
MFSM-Net: Multimodal Feature Fusion for the Semantic Segmentation of Urban-Scale Textured 3D Meshes



Abstract
1. Introduction
- (1)
- We propose a novel multimodal feature fusion network specifically designed for semantic segmentation of large-scale 3D mesh urban scenes.
- (2)
- We introduce a cross-modal information fusion module(Bridge of 2D–3D) for pixel-level alignment between 2D texture image features and 3D mesh geometric features. Additionally, we develop a Transformer-based 3D feature extraction network that complements the 2D feature extraction network.
- (3)
- Experimental results demonstrate that our network achieves state-of-the-art performance in semantic segmentation tasks on large-scale 3D mesh urban datasets.
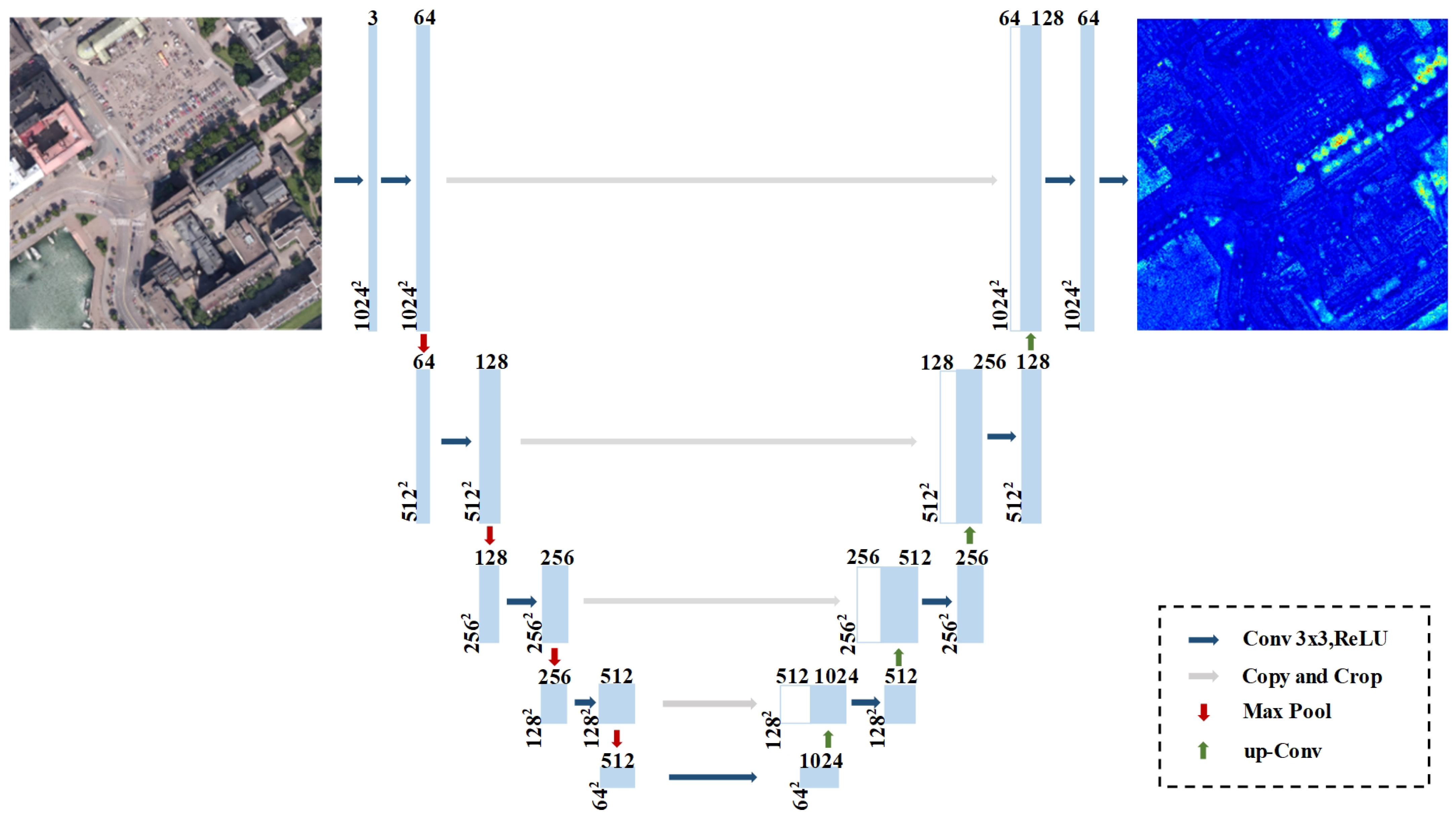
2. Method
2.1. Architecture of MFSM-Net
2.2. U-Net-Based 2D Texture Feature Extraction
2.3. Multi-Scale Transformer-Based 3D Feature Extraction
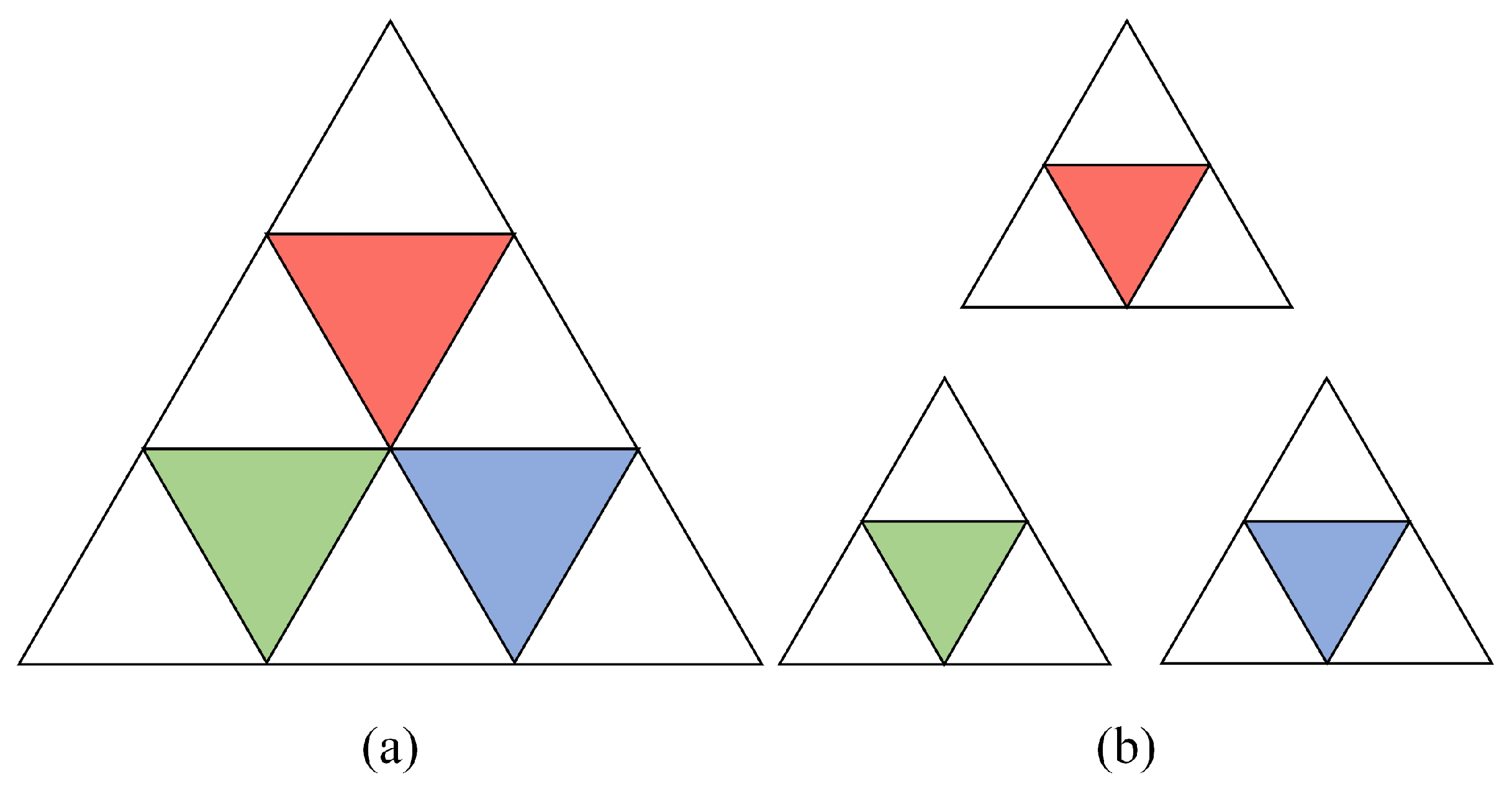
2.3.1. Adaptive Balanced Sampling
2.3.2. Self-Attention Global Feature Extraction
