
Parameter-Efficient Fine-Tuning for Individual Tree Crown Detection and Species Classification Using UAV-Acquired Imagery


Abstract
1. Introduction
- We propose an end-to-end approach for tree crown detection and species classification, leveraging a pre-trained vision model, which addresses the limitations of current open-set object detection models in the task of tree detection and species classification using UAV imagery.
- We propose a simple and effective PEFT approach, namely, ASCS, for adapting Grounding-DINO, which facilitates the model’s effective adaptation to both tree detection and tree species classification tasks using UAV imagery.
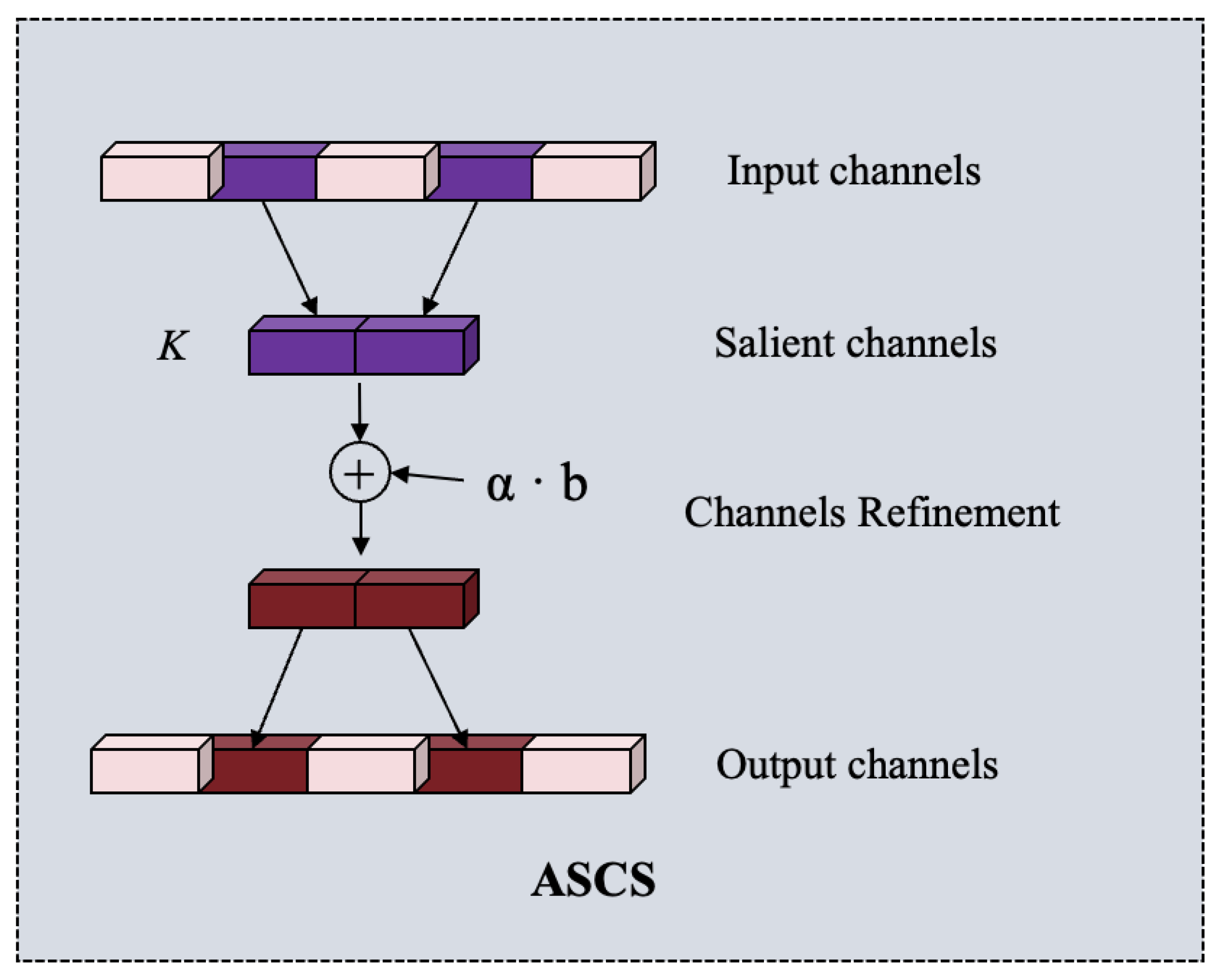
- We propose a task-specific channel selection to emphasize the most salient channel maps, wherein the channels most relevant to specific tree species are highlighted.
- Experiments were conducted on a multi-species dataset acquired via UAV, characterized by a relatively small number of image samples. The results demonstrate that the proposed method significantly outperforms the latest YOLO detection framework and surpasses the current state-of-the-art PEFT methods.
