
OEM-HWNet: A Prior Knowledge-Guided Network for Pavement Interlayer Distress Detection Based on Computer Vision Using GPR


Abstract

1. Introduction
- (1)
- This paper proposes a prior knowledge-guided network for interlayer distress detection based on GPR images, named OEM-HWNet, and demonstrates its effectiveness in comparison with the state-of-the-art algorithms such as Faster R-CNN, SSD, RetinaNet, RT-DETR [52], YOLOv3 [38], YOLOv5s, YOLOv7 [37], YOLOv8s [53], and YOLOv11s [54];
- (2)
- The OEM, based on prior knowledge, is designed and integrated into the YOLOv5s model, which fully leverages edge position information to improve localization and feature representation abilities of the model. This module not only improves the performance of the model but also increases its interpretability of the model;
- (3)
- WTConv is introduced into the YOLOv5s model. This approach effectively mitigates the limitations of a convolutional neural network (CNN) in global feature extraction and enhances the model’s ability to capture low-frequency features;
- (4)
- The number of detection heads for YOLOv5s was extended from three (small, medium, and large) to four (small, medium, large, and huge), which effectively addresses the issue of big variations in sizes of the interlayer distresses and enhances the detection ability of large objects.
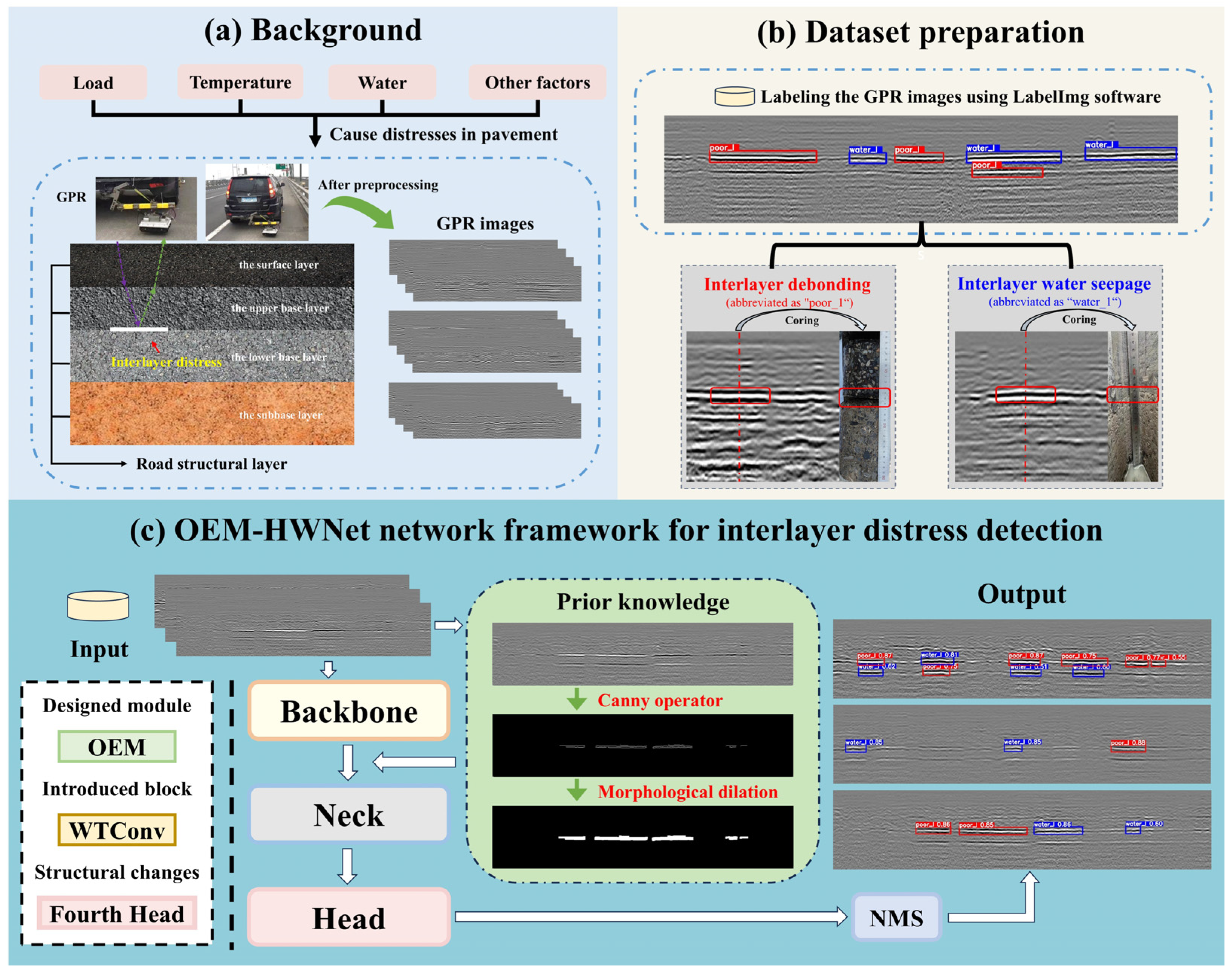
2. Methodology
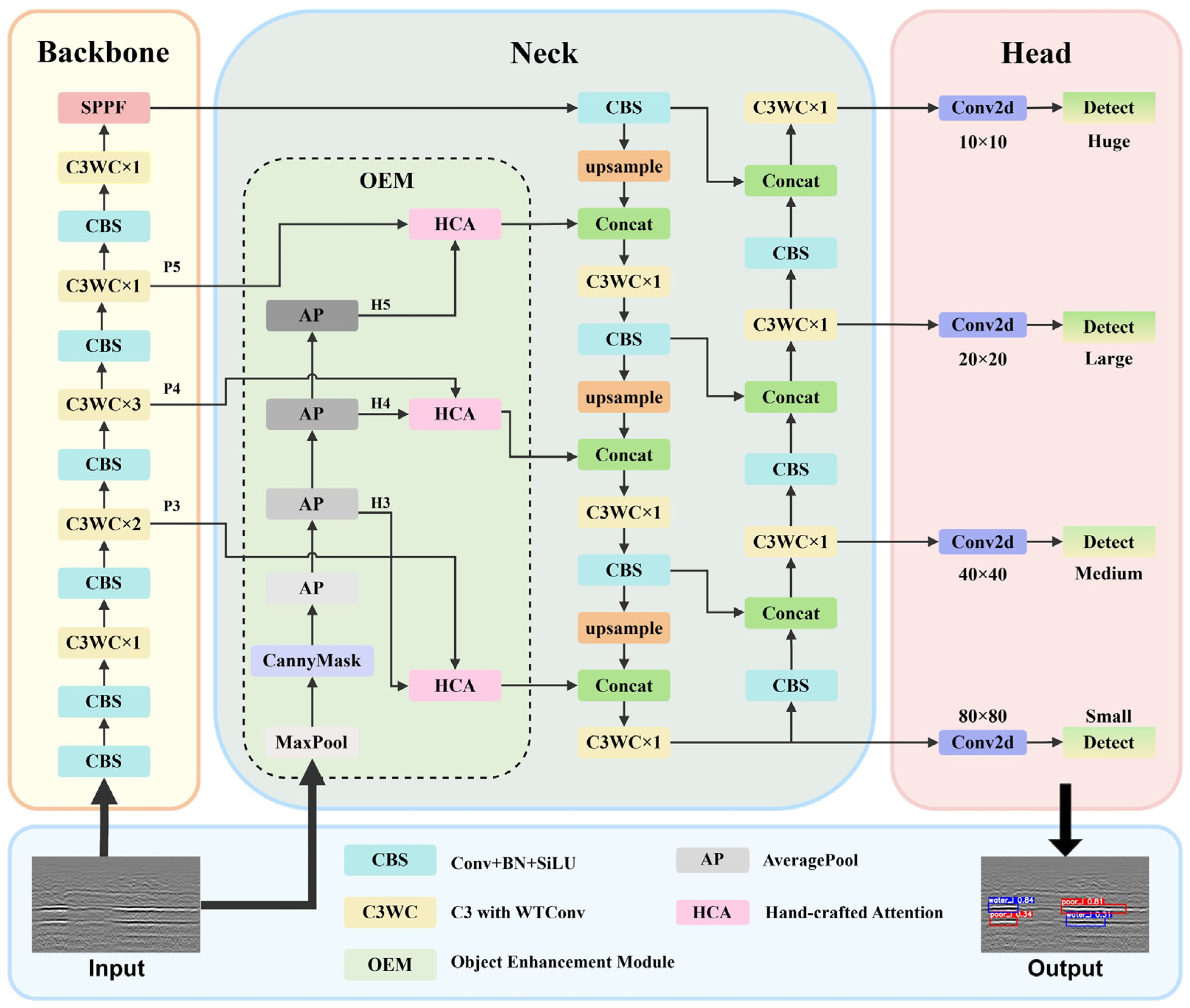
2.1. Overview of the OEM-HWNet Architecture
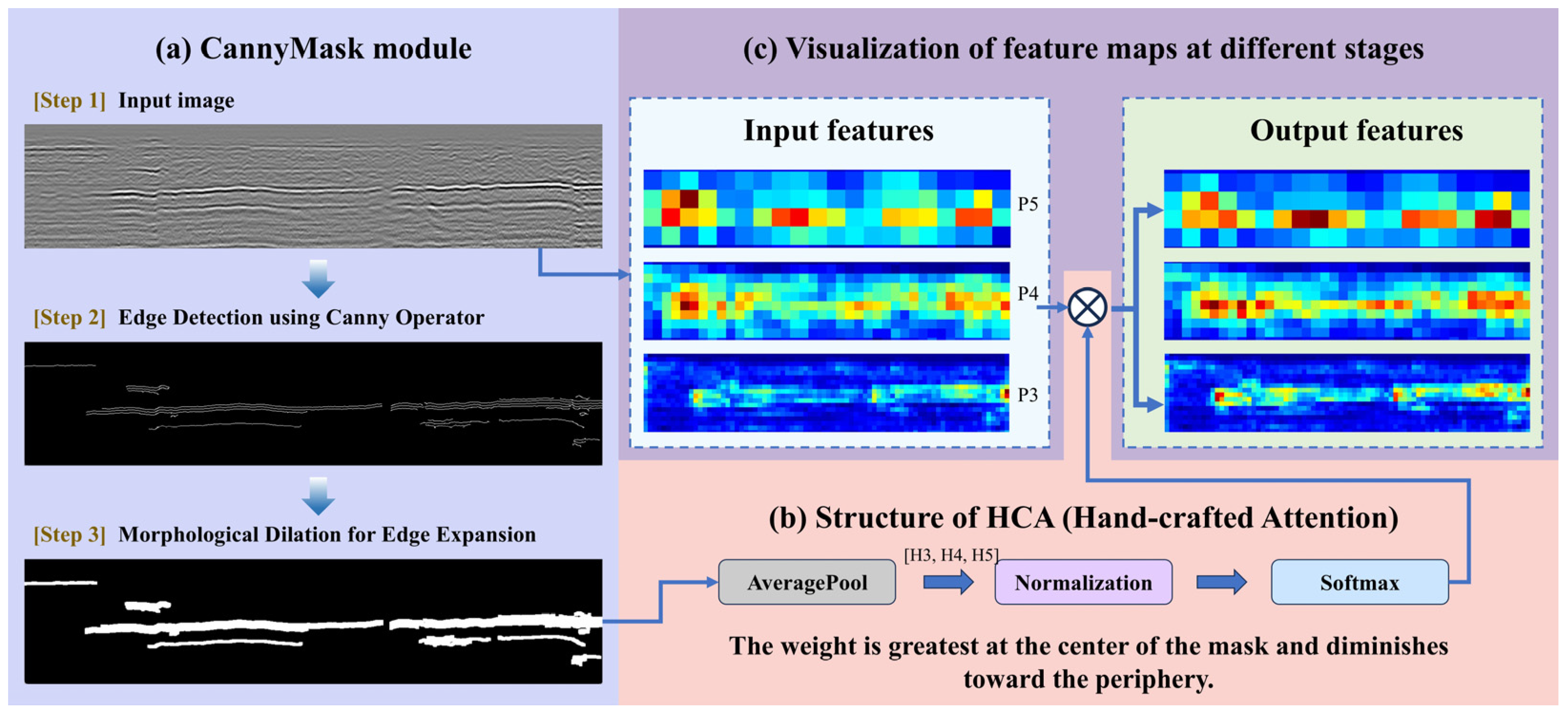
