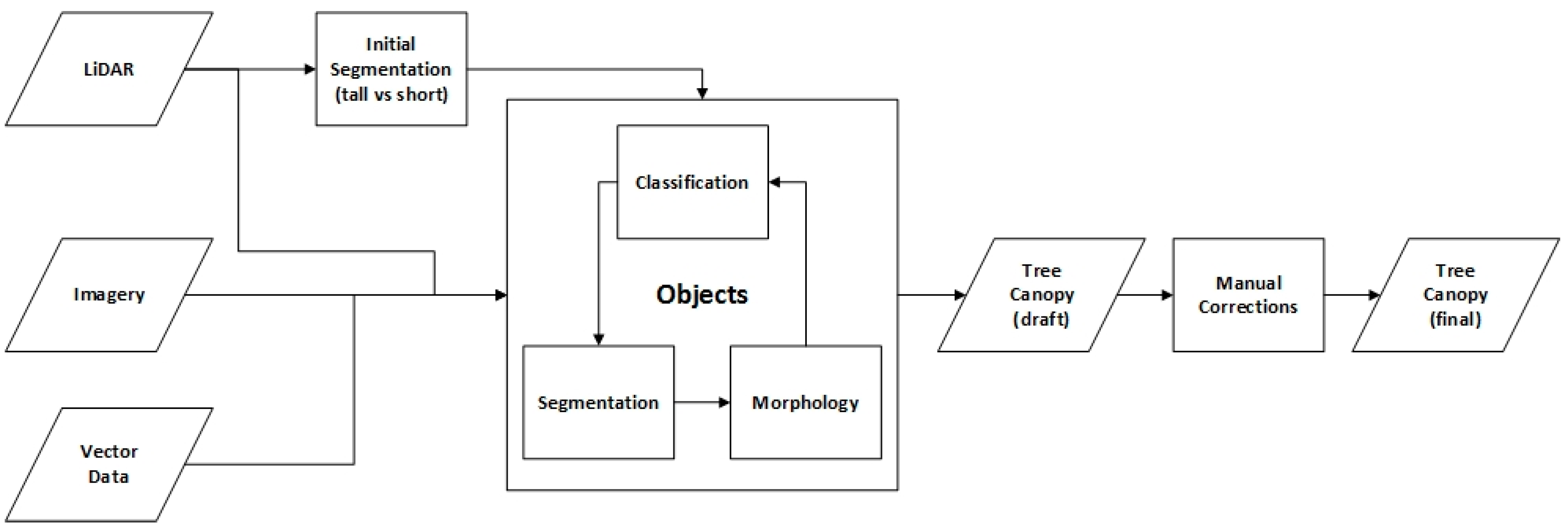
1. Introduction
Tree canopy provides many essential ecological services to human populations, both at local scales and globally. These benefits include multiple environmental functions: trees intercept rain, reducing the volume of stormwater runoff and, ultimately, water pollution [
1,
2]; they improve air quality by filtering pollutants [
3]; they moderate the heat-island effect observed in areas with large expanses of impervious surfaces [
2]; and they are an important part of the global carbon cycle, serving as a carbon sink [
4]. In addition to these direct environmental benefits, trees also have important effects on the social function of human communities, improving property values [
5], reducing crime [
6], and fostering a sense of place and safety [
2,
7], all factors integral to the perceived quality of life in urban and suburban communities.
Although the importance of healthy trees to environmental function and community welfare is increasingly well-known, forests worldwide are threatened by a host of anthropogenic and natural agents. Direct habitat loss from development is a primary factor of anthropogenic change in urban environments, and indeed land-cover conversions contributed to recent tree-canopy declines in multiple American cities [
8]. Among natural forces, numerous insect pathogens threaten trees in many parts of the world, including the Asian long-horned beetle (ALB) [
9] and emerald ash borer (EAB) [
10]. For example, thousands of trees in Worcester, Massachusetts, USA were removed after discovery of ALB in 2008, entirely eliminating mature tree cover in some neighborhoods [
11]. Other threats include fungal pathogens [
12], ice storms [
13,
14], and climate-induced drought and heat stress [
15]; some of these stressors could produce interactive effects that exacerbate tree decline [
12]. If current projections of climate change are realized, with some parts of the world experiencing more frequent and intense storms, droughts, and heat waves, increased tree mortality could produce observable forest diebacks [
16].
