Food Volume Estimation Based on Deep Learning View Synthesis from a Single Depth Map


Abstract
:1. Introduction
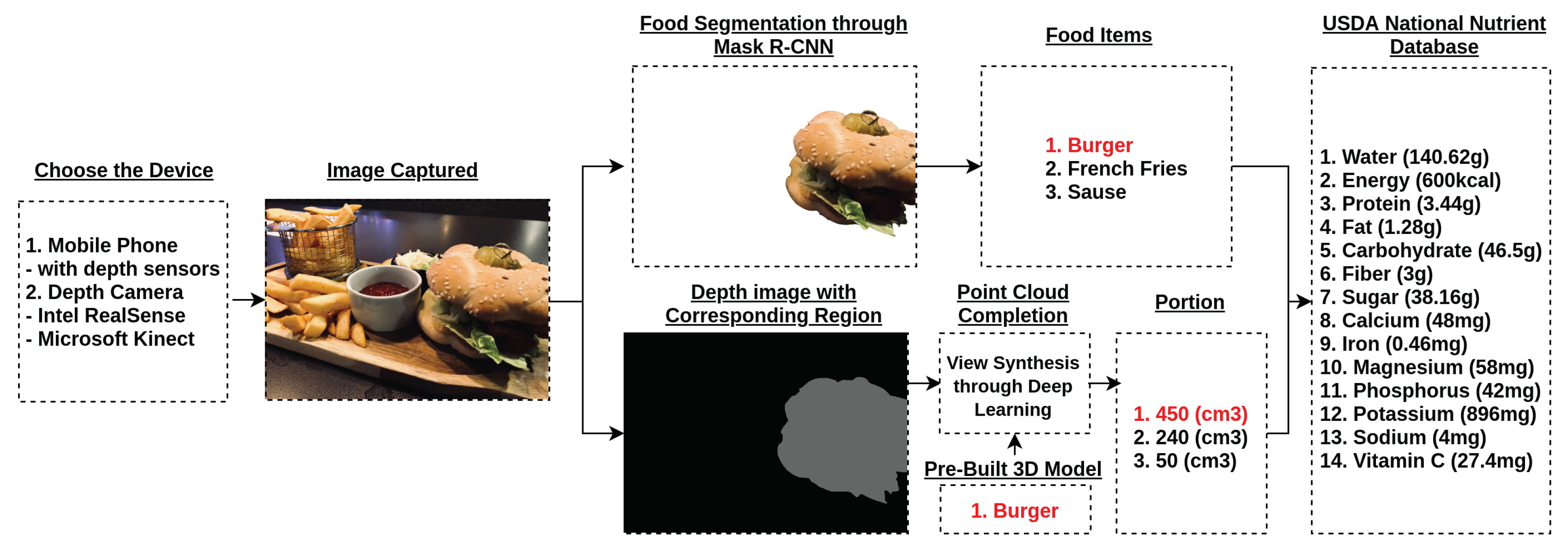
2. Detailed Information and Methods
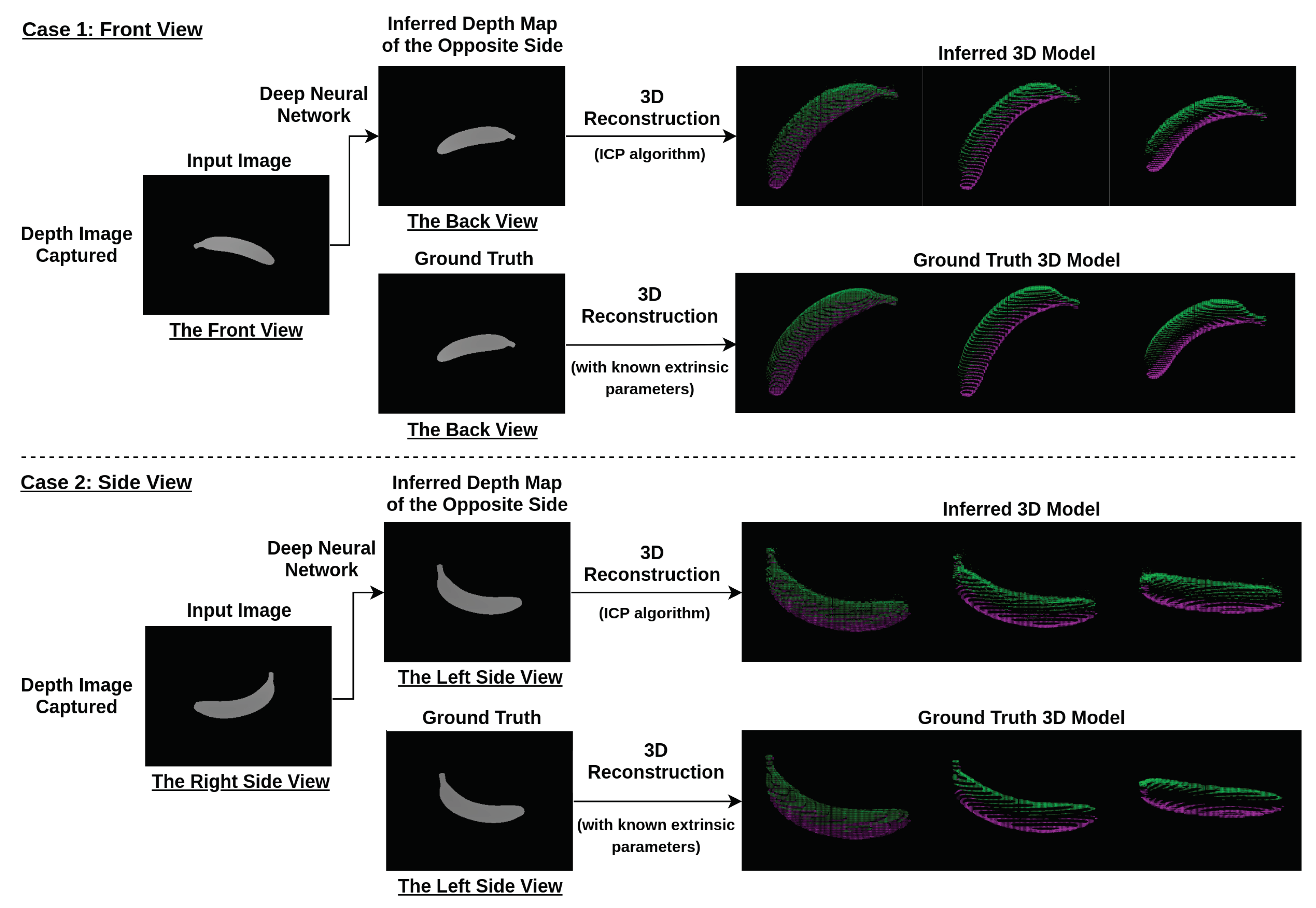
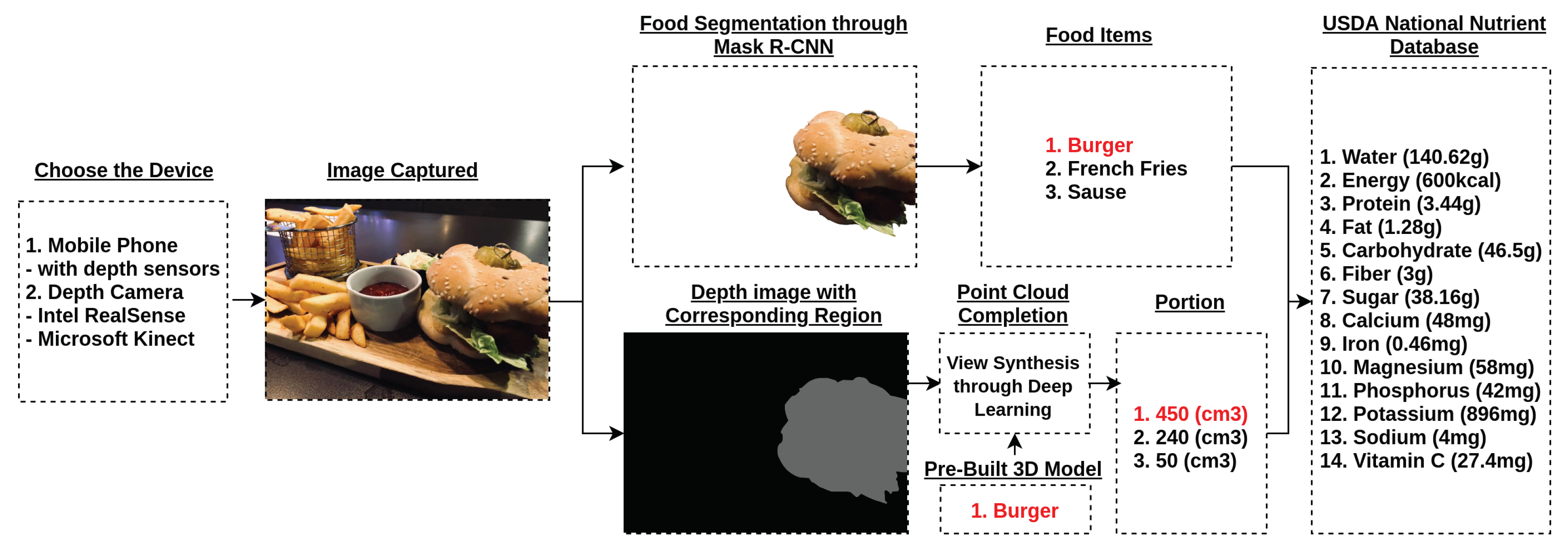
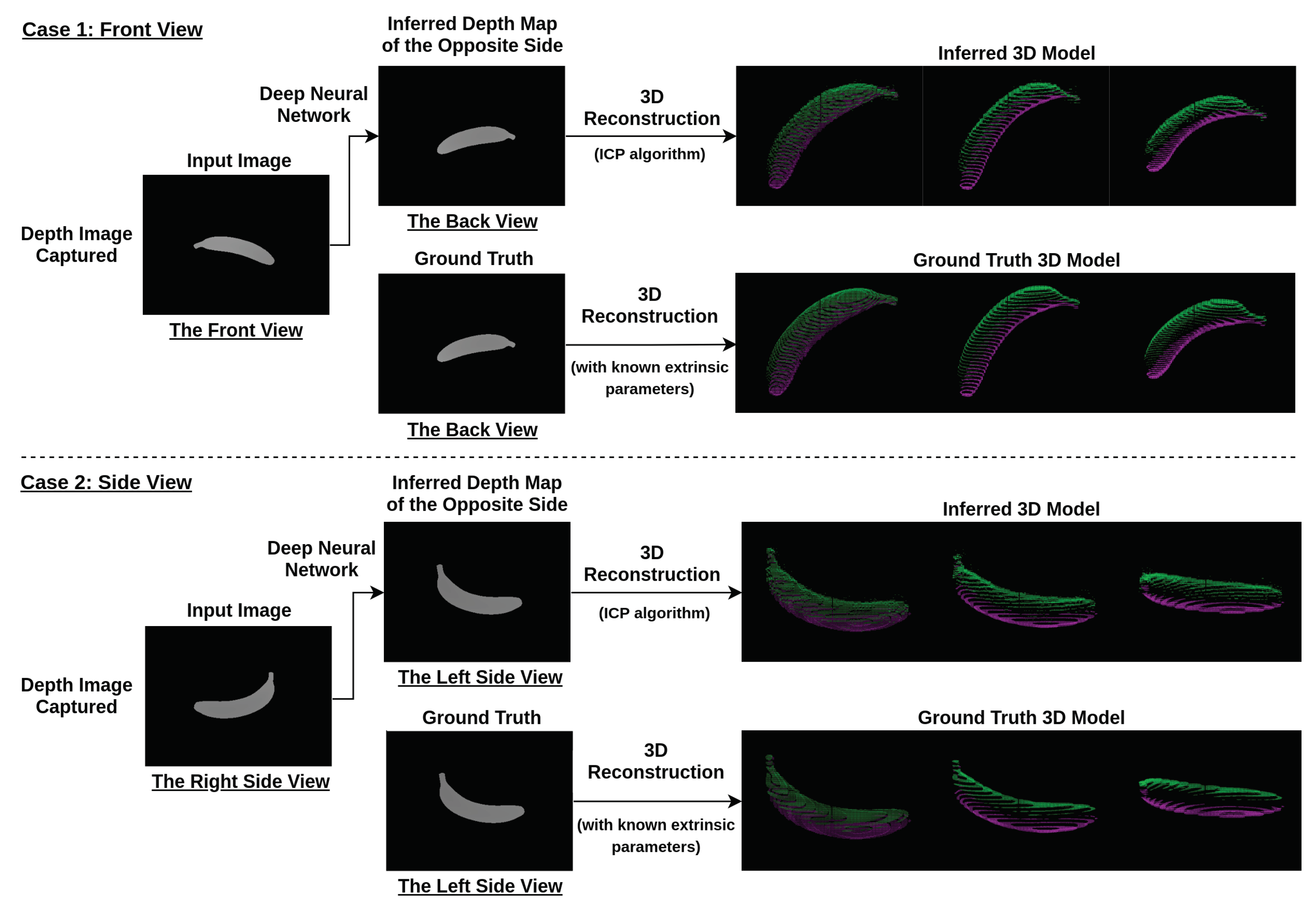
2.1. The Procedure of Deep Learning View Synthesis Approach
