The surface roughness of different objects within a building area determines the scattering pattern and affects the backscatter intensity under radar radiation. Here, surface roughness refers to small-scale roughness, i.e., surface roughness that is much smaller than the size of a resolution cell. According to the Rayleigh criterion, when
ground surface can be viewed as smooth and will cause regular reflection. In the equation,
∆h represents the root mean square of surface elevation fluctuation,
λ represents the wavelength, and
represents the incidence angle.
Generally, rooftops can be viewed as smooth surfaces that cause strong regular reflection. As a result, horizontal roofs will reflect fewer echoes, while roofs inclined toward the plane of view will show high backscatter intensity. Dihedral and trihedral angles between the walls and the ground will cause intense reflection; grassland and soil can be considered to be rough, thus causing diffuse reflection and low backscatter intensity [
34]. Accordingly, dihedral angle scattering of building areas should lead to high backscatter intensity. Since dihedral angle scattering do not span over the whole footprint of the building but are organized in discrete points and lines, SAR backscatter is related to density of the scattering centers rather than to building density itself [
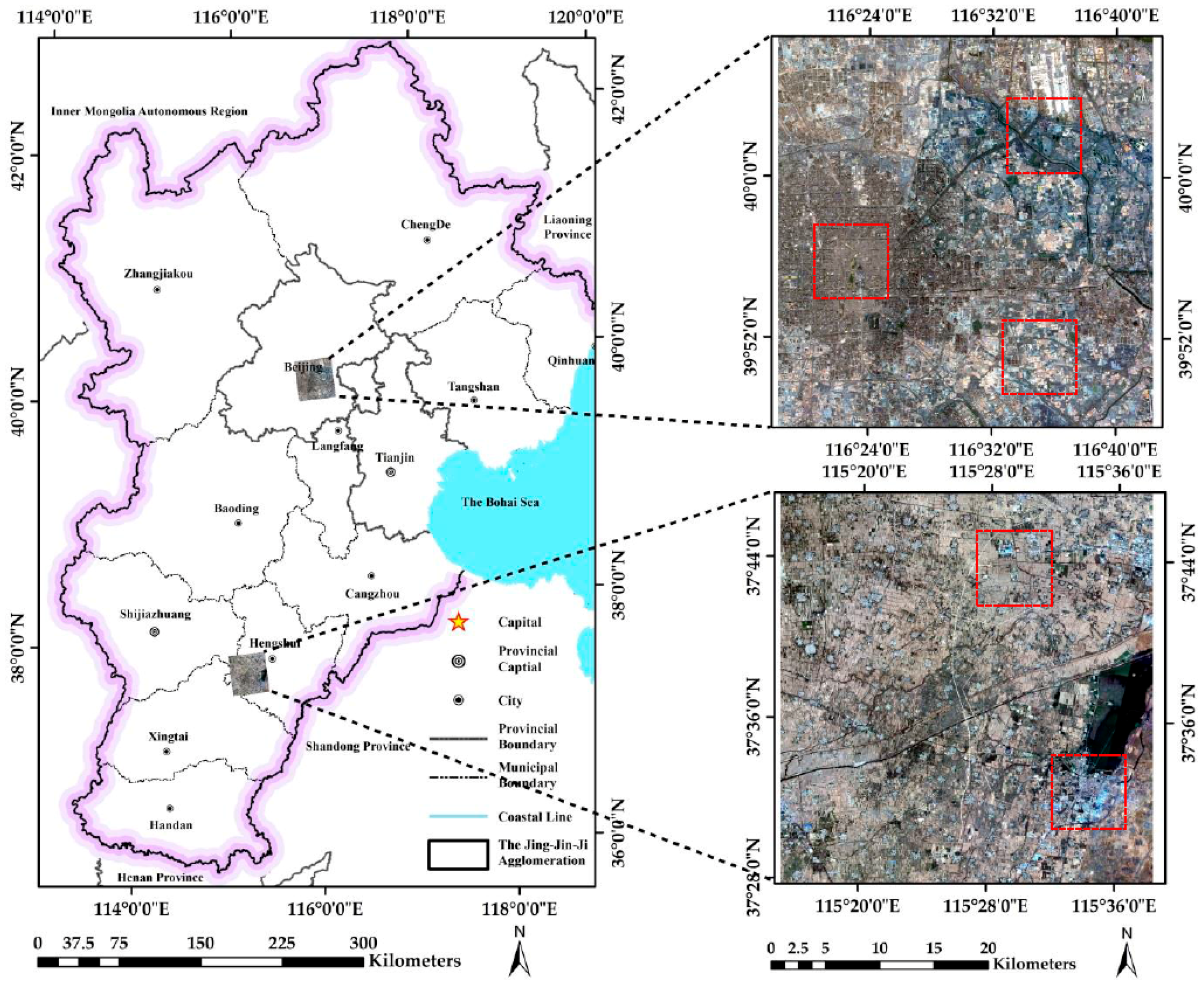
35]. Thus, an average backscatter intensity of a region, specifically the 100 m × 100 m samples used in this study, seems to be much more reliable than that of a single pixel because, at least from the point of probability, the higher the density is within a region, the stronger average intensity will likely be.
