
GD-Det: Low-Data Object Detection in Foggy Scenarios for Unmanned Aerial Vehicle Imagery Using Re-Parameterization and Cross-Scale Gather-and-Distribute Mechanisms


Abstract
1. Introduction
- (1)
- We introduce a re-parameterization feature extraction module integrating RepVGG blocks into multi-concat blocks, which can improve the model’s spatial perception and feature diversity during training while reducing parameter costs during inference.
- (2)
- We propose a cross-scale gather-and-distribute pyramid module with a self-attention mechanism and injection algorithm which can augment the relationship representations of four-scale features via flexible skip fusion and distribution and maximize the utilization of global and local features.
- (3)
- We conduct a decoupled prediction module with three branches which implements classification and regression, respectively, and enhances the detection accuracy via the fusion of the prediction accuracy of tri-level features.
- (4)
- We use a domain-adaptive training strategy with knowledge transfer to cope with low-data issues which uses the knowledge transfer and feature alignment in cross-domain scenarios and less samples to make the model convergence.
2. Related Work
2.1. Lightweight Networks
2.2. Re-Parameterization and Multi-Scale Feature Fusion
3. Methodology
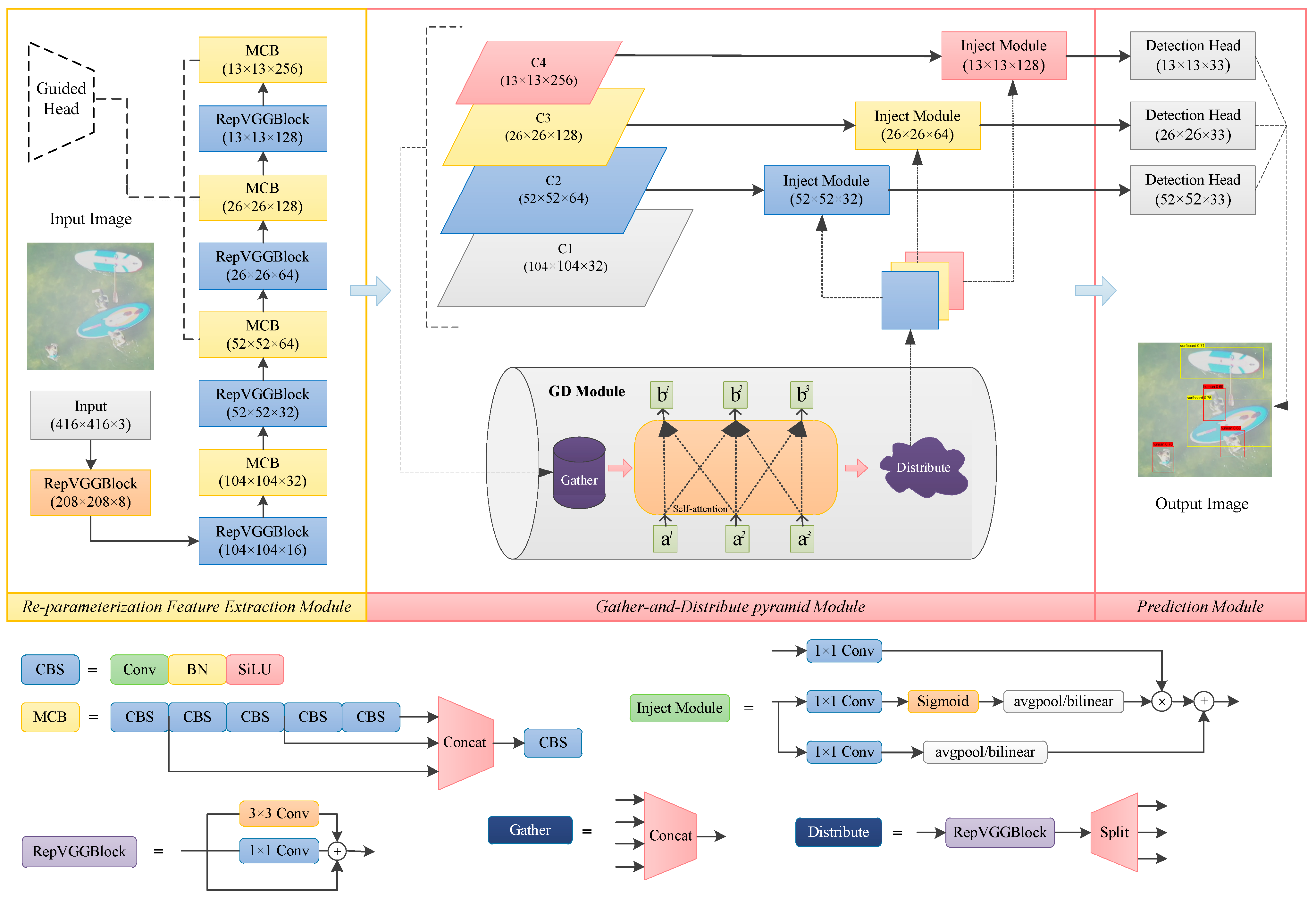
3.1. Overall Framework
3.2. Lightweight Re-Parameterized Feature Extraction Module
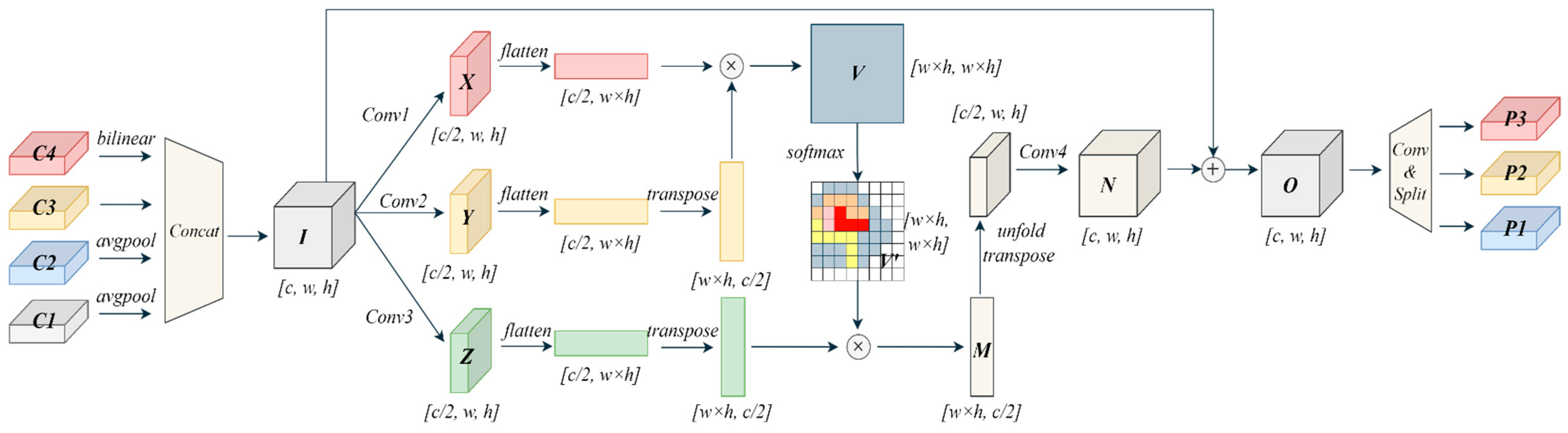
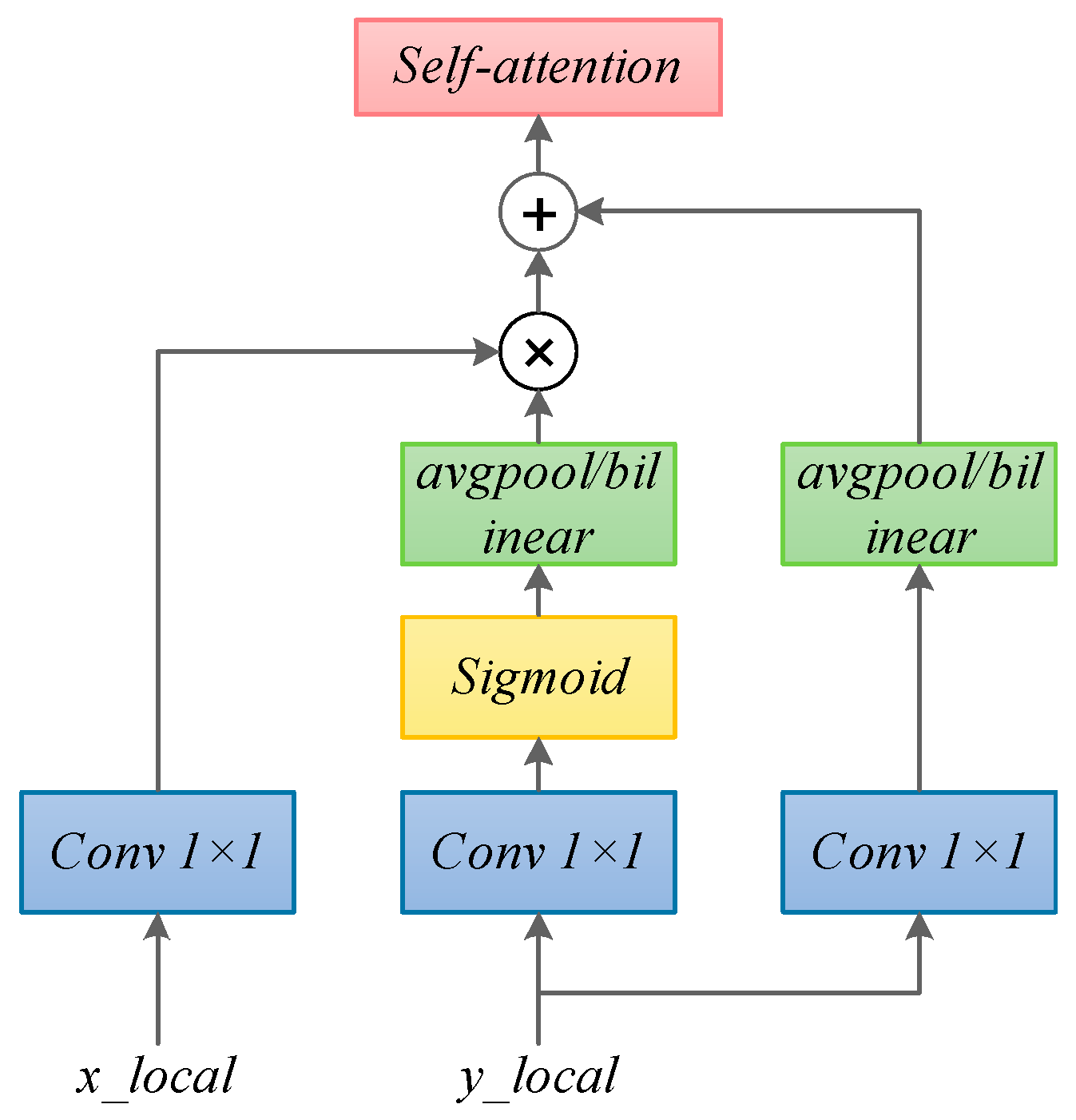