2. Materials
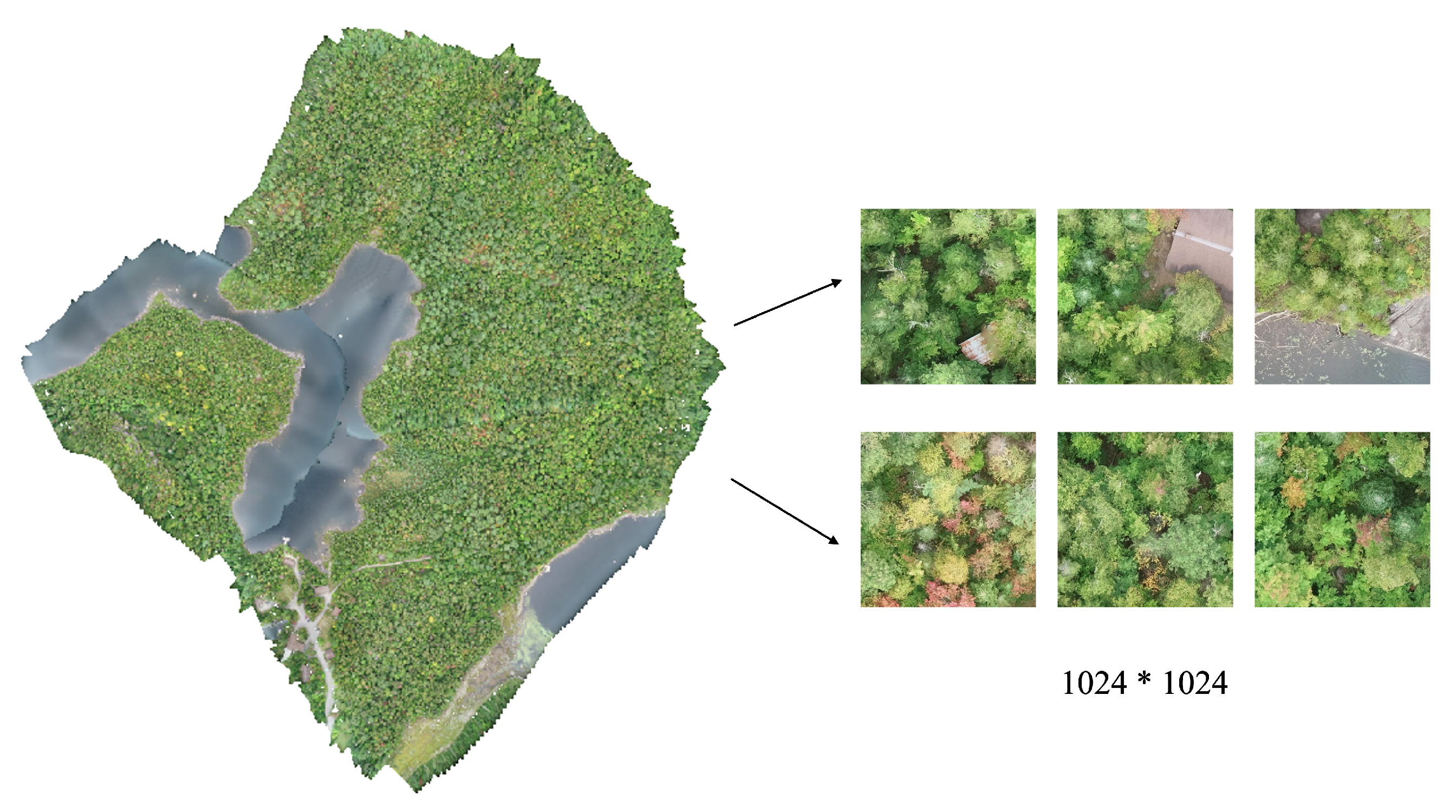
Study Area and Dataset
3. Methods
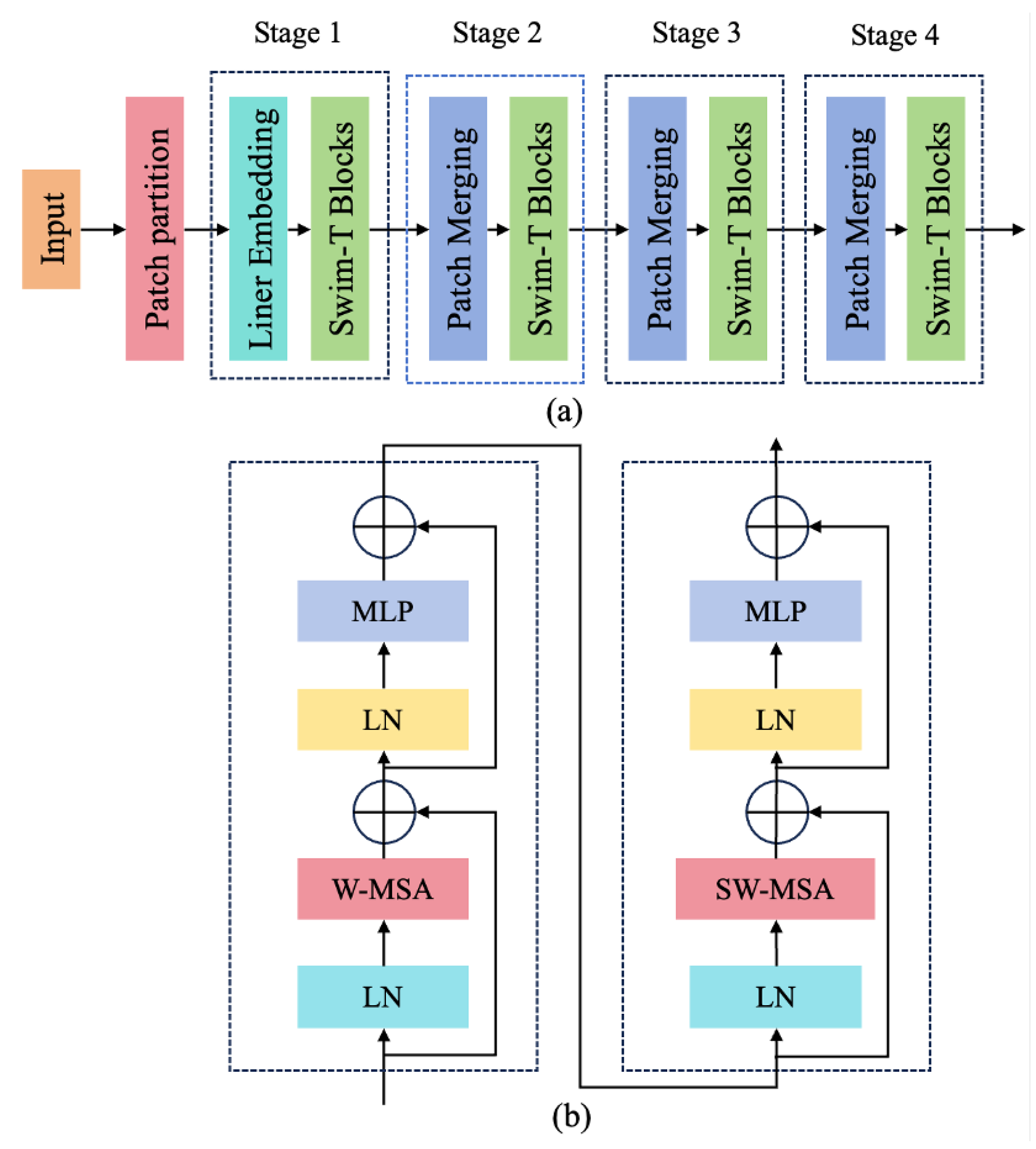
3.1. Swin Transformer
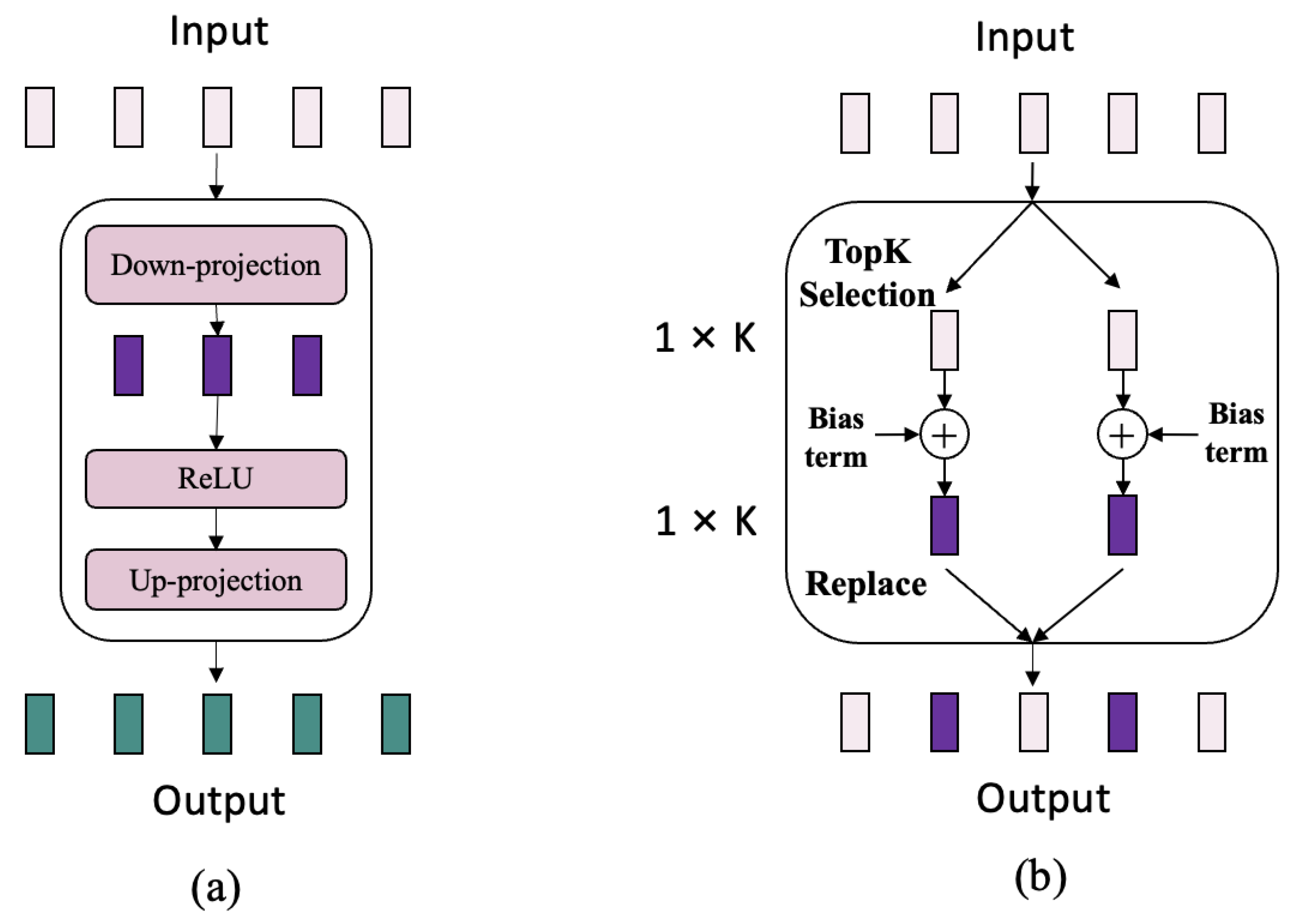
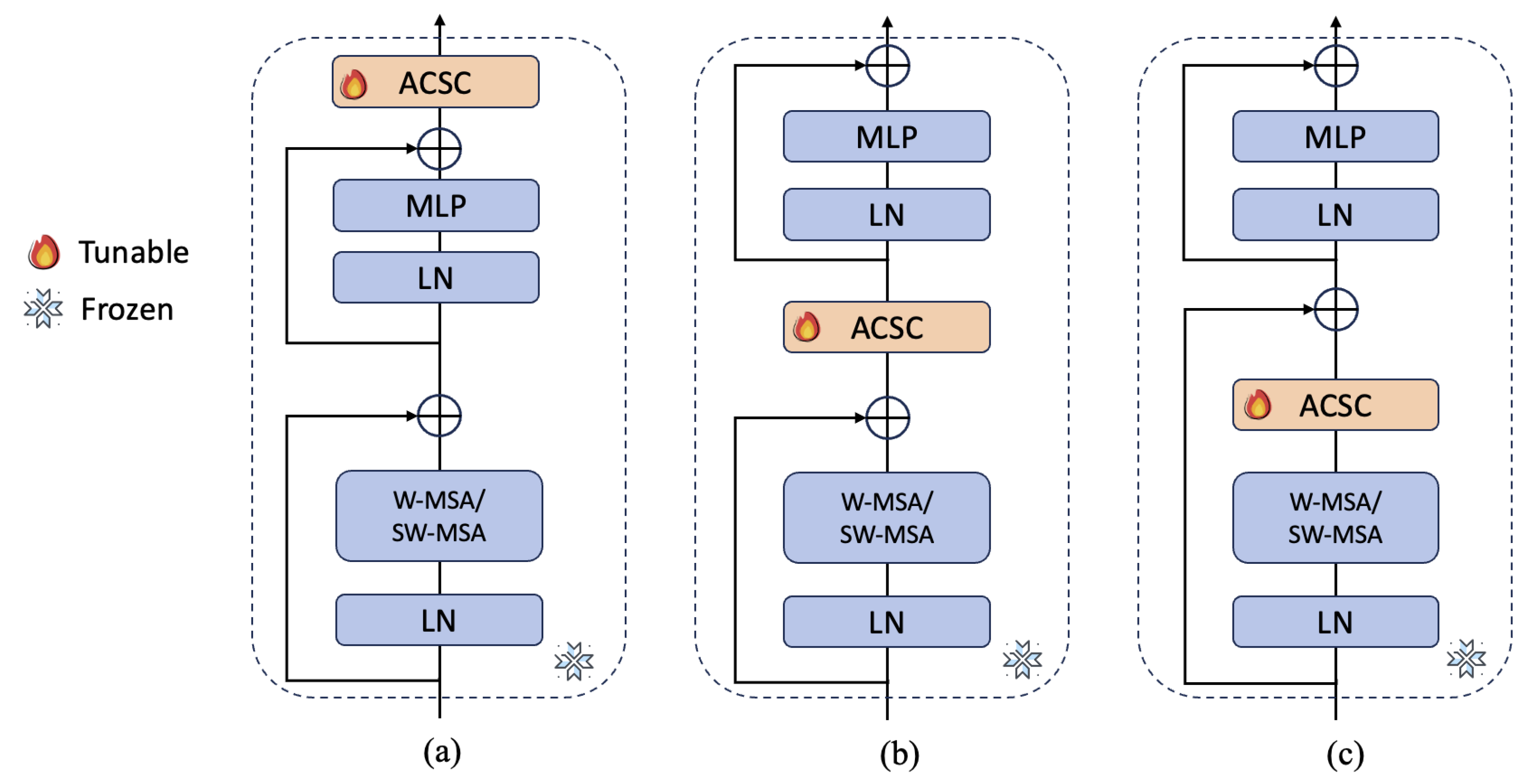
3.2. Adaptive Salient Channel Selection Fine-Tuning
4. Experiment
4.1. Experiment Setting
4.1.1. Metrics
4.1.2. Comparative Experiments
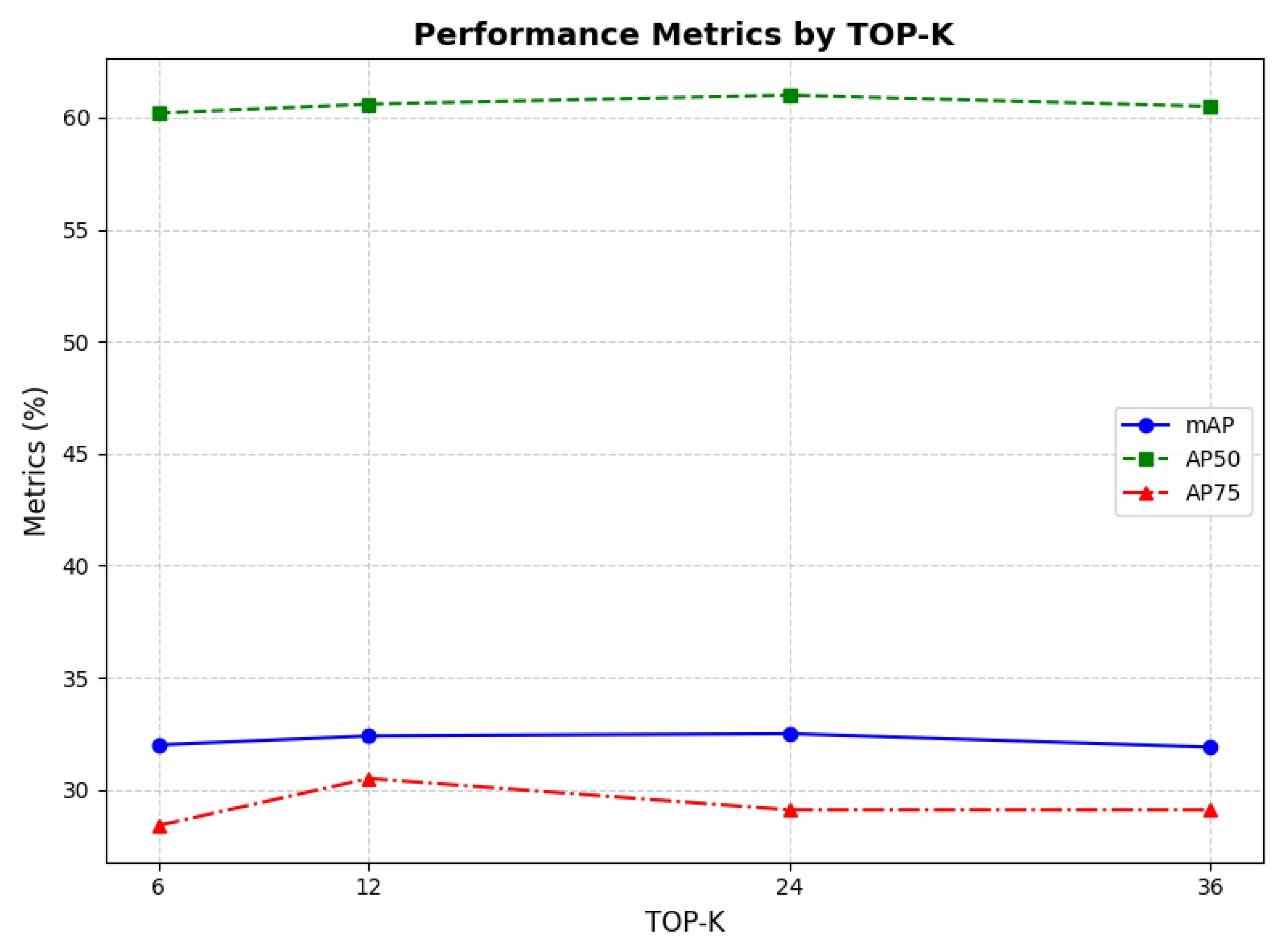
4.2. Ablation Studies
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wenhua, L. Degradation and restoration of forest ecosystems in China. For. Ecol. Manag. 2004, 201, 33–41. [Google Scholar] [CrossRef]
- Mo, L.; Zohner, C.M.; Reich, P.B.; Liang, J.; De Miguel, S.; Nabuurs, G.J.; Renner, S.S.; van den Hoogen, J.; Araza, A.; Herold, M.; et al. Integrated global assessment of the natural forest carbon potential. Nature 2023, 624, 92–101. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Latifi, H.; Stereńczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Corona, P.; Chirici, G.; McRoberts, R.E.; Winter, S.; Barbati, A. Contribution of large-scale forest inventories to biodiversity assessment and monitoring. For. Ecol. Manag. 2011, 262, 2061–2069. [Google Scholar] [CrossRef]
- Pan, Y.; Birdsey, R.A.; Fang, J.; Houghton, R.; Kauppi, P.E.; Kurz, W.A.; Phillips, O.L.; Shvidenko, A.; Lewis, S.L.; Canadell, J.G.; et al. A large and persistent carbon sink in the world’s forests. Science 2011, 333, 988–993. [Google Scholar] [CrossRef] [PubMed]
- Santopuoli, G.; Vizzarri, M.; Spina, P.; Maesano, M.; Mugnozza, G.S.; Lasserre, B. How individual tree characteristics and forest management influence occurrence and richness of tree-related microhabitats in Mediterranean mountain forests. For. Ecol. Manag. 2022, 503, 119780. [Google Scholar] [CrossRef]