2.3.3. Dual Skip Connection Upsampling
2.4. Bridge-View-Based 2D Image and 3D Mesh Alignment Algorithm
3. Experiments
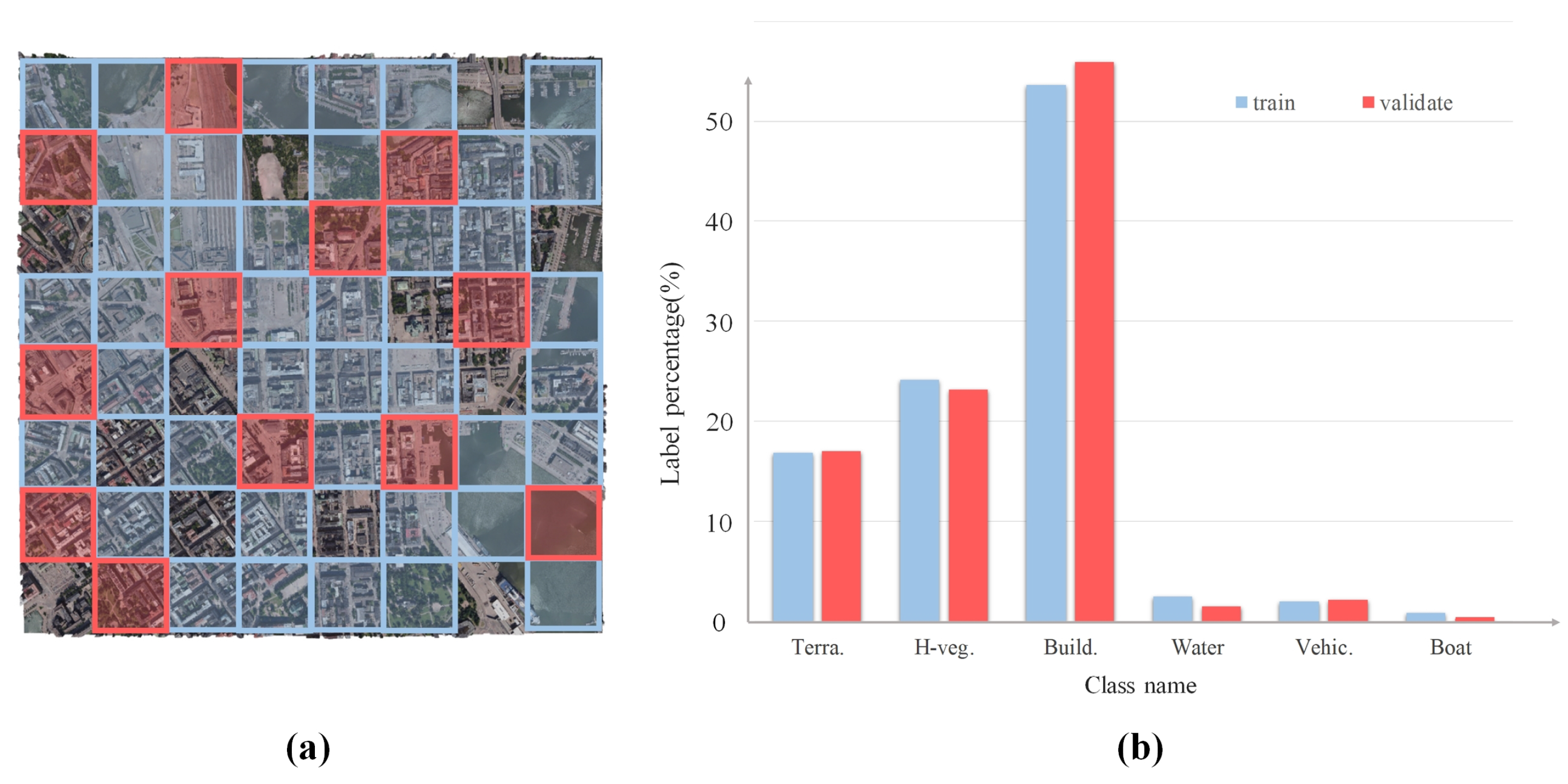
3.1. Dataset
3.2. Configurations of Multimodal Feature
3.3. Implementation Details
3.4. Semantic Segmentation Results of the 3D Mesh Urban Scene
3.5. Evaluation of Competition Methods
3.6. Evaluation of Ablation Study
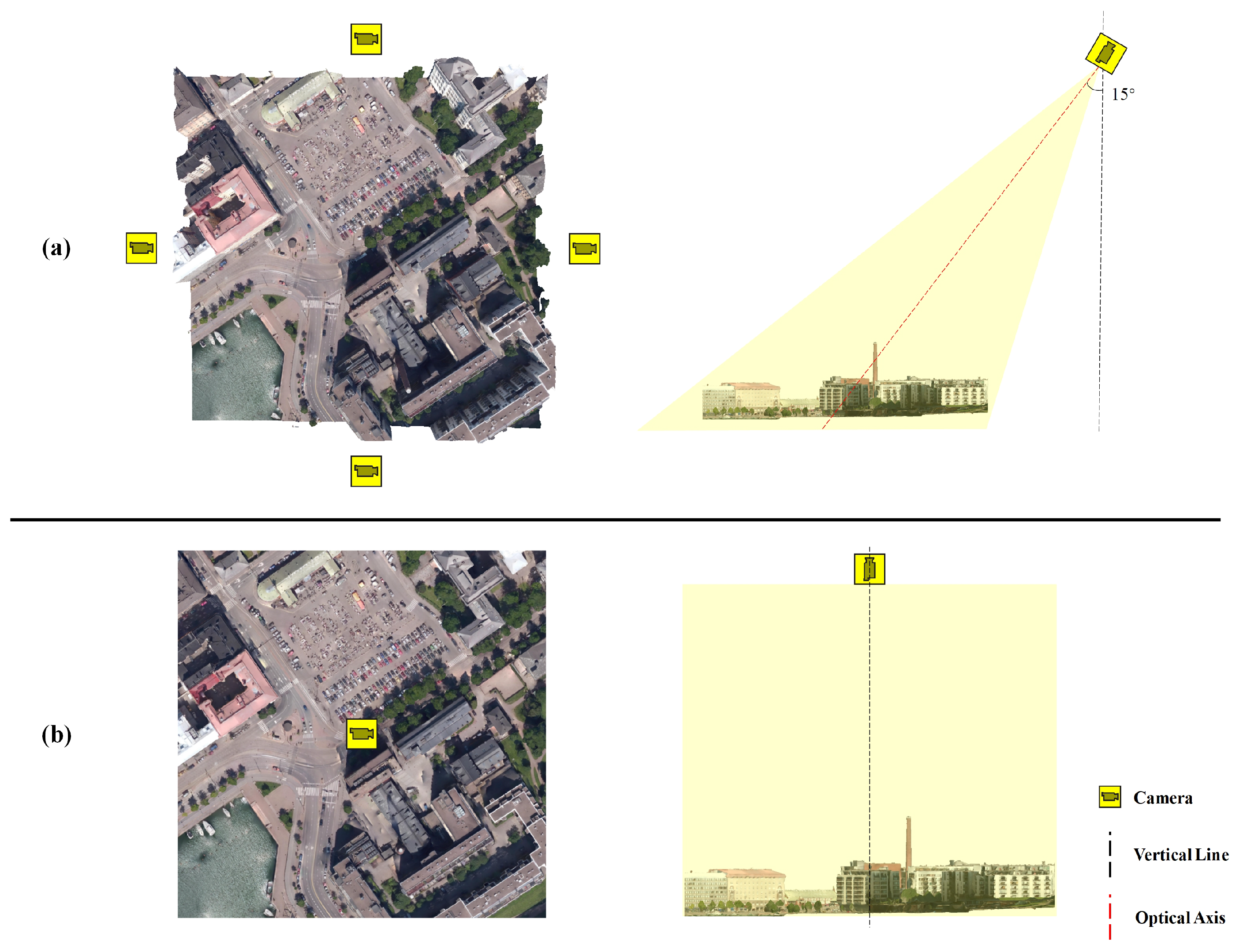
3.6.1. Impact of Using Orthogonal Views to Replace the RGB Values of Texture Sampling Points
- (1)
- Feature dimensionality and sampling points. The feature dimensionality of texture sampling points is proportional to the number of selected points. More sampling points increase the texture representativeness by covering the entire mesh more completely. For a mesh with n sampling points, the texture feature dimension is . Since urban scenes typically involve large-scale textured 3D meshes with numerous mesh faces, using a large number of sampling points to cover the entire mesh leads to an explosion in feature dimensions.