2.2. Prior Knowledge
2.2.1. Physical Basis
2.2.2. Object Region Segmentation
2.3. Object Enhancement Module (OEM) Based on Prior Knowledge
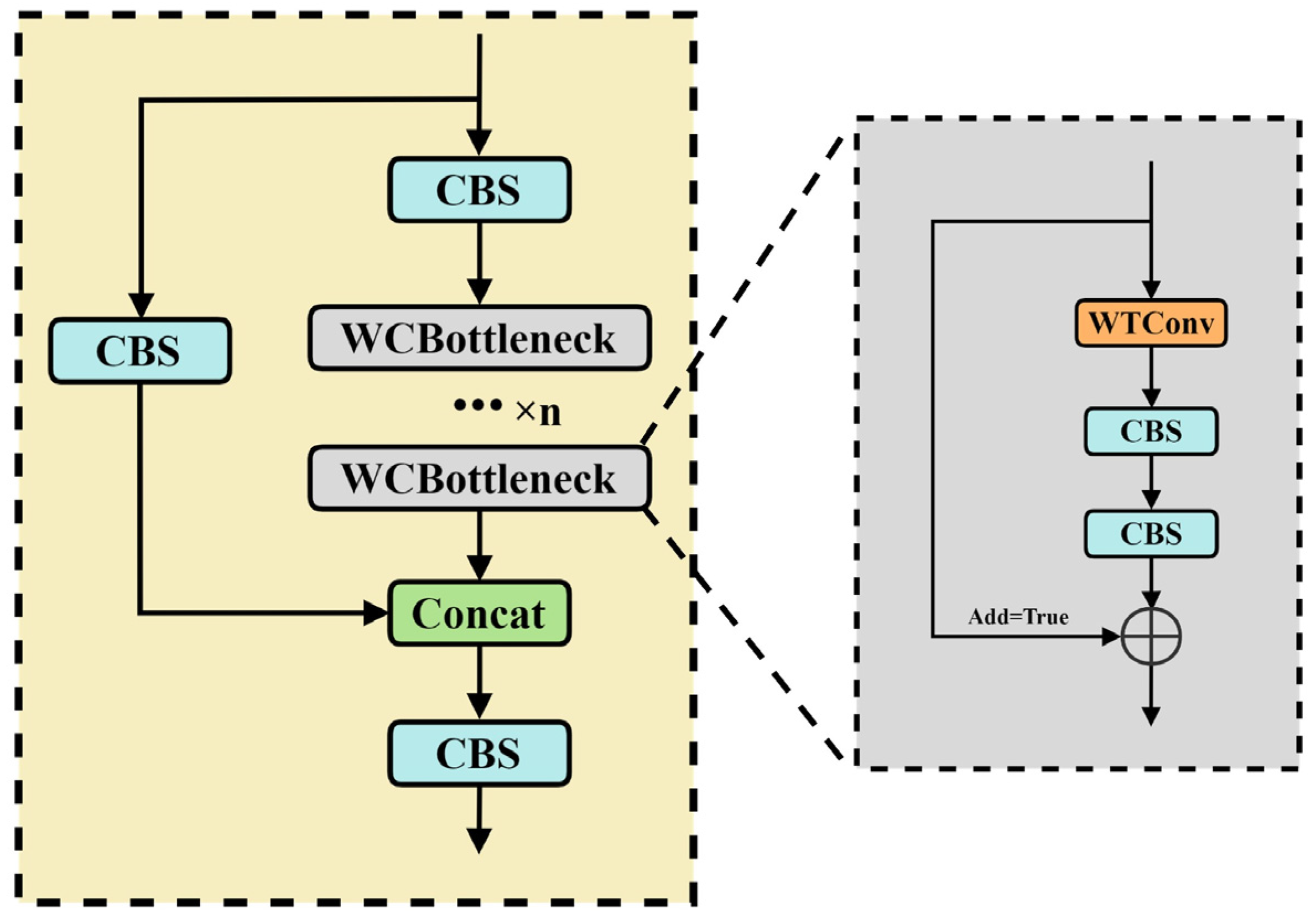
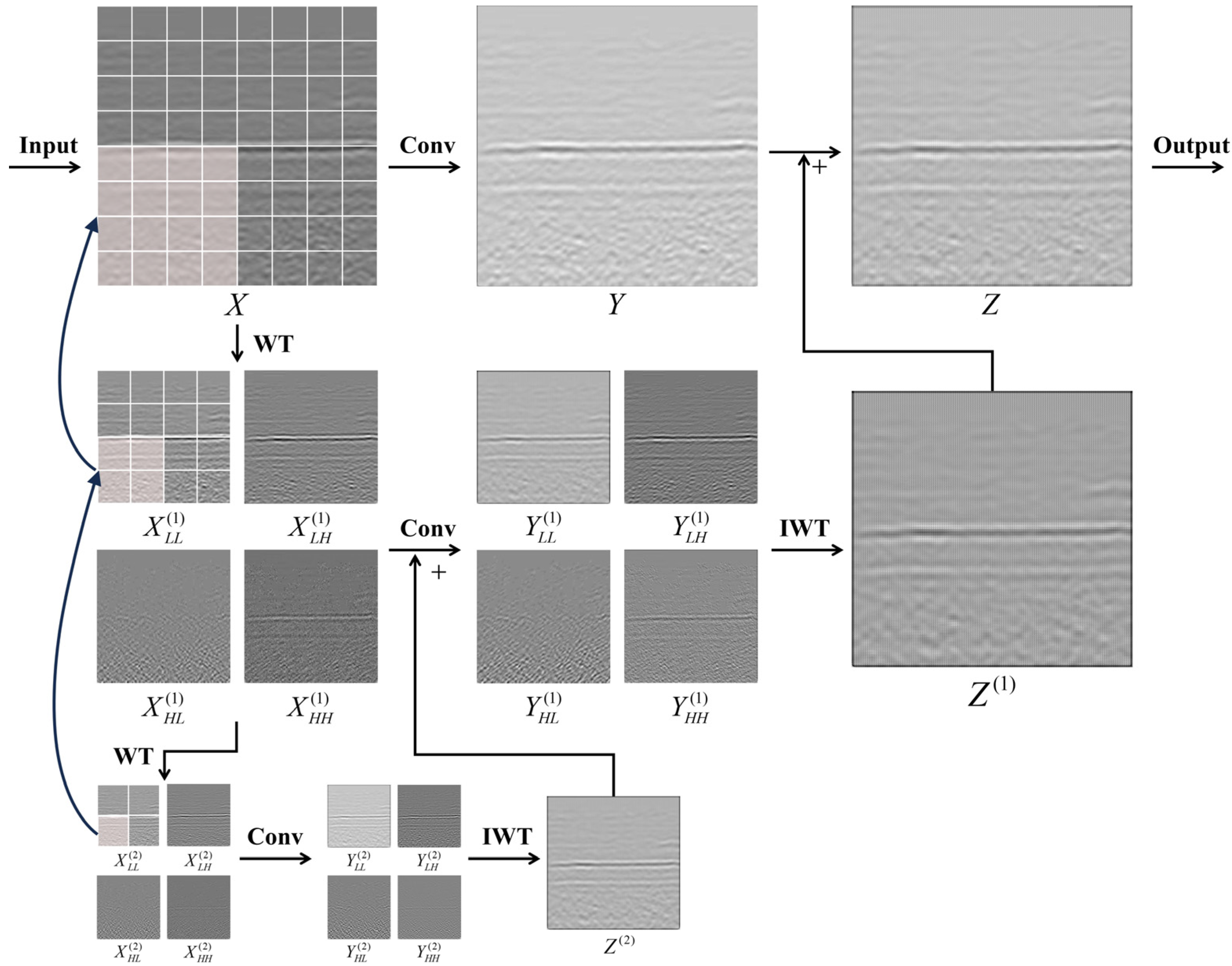
2.4. C3WC Module
3. Validation Using Field Tests
3.1. Dataset
3.1.1. Data Acquisition
3.1.2. Dataset Construction
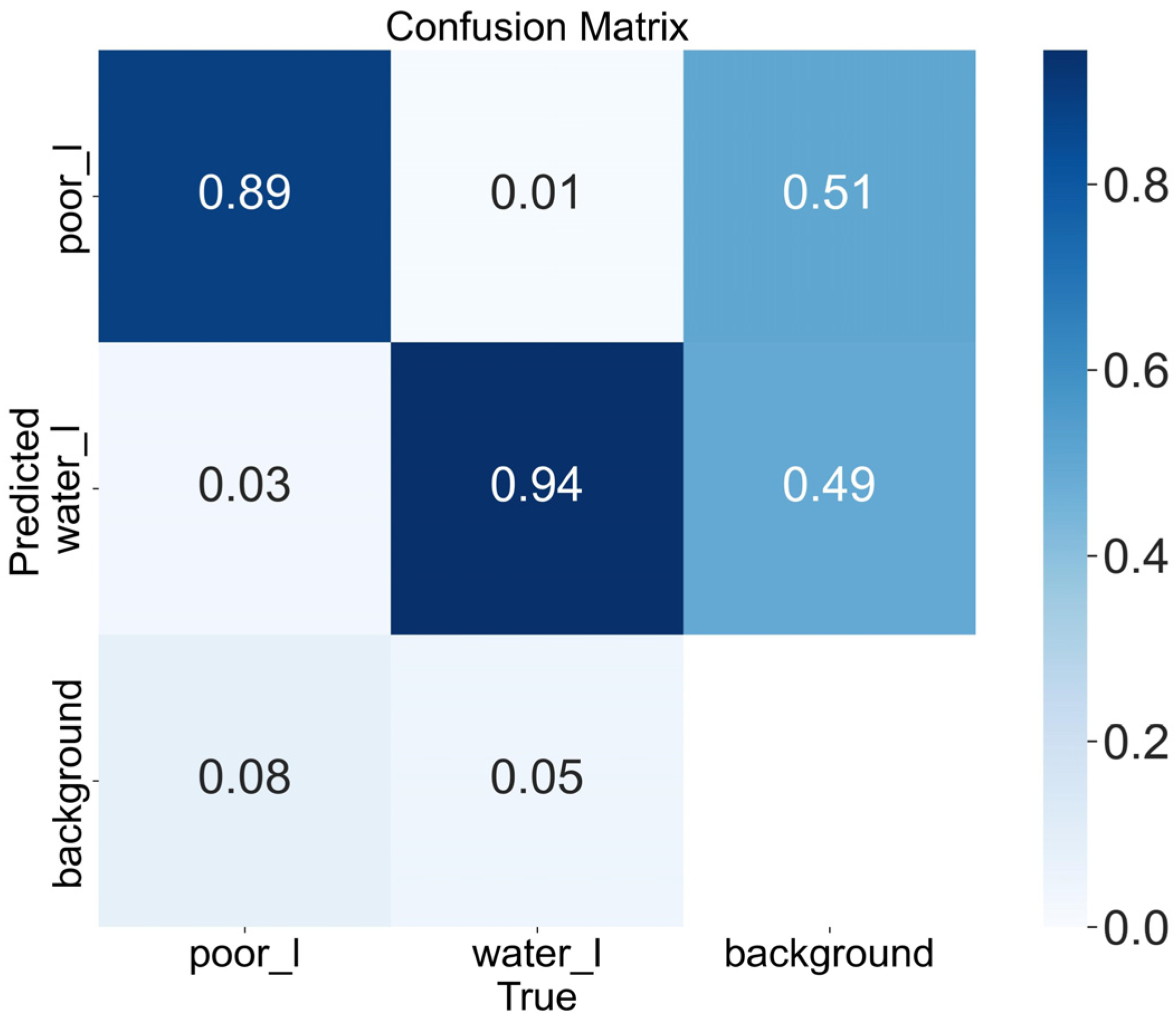
- Interlayer debonding: temperature, load, or other factors may cause a continuous separation between the layers of pavement, and interlayer delamination occurs, named interlayer debonding. There is a strong reflection in the GPR image due to the difference in permittivity of the air contained between the layers and the surrounding medium. Specifically, the image features of interlayer debonding appear as black, white, and black in vertical order (Figure 10a). Interlayer debonding is abbreviated as “poor_1”;
- Interlayer water seepage: when interlayer debonding has occurred without timely maintenance, interlayer water seepage distress between the layers occurs as rainwater seeps in. Unlike other air-containing distresses, this category of distress contains water. The permittivity of water and air are different, typically 81 for water and 1 for air. As a result, Figure 10b shows a clear polarity reversal for interlayer water seepage compared to interlayer debonding. Specifically, the image features of interlayer water seepage appear as white, black, and white in vertical order. Interlayer water seepage is abbreviated as “water_1”.
