1. Introduction
Active fire in the landscape is a major catalyst for environmental change, potentially resulting in large socio-economic impacts, including the high costs and risks associated with mitigation efforts and the disruptive evacuation of communities [
1]. Fire authorities and land managers are constantly seeking new techniques for the early detection of fire to assist in the timely informing and evacuation of the public from at-risk areas, the planning and prioritisation of asset management strategies, and feasibility assessment of possible suppression efforts. This requirement for active fire detection in near real-time has seen the adoption of remote sensing from satellite sensors as an objective means to quantify and characterise the location, spread and intensity of fire events to support these important decisions [
2]. The information derived from this imagery can also be used in conjunction with other data to provide models of an event, leading to more accurate understanding of the potential impacts of an event before they occur.
Remote sensing for fire detection and attribution has predominantly focused on imagery from low earth orbiting (LEO) sensors, which have significant advantages with regard to spatial resolution, and therefore to the minimum size of fire that can be detected. The trade-off with sensors of this type is that their orbital parameters preclude rapidly repeated observations of a single location, and without a significant investment in capital to provide for more missions, the ability to provide real-time observations of fire from these sensors will be hampered by extensive revisit times. The necessity for rapid fire detection sees the focus of fire detection shift to imagery obtained from geostationary sensors, which provide an increased revisit rate at the cost of a loss of fidelity in the spatial and radiometric realms [
3]. Despite this, the launch of new sensors such as the Japanese Meteorological Agency’s Advanced Himawai Imager (AHI) and the NOAA’s Advanced Baseline Imager (ABI) provide an enhanced opportunity to examine fire ignitions and evolution due to improved spatial, radiometric and temporal resolutions compared to their geostationary predecessors.
One of the physical limitations of some techniques used for the remote sensing of fire is determination of the background temperature of a pixel. Having an accurate measure of this temperature is vital in order to be able to classify a target pixel as containing a fire in the first place, along with being able to accurately estimate the area of the pixel containing fire and the intensity or radiative output of the fire [
2]. Background temperature tends to be a difficult value to determine accurately because of the obscuring effects of the fire’s output, which outweighs the background signal from a pixel in the medium wave infrared. Early efforts to correct for this behaviour used a bi-spectral approach [
4], which used the response of thermal infrared bands in the same area to develop an estimate of fire characteristics. Thermal infrared bands also display sensitivity to fire outputs but to a much lesser extent and are generally used for false alarm detection, especially for marginal detections from the medium wave infrared caused by solar reflection [
5]. The difference between signal response in these two bands is the basis for most current geostationary fire detection algorithms and similarly with the analysis of LEO sensor data [
2]. Issues with these algorithms start when looking at fires of smaller extents. A study by Giglio and Kendall [
6] highlighted issues with fire retrievals using the bi-spectral method, especially with regard to smaller fires and background temperature characterisation. The study found that misattribution of the background temperature by as little as 1 K for fires that covered a portion of a pixel (
) could produce errors in fire area attribution by a factor of 100 or more, with a less significant error in temperature retrieval of
K. This is of major concern for the use of geostationary sensors for detection, as fires in their early stages make up far less a proportion of a pixel from a geostationary sensor than is the case with a LEO sensor.
The most common method of deriving background temperature for a fire pixel is through the use of brightness temperatures of pixels adjacent to the target pixel [
2]. By identifying a number of pixels in the immediate area that are not affected by fire or other occlusion such as smoke and cloud, an estimate can be found by aggregation of the brightness temperature of these pixels. The assumption is made that the adjacent pixels used are of a similar nature in terms of reflectance and emissivity to the target pixel. This background characterisation is then used in comparison to the target pixel in order to identify whether the fire signal is different enough from the background to constitute a fire return. Problems occur with this method when the background temperature is misrepresented. In a study by Giglio and Schroeder [
7] estimation of the background temperature from adjacent pixels in approximately 22% of cases produced a background temperature that was higher than the brightness temperature of the detected fire, based upon the surface variability of the area surrounding the detection. This study also analysed the general performance of the MODIS bi-spectral fire detection algorithm [
8], and found that only 7% of the fire identified by the product could be accurately characterised for fire temperature and area. With the coarser spatial resolution of geostationary sensors, the authors noted that larger potential errors will affect the retrieval of fires in comparison to LEO sensors when using these methods.
