

Assessing the Impact of Mixed Pixel Proportion Training Data on SVM-Based Remote Sensing Classification: A Simulated Study



Abstract

1. Introduction
2. Materials and Methods
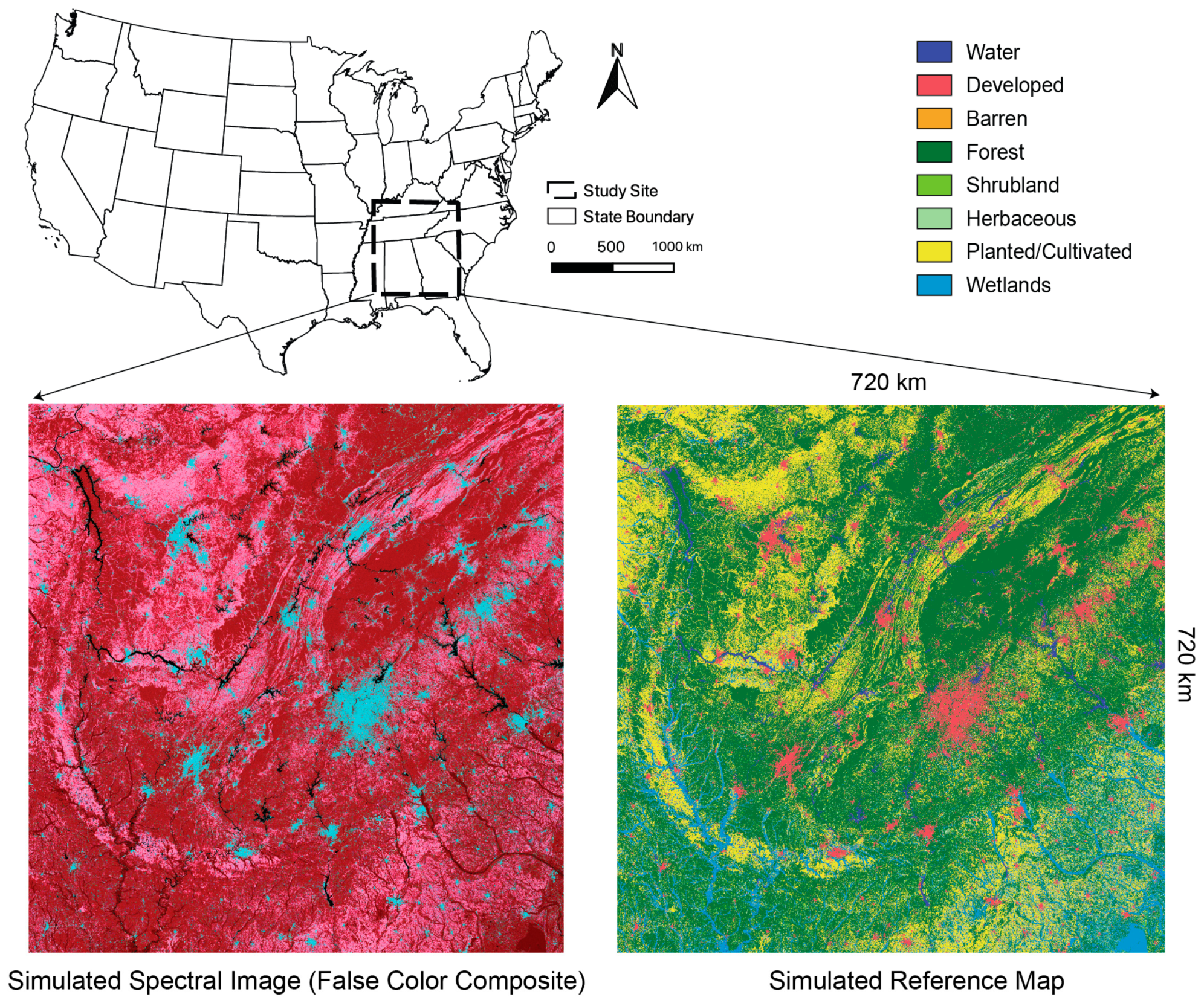
2.1. Study Site
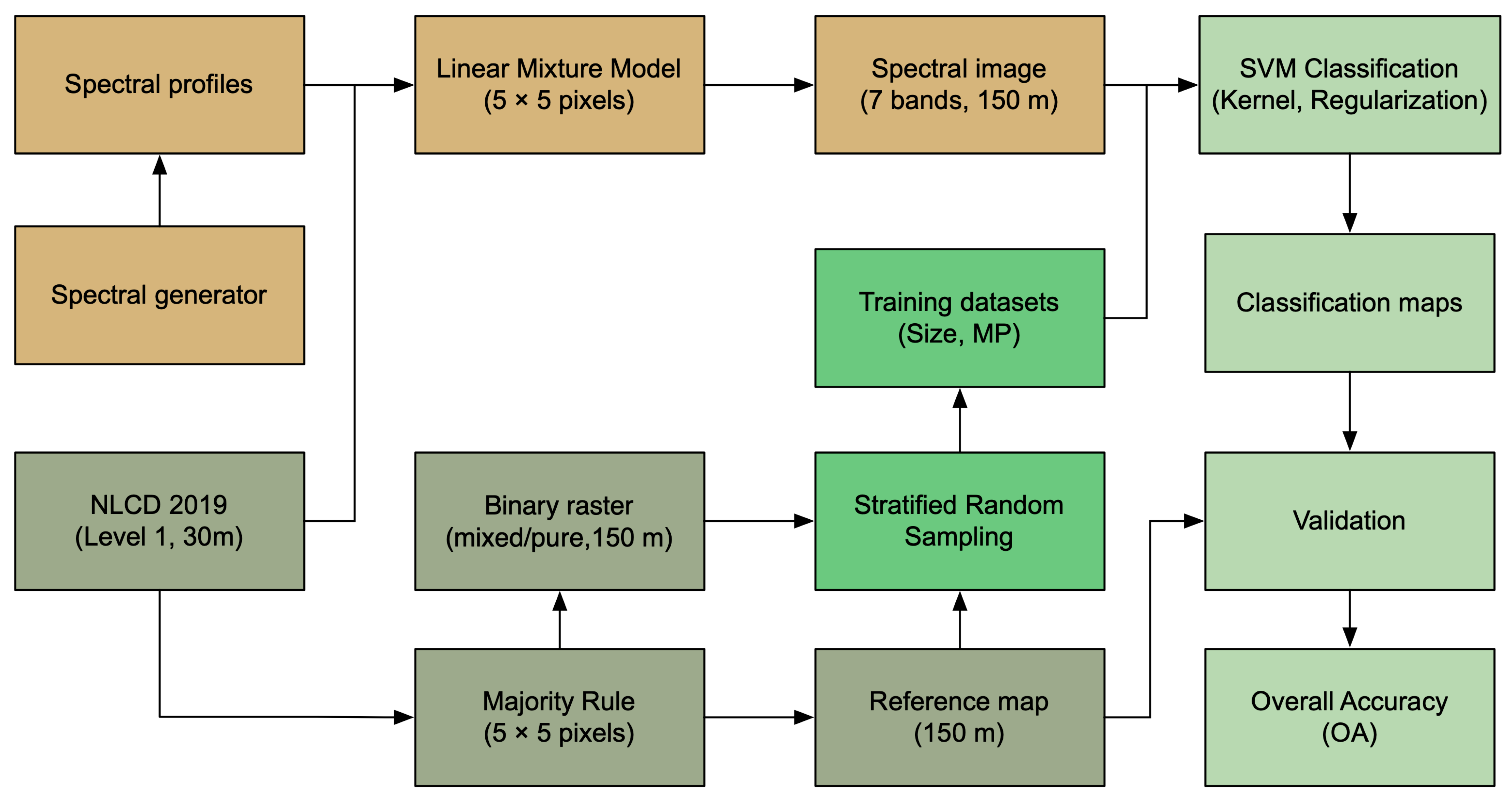
2.2. Outline of Methods
2.3. Simulate Reference Data
