
A Spatial–Frequency Combined Transformer for Cloud Removal of Optical Remote Sensing Images


Abstract
1. Introduction
- We present a novel SFCT block, which integrates dual-branch spatial attention (DBSA) and frequency self-attention (FreSA). The DBSA module enhances spatial features by capturing both spatial and channel-wise relationships, effectively addressing structural distortion artifacts inherent in conventional single-branch attention architectures. Meanwhile, the FreSA module operates in the frequency domain, leveraging spectral differences to amplify the contrast between cloud regions and the background, thereby achieving precise detection and comprehensive removal of cloud artifacts.
- We propose the dual-domain feed-forward network (DDFFN) that achieves cloud removal with detail fidelity by capturing pixel-level local textures via multi-scale convolutions and extracting global structural details via frequency transform.
- We design an innovative composite loss function, which integrates the robustness of Charbonnier loss with the perceptual fidelity ensured by SSIM loss. This dual-objective approach not only preserves pixel-level accuracy but also enhances global structural coherence and perceptual quality.
- Extensive experimental validation on multiple benchmark datasets demonstrates that the proposed SFCRFormer significantly outperforms existing state-of-the-art methods in both quantitative metrics and qualitative visual assessments. Our method consistently achieves higher PSNR and SSIM scores, while delivering more visually convincing results, underscoring its robustness and generalization capability across diverse cloud conditions.
2. Related Work
2.1. Deep Learning-Based Cloud Removal Methods
2.2. Applications of Frequency Domain in Remote Sensing
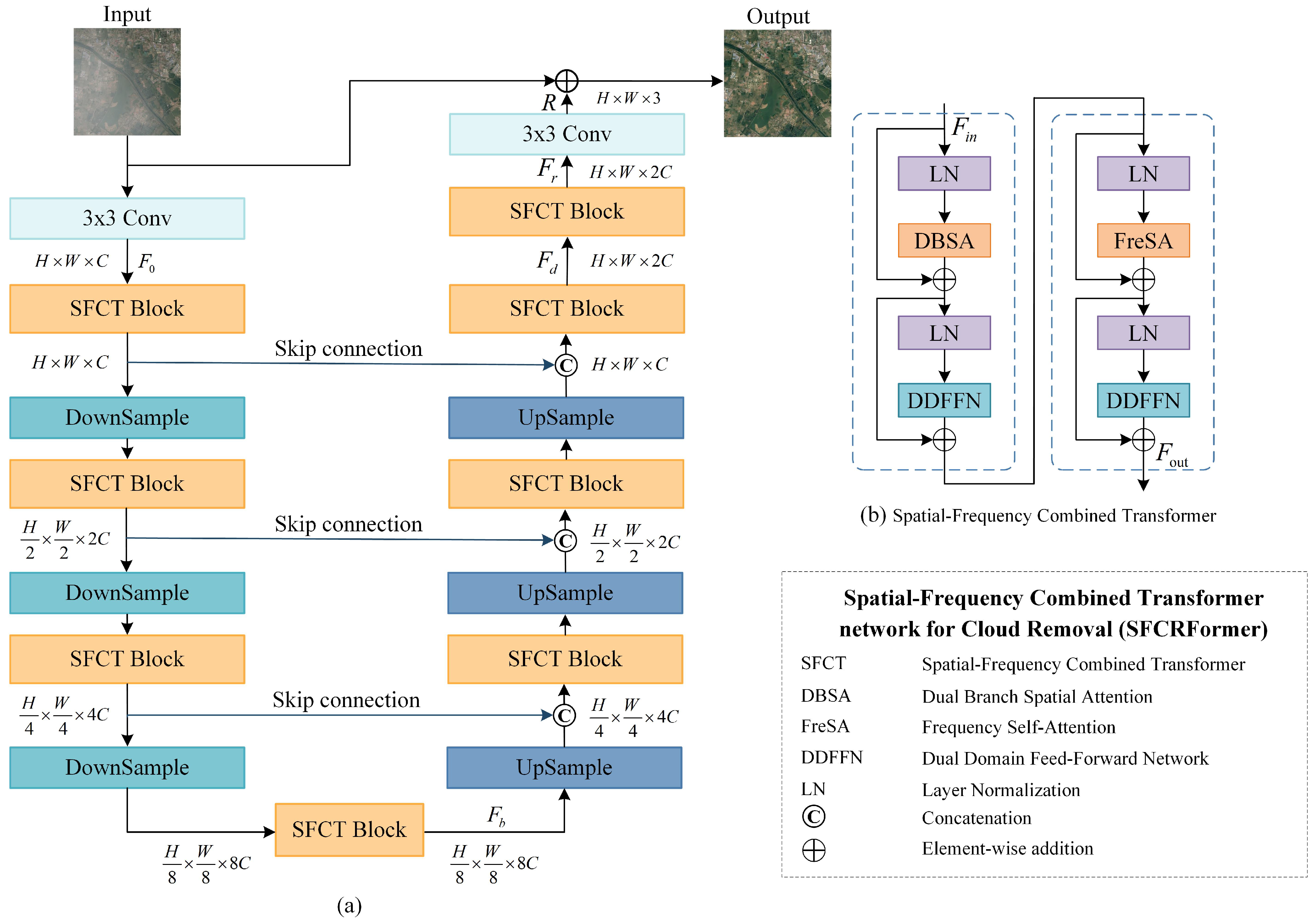
3. Method
3.1. Overview
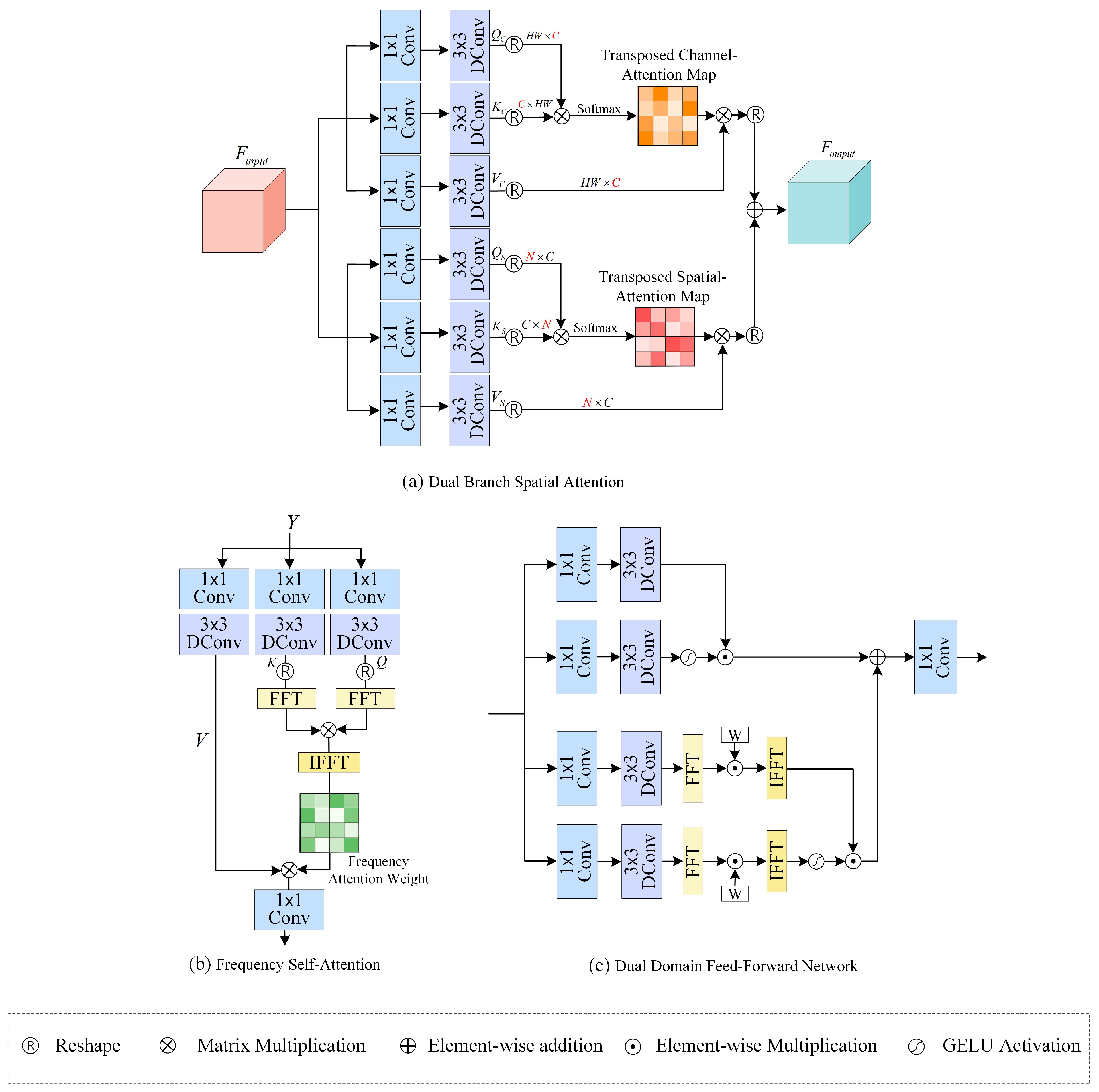
3.2. DBSA: Dual-Branch Spatial Attention
3.3. FreSA: Frequency Self-Attention
3.4. DDFFN: Dual-Domain Feed-Forward Network
3.5. Loss Function
4. Experiments
4.1. Datasets
4.1.1. RICE Dataset
4.1.2. T-Cloud Dataset
4.2. Evaluation Metrics
4.3. Experimental Settings
4.4. Experimental Results
4.4.1. Results on RICE1 Dataset
4.4.2. Results on RICE2 Dataset
4.4.3. Results on T-Cloud Dataset
