A.C.; Mkandawire, J.; Banda, L.; Andrews, R.C.; Hattersley, A.T.; Nyirenda, M.J.; Rodgers, L.R. Waist circumference and glycaemia are strong predictors of progression to diabetes in individuals with prediabetes in sub-Saharan Africa: 4-year prospective cohort study in Malawi. PLOS Glob. Public Health 2023, 3, e0001263. [Google Scholar] [CrossRef]
- Bozorgmanesh, M.; Hadaegh, F.; Azizi, F. A simple clinical model predicted diabetes progression among prediabetic individuals. Diabetes Res. Clin. Pract. 2012, 97, e34–e36. [Google Scholar] [CrossRef]
- Heo, J.; Yoon, J.G.; Park, H.; Kim, Y.D.; Nam, H.S.; Heo, J.H. Machine Learning-Based Model for Prediction of Outcomes in Acute Stroke. Stroke 2019, 50, 1263–1265. [Google Scholar] [CrossRef]
- Martinez, O.; Martinez, C.; Parra, C.A.; Rugeles, S.; Suarez, D.R. Machine learning for surgical time prediction. Comput. Methods Programs Biomed. 2021, 208, 106220. [Google Scholar] [CrossRef]
- Shi, H.; Yang, D.; Tang, K.; Hu, C.; Li, L.; Zhang, L.; Gong, T.; Cui, Y. Explainable machine learning model for predicting the occurrence of postoperative malnutrition in children with congenital heart disease. Clin. Nutr. 2022, 41, 202–210. [Google Scholar] [CrossRef]
- Kengne, A.P.; Ramachandran, A. Feasibility of prevention of type 2 diabetes in low- and middle-income countries. Diabetologia 2024, 67, 763–772. [Google Scholar] [CrossRef]
- Shin, J.Y.; Xun, P.; Nakamura, Y.; He, K. Egg consumption in relation to risk of cardiovascular disease and diabetes: A systematic review and meta-analysis. Am. J. Clin. Nutr. 2013, 98, 146–159. [Google Scholar] [CrossRef]
- Guo, J.; Hobbs, D.A.; Cockcroft, J.R.; Elwood, P.C.; Pickering, J.E.; Lovegrove, J.A.; Givens, D.I. Association between egg consumption and cardiovascular disease events, diabetes and all-cause mortality. Eur. J. Nutr. 2018, 57, 2943–2952. [Google Scholar] [CrossRef]
- Djoussé, L.; Petrone, A.B.; Hickson, D.A.; Talegawkar, S.A.; Dubbert, P.M.; Taylor, H.; Tucker, K.L. Egg consumption and risk of type 2 diabetes among African Americans: The Jackson Heart Study. Clin. Nutr. 2016, 35, 679–684. [Google Scholar] [CrossRef] [PubMed]
- de Campos Zani, S.C.; Wu, J.; Chan, C.B. Egg and Soy-Derived Peptides and Hydrolysates: A Review of Their Physiological Actions against Diabetes and Obesity. Nutrients 2018, 10, 549. [Google Scholar] [CrossRef]
- Wang, X.; Son, M.; Meram, C.; Wu, J. Mechanism and Potential of Egg Consumption and Egg Bioactive Components on Type-2 Diabetes. Nutrients 2019, 11, 357. [Google Scholar] [CrossRef] [PubMed]
- Spence, J.D.; Jenkins, D.J.; Davignon, J. Dietary cholesterol and egg yolks: Not for patients at risk of vascular disease. Can. J. Cardiol. 2010, 26, e336–e339. [Google Scholar] [CrossRef]