3.3. Cross-Scale Gather-and-Distribute Pyramid Module
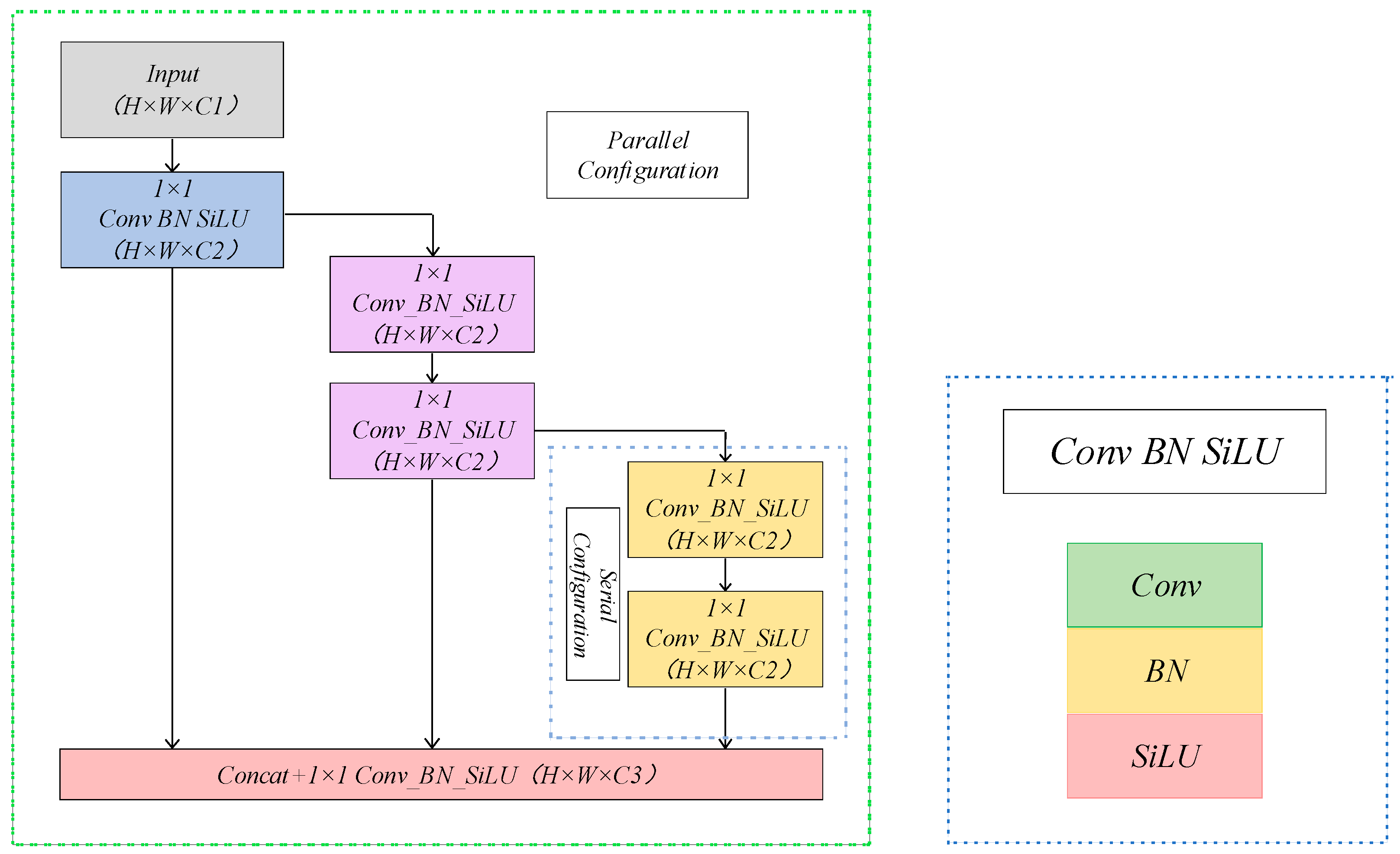
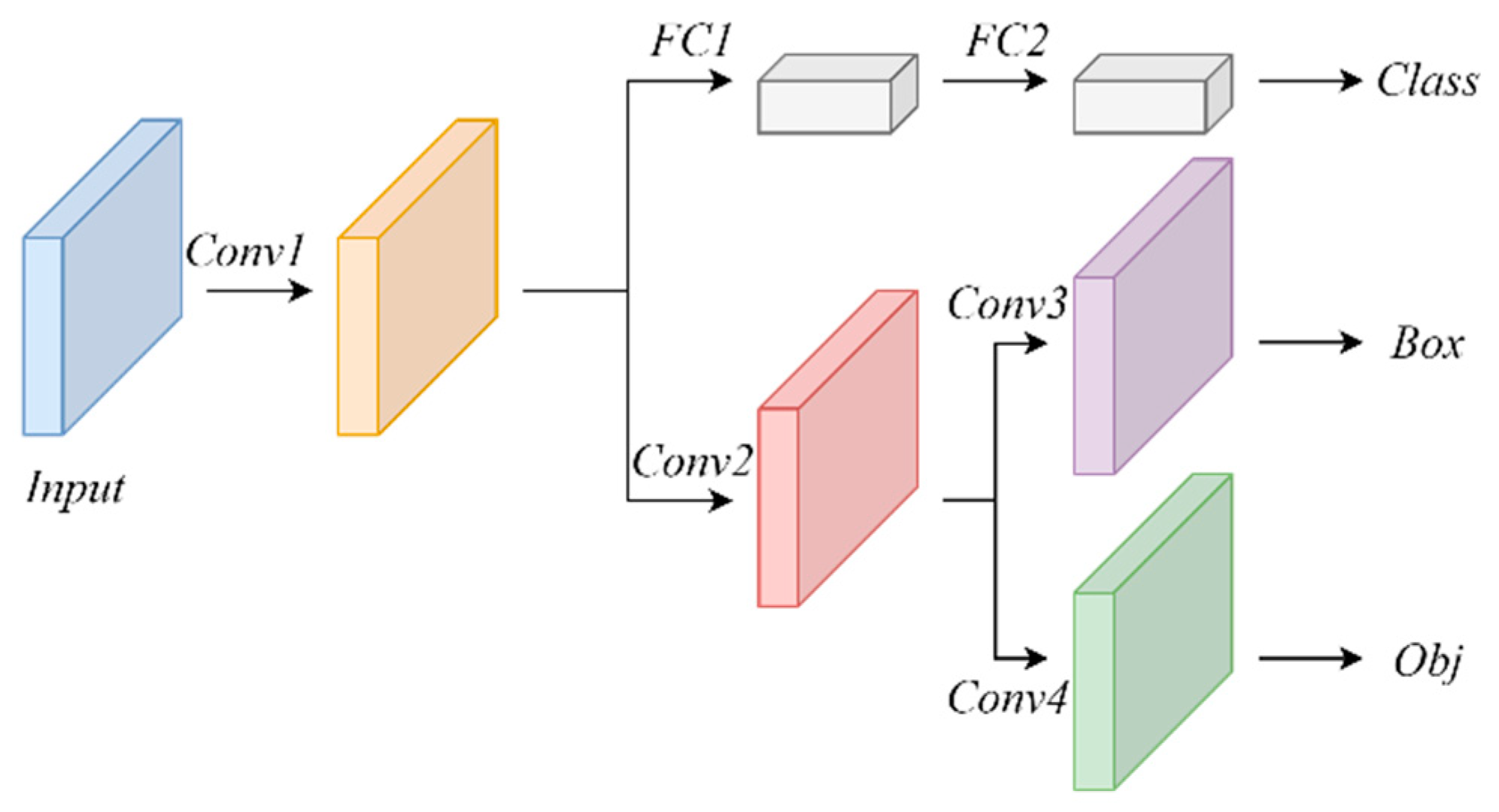
3.4. Decoupled Prediction Module with Three Branches
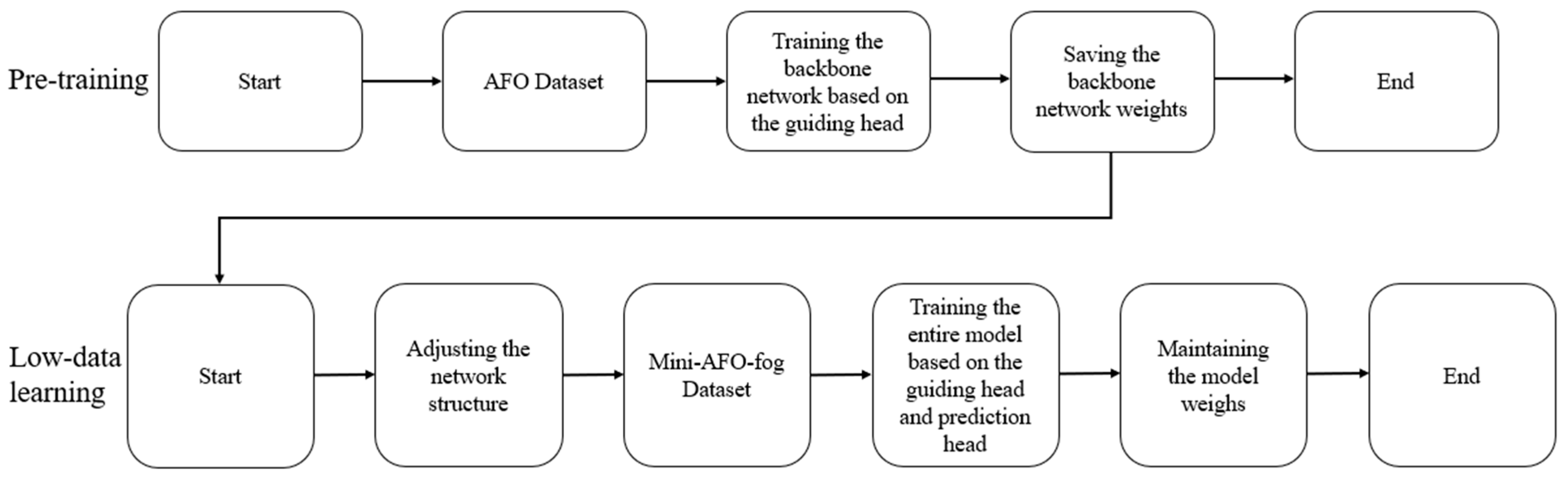
3.5. Domain-Adaptive Training Strategy with Knowledge Transfer and Feature Alignment
- (1)
- Pre-training on the source dataset and general knowledge extraction: The backbone of the low-data object detection model GD-Det with three branches is initially trained on the large-scale dataset AFO using a guide head on knowledge extraction to mine the general features of the source domain. The resulting weight parameters are then saved as pre-trained weights.
- (2)
- Joint training on the target domain dataset: The full GD-Det network, including the detection head and guide head, is then jointly trained on the dataset mini-AFO-fog. This step adapts and aligns the general features from the source domain with those of the target domain, resulting in the global weights of the network.
- (3)
- Optimization for inference phase: To minimize computational overhead during the inference phase, the guide head used in training is removed during the inference phase, minimizing the quantity of reference parameters and preserving high detection accuracy.
4. Experiments and Analysis
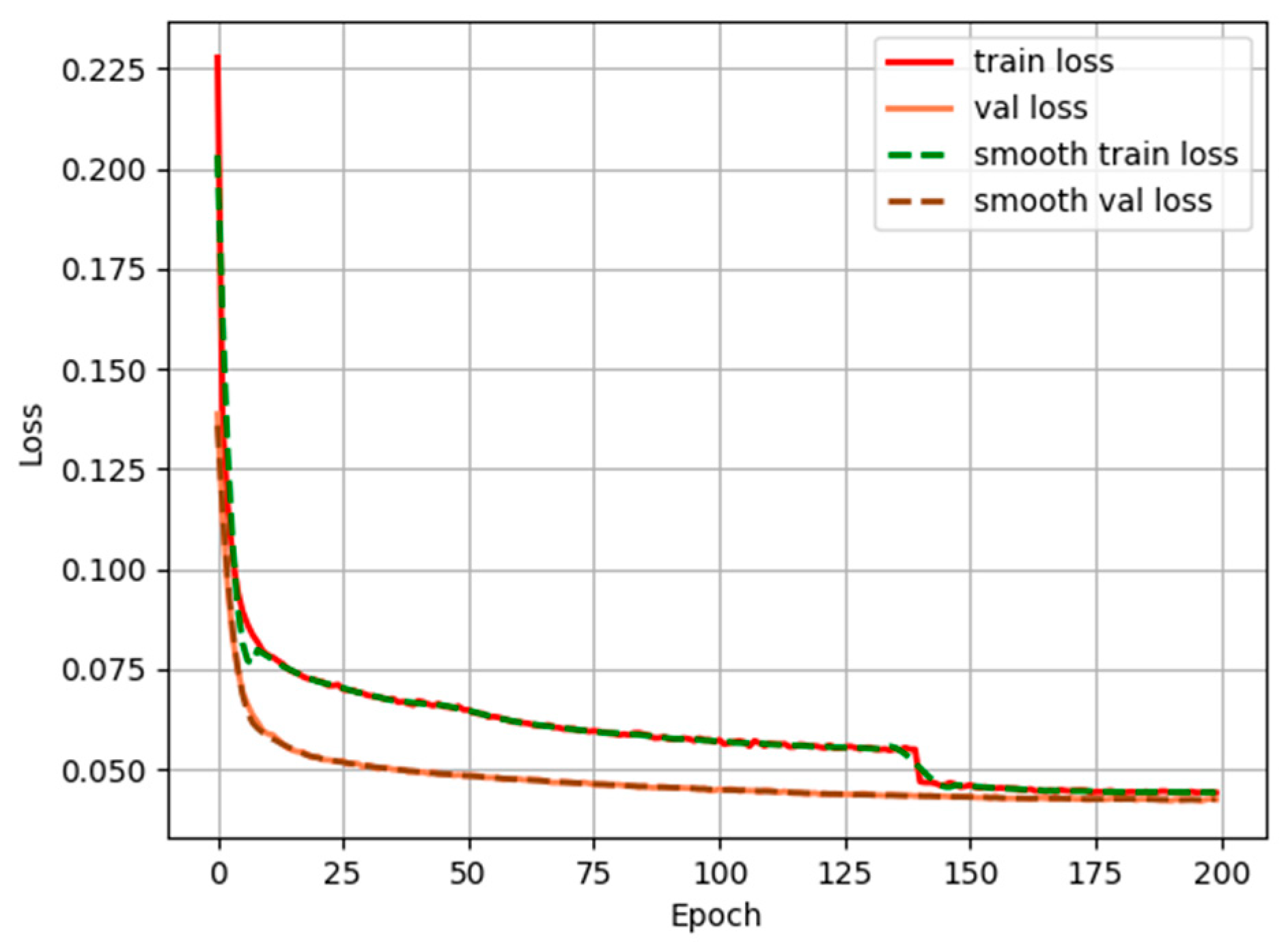
4.1. Model Training
4.2. Dataset
- (1)
- AFO
- (2)
- mini-AFO-fog
4.3. Comparison Experiments
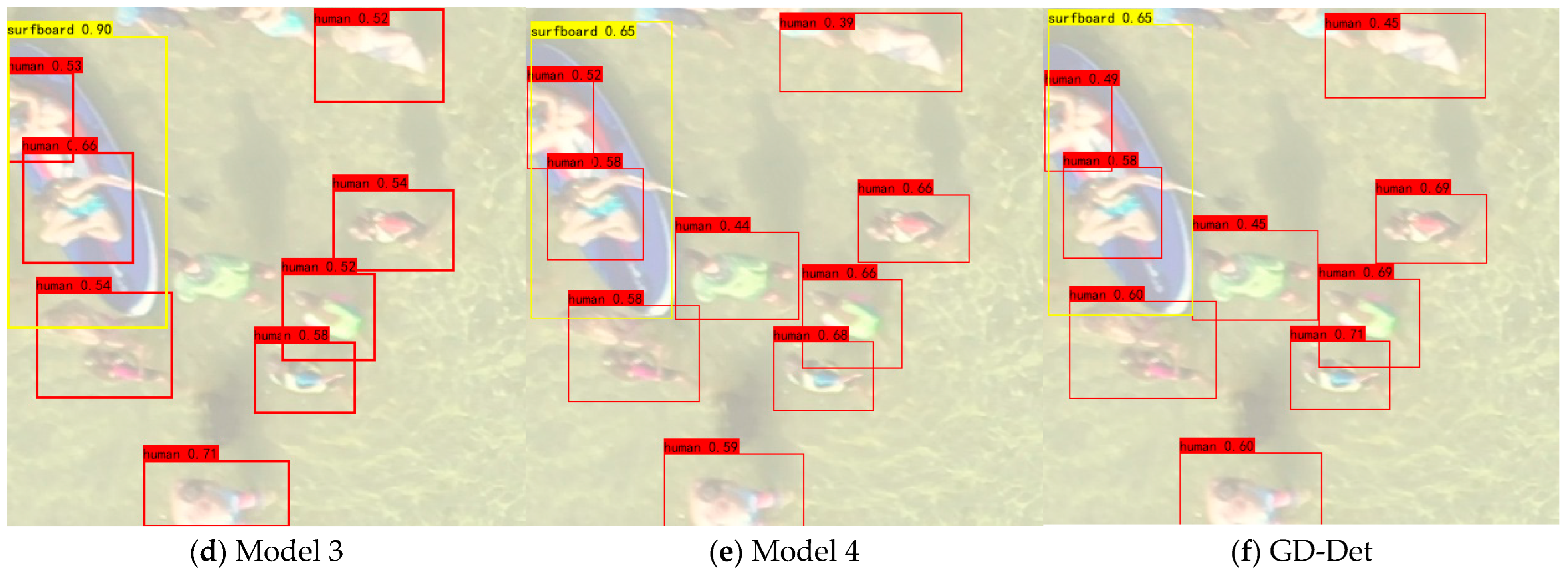