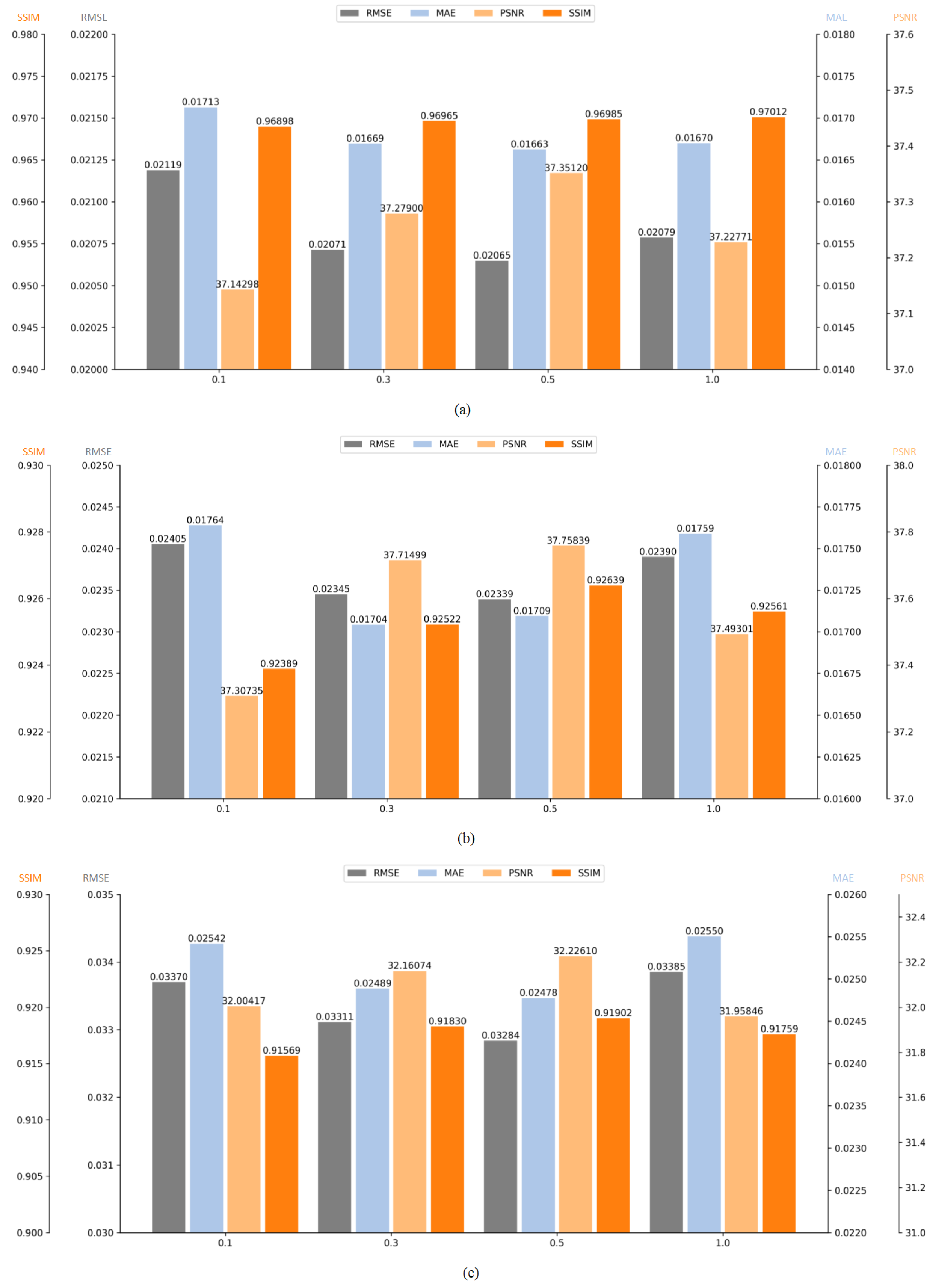
4.5. Ablation Study
4.5.1. Numerical Evaluations
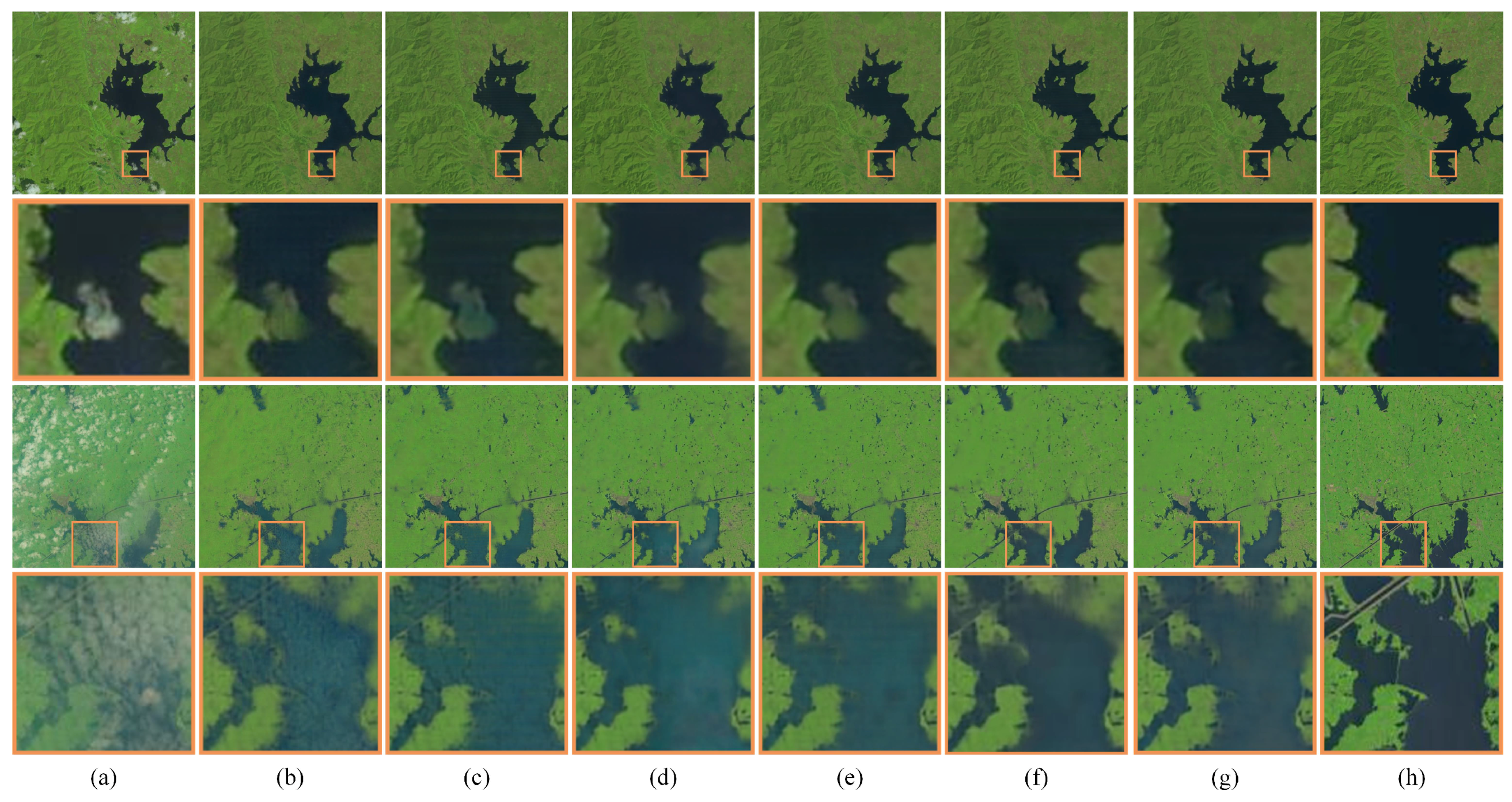
4.5.2. Visualization Analysis
4.6. Effects of Different Loss Functions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Duan, W.; Maskey, S.; Chaffe, P.L.B.; Luo, P.; He, B.; Wu, Y.; Hou, J. Recent Advancement in Remote Sensing Technology for Hydrology Analysis and Water Resources Management. Remote Sens. 2021, 13, 1097. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Tao, F.; Tong, Y.; Gao, H.; Liu, F.; Chen, Z.; Lyu, X. A Cross-Domain Coupling Network for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5005105. [Google Scholar] [CrossRef]
- Himeur, Y.; Rimal, B.; Tiwary, A.; Amira, A. Using artificial intelligence and data fusion for environmental monitoring: A review and future perspectives. Inf. Fusion 2022, 86–87, 44–75. [Google Scholar] [CrossRef]
- Qing, Y.; Ming, D.; Wen, Q.; Weng, Q.; Xu, L.; Chen, Y.; Zhang, Y.; Zeng, B. Operational earthquake-induced building damage assessment using CNN-based direct remote sensing change detection on superpixel level. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102899. [Google Scholar] [CrossRef]
- Li, Q.; Zhong, R.; Du, X.; Du, Y. TransUNetCD: A Hybrid Transformer Network for Change Detection in Optical Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5622519. [Google Scholar] [CrossRef]
- King, M.D.; Platnick, S.; Menzel, W.P.; Ackerman, S.A.; Hubanks, P.A. Spatial and temporal distribution of clouds observed by MODIS onboard the Terra and Aqua satellites. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3826–3852. [Google Scholar] [CrossRef]
- Xu, F.; Shi, Y.; Yang, W.; Xia, G.S.; Zhu, X.X. CloudSeg: A multi-modal learning framework for robust land cover mapping under cloudy conditions. ISPRS J. Photogramm. Remote Sens. 2024, 214, 21–32. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Lyu, X.; Tong, Y.; Xu, Z.; Zhou, J. A synergistical attention model for semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5400916. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Tong, Y.; Lyu, X.; Zhou, J. Semantic segmentation of remote sensing images by interactive representation refinement and geometric prior-guided inference. IEEE Trans. Geosci. Remote Sens. 2023, 62, 5400318. [Google Scholar] [CrossRef]
