


Contrastive Feature Disentanglement via Physical Priors for Underwater Image Enhancement

Abstract
1. Introduction
- We propose a novel unsupervised UIE method leveraging contrastive feature decomposition, offering a new perspective for underwater image enhancement.
- We introduce a unique cross-space and content contrastive loss, facilitating the simultaneous exploration of intra-similarity within latent spaces and inter-exclusiveness between feature spaces.
- Comprehensive experiments are conducted to evaluate the proposed method, demonstrating its outstanding performance both quantitatively and qualitatively.
2. Related Work
2.1. Traditional Methods
2.2. Physical Methods
2.3. Learning-Based Methods
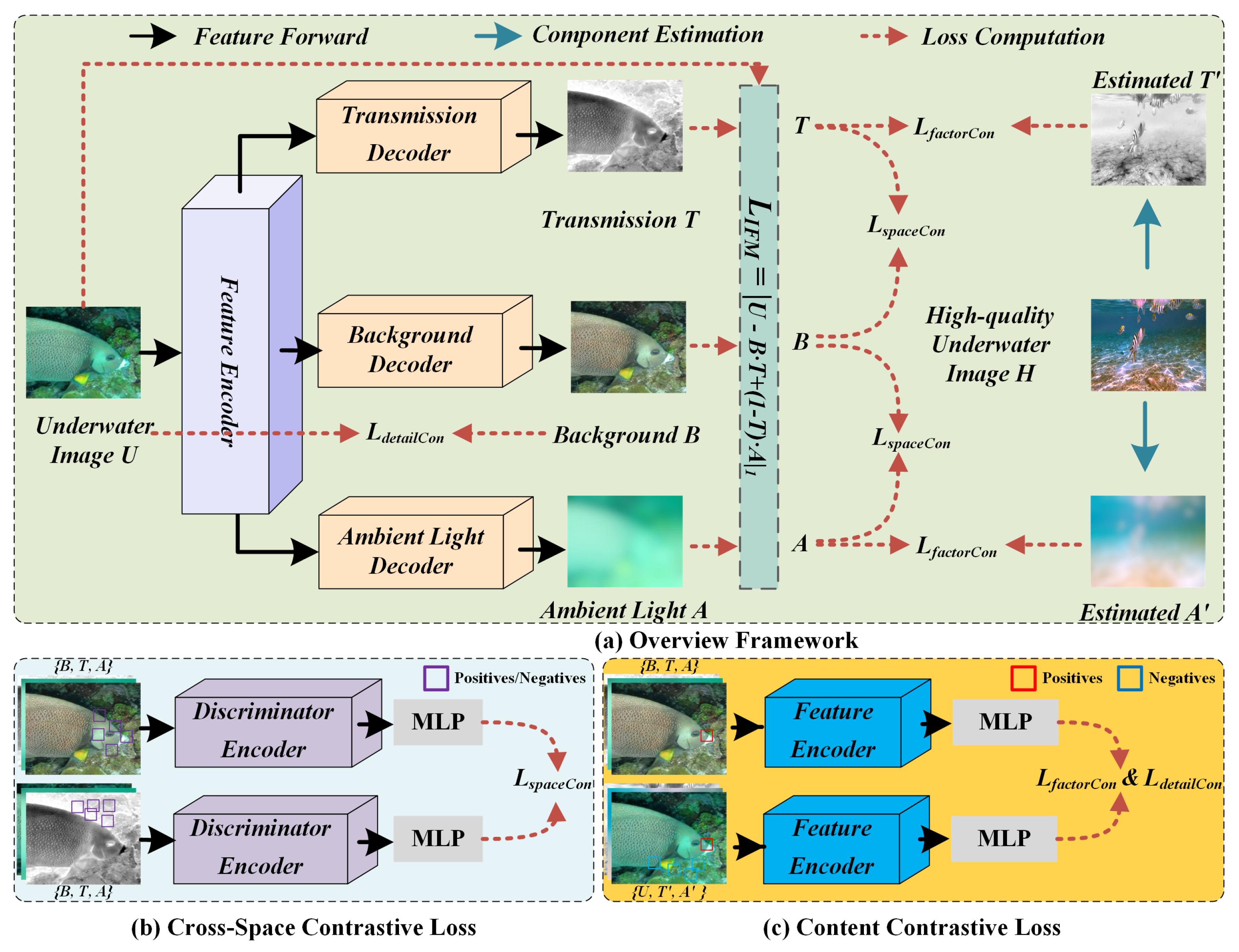
3. Proposed Method
3.1. Physics-Guided Image Formation Model
3.2. Multi-Stream Decomposition Architecture
3.3. Training Objectives
3.3.1. Hierarchical Contrastive Learning Function
3.3.2. Information Formulation Supervised Function
3.3.3. Adversarial Learning Function
4. Experiments
4.1. Implementation Details
4.2. Datasets
4.3. Quantitative and Quantitative Comparison
4.4. Ablation Study
4.5. Evaluation on Other Applications
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Song, Y.; Nakath, D.; She, M.; Köser, K. Optical imaging and image restoration techniques for deep ocean mapping: A comprehensive survey. PFG-Photogramm. Remote Sens. Geoinf. Sci. 2022, 90, 243–267. [Google Scholar] [CrossRef]
- Grimaldi, M.; Nakath, D.; She, M.; Köser, K. Investigation of the Challenges of Underwater-Visual-Monocular-SLAM. arXiv 2023, arXiv:2306.08738. [Google Scholar] [CrossRef]
- Long, H.; Shen, L.; Wang, Z.; Chen, J. Underwater Forward-Looking Sonar Images Target Detection via Speckle Reduction and Scene Prior. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Cao, X.; Ren, L.; Sun, C. Dynamic target tracking control of autonomous underwater vehicle based on trajectory prediction. IEEE Trans. Cybern. 2022, 53, 1968–1981. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, J.; He, W.; Gao, H.; Yue, H.; Zhang, Z.; Li, C. Is Underwater Image Enhancement All Object Detectors Need? IEEE J. Ocean. Eng. 2024, 49, 606–621. [Google Scholar] [CrossRef]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. Dn-detr: Accelerate detr training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13619–13627. [Google Scholar]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Pan, C.; Wang, G.; Yang, Y.; Wei, J.; Li, C.; Shen, H.T. Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1662–1671. [Google Scholar]
- Zheng, S.; Gupta, G. Semantic-guided zero-shot learning for low-light image/video enhancement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 581–590. [Google Scholar]
