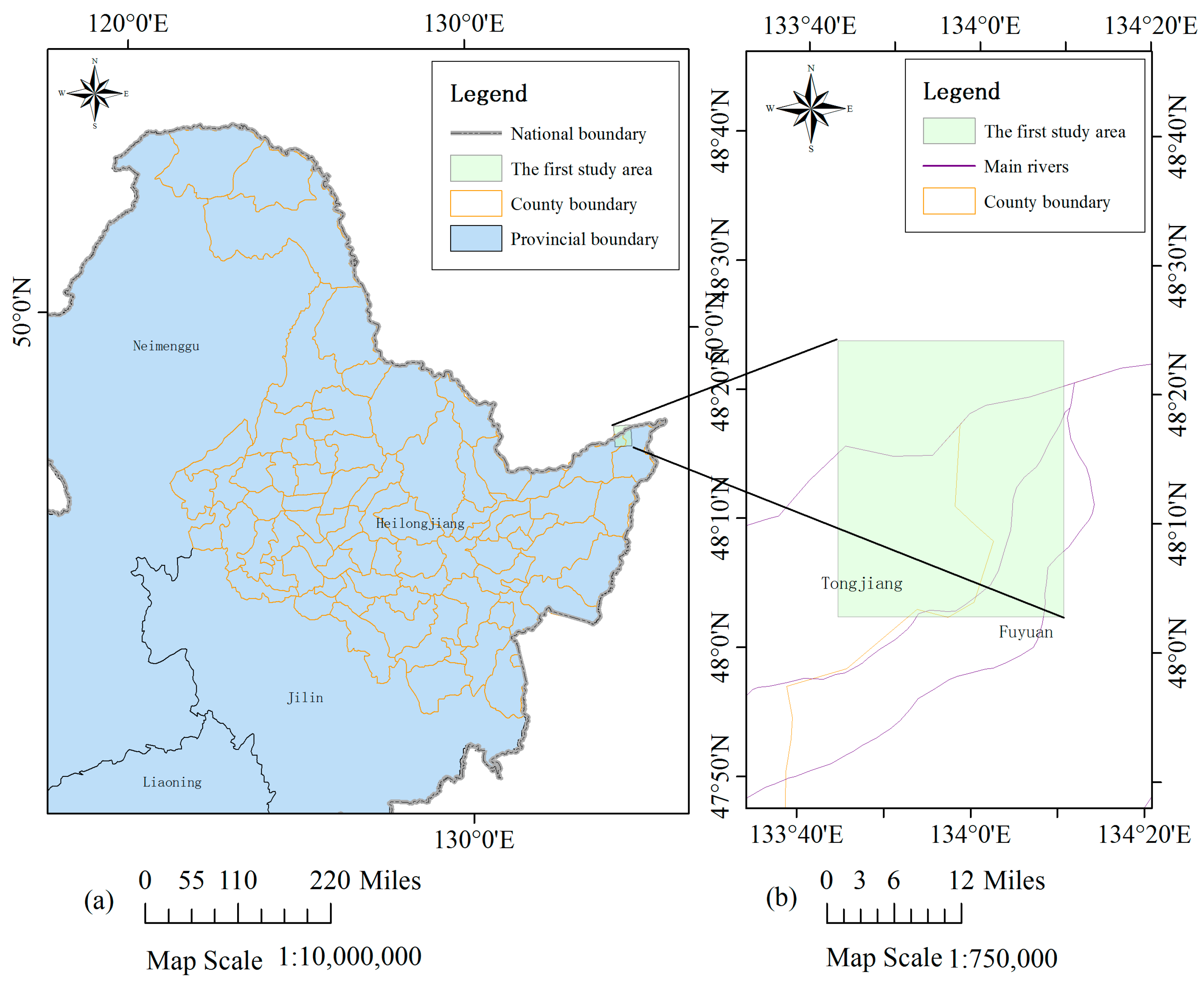
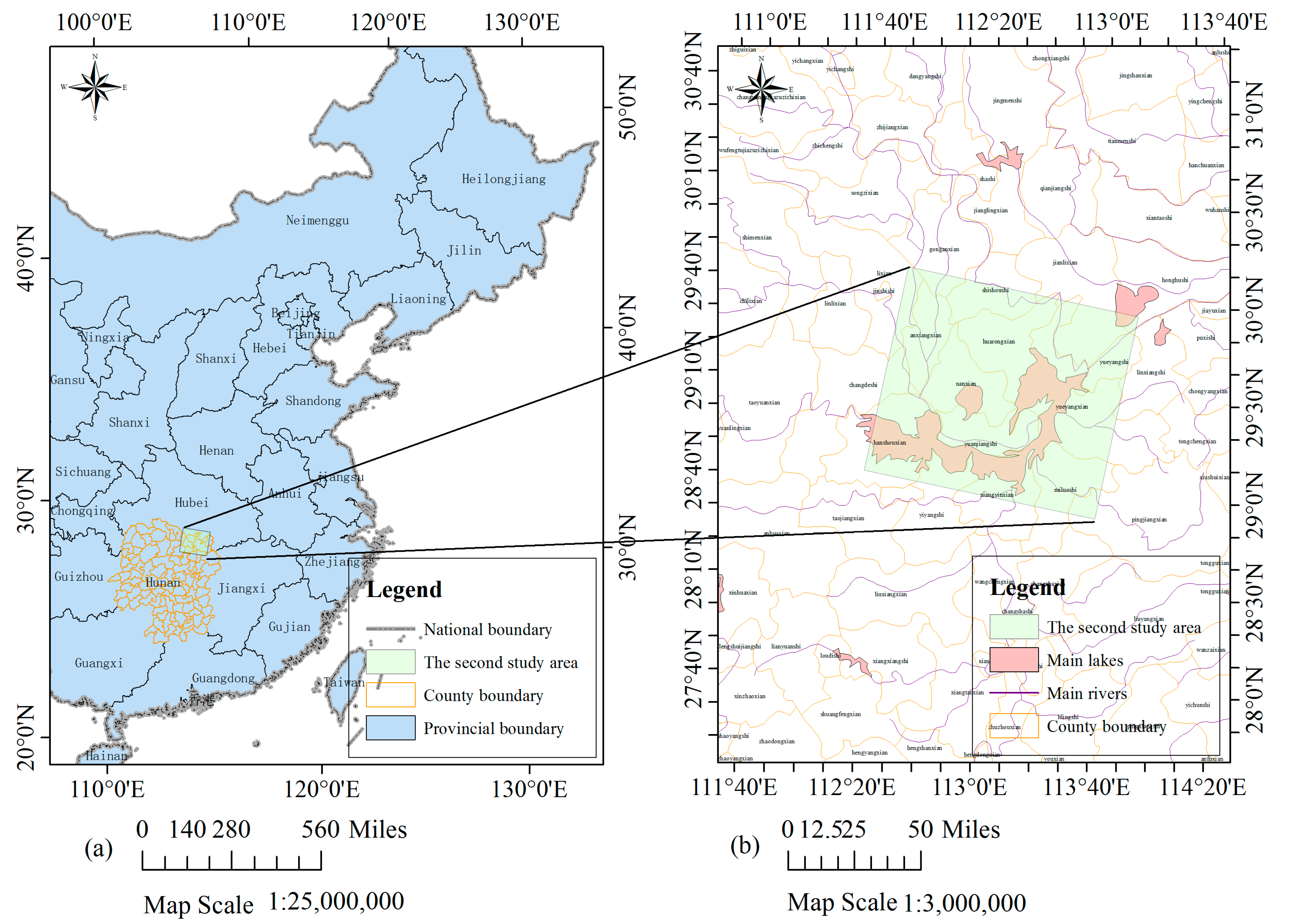
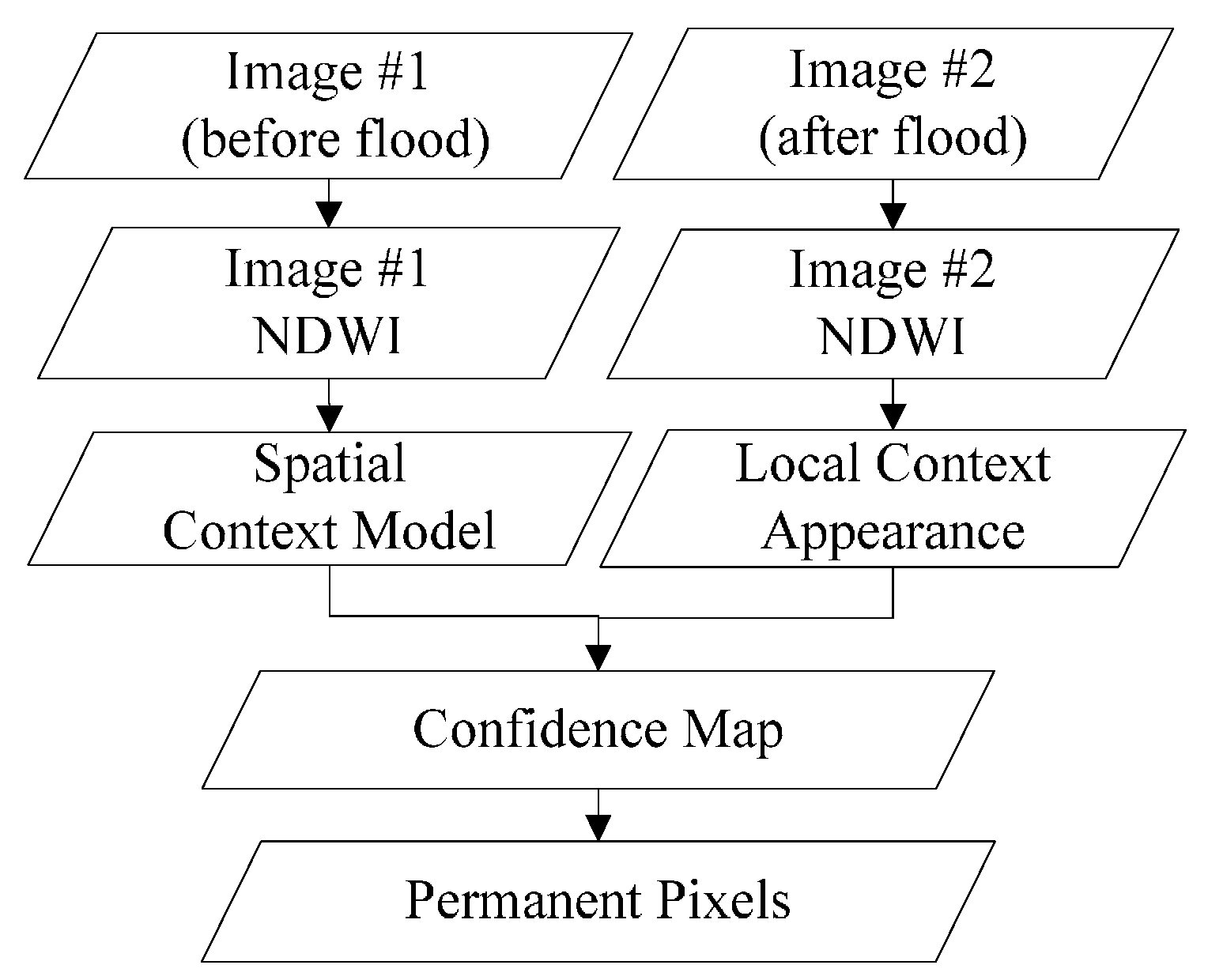
3.1. Permanent Pixel Extraction Using Spatiotemporal Context Learning
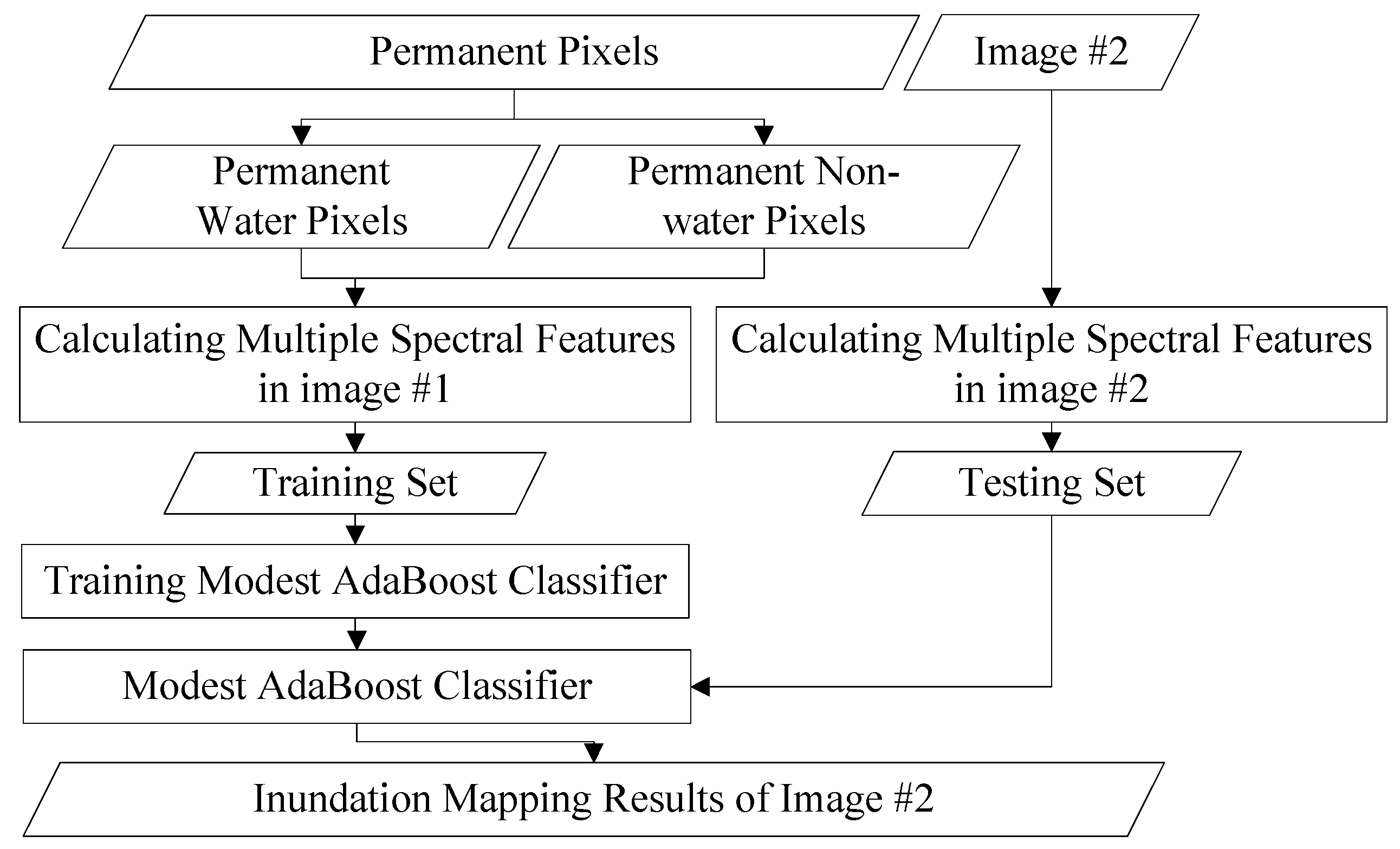
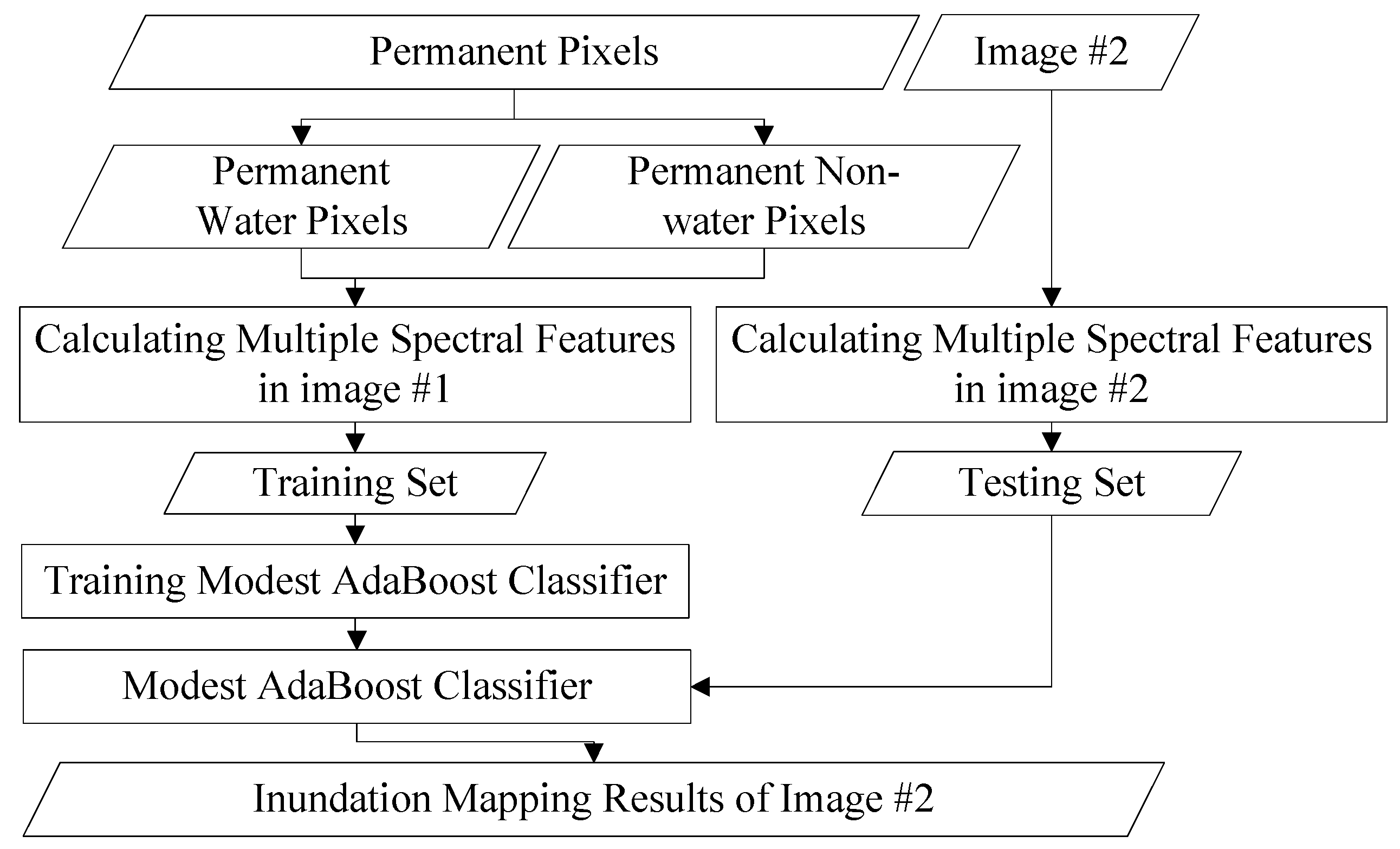
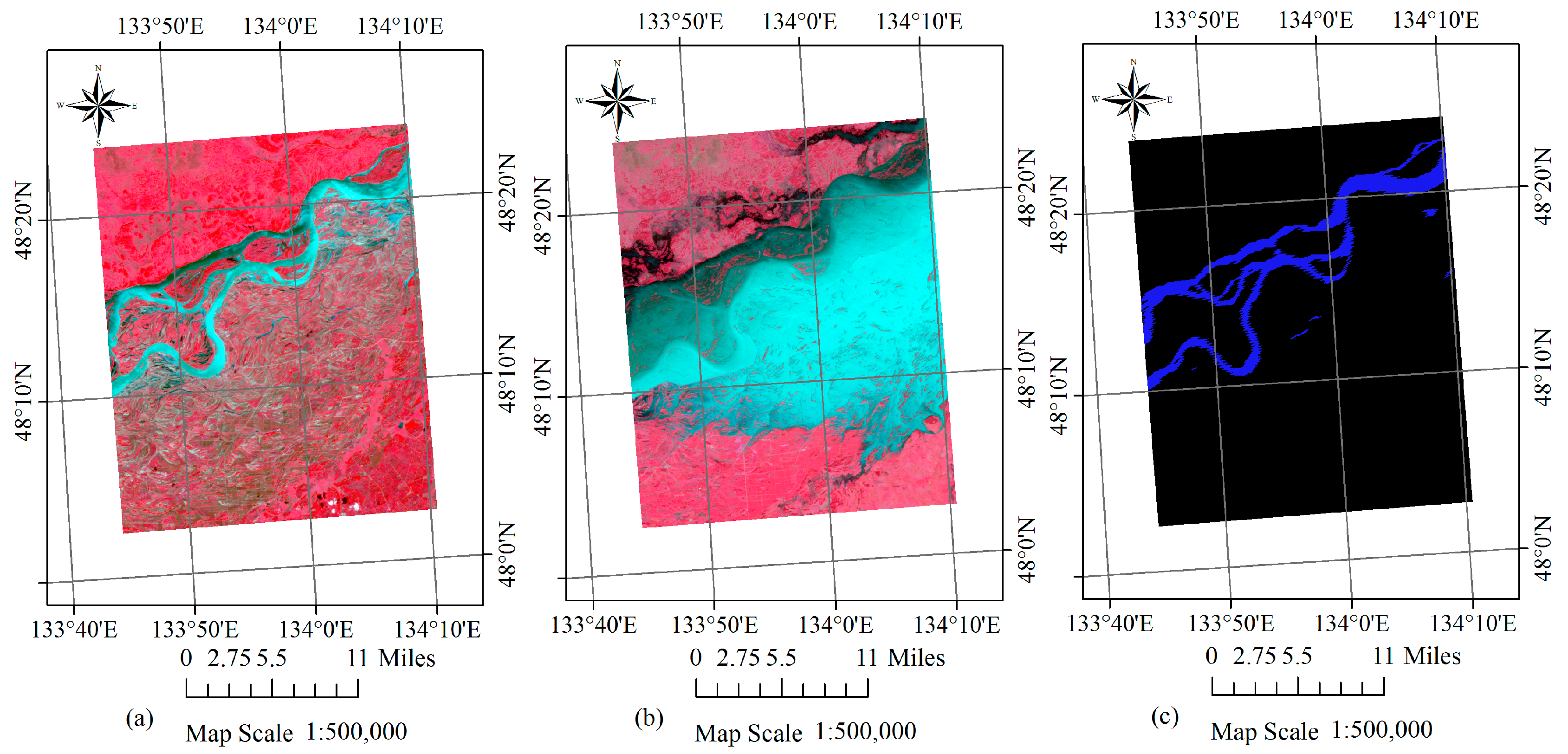
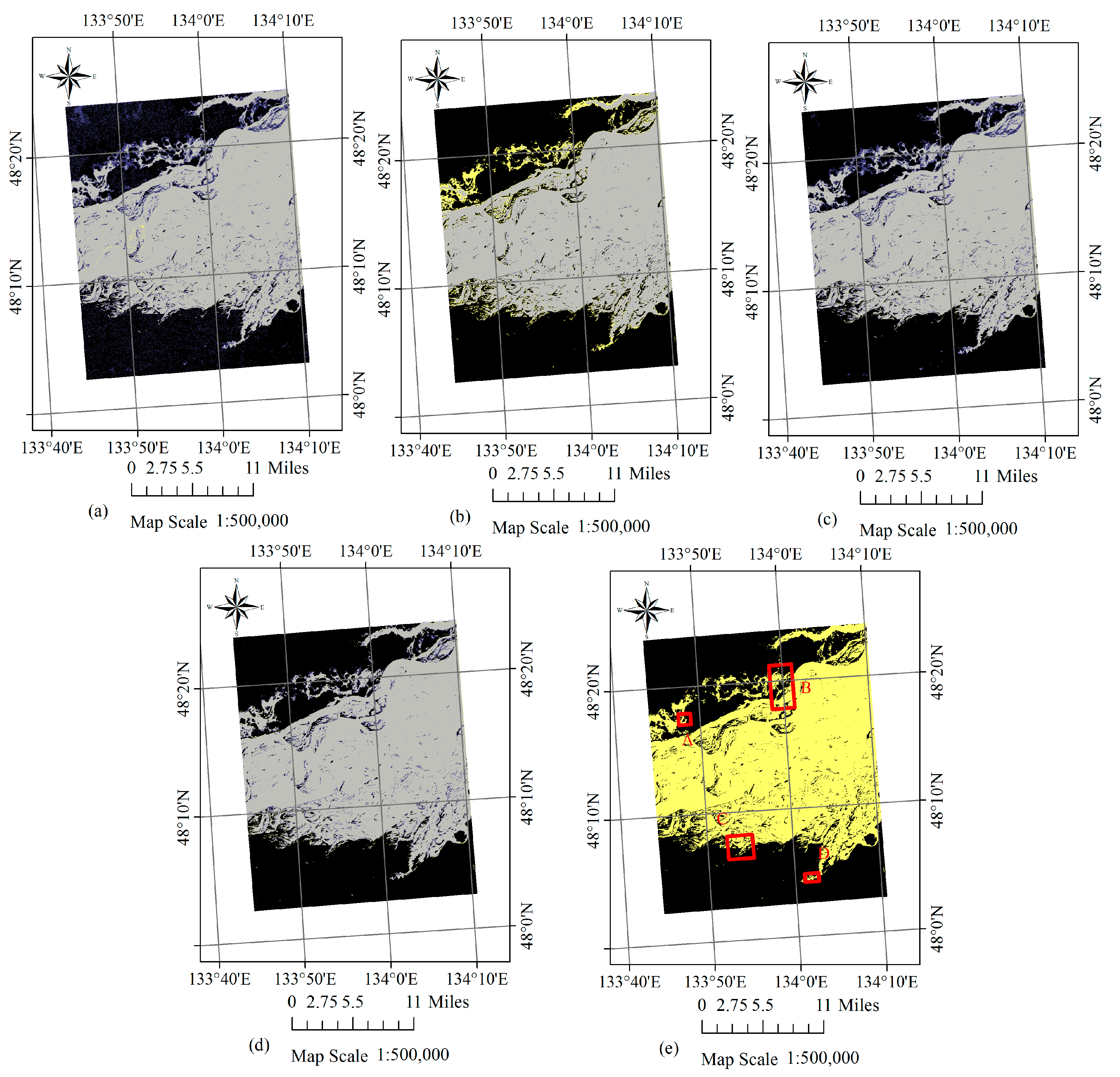
The images before and after a flood are referred to as image #1 and image #2, respectively. The pixels with a constant land cover type, no matter what the type is, are defined as permanent pixels. The proposed method is divided into two steps. First, the permanent pixels in image #1 and image #2 are extracted based on the STCL strategy. This is a method that models the relative relationship between an object and its context. We introduce it to formulate the relationship between a satellite image pixel and its context. Through comparing the models at different time points, a confidence value for whether a pixel changes or not is calculated to extract the permanent pixels. Second, using these permanent pixels as a training set, a widely adopted machine learning classifier, Modest AdaBoost, is trained and implemented for mapping inundation in image #2. Modest AdaBoost is one of the derivations of the boosting algorithm, like the original AdaBoost algorithm. It combines the performance of a set of weak classifiers, and also proves better than other boosting algorithms for convergence ability. More details about these methods will be given below. In this section, we will first discuss the procedure in the first step.
