1. Introduction
Sliding-spotlight SAR is an imaging mode that lies between the strip-map mode and the spotlight mode [
1,
2,
3,
4,
5]. It controls the antenna steering direction by constantly focusing on a virtual steering point under the ground. This allows the antenna beam to slide slowly across the imaging area, achieving higher azimuth resolution than in strip mode and a wider azimuth swath than in spotlight mode [
6]. However, there are issues of spectral and temporal aliasing in the imaging of sliding-spotlight SAR. The extended CS algorithm can avoid spectral aliasing through sub-aperture processing [
7], but this method requires spectrum splicing, which is very complex; moreover, as the azimuth swath increases, the number of sub-apertures also increases, making the subsequent radiometric correction more difficult. The back projection (BP) algorithm directly achieves focusing in the time domain, thereby avoiding the conversion of signals to the Doppler domain [
8], which efficiently circumvents the challenge of spectrum aliasing. However, compared to frequency domain algorithms, the BP algorithm incurs a considerable increase in computational load, leading to substantial consumption of computational resources and a marked decrease in processing efficiency.
The CS algorithm for strip mode imaging consists only of FFT and phase multiplication operations, characterized by high imaging accuracy and low computational complexity. Compared to other algorithms such as the range-Doppler (RD) algorithm and the BP algorithm, which require extensive interpolation operations resulting in significantly lower computational efficiency, the CS algorithm has greater potential for real-time processing [
9].
Based on the CS algorithm [
10], the Deramp preprocessing operation reduces the azimuthal Doppler bandwidth and increases the equivalent PRF, thereby resolving the issue of azimuthal spectral aliasing [
11,
12,
13,
14]. By performing azimuth zero-padding after preprocessing or SPECAN post-processing at the end of the algorithm [
15], the issue of time-domain aliasing in the imaging results can also be resolved. The main steps of Deramp and SPECAN processing both involve chirp scaling and time–frequency transformation. As a result, this algorithm only requires fast Fourier transform (FFT) and complex multiplication operations, which reduces the computational complexity.
The demand for timeliness in SAR imaging is increasing, and traditional ground-based processing methods can no longer meet these needs. There is an urgent demand for on-board processing to enhance the responsiveness of satellites [
16]. However, the current on-board processing capabilities of satellites are primarily focused on the strip mode. As data volumes increase, particularly in the sliding-spotlight SAR mode where the volume of echo data increases significantly, the complexity of imaging processing also rises [
17]. Therefore, under the constraint of limited hardware resources, it is of great significance to explore applicable imaging methods to achieve on-board real-time processing for large data volumes in both the strip mode and the sliding-spotlight mode using existing platforms.
The GPU is known for its powerful parallel computing capability and efficient data processing performance, with thousands of small cores designed to handle large volumes of data simultaneously [
18,
19]. In SAR imaging, these characteristics of GPUs provide significant advantages. Compared to FPGAs [
20,
21,
22,
23], GPUs are more suitable for this study. First, the parallel processing capability of a GPU greatly accelerates computationally intensive operations such as range and azimuth compression, speeding up the overall image processing. Additionally, the frequent use of fast Fourier transform (FFT) in SAR imaging is significantly enhanced by optimized GPU libraries like cuFFT [
24]. These benefits make GPUs highly effective for real-time SAR imaging and large-scale data processing tasks, enabling the rapid generation of high-resolution SAR images.
Compared to traditional GPUs, embedded GPUs have the advantages of lower power consumption, smaller size, and better integration, making them more suitable for on-board processing. With advancements in technology, embedded GPUs have undergone multiple iterations, continuously improving performance and reducing power consumption. Meanwhile, extensive research has been conducted on different platforms utilizing these GPUs. For example, the implementation of a SAR imaging algorithm on a Jetson TK1 platform is presented in [
25]; the implementation and testing of two synthetic aperture radar processing algorithms on a Jetson TX1 platform is described in [
26]; in [
27], sliding-spotlight SAR imaging based on the NVIDIA Jetson TX2 platform was implemented; and a distributed SAR real-time imaging method based on Jetson Nano platforms is proposed in [
23].
This paper focuses on on-board fast imaging for spaceborne sliding-spotlight SAR. Additionally, the algorithm is compatible with both the strip mode and the TOPSAR mode [
28,
29,
30]. The main contributions of this paper are as follows:
(1) An efficient imaging algorithm based on a criterion called the Method Choice Indicator (MCI) is proposed. Firstly, the theoretical model of the time–frequency transformation is analyzed. Then, the calculation methods of equivalent PRF and azimuth interval of unit pixel are given, which lays a foundation for subsequent geometric correction and calibration. On the other hand, while both azimuth zero-padding and performing a chirp scaling operation once more in post-processing can resolve the issue of time-domain aliasing, the processing time of the two methods will vary with the processed data. The computing efficiency of the two methods is analyzed [
9], and the MCI is provided for selecting an efficient method based on specific data.
(2) An application method of this algorithm on the latest generation of the Jetson series, the AGX Orin platform, is proposed, which achieves on-board near-real-time processing for sliding-spotlight mode SAR imaging. To reduce peak memory usage during image processing and enable a single AGX Orin to handle larger datasets, we propose a batch processing method to implement the adaptive and efficient imaging algorithm for the sliding-spotlight mode. Additionally, this algorithm is also compatible with strip mode imaging. Although batch processing increases the number of data transfers between the CPU and GPU, the integrated architecture of the AGX Orin significantly mitigates the negative impact. Furthermore, we have adopted a series of methods to optimize the algorithm, ultimately making it possible to achieve on-board near-real-time processing for large data volumes in the sliding-spotlight mode.
This article is organized as follows:
Section 2 analyzes the imaging process of the sliding-spotlight mode.
Section 3 presents the algorithm design and optimization methods using the AGX Orin platform.
Section 4 gives the experimental results and discussion.
Section 5 concludes the paper.