Fortunately, cities in the United States and Canada are responding to these threats, developing ambitious programs to maintain existing trees and to expand urban forest cover. Perhaps the most notable is New York City’s Million Trees Program, which aims to plant a million trees during a 10-year period [
17], but other cities with planting programs includes Washington, DC [
18], and Philadelphia, PA [
19]. These proactive cities have established specific goals for enhancing tree cover, usually expressed as a desired proportion of tree canopy relative to total land area (e.g., 40% tree canopy goal for Washington, DC). Of particular emphasis for these programs is the planting of “street” trees in road medians and along road edges, which help mitigate runoff volumes from impervious surfaces. As a matter of social justice, many programs also seek to address areas where tree canopy is most lacking; these areas are often among the poorest and most underserved neighborhoods.
To be effective, tree-planting programs first need a comprehensive assessment of existing tree canopy, a baseline documentation that supports establishment of specific community goals. Traditional methods of manual photointerpretation combined with high-resolution imagery can provide informative city-wide estimates of tree cover [
8], but these methods are laborious and do not highlight fine-scale patterns. Similarly, excellent field-based methods exist for assessing tree species distributions and volumes [
20,
21], but they are generally sample-driven and lack adequate detail for entire municipalities. Moderate-scale tree canopy maps developed from remote sensing data, such as the 30-m National Land Cover Dataset (NLCD), provide informative regional assessments of forest cover, but they too lack the needed specificity for evaluation of neighborhoods with sparse tree canopy [
22]. Ideally, tree canopy maps will be accurate to the scale of individual trees, permitting analysis of municipalities at a range of scales from broad political units (e.g., city, county, or state) to individual property parcels.
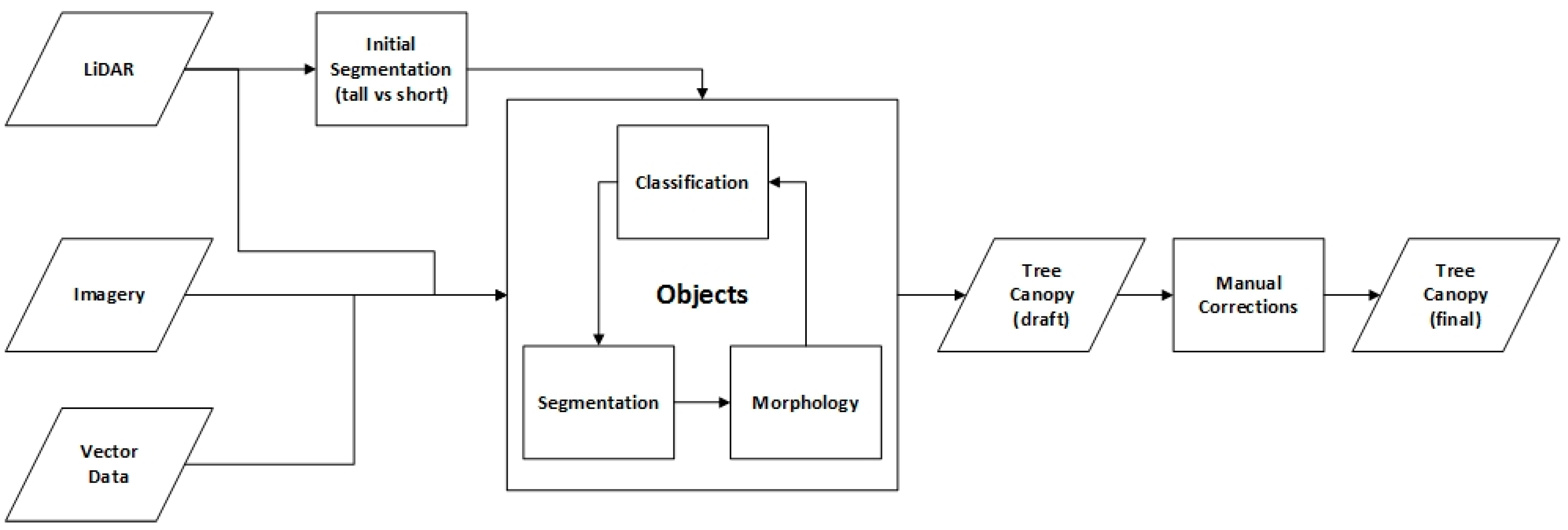
In combination with high-resolution remote sensing data, geographic object-based image analysis (GEOBIA) offers a solution to this mapping challenge. It can accommodate a variety of data types, including LiDAR cloud point data, LiDAR derivatives (e.g., digital elevation models, normalized digital surface models), multispectral imagery (e.g., WorldView-2), and thematic GIS files (e.g., roads, building footprints), providing a data-fusion capability that maximizes the value of existing geospatial data investments while minimizing or eliminating the need to acquire new datasets. It also permits efficient processing of large datasets with enterprise-processing capabilities, analyzing multiple tiles simultaneously.
