Abstract
Single-stage object detection networks are widely applied in various scenarios due to their high precision and speed. These networks typically consist of three parts structurally: backbone, neck, and head. Among these, multi-scale feature fusion in the neck is a crucial step to enhance detection effectiveness in object detection. Multi-scale feature fusion typically involves combining features from different layers through addition or concatenation. However, such methods often focus solely on the shared functionality of neighboring scale features, neglecting detailed information from higher-level features, leading to significant information loss. To address these issues, this paper proposes a novel network called GMDNet, comprising two key modules: a Global Information Sharing Module (GISM) and a Detailed Information Extraction Module (DIEM). GISM addresses different scale features with high and low-level branches, aligning and merging information across layers using structural reparameterization and Transformer techniques to enhance global information flow among different hierarchical features. DIEM extracts detailed information using three-feature fusion mapping and further integrates multi-scale information with detailed features using channel and positional attention mechanisms, effectively reintegrating previously overlooked details. Experiments conducted on multiple public datasets demonstrate that the proposed algorithm outperforms state-of-the-art methods and achieves an ideal balance between speed and accuracy across all model scales.
1. Introduction
Real-time object detection is a critical research area in computer vision, with extensive applications across various fields including multi-target tracking, medical image analysis, and intelligent robots [1,2,3]. Consequently, the deployment of high-performance, low-latency detectors on mobile and cloud GPUs is gaining significant attention. Recently, detectors for both edge and cloud devices have seen ongoing advancements. To achieve low latency, detection frameworks have shifted from two-stage methods (e.g., Faster RCNN [4]) to single-stage approaches (e.g., the Yolo series [5]); for enhanced performance, they have transitioned from anchor-based (e.g., Yolov4 [6]) to anchor-free designs (e.g., YoloX [7]). Single-stage detectors based on GPUs are increasingly popular due to their straightforward design and balanced speed and accuracy.
The typical real-time object detector comprises three main components: the backbone, neck, and head. The backbone integrates Transformer concepts from original architectures like DarkNet [8] and ResNet [9], resulting in newer structures such as ViT [10] and Swin Transformer [11], enhancing the backbone network’s feature extraction capabilities significantly. The head typically consists of convolutional layers and fully connected layers, with position and category information processing categorized into coupling and decoupling methods. These head types and their derived algorithms effectively predict target type and position. Single-stage detectors typically employ Feature Pyramid Networks (FPN) [12] and their variations as the neck to fuse multi-level features (Figure 1). Such structures typically involve multiple layers where adjacent layer information can be fused directly, but non-adjacent layer information must be fused indirectly. For instance, information from the S5 layer can only be indirectly accessed via the S4 layer after their fusion. This approach leads to significant interlayer information loss and hampers the aggregation of global information. Moreover, this structure predominantly upsamples small-scale feature maps, incorporating their information into the preceding layers post-processing, thereby neglecting detailed information from larger-scale feature layers and causing substantial loss of detail.

Figure 1.
FPN and its derivative structures. The figure shows the fusion method of each layer’s features under different structures. (a) FPN. (b) PAN. (c) BiFPN. (d) Yolov8.
To tackle these issues, we propose GMDNet and conduct experiments across multiple datasets. Experimental results demonstrate that our method effectively balances accuracy and computational complexity, offering substantial advantages over existing methods. The key contributions of this study are outlined below:
- To resolve issues such as global information exchange blockage and missing feature maps, this study introduces the Global Information Sharing Module (GISM). GISM uniformly manages and redistributes information across different feature layers, notably enhancing the neck’s information fusion capability without a substantial latency increase, thereby enhancing detection performance across multiple scales.
- To address missing information in large-scale feature layers, this study introduces the Detailed Information Extraction Module (DIEM). DIEM amplifies detailed information lost in large-scale feature layers. GISM and DIEM are then integrated to form a comprehensive, independent neck.
- Experiments conducted on VOC and VisDrone datasets show that our proposed neck outperforms state-of-the-art alternatives, confirming the efficacy of our approach.
2. Related Work
In this section, we initially review several real-time object detection algorithms based on CNN. We critically assess the limitations of CNN in the domain of object detection. Subsequently, we delve into recent advancements of transformers in the field of computer vision (CV). Lastly, we consolidate current research efforts in multi-scale feature fusion while highlighting associated drawbacks.
2.1. Object Detection with CNN
Object detection technology has made remarkable strides over the years, and can be divided into two-stage and one-stage detectors based on region usage. Single-stage algorithms have gained popularity over two-stage detectors due to shorter training times and improved detection efficiency. CNN-based one-stage detectors have become a prominent area of research owing to their effectiveness in detection tasks.
