
Detail and Deep Feature Multi-Branch Fusion Network for High-Resolution Farmland Remote-Sensing Segmentation


Abstract
1. Introduction
- Innovative Architecture: DFBNet combines multiple feature extraction branches (detail, deep, and boundary enhancement) to address the challenge of accurate farmland segmentation, especially in complex environments with uneven crop distributions.
- Boundary Enhancement Fusion: A boundary enhancement fusion mechanism is proposed to address the loss of boundary details in traditional semantic segmentation models, ensuring better edge definition and accurate crop boundary segmentation.
- High Resolution and Efficiency: The model is designed to work efficiently with high-resolution remote-sensing data, balancing accuracy and computational efficiency for practical agricultural applications.
2. Materials and Data
2.1. Dataset Sources
2.2. Dataset Preparation
3. Methods
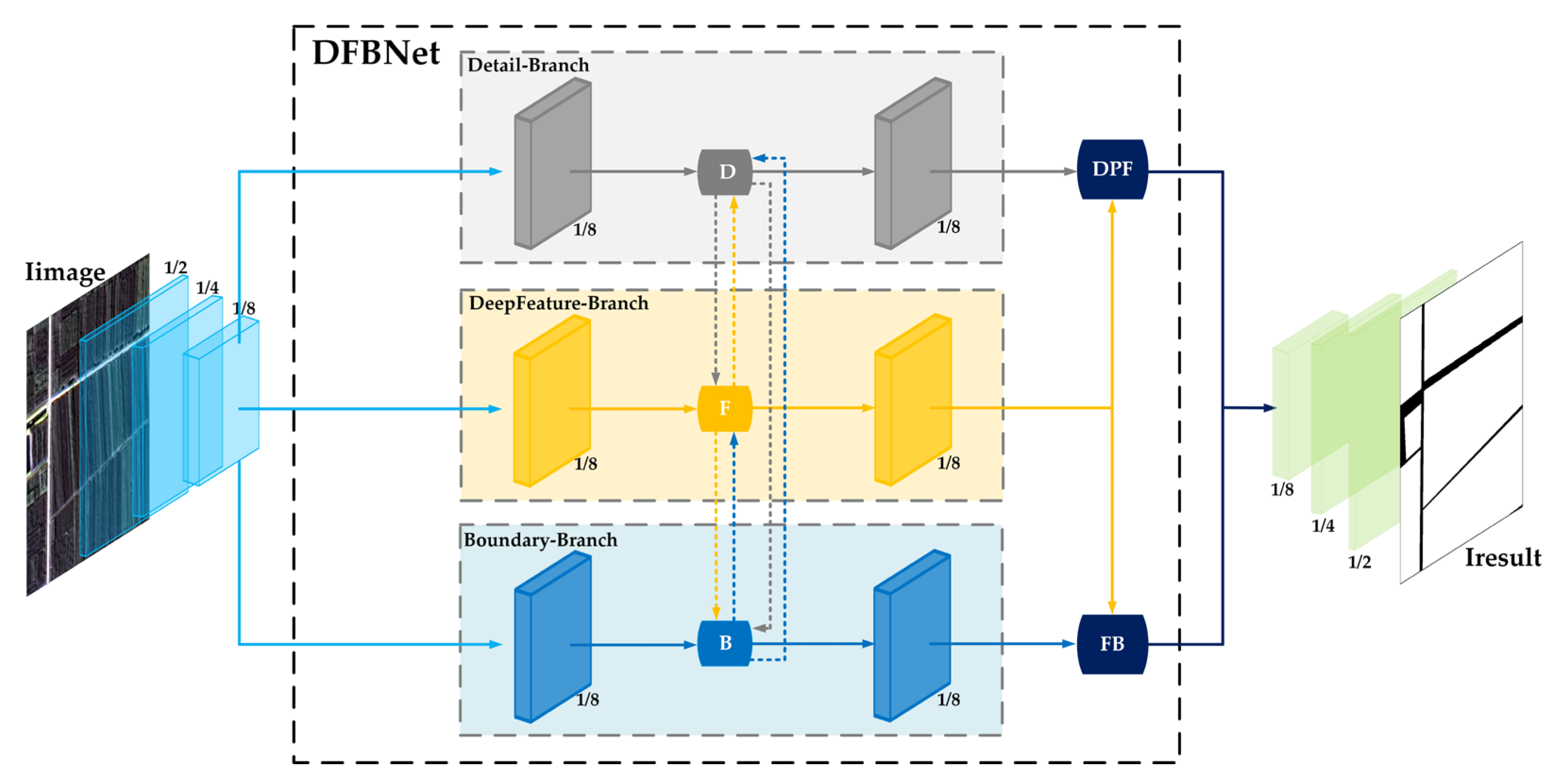
3.1. Overall Architecture of the Model
- Model input part, Minput. The main function of this part is to encode the input image Iimage. Through multi-step downsampling, the output FMpreprocessing is obtained. The purpose is to reduce the data dimension, decrease the amount of data processed by the subsequent model and the computational complexity, and provide a more appropriate data basis for the accurate judgment and processing of the subsequent model.