Recent projects have demonstrated GEOBIA’s applicability to tree-canopy mapping using rule-based expert systems in which automated workflows efficiently convert high-resolution remote sensing data into GIS-ready products [
23]. Some of the most densely-developed urban areas in the United States have been mapped with this methodology, including New York City [
24] and Philadelphia [
25]. It has proven similarly effective with larger geographic extents encompassing a spectrum of urban, suburban, and rural land uses, including every county in the state of Maryland [
26]. All of these projects have achieved classification accuracies exceeding 90%, with some as high as 98%. They have also achieved a high degree of visual realism and coherence, aesthetic factors that are very important to map end users and that often cannot be equaled with pixel-based statistical classifiers [
27].
Despite these successes, GEOBIA’s relevance to production-level land-cover mapping has not been widely documented. The GEOBIA literature has traditionally focused on development, refinement, and optimal use of segmentation algorithms [
27]. This emphasis is vital to continued innovation in GEOBIA techniques and broadened application to natural resources assessment and management, but it overlooks GEOBIA’s capacity for accommodating huge datasets in short timeframes, producing output that covers large geographic extents and is intended for immediate use in practical settings. GEOBIA is more than an experimental approach; it is a well-tested and adaptable set of tools that geospatial analysts can use in production environments where the emphasis is on rapid conversion of data into information.
This paper demonstrates a GEOBIA-based tree canopy mapping protocol developed by the University of Vermont Spatial Analysis Laboratory (SAL) in conjunction with the United States Department of Agriculture (USDA) Forest Service. The original impetus for this method, termed the Urban Tree Canopy (UTC) Assessment Protocol, was the growing need for high-resolution land cover maps that could accurately summarize tree canopy at the scale of individual property parcels, information that in turn could help document current conditions and prioritize tree-planting efforts in urban and suburban landscapes. It has proven to be a highly flexible method for characterizing the green infrastructure of cities, counties, and now entire states, accommodating input datasets of varying quality and quantity and providing the statistical accuracy and visual realism demanded by a diversity of stakeholders: planners, policy analysts, research scientists, elected officials, and citizens. It offers a model for producing accurate land cover data across large areas in a timely and cost-effective manner, data that will facilitate legitimate time-series analysis as tree canopy changes in response to future environmental and social conditions. To date, this protocol has been performed for more than 70 communities in North America, yielding more than 1 trillion pixels of land cover data.
