
TPNet: A High-Performance and Lightweight Detector for Ship Detection in SAR Imagery


Abstract
1. Introduction
- We introduce TPNet, a novel SAR ship detector inspired by CenterNet. TPNet significantly enhances the detection of small ships by leveraging high-resolution feature layers for prediction. This approach addresses the limitations of existing methods in detecting small ships while maintaining computational efficiency.
- TPNet achieves lightweight design through the introduction of MBlock, reducing computational cost to only 0.485 G FLOPs, a 92.5% reduction compared to CenterNet. Additionally, Dynamic Feature Refinement Module (DFRM), Refine Bounding-Box Head (RBH), Refine Scoring Branch (RSB), Weighted GIoU(WGIoU) Loss, and Weighted Squeeze-and-Excitation (WSE) Attention Mechanism are integrated to further boost performance.
- Extensive experiments on the open-source SAR-Ship-Dataset demonstrate that TPNet achieves state-of-the-art performance with an average precision of 95.7% at an IoU threshold of 0.5 (). Experiments on additional datasets (SSDD and HRSID) validate TPNet’s strong generalization ability. Comprehensive ablation studies also highlight the individual and combined contributions of each proposed mechanism.
2. Methodology
2.1. The Basic Structure of TPNet
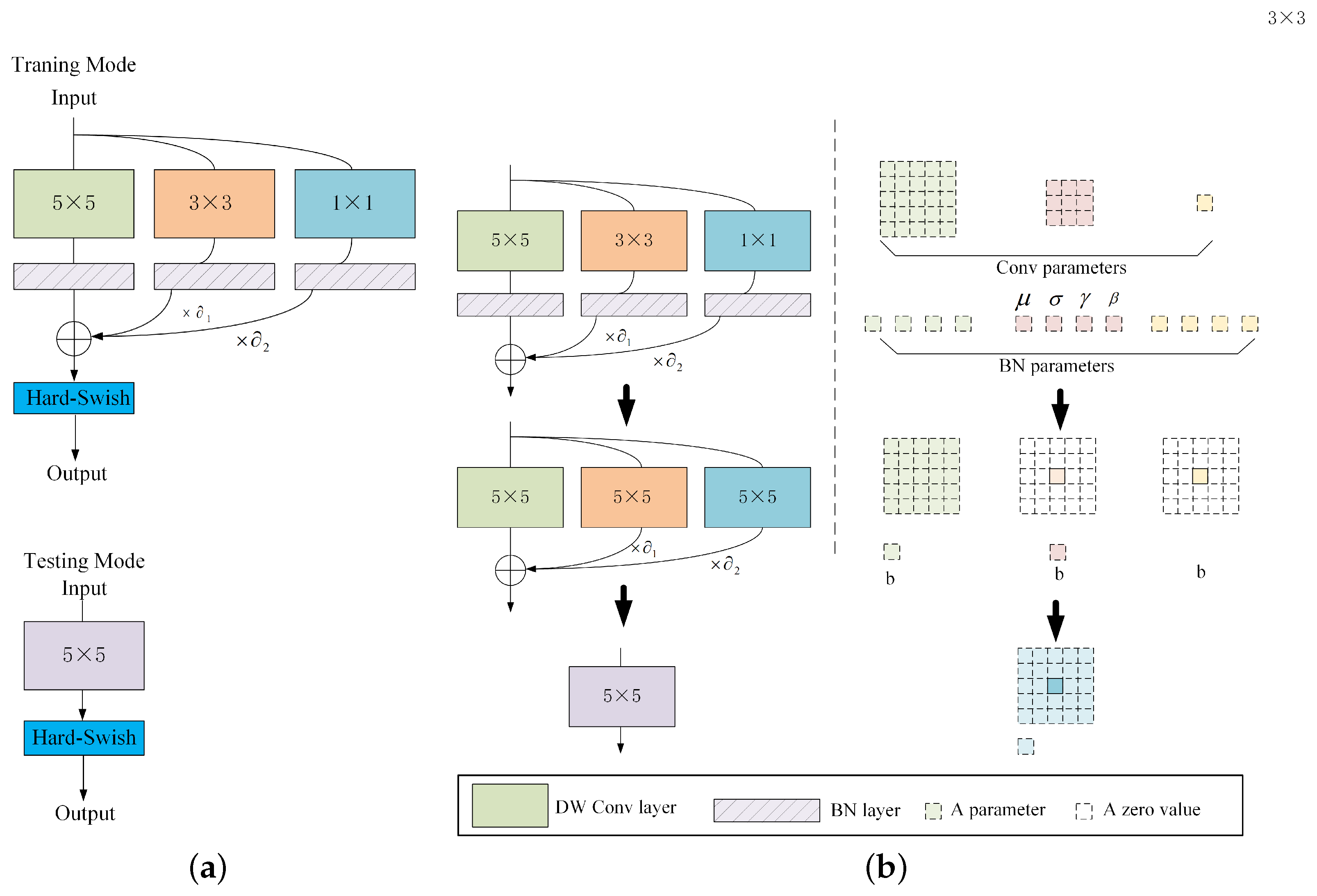
2.2. MNet: An Efficient Backbone Architecture for Feature Extraction
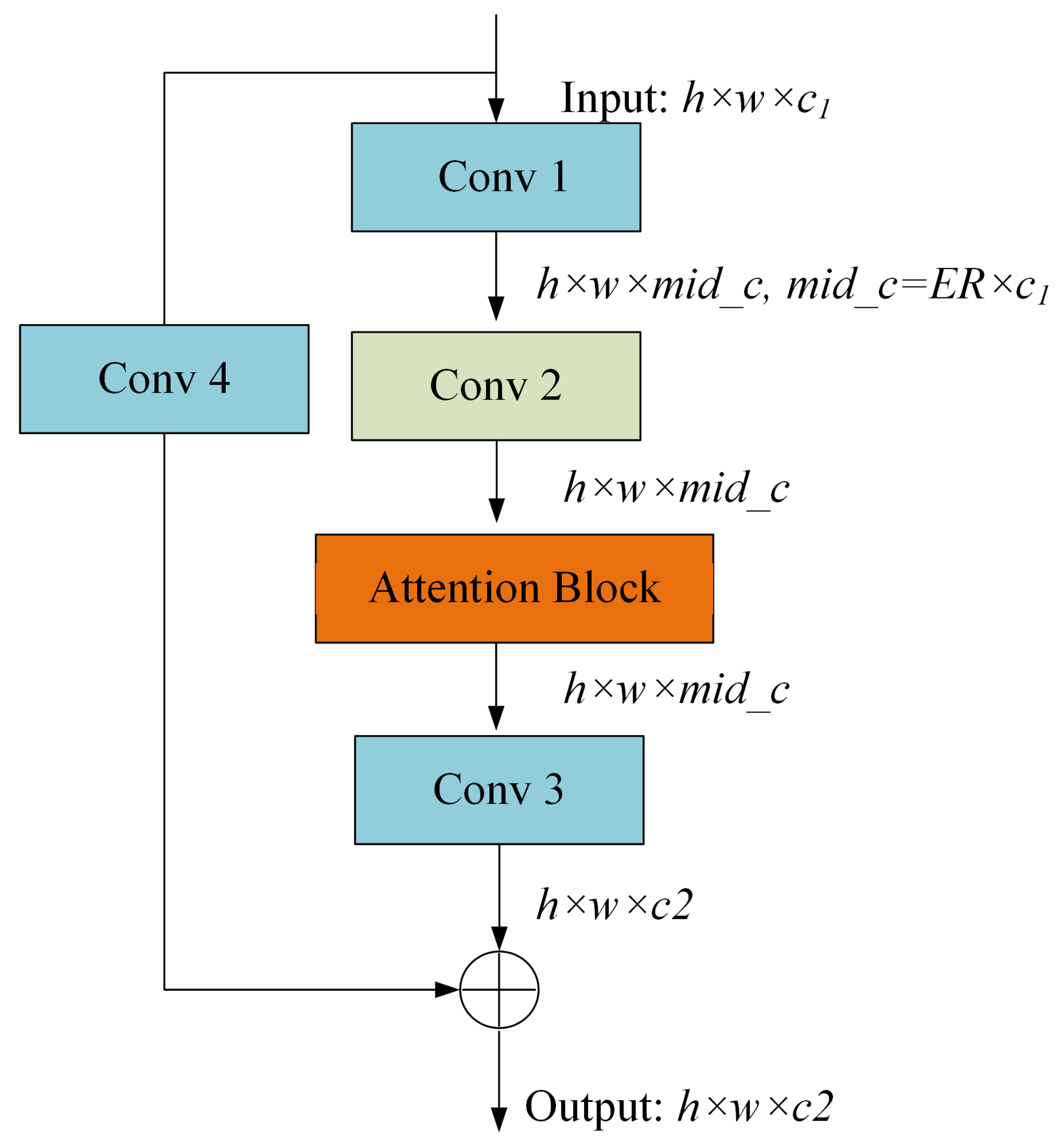
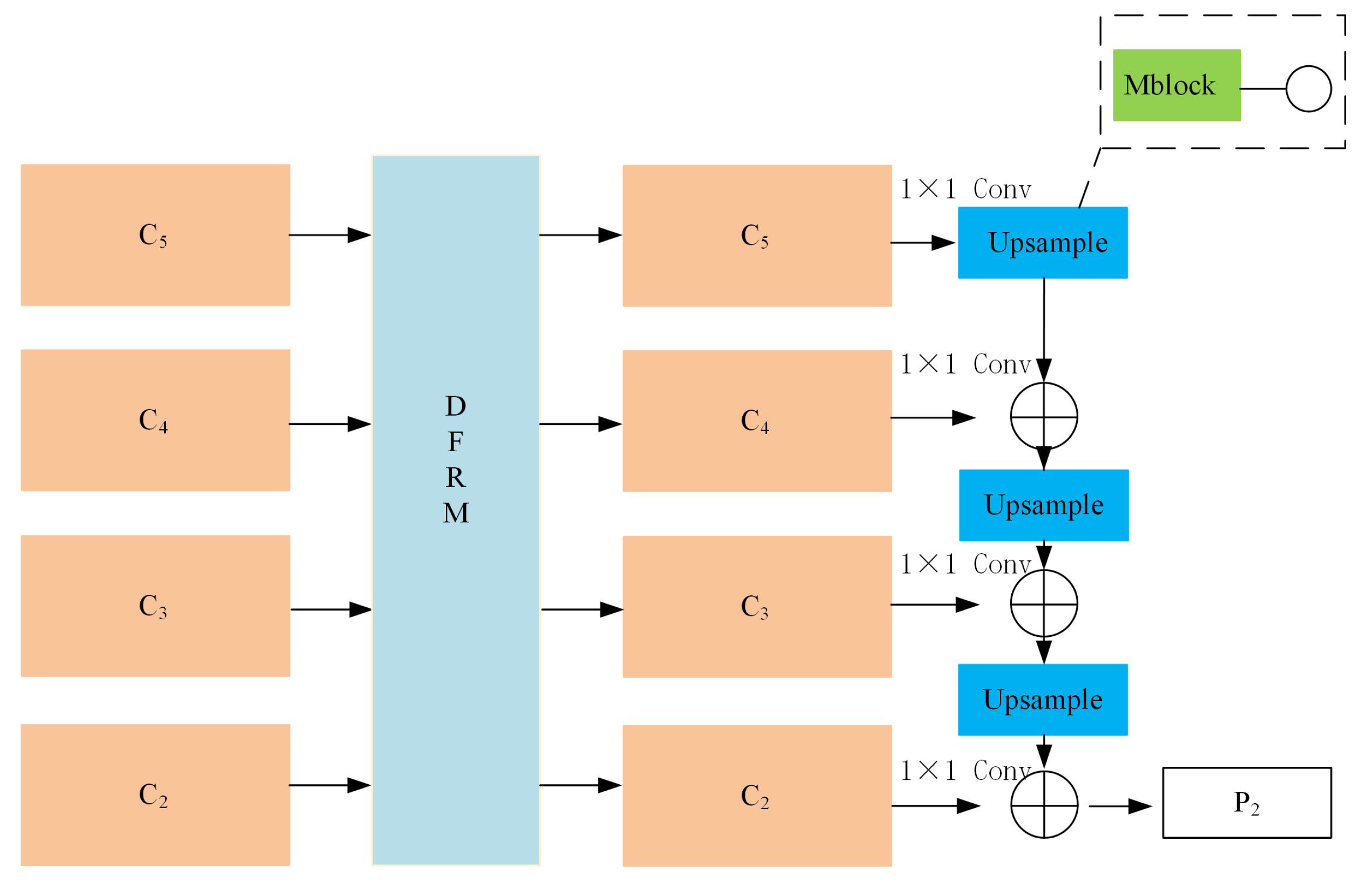
2.3. MFPN: An Enhanced Feature Extraction Neck for Robust Feature Fusion
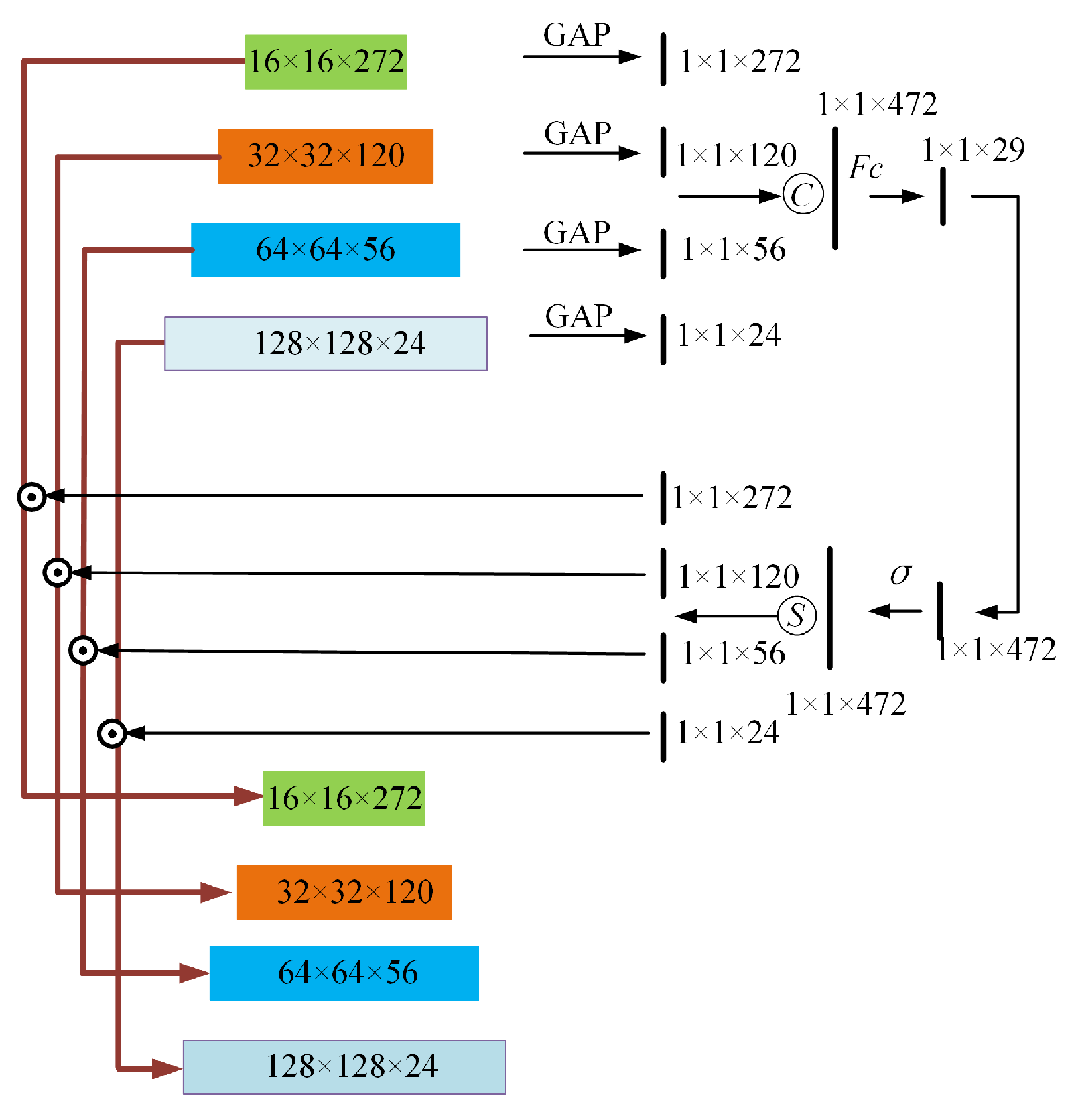
- Global information extraction: adaptive average pooling is applied to each feature map to capture global information. These global feature descriptors are subsequently concatenated and processed through lightweight convolutional layers to learn a set of weights.
