


A Multi-Scale Spatio-Temporal Fusion Network for Occluded Small Object Detection in Geiger-Mode Avalanche Photodiode LiDAR Systems

Abstract
1. Introduction
- An MSTOD-Net designed for small and occluded objects has been developed to fully extract the spatial and temporal information from input data and utilizes a dual-channel structure to associate effective features between intensity and range images.
- Considering the differences in the data characteristics between intensity and range images, the FF module and the MSCA module are designed to fuse multi-scale effective features. This approach enables the mapping of data with differing characteristics into a unified semantic space, thereby facilitating comprehensive feature interaction.
- Given the lack of detailed information in the small object data acquired from the Gm-APD LiDAR system, we designed the EDGP module to enhance the edge perception, enabling the network to focus on more useful object edge information.
- Our proposed MSTOD-Net is evaluated on the established Gm-APD LiDAR dataset. Compared to other state-of-the-art object detection algorithms, our method demonstrates a superior performance and achieves an improved object detection precision.
2. Related Work
2.1. Small Object Detection
2.2. Occluded Object Detection
3. Methodology
3.1. The Overall Architecture
3.2. The Backbone Network
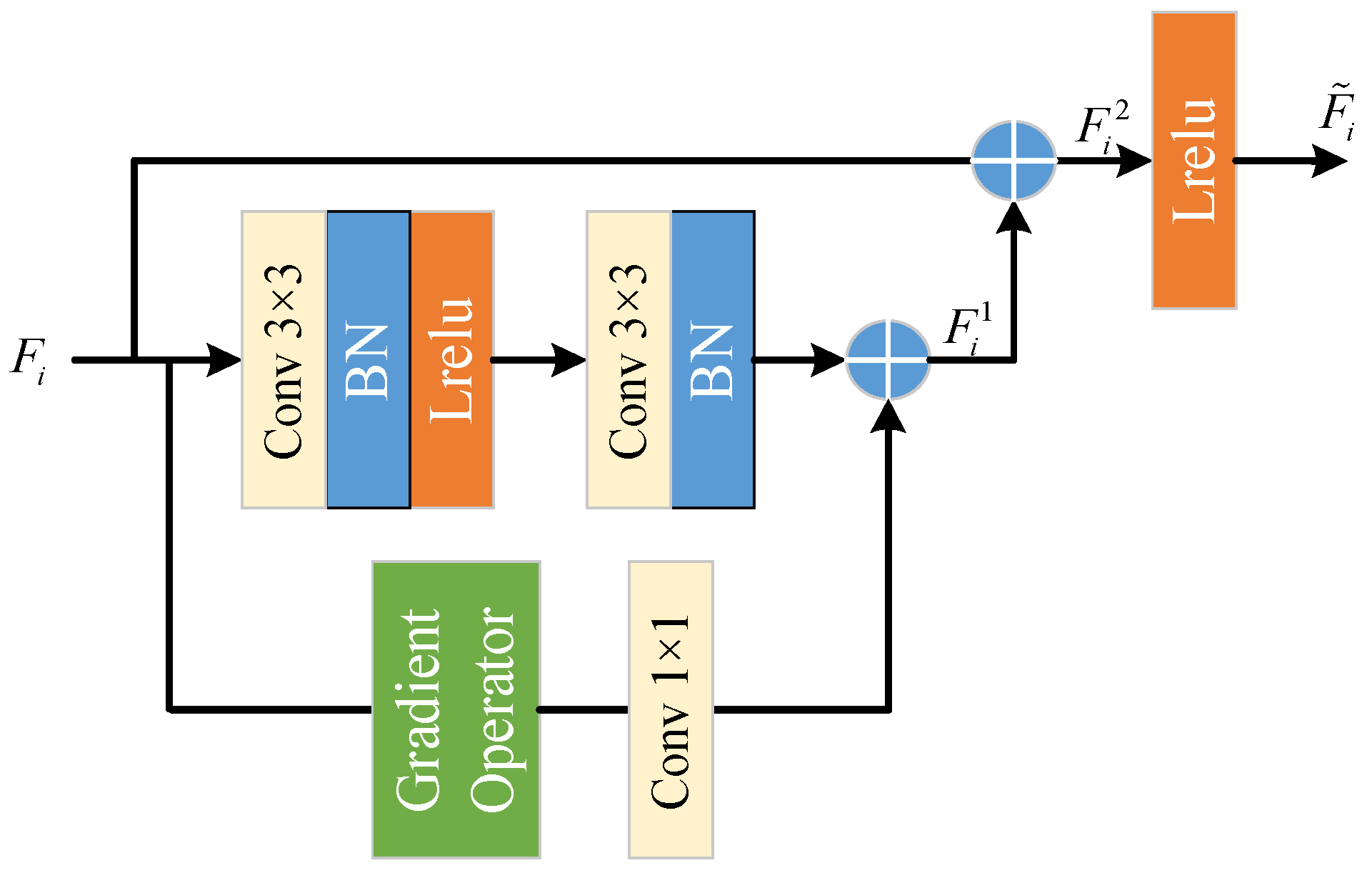
3.3. The EDGP Module
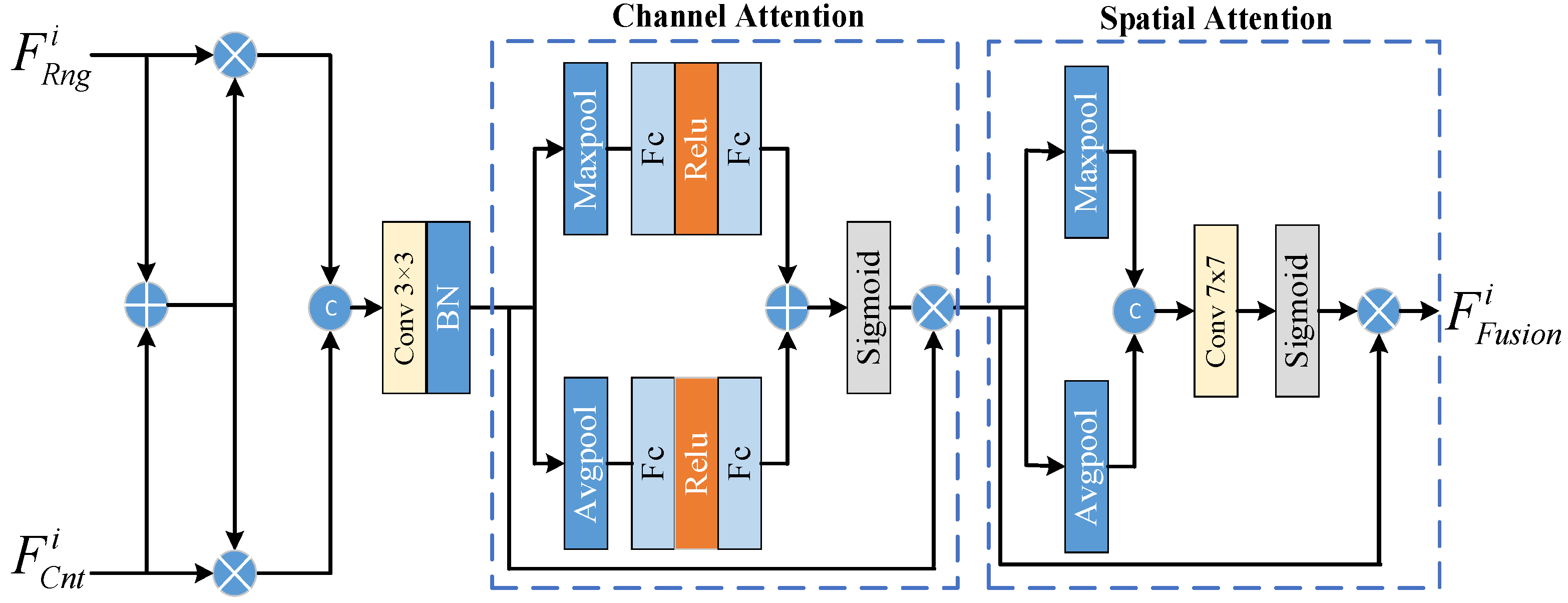
3.4. The FF Module
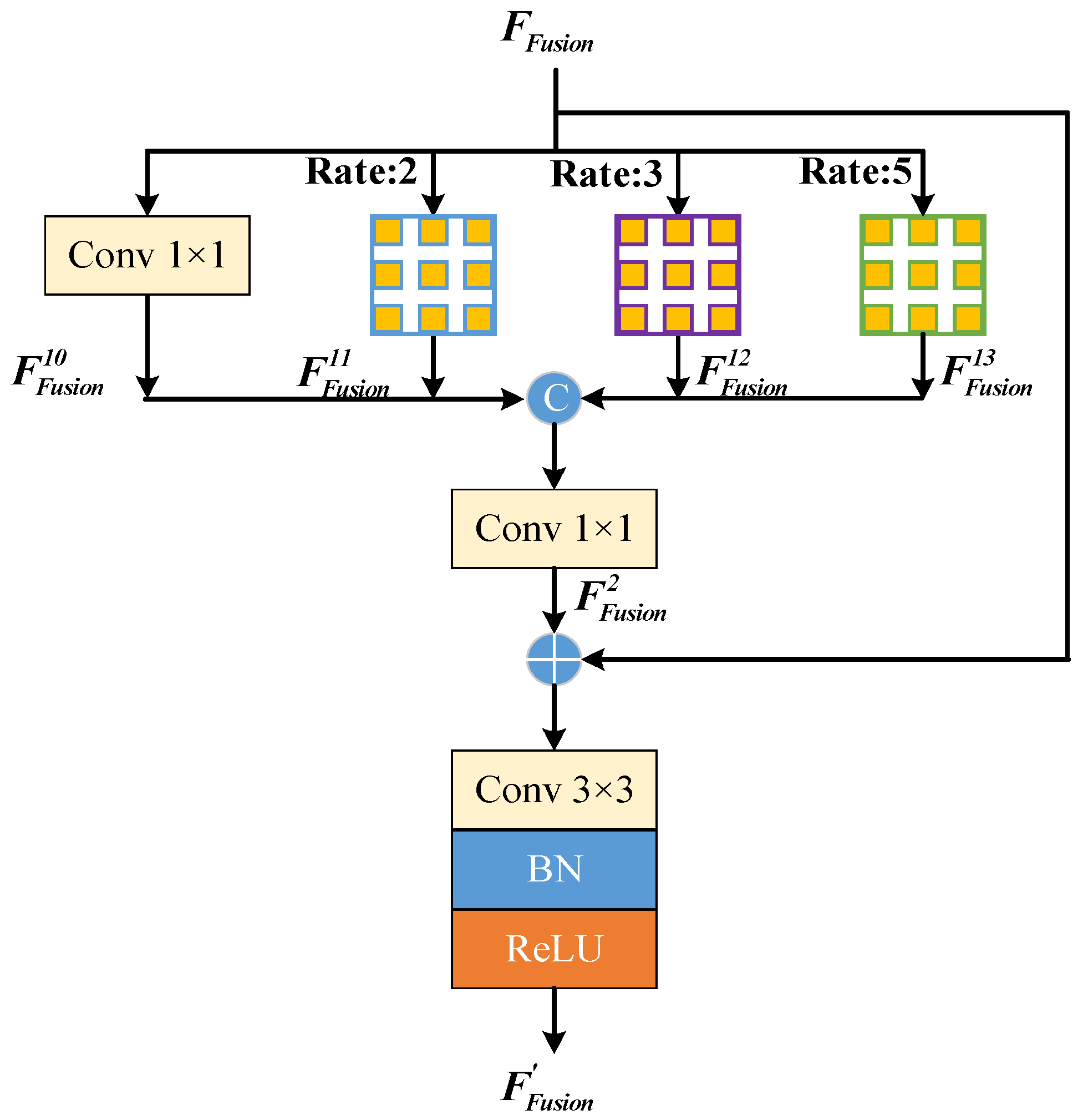
3.5. The MSCA Module
3.6. The Loss Function
- is the object center point loss;
- is the object size loss;
- is the center point offset loss;
- is the object displacement loss.
