
VibrantVS: A High-Resolution Vision Transformer for Forest Canopy Height Estimation

 , , , , , , , ,
, , , , , , , ,
Abstract
1. Introduction
2. Materials and Methods
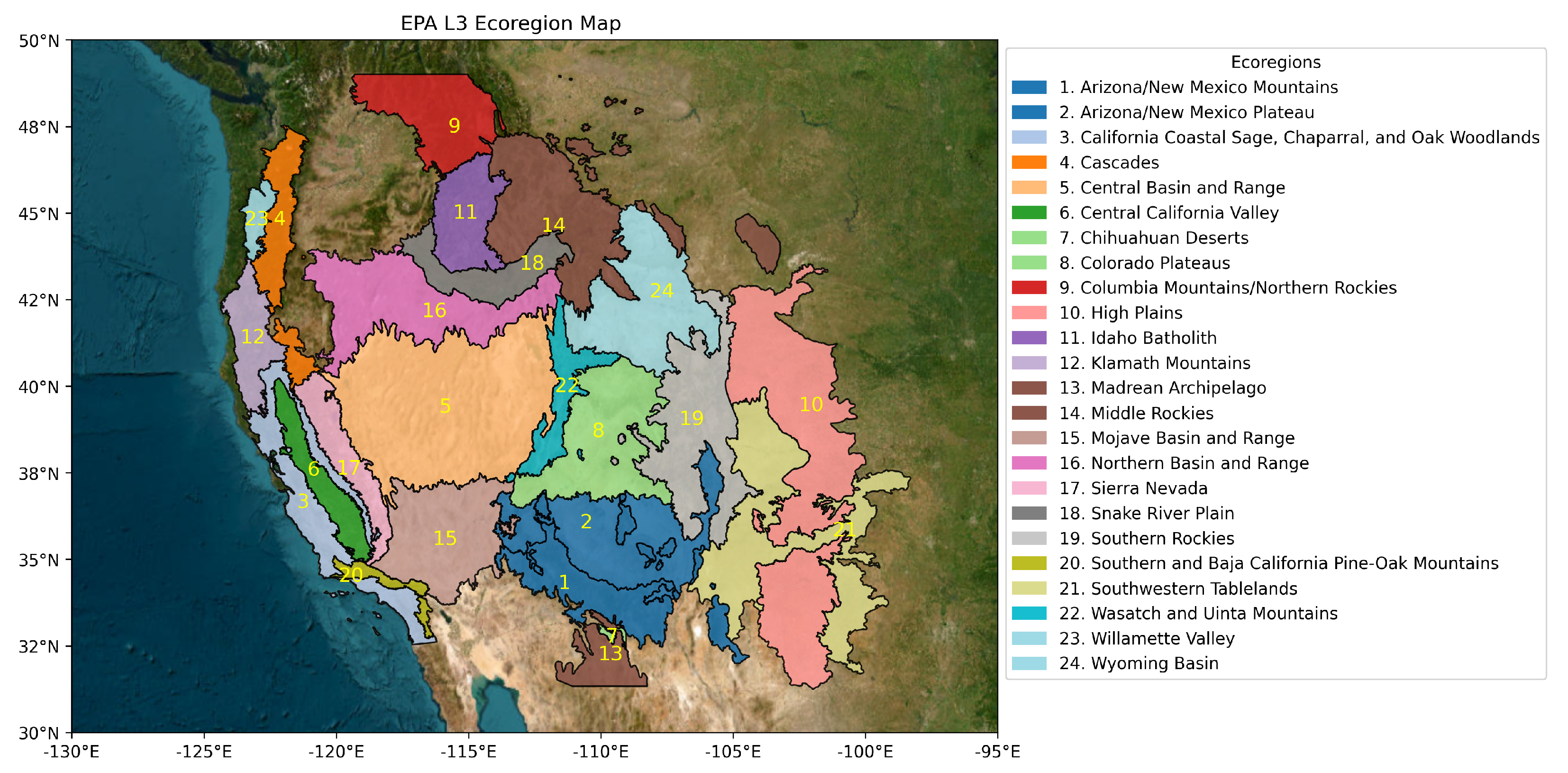
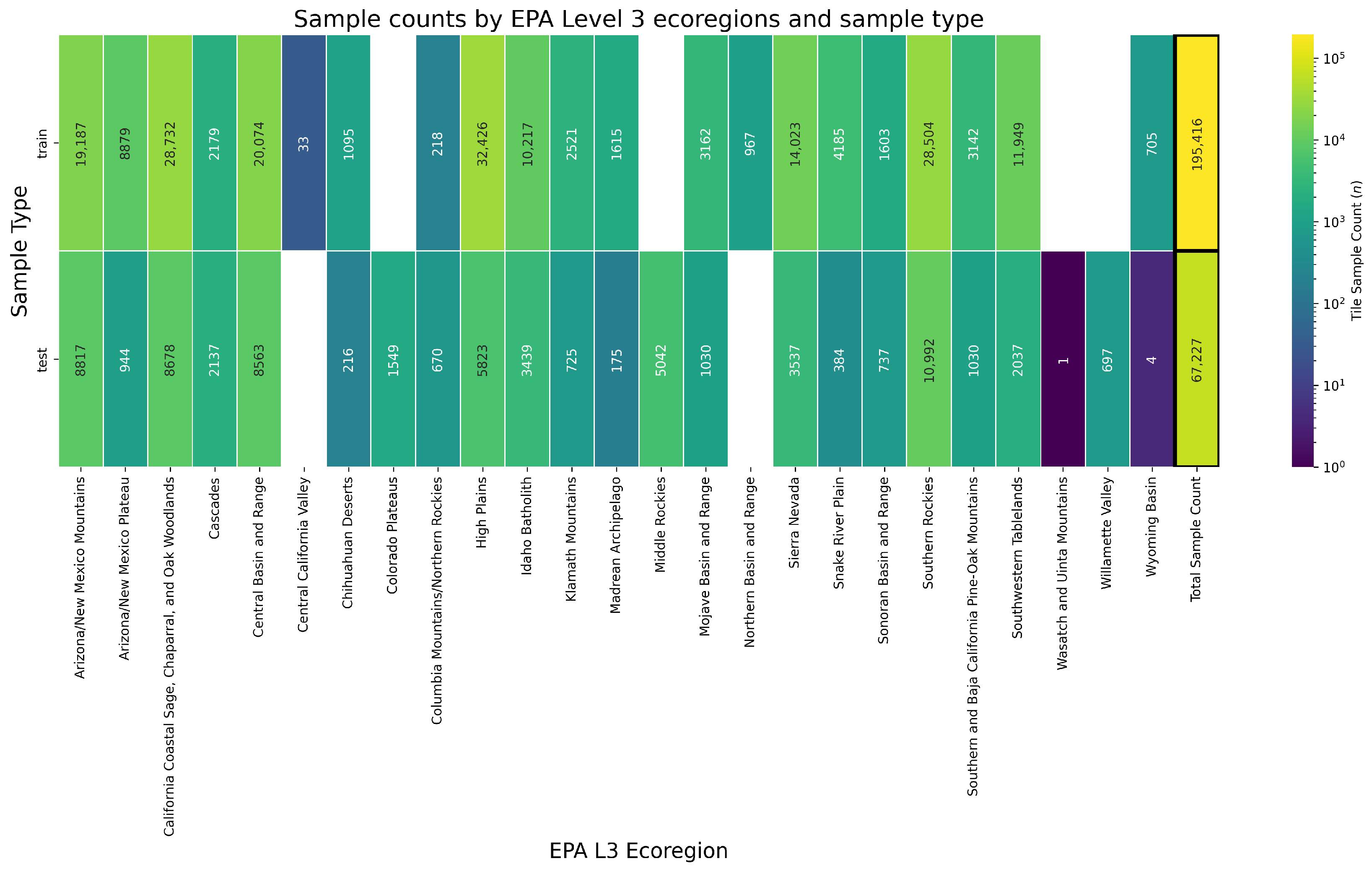
2.1. Study Area and Data
- The Wildfire Crisis Strategy (WCS) landscapes defined by the United States Forest Service (USFS) to prioritize regions at the greatest risk of severe wildfire [28].
- National Ecological Observatory Network (NEON) research sites within the western United States, due to their independent collection of individual field-based tree-height measurements and aerial lidar against which to validate model predictions [29].
- Areas that intersect the spatial extent for the 3D Elevation Program (3DEP) work units in the Work Unit Extent Spatial Metadata (WESM) dataset [30] that meet the seamless and 1 m DEM quality criteria.