2.2. Image Rendering
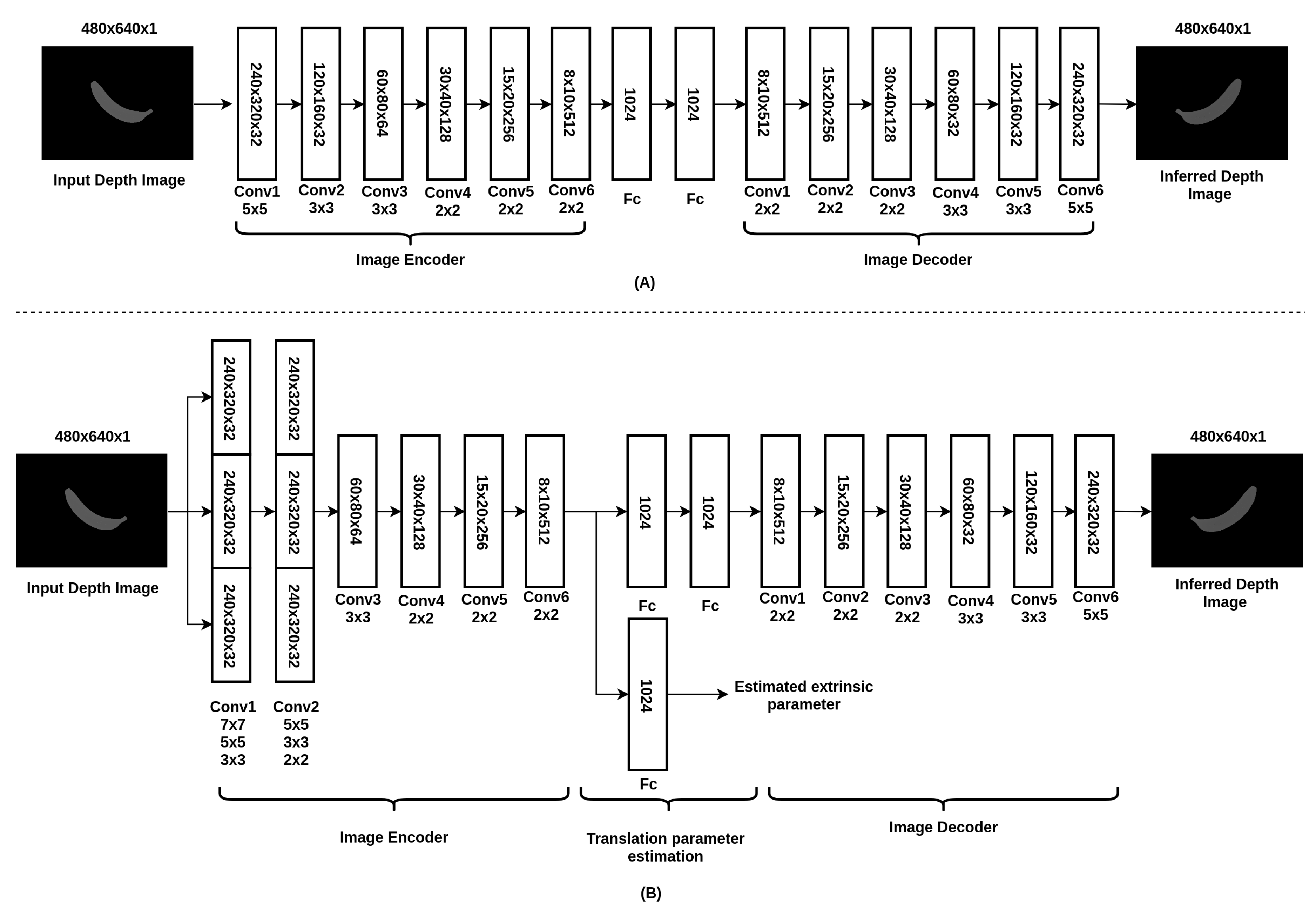
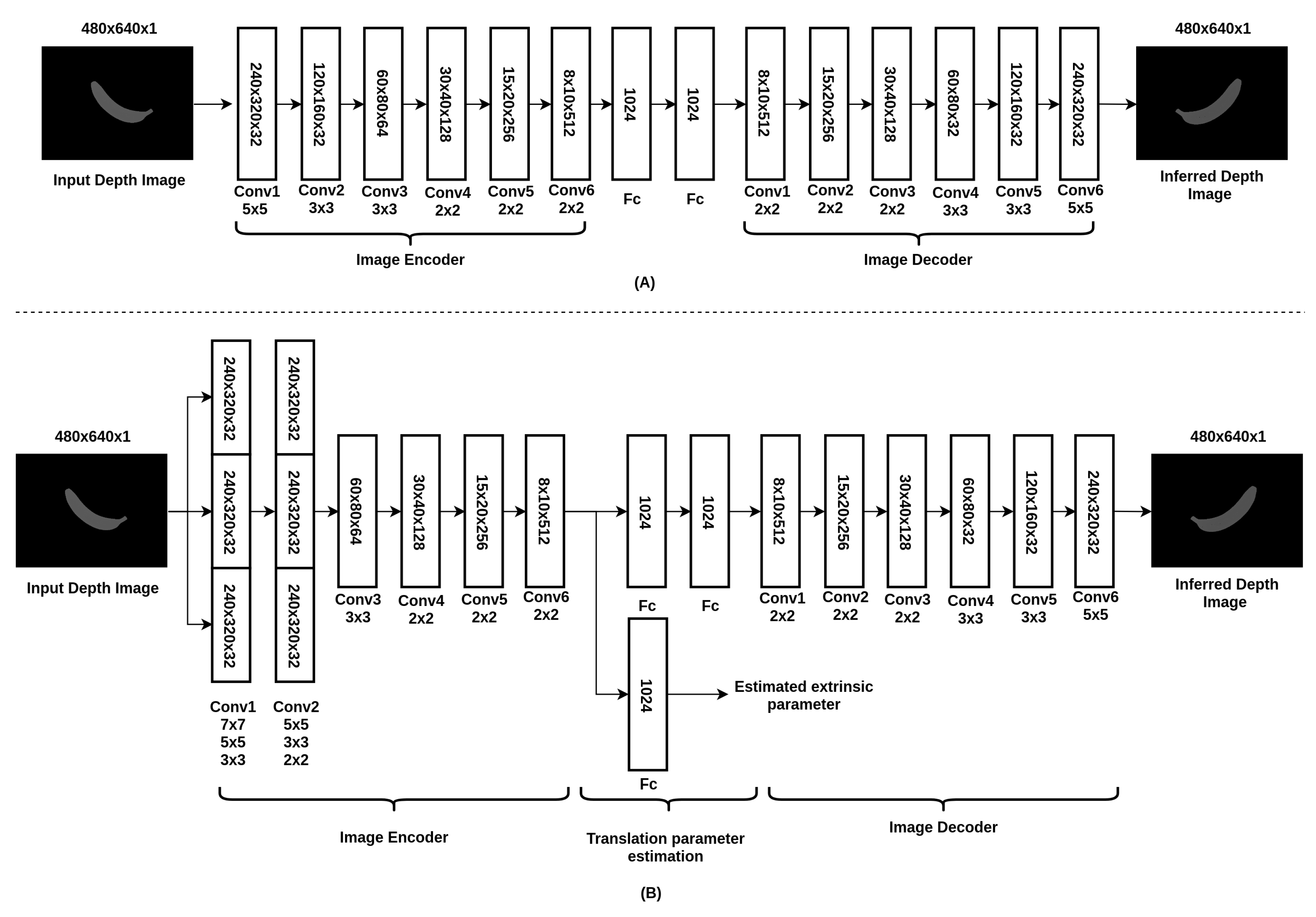
2.3. Neural Network Architecture
- Cost function for depth image prediction:where and refer to the pixels from the estimated depth image and the ground truth of depth image, respectively. w and h refer to the width and height of the image, respectively. is the regularization term added to the cost function to better train the neural network. Noted that is determined empirically. The selection of will affect the convergence speed of the network ( is used in the cost function). and t refer to the estimated extrinsic parameter (translation matrix) and the ground truth of the extrinsic parameter, respectively.