2. Methodology
2.1. Data Acquisition and Processing
Limited financial resources are available to perform most UTC assessments. The SAL almost exclusively relies on existing geospatial datasets in its tree canopy mapping projects. This approach helps cities and counties demonstrate the utility of their GIS programs and remote sensing data collections, and makes many UTC assessments feasible by keeping project costs relatively low. Use of existing datasets also reduces or eliminates the time needed to acquire, process, and distribute new datasets. The input datasets for these projects are often highly variable in content and quality, reflecting the diverse motives and practices underlying data acquisition and processing. Unless datasets are systematically and irreparably flawed, however, most have some value in GEOBIA; sometimes even the approximate location of features can facilitate mapping, especially thematic GIS layers representing non-tree canopy landscape elements (e.g., road centerlines, utility transmission line rights-of-way). These layers can help refine the initial tree canopy classification by eliminating objects that are unlikely to represent actual trees.
2.1.1. Multispectral Data
Free or low-cost multispectral imagery exists for many parts of the United States. In particular, the National Agriculture Imagery Program (NAIP) provides 1-m ground sample distance (GSD), leaf-on aerial imagery for the 48 conterminous states [
28]. Acquired for each state since 2002, usually at 2–3 year intervals, the standard NAIP acquisition is 4-band imagery (blue, green, red, and near-infrared). The 4-band datasets are preferred for tree canopy mapping because the near infrared band is necessary for calculating vegetation indices such as the normalized difference vegetation index (NDVI) [
29]. When no higher resolution datasets are available, NAIP imagery is a useful input for discriminating vegetation from other land cover features, although locational errors can occur in areas with variable terrain [
26].
Some municipalities also coordinate acquisition of high-resolution aerial orthoimagery (
i.e., imagery orthorectified to accommodate relief displacement) for their planning and monitoring activities. The additional spatial detail often provided by these datasets further aids in vegetation discrimination, and the SAL has used orthoimagery with cell resolutions as high as 0.152-m GSD [
24]. These data are typically acquired under leaf-off conditions to better facilitate the updating of cadastral maps. Often the local orthoimagery only contains the visible bands. In addition to these aerial imagery datasets, high-resolution satellite imagery has been available for some projects, such as WorldView-2 [
30].
Most multispectral datasets require relatively little processing before use in GEOBIA automated feature extraction. NAIP imagery and other datasets are often obtained as multiple separate tiles covering the area of interest, and the usual protocol is to mosaic the tiles into a single scene. If high-resolution satellite data are used, more intensive pre-processing is required, such as pansharpening and orthorectification. These preprocessing tasks are carried out using ERDAS IMAGINE.
2.1.2. LiDAR
LiDAR point clouds in LAS format with ground point classified and a minimum of four returns are preferred for tree canopy mapping, providing maximum flexibility for examining the original LiDAR points and extracting necessary derivative products. More recent tree canopy mapping projects involve direct manipulation of LiDAR point clouds within GEOBIA software, which eliminates many of the LiDAR layer generation tasks listed below. Most projects to date, however, have relied on datasets derived from raster-based summaries of specific LiDAR components. Most notable is the normalized digital surface model (nDSM), which indicates the height of aboveground features such as trees and buildings. Various software packages are available for examining and filtering point clouds and exporting desired components to raster output, but the SAL usually uses Quick Terrain Modeler (Applied Imagery, Silver Spring, Maryland, USA) or SCALGO (Scalable Algorithmics, Aarhus, Denmark). These programs permit data extraction and a multitude of processing and output options.
Original point clouds are not always available for individual projects, and sometimes the SAL relies on LiDAR derivatives produced by other entities. This scenario eliminates processing flexibility and quality control of the final products but reduces the labor devoted to data pre-processing.
DEM
When a classified LiDAR point cloud is available, the first processing step is development of a digital elevation model (DEM) that characterizes the ground topography. In Quick Terrain Modeler or a similar program, all LiDAR returns classified as ASPRS Class 2 (Ground) [
31] are filtered and exported to a raster file, in IMAGINE format (.img). The gridding options are
Mean Z (LiDAR elevation) and
Adaptive Triangulation with no smoothing. The output cell resolution is set according to the nominal post spacing of the LiDAR point cloud, which has been at or near 1 m for most recent projects.