- Tomppo, E.; Olsson, H.; Ståhl, G.; Nilsson, M.; Hagner, O.; Katila, M. Combining national forest inventory field plots and remote sensing data for forest databases. Remote Sens. Environ. 2008, 112, 1982–1999. [Google Scholar] [CrossRef]
- Senf, C.; Seidl, R.; Hostert, P. Remote sensing of forest insect disturbances: Current state and future directions. Int. J. Appl. Earth Obs. Geoinf. 2017, 60, 49–60. [Google Scholar] [CrossRef]
- Chen, B.; Wang, L.; Fan, X.; Bo, W.; Yang, X.; Tjahjadi, T. Semi-FCMNet: Semi-supervised learning for forest cover mapping from satellite imagery via ensemble self-training and perturbation. Remote Sens. 2023, 15, 4012. [Google Scholar] [CrossRef]
- Kayet, N. Forest Health Monitoring using Hyperspectral Remote Sensing Techniques. In Spatial Modeling in Forest Resources Management: Rural Livelihood and Sustainable Development; Springer: Berlin/Heidelberg, Germany, 2021; pp. 239–257. [Google Scholar]
- Roy, P. Forest fire and degradation assessment using satellite remote sensing and geographic information system. In Satellite Remote Sensing and GIS Applications in Agricultural Meteorology; World Meteorological Organisation: Geneva, Switzerland, 2003; Volume 361, pp. 361–400. [Google Scholar]
- He, Y.; Chen, G.; Potter, C.; Meentemeyer, R.K. Integrating multi-sensor remote sensing and species distribution modeling to map the spread of emerging forest disease and tree mortality. Remote Sens. Environ. 2019, 231, 111238. [Google Scholar] [CrossRef]
- Bo, W.; Liu, J.; Fan, X.; Tjahjadi, T.; Ye, Q.; Fu, L. BASNet: Burned area segmentation network for real-time detection of damage maps in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar]