3.2. Evaluation Metrics and Experimental Configuration
4. Experimental Results
4.1. Preliminary Analysis of OEM-HWNet
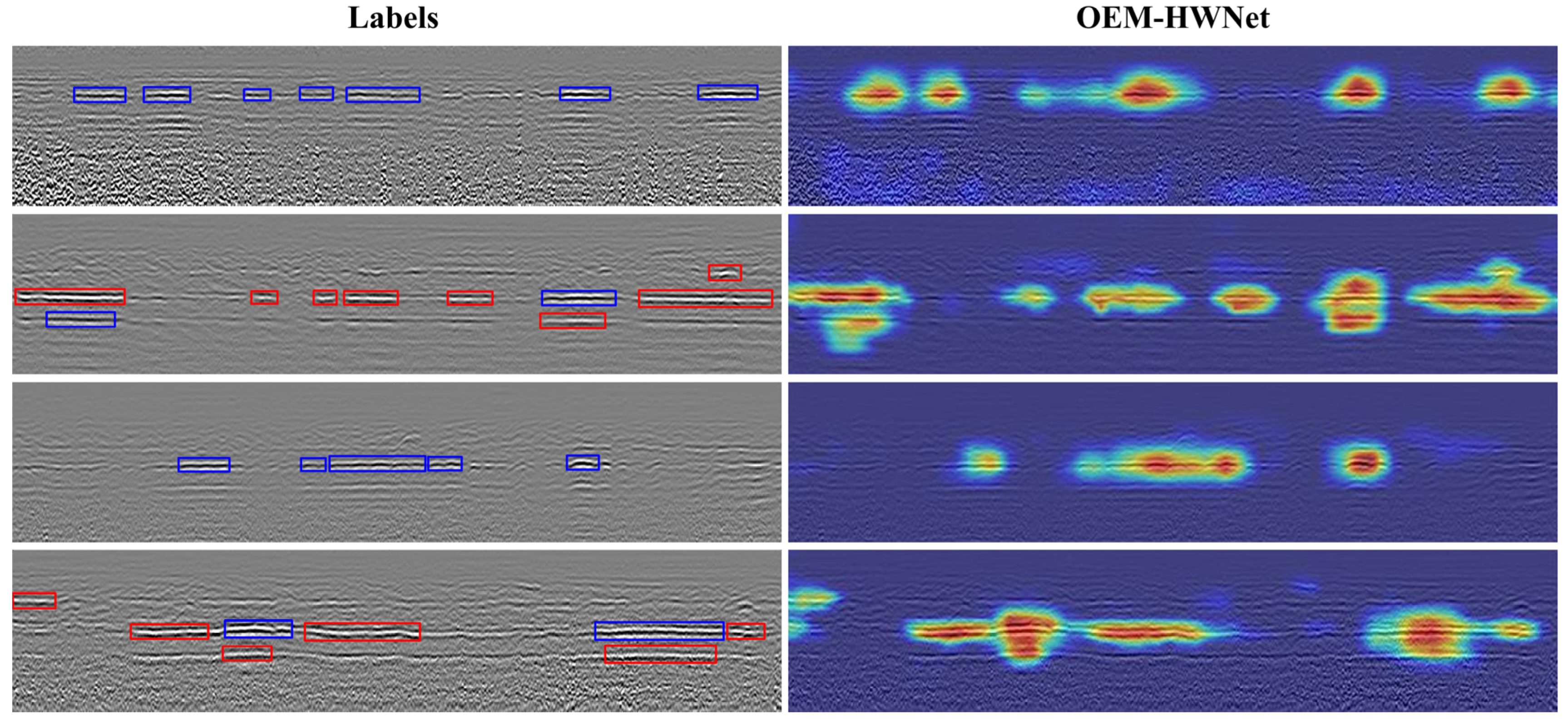
4.1.1. Detection Results of OEM-HWNet
4.1.2. Visualization of Attention Maps
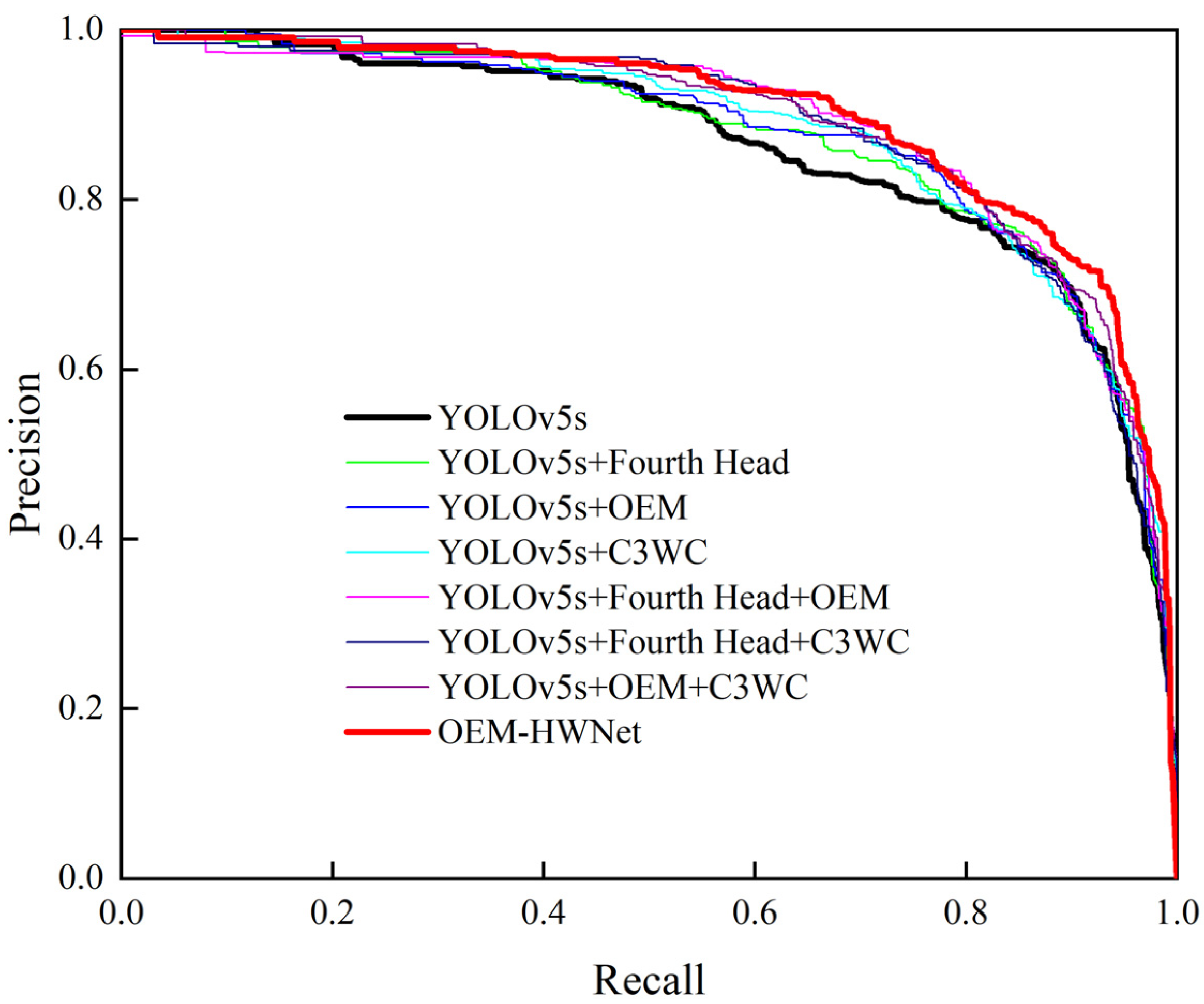
4.2. Ablation Experiments
4.3. Comparison with the State-of-the-Art Methods
5. Conclusions
- (1)
- The existing methods may cause inaccurate locations for interlayer distress due to the interference of similar background features. Based on prior knowledge, the OEM can accurately locate the object region to allow the focusing of the learning of the model on that region without imposing additional parameters;
- (2)
- The proposed OEM-HWNet model achieves an average precision (AP) of 87.8% for interlayer debonding and 91.5% for interlayer water seepage, resulting in a mAP of 89.6%. Meanwhile, the comparative results with the original YOLOv5s model represent a 3.3% increase in mAP. Moreover, the results also indicate that the OEM-HWNet model surpasses other advanced models in detection accuracy;
- (3)
- The proposed method may be used for automatic and real-time interlayer distress detection of asphalt pavement using GPR. An extensive GPR dataset from four highways was constructed to evaluate the detection model rigorously. Future research may validate the proposed method with more testing datasets from asphalt pavement. Incorporating more interpretable prior knowledge to guide the design of the detection network is suggested.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Solla, M.; Pérez-Gracia, V.; Fontul, S. A Review of GPR Application on Transport Infrastructures: Troubleshooting and Best Practices. Remote Sens. 2021, 13, 672. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, S.; Al-Qadi, I.L. Real-Time Density and Thickness Estimation of Thin Asphalt Pavement Overlay During Compaction Using Ground Penetrating Radar Data. Surv. Geophys. 2020, 41, 431–445. [Google Scholar] [CrossRef]
- Xu, X.; Peng, S.; Xia, Y.; Ji, W. The Development of a Multi-Channel GPR System for Roadbed Damage Detection. Microelectron. J. 2014, 45, 1542–1555. [Google Scholar] [CrossRef]
- Todkar, S.S.; Le Bastard, C.; Baltazart, V.; Ihamouten, A.; Derobort, X. Comparative Study of Classification Algorithms to Detect Interlayer Debondings within Pavement Structures from Step-Frequency Radar Data. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: New York, NY, USA, 2018; pp. 6820–6823. [Google Scholar]
- Guo, S.; Xu, Z.; Li, X.; Zhu, P. Detection and Characterization of Cracks in Highway Pavement with the Amplitude Variation of GPR Diffracted Waves: Insights from Forward Modeling and Field Data. Remote Sens. 2022, 14, 976. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, J.; Sun, W. Recognition of the Typical Distress in Concrete Pavement Based on GPR and 1D-CNN. Remote Sens. 2021, 13, 2375. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, X.; Li, W.; Zhang, S.; Jia, Y. Automatic Detection of Moisture Damages in Asphalt Pavements from GPR Data with Deep CNN and IRS Method. Autom. Constr. 2020, 113, 103119. [Google Scholar] [CrossRef]
- Liang, X.; Yu, X.; Chen, C.; Jin, Y.; Huang, J. Automatic Classification of Pavement Distress Using 3D Ground-Penetrating Radar and Deep Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22269–22277. [Google Scholar] [CrossRef]
- Hou, F.; Lei, W.; Li, S.; Xi, J. Deep Learning-Based Subsurface Target Detection From GPR Scans. IEEE Sens. J. 2021, 21, 8161–8171. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Mizutani, T.; Meguro, K.; Hirano, T. Detecting Subsurface Voids From GPR Images by 3-D Convolutional Neural Network Using 2-D Finite Difference Time Domain Method. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3061–3073. [Google Scholar] [CrossRef]
- Li, N.; Wu, R.; Li, H.; Wang, H.; Gui, Z.; Song, D. MV-GPRNet: Multi-View Subsurface Defect Detection Network for Airport Runway Inspection Based on GPR. Remote Sens. 2022, 14, 4472. [Google Scholar] [CrossRef]
