
SCF-CIL: A Multi-Stage Regularization-Based SAR Class-Incremental Learning Method Fused with Electromagnetic Scattering Features



Abstract

1. Introduction
- (1)
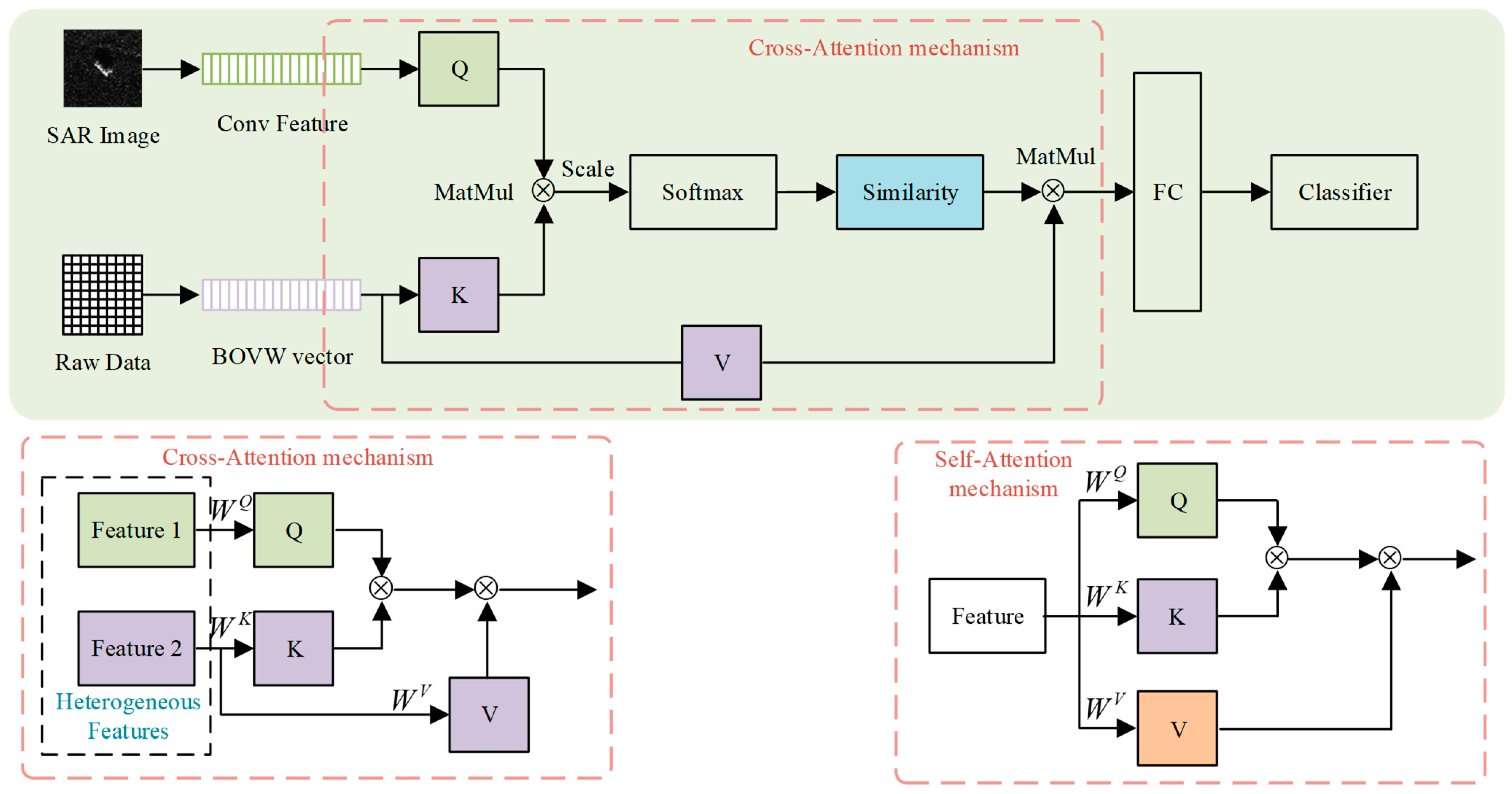
- To make full use of the information contained in SAR echo data and to generalize a more balanced feature representation in terms of stability and plasticity, a feature fusion network, called SCF-Net, is proposed. First of all, the VGG16 [30] network is modified as a CNN feature extractor to extract the image feature. Meanwhile, we apply the bag of visual words (BOVW) model—originally proposed in [31,32] and recently applied to scattering feature transformation in [33]—to convert the electromagnetic attributed scattering center feature (SC feature) into a feature vector. Inspired by the effects of the attention mechanism on information processing, we utilize the cross-attention architecture to fuse the SC feature and CNN feature, and by integrating the stable inherent electromagnetic characteristics with plastic CNN feature, a more balanced representation in terms of stability and plasticity is generated.
