
TA-MSA: A Fine-Tuning Framework for Few-Shot Remote Sensing Scene Classification

 , and
, and 
Abstract
1. Introduction
2. Related Work
2.1. Few-Shot Remote Sensing Scene Classification
2.2. Cross-Domain Generalization
2.3. Task Adaptation with Few Labeled Samples
3. Methods
3.1. Preliminary
3.2. Overview of the Proposed TA-MSA Fine-Tuning Framework
| Algorithm 1: The TA-MSA fine-tuning framework. |
 |
3.3. Layer-Specific Optimizer in the Task-Adaptive Fine-Tuning Strategy
3.4. Task-Specific Training Scheme in the Task-Adaptive Fine-Tuning Strategy
3.5. Multi-Level Spatial Features Aggregation Module
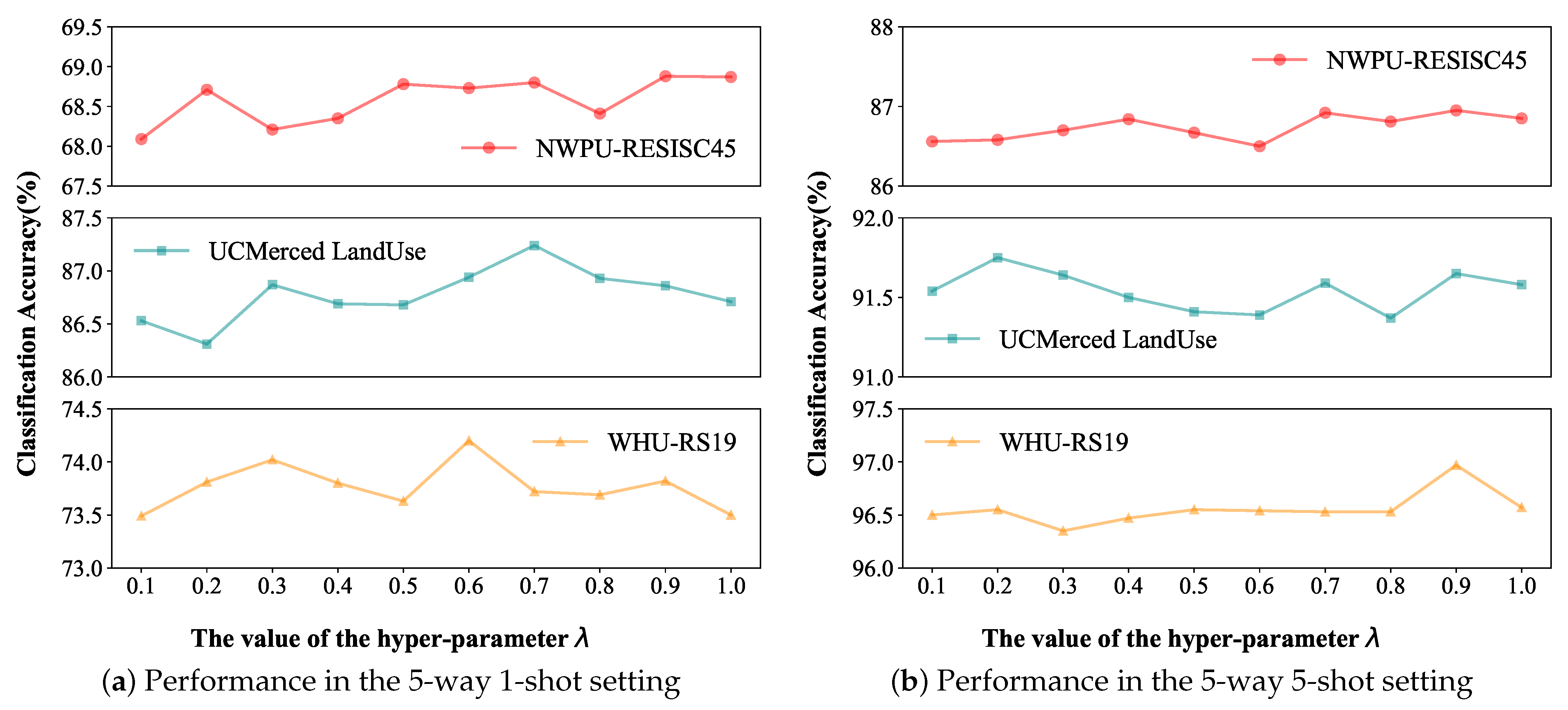
4. Experiments
4.1. Experimental Settings
4.2. Comparison Results on the FS-RSSC Tasks
4.3. Ablation Study
4.4. Visualization Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tripathi, D. Land Resource Investigation Using Remote Sensing and Geographic Information System: A Case Study. Int. J. Innov. Sci. Eng. Technol. 2017, 4, 125–132. [Google Scholar]
- Li, Y.; Ma, J.; Zhang, Y. Image retrieval from remote sensing big data: A survey. Inf. Fusion 2021, 67, 94–115. [Google Scholar] [CrossRef]
- Li, J.; Pei, Y.; Zhao, S.; Xiao, R.; Sang, X.; Zhang, C. A review of remote sensing for environmental monitoring in China. Remote Sens. 2020, 12, 1130. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.; Dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Tang, X.; Ma, Q.; Zhang, X.; Liu, F.; Ma, J.; Jiao, L. Attention consistent network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2030–2045. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Zhang, L.; Lan, M.; Zhang, J.; Tao, D. Stagewise unsupervised domain adaptation with adversarial self-training for road segmentation of remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5609413. [Google Scholar] [CrossRef]
- Jia, Y.; Gao, J.; Huang, W.; Yuan, Y.; Wang, Q. Exploring Hard Samples in Multi-View for Few-Shot Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5615714. [Google Scholar] [CrossRef]
- Wang, L.; Zhuo, L.; Li, J. Few-shot Remote Sensing Scene Classification with Spatial Affinity Attention and Class Surrogate-based Supervised Contrastive Learning. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 4705714. [Google Scholar] [CrossRef]
- Tang, X.; Lin, W.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. Class-level prototype guided multiscale feature learning for remote sensing scene classification with limited labels. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5622315. [Google Scholar] [CrossRef]
- Li, H.; Cui, Z.; Zhu, Z.; Chen, L.; Zhu, J.; Huang, H.; Tao, C. RS-MetaNet: Deep Metametric Learning for Few-Shot Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6983–6994. [Google Scholar] [CrossRef]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Li, X.; Luo, H.; Zhou, G.; Peng, X.; Wang, Z.; Zhang, J.; Liu, D.; Li, M.; Liu, Y. Learning general features to bridge the cross-domain gaps in few-shot learning. Knowl.-Based Syst. 2024, 299, 112024. [Google Scholar] [CrossRef]