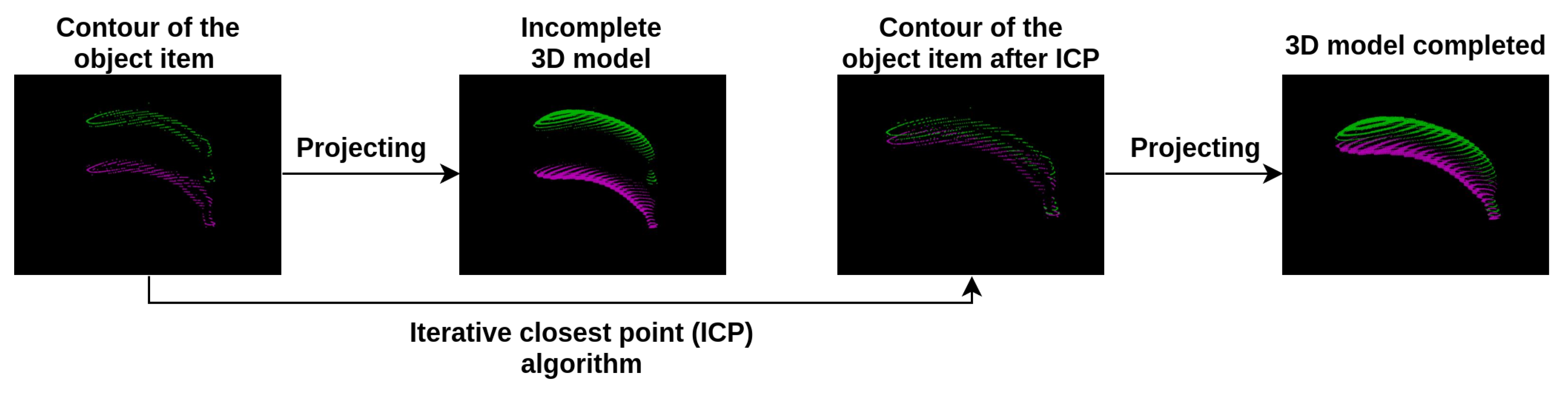
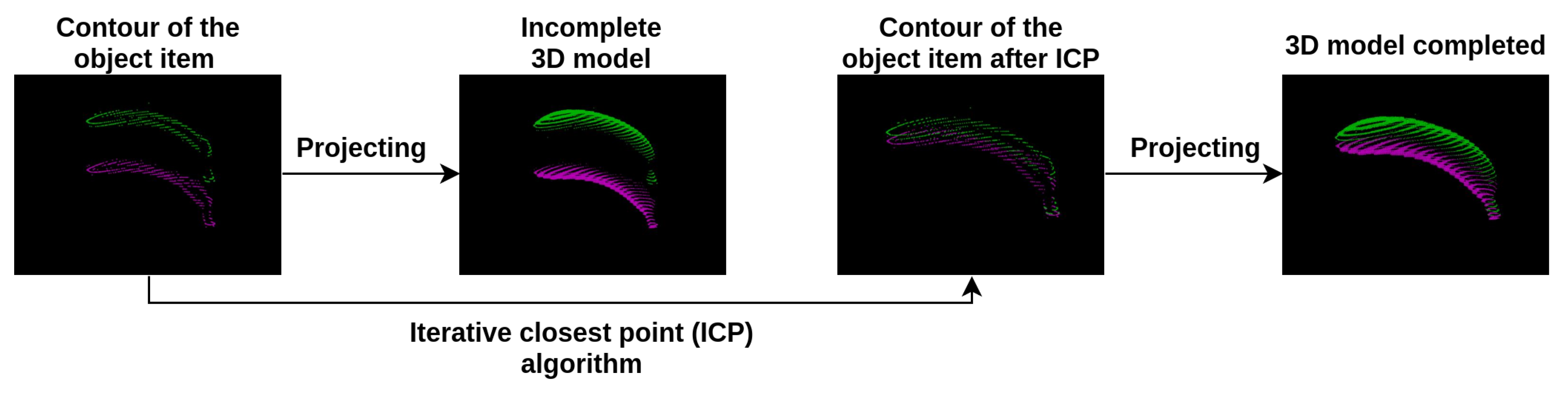
2.4. Point Cloud Completion
2.5. Iterative Closest Point (ICP)
2.6. Meshing
3. Experimental Results
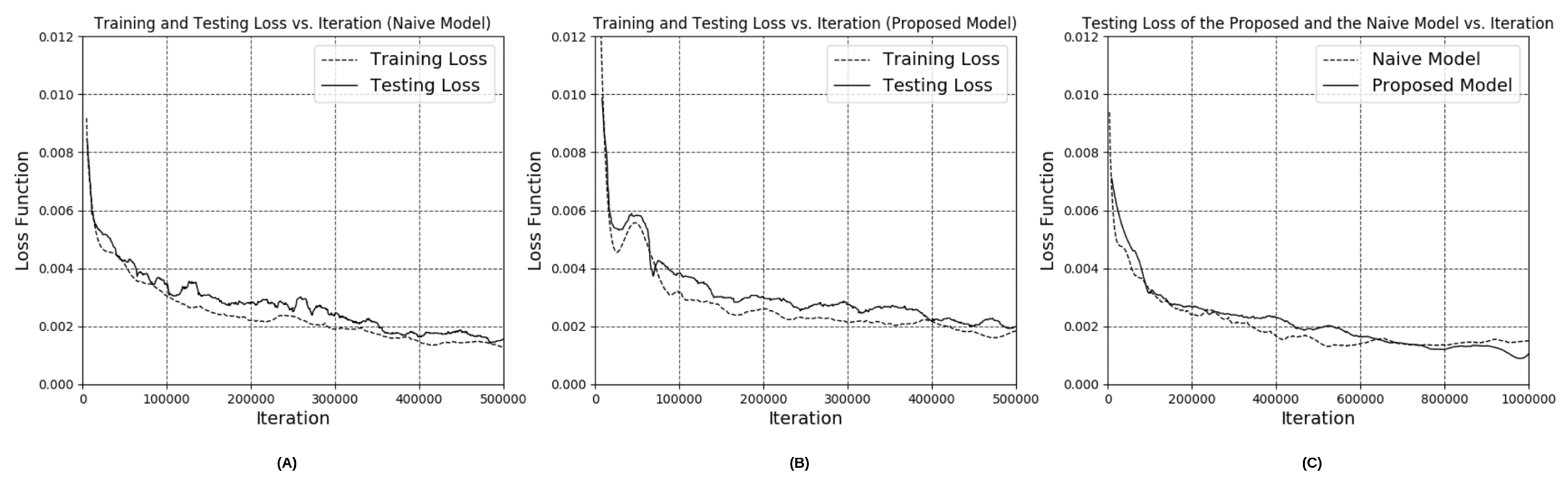
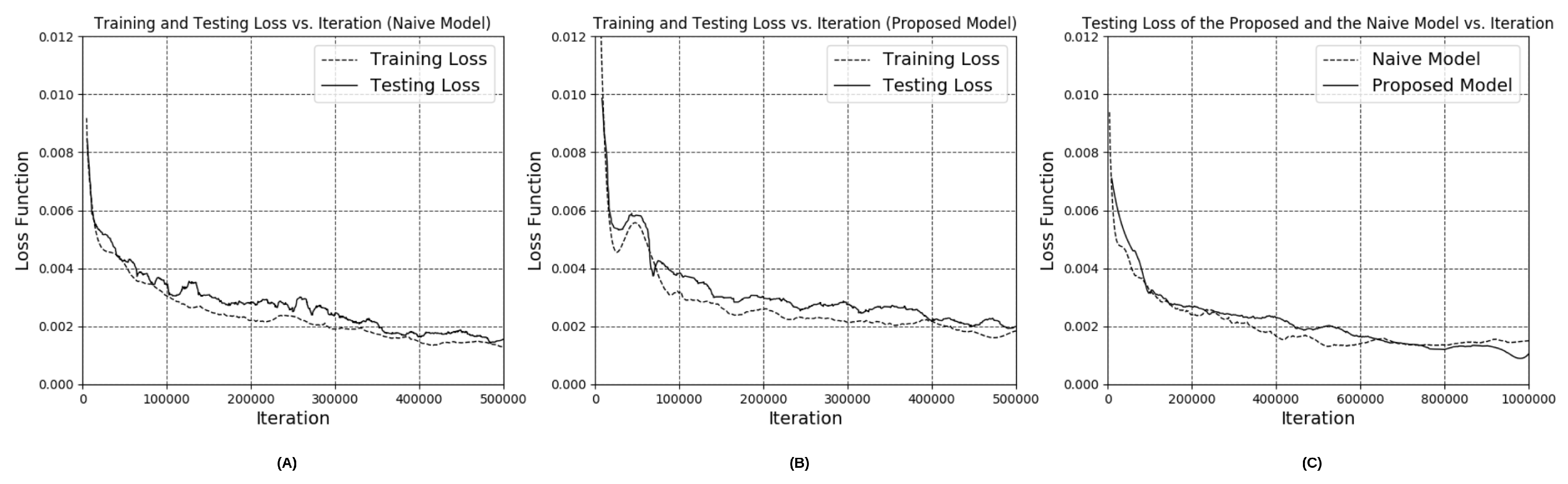
3.1. Performance of Depth Estimation Based on the Modified Encoder-Decoder Neural Network
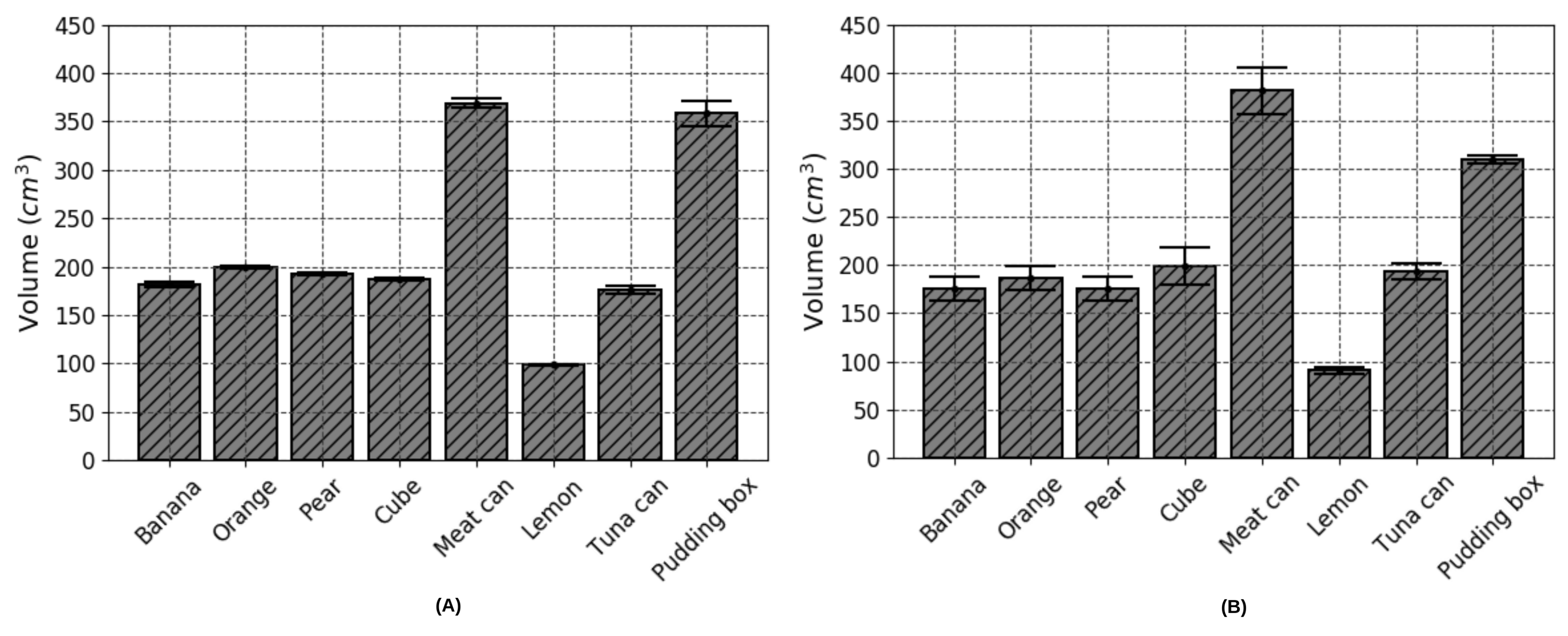
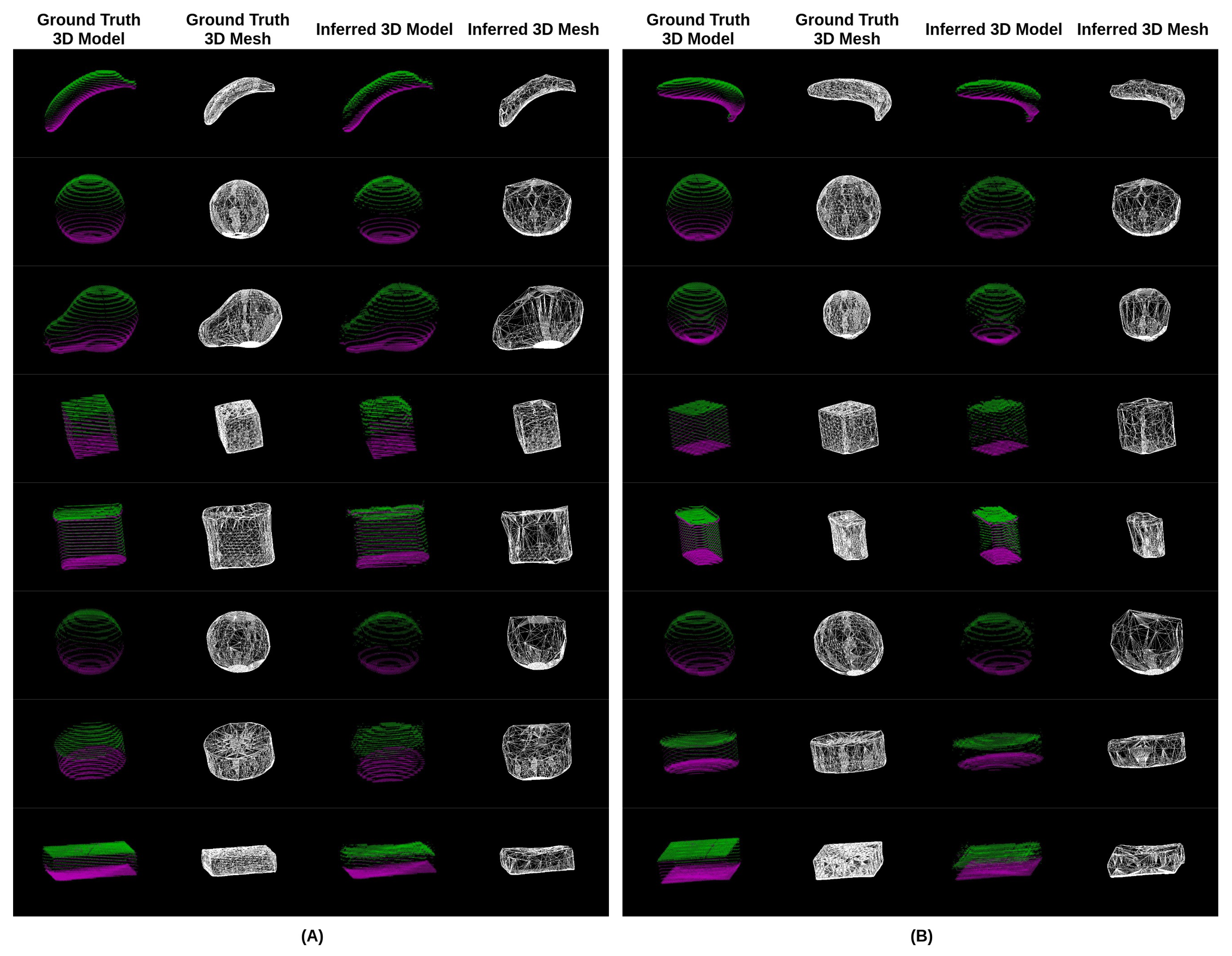
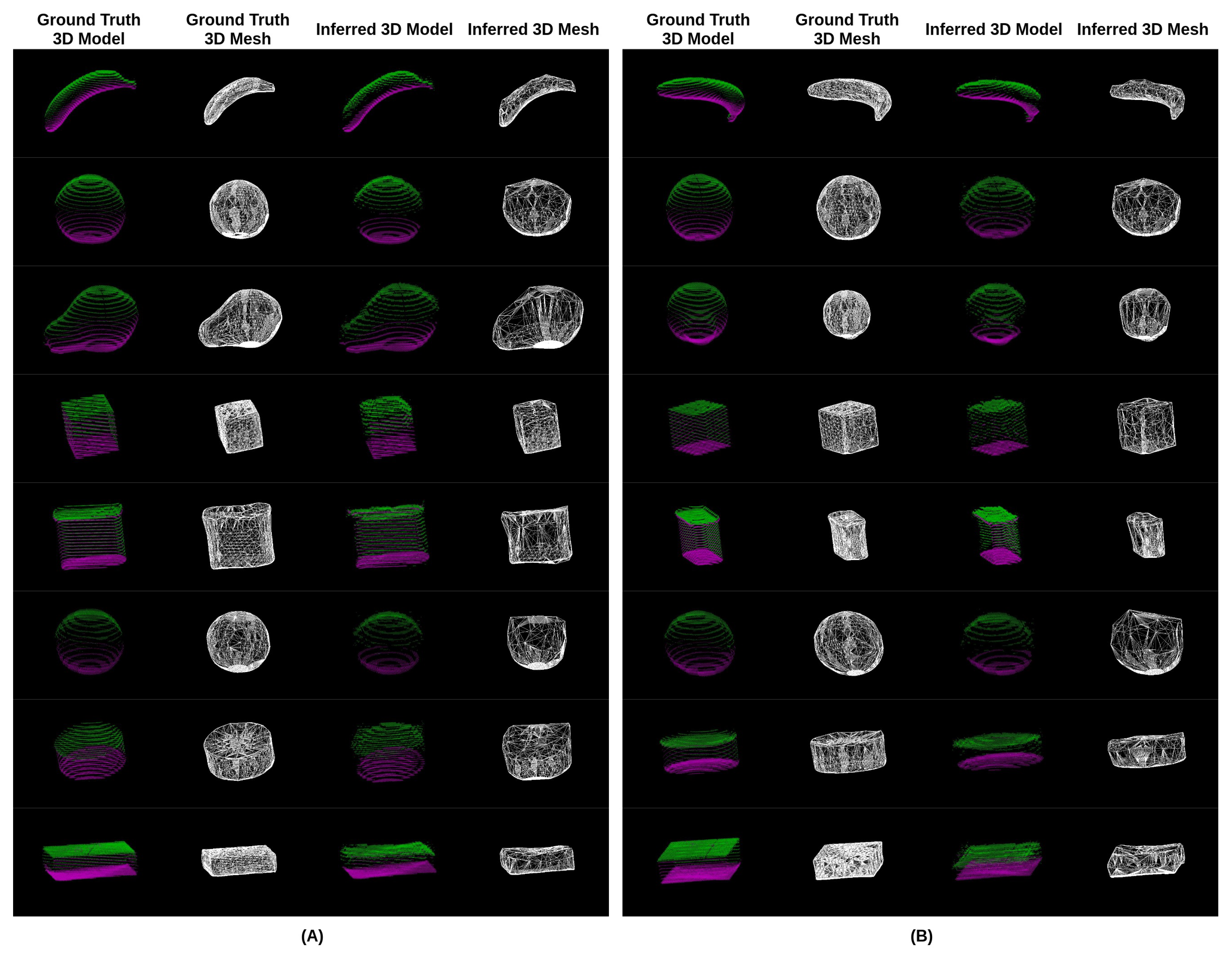
3.2. Accuracy of Volume Estimation Based on Point Cloud Completion and ICP Algorithms
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ainaa Fatehah, A.; Poh, B.K.; Nik Shanita, S.; Wong, J.E. Feasibility of Reviewing Digital Food Images for Dietary Assessment among Nutrition Professionals. Nutrients 2018, 10. [Google Scholar] [CrossRef]
- Howes, E.; Boushey, C.J.; Kerr, D.A.; Tomayko, E.J.; Cluskey, M. Image-Based Dietary Assessment Ability of Dietetics Students and Interns. Nutrients 2017, 9. [Google Scholar] [CrossRef] [PubMed]
- Sun, M.; Burke, L.E.; Baranowski, T.; Fernstrom, J.D.; Zhang, H.; Chen, H.C.; Bai, Y.; Li, Y.; Li, C.; Yue, Y.; et al. An exploratory study on a chest-worn computer for evaluation of diet, physical activity and lifestyle. J. Healthc. Eng. 2015, 6, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; He, Y.; Khanna, N.; Boushey, C.J.; Delp, E.J. Model-based food volume estimation using 3D pose. In Proceedings of the 2013 20th IEEE International Conference on Image Processing (ICIP), Melbourne, Australia, 15–18 September 2013; pp. 2534–2538. [Google Scholar]
- Zhu, F.; Bosch, M.; Woo, I.; Kim, S.; Boushey, C.J.; Ebert, D.S.; Delp, E.J. The use of mobile devices in aiding dietary assessment and evaluation. IEEE J. Sel. Top. Signal Process. 2010, 4, 756–766. [Google Scholar] [PubMed]
- Polfuss, M.; Moosreiner, A.; Boushey, C.J.; Delp, E.J.; Zhu, F. Technology-Based Dietary Assessment in Youth with and Without Developmental Disabilities. Nutrients 2018, 10. [Google Scholar] [CrossRef] [PubMed]
- Khanna, N.; Boushey, C.J.; Kerr, D.; Okos, M.; Ebert, D.S.; Delp, E.J. An overview of the technology assisted dietary assessment project at Purdue University. In Proceedings of the 2010 IEEE International Symposium on Multimedia (ISM), Taichung, Taiwan, 13–15 December 2010; pp. 290–295. [Google Scholar]
