
Application of Deep Learning on Global Spaceborne Radar and Multispectral Imagery for the Estimation of Urban Surface Height Distribution



Abstract
1. Introduction
1.1. Existing Global DSM Products Using Interferometry
1.2. Height Reconstruction from SAR Intensity
1.3. Contribution
2. Material and Methods
2.1. Sentinel 1 and 2 Yearly Median
2.2. LiDAR-Derived NDSM
2.3. Training Approach
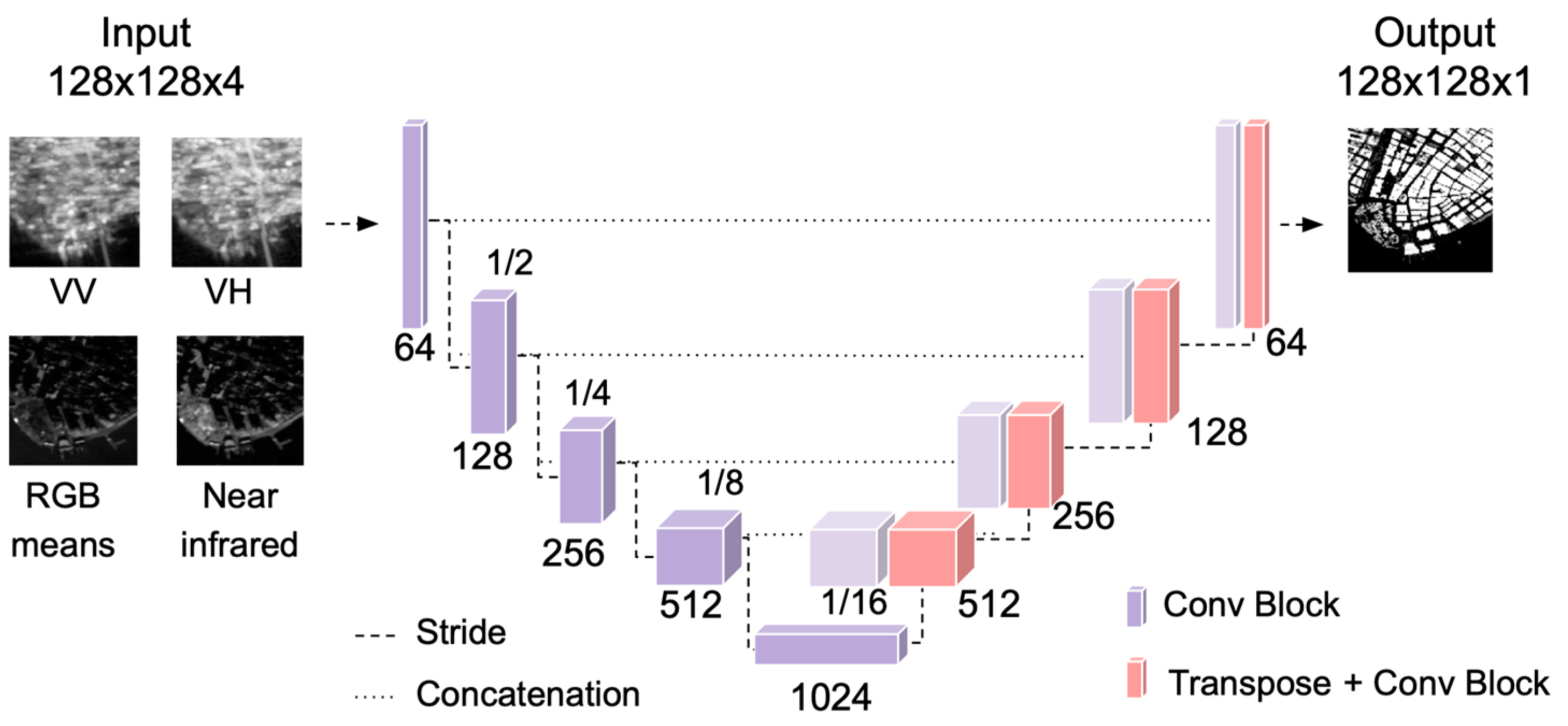