4. The Experiment
4.1. Dataset Acquisition and Implementation Details
4.1.1. Dataset Acquisition
4.1.2. Implementation Details
4.2. Evaluation Indexes
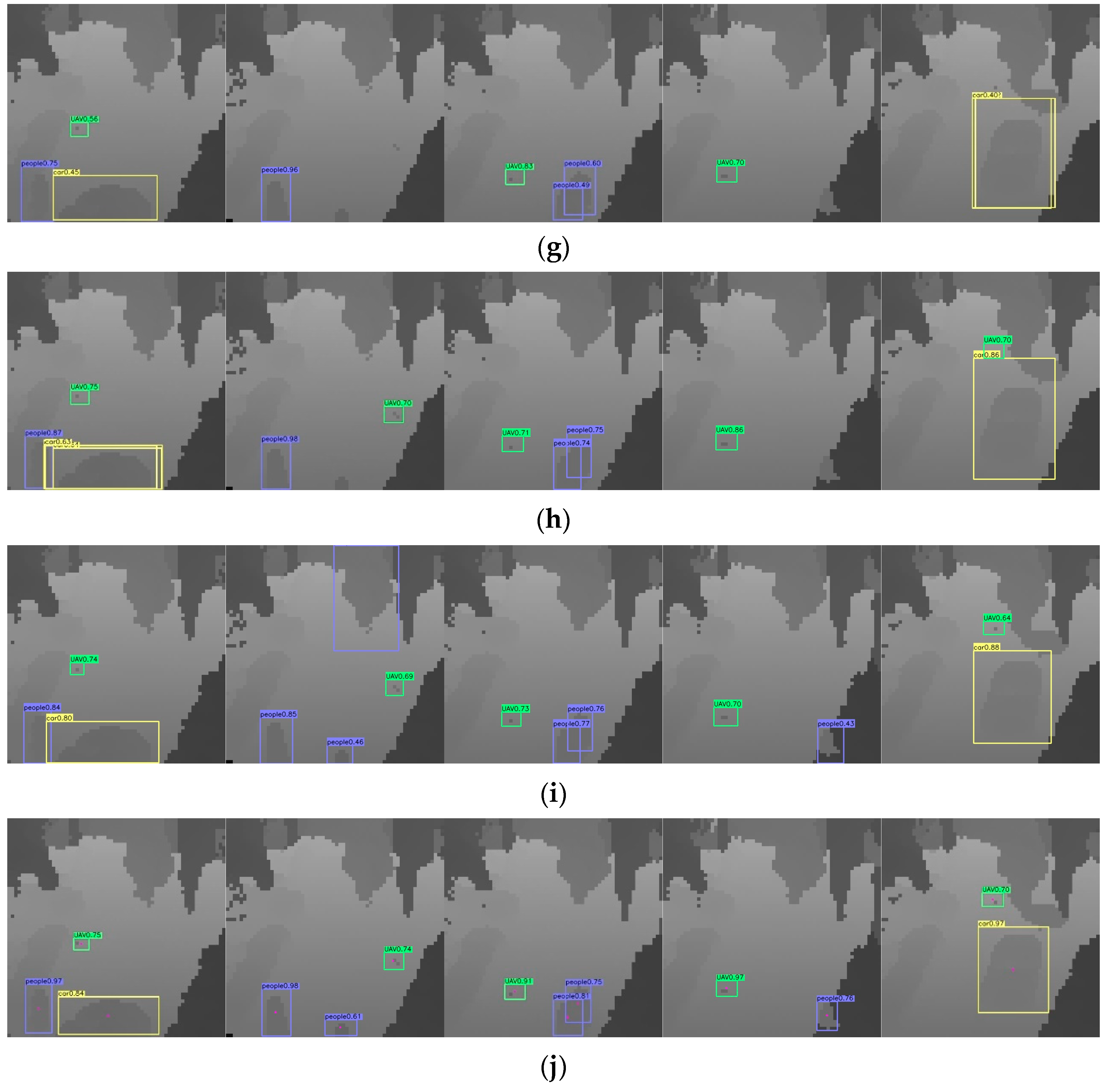
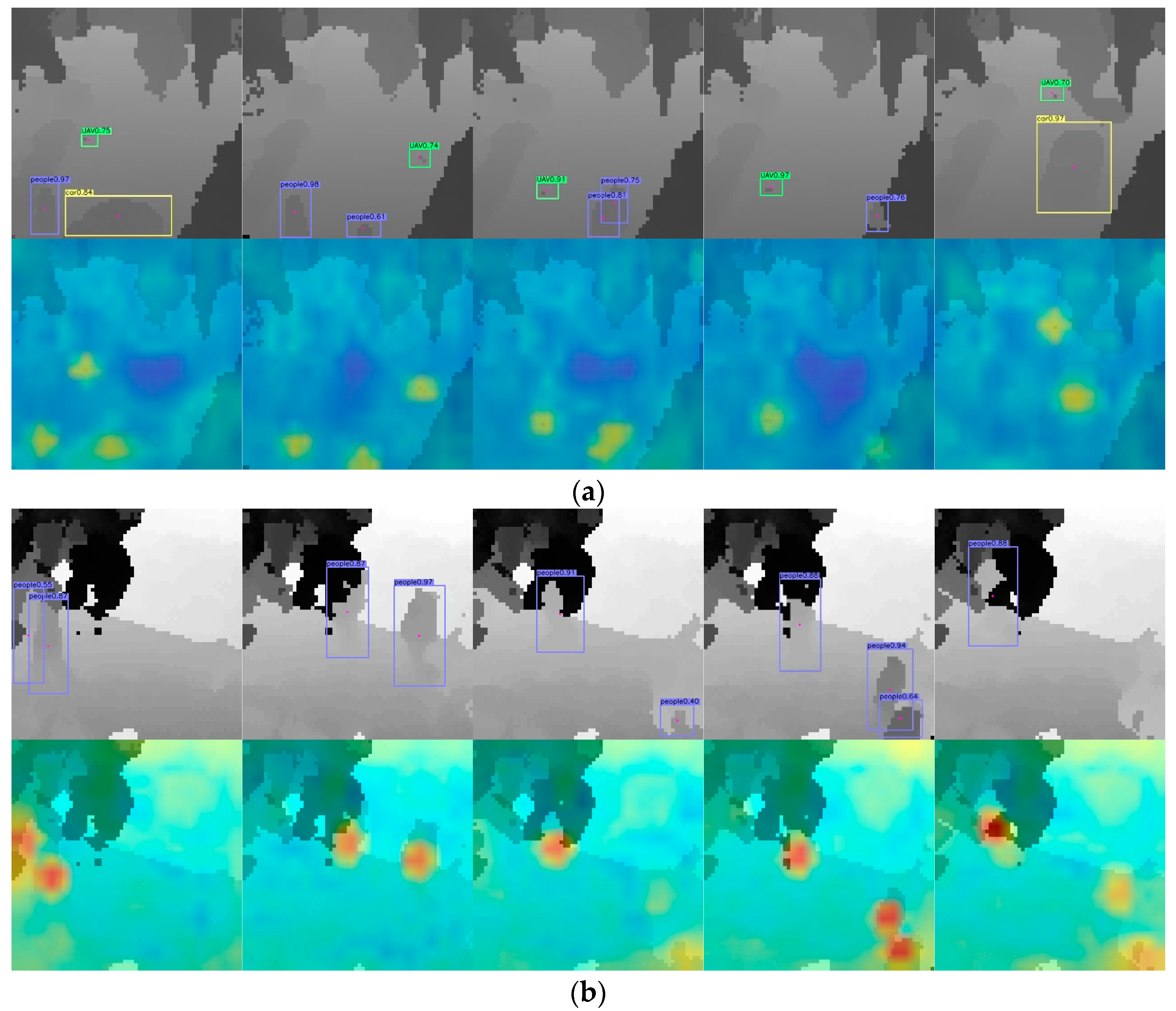
4.3. The Detection Results for Different Methods
4.4. Ablation Experiments
4.4.1. Analysis of the Different Modules
- Analysis of the CFAPF Module
- 2.
- Analysis of the FF module
- 3.
- Analysis of the EDGP module
- 4.