- Puri, M.; Zhu, Z.; Yu, Q.; Divakaran, A.; Sawhney, H. Recognition and volume estimation of food intake using a mobile device. In Proceedings of the 2009 Workshop on Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009; pp. 1–8. [Google Scholar]
- Dehais, J.; Anthimopoulos, M.; Shevchik, S.; Mougiakakou, S. Two-view 3d reconstruction for food volume estimation. IEEE Trans. Multimed. 2017, 19, 1090–1099. [Google Scholar] [CrossRef]
- Meyers, A.; Johnston, N.; Rathod, V.; Korattikara, A.; Gorban, A.; Silberman, N.; Guadarrama, S.; Papandreou, G.; Huang, J.; Murphy, K.P. Im2Calories: Towards an automated mobile vision food diary. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1233–1241. [Google Scholar]
- Fang, S.; Zhu, F.; Jiang, C.; Zhang, S.; Boushey, C.J.; Delp, E.J. A comparison of food portion size estimation using geometric models and depth images. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 Septemmber 2016; pp. 26–30. [Google Scholar]
- Gao, A.; Lo, P.; Lo, B. Food volume estimation for quantifying dietary intake with a wearable camera. In Proceedings of the 2018 IEEE 15th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Las Vegas, NV, USA, 4–7 March 2018. [Google Scholar]
- Christ, P.F.; Schlecht, S.; Ettlinger, F.; Grün, F.; Heinle, C.; Tatavarty, S.; Ahmadi, S.A.; Diepold, K.; Menze, B.H. Diabetes60-Inferring Bread Units From Food Images Using Fully Convolutional Neural Networks. In Proceedings of the ICCV Workshops, Venice, Italy, 22–29 October 2017; pp. 1526–1535. [Google Scholar]
- Song, S.; Xiao, J. Sliding shapes for 3d object detection in depth images. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 634–651. [Google Scholar]
- Zollhöfer, M.; Thies, J.; Garrido, P.; Bradley, D.; Beeler, T.; Pérez, P.; Stamminger, M.; Nießner, M.; Theobalt, C. State of the Art on Monocular 3D Face Reconstruction, Tracking, and Applications. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2018; Volume 37, pp. 523–550. [Google Scholar]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 1 November 2017).
- Bhagwat, S.; Haytowitz, D.B.; Holden, J.M. USDA Database for the Flavonoid Content of Selected Foods, Release 3.1; US Department of Agriculture: Beltsville, MD, USA, 2014.
