



Supervised Semantic Segmentation of Urban Area Using SAR



Abstract
:1. Introduction
- Assessment of the various textural features from X-band and C-band SAR images for discriminating urban land classes;
- Evaluation of the performances of three supervised classifiers on an urban area segmentation dataset.
Background and State of the Art of SAR Imaging for Urbanized Area Analysis
2. Materials and Methods
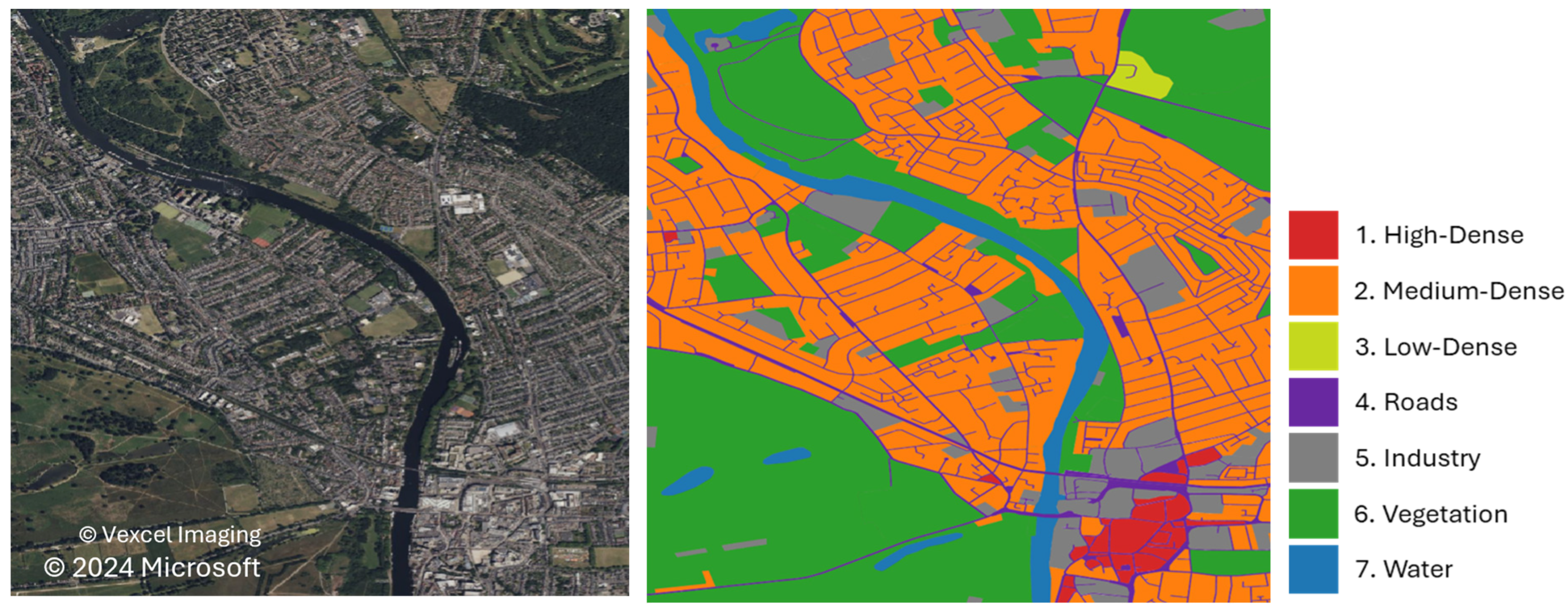
2.1. Datasets and Research Area
2.2. Urban Class Definition
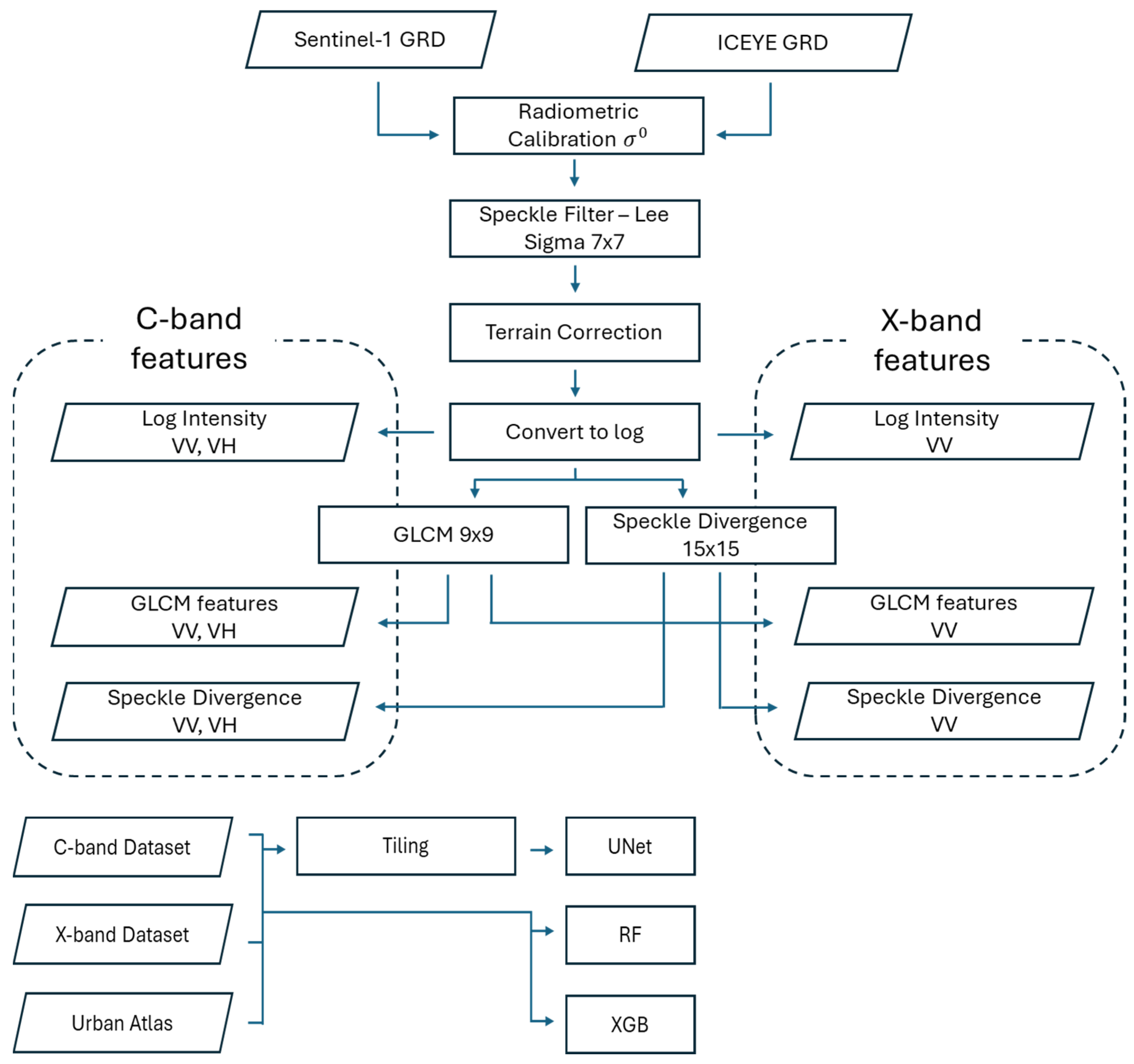
2.3. SAR Processing and Features
2.3.1. Log Intensity
2.3.2. Speckle Divergence
2.3.3. GLCM
2.4. SAR Data Classification
2.4.1. Random Forest (RF)
2.4.2. Extreme Gradient Boosting (XGB)
2.4.3. U-Net (Unet)
2.5. Preprocessing
2.6. Evaluation
3. Results