- (2)
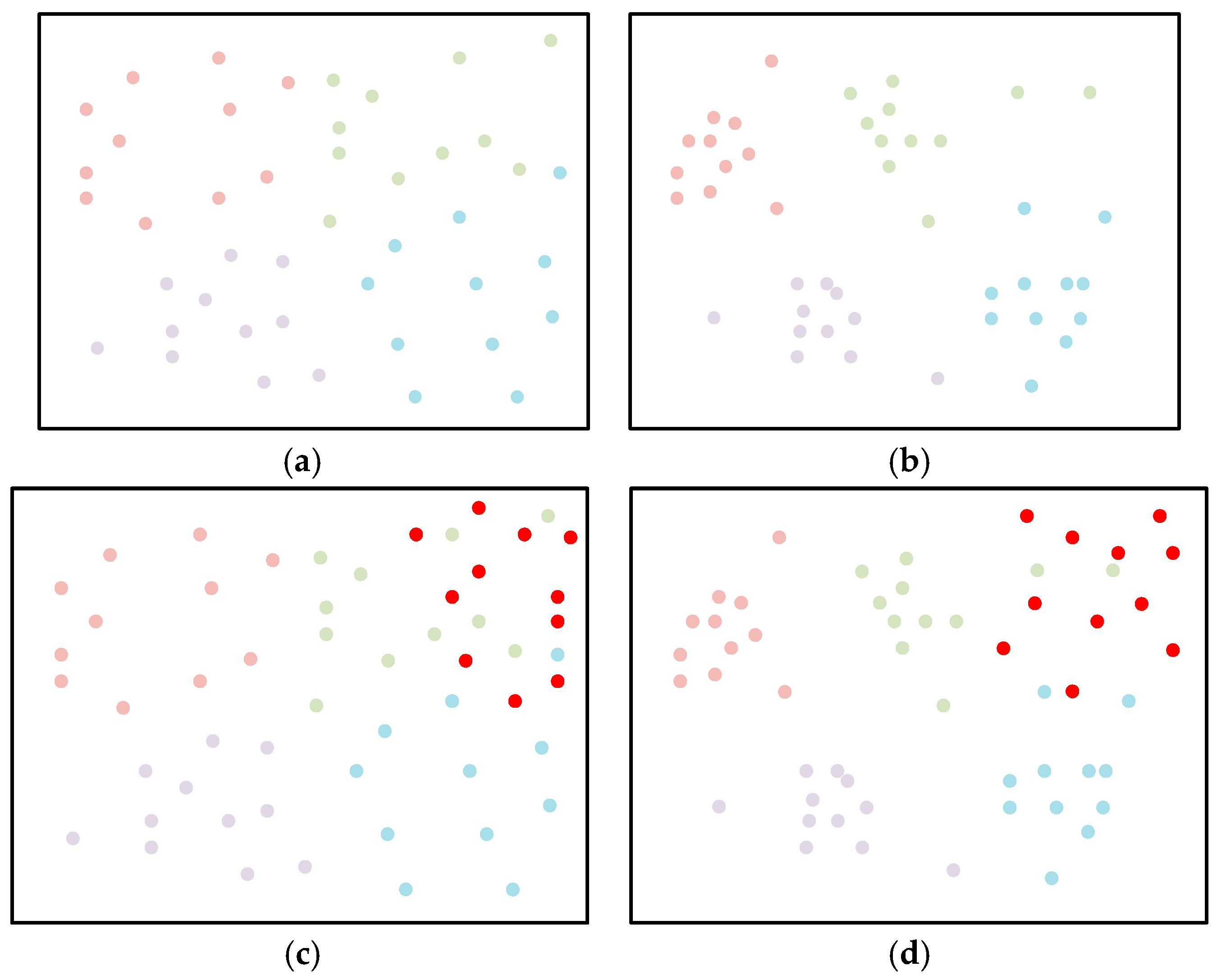
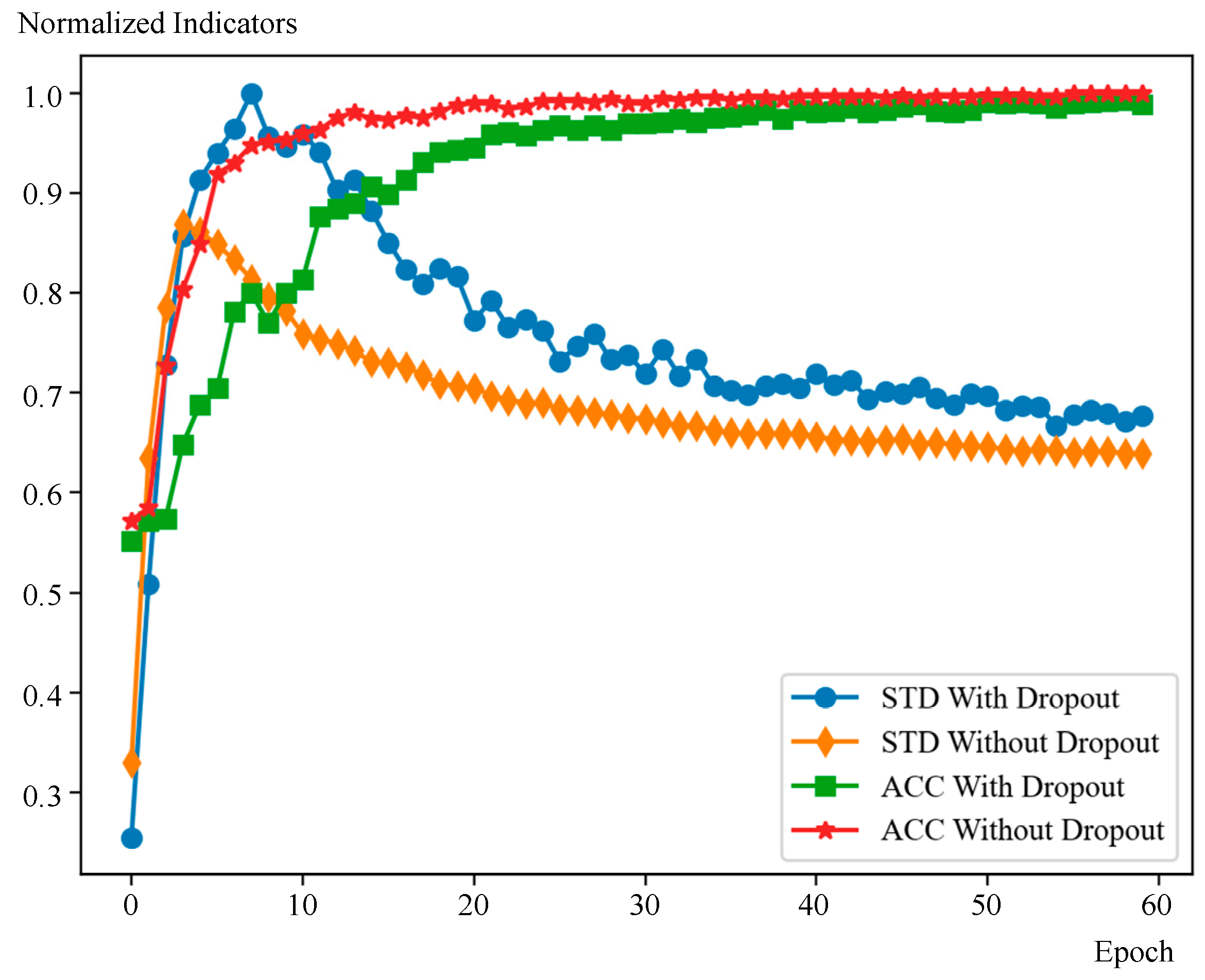
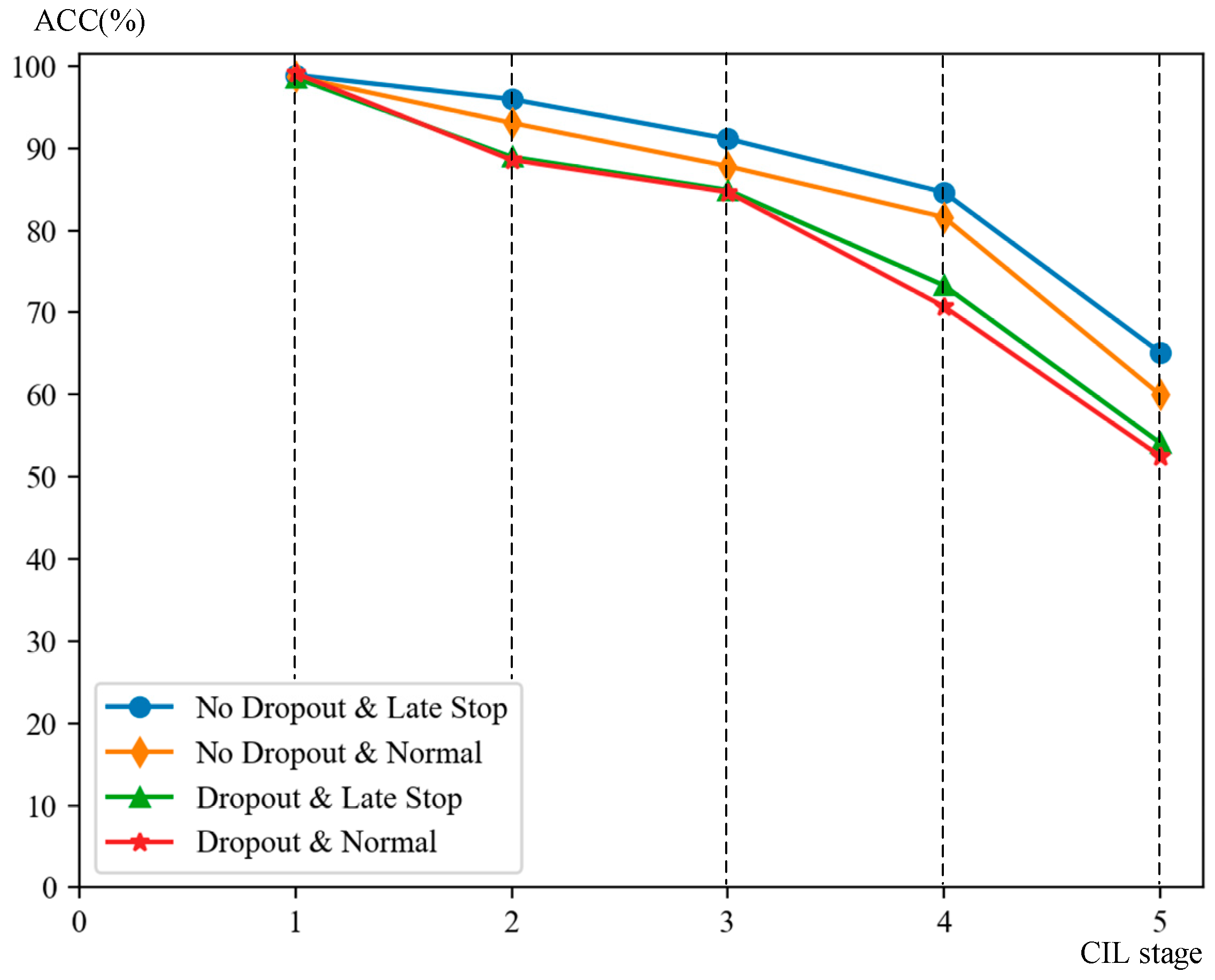
- Analyzing the feature clustering in feature space, this paper concludes that an appropriate degree of overfitting could improve the performance of CIL in our specific model setting. Researchers always try to avoid overfitting in network training to improve the performance. However, for our feature that is fused with the stable SC feature, slight overfitting can make the features of the current classes to cluster more tightly in feature space, thereby improving classification performance when new classes are added, albeit at the cost of a slight decrease in recognition accuracy. According to this conclusion, two measures are applied, including removing the dropout structure and applying the “late-stop” strategy. By improving the feature clustering degree, our training strategy can reduce the probability that features of former classes fall into the new class subspace when trained with newly arrived data. This is another improvement in our optimization of the balance between plasticity and stability.