- Han, S.; Wang, J.; Zhang, S. Former-CR: A transformer-based thick cloud removal method with optical and SAR imagery. Remote Sens. 2023, 15, 1196. [Google Scholar] [CrossRef]
- Chen, Y.; Cai, Z.; Yuan, J.; Wu, L. A novel dense-attention network for thick cloud removal by reconstructing semantic information. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2339–2351. [Google Scholar] [CrossRef]
- Xia, Q.; Gao, X.; Chu, W.; Sorooshian, S. Estimation of daily cloud-free, snow-covered areas from MODIS based on variational interpolation. Water Resour. Res. 2012, 48, 9523. [Google Scholar] [CrossRef]
- Zhang, C.; Li, W.; Travis, D.J. Restoration of clouded pixels in multispectral remotely sensed imagery with cokriging. Int. J. Remote Sens. 2009, 30, 2173–2195. [Google Scholar] [CrossRef]
- Shen, H.; Li, H.; Qian, Y.; Zhang, L.; Yuan, Q. An effective thin cloud removal procedure for visible remote sensing images. ISPRS J. Photogramm. Remote Sens. 2014, 96, 224–235. [Google Scholar] [CrossRef]
- Yu, G.; Sun, W.B.; Liu, G.; Zhou, M.Y. A Thin Cloud Removal Method for Optical Image Based on Improved Homomorphism Filtering. Appl. Mech. Mater. 2014, 618, 519–522. [Google Scholar] [CrossRef]
- Li, X.; Jing, Y.; Shen, H.; Zhang, L. The recent developments in cloud removal approaches of MODIS snow cover product. Hydrol. Earth Syst. Sci. 2019, 23, 2401–2416. [Google Scholar] [CrossRef]
- Hu, G.; Sun, X.; Liang, D.; Sun, Y. Cloud removal of remote sensing image based on multi-output support vector regression. J. Syst. Eng. Electron. 2014, 25, 1082–1088. [Google Scholar] [CrossRef]
- Tahsin, S.; Medeiros, S.C.; Hooshyar, M.; Singh, A. Optical cloud pixel recovery via machine learning. Remote Sens. 2017, 9, 527. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, L.; Zhu, X.; Ge, Y.; Tong, X.; Atkinson, P.M. Remote sensing image gap filling based on spatial-spectral random forests. Sci. Remote Sens. 2022, 5, 100048. [Google Scholar] [CrossRef]
- Li, J.; Zheng, K.; Gao, L.; Ni, L.; Huang, M.; Chanussot, J. Model-Informed Multistage Unsupervised Network for Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5516117. [Google Scholar] [CrossRef]