- Weight calculation: the weights are derived via convolutional operations followed by a sigmoid activation function. These weights reflect the importance of each feature map in the current scene.
- Feature refinement: the refined features are obtained by channel-wise multiplication of the weights with the corresponding feature maps.
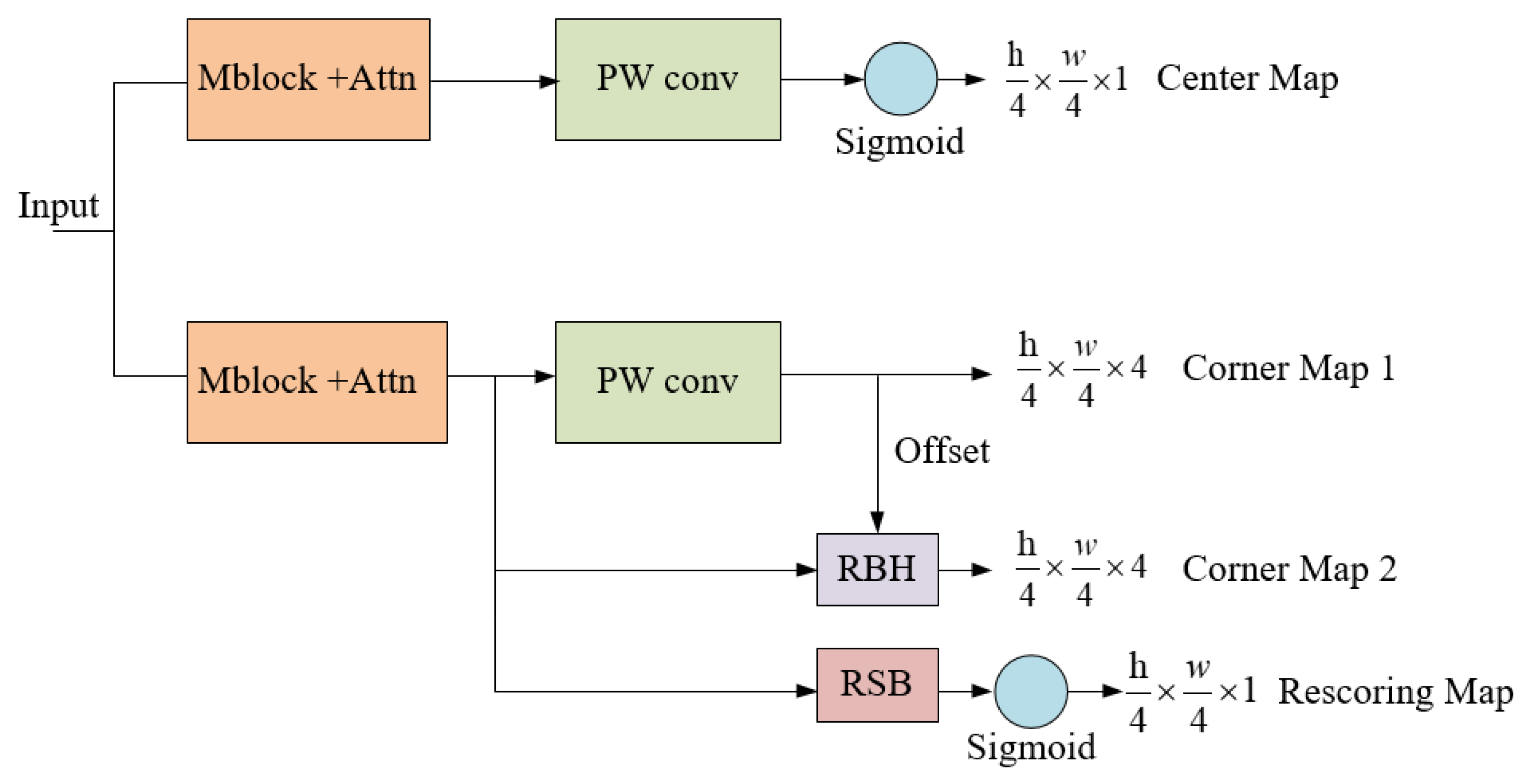
2.4. Detection Head Architecture and Output Components
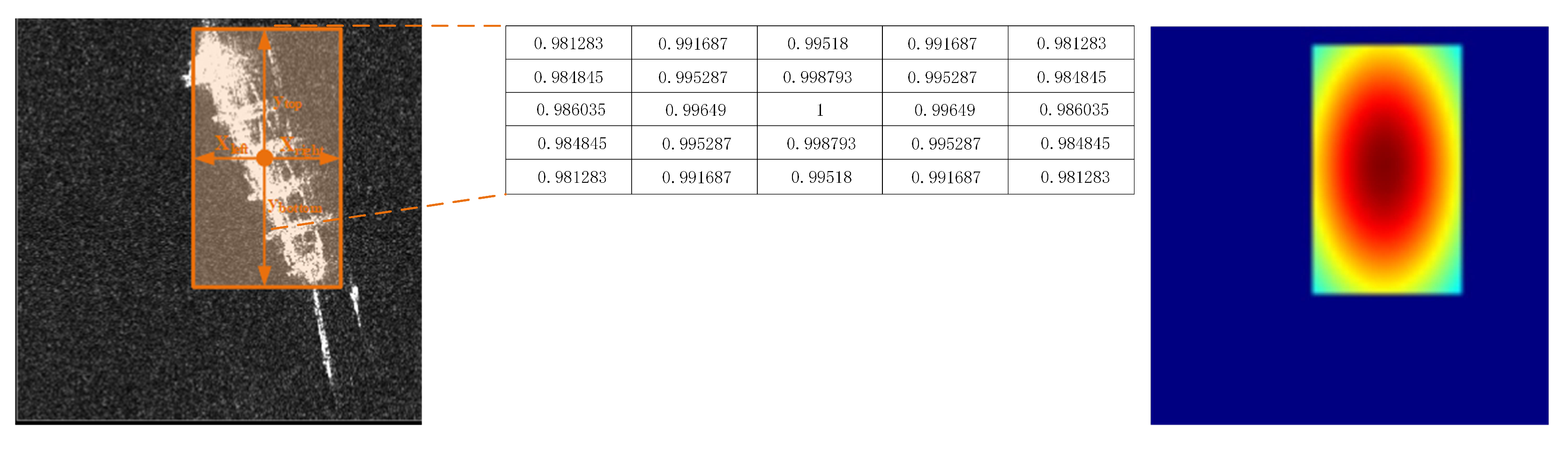
2.4.1. Center Map for Classification
2.4.2. Corner Map1 for Localization
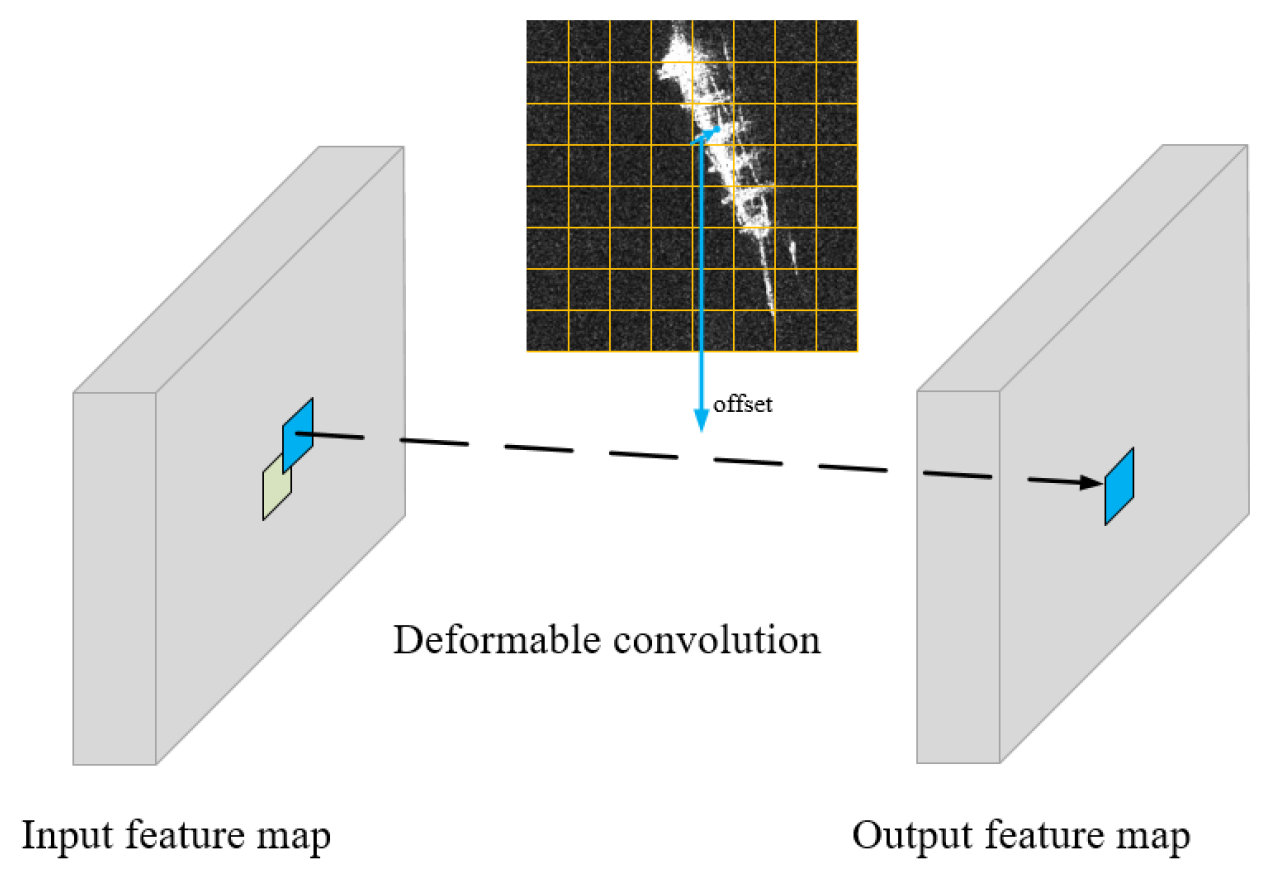
2.4.3. Corner Map2 for Refining Bounding Box
2.4.4. RSB for Refining Center Map
2.5. WGIoU Loss Function
| Algorithm 1 The calculation process of WGIoU loss |
Input: Center map: , Corner map1: , Corner map2: Output:
|
2.6. WSE Attention Module
| Algorithm 2 The calculation process of the WSE layer |
Input: Tensor Output: Tensor Require: a 1x1 convolutional layer conv whose input channels is C and output channels is 1, and two FC layers fc1 and fc2
|
2.7. The Workflow of TPNet
- Step 1: Pre-process the detected image and feed the pre-processed image to MNet. The features generated by MNet are further processed by the neck to obtain a feature map, then this feature map is fed to the Head.
- Step 2: As shown in Figure 7, the Head generates a center map, a corner map1, a corner map2, and a rescoring map. The final center map is obtained by multiplying the center map and the rescoring map. Points on the center map with values greater than the set threshold (0.1) are identified as positive and recorded as (, ), (, ), etc.
- Step 3: Using Equation (10) and the corner map1 and corner map2, bounding boxes corresponding to these points are obtained and recorded as , , etc.
- Step 4: The bounding boxes from Corner map2 and their corresponding scores on the refined center map are integrated and processed through NMS to yield the final predicted ships.
3. Experiment Settings
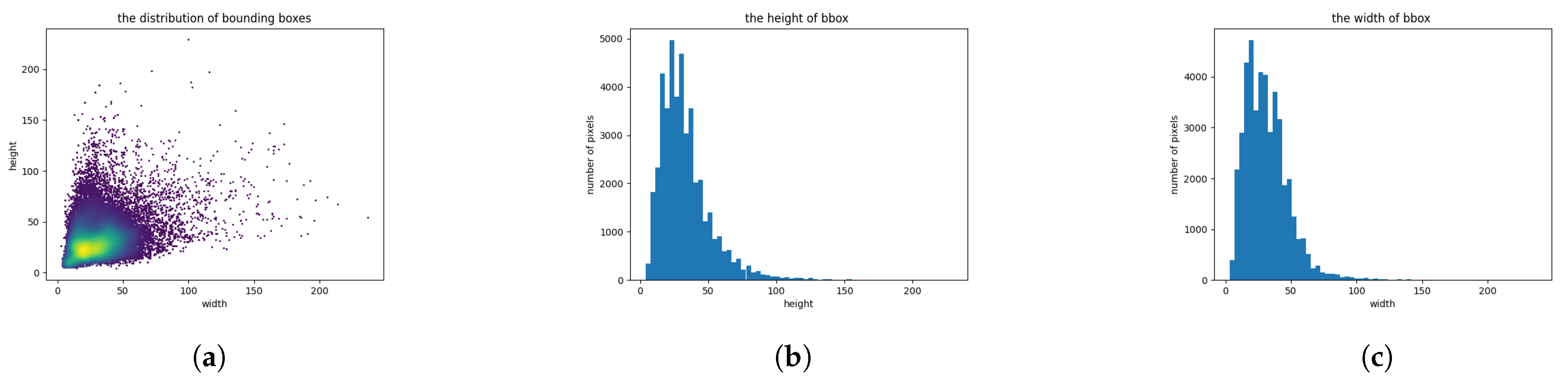
3.1. Datasets
3.2. Evaluation Metrics
3.3. Experimental Environment, and Implementation Details
4. Experimental Results
4.1. Comparative Experiments
4.1.1. Visualization of Detection Results
4.1.2. Comparison of Experimental Results
4.2. Ablation Experiments
4.2.1. Ablation Experiments on Downsample Ratio
4.2.2. Ablation Experiments on MBlock
4.2.3. Ablation Experiments on Expansion Ratio
4.2.4. Ablation Study of DFRM Module
4.2.5. Ablation Experiments on RBH
4.2.6. Ablation Experiments on RSB
4.2.7. Ablation Experiments on WGIoU Loss
4.2.8. Ablation Experiments on WSE Layer
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Full Name |
|---|---|
| TPNet | Three Points Network |
| MNet | MBlock Network |
| ER | Expansion Ratio |
| DR | Downsample Ratio |
| DW | Depthwise |
| PW | Pointwise |
| BN | Batch Normalization |
| FLOPs | Floating Point Operations |
| MFPN | MBlock FPN |
| DFRM | Dynamic Feature Refinement Module |
| RBH | Refining Bbox Head |
| RSB | Refining Score Branch |
| IoU | Intersection over Union |
| NMS | Non-Maximum Suppression |
| GIoU | Generalized Intersection over Union |
| WGIoU | Weighted GIoU |
| SE | Squeeze-and-Excitation |
| WSE | Weighted Squeeze-and-Excitation |
| CBAM | Convolutional Block Attention Module |
| CA | Coordinate Attention |
| ECA | Efficient Channel Attention |
| eSE | effective Squeeze-and-Excitation |
| FC | Fully-Connected |
References
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Marr, D.; Hildreth, E. Theory of Edge Detection. Proc. R. Soc. Lond. Ser. B. Biol. Sci. 1980, 207, 187–217. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Gan, L.; Liu, P.; Wang, L. Rotation Sliding Window of the HOG Feature in Remote Sensing Images for Ship Detection. In Proceedings of the 2015 8th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 12–13 December 2015; IEEE: Piscataway, NJ, USA, 2015; Volume 1, pp. 401–404. [Google Scholar]