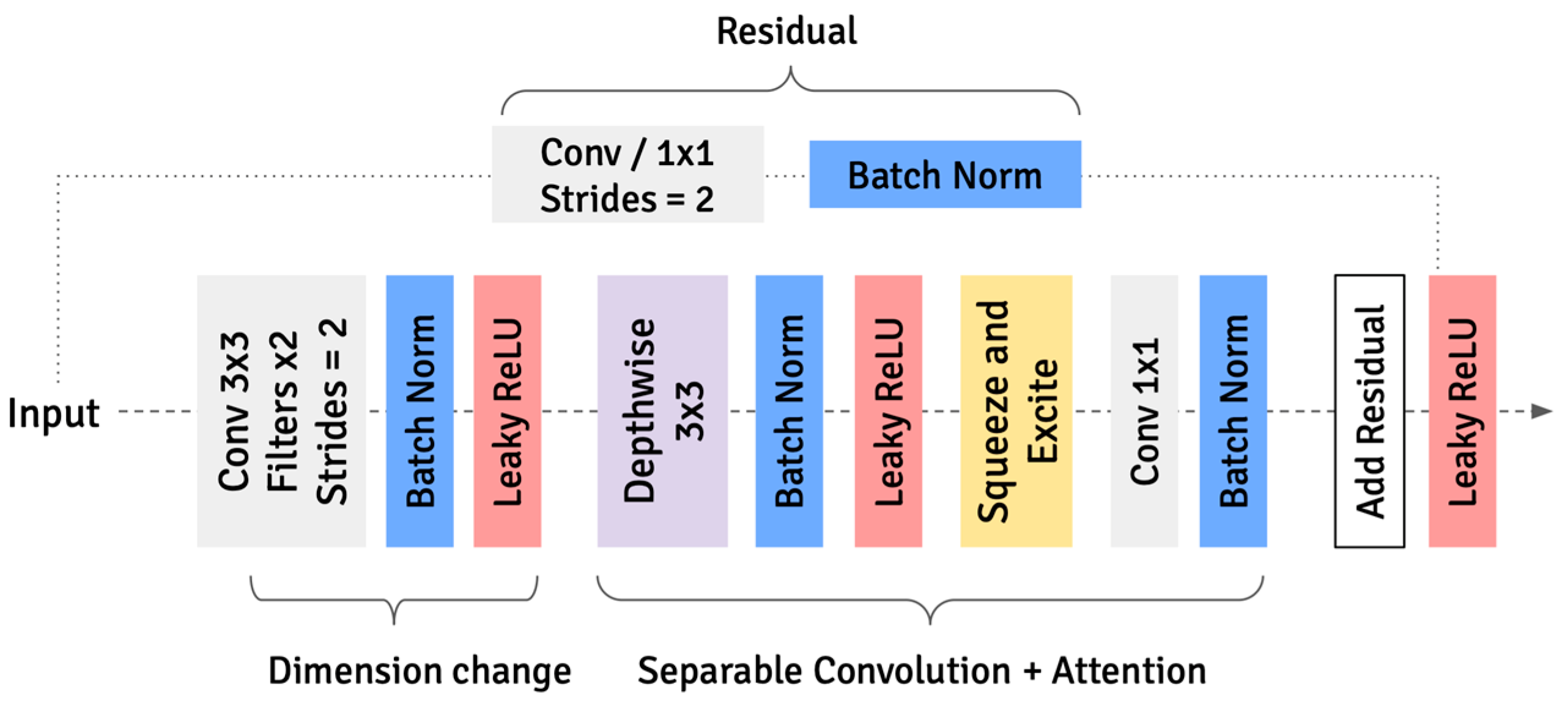
2.4. U-Net Architecture
2.5. Hyperparameter, Loss Functions and Metrics
3. Results
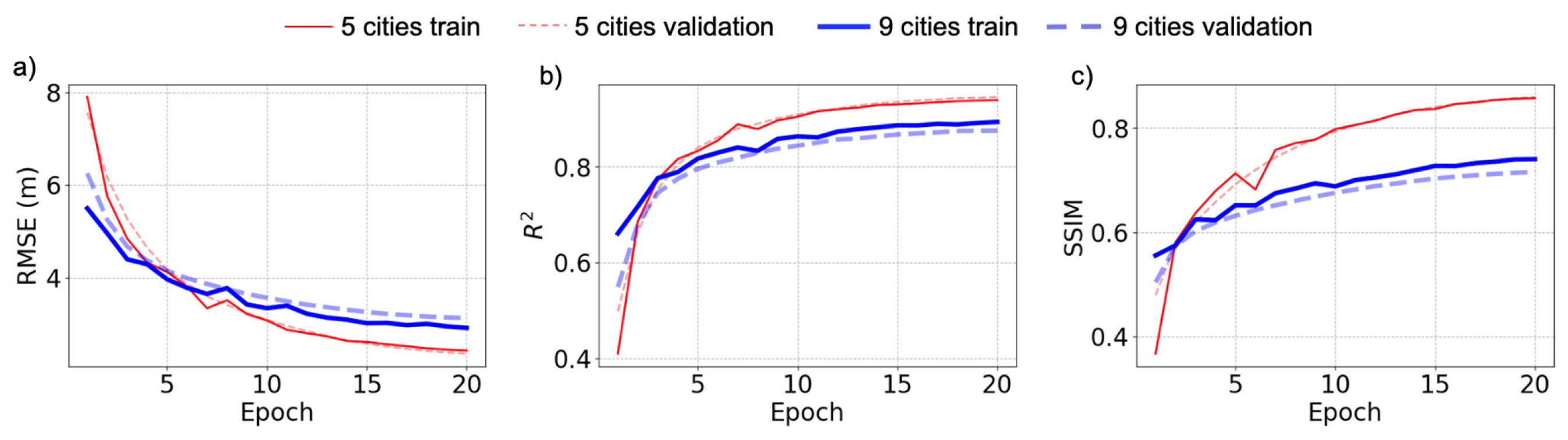
3.1. Training Performance
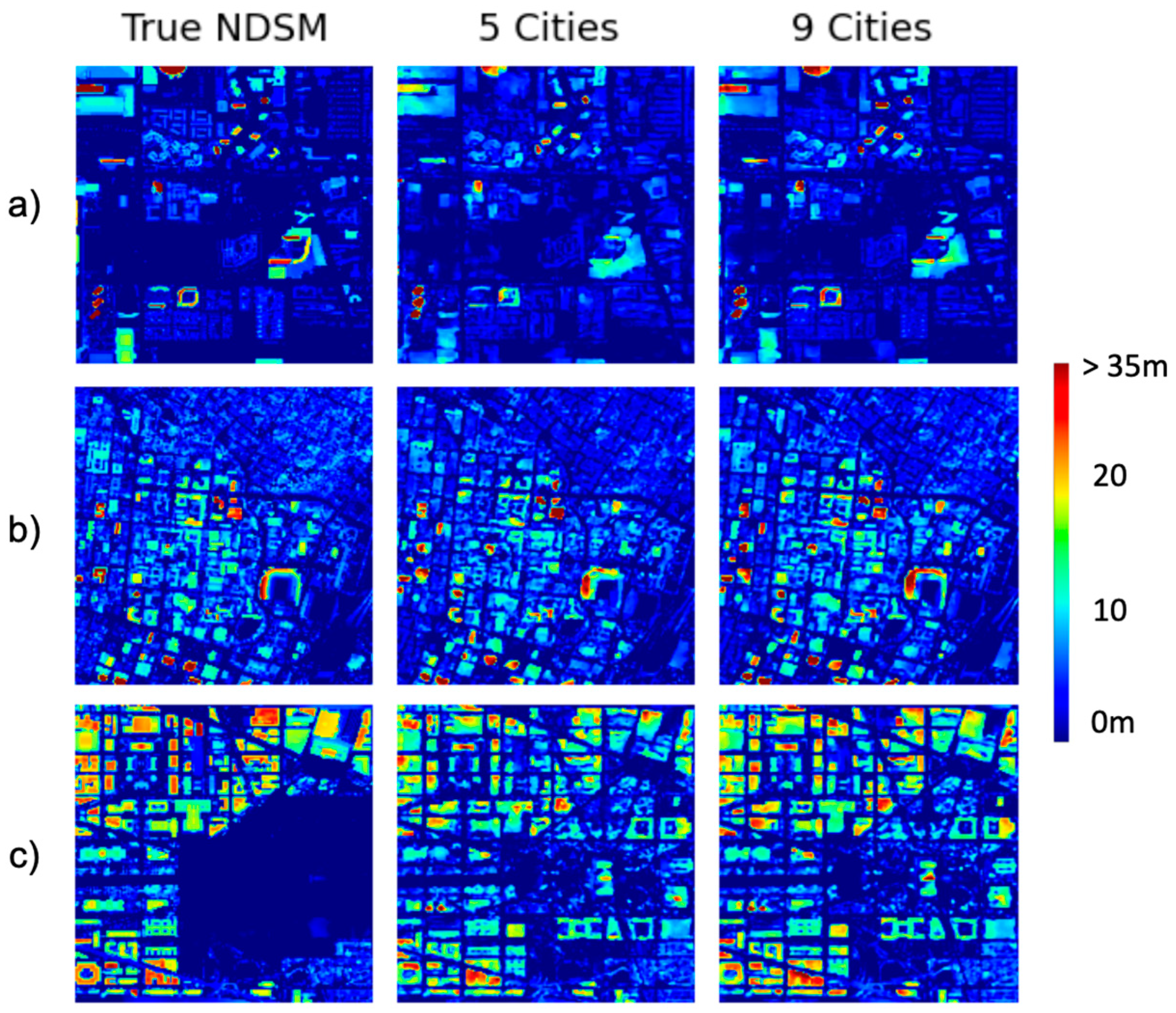
3.2. Inference Comparison on Test Dataset
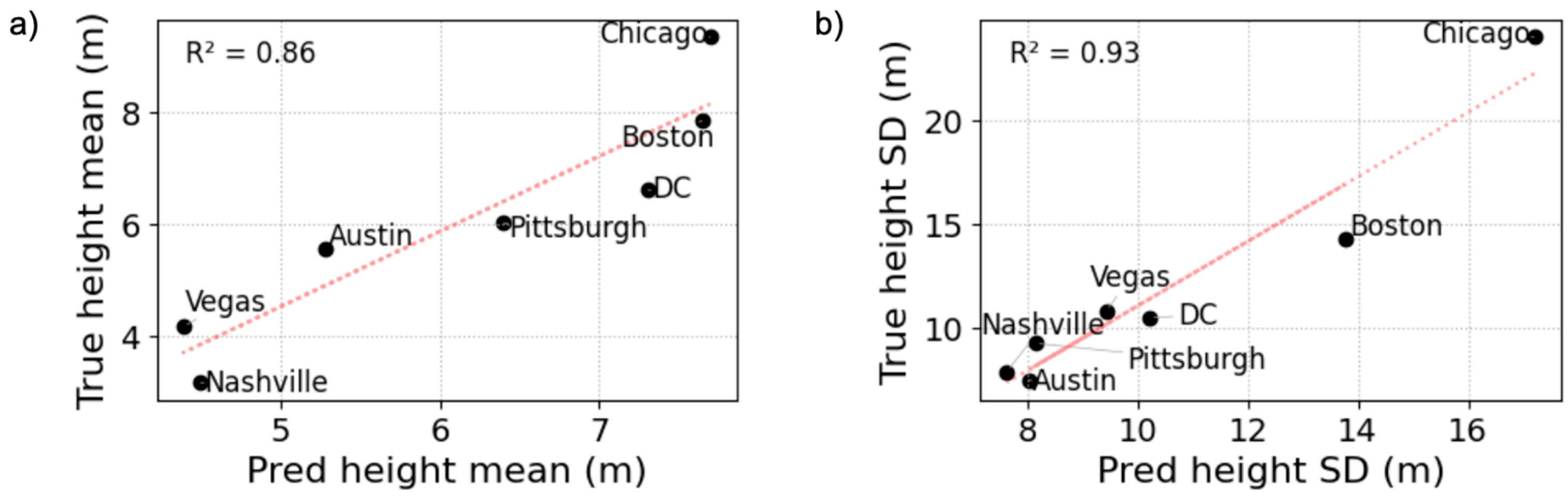
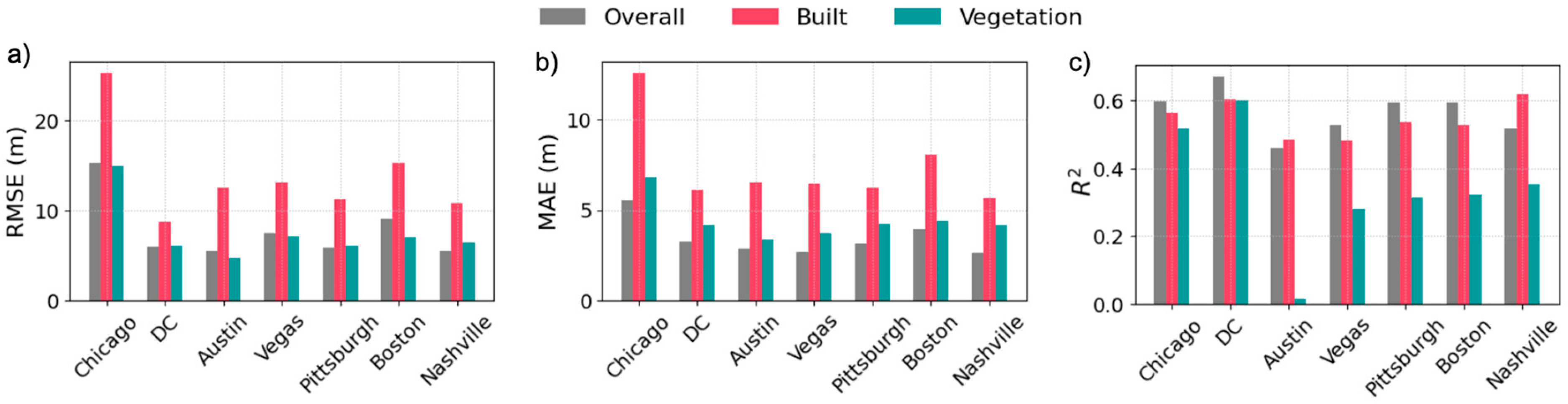
3.3. Height Estimation on Test Cities
4. Discussion