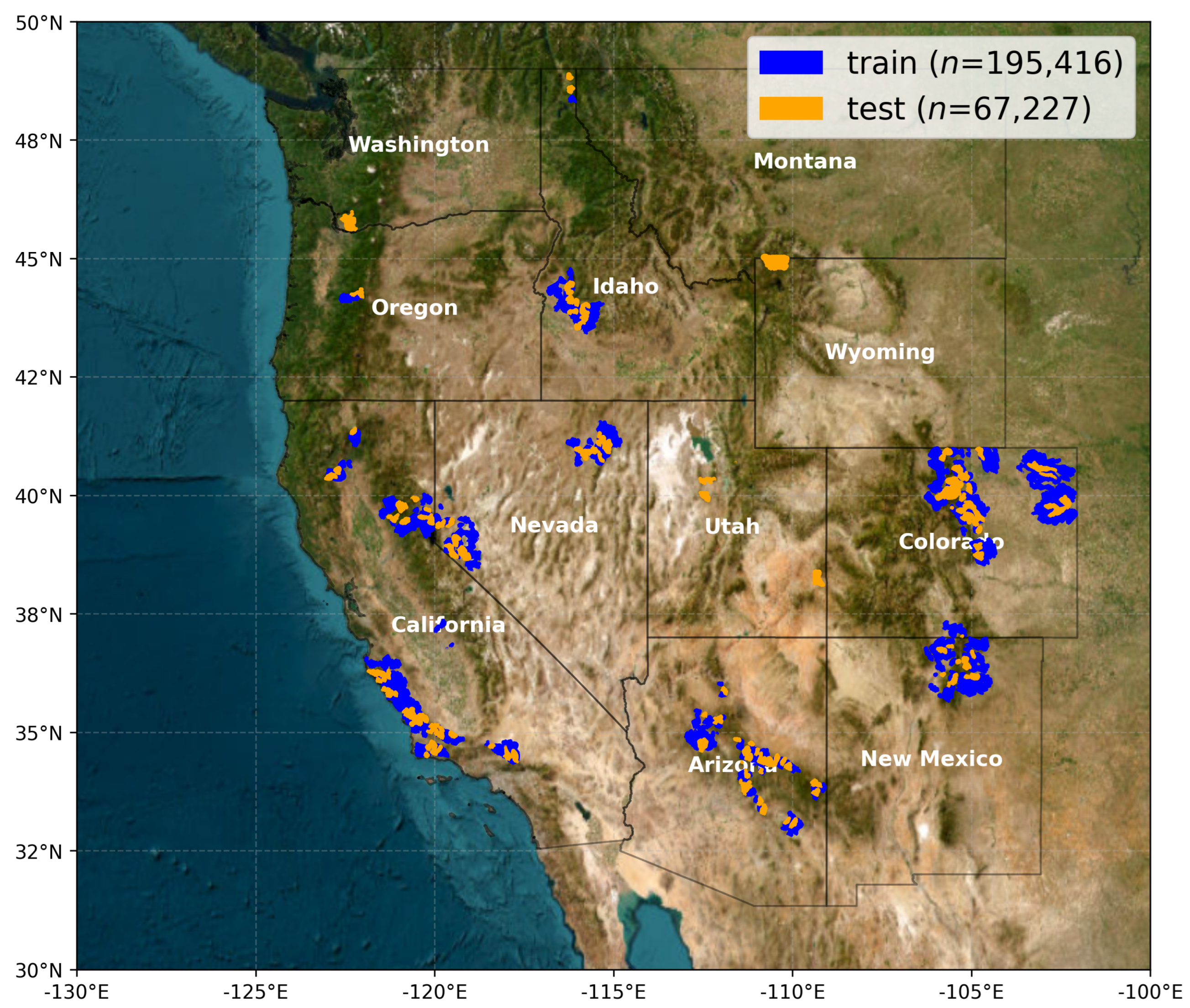
2.2. Predictor Data
NAIP Imagery
- Resampling all images to a uniform spatial resolution of 0.5 m using bilinear interpolation to ensure consistency across different acquisition years and states.
- Tiling the images into standardized 1 × 1 km2 spatial footprint tiles for efficient storage and processing.
- Storing processed imagery in AWS S3 storage buckets using the Cloud-Optimized GeoTIFF (COG) format to facilitate fast retrieval and scalable cloud-based processing.
- Filtered NAIP tile data to be within one year prior of the spatially coincident lidar acquisition date to reduce opportunities for incorrect labels for the same tile due to disturbances such as wildfires.
2.3. Label Data
3DEP Lidar
- Downloading, reprojecting, and tiling raw lidar point cloud data to a common coordinate system (EPSG: 6931, NSIDC EASE-Grid 2.0 North).
- Filtering outliers and noise from the raw point clouds using statistical-based and density-based methods to remove erroneous elevation points.
- Generating Digital Terrain Models (DTMs) by interpolating ground-classified lidar points to create a continuous representation of the bare-earth surface.
- Creating Digital Surface Models (DSMs) by using the highest return point in each grid cell to capture canopy top elevations.
- Computing Canopy Height Models (CHMs) by subtracting the DTM from the DSM, ensuring that derived canopy heights are accurately represented.
2.4. Baseline Evaluation Data
2.4.1. Meta Data for Good (Meta) High-Resolution Canopy Height—DINOv2 Architecture
2.4.2. LANDFIRE Forest Canopy Height Model
2.4.3. ETH Global Canopy Height Model
3. Methodology
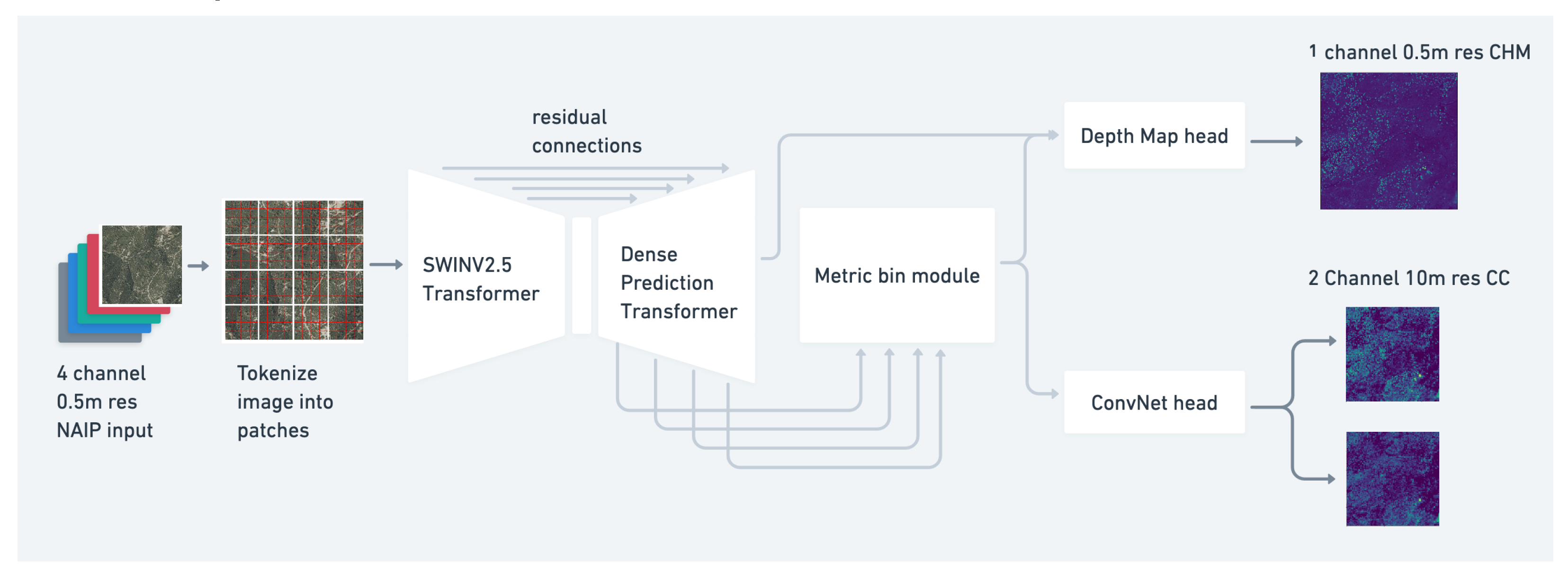
3.1. Vibrant Planet Multi-Task Vegetation Structure ViT: VibrantVS
3.2. Calculating Error Metrics
- The majority spatial intersection of tiles with the corresponding EPA L3 ecoregion to determine ecoregion-level accuracies.