- Ye, H.J.; Sheng, X.R.; Zhan, D.C. Few-shot learning with adaptively initialized task optimizer: A practical meta-learning approach. Mach. Learn. 2020, 109, 643–664. [Google Scholar] [CrossRef]
- Sun, Z.; Zheng, W.; Guo, P.; Wang, M. TST_MFL: Two-stage training based metric fusion learning for few-shot image classification. Inf. Fusion 2025, 113, 102611. [Google Scholar] [CrossRef]
- Ma, J.; Lin, W.; Tang, X.; Zhang, X.; Liu, F.; Jiao, L. Multipretext-task prototypes guided dynamic contrastive learning network for few-shot remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5614216. [Google Scholar] [CrossRef]
- Zhang, B.; Feng, S.; Li, X.; Ye, Y.; Ye, R.; Luo, C.; Jiang, H. SGMNet: Scene graph matching network for few-shot remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5628915. [Google Scholar] [CrossRef]
- Chen, X.; Zhu, G.; Wei, J. MMML: Multi-manifold Metric Learning for Few-Shot Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5618714. [Google Scholar] [CrossRef]
- Tian, F.; Lei, S.; Zhou, Y.; Cheng, J.; Liang, G.; Zou, Z.; Li, H.C.; Shi, Z. HiReNet: Hierarchical-Relation Network for Few-Shot Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5603710. [Google Scholar] [CrossRef]
- Lu, X.; Gong, T.; Zheng, X. Domain Mapping Network for Remote Sensing Cross-Domain Few-Shot Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5606411. [Google Scholar] [CrossRef]
- Zhu, J.; Li, Y.; Yang, K.; Guan, N.; Fan, Z.; Qiu, C.; Yi, X. MVP: Meta Visual Prompt Tuning for Few-Shot Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5610413. [Google Scholar] [CrossRef]
- Luo, X.; Wu, H.; Zhang, J.; Gao, L.; Xu, J.; Song, J. A closer look at few-shot classification again. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2023; pp. 23103–23123. [Google Scholar]
- Wang, H.; Deng, Z.H. Cross-domain few-shot classification via adversarial task augmentation. arXiv 2021, arXiv:2104.14385. [Google Scholar]
- Hu, Y.; J, A.J.M. Adversarial Feature Augmentation for Cross-domain Few-Shot Classification. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 20–37. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Subramanian, V. Deep Learning with PyTorch: A Practical Approach to Building Neural Network Models Using PyTorch; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zou, Y.; Yi, S.; Li, Y.; Li, R. A Closer Look at the CLS Token for Cross-Domain Few-Shot Learning. Adv. Neural Inf. Process. Syst. 2025, 37, 85523–85545. [Google Scholar]
- Luo, X.; Xu, J.; Xu, Z. Channel importance matters in few-shot image classification. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2022; pp. 14542–14559. [Google Scholar]
- Chen, W.Y.; Liu, Y.C.; Kira, Z.; Wang, Y.C.F.; Huang, J.B. A closer look at few-shot classification. arXiv 2019, arXiv:1904.04232. [Google Scholar]