There have been many excellent algorithms in one-stage detectors, such as the SSD algorithm based on VGG [13], and RetinaNet [14] was the first to determine the leading advantage of one-stage detectors, but these algorithms struggle to strike an appropriate balance between detection speed and accuracy. However, the Yolo series models have effectively balanced the contradiction between detection speed and accuracy, making them the most widely used one-stage detectors. The Yolo series models have been developed for 11 generations to date. Yolov1 to v3 versions established the initial Yolo model, which can be decomposed into three parts: head, neck, and backbone. Through multi-scale branching, good prediction results were obtained. Yolov4 made a series of improvements in the activation function of the backbone and neck. Yolov5 [15] further optimized data augmentation and model changes while retaining the improvements of Yolov4. Yolov6 [16,17] proposed the EifficientRep backbone and Rep PAN neck. Yolov7 [18] focuses on the overall impact of gradients and proposes the E-ELAN structure to significantly enhance detection accuracy. Yolov8 [19] improved the C2f backbone and optimized the label allocation strategy to improve detection efficiency. Yolov9 [20] introduces new PGI and GELAN image formats, which are more focused on improving the performance of image segmentation. Yolov10 [21] focuses more on improving detection speed, with little improvement in accuracy. Yolov11 is the latest version of the Yolo series, and focuses more on innovation in image segmentation, image classification, and other aspects, but its performance improvement in object detection is not significant. Although one-stage detectors have been developed for many years, CNN-based one-stage detectors still have problems such as low detection accuracy and poor robustness, and one-stage detectors still have broad innovation prospects.
2.2. Object Detection with Transformer
CNN-based object detection comprises three main components: feature learning, target estimation, and label matching. However, convolution operations lack the ability to capture global image information, hindering the establishment of dependency relationships between model features. Consequently, researchers have explored the adaptation of Transformer models from natural language processing to visual tasks.
The Vision Transformer (ViT), introduced by Google at ICLR 2020, pioneered the application of Transformer models in the field of vision. Beal J introduced the influential ViT-FRCNN [22] algorithm, employing Transformer as the backbone for image feature encoding, in the same year. Liu et al. proposed the Swin Transformer model, utilizing sliding windows to construct a hierarchical detection model, and subsequently developed Swin Transformer V2 [23] using a larger visual model. Wang et al. [24] introduced the Pyramid Vision Transformer (PVT), which downsamples input and incorporates a Progressive Shrinking Pyramid structure and a Spatial Reduction Attention mechanism to reduce computational complexity.
Moreover, CNN requires a large amount of prior design and prior parameters in its network structure, which poses a huge challenge to the universality of the network. DETR (Detection Transformer) [25] based on Transformer removes prior design and manual operation. Efficient DETR [26] addresses long convergence times, significantly reducing them. Additionally, Deformable DETR [27] integrates Deformable Convolution to enhance network localization capabilities, thereby greatly improving detection accuracy. Applying Transformer theory to CNN object detection networks leads to significant performance improvements. Thus, applying Transformer theory to the neck for multi-scale information fusion shows promising application prospects.
2.3. Multi-Scale Feature Fusion
Features at different levels exhibit distinct characteristics. Deep networks feature a larger receptive field and stronger semantic representation but produce low-resolution maps with limited geometric detail. In contrast, low-level networks offer higher resolution and strong geometric detail representation but weaker semantic understanding. Integrating multi-scale features captures more comprehensive information, posing a challenge to the neck’s multi-scale feature fusion capability.
The Feature Pyramid Network (FPN) significantly improves network information exchange by integrating features across multiple scales, thereby establishing an effective framework for multi-scale feature fusion. Unlike FPN’s top-down approach, PANet [28] introduces a bottom-up path aggregation module that streamlines information flow through convolutional layers. However, PANet entails significant computation and parameter overheads, prompting the proposal of a weighted fusion method (BiFPN) to enhance efficiency and reduce computational load [29].
Additionally, CFPNet by Y Quan [30] emphasizes individual feature information, while M2Det by Qijie Zhao [31] focuses on efficient fusion capabilities. Other studies have explored altering interactions between shallow and deep layers [32], and AFPN proposed by [33] has enhanced multi-scale feature fusion to some extent. However, these methods often introduce direct or indirect connections between levels, potentially resulting in complex structures, slow information exchange, and significant global information loss.
3. Method
In this section, we present the framework of GMDNet, depicted in Figure 2. We begin by addressing specific shortcomings of traditional neck structures. Based on these observations, GMDNet is introduced in detail, consisting primarily of GISM and DIEM. GISM enhances multi-scale object detection by integrating global information interaction, while DIEM improves detailed feature extraction within the feature layer. GMDNet effectively enhances the performance of multi-scale feature fusion.