- Lin, H.; Song, S.; Yang, J. Ship Classification Based on MSHOG Feature and Task-Driven Dictionary Learning with Structured Incoherent Constraints in SAR Images. Remote Sens. 2018, 10, 190. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, C.; Wu, F.; Zhang, B.; Zhang, H.; Tang, Y. Ship Detection for Radarsat-2 ScanSAR Data Using DoG Scale-Space. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium—IGARSS, Melbourne, VIC, Australia, 21–26 July 2013; pp. 1881–1884. [Google Scholar] [CrossRef]
- Guo, J.; Zhu, C.R. A Novel Method of Ship Detection from Spaceborne Optical Image Based on Spatial Pyramid Matching. Appl. Mech. Mater. 2012, 190, 1099–1103. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Yang, K.; Zou, H. A Bilateral CFAR Algorithm for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1536–1540. [Google Scholar] [CrossRef]
- Wang, C.; Bi, F.; Zhang, W.; Chen, L. An Intensity-Space Domain CFAR Method for Ship Detection in HR SAR Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 529–533. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 February 2023).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.; Shen, H.; Ren, J.; Han, S.; Ding, E.; et al. PP-YOLO: An Effective and Efficient Implementation of Object Detector. arXiv 2020, arXiv:2007.12099. [Google Scholar]
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Long, X.; Deng, K.; Dang, Q.; Han, S.; Liu, Q.; Hu, X.; et al. PP-YOLOv2: A Practical Object Detector. arXiv 2021, arXiv:2104.10419. [Google Scholar]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. PP-YOLOE: An Evolved Version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship Detection in SAR Images Based on an Improved Faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Chang, Y.L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.Y.; Lee, W.H. Ship Detection Based on YOLOv2 for SAR Imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. High-Speed Ship Detection in SAR Images Based on a Grid Convolutional Neural Network. Remote Sens. 2019, 11, 1206. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. Depthwise Separable Convolution Neural Network for High-Speed SAR Ship Detection. Remote Sens. 2019, 11, 2483. [Google Scholar] [CrossRef]
- Gui, Y.; Li, X.; Xue, L.; Lv, J. A Scale Transfer Convolution Network for Small Ship Detection in SAR Images. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 24–26 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1845–1849. [Google Scholar]
- Jiao, J.; Zhang, Y.; Sun, H.; Yang, X.; Gao, X.; Hong, W.; Fu, K.; Sun, X. A Densely Connected End-to-End Neural Network for Multiscale and Multiscene SAR Ship Detection. IEEE Access 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Li, Y.; Ding, Z.; Zhang, C.; Wang, Y.; Chen, J. SAR Ship Detection Based on ResNet and Transfer Learning. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1188–1191. [Google Scholar]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and Excitation Rank Faster R-CNN for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention Receptive Pyramid Network for Ship Detection in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Bao, W.; Huang, M.; Zhang, Y.; Xu, Y.; Liu, X.; Xiang, X. Boosting Ship Detection in SAR Images with Complementary Pretraining Techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8941–8954. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. HyperLi-Net: A Hyper-Light Deep Learning Network for High-Accurate and High-Speed Ship Detection from Synthetic Aperture Radar Imagery. ISPRS J. Photogramm. Remote Sens. 2020, 167, 123–153. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X. Quad-FPN: A Novel Quad Feature Pyramid Network for SAR Ship Detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, X.; Zhang, T. Lite-YOLOv5: A Lightweight Deep Learning Detector for On-Board Ship Detection in Large-Scene Sentinel-1 SAR Images. Remote Sens. 2022, 14, 1018. [Google Scholar] [CrossRef]
