
Refined Deformable-DETR for SAR Target Detection and Radio Signal Detection

Abstract
1. Introduction
- Half-window filtering technology: By proposing the half-window filter (HWF), which leverages prior knowledge from SAR signal processing, the feature extraction process is enhanced, significantly improving the recognition performance for targets of different scales. While Transformer-based models have demonstrated strong performance in image processing, SAR target detection and electromagnetic signal detection, they have not yet fully integrated SAR signal processing priors, which this approach addresses.
- Auxiliary feature extractors: During training, auxiliary feature extractors are introduced to provide additional supervision signals, enhancing the model’s encoding and decoding capabilities. Traditional object detection algorithms have shown poor performance on SAR target detection tasks. The introduction of auxiliary feature extractors significantly improves this by providing more robust feature learning and enhancing overall recognition accuracy.
- Multi-scale adapter: The multi-scale adapter dynamically constructs feature pyramids through upsampling and downsampling operations, enhancing multi-scale feature alignment and significantly improving detection accuracy for targets of varying sizes and scales.
2. Related Work
2.1. Detection Transformer
2.2. SAR Target Detection
2.3. Filtering Technology
2.4. Auxiliary Supervision
3. Method
3.1. Half-Window Filter
3.2. Multi-Scale Adapter
3.3. Auxiliary Feature Extractor
3.4. Loss Function and Optimization
4. Results
4.1. Dataset and Experimental Settings
4.2. Comparative Results on HRSiD Dataset
4.3. Comparative Results on Spectrogram Dataset
4.4. Ablation Study
5. Discussion
5.1. Performance Comparison with State-of-the-Art
5.2. Robustness and Generalization
5.3. Effectiveness of the HWF Module
5.4. Remaining Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, C.; He, C.; Hu, C.; Pei, H.; Jiao, L. MSARN: A Deep Neural Network Based on an Adaptive Recalibration Mechanism for Multiscale and Arbitrary-Oriented SAR Ship Detection. IEEE Access 2019, 7, 159262–159283. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H. Ship Classification in High-Resolution SAR Images Using Deep Learning of Small Datasets. Sensors 2018, 18, 2929. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional Radio Modulation Recognition Networks. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Aberdeen, UK, 2–5 September 2016; pp. 213–226. [Google Scholar]