Due to its capacity for targeting specific land cover type and reducing influence from inconstant band representation, spectral indices are commonly used in diverse remote sensing applications, such as disaster monitoring, land cover mapping and disease prevention [
26,
27,
28]. For mapping different cover types in different applications, various indices have been proposed, including the normalised difference vegetation index (NDVI), the enhanced vegetation index (EVI), NDWI, and the normalised difference built-up index (NDBI) and so on. Among these indices, the NDWI has been successfully applied to mapping land surface water, and proved more effective than other general feature classification methods [
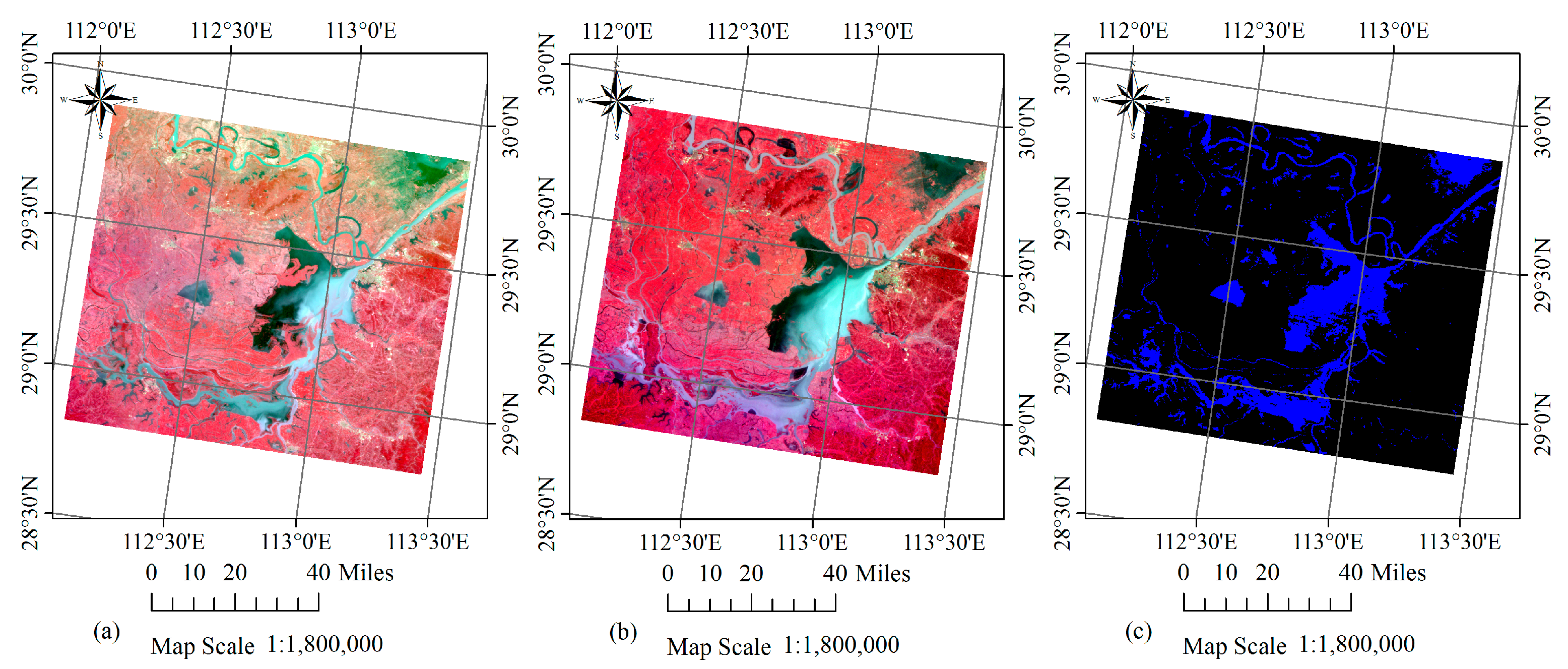
29]. In this study, we calculate the NDWI in the experimental datasets (the HJ-1A CCD data for the first case study and the GF-4 PMS data for the second case study) first. Then, the steps for extracting permanent pixels will be executed on the NDWI data. The NDWI is calculated as:
where
and
are the reflected green and near infrared radiance, respectively, which are replaced by band 2 and band 4 in the HJ1-A CCD data case, and band 3 and band 5 in the GF-4 PMS data case [
15]. NDWI can eliminate the influence from the band value difference, but not the influence caused by the different weather conditions. However, as it is the relative relationship between neighbouring pixels that we use, influences from changes of overall brightness are limited in the proposed procedure.
In the visual tracking field, as the video frames usually change continuously, a strong spatiotemporal correlation is thought to exist between a target and its surroundings. In order to make better use of this relative relationship, Zhang et al. [
30] proposed the STCL method. In this method, a rectangular contextual region was first built with the target in the centre. With the low-level features (including the image density and location) of the contextual region, the relative relationship between the target and its surroundings in contextual region was modelled. When a new frame came, it was put into the model to calculate a confidence map, indicating the location that best matched the contextual relationship of previous frames. This location was the inferred location of the target in the new frame. As it depended on a kind of relative relationship, the illumination difference during the frames cannot influence the result. Extensive experiments showed its effectiveness and good degree of precision. This method has also been further employed and extended in other visual trackers [
31,
32].
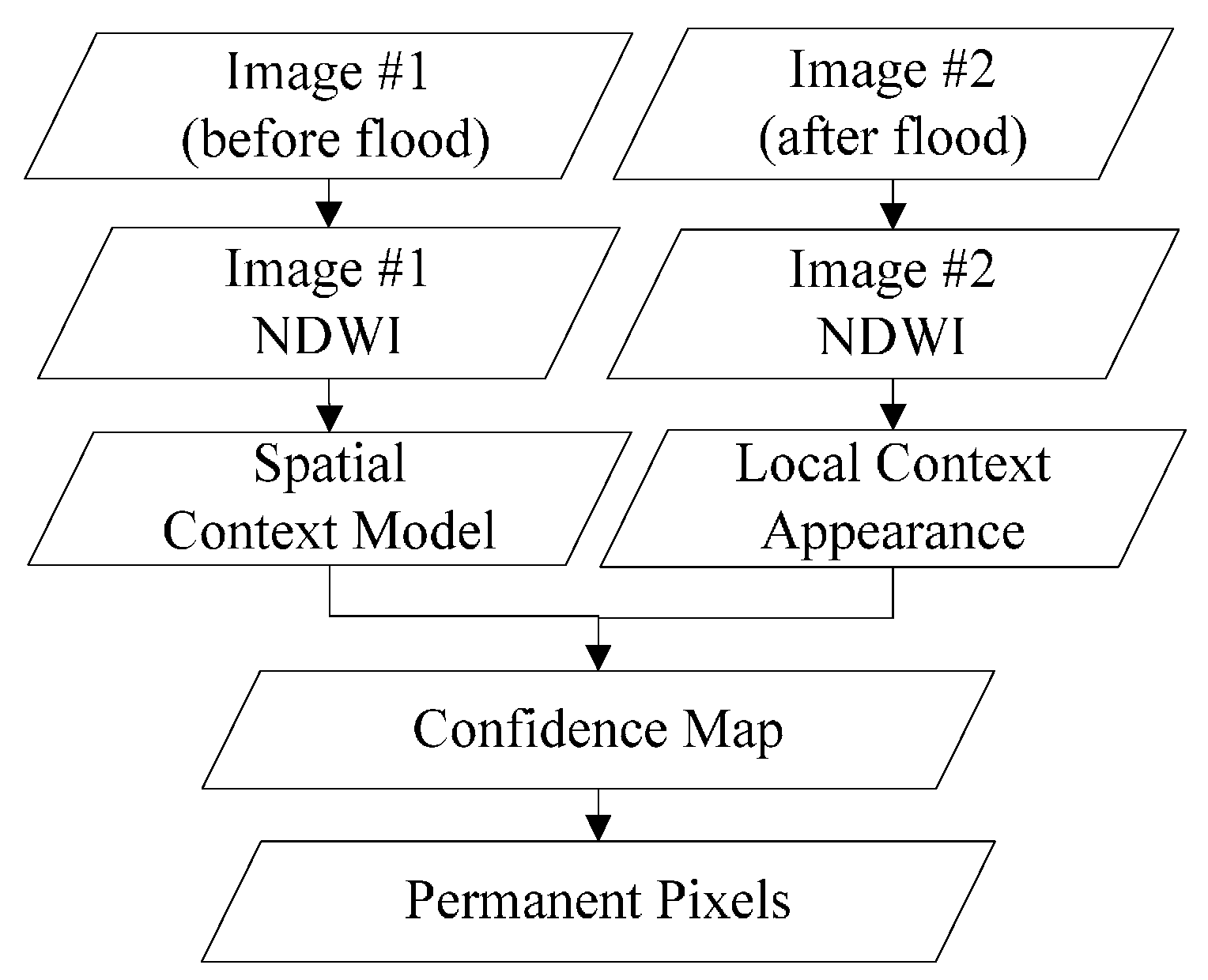
A remote sensing image time series shares many similar characteristics with video data, although video sequence images have a higher sampling rate. It can be inferred that there is also a relationship between a target pixel and its spatiotemporal neighbourhoods in a local scene of RS images, if the images are of good quality, without too many clouds and shadows. Due to the constant changes in weather and light conditions, radiation values of the same cover type can vary greatly in different scenes. Furthermore, it is rather difficult to calibrate the radiation of two RS images to absolute consistency. As a result, more false positives can be introduced in mapping the changes. While the relative relationship between unchanged pixels and their nearby pixels is relatively constant, the STCL method, which aims at modelling this kind of relationship, is supposed to be robust also to illumination variation in RS images. What is more, the STCL method provides a fast solution to online problems. In this work, we borrow the concept of STCL to build a procedure for extracting permanent pixels for flood mapping. The proposed flowchart for extracting permanent pixels is shown in
Figure 3.
One core of the STCL method is its utilisation of the attention focus property in biological visual systems. In the mechanism of biological vision, assume that we are observing a point in a picture. Besides the point itself, which draws most of our attention, other points around the target point are the part we pay the second most attention to in the picture. The further one point is from the target point, the less concern it will get from the visual system. On the contrary, if someone tries to find a known point in an image, the visual mechanism first roughly figures out the background of the target, and then, on the basis of a correlation between the background and the point, the point can be easily targeted. But if only the feature of the target itself is considered, the search will be time and labour intensive. In the visual tracking field, it means the tracker may get lost.