- Gao, Y.; Wu, Z.; Ren, M.; Wu, C. Improved YOLOv4 Based on Attention Mechanism for Ship Detection in SAR Images. IEEE Access 2022, 10, 23785–23797. [Google Scholar] [CrossRef]
- Jiang, J.; Fu, X.; Qin, R.; Wang, X.; Ma, Z. High-Speed Lightweight Ship Detection Algorithm Based on YOLO-v4 for Three-Channels RGB SAR Image. Remote Sens. 2021, 13, 1909. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, S.; Zhan, R.; Wang, W.; Zhang, J. SAR Ship Detection Based on YOLOv5 Using CBAM and BiFPN. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2147–2150. [Google Scholar]
- Tang, X.; Zhang, J.; Xia, Y.; Xiao, H. DBW-YOLO: A High-Precision SAR Ship Detection Method for Complex Environments. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 7029–7039. [Google Scholar] [CrossRef]
- Liu, L.; Fu, L.; Zhang, Y.; Ni, W.; Wu, B.; Li, Y.; Shang, C.; Shen, Q. CLFR-Det: Cross-Level Feature Refinement Detector for Tiny-Ship Detection in SAR Images. Knowl.-Based Syst. 2024, 284, 111284. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Gao, F.; He, Y.; Wang, J.; Hussain, A.; Zhou, H. Anchor-Free Convolutional Network with Dense Attention Feature Aggregation for Ship Detection in SAR Images. Remote Sens. 2020, 12, 2619. [Google Scholar] [CrossRef]
- Feng, Y.; Chen, J.; Huang, Z.; Wan, H.; Xia, R.; Wu, B.; Sun, L.; Xing, M. A Lightweight Position-Enhanced Anchor-Free Algorithm for SAR Ship Detection. Remote Sens. 2022, 14, 1908. [Google Scholar] [CrossRef]
- Yao, C.; Xie, P.; Zhang, L.; Fang, Y. ATSD: Anchor-Free Two-Stage Ship Detection Based on Feature Enhancement in SAR Images. Remote Sens. 2022, 14, 6058. [Google Scholar] [CrossRef]
- He, B.; Zhang, Q.; Tong, M.; He, C. An Anchor-Free Method Based on Adaptive Feature Encoding and Gaussian-Guided Sampling Optimization for Ship Detection in SAR Imagery. Remote Sens. 2022, 14, 1738. [Google Scholar] [CrossRef]
- Zhu, M.; Hu, G.; Zhou, H.; Wang, S.; Feng, Z.; Yue, S. A Ship Detection Method via Redesigned FCOS in Large-Scale SAR Images. Remote Sens. 2022, 14, 1153. [Google Scholar] [CrossRef]
- Sun, Z.; Dai, M.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. An Anchor-Free Detection Method for Ship Targets in High-Resolution SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7799–7816. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-Style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Wu, S.; Li, X.; Wang, X. IoU-aware single-stage object detector for accurate localization. Image Vis. Comput. 2020, 97, 103911. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Lee, Y.; Park, J. Centermask: Real-Time Anchor-Free Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13906–13915. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR Dataset of Ship Detection for Deep Learning under Complex Backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A High-Resolution SAR Images Dataset for Ship Detection and Instance Segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- PaddlePaddle. PaddleDetection. Available online: https://github.com/PaddlePaddle/PaddleDetection.git (accessed on 1 February 2023).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Jocher, G.; Qiu, J. Ultralytics YOLO11. 2024. Version 11.0.0, Licensed Under AGPL-3.0. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 February 2023).