- Sturmel, N.; Daudet, L. Signal Reconstruction from STFT Magnitude: A State of the Art. In Proceedings of the International Conference on Digital Audio Effects (DAFx), Paris, France, 19–23 September 2011; pp. 375–386. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Krasner, N. Optimal Detection of Digitally Modulated Signals. IEEE Trans. Commun. 1982, 30, 885–895. [Google Scholar] [CrossRef]
- Rahman, M.H.; Sejan, M.A.S.; Aziz, M.A.; Baik, J.I.; Kim, D.S.; Song, H.K. Deep Learning Based Improved Cascaded Channel Estimation and Signal Detection for Reconfigurable Intelligent Surfaces-Assisted MU-MISO Systems. IEEE Trans. Green Commun. Netw. 2023, 7, 1515–1527. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3651–3660. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. Dab-detr: Dynamic anchor boxes are better queries for detr. arXiv 2022, arXiv:2201.12329. [Google Scholar]
- Ding, S.G.; Nie, X.L.; Qiao, H.; Zhang, B. Online classification for SAR target recognition based on SVM and approximate convex hull vertices selection. In Proceedings of the 11th World Congress on Intelligent Control and Automation, Shenyang, China, 29 June–4 July 2014; pp. 1473–1478. [Google Scholar]
- Yu, G.; Ying, X. Architecture design of deep convolutional neural network for SAR target recognition. J. Image Graph. 2018, 23, 928–936. [Google Scholar]
- Kang, M.; Leng, X.; Lin, Z.; Ji, K. A modified faster R-CNN based on CFAR algorithm for SAR ship detection. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Oh, J.; Kim, M. PeaceGAN: A GAN-Based Multi-Task Learning Method for SAR Target Image Generation with a Pose Estimator and an Auxiliary Classifier. Remote Sens. 2021, 13, 3939. [Google Scholar] [CrossRef]
- Lu, D.; Cao, L.; Liu, H. Few-Shot Learning Neural Network for SAR Target Recognition. In Proceedings of the 2019 6th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Xiamen, China, 26–29 November 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Zhu, X.; Mori, H. Data augmentation using style transfer in SAR automatic target classification. In Proceedings of the Artificial Intelligence and Machine Learning in Defense Applications III, Online, 13–17 September 2021; p. 12. [Google Scholar] [CrossRef]
- Gong, Y.; Sbalzarini, I.F. Curvature Filters Efficiently Reduce Certain Variational Energies. IEEE Trans. Image Process. 2017, 26, 1786–1798. [Google Scholar] [CrossRef]
- Ibrahim, M.; Chen, K.; Brito-Loeza, C. A novel variational model for image registration using Gaussian curvature. Geom. Imaging Comput. 2014, 1, 417–446. [Google Scholar] [CrossRef]
- Zhu, H.; Shu, H.; Zhou, J.; Bao, X.; Luo, L. Bayesian algorithms for PET image reconstruction with mean curvature and Gauss curvature diffusion regularizations. Comput. Biol. Med. 2007, 37, 793–804. [Google Scholar] [CrossRef] [PubMed]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Amanda, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, PMLR 139, Virtual, 18–24 July 2021. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Jaderberg, M.; Mnih, V.; Czarnecki, W.; Schaul, T.; Leibo, J.; Silver, D.; Kavukcuoglu, K. Reinforcement Learning with Unsupervised Auxiliary Tasks. arXiv 2016, arXiv:1611.05397. [Google Scholar]