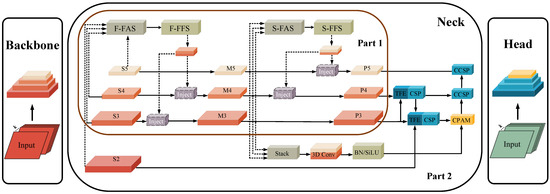
Figure 2.
Overall Framework of GMDNet. Part 1 depicts the GISM framework, with its left and right branches representing the first and second branches, respectively. Part 2 illustrates the DIEM component.
3.1. Overall Architecture
Adapted to the development of the backbone, new demands are placed on the extraction and fusion of multi-scale features. The FPN network addresses the problem of multi-scale feature fusion effectively by enabling fusion of adjacent-layer features, making FPN and its derivatives the most commonly used networks for multi-scale feature fusion. However, FPN and its derivatives have encountered the following difficult problems to solve:
- Difficulty in acquiring cross-layer features: As shown in Figure 1, if layer S3 needs features from layer S5, it can only access fused features from layers S4 and S5. Therefore, cross-layer feature acquisition is incomplete, with many features being discarded during the initial fusion.
- From a global perspective, the effective fusion range of single-layer features is limited to neighboring layers, thereby restricting the fusion effectiveness of global features.
- These structures typically only perform upsampling on small-scale feature layers, decomposing or adding features while neglecting detailed information from large-scale feature layers.
Therefore, commonly used necks lack the capability to integrate global information effectively and exhibit weaker perception of feature details. In addition, a large amount of effective information has not been fully utilized when aligning multi-scale features. To address these issues, this paper proposes a novel approach called GMDNet. GMDNet introduces a centralized processing branch in the fusion network to consolidate processed information and distribute it to various levels, effectively mitigating information loss in the neck. Furthermore, by integrating a three-dimensional feature encoder that enhances global fusion capability through attentive handling of channel and positional information, GMDNet improves the perception of feature details and greatly enhances the multi-scale feature fusion capability.
3.2. Global Information Sharing Module (GISM)
GISM is responsible for the re-collection and re-injection of multi-scale features in GMDNet. GISM consists of two branches, each comprising three components: feature alignment, feature fusion, and feature injection. In the first branch, the input to the neck consists of S2, S3, S4, and S5 from the backbone, which are fused together. In the second branch, the inputs are M3, M4, and M5, which are also fused together. The structure is illustrated in the diagram.
Feature Alignment Section:
To reconcile the trade-off between preserving bottom-level information and managing computational complexity across layers, this paper opts to use the S4 layer as the anchor layer for feature alignment in the first branch.
In F-FAS, feature alignment between and is achieved through Avgpool and Bilinear operations (), ensuring inputs are optimized for F-FFS. This method efficiently aggregates information across layers while also managing the computational complexity of the neck.
Aligned with the feature alignment module’s requirement in the first branch, which aims to balance preserving bottom-level information with managing computational complexity across layers, this paper opts to use the M5 layer as the reference layer for feature alignment in the second branch. Within S-FAS, the use of average pooling (Avgpool) aligns features with , resulting in (. H-FIM efficiently aggregates information across layers and reduces the computational load of the GAU module.
Feature fusion section:
F-FFS comprises multi-layer online reparameterized convolutional blocks (OREPA) [34] and separation operations. To enhance deep model performance without increasing inference time costs, structural reparameterization is applied at the fusion endpoint. However, the accuracy of structural reparameterization relies on complex training procedures, inevitably escalating training costs [14,35,36,37].
OREPA greatly eliminates additional training time and saves a lot of computing resources through two steps. In the first step, OREPA removes all non-linear layers and uses linear scaling layers. In addition, the linear scaling layers can be merged into convolutional layers, which further saves computational resources. In the second step, a new method of converting linear layers into convolutional layers is introduced, which relieves the computational pressure of many layers. Therefore, OREPA effectively reduces GPU usage pressure and enhances inference efficiency. In summary, OREPA eliminates all nonlinear layers, replacing them with linear scaling layers, and incorporates a BN layer at the end of its structure. This enhancement condenses complex training processes into a single convolution, thereby significantly reducing training expenses. The simplified formulas for the sequential and parallel structures of OREPA are as follows:
where represents the weights of the j-th layer, denotes the weights of the m-th branch, and signifies the unified weight distribution across all branches.
The input of OREPA is sourced from the output end of F-FAS. The output of OREPA undergoes separation operations to produce the final outputs and of F-FFS, as depicted in Figure 3a.