- (3)
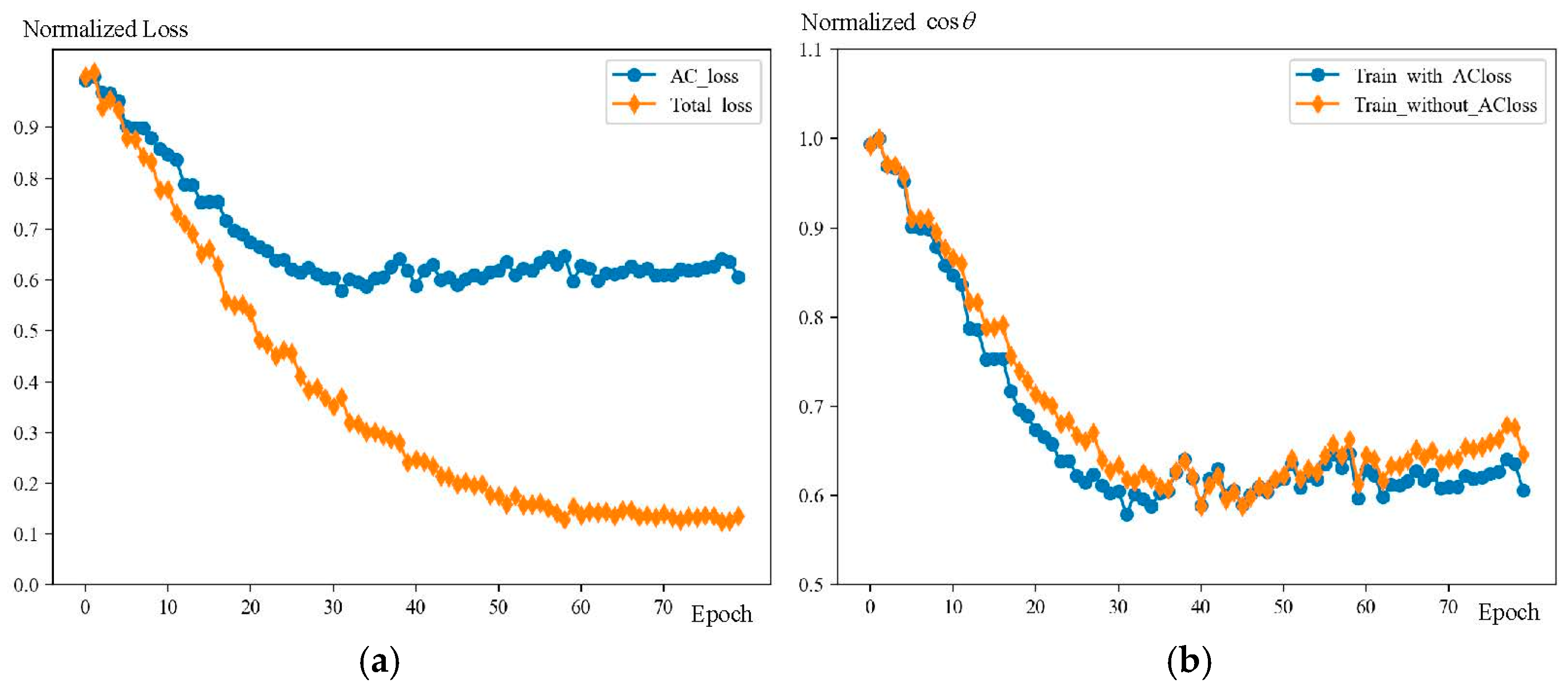
- For the classifier in the network, a multi-stage regularization method is proposed to correct the recognition bias caused by catastrophic forgetting. Through analyzing the operation of the classifier, the regularization is applied to three parts involved in the classifying calculation, including the magnitude of the feature vector, the magnitude of the classifier weight vector, and the angle between them. By a staged regularization operation, the impact of catastrophic forgetting is transferred to the vector magnitude that is easier to correct. In this part, an angle constraining loss (AC loss) is introduced to constrain the angle change between new instances and old class classifier weights.