3.1. Algorithm and Feature Comparison
3.2. Label Aggregation Comparison
4. Discussion
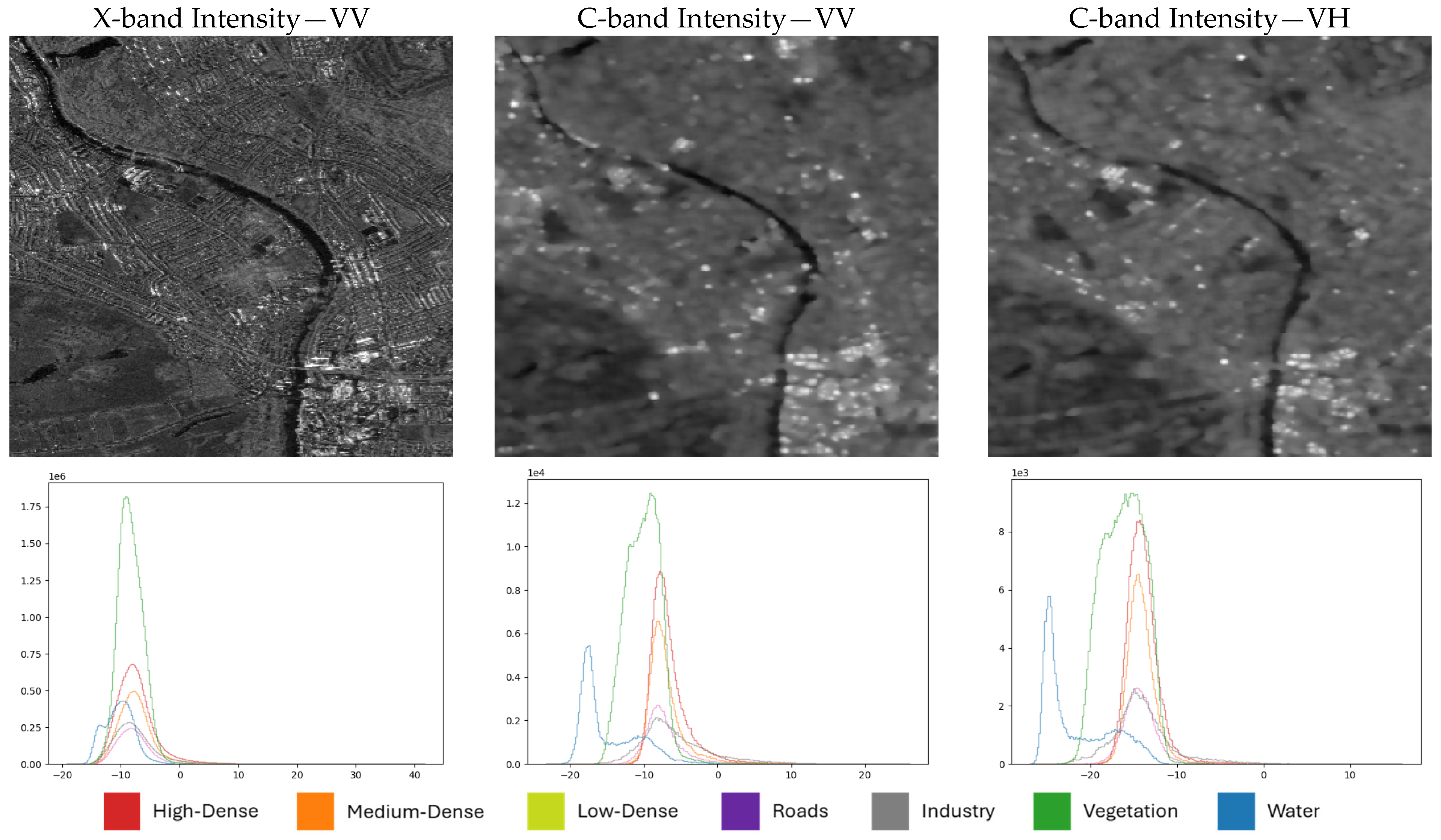
4.1. Effects of SAR Sensors
4.2. Reliability of Urban Atlas
4.3. Accuracy of the Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- GHSL. Global Human Settlement—GHSL Homepage—European Commission. Available online: https://human-settlement.emergency.copernicus.eu/ (accessed on 28 June 2024).