4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Martinez-Esteso, J.; Castellanos, F.; Calvo-Zaragoza, J.; Gallego, A. Maritime Search and Rescue Missions with Aerial Images: A Survey. arXiv 2024, arXiv:2411.07649. [Google Scholar]
- Qiu, T.; Zeng, W.; Chen, C. FFDFA-YOLO: An Enhanced YOLOv8 Model for UAV-Assisted Maritime Rescue Missions. In Proceedings of the 2024 9th International Symposium on Computer and Information Processing Technology (ISCIPT), Xi’an, China, 24–26 May 2024; pp. 60–63. [Google Scholar]
- Kapoor, C.; Warrier, A.; Singh, M.; Narang, P.; Puppala, H.; Rallapalli, S. Fast and lightweight UAV-based road image enhancement under multiple Low-Visibility conditions. In Proceedings of the 2023 IEEE International Conference on Pervasive Computing and Communications (PerCom) Workshops and Other Affiliated Events, Atlanta, GA, USA, 13–17 March 2023; pp. 154–159. [Google Scholar]
- Duan, R.; Wu, B.; Zhou, H.; Zhou, H.; He, Z.; Xiao, Z.; Fu, C. E3-Net: Event-Guided Edge-Enhancement Network for UAV-based Crack Detection. In Proceedings of the 2024 International Conference on Advanced Robotics and Mechatronics (ICARM), Tokyo, Japan, 6–8 July 2024; pp. 272–277. [Google Scholar]
- Zhao, C.; Liu, R.; Qu, J.; Gao, R. Deep learning-based object detection in maritime unmanned aerial vehicle imagery: Review and experimental comparisons. Eng. Appl. Artif. Intell. 2024, 128, 107513. [Google Scholar] [CrossRef]
- Liu, H.; Galindo, M.; Xie, H.; Wong, L.; Shuai, H.; Li, Y.; Cheng, W. Lightweight Deep Learning for Resource-Constrained Environments: A Survey. ACM Comput. Surv. 2024, 56, 1–42. [Google Scholar] [CrossRef]