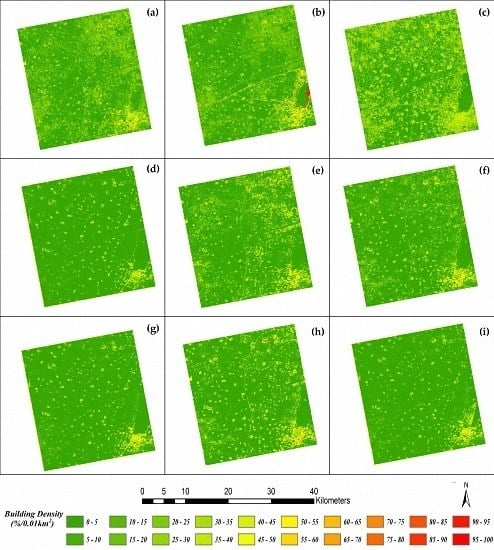
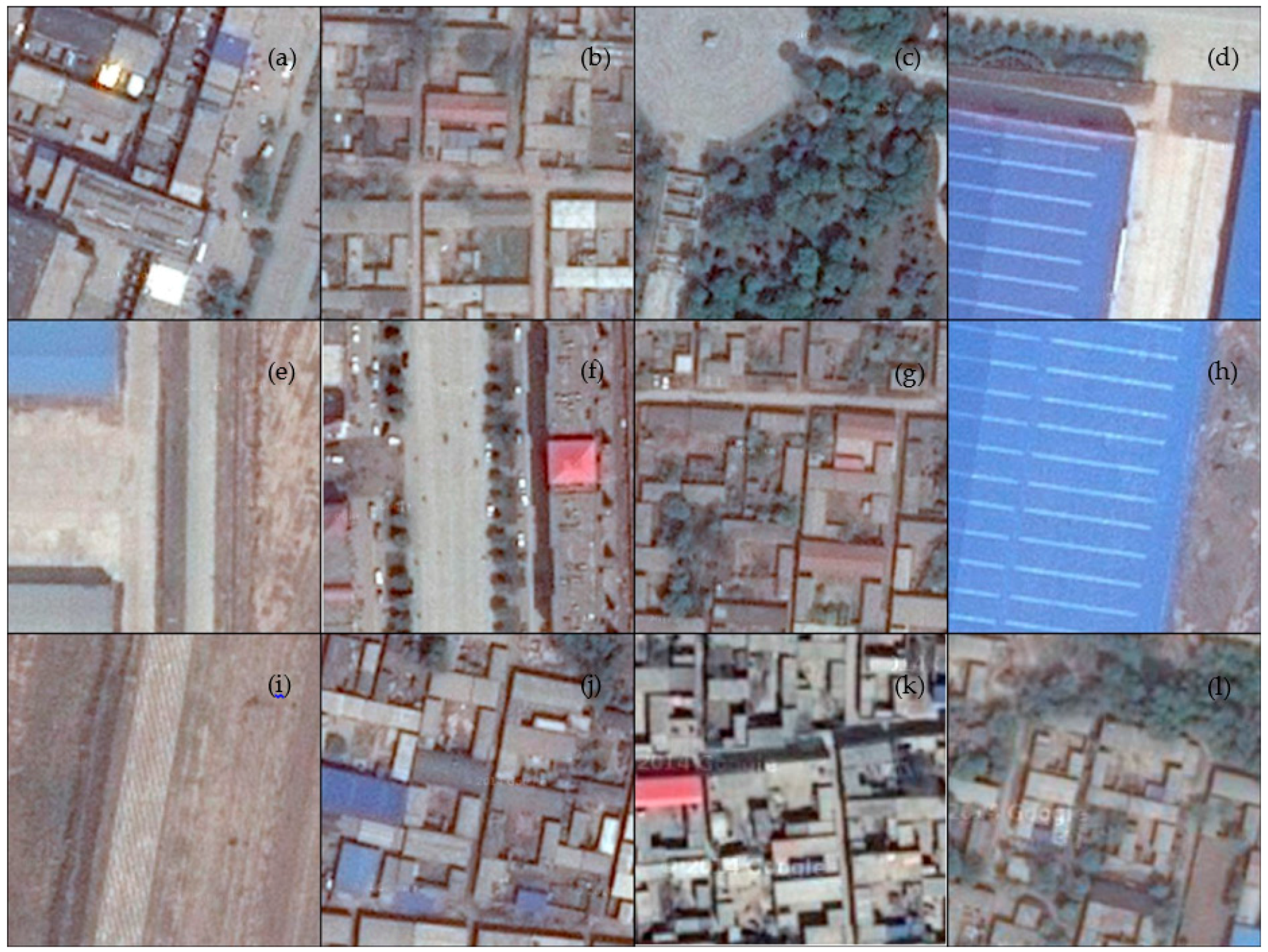
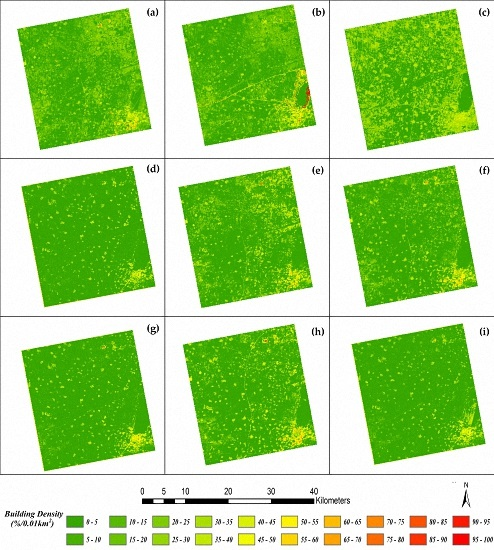
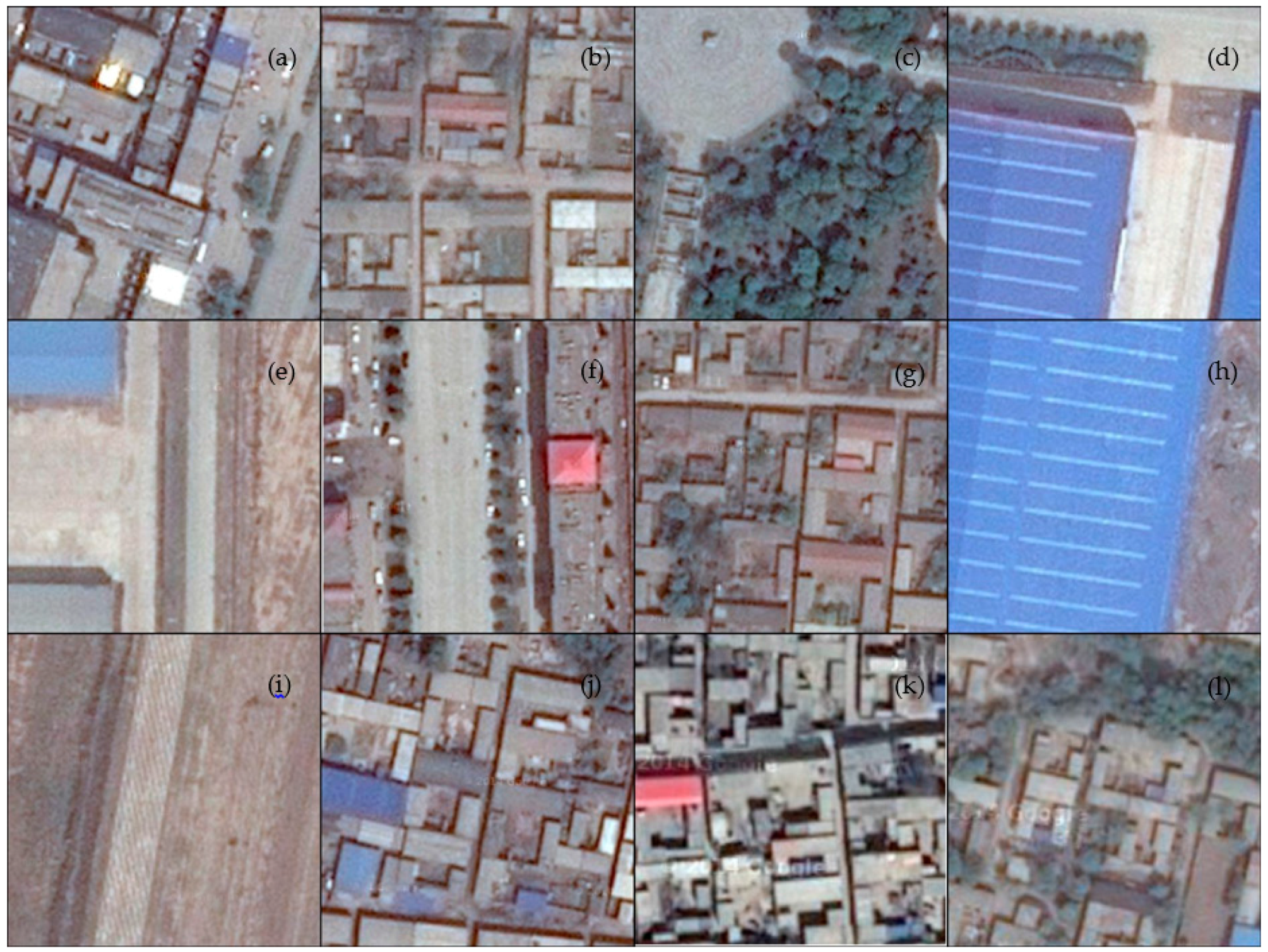
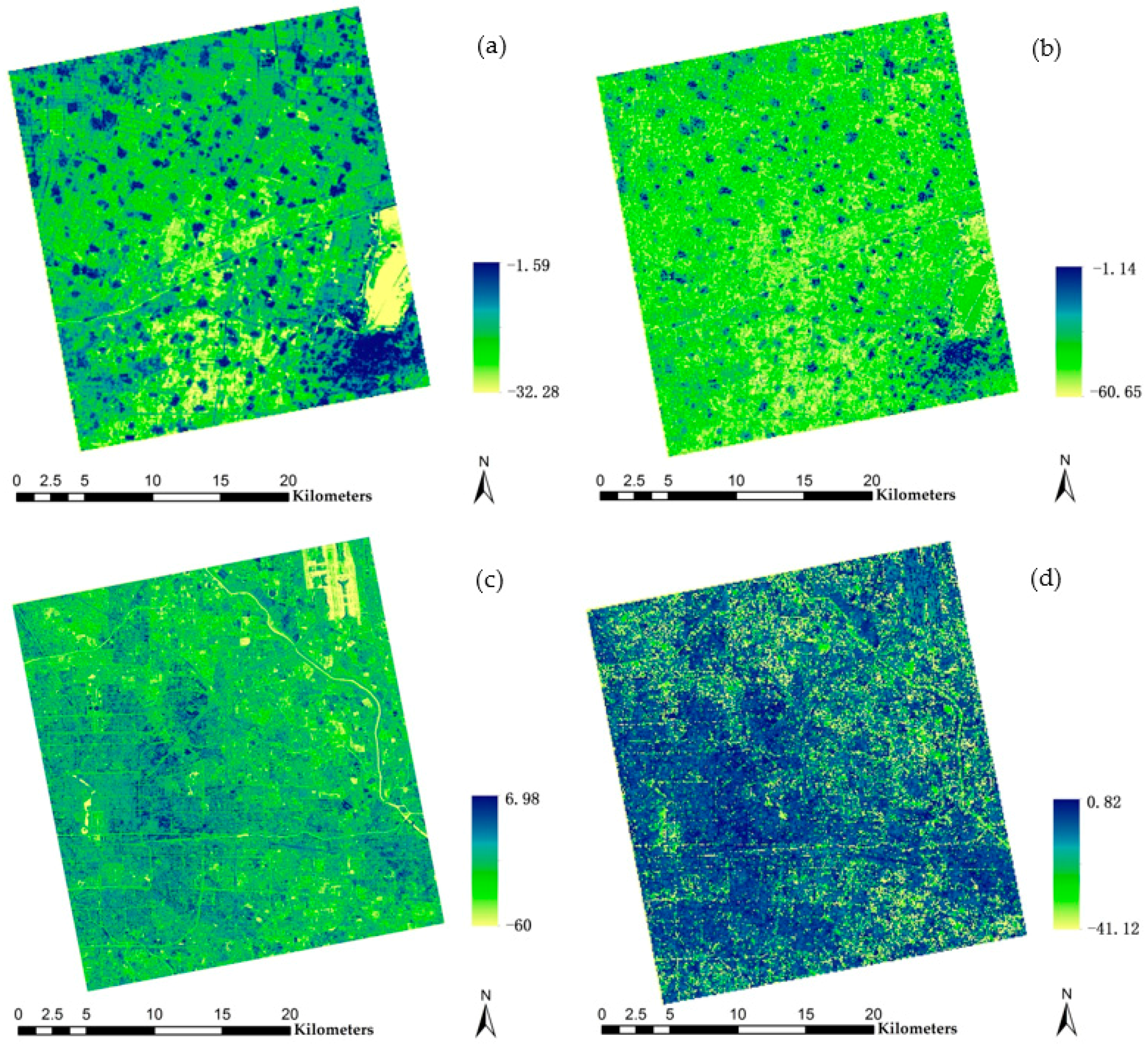
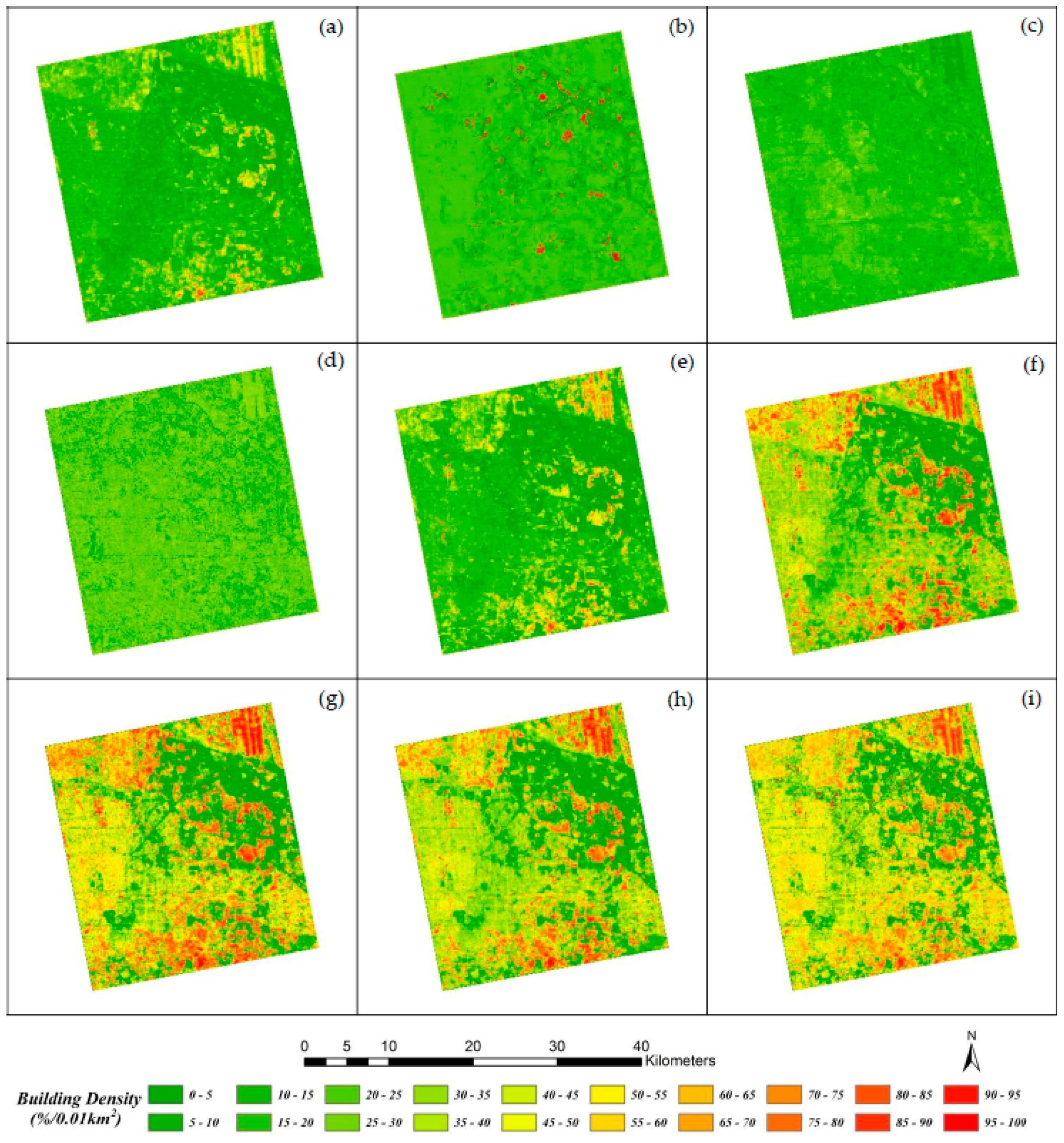
However, dihedral angle scattering not only relates to building density, but also relates to the spatial pattern of buildings because different areas with same density can display disparate intensity on account of their different distributions, sizes, and surroundings. As a result, backscatter intensity within a region can be influenced by both building density and spatial pattern. To illustrate this, six samples with similar densities (42.02%–44.71%) were selected and are shown in
Figure 4. From data displays in
Table 2, it is obvious that intensities of those areas vary significantly due to buildings’ position, size, and existence of other object (e.g., a road or a lawn).
Figure 4a,d shows two areas with almost totally same density (i.e., 42.43% and 42.02%) but disparate spatial features, which result in the fluctuant intensities (i.e., −15.81 and −9.86). When there is a lawn, as shown in
Figure 4e, the intensity suddenly decreases to −16.91. Even the change of building size, as shown in
Figure 4b,c, can cause fluctuation in intensities. These diverse intensities indicate that spatial pattern indeed plays an important role.