- European Commission, Joint Research Centre. GHSL Data Package 2023; Publications Office: Luxembourg, 2023; Available online: https://data.europa.eu/doi/10.2760/098587 (accessed on 26 July 2024).
- Pesaresi, M. GHS-BUILT-S R2023A—GHS Built-up Surface Grid, Derived from Sentinel2 Composite and Landsat, Multitemporal (1975–2030); European Commission, Joint Research Centre (JRC): Brussels, Belgium, 2023. [Google Scholar] [CrossRef]
- Florczyk, A.; Corbane, C.; Schiavina, M.; Pesaresi, M.; Freire, S.; Sabo, F.; Tommasi, P.; Airaghi, D.; Ehrlich, D.; Melchiorri, M.; et al. GHS-UCDB R2019A—GHS Urban Centre Database 2015, Multitemporal and Multidimensional Attributes; European Commission, Joint Research Centre (JRC): Brussels, Belgium, 2019. [Google Scholar] [CrossRef]
- Denis, M. Selected Issues Regarding Small Compact City—Advantages And Disadvantages. piF 2018, 2018, 151–162. [Google Scholar] [CrossRef]
- Salem, A. Determining an Adequate Population Density to Achieve Sustainable Development and Quality of Life. In The Role of Design, Construction, and Real Estate in Advancing the Sustainable Development Goals; Walker, T., Cucuzzella, C., Goubran, S., Geith, R., Eds.; Sustainable Development Goals Series; Springer International Publishing: Cham, Switzerland, 2023; pp. 105–128. [Google Scholar] [CrossRef]
- Denis, M.; Cysek-Pawlak, M.M.; Krzysztofik, S.; Majewska, A. Sustainable and vibrant cities. Opportunities and threats to the development of Polish cities. Cities 2021, 109, 103014. [Google Scholar] [CrossRef]
- Batty, M. The Size, Scale, and Shape of Cities. Science 2008, 319, 769–771. [Google Scholar] [CrossRef]
- Pluto-Kossakowska, J. Automatic detection of grey infrastructure based on vhr image. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B3-2020, 181–187. [Google Scholar] [CrossRef]
- De Sousa, F.L. Are smallsats taking over bigsats for land Earth observation? Acta Astronaut. 2023, 213, 455–463. [Google Scholar] [CrossRef]
- Li, X.; Zhang, G.; Cui, H.; Hou, S.; Wang, S.; Li, X.; Chen, Y.; Li, Z.; Zhang, L. MCANet: A joint semantic segmentation framework of optical and SAR images for land use classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102638. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E.; Rogan, J.; Kellndorfer, J. Assessment of spectral, polarimetric, temporal, and spatial dimensions for urban and peri-urban land cover classification using Landsat and SAR data. Remote Sens. Environ. 2012, 117, 72–82. [Google Scholar] [CrossRef]
- Bi, H.; Xu, L.; Cao, X.; Xue, Y.; Xu, Z. Polarimetric SAR Image Semantic Segmentation With 3D Discrete Wavelet Transform and Markov Random Field. IEEE Trans. Image Process. 2020, 29, 6601–6614. [Google Scholar] [CrossRef]