- Calli, B.; Singh, A.; Bruce, J.; Walsman, A.; Konolige, K.; Srinivasa, S.; Abbeel, P.; Dollar, A.M. Yale-CMU-Berkeley dataset for robotic manipulation research. Int. J. Robot. Res. 2017, 36, 261–268. [Google Scholar] [CrossRef]
- Lunscher, N.; Zelek, J.S. Deep Learning Anthropomorphic 3D Point Clouds from a Single Depth Map Camera Viewpoint. In Proceedings of the ICCV Workshops, Venice, Italy, 22–29 October 2017; pp. 689–696. [Google Scholar]
- Tatarchenko, M.; Dosovitskiy, A.; Brox, T. Multi-view 3d models from single images with a convolutional network. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 322–337. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J. A Point Set Generation Network for 3D Object Reconstruction from a Single Image. In Proceedings of the CVPR, Honolulu, Hawaii, 21–26 July 2017; Volume 2, p. 6. [Google Scholar]
- Rezende, D.J.; Eslami, S.A.; Mohamed, S.; Battaglia, P.; Jaderberg, M.; Heess, N. Unsupervised learning of 3d structure from images. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: NewYork, NY, USA, 2016; pp. 4996–5004. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 628–644. [Google Scholar]
- Yang, Q.; Yang, R.; Davis, J.; Nister, D. Spatial-Depth Super Resolution for Range Images. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Chen, L.; Lin, H.; Li, S. Depth image enhancement for Kinect using region growing and bilateral filter. In Proceedings of the 2012 21st International Conference on Pattern Recognition (ICPR), Tsukuba, Japan, 11–15 November 2012; pp. 3070–3073. [Google Scholar]
- Yang, J.; Li, H.; Campbell, D.; Jia, Y. Go-ICP: A globally optimal solution to 3D ICP point-set registration. arXiv, 2016; arXiv:1605.03344. [Google Scholar] [CrossRef] [PubMed]
- Suzuki, T.; Futatsuishi, K.; Kobayashi, K. Food Volume Estimation Using 3D Shape Approximation for Medication Management Support. In Proceedings of the 2018 3rd Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Singapore, 21–23 July 2018; pp. 107–111. [Google Scholar]
- Chopin, J.; Laga, H.; Miklavcic, S.J. A new method for accurate, high-throughput volume estimation from three 2D projective images. Int. J. Food Prop. 2017, 20, 2344–2357. [Google Scholar] [CrossRef]
- Edelsbrunner, H. Smooth surfaces for multi-scale shape representation. In Foundations of Software Technology and Theoretical Computer Science; Thiagarajan, P.S., Ed.; Springer: Berlin/Heidelberg, Germany, 1995; pp. 391–412. [Google Scholar]