DSM
A similar LiDAR-derived layer is a digital surface model (DSM) that shows the topmost elements of aboveground features, including trees and buildings. It is created by filtering all non-spurious
first LiDAR returns, regardless of classification. The gridding options are
Max Z and
Adaptive Triangulation with a smoothing filter (
Radius, 1.00 Bins;
Z Tolerance, 3 m). The output cell size is again the nominal post spacing. An example 0.457-m GSD DSM for Virginia Beach, Virginia, USA is shown in
Figure 1b; for comparison, a true-color 0.152-m GSD orthoimage is shown in
Figure 1a.
DTM
A third surface is a digital terrain model (DTM), which helps characterize the lower sections of three-dimensional objects. In contrast to the DSM, the DTM is created by filtering
last LiDAR returns from the original point cloud, regardless of classification. The gridding options are the same as those used for the DSM and the final cell resolution is based on the nominal LiDAR post spacing. This surface capitalizes on LiDAR’s penetration of partially pervious features such as trees by one or more of the pulse returns; some of the returns capture topmost leaves and branches, some penetrate to interior branches and the tree bole, and others reach the ground. An example DTM is shown in
Figure 1c.
nDSM
After creating the initial LiDAR derivatives, a normalized DSM (nDSM) is created by subtracting the DEM from the DSM. This raster-processing step can be performed in many different programs; the SAL usually uses the Two Image Function option with the subtraction operator in ERDAS Imagine. The final product indicates the height of features aboveground, including the upper leaves and branches of tree canopy. An example nDSM is shown in
Figure 1d.
nDTM
A normalized DTM (nDTM) is also created using the Two Image Function option, subtracting the DEM from the DSM. The resulting surface superficially resembles the nDSM, but for trees the layers capture fundamentally distinct elements in the vertical plane: the topmost features of the canopy (nDSM)
versus a range of features from the canopy to mid-level branches to the tree bole (nDTM). For buildings, the nDSM and nDTM are essentially the same. An example nDTM is shown in
Figure 1e.
nDSM/nDTM Difference
The difference between the nDSM and nDTM is a key modeling parameter in the preferred approach to tree canopy mapping, distinguishing highly variable, partially pervious features such as trees from impervious features with smooth surfaces, such as buildings. When the difference is high, indicating high variability in the vertical complexity of LiDAR returns, a feature is likely a tree; when the difference is low, suggesting smooth features, it is probably a building. The SAL usually calculates this layer in eCognition using
Layer Arithmetics after importing the nDSM and nDTM layers, but it could be created in any raster-processing software. An example nDSM/nDTM Difference layer is shown in
Figure 1f.
Intensity
LiDAR intensity values indicate the strength of individual returns and are extracted from point clouds by importing them along with all first returns, regardless of classification. The gridding options are the same as for the DSM. Intensity is generally not useful for discrimination of trees from other vegetation, but it does help distinguish impervious surfaces and thus can be helpful for removing developed features from consideration during classification.
Mean Number of Returns
The SAL’s current protocol focuses on derivation of nDSM and nDTMs, but for past projects other LiDAR derivatives have been useful for characterizing the texture of aboveground features. To create a layer showing the mean number of returns per unit area, all returns are imported regardless of classification and then summarized according to specified statistical criteria. In Quick Terrain Modeler, this operation is performed using Grid Statistics by specifying the variable as Number of Returns and the statistic as Mean. To ensure adequate statistical precision, a coarser resolution is necessary; as a rule of thumb, the output cell size should be three times the nominal post spacing.
Figure 1.
Common source datasets for GEOBIA-based tree-canopy mapping. (a) A 0.152-m GSD true-color orthoimage for Virginia Beach, Virginia, USA. (b) A LiDAR-derived 0.457-m GSD digital surface model (DSM). (c) Digital terrain model (DTM). (d) Normalized digital surface model (nDSM). (e) Normalized digital terrain model (nDTM). (f) Difference between nDSM and nDTM. Trees are shown as high positive values (white); other aboveground features (e.g., buildings) have values equal to or near zero (black).