3. Implementation and Optimization
In this section, the previously discussed CS imaging algorithm for the strip mode and the two imaging algorithms for the sliding-spotlight mode are implemented in a batch-processing manner and optimized on the embedded GPU platform AGX Orin. Given the similar time–frequency characteristics of echo signals in both TOPSAR and sliding-spotlight modes, the proposed algorithm is also well-suited for TOPSAR mode imaging [
27,
28,
29]. The specific content includes the characteristics and advantages of the AGX Orin platform, the method for implementing batch processing, as well as the program optimization method.
3.1. NVIDIA Jetson AGX Orin
The NVIDIA Jetson AGX Orin is classified as a system-on-module (SoM), which primarily belongs to an integrated architecture. In discrete architectures, the CPU and GPU are independent, with the GPU having its own dedicated memory. In contrast, in integrated architectures, the CPU and GPU share the same memory, which greatly speeds up data transfer between the CPU and GPU during batch processing. Furthermore, it uses a GPU based on the Ampere architecture with up to 2048 CUDA cores and 64 Tensor cores, and its CPU is an ARM Cortex-A78AE with 12 cores (Infineon, Neubiberg, Germany), which is designed by ARM Holdings, a semiconductor and software design company headquartered in Cambridge, United Kingdom. The integration of all these components makes it highly efficient. With 64 GB of LPDDR5 memory and a bandwidth of 204.8 GB/s, it is capable of processing much larger scale data.
Figure 5a is the image of the AGX Orin, and
Figure 5b is the schematic diagram of the integrated architecture.