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, Z.; Zheng, T.; Xu, G.; Yang, Z.; Liu, H.; Cai, D. Training-Time-Friendly Network for Real-Time Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11685–11692. [Google Scholar]


| Operator | Kernel Size | Stride | attn | Input Size | Output Size |
|---|---|---|---|---|---|
| MBlock | 7 | 2 | False | 256 × 256 × 3 | 128 × 128 × 24 |
| Maxpool | 3 | 2 | False | 128 × 128 × 24 | 64 × 64 × 24 |
| MBlock | 5 | 2 | False | 64 × 64 × 24 | 32 × 32 × 56 |
| MBlock | 5 | 1 | True | 32 × 32 × 56 | 32 × 32 × 56 |
| MBlock | 5 | 2 | False | 32 × 32 × 56 | 16 × 16 × 120 |
| MBlock | 5 | 1 | True | 16 × 16 × 120 | 16 × 16 × 120 |
| MBlock | 5 | 2 | False | 16 × 16 × 120 | 8 × 8 × 272 |
| MBlock | 5 | 1 | True | 8 × 8 × 272 | 8 × 8 × 272 |
| Position | Coordinates |
|---|---|
| Center | |
| Left | |
| Right | |
| Top | |
| Bottom | |
| Top-Left | |
| Top-Right | |
| Bottom-Left | |
| Bottom-Right |
| Dataset | Num of Images | Num of Ships | Satellites | Resolution (m) |
|---|---|---|---|---|
| SAR-ship-dataset | 43,819 | 59,535 | GF3 Sentinel-1 | 5–20 |
| SSDD | 5604 | 16,951 | TerraSAR-X Sentinel-1 RadarSat-2 | 1–10 |
| HRSID | 1160 | 2540 | TerraSAR-X Sentinel-1B TanDEM | 0.5–3 |
| Algorithm | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|---|---|
| YOLOv3 [16] | 94.6 | 60.7 | 55.8 | 51.9 | 61.4 | 55.9 | 12.377 | 302.2 |
| YOLOv4 [17] | 91.6 | 53.4 | 51.6 | 46.9 | 58.0 | 54.3 | 9.766 | 300.5 |
| YOLOv5 [18] | 94.1 | 66.1 | 58.2 | 54.0 | 66.4 | 53.0 | 8.637 | 298.7 |
| YOLOv7 [66] | 84.3 | 48.2 | 47.2 | 42.5 | 54.2 | 25.6 | 8.391 | 293.2 |
| YOLOv8 [67] | 93.2 | 64.2 | 57.7 | 53.2 | 64.0 | 59.6 | 15.378 | 305.7 |
| YOLOv10 [68] | 93.7 | 67.5 | 59.2 | 54.6 | 65.9 | 63.8 | 9.632 | 233.7 |
| YOLOv11 [67] | 93.4 | 65.5 | 58.1 | 53.6 | 64.5 | 59.1 | 14.664 | 297.1 |
| PP-YOLO [20] | 92.6 | 62.3 | 55.9 | 51.2 | 62.5 | 63.6 | 9.153 | 300.0 |
| PP-YOLOv2 [21] | 94.7 | 70.1 | 60.3 | 56.0 | 66.5 | 63.7 | 9.153 | 303.7 |
| PP-YOLOE [22] | 93.8 | 66.8 | 59.2 | 54.5 | 66.0 | 65.0 | 8.879 | 298.9 |
| RetinaNet [69] | 80.2 | 34.1 | 39.5 | 31.4 | 51.6 | 43.8 | 12.988 | 103.6 |
| CenterNet [41] | 91.8 | 55.1 | 52.8 | 46.5 | 61.4 | 73.6 | 6.433 | 38.7 |
| TTFNet [70] | 92.7 | 64.5 | 57.6 | 51.9 | 65.2 | 69.4 | 11.931 | 119.4 |
| FCOS [42] | 90.0 | 56.9 | 52.9 | 44.9 | 63.7 | 52.6 | 12.865 | 298.0 |
| TPNet | 95.7 | 71.4 | 62.1 | 56.4 | 69.3 | 73.3 | 0.485513 | 316.9 |
| Algorithm | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) |
|---|---|---|---|---|---|---|
| YOLOv3 [16] | 69.1 | 41.9 | 40.1 | 43.4 | 24.7 | 1.1 |
| YOLOv4 [17] | 71.1 | 41.7 | 40.2 | 43.4 | 28.1 | 1.1 |
| YOLOv5 [18] | 65.9 | 40.5 | 38.6 | 42.4 | 19.5 | 0.0 |
| YOLOv7 [66] | 64.1 | 41.9 | 37.9 | 41.1 | 22.0 | 0.0 |
| YOLOv8 [67] | 71.2 | 47.0 | 43.1 | 47.2 | 25.4 | 0.1 |
| YOLOv10 [68] | 71.5 | 49.4 | 44.3 | 48.0 | 28.7 | 0.8 |
| YOLOv11 [67] | 72.4 | 49.3 | 44.5 | 48.5 | 28.6 | 0.3 |
| PP-YOLO [20] | 59.7 | 38.5 | 35.4 | 38.7 | 20.8 | 0.2 |
| PP-YOLOv2 [21] | 70.7 | 45.5 | 42.2 | 45.8 | 26.1 | 0.4 |
| PP-YOLOE [22] | 69.6 | 47.9 | 43.2 | 46.3 | 34.8 | 2.5 |
| RetinaNet [69] | 59.4 | 25.3 | 29.1 | 31.7 | 24.0 | 0.2 |
| CenterNet [41] | 70.4 | 44.9 | 41.9 | 44.9 | 29.4 | 0.9 |
| TTFNet [70] | 73.2 | 46.3 | 43.3 | 46.8 | 27.1 | 0.1 |
| FCOS [42] | 55.8 | 15.9 | 24.3 | 31.0 | 14.8 | 0.1 |
| TPNet | 71.0 | 47.7 | 43.3 | 46.6 | 35.5 | 0.3 |
| Algorithm | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) |
|---|---|---|---|---|---|---|
| YOLOv3 [16] | 77.7 | 28.9 | 37.2 | 35.9 | 40.7 | 26.6 |
| YOLOv4 [17] | 78.9 | 29.5 | 37.4 | 36.8 | 40.3 | 20.3 |
| YOLOv5 [18] | 45.9 | 10.6 | 18.6 | 18.8 | 19.6 | 3.5 |
| YOLOv7 [66] | 72.5 | 33.1 | 36.6 | 33.1 | 37.5 | 38.2 |
| YOLOv8 [67] | 78.4 | 30.6 | 38.1 | 38.0 | 40.5 | 12.2 |
| YOLOv10 [68] | 82.5 | 34.3 | 40.3 | 39.9 | 42.9 | 21.1 |
| YOLOv11 [67] | 78.3 | 32.4 | 38.5 | 38.3 | 40.9 | 16.3 |
| PP-YOLO [20] | 82.9 | 36.8 | 41.6 | 40.5 | 45.0 | 23.2 |
| PP-YOLOv2 [21] | 79.6 | 34.7 | 39.7 | 38.0 | 43.5 | 29.2 |
| PP-YOLOE [22] | 71.9 | 30.8 | 35.6 | 29.5 | 45.8 | 38.8 |
| RetinaNet [69] | 74.4 | 23.8 | 33.6 | 33.8 | 36.2 | 20.9 |
| CenterNet [41] | 75.5 | 31.0 | 37.1 | 35.5 | 41.7 | 16.8 |
| TTFNet [70] | 74.6 | 25.3 | 34.1 | 34.7 | 35.0 | 11.5 |
| FCOS [42] | 69.2 | 17.3 | 28.7 | 29.4 | 30.7 | 19.4 |
| TPNet | 86.1 | 44.2 | 45.9 | 44.1 | 50.8 | 21.6 |