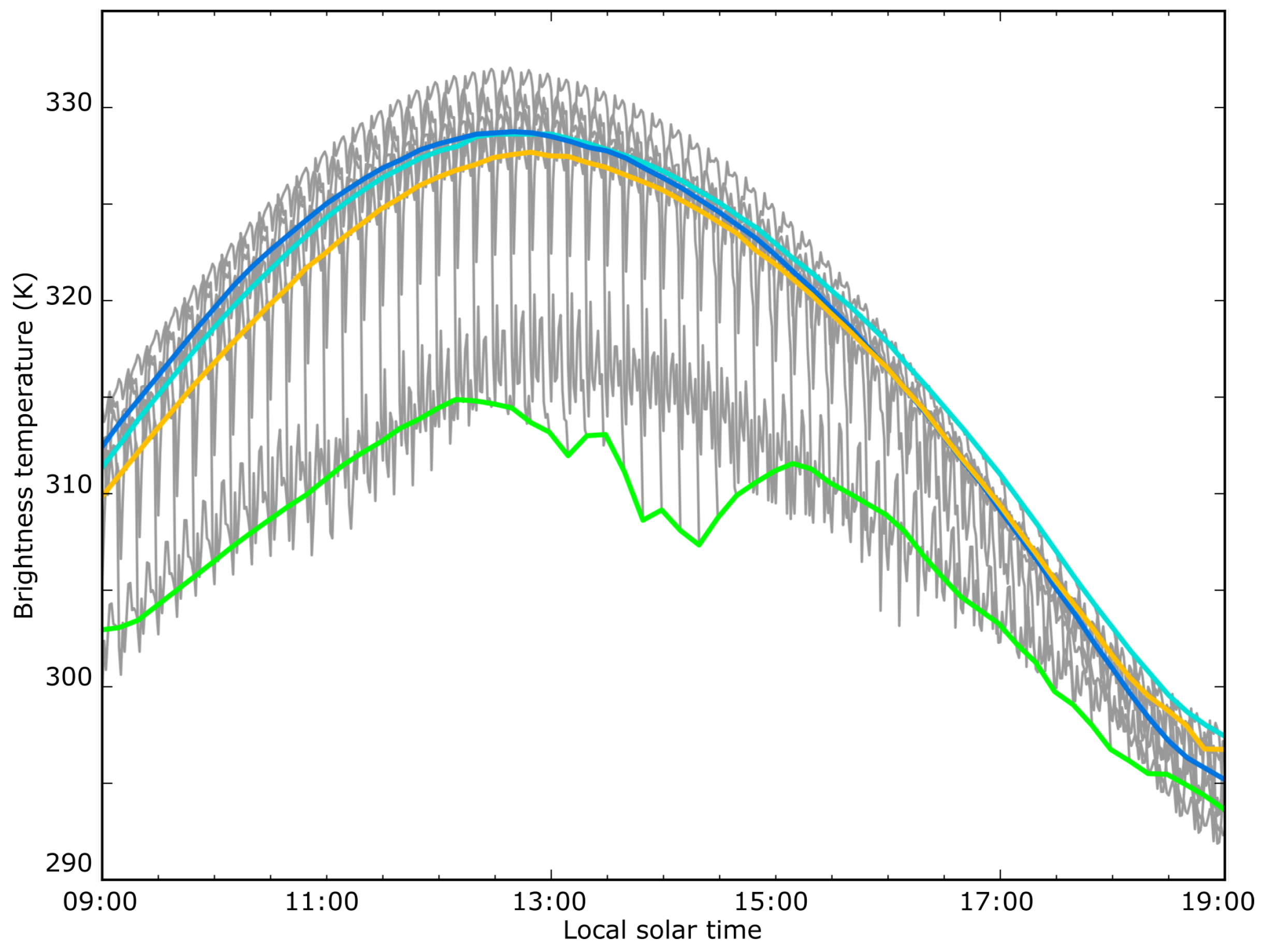
A promising method for background temperature determination is through the use of time series data from geostationary sensors. This time series data can be utilised based upon the premise that upwelling radiation can be predicted based upon incident solar radiation, which varies chiefly by time of day, with some variation due to weather effects and occlusion. Modelling of this Diurnal Temperature Cycle (DTC) has been approached using many different techniques. Earlier work on the modelling of the DTC looked to provide a parameter-based description based upon fitting to discrete mathematical functions, such as the model proposed by Göttsche and Olesen [
9]. This work applied the modelled DTC estimate directly to measured brightness temperatures using empirically derived parameters. This approach tended to be insensitive to functional variation due to synoptic effects, and performed inadequately during the period of rapid temperature change in the early morning. The work of van den Bergh and Frost [
10] was the first to utilise a set of prior observations as training data for a signal fitting process, using the mean of previous observations as a state vector for a Kalman filter, which due to the sensitivity of a mean-based estimate to outlying observations, application was limited to cloud-free data only.
The influence of outliers on the training data used for signal fitting was addressed in part by the study of Roberts and Wooster [
11], who looked at a selective process whereby previous days DTCs were included in the training data of a pixel based upon the amount of disturbance in the day’s observations, with a limit of six cloud or fire affected observations out of a 96 image DTC permitted. These limits eliminated much of the effects of outliers on the subsequent single value decomposition (SVD) used for the initial fitting of background temperature. Issues occurred in areas where there were insufficient anomaly-free days for a fitting to be performed, even with a sampling size of the previous thirty days, in which case DTCs were selected from a library of known anomaly-free DTCs from a similar area. The process was reliant on an accurate cloud mask to determine which days were anomaly-free, and the training data derivation was data intensive, with DTC vectors having to be extracted and calculated for each individual pixel prior to fitting using the SVD process. These issues lead to training data fragility, and introduced some of the issues that are common error sources in contextual algorithms for fire detection.