Although the host and device share the same memory on the AGX Orin platform, explicit data transfers are still typically used for processing, primarily for the following reasons. First, memory access efficiency differs between the GPU and CPU, with GPUs performing better when accessing local cache or dedicated memory regions. Second, memory consistency must be maintained when both access the same data simultaneously, with explicit transfers clearly defining data ownership boundaries and synchronization points. Additionally, despite hardware unified access support, the CUDA programming model traditionally relies on explicit data transfers, influencing existing algorithms and libraries. Finally, GPUs and CPUs have different cache hierarchies, where explicit data movement ensures that data resides at the optimal cache level. While data transfers between the host and device are still necessary, sharing the same memory eliminates the need for data transmission over the PCIe bus, greatly improving transfer efficiency.
When mounting a device on a satellite, factors such as the device’s size, weight, and power consumption must all be carefully considered. The AGX Orin is compact, measuring 105 mm × 105 mm × 50 mm, and weighs approximately 700 g, with maximum power consumption of no more than 60 W, making on-board real-time processing feasible.
3.2. Batch Processing
Although the AGX Orin has 64 GB of memory, many steps in the imaging process, such as calling the cuFFT library for FFT and performing matrix transpositions, require additional memory equivalent to the data size. Therefore, if the entire data block is processed at once, peak memory usage during imaging can be substantial, limiting the size of the data that can be processed. Therefore, it is necessary to perform batch processing on the data.
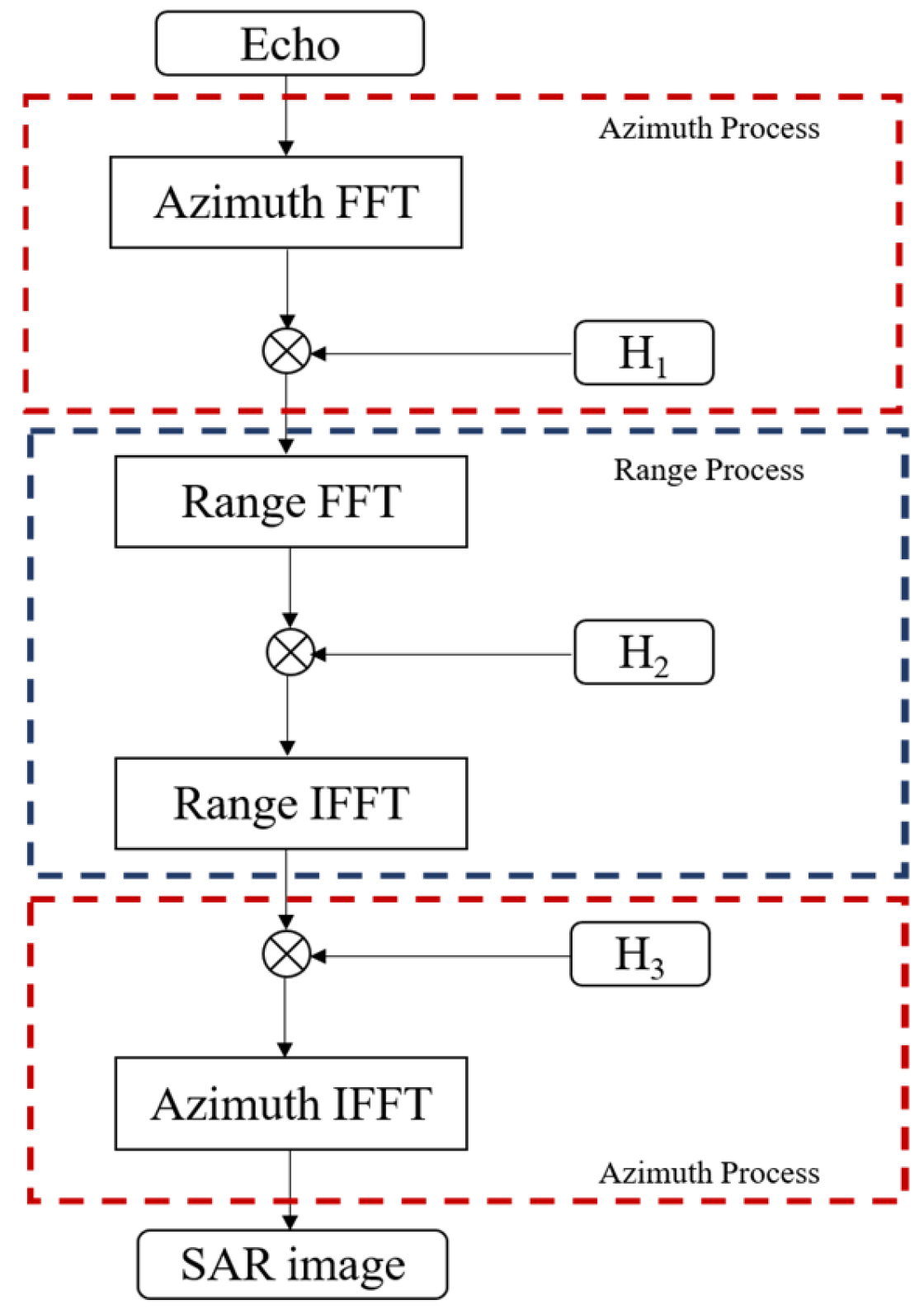
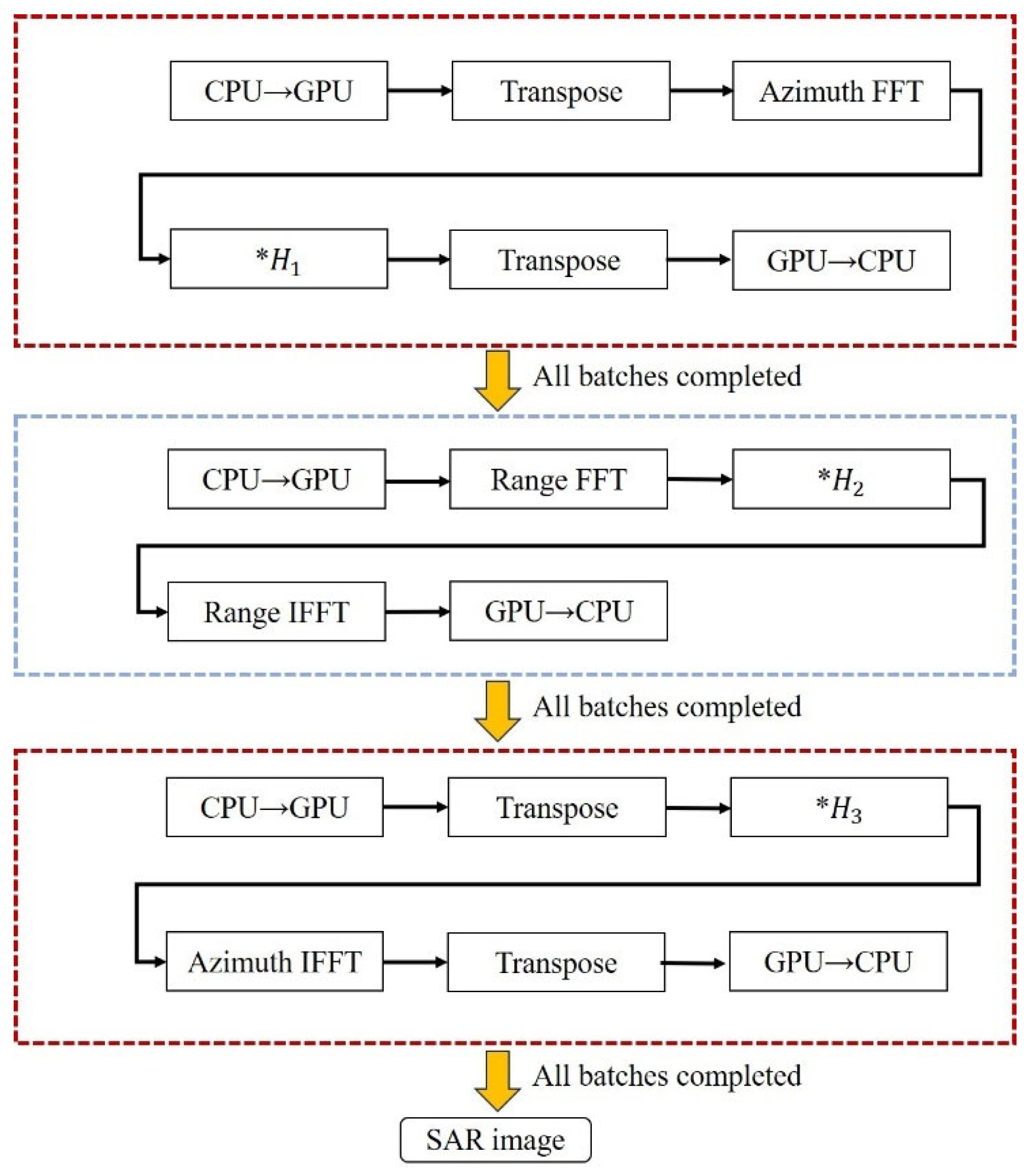
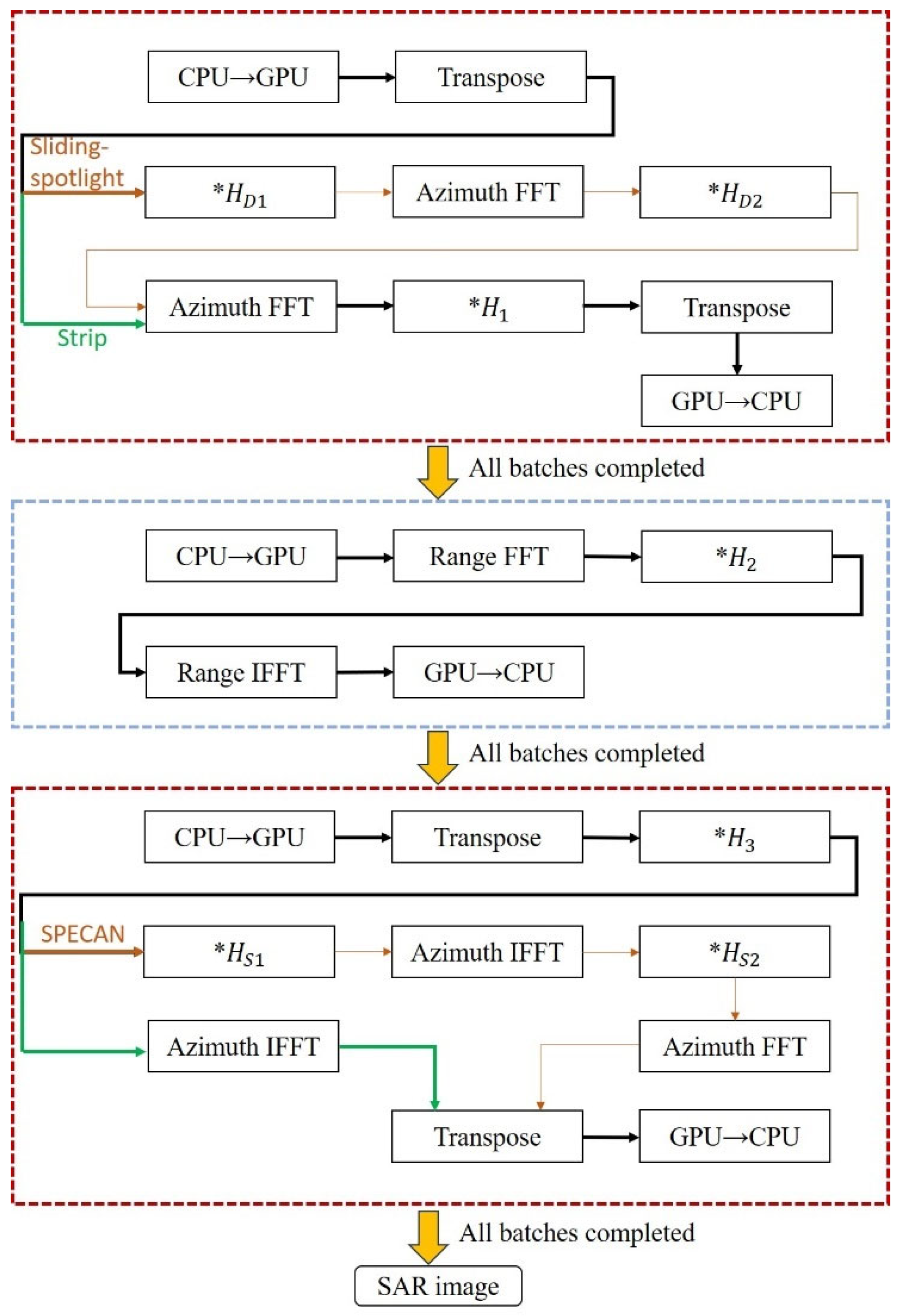
As shown in