- Individual height bins within each tile to determine height-class accuracies.
4. Results
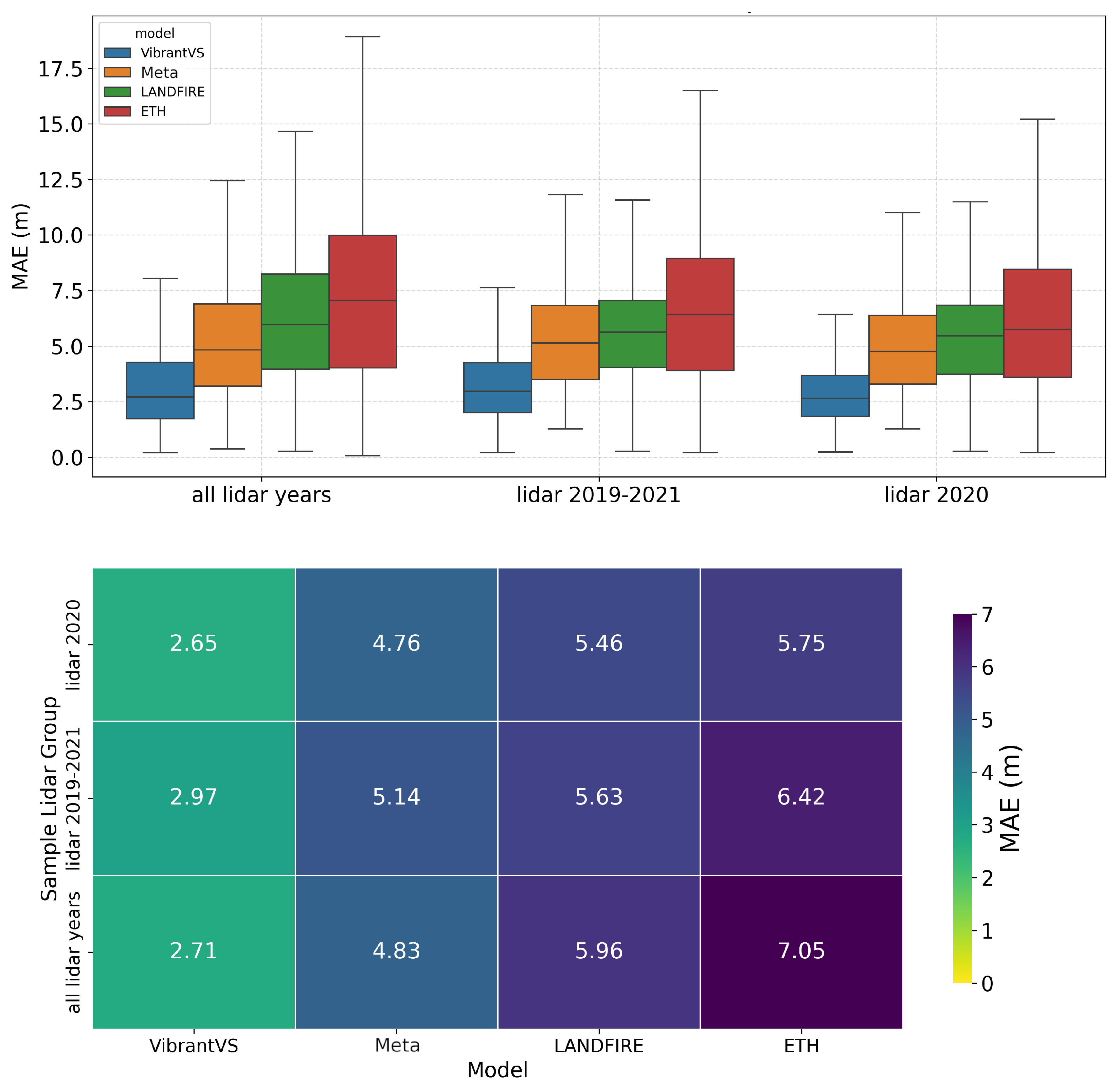
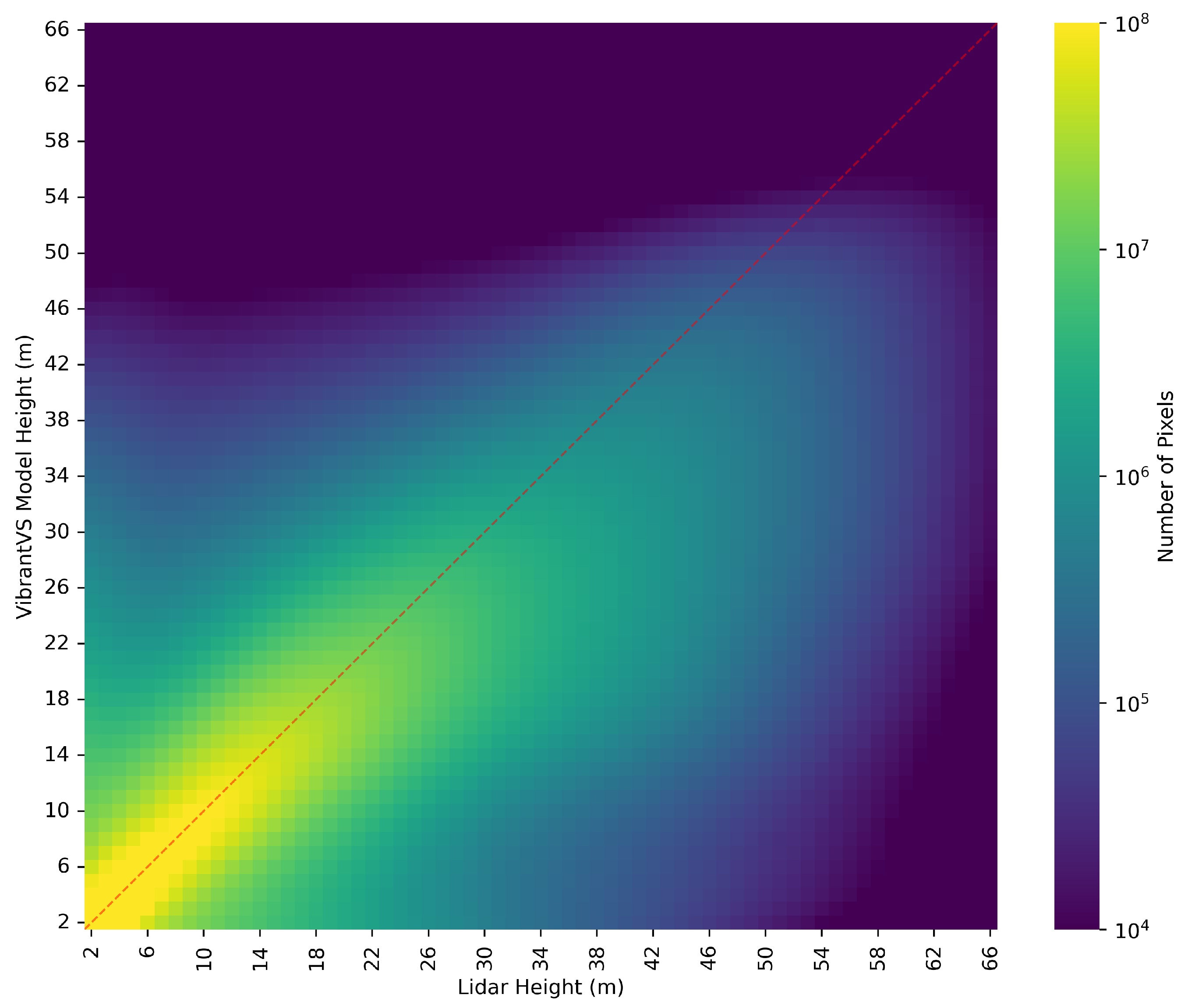
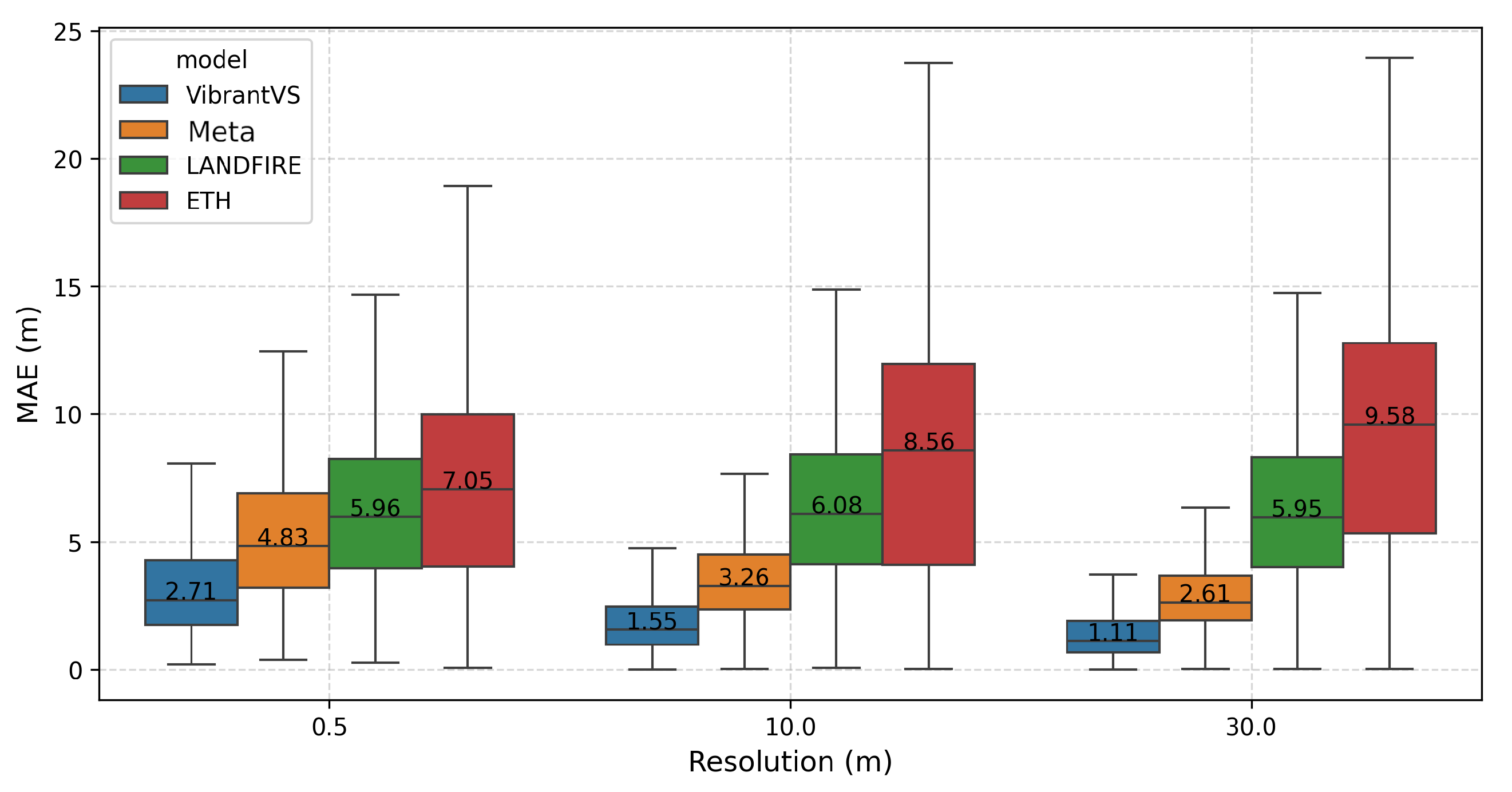
4.1. Overall Model Performance
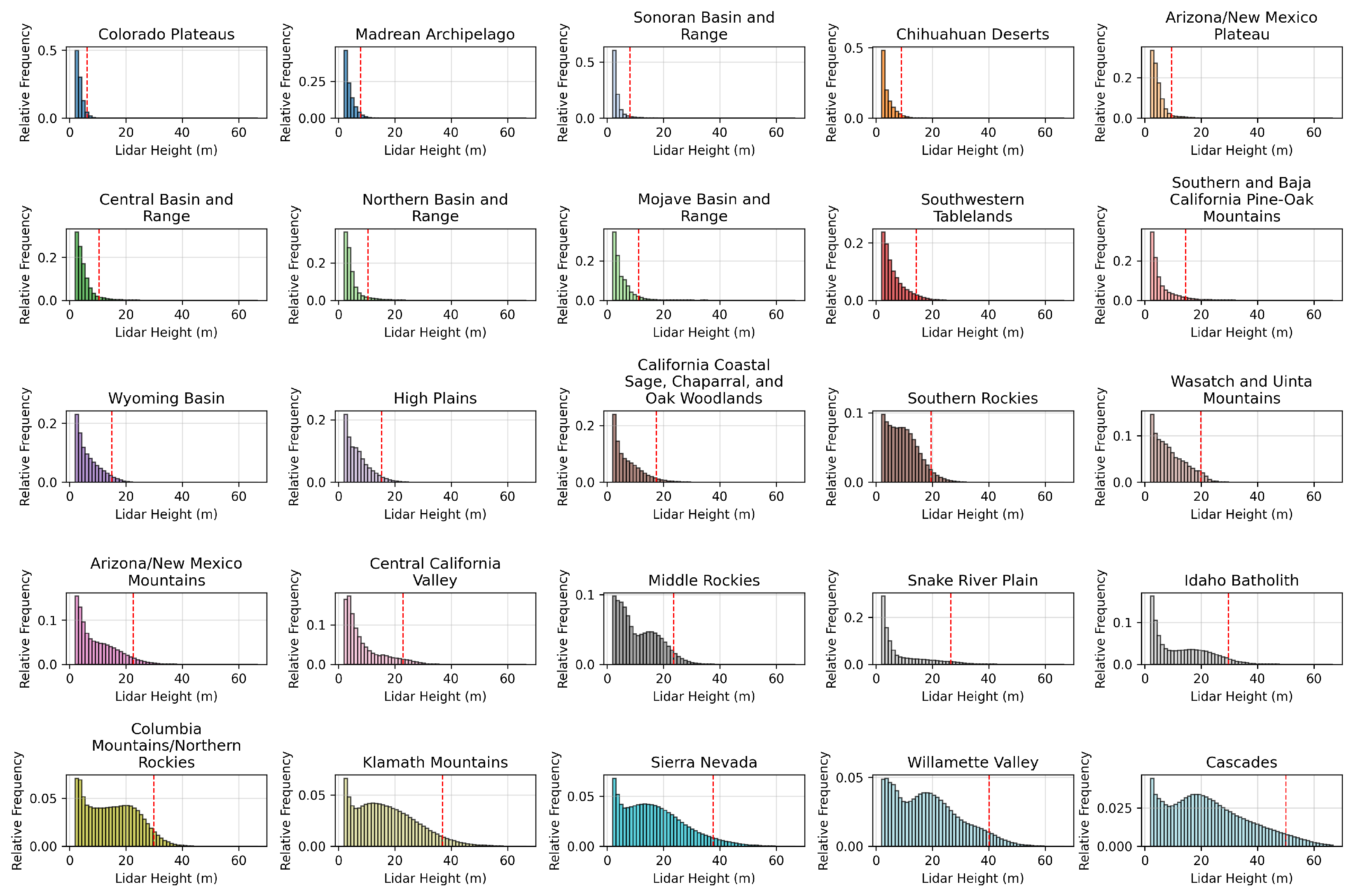
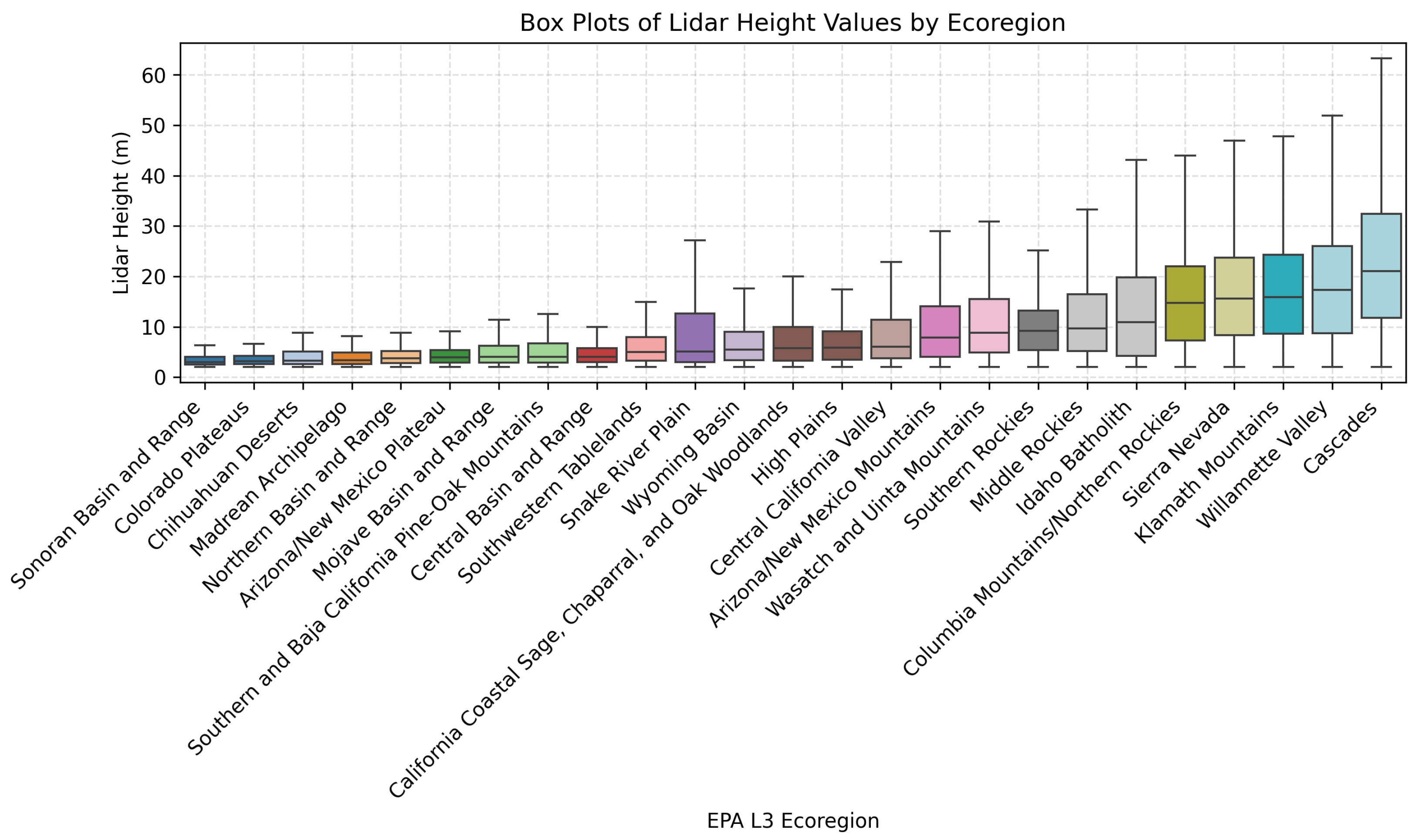
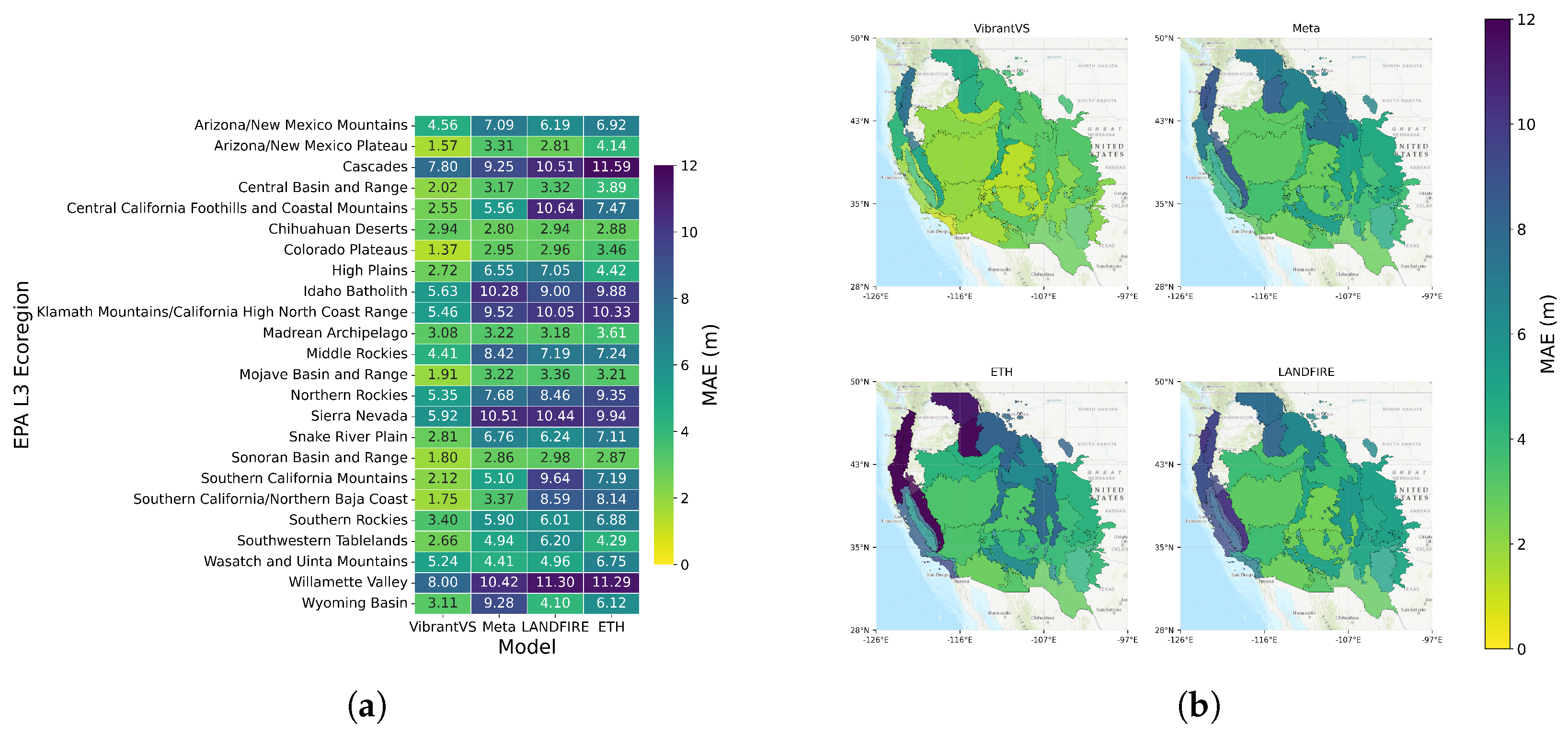
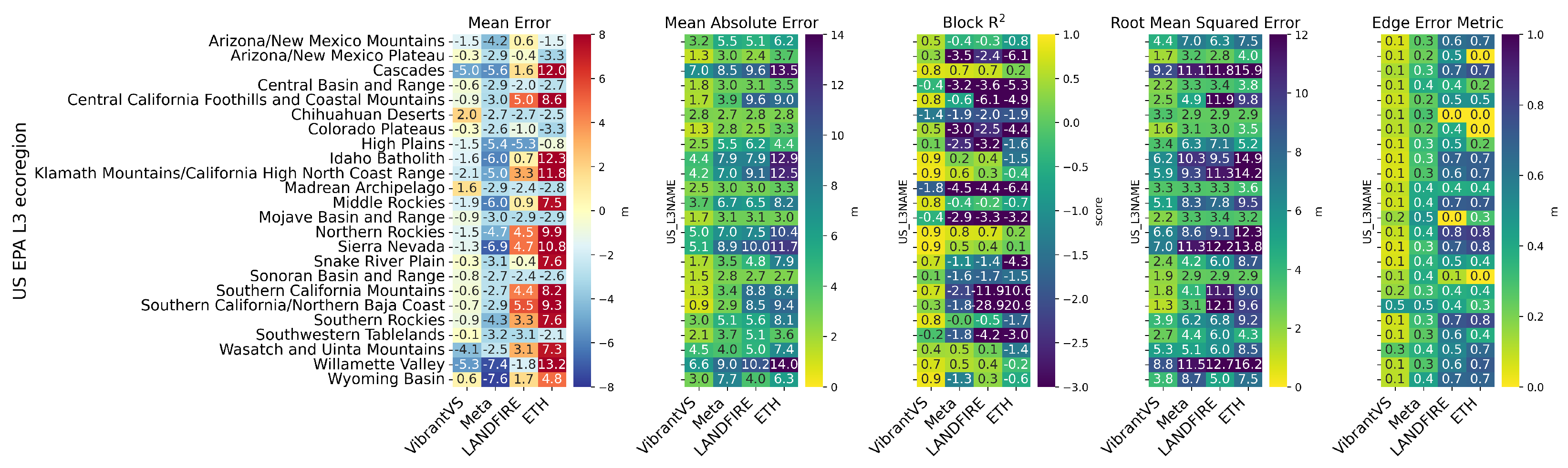
4.2. Performance Across Ecoregions
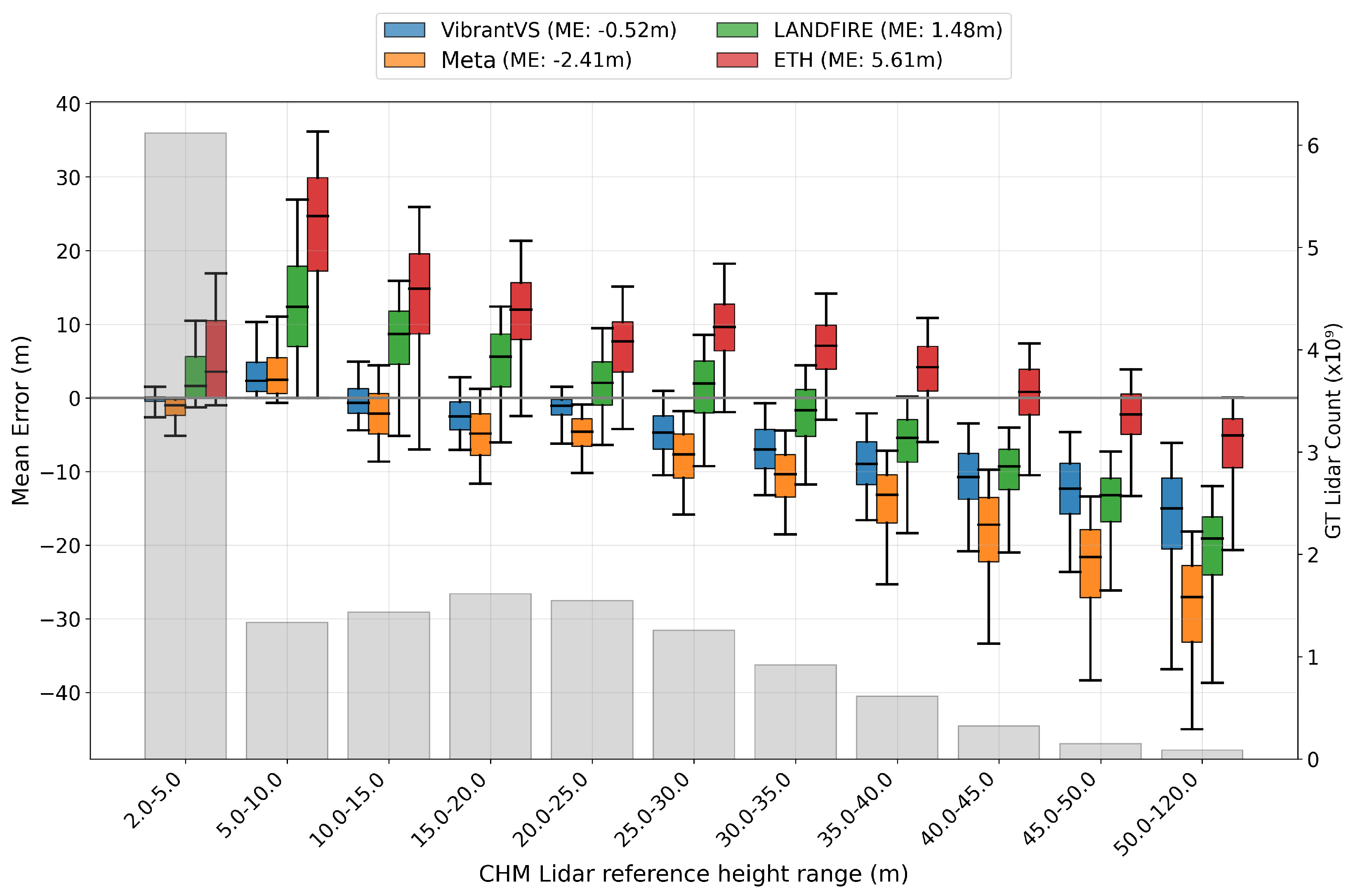
4.3. Performance Across Binned Tree Heights
4.4. Qualitative Analysis
5. Discussion
- More refinements can be made to the evaluations of the lowest height bin. MAE values are higher in this category because the spatial footprint of tree crowns appear larger in NAIP data compared to lidar-based tree crowns. This aerial image-based effect causes the VibrantVS model to infer a wider canopy crown that results in an overestimation of values where the lidar data are closer to 0. If we use the block metrics of Tolan et al. [25], rather than the pixel-wise metrics of Lang et al. [26], then we expect the lowest bin error of overestimation to disappear.