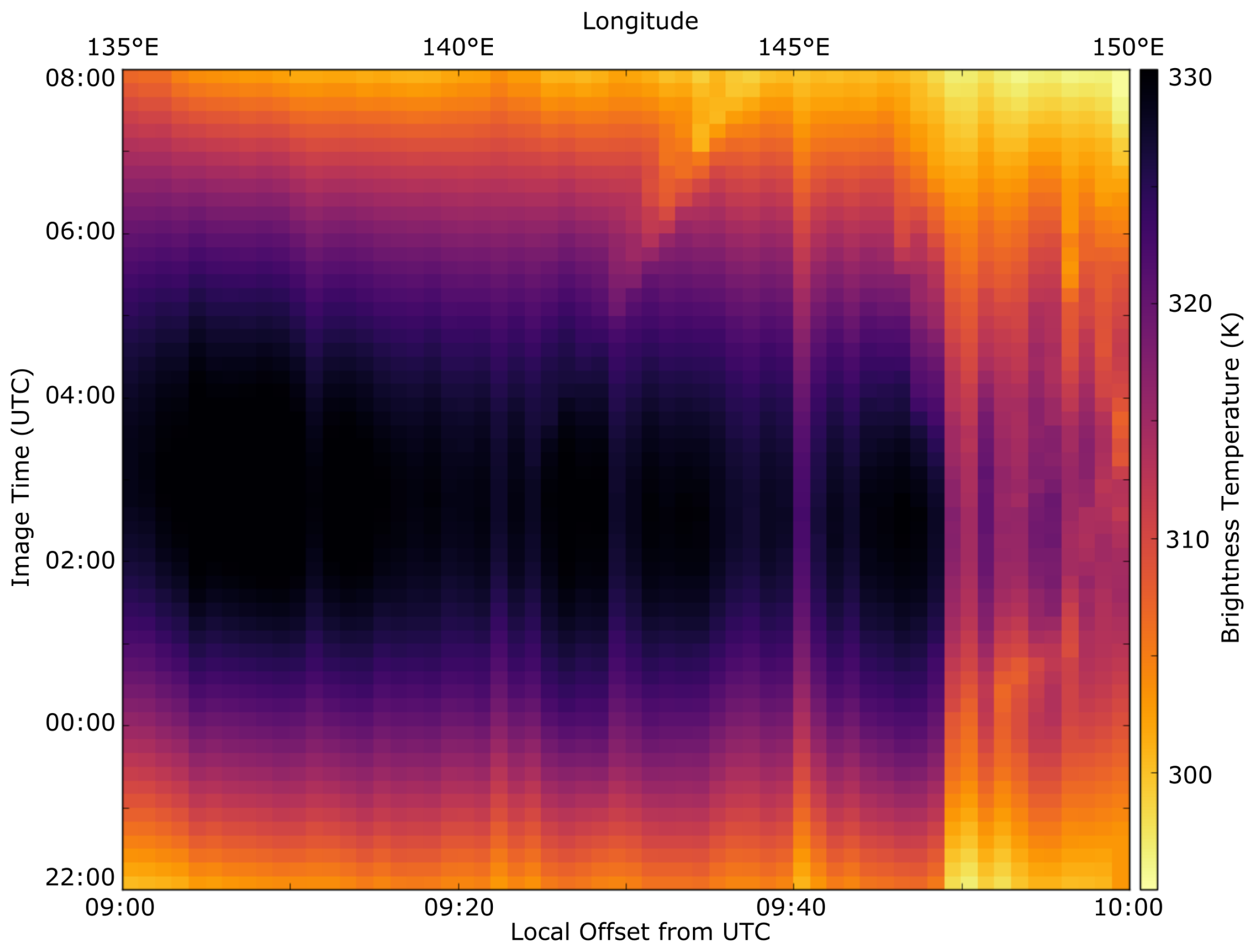
In order to address the issues caused by sampling training data from a pixel-based approach, this paper presents a new method for deriving training data based upon a broad-area method. This method exploits similarities in incident solar radiation found at similar latitudes to derive training data for a pixel. Geostationary sensor data is aggregated by latitude and an area’s local solar time, and formed into a time series based upon a sensor’s temporal resolution. This paper will compare the results obtained using this method to training data derived from individual pixels, such as in the study by Roberts and Wooster [
11], and with contextual methods of background temperature determination, to compare the accuracy, efficiency and availability of each method.
4. Discussion
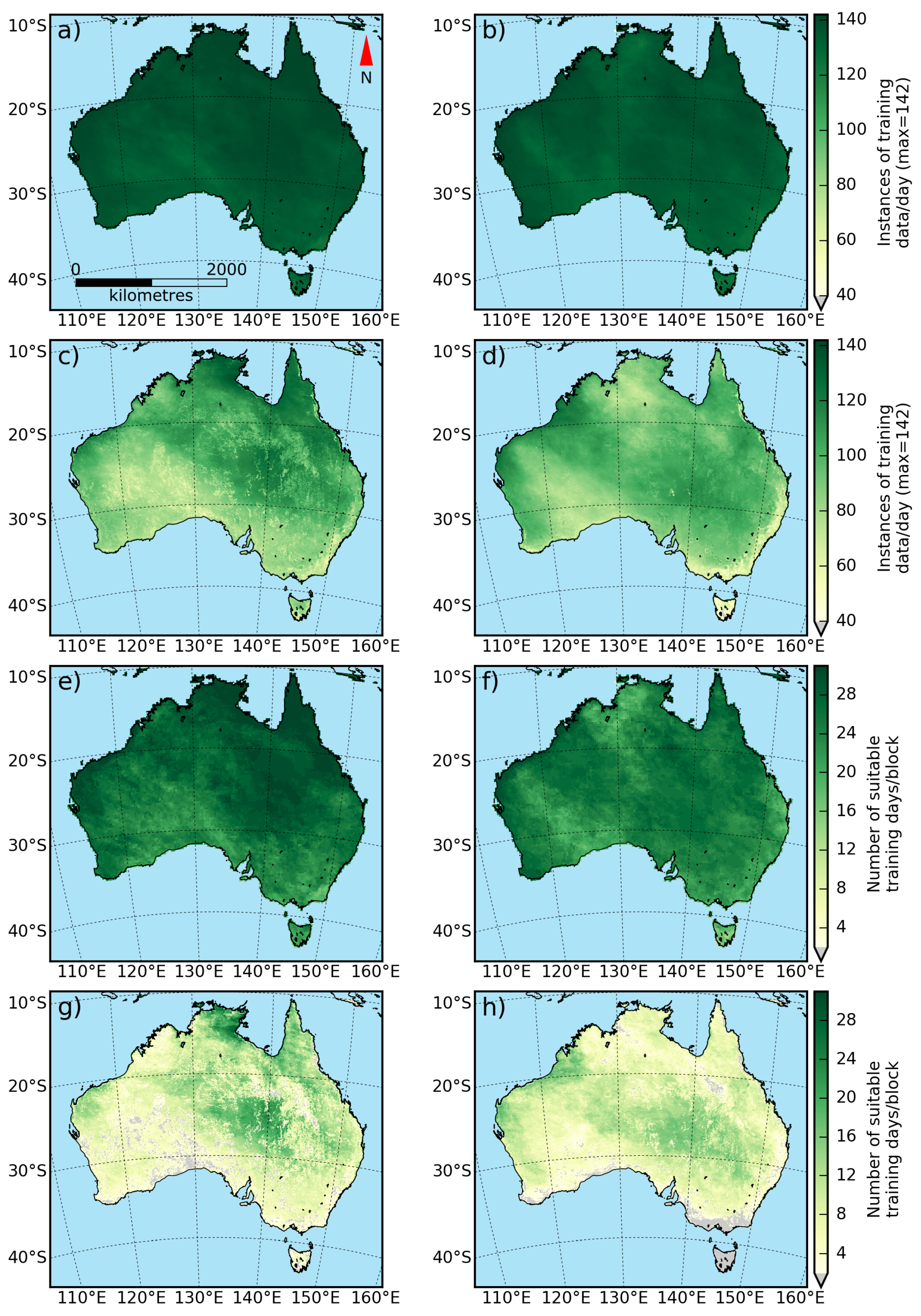
The advantages of using the BAT method for deriving training data for temperature fitting include robustness against localised cloud, especially in areas with persistent standing cloud such as coasts and mountainous areas; the ability to minimise the number of training days required for deriving a brightness temperature fitting due to the increased availability of training data; and a reduction in the storage of data and processing time of training data for temperature fitting. Whilst in this study the training data is used to feed an SVD fitting of the DTC, the data could easily be applied to other fitting techniques, such as a random forest classifier or as a state vector for Kalman filtering. The nature of the fitting process removes the need for tracking locations that have standing hotspots, as the fitting process is completely context independent, and eliminates