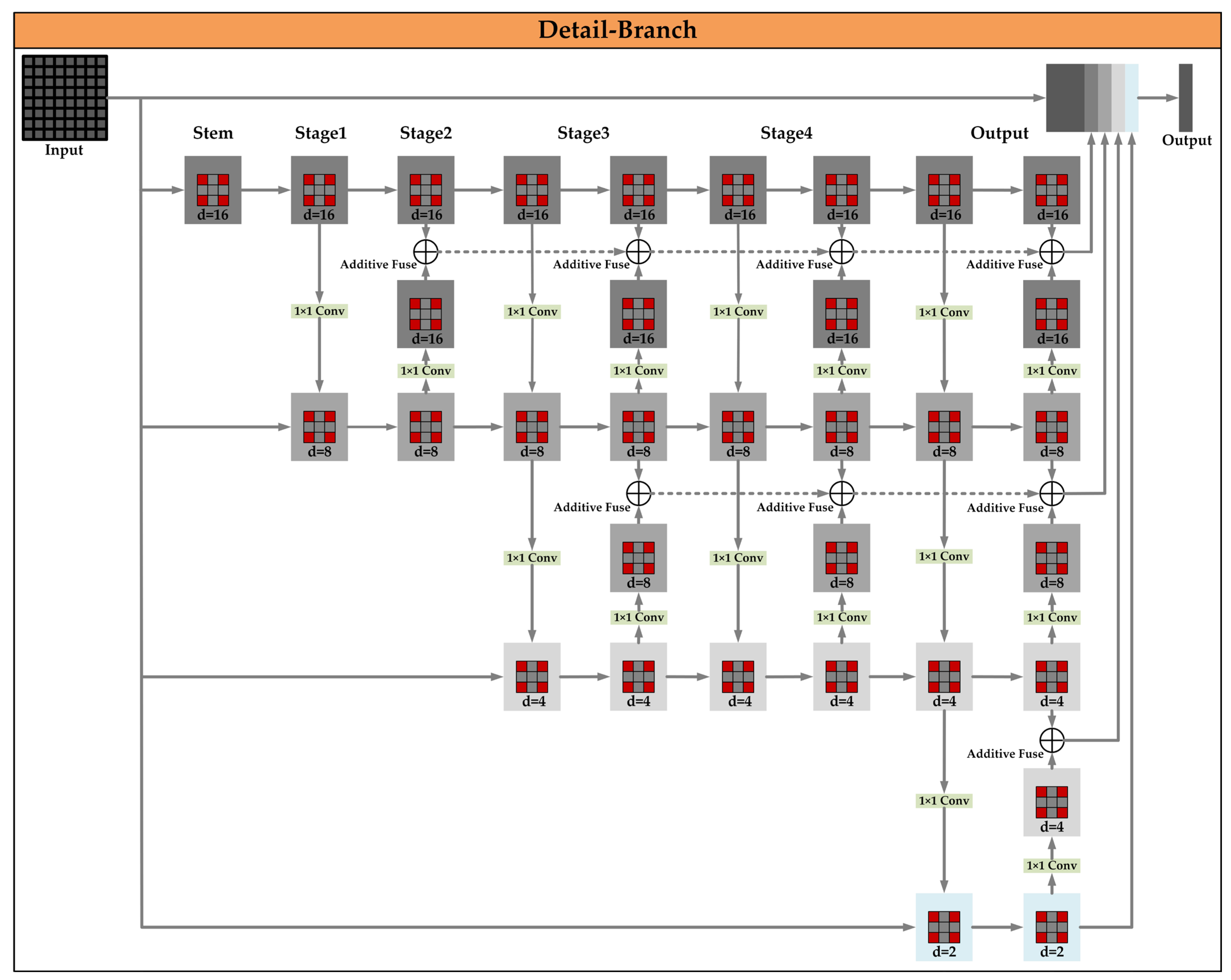
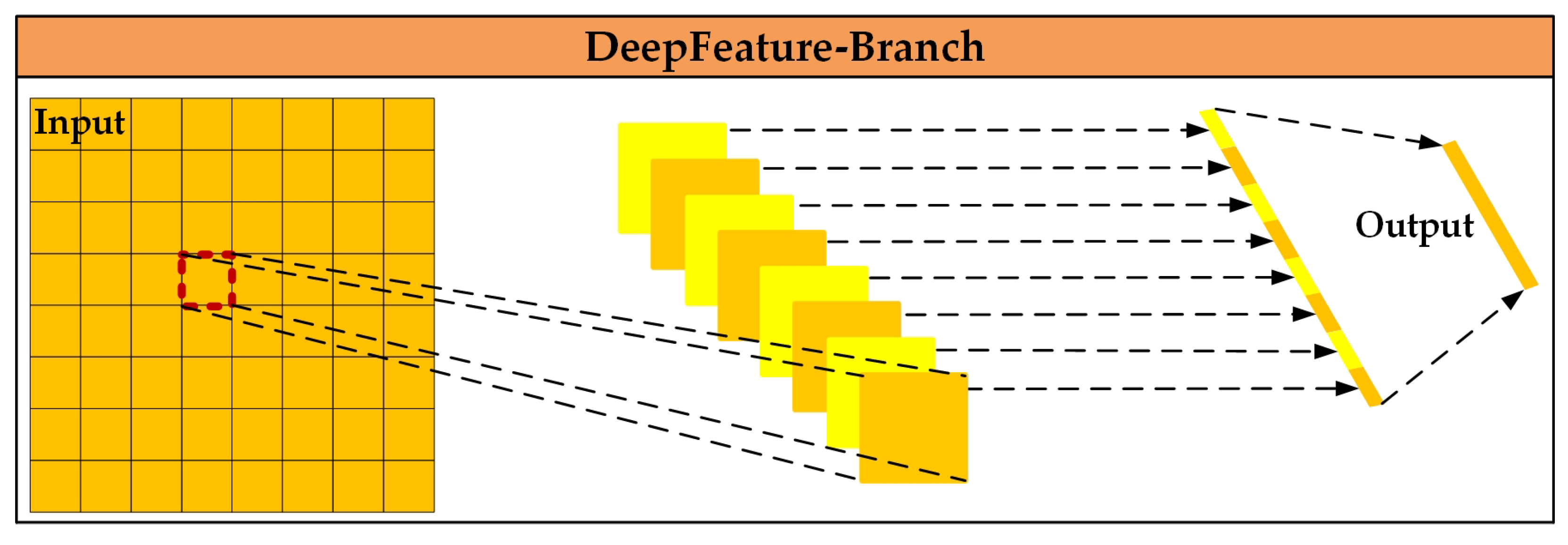
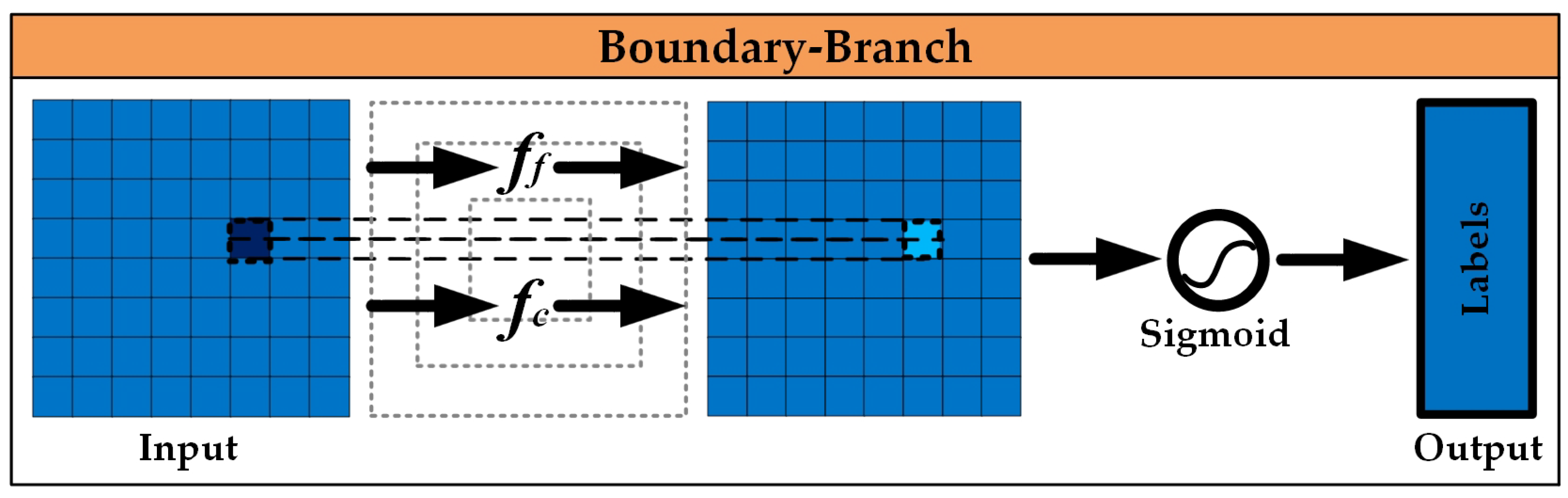
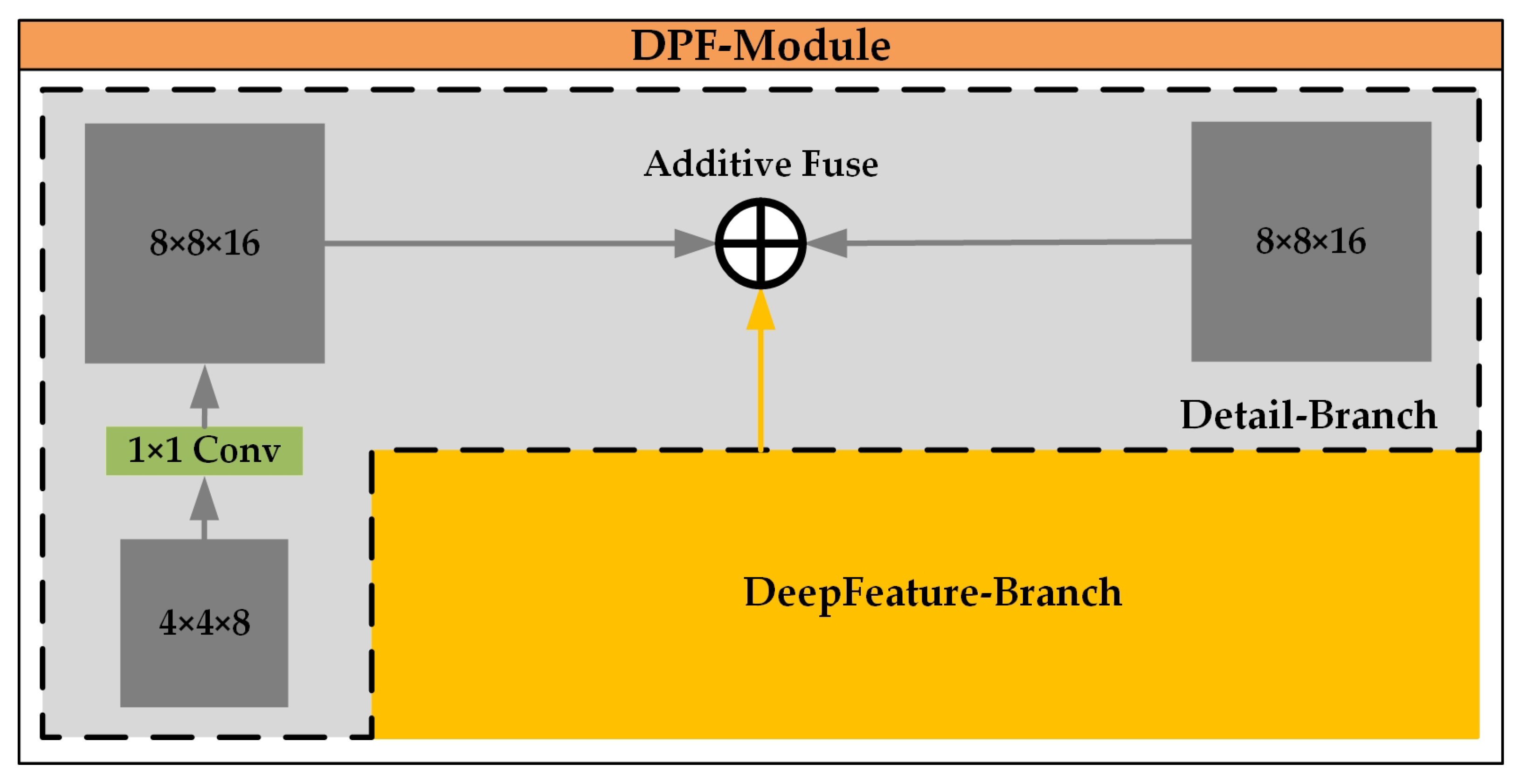
- Detail feature extraction branch, MDetail-Brunch. With the model input FMpreprocessing, the main function of this part is to perform convolution and fusion operations on the input image block FMpreprocessing to extract detail features and obtain the output FMDBR. The value of this part lies in its ability to accurately capture detail features from the preprocessed image (FMpreprocessing). Through convolution and fusion operations, details that are of great value for farmland identification, such as the edges and textures of furrows, are mined, and the output FMDBR provides detailed feature data for more accurate judgment and analysis in the subsequent steps.Deep feature mining branch, MDeepFeature-Brunch. With the model input FMpreprocessing, the main function of this part is to perform pooling operations on the input image block FMpreprocessing to mine deep features and obtain the output FMFBR. The value of this part lies in its ability to deeply mine the deep features in the image (FMpreprocessing) through pooling operations, extract more representative and high-level semantic information, so that the output FMFBR can help the subsequent model better understand the image content, and improve the processing effect of farmland image analysis.Boundary enhancement fusion branch, MBoundary-Brunch. With the model input FMpreprocessing, the main function of this part is to enhance the boundary features of the input image block FMpreprocessing and obtain the output FMBBR. The value of this part lies in its focus on the boundary features of the image (FMpreprocessing). Through enhancement processing, the boundary information in the image is highlighted, and the output FMBBR enables the model to more clearly capture key boundary features such as farmland boundaries, which helps to improve the accuracy of the overall image analysis and related task processing in the subsequent steps.
- Model aggregation parts, Mconcatenate-DPF and Mconcatenate-FB. FMDBR and FMFBR allow information to communicate and be enhanced among different levels through Mconcatenate-DPF, obtaining the output FMDPFR; FMFBR and FMBBR mine the synergistic information among features through Mconcatenate-BF and obtain the output FMBFR. The value of this part lies in the fact that through specific aggregation operations (Mconcatenate-DPF and Mconcatenate-BF), the features extracted by different branches (such as FMDBR, FMFBR, and FMBBR) can be fused and communicated with each other, the synergistic information among features can be mined, and FMDPFR and FMBFR can be output, respectively, providing a rich and fused feature basis for the subsequent model to output more comprehensive and relevant results.
- Model inverse encoding part, MInverse. The main function of this part is to inversely encode the information of FMDPFR and FMBFR in the model aggregation part. Through multi-step upsampling and feature adjustment, the output IResult is obtained. The value of this part lies in inversely encoding the aggregated features (FMDPFR and FMBFR), using multi-step upsampling and feature adjustment operations to restore the features to an appropriate form and output IResult, so that the model can finally output results that meet the requirements of the task and contain valid information, helping to complete the task of farmland image segmentation.