- (2)
- Variation in mesh sizes. Different objects in urban scene textured 3D meshes have varying levels of detail and size, which results in texture images with significantly different pixel counts. For a fixed number of texture sampling points, the coverage and texture representativeness differ greatly across meshes of different sizes.
- (3)
- Noise in texture images. Texture images often contain noise, which complicates the process. When sampling points are located in noisy regions, the extracted RGB values may differ substantially from the mesh’s average RGB values, leading to inaccurate results. Even if the sampling points fall on noise-free regions, the relative position relationships between the sampling points are still disrupted. Since different combinations of RGB values in different positions can represent different features, discrete texture sampling points may fail to properly represent the texture features of urban scenes.
3.6.2. Impact of Orthogonal Views Compared to Perspective Views
4. Discussion
4.1. Impact of the Mesh Coverage Rate in Texture Views on Segmentation Performance
4.2. Discussion of the Impact of Virtual vs. Real Urban Scenes on Segmentation Performance
5. Conclusions
- (1)
- Enhanced view coverage: We will explore the use of texture images generated from additional virtual viewpoints to improve mesh coverage in texture space, thereby enhancing the model’s perception of occluded and structurally complex regions.
- (2)
- We plan to investigate more expressive multimodal fusion strategies by jointly embedding high-level 2D texture features and 3D geometric features (e.g., coordinates and normal vectors) into a unified network to better capture multi-scale and global contextual information.
- (3)
- With the ongoing advances in 3D reconstruction techniques and remote sensing imagery, we aim to replace synthetic texture views with real-world remote sensing images. This transition is expected to significantly improve the realism and semantic expressiveness of the texture views, thereby enhancing the generalization capability and practical value of the proposed method in real-world urban scenarios.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Z.; Deng, L.; Luo, Y.; Li, D.; Junior, J.M.; Gonçalves, W.N.; Nurunnabi, A.A.M.; Li, J.; Wang, C.; Li, D. Road Extraction in Remote Sensing Data: A Survey. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102833. [Google Scholar] [CrossRef]
- Chen, Y.; Feng, M. Urban form simulation in 3D based on cellular automata and building objects generation. Build. Environ. 2022, 226, 109727. [Google Scholar] [CrossRef]
- Yang, X. Urban Remote Sensing: Monitoring, Synthesis and Modeling in the Urban Environment, 2nd ed.; Wiley-Blackwell: Hoboken, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Hong, Z.; Yang, Y.; Liu, J.; Jiang, S.; Pan, H.; Zhou, R.; Zhang, Y.; Han, Y.; Wang, J.; Yang, S.; et al. Enhancing 3D Reconstruction Model by Deep Learning and Its Application in Building Damage Assessment after Earthquake. Appl. Sci. 2022, 12, 9790. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, X.; Chen, Z.; Lu, Z. A review of deep learning-based semantic segmentation for point cloud. IEEE Access 2019, 7, 179118–179133. [Google Scholar] [CrossRef]
- Liu, W.; Sun, J.; Li, W.; Hu, T.; Wang, P. Deep Learning on Point Clouds and Its Application: A Survey. Sensors 2019, 19, 4188. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Byrne, J.; Moloney, D.; Watson, S.; Yin, H. Tree Annotations in LiDAR Data Using Point Densities and Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2020, 58, 971–981. [Google Scholar] [CrossRef]