2.4. Simulate a Multispectral Image
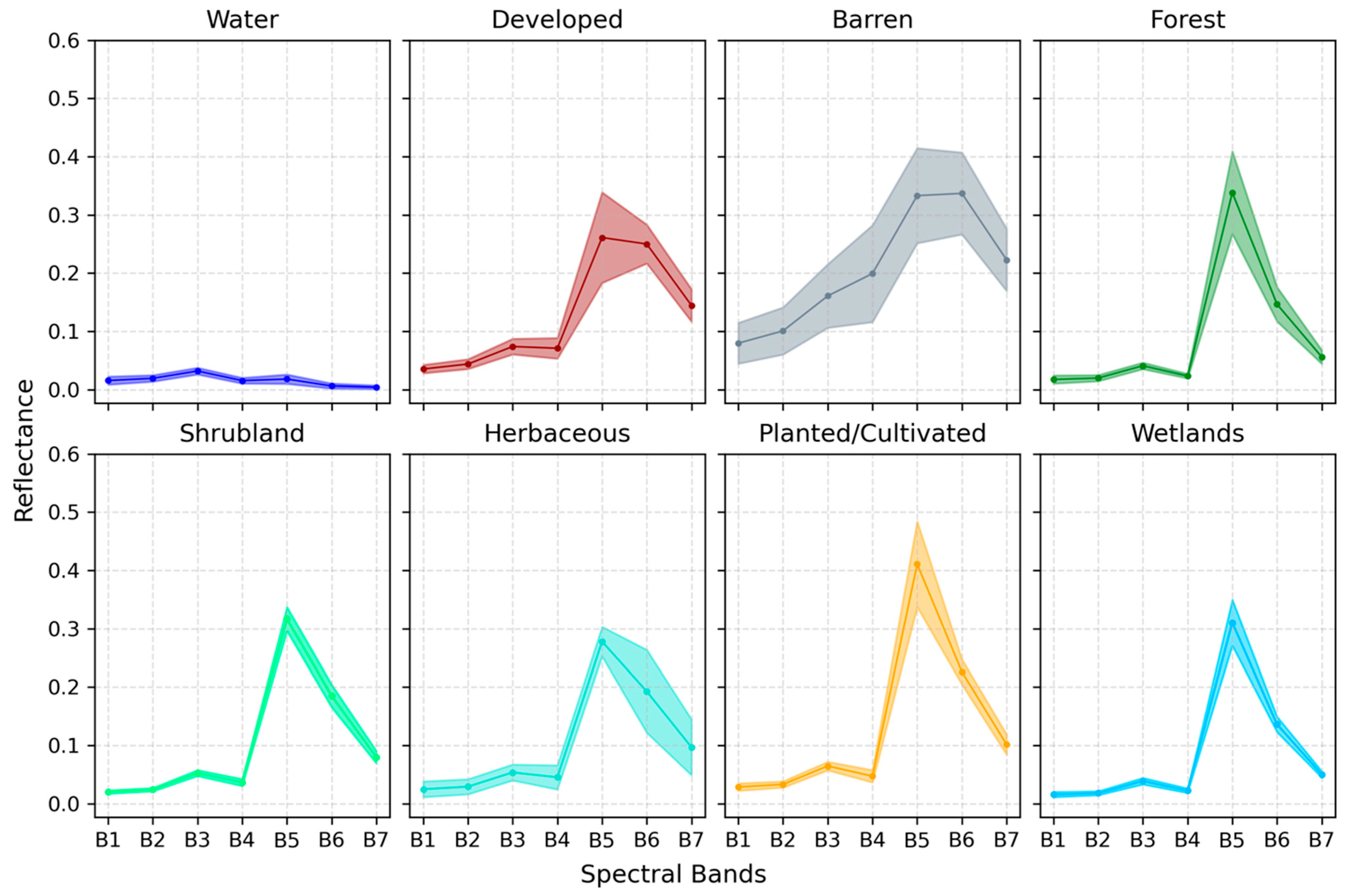
2.4.1. Collect Spectral Profiles for a Label
2.4.2. Simulate a Spectral Image
2.5. SVM Classification
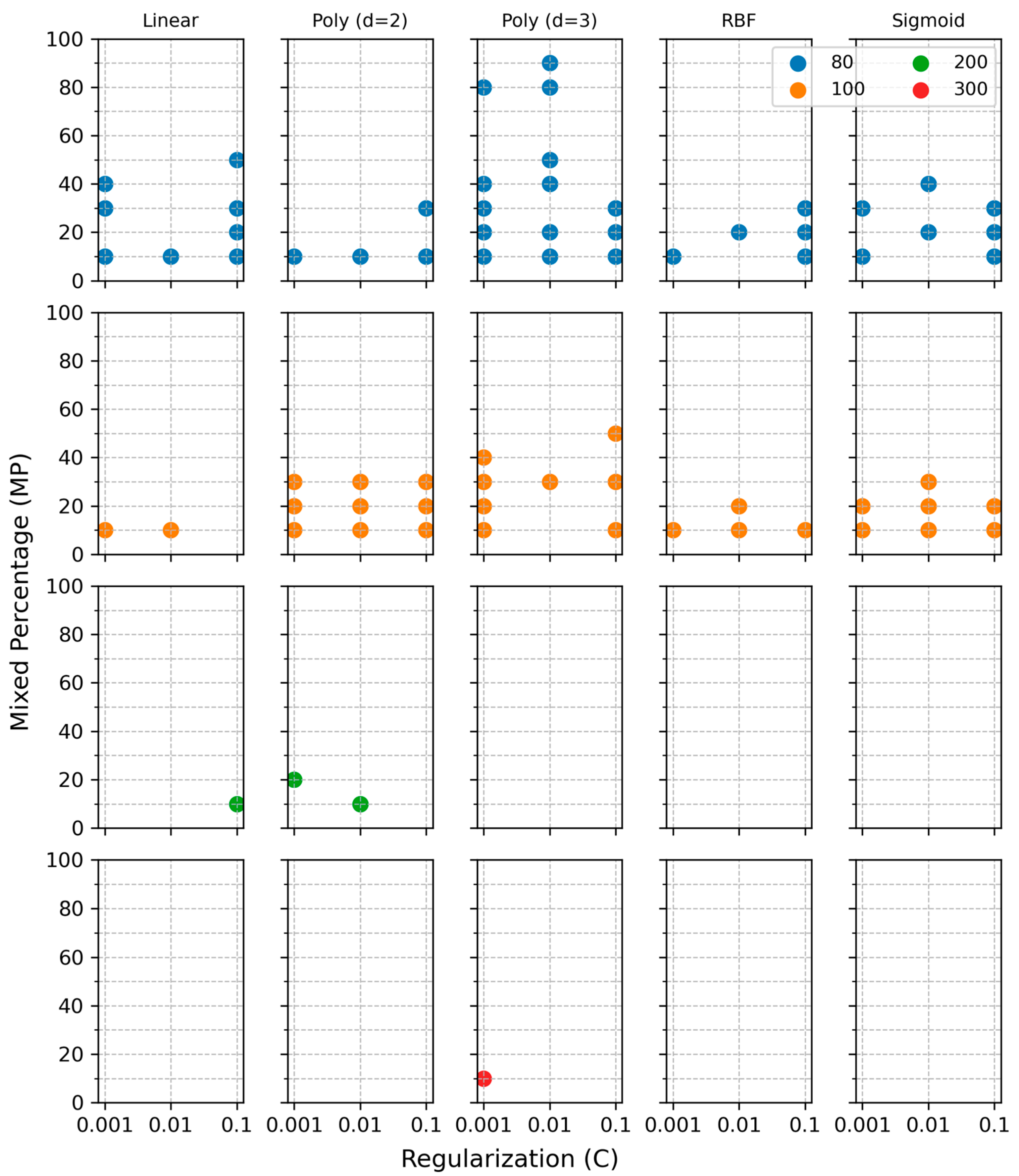
2.5.1. Training Data Selection
2.5.2. SVM with Various Kernel Parameters
2.5.3. Accuracy Assessment