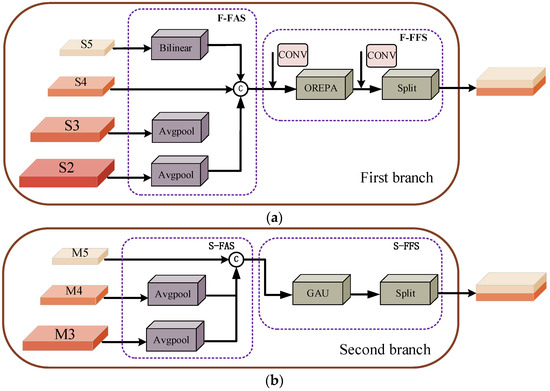
Figure 3.
(a,b) illustrate the first and second branches of GISM, each focusing on different features. Each branch consists of three components: feature alignment, feature fusion, and feature injection. (a) The first branch. (b) The second branch.
S-FFM comprises stacked GAU modules [38] and separation modules. The core idea of GAU originates from the FFN layer in Transformer. GLU has found through research that using simple linear gating units to stack convolutional layers can effectively parallelize tokens. The use of parallelization reduces the complexity of the algorithm. Due to the use of sigmoid, this measure leads to gradient loss, so residual structures need to be added to the network, and finally Adaptive Softmax is added as the normalization function, effectively increasing the training efficiency of the model. Based on the research of GLU, GAU regards attention and GLU as a unified layer and extensively uses parallel computing to achieve computational efficiency. In summary, these modules are built upon Transformer theory, combining self-attention and GLU [39] into a single layer that shares computations, thereby improving computational efficiency and reducing parameter count. The specific formula is as follows:
where encompasses token–token attention weights, Z denotes , with and representing two simplified transformations, and b signifying relative positional deviation.
S-FFS operates in three main steps:
- Initially, it acquires high-level aligned input from the S-FAS module.
- Next, the high-level aligned is inputted into stacked GAU modules to generate the fused high-level feature .
- Finally, the fused high-level feature fuse undergoes segmentation through separation modules, dividing it along the channel dimension into and , which are subsequently fused with their respective feature layers. This specific structure is depicted in Figure 3b.
Feature Injection section:
To integrate the output information from the S-FFS module into various layers, this study employs attention-based fusion between the local feature and the injected information. At the input of this layer, the LAF module aligns the input features using Avgpool and Bilinear operations before passing them into the injection module. For global information alignment, a dual convolution approach is utilized. Following attention fusion, the OREPA module further extracts information.
The injection of output information from the S-FFS module into different layers involves attention-based fusion combining the local feature. Similar to the injection module in the first branch, global information integration is employed. However, at the input end of the LAF module in the second branch, only Avgpool is used for alignment. The specific structure is illustrated in Figure 4.
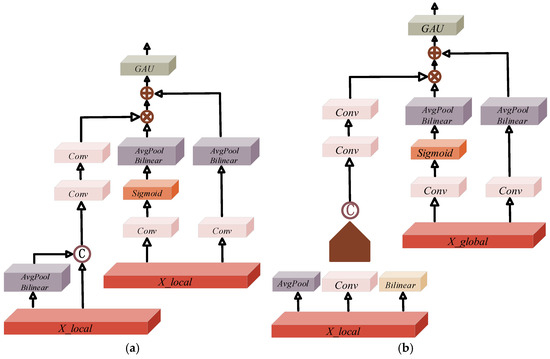
Figure 4.
The figure illustrates the overall framework of the injection part of the first branch. Similarly, the second branch utilizes Avgpool only at the input end for alignment, consistent with other sections of the first branch. (a) The first branch. (b) The second branch.
3.3. Detailed Information Extraction Module (DIEM)
In existing multi-scale feature fusion methods, a large number of multi-scale features are lost in the transformation—in particular, the detailed information of upper-level features is largely ignored—and DIEM is used to reuse this lost information. It solves the problem of incomplete pyramid feature maps through Stack, 3D Convolution, and BN/SILU, seamlessly connecting the high-dimensional information of deep feature maps with the detailed information of shallow feature maps. The input formula for this port is as follows:
where represents the two-dimensional input of the image, and is obtained by two-dimensional Gaussian filtering and smoothing.
After unifying the resolution, concatenating and overlaying feature maps of different scales, and applying 3D convolution to extract scale sequence features, this article utilizes the M3 layer as the reference layer, focusing on detailed and key information. The specific structure includes the following:
- Employing a single convolution to standardize the number of channels in M4 and M5.
- Utilizing nearest neighbor interpolation for aligning features.
- Applying “unsqueeze” to convert the input 3D feature map into a 4D feature map, thereby adding depth information.
- Stitching four-dimensional feature maps using 3D techniques based on depth information.
- Employing 3D convolution, normalization, and SILU for extracting scale sequence features.