- Chen, L.; Jiang, Z.; Tong, L.; Liu, Z.; Zhao, A.; Zhang, Q.; Dong, J.; Zhou, H. Perceptual underwater image enhancement with deep learning and physical priors. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 3078–3092. [Google Scholar] [CrossRef]
- Li, C.; Anwar, S.; Hou, J.; Cong, R.; Guo, C.; Ren, W. Underwater image enhancement via medium transmission-guided multi-color space embedding. IEEE Trans. Image Process. 2021, 30, 4985–5000. [Google Scholar] [CrossRef]
- Peng, Y.T.; Cao, K.; Cosman, P.C. Generalization of the dark channel prior for single image restoration. IEEE Trans. Image Process. 2018, 27, 2856–2868. [Google Scholar] [CrossRef] [PubMed]
- Rahman, Z.u.; Jobson, D.J.; Woodell, G.A. Multi-scale retinex for color image enhancement. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 16–19 September 1996; Volume 3, pp. 1003–1006. [Google Scholar]
- Ren, X.; Yang, W.; Cheng, W.H.; Liu, J. LR3M: Robust low-light enhancement via low-rank regularized retinex model. IEEE Trans. Image Process. 2020, 29, 5862–5876. [Google Scholar] [CrossRef]
- Fu, C.; Liu, R.; Fan, X.; Chen, P.; Fu, H.; Yuan, W.; Zhu, M.; Luo, Z. Rethinking general underwater object detection: Datasets, challenges, and solutions. Neurocomputing 2023, 517, 243–256. [Google Scholar] [CrossRef]
- Islam, M.J.; Edge, C.; Xiao, Y.; Luo, P.; Mehtaz, M.; Morse, C.; Enan, S.S.; Sattar, J. Semantic segmentation of underwater imagery: Dataset and benchmark. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 1769–1776. [Google Scholar]
- Huang, S.; Wang, K.; Liu, H.; Chen, J.; Li, Y. Contrastive semi-supervised learning for underwater image restoration via reliable bank. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18145–18155. [Google Scholar]
- Han, J.; Shoeiby, M.; Malthus, T.; Botha, E.; Anstee, J.; Anwar, S.; Wei, R.; Armin, M.A.; Li, H.; Petersson, L. Underwater image restoration via contrastive learning and a real-world dataset. Remote Sens. 2022, 14, 4297. [Google Scholar] [CrossRef]
- Liu, X.; Gao, Z.; Chen, B.M. IPMGAN: Integrating physical model and generative adversarial network for underwater image enhancement. Neurocomputing 2021, 453, 538–551. [Google Scholar] [CrossRef]
- Qi, H.; Dong, X. Physics-aware semi-supervised underwater image enhancement. arXiv 2023, arXiv:2307.11470. [Google Scholar]
- Zhou, Y.; Yan, K.; Li, X. Underwater image enhancement via physical-feedback adversarial transfer learning. IEEE J. Ocean. Eng. 2021, 47, 76–87. [Google Scholar] [CrossRef]
- Liu, Y.C.; Chan, W.H.; Chen, Y.Q. Automatic white balance for digital still camera. IEEE Trans. Consum. Electron. 1995, 41, 460–466. [Google Scholar]
