1. Introduction
There has been a rapid growth in the application of airborne light detection and ranging (LiDAR) data for forestry, especially with respect to the potential production of enhanced forest resource inventories (eFRI) and much improved land base feature delineation. Numerous studies have demonstrated that forest inventory variables can be measured and modeled accurately (and precisely) from LiDAR height and density metrics [
1–
3]. These include critical parameters, such as species identification [
4], mean diameter at breast height (DBH) [
5,
6], stand and canopy structural complexity [
7,
8], forest succession [
8], fractional cover [
9], leaf area index (LAI) [
9,
10], crown closure [
11], timber volume [
6,
12,
13] and biomass [
14–
17]. Estimation of many forest inventory variables using LiDAR data is now moving beyond the research realm and into the operational forum [
18–
22].
However, standards for the acquisition, processing and application of LiDAR data for forestry and natural resources inventory and management are not well defined, nor are they likely to be standardized across all inventory variables or forest types. For example, data acquisition standards that determine the optimal acquisition of LiDAR data for forestry (in terms of forest variable estimation and cost efficiency) have not been universally defined, nor is there documentation of expert knowledge defining suitable acquisition criteria (i.e., survey design) for estimating forest variables. These standards are required for the forest industry to gain the best possible return from the technology across a range of forest conditions and for specific operational requirements, as well as to maintain consistency across surveys within regions. This deficiency must be addressed to provide the forest sector, both in industry and government, with a distinct competitive advantage in achieving truly sustainable forest management that encompasses economic, ecological, and social values.
The overall goal of our research has been to examine acquisition standards for collecting, processing and analyzing LiDAR data to derive forest inventory attributes that lead to the production of an eFRI for Ontario forests. A number of researchers have examined the impacts of different sensor and survey parameters on estimating forest inventory variables [
23–
33]. It has been shown that the plot-level vertical distribution of LiDAR pulse returns remains relatively consistent with flying altitude, albeit with some subtle differences [
27,
28]. Næsset [
32] also examined the effects of different sensors, flying altitudes and pulse repetition frequencies on LiDAR-derived metrics for estimating mean tree height and timber volume for Norway Spruce (
Picea abies (L.) Karst) and Scots Pine (
Pinus sylvestris L.). Results revealed minor differences in precision for the various acquisition parameters and systematic differences between acquisitions of up to 2.5% for mean tree height and 10.7% for timber volume. However, it is not clear as to what impact pulse repetition frequency has on these estimates, since this variable could not be isolated between acquisitions, due to integrated effects of different sensors and flying heights.
Further, it has been demonstrated that pulse power has significant impacts on canopy attribute characterization, a variable that will vary with sensor pulse repetition frequency and flying altitude [
26]. The minimum distance between first and last returns also appears to increase with increasing flying altitude, potentially altering the statistical distribution of LiDAR returns within a forest canopy [
31]. However, Lim
et al. [
34] examined the statistical nature of 23 LiDAR-derived height and density metrics for two LiDAR sampling densities (data acquired on separate acquisitions at different altitudes). Only a very small number of metrics corresponding to the tails of the distribution of the laser canopy heights differed between the two surveys, indicating that plot-level data characterized by higher laser sampling densities do not necessarily result in richer data for biophysical variable estimation. Similarly, Bater
et al. [
33] also observed that most LiDAR first return vegetation height metrics did not differ between flight lines of identical sensor and survey parameters, but with differing point densities in areas of overlap. The authors concluded that when sensor setting and data acquisition parameters are held constant, and time dependent forest dynamics have not changed, LiDAR data are suitable for forest monitoring.
The above studies provide substantial insight into the effects of sensor characteristics and survey designs on LiDAR data point distributions, metrics and variable estimation. However, it is difficult to isolate single sensor or data acquisition parameters when trying to examine their effects, due to their integrated nature and co-dependency. In addition, these studies also exhibit different experimental designs across contrasting forest environments, which make comparison difficult [
32,
33].