- Pan, C.; Fan, X.; Tjahjadi, T.; Guan, H.; Fu, L.; Ye, Q.; Wang, R. Vision foundation model guided multi-modal fusion network for remote sensing semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025. [Google Scholar] [CrossRef]
- Wang, J.; Fan, X.; Yang, X.; Tjahjadi, T.; Wang, Y. Semi-supervised learning for forest fire segmentation using UAV imagery. Forests 2022, 13, 1573. [Google Scholar] [CrossRef]
- Dash, J.P.; Watt, M.S.; Pearse, G.D.; Heaphy, M.; Dungey, H.S. Assessing very high resolution UAV imagery for monitoring forest health during a simulated disease outbreak. ISPRS J. Photogramm. Remote Sens. 2017, 131, 1–14. [Google Scholar] [CrossRef]
- Li, Y.; Xu, C.; Zhong, W.; Luan, Q.; Wu, C. UAV-driven GWAS analysis of canopy temperature and new shoots genetics in slash pine. Industrial Crops Prod. 2024, 212, 118330. [Google Scholar]
- Diez, Y.; Kentsch, S.; Fukuda, M.; Caceres, M.L.L.; Moritake, K.; Cabezas, M. Deep learning in forestry using uav-acquired rgb data: A practical review. Remote Sens. 2021, 13, 2837. [Google Scholar] [CrossRef]
- Guimarães, N.; Pádua, L.; Marques, P.; Silva, N.; Peres, E.; Sousa, J.J. Forestry remote sensing from unmanned aerial vehicles: A review focusing on the data, processing and potentialities. Remote Sens. 2020, 12, 1046. [Google Scholar] [CrossRef]
- Gu, J.; Grybas, H.; Congalton, R.G. Individual tree crown delineation from UAS imagery based on region growing and growth space considerations. Remote Sens. 2020, 12, 2363. [Google Scholar] [CrossRef]
- Safonova, A.; Hamad, Y.; Dmitriev, E.; Georgiev, G.; Trenkin, V.; Georgieva, M.; Dimitrov, S.; Iliev, M. Individual tree crown delineation for the species classification and assessment of vital status of forest stands from UAV images. Drones 2021, 5, 77. [Google Scholar] [CrossRef]