Figure 1, the CS algorithm for the strip mode can be divided into three parts: the first and third parts handle azimuth processing, while the second part handles range processing. Before processing each part, the data is transferred in batches from the host to the device, and after each batch is processed, the data is transferred back from the device to the host. The complete flowchart of the CS algorithm implementation is shown in
Figure 6.
Before the imaging process, the SAR raw data to be processed is read from the file into the host memory
. As shown on the left side of
Figure 7,
is arranged in memory in a row-continuous manner, with the range direction being ordered first.
For range processing, the data in the host is partitioned as shown in
Figure 7. Each block of data is sequentially copied from the host memory to the device memory. After the range processing is completed, the processed block is copied back to the corresponding position in
. Since the processed data is continuously arranged, issues related to uncoalesced memory access will not occur.
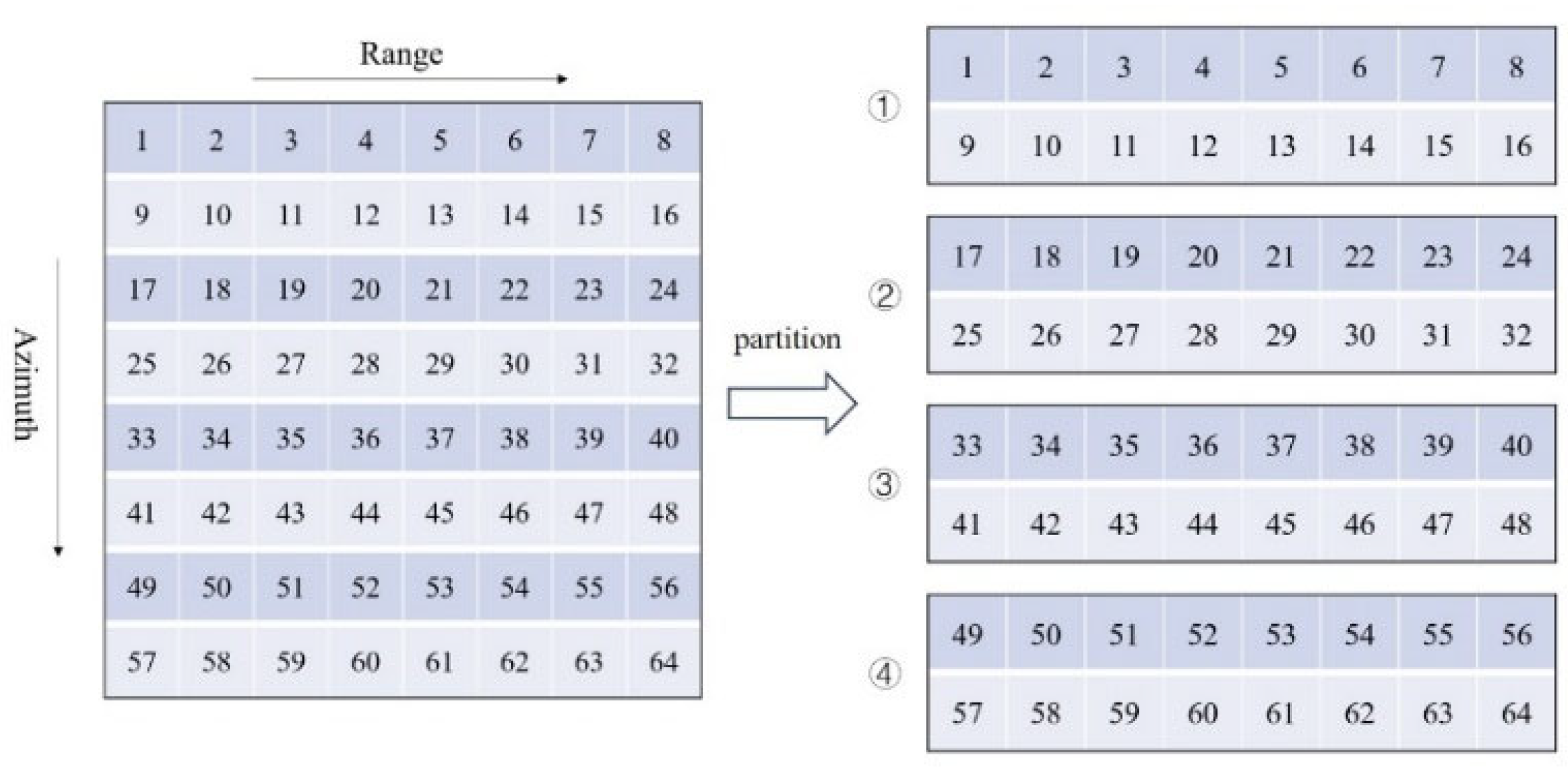
For azimuth processing, the data in the host is partitioned as shown in
Figure 8. Each block of data is still copied from the host memory to the device memory. However, when performing azimuth processing with the current data arrangement, the azimuth data is not contiguous, leading to uncoalesced memory access, which reduces processing efficiency. Therefore, after completing the data transfer from the host to the device, the data needs to be transposed to ensure that during subsequent azimuth processing, coalesced memory access can be achieved to improve efficiency. The arrangement of the transposed data is shown in
Figure 8. After completing azimuth processing, the data needs to be transposed again before being copied back to the host, ensuring it can be placed in the correct corresponding position in
.