- Analysis of the MSCA module
4.4.2. Analysis of Different Backbone Networks
4.4.3. Analysis of Data with Different Occlusion Ratios
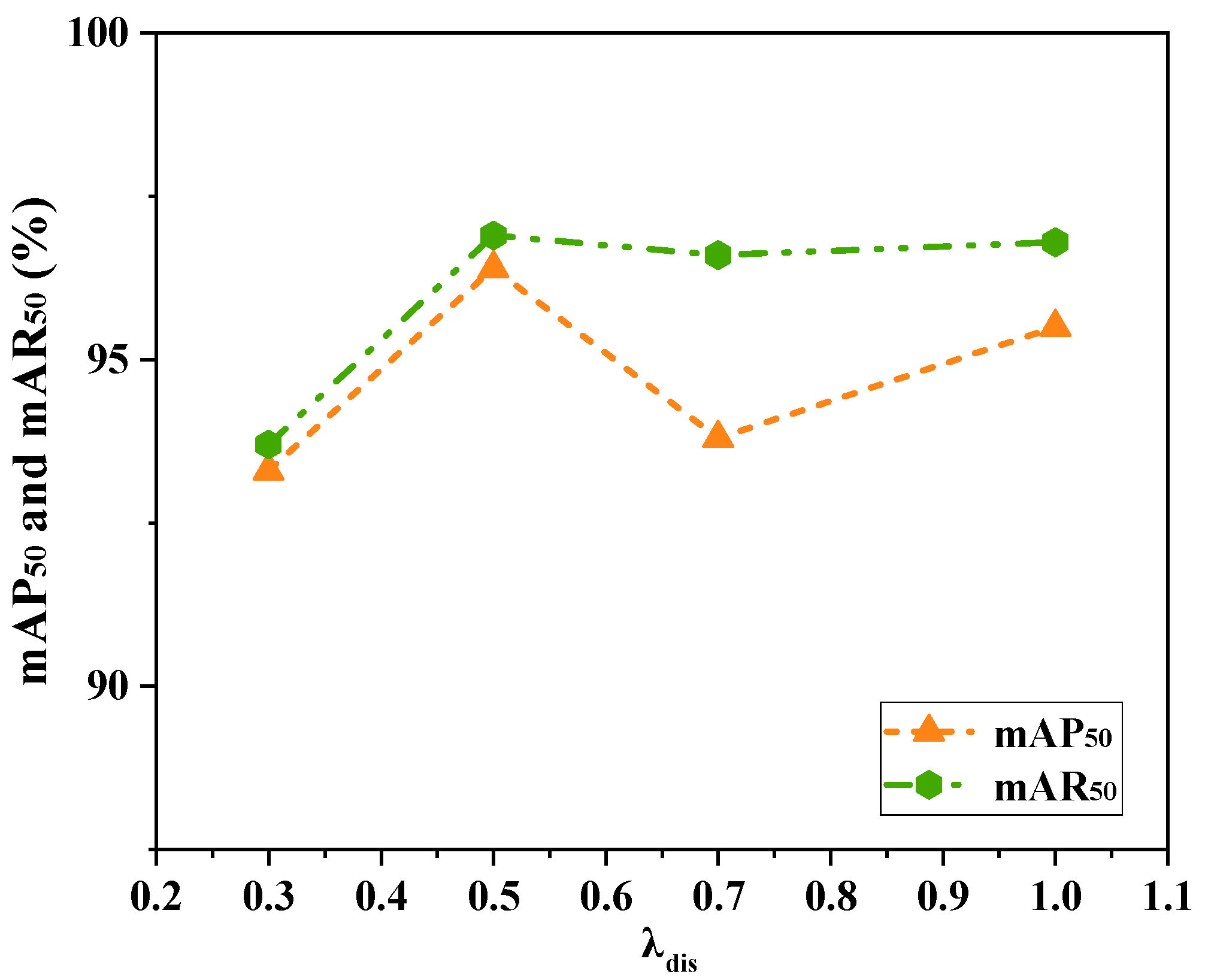
4.4.4. Analysis of Different λ Values in Loss Functions
4.4.5. Analysis of Bidirectional Scene Generalization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, S.; Chen, P.; Ding, L.; Pan, D. A New Semi-Analytical MC Model for Oceanic LIDAR Inelastic Signals. Remote Sens. 2023, 15, 684. [Google Scholar] [CrossRef]
- Jiang, J. Moving object detection algorithm and motion capture based on 3D LiDAR. Opt. Quantum Electron. 2024, 56, 585. [Google Scholar] [CrossRef]
- Cho, Y.; Kim, G.; Lee, S.; Ryu, J.-H. OpenStreetMap-Based LiDAR Global Localization in Urban Environment Without a Prior LiDAR Map. IEEE Robot. Autom. Lett. 2022, 7, 4999–5006. [Google Scholar] [CrossRef]
- Zha, B.; Xu, G.; Chen, Z.; Tan, Y.; Qin, J.; Zhang, H. Design of Scanning Units for the Underwater Circumferential-Scanning LiDAR Based on Pyramidal-Shaped Reflectors and a Rapid Detection Method for Object Orientation. Remote Sens. 2024, 16, 2131. [Google Scholar] [CrossRef]
- Xu, W.; Cai, Y.; He, D.; Lin, J.; Zhang, F. FAST-LIO2: Fast Direct LiDAR-Inertial Odometry. IEEE Trans. Robot. 2022, 38, 2053–2073. [Google Scholar] [CrossRef]
- Zhang, X.; Li, S.; Sun, J.; Ma, L.; Zhou, X.; Yang, X.; He, R. Dynamic object feature selection in pixel change space for array GM-APD lidar. Infrared Phys. Technol. 2024, 140, 105396. [Google Scholar] [CrossRef]
- Liu, D.; Sun, J.; Lu, W.; Li, S.; Zhou, X. 3D reconstruction of the dynamic scene with high-speed objects for GM-APD LiDAR. Opt. Laser Technol. 2023, 161, 109114. [Google Scholar] [CrossRef]
- Tao, B.; Yan, F.; Yin, Z.; Nie, L.; Miao, M.; Jiao, Y.; Lei, C. A Multimodal 3D Detector with Attention from the Corresponding Modal. IEEE Sens. J. 2023, 23, 8581–8590. [Google Scholar] [CrossRef]
- Xu, C.; Wang, J.; Yang, W.; Yu, H.; Yu, L.; Xia, G.S. RFLA: Gaussian Receptive Field Based Label Assignment for Tiny Object Detection. Eur. Conf. Comput. Vis. 2022, 13669, 526–543. [Google Scholar]
- Ma, R.; Yin, Y.; Chen, J.; Chang, R. Multi-modal information fusion for LiDAR-based 3D object detection framework. Multimed Tools Appl. 2024, 83, 7995–8012. [Google Scholar] [CrossRef]
- Hong, M.; Li, S.; Yang, Y.; Zhu, F.; Zhao, Q.; Lu, L. SSPNet: Scale Selection Pyramid Network for Tiny Person Detection from UAV Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. Comput. Vis. Pattern Recognit. 2018, 1804, 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 12 April 2021).