Regarding the fusion part of DIEM, the first step is to input the TFE+CSP module from the P4 and P3 layers, and the output is then combined with the two parallel outputs obtained by inputting the TFE+CSP module from the P3 layer. The second step is to input the P5 layer and two parallel outputs into the CCSP layer (CONCAT+CSP), CCSP layer, and CPAM layer, respectively. Finally, the outputs of the CCSP layer (CONCAT+CSP), CCSP layer, and CPAM layer are inputted into the head section.
Triple Feature Encoding Module (TFE):
The Triple Feature Encoding (TFE) module [40] addresses the issue of information loss inherent in pyramid structures, where downsampling primarily affects the top feature layer. TFE categorizes features into large, medium, and small categories and employs feature scaling to preserve detailed information. The structure of TFE involves the following: first, the number of channels is standardized and consistency ensured, applying ConvBNSiLU operations uniformly to the three feature maps. Second, large-scale feature maps are downsampled using Avg+MaxPooling, followed by ConvBNSiLU operations to maintain feature diversity. Medium-scale feature maps undergo ConvBNSiLU operations for mesoscale output, while small-scale feature maps are downsampled using the Nearest method and then subjected to ConvBNSiLU operations to prevent information loss. Finally, the three outputs are convolved and concatenated as depicted in Figure 5a.
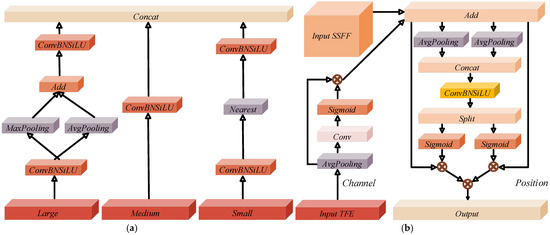
Figure 5.
(a,b) are two important components of DIEM. (a) Structure of TFE. (b) Structure of CPAM.
Channel and Position Attention Mechanism (CPAM):
The Channel and Position Attention Mechanism (CPAM) integrates detailed and scale-specific information across multiple channels. CPAM takes as input complementary position attention information and channel attention information (output of P3 layer TFE+CSP [15] module). Following pooling and convolution, the channel attention information serves as the input for the bottom layer, while the position information enters the next layer concurrently. Finally, the output from CPAM enters the head section, as illustrated in Figure 5b.
4. Experiments and Analysis
This section presents a detailed description of the experimental settings used in this article, which were applied to two publicly available datasets. The algorithm is evaluated against the current state-of-the-art (SOTA) method, assessing its effectiveness across multiple metrics to demonstrate its superiority.
4.1. Dataset Description
To effectively demonstrate the efficacy of the proposed neck, this paper conducts experiments on two publicly available datasets. The general dataset chosen is VOC, sourced from the PASCAL VOC Challenge, while the drone perspective dataset selected is VisDrone.
VOC Dataset [41,42]: The VOC dataset originates from the PASCAL VOC Challenge and covers diverse content, including object classification, detection, segmentation, human layout, and action classification. It includes four main object categories (vehicles, household items, animals, people) with 20 subcategories. This experiment uses the VOC2007 and VOC2012 datasets.
VisDrone Dataset [43]: The VisDrone dataset, compiled by the AISKYEYE team at Tianjin University, comprises 288 video clips totaling 261,908 frames and 10,209 static images. It encompasses footage from various drone cameras across diverse settings, including 14 cities in China spanning thousands of kilometers, different environments (urban and rural), and various objects (pedestrians, vehicles, bicycles). The dataset captures scenes with varying densities, collected using multiple drone models under diverse conditions of weather and lighting. It features over 2.6 million annotated target boxes (e.g., pedestrians, cars, bicycles, tricycles) with attributes such as scene visibility, object categories, and occlusion. This article utilizes the VisDrone2019 dataset.
4.2. Setups
In this section, a detailed test analysis will be conducted on GMDNet, which requires sufficient power and storage space for training, testing, and evaluation while meeting sufficient computational conditions. This algorithm will be deployed on the server side. In order to ensure the normal operation of the server side, necessary configurations have been made on the server side. The following Table 1 details the relevant environment and configuration information to ensure the accuracy and learnability of the experiment.

Table 1.
Training environment.
All experiments in this article were conducted without pre-training or the use of pre-trained weights, with fixed initial seeds. The backbone predominantly employed EfficientRep, while the neck utilized GMDNet. The head consisted of a three-layer Box output paired with DIEM and a Mask output in the first layer. Optimization was performed using stochastic gradient descent (SGD), momentum, and cosine decay for learning rate adjustment. Data augmentation techniques included Mosaic [6] and Mixup [44]. Unless specified otherwise, experiments were trained for 150 epochs without employing pruning, distillation, or acceleration methods. The primary datasets used were partial VOC2007 and VOC2012, with these datasets also utilized in the ablation studies. For generalization validation, the VisDrone dataset was employed. The detailed parameters are shown in Table 2.