By using batch processing, peak memory usage during data transfer is reduced. For example, if the data size in
Figure 7 is 8 GB and is divided into four batches for processing, each batch will handle 2 GB of data. Compared to directly transferring the entire data block, which would require 16 GB of memory, batch processing reduces the memory usage to 10 GB.
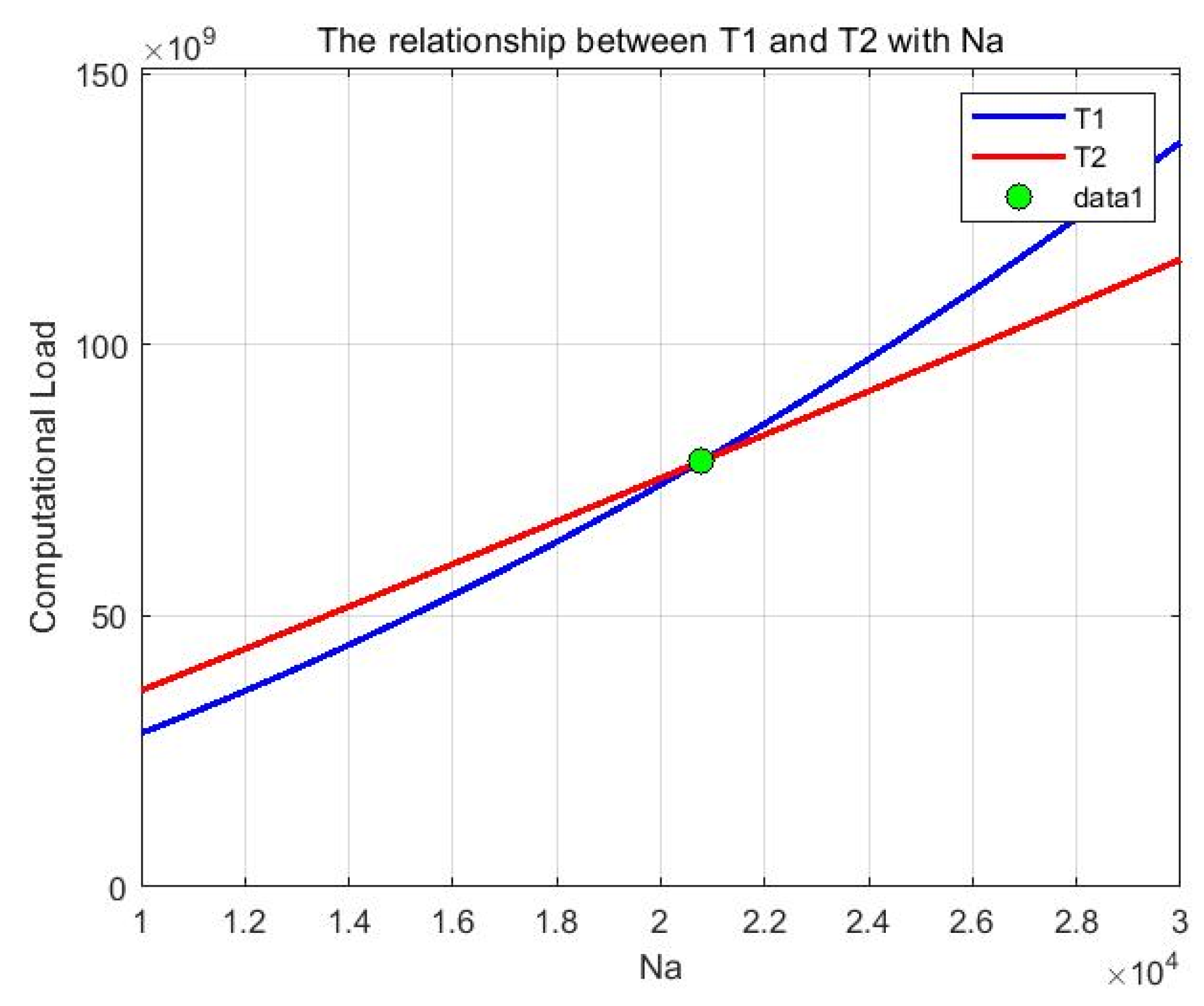
Batch processing must ensure that the program does not run out of memory during execution, but as the number of chunks increases, the efficiency of the program decreases. Therefore, ideally, fewer chunks are better as long as the program does not overflow the memory. Let
denote the available memory of the processor and
represent the data size. Considering that operations like FFT require additional memory during processing, a safety margin should be reserved. The number of blocks N can be calculated as follows:
In this formula, dividing by 2 and applying ceiling rounding ensures that the number of blocks is sufficient to avoid memory overflow.