- Leng, J.; Liu, Y.; Gao, X.; Wang, Z. CRNet: Context-guided Reasoning Network for Detecting Hard Objects. IEEE Trans. Multimed. 2024, 26, 3765–3777. [Google Scholar] [CrossRef]
- Liu, W.; Zhou, B.; Wang, Z.; Yu, G.; Yang, S. FPPNet: A Fixed-Perspective-Perception Module for Small Object Detection Based on Background Difference. IEEE Sens. J. 2023, 23, 11057–11069. [Google Scholar] [CrossRef]
- Wang, F.; Yang, X.; Wei, J. YOLO-ESL: An Enhanced Pedestrian Recognition Network Based on YOLO. Appl. Sci. 2024, 14, 9588. [Google Scholar] [CrossRef]
- Han, Y.; Wang, F.; Wang, W.; Li, X.; Zhang, J. YOLO-SG: Small traffic signs detection method in complex scene. J. Supercomput. 2024, 80, 2025–2046. [Google Scholar] [CrossRef]
- Zhou, L.; Xu, J. Enhanced Abandoned Object Detection through Adaptive Dual-Background Modeling and SAO-YOLO Integration. Sensors 2024, 24, 6572. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A Critical Feature Capturing Network for Arbitrary-Oriented Object Detection in Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In European Conference Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2019, 128, 642–656. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 January 2023).
- Feng, J.; Liang, Y.; Zhang, X.; Zhang, J.; Jiao, L. SDANet: Semantic-Embedded Density Adaptive Network for Moving Vehicle Detection in Satellite Videos. IEEE Trans. Image Process. 2023, 32, 1788–1801. [Google Scholar] [CrossRef]
- Shen, J.; Zhou, W.; Liu, N.; Sun, H.; Li, D.; Zhang, Y. An Anchor-Free Lightweight Deep Convolutional Network for Vehicle Detection in Aerial Images. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24330–24342. [Google Scholar] [CrossRef]
- Yi, C.; Zhao, Y.-Q.; Chan, J.C.-W. Spectral super-resolution for multispectral image based on spectral improvement strategy and spatial preservation strategy. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9010–9024. [Google Scholar] [CrossRef]
- Yu, L.; Zhi, X.; Hu, J.; Jiang, S.; Zhang, W.; Chen, W. Small-Sized Vehicle Detection in Remote Sensing Image Based on Keypoint Detection. Remote Sens. 2021, 13, 4442. [Google Scholar] [CrossRef]
- Wang, M.; Ma, H.; Liu, S.; Yang, Z. A novel small-scale pedestrian detection method base on residual block group of CenterNet. Comput. Stand. Interfaces 2023, 84, 103702. [Google Scholar] [CrossRef]
- Min, L.; Fan, Z.; Lv, Q.; Reda, M.; Shen, L.; Wang, B. YOLO-DCTI: Small Object Detection in Remote Sensing Base on Contextual Transformer Enhancement. Remote Sens. 2023, 15, 3970. [Google Scholar] [CrossRef]
- Cao, X.; Wang, H.; Wang, X.; Hu, B. DFS-DETR: Detailed-Feature-Sensitive Detector for Small Object Detection in Aerial Images Using Transformer. Electronics 2024, 13, 3404. [Google Scholar] [CrossRef]
- Qin, C.; Zhang, L.; Wang, X.; Li, G.; He, Y.; Liu, Y. RDB-DINO: An Improved End-to-End Transformer with Refined De-Noising and Boxes for Small-Scale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–17. [Google Scholar] [CrossRef]
- Palffy, A.; Kooij, J.F.P.; Gavrila, D.M. Detecting darting out pedestrians with occlusion aware sensor fusion of radar and stereo camera. IEEE Trans. Intell. Veh. 2023, 8, 1459–1472. [Google Scholar] [CrossRef]
- Li, Q.; Su, Y.; Gao, Y.; Xie, F.; Li, J. OAF-Net: An Occlusion-Aware Anchor-Free Network for Pedestrian Detection in a Crowd. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21291–21300. [Google Scholar] [CrossRef]
- Bao, H.; Shu, P.; Zhang, H.; Liu, X. Siamese-based twin attention network for visual tracking. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 847–860. [Google Scholar] [CrossRef]