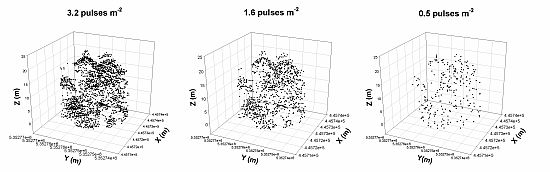
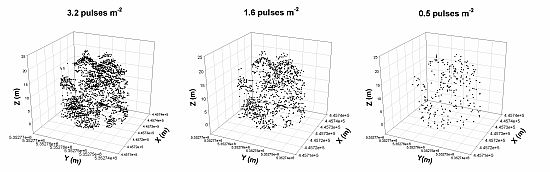
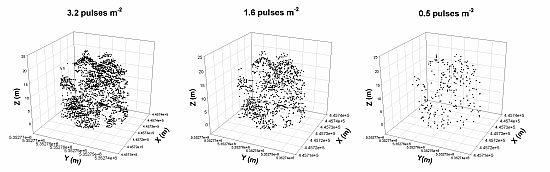
Specifically, a key question that has yet to be isolated and fully addressed, and that the forest industry continues to ask as it considers operationalizing the use of LiDAR in forest resource inventories, is: What is the optimal point density for predicting forest inventory variables? It is still not clear how LiDAR data collected at different point densities impacts the estimation of a full range of forest biophysical variables for forest ecosystems across Ontario. Point density is a function of flight and sensor parameters which continue to evolve with the development of new sensor technologies. These developments will continue to impact data acquisition costs. This research focuses specifically on sampling density in order to determine the impacts of LiDAR point density on the prediction of forest inventory variables, independent of sensor or flight parameters. It is assumed that lower LiDAR point densities will translate into reduced data acquisition costs, always a consideration when conducting forest resource inventories. To investigate this question, we examined the impact of three point densities (3.2, 1.6, and 0.5 pulses m−2) derived from the same LiDAR data acquisition on the prediction of several forest inventory variables for forest types common across Ontario. In this manner, we were able to isolate the effect of sampling density on the estimation of forest biophysical variables for a range of forest ecosystems.
3. Results and Discussion
For illustration purposes, the models developed for each variable for Boreal-SB and Boreal-IH plot data are presented in
Tables 3 and
4. For black spruce, the models typically exhibit very high coefficients of determination (
i.e.,
R2 and
R2(adj)) with RMSEs, expressed as a percentage of the predicted means, ranging from approximately 4–19%, typically with only one or two input variables (
Table 3). Models developed for variables based on intolerant hardwood plots in the RMF also exhibited high adjusted coefficients of determination (
i.e.,
R2(adj) = 0.201–0.939) with RMSEs ranging from 4 to 23%. Variable-by-stand type results indicate that height-related models (
i.e., AVGHT; TOPHT; QMDBH) tended to perform well (
i.e., RMSEs < 10%) and volume/biomass-related models (
i.e., SUMBA; SUMGTV, SUMGMV, SUMBIO) performed moderately well (RMSEs typically 10–20%). Density models tended to exhibit the highest RMSEs (
Table 5).