3. Results
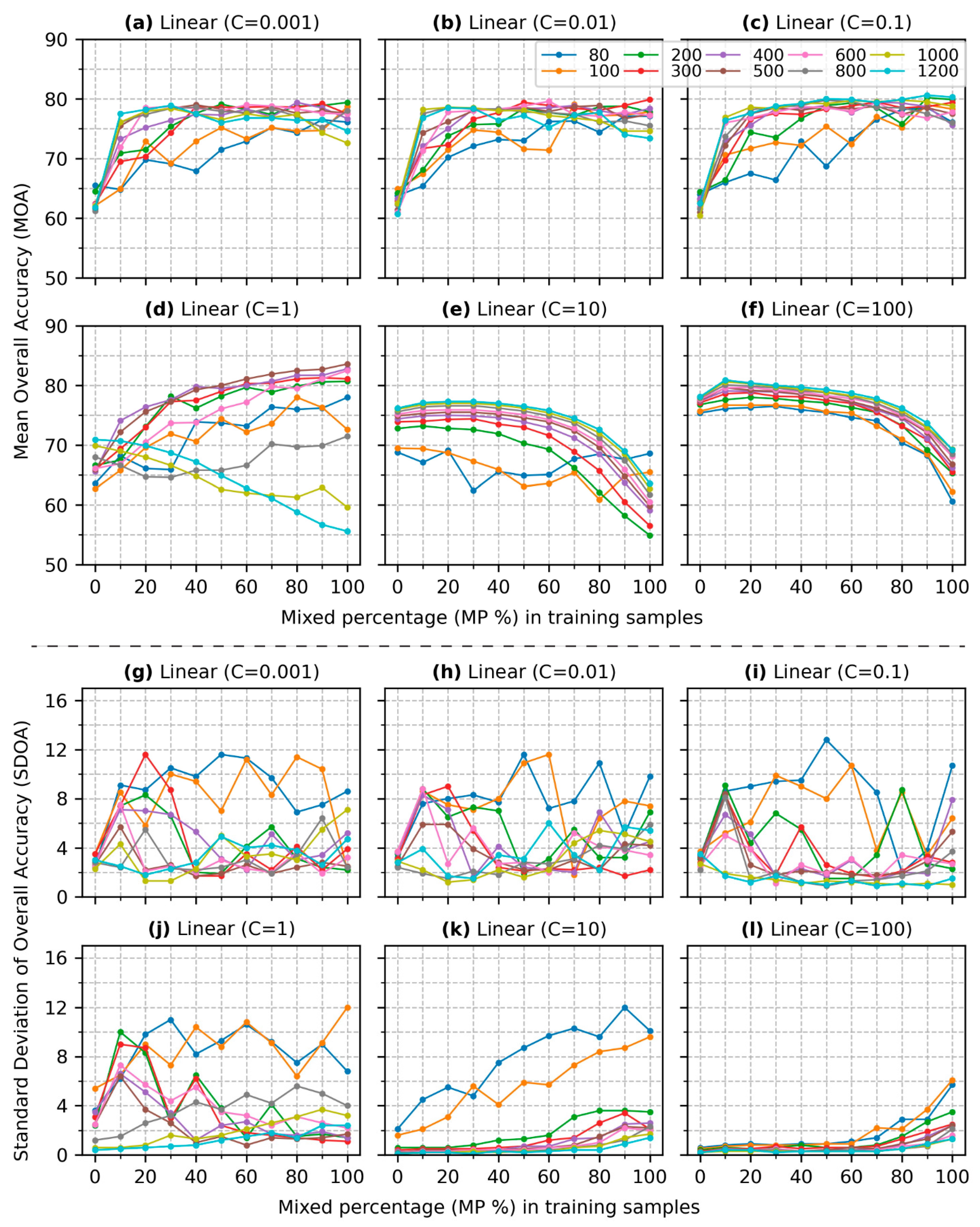
- (1)
- Figure 4a presents the results for a value of 0.001. When is 80, the MOA begins at 65.5% with no mixed pixels () in the training data. As increases from 10% to 100%, the MOA generally exhibits an upward trend, with slight declines observed at levels of 10% and 40%. The MOA peaks at 76.1% when the training data consist entirely of mixed pixels (). The SDOA (Figure 4g) shows a marked increase from 2.4 to 11.6 as rises from 0 to 50%. However, as MP continues to increase to 100%, the SDOA decreases slightly to 8.6. The patterns observed for in both MOA and SDOA are consistent with those for .