- Li, J.; Zheng, K.; Li, Z.; Gao, L.; Jia, X. X-Shaped Interactive Autoencoders With Cross-Modality Mutual Learning for Unsupervised Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5518317. [Google Scholar] [CrossRef]
- Sintarasirikulchai, W.; Kasetkasem, T.; Isshiki, T.; Chanwimaluang, T.; Rakwatin, P. A multi-temporal convolutional autoencoder neural network for cloud removal in remote sensing images. In Proceedings of the 2018 15th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Chiang Rai, Thailand, 18–21 July 2018; pp. 360–363. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Enomoto, K.; Sakurada, K.; Wang, W.; Fukui, H.; Matsuoka, M.; Nakamura, R.; Kawaguchi, N. Filmy cloud removal on satellite imagery with multispectral conditional generative adversarial nets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 48–56. [Google Scholar]
- Wang, Z.; Zhao, J.; Zhang, R.; Li, Z.; Lin, Q.; Wang, X. UATNet: U-shape attention-based transformer net for meteorological satellite cloud recognition. Remote Sens. 2021, 14, 104. [Google Scholar] [CrossRef]
- Li, W.; Li, Y.; Chen, D.; Chan, J.C.W. Thin cloud removal with residual symmetrical concatenation network. ISPRS J. Photogramm. Remote Sens. 2019, 153, 137–150. [Google Scholar] [CrossRef]
- Shao, Z.; Pan, Y.; Diao, C.; Cai, J. Cloud detection in remote sensing images based on multiscale features-convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4062–4076. [Google Scholar] [CrossRef]
- Li, J.; Zheng, K.; Gao, L.; Han, Z.; Li, Z.; Chanussot, J. Enhanced Deep Image Prior for Unsupervised Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5504218. [Google Scholar] [CrossRef]
- Singh, P.; Komodakis, N. Cloud-gan: Cloud removal for sentinel-2 imagery using a cyclic consistent generative adversarial networks. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1772–1775. [Google Scholar]
- Wang, X.; Xu, G.; Wang, Y.; Lin, D.; Li, P.; Lin, X. Thin and thick cloud removal on remote sensing image by conditional generative adversarial network. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1426–1429. [Google Scholar]
- Christopoulos, D.; Ntouskos, V.; Karantzalos, K. Cloudtran: Cloud removal from multitemporal satellite images using axial transformer networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 43, 1125–1132. [Google Scholar] [CrossRef]