errors that may be caused by large variations in response to solar radiation and emission between adjacent pixels. As the broad area method relies on as few as one cloud-free pixel per block from which to derive a median temperature, the method is far more robust in response to occlusion than the pixel-based method. When banks of cloud associated with large weather systems are present, a single block may be totally covered by cloud in one or several images. However, the redundancy associated with evaluation on a continental scale means that this lack of data has a minimal effect on the training data for the same time period.
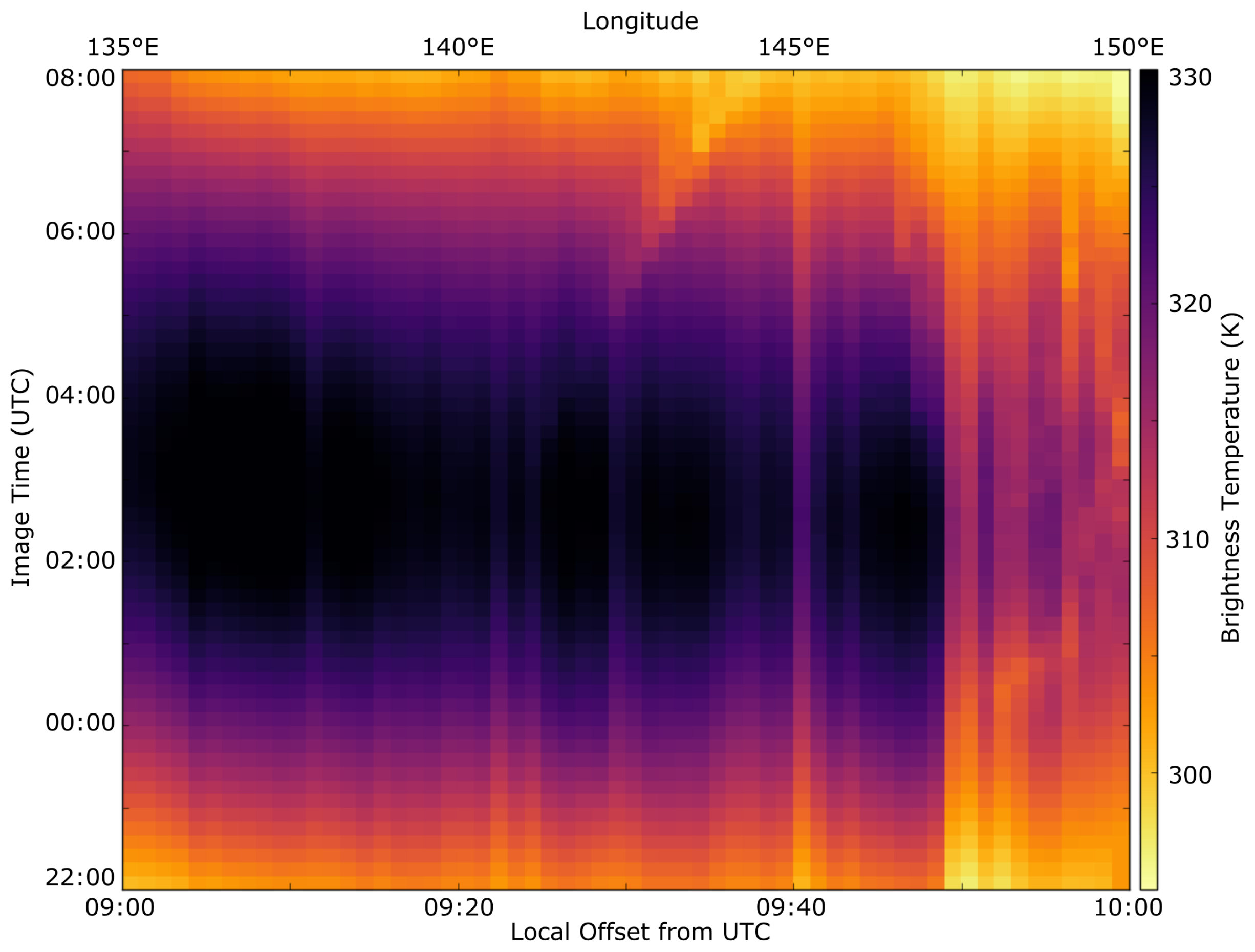
The quality of the training data used in the process relies on a couple of factors. For example, the width of the longitudinal swath at any given latitude is affected by the amount of ground available to sample that swath. In Australia, latitudes between 25°S–30°S have the full width of the continent to sample temperatures from, with anywhere up to 160 blocks of data per image. This provides a large amount of redundancy in the training data, reducing the affect of outliers in the training set. In contrast, a smaller swath width results in fewer blocks to formulate the training data, with a greater risk of anomalous returns affecting the resultant fitting processes. A smaller swath width also increases the influence of edge cases such as coastlines, which tend to moderate land surface temperature variance if they are not handled by an adequate ocean mask. A buffer of two pixels (between 3 and 6 km) was used to eliminate these edge cases for ocean boundaries, but water bodies such as lakes and reservoirs may also contribute to erroneous training data if the number of blocks used for training data is low. Discontinuous and inadequate areas to derive training data from may prove a challenge, and evaluating the performance of the BAT method in a region like Indonesia where cloud cover is high and land areas are discontinuous would properly test the limits of the method.
Deriving training data using the BAT method is not without its issues. The method involves the use of a median value for the entirety of a 0.25°× 0.25° block without taking into account factors such as land cover, land use type, slope and aspect, and surface emissivity, all variables that can vary significantly between pixels in a block. The application of the training data back to the pixel brightness temperature using the SVD process also omits consideration of differing albedo between adjacent pixels in a block. These issues may both be resolved by using a weight from each pixel at different times of the day to take into account the differing emissivity and reflection and how they affect the DTC of each location. The training dataset also has a minimum cutoff temperature of 270 K to minimise the influence of cloud affecting the training data in lieu of an operational cloud mask which may produce large areas of missing data in places where surface temperature and reflection components sit under this value for long periods of time. If a method such as this is used to track surface upwelling radiation in areas that have sustained brightness temperatures below 270 K, a cloud mask could be substituted in this case to eliminate major outlying temperatures instead. The effect of snow on brightness temperature tracking using this method has not been explored, mainly due to the study site and time of year chosen.