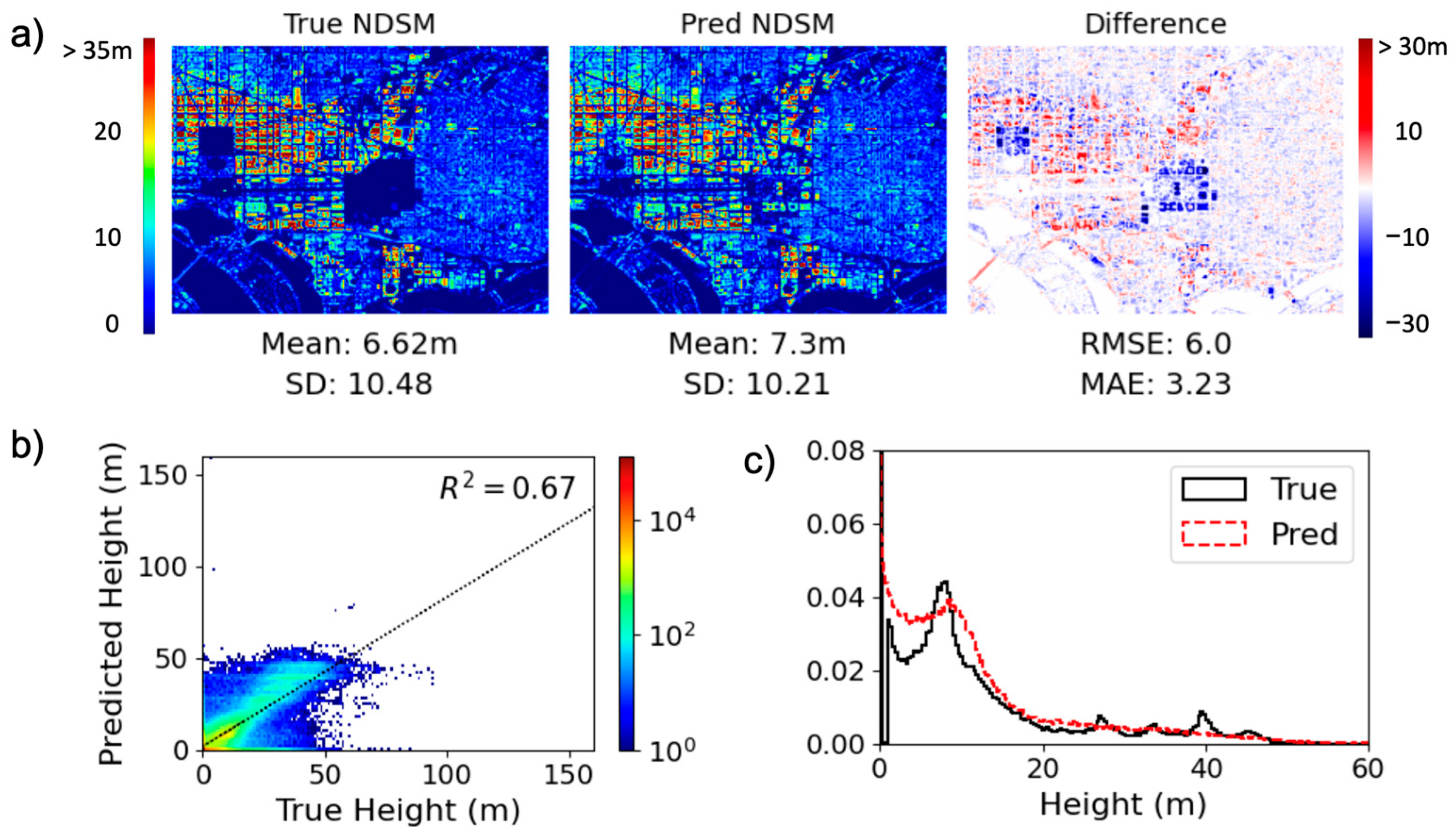
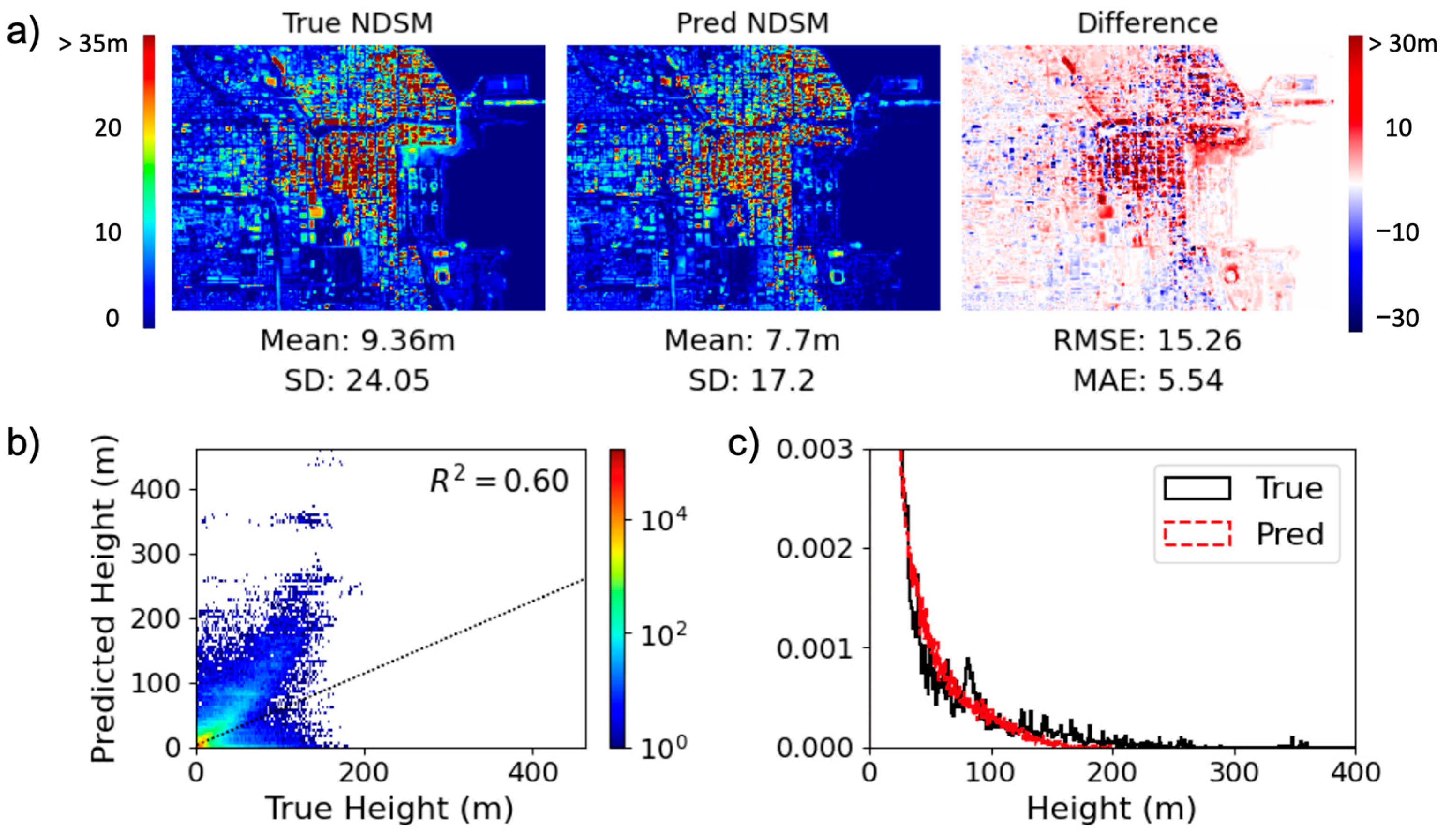
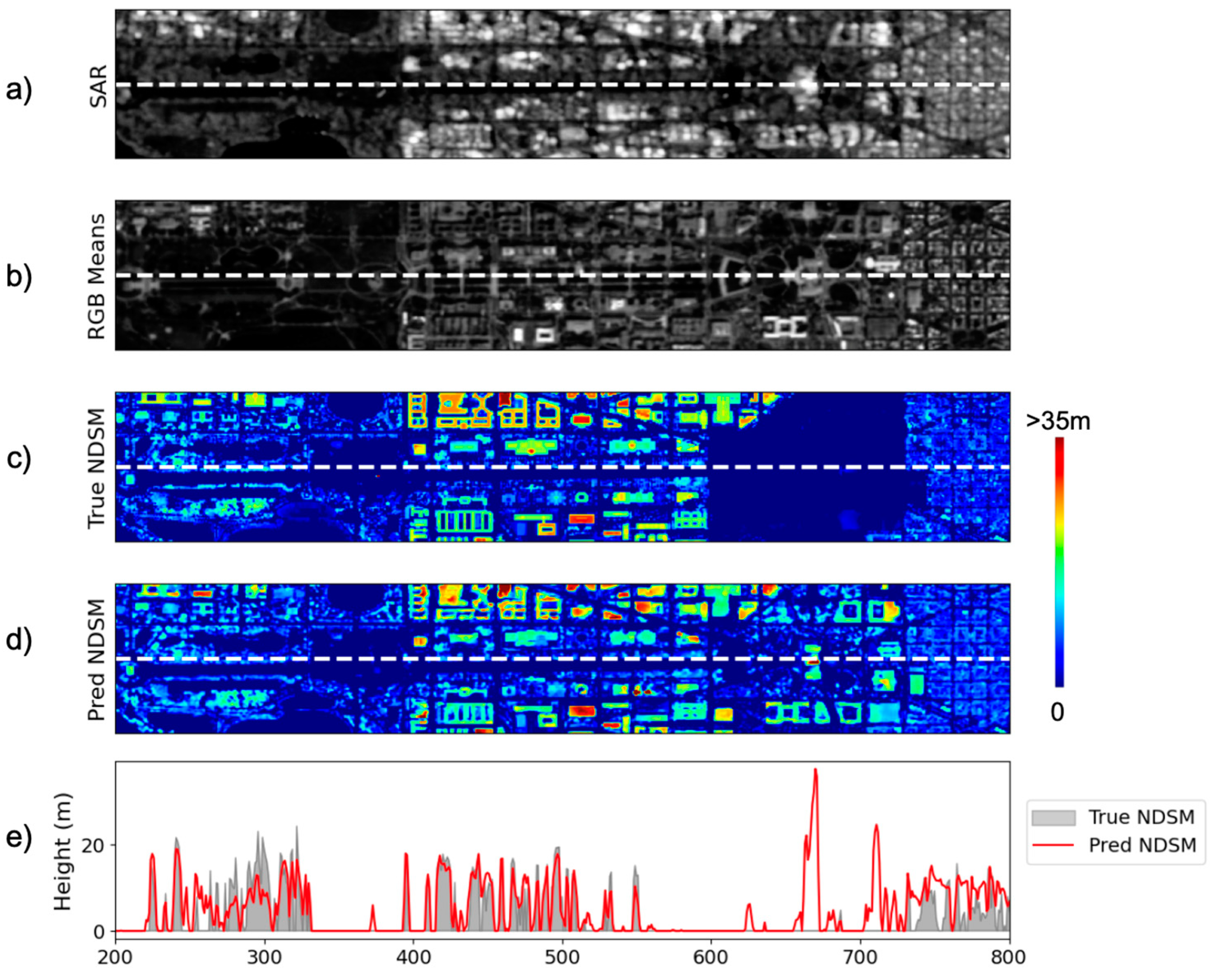
4.1. Comparative Study: Washington DC vs. Chicago
4.2. Cross-Section Analysis
4.3. Challenges and Paths to Model Improvement
- Overfitting: Although increasing the size and city variability of the training dataset improves the overall inference performance on the test dataset, the average RMSE (10.22 m) of the test set is much larger than the RMSE of the validation set (2.43 m). Similarly, the average R2 for the test set is well below the validation R2. While the cross-section provides valuable insights and demonstrates certain strengths, there remains a need to address the estimation bias to achieve generalization and more accurate results.To improve the model’s performance and reduce overfitting, there is a need for a refined approach to data curation as different cities possess unique complexity. Such curation could involve a study focusing on creating a better-balanced dataset based on machine learning clustering analysis that accurately characterizes the diverse height distribution of the urban features, relating to how they are represented in the input satellite imagery. Additionally, alternative training methods such as ensemble learning utilizing k-fold cross-validation could be explored to enhance the robustness of the model. Other potential strategies, such as the incorporation of multi-task learning, as in the approach by Cai et al. where the model outputs both building heights and footprints, could leverage the model’s mechanism in alleviating biases and enhance the capability of generalizing across varying urban landscapes.