Figure 1.
Common source datasets for GEOBIA-based tree-canopy mapping. (a) A 0.152-m GSD true-color orthoimage for Virginia Beach, Virginia, USA. (b) A LiDAR-derived 0.457-m GSD digital surface model (DSM). (c) Digital terrain model (DTM). (d) Normalized digital surface model (nDSM). (e) Normalized digital terrain model (nDTM). (f) Difference between nDSM and nDTM. Trees are shown as high positive values (white); other aboveground features (e.g., buildings) have values equal to or near zero (black).
Z Deviation
A similar LiDAR-derived texture layer focuses on variability in height values (Z). It can be created in Quick Terrain Modeler by specifying the variable as Z and the statistic as Standard Deviation, and the output resolution should also be three times the nominal post spacing. Both Z Deviation and Mean Number of Returns show trees as highly variable surfaces while buildings and other anthropogenic features are smooth. The SAL has found that the higher-resolution nDTM is a better indicator of object texture in GEOBIA modeling, but Z Deviation and Mean Number of Returns can be useful derivatives from lower-quality LiDAR datasets containing few returns per pulse.
2.1.3. Thematic GIS Layers
Many municipalities have developed detailed vector GIS datasets representing buildings, road surfaces, road centerlines, parking lots, sidewalks, hydrology, and other elements of the natural and built environments. These datasets can substantially aid development of tree canopy maps by identifying landscape features where trees are unlikely to grow or are heavily circumscribed by anthropogenic elements. For all projects, the SAL requests all pertinent datasets from the individual municipalities or downloads them from public GIS clearinghouses. It then reviews the metadata for these layers and layers themselves, assessing whether they are sufficiently accurate and informative for discriminating trees from other features.
Occasionally, the SAL also develops its own thematic GIS datasets, usually to help distinguish easily confused landscape features. Examples include bare soil and utility rights-of-way. This work is performed in ArcGIS using heads-up digitizing techniques. In certain instances, existing vector datasets may be manually updated to reflect the conditions present in the source remotely sensed data. GEOBIA routines are often used to screen the vector data to highlight areas of possible change. The overall goal in these manipulations is not to produce stand-alone products for subsequent use by municipalities but rather to directly inform automated feature extraction. For example, the utility rights-of-way polygons that are developed are rough approximations of areas in which utility lines are present. The decision whether to create or modify thematic GIS layers is contingent on the quality of the available multispectral and LiDAR datasets: Are the remote sensing datasets sufficiently detailed to ensure high-accuracy GEOBIA output? If the answer is no or uncertain, it may be more efficient to first identify and map confounding landscape features for subsequent use in automated feature extraction.
2.3. Manual Corrections
No map produced by automated feature extraction will achieve perfect accuracy; tree canopy is usually too variable, especially in densely developed areas with small street trees and other plantings that are easily confused with anthropogenic features (e.g., utility poles). To gain a final measure of accuracy and to eliminate obvious, non-systematic errors, the SAL reviews all draft tree canopy maps in ArcGIS and manually draws polygons around errors of commission and omission over the raster land cover. The scale at which maps are reviewed depends on the initial quality of the map, the time and labor costs needed, and the desired level of accuracy, but often it is about 1:3000. All reviews are performed by geospatial technicians who are well versed in the fundamentals of image interpretation and land cover mapping. A separate eCognition rule set is used to incorporate manual corrections into a final land cover map. This routine segments and re-classifies tree canopy objects according to the thematic correction polygons: erroneous objects are removed and omitted objects are added.
2.4. Accuracy Assessment
For projects requiring an accuracy assessment, an adequate number of random points are selected for a study area, following standard recommendations for per-pixel assessments [
32]. Although various studies have attempted assessments more appropriate for GEOBIA-produced maps, no standards or rules-of-thumb have yet been developed that can be efficiently and consistently applied to tree canopy maps. The actual land cover at each random point is determined by reviewing high-resolution reference data, usually in ArcGIS. An error matrix is produced containing the user’s, producer’s, and overall accuracies.