- Zong, Z.; Song, G.; Liu, Y. DETRs with Collaborative Hybrid Assignments Training. arXiv 2022, arXiv:2211.12860. [Google Scholar]
- Zhang, J.; Tian, G.; Mu, Y.; Fan, W. Supervised deep learning with auxiliary networks. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014. [Google Scholar] [CrossRef]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A High-Resolution SAR Images Dataset for Ship Detection and Instance Segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Yue, T.; Zhang, Y.; Liu, P.; Xu, Y.; Yu, C. A Generating-Anchor Network for Small Ship Detection in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7665–7676. [Google Scholar] [CrossRef]
- Gao, F.; Cai, C.; Tang, W.; He, Y. A compact and high-efficiency anchor-free network based on contour key points for SAR ship detection. IEEE Geosci. Remote Sens. Lett. 2024, 21, 4002705. [Google Scholar] [CrossRef]
- Bai, L.; Yao, C.; Ye, Z.; Xue, D.; Lin, X.; Hui, M. Feature Enhancement Pyramid and Shallow Feature Reconstruction Network for SAR Ship Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1042–1056. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Liu, C.; Shi, J.; Wei, S.; Ahmad, I.; Zhan, X.; Zhou, Y.; Pan, D.; Li, J.; et al. Balance learning for ship detection from synthetic aperture radar remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 182, 190–207. [Google Scholar] [CrossRef]
- Bai, L.; Yao, C.; Ye, Z.; Xue, D.; Lin, X.; Hui, M. A Novel Anchor-Free Detector Using Global Context-Guide Feature Balance Pyramid and United Attention for SAR Ship Detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 4003005. [Google Scholar] [CrossRef]
- Chen, C.; Zeng, W.; Zhang, X.; Zhou, Y. CS n Net: A Remote Sensing Detection Network Breaking the Second-Order Limitation of Transformers with Recursive Convolutions. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4207315. [Google Scholar] [CrossRef]



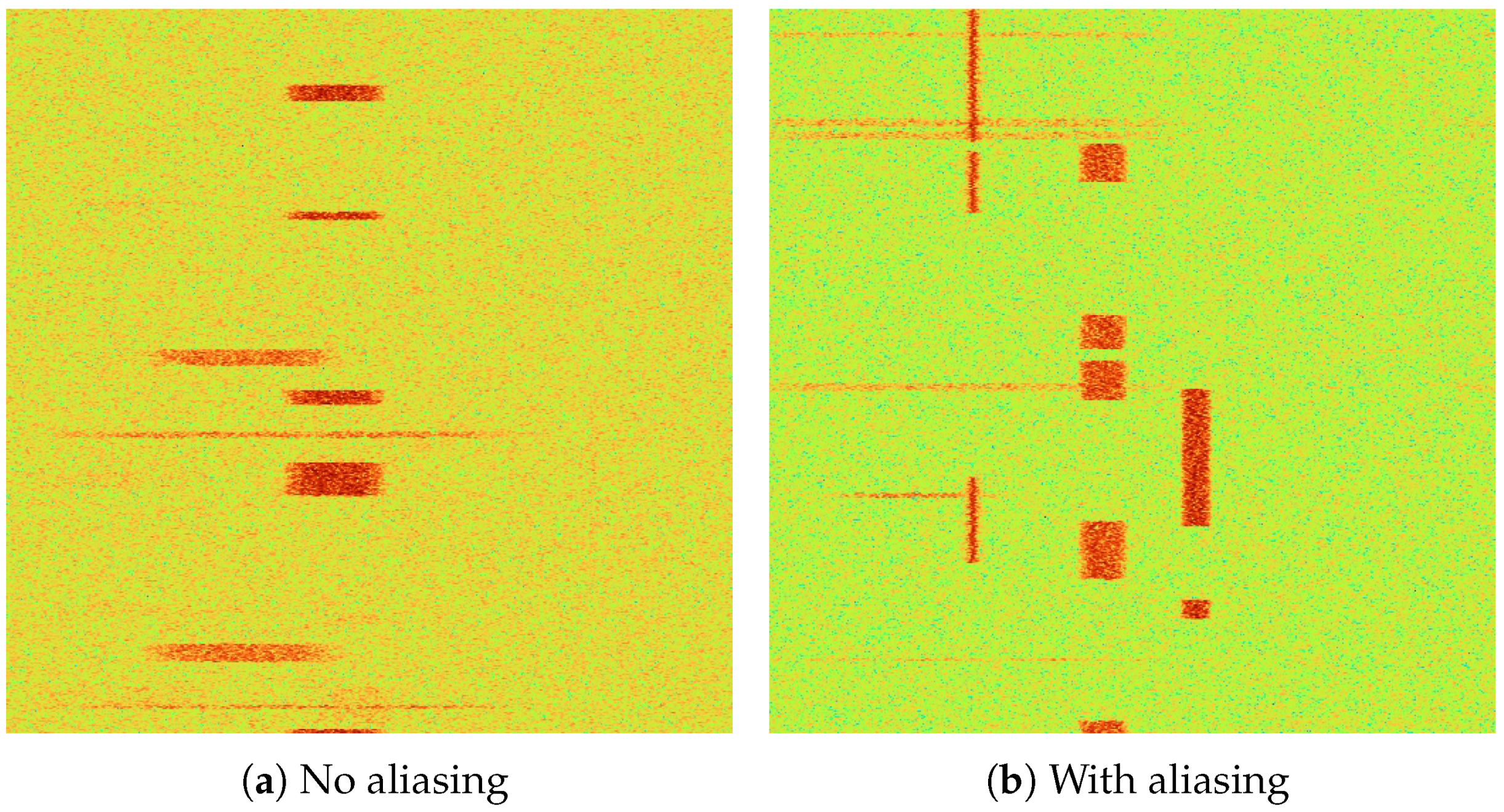


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Total sample | 12,500 |
| Sampling rate | 1024 kHz |
| Bandwidth | [10, 20, 50, 100, 150] Hz |
| Signal Power | [0.1, 0.125, 0.25, 0.5, 1, 2, 4, 8, 10, 100] |
| Modulation methods | BPSK, QPSK, 8PSK, OQPSK, 16PSK, 16QAM, 64QAM, 256QAM, 2FSK, 4FSK |
| Noise Power | 1 |
| Size of spectrograms | (512, 512) |
| Ratio of dataset | train:validation:test = 8:1:1 |
| Method | mAP50 | mAP |
|---|---|---|