- Li, H.; Li, N.; Wu, R.; Wang, H.; Gui, Z.; Song, D. GPR-RCNN: An Algorithm of Subsurface Defect Detection for Airport Runway Based on GPR. IEEE Robot. Autom. Lett. 2021, 6, 3001–3008. [Google Scholar] [CrossRef]
- Kim, N.; Kim, S.; An, Y.-K.; Lee, J.-J. Triplanar Imaging of 3-D GPR Data for Deep-Learning-Based Underground Object Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4446–4456. [Google Scholar] [CrossRef]
- Yang, J.; Ruan, K.; Gao, J.; Yang, S.; Zhang, L. Pavement Distress Detection Using Three-Dimension Ground Penetrating Radar and Deep Learning. Appl. Sci. 2022, 12, 5738. [Google Scholar] [CrossRef]
- Liu, C.; Du, Y.; Yue, G.; Li, Y.; Wu, D.; Li, F. Advances in Automatic Identification of Road Subsurface Distress Using Ground Penetrating Radar: State of the Art and Future Trends. Autom. Constr. 2024, 158, 105185. [Google Scholar] [CrossRef]
- Li, Y.; Liu, C.; Yue, G.; Gao, Q.; Du, Y. Deep Learning-Based Pavement Subsurface Distress Detection via Ground Penetrating Radar Data. Autom. Constr. 2022, 142, 104516. [Google Scholar] [CrossRef]
- Li, S.; Gu, X.; Xu, X.; Xu, D.; Zhang, T.; Liu, Z.; Dong, Q. Detection of Concealed Cracks from Ground Penetrating Radar Images Based on Deep Learning Algorithm. Constr. Build. Mater. 2021, 273, 121949. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, W.; Gu, X.; Li, S.; Wang, L.; Zhang, T. Application of Combining YOLO Models and 3D GPR Images in Road Detection and Maintenance. Remote Sens. 2021, 13, 1081. [Google Scholar] [CrossRef]
- Xiong, X.; Meng, A.; Lu, J.; Tan, Y.; Chen, B.; Tang, J.; Zhang, C.; Xiao, S.; Hu, J. Automatic Detection and Location of Pavement Internal Distresses from Ground Penetrating Radar Images Based on Deep Learning. Constr. Build. Mater. 2024, 411, 134483. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, Y.; Yang, Z.; Zhu, X.; Zheng, T.; Liu, X.; Tian, Y.; Li, W. Recognition of Void Defects in Airport Runways Using Ground-Penetrating Radar and Shallow CNN. Autom. Constr. 2022, 138, 104260. [Google Scholar] [CrossRef]
- Liu, Q.; Yan, S. Measurement and Assessement of Road Poor Interlayer Bonding Assessment Using Ground Penetrating Radar. In Proceedings of the 2023 5th International Conference on Intelligent Control, Measurement and Signal Processing (ICMSP), Chengdu, China, 19–21 May 2023; pp. 671–674. [Google Scholar] [CrossRef]
- Xue, B.; Gao, J.; Hu, S.; Li, Y.; Chen, J.; Pang, R. Ground Penetrating Radar Image Recognition for Earth Dam Disease Based on You Only Look Once V5s Algorithm. Water 2023, 15, 3506. [Google Scholar] [CrossRef]
- Liu, C.; Yao, Y.; Li, J.; Qian, J.; Liu, L. Research on Lightweight GPR Road Surface Disease Image Recognition and Data Expansion Algorithm Based on YOLO and GAN. Case Stud. Constr. Mater. 2024, 20, e02779. [Google Scholar] [CrossRef]
- Xiong, X.; Tan, Y.; Hu, J.; Hong, X.; Tang, J. Evaluation of Asphalt Pavement Internal Distresses Using Three-Dimensional Ground-Penetrating Radar. Int. J. Pavement Res. Technol. 2024, 1–12. [Google Scholar] [CrossRef]
- Jiang, B.; Xu, L.; Cao, Z.; Yang, Y.; Sun, Z.; Xiao, F. Interlayer Distress Characteristics and Evaluations of Semi-Rigid Base Asphalt Pavements: A Review. Constr. Build. Mater. 2024, 431, 136441. [Google Scholar] [CrossRef]
- Jin, G.; Liu, Q.; Cai, W.; Li, M.; Lu, C. Performance Evaluation of Convolutional Neural Network Models for Classification of Highway Hidden Distresses with GPR B-Scan Images. Appl. Sci. 2024, 14, 4226. [Google Scholar] [CrossRef]
- Cai, W.; Li, M.; Jin, G.; Liu, Q.; Lu, C. Comparison of Residual Network and Other Classical Models for Classification of Interlayer Distresses in Pavement. Appl. Sci. 2024, 14, 6568. [Google Scholar] [CrossRef]
- Bugarinović, Ž.; Pajewski, L.; Ristić, A.; Vrtunski, M.; Govedarica, M.; Borisov, M. On the Introduction of Canny Operator in an Advanced Imaging Algorithm for Real-Time Detection of Hyperbolas in Ground-Penetrating Radar Data. Electronics 2020, 9, 541. [Google Scholar] [CrossRef]