- Hu, X.; Yuan, Y. Deep-learning-based classification for DTM extraction from ALS point cloud. Remote Sens. 2016, 8, 730. [Google Scholar] [CrossRef]
- Rizaldy, A.; Persello, C.; Gevaert, C.; Oude Elberink, S.; Vosselman, G. Ground and multi-class classification of airborne laser scanner point clouds using fully convolutional networks. Remote Sens. 2018, 10, 1723. [Google Scholar] [CrossRef]
- Ma, L.; Li, Y.; Li, J.; Tan, W.; Yu, Y.; Chapman, M.A. Multi-scale point-wise convolutional neural networks for 3D object segmentation from LiDAR point clouds in large-scale environments. IEEE Trans. Intell. Transp. Syst. 2019, 22, 821–836. [Google Scholar] [CrossRef]
- Wu, W.; Qi, Z.; Fuxin, L. Pointconv: Deep convolutional networks on 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9621–9630. [Google Scholar]
- Rouhani, M.; Lafarge, F.; Alliez, P. Semantic segmentation of 3D textured meshes for urban scene analysis. ISPRS J. Photogramm. Remote Sens. 2017, 123, 124–139. [Google Scholar] [CrossRef]
- Tutzauer, P.; Laupheimer, D.; Haala, N. Semantic Urban Mesh Enhancement Utilizing a Hybrid Model. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 4, 175–182. [Google Scholar] [CrossRef]
- Cun, Y.L.; Boser, B.; Denker, J.S.; Howard, R.E.; Habbard, W.; Jackel, L.D.; Henderson, D. Handwritten digit recognition with a back-propagation network. In Advances in Neural Information Processing Systems 2; David, S.T., Ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1990; pp. 396–404. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lee, J.-S.; Park, T.-H. Fast road detection by cnn-based camera–lidar fusion and spherical coordinate transformation. IEEE Trans. Intell. Transp. Syst. 2021, 22, 5802–5810. [Google Scholar] [CrossRef]
- Gu, S.; Lu, T.; Zhang, Y.; Alvarez, J.M.; Yang, J.; Kong, H. 3-D LiDAR + monocular camera: An inverse-depth-induced fusion framework for urban road detection. IEEE Trans. Intell. Veh. 2018, 3, 351–360. [Google Scholar] [CrossRef]
- Qi, X.; Liao, R.; Jia, J.; Fidler, S.; Urtasun, R. 3d graph neural networks for rgbd semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 5199–5208. [Google Scholar]
- Dai, A.; Nießner, M. 3dmv: Joint 3d-multi-view prediction for 3d semantic scene segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 452–468. [Google Scholar]
- Yang, F.; Wang, H.; Jin, Z. A fusion network for road detection via spatial propagation and spatial transformation. Pattern Recognit. 2020, 100, 107141. [Google Scholar] [CrossRef]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, V.; Yang, M.-H.; Kautz, J. SPLATNet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Masci, J.; Boscaini, D.; Bronstein, M.; Vandergheynst, P. Geodesic convolutional neural networks on riemannian manifolds. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Washington, DC, USA, 7–13 December 2015; pp. 37–45. [Google Scholar]