2. Related Works
2.1. Class-Incremental Learning Methods
2.2. Electromagnetic Scattering Center Feature for SAR Target Classification
3. Materials and Methods
3.1. Feature Fusing Based on Cross Attention Mechanism (SCF-Net)
3.2. “Overfitting” Training Strategy for SCF-CIL
3.3. A Multi-Stage Regularization Method to Realize Fair Classification
4. Results
4.1. Experimental Dataset
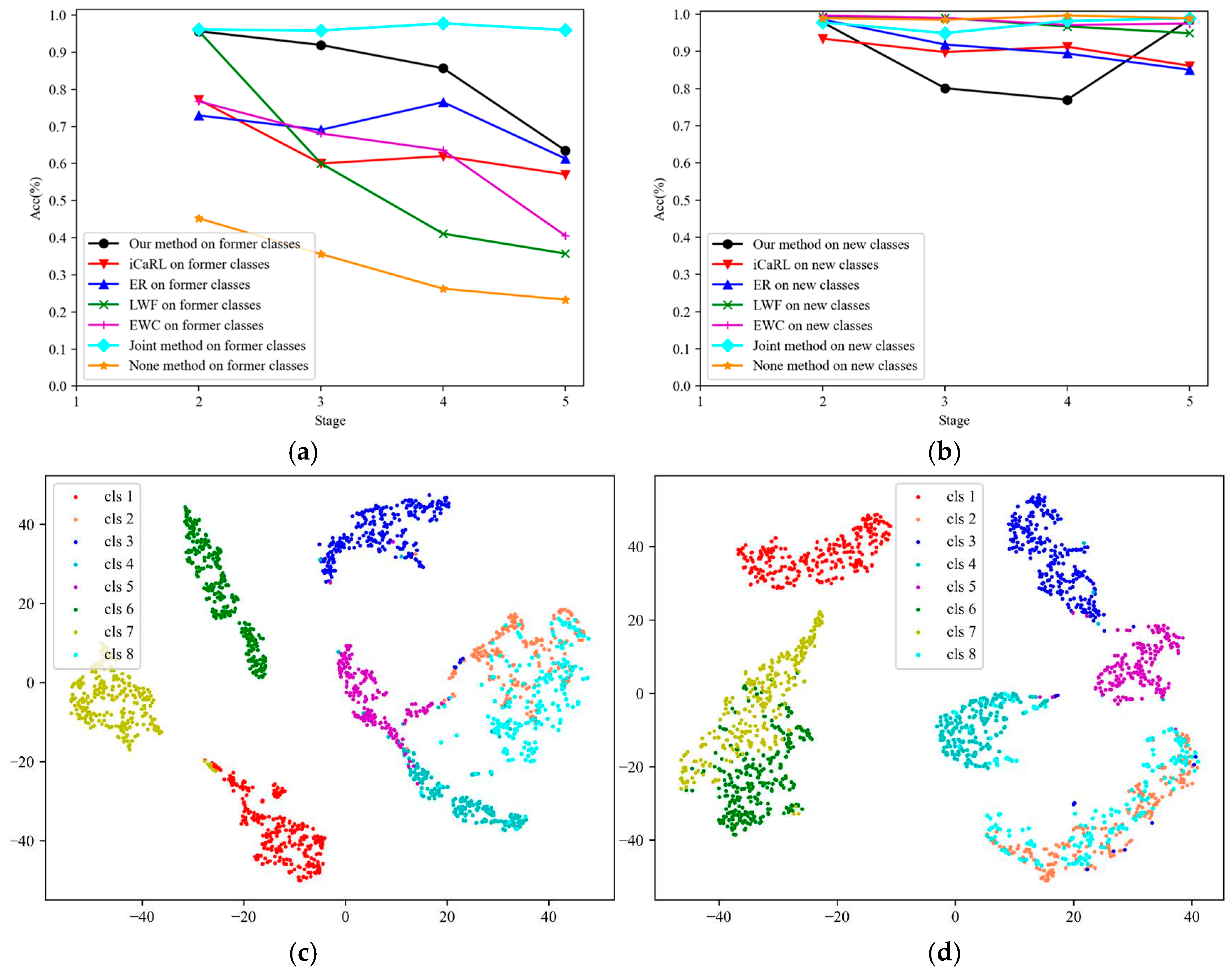
4.2. Experimental Results
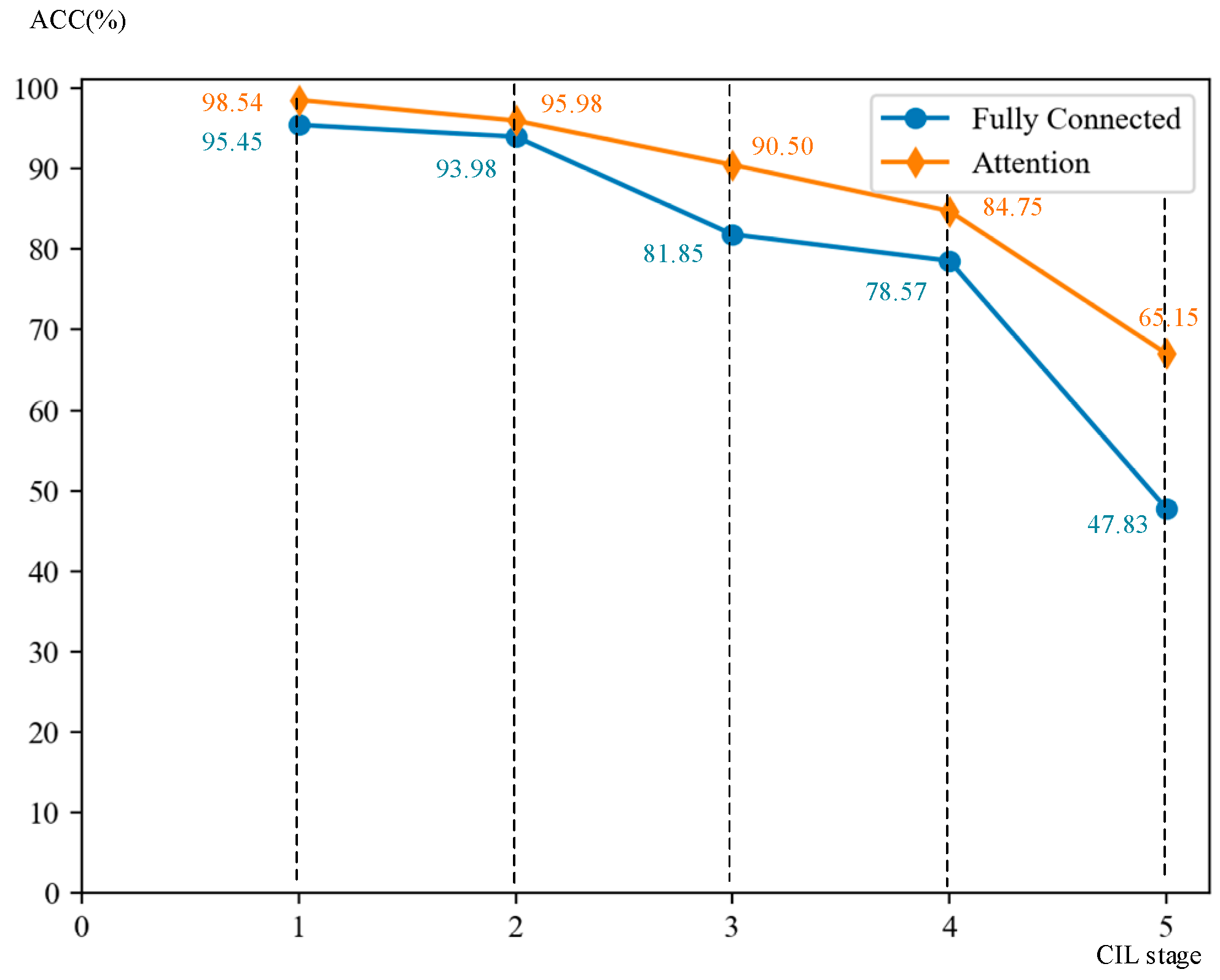
5. Discussion
5.1. Experiments on Scattering Center Feature
5.2. Experiments on Overfitting Mechanism
5.3. Experiments on AC Loss Function
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, G.; Zhang, B.; Yu, H.; Chen, J.; Xing, M.; Hong, W. Sparse Synthetic Aperture Radar Imaging from Compressed Sensing and Machine Learning: Theories, applications, and trends. IEEE Geosci. Remote Sens. Mag. 2022, 10, 32–69. [Google Scholar] [CrossRef]
- Ni, P.; Xu, G.; Zhong, Z.; Chen, J.; Hong, W. SAR Target Recognition Using Complex Manifold Multiscale Feature Fusion Network. In Proceedings of the IGARSS 2024—2024 IEEE International Geoscience and Remote Sensing Symposium, Athens, Greece, 7–12 July 2024; pp. 3532–3535. [Google Scholar]
- Huang, Y.; Wang, D.; Wu, B.; An, D. NST-YOLO11: ViT Merged Model with Neuron Attention for Arbitrary-Oriented Ship Detection in SAR Images. Remote Sens. 2024, 16, 4760. [Google Scholar] [CrossRef]
- Li, S.; Yang, X.; Lv, X.; Li, J. SAR-MINF: A Novel SAR Image Descriptor and Matching Method for Large-Scale Multidegree Overlapping Tie Point Automatic Extraction. Remote Sens. 2024, 16, 4696. [Google Scholar] [CrossRef]
- Feng, S.; Fu, X.; Feng, Y.; Lv, X. Single-Scene SAR Image Data Augmentation Based on SBR and GAN for Target Recognition. Remote Sens. 2024, 16, 4427. [Google Scholar] [CrossRef]
- Li, G.; Liu, W.; Gao, Q.; Wang, Q.; Han, J.; Gao, X. Self-Supervised Edge Perceptual Learning Framework for High-Resolution Remote Sensing Images Classification. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 6024–6038. [Google Scholar] [CrossRef]
- Ai, J.; Mao, Y.; Luo, Q.; Jia, L.; Xing, M. SAR Target Classification Using the Multikernel-Size Feature Fusion-Based Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Oh, J.; Youm, G.Y.; Kim, M. SPAM-Net: A CNN-based SAR target recognition network with pose angle marginalization learning. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 701–714. [Google Scholar] [CrossRef]
- Geng, J.; Ma, W.; Jiang, W. Causal Intervention and Parameter-Free Reasoning for Few-Shot SAR Target Recognition. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 12702–12714. [Google Scholar] [CrossRef]
- Wang, R.; Su, T.; Xu, D.; Chen, J.; Liang, Y. MIGA-Net: Multi-view Image Information Learning Based on Graph Attention Network for SAR Target Recognition. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 10779–10792. [Google Scholar] [CrossRef]
- Wu, J.; Fang, L.; Yue, J. TAKD: Target-Aware Knowledge Distillation for Remote Sensing Scene Classification. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 8188–8200. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Mirza, M.; Xiao, D.; Courville, A.; Bengio, Y. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv 2014, arXiv:1312.6211. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Nat. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- McCloskey, M.; Cohen, N.J. Catastrophic interference in connectionist networks: The sequential learning problem. Psychol. Learn. Motiv. 1989, 24, 109–165. [Google Scholar]