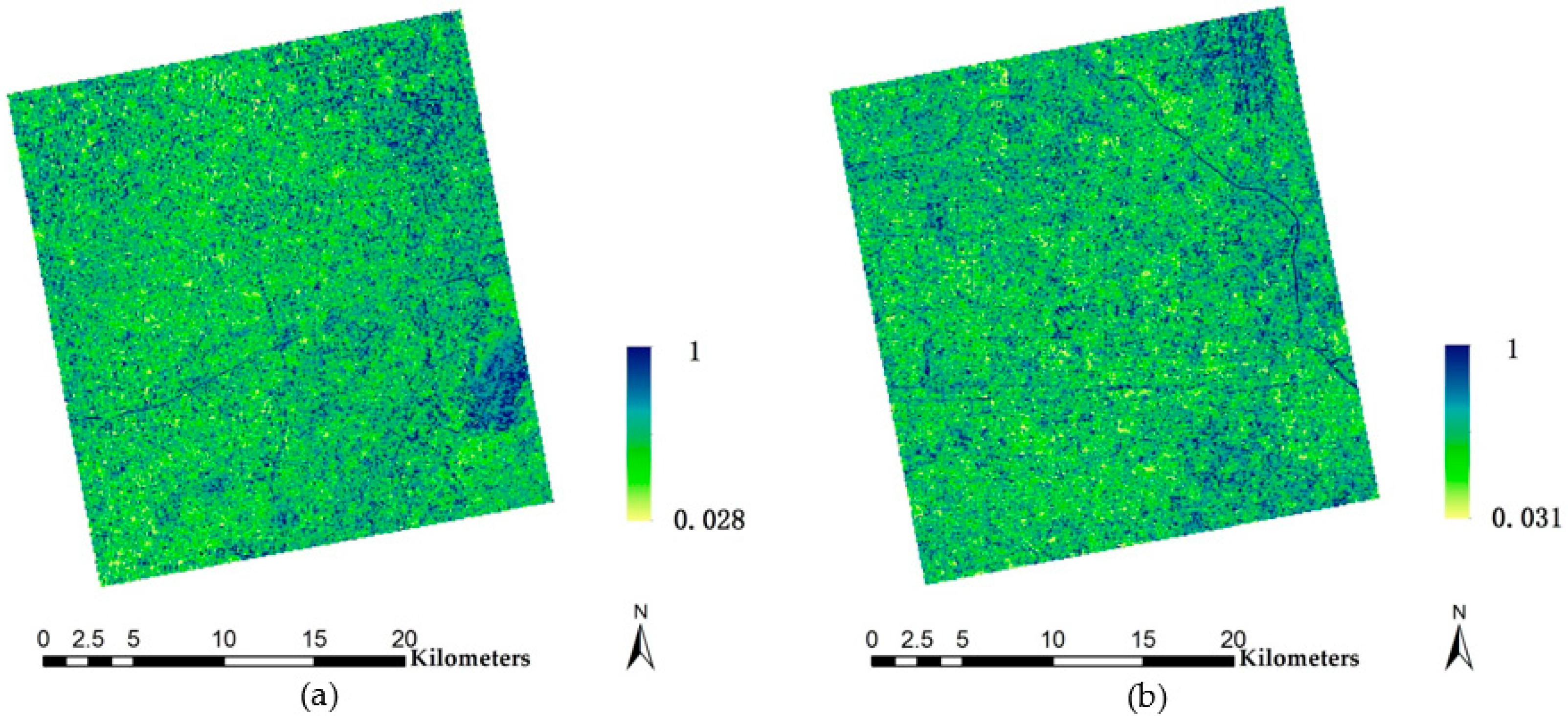
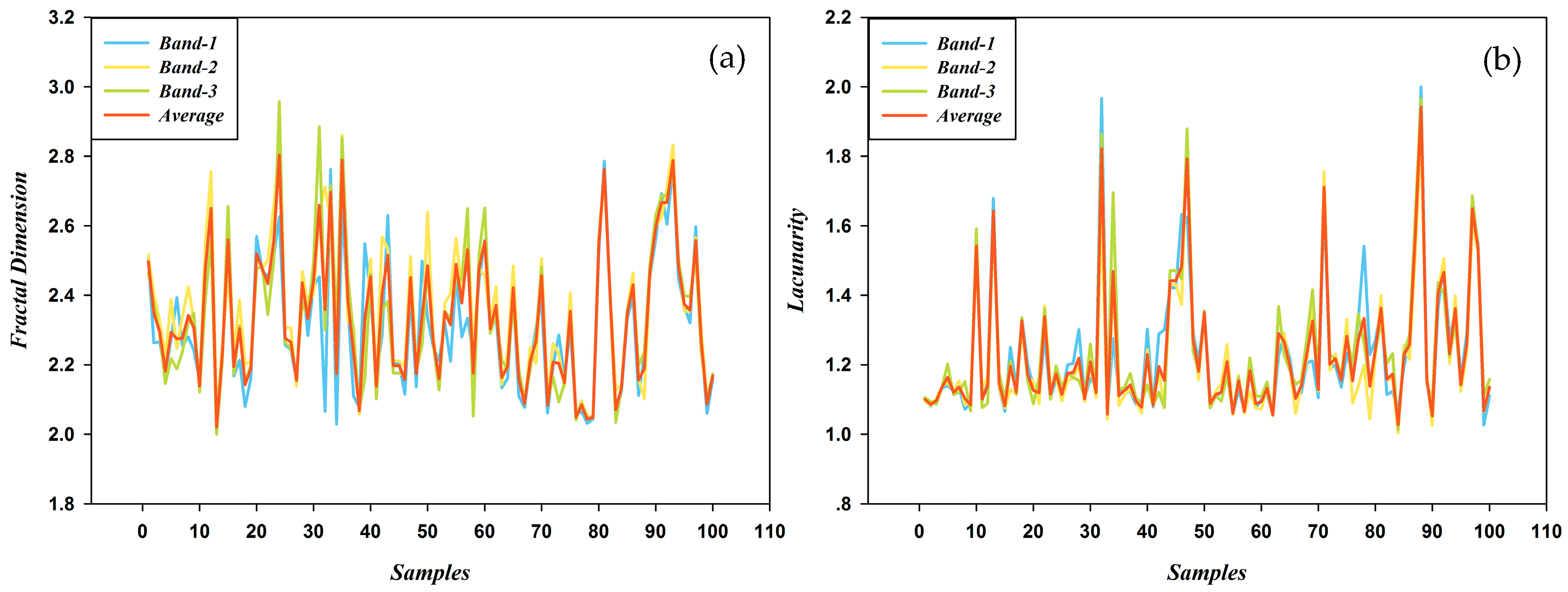
Therefore, backscatter intensity can highlight built-up areas and restrain some confusing areas (e.g., bare soil and other impervious surface). However, it does not strictly and precisely reflect the region’s building density. With the hope to solve this, a new index—amended backscatter intensity—is introduced. To achieve this, fractal dimension and lacunarity, which are also listed in
Table 2, are used to depict the information of spatial pattern. Given that the 8 m-resolution GF-1 PMS image presents relatively clear spatial information and the calculation is time-efficient, GF-1 images will be the provider of those two indicators. The expectation for this index is to eliminate the effect of spatial pattern and make its value directly reflect the level of building density.
3.2.1. Fractal Dimension and Lacunarity
Fractal geometry was introduced and popularized by Mandelbrot as a means of describing highly complex forms characteristic of natural phenomena such as coastlines and landscapes [
36] and has been widely applied to segmentation, classification, and characterization of the overall spatial complexity of remotely sensed images. Myint [
37] employed it to classify urban land use types in Norman, Oklahoma, USA, and Jong [
38] classified vegetation types in the Mediterranean.