- Hanocka, R.; Hertz, A.; Fish, N.; Giryes, R.; Fleishman, S.; Cohen-Or, D. Meshcnn: A network with an edge. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Springenberg, J.T.; Riedmiller, M.; Brox, T. Discriminative unsupervised feature learning with convolutional neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 766–774. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Lai, X.; Liu, J.; Jiang, L.; Wang, L.; Zhao, H.; Liu, S.; Qi, X.; Jia, J. Stratified transformer for 3d point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 8500–8509. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-XL: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Hu, H.; Zhang, Z.; Xie, Z.; Lin, S. Local relation networks for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3464–3473. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. Adv. Neural Inf. Process. Syst. 2019, 32, 3–5. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10076–10085. [Google Scholar]
- Xie, S.; Liu, S.; Chen, Z.; Tu, Z. Attentional shapecontextnet for point cloud recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4606–4615. [Google Scholar]
- Zhang, C.; Wan, H.; Liu, S.; Shen, X.; Wu, Z. Pvt: Point-voxel transformer for 3d deep learning. arXiv 2021, arXiv:2108.06076. [Google Scholar]
- Gao, W.; Nan, L.; Boom, B.; Ledoux, H. SUM: A benchmark dataset of semantic urban meshes. ISPRS J. Photogramm. Remote Sens. 2021, 179, 108–120. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 16259–16268. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2D-Branch | 3D-Branch | cf.1 | cf.2 | cf.3 | cf.4 |
|---|---|---|---|---|---|
| * | XYZ + NV | ✓ | |||
| RGB-tsp | XYZ + NV | ✓ | |||
| Per-us | XYZ + NV | ✓ | |||
| Ort-us | XYZ + NV | ✓ |
| Method | Terra. | H-veg. | Build. | Water | Vehic. | Boat | OA | mAcc | mIoU | mF1 |
|---|---|---|---|---|---|---|---|---|---|---|
| Ours | 79.6 | 89.0 | 94.1 | 83.3 | 51.3 | 30.1 | 94.0 | 81.5 | 71.4 | 79.7 |
| PT | 78.4 | 58.0 | 80.1 | 95.6 | 1.7 | 28.5 | 85.2 | 66.5 | 57.1 | 66.0 |
| PointNet | 56.3 | 14.9 | 66.7 | 83.8 | 0.0 | 0.0 | 71.4 | 46.1 | 36.9 | 44.6 |
| PointNet++ | 68.0 | 73.1 | 84.2 | 69.9 | 0.5 | 1.6 | 85.5 | 57.8 | 49.5 | 57.1 |
| SPG | 56.4 | 61.8 | 87.4 | 36.5 | 34.4 | 6.2 | 79.0 | 64.8 | 47.1 | 59.6 |
| RandLA-Net | 38.9 | 59.6 | 81.5 | 27.7 | 22.0 | 2.1 | 74.9 | 53.3 | 38.6 | 49.9 |
| KPConv | 86.5 | 88.5 | 92.7 | 77.7 | 54.3 | 13.3 | 93.3 | 73.3 | 68.8 | 76.7 |
| Texture Input Format | Terra. | H-veg. | Build. | Water | Vehic. | Boat | OA | mAcc | mIoU | mF1 |
|---|---|---|---|---|---|---|---|---|---|---|
| cf.1 | 70.2 | 75.3 | 79.8 | 50.1 | 30.4 | 10.2 | 85.5 | 45.2 | 60.1 | 50.3 |
| cf.2 | 77.9 | 78.4 | 88.1 | 56.0 | 40.3 | 15.6 | 92.2 | 73.4 | 59.4 | 65.6 |
| cf.3 | 74.5 | 81.1 | 88.4 | 47.5 | 42.1 | 40.1 | 91.3 | 72.5 | 62.4 | 70.3 |
| cf.4 | 79.6 | 89.0 | 94.1 | 83.3 | 51.3 | 30.1 | 94.0 | 81.5 | 71.4 | 79.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, X.; Wang, J.; Leng, W.; Zhang, R.; Zhang, G. MFSM-Net: Multimodal Feature Fusion for the Semantic Segmentation of Urban-Scale Textured 3D Meshes. Remote Sens. 2025, 17, 1573. https://doi.org/10.3390/rs17091573
Hao X, Wang J, Leng W, Zhang R, Zhang G. MFSM-Net: Multimodal Feature Fusion for the Semantic Segmentation of Urban-Scale Textured 3D Meshes. Remote Sensing. 2025; 17(9):1573. https://doi.org/10.3390/rs17091573
Chicago/Turabian StyleHao, Xinjie, Jiahui Wang, Wei Leng, Rongting Zhang, and Guangyun Zhang. 2025. "MFSM-Net: Multimodal Feature Fusion for the Semantic Segmentation of Urban-Scale Textured 3D Meshes" Remote Sensing 17, no. 9: 1573. https://doi.org/10.3390/rs17091573
APA StyleHao, X., Wang, J., Leng, W., Zhang, R., & Zhang, G. (2025). MFSM-Net: Multimodal Feature Fusion for the Semantic Segmentation of Urban-Scale Textured 3D Meshes. Remote Sensing, 17(9), 1573. https://doi.org/10.3390/rs17091573