3.2. Model Input
- First downsampling: Firstly, a convolution operation is performed. A set of 3 × 3 convolution kernels are used to convolve the input image Iimage, and the number of convolution kernels is 3. Then, the ReLU activation function operation is carried out so that the feature map possesses nonlinear characteristics. After that, a 2 × 2 max pooling operation is conducted. This step will halve the spatial dimension of the image, resulting in an image with a size of 256 × 256 × 3.
- Second to fifth downsampling: The steps of the above downsampling are continuously repeated to gradually reduce the size of the image block. After the fifth downsampling, the spatial dimension of the image becomes 16 × 16 × 3.
- Sixth downsampling: The 3 × 3 convolution operation, the ReLU activation function operation, and the max pooling operation are carried out again. After six downsampling operations, an 8 × 8 × 3 multi-band remote-sensing image block FMpreprocessing is finally obtained as the output.
3.3. Model Branches
3.3.1. Detail Feature Extraction Branch
3.3.2. Deep Feature Mining Branch
3.3.3. Boundary Enhancement Fusion Branch
3.4. Model Information Fusion
3.4.1. FMDBR and FMFBR Allow Information to Communicate and Be Enhanced Among Different Levels Through Mconcatenate-DPF
3.4.2. FMFBR and FMBBR Mine the Synergistic Information Among Features Through Mconcatenate-BF
3.5. Model Output
3.6. Experimental Environment
- Hyperparameters: The initial learning rate was set to 0.001 and adjusted using cosine annealing. The batch size was fixed at 32. The Adam optimizer was used for training with a combination of cross-entropy and Dice loss functions to improve boundary sensitivity.