- (2)
- For ranging from 200 to 1200 (Figure 4a), the MOA curves demonstrate a similar upward trend, with larger values leading to higher MOA outcomes. When is below 40%, the growth rate of MOA varies with each additional 10% of mixed pixels incorporated into to the training. Notably, the inclusion of 10% mixed pixels results in the most significant increase in MOA, with a maximum improvement of 15.7% observed when = 1200. When is over 40%, the MOA lines tend to stabilize, indicating a plateau in accuracy gains. The highest MOA is achieved at 79.4% when is 80% and is 400. The SDOA generally reduces as increases from 200 to 1200 (Figure 4g). For instance, when is 20, the SDOA value declines from 11.6 to 1.8 as increases from 200 to 1200. In addition, SDOA curves for ranging from 200 to 800 initially rise and then significantly drop when approaches 50%.
- (3)
- (4)
- However, the outcomes in Figure 4d, where is 1, differ considerably. When is 0%, most MOA values in Figure 4d are above 65%, which is higher than the results in Figure 4a. As grows, the MOA rises when is below 800. The MOA reaches up to 83.6% when and . As the reaches 1000 or higher, incorporating more mixed pixels in the training data leads to lower MOA values.
- (5)
- The results in Figure 4e, where , contrast sharply with those in the previous subfigures. Compared to Figure 4d, the MOA values of being 0% in Figure 4e, are concentrated around 75% except for and 100. As increases, the MOA values decrease consistently. The SDOA values remain below 4% except for when the and 100, which shows a growing trend as inclines.
- (6)
- The findings in Figure 4f are similar to those in Figure 4e. The difference is that MOA values are all above 75% when is 0% and decrease as the becomes higher. The SDOA values in Figure 4l are generally lower than those in Figure 4k except for and 100, which shows a slight increase when exceeds 80%.

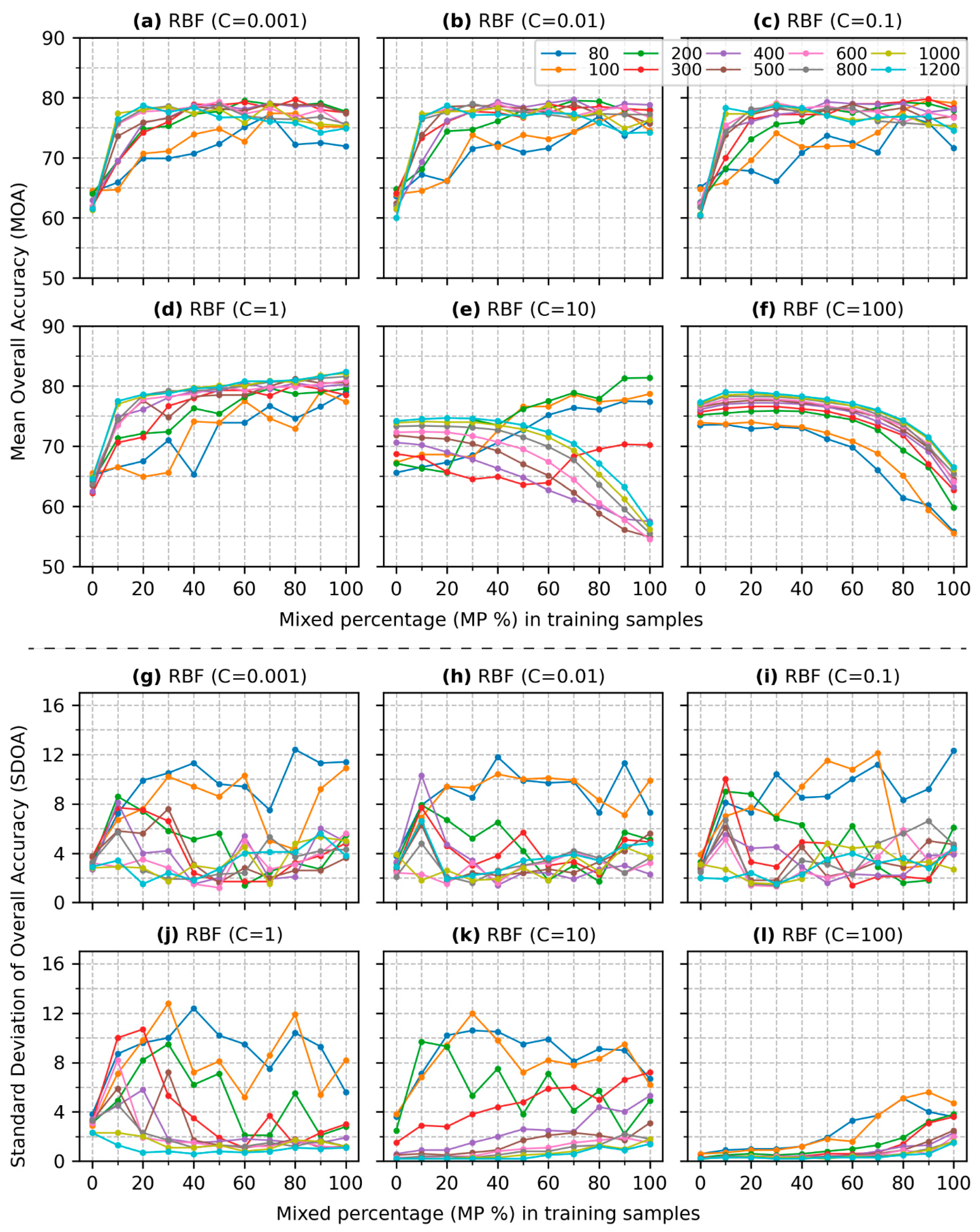
- (1)
- Most MOA values in Figure 5a, derived from pure samples (), are under 60%, which is lower the results obtained with a linear kernel in Figure 4a. However, when 10% of mixed pixels are included in the training data, the MOA values increase significantly, except when . The increase reaches up to 28.3% when . As increases, the MOA values continue to rise. Similar to Figure 4a, when is beyond 40%, the MOA curves tend to stabilize, with the highest accuracy reaching 82.2% when and .