- Huang, H.; Li, X.; Chen, C. Individual tree crown detection and delineation from very-high-resolution UAV images based on bias field and marker-controlled watershed segmentation algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2253–2262. [Google Scholar]
- Wang, L.; Gong, P.; Biging, G.S. Individual tree-crown delineation and treetop detection in high-spatial-resolution aerial imagery. Photogramm. Eng. Remote Sens. 2004, 70, 351–357. [Google Scholar] [CrossRef]
- Santos, A.A.d.; Marcato Junior, J.; Araújo, M.S.; Di Martini, D.R.; Tetila, E.C.; Siqueira, H.L.; Aoki, C.; Eltner, A.; Matsubara, E.T.; Pistori, H.; et al. Assessment of CNN-based methods for individual tree detection on images captured by RGB cameras attached to UAVs. Sensors 2019, 19, 3595. [Google Scholar] [CrossRef] [PubMed]
- Jintasuttisak, T.; Edirisinghe, E.; Elbattay, A. Deep neural network based date palm tree detection in drone imagery. Comput. Electron. Agric. 2022, 192, 106560. [Google Scholar] [CrossRef]
- Wu, W.; Fan, X.; Qu, H.; Yang, X.; Tjahjadi, T. TCDNet: Tree crown detection from UAV optical images using uncertainty-aware one-stage network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Gan, Y.; Wang, Q.; Iio, A. Tree crown detection and delineation in a temperate deciduous forest from UAV RGB imagery using deep learning approaches: Effects of spatial resolution and species characteristics. Remote Sens. 2023, 15, 778. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Lin, T. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Paris, France, 26–27 March 2025; Springer: Berlin/Heidelberg, Germany, 2025; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2025, arXiv:2405.14458. [Google Scholar]
- Weinstein, B.G.; Marconi, S.; Aubry-Kientz, M.; Vincent, G.; Senyondo, H.; White, E.P. DeepForest: A Python package for RGB deep learning tree crown delineation. Methods Ecol. Evol. 2020, 11, 1743–1751. [Google Scholar]