Table 2.
Neural network parameter settings.
4.3. Evaluation Metrics
To rigorously quantify algorithm performance across diverse datasets and enable visual comparisons, this paper adopts widely recognized evaluation metrics in the field of object detection. Object detection results are categorized into four types: true positive (TP), false positive (FP), true negative (TN), and false negative (FN). Precision and recall can be calculated by counting the number of samples per case as follows:
The precision and recall metrics, derived from Equations (9) and (10), define the average precision (AP), visually represented by the area under the PR curve on the image. mAP denotes the average AP calculated across all detected object categories.
where C is the total number of categories and k represents the category index. In particular, mAP50:95 represents the multi-threshold mAP averaged with ten different IoU thresholds, i.e., 0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, and 0.95.
4.4. Comparisons
This paper focuses on evaluating the relationship between FLOPs and AP. The aim is to assess the overall performance of deploying the model on mobile or cloud platforms. The studied detector is compared with other state-of-the-art detectors, and experiments are conducted on the same machine for fair comparison. The experimental comparisons are illustrated in the Figure 6 as depicted.
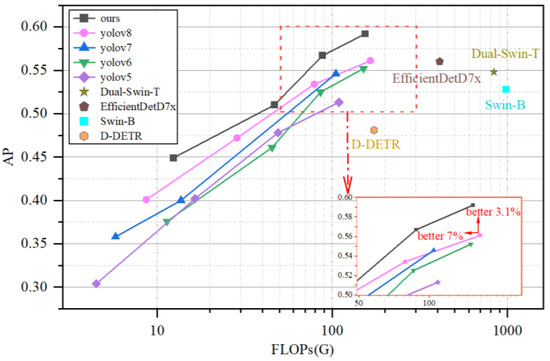
Figure 6.
Comparison with other real-time object detectors: our proposed methods achieve state-of-the-art performance.
From Table 3 and Figure 6, it is evident that OURS-l shows significant improvements in detection accuracy compared to Yolov5-l, Yolov6-l, EfficientDet-D7x, and Yolov8-l, achieving improvements of 7.9%, 4.0%, 3.2%, and 3.1%, respectively. Regarding model computational complexity, OURS-l exhibits comparable computational requirements to Yolov6-l, an approximately 63% reduction compared to EfficientDet-D7x, and a 7% reduction compared to Yolov8-l.
Table 3.
Detection results on VOC of different networks.
Therefore, the research algorithm in this paper demonstrates improvements of 3.1% in detection accuracy and 7% in model computational complexity compared to the current state-of-the-art (SOTA) model, Yolov8-l. The algorithm proposed in this paper holds a dual advantage over mainstream algorithms in terms of both accuracy enhancement and model lightweight design.
4.5. Ablation Experiments
This section presents ablation experiments conducted from two perspectives. First, we analyze the individual components of our algorithm and investigate their collaborative performance. Second, we assess the adaptability of the neck proposed in this article to mainstream backbones, comparing it with multiple existing necks. The specific details of the ablation experiments are as follows:
- To assess the efficacy of feature pyramid analysis and detailed feature extraction as proposed in this article, and to evaluate the overall effectiveness of our algorithm, each module was independently tested. The experimental results are detailed in Table 4. The findings indicate that both branches in the FLIS module significantly enhance overall performance, while the GISM and DIEM modules contribute to further improving network performance. Moreover, the experiments demonstrate a synergistic effect between the GISM and DIEM modules in enhancing overall network performance.
Table 4. The impact of each module on overall performance.
- To validate the advantages of the proposed neck, comparisons were made with other necks, and its adaptability across different backbones was assessed. The experimental results are presented in Table 5 and Table 6. Analysis reveals that the first and second branches address different size targets within the feature map, while the DIFM module provides detailed position information for channel attention. Optimal performance is achieved through their collaborative operation. Further ablation experiments on ResNet and EfficientRep backbones confirm our algorithm’s consistent advantages across different architectures. Comparative analysis with mainstream necks demonstrates that the proposed neck excels in fusion performance.
Table 5. Comparison of necks in EfficientRep backbone.
Table 6. Comparison of necks in ResNet backbone.
4.6. Generalization Experiment
To evaluate the generalization performance of GMDNet, this paper conducted additional experiments using the VisDrone dataset. The experiment uses EfficientRep as the backbone and GMDNet as the neck, with three layers of Box output and one layer of Mask output. We selected the Yolo series algorithms and QueryDet [45], CNXResNet [46], MC-Yolov5 [47], UAV-Yolov8 [48], EDGS-Yolov8 [49], and other algorithms for comparative experiments. The experimental results are shown in Table 7 and Table 8. The analysis shows that, compared with existing advanced networks and Yolo series algorithms, GMDNet exhibits excellent performance on the VisDrone dataset, achieving the best FLOP and computational accuracy. These experiments have demonstrated the practicality and effectiveness of the algorithm on multiple datasets.