- (2)
- The patterns observed in Figure 5b–e are similar to those in Figure 5a. However, when becomes 100 (Figure 5f), the MOA decreases with the inclusion of higher for 800, 1000, and 1200. The pattern and trend of SDOA values in Figure 5g–l are similar, with SDOA values generally decreasing as the training size increases.
- (3)
- When the degree of the polynomial kernel grows from 2 to 3 (comparing Figure 6 to Figure 5), the patterns of accuracy improvement remain similar, except for that of Figure 6f. All MOA values in Figure 6 are under 60% when is 0, and the highest MOA achieves 71.5% when mixed samples are included in the training, compared to a peak MOA of 81.5% in Figure 5. The pattern of a higher leading to a higher MOA is consistent across all values.
- (4)
4. Discussion
5. Conclusions
- (1)
- The incorporation of mixed pixels in training does not always enhance SVM performance. When regularization parameter is greater than 1, the MOA decreases, with a higher for all kernels except for the polynomial kernel of degree 3.
- (2)
- When the regularization parameter is lower than 1, a general of rule of thumb is to include at least 50 mixed pixels per class in the training dataset to ensure a robust improvement in classification.
- (3)
- Within these conditions, accuracy increases substantially, with a training size up to 300 and a mixed pixel percentage up to 40%. Beyond these thresholds, adding more mixed pixels or training samples leads to minor gains in accuracy. A training dataset with and can achieve a classification accuracy comparable to that of any larger training size or higher mixed pixel percentage.
- (4)
- Optimizing the proportion of mixed pixels and carefully selecting regularization parameters are crucial for maximizing SVM performance in remote sensing applications.
- (5)
- Despite these findings, this study has several limitations, including the simulation of spectral images and reference data, the selection of spectral profiles, and the choice of study sites. The gamma parameter in the SVM model was held constant, which represents another factor that could be explored in future studies. Additionally, mixed pixels are more challenging to interpret than pure pixels, which may lead to mislabeling in the training process. Future research should carefully balance the benefits of incorporating mixed pixels to enhance SVM performance against the risk of misinterpretation.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bartholomé, E.; Belward, A.S. GLC2000: A new approach to global land cover mapping from Earth observation data. Int. J. Remote Sens. 2005, 26, 1959–1977. [Google Scholar]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; Mills, J. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar]
- Jin, S.; Homer, C.; Yang, L.; Danielson, P.; Dewitz, J.; Li, C.; Zhu, Z.; Xian, G.; Howard, D. Overall Methodology Design for the United States National Land Cover Database 2016 Products. Remote Sensing 2019, 11, 2971. [Google Scholar] [CrossRef]
- Mantyka-Pringle, C.S.; Visconti, P.; Di Marco, M.; Martin, T.G.; Rondinini, C.; Rhodes, J.R. Climate change modifies risk of global biodiversity loss due to land-cover change. Biol. Conserv. 2015, 187, 103–111. [Google Scholar]
- Padbhushan, R.; Kumar, U.; Sharma, S.; Rana, D.S.; Kumar, R.; Kohli, A.; Kumari, P.; Parmar, B.; Kaviraj, M.; Sinha, A.K.; et al. Impact of Land-Use Changes on Soil Properties and Carbon Pools in India: A Meta-analysis. Front. Environ. Sci. 2022, 9, 794866. [Google Scholar]
- Feddema, J.J.; Oleson, K.W.; Bonan, G.B.; Mearns, L.O.; Buja, L.E.; Meehl, G.A.; Washington, W.M. The importance of land-cover change in simulating future climates. Science 2005, 310, 1674–1678. [Google Scholar]
- Zhao, L.; Lee, X.; Smith, R.B.; Oleson, K. Strong contributions of local background climate to urban heat islands. Nature 2014, 511, 216–219. [Google Scholar]
- Congalton, R.G.; Gu, J.; Yadav, K.; Thenkabail, P.; Ozdogan, M. Global Land Cover Mapping: A Review and Uncertainty Analysis. Remote Sens. 2014, 6, 12070–12093. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Shetty, S.; Gupta, P.K.; Belgiu, M.; Srivastav, S.K. Assessing the Effect of Training Sampling Design on the Performance of Machine Learning Classifiers for Land Cover Mapping Using Multi-Temporal Remote Sensing Data and Google Earth Engine. Remote Sens. 2021, 13, 1433. [Google Scholar] [CrossRef]