- Ball, J.G.; Hickman, S.H.; Jackson, T.D.; Koay, X.J.; Hirst, J.; Jay, W.; Archer, M.; Aubry-Kientz, M.; Vincent, G.; Coomes, D.A. Accurate delineation of individual tree crowns in tropical forests from aerial RGB imagery using Mask R-CNN. Remote Sens. Ecol. Conserv. 2023, 9, 641–655. [Google Scholar] [CrossRef]
- Zhang, H.; Sun, A.; Jing, W.; Zhou, J.T. Temporal sentence grounding in videos: A survey and future directions. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10443–10465. [Google Scholar] [PubMed]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Jiang, Q.; Li, C.; Yang, J.; Su, H.; et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In Proceedings of the European Conference on Computer Vision, Paris, France, 26–27 March 2025; Springer: Berlin/Heidelberg, Germany, 2025; pp. 38–55. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Fu, Z.; Yang, H.; So, A.M.C.; Lam, W.; Bing, L.; Collier, N. On the effectiveness of parameter-efficient fine-tuning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 12799–12807. [Google Scholar]
- Xu, L.; Xie, H.; Qin, S.Z.J.; Tao, X.; Wang, F.L. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment. arXiv 2023, arXiv:2312.12148. [Google Scholar]
- Zhang, J.O.; Sax, A.; Zamir, A.; Guibas, L.; Malik, J. Side-tuning: A baseline for network adaptation via additive side networks. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 698–714. [Google Scholar]
- Cai, H.; Gan, C.; Zhu, L.; Han, S. Tinytl: Reduce memory, not parameters for efficient on-device learning. Adv. Neural Inf. Process. Syst. 2020, 33, 11285–11297. [Google Scholar]