- Pizer, S.M. Contrast-limited adaptive histogram equalization: Speed and effectiveness stephen m. pizer, r. eugene johnston, james p. ericksen, bonnie c. yankaskas, keith e. muller medical image display research group. In Proceedings of the First Conference on Visualization in Biomedical Computing, Atlanta, GA, USA, 22–25 May 1990; Volume 337, p. 2. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing underwater images and videos by fusion. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar]
- Hitam, M.S.; Awalludin, E.A.; Yussof, W.N.J.H.W.; Bachok, Z. Mixture contrast limited adaptive histogram equalization for underwater image enhancement. In Proceedings of the 2013 International Conference on Computer Applications Technology (ICCAT), Sousse, Tunisia, 20–22 January 2013; pp. 1–5. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission estimation in underwater single images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 825–830. [Google Scholar]
- Galdran, A.; Pardo, D.; Picón, A.; Alvarez-Gila, A. Automatic red-channel underwater image restoration. J. Vis. Commun. Image Represent. 2015, 26, 132–145. [Google Scholar] [CrossRef]
- Akkaynak, D.; Treibitz, T. Sea-thru: A method for removing water from underwater images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1682–1691. [Google Scholar]
- Liang, Z.; Zhang, W.; Ruan, R.; Zhuang, P.; Xie, X.; Li, C. Underwater image quality improvement via color, detail, and contrast restoration. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 1726–1742. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, J.; Cao, Y.; Wang, Z. A deep CNN method for underwater image enhancement. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1382–1386. [Google Scholar]
- Li, C.; Anwar, S.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Robot. Autom. Lett. 2017, 3, 387–394. [Google Scholar] [CrossRef]
- Li, C.; Guo, J.; Guo, C. Emerging from water: Underwater image color correction based on weakly supervised color transfer. IEEE Signal Process. Lett. 2018, 25, 323–327. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G.E. Big self-supervised models are strong semi-supervised learners. Adv. Neural Inf. Process. Syst. 2020, 33, 22243–22255. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Wu, H.; Qu, Y.; Lin, S.; Zhou, J.; Qiao, R.; Zhang, Z.; Xie, Y.; Ma, L. Contrastive learning for compact single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10551–10560. [Google Scholar]