Table 7.
Detection results on VisDrone of different networks.
Table 8.
The inference times of different networks.
In order to demonstrate the advantages of GMDNet as a neck more intuitively and concretely, this article presents experimental data from the aspects of PR curve and F1 parameter indicators. The specific experimental parameters are shown in Figure 7.
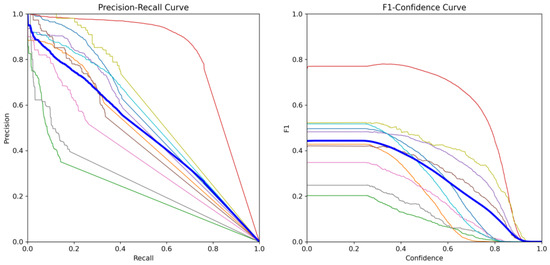
Figure 7.
Precision-Recall Curve and F1-Condfidence Curve index corresponding to GMDNet. There are a total of 11 lines in the figure, with the bold blue line representing the overall target curve and the other 10 lines representing various types of target curves.
4.7. CAM Visualization Experiment
In neural networks, each convolutional layer generates multiple feature maps, each associated with a convolutional kernel. CAM technology employs Global Average Pooling to extract features relevant to the target category from each feature map. These features are then spatially mapped onto the input image to generate Class Activation Maps for each category. GradCAM [50], on the other hand, calculates weights using the global average of gradients, providing a clearer representation of regions crucial for the network’s classification decisions, as shown in Figure 8.
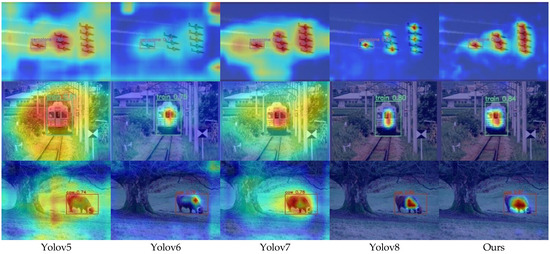
Figure 8.
The GradCAM visualization results of the neck for Yolov5, Yolov6, Yolov7, Yolov8, and Ours. The brighter the color in the figure, the more interesting the parts predicted by the network, while the darker parts indicate the parts that are not related to the target.
To visually assess the detection performance, Yolov5, Yolov6, Yolov7, and Yolov8 were compared with the algorithm proposed in this paper. Figure 9 demonstrates that the proposed algorithm assigns greater importance to the detection target area.

Figure 9.
Comparison of detection performance on the VisDrone dataset between our research algorithm, Yolov5, and Yolov8.
4.8. Results on the VisDrone Dataset
The algorithm in this article also has a significant improvement in detection performance, greatly enhancing the detection effect. Now, a visual comparison is made regarding three aspects: missed detection, false detection, and overall effect. The red circled area in the figure represents missed detections, while the purple circled area represents false detections, shown in Figure 9. The overall detection results are shown in Figure 10.

Figure 10.
VisDrone dataset visualization.
5. Conclusions
The most significant advantage of the GMDNet proposed in this article compared to existing necks lies in the re-extraction and re-allocation of global information, and it has great advantages in multi-scale feature fusion. Existing necks only connect multi-scale feature fusion through a single path for information exchange. Although this approach obtains some feature information at different scales, it also loses a large amount of information overall, which directly leads to a loss in accuracy. The GMDNet proposed in this article uniformly processes information of different scales into the corresponding scales required by each level, and then assigns them to each corresponding scale layer. This approach preserves a large number of features lost due to convolution and obtains mixed features. At the same time, this article relies on DIEM to obtain a large amount of detailed information lost in the neck while processing multi-scale features centrally, which greatly improves the detection accuracy of the GMDNet proposed in this article.
This article proposes GMDNet, a novel neck designed with global perception capability to address limitations observed in traditional feature pyramid networks and their derivatives, particularly in lacking global information perception and detailed feature-layer information. We critically analyze the constraints of current necks, focusing on information transmission and extraction. The GISM module centralizes and redistributes global information, facilitating enhanced integration of multi-scale features. Meanwhile, the DIEM module utilizes 3D features and channel and position attention mechanisms to fuse multi-scale and detailed information effectively for output. GMDNet serves as the core for object detection tasks, achieving 3.1% and 7% improvements in detection accuracy and model computation on the VOC dataset, along with a 9.5% improvement on the VisDrone dataset. It strategically enhances the effectiveness and efficiency of information fusion and transmission, mitigating unnecessary losses. Additionally, the introduction of a detailed information acquisition mechanism synergistically enhances the model’s detection capability.