- Beloiu, M.; Heinzmann, L.; Rehush, N.; Gessler, A.; Griess, V.C. Individual tree-crown detection and species identification in heterogeneous forests using aerial RGB imagery and deep learning. Remote Sens. 2023, 15, 1463. [Google Scholar] [CrossRef]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR: Birmingham, UK, 2019; pp. 2790–2799. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Jia, M.; Tang, L.; Chen, B.C.; Cardie, C.; Belongie, S.; Hariharan, B.; Lim, S.N. Visual prompt tuning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 709–727. [Google Scholar]
- Cloutier, M.; Germain, M.; Laliberté, E. Influence of temperate forest autumn leaf phenology on segmentation of tree species from UAV imagery using deep learning. Remote Sens. Environ. 2024, 311, 114283. [Google Scholar]
- Alexey, D. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zaken, E.B.; Ravfogel, S.; Goldberg, Y. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv 2021, arXiv:2106.10199. [Google Scholar]
- Liu, W.; Shen, X.; Pun, C.M.; Cun, X. Explicit visual prompting for universal foreground segmentations. arXiv 2023, arXiv:2305.18476. [Google Scholar]
- Giannou, A.; Rajput, S.; Papailiopoulos, D. The expressive power of tuning only the Norm layers. arXiv 2023, arXiv:2302.07937. [Google Scholar]
- Zhao, H.H.; Wang, P.; Zhao, Y.; Luo, H.; Wang, F.; Shou, M.Z. Sct: A simple baseline for parameter-efficient fine-tuning via salient channels. Int. J. Comput. Vis. 2024, 132, 731–749. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Params | mAP | AP50 | AP75 |
|---|---|---|---|---|
| FULL | 100.00% | 33.5 | 60.7 | 31.1 |
| FIXED | 0.00% | 31.2 | 60.0 | 28.6 |
| BITFIT | 0.28% | 31.3 | 59.3 | 29.2 |
| NORM-TUNING | 0.09% | 31.8 | 60.5 | 29.6 |
| LORA | 4.11% | 31.5 | 59.9 | 28.6 |
| VPT | 0.26% | 31.8 | 58.7 | 29.8 |
| EVP2 | 19.83% | 32.2 | 59.9 | 29.2 |
| SCT | 0.01% | 30.9 | 57.7 | 27.4 |
| Adapter | 4.15% | 31.7 | 60.4 | 28.4 |