- More importantly, we have to address the underestimation of height among trees that are taller than 35 m, and especially trees taller than 50 m. There is an imbalance in the number of training samples of tall trees. Trees taller than 50 m represent less than 0.5% of our training data. We are undertaking a specific retraining exercise to address this underestimation and to compensate for the label imbalance.
- We would like to integrate topography data into our model, as we suspect that this could improve accuracy, especially on steep slopes and in high-altitude regions.
- We are also planning to expand our range of applications to more ecoregions, especially in the central and eastern United States. This would allow us to include additional tree species and also shrub vegetation types and to evaluate CHMs at heights lower than 2 m.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 3DEP | 3D Elevation Program |
| AWS S3 | Amazon Web Services Simple Storage Service |
| CC | Canopy Cover |
| CHM | Canopy Height Model |
| DEM | Digital Elevation Model |
| DINOv2 | Self DIstillation With NO Labels |
| DPT | Dense Prediction Transformer |
| DSM | Digital Surface Model |
| DTM | Digital Terrain Model |
| EE | Edge Error |
| EPA | Environmental Protection Agency |
| ETH | Eidgenössische Technische Hochschule Zürich |
| FCH | Forest Canopy Height |
| FIA | Forest Inventory and Analysis |
| GEDI | Global Ecosystem Dynamics Investigation |
| GPU | Graphics Processing Unit |
| LANDFIRE | Landscape Fire and Resource Management Planning Tools |
| L3 | Level 3 Ecoregion |
| MAE | Mean Absolute Error |
| ME | Mean Error |
| NAIP | National Agriculture Inventory Program |
| NEON | National Ecological Observatory Network |
| RMSE | Root Mean Squared Error |
| RMSNORM | Root Mean Square Layer Normalization |
| SWIGLU | Swish Gated Linear Unit |
| SWINv2 | Shifted Window |
| TAO | Tree Approximate Object |
| TIFF | Tagged Image File Format |
| USFS | United States Forest Service |
| USGS | United States Geological Survey |
| ViT | Vision Transformer |
| WCS | Wildfire Crisis Strategy |
| WESM | Work Unit Extent Spatial Metadata |
Appendix A
Appendix A.1. Additional Tables and Figures

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Spatial Resolution | Spatial Extent | Temporal Coverage | Architecture | Predictor Data | Label Data |
|---|---|---|---|---|---|---|
| VibrantVS | 0.5 m | Western United States | 2014–2021 | Multi-task vision transformer | 4-band NAIP imagery | USGS 3DEP aerial lidar |
| Meta [25] | 1 m | Global | 2020 | Encoder, dense prediction transformer, correction and rescaling network | Maxar Vivid2 0.5 m resolution mosaics | NEON aerial lidar CHMs, GEDI data, and a labeled 9000 tile tree/no tree segmentation dataset |
| LANDFIRE [43] | 30 m | United States | 2016, 2020, 2022, 2023 | Regression-tree based methods | Spectral information from Landsat, landscape features such as topography, and biophysical information | Field-measured height |
| ETH [26] | 10 m | Global | 2020 | Deep learning ensemble | Sentinel-2-L2A multi-spectral imagery, sin-cos embeddings of longitudinal coordinates | Sparse GEDI lidar data |
Appendix A.2. Error Metrics
- Mean Absolute Error (MAE)
- Block-R2where B is the number of blocks, is the ground truth value in block b, is the model estimate for block b, and is the mean of the ground-truth values in block b.
- Root Mean Square Error (RMSE)
- Mean Error (ME)
- Edge Error Metric (EE)where represents Sobel edge detection operation on the data (also compare Tolan et al. [25]).