- Liu, R.; Jiang, Z.; Yang, S.; Fan, X. Twin adversarial contrastive learning for underwater image enhancement and beyond. IEEE Trans. Image Process. 2022, 31, 4922–4936. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Wang, C.; Guo, X.; Tao, D. Robust Unpaired Image Dehazing via Density and Depth Decomposition. Int. J. Comput. Vis. 2024, 132, 1557–1577. [Google Scholar] [CrossRef]
- Chang, Y.; Guo, Y.; Ye, Y.; Yu, C.; Zhu, L.; Zhao, X.; Yan, L.; Tian, Y. Unsupervised Deraining: Where Asymmetric Contrastive Learning Meets Self-similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 2638–2657. [Google Scholar] [CrossRef]
- Demir, U.; Unal, G. Patch-based image inpainting with generative adversarial networks. arXiv 2018, arXiv:1803.07422. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Peng, L.; Zhu, C.; Bian, L. U-shape transformer for underwater image enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef] [PubMed]
- Ehsan, S.M.; Imran, M.; Ullah, A.; Elbasi, E. A single image dehazing technique using the dual transmission maps strategy and gradient-domain guided image filtering. IEEE Access 2021, 9, 89055–89063. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-world underwater enhancement: Challenges, benchmarks, and solutions under natural light. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Zhang, W.; Zhuang, P.; Sun, H.H.; Li, G.; Kwong, S.; Li, C. Underwater image enhancement via minimal color loss and locally adaptive contrast enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiang, Z.; Ma, L.; Liu, J.; Fan, X.; Liu, R. HUPE: Heuristic Underwater Perceptual Enhancement with Semantic Collaborative Learning. Int. J. Comput. Vis. 2025, 1–19. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Yang, M.; Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef]
- Ke, J.; Wang, Q.; Wang, Y.; Milanfar, P.; Yang, F. Musiq: Multi-scale image quality transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5148–5157. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | UIQM ↑ | UCIQE ↑ | MUSIQ ↑ | NIQE ↓ | Efficiency | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RUIE | SUIM | EVUP | UIEB | RUIE | SUIM | EVUP | UIEB | RUIE | SUIM | EVUP | UIEB | RUIE | SUIM | EVUP | UIEB | FLOPs (G) | Time (ms) | |
| Original | 2.294 | 2.027 | 2.254 | 1.677 | 0.523 | 0.597 | 0.543 | 0.533 | 33.874 | 60.855 | 43.678 | 41.697 | 5.062 | 3.957 | 4.976 | 6.905 | - | - |
| GDCP [13] | 2.738 | 1.970 | 2.337 | 1.899 | 0.608 | 0.678 | 0.638 | 0.624 | 32.671 | 58.897 | 40.886 | 51.002 | 4.738 | 3.885 | 4.697 | 5.190 | - | 173.8 |
| MMLE [53] | 2.871 | 2.137 | 2.337 | 1.953 | 0.567 | 0.612 | 0.638 | 0.580 | 36.510 | 62.704 | 40.886 | 40.345 | 4.859 | 4.045 | 4.697 | 4.845 | - | 91.7 |
| WaterNet [51] | 3.168 | 2.644 | 3.077 | 2.317 | 0.568 | 0.607 | 0.597 | 0.581 | 30.289 | 60.280 | 42.402 | 40.006 | 4.755 | 4.007 | 4.420 | 5.702 | 571.8 | 40.6 |