- Zhang, X.; Fan, X.; Wang, G.; Chen, P.; Tang, X.; Jiao, L. MFGNet: Multibranch Feature Generation Networks for Few-Shot Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Li, L.; Han, J.; Yao, X.; Cheng, G.; Guo, L. DLA-MatchNet for few-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7844–7853. [Google Scholar] [CrossRef]
- Guo, Y.; Codella, N.C.; Karlinsky, L.; Codella, J.V.; Smith, J.R.; Saenko, K.; Rosing, T.; Feris, R. A broader study of cross-domain few-shot learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVII 16; Springer International Publishing: Cham, Switzerland, 2020; pp. 124–141. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2019; pp. 2790–2799. [Google Scholar]
- Wang, H.; Yang, X.; Chang, J.; Jin, D.; Sun, J.; Zhang, S.; Luo, X.; Tian, Q. Parameter-efficient tuning of large-scale multimodal foundation model. Adv. Neural Inf. Process. Syst. 2024, 36, 15752–15774. [Google Scholar]
- Li, J.; Gong, M.; Liu, H.; Zhang, Y.; Zhang, M.; Wu, Y. Multiform ensemble self-supervised learning for few-shot remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Zhou, K.; Liu, Z.; Qiao, Y.; Xiang, T.; Loy, C.C. Domain generalization: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4396–4415. [Google Scholar] [CrossRef]
- Oh, J.; Kim, S.; Ho, N.; Kim, J.H.; Song, H.; Yun, S.Y. Understanding cross-domain few-shot learning based on domain similarity and few-shot difficulty. Adv. Neural Inf. Process. Syst. 2022, 35, 2622–2636. [Google Scholar]
- Tseng, H.Y.; Lee, H.Y.; Huang, J.B.; Yang, M.H. Cross-Domain Few-Shot Classification via Learned Feature-Wise Transformation. arXiv 2020, arXiv:2001.08735. [Google Scholar]
- Hu, Z.; Sun, Y.; Yang, Y. Switch to generalize: Domain-switch learning for cross-domain few-shot classification. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Li, S.; Song, S.; Huang, G.; Ding, Z.; Wu, C. Domain invariant and class discriminative feature learning for visual domain adaptation. IEEE Trans. Image Process. 2018, 27, 4260–4273. [Google Scholar] [CrossRef] [PubMed]
- Ji, F.; Chen, Y.; Liu, L.; Yuan, X.T. Cross-Domain Few-Shot Classification via Dense-Sparse-Dense Regularization. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 1352–1363. [Google Scholar] [CrossRef]
- Lee, Y.; Chen, A.S.; Tajwar, F.; Kumar, A.; Yao, H.; Liang, P.; Finn, C. Surgical Fine-Tuning Improves Adaptation to Distribution Shifts. In Proceedings of the The Eleventh International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- Li, W.H.; Liu, X.; Bilen, H. Cross-domain few-shot learning with task-specific adapters. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7161–7170. [Google Scholar]
- Liu, X.; Ji, Z.; Pang, Y.; Han, Z. Self-taught cross-domain few-shot learning with weakly supervised object localization and task-decomposition. Knowl.-Based Syst. 2023, 265, 110358. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, T.; Li, J.; Tian, Y. Dual adaptive representation alignment for cross-domain few-shot learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11720–11732. [Google Scholar] [CrossRef]