- Liang, J.; Wu, Y.; Qin, Y.; Wang, H.; Li, X.; Peng, Y.; Xie, X. CPDet: Circle-Permutation-Aware Object Detection for Heat Exchanger Cleaning. Appl. Sci. 2024, 14, 9115. [Google Scholar] [CrossRef]
- Wang, S.; Chen, D.; Xiang, J.; Zhang, C. A Deep-Learning-Based Detection Method for Small Target Tomato Pests in Insect Traps. Agronomy 2024, 14, 2887. [Google Scholar] [CrossRef]
- Du, L.; Zhang, R.; Wang, X. Overview of two-stage object detection algorithms. J. Phys. Conf. Ser. 2020, 1544, 012033. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9259–9266. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, VA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Shi, J. Foveabox: Beyond anchor-based object detector. arXiv 2019, arXiv:1904.0379729. [Google Scholar]
- Bousetouane, F.; Morris, B. Fast CNN surveillance pipeline for fine-grained vessel classification and detection in maritime scenarios. In Proceedings of the 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 242–248. [Google Scholar]
- Yang, Y.; Chen, T.; Zhou, G. Domain Adaptive Multitask Model for Object Detection in Foggy Weather Conditions. In Proceedings of the 2023 China Automation Congress (CAC), Chongqing, China, 17–19 November 2023; pp. 7280–7285. [Google Scholar]
- Ma, J.; Lin, M.; Zhou, G.; Jia, Z. Joint Image Restoration For Domain Adaptive Object Detection In Foggy Weather Condition. In Proceedings of the International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 27–30 October 2024; pp. 542–548. [Google Scholar]