- Xia, Y.; He, W.; Huang, Q.; Yin, G.; Liu, W.; Zhang, H. CRformer: Multi-modal data fusion to reconstruct cloud-free optical imagery. Int. J. Appl. Earth Obs. Geoinf. 2024, 128, 103793. [Google Scholar] [CrossRef]
- Jiang, B.; Li, X.; Chong, H.; Wu, Y.; Li, Y.; Jia, J.; Wang, S.; Wang, J.; Chen, X. A deep-learning reconstruction method for remote sensing images with large thick cloud cover. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103079. [Google Scholar] [CrossRef]
- Wu, C.; Xu, F.; Li, X.; Wang, X.; Xu, Z.; Fang, Y.; Lyu, X. Multi-Stage Frequency Attention Network for Progressive Optical Remote Sensing Cloud Removal. Remote Sens. 2024, 16, 2867. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Yan, Z.; Fu, K. DABNet: Deformable contextual and boundary-weighted network for cloud detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5601216. [Google Scholar] [CrossRef]
- Meraner, A.; Ebel, P.; Zhu, X.X.; Schmitt, M. Cloud removal in Sentinel-2 imagery using a deep residual neural network and SAR-optical data fusion. ISPRS J. Photogramm. Remote Sens. 2020, 166, 333–346. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wu, Z.; Hu, Z.; Zhang, J.; Li, M.; Mo, L.; Molinier, M. Thin cloud removal in optical remote sensing images based on generative adversarial networks and physical model of cloud distortion. ISPRS J. Photogramm. Remote Sens. 2020, 166, 373–389. [Google Scholar] [CrossRef]
- Ran, X.; Ge, L.; Zhang, X. RGAN: Rethinking generative adversarial networks for cloud removal. Int. J. Intell. Syst. 2021, 36, 6731–6747. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Li, L.; Xu, N.; Liu, F.; Yuan, C.; Chen, Z.; Lyu, X. AAFormer: Attention-Attended Transformer for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5002805. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, Y.; Li, Y.; Wan, Y.; Yao, Y. CloudViT: A lightweight vision transformer network for remote sensing cloud detection. IEEE Geosci. Remote Sens. Lett. 2022, 20, 5000405. [Google Scholar] [CrossRef]
- Ge, W.; Yang, X.; Jiang, R.; Shao, W.; Zhang, L. CD-CTFM: A Lightweight CNN-Transformer Network for Remote Sensing Cloud Detection Fusing Multiscale Features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4538–4551. [Google Scholar] [CrossRef]