- SAR artifacts: The model inference performs poorly on areas with heavy geometric distortion where the SAR intensity image is dominated with layovers. In the case of Chicago, the layover from the densely populated tall buildings spills onto the surrounding areas. Such distortion expectedly creates a significant challenge for the model to extract surface height information and maintain fine shapes of features.Applying CNN to a geometrically distorted image is always a challenge. Recla & Schmitt [12] introduced a preprocessing method that projected true NDSM for training onto the SAR coordinate system, with an addition of parameter injection into the model to improve the overall estimation. The performance of the model, however, still possesses drawbacks in denser areas with tall buildings, where individual buildings’ layovers are indistinguishable from one another. The option to create aggregate intensity at larger resolutions, such as the approach applied by Li et al. [15] may not be suitable for urban applications as it significantly reduces the resolution of the image. This challenge leads to the need for expanding the understanding of the convolutions and their corresponding weights. Techniques from explainable AI can offer deeper insights into the relationship between the input satellite imagery and the generated NDSM, therefore providing a clearer interpretation of the underlying mechanism which can be leveraged to produce a more effective convolutional block that fully captures the height information.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Braun, A. Retrieval of Digital Elevation Models from Sentinel-1 Radar Data—Open Applications, Techniques, and Limitations. Open Geosci. 2021, 13, 532–569. [Google Scholar] [CrossRef]
- Soergel, U. (Ed.) Radar Remote Sensing of Urban Areas; Remote Sensing and Digital Image Processing; Springer Netherlands: Dordrecht, The Netherlands, 2010; Volume 15, ISBN 978-90-481-3750-3. [Google Scholar]
- Thiele, A.; Wurth, M.M.; Even, M.; Hinz, S. Extraction of Builidng Shape from Tandem-X Data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-1/W1, 345–350. [Google Scholar] [CrossRef]
- Koppel, K.; Zalite, K.; Voormansik, K.; Jagdhuber, T. Sensitivity of Sentinel-1 Backscatter to Characteristics of Buildings. Int. J. Remote Sens. 2017, 38, 6298–6318. [Google Scholar] [CrossRef]
- Rodríguez, E.; Morris, C.S.; Belz, J.E. A Global Assessment of the SRTM Performance. Photogramm. Eng Remote Sens. 2006, 72, 249–260. [Google Scholar] [CrossRef]
- Misra, P.; Avtar, R.; Takeuchi, W. Comparison of Digital Building Height Models Extracted from AW3D, TanDEM-X, ASTER, and SRTM Digital Surface Models over Yangon City. Remote Sens. 2018, 10, 2008. [Google Scholar] [CrossRef]
- Uuemaa, E.; Ahi, S.; Montibeller, B.; Muru, M.; Kmoch, A. Vertical Accuracy of Freely Available Global Digital Elevation Models (ASTER, AW3D30, MERIT, TanDEM-X, SRTM, and NASADEM. Remote Sens. 2020, 12, 3482. [Google Scholar] [CrossRef]
- Gross, K.; Corseaux, A. Copernicus DEMs Quality Assessment Summary; European Space Agency (ESA): Paris, France; Telespazio: Rome, Italy, 2021.
- Copernicus Data Space Ecosystem. Copernicus Copernicus DEM—Global and European Digital Elevation Model. Available online: https://dataspace.copernicus.eu/explore-data/data-collections/copernicus-contributing-missions/collections-description/COP-DEM (accessed on 30 July 2024).