- Thrun, S. Is learning the n-th thing any easier than learning the first? Proc. Adv. Neural Inf. Process. Syst. 1996, 8, 640–646. [Google Scholar]
- Li, Z.; Jin, K.; Xu, B.; Zhou, W.; Yang, J. An improved attributed scattering model optimized by incremental sparse Bayesian learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2973–2987. [Google Scholar] [CrossRef]
- Fan, J.; Wang, X.; Wang, X.; Zhao, J.; Liu, X. Incremental Wishart broad learning system for fast polsar image classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1854–1858. [Google Scholar] [CrossRef]
- Dang, S.; Cao, Z.; Cui, Z.; Pi, Y.; Liu, N. Open set incremental learning for automatic target recognition. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4445–4456. [Google Scholar] [CrossRef]
- Rebuffi, S.-A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. ICaRL: Incremental classifier and representation learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2001–2010. [Google Scholar]
- Lopez-Paz, D.; Ranzato, M. Gradient episodic memory for continual learning. Proc. Adv. Neural Inf. Process. Syst. 2017, 30, 6467–6476. [Google Scholar]
- Mallya, A.; Lazebnik, S. PackNet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7765–7773. [Google Scholar]
- Serra, J.; Suris, D.; Miron, M.; Karatzoglou, A. Overcoming catastrophic forgetting with hard attention to the task. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 4548–4557. [Google Scholar]
- Tang, J.; Xiang, D.; Zhang, F.; Ma, F.; Zhou, Y.; Li, H. Incremental SAR automatic target recognition with error correction and high plasticity. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2022, 15, 1327–1339. [Google Scholar] [CrossRef]
- Ammour, N.; Bazi, Y.; Alhichri, H.; Alajlan, N. Continual learning approach for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, Y.; Wu, W.; Luo, X.; Zheng, M.; Zhang, Y.; Peng, B. A Survey: Navigating the Landscape of Incremental Learning Techniques and Trends. In Proceedings of the 2023 18th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Fuzhou, China, 17–19 November 2023; pp. 163–169. [Google Scholar]
- Park, J.-I.; Park, S.-H.; Kim, K.-T. New discrimination features for SAR automatic target recognition. IEEE Geosci. Remote Sens. Lett. 2013, 10, 476–480. [Google Scholar] [CrossRef]
- Clemente, C.; Pallotta, L.; Gaglione, D.; De Maio, A.; Soraghan, J.J. Automatic target recognition of military vehicles with Krawtchouk moments. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 493–500. [Google Scholar] [CrossRef]
- Kang, M.; Ji, K.; Leng, X.; Xing, X.; Zou, H. Synthetic aperture radar target recognition with feature fusion based on a stacked autoencoder. Sensors 2017, 17, 192. [Google Scholar] [CrossRef]
- Ding, B.; Wen, G.; Ma, C.; Yang, X. An efficient and robust framework for SAR target recognition by hierarchically fusing global and local features. IEEE Trans. Image Process. 2018, 27, 5983–5995. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Filliat, D. A visual bag of words method for interactive qualitative localization and mapping. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Rome, Italy, 10–14 April 2007; pp. 3921–3926. [Google Scholar]