- Chen, Y.; Li, Y.; Mao, H.; Chai, X.; Jiao, L. A novel deep nearest neighbor neural network for few-shot remote sensing image scene classification. Remote Sens. 2023, 15, 666. [Google Scholar] [CrossRef]
- Cheng, G.; Cai, L.; Lang, C.; Yao, X.; Chen, J.; Guo, L.; Han, J. SPNet: Siamese-prototype network for few-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, R.; He, B.; Zhou, A.; Wang, D.; Zhao, B.; Gao, P. Not all features matter: Enhancing few-shot clip with adaptive prior refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 2605–2615. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 270–279. [Google Scholar]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Qin, A.; Chen, F.; Li, Q.; Tang, L.; Yang, F.; Zhao, Y.; Gao, C. Deep Updated Subspace Networks for Few-Shot Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–14. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4077–4087. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2017; pp. 1126–1135. [Google Scholar]
- Oreshkin, B.; Rodríguez López, P.; Lacoste, A. Tadam: Task dependent adaptive metric for improved few-shot learning. Adv. Neural Inf. Process. Syst. 2018, 31, 721–731. [Google Scholar]
- Zhang, P.; Fan, G.; Wu, C.; Wang, D.; Li, Y. Task-adaptive embedding learning with dynamic kernel fusion for few-shot remote sensing scene classification. Remote Sens. 2021, 13, 4200. [Google Scholar] [CrossRef]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting local descriptor based image-to-class measure for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7260–7268. [Google Scholar]
- Dong, Z.; Lin, B.; Xie, F. Optimizing few-shot remote sensing scene classification based on an improved data augmentation approach. Remote Sens. 2024, 16, 525. [Google Scholar] [CrossRef]
- Chen, Y.; Li, Y.; Mao, H.; Liu, G.; Chai, X.; Jiao, L. A Novel Discriminative Enhancement Method for Few-Shot Remote Sensing Image Scene Classification. Remote Sens. 2023, 15, 4588. [Google Scholar] [CrossRef]
- Ji, Z.; Hou, L.; Wang, X.; Wang, G.; Pang, Y. Dual contrastive network for few-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Zhang, R.; Hu, X.; Li, B.; Huang, S.; Deng, H.; Qiao, Y.; Gao, P.; Li, H. Prompt, generate, then cache: Cascade of foundation models makes strong few-shot learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15211–15222. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual Instruction Tuning. Adv. Neural Inf. Process. Syst. 2023, 36, 34892–34916. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block Index | Architecture | Output Size |
|---|---|---|
| block 1 | 7 × 7, 64, stride = 2 3 × 3, maxpool, stride = 2 [3 × 3, 64, stride = 1] × 4 | 64 × 56 × 56 |
| block 2 | [3 × 3, 128, stride = 1] × 4 | 128 × 28 × 28 |