References
- Moritz, M.A.; Batllori, E.; Bradstock, R.A.; Gill, A.M.; Handmer, J.; Hessburg, P.F.; Leonard, J.; McCaffrey, S.; Odion, D.C.; Schoennagel, T.; et al. Learning to coexist with wildfire. Nature 2014, 515, 58–66. [Google Scholar] [CrossRef] [PubMed]
- Westerling, A.L. Increasing western US forest wildfire activity: Sensitivity to changes in the timing of spring. Philos. Trans. R. Soc. B Biol. Sci. 2016, 371, 20150178. [Google Scholar] [CrossRef] [PubMed]
- Abatzoglou, J.T.; Williams, A.P. Impact of anthropogenic climate change on wildfire across western US forests. Proc. Natl. Acad. Sci. USA 2016, 113, 11770–11775. [Google Scholar] [CrossRef]
- Stevens-Rumann, C.S.; Kemp, K.B.; Higuera, P.E.; Harvey, B.J.; Rother, M.T.; Donato, D.C.; Morgan, P.; Veblen, T.T. Evidence for declining forest resilience to wildfires under climate change. Ecol. Lett. 2018, 21, 243–252. [Google Scholar] [CrossRef] [PubMed]
- Hessburg, P.F.; Agee, J.K.; Franklin, J.F. Dry forests and wildland fires of the inland Northwest USA: Contrasting the landscape ecology of the pre-settlement and modern eras. For. Ecol. Manag. 2005, 211, 117–139. [Google Scholar] [CrossRef]
- Hoffman, K.M.; Davis, E.L.; Wickham, S.B.; Schang, K.; Johnson, A.; Larking, T.; Lauriault, P.N.; Quynh Le, N.; Swerdfager, E.; Trant, A.J. Conservation of Earth’s biodiversity is embedded in Indigenous fire stewardship. Proc. Natl. Acad. Sci. USA 2021, 118, e2105073118. [Google Scholar] [CrossRef]
- Van Leeuwen, M.; Nieuwenhuis, M. Retrieval of forest structural parameters using LiDAR remote sensing. Eur. J. For. Res. 2010, 129, 749–770. [Google Scholar] [CrossRef]
- Means, J.E.; Acker, S.A.; Harding, D.J.; Blair, J.B.; Lefsky, M.A.; Cohen, W.B.; Harmon, M.E.; McKee, W.A. Use of large-footprint scanning airborne lidar to estimate forest stand characteristics in the Western Cascades of Oregon. Remote Sens. Environ. 1999, 67, 298–308. [Google Scholar] [CrossRef]
- Riaño, D.; Meier, E.; Allgöwer, B.; Chuvieco, E.; Ustin, S.L. Modeling airborne laser scanning data for the spatial generation of critical forest parameters in fire behavior modeling. Remote Sens. Environ. 2003, 86, 177–186. [Google Scholar] [CrossRef]
- Andersen, H.E.; McGaughey, R.J.; Reutebuch, S.E. Estimating forest canopy fuel parameters using LIDAR data. Remote Sens. Environ. 2005, 94, 441–449. [Google Scholar] [CrossRef]
- Silva, C.A.; Hudak, A.T.; Vierling, L.A.; Loudermilk, E.L.; O’Brien, J.J.; Hiers, J.K.; Jack, S.B.; Gonzalez-Benecke, C.; Lee, H.; Falkowski, M.J.; et al. Imputation of individual longleaf pine (Pinus palustris Mill.) tree attributes from field and LiDAR data. Can. J. Remote Sens. 2016, 42, 554–573. [Google Scholar] [CrossRef]
- Popescu, S.C.; Wynne, R.H. Seeing the trees in the forest. Photogramm. Eng. Remote Sens. 2004, 70, 589–604. [Google Scholar] [CrossRef]
- Vierling, K.T.; Vierling, L.A.; Gould, W.A.; Martinuzzi, S.; Clawges, R.M. Lidar: Shedding new light on habitat characterization and modeling. Front. Ecol. Environ. 2008, 6, 90–98. [Google Scholar] [CrossRef]
- Lefsky, M.A.; Cohen, W.B.; Parker, G.G.; Harding, D.J. Lidar remote sensing for ecosystem studies. BioScience 2002, 52, 19–30. [Google Scholar] [CrossRef]
- Beland, M.; Parker, G.; Sparrow, B.; Harding, D.; Chasmer, L.; Phinn, S.; Antonarakis, A.; Strahler, A. On promoting the use of lidar systems in forest ecosystem research. For. Ecol. Manag. 2019, 450, 117484. [Google Scholar] [CrossRef]
- Wulder, M.A.; Bater, C.W.; Coops, N.C.; Hilker, T.; White, J.C. The role of LiDAR in sustainable forest management. For. Chron. 2008, 84, 807–826. [Google Scholar] [CrossRef]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote sensing technologies for enhancing forest inventories: A review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef]
- Olszewski, J.H.; Bailey, J.D. LiDAR as a Tool for Assessing Change in Vertical Fuel Continuity Following Restoration. Forests 2022, 13, 503. [Google Scholar] [CrossRef]
- Kramer, H.A.; Collins, B.M.; Kelly, M.; Stephens, S.L. Quantifying ladder fuels: A new approach using LiDAR. Forests 2014, 5, 1432–1453. [Google Scholar] [CrossRef]
- Franklin, S.E.; Lavigne, M.B.; Wulder, M.A.; Stenhouse, G.B. Change detection and landscape structure mapping using remote sensing. For. Chron. 2002, 78, 618–625. [Google Scholar] [CrossRef]
- Dubayah, R.O.; Drake, J.B. Lidar remote sensing for forestry. J. For. 2000, 98, 44–46. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Valbuena, R.; O’Connor, B.; Zellweger, F.; Simonson, W.; Vihervaara, P.; Maltamo, M.; Silva, C.A.; Almeida, D.R.A.D.; Danks, F.; Morsdorf, F.; et al. Standardizing ecosystem morphological traits from 3D information sources. Trends Ecol. Evol. 2020, 35, 656–667. [Google Scholar] [CrossRef] [PubMed]
- Wagner, F.H.; Roberts, S.; Ritz, A.L.; Carter, G.; Dalagnol, R.; Favrichon, S.; Hirye, M.C.; Brandt, M.; Ciais, P.; Saatchi, S. Sub-meter tree height mapping of California using aerial images and LiDAR-informed U-Net model. Remote Sens. Environ. 2024, 305, 114099. [Google Scholar] [CrossRef]
- Tolan, J.; Yang, H.I.; Nosarzewski, B.; Couairon, G.; Vo, H.V.; Brandt, J.; Spore, J.; Majumdar, S.; Haziza, D.; Vamaraju, J.; et al. Very high resolution canopy height maps from RGB imagery using self-supervised vision transformer and convolutional decoder trained on aerial lidar. Remote Sens. Environ. 2024, 300, 113888. [Google Scholar] [CrossRef]
- Lang, N.; Jetz, W.; Schindler, K.; Wegner, J.D. A high-resolution canopy height model of the Earth. Nat. Ecol. Evol. 2023, 7, 1778–1789. [Google Scholar] [CrossRef]
- Li, S.; Brandt, M.; Fensholt, R.; Kariryaa, A.; Igel, C.; Gieseke, F.; Nord-Larsen, T.; Oehmcke, S.; Carlsen, A.H.; Junttila, S.; et al. Deep learning enables image-based tree counting, crown segmentation, and height prediction at national scale. PNAS Nexus 2023, 2, pgad076. [Google Scholar] [CrossRef]
- U.S. Forest Service. Initial Landscape Investments to Support the National Wildfire Crisis Strategy; U.S. Department of Agriculture: Washington, DC, USA, 2022.
- Thibault, K.M.; Laney, C.M.; Yule, K.M.; Franz, N.M.; Mabee, P.M. The US National Ecological Observatory Network and the Global Biodiversity Framework: National research infrastructure with a global reach. J. Ecol. Environ. 2023, 47, 21. [Google Scholar] [CrossRef]
- U.S. Geological Survey. WESM Data Dictionary. 2024. Available online: https://www.usgs.gov/ngp-standards-and-specifications/wesm-data-dictionary/ (accessed on 7 August 2024).
- Omernik, J.M.; Griffith, G.E. Ecoregions of the conterminous United States: Evolution of a hierarchical spatial framework. Environ. Manag. 2014, 54, 1249–1266. [Google Scholar] [CrossRef]
- Earth Resources Observation And Science (EROS) Center. National Agriculture Imagery Program (NAIP); Earth Resources Observation and Science (EROS) Center: Sioux Falls, SD, USA, 2017. [CrossRef]
- AWS Open Data Registry. NAIP: National Agriculture Imagery Program. 2024. Available online: https://registry.opendata.aws/naip/ (accessed on 26 September 2024).
- Sugarbaker, L.J.; Constance, E.W.; Heidemann, H.K.; Jason, A.L.; Lukas, V.; Saghy, D.L.; Stoker, J.M. The 3D Elevation Program Initiative: A Call for Action; Technical report; U.S. Geological Survey: Reston, VA, USA, 2014.