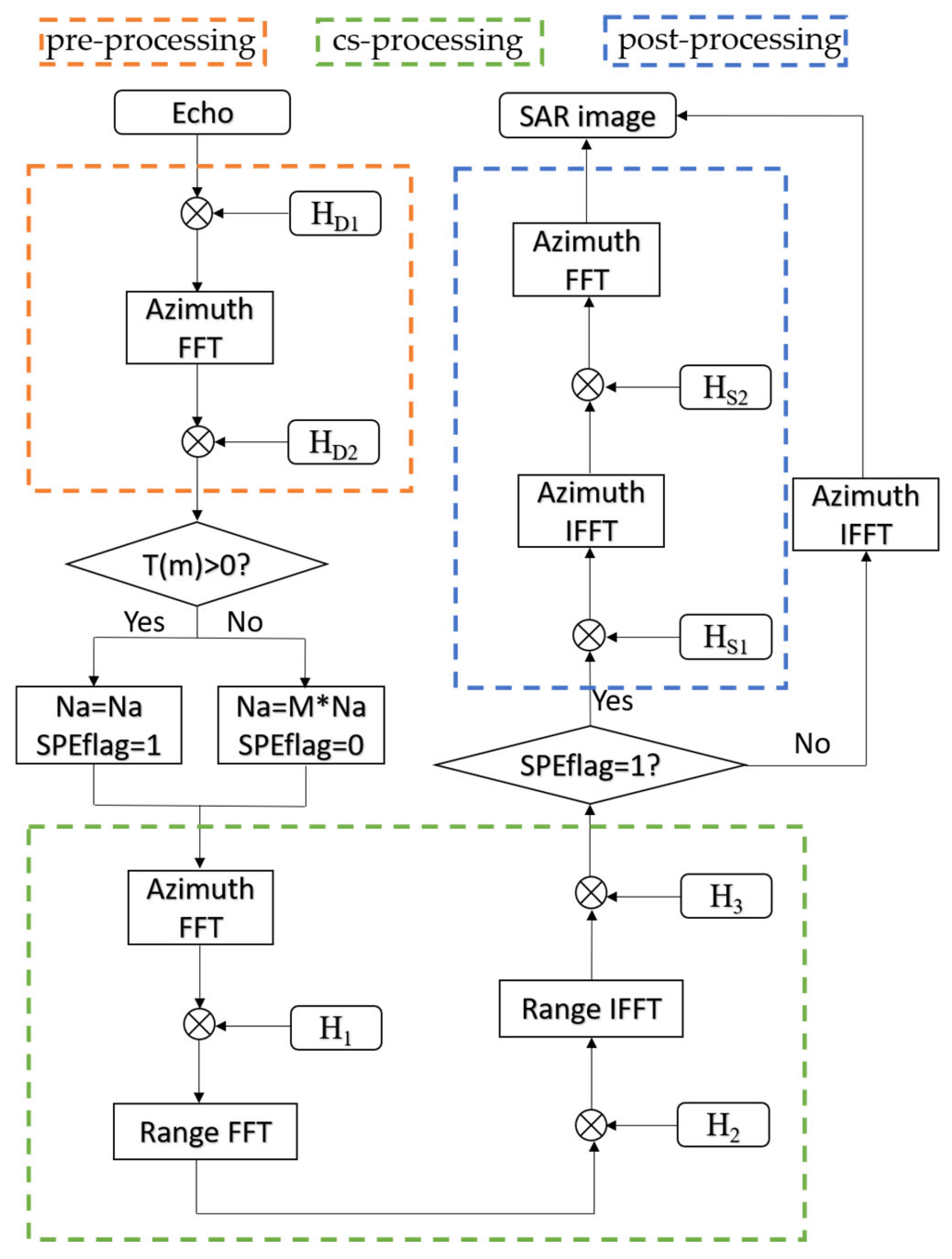
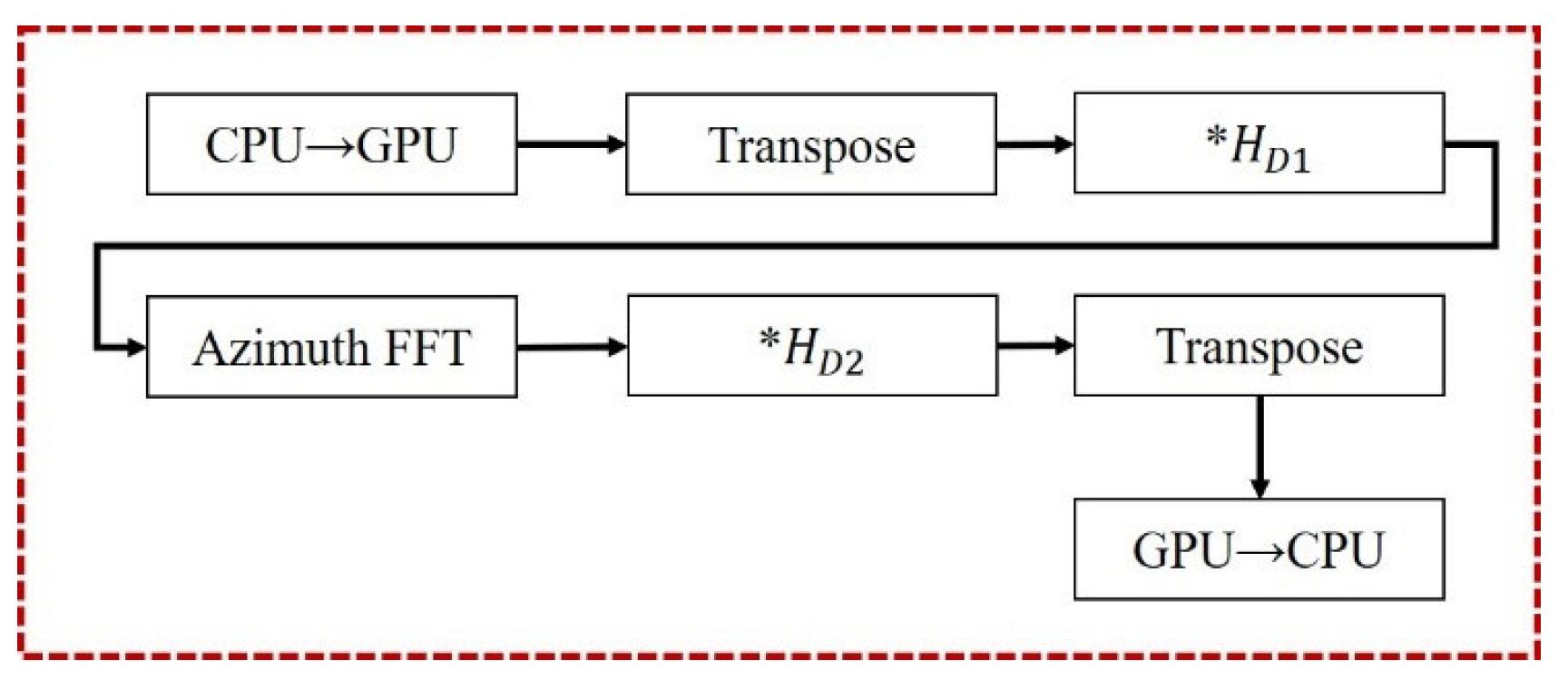
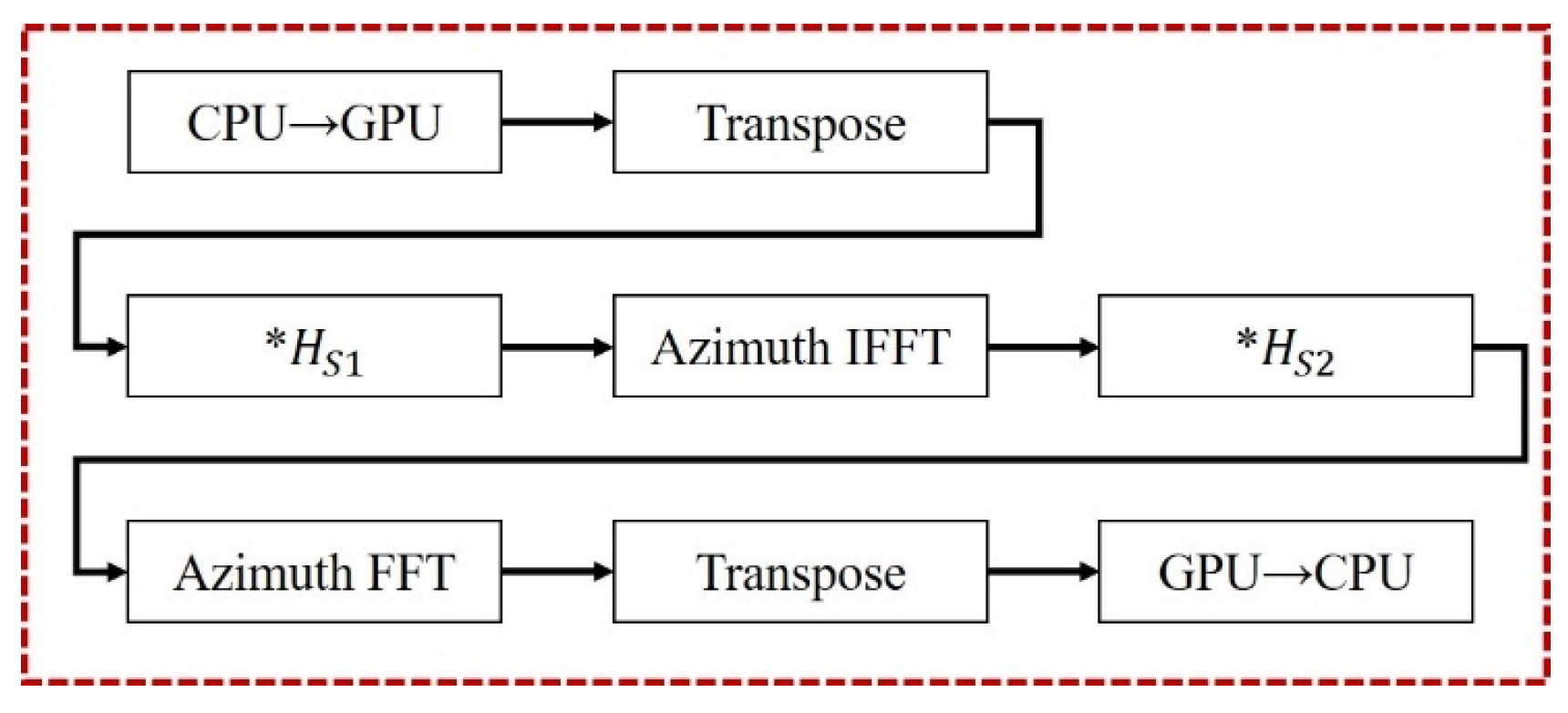
Compared to the CS algorithm in the strip mode, the two imaging algorithms for the sliding-spotlight mode introduce different enhancements: one algorithm adds azimuthal preprocessing, while the other incorporates both preprocessing and post-processing operations. The preprocessing and post-processing steps that need to be added are shown in
Figure 9 and
Figure 10. As shown in the flowchart in
Figure 3, the algorithm can be divided into three parts based on the functions of its individual modules. Since both preprocessing and post-processing are azimuth operations, the entire algorithm, in its most complex form, includes up to four azimuth processing steps and one range processing step. However, this implementation is not optimal.
It can be observed that in the CS algorithm, azimuth processing is involved both immediately after preprocessing and just before post-processing. This means that the two newly added processing steps can be merged into the adjacent azimuth processing steps of the CS algorithm, thereby reducing a total of four data transfers between the host and device as well as four matrix transposition operations.
The complete flowchart of the extended algorithm is shown in
Figure 11. Conditional statements can be used to select either the CS imaging algorithm for the strip mode or one of the two algorithms for the sliding-spotlight mode. This algorithm not only enables SAR imaging for both the strip mode and the sliding-spotlight mode but also allows for the selection of a more efficient imaging algorithm based on the characteristics of sliding-spotlight mode data.
3.3. CUDA Programming Techniques and Optimization
Although the algorithm is designed to run on the embedded GPU platform AGX Orin, the methods for writing and optimizing it are almost identical to those used on a traditional GPU and are also implemented using CUDA. From the flowchart of the algorithm, the main steps include data transfer between the CPU and GPU, matrix transposition, FFT and IFFT operations, and phase multiplication. This subsection focuses on how to optimize these parts to improve processing efficiency.