| block 3 | [3 × 3, 256, stride = 1] × 4 | 256 × 14 × 14 |
| block 4 | [3 × 3, 512, stride = 1] × 4 7 × 7, avgpool, stride = 7 | 512 × 1 × 1 |
| NWPU-RESISC45 | WHU-RS19 | UCMerced-LandUse |
|---|---|---|
| Airport; Circular farmland; Basketball court; Dense residential; Ground track field; Forest; Medium residential; Intersection; River; Parking lot; | Meadow; Commercial; Pond; Viaduct; River; | Golf course; River; Mobile home park; Tennis court; Sparse residential; Beach; |
| Method | Backbone | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|---|
| MatchingNet * [12] | ResNet-18 | 64.41 ± 0.86 | 76.33 ± 0.65 |
| ProtoNet * [54] | ResNet-18 | 65.20 ± 0.84 | 80.52 ± 0.55 |
| RelationNet * [55] | ResNet-18 | 60.04 ± 0.85 | 80.39 ± 0.56 |
| MAML [56] | ResNet-12 | 56.01 ± 0.87 | 72.94 ± 0.63 |
| TADAM [57] | ResNet-12 | 62.25 ± 0.79 | 82.36 ± 0.54 |
| DLA-MatchNet [32] | ConvNet | 68.80 ± 0.70 | 81.63 ± 0.46 |
| TAE-Net [58] | ResNet-12 | 69.13 ± 0.83 | 82.37 ± 0.52 |
| DN4 [59] | ResNet-18 | 66.39 ± 0.86 | 83.24 ± 0.87 |
| SPNet [48] | ResNet-18 | 67.84 ± 0.87 | 83.94 ± 0.50 |
| HiReNet [19] | Conv + ViT | 70.43 ± 0.90 | 81.24 ± 0.58 |
| MPCL [16] | ConvNet | 55.94 ± 0.04 | 76.24 ± 0.12 |
| ODS [60] | ResNet-12 | 67.47 ± 1.17 | 80.59 ± 0.86 |
| DN4AM [47] | ResNet-18 | 70.75 ± 0.81 | 86.79 ± 0.51 |
| DEADN4 [61] | ResNet-18 | 73.56 ± 0.83 | 87.28 ± 0.50 |
| TA-MSA (Ours) | ResNet-18 | 68.88 ± 0.63 | 86.95 ± 0.36 |
| Method | Backbone | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|---|
| MatchingNet * [12] | ResNet-18 | 48.18 ± 0.75 | 67.39 ± 0.50 |
| ProtoNet * [54] | ResNet-18 | 53.85 ± 0.78 | 71.23 ± 0.48 |
| RelationNet * [55] | ResNet-18 | 50.07 ± 0.72 | 65.22 ± 0.52 |
| MAML [56] | ResNet-12 | 43.65 ± 0.68 | 58.43 ± 0.64 |
| DLA-MatchNet [32] | ConvNet | 53.76 ± 0.62 | 63.01 ± 0.51 |
| TAE-Net [58] | ResNet-12 | 60.21 ± 0.72 | 77.44 ± 0.51 |
| DN4 [59] | ResNet-18 | 57.25 ± 1.01 | 79.74 ± 0.78 |
| SPNet [48] | ResNet-18 | 57.64 ± 0.73 | 73.52 ± 0.51 |
| HiReNet [19] | Conv + ViT | 58.60 ± 0.80 | 76.84 ± 0.56 |
| DUSN [53] | Conv5 | 62.20 ± 0.84 | 79.44 ± 0.47 |
| MFGNet [31] | ResNet-12 | 61.76 ± 0.59 | 76.55 ± 0.40 |
| DCN [62] | ResNet-12 | 58.64 ± 0.71 | 76.61 ± 0.49 |
| MPCL [16] | ConvNet | 56.46 ± 0.21 | 76.57 ± 0.07 |
| ODS [60] | ResNet-12 | 60.35 ± 1.02 | 72.67 ± 0.73 |
| DN4AM [61] | ResNet-18 | 65.49 ± 0.72 | 85.73 ± 0.47 |
| DEADN4 [61] | ResNet-18 | 67.27 ± 0.74 | 87.69 ± 0.44 |
| TA-MSA (Ours) | ResNet-18 | 74.20 ± 0.49 | 91.75 ± 0.25 |
| Method | Backbone | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|---|
| MatchingNet * [12] | ResNet-18 | 67.78 ± 0.67 | 85.01 ± 0.38 |
| ProtoNet * [54] | ResNet-18 | 76.36 ± 0.67 | 85.00 ± 0.36 |
| RelationNet * [55] | ResNet-18 | 65.01 ± 0.72 | 79.75 ± 0.32 |
| MAML [56] | ResNet-12 | 59.19 ± 0.92 | 72.34 ± 0.75 |
| DLA-MatchNet [32] | ConvNet | 68.27 ± 1.83 | 79.89 ± 0.33 |
| TAE-Net [58] | ResNet-12 | 73.67 ± 0.74 | 88.95 ± 0.53 |