- Rossi, C.; Gernhardt, S. Urban DEM Generation, Analysis and Enhancements Using TanDEM-X. ISPRS J. Photogramm. Remote Sens. 2013, 85, 120–131. [Google Scholar] [CrossRef]
- Sun, Y.; Montazeri, S.; Wang, Y.; Zhu, X.X. Automatic Registration of a Single SAR Image and GIS Building Footprints in a Large-Scale Urban Area. ISPRS J. Photogramm. Remote Sens. 2020, 170, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Recla, M.; Schmitt, M. Deep-Learning-Based Single-Image Height Reconstruction from Very-High-Resolution SAR Intensity Data. ISPRS J. Photogramm. Remote Sens. 2022, 183, 496–509. [Google Scholar] [CrossRef]
- Shi, C.; Zuo, X.; Zhang, J.; Zhu, D.; Li, Y.; Bu, J. Accuracy Assessment of Geometric-Distortion Identification Methods for Sentinel-1 Synthetic Aperture Radar Imagery in Highland Mountainous Regions. Sensors 2024, 24, 2834. [Google Scholar] [CrossRef] [PubMed]
- Tao, J.; Palubinskas, G.; Reinartz, P.; Auer, S. Interpretation of SAR Images in Urban Areas Using Simulated Optical and Radar Images. In Proceedings of the 2011 Joint Urban Remote Sensing Event, Munich, Germany, 11–13 April 2011; pp. 41–44. [Google Scholar]
- Li, X.; Zhou, Y.; Gong, P.; Seto, K.C.; Clinton, N. Developing a Method to Estimate Building Height from Sentinel-1 Data. Remote Sens. Environ. 2020, 240, 111705. [Google Scholar] [CrossRef]
- Frantz, D.; Schug, F.; Okujeni, A.; Navacchi, C.; Wagner, W.; van der Linden, S.; Hostert, P. National-Scale Mapping of Building Height Using Sentinel-1 and Sentinel-2 Time Series. Remote Sens. Environ. 2021, 252, 112128. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Cai, B.; Shao, Z.; Huang, X.; Zhou, X.; Fang, S. Deep Learning-Based Building Height Mapping Using Sentinel-1 and Sentienl-2 Data. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103399. [Google Scholar]
- Nascetti, A.; Yadav, R.; Ban, Y. A CNN Regression Model to Estimate Buildings Height Maps Using Sentinel-1 SAR and Sentinel-2 MSI Time Series. In Proceedings of the IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; pp. 2831–2834. [Google Scholar]
- Cao, Y.; Weng, Q. A Deep Learning-Based Super-Resolution Method for Building Height Estimation at 2.5 m Spatial Resolution in the Northern Hemisphere. Remote Sens. Environ. 2024, 310, 114241. [Google Scholar] [CrossRef]
- European Space Agency Sentinel-1: ESA’s Radar Observatory Mission for GMES Operational Services 2013. Available online: https://esamultimedia.esa.int/docs/S1-Data_Sheet.pdf (accessed on 30 November 2024).
- European Space Agency Sentinel-2: Optical High-Resolution Mission for GMES Operational Services 2013. Available online: https://esamultimedia.esa.int/docs/S2-Data_Sheet.pdf (accessed on 30 November 2024).
- U.S. Geological Survey. LiDAR Point Cloud Data for Various U.S. Cities. 2017–2022. Available online: https://apps.nationalmap.gov/downloader/ (accessed on 30 May 2024).
- New York City Department of Environmental Protection. NYC LiDAR 2017 Dataset. 2017. Available online: https://data.cityofnewyork.us (accessed on 30 May 2024).
- District of Columbia Government. DC LiDAR 2022 Dataset. 2022. Available online: https://opendata.dc.gov (accessed on 30 May 2024).
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-Net and Its Variants for Medical Image Segmentation: A Review of Theory and Applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Amirkolaee, H.A.; Arefi, H. Height Estimation from Single Aerial Images Using a Deep Convolutional Encoder-Decoder Network. ISPRS J. Photogramm. Remote Sens. 2019, 149, 50–66. [Google Scholar]
- Mou, L.; Zhu, X.X. IM2HEIGHT: Height Estimation from Single Monocular Imagery via Fully Residual Convolutional-Deconvolutional Network 2018. arXiv 2018, arXiv:1802.10249. [Google Scholar]
- Liu, C.J.; Krylov, V.A.; Kane, P.; Kavanagh, G.; Dahyot, R. IM2ELEVATION: Building Height Estimation from Single-View Aerial Imagery. Remote Sens. 2020, 12, 2719. [Google Scholar] [CrossRef]
- Karatsiolis, S.; Kamilaris, A.; Cole, I. IMG2NDSM: Height Estimation from Single Airborne Rgb Images with Deep Learning. Remote Sens. 2021, 13, 2417. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2559–2567. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the Radiometric and Biophysical Performance of the MODIS Vegetation Indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Size | RMSE (m) | RMSE Built (m) | RMSE Veg (m) | MAE (m) | MAE Built (m) | MAE Veg (m) | R2 | R2 Built | R2 Veg |
|---|---|---|---|---|---|---|---|---|---|
| 5 Cities | 10.84 | 16.08 | 11.47 | 5.86 | 10.51 | 6.97 | 0.54 | 0.45 | 0.21 |
| 9 Cities | 10.22 | 14.99 | 10.38 | 5.28 | 9.41 | 6.24 | 0.58 | 0.52 | 0.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rinaldi, V.; Ghandehari, M. Application of Deep Learning on Global Spaceborne Radar and Multispectral Imagery for the Estimation of Urban Surface Height Distribution. Remote Sens. 2025, 17, 1297. https://doi.org/10.3390/rs17071297
Rinaldi V, Ghandehari M. Application of Deep Learning on Global Spaceborne Radar and Multispectral Imagery for the Estimation of Urban Surface Height Distribution. Remote Sensing. 2025; 17(7):1297. https://doi.org/10.3390/rs17071297
Chicago/Turabian StyleRinaldi, Vivaldi, and Masoud Ghandehari. 2025. "Application of Deep Learning on Global Spaceborne Radar and Multispectral Imagery for the Estimation of Urban Surface Height Distribution" Remote Sensing 17, no. 7: 1297. https://doi.org/10.3390/rs17071297
APA StyleRinaldi, V., & Ghandehari, M. (2025). Application of Deep Learning on Global Spaceborne Radar and Multispectral Imagery for the Estimation of Urban Surface Height Distribution. Remote Sensing, 17(7), 1297. https://doi.org/10.3390/rs17071297