- Training Settings: All experiments were conducted on a workstation equipped with an NVIDIA GeForce RTX 2080 Ti GPU, an Intel Core i7-8700K CPU, and 32 GB of RAM. The training process ran for 100 epochs with early stopping to prevent overfitting.
- Data Preprocessing: The Hi-CNA dataset and the Netherlands Agricultural Land Dataset were resized to 512 × 512 pixels and normalized to [0, 1]. Data augmentation techniques, such as random rotation, flipping, and color jittering, were applied during training.
4. Results
4.1. Model Comparison
4.2. Evaluation of Different Models
4.3. Test Results of Different Models
4.3.1. Test Results of the Hi-CNA Dataset
4.3.2. Test Results of the Netherlands Agricultural Land Remote-Sensing Image Dataset
4.4. Ablation Experiment
4.4.1. Determine the Ablation Objects
4.4.2. Ablation Experimental Setup
4.4.3. Result Analysis
4.5. Statistical Significance Testing
4.5.1. Experimental Setup
4.5.2. Student’s t-Test Analysis
4.5.3. Discussion
5. Discussion
5.1. Summary of Research Results
- Segmentation Accuracy: Experimental results demonstrate that DFBNet excels in the segmentation accuracy of farmland boundaries. It effectively identifies farmland areas and accurately segments their boundaries. Compared with traditional methods and existing deep learning models, DFBNet shows clear advantages in segmentation accuracy-related metrics, such as accuracy, pixel accuracy, and IoU. The structural design of DFBNet enables it to capture complex farmland features and boundary details, refining segmentation from small-area plots to entire farmland boundaries, meeting the requirements for precise boundary delineation.
- Anti-Interference Capability: When faced with complex background interference in remote-sensing images, such as shadows, weeds, and differences in farmland morphology, DFBNet exhibits strong anti-interference capability. Its dual-branch feature learning and progressive boundary refinement processes allow the model to distinguish essential features of farmland from interference factors. As a result, it reliably identifies farmland areas even in challenging environments, providing accurate boundary information. This robustness offers significant technical support for monitoring farmland boundaries in practical agricultural production.
5.2. Comparison with Existing Methods
- Traditional Image Processing Methods: Traditional image processing methods, such as UNet and SegFormer, have notable limitations in farmland boundary segmentation. These methods are highly sensitive to illumination conditions, noise, and the complex structures of farmland areas. For instance, under uneven illumination, threshold-based methods struggle to determine appropriate thresholds, leading to inaccurate and fragmented segmentation results. In contrast, DFBNet, with its deep learning architecture, can automatically learn features of small-area plots and boundary information. This ensures greater robustness to illumination variations and noise.
- General Deep Learning Models: Although general deep learning models have achieved some success in image segmentation, they often face challenges in segmenting farmland boundaries. Issues such as occlusion, overlapping, and complex backgrounds in small-area farmland plots reduce their effectiveness. For example, methods such as UNet and DeepLabV3+ fail to fully capture subtle features and intricate structures, resulting in inaccurate boundary delineation. In contrast, DFBNet overcomes these challenges through its innovative architecture, which includes the detail feature extraction branch (Detail-Branch), deep feature mining branch (Deep Feature-Branch), and boundary enhancement fusion branch (Boundary-Branch). The Detail-Branch focuses on extracting fine-grained information from images, the Deep Feature-Branch specializes in obtaining high-level semantic features, and the Boundary-Branch emphasizes boundary enhancement. Combined with the dual-path feedback and bilinear fusion structures, these components progressively refine boundary segmentation, improving the model’s ability to handle complex farmland features effectively.
5.3. Computational Efficiency
5.4. Limitations and Future Work
- Performance on Unseen Farmland Types: DFBNet performs well on the datasets it was trained on, such as the Hi-CNA dataset and the Netherlands Agricultural Land dataset, but it faces challenges when applied to unseen farmland areas with different crop types, terrain, and environmental conditions. The model may struggle in regions with unfamiliar crops or geographic features.
- Pixel-Level Crop Classification: DFBNet is effective at segmenting farmland boundaries but does not perform pixel-level crop classification. This limitation is especially noticeable when distinguishing between crops with similar spectral properties (e.g., wheat and barley). This could lead to inaccuracies in crop distribution prediction.
- Impact of Different Crop Types: The segmentation accuracy can be affected by the presence of different crop types, particularly those with similar spectral characteristics or crops at different growth stages. This can complicate the segmentation task, especially when crops are grown close together.
- Enhancing Generalization to Unseen Farmland Types: We will explore domain adaptation techniques—for example, using self-supervised feature learning and clustering-based methods in an unsupervised framework, and employing consistency regularization and pseudo-labeling in a semi-supervised setup. These approaches pose challenges such as ensuring pseudo-label quality and handling unlabeled data variability. Additionally, transfer learning will be used to fine-tune the model on new, diverse agricultural datasets, though domain shifts may require advanced alignment strategies.
- Integrating Pixel-Level Crop Classification: Future versions of DFBNet will incorporate pixel-level crop classification alongside segmentation tasks. This could be achieved by combining segmentation and pixel-wise classification in a unified framework. Multi-source data such as vegetation indices will also be integrated to enhance the model’s ability to distinguish between similar crop types.
- Improving Handling of Crop Diversity: To address the impact of different crop types, we will explore multi-scale feature extraction and integrate time-series remote-sensing data. These additions will help the model to better manage crops at different growth stages and sizes, improving segmentation accuracy in diverse agricultural settings.
6. Conclusions
- Precision Agriculture Management: Through high-precision farmland segmentation, DFBNet can help farmers to achieve precise fertilization, precision irrigation, and other agricultural management means, thereby reducing resource waste and improving agricultural production efficiency.