Author Contributions
Conceptualization, Z.Z. and W.S.; methodology, Z.Z.; validation, W.S., C.S. and R.H.; writing—review and editing, Z.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This paper was funded by the National Natural Science Foundation of China (62173330, 62371375); Shaanxi Key R&D Plan Key Industry Innovation Chain Project (2022ZDLGY03-01); China College Innovation Fund of Production, Education and Research (2021ZYAO8004); and Xi’an Science and Technology Plan Project (2022JH-RGZN-0039).
Data Availability Statement
Publicly available datasets were analyzed in this study. These data can be found here: https://github.com/VisDrone/VisDrone-Dataset (accessed on 2 January 2024), and http://host.robots.ox.ac.uk/pascal/VOC/ (accessed on 5 January 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. BYTETrack: Multi-object tracking by associating every detection box. arXiv 2021, arXiv:2110.06864. [Google Scholar]
- Li, Z.; Dong, M.; Wen, S.; Hu, X.; Zhou, P.; Zeng, Z. CLU-CNNs: Object detection for medical images. Neurocomputing 2019, 350, 53–59. [Google Scholar] [CrossRef]
- Karaoguz, H.; Jensfelt, P. Object detection approach for robot grasp detection. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4953–4959. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Glenn, J. Yolov5 Release v6.1. 2022. Available online: https://github.com/ultralytics/yolov5/releases/tag/v6.1 (accessed on 15 December 2022).
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. Yolov6 v3. 0: A full-scale reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Yolov7: Trainable bag-offreebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Glenn, J. Ultralytics Yolov8. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 15 December 2022).
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458v2. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward transformer-based object detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. arXiv 2021, arXiv:2102.12122. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Computer Vision–ECCV 2020, Proceedings of the European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Yao, Z.; Ai, J.; Li, B.; Zhang, C. Efficient detr: Improving end-to-end object detector with dense prior. arXiv 2021, arXiv:2104.01318. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159, preprint. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized feature pyramid for object detection. arXiv 2022, arXiv:2210.02093. [Google Scholar] [CrossRef]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Chen, P.-Y.; Hsieh, J.-W.; Wang, C.-Y.; Liao, H.-Y.M. Recursive hybrid fusion pyramid network for real-time small object detection on embedded devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 402–403. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. Afpn: Asymptotic feature pyramid network for object detection. arXiv 2023, arXiv:2306.15988. [Google Scholar]
- Hu, M.; Feng, J.; Hua, J.; Lai, B. Online Convolutional Re-parameterization. arXiv 2022, arXiv:2204.00826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep neural networks. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; Volume 7. [Google Scholar]
- Meng, F.; Cheng, H.; Zhuang, J.; Li, K.; Sun, X. Rmnet: Equivalently removing residual connection from networks. arXiv 2021, arXiv:2111.00687. [Google Scholar]
- Hua, W.; Dai, Z.; Liu, H.; Le, Q.V. Transformer Quality in Linear Time. arXiv 2022, arXiv:2202.10447. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. arXiv 2017, arXiv:1612.08083. [Google Scholar]
- Kang, M.; Ting, C.-M.; Ting, F.F.; Phan, R.C.-W. ASF-YOLO: A Novel YOLO Model with Attentional Scale Sequence Fusion for Cell Instance Segmentation. arXiv 2024, arXiv:2312.06458. [Google Scholar] [CrossRef]
- Zou, Z.X.; Shi, Z.W.; Guo, Y.H.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2019, 111, 257–276. [Google Scholar] [CrossRef]
- Everingham, M.; Gool, L.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2014, 111, 98–136. [Google Scholar] [CrossRef]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision Meets Drones: A Challenge. arXiv 2018, arXiv:1804. 07437. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Yang, C.; Huang, Z.; Wang, N. Querydet: Cascaded sparse query for accelerating high-resolution small object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13668–13677. [Google Scholar]
- Cai, Z.; Hong, Z.; Yu, W.; Zhang, W. CNXResNet: A Light-weight Backbone based on PP-YOLOE for Drone- captured Scenarios. In Proceedings of the International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 8–10 July 2023; pp. 460–464. [Google Scholar]
- Chen, H.; Liu, H.; Sun, T.; Lou, H.; Duan, X.; Bi, L.; Liu, L. MC-YOLOv5: A MultiClass small object detection algorithm. Biomimetics 2023, 8, 342. [Google Scholar] [CrossRef]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A SmallObject-Detection model based on improved YOLOv8for UAVaerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef]
- Li, Y.; Fan, Q.; Huang, H.; Han, Z.; Gu, Q. A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition. Drones 2023, 7, 304. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. arXiv 2019, arXiv:1610.02391. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).