- Harkat, H.; Dosse Bennani, S. Ground Penetrating Radar Imaging for Buried Cavities in a Dispersive Medium: Profile Reconstruction Using a Modified Hough Transform Approach and a Time-Frequency Analysis. Int. J. Commun. Antenna Propag. IRECAP 2015, 5, 78. [Google Scholar] [CrossRef]
- Todkar, S.S.; Le Bastard, C.; Baltazart, V.; Ihamouten, A.; Dérobert, X. Performance Assessment of SVM-Based Classification Techniques for the Detection of Artificial Debondings within Pavement Structures from Stepped-Frequency A-Scan Radar Data. NDT E Int. 2019, 107, 102128. [Google Scholar] [CrossRef]
- Frigui, H.; Gader, P. Detection and Discrimination of Land Mines in Ground-Penetrating Radar Based on Edge Histogram Descriptors and a Possibilistic K-Nearest Neighbor Classifier. IEEE Trans. Fuzzy Syst. 2009, 17, 185–199. [Google Scholar] [CrossRef]
- Sun, Z.; Caetano, E.; Pereira, S.; Moutinho, C. Employing Histogram of Oriented Gradient to Enhance Concrete Crack Detection Performance with Classification Algorithm and Bayesian Optimization. Eng. Fail. Anal. 2023, 150, 107351. [Google Scholar] [CrossRef]
- Xie, X.; Li, P.; Qin, H.; Liu, L.; Nobes, D.C. GPR Identification of Voids inside Concrete Based on the Support Vector Machine Algorithm. J. Geophys. Eng. 2013, 10, 034002. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 6154–6162. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; IEEE: New York, NY, USA; pp. 7464–7475. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Germany, 2016; Volume 9905, pp. 21–37. ISBN 978-3-319-46447-3. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Germany, 2020; Volume 12346, pp. 213–229. ISBN 978-3-030-58451-1. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Luo, T.X.; Zhou, Y.; Zheng, Q.; Hou, F.; Lin, C. Lightweight Deep Learning Model for Identifying Tunnel Lining Defects Based on GPR Data. Autom. Constr. 2024, 165, 105506. [Google Scholar] [CrossRef]
- Zheng, X.; Fang, S.; Chen, H.; Peng, L.; Ye, Z. Internal Detection of Ground-Penetrating Radar Images Using YOLOX-s with Modified Backbone. Electronics 2023, 12, 3520. [Google Scholar] [CrossRef]
- Hu, H.; Fang, H.; Wang, N.; Ma, D.; Dong, J.; Li, B.; Di, D.; Zheng, H.; Wu, J. Defects Identification and Location of Underground Space for Ground Penetrating Radar Based on Deep Learning. Tunn. Undergr. Space Technol. 2023, 140, 105278. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhou, S.; Li, S.; Li, H.; Yang, H. Tunnel Lining Quality Detection Based on the YOLO-LD Algorithm. Constr. Build. Mater. 2024, 449, 138240. [Google Scholar] [CrossRef]
- Liu, Z.; Gu, X.; Yang, H.; Wang, L.; Chen, Y.; Wang, D. Novel YOLOv3 Model With Structure and Hyperparameter Optimization for Detection of Pavement Concealed Cracks in GPR Images. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22258–22268. [Google Scholar] [CrossRef]
- Ma, Y.; Song, X.; Li, Z.; Li, H.; Qu, Z. A Prior Knowledge-Guided Semi-Supervised Deep Learning Method for Improving Buried Pipe Detection on GPR Data. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Chen, H.; Yang, X.; Gong, J.; Lan, T. Multidirectional Enhancement Model Based on SIFT for GPR Underground Pipeline Recognition. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5928614. [Google Scholar] [CrossRef]
- Tag, A.; Shouman, O.; Heggy, E.; Khattab, T. Automatic Groundwater Detection from GPR Data Using YOLOv8. In Proceedings of the IGARSS 2024—2024 IEEE International Geoscience and Remote Sensing Symposium, Athens, Greece, 7–12 July 2024; IEEE: New York, NY, USA, 2024; pp. 8326–8329. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Zeng, Y.; Wang, C.; Abhiram, V.; et al. Ultralytics/Yolov5: V7.0—YOLOv5 SOTA Realtime Instance Segmentation. Available online: https://zenodo.org/records/7347926 (accessed on 13 October 2024).