- Qu, J.; Qiu, X.; Wang, W.; Wang, Z.; Lei, B.; Ding, C. A Comparative Study on Classification Features between High-Resolution and Polarimetric SAR Images through Unsupervised Classification Methods. Remote Sens. 2022, 14, 1412. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Gill, E.; Molinier, M. A new fully convolutional neural network for semantic segmentation of polarimetric SAR imagery in complex land cover ecosystem. ISPRS J. Photogramm. Remote Sens. 2019, 151, 223–236. [Google Scholar] [CrossRef]
- Hall-Beyer, M. Practical guidelines for choosing GLCM textures to use in landscape classification tasks over a range of moderate spatial scales. Int. J. Remote Sens. 2017, 38, 1312–1338. [Google Scholar] [CrossRef]
- Dell’Acqua, F.; Gamba, P. Texture-based characterization of urban environments on satellite SAR images. IEEE Trans. Geosci. Remote Sens. 2003, 41, 153–159. [Google Scholar] [CrossRef]
- Holobâcă, I.-H.; Ivan, K.; Mircea, A. Extracting built-up areas from Sentinel-1 imagery using land-cover classification and texture analysis. Int. J. Remote Sens. 2019, 40, 8054–8069. [Google Scholar] [CrossRef]
- Kupidura, P.; Uwarowa, I. The comparison of GLCM and granulometry for distinction of different classes of urban area. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, United Arab Emirates, 6–8 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Molch, K.; Radar Earth Observation Imagery for Urban Area Characterisation. JRC Publications Repository. Available online: https://publications.jrc.ec.europa.eu/repository/handle/JRC50451 (accessed on 28 June 2024).
- Goodman, J.W. Some fundamental properties of speckle*. J. Opt. Soc. Am. 1976, 66, 1145. [Google Scholar] [CrossRef]
- Eckardt, R.; Urbazaev, M.; Salepci, N.; Schmullius, C.; Woodhouse, I.; Stewart, C. “MOOC on SAR: Echoes in Space,” Eo Science for Society. Available online: https://eo4society.esa.int/resources/echoes-in-space/ (accessed on 28 June 2024).
- Snitkowska, E. Analiza Tekstur w Obrazach Cyfrowych i jej Zastosowanie do Obrazów Angiograficznych. Warszawa, 2004. Available online: https://www.ia.pw.edu.pl/~wkasprza/PAP/PhDEwaSnitkowska.pdf (accessed on 28 June 2024).
- Dell’Acqua, F.; Gamba, P.; Trianni, G. Semi-automatic choice of scale-dependent features for satellite SAR image classification. Pattern Recognit. Lett. 2006, 27, 244–251. [Google Scholar] [CrossRef]
- Kamusoko, C. Optical and SAR Remote Sensing of Urban Areas: A Practical Guide; Springer geography; Springer: Singapore, 2022. [Google Scholar]
- Huang, X.; Zhang, T. Morphological Building Index (MBI) and Its Applications to Urban Areas. In Urban Remote Sensing, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2018; pp. 33–49. [Google Scholar]
- Hall-Beyer, M. GLCM Texture: A Tutorial v. 3.0 March 2017. 2017. Available online: http://hdl.handle.net/1880/51900 (accessed on 28 June 2024).
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Esch, T.; Roth, A. Semi-Automated Classification of Urban Areas by Means of High Resolution Radar Data. 2004. Available online: https://www.isprs.org/proceedings/xxxv/congress/comm7/papers/93.pdf (accessed on 28 June 2024).