2.5. Retrospective Change-Detection Analysis
After production of a high-resolution tree canopy map, it is possible to gauge recent changes in forest cover by performing retrospective change analyses. A retrospective analysis assumes that the best possible GEOBIA methods and high-resolution input datasets have been used to produce a map for a near-current time period. This map is then compared to data sources from an earlier time period and modified to accommodate changes in tree canopy: gain or loss. One method involves manual comparison of a high-resolution tree canopy map to earlier multispectral imagery, drawing polygons around gained or lost tree canopy in a GIS program. The polygons are then incorporated into a new raster layer that indicates change with three thematic classes: No Change, Gain, and Loss. As with manual corrections, the SAL has found that the change-detection layer is most easily produced in eCognition by segmenting and classifying tree canopy for the latter time period using the thematic polygons. The driving factor behind this approach is the fact that the latter time period data is typically higher in quality (e.g., better horizontal accuracy and higher LiDAR point cloud density).
An alternative automated method of change detection is possible when two time periods of interest have similar high-resolution input datasets, preferably LiDAR and its derivatives. In this method, tree canopy for the latter period is mapped first using GEOBIA and then subjected to manual review. After incorporating any necessary corrections, a separate eCognition rule set is created that maps tree canopy for the earlier time period and then compares it to the corrected map for the later period, creating the three thematic classes of interest (No Change, Gain, and Loss). Last, the draft change-detection layer is reviewed relative to the high-resolution inputs for the earlier time period and corrected as necessary.
4. Conclusions
It is possible to move GEOBIA from a purely academic setting to a production environment, shifting focus from parameter experimentation to timely conversion of huge volumes of data into usable information. Administrators and planners at all levels of government need current and accurate tree canopy maps, but for many parts of the United States and Canada the available data are too coarse or limited in extent. GEOBIA techniques offer solutions to this information gap, facilitating simultaneous analysis of multiple pertinent inputs, including many high-resolution datasets already acquired at substantial cost but underutilized or overlooked. Many possible modeling approaches exist, and indeed the specific segmentation and classification procedures for individual projects must be tailored to the available datasets, time, funds, and processing capabilities; no single solution is optimal for all cases.
LiDAR derivatives such as Normalized Digital Surface Models (nDSMs) and Normalized Digital Terrain Models (nDTMs) have consistently proven to be the most important remote sensing datasets for mapping tree canopy, permitting efficient discrimination of tall, highly textured objects from other aboveground features. However, GEOBIA can accommodate many different types of data and varying levels of quality, providing a robust method for differentiating trees from surrounding landscape features. Context is also key to tree canopy mapping; procedures that identify contrast with other features best approximate the way humans perceive variability among landscape features. Combined with GEOBIA’s versatile data fusion capabilities, this contextual, expert system based approach provides both a quantitative accuracy and high visual realism that per-pixel, probabilistic methods cannot match. As more communities acquire second rounds of temporally distinct LiDAR, it will be possible to perform more retrospective change detection analyses that help document the effects of anthropogenic and natural environmental change.
Production environment GEOBIA is feasible for many other landscape mapping efforts covering large geographic extents, including comprehensive land use/land cover (LULC) mapping, vegetation classification, wetlands delineation, agricultural monitoring, forest characterization, and river channel modeling. As always, overall quantitative accuracy will depend on the quality and resolution of the input imagery, LiDAR, and thematic datasets, along with a fundamental understanding of the features of interest and their relationship to other landscape objects. Where output products are expected to be highly scrutinized, manual editing helps remove non-systematic inconsistencies that affect end-user confidence, even if its effect on quantitative accuracy is negligible. GEOBIA thus integrates the old with the new, joining sophisticated automated feature extraction with time-tested elements of image interpretation into a single, efficient expert system.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}