- Zhang, L.; Zhang, N.; Shi, R.; Wang, G.; Xu, Y.; Chen, Z. Sg-det: Shuffle-ghostnetbased detector for real-time maritime object detection in uav images. Remote Sens. 2023, 15, 3365. [Google Scholar] [CrossRef]
- Yue, T.; Yang, Y.; Niu, J.M. A Light-weight Ship Detection and Recognition Method Based on YOLOv4. In Proceedings of the 2021 4th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), Changsha, China, 26–28 March 2021; pp. 661–670. [Google Scholar]
- Kozlov, A.; Andronov, V.; Gritsenko, Y. Lightweight network architecture for real-time action recognition. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3 April 2020; pp. 2074–2080. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Hajishirziet, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the european conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 552–568. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zheng, M.; Sun, L.; Dong, J.; Pan, J. SMFANet: A Lightweight Self-Modulation Feature Aggregation Network for Efficient Image Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024; pp. 359–375. [Google Scholar]
- Potje, G.; Cadar, F.; Araujo, A.; Martins, R.; Nascimento, E. XFeat: Accelerated Features for Lightweight Image Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 2682–2691. [Google Scholar]
- Zhang, H.; Gong, Y.; Yao, F.; Zhang, H. Research on real-time detection algorithm for pedestrian and vehicle in foggy weather based on lightweight XM-YOLOViT. IEEE Access 2024, 12, 7864–7883. [Google Scholar] [CrossRef]