- Crop Yield Forecast: By accurately classifying crop areas, DFBNet can provide more accurate crop yield prediction to support agricultural production planning and decision-making.
- Farmland Monitoring and Disaster Warning: The model can be used to monitor the growth state of the farmland, and find the problems such as pests and diseases and drought in time, so as to improve the emergency response ability of agricultural production.
- Multi-Source Remote-Sensing Data Fusion: DFBNet can also be combined with other remote-sensing data (e.g., radar, LIDAR) to provide more accurate field plot division and crop monitoring.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, Z.; Li, W.; Warner, T.A.; He, C.; Wang, X.; Zhang, Y.; Guo, C.; Cheng, T.; Zhu, Y.; Cao, W. A framework combined stacking ensemble algorithm to classify crop in complex agricultural landscape of high altitude regions with Gaofen-6 imagery and elevation data. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103386. [Google Scholar] [CrossRef]
- Yeom, J.-M.; Jeong, S.; Deo, R.C.; Ko, J. Mapping rice area and yield in northeastern Asia by incorporating a crop model with dense vegetation index profiles from a geostationary satellite. GIScience Remote Sens. 2021, 58, 1–27. [Google Scholar] [CrossRef]
- Chen, W.; Liu, G. A novel method for identifying crops in parcels constrained by environmental factors through the integration of a Gaofen-2 high-resolution remote sensing image and Sentinel-2 time series. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 450–463. [Google Scholar] [CrossRef]
- Jo, H.-W.; Park, E.; Sitokonstantinou, V.; Kim, J.; Lee, S.; Koukos, A.; Lee, W.-K. Recurrent U-Net based dynamic paddy rice mapping in South Korea with enhanced data compatibility to support agricultural decision making. GIScience Remote Sens. 2023, 60, 2206539. [Google Scholar] [CrossRef]
- Awad, B.; Erer, I. FAUNet: Frequency Attention U-Net for Parcel Boundary Delineation in Satellite Images. Remote Sens. 2023, 15, 5123. [Google Scholar] [CrossRef]
- Yang, M.-D.; Huang, K.-S.; Kuo, Y.-H.; Tsai, H.P.; Lin, L.-M. Spatial and spectral hybrid image classification for rice lodging assessment through UAV imagery. Remote Sens. 2017, 9, 583. [Google Scholar] [CrossRef]
- Liu, W.; Dong, J.; Xiang, K.; Wang, S.; Han, W.; Yuan, W. A sub-pixel method for estimating planting fraction of paddy rice in Northeast China. Remote Sens. Environ. 2018, 205, 305–314. [Google Scholar] [CrossRef]
- Matton, N.; Sepulcre Canto, G.; Waldner, F.; Valero, S.; Morin, D.; Inglada, J.; Arias, M.; Bontemps, S.; Koetz, B.; Defourny, P. An automated method for annual cropland mapping along the season for various globally-distributed agrosystems using high spatial and temporal resolution time series. Remote Sens. 2015, 7, 13208–13232. [Google Scholar] [CrossRef]
- Yang, L.; Wang, L.; Abubakar, G.A.; Huang, J. High-resolution rice mapping based on SNIC segmentation and multi-source remote sensing images. Remote Sens. 2021, 13, 1148. [Google Scholar] [CrossRef]
- Yang, Y.; Huang, Q.; Wu, W.; Luo, J.; Gao, L.; Dong, W.; Wu, T.; Hu, X. Geo-parcel based crop identification by integrating high spatial-temporal resolution imagery from multi-source satellite data. Remote Sens. 2017, 9, 1298. [Google Scholar] [CrossRef]
- Valero, S.; Morin, D.; Inglada, J.; Sepulcre, G.; Arias, M.; Hagolle, O.; Dedieu, G.; Bontemps, S.; Defourny, P.; Koetz, B. Production of a dynamic cropland mask by processing remote sensing image series at high temporal and spatial resolutions. Remote Sens. 2016, 8, 55. [Google Scholar] [CrossRef]
- Rydberg, A.; Borgefors, G. Integrated method for boundary delineation of agricultural fields in multispectral satellite images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2514–2520. [Google Scholar] [CrossRef]
- Yu, J.; Tan, J.; Wang, Y. Ultrasound speckle reduction by a SUSAN-controlled anisotropic diffusion method. Pattern Recognit. 2010, 43, 3083–3092. [Google Scholar] [CrossRef]
- Fetai, B.; Oštir, K.; Kosmatin Fras, M.; Lisec, A. Extraction of visible boundaries for cadastral mapping based on UAV imagery. Remote Sens. 2019, 11, 1510. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, L.; Du, B.; Chen, H.; Wang, J.; Zhong, H. UNet-Like Remote Sensing Change Detection: A review of current models and research directions. IEEE Geosci. Remote Sens. Mag. 2024, 12, 305–334. [Google Scholar] [CrossRef]
- Fu, B.; He, X.; Yao, H.; Liang, Y.; Deng, T.; He, H.; Fan, D.; Lan, G.; He, W. Comparison of RFE-DL and stacking ensemble learning algorithms for classifying mangrove species on UAV multispectral images. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102890. [Google Scholar] [CrossRef]