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet Convolutions for Large Receptive Fields. In Computer Vision—ECCV 2024; Springer: Cham, Germany, 2024. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-Time Object Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; IEEE: New York, NY, USA; pp. 16965–16974. [Google Scholar]
- Jocher, G. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 January 2023).
- Jocher, G. YOLO11. Available online: https://github.com/ultralytics/ultralytics/blob/main/docs/en/models/yolo11.md (accessed on 30 September 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar] [CrossRef]
- Jol, H.M. Ground Penetrating Radar: Theory and Applications, 1st ed.; Elsevier Science: Amsterdam, The Netherlands, 2009; ISBN 978-0-444-53348-7. [Google Scholar]
- Daniels, D.J. Ground Penetrating Radar; Institution of Engineering and Technology: London, UK, 2004; ISBN 978-0-86341-360-5. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Haralick, R.M.; Sternberg, S.R.; Zhuang, X. Image Analysis Using Mathematical Morphology. IEEE Trans. Pattern Anal. Mach. Intell. 1987, PAMI-9, 532–550. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA; pp. 1800–1807. [Google Scholar]
- Raghuram, A.S.S.; Dasaka, S.M. Forensic Analysis of a Distressed RE Wall and Rigid Pavement in a Newly Constructed Highway Approach. Int. J. Geosynth. Ground Eng. 2022, 8, 38. [Google Scholar] [CrossRef]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for Small Object Detection. In Proceedings of the 9th International Conference on Advances in Computing and Information Technology (ACITY 2019), Sydney, Australia, 21–22 December 2019; Aircc Publishing Corporation: Chennai, India, 2019; pp. 119–133. [Google Scholar]
- Ketkar, N. Stochastic Gradient Descent. In Deep Learning with Python; Apress: Berkeley, CA, USA, 2017; pp. 113–132. ISBN 978-1-4842-2765-7. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Version |
|---|---|
| Pytorch | 2.1.0 |
| CUDA | 12.1 |
| Python | 3.8.18 |
| Numpy | 1.23.5 |
| Distress Category | Total | Width (Pixel) | Height (Pixel) | ||||
|---|---|---|---|---|---|---|---|
| Max | Min | Average | Max | Min | Average | ||
| poor_l | 2751 | 648 | 22 | 80.0 | 40 | 14 | 19.3 |
| water_l | 2862 | 574 | 24 | 82.5 | 27 | 19 | 20.3 |
| Model | AP | mAP@0.5 | Parameters | P | R | F1 | |
|---|---|---|---|---|---|---|---|
| Poor_l | Water_l | (M) | |||||
| YOLOv5s (baseline) | 84.0% | 88.5% | 86.3% | 7.24 | 77.1% | 82.3% | 0.7962 |
| +Fourth Head | 84.9% | 89.2% | 87.0% | 12.63 | 80.2% | 79.8% | 0.8000 |
| +OEM | 85.0% | 89.5% | 87.3% | 7.24 | 81.3% | 79.4% | 0.8034 |
| +C3WC | 85.8% | 89.7% | 87.8% | 7.70 | 76.2% | 84.4% | 0.8009 |
| +Fourth Head + OEM | 86.7% | 90.2% | 88.5% | 12.63 | 81.3% | 79.5% | 0.8039 |
| +Fourth Head + C3WC | 85.5% | 90.6% | 88.1% | 13.29 | 79.5% | 81.8% | 0.8063 |
| +OEM + C3WC | 87.6% | 89.9% | 88.8% | 7.70 | 80.5% | 80.5% | 0.8050 |
| +Fourth Head + OEM+ C3WC | 87.8% | 91.5% | 89.6% | 13.29 | 80.7% | 82.4% | 0.8154 |
| Model | Average Precision | mAP@0.5 | Size (MB) | FPS | |
|---|---|---|---|---|---|
| Poor_l | Water_l | ||||
| Faster R-CNN [35] | 84.4% | 87.9% | 86.1% | 330.35 | 13 |
| RetinaNet [41] | 79.6% | 84.2% | 81.9% | 257.26 | 15 |
| SSD [39] | 77.6% | 85.1% | 81.4% | 106.11 | 42 |
| RT-DETR [52] | 84.9% | 88.5% | 86.7% | 82.08 | 80 |
| YOLOv3 [38] | 85.0% | 88.4% | 86.7% | 117.69 | 71 |
| YOLOv5s [50] | 84.0% | 88.5% | 86.3% | 13.63 | 160 |
| YOLOv7 [37] | 83.7% | 90.0% | 86.9% | 71.30 | 110 |
| YOLOv8s [53] | 83.5% | 89.9% | 86.7% | 21.45 | 145 |
| YOLOv11s [54] | 82.9% | 88.3% | 85.6% | 18.27 | 149 |
| OEM-HWNet (ours) | 87.8% | 91.5% | 89.6% | 25.31 | 84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, C.; Cao, S.; Wang, X.; Jin, G.; Wang, S.; Cai, W. OEM-HWNet: A Prior Knowledge-Guided Network for Pavement Interlayer Distress Detection Based on Computer Vision Using GPR. Remote Sens. 2025, 17, 1554. https://doi.org/10.3390/rs17091554
Lu C, Cao S, Wang X, Jin G, Wang S, Cai W. OEM-HWNet: A Prior Knowledge-Guided Network for Pavement Interlayer Distress Detection Based on Computer Vision Using GPR. Remote Sensing. 2025; 17(9):1554. https://doi.org/10.3390/rs17091554
Chicago/Turabian StyleLu, Congde, Senguo Cao, Xiao Wang, Guanglai Jin, Siqi Wang, and Wenlong Cai. 2025. "OEM-HWNet: A Prior Knowledge-Guided Network for Pavement Interlayer Distress Detection Based on Computer Vision Using GPR" Remote Sensing 17, no. 9: 1554. https://doi.org/10.3390/rs17091554
APA StyleLu, C., Cao, S., Wang, X., Jin, G., Wang, S., & Cai, W. (2025). OEM-HWNet: A Prior Knowledge-Guided Network for Pavement Interlayer Distress Detection Based on Computer Vision Using GPR. Remote Sensing, 17(9), 1554. https://doi.org/10.3390/rs17091554