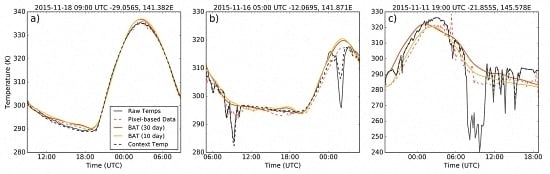
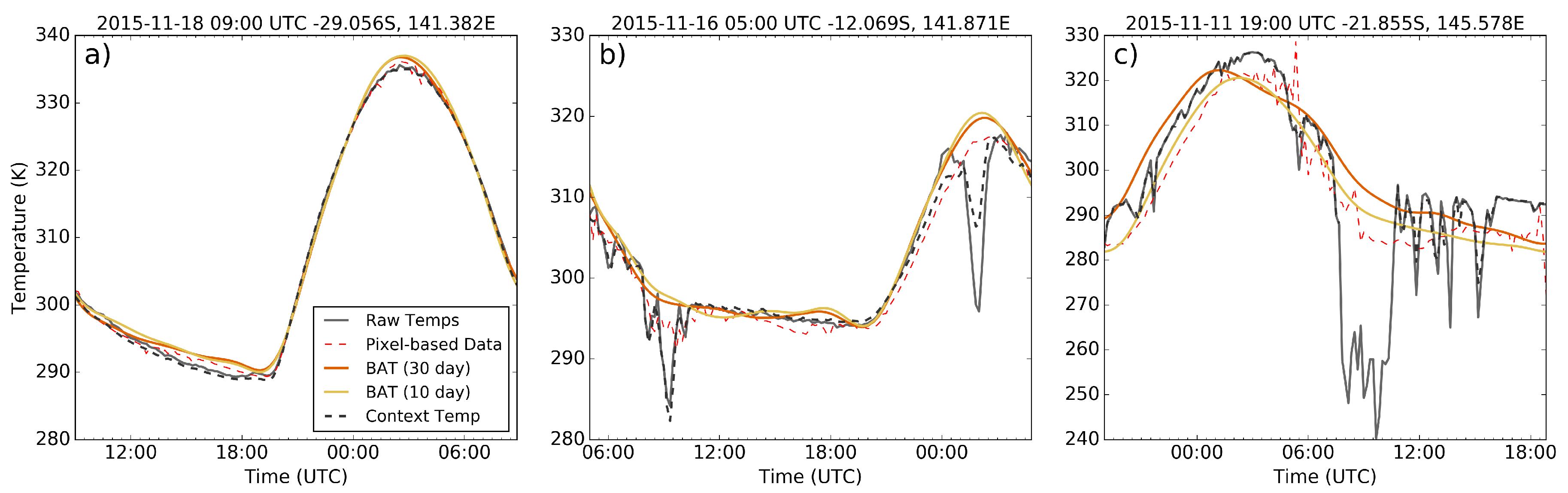
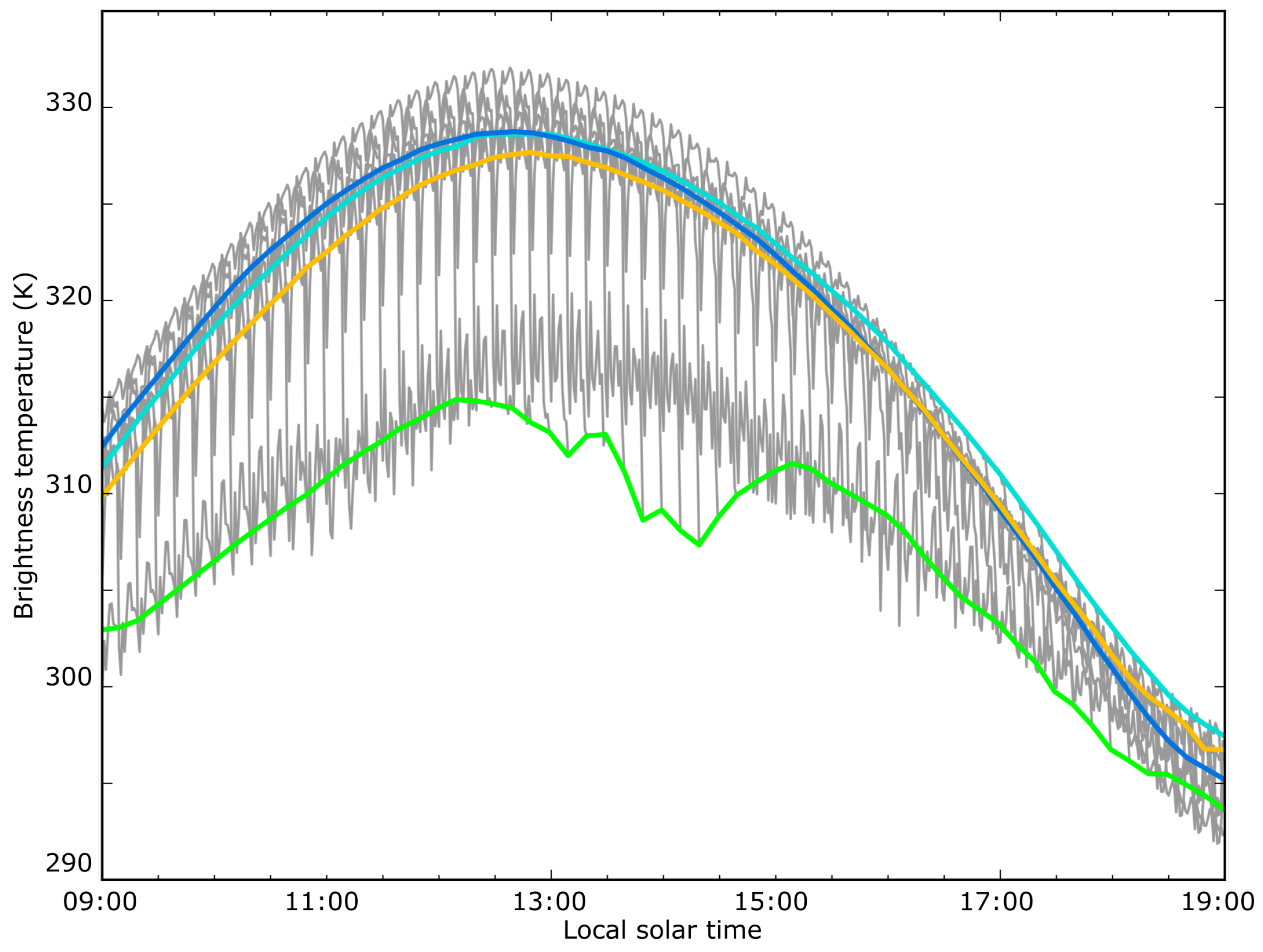
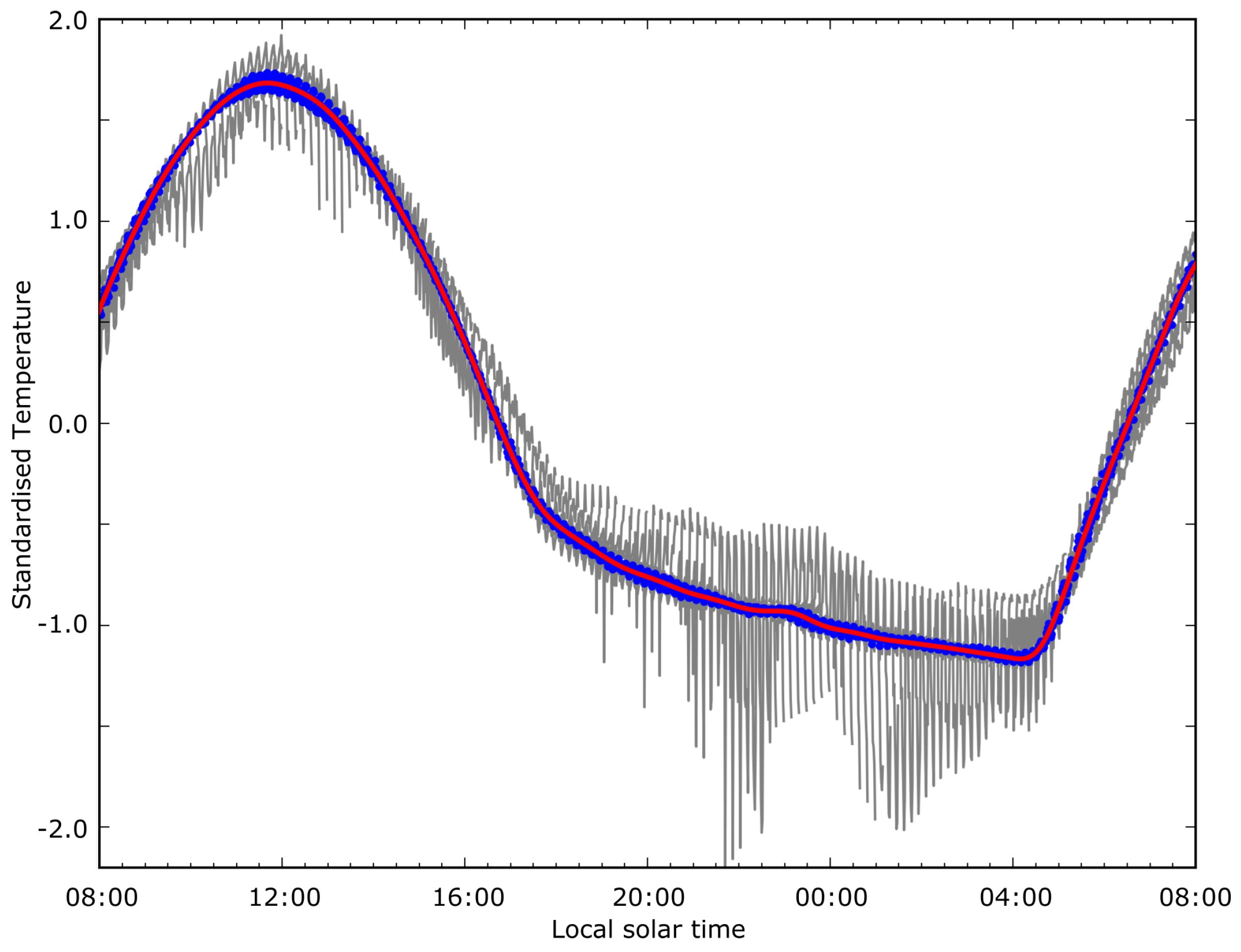
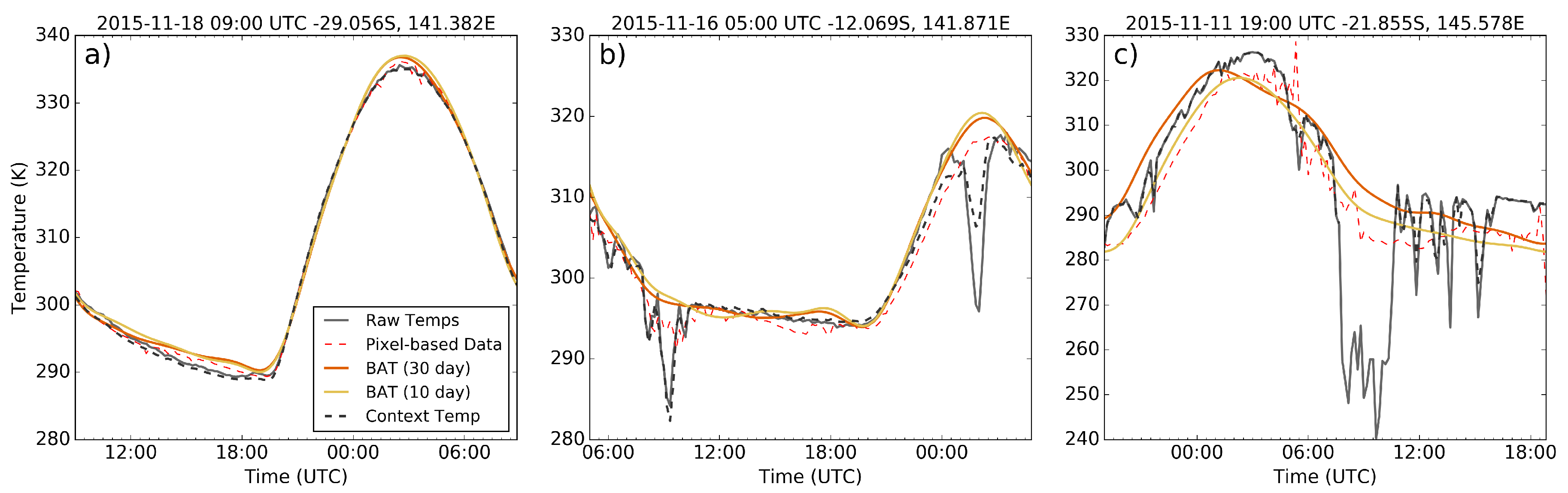
Considering the evaluation of the various methods for accuracy of fitting, the block-based training data based upon thirty previous days performed reasonably well for fitting accuracy in comparison to the pixel-based training data for all anomaly classifications, and the results derived from the 10-day block training data were of similar accuracy. If a threshold for suitability of fitting is placed on the results, such as would be for a fire detection model, the 30-day block-based method is far more robust with respect to anomalies and would continue tracking the expected upwelling radiation with up to one quarter of the time series obscured. A full sensitivity analysis using in-situ upwelling radiation data along with a verified cloud mask would be of value to confirm the shape of the diurnal model in order to provide an independent confirmation of the method’s accuracy. Of note here is the apparently extremely good performance of the contextual method for providing background temperature, which is an unfortunate side effect of methods for evaluating the accuracy of the model fitting process. The high spatial autocorrelation demonstrated by upwelling radiation results in a contextual based temperature tracking extremely closely to the raw temperature measurements regardless of whether the surrounds themselves are affected by anomalies such as cloud, smoke or fire.
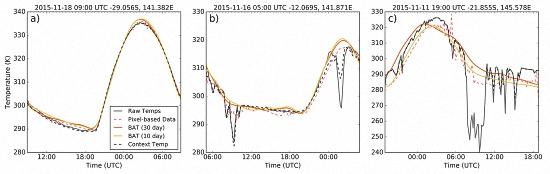
Whilst the accuracy of the fitting method used in this study for days of limited thermal anomalies is quite good, the accuracy of fitting provided by the SVD process breaks down once a large number of anomalies are encountered in the fitted data. This behaviour, which manifests in the type of “wandering” curves displayed in