- Ma, X.; Huang, Y.; Zhang, X.; Pun, M.O.; Huang, B. Cloud-egan: Rethinking cyclegan from a feature enhancement perspective for cloud removal by combining cnn and transformer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4999–5012. [Google Scholar] [CrossRef]
- Wang, M.; Song, Y.; Wei, P.; Xian, X.; Shi, Y.; Lin, L. IDF-CR: Iterative Diffusion Process for Divide-and-Conquer Cloud Removal in Remote-sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5615014. [Google Scholar] [CrossRef]
- Chi, K.; Yuan, Y.; Wang, Q. Trinity-Net: Gradient-guided Swin transformer-based remote sensing image dehazing and beyond. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4702914. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Yu, A.; Lyu, X.; Gao, H.; Zhou, J. A Frequency Decoupling Network for Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5607921. [Google Scholar] [CrossRef]
- Hsu, W.Y.; Chang, W.C. Wavelet approximation-aware residual network for single image deraining. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15979–15995. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; He, W.; Xia, Y.; Zhang, H. Blind single-image-based thin cloud removal using a cloud perception integrated fast Fourier convolutional network. ISPRS J. Photogramm. Remote Sens. 2023, 206, 63–86. [Google Scholar] [CrossRef]
- Zhou, Y.; Feng, Y.; Huo, S.; Li, X. Joint frequency-spatial domain network for remote sensing optical image change detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5627114. [Google Scholar] [CrossRef]
- Jiang, B.; Chong, H.; Tan, Z.; An, H.; Yin, H.; Chen, S.; Yin, Y.; Chen, X. FDT-Net: Deep-Learning Network for Thin-Cloud Removal in Remote Sensing Image Using Frequency Domain Training Strategy. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1002405. [Google Scholar] [CrossRef]
- Charbonnier, P.; Blanc-Feraud, L.; Aubert, G.; Barlaud, M. Two deterministic half-quadratic regularization algorithms for computed imaging. In Proceedings of the 1st International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; Volume 2, pp. 168–172. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Lin, D.; Xu, G.; Wang, X.; Wang, Y.; Sun, X.; Fu, K. A remote sensing image dataset for cloud removal. arXiv 2019, arXiv:1901.00600. [Google Scholar]