- Semenzato, A.; Pappalardo, S.E.; Codato, D.; Trivelloni, U.; De Zorzi, S.; Ferrari, S.; De Marchi, M.; Massironi, M. Mapping and Monitoring Urban Environment through Sentinel-1 SAR Data: A Case Study in the Veneto Region (Italy). IJGI 2020, 9, 375. [Google Scholar] [CrossRef]
- Stasolla, M.; Gamba, P. Spatial Indexes for the Extraction of Formal and Informal Human Settlements From High-Resolution SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2008, 1, 98–106. [Google Scholar] [CrossRef]
- Soergel, U. (Ed.) Radar remote sensing of urban areas. In Remote Sensing and Digital Image Processing; Springer: Dordrecht, The Netherlands; New York, NY, USA, 2010. [Google Scholar]
- Wangiyana, S.; Samczyński, P.; Gromek, A. Data Augmentation for Building Footprint Segmentation in SAR Images: An Empirical Study. Remote Sens. 2022, 14, 2012. [Google Scholar] [CrossRef]
- Bruzzone, L.; Marconcini, M.; Wegmuller, U.; Wiesmann, A. An advanced system for the automatic classification of multitemporal SAR images. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1321–1334. [Google Scholar] [CrossRef]
- Kupidura, P. The Comparison of Different Methods of Texture Analysis for Their Efficacy for Land Use Classification in Satellite Imagery. Remote Sens. 2019, 11, 1233. [Google Scholar] [CrossRef]
- Su, W.; Li, J.; Chen, Y.; Liu, Z.; Zhang, J.; Low, T.M.; Suppiah, I.; Hashim, S.A.M. Textural and local spatial statistics for the object-oriented classification of urban areas using high resolution imagery. Int. J. Remote Sens. 2008, 29, 3105–3117. [Google Scholar] [CrossRef]
- Urban Atlas, G. Urban Atlas—Copernicus Land Monitoring Service. Available online: https://land.copernicus.eu/en/products/urban-atlas (accessed on 28 June 2024).
- Thiel, M.; Esch, T.; Schenk, A. Object-Oriented Detection Of Urban Areas From TerraSAR-X Data. In Proceedings of the ISPRS 2008 Congress, Beijing, China, 3–11 July 2008; Volume XXXVII Part B8. [Google Scholar]
- Zhai, W.; Shen, H.; Huang, C.; Pei, W. Fusion of polarimetric and texture information for urban building extraction from fully polarimetric SAR imagery. Remote Sens. Lett. 2016, 7, 31–40. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Raschka, S.; Patterson, J.; Nolet, C. Machine Learning in Python: Main developments and technology trends in data science, machine learning, and artificial intelligence. arXiv 2020. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar] [CrossRef]
- Iakubovskii. Qubvel/Segmentation_Models.Pytorch. Available online: https://github.com/qubvel/segmentation_models.pytorch (accessed on 9 September 2023).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Seferbekov, S.S.; Iglovikov, V.I.; Buslaev, A.V.; Shvets, A.A. Feature Pyramid Network for Multi-Class Land Segmentation. arXiv 2018. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Ji, K.; Wu, Y. Scattering Mechanism Extraction by a Modified Cloude-Pottier Decomposition for Dual Polarization SAR. Remote Sens. 2015, 7, 7447–7470. [Google Scholar] [CrossRef]