- Hou, W.; Cui, K.; Yan, J.; Chang, J. Lightweight Foggy Weather Detection Algorithm Based on YOLOv5. In Proceedings of the 2024 4th International Conference on Machine Learning and Intelligent Systems Engineering (MLISE), Zhuhai, China, 28–30 June 2024; pp. 338–341. [Google Scholar]
- Zhang, L.; Xu, M.; Wang, G.; Shi, R.; Xu, Y.; Yan, R. SiameseNet Based Fine-Grained Semantic Change Detection for High Resolution Remote Sensing Images. Remote Sens. 2023, 15, 5631. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021; pp. 10886–10895. [Google Scholar]
- Kang, M.; Ting, C.; Ting, F. RCS-YOLO: A fast and high-accuracy object detector for brain tumor detection. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; pp. 600–610. [Google Scholar]
- Zhang, Z.; Dong, Z.; Xu, W.; Han, J. Re-Parameterization of Lightweight Transformer for On-Device Speech Emotion Recognition. IEEE Internet Things J. 2024. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar] [CrossRef]
- Deng, X.; Mao, Y.; Deng, D. Deep Convolutional Neural Network Algorithm Based on Im2Col and Non-Local Mean Filter. In Proceedings of the 2023 4th International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT), Nanjing, China, 16–18 June 2023; pp. 6–10. [Google Scholar]
- Gasienica-Jozkowy, J.; Knapik, M.; Cyganek, B. An ensemble deep learning method with optimized weights for drone-based water rescue and surveillance. Integr. Comput.-Aided Eng. 2021, 28, 221–235. [Google Scholar] [CrossRef]