- Zhang, Y.; Jin, R.; Zhou, Z.-H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Zhang, J.; Xing, M.; Xie, Y. FEC: A feature fusion framework for SAR target recognition based on electromagnetic scattering features and deep CNN features. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2174–2187. [Google Scholar] [CrossRef]
- Lu, X.; Sun, X.; Diao, W.; Feng, Y.; Wang, P.; Fu, K. LIL: Lightweight incremental learning approach through feature transfer for remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar] [CrossRef]
- Shin, H.; Lee, J.K.; Kim, J.; Kim, J. Continual learning with deep generative replay. Proc. Adv. Neural Inf. Process. Syst. 2017, 30, 2990–2999. [Google Scholar]
- Iscen, A.; Zhang, J.; Lazebnik, S.; Schmid, C. Memory-efficient incremental learning through feature adaptation. arXiv 2020, arXiv:2004.00713. [Google Scholar]
- Riemer, M.; Cases, I.; Ajemian, R.; Liu, M.; Rish, I.; Tu, Y.; Tesauro, G. Learning to learn without forgetting by maximizing transfer and minimizing interference. arXiv 2018, arXiv:1810.11910. [Google Scholar]
- van de Ven, G.M.; Siegelmann, H.T.; Tolias, A.S. Brain-inspired replay for continual learning with artificial neural networks. Nat. Commun. 2020, 11, 4069. [Google Scholar] [CrossRef] [PubMed]
- Hou, S.; Pan, X.; Loy, C.C.; Wang, Z.; Lin, D. Lifelong learning via progressive distillation and retrospection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 437–452. [Google Scholar]
- Castro, F.M.; Marín-Jiménez, M.J.; Guil, N.; Schmid, C.; Alahari, K. End-to-end incremental learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 233–248. [Google Scholar]
- Dhar, P.; Singh, R.V.; Peng, K.-C.; Wu, Z.; Chellappa, R. Learning without memorizing. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5138–5146. [Google Scholar]
- Liu, X.; Masana, M.; Herranz, L.; Van de Weijer, J.; Lopez, A.M.; Bagdanov, A.D. Rotate your networks: Better weight consolidation and less catastrophic forgetting. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2262–2268. [Google Scholar]
- Cermelli, F.; Mancini, M.; Bulo, S.R.; Ricci, E.; Caputo, B. Modeling the background for incremental learning in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9233–9242. [Google Scholar]
- Zenke, F.; Poole, B.; Ganguli, S. Continual learning through synaptic intelligence. Proc. Mach. Learn. Res. 2017, 70, 3987. [Google Scholar] [PubMed]
- Li, Z.; Hoiem, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2935–2947. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, J.; Ghosh, S.; Li, D.; Tasci, S.; Heck, L.; Zhang, H.; Kuo, C.C.J. Class-incremental learning via deep model consolidation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 1120–1129. [Google Scholar]
- Zhang, X.; Feng, S.; Zhao, C.; Sun, Z.; Zhang, S.; Ji, K. MGSFA-Net: Multi-scale global scattering feature association network for SAR ship target recognition. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2024, 17, 4611–4625. [Google Scholar] [CrossRef]