- Akkiraju, N.; Edelsbrunner, H.; Facello, M.; Fu, P.; Mucke, E.; Varela, C. Alpha shapes: Definition and software. In Proceedings of the 1st International Computational Geometry Software Workshop, Baltimore, MD, USA; 1995; Volume 63, p. 66. [Google Scholar]
- Varley, J.; DeChant, C.; Richardson, A.; Ruales, J.; Allen, P. Shape completion enabled robotic grasping. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 2442–2447. [Google Scholar]
- Zelek, J.; Lunscher, N. Point cloud completion of foot shape from a single depth map for fit matching using deep learning view synthesis. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; pp. 2300–2305. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Author | Accuracy in Volume Estimation | Common Advantages | Common Limitations |
|---|---|---|---|---|
| Stereo-based approach | Gao et al. (2018) [12] Dehais et al. (2017) [9] Puri et al. (2009) [8] | 80.8–88.3% 90.2–91.8% 90.5–92.0% | 1. Has the ability to handle irregular food items 2. No prior knowledge required 3. No pre-built 3D models required | 1. Required to capture images from different viewing angles 2. Slow processing time due to feature detection and matching 3. Unable to handle the issue of occlusion 4. Fiducial marker required |
| Model-based approach | Sun et al.(2015) [3] Xu et al. (2013) [4] Khanna et al. (2010) [7] | 79.5% 87.7–96.4% 90.0% | 1. Robust performance for certain general food shapes 2. High accuracy in pre-trained food items | 1. Unable to tackle irregular food shapes 2. Pre-trained 3D model library required 3. Manual refining needed |
| Depth camera-based approach | Fang et al. (2016) [11] | 66.1–89.0% | 1. Robust performance in volume estimation 2. No fiducial marker required | 1. Unable to handle the issue of occlusion 2. Depth sensing camera is not always embedded in smart devices |
| Deep learning approach | Christ et al. (2017) [13] Meyers et al. (2015) [10] | 1.53 bread units (error in bread units) 50–400 mL (error in volume) | 1. Has the ability to handle irregular food items 2. Generalization capability of neural networks | 1. A large number of food images required for training 2. A high error rate in depth image prediction |