| Algorithm | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) |
|---|---|---|---|---|---|---|
| YOLOv3 [16] | 146.8 | 70.8 | 77.3 | 79.3 | 65.4 | 27.7 |
| YOLOv4 [17] | 150.0 | 71.2 | 77.6 | 80.2 | 68.4 | 21.4 |
| YOLOv5 [18] | 111.8 | 51.1 | 57.2 | 61.2 | 39.1 | 3.5 |
| YOLOv7 [66] | 136.6 | 75.0 | 74.5 | 74.2 | 59.5 | 38.2 |
| YOLOv8 [67] | 149.6 | 77.6 | 81.2 | 85.2 | 65.9 | 12.3 |
| YOLOv10 [68] | 154.0 | 83.7 | 84.6 | 87.9 | 71.6 | 21.9 |
| YOLOv11 [67] | 150.7 | 81.7 | 83.0 | 86.8 | 69.5 | 16.6 |
| PP-YOLO [20] | 142.6 | 75.3 | 77.0 | 79.2 | 65.8 | 23.4 |
| PP-YOLOv2 [21] | 150.3 | 80.2 | 81.9 | 83.8 | 69.6 | 29.6 |
| PP-YOLOE [22] | 141.5 | 78.7 | 78.8 | 75.8 | 80.6 | 41.3 |
| RetinaNet [69] | 133.8 | 49.1 | 62.7 | 65.5 | 60.2 | 21.1 |
| CenterNet [41] | 145.9 | 75.9 | 79.0 | 80.4 | 71.1 | 17.7 |
| TTFNet [70] | 147.8 | 71.6 | 77.4 | 81.5 | 62.1 | 11.6 |
| FCOS [42] | 125.0 | 33.2 | 53.0 | 60.4 | 72.5 | 19.5 |
| TPNet | 157.1 | 91.9 | 89.2 | 90.7 | 86.3 | 21.9 |
| Dataset | DR | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|
| SAR-Ship Dataset | 4 | 95.7 | 71.4 | 62.1 | 56.4 | 69.3 | 73.3 | 0.485513 |
| 8 | 94.9 | 67.6 | 59.5 | 54.0 | 67.8 | 61.1 | 0.378620 | |
| HRSID | 4 | 71.0 | 47.7 | 43.3 | 46.6 | 35.5 | 0.3 | - |
| 8 | 63.7 | 32.5 | 33.7 | 37.6 | 25.2 | 0.0 | - | |
| SSDD | 4 | 86.1 | 44.2 | 45.9 | 44.1 | 50.8 | 21.6 | - |
| 8 | 84.4 | 34.8 | 41.4 | 40.4 | 44.6 | 22.7 | - | |
| HRSID and SSDD | 4 | 157.1 | 91.9 | 89.2 | 90.7 | 86.3 | 21.9 | - |
| 8 | 148.1 | 67.3 | 75.1 | 78.0 | 69.8 | 22.7 | - |
| Dataset | Operator | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|
| SAR-Ship Dataset | Traditional Convolution | 95.2 | 70.0 | 61.0 | 54.9 | 68.7 | 63.9 | 1.000 |
| MBlock | 95.7 | 71.4 | 62.1 | 56.4 | 69.3 | 73.3 | 0.485513 | |
| HRSID | Traditional Convolution | 65.0 | 39.2 | 36.9 | 40.9 | 28.2 | 0.0 | 0 |
| MBlock | 71.0 | 47.7 | 43.3 | 46.6 | 35.5 | 0.3 | 0 | |
| SSDD | Traditional Convolution | 81.6 | 30.4 | 38.6 | 39.3 | 39.3 | 17.0 | 0 |
| MBlock | 86.1 | 44.2 | 45.9 | 44.1 | 50.8 | 21.6 | 0 | |
| HRSID and SSDD | Traditional Convolution | 146.6 | 69.6 | 75.5 | 80.2 | 67.5 | 17.0 | 0 |
| MBlock | 157.1 | 91.9 | 89.2 | 90.7 | 86.3 | 21.9 | 0 |
| Dataset | ER | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|
| SAR-Ship Dataset | 1 | 95.1 | 68.8 | 60.6 | 55.1 | 67.9 | 68.9 | 0.234794 |
| 2 | 95.3 | 70.3 | 61.7 | 56.1 | 69.1 | 72.3 | 0.360131 | |
| 3 | 95.7 | 71.4 | 62.1 | 56.4 | 69.3 | 73.3 | 0.485513 | |
| 4 | 95.7 | 72.6 | 62.5 | 56.7 | 69.8 | 70.4 | 0.610942 | |
| 5 | 95.6 | 72.1 | 62.2 | 56.4 | 69.5 | 68.4 | 0.736417 | |
| 6 | 95.8 | 72.5 | 62.7 | 56.9 | 70.0 | 72.7 | 0.861937 | |
| HRSID | 1 | 71.3 | 46.7 | 43.2 | 45.6 | 40.1 | 0.2 | 0 |
| 2 | 71.0 | 46.4 | 42.9 | 46.0 | 35.8 | 0.1 | 0 | |
| 3 | 71.0 | 47.7 | 43.3 | 46.6 | 35.5 | 0.3 | 0 | |
| 4 | 70.4 | 50.2 | 44.6 | 47.5 | 38.6 | 0.0 | 0 | |
| 5 | 71.8 | 50.6 | 43.3 | 47.8 | 40.8 | 0.7 | 0 | |
| 6 | 71.6 | 49.2 | 44.6 | 47.7 | 37.0 | 0.5 | 0 | |
| SSDD | 1 | 84.9 | 39.2 | 43.4 | 41.6 | 47.9 | 19.8 | 0 |
| 2 | 83.7 | 39.9 | 43.1 | 41.2 | 47.6 | 23.5 | 0 | |
| 3 | 86.1 | 44.2 | 45.9 | 44.1 | 50.8 | 21.6 | 0 | |
| 4 | 85.8 | 39.8 | 43.9 | 43.6 | 46.4 | 20.8 | 0 | |
| 5 | 84.2 | 40.9 | 44.0 | 40.8 | 50.2 | 25.7 | 0 | |
| 6 | 83.1 | 38.6 | 42.8 | 41.1 | 47.5 | 20.5 | 0 | |
| HRSID and SSDD | 1 | 156.2 | 85.9 | 86.6 | 87.2 | 88.0 | 20.0 | 0 |
| 2 | 154.7 | 86.3 | 86.0 | 87.2 | 83.4 | 23.6 | 0 | |
| 3 | 157.1 | 91.9 | 89.2 | 90.7 | 86.3 | 21.9 | 0 | |
| 4 | 156.2 | 90.0 | 88.5 | 91.1 | 85.0 | 20.8 | 0 | |
| 5 | 156.0 | 91.5 | 87.3 | 88.6 | 91.0 | 26.4 | 0 | |
| 6 | 154.7 | 87.8 | 87.4 | 88.8 | 84.5 | 21.0 | 0 |
| Dataset | Whether to Use DFRM | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|
| SAR-Ship Dataset | No | 95.3 | 69.9 | 61.3 | 55.6 | 68.7 | 71.9 | 0.485452 |
| Yes | 95.7 | 71.4 | 62.1 | 56.4 | 69.3 | 73.3 | 0.485513 | |
| HRSID | No | 71.6 | 49.4 | 44.9 | 48.0 | 36.7 | 0.2 | - |
| Yes | 71.0 | 47.7 | 43.3 | 46.6 | 35.5 | 0.3 | - | |
| SSDD | No | 84.5 | 40.2 | 43.5 | 42.4 | 47.1 | 22.0 | - |
| Yes | 86.1 | 44.2 | 45.9 | 44.1 | 50.8 | 21.6 | - | |
| HRSID and SSDD | No | 156.1 | 89.6 | 88.4 | 90.4 | 83.8 | 22.2 | - |
| Yes | 157.1 | 91.9 | 89.2 | 90.7 | 86.3 | 21.9 | - |
| Dataset | With RBH | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|
| SAR-Ship Dataset | NO | 95.6 | 70.5 | 61.4 | 55.7 | 68.7 | 66.9 | 0.474843 |