Figure 4c, is caused in part by the standardisation process applied to pixel brightness temperatures, where significant numbers of cloud incidences, especially from thick cold clouds, can act to drop the mean and increase the standard deviation of temperatures across the fitted period. This affects the initial estimation given from the SVD process to the point where the outlier elimination process disregards correct temperature measurements by mistake. One of the limitations of using the SVD fitting method is that outlying measurements in the raw brightness temperatures cannot be easily eliminated from the function evaluation. Whilst applying a more rigorous cloud mask or deriving a standard model for brightness temperatures at a given location and date could be ways of eliminating this mainly low temperature biasing; investigation of other methods for applying the training data for temperature fitting should be a priority.
Overall, the BAT method described in this paper performed adequately from an accuracy standpoint, but the real benefits of the method lie in the improvements in processing time and availability. The BAT method processed an individual fitting at about ten times the speed of the pixel-based training data method, mostly due to the lack of need for cloud mask evaluation of the training data vectors prior to fitting. This issue with the pixel-based training method could be alleviated somewhat by smaller file sizes, as the major issue with processing of the pixel training seems to be the bulkiness of cloud data produced for this sensor (typical file sizes for the AHI cloud product are approximately 90–100 MB). Given the ten day BAT method performed similarly to the pixel-based training method for temperature accuracy, using this data set instead of the thirty day block training set could be justified in situations where processing time of large image sets is of greater importance than extreme accuracy, especially when used for initial anomaly detection purposes.