Remotely sensed imagery can be viewed as fluctuating surfaces whose elevations correspond to the digital number values. In this sense, its fractal dimension ranges from two to three. Different landscapes have distinct spatial complexities, which leads to varying fractal dimensions. According to Qiu [
39] and Lam [
40], the most complex areas (i.e., urban areas) have the highest fractal dimension, while less complex rural settlements and farmland have lower fractal dimension. Similarly, within urban areas, regions with different building densities (e.g., residential areas, block junctions, industrial areas, and non-built-up areas) display extremely varying spatial complexity. Residential areas have many buildings, crisscrossing roads, and other types of objects. As such, they have the highest complexity and fractal dimension. Buildings in junction areas share the same features as residential areas, but the presence of a wide and homogeneous road lowers the complexity. Industrial areas are often occupied by large buildings with regular shapes and homogeneous backscatter intensity, and non-built-up areas such as farmland or natural landscapes are characterized as self-similar. Theoretically, the fractal dimension continuously decreases from residential to non-built-up areas.
The fractal dimension of a strictly self-similar object can be derived mathematically [
41]:
where
Nr represents the number of smaller copies of the object obtained by scaling its unit of measurement down by a ratio of
r [
36]. For non-self-similar objects, fractal dimension cannot be directly derived from this equation as a change in r will alter
D; therefore, empirical estimation should be employed for such objects. Many algorithms have been proposed for calculating the fractal dimension of non-self-similar objects; here, we will employ improved triangular prism method developed by Sun [
42].
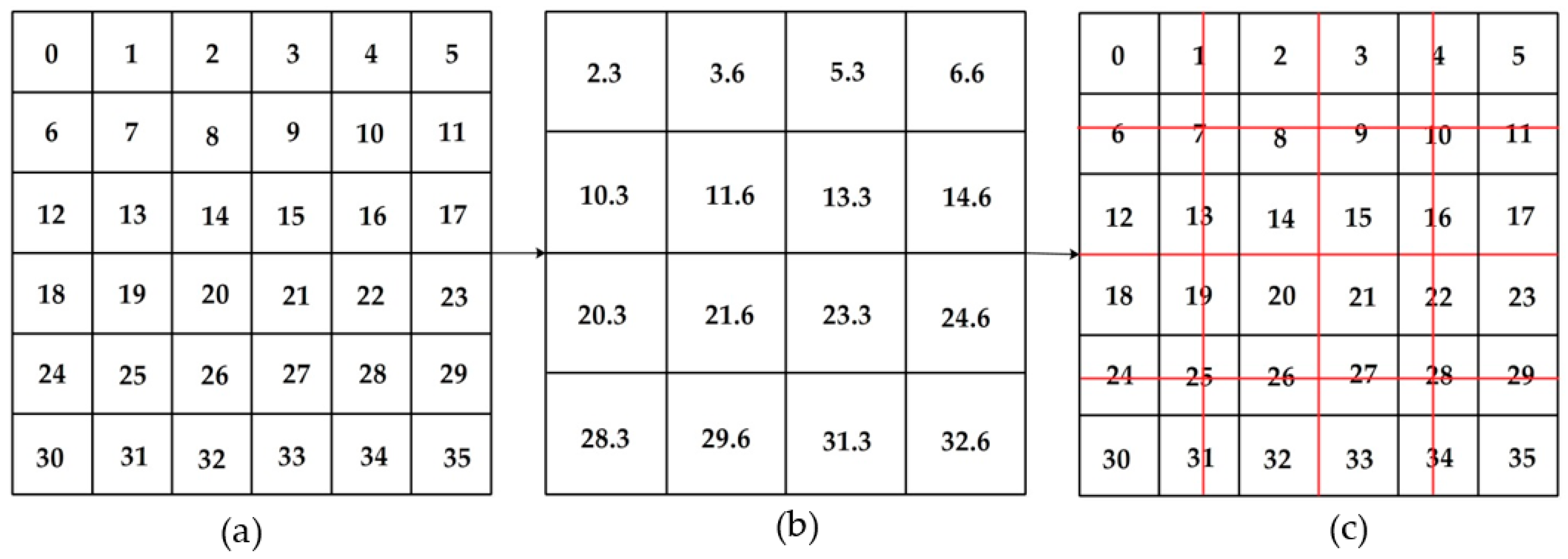
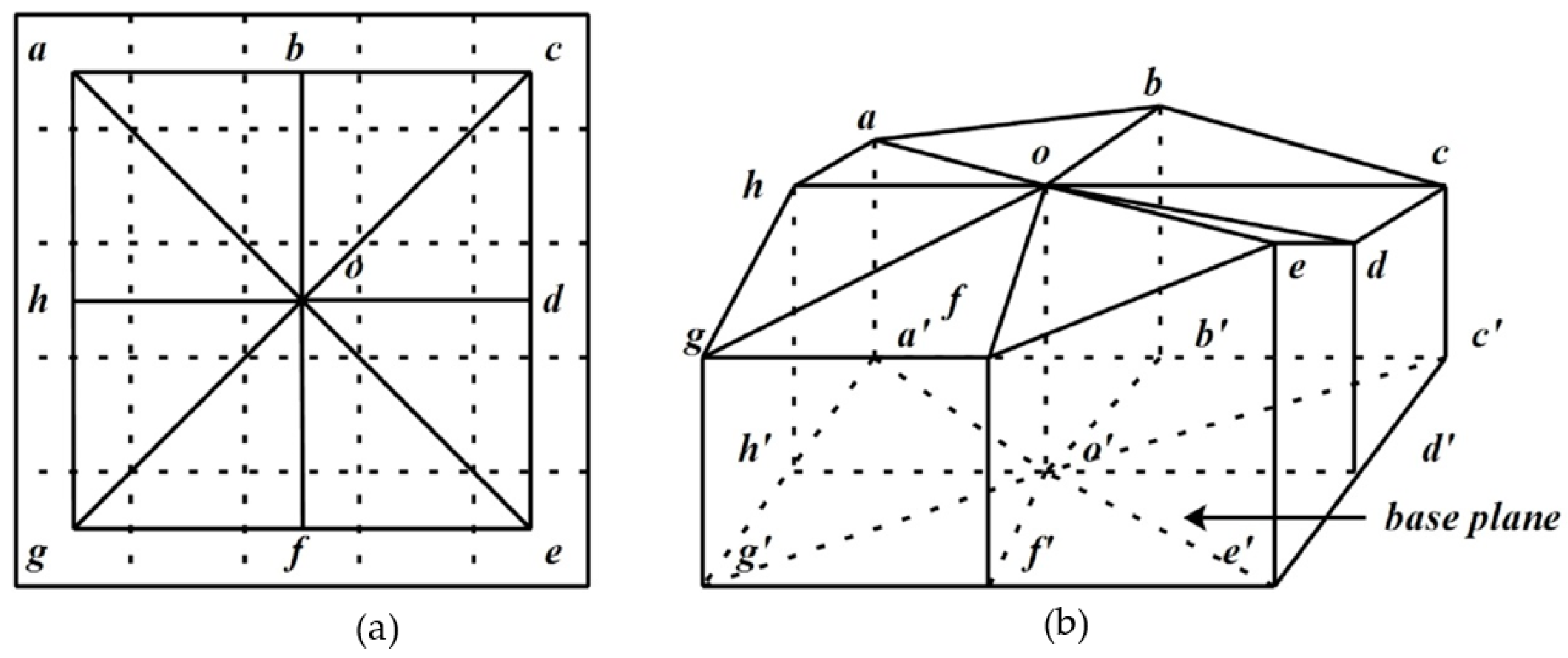
As illustrated by
Figure 5, this method uses eight pixels on the edges of a square to represent the surface. According to Sun, four steps are implemented to obtain the fractal dimension.