According to this conception, the STCL proposed by Zhang et al. [
30] in the visual tracking field uses the distribution of the attention focus, which is formulated as a curved surface function. In the function, the peak is located at the target point and its surroundings gradually decrease. With the weights from this function, the correlation of the target with its local background in image density and location are modelled. If the target location gradually changes, this context model will gradually change as well, and will be updated in each frame. When a new frame comes, although there are illumination variation and occlusion problems, the new location of the target can still be found by comparing the model with that of each pixel in the image. We borrow the concept and the formulation of the spatiotemporal context in STCL, and propose a method based on this context information for extracting permanent pixels. Details of the method are described as follows. The core of this problem is calculating the confidence map
between image #1 and image #2, which is also the probability of that the pixel is permanent. It can be formulated as
where
is a pixel location, and
is the probability. The higher
is, the more likely
will be permanent. After transformation,
can be given by
where
.
denotes the pixel value, i.e., the NDWI value, at location
, and
is the neighbourhood of location
.
is the context prior probability that models the appearance of the local context, and
represents the relative relationship between
and its neighbourhood, which is defined as the spatial context model
In image #1,
and
are, respectively, the locations of the target pixel and its local context. For context prior probability, when
is permanent, if the values of
and
, as well as
and
, are closer, there is a higher probability that the pixel at location
will also be permanent. Different from the original solution for the tracking problem, we model the context prior probability
as
where
is a spatial weight function. With regard to the attention focus principle, if the local context pixel
is located closer to the object
,
should make a greater contribution to the contextual characteristics of