From a fitting availability standpoint, the BAT method significantly increases the distribution of areas that are able to have a temperature fitting applied to them. In comparison to pixel-based methods, the increase of fitting availability is especially marked in areas such as the east and south east coasts and the island of Tasmania. These areas are heavily populated in comparison to much of the Australian continent, and are at significant risk from rapidly changing events, such as fire and flood. The extended utility and application of the BAT method will be of great interest to land management authorities in these areas.
The BAT method formulated in this paper is designed specifically for the process of providing data to inform fitting processes for positive thermal anomaly detection, such as for fire detection. An enhanced understanding of background temperature behaviour in the MWIR space could lead to improvements in the determination of fire detection thresholds, potentially leading to delineation of fire thresholds using time of day, latitude and solar aspect, along with a greater understanding of how the mix of solar reflection and thermal emission in a pixel contributes to the minimum detectable characteristics of a fire from a particular sensor. Applications of this technique could also look to provide ongoing monitoring of fires using metrics such as area, temperature and fire radiative power utilising the improved estimation of this background temperature.
In addition to improvements in the fire detection space, this method could have applications in a number of other fields that require change detection over a short period of time. Likely applications could see aggregation of data based upon land cover classification along with local solar time and latitude to provide a baseline for mapping soil dryness changes, or for tracking the spread and severity of phenomena such as flooding and volcanic activity from geostationary imagery.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}