- Jin, H.; Stehman, S.V.; Mountrakis, G. Assessing the impact of training sample selection on accuracy of an urban classification: A case study in Denver, Colorado. Int. J. Remote Sens. 2014, 35, 2067–2081. [Google Scholar] [CrossRef]
- Maulik, U.; Chakraborty, D. Remote Sensing Image Classification: A survey of support-vector-machine-based advanced techniques. IEEE Geosci. Remote Sens. Mag. 2017, 5, 33–52. [Google Scholar] [CrossRef]
- Scholkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Patle, A.; Chouhan, D.S. SVM kernel functions for classification. In Proceedings of the 2013 International Conference on Advances in Technology and Engineering (ICATE), Mumbai, India, 23–25 January 2013. [Google Scholar]
- Wang, L. Support Vector Machines: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2005; Volume 177. [Google Scholar]
- Nalepa, J.; Kawulok, M. Selecting training sets for support vector machines: A review. Artif. Intell. Rev. 2019, 52, 857–900. [Google Scholar] [CrossRef]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support Vector Machine Versus Random Forest for Remote Sensing Image Classification: A Meta-Analysis and Systematic Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Croci, M.; Impollonia, G.; Blandinières, H.; Colauzzi, M.; Amaducci, S. Impact of Training Set Size and Lead Time on Early Tomato Crop Mapping Accuracy. Remote Sensing 2022, 14, 4540. [Google Scholar] [CrossRef]
- Gao, Z.; Guo, D.; Ryu, D.; Western, A.W. Training sample selection for robust multi-year within-season crop classification using machine learning. Comput. Electron. Agric. 2023, 210, 107927. [Google Scholar] [CrossRef]
- Heydari, S.S.; Mountrakis, G. Effect of classifier selection, reference sample size, reference class distribution and scene heterogeneity in per-pixel classification accuracy using 26 Landsat sites. Remote Sens. Environ. 2018, 204, 648–658. [Google Scholar] [CrossRef]
- Chabalala, Y.; Adam, E.; Ali, K.A. Exploring the Effect of Balanced and Imbalanced Multi-Class Distribution Data and Sampling Techniques on Fruit-Tree Crop Classification Using Different Machine Learning Classifiers. Geomatics 2023, 3, 70–92. [Google Scholar] [CrossRef]
- Kurbakov, M.Y.; Sulimova, V.V. Fast SVM-based One-Class Classification in Large Training Sets. In Proceedings of the 2023 IX International Conference on Information Technology and Nanotechnology (ITNT), Samara, Russia, 17–21 April 2023; pp. 1–6. [Google Scholar]
- Zhang, J.; Liu, C. Fast instance selection method for SVM training based on fuzzy distance metric. Appl. Intell. 2023, 53, 18109–18124. [Google Scholar] [CrossRef]
- Zhao, M.; Cheng, Y.; Qin, X.; Yu, W.; Wang, P. Semi-Supervised Classification of PolSAR Images Based on Co-Training of CNN and SVM with Limited Labeled Samples. Sensors 2023, 23, 2109. [Google Scholar] [CrossRef] [PubMed]
- Douzas, G.; Bacao, F.; Fonseca, J.; Khudinyan, M. Imbalanced Learning in Land Cover Classification: Improving Minority Classes’ Prediction Accuracy Using the Geometric SMOTE Algorithm. Remote Sens. 2019, 11, 3040. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Mogollon-Gutierrez, O.; Moreno-Álvarez, S.; Sancho, J.C.; Haut, J.M. A Comprehensive Survey of Imbalance Correction Techniques for Hyperspectral Data Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 5297–5314. [Google Scholar] [CrossRef]
- Chen, W.; Yang, K.; Yu, Z.; Shi, Y.; Chen, C.L.P. A survey on imbalanced learning: Latest research, applications and future directions. Artif. Intell. Rev. 2024, 57, 1–51. [Google Scholar] [CrossRef]
- Su, Y.; Li, X.; Yao, J.; Dong, C.; Wang, Y. A Spectral–Spatial Feature Rotation-Based Ensemble Method for Imbalanced Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–18. [Google Scholar] [CrossRef]
- Chowdhury, K.; Chaudhuri, D.; Pal, A.K. A faster SVM classification technique for remote sensing images using reduced training samples. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 16807–16827. [Google Scholar] [CrossRef]
- Xu, B.; Wen, Z.; Yan, L.; Zhao, Z.; Yin, Z.; Liu, W.; He, B. Leveraging Data Density and Sparsity for Efficient SVM Training on GPUs. In Proceedings of the 2023 IEEE International Conference on Data Mining (ICDM), Shanghai, China, 1–4 December 2023; pp. 698–707. [Google Scholar]
- Tavara, S. Parallel Computing of Support Vector Machines: A Survey. ACM Comput. Surv. 2019, 51, 1–38. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. The use of small training sets containing mixed pixels for accurate hard image classification: Training on mixed spectral responses for classification by a SVM. Remote Sens. Environ. 2006, 103, 179–189. [Google Scholar] [CrossRef]