- Zhang, N.; Zhang, L.; Cheng, Z. Towards simulating foggy and hazy images and evaluating their authenticity. In Proceedings of the Neural Information Processing: 24th International Conference (ICONIP), Guangzhou, China, 14–18 November 2017; pp. 405–415. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Specific Information |
|---|---|
| Input Size | 416 × 416 |
| batch-size | 16 |
| epoch | 200 |
| lr | 0.01 |
| lr decay | cos |
| optimizer | sgd |
| weight decay | 0.0005 |
| momentum | 0.937 |
| Object Categories | Sample Size |
|---|---|
| Human | 1249 |
| Surfboard | 631 |
| Boat | 566 |
| Buoy | 530 |
| Sailboat | 507 |
| Kayak | 628 |
| Model | mAP | mAP@0.5 | mAP@0.9 | FPS | GFLOPs | Param | Precision | Recall |
|---|---|---|---|---|---|---|---|---|
| YOLOv5-s | 79.7% | 85.0% | 74.4% | 27.2 | 6.7 G | 7.0 M | 85.3 | 88.1 |
| YOLOv7-tiny | 83.2% | 88.0% | 80.5% | 35.2 | 5.5 G | 6.0 M | 80.9 | 78.1 |
| YOLOX-tiny | 80.9% | 85.5% | 75.7% | 38.0 | 6.4 G | 5.0 M | 63.4 | 59.8 |
| YOLOv8-s | 84.7% | 89.0% | 80.6% | 33.4 | 11.6 G | 11.1 M | 87.1 | 92.3 |
| EfficientDet | 83.0% | 87.5% | 78.1% | 19.2 | 4.6 G | 3.8 M | 90.2 | 89.8 |
| NanoDet | 77.6% | 82.5% | 70.4% | 42.1 | 2.4 G | 2.0 M | 83.0 | 81.9 |
| RetinaNet | 83.8% | 87.6% | 79.4% | 37.8 | 4.8 G | 15 M | 80.1 | 79.5 |
| GD-Det | 84.8% | 89.2% | 82.9% | 36.5 | 3.7 G | 3.2 M | 92.2 | 94.1 |
| Model | RepVGG | MCB | Gather Distribute | Decoupled Head | Guided Head | mAP | FPS | GFLOPs | Param |
|---|---|---|---|---|---|---|---|---|---|