in (5), and a higher weight should be given to it, and vice versa. Given that the weight should decrease smoothly with the increase of the distance to the object,
is defined as an exponential type as
where
is a normalising constant that restricts
to a range from 0 to 1.
is the scale parameter. As there are no changes occurring to
in image #1, we set its confidence value
. According to the correlation between adjacent pixels, if the context pixel is located closer to the object, it should be more likely to be permanent. Therefore, the confidence function in image #1 can be modelled as
where
is a scale parameter and
is a shape parameter. The confidence value changes monotonically with the values of
and
. Therefore, these two parameters can be neither too large nor too small. For instance, if
is too large, the model can easily get over-fitted. While if
is too small, the smoothing may cause some errors. We empirically set
and
for all the experiments here. Based on (2)–(5), it can be inferred that
where
denotes the convolution operation. According to (7), (8) can be transformed to the frequency domain as:
where
donates the Fourier transform function.
is the element-wise product. So, for image #1, the spatial context model is
With the spatial context model gained from image #1, according to (9), the confidence map of image #2 can be calculated by
where
is the location of the target pixel in image #2, and
and
, respectively, represent the context prior probability and image intensity in image #2 [
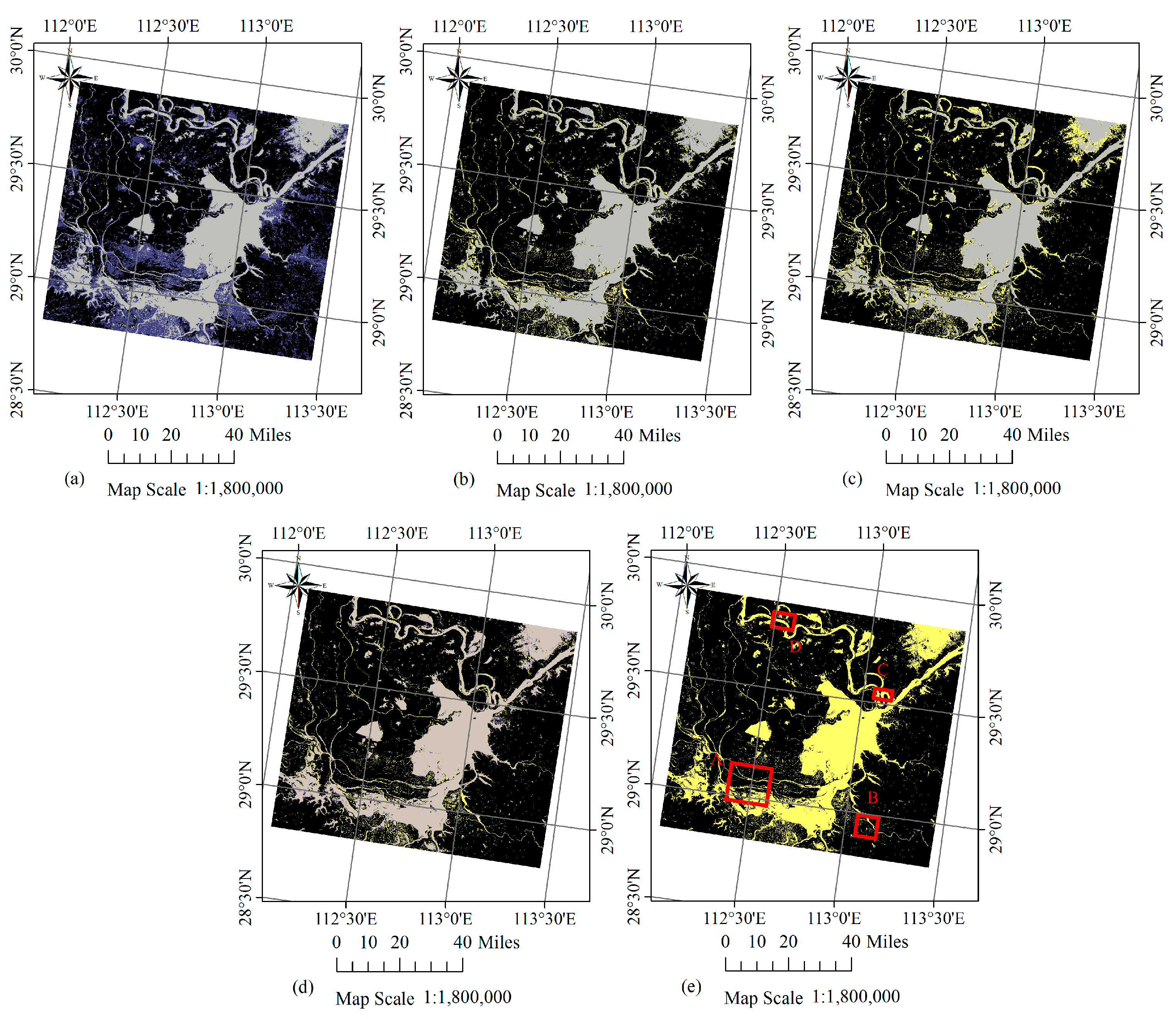
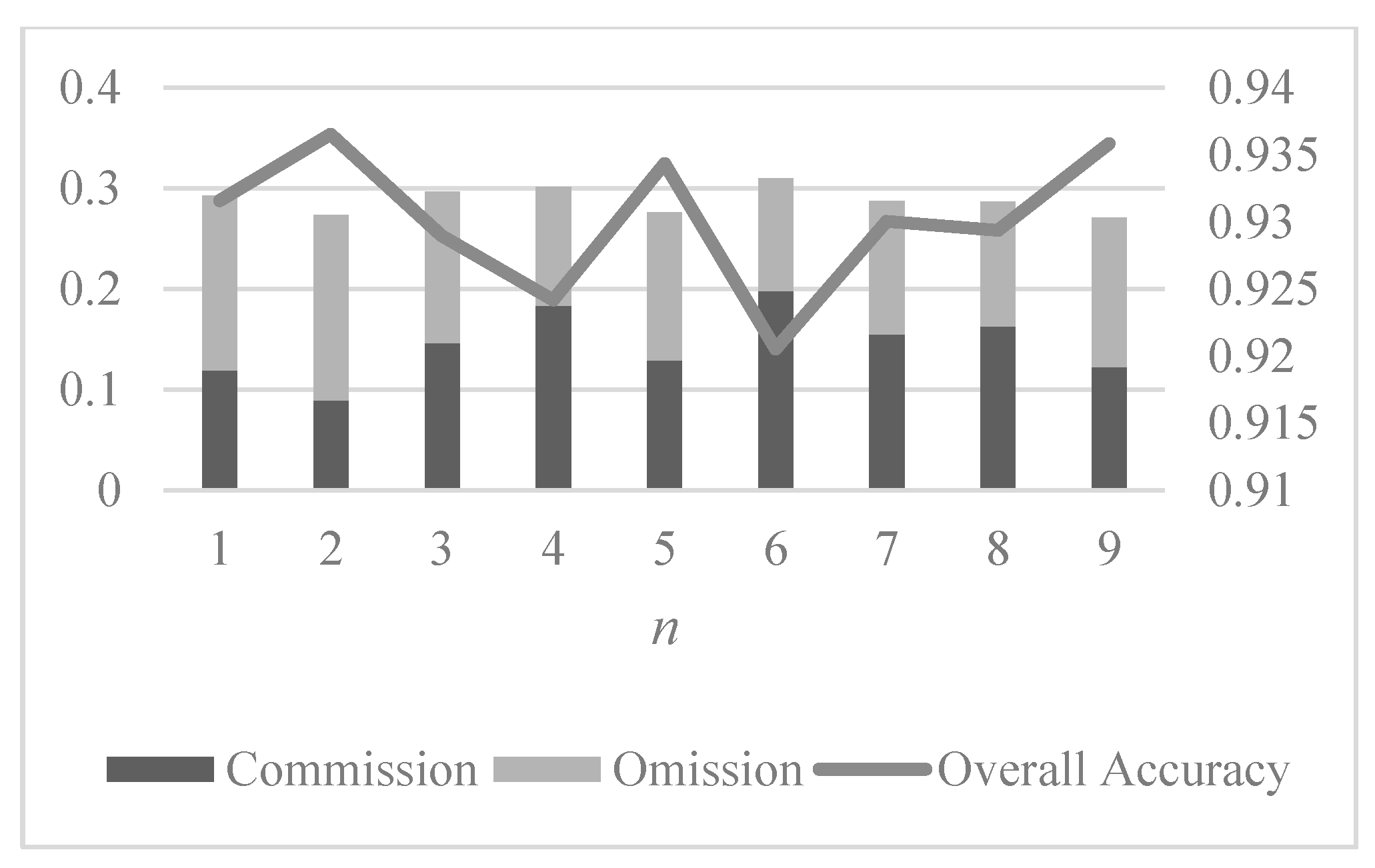
30]. After the permanence confidence map is calculated for image #2, obtained after a flood, we select the pixels with top
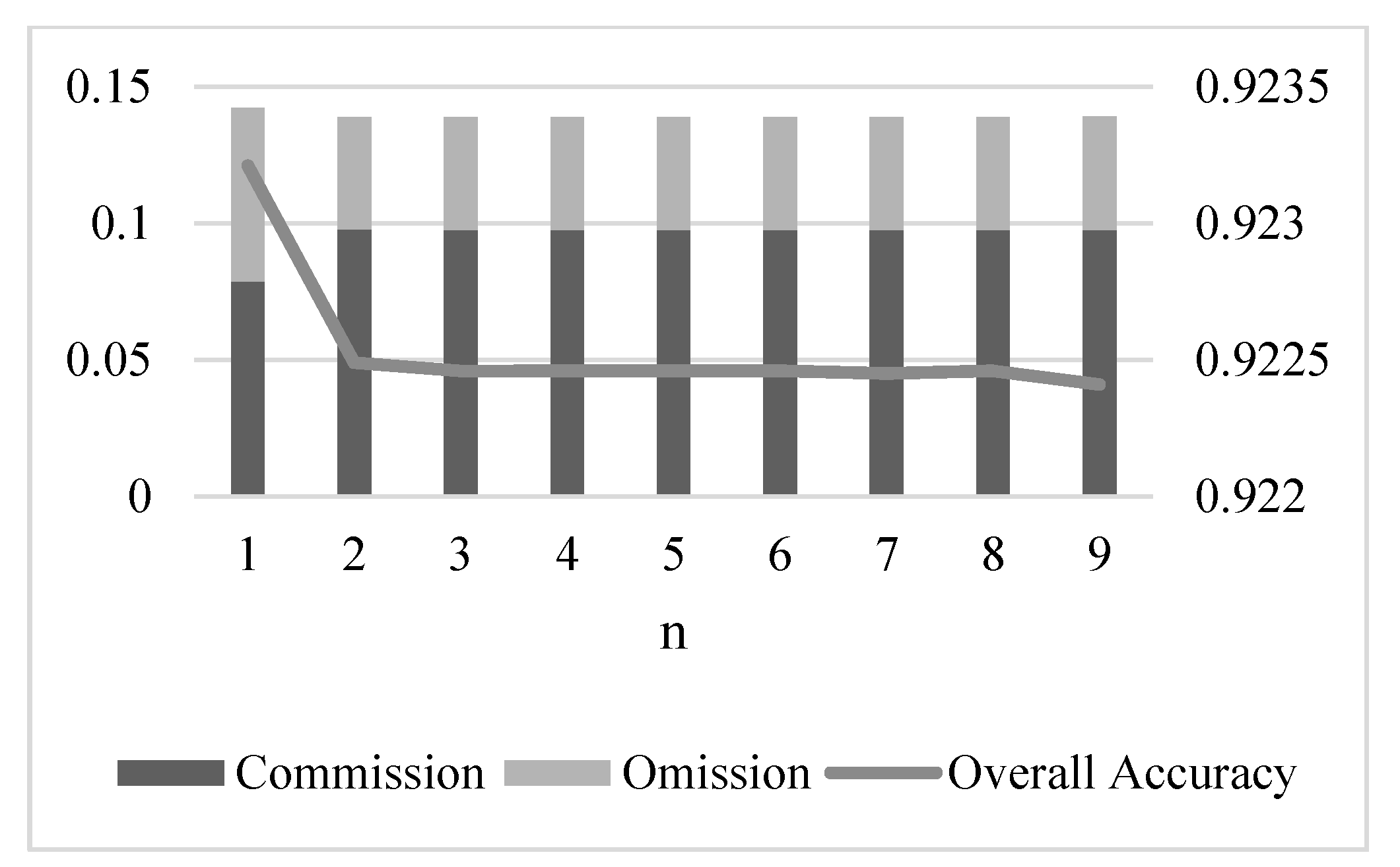
confidence values as the final permanent pixels. In this work, we choose
. More discussion on how
influences the result will be given later.



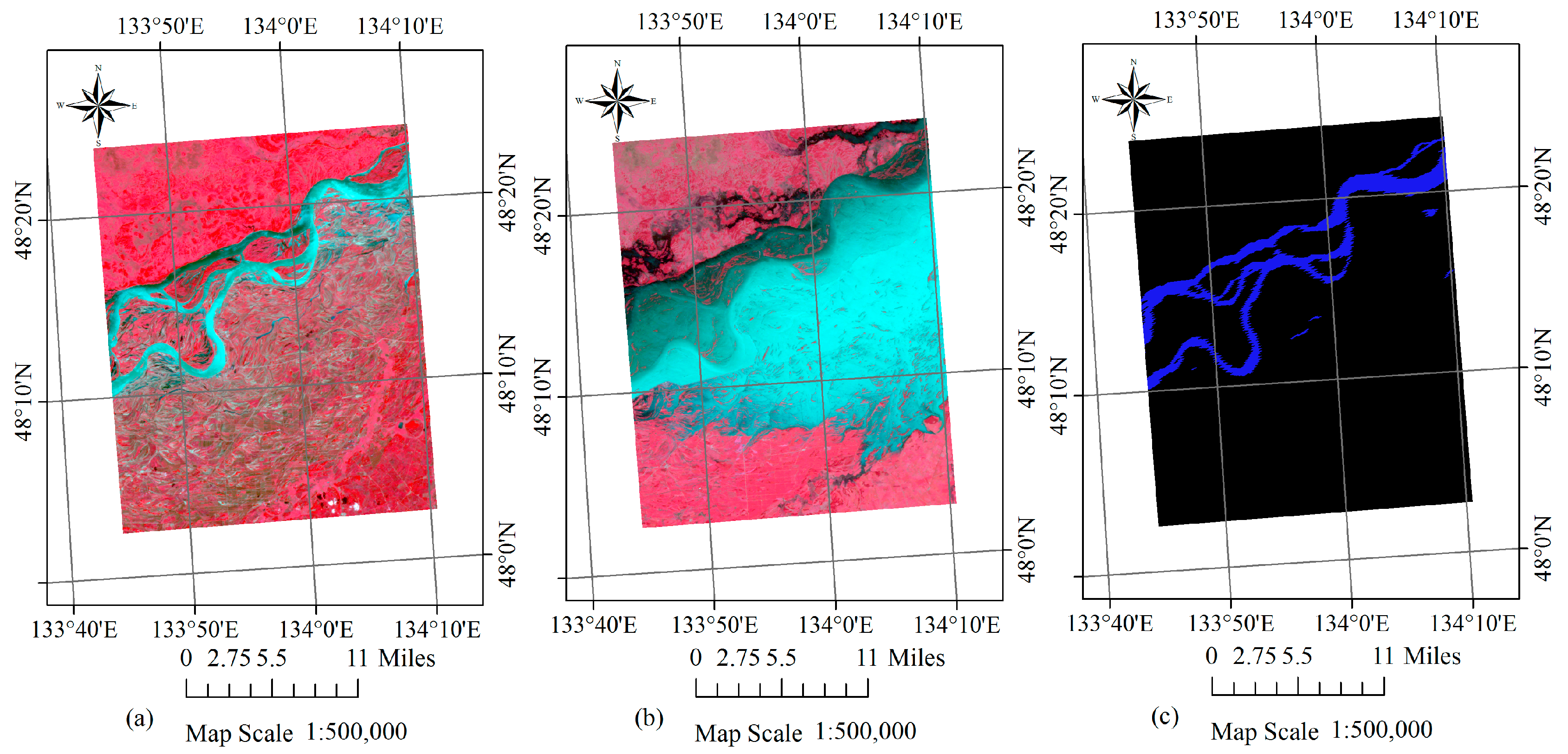
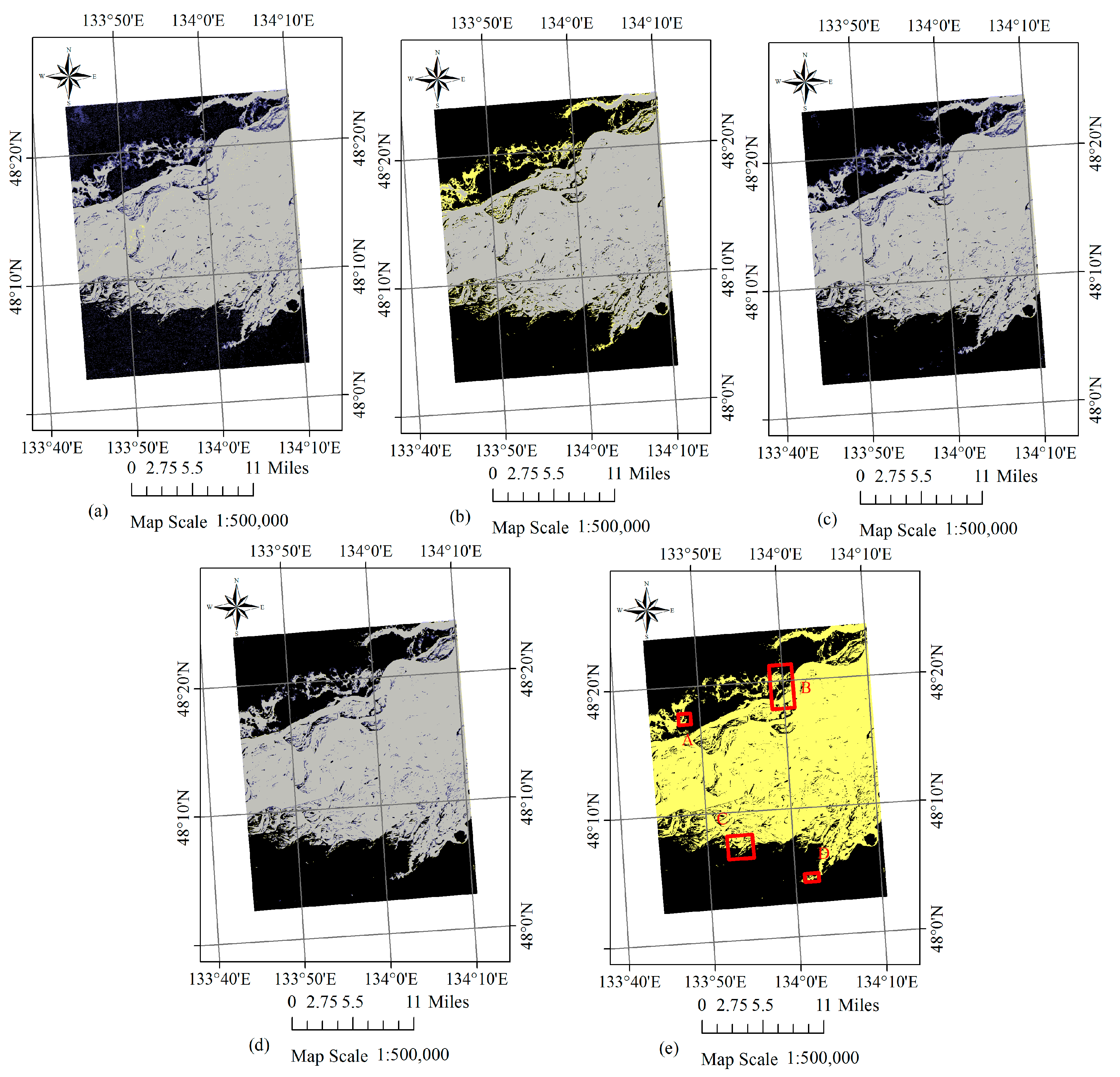

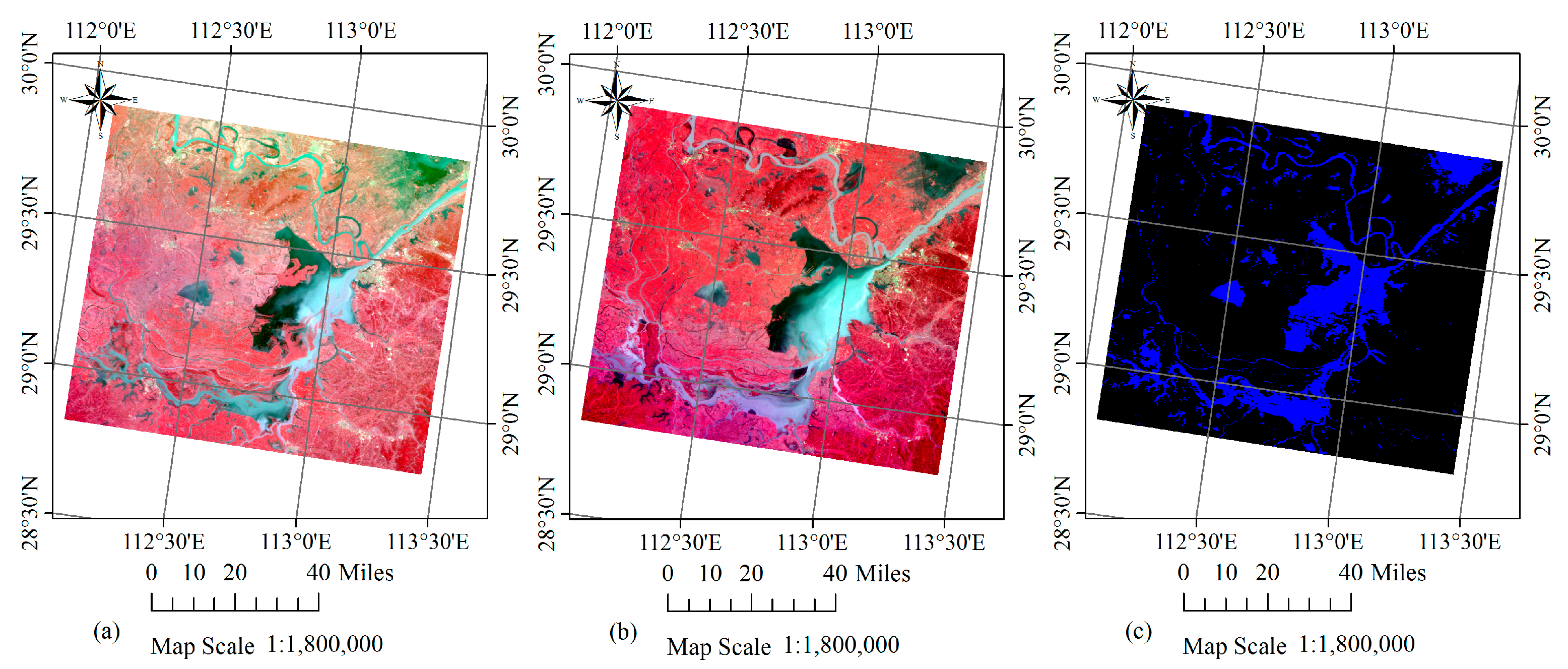
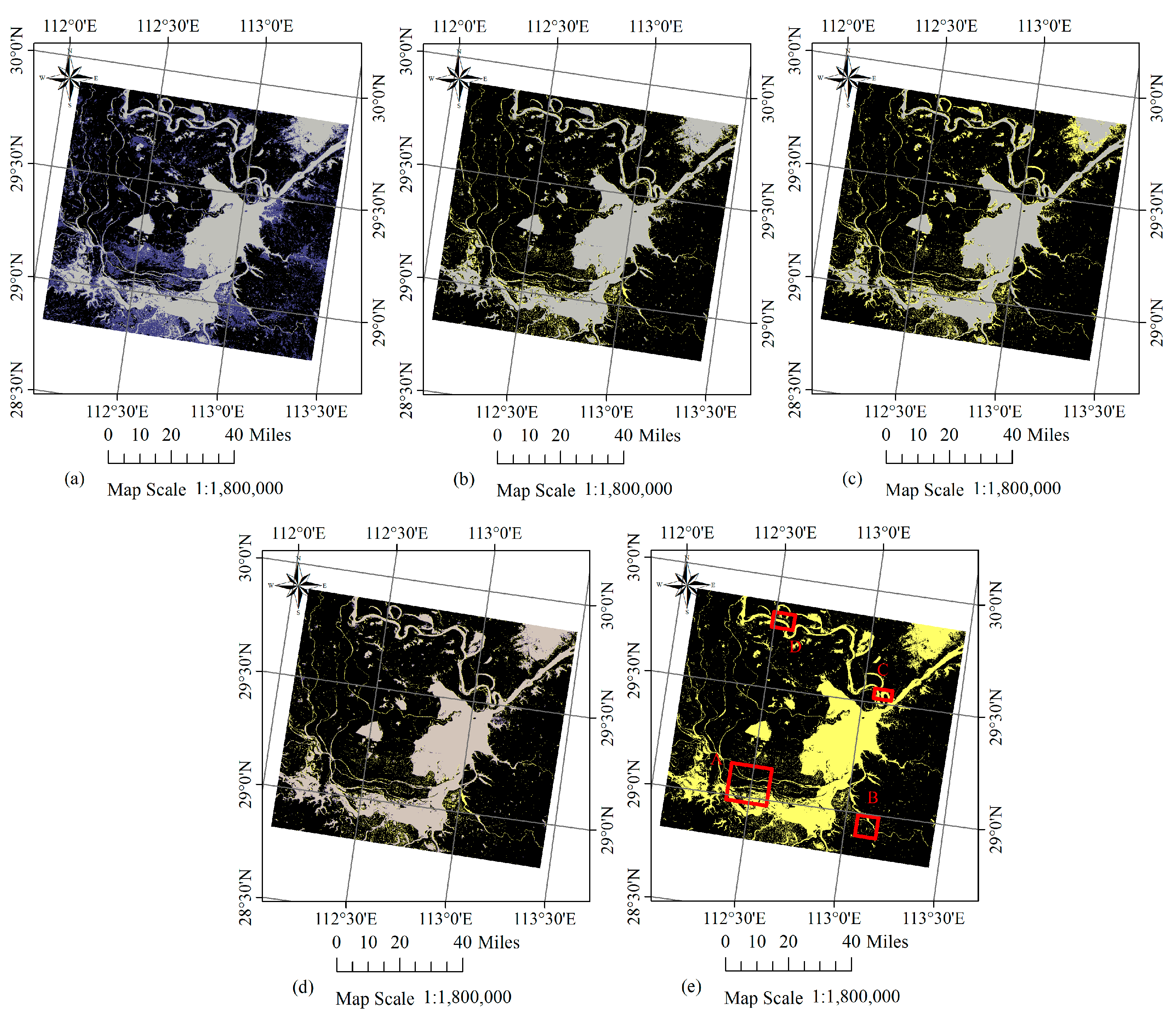

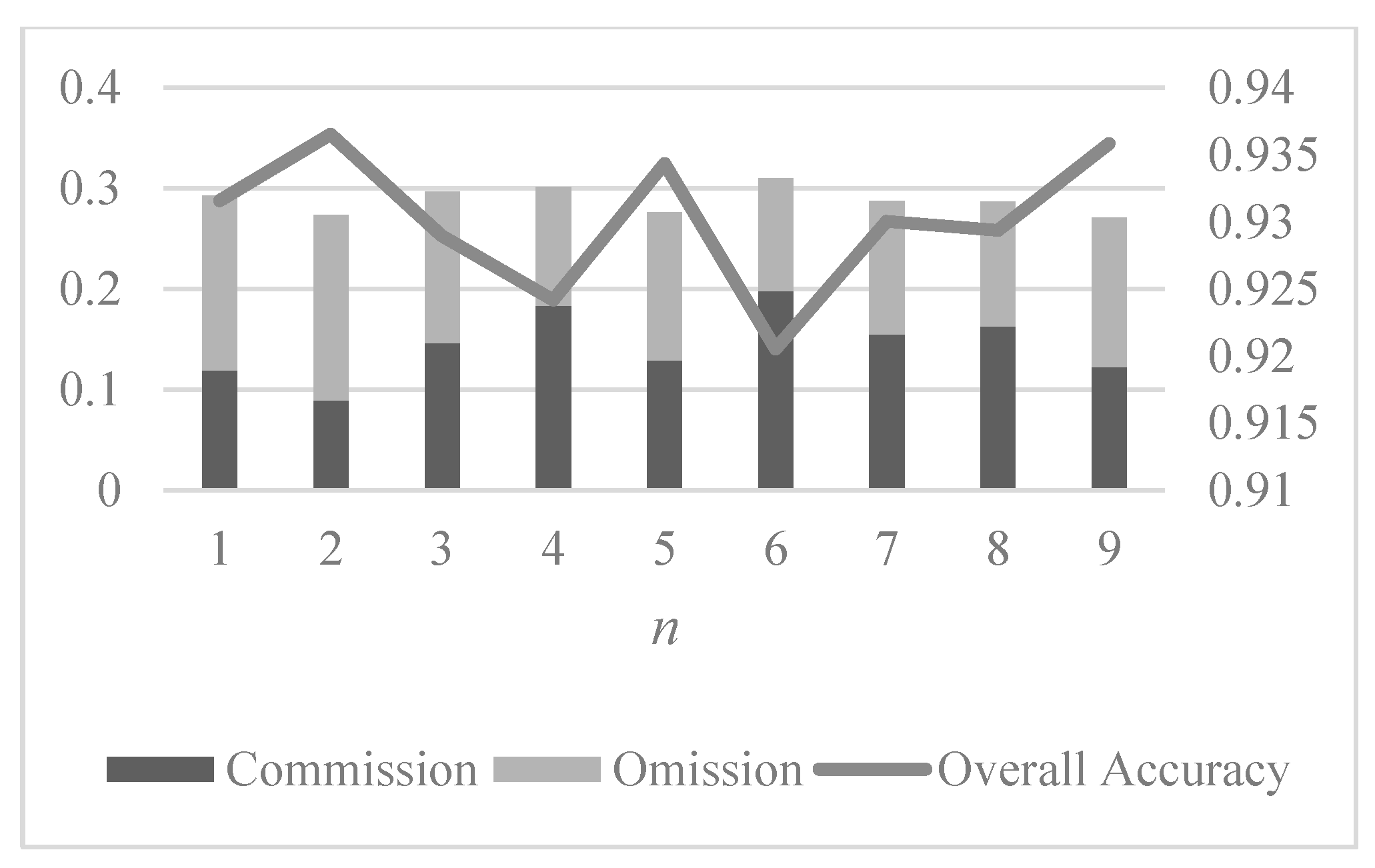

{kind=link}
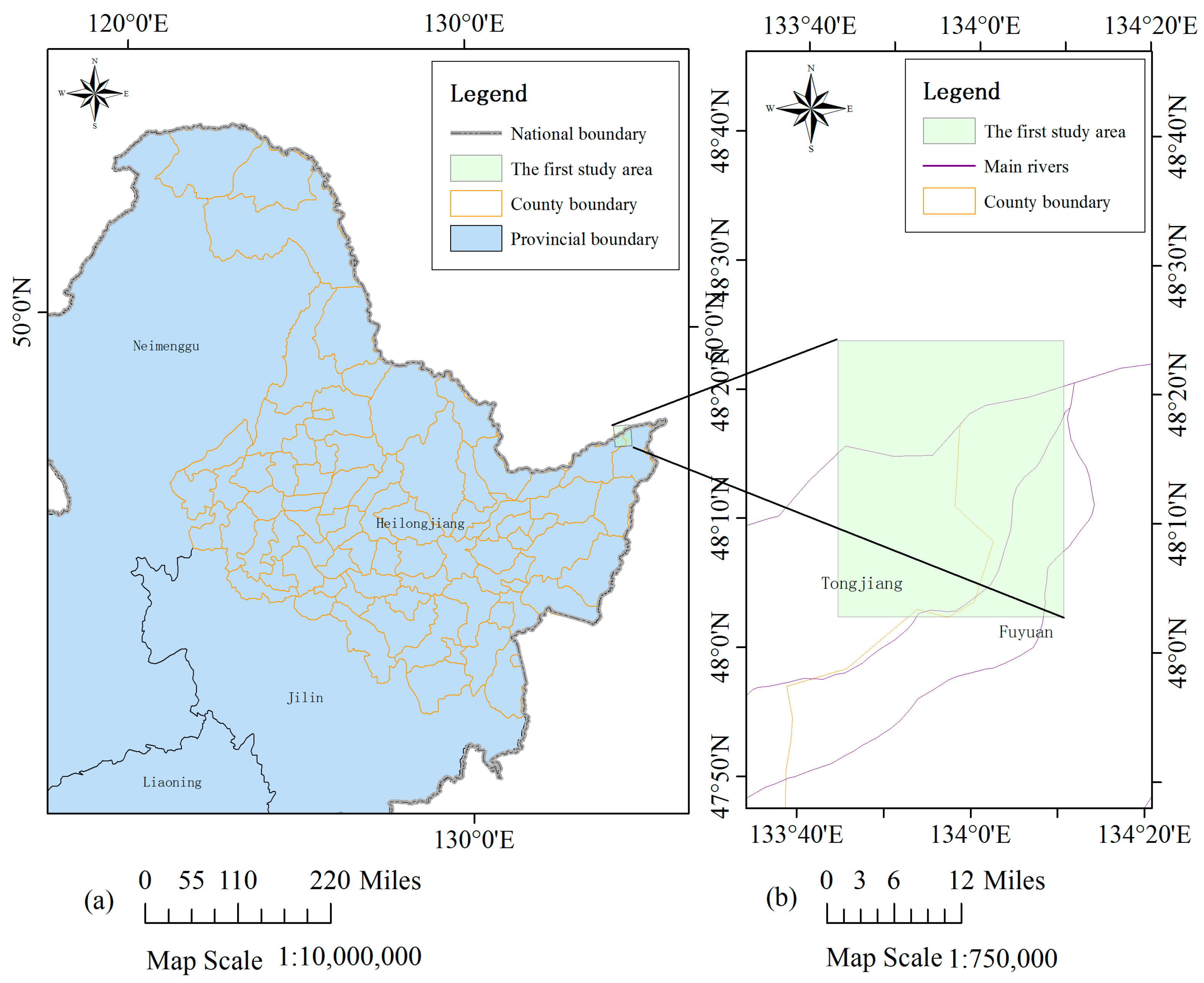
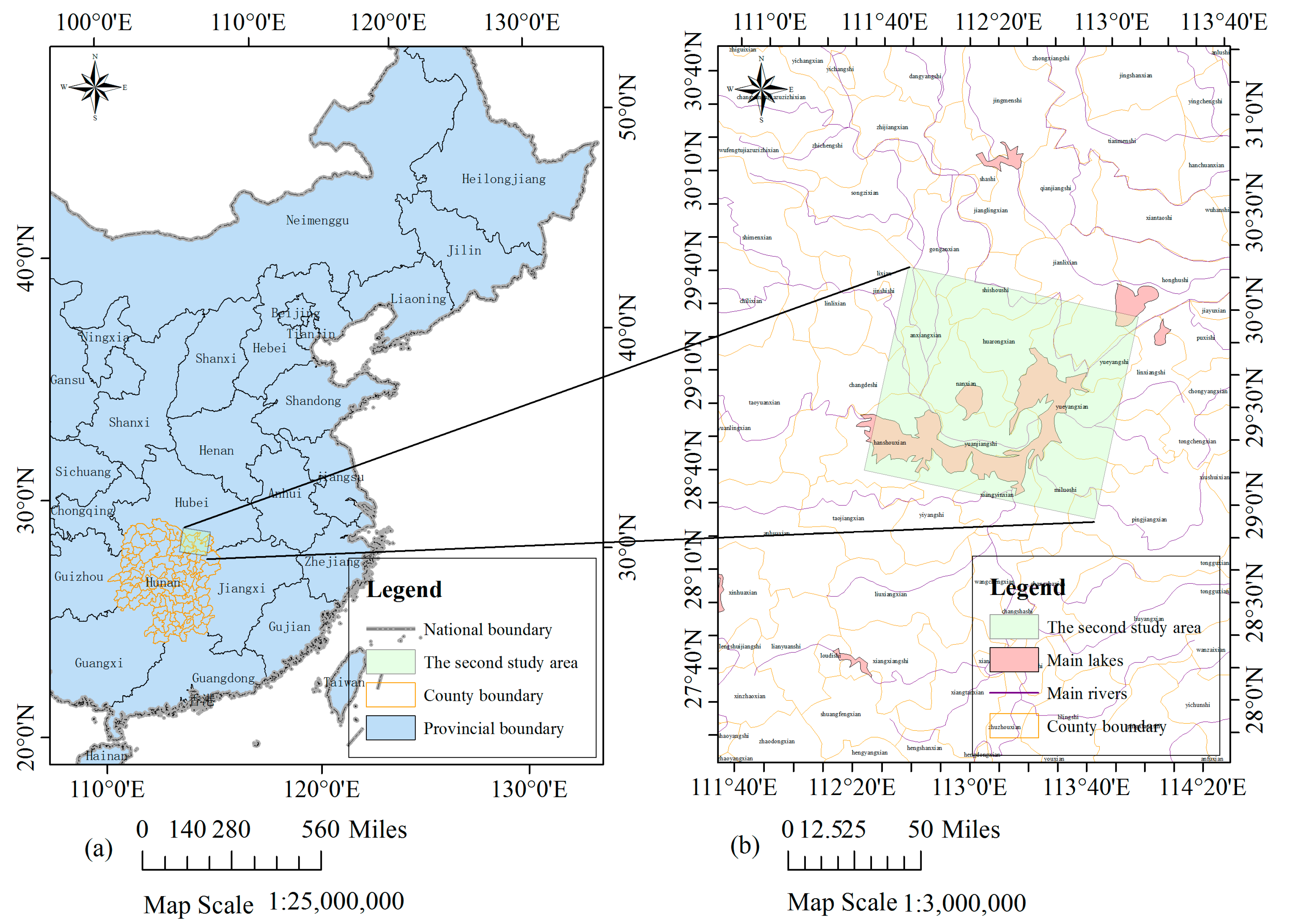{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}