Step 1: Calculate base distances. There are three different kinds of base distances. The first is the base distance between the central pixel and each of the corner pixels (e.g.,
in
Figure 5) and they are all equal to
, where
is the side length of the base plain called step size. The second base distance is the one between the central pixel and middle pixel (e.g.,
in
Figure 6), which has the value of
. The last one is the base distance between two neighboring edge pixels (e.g.,
in
Figure 6), which also has the value of
.
Step 2: Calculate lengths of sides of triangles. Based distances together with the DN values of the central pixel, the corner pixels and the middle pixels are used to solve the lengths by the Pythagorean Theorem.
Step 3: Calculate of the top surface area. The top surface area of each prism then can be computed using Heron’s formula.
Step 4: Compute the fractal dimension value. The total area of the top surface can be calculated repeatedly for increasing step sizes by iterating Steps 1 to 3. As the size of the window used to cover the surface increases, more details in the top surface get lost and, as a result, the estimated total area of the top surface decreases (
Figure 6). Once the total areas of the top surface are calculated for a certain number of step sizes, plot log (total top surface area) against log (step size) fit a least-squares regression line through the data points. The fractal dimension of the surface then is computed as
, where
b is the slope of the log-log regression line.
The concept of lacunarity was originally proposed by Mandlebrot [
41] to distinguish objects sharing the same fractal dimension but having differing appearance [
43]. Lacunarity represents the distribution of gap size: low lacunarity geometric objects are homogeneous because all gap sizes are the same, while high lacunarity objects are heterogeneous [
44].
Regions with different building density also show completely different lacunarity features owing to the discrepancies in building structures and surrounding objects. Buildings in residential areas are distributed regularly, homogeneously and at a small-scale, and are therefore less aggregated. Junction areas are more aggregated than residential areas owing to the presence of a middle-scale road. As industrial buildings are characterized as large scale because of their specific utility, they are the most aggregated.
Several algorithms have been proposed to calculate lacunarity, including Voss’s box counting algorithm [
45], Dong’s differential box counting algorithm [
46], Gan’s relative differential box counting algorithm [
47], and Backes’ improved differential box counting algorithm [
48]. Here, we chose relative differential box counting algorithm to calculate lacunarity.
The calculation is based on the equation:
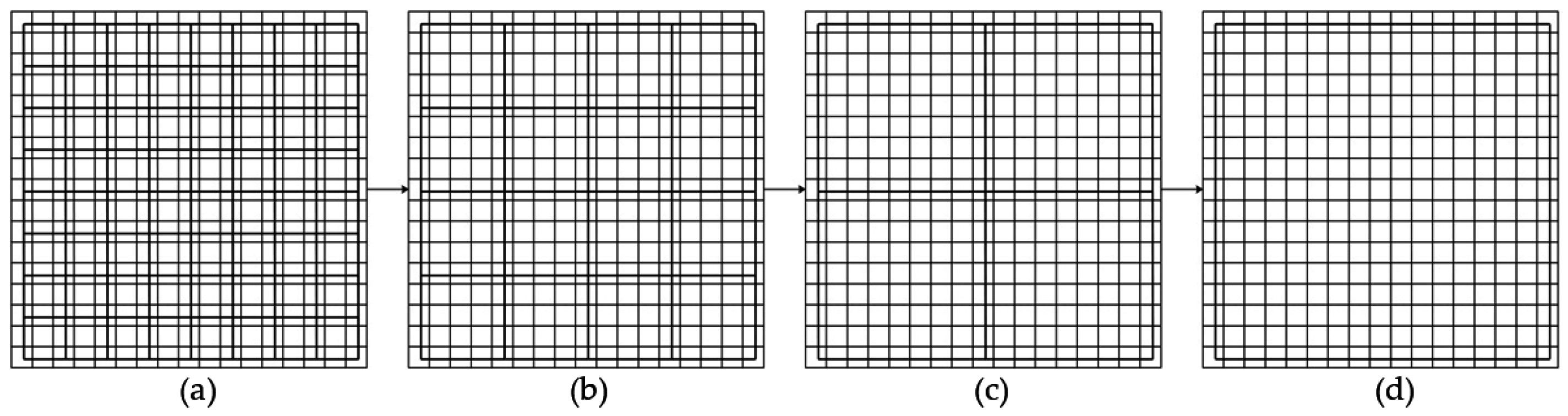
As shown in
Figure 7, a cubic of size
is placed over the upper left corner of an image window of size
, which is an odd number, and
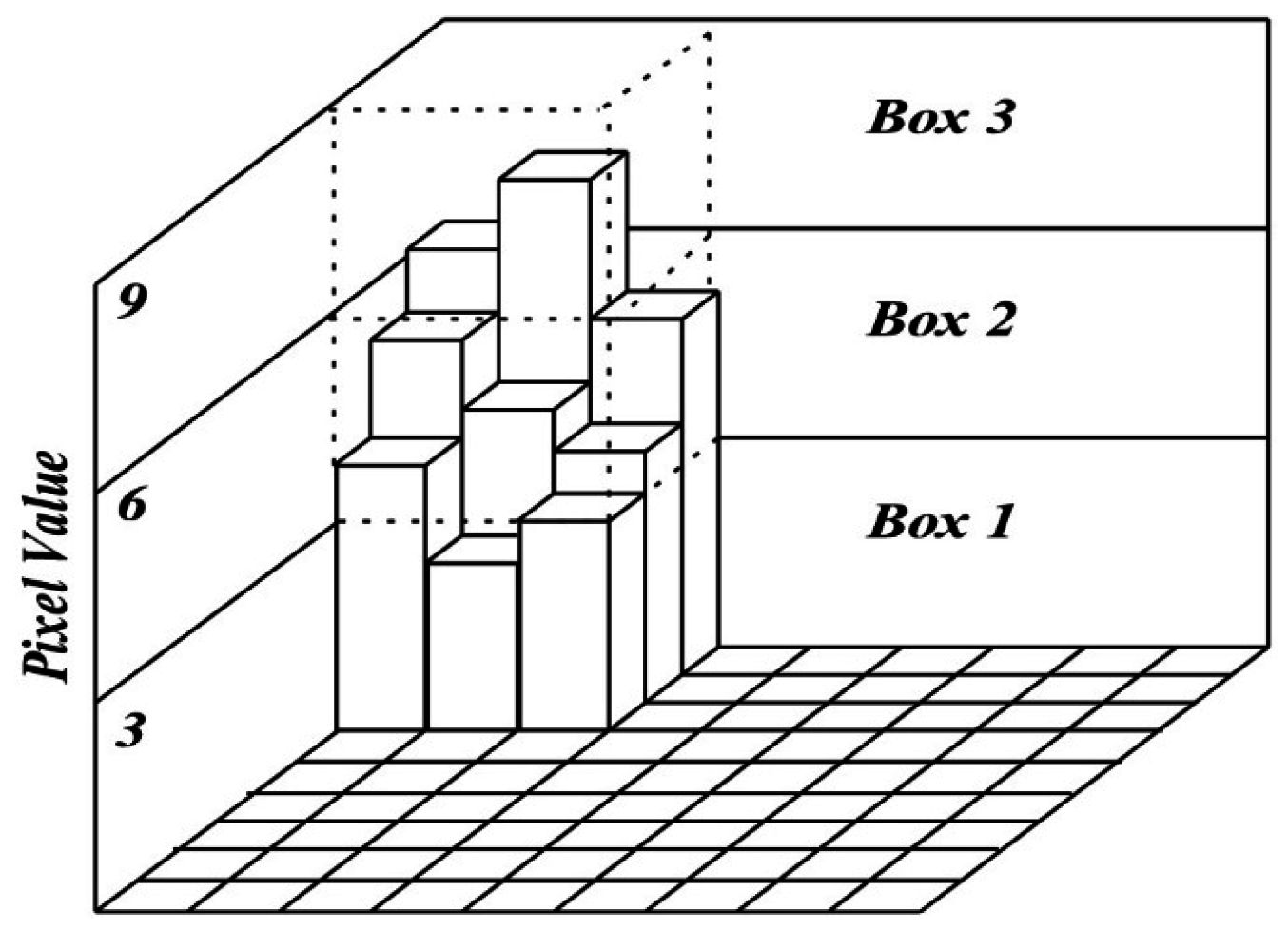
. Depending on the pixel values in the