- Yu, B.-H.; Chi, K.-H. Support vector machine classification using training sets of small mixed pixels: An appropriateness assessment of IKONOS imagery. Korean J. Remote Sens. 2008, 24, 507–515. [Google Scholar]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Reis, S. Performance Analysis of Maximum Likelihood and Artificial Neural Network Classifiers for Training Sets with Mixed Pixels. GIScience Remote Sens. 2013, 45, 330–342. [Google Scholar]
- Costa, H.; Foody, G.M.; Boyd, D.S. Using mixed objects in the training of object-based image classifications. Remote Sens. Environ. 2017, 190, 188–197. [Google Scholar] [CrossRef]
- Li, X.; Jia, X.; Wang, L.; Zhao, K. On Spectral Unmixing Resolution Using Extended Support Vector Machines. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4985–4996. [Google Scholar]
- McGarigal, K.; Marks, B.J. FRAGSTATS: Spatial Pattern Analysis Program for Quantifying Landscape Structure; U.S. Department of Agriculture, Forest Service, Pacific Northwest Research Station: Portland, OR, USA, 1995. [Google Scholar]
- Small, C. High spatial resolution spectral mixture analysis of urban reflectance. Remote Sens. Environ. 2003, 88, 170–186. [Google Scholar] [CrossRef]
- Ichoku, C.; Karnieli, A. A review of mixture modeling techniques for sub-pixel land cover estimation. Remote Sens. Rev. 1996, 13, 161–186. [Google Scholar]
- Tharwat, A. Parameter investigation of support vector machine classifier with kernel functions. Knowl. Inf. Syst. 2019, 61, 1269–1302. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Duchesnay, É. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Foody, G.M.; Mathur, A. Toward intelligent training of supervised image classifications: Directing training data acquisition for SVM classification. Remote Sens. Environ. 2004, 93, 107–117. [Google Scholar]
- Justice, C.; Townshend, J.; Vermote, E.; Masuoka, E.; Wolfe, R.; Saleous, N.; Roy, D.; Morisette, J. An overview of MODIS Land data processing and product status. Remote Sens. Environ. 2002, 83, 3–15. [Google Scholar]
- Foody, G.M. The effect of mis-labeled training data on the accuracy of supervised image classification by SVM. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 13–18 July 2015. [Google Scholar]
- He, Y.; Lee, E.; Warner, T.A. A time series of annual land use and land cover maps of China from 1982 to 2013 generated using AVHRR GIMMS NDVI3g data. Remote Sens. Environ. 2017, 199, 201–217. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level 1 | Class Name | Level 2 | Class Name |
|---|---|---|---|
| 1 | Water | 11 | Open Water |
| 12 | Perennial Ice/Snow (#) | ||
| 2 | Developed | 21 | Developed, Open space |
| 22 | Developed, Low intensity | ||
| 23 | Developed, Medium intensity | ||
| 24 | Developed, High intensity | ||
| 3 | Barren | 31 | Barren Land |
| 4 | Forest | 41 | Deciduous Forest |
| 42 | Evergreen Forest | ||
| 43 | Mixed Forest | ||
| 5 | Shrubland | 51 | Dwarf Scrub (#) |
| 52 | Shrub/Scrub | ||
| 7 | Herbaceous | 71 | Grassland/Herbaceous |
| 72 | Sedge/Herbaceous (#) | ||
| 73 | Lichens (#) | ||
| 74 | Moss (#) | ||
| 8 | Planted/ Cultivated | 81 | Pasture/Hay |
| 82 | Cultivated Crops | ||
| 9 | Wetlands | 90 | Woody Wetlands |
| 95 | Emergent Herbaceous Wetlands |
| N. | Kernel | Kernel Equation | Degree | Regularization | Gamma | Bias |
|---|---|---|---|---|---|---|
| 1 | Linear | - | [0.001, 0.01, 0.1, 1, 10, 100] | - | - | |
| 2 | Polynomial | [2,3] | 0.1429 | 0 | ||
| 3 | RBF | - | - | |||
| 4 | Sigmoid | - | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, J.; Congalton, R.G. Assessing the Impact of Mixed Pixel Proportion Training Data on SVM-Based Remote Sensing Classification: A Simulated Study. Remote Sens. 2025, 17, 1274. https://doi.org/10.3390/rs17071274
Gu J, Congalton RG. Assessing the Impact of Mixed Pixel Proportion Training Data on SVM-Based Remote Sensing Classification: A Simulated Study. Remote Sensing. 2025; 17(7):1274. https://doi.org/10.3390/rs17071274
Chicago/Turabian StyleGu, Jianyu, and Russell G. Congalton. 2025. "Assessing the Impact of Mixed Pixel Proportion Training Data on SVM-Based Remote Sensing Classification: A Simulated Study" Remote Sensing 17, no. 7: 1274. https://doi.org/10.3390/rs17071274
APA StyleGu, J., & Congalton, R. G. (2025). Assessing the Impact of Mixed Pixel Proportion Training Data on SVM-Based Remote Sensing Classification: A Simulated Study. Remote Sensing, 17(7), 1274. https://doi.org/10.3390/rs17071274