- Nie, Y.; Bian, C.; Li, L. Object Tracking in Satellite Videos Based on Siamese Network with Multidimensional Information-Aware and Temporal Motion Compensation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, T.; Han, Z.; Xu, H.; Zhang, B.; Ye, Q. CircleNet: Reciprocating Feature Adaptation for Robust Pedestrian Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4593–4604. [Google Scholar] [CrossRef]
- Cui, K.; Tang, W.; Zhu, R.; Wang, M.; Larsen, G.D.; Pauca, V.P.; Alqahtani, S.; Yang, F.; Segurado, D.; Fine, P.; et al. Real-Time Localization and Bimodal Point Pattern Analysis of Palms Using UAV Imagery would provide valuable insights. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 19–21 June 2024. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Sobel, I.; Feldman, G. A 3x3 isotropic gradient operator for image processing. Pattern Classif. Scene Anal. 1968, 1968, 271–272. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Lin, T.T. LabelImg. Available online: https://github.com/tzutalin/labelImg (accessed on 1 January 2020).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Output Size | Output Channel | Conv Kernel |
|---|---|---|---|
| Conv1 | (256, 256) | 64 | 7 × 7 |
| Maxpooling | (128, 128) | 64 | 3 × 3 |
| EDGP | (128, 128) | 64 | 3 × 3 |
| ResBlock1 | (64, 64) | 128 | 3 × 3 |
| ResBlock2 | (32, 32) | 256 | 3 × 3 |
| ResBlock1 | (16, 16) | 512 | 3 × 3 |
| Scenario 1 | ||||
|---|---|---|---|---|
| Seq collection time | Num of seq frames | Seq collection time | Num of seq frames | |
| Seq 1: 19:03:22 | 250 | Seq 6: 19:07:07 | 250 | |
| Seq 2: 19:04:18 | 250 | Seq 7: 19:07:20 | 250 | |
| Seq 3: 19:05:22 | 250 | Seq 8: 19:07:55 | 250 | |
| Seq 4: 19:05:56 | 250 | Seq 9: 19:08:31 | 250 | |
| Seq 5: 19:06:29 | 250 | Seq 10: 19:09:02 | 250 | |
| Scenario 2 | ||||
| Seq 1: 15:38:59 | 971 | Seq 3: 15:41:30 | 1575 | |
| Seq 2: 15:40:05 | 1278 |
| Method | Backbone | People | UAV | Car | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP50 (%) | AP75 (%) | AP (%) | AP50 (%) | AP75 (%) | AP (%) | AP50 (%) | AP75 (%) | AP (%) | mAP50 (%) | mAR50 (%) | Param s(M) | FLOP s(G) | ||
| Anchor-based | ||||||||||||||
| Faster-RCNN | ResNet50 | 95.8 | 72.9 | 61.1 | 93.7 | 23.6 | 41.3 | 89.8 | 75.0 | 53.8 | 93.1 | 96.0 | 41.75 | 63.58 |
| SSD | VGG16 | 94.4 | 61.3 | 55.1 | 82.7 | 9.3 | 28.9 | 93.2 | 55.5 | 54.2 | 90.1 | 95.8 | 24.01 | 87.83 |
| RetinaNet | ResNet18 | 93.6 | 75.4 | 60.0 | 86.0 | 39.7 | 45.8 | 87.3 | 74.5 | 58.9 | 89.0 | 90.4 | 19.81 | 39.53 |
| YOLOv3 | DarkNet53 | 95.6 | 75.2 | 62.5 | 90.7 | 49.9 | 49.3 | 90.1 | 90.1 | 67.6 | 92.1 | 92.8 | 61.54 | 49.58 |
| YOLOv5 | CSPDarknet53 | 96.2 | 73.4 | 61.7 | 94.5 | 37.7 | 47.3 | 92.0 | 69.0 | 56.8 | 94.2 | 96.1 | 21.20 | 49.00 |
| Anchor-free | ||||||||||||||
| CenterNet | ResNet18 | 92.5 | 74.9 | 61.7 | 93.6 | 39.3 | 48.5 | 75.8 | 89.0 | 57.5 | 91.7 | 92.8 | 19.27 | 39.81 |
| Focs | ResNet18 | 93.6 | 73.4 | 61.1 | 90.9 | 44.6 | 48.8 | 95.3 | 88.4 | 69.5 | 93.3 | 95.5 | 19.10 | 38.86 |
| YOLOX | CSPDarknet53 | 93.6 | 78.1 | 62.4 | 91.0 | 45.7 | 48.8 | 98.5 | 92.9 | 70.7 | 94.4 | 95.4 | 25.30 | 73.80 |
| YOLOv8 | CSPDarknet53 | 93.7 | 78.6 | 63.3 | 91.9 | 38.3 | 46.4 | 98.4 | 92.7 | 71.8 | 94.7 | 95.6 | 25.90 | 78.90 |
| Ours | Modified ResNet | 95.7 | 79.4 | 63.0 | 93.9 | 46.0 | 49.8 | 99.5 | 92.4 | 72.1 | 96.4 | 96.9 | 12.43 | 37.08 |
| Method | CFAPF | FF | EDGP | MSCA | Param | Method | CFAPF | FF | EDGP | MSCA |
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 7.57 | 20.67 | 56.4 | 66.4 | 90.0 | 91.2 | ||||