| DN4 [59] | ResNet-18 | 82.14 ± 0.80 | 96.02 ± 0.33 |
| SPNet [48] | ResNet-18 | 81.07 ± 0.60 | 88.04 ± 0.28 |
| DCN [62] | ResNet-12 | 81.74 ± 0.55 | 91.67 ± 0.25 |
| DN4AM [61] | ResNet-18 | 85.05 ± 0.52 | 96.94 ± 0.21 |
| DEADN4 [61] | ResNet-18 | 86.89 ± 0.57 | 97.63 ± 0.19 |
| TA-MSA (Ours) | ResNet-18 | 87.24 ± 0.32 | 96.97 ± 0.14 |
| Model | NWPU-RESISC45 | UC Merced-LandUse | WHU-RS19 | Ave |
|---|---|---|---|---|
| baseline | 67.33 ± 0.64 | 71.80 ± 0.47 | 85.20 ± 0.34 | – |
| BS + TA1 | 67.42 ± 0.64 | 72.37 ± 0.50 | 84.95 ± 0.33 | + 0.14 |
| BS + TA2 | 67.53 ± 0.66 | 72.96 ± 0.51 | 85.83 ± 0.34 | + 0.66 |
| BS + TA | 68.25 ± 0.65 | 73.25 ± 0.49 | 85.53 ± 0.32 | + 0.90 |
| BS + MSA | 68.58 ± 0.63 | 72.58 ± 0.51 | 86.41 ± 0.32 | + 1.08 |
| TA-MSA | 68.88 ± 0.63 | 73.62 ± 0.51 | 87.24 ± 0.32 | + 1.80 |
| Model | NWPU-RESISC45 | UC Merced-LandUse | WHU-RS19 | Ave |
|---|---|---|---|---|
| baseline | 85.20 ± 0.38 | 90.16 ± 0.27 | 95.71 ± 0.15 | – |
| BS + TA1 | 85.11 ± 0.39 | 90.73 ± 0.26 | 95.54 ± 0.17 | + 0.10 |
| BS + TA2 | 86.11 ± 0.37 | 90.73 ± 0.27 | 96.16 ± 0.15 | + 0.64 |
| BS + TA | 86.13 ± 0.38 | 91.03 ± 0.26 | 95.93 ± 0.16 | + 0.67 |
| BS + MSA | 85.97 ± 0.39 | 90.57 ± 0.27 | 96.46 ± 0.14 | + 0.64 |
| TA-MSA | 86.95 ± 0.36 | 91.75 ± 0.25 | 96.97 ± 0.13 | + 1.53 |
| NWPU-RESISC45 | UC Merced-LandUse | WHU-RS19 | |
|---|---|---|---|
| 0.0001 | 67.47 ± 0.66 | 91.45 ± 0.25 | 83.95 ± 0.18 |
| 0.0005 | 68.88 ± 0.66 | 91.75 ± 0.25 | 87.24 ± 0.14 |
| 0.001 | 68.72 ± 0.66 | 91.63 ± 0.25 | 86.84 ± 0.14 |
| 0.0015 | 68.58 ± 0.67 | 91.17 ± 0.27 | 87.02 ± 0.14 |
| 0.002 | 67.46 ± 0.64 | 90.61 ± 0.27 | 86.79 ± 0.14 |
| NWPU-RESISC45 | UC Merced-LandUse | WHU-RS19 | |
|---|---|---|---|
| 0.0001 | 85.75 ± 0.39 | 73.86 ± 0.48 | 94.81 ± 0.31 |
| 0.0005 | 86.95 ± 0.37 | 74.20 ± 0.50 | 96.97 ± 0.32 |
| 0.001 | 87.03 ± 0.35 | 74.10 ± 0.49 | 96.57 ± 0.34 |
| 0.0015 | 86.33 ± 0.37 | 73.16 ± 0.50 | 96.61 ± 0.32 |
| 0.002 | 86.15 ± 0.37 | 72.15 ± 0.53 | 96.76 ± 0.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Sun, Y.; Peng, X.; Zhang, J.; Qi, G.; Liu, D. TA-MSA: A Fine-Tuning Framework for Few-Shot Remote Sensing Scene Classification. Remote Sens. 2025, 17, 1395. https://doi.org/10.3390/rs17081395
Li X, Sun Y, Peng X, Zhang J, Qi G, Liu D. TA-MSA: A Fine-Tuning Framework for Few-Shot Remote Sensing Scene Classification. Remote Sensing. 2025; 17(8):1395. https://doi.org/10.3390/rs17081395
Chicago/Turabian StyleLi, Xiang, Yumei Sun, Xiaoming Peng, Jianlin Zhang, Guanglin Qi, and Dongxu Liu. 2025. "TA-MSA: A Fine-Tuning Framework for Few-Shot Remote Sensing Scene Classification" Remote Sensing 17, no. 8: 1395. https://doi.org/10.3390/rs17081395
APA StyleLi, X., Sun, Y., Peng, X., Zhang, J., Qi, G., & Liu, D. (2025). TA-MSA: A Fine-Tuning Framework for Few-Shot Remote Sensing Scene Classification. Remote Sensing, 17(8), 1395. https://doi.org/10.3390/rs17081395