- Bai, Y.; Adriano, B.; Mas, E.; Koshimura, S. Building Damage Assessment in the 2015 Gorkha, Nepal, Earthquake Using Only Post-Event Dual Polarization Synthetic Aperture Radar Imagery. Earthq. Spectra 2017, 33, 185–195. [Google Scholar] [CrossRef]
- Jiang, H.; Nachum, O. Identifying and Correcting Label Bias in Machine Learning. arXiv 2019. [Google Scholar] [CrossRef]
- Sarkar, S.; Halder, T.; Poddar, V.; Gayen, R.K.; Ray, A.M.; Chakravarty, D. A Novel Approach for Urban Unsupervised Segmentation Classification in SAR Polarimetry. In Proceedings of the 2021 2nd International Conference on Range Technology (ICORT), Chandipur, Balasore, India, 5–6 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Corbane, C.; Faure, J.-F.; Baghdadi, N.; Villeneuve, N.; Petit, M. Rapid Urban Mapping Using SAR/Optical Imagery Synergy. Sensors 2008, 8, 7125–7143. [Google Scholar] [CrossRef] [PubMed]
- Corbane, C.; Sabo, F. European Settlement Map from Copernicus Very High Resolution Data for Reference Year 2015, Public Release 2019; European Commission, Joint Research Centre (JRC): Brussels, Belgium, 2019. [Google Scholar] [CrossRef]
- Shao, Z.; Ahmad, M.N.; Javed, A. Comparison of Random Forest and XGBoost Classifiers Using Integrated Optical and SAR Features for Mapping Urban Impervious Surface. Remote Sens. 2024, 16, 665. [Google Scholar] [CrossRef]
- Ahmad, M.N.; Shao, Z.; Xiao, X.; Fu, P.; Javed, A.; Ara, I. A novel ensemble learning approach to extract urban impervious surface based on machine learning algorithms using SAR and optical data. Int. J. Appl. Earth Obs. Geoinf. 2024, 132, 104013. [Google Scholar] [CrossRef]
- Tayi, S.; Radoine, H. Mapping built-up area: Combining Radar and Optical Imagery using Google Earth Engine. In Proceedings of the 2023 Joint Urban Remote Sensing Event (JURSE), Heraklion, Greece, 17–19 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Kanade, D.S.; Vanama, V.S.K.; Shitole, S. Urban area classification with quad-pol L-band ALOS-2 SAR data: A case of Chennai city, India. In Proceedings of the 2020 IEEE India Geoscience and Remote Sensing Symposium (InGARSS), Ahmedabad, India, 1–4 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 58–61. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | London | Warsaw | ||
|---|---|---|---|---|
| Imaging Mode | ICEYE SLEA | Sentinel-1 IW | ICEYE SM | Sentinel-1 IW |
| Band (frequency GHz) | X (9.6) | C (5.4) | X (9.6) | C (5.4) |
| Input format | GRD | GRD | GRD | GRD |
| Polarization | VV | VV, VH | VV | VV, VH |
| Orbit | Ascending | Descending | Descending | Descending |
| Look side | Right | Right | Right | Right |
| Ground resolution (m) | 0.5 × 0.5 | 10.0 × 10.0 | 2.5 × 2.5 | 10.0 × 10.0 |
| Date | 20-12-2021 | 18-12-2021 | 18-09-2019 | 19-09-2019 |
| Area (km2) | 253 | 253 | 267 | 267 |
| Class ID | Class Names | London (%) | Warsaw (%) |
|---|---|---|---|
| 0 | Background (NoData) | 3.22 | 5.59 |
| 1 | High-Density | 0.34 | 26.53 |
| 2 | Medium-Density | 32.75 | 6.12 |
| 3 | Low-Density | 0.26 | 0.21 |
| 4 | Roads | 7.49 | 10.35 |
| 5 | Industry | 17.24 | 18.43 |
| 6 | Vegetation | 33.55 | 30.47 |
| 7 | Water | 5.14 | 2.31 |
| Algorithm | Features | X-Band | C-Band | ||||||