| 1 | √ | 7.71 | 23.09 | 58.8 | 69.6 | 92.4 | 94.8 | |||
| 2 | √ | √ | 11.31 | 36.75 | 60.2 | 70.3 | 94.7 | 95.7 | ||
| 3 | √ | √ | √ | 11.32 | 36.80 | 61.6 | 70.8 | 95.9 | 96.5 | |
| 4 | √ | √ | √ | √ | 12.43 | 37.08 | 61.7 | 72.6 | 96.4 | 96.9 |
| Backbone | Param s(M) | FLOP s(G) | mAP (%) | mAP75 (%) | mAP50 (%) | mAR50 (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| ResNet18 | 30.59 | 54.94 | 61.0 | 72.7 | 94.8 | 95.3 | 0.03097 |
| ResNet34 | 40.69 | 74.31 | 60.1 | 70.0 | 94.9 | 95.4 | 0.03305 |
| Ours | 12.43 | 37.08 | 61.7 | 72.6 | 96.4 | 96.9 | 0.03091 |
| Method | Light Occlusion (<30%) | Medium Occlusion (30%~70%) | Heavy Occlusion (>70%) | |||
|---|---|---|---|---|---|---|
| mAP50 (%) | mAR50 (%) | mAP50 (%) | mAR50 (%) | mAR50 (%) | mAP50 (%) | |
| Anchor-based | ||||||
| Faster-RCNN | 89.7 | 90.7 | 82.8 | 83.0 | 61.4 | 61.8 |
| SSD | 91.3 | 93.6 | 82.2 | 82.5 | 61.6 | 62.8 |
| RetinaNet | 90.7 | 91.8 | 81.4 | 81.5 | 60.2 | 60.5 |
| YOLOv3 | 92.0 | 93.6 | 84.8 | 85.3 | 62.0 | 62.1 |
| YOLOv5 | 92.8 | 93.8 | 85.3 | 85.8 | 62.3 | 62.4 |
| Anchor-free | ||||||
| CenterNet | 85.4 | 86.6 | 81.7 | 82.1 | 57.1 | 58.2 |
| Focs | 88.6 | 89.7 | 85.0 | 85.3 | 58.4 | 58.8 |
| YOLOX | 91.7 | 92.9 | 85.1 | 85.9 | 63.0 | 63.0 |
| YOLOv8 | 92.5 | 93.6 | 85.6 | 86.0 | 63.2 | 63.5 |
| Ours | 92.9 | 93.8 | 87.8 | 88.6 | 67.3 | 67.6 |
| Method | Backbone | People | |
|---|---|---|---|
| AP50 (%) | AR50 (%) | ||
| Anchor-based | |||
| Faster-RCNN | ResNet50 | 75.6 | 79.7 |
| SSD | VGG16 | 69.8 | 74.7 |
| RetinaNet | ResNet18 | 59.4 | 60.7 |
| YOLOv3 | DarkNet53 | 74.6 | 75.9 |
| YOLOv5 | CSPDarknet53 | 77.0 | 81.2 |
| Anchor-free | |||
| CenterNet | ResNet18 | 65.7 | 66.2 |
| Focs | ResNet18 | 72.7 | 75.1 |
| YOLOX | CSPDarknet53 | 75.8 | 77.1 |
| YOLOv8 | CSPDarknet53 | 78.1 | 82.7 |
| Ours | Modified ResNet | 80.5 | 82.0 |
| Method | Backbone | People | |
|---|---|---|---|
| AP50 (%) | AR50 (%) | ||
| Anchor-based | |||
| Faster-RCNN | ResNet50 | 77.5 | 81.7 |
| SSD | VGG16 | 72.6 | 78.5 |
| RetinaNet | ResNet18 | 65.7 | 66.2 |
| YOLOv3 | DarkNet53 | 77.5 | 78.6 |
| YOLOv5 | CSPDarknet53 | 79.9 | 79.9 |
| Anchor-free | |||
| CenterNet | ResNet18 | 67.4 | 68.2 |
| Focs | ResNet18 | 73.4 | 76.5 |
| YOLOX | CSPDarknet53 | 77.1 | 80.1 |
| YOLOv8 | CSPDarknet53 | 79.1 | 79.9 |
| Ours | Modified ResNet | 82.7 | 84.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Y.; Du, D.; Sun, J.; Ma, L.; Yang, X.; He, R.; Lu, J.; Qu, Y. A Multi-Scale Spatio-Temporal Fusion Network for Occluded Small Object Detection in Geiger-Mode Avalanche Photodiode LiDAR Systems. Remote Sens. 2025, 17, 764. https://doi.org/10.3390/rs17050764
Ding Y, Du D, Sun J, Ma L, Yang X, He R, Lu J, Qu Y. A Multi-Scale Spatio-Temporal Fusion Network for Occluded Small Object Detection in Geiger-Mode Avalanche Photodiode LiDAR Systems. Remote Sensing. 2025; 17(5):764. https://doi.org/10.3390/rs17050764
Chicago/Turabian StyleDing, Yuanxue, Dakuan Du, Jianfeng Sun, Le Ma, Xianhui Yang, Rui He, Jie Lu, and Yanchen Qu. 2025. "A Multi-Scale Spatio-Temporal Fusion Network for Occluded Small Object Detection in Geiger-Mode Avalanche Photodiode LiDAR Systems" Remote Sensing 17, no. 5: 764. https://doi.org/10.3390/rs17050764
APA StyleDing, Y., Du, D., Sun, J., Ma, L., Yang, X., He, R., Lu, J., & Qu, Y. (2025). A Multi-Scale Spatio-Temporal Fusion Network for Occluded Small Object Detection in Geiger-Mode Avalanche Photodiode LiDAR Systems. Remote Sensing, 17(5), 764. https://doi.org/10.3390/rs17050764