- Roussel, J.R.; Auty, D.; Coops, N.C.; Tompalski, P.; Goodbody, T.R.; Meador, A.S.; Bourdon, J.F.; de Boissieu, F.; Achim, A. lidR: An R package for analysis of Airborne Laser Scanning (ALS) data. Remote Sens. Environ. 2020, 251, 112061. [Google Scholar] [CrossRef]
- Maxar Technologies. Maxar Vivid2 Mosaic Imagery Data. 2024. Available online: https://developers.maxar.com/docs/streaming-basemap (accessed on 8 August 2024).
- Dubayah, R.; Armston, J.; Healey, S.P.; Bruening, J.M.; Patterson, P.L.; Kellner, J.R.; Duncanson, L.; Saarela, S.; Ståhl, G.; Yang, Z.; et al. GEDI launches a new era of biomass inference from space. Environ. Res. Lett. 2022, 17, 095001. [Google Scholar] [CrossRef]
- Meta; World Resources Institute (WRI). High Resolution Canopy Height Maps (CHM). 2024. Available online: https://registry.opendata.aws/dataforgood-fb-forests (accessed on 27 September 2024).
- Rollins, M.G.; Keane, R.E.; Zhu, Z.; Menakis, J.P. An overview of the LANDFIRE prototype project. In The LANDFIRE Prototype Project: Nationally Consistent and Locally Relevant Geospatial Data for Wildland Fire Management Gen. Tech. Rep. RMRS-GTR-175; Rollins, M.G., Frame, C.K., Eds.; US Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2006; Volume 175, pp. 5–43. [Google Scholar]
- Watts, K.F.; Koehler, D.W.; Todd, D.; Gillett, N. Integration of LANDFIRE Data into Fire Modeling: Enhancing Accuracy and Consistency. J. Appl. Meteorol. Climatol. 2017, 56, 2017JA024010. [Google Scholar] [CrossRef]
- Steenburgh, S.L.; Schmid, K.R. LANDFIRE Program: Fuel Data for Fire and Resource Management Planning. Fire Ecol. 2012, 8, 89–96. [Google Scholar]
- Lane, M.L.; Swetnam, T.W.; Oki, T. Fuel Models and LANDFIRE: Standardizing Inputs for Fire Simulation. Int. J. Wildland Fire 2011, 20, 845–856. [Google Scholar]
- Rollins, M.G. LANDFIRE: A nationally consistent vegetation, wildland fire, and fuel assessment. Int. J. Wildland Fire 2009, 18, 235–249. [Google Scholar] [CrossRef]
- U.S. Geological Survey. LANDFIRE Fuels—Forest Canopy Height. 2022. Available online: https://www.landfire.gov/fuel/ch (accessed on 27 April 2024).
- ETH Zurich. Global Canopy Height Map for the Year 2020 Derived from Sentinel-2 and GEDI (Version 1); ETH Zurich Research Collection: Zurich, Switzerland, 2023. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32, San Diego, CA, USA, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; Volume 32, pp. 8024–8035. [Google Scholar]
- Bhat, S.F.; Birkl, R.; Wofk, D.; Wonka, P.; Müller, M. Zoedepth: Zero-shot transfer by combining relative and metric depth. arXiv 2023, arXiv:2302.12288. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1623–1637. [Google Scholar] [CrossRef]
- Darcet, T.; Oquab, M.; Mairal, J.; Bojanowski, P. Vision transformers need registers. arXiv 2023, arXiv:2309.16588. [Google Scholar]
- Ainslie, J.; Lee-Thorp, J.; de Jong, M.; Zemlyanskiy, Y.; Lebrón, F.; Sanghai, S. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv 2023, arXiv:2305.13245. [Google Scholar]
- Dao, T. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv 2023, arXiv:2307.08691. [Google Scholar]
- Shazeer, N. Glu variants improve transformer. arXiv 2020, arXiv:2002.05202. [Google Scholar]
- Zhang, B.; Sennrich, R. Root mean square layer normalization. In Proceedings of the NeurIPS Conference on Advances in Neural Information Processing Systems 32, Vancouver, CA, USA, 8–14 December 2019; pp. 12381–12392. [Google Scholar]
- Defazio, A.; Mehta, H.; Mishchenko, K.; Khaled, A.; Cutkosky, A. The Road Less Scheduled. arXiv 2024, arXiv:2405.15682. [Google Scholar]
- Dettmers, T.; Lewis, M.; Shleifer, S.; Zettlemoyer, L. 8-bit Optimizers via Block-wise Quantization. arXiv 2021, arXiv:abs/2110.02861. [Google Scholar]
- Smith, L.N. A Disciplined Approach to Neural Network Hyper-Parameters: Part 1—Learning Rate, Batch Size, Momentum, and Weight Decay. arXiv 2018, arXiv:1803.09820. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-Propagating Errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Ferraz, A.; Bretar, F.; Jacquemoud, S.; Gonçalves, G.; Pereira, L.; Tomé, M.; Soares, P. 3D mapping of a multi-layered Mediterranean forest using ALS data. Remote Sens. Environ. 2012, 121, 210–223. [Google Scholar] [CrossRef]
- Jeronimo, S.M.A.; Kane, V.R.; Churchill, D.J.; McGaughey, R.J.; Franklin, J.F. Applying LiDAR Individual Tree Detection to Management of Structurally Diverse Forest Landscapes. J. For. 2018, 116, 336–346. [Google Scholar] [CrossRef]
- Team, R.L. LiDAR Data Analysis with R: Canopy Height Models. 2024. Available online: https://r-lidar.github.io/lidRbook/dsm.html?utm_source=chatgpt.com (accessed on 3 December 2024).
- Ritu, T.; James, H.; ad Reinke Karin, W.L.; Simon, J. Effect of fuel spatial resolution on predictive wildfire models. Int. J. Wildland Fire 2021, 30, 776–789. [Google Scholar] [CrossRef]



| Training | ||
|---|---|---|
| Lidar Acq. Year | n Samples | Unique Ecoregions |
| 2014 | 523 | 2 |
| 2015 | 6568 | 2 |
| 2016 | 24,838 | 7 |
| Lidar Acq. Year | n Samples | Unique Ecoregions |
| 2017 | 32,880 | 8 |
| 2018 | 54,114 | 11 |
| 2019 | 24,974 | 11 |
| 2020 | 44,003 | 6 |
| 2021 | 7516 | 6 |
| 2015 | 1384 | 2 |
| 2016 | 7966 | 6 |
| 2017 | 9616 | 7 |
| 2018 | 13,747 | 12 |
| 2019 | 8748 | 9 |
| 2020 | 22,459 | 7 |
| 2021 | 3307 | 6 |
| Model Name | MAE | Mean Error | Block-R2 | Edge Error |
|---|---|---|---|---|
| VibrantVS | 2.71 | −1.11 | 0.69 | 0.08 |
| Meta | 4.83 | −4.03 | −0.60 | 0.30 |
| LANDFIRE | 5.96 | 0.92 | −1.45 | 0.63 |
| ETH | 7.05 | 5.65 | −1.85 | 0.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, T.; Ndegwa, K.; Gros, A.; Landau, V.A.; Zachmann, L.J.; State, B.; Gritts, M.A.; Miller, C.W.; Rutenbeck, N.E.; Conway, S.; et al. VibrantVS: A High-Resolution Vision Transformer for Forest Canopy Height Estimation. Remote Sens. 2025, 17, 1017. https://doi.org/10.3390/rs17061017
Chang T, Ndegwa K, Gros A, Landau VA, Zachmann LJ, State B, Gritts MA, Miller CW, Rutenbeck NE, Conway S, et al. VibrantVS: A High-Resolution Vision Transformer for Forest Canopy Height Estimation. Remote Sensing. 2025; 17(6):1017. https://doi.org/10.3390/rs17061017
Chicago/Turabian StyleChang, Tony, Kiarie Ndegwa, Andreas Gros, Vincent A. Landau, Luke J. Zachmann, Bogdan State, Mitchell A. Gritts, Colton W. Miller, Nathan E. Rutenbeck, Scott Conway, and et al. 2025. "VibrantVS: A High-Resolution Vision Transformer for Forest Canopy Height Estimation" Remote Sensing 17, no. 6: 1017. https://doi.org/10.3390/rs17061017
APA StyleChang, T., Ndegwa, K., Gros, A., Landau, V. A., Zachmann, L. J., State, B., Gritts, M. A., Miller, C. W., Rutenbeck, N. E., Conway, S., & Bayes, G. (2025). VibrantVS: A High-Resolution Vision Transformer for Forest Canopy Height Estimation. Remote Sensing, 17(6), 1017. https://doi.org/10.3390/rs17061017