- Reynolds, A.N.; Akerman, A.P.; Mann, J. Dietary fibre and whole grains in diabetes management: Systematic review and meta-analyses. PLoS Med. 2020, 17, e1003053. [Google Scholar] [CrossRef] [PubMed]
- Wolk, A. Potential health hazards of eating red meat. J. Intern. Med. 2017, 281, 106–122. [Google Scholar] [CrossRef]
- Nishi, S.K.; Viguiliouk, E.; Kendall, C.W.C.; Jenkins, D.J.A.; Hu, F.B.; Sievenpiper, J.L.; Atzeni, A.; Misra, A.; Salas-Salvadó, J. Nuts in the Prevention and Management of Type 2 Diabetes. Nutrients 2023, 15, 878. [Google Scholar] [CrossRef]
- Gong, D.; Chen, X.; Yang, L.; Zhang, Y.; Zhong, Q.; Liu, J.; Yan, C.; Cai, Y.; Yang, W.; Wang, J. From normal population to prediabetes and diabetes: Study of influencing factors and prediction models. Front. Endocrinol. 2023, 14, 1225696. [Google Scholar] [CrossRef]

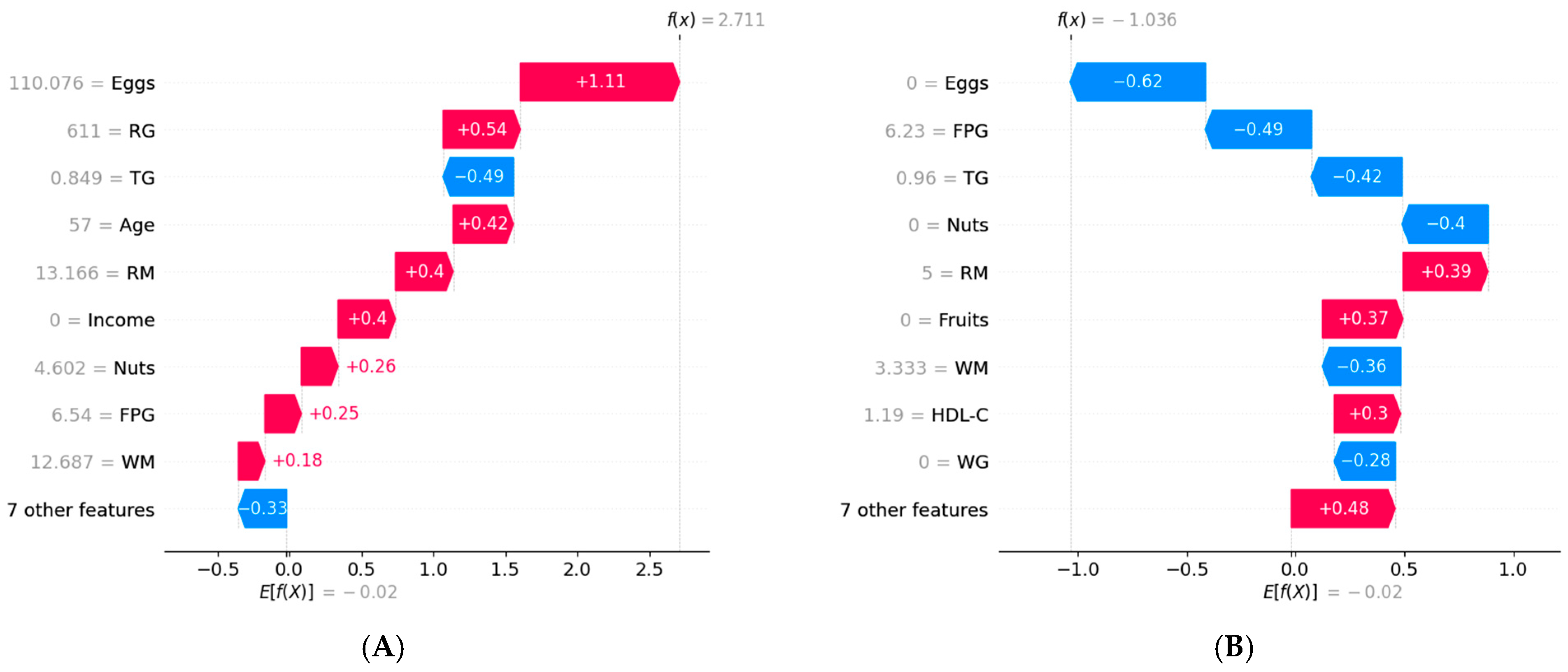

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Regressed to NGT (n = 1361) | Remained as Prediabetes (n = 480) | Progressed to T2DM (n = 374) | p Values |
|---|---|---|---|---|
| Age [years, M (P25, P75)] | 59 (51.66) | 60 (51.65) | 61 (52.65) | 0.096 |
| Gender, n (%) | 0.483 | |||
| Female | 783 (57.53%) | 282 (58.75%) | 228 (60.96%) | |
| Male | 578 (42.47%) | 198 (41.25%) | 146 (39.04%) | |
| Educational levels, n (%) | 0.003 | |||
| Illiteracy and primary school | 619 (45.48%) | 255 (53.12%) | 196 (52.41%) | |
| Middle school and above | 742 (54.52%) | 225 (46.88%) | 178 (47.59%) | |
| Marriage, n (%) | 0.921 | |||
| Married/cohabiting | 1221 (89.71%) | 431 (89.79%) | 333 (89.04%) | |
| Unmarried/divorced/widowed | 140 (10.29%) | 49 (10.21%) | 41 (10.96%) | |
| Per capita monthly income, n (%) | 0.063 | |||
| <500, RMB | 508 (37.32%) | 181 (37.71%) | 159 (42.51%) | |
| 500~, RMB | 454 (33.36%) | 140 (29.17%) | 122 (32.62%) | |
| 1000~, RMB | 399 (29.32%) | 159 (33.12%) | 93 (24.87%) | |
| Smoking status, n (%) | 0.529 | |||
| Never | 968 (71.13%) | 345 (71.88%) | 271 (72.46%) | |
| Ever | 136 (9.99%) | 48 (10.00%) | 45 (12.03%) | |
| Current | 257 (18.88%) | 87 (18.12%) | 58 (15.51%) | |
| Drinking status, n (%) | 0.011 | |||
| Never | 1007 (73.99%) | 371 (77.29%) | 283 (75.67%) | |
| Ever | 51 (3.75%) | 31 (6.46%) | 19 (5.08%) | |
| Current | 303 (22.26%) | 78 (16.25%) | 72 (19.25%) | |
| Physical activity, n (%) | 0.182 | |||
| Low | 56 (4.12%) | 13 (2.71%) | 15 (4.01%) | |
| Moderate | 145 (10.65%) | 37 (7.71%) | 33 (8.82%) | |
| High | 1160 (85.23%) | 430 (89.58%) | 326 (87.17%) | |
| Pittsburgh Sleep Quality Index [M (P25, P75)] | 3 (2,5) | 3 (2,5) | 3 (2,5) | 0.350 |
| Hypertension, n (%) | 0.605 | |||
| No | 704 (51.73%) | 261 (54.38%) | 197 (52.67%) | |
| Yes | 657 (48.27%) | 219 (45.62%) | 177 (47.33%) | |