| OURS | 0.28% | 32.4 | 60.6 | 30.5 |
| Model | AP50 |
|---|---|
| YOLOv8 | 18.0 |
| YOLOv10 | 22.6 |
| YOLOv11 | 21.2 |
| Grounding-DINO | 2.4 |
| DETR | 57.5 |
| Proposed | 60.6 |
| Architecture | mAP | AP50 | AP75 |
|---|---|---|---|
| Channel selection + Adapter | 31.2 | 59.8 | 28.2 |
| All channels + bias term | 31.4 | 59.1 | 28.5 |
| Channel selection + bias term | 32.4 | 60.6 | 30.5 |
| Bias | mAP | AP50 | AP75 |
|---|---|---|---|
| Frozen | 31.1 | 58.2 | 28.3 |
| Tuned | 32.4 | 60.6 | 30.5 |
| Position | mAP | AP50 | AP75 |
|---|---|---|---|
| ASCS-MLP | 31.2 | 58.6 | 29.3 |
| ASCS-Attn1 | 32.1 | 60.8 | 29.5 |
| ASCS-Attn2 | 32.4 | 60.6 | 30.5 |
| mAP | AP50 | AP75 | |
|---|---|---|---|
| 0.5 | 32.3 | 60.4 | 29.8 |
| 1 | 31.8 | 60.2 | 29.1 |
| 2 | 32.4 | 60.6 | 30.5 |
| 3 | 31.2 | 58.9 | 28.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Lei, F.; Fan, X. Parameter-Efficient Fine-Tuning for Individual Tree Crown Detection and Species Classification Using UAV-Acquired Imagery. Remote Sens. 2025, 17, 1272. https://doi.org/10.3390/rs17071272
Zhang J, Lei F, Fan X. Parameter-Efficient Fine-Tuning for Individual Tree Crown Detection and Species Classification Using UAV-Acquired Imagery. Remote Sensing. 2025; 17(7):1272. https://doi.org/10.3390/rs17071272
Chicago/Turabian StyleZhang, Jiuyu, Fan Lei, and Xijian Fan. 2025. "Parameter-Efficient Fine-Tuning for Individual Tree Crown Detection and Species Classification Using UAV-Acquired Imagery" Remote Sensing 17, no. 7: 1272. https://doi.org/10.3390/rs17071272
APA StyleZhang, J., Lei, F., & Fan, X. (2025). Parameter-Efficient Fine-Tuning for Individual Tree Crown Detection and Species Classification Using UAV-Acquired Imagery. Remote Sensing, 17(7), 1272. https://doi.org/10.3390/rs17071272