| Model 1 | ✓ | 65.0% | 27.3 | 1.1 G | 0.8 M | ||||
| Model 2 | ✓ | ✓ | 70.2% | 31.9 | 1.3 G | 1.0 M | |||
| Model 3 | ✓ | ✓ | ✓ | 80.2% | 31.8 | 3.3 G | 2.9 M | ||
| Model 4 | ✓ | ✓ | ✓ | ✓ | 82.5% | 36.2 | 3.7 G | 3.2 M | |
| GD-Det | ✓ | ✓ | ✓ | ✓ | ✓ | 84.8% | 36.5 | 3.7 G | 3.2 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, R.; Zhang, L.; Wang, G.; Jia, S.; Zhang, N.; Wang, C. GD-Det: Low-Data Object Detection in Foggy Scenarios for Unmanned Aerial Vehicle Imagery Using Re-Parameterization and Cross-Scale Gather-and-Distribute Mechanisms. Remote Sens. 2025, 17, 783. https://doi.org/10.3390/rs17050783
Shi R, Zhang L, Wang G, Jia S, Zhang N, Wang C. GD-Det: Low-Data Object Detection in Foggy Scenarios for Unmanned Aerial Vehicle Imagery Using Re-Parameterization and Cross-Scale Gather-and-Distribute Mechanisms. Remote Sensing. 2025; 17(5):783. https://doi.org/10.3390/rs17050783
Chicago/Turabian StyleShi, Rui, Lili Zhang, Gaoxu Wang, Shutong Jia, Ning Zhang, and Chensu Wang. 2025. "GD-Det: Low-Data Object Detection in Foggy Scenarios for Unmanned Aerial Vehicle Imagery Using Re-Parameterization and Cross-Scale Gather-and-Distribute Mechanisms" Remote Sensing 17, no. 5: 783. https://doi.org/10.3390/rs17050783
APA StyleShi, R., Zhang, L., Wang, G., Jia, S., Zhang, N., & Wang, C. (2025). GD-Det: Low-Data Object Detection in Foggy Scenarios for Unmanned Aerial Vehicle Imagery Using Re-Parameterization and Cross-Scale Gather-and-Distribute Mechanisms. Remote Sensing, 17(5), 783. https://doi.org/10.3390/rs17050783