- Ding, H.; Zi, Y.; Xie, F. Uncertainty-based thin cloud removal network via conditional variational autoencoders. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022; pp. 469–485. [Google Scholar]
- Pan, H. Cloud removal for remote sensing imagery via spatial attention generative adversarial network. arXiv 2020, arXiv:2009.13015. [Google Scholar]
- Xu, M.; Deng, F.; Jia, S.; Jia, X.; Plaza, A.J. Attention mechanism-based generative adversarial networks for cloud removal in Landsat images. Remote Sens. Environ. 2022, 271, 112902. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Dai, J.; Shi, N.; Zhang, T.; Xu, W. TCME: Thin Cloud removal network for optical remote sensing images based on Multi-dimensional features Enhancement. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5641716. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR (↑) | SSIM (↑) | MAE (↓) | RMSE (↓) |
|---|---|---|---|---|
| SpA GAN | 29.5965 | 0.9165 | 0.03970 | 0.05013 |
| AMGAN | 25.2576 | 0.7632 | 0.06761 | 0.08374 |
| CVAE | 32.1995 | 0.9485 | 0.02874 | 0.03624 |
| Restormer | 36.5432 | 0.9605 | 0.01786 | 0.02273 |
| TCME | 36.5279 | 0.9590 | 0.01806 | 0.02292 |
| SFCRFormer | 37.3512 | 0.9699 | 0.01662 | 0.02064 |
| Method | PSNR (↑) | SSIM (↑) | MAE (↓) | RMSE (↓) |
|---|---|---|---|---|
| SpA GAN | 30.0268 | 0.8244 | 0.03751 | 0.04508 |
| AMGAN | 27.1915 | 0.8057 | 0.05312 | 0.06705 |
| CVAE | 32.3241 | 0.8566 | 0.02763 | 0.03698 |
| Restormer | 36.2070 | 0.9155 | 0.01884 | 0.02554 |
| TCME | 36.8512 | 0.9179 | 0.01871 | 0.02530 |
| SFCRFormer | 37.7584 | 0.9264 | 0.01709 | 0.02339 |
| Method | PSNR (↑) | SSIM (↑) | MAE (↓) | RMSE (↓) |
|---|---|---|---|---|
| SpA GAN | 25.8115 | 0.8204 | 0.05473 | 0.06836 |
| AMGAN | 24.8218 | 0.8091 | 0.06342 | 0.07933 |
| CVAE | 27.3892 | 0.8605 | 0.04456 | 0.05618 |
| Restormer | 30.9301 | 0.9026 | 0.02929 | 0.03837 |
| TCME | 31.7727 | 0.9104 | 0.02622 | 0.03451 |
| SFCRFormer | 32.2261 | 0.9190 | 0.02477 | 0.03283 |
| Dataset | Module | PSNR (↑) | SSIM (↑) | MAE (↓) | RMSE (↓) | ||||
|---|---|---|---|---|---|---|---|---|---|
| Baseline | DBSA | FreSA | Std. Att. | DDFFN | |||||
| RICE1 | ✓ | × | × | × | × | 36.5432 | 0.9605 | 0.01786 | 0.02273 |
| ✓ | ✓ | × | × | × | 36.8385 | 0.9674 | 0.01752 | 0.02174 | |
| ✓ | × | ✓ | × | × | 36.9646 | 0.9682 | 0.01737 | 0.02128 | |