gliding-box, a column with more than one cube may be needed to cover the image intensity surface. Assign numbers 1, 2, and 3 to the cubic boxes from bottom to top. For each
gliding-box, let the minimum and maximum pixel values in the gliding-box fall in box number
u and
v, respectively. Then the relative height of the column is:
where
i and
j are image coordinates. When the
gliding-box moves throughout the
image window, we have:
where
k is expressed as
, and
g is the maximum pixel value within the
window. The
M in the equation is replaced by
Mr. Define
to be the number of gliding boxes with size
r and mass
Mr, and then
can be defined as
3.2.2. Deviation Degree
Before calculating amended backscatter intensity, an important concept called deviation degree (
DD) should be introduced. According to previous studies on lacunarity and fractal dimension, we know that lacunarity ranges from 1 to infinity and fractal dimension ranges from 2 to 3 when applied to satellite images. Generally, areas with homogeneous surface (e.g., a water body or farmland) can be viewed as having only one significant gap. Therefore, they have infinite lacunarities. Because building areas are dotted with many gaps, their lacunarities range from 1 to 2 in most cases. Areas with high complexity, as discussed in
Section 3.2.1, have a high fractal dimension; thus,
DD is defined as
where
LCU represents lacunarity and
FD represents fractal dimension. Considering that most lacunarities are lower than 2 with only 3% out of this range, lacunarities higher than this value were set to 2.
As previously discussed, the value of only represents the degree of being away from highly complex and even two regions sharing same value can show totally different distribution pattern. The addition of complements this by representing the degree of being away from homogeneously distributed. Therefore, DD is a comprehensive effort about complexity and distribution. The coefficient was used for normalization. It is obvious that the more an area deviates from being homogenously distributed and highly complex, the higher its DD becomes.
3.2.3. Calculation of Amended Backscatter Intensity
With
DD, the new feature—amended backscatter intensity (
ABI)—could be generated by following equation.
The key point of this Equation (14) is to determine whether the coefficient of DD should be 1, −1, or 0, i.e., to determine whether ABI is higher than BI or lower. Things differ in different areas. In industrial areas, building densities are relatively high, usually up to 50% or above. However, their BI are not correspondingly high, thus the ABI should be increased. In non-built-up areas, of course with building density of 0%, although most of them have low BI, they cannot be clearly distinguished from low density areas. Therefore, their ABI should be decreased. From this point, a classification is required to determine the coefficient for each urban land use class before the calculation of ABI. Similarly, CART algorithm will be employed to perform the classification.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}