| Integrated approach | - | 93.1% | 1. Able to handle irregular food items after training 2. Able to handle occluded food items 3. No manual intervention 4. No fiducial marker required | 1. A large number of food images required for training |
| Azimuth | Elevation | Height | Shifting | |
|---|---|---|---|---|
| Initial viewing angle | 0 to 360 degree | 90 to 270 degree | 0.5 to 0.6 m | x: −0.1 to 0.1; y: −0.1 to 0.1 |
| Opposite viewing angle | 0 to 360 degree | 270 to 450 degree | −0.5 to −0.6 m | x: −0.1 to 0.1; y: −0.1 to 0.1 |
| Naive Version | Our (Extrinsic Parameters) | Our (Inception Layers + Extrinsic Parameters) | |
|---|---|---|---|
| Training Loss | 0.00101 | 0.00093 | 0.00077 |
| Testing Loss | 0.00112 | 0.00104 | 0.00083 |
| Iteration | 1,000,000 | 1,000,000 | 1,000,000 |
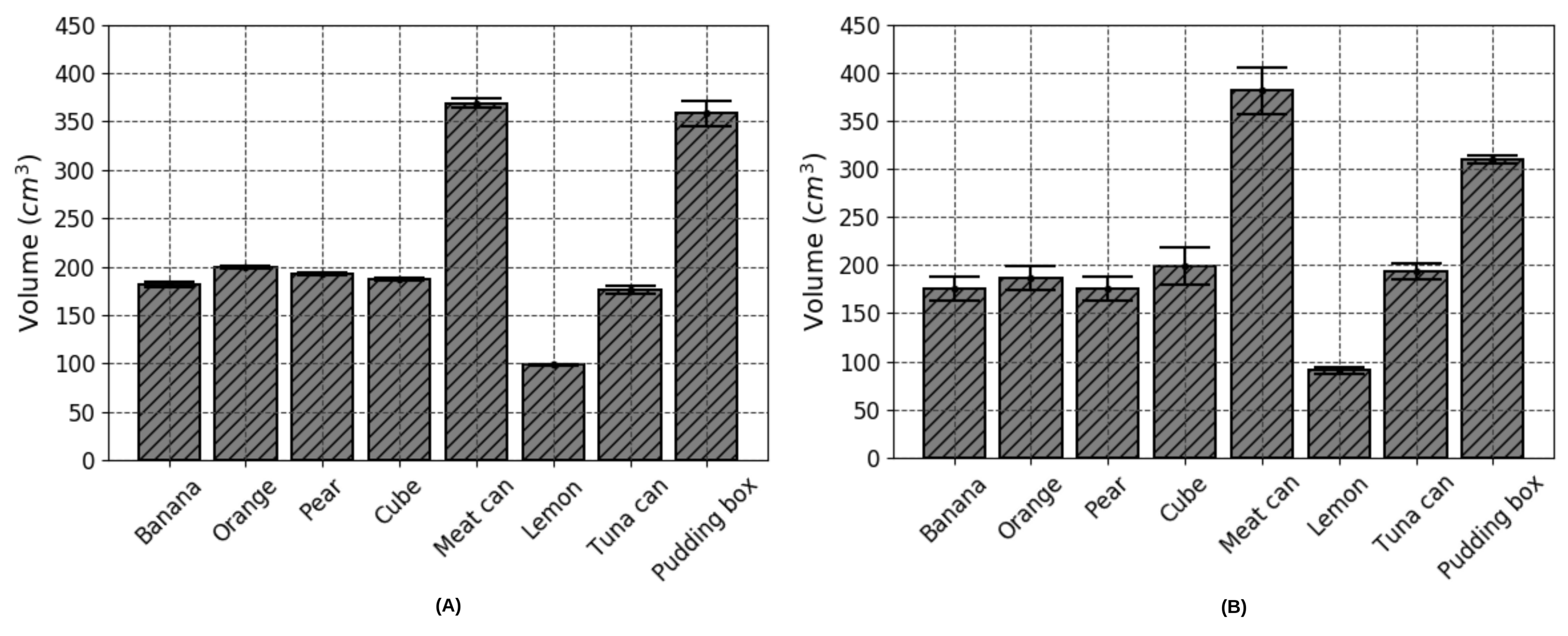
| Food Object Item | Ground Truth (cm) | Estimated Volume (cm) | SD of (cm) | Error of (%) | Estimated Volume (cm) | SD of (cm) | Error of e (%) |
|---|---|---|---|---|---|---|---|
| 1—Banana | - | 181.6 | 2.8 | - | 175.6 | 12.6 | 3.3 |
| 2—Orange | 203.0 | 199.5 | 1.2 | 1.7 | 186.7 | 12.1 | 8.0 |
| 3—Pear | - | 192.75 | 0.9 | - | 175.5 | 12.8 | 8.9 |
| 4—Cube | 185.2 | 187.0 | 0.8 | 1.0 | 198.6 | 19.3 | 7.2 |
| 5—Potted Meat Can | - | 369.0 | 4.5 | - | 381.0 | 24.5 | 3.3 |
| 6—Lemon | - | 98.5 | 1.3 | - | 91.0 | 3.4 | 7.6 |
| 7—Tuna Fish Can | 180.0 | 176.0 | 4.2 | 2.2 | 193.3 | 8.3 | 7.3 |
| 8—Pudding Box | 342.0 | 358.5 | 13.2 | 4.8 | 309.7 | 3.5 | 9.4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lo, F.P.-W.; Sun, Y.; Qiu, J.; Lo, B. Food Volume Estimation Based on Deep Learning View Synthesis from a Single Depth Map. Nutrients 2018, 10, 2005. https://doi.org/10.3390/nu10122005
Lo FP-W, Sun Y, Qiu J, Lo B. Food Volume Estimation Based on Deep Learning View Synthesis from a Single Depth Map. Nutrients. 2018; 10(12):2005. https://doi.org/10.3390/nu10122005
Chicago/Turabian StyleLo, Frank P. -W., Yingnan Sun, Jianing Qiu, and Benny Lo. 2018. "Food Volume Estimation Based on Deep Learning View Synthesis from a Single Depth Map" Nutrients 10, no. 12: 2005. https://doi.org/10.3390/nu10122005
APA StyleLo, F. P.-W., Sun, Y., Qiu, J., & Lo, B. (2018). Food Volume Estimation Based on Deep Learning View Synthesis from a Single Depth Map. Nutrients, 10(12), 2005. https://doi.org/10.3390/nu10122005