- Zhan, Z.; Xiong, Z.; Huang, X.; Yang, C.; Liu, Y.; Wang, X. Multi-Scale Feature Reconstruction and Inter-Class Attention Weighting for Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 1921–1937. [Google Scholar] [CrossRef]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Lu, Y.; James, T.; Schillaci, C.; Lipani, A. Snow detection in alpine regions with Convolutional Neural Networks: Discriminating snow from cold clouds and water body. GIScience Remote Sens. 2022, 59, 1321–1343. [Google Scholar] [CrossRef]
- Qi, L.; Zuo, D.; Wang, Y.; Tao, Y.; Tang, R.; Shi, J.; Gong, J.; Li, B. Convolutional Neural Network-Based Method for Agriculture Plot Segmentation in Remote Sensing Images. Remote Sens. 2024, 16, 346. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-resolution context extraction network for semantic segmentation of remote sensing images. Remote Sens. 2020, 13, 71. [Google Scholar] [CrossRef]
- Xu, Y.; Jiang, J. High-resolution boundary-constrained and context-enhanced network for remote sensing image segmentation. Remote Sens. 2022, 14, 1859. [Google Scholar] [CrossRef]
- Gonçalves, D.N.; Marcato, J., Jr.; Carrilho, A.C.; Acosta, P.R.; Ramos, A.P.M.; Gomes, F.D.G.; Osco, L.P.; Oliveira, M.D.; Martins, J.A.C.; Damasceno, G.A., Jr.; et al. Transformers for mapping burned areas in Brazilian Pantanal and Amazon with PlanetScope imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 116, 103151. [Google Scholar] [CrossRef]
- Lu, T.Y.; Gao, M.X.; Wang, L. Crop classification in high-resolution remote sensing images based on multi-scale feature fusion semantic segmentation model. Front. Plant Sci. 2023, 14, 1196634. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Xu, S.; Sun, J.; Ou, D.; Wu, X.; Wang, M. Unsupervised adversarial domain adaptation for agricultural land extraction of remote sensing images. Remote Sens. 2022, 14, 6298. [Google Scholar] [CrossRef]
- Ma, X.; Wu, Q.; Zhao, X.; Zhang, X.; Pun, M.-O.; Huang, B. Sam-assisted remote sensing imagery semantic segmentation with object and boundary constraints. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5636916. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Li, J.; Pei, Y.; Zhao, S.; Xiao, R.; Sang, X.; Zhang, C. A review of remote sensing for environmental monitoring in China. Remote Sens. 2020, 12, 1130. [Google Scholar] [CrossRef]
- Waldner, F.; Diakogiannis, F.I. Deep learning on edge: Extracting field boundaries from satellite images with a convolutional neural network. Remote Sens. Environ. 2020, 245, 111741. [Google Scholar] [CrossRef]
- Sun, Z.; Zhong, Y.; Wang, X.; Zhang, L. Identifying cropland non-agriculturalization with high representational consistency from bi-temporal high-resolution remote sensing images: From benchmark datasets to real-world application. ISPRS J. Photogramm. Remote Sens. 2024, 212, 454–474. [Google Scholar] [CrossRef]
- Li, M.; Long, J.; Stein, A.; Wang, X. Using a semantic edge-aware multi-task neural network to delineate agricultural parcels from remote sensing images. ISPRS J. Photogramm. Remote Sens. 2023, 200, 24–40. [Google Scholar] [CrossRef]
- Zhu, Y.; Pan, Y.; Zhang, D.; Wu, H.; Zhao, C. A deep learning method for cultivated land parcels (CLPs) delineation from high-resolution remote sensing images with high-generalization capability. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4410525. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. pp. 234–241. [Google Scholar]
- Wang, Z.; Xia, X.; Chen, Z.; He, X.; Guo, Y.; Gong, M.; Liu, T. Open-vocabulary segmentation with unpaired mask-text supervision. arXiv 2024, arXiv:2402.08960. [Google Scholar]
- Maulik, U.; Chakraborty, D. Remote Sensing Image Classification: A survey of support-vector-machine-based advanced techniques. IEEE Geosci. Remote Sens. Mag. 2017, 5, 33–52. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Ebrahimy, H.; Zhang, Z. Per-pixel accuracy as a weighting criterion for combining ensemble of extreme learning machine classifiers for satellite image classification. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103390. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhang, X.; Yan, J.; Tian, J.; Li, W.; Gu, X.; Tian, Q. Objective evaluation-based efficient learning framework for hyperspectral image classification. GIScience Remote Sens. 2023, 60, 2225273. [Google Scholar] [CrossRef]
- Jung, H.; Choi, H.-S.; Kang, M. Boundary enhancement semantic segmentation for building extraction from remote sensed image. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5215512. [Google Scholar] [CrossRef]