For data transfer between the CPU and GPU during azimuth processing, since the data in a block is not contiguous in memory, block copying can be achieved by calling the memory copy functions cudaMemcpy2D or cudaMemcpy2DAsync provided by the CUDA programming interface, which support segmented copying. For range processing, since the data within a block is stored contiguously, in addition to using the two functions mentioned above, it is also feasible to directly use cudaMemcpy or cudaMemcpyAsync for data transfer. Compared to discrete architectures, the integrated architecture of the AGX Orin platform significantly improves data transfer efficiency between the CPU and GPU. Since multiple data transfers between the CPU and GPU in the program are related to , we can register as pinned memory, also known as page-locked memory, to further improve data transfer efficiency. Pinned memory is allocated by locking physical memory pages, which avoids paging operations during data transfers between the CPU and GPU, thereby significantly improving data transfer speed. However, it is important to note that pinned memory consumes more physical memory resources, so it should be used carefully.
The program contains a total of four matrix transposition operations, so the optimization of the matrix transposition is also important. A typical matrix transposition operation involves reading data from global memory by row and writing by column, or reading by column and writing by row, to achieve the transposition effect. However, in such operations, one memory access will inevitably be non-contiguous, resulting in uncoalesced memory access, which ultimately reduces processing efficiency. To address this issue, shared memory can be used to optimize matrix transposition. As shown in
Figure 12, the data is read from global memory by row into shared memory. Then, the data is read from shared memory by column and finally written back into global memory by row, completing the matrix transposition. Although the reading from the shared memory is performed column-wise, the access speed within the local memory is very fast, which significantly improves overall performance. The shared memory is divided into banks, and accessing multiple elements from the same bank simultaneously can cause serialization (bank conflicts), leading to performance loss. To avoid this, the data structure is adjusted to ensure that threads access different memory banks. For example, padding arrays can help prevent conflicts.
FFT and IFFT operations can be efficiently implemented using the cuFFT library provided by CUDA. To improve efficiency, the cuFFT plan should be configured once at the beginning of each module and released at the end, rather than configuring and releasing it multiple times.
For the multiple phase multiplication operations in the program, the following optimization techniques can be applied. First, precompute parameters that are used repeatedly in the calculations to avoid repeated computations. In CUDA programming, the pow function is inefficient. For calculating square and cubic terms in the program, replacing the pow function with multiple multiplications can improve efficiency. For instance, use for squares and for cubic terms. In addition, the SAR raw data is in single precision, but many parameters used in imaging are in double precision. The program will automatically compute in double precision, which reduces processing efficiency. To improve efficiency, the parameters can be converted from double precision to single precision before imaging, and trigonometric functions like sin and cos can be replaced with their single precision counterparts, sinf and cosf. It is important to note that such changes may lead to a decline in imaging quality. Experiments have shown that while converting other computations to single precision results in outcomes very close to the original and significantly improves efficiency, changing the multiplication with to single precision causes a noticeable degradation in imaging quality.
5. Discussion
The final optimized imaging processing time was 19.25 s, while the satellite acquisition time for the data was 11.43 s. The ratio of data acquisition time to processing time was
Typically, when this ratio reaches 1, the processing can be considered real-time. Therefore, the optimized processing can be regarded as near-real-time processing [
32,
33].
Figure 15 shows the final imaging result after a series of optimizations listed in
Table 5. It can be observed that there was no significant difference in image quality compared to that of the original result.
It took 54 s before optimization compared to 20 s after optimization to image the same data using the zero-padding method, resulting in a speedup ratio of 2.7. Using another set of data in the strip mode with a size of 21,211 39,424 for CS algorithm imaging, the processing time was 23.4 s before optimization and 7.7 s after optimization, resulting in a speedup ratio of 3.0.
In addition, the optimized program was ported to NVIDIA A6000 (designed by NVIDIA Corporation, Santa Clara, USA; GPU chips fabricated by TSMC, Hsinchu, Taiwan, China) for experimentation. Using the same data in the sliding-spotlight mode as before, with the post-processing method for imaging, the processing time was approximately 9.5 s. Although the A6000 took less time than the AGX Orin did, it had higher power consumption than the AGX Orin. To better compare the performance of the algorithm on the two platforms, the performance-to-power ratio can be used as a reference. Since the same data was used, the data size can be excluded from the formula, leaving only time and power. Clearly, the product of time and power is a representation of energy, which can be understood as the amount of energy consumed during the imaging process for this data. Since the A6000 has a power consumption of 300 W and the AGX Orin has a power consumption of 60 W, the energy consumed during the imaging process is 2850 J and 1320 J, respectively. Therefore, the AGX Orin demonstrates better overall performance compared to the A6000. A major reason is that the A6000 uses a discrete architecture, which results in lower data transfer efficiency between the CPU and GPU. The A6000 is more suited for ground processing, as it is not constrained by factors such as size, weight, and power consumption.
6. Conclusions
In this article, an adaptive and efficient imaging algorithm was proposed to process spaceborne sliding-spotlight SAR data. A selection criterion called the MCI for the two methods was provided. This is the basis for implementing and optimizing the algorithm on the AGX Orin. Furthermore, a detailed analysis of the changes in the signal before and after the time–frequency transformation and its function in Deramp preprocessing and chirp scaling post-processing were introduced, laying the foundation for subsequent geometric correction and calibration.
Subsequently, the batch processing design and optimization of the algorithm were carried out on the AGX Orin. As a result, imaging in the sliding-spotlight mode for data of size 42,966 27,648 was completed in just 22 s, achieving a speedup ratio of 2.9. This makes near-real-time SAR imaging for large datasets in the sliding-spotlight mode on-board possible. In addition, the proposed algorithm is compatible with both the strip mode and the sliding-spotlight mode imaging algorithms. The algorithm is also applicable to the TOPSAR mode. Finally, a comparison between the AGX Orin and A6000 was conducted, showing that the AGX is more suitable for on-board processing.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}