|---|---|---|---|---|---|---|---|---|---|
| int | spk | glcm | OA | mIoU | mF1 | OA | mIoU | mF1 | |
| RF | ✓ | 0.4004 | 0.0981 | 0.1529 | 0.5513 | 0.2134 | 0.2977 | ||
| ✓ | ✓ | 0.5263 | 0.1356 | 0.1917 | 0.6240 | 0.2605 | 0.3493 | ||
| ✓ | ✓ | 0.5317 | 0.1426 | 0.2001 | 0.6359 | 0.2612 | 0.3473 | ||
| ✓ | ✓ | ✓ | 0.5523 | 0.1507 | 0.2078 | 0.6519 | 0.2751 | 0.3623 | |
| XGB | ✓ | 0.3988 | 0.0980 | 0.1529 | 0.6075 | 0.2374 | 0.3236 | ||
| ✓ | ✓ | 0.5393 | 0.1454 | 0.2027 | 0.6285 | 0.2623 | 0.3506 | ||
| ✓ | ✓ | 0.5347 | 0.1466 | 0.2076 | 0.6428 | 0.2648 | 0.3504 | ||
| ✓ | ✓ | ✓ | 0.5553 | 0.1546 | 0.2151 | 0.6604 | 0.2800 | 0.3663 | |
| Unet | ✓ | 0.7701 | 0.3585 | 0.4483 | 0.7233 | 0.3182 | 0.3971 | ||
| ✓ | ✓ | 0.7843 | 0.3926 | 0.4960 | 0.7167 | 0.3140 | 0.3934 | ||
| ✓ | ✓ | 0.7718 | 0.3708 | 0.4715 | 0.7318 | 0.3214 | 0.4019 | ||
| ✓ | ✓ | ✓ | 0.7823 | 0.3710 | 0.4660 | 0.7175 | 0.3134 | 0.3939 | |
| Band | Labels | IoU | mIoU | OA | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Urban Density | Road | Industry | Vegetation | Water | ||||||
| High | Medium | Low | ||||||||
| X-band | 7c | 0.0941 | 0.7295 | 0.0000 | 0.1744 | 0.3430 | 0.7713 | 0.6363 | 0.3926 | 0.7843 |
| 7c weighted | 0.0722 | 0.6675 | 0.0111 | 0.1863 | 0.3227 | 0.7404 | 0.5512 | 0.3645 | 0.7442 | |
| 5c | 0.7203 | 0.1654 | 0.3355 | 0.7657 | 0.6158 | 0.5206 | 0.7879 | |||
| C-band | 7c | 0.0000 | 0.6146 | 0.0000 | 0.0000 | 0.2783 | 0.6816 | 0.6754 | 0.3214 | 0.7318 |
| 7c weighted | 0.2147 | 0.5522 | 0.0000 | 0.0667 | 0.2021 | 0.6548 | 0.6534 | 0.3349 | 0.6737 | |
| 5c | 0.6205 | 0.0014 | 0.2680 | 0.6811 | 0.6528 | 0.4448 | 0.7349 | |||
| Band | Labels | IoU | mIoU | OA | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Urban Fabric | Road | Industry | Vegetation | Water | ||||||
| High | Medium | Low | ||||||||
| X-band | 7c | 0.4932 | 0.0268 | 0.0000 | 0.1993 | 0.3269 | 0.6671 | 0.7565 | 0.3528 | 0.6287 |
| 7c weighted | 0.5154 | 0.0671 | 0.0000 | 0.2434 | 0.3541 | 0.6614 | 0.7168 | 0.3654 | 0.6447 | |
| 5c | 0.5619 | 0.2289 | 0.3691 | 0.6286 | 0.7706 | 0.5118 | 0.6811 | |||
| C-band | 7c | 0.4722 | 0.0629 | 0.0000 | 0.0102 | 0.3250 | 0.6178 | 0.6770 | 0.3093 | 0.6004 |
| 7c weighted | 0.4289 | 0.0916 | 0.0000 | 0.0943 | 0.2945 | 0.5700 | 0.6680 | 0.3068 | 0.5365 | |
| 5c | 0.5173 | 0.0692 | 0.3035 | 0.5938 | 0.6852 | 0.4338 | 0.6386 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pluto-Kossakowska, J.; Wangiyana, S. Supervised Semantic Segmentation of Urban Area Using SAR. Remote Sens. 2025, 17, 1606. https://doi.org/10.3390/rs17091606
Pluto-Kossakowska J, Wangiyana S. Supervised Semantic Segmentation of Urban Area Using SAR. Remote Sensing. 2025; 17(9):1606. https://doi.org/10.3390/rs17091606
Chicago/Turabian StylePluto-Kossakowska, Joanna, and Sandhi Wangiyana. 2025. "Supervised Semantic Segmentation of Urban Area Using SAR" Remote Sensing 17, no. 9: 1606. https://doi.org/10.3390/rs17091606
APA StylePluto-Kossakowska, J., & Wangiyana, S. (2025). Supervised Semantic Segmentation of Urban Area Using SAR. Remote Sensing, 17(9), 1606. https://doi.org/10.3390/rs17091606