| Faster RCNN | 0.720 | 0.465 |
| RetinaNet | 0.789 | 0.536 |
| YOLOv6n | 0.882 | 0.628 |
| YOLOv7-tiny | 0.854 | 0.572 |
| YOLOv8n | 0.911 | 0.669 |
| YOLOv11n | 0.897 | 0.658 |
| Yue et al. [37] * | 0.911 | 0.665 |
| CPoints-Net [38] * | 0.905 | - |
| FEPS-Net [39] * | 0.907 | 0.657 |
| BL-Net [40] * | 0.867 | - |
| FBUA-Net [41] * | 0.903 | - |
| Net [42] * | 0.912 | 0.660 |
| Refined Deformable-DETR | 0.902 | 0.682 |
| Method | Backbone | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|
| CenterNet | Resnet18 | 0.169 | 0.299 | 0.160 | 0.122 | 0.301 | 0.417 |
| Faster-RCNN | Resnet50 | 0.139 | 0.164 | 0.156 | 0.037 | 0.417 | 0.551 |
| YOLOv3 | Darknet | 0.004 | 0.011 | 0.003 | 0.001 | 0.012 | 0.102 |
| CornerNet | HourglassNet | 0.207 | 0.315 | 0.217 | 0.162 | 0.335 | 0.421 |
| DETR | Resnet18 | 0.266 | 0.513 | 0.238 | 0.170 | 0.503 | 0.780 |
| DETR | Resnet50 | 0.086 | 0.178 | 0.076 | 0.051 | 0.201 | 0.770 |
| Deformable-DETR | Resnet50 | 0.257 | 0.405 | 0.273 | 0.225 | 0.372 | 0.997 |
| DAB-DETR | Resnet50 | 0.211 | 0.391 | 0.195 | 0.170 | 0.360 | 0.898 |
| Conditional-DETR | Resnet50 | 0.112 | 0.223 | 0.093 | 0.078 | 0.221 | 0.788 |
| Refined Deformable-DETR | Resnet50 | 0.540 | 0.804 | 0.586 | 0.462 | 0.791 | 0.986 |
| Auxiliary Feature Extractor | HWF | AP | AP50 | Inference Time (ms) |
|---|---|---|---|---|
| YOLOv3 based AFE | enabled | 0.682 | 0.902 | 45.3 |
| disabled | 0.619 | 0.887 | 38.7 | |
| Faster-RCNN based AFE | enabled | 0.602 | 0.858 | 72.1 |
| disabled | 0.587 | 0.822 | 66.5 | |
| ATSS based AFE | enabled | 0.677 | 0.882 | 58.9 |
| disabled | 0.652 | 0.837 | 50.4 |
| Auxiliary Feature Extractor | HWF | AP | AP50 | Inference Time (ms) |
|---|---|---|---|---|
| YOLOv3 based AFE | enabled | 0.540 | 0.804 | 41.2 |
| disabled | 0.525 | 0.794 | 35.6 | |
| Faster-RCNN based AFE | enabled | 0.527 | 0.782 | 69.8 |
| disabled | 0.499 | 0.664 | 63.4 | |
| ATSS based AFE | enabled | 0.533 | 0.771 | 55.7 |
| disabled | 0.510 | 0.752 | 48.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zhou, X. Refined Deformable-DETR for SAR Target Detection and Radio Signal Detection. Remote Sens. 2025, 17, 1406. https://doi.org/10.3390/rs17081406
Li Z, Zhou X. Refined Deformable-DETR for SAR Target Detection and Radio Signal Detection. Remote Sensing. 2025; 17(8):1406. https://doi.org/10.3390/rs17081406
Chicago/Turabian StyleLi, Zhenghao, and Xin Zhou. 2025. "Refined Deformable-DETR for SAR Target Detection and Radio Signal Detection" Remote Sensing 17, no. 8: 1406. https://doi.org/10.3390/rs17081406
APA StyleLi, Z., & Zhou, X. (2025). Refined Deformable-DETR for SAR Target Detection and Radio Signal Detection. Remote Sensing, 17(8), 1406. https://doi.org/10.3390/rs17081406