| Family history of type 2 diabetes mellitus, n (%) | 0.122 | |||
| No | 1304 (95.81%) | 452 (94.17%) | 350 (93.58%) | |
| Yes | 57 (4.19%) | 28 (5.83%) | 24 (6.42%) | |
| Cancer, n (%) | 0.725 | |||
| No | 1348 (99.04%) | 475 (98.96%) | 369 (98.66%) | |
| Yes | 13 (0.96%) | 5 (1.04%) | 5 (1.34%) | |
| Kidney failure, n (%) | 0.356 | |||
| No | 1360 (99.93%) | 480 (100.00%) | 373 (99.73%) | |
| Yes | 1 (0.07%) | 0 (0.00%) | 1 (0.27%) | |
| Fasting plasma glucose [mmol/L, M (P25, P75)] | 6.31 (6.20,6.56) | 6.40 (6.21,6.60) | 6.49 (6.30,6.70) | <0.001 |
| Total cholesterol [mmol/L, M (P25, P75)] | 5.10 (4.42,5.80) | 4.95 (4.37,5.77) | 4.83 (4.23,5.50) | <0.001 |
| Triglyceride [mmol/L, M (P25, P75)] | 1.49 (1.07,2.21) | 1.58 (1.14,2.54) | 1.74 (1.23,2.54) | <0.001 |
| High-density lipoprotein cholesterol [mmol/L, M (P25, P75)] | 1.26 (1.08,1.48) | 1.23 (1.05,1.45) | 1.19 (1.02,1.39) | <0.001 |
| Low-density lipoprotein cholesterol [mmol/L, M (P25, P75)] | 3.02 (2.48,3.60) | 3.01 (2.51,3.69) | 2.98 (2.46,3.48) | 0.256 |
| Systolic pressure [mmHg, M (P25, P75)] | 132 (120,146) | 130 (118,145) | 132 (120,147) | 0.490 |
| Diastolic pressure [mmHg, M (P25, P75)] | 82 (74,90) | 80 (72,89) | 81 (74,89) | 0.185 |
| Heart rate [time/minutes, M (P25, P75)] | 77 (70,86) | 76 (69,84) | 76 (69,84) | 0.030 |
| Body mass index [kg/m2, M (P25, P75)] | 25.9 (23.6,28.2) | 25.9 (23.9,27.9) | 26.3 (24.2,28.7) | 0.107 |
| Waist circumference [cm, M (P25, P75)] | 88.1 (81.1,94.8) | 87.0 (81.1,94.4) | 89.0 (82.8,96.0) | 0.069 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Li, Y.; Mao, Z.; Wang, C.; Hou, J.; Zhao, J.; Wang, J.; Tian, Y.; Li, L. Machine Learning Models Integrating Dietary Indicators Improve the Prediction of Progression from Prediabetes to Type 2 Diabetes Mellitus. Nutrients 2025, 17, 947. https://doi.org/10.3390/nu17060947
Li Z, Li Y, Mao Z, Wang C, Hou J, Zhao J, Wang J, Tian Y, Li L. Machine Learning Models Integrating Dietary Indicators Improve the Prediction of Progression from Prediabetes to Type 2 Diabetes Mellitus. Nutrients. 2025; 17(6):947. https://doi.org/10.3390/nu17060947
Chicago/Turabian StyleLi, Zhuoyang, Yuqian Li, Zhenxing Mao, Chongjian Wang, Jian Hou, Jiaoyan Zhao, Jianwei Wang, Yuan Tian, and Linlin Li. 2025. "Machine Learning Models Integrating Dietary Indicators Improve the Prediction of Progression from Prediabetes to Type 2 Diabetes Mellitus" Nutrients 17, no. 6: 947. https://doi.org/10.3390/nu17060947
APA StyleLi, Z., Li, Y., Mao, Z., Wang, C., Hou, J., Zhao, J., Wang, J., Tian, Y., & Li, L. (2025). Machine Learning Models Integrating Dietary Indicators Improve the Prediction of Progression from Prediabetes to Type 2 Diabetes Mellitus. Nutrients, 17(6), 947. https://doi.org/10.3390/nu17060947