| ✓ | ✓ | ✓ | × | × | 36.9834 | 0.9685 | 0.01723 | 0.02131 | |
| ✓ | ✓ | × | ✓ | ✓ | 36.8753 | 0.9689 | 0.01701 | 0.02095 | |
| ✓ | ✓ | ✓ | × | ✓ | 37.3512 | 0.9699 | 0.01662 | 0.02064 | |
| RICE2 | ✓ | × | × | × | × | 36.2070 | 0.9155 | 0.01884 | 0.02554 |
| ✓ | ✓ | × | × | × | 36.7490 | 0.9216 | 0.01894 | 0.02541 | |
| ✓ | × | ✓ | × | × | 36.8821 | 0.9238 | 0.01773 | 0.02445 | |
| ✓ | ✓ | ✓ | × | × | 37.2963 | 0.9242 | 0.01766 | 0.02419 | |
| ✓ | ✓ | × | ✓ | ✓ | 37.2762 | 0.9223 | 0.01767 | 0.02381 | |
| ✓ | ✓ | ✓ | × | ✓ | 37.7584 | 0.9264 | 0.01709 | 0.02339 | |
| T-Cloud | ✓ | × | × | × | × | 30.9301 | 0.9026 | 0.02929 | 0.03837 |
| ✓ | ✓ | × | × | × | 31.6029 | 0.9126 | 0.02687 | 0.03521 | |
| ✓ | × | ✓ | × | × | 31.9512 | 0.9140 | 0.02598 | 0.03473 | |
| ✓ | ✓ | ✓ | × | × | 31.9875 | 0.9152 | 0.02542 | 0.03432 | |
| ✓ | ✓ | × | ✓ | ✓ | 32.0129 | 0.9154 | 0.02570 | 0.03391 | |
| ✓ | ✓ | ✓ | × | ✓ | 32.2261 | 0.9190 | 0.02477 | 0.03283 | |
| Dataset | Loss | PSNR (↑) | SSIM (↑) | MAE (↓) | RMSE (↓) | |
|---|---|---|---|---|---|---|
| RICE1 | ✓ | × | 36.8561 | 0.9673 | 0.01776 | 0.02207 |
| ✓ | ✓ | 37.3512 | 0.9699 | 0.01662 | 0.02064 | |
| RICE2 | ✓ | × | 36.2071 | 0.9155 | 0.01882 | 0.02553 |
| ✓ | ✓ | 37.7584 | 0.9264 | 0.01709 | 0.02339 | |
| T-Cloud | ✓ | × | 30.9301 | 0.9026 | 0.02926 | 0.03835 |
| ✓ | ✓ | 32.2261 | 0.9190 | 0.02477 | 0.03283 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, F.; Ding, C.; Li, X.; Xia, R.; Wu, C.; Lyu, X. A Spatial–Frequency Combined Transformer for Cloud Removal of Optical Remote Sensing Images. Remote Sens. 2025, 17, 1499. https://doi.org/10.3390/rs17091499
Zhao F, Ding C, Li X, Xia R, Wu C, Lyu X. A Spatial–Frequency Combined Transformer for Cloud Removal of Optical Remote Sensing Images. Remote Sensing. 2025; 17(9):1499. https://doi.org/10.3390/rs17091499
Chicago/Turabian StyleZhao, Fulian, Chenlong Ding, Xin Li, Runliang Xia, Caifeng Wu, and Xin Lyu. 2025. "A Spatial–Frequency Combined Transformer for Cloud Removal of Optical Remote Sensing Images" Remote Sensing 17, no. 9: 1499. https://doi.org/10.3390/rs17091499
APA StyleZhao, F., Ding, C., Li, X., Xia, R., Wu, C., & Lyu, X. (2025). A Spatial–Frequency Combined Transformer for Cloud Removal of Optical Remote Sensing Images. Remote Sensing, 17(9), 1499. https://doi.org/10.3390/rs17091499