- Liao, L.; Du, L.; Chen, J.; Cao, Z.; Zhou, K. EMI-Net: An End-to-End Mechanism-Driven Interpretable Network for SAR Target Recognition Under EOCs. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–18. [Google Scholar] [CrossRef]
- Feng, S.; Ji, K.; Wang, F.; Zhang, L.; Ma, X.; Kuang, G. PAN—Part attention network integrating electromagnetic characteristics for interpretable SAR vehicle target recognition. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Duan, J.; Zhang, L.; Xing, M.; Liang, Y. Novel feature extraction method for synthetic aperture radar targets. J. Xidian Univ. (Natural Sci.) 2014, 41, 13–19. [Google Scholar]
- Liu, M.; Huang, L. Teamwork is not always good: An empirical study of classifier drift in class-incremental information extraction. arXiv 2023, arXiv:2305.16559. [Google Scholar]
- Rolnick, D.; Ahuja, A.; Schwarz, J.; Lillicrap, T.; Wayne, G. Experience replay for continual learning. Proc. Int. Conf. Neural Inf. Process. Syst. 2019, 32, 350–360. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Serial | Training Set () | Testing Set () | CIL Stages |
|---|---|---|---|---|
| ZSU_23_4 | d08 | 299 | 274 | stage 5 |
| ZIL131 | E12 | 299 | 274 | stage 4 |
| T72 | 132 | 232 | 196 | stage 3 |
| T62 | A51 | 299 | 273 | stage 2 |
| D7 | 13015 | 299 | 274 | Basic Learning (stage 1) |
| BTR70 | c71 | 233 | 196 | |
| BTR60 | 7532 | 256 | 195 | |
| BRDM2 | E-71 | 298 | 274 | |
| BMP2 | 9563 | 233 | 195 | |
| 2S1 | B01 | 299 | 274 |
| Basic Learning | Stage 2 | Stage 3 | Stage 4 | Stage 5 | |
|---|---|---|---|---|---|
| None | 98.082 | 52.893 | 43.469 | 34.420 | 30.861 |
| Joint training | 98.082 | 96.377 | 95.761 | 97.829 | 96.284 |
| ICaRL [19] | 97.995 | 79.536 | 63.801 | 65.272 | 60.000 |
| ER [52] | 98.082 | 76.634 | 71.932 | 77.997 | 63.719 |
| LWF [45] | 98.082 | 96.252 | 64.933 | 47.282 | 41.645 |
| EWC [13] | 98.082 | 80.043 | 71.970 | 67.321 | 46.267 |
| Ours | 98.540 | 95.984 | 90.495 | 84.749 | 67.044 |
| Line | Blue | Orange | Green | Red |
|---|---|---|---|---|
| Removing dropout | ✔ | ✔ | - | - |
| “Late-stop” | ✔ | - | ✔ | - |
| 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.95 | |
| CEloss | 0.21 | 0.18 | 0.16 | 0.14 | 0.16 | 0.13 | 0.11 |
| ACloss + CEloss | 0.16 | 0.14 | 0.14 | 0.15 | 0.15 | 0.12 | 0.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Xing, M.; Zhang, J.; Vitale, S. SCF-CIL: A Multi-Stage Regularization-Based SAR Class-Incremental Learning Method Fused with Electromagnetic Scattering Features. Remote Sens. 2025, 17, 1586. https://doi.org/10.3390/rs17091586
Zhang Y, Xing M, Zhang J, Vitale S. SCF-CIL: A Multi-Stage Regularization-Based SAR Class-Incremental Learning Method Fused with Electromagnetic Scattering Features. Remote Sensing. 2025; 17(9):1586. https://doi.org/10.3390/rs17091586
Chicago/Turabian StyleZhang, Yunpeng, Mengdao Xing, Jinsong Zhang, and Sergio Vitale. 2025. "SCF-CIL: A Multi-Stage Regularization-Based SAR Class-Incremental Learning Method Fused with Electromagnetic Scattering Features" Remote Sensing 17, no. 9: 1586. https://doi.org/10.3390/rs17091586
APA StyleZhang, Y., Xing, M., Zhang, J., & Vitale, S. (2025). SCF-CIL: A Multi-Stage Regularization-Based SAR Class-Incremental Learning Method Fused with Electromagnetic Scattering Features. Remote Sensing, 17(9), 1586. https://doi.org/10.3390/rs17091586