For all forest variables tested, overall model prediction precision varied strongly with forest/type (
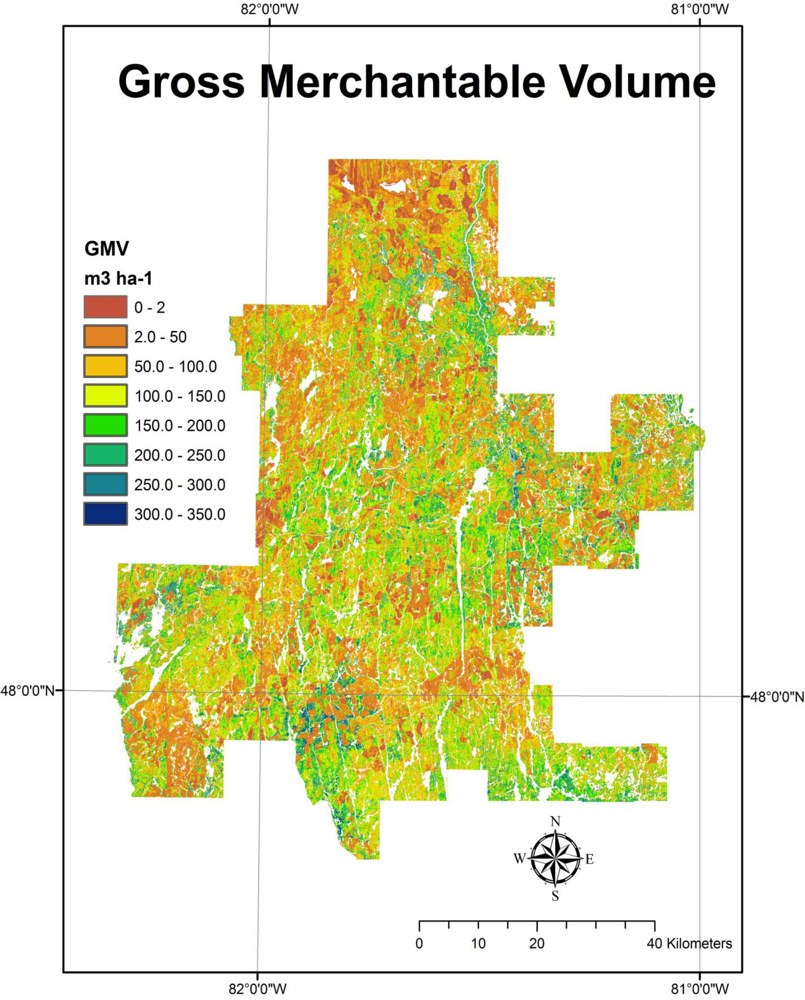
p ≤ 0.02;
Table 6). Boreal-SB variables tended to be predicted with the greatest precision (lowest mean absolute errors) and GrtLks-Pine variables with the least precision. The Boreal-SB stands were quite similar in that the majority were upland sites with mature black spruce of natural origin, whereas the GrtLks-Pine communities were more diverse in terms of species, management, and origin. The range of conditions sampled included unmanaged white pine, shelterwood white and red pine, thinned and unmanaged red pine plantations, as well as some natural jack pine stands. In future work, this group will be subdivided further to better consider the volume/height relationships for these species and management conditions.
With the exception of 2 of the 8 forest variables tested, we generally found little evidence to reject the null hypothesis that decimation of the LiDAR point cloud has no affect on model precision (
p > 0.10;
Table 6). In overall analyses, mean prediction errors tended to increase with decimation for the variables DENSITY and AVGHT (
p ≤ 0.02), but there was evidence to suggest that this situation was not consistent across all forest/types studied (
p ≤ 0.10). More specifically, DENSITY prediction errors for Boreal-PJ increased from 226 stems ha
−1 at 3.2 pulses m
−2, to 299 and 324 stems ha
−1 through decimation to 1.6 and 0.5 pulses m
−2 respectively (decimation linear,
p < 0.01).
To a lesser extent, prediction errors for GrtLks-Pine increased from 171 stems ha−1 at 3.2 pulses m−2, to 211 and 192 stems ha−1 through decimation to 1.6 and 0.5 pulses m−2 respectively (decimation quadratic, p = 0.09). Thinning treatments had been applied to these forests/types potentially giving rise to increased error as a function of insufficient sample size to account for a suitable range of density conditions.
Similarly, AVGHT prediction errors for Boreal-MW and GrtLks-Pine tended to increase sharply (30 to 40%) with the highest level of decimation (i.e., 0.5 pulses m−2) (decimation quadratic, p ≤ 0.10). However, these examples appear rare in the context of the overall data set and one may argue that with a significance level of 10%, we might expect to observe trends that suggest rejection of H0 up to 10% of the time simply through random chance alone. Thus, we feel that it is reasonable to conclude that decimation of the LiDAR point cloud from 3.2 to 1.6 and 0.5 pulses m−2 did not reduce the prediction precision of the forest variables tested.
The ability to significantly reduce LiDAR pulse density for forest inventory modeling without affecting prediction accuracy or precision provides significant financial savings in data acquisition and processing. Although not tested in this study, it is anticipated that accurate and precise digital elevation models (DEMs) of a finer scale than possible in the past can also be derived from low density LiDAR data, even in leaf-on conditions.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}