| FUINE [1] | 3.145 | 2.557 | 2.944 | 2.867 | 0.538 | 0.610 | 0.572 | 0.552 | 28.726 | 60.158 | 38.110 | 46.827 | 4.906 | 3.611 | 5.106 | 5.299 | 81.91 | 2.9 |
| CWR [19] | 3.154 | 2.847 | 3.008 | 2.459 | 0.583 | 0.637 | 0.618 | 0.607 | 25.310 | 58.915 | 37.854 | 30.131 | 4.730 | 4.058 | 4.744 | 5.338 | 338.9 | 20.8 |
| SEMUIR [18] | 3.063 | 2.502 | 2.957 | 2.164 | 0.554 | 0.636 | 0.599 | 0.570 | 32.446 | 62.272 | 47.882 | 42.460 | 4.633 | 3.439 | 4.352 | 5.697 | 105.6 | 43.4 |
| HUPE [54] | 3.000 | 2.481 | 2.779 | 2.198 | 0.550 | 0.637 | 0.602 | 0.582 | 29.766 | 54.57 | 38.817 | 35.559 | 4.598 | 4.148 | 5.136 | 7.771 | 87.5 | 50.2 |
| Ours | 3.227 | 3.117 | 3.116 | 2.793 | 0.558 | 0.620 | 0.600 | 0.569 | 34.398 | 61.348 | 47.175 | 39.412 | 3.922 | 2.863 | 3.639 | 3.938 | 147.5 | 19.3 |
| Category | Components | UIQM ↑ | UIQM | UCIQE ↑ | UCIQE | MUSIQ ↑ | MUSIQ | NIQE ↓ | NIQE |
|---|---|---|---|---|---|---|---|---|---|
| Physical only | 1.667 | −40.3% | 0.572 | −1.2% | 39.476 | −4.7% | 4.107 | −9.9% | |
| Feature contrastive | + | 2.506 | −10.3% | 0.522 | −8.3% | 38.912 | −6.0% | 4.246 | −13.6% |
| + | 2.301 | −17.6% | 0.551 | −3.2% | 39.102 | −5.6% | 4.102 | −9.7% | |
| + | 2.410 | −13.7% | 0.563 | −1.1% | 39.875 | −3.7% | 3.980 | −6.5% | |
| Adversarial | + | 2.155 | −22.8% | 0.548 | −3.7% | 40.213 | −2.9% | 3.890 | −4.1% |
| Full | All | 2.793 | - | 0.569 | - | 41.412 | - | 3.738 | - |
| GDCP | MMLE | WaterNet | FUNIE | CWR | SEMUIR | HUPE | Ours | |
|---|---|---|---|---|---|---|---|---|
| PA ↑ | 0.812 | 0.805 | 0.655 | 0.806 | 0.800 | 0.816 | 0.826 | 0.830 |
| MPA ↑ | 0.301 | 0.304 | 0.261 | 0.297 | 0.300 | 0.304 | 0.312 | 0.319 |
| mIoU ↑ | 0.267 | 0.268 | 0.200 | 0.264 | 0.268 | 0.273 | 0.284 | 0.284 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, F.; Wan, L.; Zheng, J.; Wang, L.; Xi, Y. Contrastive Feature Disentanglement via Physical Priors for Underwater Image Enhancement. Remote Sens. 2025, 17, 759. https://doi.org/10.3390/rs17050759
Li F, Wan L, Zheng J, Wang L, Xi Y. Contrastive Feature Disentanglement via Physical Priors for Underwater Image Enhancement. Remote Sensing. 2025; 17(5):759. https://doi.org/10.3390/rs17050759
Chicago/Turabian StyleLi, Fei, Li Wan, Jiangbin Zheng, Lu Wang, and Yue Xi. 2025. "Contrastive Feature Disentanglement via Physical Priors for Underwater Image Enhancement" Remote Sensing 17, no. 5: 759. https://doi.org/10.3390/rs17050759
APA StyleLi, F., Wan, L., Zheng, J., Wang, L., & Xi, Y. (2025). Contrastive Feature Disentanglement via Physical Priors for Underwater Image Enhancement. Remote Sensing, 17(5), 759. https://doi.org/10.3390/rs17050759