| YES | 95.7 | 71.4 | 62.1 | 56.4 | 69.3 | 73.3 | 0.485513 | |
| HRSID | NO | 68.4 | 45.9 | 41.0 | 44.6 | 31.1 | 0.3 | - |
| YES | 71.0 | 47.7 | 43.3 | 46.6 | 35.5 | 0.3 | - | |
| SSDD | NO | 84.3 | 40.3 | 44.1 | 42.6 | 48.1 | 23.3 | - |
| YES | 86.1 | 44.2 | 45.9 | 44.1 | 50.8 | 21.6 | - | |
| HRSID and SSDD | NO | 152.7 | 86.2 | 85.1 | 87.2 | 79.2 | 23.6 | - |
| YES | 157.1 | 91.9 | 89.2 | 90.7 | 86.3 | 21.9 | - |
| Dataset | With RSB | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|
| SAR-Ship Dataset | NO | 95.4 | 70.1 | 61.5 | 55.5 | 68.5 | 72.2 | 0.485378 |
| YES | 95.7 | 71.4 | 62.1 | 56.4 | 69.3 | 73.3 | 0.485513 | |
| HRSID | NO | 69.4 | 45.6 | 41.6 | 44.9 | 33.2 | 0.0 | - |
| YES | 71.0 | 47.7 | 43.3 | 46.6 | 35.5 | 0.3 | - | |
| SSDD | NO | 84.3 | 40.3 | 44.1 | 42.6 | 48.1 | 22.3 | - |
| YES | 86.1 | 44.2 | 45.9 | 44.1 | 50.8 | 21.6 | - | |
| HRSID and SSDD | NO | 153.7 | 85.9 | 85.7 | 87.5 | 81.3 | 22.3 | - |
| YES | 157.1 | 91.9 | 89.2 | 90.7 | 86.3 | 21.9 | - |
| Dataset | Loss Function | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) |
|---|---|---|---|---|---|---|---|
| SAR-Ship Dataset | Smooth L1 | 92.9 | 59.5 | 55.2 | 50.2 | 62.4 | 59.4 |
| GIoU | 95.3 | 69.1 | 60.5 | 55.1 | 67.4 | 71.5 | |
| WGIoU | 95.7 | 71.4 | 62.1 | 56.4 | 69.3 | 73.3 | |
| HRSID | Smooth L1 | 66.1 | 41.4 | 38.8 | 42.8 | 29.4 | 0.0 |
| GIoU | 65.7 | 39.9 | 37.6 | 42.6 | 27.1 | 0.0 | |
| WGIoU | 71.0 | 47.7 | 43.3 | 46.6 | 35.5 | 0.3 | |
| SSDD | Smooth L1 | 81.6 | 33.3 | 40.3 | 41.0 | 42.6 | 14.6 |
| GIoU | 83.7 | 34.6 | 41.2 | 42.1 | 42.7 | 20.4 | |
| WGIoU | 86.1 | 44.2 | 45.9 | 44.1 | 50.8 | 21.6 | |
| HRSID and SSDD | Smooth L1 | 147.7 | 74.7 | 79.1 | 83.8 | 72.0 | 14.6 |
| GIoU | 149.4 | 74.5 | 78.8 | 84.7 | 69.8 | 20.4 | |
| WGIoU | 157.1 | 91.9 | 89.2 | 90.7 | 86.3 | 21.9 |
| Dataset | Attention Module | AP50 (%) | AP75 (%) | AP (%) | APsmall (%) | APmiddle (%) | APlarge (%) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|
| SAR-Ship Dataset | Baseline | 95.4 | 70.5 | 61.4 | 55.3 | 68.3 | 61.7 | 0.483484 |
| SE | 95.5 | 71.0 | 61.9 | 56.3 | 68.9 | 65.8 | 0.483787 | |
| eSE | 95.3 | 71.3 | 61.7 | 55.9 | 69.1 | 67.1 | 0.484338 | |
| CBAM | 95.0 | 70.9 | 61.8 | 56.1 | 69.0 | 64.5 | 0.485767 | |
| CA | 95.6 | 71.3 | 61.9 | 56.2 | 69.7 | 69.5 | 0.517191 | |
| ECA | 95.3 | 69.9 | 61.0 | 55.3 | 68.5 | 62.9 | 0.485767 | |
| WSE | 95.7 | 71.4 | 62.1 | 56.4 | 69.3 | 73.3 | 0.485513 | |
| HRSID | Baseline | 68.7 | 45.4 | 41.9 | 45.2 | 31.6 | 0.0 | - |
| SE | 66.3 | 44.5 | 40.6 | 43.6 | 31.5 | 0.0 | - | |
| eSE | 68.2 | 43.5 | 40.3 | 43.8 | 30.7 | 0.0 | - | |
| CBAM | 67.2 | 44.1 | 40.8 | 44.3 | 30.1 | 0.0 | - | |
| CA | 68.3 | 44.1 | 40.9 | 44.5 | 29.4 | 0.0 | - | |
| ECA | 67.6 | 43.2 | 39.9 | 43.9 | 30.2 | 0.0 | - | |
| WSE | 71.0 | 47.7 | 43.3 | 46.6 | 35.5 | 0.3 | - | |
| SSDD | Baseline | 81.7 | 36.2 | 40.9 | 41.9 | 41.6 | 20.4 | - |
| SE | 82.9 | 36.0 | 41.1 | 42.6 | 41.3 | 17.0 | - | |
| eSE | 80.7 | 32.5 | 39.6 | 40.9 | 40.4 | 15.4 | - | |
| CBAM | 84.2 | 36.6 | 41.9 | 42.0 | 44.0 | 18.7 | - | |
| CA | 83.3 | 34.7 | 41.3 | 41.3 | 43.4 | 15.8 | - | |
| ECA | 81.9 | 30.8 | 39.3 | 40.3 | 41.2 | 10.1 | - | |
| WSE | 86.1 | 44.2 | 45.9 | 44.1 | 50.8 | 21.6 | - | |
| HRSID and SSDD | Baseline | 150.4 | 81.6 | 82.8 | 87.1 | 73.2 | 20.4 | - |
| SE | 149.2 | 80.5 | 81.7 | 86.2 | 72.8 | 17.0 | - | |
| eSE | 148.9 | 76.0 | 79.9 | 84.7 | 71.1 | 15.4 | - | |
| CBAM | 151.4 | 80.7 | 82.7 | 86.3 | 74.1 | 18.7 | - | |
| CA | 151.6 | 78.8 | 82.2 | 85.8 | 72.8 | 15.8 | - | |
| ECA | 149.5 | 74.0 | 79.2 | 84.2 | 71.4 | 10.1 | - | |
| WSE | 157.1 | 91.9 | 89.2 | 90.7 | 86.3 | 21.9 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuo, W.; Fang, S. TPNet: A High-Performance and Lightweight Detector for Ship Detection in SAR Imagery. Remote Sens. 2025, 17, 1487. https://doi.org/10.3390/rs17091487
Zuo W, Fang S. TPNet: A High-Performance and Lightweight Detector for Ship Detection in SAR Imagery. Remote Sensing. 2025; 17(9):1487. https://doi.org/10.3390/rs17091487
Chicago/Turabian StyleZuo, Weikang, and Shenghui Fang. 2025. "TPNet: A High-Performance and Lightweight Detector for Ship Detection in SAR Imagery" Remote Sensing 17, no. 9: 1487. https://doi.org/10.3390/rs17091487
APA StyleZuo, W., & Fang, S. (2025). TPNet: A High-Performance and Lightweight Detector for Ship Detection in SAR Imagery. Remote Sensing, 17(9), 1487. https://doi.org/10.3390/rs17091487