- Hosseinpour, H.; Samadzadegan, F.; Javan, F.D. A Novel Boundary Loss Function in Deep Convolutional Networks to Improve the Buildings Extraction From High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4437–4454. [Google Scholar] [CrossRef]
- Pal, N.R.; Pal, S.K. A review on image segmentation techniques. Pattern Recognit. 1993, 26, 1277–1294. [Google Scholar] [CrossRef]
- Hossain, M.D.; Chen, D. Segmentation for Object-Based Image Analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Configuration |
|---|---|
| CPU | Intel Core(TM) i7-8700K 32 G, Intel Corporation, Santa Clara, CA, USA |
| GPU | NVIDIA GeForce RTX 2080 Ti, NVIDIA, Santa Clara, CA, USA |
| Operating System | Windows 10 |
| Deep Learning Framework | Pytorch1.12 |
| Models | Accuracy (%) | Pixel Accuracy (%) | IoU (%) | Val Loss |
|---|---|---|---|---|
| UNet [35] | 80.06 | 79.89 | 68.55 | 0.173 |
| DeepLabV3+ [28] | 81.3 | 81.33 | 69.57 | 0.382 |
| SegFormer [29] | 81.27 | 83.29 | 72.54 | 0.112 |
| Mask2Former [18] | 83.92 | 84.52 | 74.24 | 0.159 |
| OVSeg [36] | 82.7 | 82.08 | 71.58 | 0.147 |
| DFBNet (Ours) | 88.34 | 89.41 | 78.75 | 0.168 |
| Models | Accuracy (%) | Pixel Accuracy (%) | IoU (%) | Val Loss |
|---|---|---|---|---|
| UNet [35] | 80.23 | 80.13 | 70.84 | 0.137 |
| DeepLabV3+ [28] | 82.8 | 81.79 | 69.62 | 0.479 |
| SegFormer [29] | 84.23 | 83.09 | 74.69 | 0.255 |
| Mask2Former [18] | 85.42 | 85.65 | 77.83 | 0.267 |
| OVSeg [36] | 83.62 | 83.9 | 72.89 | 0.249 |
| DFBNet (Ours) | 90.63 | 91.6 | 83.67 | 0.256 |
| Datasets | Models | Accuracy (%) | Pixel Accuracy (%) | IoU (%) | Val Loss |
|---|---|---|---|---|---|
| The Hi-CNA Dataset | DFBNet | 88.34 | 89.41 | 78.75 | 0.168 |
| DFBNet-DPF | 86.50 | 84.73 | 72.14 | 0.184 | |
| DFBNet-BF | 87.05 | 85.10 | 73.25 | 0.175 | |
| The Netherlands Agricultural Land Remote-Sensing Image Dataset | DFBNet | 90.63 | 91.6 | 83.67 | 0.256 |
| DFBNet-DPF | 89.15 | 87.10 | 75.83 | 0.269 | |
| DFBNet-BF | 89.40 | 87.35 | 76.42 | 0.262 |
| Datasets | Models | Accuracy (%) | Pixel Accuracy (%) | IoU (%) |
|---|---|---|---|---|
| The Hi-CNA Dataset | UNet [35] | 80.06 ± 0.50 | 79.89 ± 0.60 | 68.55 ± 0.80 |
| DeepLabV3+ [28] | 81.30 ± 0.55 | 81.33 ± 0.65 | 69.57 ± 0.75 | |
| SegFormer [29] | 81.27 ± 0.60 | 83.29 ± 0.70 | 72.54 ± 0.80 | |
| Mask2Former [18] | 83.92 ± 0.65 | 84.52 ± 0.70 | 74.24 ± 0.85 | |
| OVSeg [36] | 82.70 ± 0.60 | 82.08 ± 0.65 | 71.58 ± 0.80 | |
| DFBNet (Ours) | 88.34 ± 0.70 | 89.41 ± 0.75 | 78.75 ± 0.85 | |
| The Netherlands Agricultural Land Remote-Sensing Image Dataset | UNet [35] | 80.23 ± 0.55 | 80.13 ± 0.60 | 70.84 ± 0.80 |
| DeepLabV3+ [28] | 82.80 ± 0.58 | 81.79 ± 0.63 | 69.62 ± 0.75 | |
| SegFormer [29] | 84.23 ± 0.65 | 83.09 ± 0.70 | 74.69 ± 0.85 | |
| Mask2Former [18] | 85.42 ± 0.62 | 85.65 ± 0.70 | 77.83 ± 0.90 | |
| OVSeg [36] | 83.62 ± 0.60 | 83.90 ± 0.65 | 72.89 ± 0.85 | |
| DFBNet (Ours) | 90.63 ± 0.50 | 91.60 ± 0.55 | 83.67 ± 0.80 |
| Datasets | Compared Models | Accuracy p-Value | Pixel Accuracy p-Value | IoU p-Value |
|---|---|---|---|---|
| The Hi-CNA Dataset | UNet [35] | 0.001 | 0.001 | 0.002 |
| DeepLabV3+ [28] | 0.001 | 0.001 | 0.001 | |
| SegFormer [29] | 0.001 | 0.000 | 0.001 | |
| Mask2Former [18] | 0.002 | 0.001 | 0.002 | |
| OVSeg [36] | 0.001 | 0.001 | 0.001 | |
| The Netherlands Agricultural Land Remote-Sensing Image Dataset | UNet [35] | 0.001 | 0.001 | 0.001 |
| DeepLabV3+ [28] | 0.001 | 0.001 | 0.001 | |
| SegFormer [29] | 0.002 | 0.001 | 0.001 | |
| Mask2Former [18] | 0.002 | 0.001 | 0.002 | |
| OVSeg [36] | 0.001 | 0.001 | 0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Z.; Pan, X.; She, X.; Ma, J.; Zhao, J. Detail and Deep Feature Multi-Branch Fusion Network for High-Resolution Farmland Remote-Sensing Segmentation. Remote Sens. 2025, 17, 789. https://doi.org/10.3390/rs17050789
Tang Z, Pan X, She X, Ma J, Zhao J. Detail and Deep Feature Multi-Branch Fusion Network for High-Resolution Farmland Remote-Sensing Segmentation. Remote Sensing. 2025; 17(5):789. https://doi.org/10.3390/rs17050789
Chicago/Turabian StyleTang, Zhankui, Xin Pan, Xiangfei She, Jing Ma, and Jian Zhao. 2025. "Detail and Deep Feature Multi-Branch Fusion Network for High-Resolution Farmland Remote-Sensing Segmentation" Remote Sensing 17, no. 5: 789. https://doi.org/10.3390/rs17050789
APA StyleTang, Z., Pan, X., She, X., Ma, J., & Zhao, J. (2025). Detail and Deep Feature Multi-Branch Fusion Network for High-Resolution Farmland Remote-Sensing Segmentation. Remote Sensing, 17(5), 789. https://doi.org/10.3390/rs17050789